
Investigating Autonomous Vehicle Driving Strategies in Highway Ramp Merging Zones


Abstract
1. Introduction
- Investigation of Autonomous Driving Strategies in Realistic Highway Ramp Merging Scenarios: A highway ramp merging scenario was developed on the SUMO simulation platform, replicating real-world conditions. Two autonomous driving traffic flows—rule-based and deep reinforcement learning—were constructed to ensure that AVs exhibit the behavior of experienced drivers during ramp merging. Theoretically, this provides a valuable benchmark for autonomous vehicle control and traffic simulation research. Practically, it demonstrates the feasibility of deploying AVs in complex traffic environments.
- Development of a Deep Reinforcement Learning-Based Control Model: This research proposes a novel DRL-based control framework that integrates both longitudinal and lateral strategies for AVs in highway ramp merging areas. The model addresses the challenges posed by complex interactions between AVs and HDVs and supports rapid decision-making under dynamic traffic conditions.
- Comprehensive Traffic Performance Analysis: This research provides a holistic evaluation of traffic performance by assessing multiple metrics, such as congestion reduction, safety enhancement, and travel time efficiency. Using the SUMO platform, the study explores the impact of AV deployment in mixed traffic, offering valuable insights into AV integration and its influence on traffic flow under various penetration rates.
2. Methods
- SUMO-Simulated Autonomous Vehicle Flow (ZD1): The IDM model is used to simulate the longitudinal behavior, and the LC2013 model is used to simulate the lateral behavior of ZD1 vehicles.
- Deep Reinforcement Learning Controlled Autonomous Vehicle Flow (ZD2): The longitudinal following and lateral lane-changing behaviors of ZD2 vehicles are regulated by the deep reinforcement learning algorithm.
2.1. Vehicle Basic Control Model
2.1.1. Car-Following Model
2.1.2. Lane-Change Model
- Strategic Lane Change: Undertaken when it is not possible to reach the subsequent section of the route by continuing in the original lane.
- Cooperative Lane Change: A lateral movement in the same direction as the prevailing traffic flow, facilitating the smooth entry of a vehicle from an adjacent lane.
- Tactical Lane Change: Employed by a driver to increase velocity and overall efficiency when the driving state of the preceding vehicle restricts the driver’s ability to achieve the desired velocity. The objective is to expedite and optimize traffic flow by changing lanes.
- Obligatory Lane Change: Previously defined as “mandatory lane changing”. The driver must adhere to established traffic regulations and promptly resume their original lane, typically the left lane, to guarantee optimal utilization of the overtaking lane (default position for the left lane).
2.2. Deep Reinforcement Learning
2.3. Problem Description
- Data Collection: The autonomous vehicle gathers real-time data, including its own speed, position, acceleration, and the relative positions and velocities of surrounding vehicles.
- State Representation: These data are processed to form a comprehensive state representation, which serves as the input for the DRL model.
- Action Selection: Based on the current state and the policy learned through PPO, the vehicle selects the optimal action (e.g., accelerating, decelerating, lane changing).
- Reward Calculation: The selected action is executed, and the resultant state change is evaluated to calculate a reward. The reward function considers factors such as safety, efficiency, and comfort.
- Policy Update: Using the calculated reward, the PPO algorithm updates the policy to improve future decision-making.
