
A Secure and Fair Federated Learning Framework Based on Consensus Incentive Mechanism


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Limitations of blockchain-based federated learning solutions focused on a single aspect: Current blockchain-based federated learning methods primarily concentrate on addressing specific aspects of trustworthy federated learning. Some approaches focus on mitigating the impact of malicious attacks through consensus mechanisms, while others emphasize selecting high-quality clients based on reputation scores. However, these approaches fail to provide a comprehensive consideration of potential threats throughout the entire federated learning process.
- Limitations in identifying malicious clients: Although blockchain technology can record and verify the behavior of nodes, relying solely on its transparency and immutability for identifying malicious clients has limitations. For instance, malicious clients may evade detection by submitting fabricated model updates, and blockchain alone is insufficient to fully prevent such stealthy attacks.
- Lack of fair consensus and incentive mechanisms: The reward distribution process is vulnerable to free-rider behavior from inactive or low-quality participants, and existing methods are unable to fully eliminate this unfairness. Furthermore, malicious clients may intentionally exaggerate or falsely report their contributions, leading to inaccurate assessments of their performance.
- Blockchain-based framework for trustworthy federated learning: We propose a federated learning framework that ensures both trustworthiness and fairness. This framework leverages blockchain technology and smart contract mechanisms to secure the entire collaborative process, offering a comprehensive federated learning solution that addresses client management, malicious client detection, data and model security, and fairness in incentive mechanisms.
- Generalized secure global aggregation: To ensure secure global model aggregation in federated learning, we introduce a feature fusion-based approach for detecting malicious clients. This method enhances the reliability of global model aggregation while mitigating the impact of potential malicious participants.
- Efficient and fair blockchain consensus incentive mechanism: We propose a fair blockchain consensus incentive mechanism. By employing robust model watermarking techniques and parameter distance algorithms, the mechanism ensures equitable distribution of rewards based on actual contributions, addressing the limitations of traditional incentive schemes that rely solely on reputation or self-reporting. During the model aggregation phase, the creator of the best model is granted the right to write to the blockchain, promoting active participation in both local training and model aggregation.
2. Related Work
2.1. Trustworthy Federated Learning
2.2. Trustworthy Federated Learning Base on Blockchain
2.3. Contribution Evaluation and Incentive Mechanism
3. Problem Formulation
3.1. Architectural Design
3.2. Threat Model
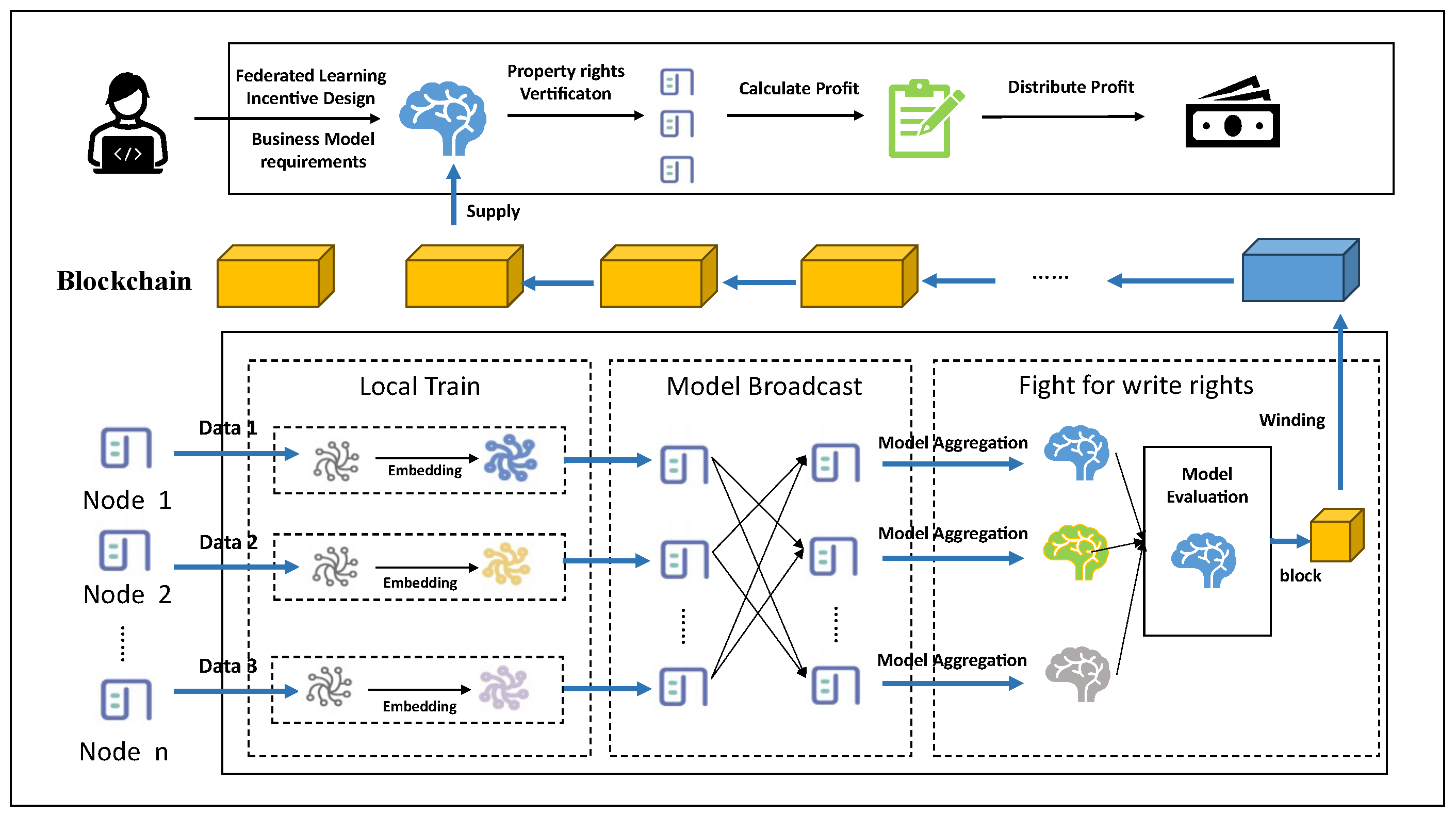
4. Proposed Framework
4.1. Architectural Design
4.2. Secure Identification Framework
4.3. Fair Federated Consensus Algorithm
4.3.1. Consensus
| Algorithm 1 Algorithm of federated consensus mechanism |