2.3.1. State Space
2.3.2. Action Space
2.3.3. Reward
- Safety reward
- Efficiency reward
- Comfort reward
- Low-disturbance reward
- Total reward
3. Modeling and Experiment
3.1. Configuration of Road Structures
3.2. Configuration of Vehicles
3.3. Details of the Experiments
4. Results
4.1. Learning Performance
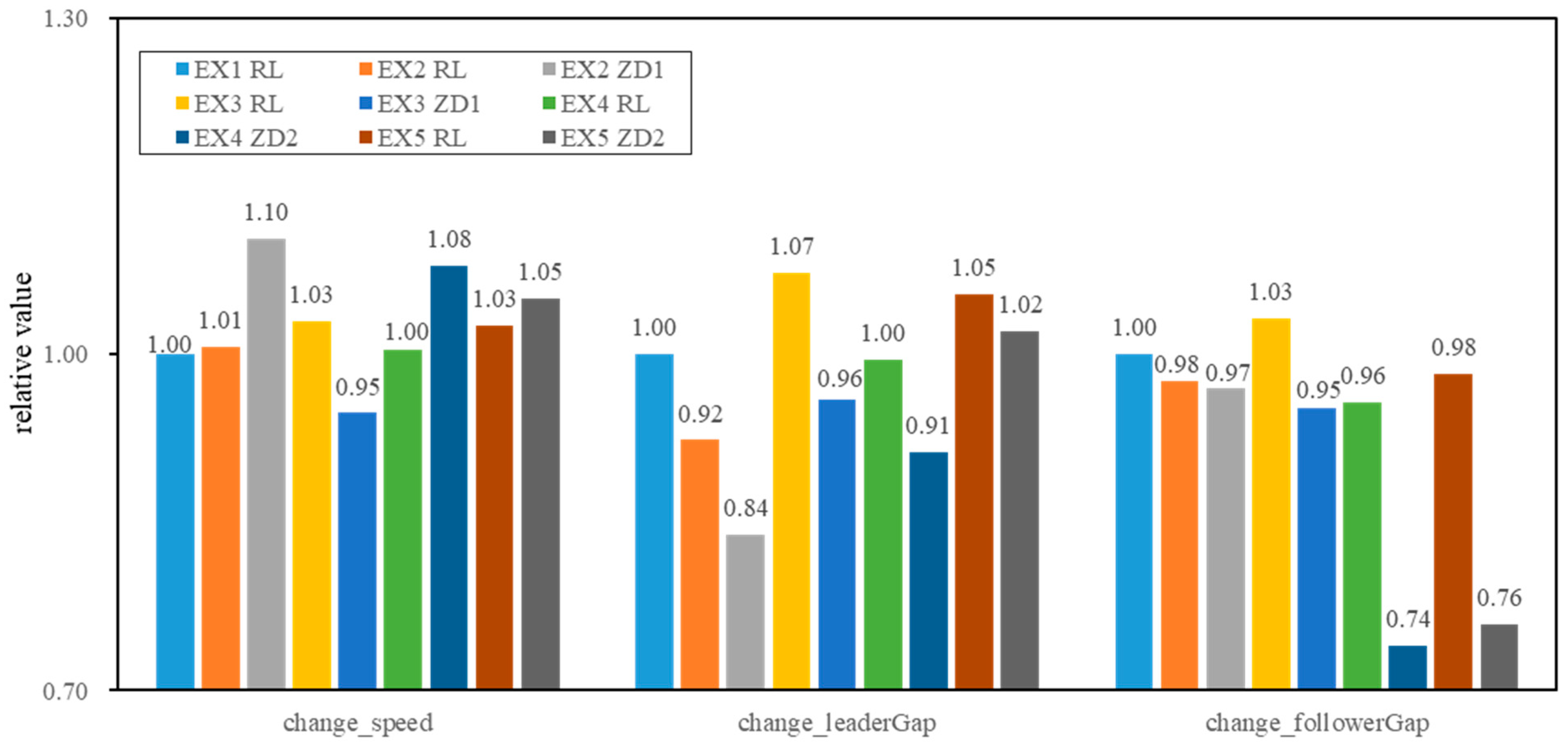
4.2. Traffic Analysis
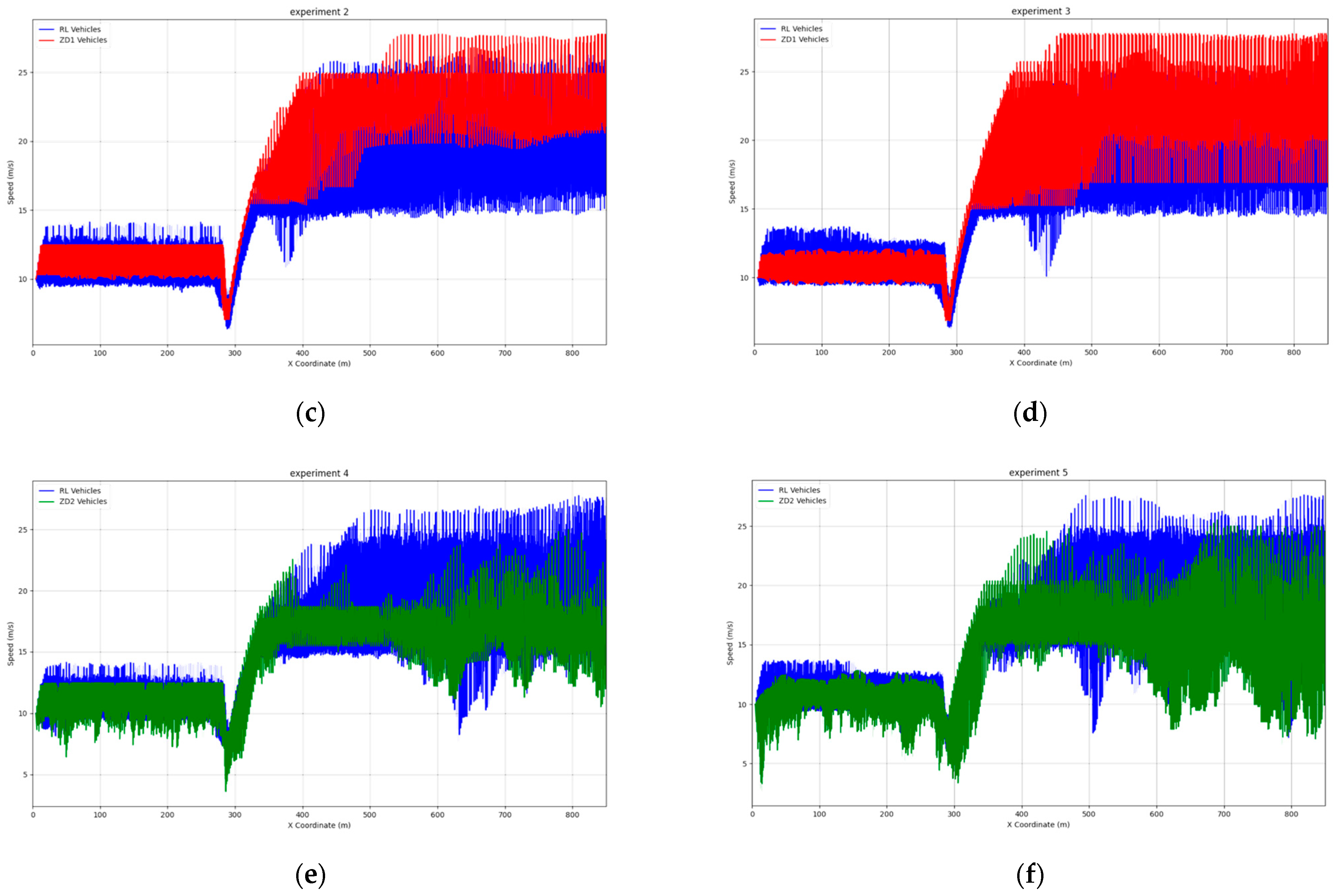
4.2.1. Velocity Aspect
4.2.2. Acceleration Aspect
4.2.3. Lane-Change Aspect
4.2.4. Comparison
5. Discussions
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Bose, A.; Ioannou, P. Mixed manual/semi-automated traffic: A macroscopic analysis. Transp. Res. Part C Emerg. Technol. 2003, 11, 439–462. [Google Scholar] [CrossRef]
- Fagnant, D.J.; Kockelman, K. Preparing a nation for autonomous vehicles: Opportunities, barriers and policy recommendations. Transp. Res. Part A Policy Pract. 2015, 77, 167–181. [Google Scholar] [CrossRef]
- Qin, Y.Y.; Wang, H.; Ran, B. Impact of Connected and Automated Vehicles on Passenger Comfort of Traffic Flow with Vehicle-to-vehicle Communications. KSCE J. Civ. Eng. 2019, 23, 821–832. [Google Scholar] [CrossRef]
- Grigorescu, S.; Trasnea, B.; Cocias, T.; Macesanu, G. A Survey of Deep Learning Techniques for Autonomous Driving. J. Field Robot. 2020, 37, 362–386. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Talebpour, A.; Mahmassani, H.S. Influence of Connected and Autonomous Vehicles on Traffic Flow Stability and Throughput. Transp. Res. Part C Emerg. Technol. 2016, 71, 143–163. [Google Scholar] [CrossRef]
- Song, H.F.; Li, L.L.; Li, Y.; Tan, L.G.; Dong, H.R. Functional Safety and Performance Analysis of Autonomous Route Management for Autonomous Train Control System. IEEE Trans. Intell. Transp. Syst. 2024, 25, 13291–13304. [Google Scholar] [CrossRef]
- Zhou, S.; Zhuang, W.; Yin, G.; Liu, H.; Qiu, C. Cooperative On-Ramp Merging Control of Connected and Automated Vehicles: Distributed Multi-Agent Deep Reinforcement Learning Approach. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 402–408. [Google Scholar] [CrossRef]
- Paden, B.; Cap, M.; Yong, S.Z.; Yershov, D.; Frazzoli, E. A Survey of Motion Planning and Control Techniques for Self-Driving Urban Vehicles. IEEE Trans. Intell. Veh. 2016, 1, 33–55. [Google Scholar] [CrossRef]
- Jiang, W.; Huang, Z.; Wu, Z.; Su, H.; Zhou, X. Quantitative Study on Human Error in Emergency Activities of Road Transportation Leakage Accidents of Hazardous Chemicals. Int. J. Environ. Res. Public Health 2022, 19, 14662. [Google Scholar] [CrossRef]
- Jin, Z.; RuiChun, H.E. Research on Road Traffic Safety Based on Hammer’s Human Error Theory. China Saf. Sci. J. 2008, 18, 53–58. [Google Scholar]
- Hirst, W.M.; Mountain, L.J.; Maher, M.J. Sources of error in road safety scheme evaluation: A method to deal with outdated accident prediction models. Accid. Anal. Prev. 2004, 36, 717–727. [Google Scholar] [CrossRef] [PubMed]
- McCorry, B.; Murray, W. Reducing commercial vehicle road accident costs. Int. J. Phys. Distrib. Logist. Manag. 1993, 23, 35–41. [Google Scholar] [CrossRef]
- Xu, D.; Zhang, B.; Qiu, Q.; Li, H.; Guo, H.; Wang, B. Graph-Based Multi-Agent Reinforcement Learning for On-Ramp Merging in Mixed Traffic. Appl. Intell. 2024, 54, 6400–6414. [Google Scholar] [CrossRef]
- Irshayyid, A.; Chen, J.; Xiong, G. A Review on Reinforcement Learning-Based Highway Autonomous Vehicle Control. Green Energy Intell. Transp. 2024, 3, 100156. [Google Scholar] [CrossRef]
- Liu, K.W.; Li, N.; Tseng, H.E.; Kolmanovsky, I.; Girard, A. Interaction-Aware Trajectory Prediction and Planning for Autonomous Vehicles in Forced Merge Scenarios. IEEE Trans. Intell. Transp. Syst. 2023, 24, 474–488. [Google Scholar] [CrossRef]
- Hu, J.B.; He, L.C.; Wang, R.H. Safety evaluation of freeway interchange merging areas based on driver workload theory. Sci. Prog. 2020, 103, 0036850420940878. [Google Scholar] [CrossRef]
- Zhu, J.; Tasic, I. Safety analysis of freeway on-ramp merging with the presence of autonomous vehicles. Accid. Anal. Prev. 2021, 152, 105966. [Google Scholar] [CrossRef]
- Ntousakis, I.A.; Nikolos, L.K.; Papageorgiou, M. Optimal vehicle trajectory planning in the context of cooperative merging on highways. Transp. Res. Part C-Emerg. Technol. 2016, 71, 464–488. [Google Scholar] [CrossRef]
- Sarvi, M.; Kuwahara, M. Microsimulation of freeway ramp merging processes under congested traffic conditions. IEEE Trans. Intell. Transp. Syst. 2007, 8, 470–479. [Google Scholar] [CrossRef]
- Li, W.; Zhao, Z.; Liang, K.; Zhao, K. Coordinated Longitudinal and Lateral Motions Control of Automated Vehicles Based on Multi-Agent Deep Reinforcement Learning for On-Ramp Merging; SAE Technical Paper, 2024-01-2560; SAE International: Warrendale, PA, USA, 2024. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, L.; Liu, H.; Wang, Y.; Li, H.; Xu, B. High-Speed Ramp Merging Behavior Decision for Autonomous Vehicles Based on Multiagent Reinforcement Learning. IEEE Internet Things J. 2023, 10, 22664–22672. [Google Scholar] [CrossRef]