| Input: The Block ; The set of Node ; Then initial weight ; Output: N;
|
4.3.2. Incentive Mechanism
5. Experimental Evaluation
5.1. Experimental Setup
5.2. Secure Identification Algorithm Evaluation
5.2.1. Baseline
5.2.2. Attack Types
5.2.3. Accuracy
5.2.4. Clustering Results
5.2.5. Result Analysis
5.3. Fair Federated Consensus Algorithm Evaluation
5.3.1. Election Probability
5.3.2. Communication Overhead
5.3.3. Reward Allocation
5.4. The Difference between Blockchain Based Trusted Federated Learning Framework and Non Blockchain Based Framework
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Qu, Y.; Uddin, M.P.; Gan, C.; Xiang, Y.; Gao, L.; Yearwood, J. Blockchain-enabled federated learning: A survey. Acm Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Li, S.; Cheng, Y.; Wang, W.; Liu, Y.; Chen, T. Learning to detect malicious clients for robust federated learning. arXiv 2020, arXiv:2002.00211. [Google Scholar]
- Chen, L.; Dong, C.; Qiao, S.; Huang, Z.; Wang, K.; Nie, Y.; Hou, Z.; Tan, C. FedDRL: A Trustworthy Federated Learning Model Fusion Method Based on Staged Reinforcement Learning. arXiv 2023, arXiv:2307.13716. [Google Scholar] [CrossRef]
- Zhang, Z.; Cao, X.; Jia, J.; Gong, N.Z. Fldetector: Defending federated learning against model poisoning attacks via detecting malicious clients. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2545–2555. [Google Scholar]
- Andreina, S.; Marson, G.A.; Möllering, H.; Karame, G. Baffle: Backdoor detection via feedback-based federated learning. In Proceedings of the 2021 IEEE 41st International Conference on Distributed Computing Systems (ICDCS), Washington, DC, USA, 7–10 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 852–863. [Google Scholar]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. Adv. Neural Inf. Process. Syst. 2017, 30, 119–129. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Abdel-Basset, M.; Moustafa, N.; Hawash, H. Privacy-preserved cyberattack detection in Industrial Edge of Things (IEoT): A blockchain-orchestrated federated learning approach. IEEE Trans. Ind. Inform. 2022, 18, 7920–7934. [Google Scholar] [CrossRef]
- Li, Y.; Chen, C.; Liu, N.; Huang, H.; Zheng, Z.; Yan, Q. A blockchain-based decentralized federated learning framework with committee consensus. IEEE Netw. 2020, 35, 234–241. [Google Scholar] [CrossRef]
- Shayan, M.; Fung, C.; Yoon, C.J.M.; Beschastnikh, I. Biscotti: A Blockchain System for Private and Secure Federated Learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1513–1525. [Google Scholar] [CrossRef]
- Ma, C.; Li, J.; Shi, L.; Ding, M.; Wang, T.; Han, Z.; Poor, H.V. When Federated Learning Meets Blockchain: A New Distributed Learning Paradigm. IEEE Comput. Intell. Mag. 2022, 17, 26–33. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Zou, Y.; Zhang, Y.; Guizani, M. Reliable federated learning for mobile networks. IEEE Wirel. Commun. 2020, 27, 72–80. [Google Scholar] [CrossRef]
- Zhang, Q.; Ding, Q.; Zhu, J.; Li, D. Blockchain empowered reliable federated learning by worker selection: A trustworthy reputation evaluation method. In Proceedings of the 2021 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Nanjing, China, 29 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Qi, J.; Lin, F.; Chen, Z.; Tang, C.; Jia, R.; Li, M. High-quality model aggregation for blockchain-based federated learning via reputation-motivated task participation. IEEE Internet Things J. 2022, 9, 18378–18391. [Google Scholar] [CrossRef]