- Zhao, R.; Sun, Z.; Ji, A. A Deep Reinforcement Learning Approach for Automated OnRamp Merging. In Proceedings of the 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC), Macau, China, 8–12 October 2022; pp. 3800–3806. [Google Scholar] [CrossRef]
- Zhou, Y.J.; Zhu, H.B.; Guo, M.M.; Zhou, J.L. Impact of CACC vehicles’ cooperative driving strategy on mixed four-lane highway traffic flow. Physica A 2020, 540, 122721. [Google Scholar] [CrossRef]
- Song, H.F.; Gao, S.G.; Li, Y.D.; Liu, L.; Dong, H.R. Train-Centric Communication Based Autonomous Train Control System. IEEE Trans. Intell. Veh. 2023, 8, 721–731. [Google Scholar] [CrossRef]
- Weaver, S.M.; Balk, S.A.; Philips, B.H. Merging into strings of cooperative-adaptive cruise-control vehicles. J. Intell. Transport. Syst. 2021, 25, 401–411. [Google Scholar] [CrossRef]
- Pei, Y.; Chi, B.; Lyu, J.; Yue, Z. An Overview of Traffic Management in “Automatic+Manual” Driving Environment. J. Transp. Inf. Saf. 2021, 39, 1–11. [Google Scholar]
- Ozioko, E.F.; Kunkel, J.; Stahl, F. Road Intersection Coordination Scheme for Mixed Traffic (Human-Driven and Driverless Vehicles): A Systematic Review. J. Adv. Transp. 2022, 2022, 15. [Google Scholar] [CrossRef]
- Guo, L.X.; Jia, Y.Y. Predictive Control of Connected Mixed Traffic under Random Communication Constraints. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2020; IEEE: New York, NY, USA, 2020; pp. 11817–11823. [Google Scholar] [CrossRef]
- Imbsweiler, J.; Palyafári, R.; León, F.P.; Deml, B. Investigation of decision-making behavior in cooperative traffic situations using the example of a narrow passage. AT-Autom. 2017, 65, 477–488. [Google Scholar] [CrossRef]
- Cui, X.T.; Li, X.S.; Zheng, X.L.; Zhang, X.Y.; Zhao, L.; Zhang, J.H. Research on Traffic Characteristics of Signal Intersections with Mixed Traffic Flow. In Proceedings of the IEEE 5th International Conference on Intelligent Transportation Engineering (ICITE), Beijing, China, 11–13 September 2020; IEEE: New York, NY, USA, 2020; pp. 306–312. [Google Scholar] [CrossRef]
- Ramezani, M.; Machado, J.A.; Skabardonis, A.; Geroliminis, N. Capacity and Delay Analysis of Arterials with Mixed Autonomous and Human-Driven Vehicles. In Proceedings of the 5th IEEE International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Napoli, Italy, 26–28 June 2017; IEEE: New York, NY, USA, 2017; pp. 280–284. [Google Scholar]
- Wang, X.P.; Wu, C.Z.; Xue, J.; Chen, Z.J. A Method of Personalized Driving Decision for Smart Car Based on Deep Reinforcement Learning. Information 2020, 11, 295. [Google Scholar] [CrossRef]
- Silver, D.; Huang, A.; Maddison, C.J.; Guez, A.; Sifre, L.; van den Driessche, G.; Schrittwieser, J.; Antonoglou, I.; Panneershelvam, V.; Lanctot, M.; et al. Mastering the game of Go with deep neural networks and tree search. Nature 2016, 529, 484–489. [Google Scholar] [CrossRef]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Yuan, S.H.; Yin, X.F.; Li, X.Y.; Tang, S.X. Research into Autonomous Vehicles Following and Obstacle Avoidance Based on Deep Reinforcement Learning Method under Map Constraints. Sensors 2023, 23, 844. [Google Scholar] [CrossRef] [PubMed]
- Bin Issa, R.; Das, M.; Rahman, M.S.; Barua, M.; Rhaman, M.K.; Ripon, K.S.N.; Alam, M.G.R. Double Deep Q-Learning and Faster R-CNN-Based Autonomous Vehicle Navigation and Obstacle Avoidance in Dynamic Environment. Sensors 2021, 21, 1468. [Google Scholar] [CrossRef] [PubMed]
- Chen, D.; Hajidavalloo, M.R.; Li, Z.; Chen, K.; Wang, Y.; Jiang, L.; Wang, Y. Deep Multi-Agent Reinforcement Learning for Highway On-Ramp Merging in Mixed Traffic. IEEE Trans. Intell. Transp. Syst. 2023, 24, 11623–11638. [Google Scholar] [CrossRef]
- Lee, J.; Eom, C.; Lee, D.; Kwon, M. Deep Reinforcement Learning-Based Autonomous Driving Strategy under On-Ramp Merge Scenario. Trans. KSAE 2024, 32, 569–581. [Google Scholar] [CrossRef]
- Qiao, L.; Bao, H.; Xuan, Z.; Liang, J.; Pan, F. Autonomous Driving Ramp Merging Model Based on Reinforcement Learning. Comput. Eng. 2018, 44, 20–24. [Google Scholar] [CrossRef]
- Treiber, M.; Hennecke, A.; Helbing, D. Congested traffic states in empirical observations and microscopic simulations. Phys. Rev. E 2000, 62, 1805–1824. [Google Scholar] [CrossRef]
- Krajzewicz, D.; Erdmann, J.; Behrisch, M.; Bieker, L. Recent development and applications of SUMO—Simulation of urban mobility. Int. J. Adv. Syst. Meas. 2012, 5, 128–138. [Google Scholar]
- Erdmann, J. SUMO’s Lane-Changing Model. In Proceedings of the 2nd SUMO User Conference (SUMO), Berlin, Germany, 15–16 May 2014; Springer: Berlin/Heidelberg, Germany, 2015; pp. 105–123. [Google Scholar] [CrossRef]
- Helbing, D.; Hennecke, A.; Shvetsov, V.; Treiber, M. Micro- and macro-simulation of freeway traffic. Math. Comput. Model. 2002, 35, 517–547. [Google Scholar] [CrossRef]
- Zhu, L.; Lu, L.J.; Wang, X.N.; Jiang, C.M.; Ye, N.F. Operational Characteristics of Mixed-Autonomy Traffic Flow on the Freeway With On- and Off-Ramps and Weaving Sections: An RL-Based Approach. IEEE Trans. Intell. Transp. Syst. 2022, 23, 13512–13525. [Google Scholar] [CrossRef]
- Zeng, X.; Lin, H.; Wang, Y.; Yuan, T.; He, Q.; Huang, J. Safety Risk Identification of Rail Transit Signaling System Based on Accident Data. J. Tongji University Nat. Sci. 2022, 50, 418–424. [Google Scholar]