- Martinez, I.; Francis, S.; Hafid, A.S. Record and reward federated learning contributions with blockchain. In Proceedings of the 2019 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), Guilin, China, 17–19 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 50–57. [Google Scholar]
- Wei, S.; Tong, Y.; Zhou, Z.; Song, T. Efficient and fair data valuation for horizontal federated learning. In Federated Learning: Privacy and Incentive; Springer: Berlin/Heidelberg, Germany, 2020; pp. 139–152. [Google Scholar]
- Yan, B.; Liu, B.; Wang, L.; Zhou, Y.; Liang, Z.; Liu, M.; Xu, C.Z. Fedcm: A real-time contribution measurement method for participants in federated learning. In Proceedings of the 2021 International Joint Conference on Neural Networks (IJCNN), Shenzhen, China, 18–22 July 2021; IEEE: Piscataway, NJ, USA; 2021; pp. 1–8. [Google Scholar]
- Liu, Z.; Chen, Y.; Yu, H.; Liu, Y.; Cui, L. Gtg-shapley: Efficient and accurate participant contribution evaluation in federated learning. Acm Trans. Intell. Syst. Technol. 2022, 13, 1–21. [Google Scholar] [CrossRef]
- Kang, J.; Xiong, Z.; Niyato, D.; Xie, S.; Zhang, J. Incentive mechanism for reliable federated learning: A joint optimization approach to combining reputation and contract theory. IEEE Internet Things J. 2019, 6, 10700–10714. [Google Scholar] [CrossRef]
- Gao, L.; Li, L.; Chen, Y.; Xu, C.; Xu, M. FGFL: A blockchain-based fair incentive governor for Federated Learning. J. Parallel Distrib. Comput. 2022, 163, 283–299. [Google Scholar] [CrossRef]
- Yu, H.; Liu, Z.; Liu, Y.; Chen, T.; Cong, M.; Weng, X.; Niyato, D.; Yang, Q. A fairness-aware incentive scheme for federated learning. In Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, New York, NY, USA, 7–8 February 2020; pp. 393–399. [Google Scholar]
- Chen, Z.; Liu, Z.; Ng, K.L.; Yu, H.; Liu, Y.; Yang, Q. A gamified research tool for incentive mechanism design in federated learning. In Federated Learning: Privacy and Incentive; Springer: Berlin/Heidelberg, Germany, 2020; pp. 168–175. [Google Scholar]
- García-Pérez, Á.; Gotsman, A.; Meshman, Y.; Sergey, I. Paxos consensus, deconstructed and abstracted. In Programming Languages and Systems: 27th European Symposium on Programming, ESOP 2018, Held as Part of the European Joint Conferences on Theory and Practice of Software, ETAPS 2018; Springer International Publishing: Thessaloniki, Greece, 2018; pp. 912–939. [Google Scholar]










Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, F.; Hu, F.; Zhao, Y.; Chen, B.; Tan, X. A Secure and Fair Federated Learning Framework Based on Consensus Incentive Mechanism. Mathematics 2024, 12, 3068. https://doi.org/10.3390/math12193068
Zhu F, Hu F, Zhao Y, Chen B, Tan X. A Secure and Fair Federated Learning Framework Based on Consensus Incentive Mechanism. Mathematics. 2024; 12(19):3068. https://doi.org/10.3390/math12193068
Chicago/Turabian StyleZhu, Feng, Feng Hu, Yanchao Zhao, Bing Chen, and Xiaoyang Tan. 2024. "A Secure and Fair Federated Learning Framework Based on Consensus Incentive Mechanism" Mathematics 12, no. 19: 3068. https://doi.org/10.3390/math12193068