- Zeng, X.; Lin, H.; Fang, Y.; Wang, Y.; Liu, Y.; Ma, Z. Safety Target Assignment Analysis Method Based on Complexity Algorithm. J. Tongji University Nat. Sci. 2022, 50, 1–5. [Google Scholar]
- Pu, Z.Y.; Li, Z.B.; Jiang, Y.; Wang, Y.H. Full Bayesian Before-After Analysis of Safety Effects of Variable Speed Limit System. IEEE Trans. Intell. Transp. Syst. 2021, 22, 964–976. [Google Scholar] [CrossRef]
- Vogel, K. A comparison of headway and time to collision as safety indicators. Accid. Anal. Prev. 2003, 35, 427–433. [Google Scholar] [CrossRef]
- Vinitsky, E.; Kreidieh, A.; Flem, L.L.; Kheterpal, N.; Jang, K.; Wu, C.; Wu, F.; Liaw, R.; Liang, E.; Bayen, A.M. Benchmarks for reinforcement learning in mixed-autonomy traffic. In Proceedings of the 2nd Conference on Robot Learning, Zürich, Switzerland, 29–31 October 2019. [Google Scholar]
- Zhang, G.H.; Wang, Y.H.; Wei, H.; Chen, Y.Y. Examining headway distribution models with urban freeway loop event data. Transp. Res. Rec. 2007, 1999, 141–149. [Google Scholar] [CrossRef]
- Zhu, M.X.; Wang, Y.H.; Pu, Z.Y.; Hu, J.Y.; Wang, X.S.; Ke, R.M. Safe, efficient, and comfortable velocity control based on reinforcement learning for autonomous driving. Transp. Res. Part C Emerg. Technol. 2020, 117, 102662. [Google Scholar] [CrossRef]
- Belletti, F.; Haziza, D.; Gomes, G.; Bayen, A.M. Expert Level Control of Ramp Metering Based on Multi-Task Deep Reinforcement Learning. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1198–1207. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute Category | Specific Parameters | RL | ZD1 | Definition |
|---|---|---|---|---|
| Vehicle type | Vehicle-type | Human-driven vehicles | Autonomous vehicles under the SUMO strategy | Different vehicle types |
| Vehicle physical attributes | Length (m) | 5.0 | 5.0 | Vehicle clear length |
| Width (m) | 1.8 | 1.8 | Vehicle clear width | |
| Height (m) | 1.5 | 1.5 | Vehicle clear height | |
| Color | (1,0,0) | (1,1,0) | Red (RL) and Yellow (ZD1) | |
| Car-following | ) | 3.0 | 3.0 | Maximum acceleration |
| ) | 7.5 | 7.5 | Maximum deceleration capacity | |
| maxVelocity (km/h) | 100 | 100 | Maximum velocity | |
| tau | 1.5 | 0.5 | Driver reaction time | |
| sigma | 0.5 | 0 | Driving proficiency level | |
| minGap (m) | 2.5 | 1.0 | Minimum headway distance | |
| Lane-change | lcStrategic | 0.5 | 0.5 | Readiness to implement strategic change |
| lcCooperative | 0.5 | 0.5 | Readiness to implement cooperative change | |
| lcVelocityGain | 0.1 | 1 | Willingness to change lanes for higher velocity |
| Number | ID | Length (m) | Color | Car-Following Model | Lane-Change Model | Parameters of Car-Following Model | Parameters of Lane-Change Model |
|---|---|---|---|---|---|---|---|
| 1 | RL | 5 | Red | IDM | LC2013 | Modify the IDM model parameters | Default |
| 2 | ZD1 | 5 | Yellow | IDM | LC2013 | Modify the IDM model parameters | Default |
| 3 | ZD2 | 5 | Yellow | DRL | DRL | DRL | DRL |
| Name | Version |
|---|---|
| Python | 3.7.4 |
| SUMO | 1.19.0 |
| PyCharm | 2021.3 |
| Traci | 1.19.0 |
| numpy | 1.21.6 |
| gymnasium | 0.28.1 |
| stable-baseline3 | 2.0.0 |
| Experiment No. | Vehicle Type | Model | Velocity Recovery | Acceleration Consistency | Lane Change and Gap Behavior |
|---|---|---|---|---|---|
| 1 | RL | Default | Moderate, unstable | Moderate fluctuations | Erratic lane changes, inconsistent gaps |
| 2 | RL | Default | Slower, erratic | High fluctuation levels | Delayed lane changes, inconsistent gaps |
| ZD1 | IDM | Rapid, consistent | High acceleration, prone to abrupt changes | Fast lane changes, moderate gaps | |
| 3 | RL | Default | Slower, erratic | Moderate fluctuations | Delayed lane changes, inconsistent gaps |
| ZD1 | IDM | Rapid, consistent | High but slightly reduced fluctuations | Improved lane-changing, less optimal gaps | |
| 4 | RL | Default | Slower, erratic | Moderate fluctuations | Erratic changes, frequent corrections |
| ZD2 | DRL | Pronounced, stable | Low and stable acceleration | Smooth changes, optimal gaps | |
| 5 | RL | Default | Slower, erratic | Moderate fluctuations | Erratic changes, slow response |
| ZD2 | DRL | Pronounced, stable | Low and stable acceleration | Consistent changes, well-managed gaps |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Z.; Wang, Y.; Hu, H.; Zhang, Z.; Zhang, C.; Zhou, S. Investigating Autonomous Vehicle Driving Strategies in Highway Ramp Merging Zones. Mathematics 2024, 12, 3859. https://doi.org/10.3390/math12233859
Chen Z, Wang Y, Hu H, Zhang Z, Zhang C, Zhou S. Investigating Autonomous Vehicle Driving Strategies in Highway Ramp Merging Zones. Mathematics. 2024; 12(23):3859. https://doi.org/10.3390/math12233859
Chicago/Turabian StyleChen, Zhimian, Yizeng Wang, Hao Hu, Zhipeng Zhang, Chengwei Zhang, and Shukun Zhou. 2024. "Investigating Autonomous Vehicle Driving Strategies in Highway Ramp Merging Zones" Mathematics 12, no. 23: 3859. https://doi.org/10.3390/math12233859
APA StyleChen, Z., Wang, Y., Hu, H., Zhang, Z., Zhang, C., & Zhou, S. (2024). Investigating Autonomous Vehicle Driving Strategies in Highway Ramp Merging Zones. Mathematics, 12(23), 3859. https://doi.org/10.3390/math12233859