
Finite State Automata on Multi-Word Units for Efficient Text-Mining †


Abstract
1. Introduction
1.1. The Growth of Natural Language Textual Documents
1.2. Text Mining
- Pre-processing,
- Text Representation,
- Dimensionality Reduction,
- Features Extraction,
- Document Classification,
- Evaluation.
1.3. Brief Description of the Proposal
1.4. Structure of the Paper
2. Large Language Models: A Recent Milestone in NLP
2.1. Large Pre-Trained Language Models (PLM)
- Transformer Architectures: The Transformer architecture, introduced by Vaswani et al. [66], is a neural network architecture highly effective in capturing complex relationships in sequential data, such as language.
- Versatility: PLMs find applications in various NLP tasks, including text classification, named entity recognition, question answering, sentiment analysis, language translation, and more.
2.2. BERT (Bidirectional Encoder Representations from Transformers)
2.3. GPT (Generative Pre-Trained Transformer)
- While GPT and BERT have distinct training objectives and optimize for different tasks, their shared foundation highlights commonalities in handling contextualized language representations.
- Both GPT and BERT aim to capture contextual understanding of language. GPT achieves this by predicting the next word in a sequence (left-to-right), while BERT focuses on bidirectional representations, considering context from both the left and right sides of a word.
- Both GPT and BERT are designed to be versatile and adaptable to various natural language processing tasks. They can be fine-tuned for specific applications, such as sentiment analysis, named entity recognition, question answering, and more.
3. System Description
3.1. Simple Words and Multi-Word Units
- Idiomatic Expressions: Kick the bucket (to die) or Break a leg (good luck) or Hit the hay (go to sleep).
- Collocations: Make a decision or Take a shower or Strong coffee.
- Phrasal Verbs: Turn on (activate) or Look up (search for information).
- Proverbs: Too many cooks spoil the broth (when too many people are involved in a task, it may not turn out well) or Don’t count your chickens before they hatch (do not make plans or celebrate success prematurely).
- Technical Terms: Artificial intelligence (the simulation of human intelligence in machines) or Climate change (long-term change in the average weather patterns).
- Compound Words: Airplane (Air+plane) or Raincoat (Rain+coat) or Sunglasses (Sun+glasses).
- Fixed Expressions (or Prepositional Phrases): By the way (incidentally) or In the meantime (meanwhile) or All of a sudden (unexpectedly).
- Named Entities: New York City or United States or Mona Lisa (the name of a picture).
- Acronyms and Initialisms: NASA (National Aeronautics and Space Administration) or UNESCO (United Nations Educational, Scientific and Cultural Organization).
- Technical Terminology: Quantum mechanics or Genetic engineering or Nuclear fusion.
3.2. Ontology System
3.3. System Functionality
3.3.1. Preliminary Linguistic Step
- Step 1
- Multi-Word Unit Choice and Normalization: Experts in the sector identify all multi-word units of the knowledge domain (metadata) and normalize the data by transforming the set of multi-word units into a standard format, following the normalization choices determined in the previous step.
- Step 2
- Association of the Semantic Domain with Each Multi-Word Unit: The system builds a linguistic model that associates one or more semantic domains with each of the multi-word units identified in the previous step.
- Step 3
- Ontology Construction: A digital data structure is created, containing all possible multi-word units in the form of an ontology. Each line in the ontology includes a multi-word unit and its associated semantic domains.
3.3.2. Algorithmic Step
- Pre-Processing:
- The system builds a finite automaton data structure based on user-selected ontologies.
- Matching:
- The algorithm reads the input text character by character, navigating through the finite automaton, where each character of the input text corresponds to a state of the finite automaton. It identifies terminological multi-word units immediately and simultaneously, even if they are partially or completely overlapped, without revisiting previous characters.
- Analysis:
- After reading the entire input text, the algorithm analyzes metadata and classifies the text based on its knowledge domains.
4. Algorithm Performances
- Phase 1: Preprocessing
- Phase 2: Matching
- Phase 3: Analysis
5. System Performances
- Laptop: DELL INSPIRON 16;
- CPU: 11th Gen Intel(R) Core(TM) i7-11800H @ 2.30GHz 2.30 GHz;
- RAM: 32.0 GB;
- OS: Windows 11 Home, 64-bit, x64, ver. 22H2.
5.1. AUTOMETA at Work
- On the entire document.
- On the first two thirds of the document.
- On the first third of the document.
- On the central part of the document.
- On the union of the first and last paragraphs of the document.
5.2. Running System Performances
6. Case Study Description
6.1. Corpus
6.2. Methodology
6.3. Results
- from 85% upwards, we considered the objective fully achieved;
- between 70% and 84%, we considered the objective well achieved;
- between 50% and 69%, we considered the objective achieved;
- between 30% and 49%, we considered the objective poorly achieved;
- from 29% down, we considered the objective not reached.
7. Natural Language Texts Main Issues
7.1. Ambiguity
7.1.1. Lessical Ambiguity
7.1.2. Syntactical Ambiguity
- Mario is in the park and (Mario) has binoculars (with which he saw Franco);
- Mario is in the park and saw Franco (who may not be in the park) who has binoculars;
- Franco is in the park and Mario has binoculars (with which he saw Franco);
- Franco is in the park and has binoculars and Mario saw him.
7.2. Word Variability
7.2.1. Synonyms
7.2.2. Variations in Spelling
- British vs. American English: Color (American) vs. Colour (British)
- Alternative Spellings: Traveling vs. Travelling
- Abbreviations and Contractions: Can’t vs. Cannot
- Improper Word Usage due to dialectical habits (e.g., “the teacher learns me to speak” instead of “teaches”)
- Neologisms: Emergence of new words borrowed from online dialogues (e.g., “L8er” for “later”)
7.2.3. Typos and Misspellings
- non-existing word (e.g., banf instead of band);
- existing word (e.g., bank instead of band) that could change the meaning of a sentence (“the bank went bankrupt” is a possible thing, just like “the band went bankrupt”).
7.3. Writing Style: Standardization and Formatting Problems
- Various uses of accented characters (only for vowel “a” there are 10 variants: á, à, â, , , , , , , ),
- Varied use of apostrophes (e.g., pò instead of po’ in Italian) highlights dialectical nuances.
- Variations in punctuation and capitalization.
- Diverse sentence structures contribute to the uniqueness of writing styles.
- Colloquial Expressions are also widely present, ranging from online texts to more formal contexts like literature, politics, and journalism.
7.4. Hidden Information
- Euphemisms, Disguises, and Metaphors to convey nuanced meanings.
- Irony and Rhetorical Figures to add layers of meaning.
8. Comparisons
8.1. PLM Family Systems Main Issues
- Pre-training:
- The process involves training a language model on a corpus of textual data. Schramowski et al. [84] explore the ethical and moral dimensions of LLMs. They emphasize that during pre-training, PLMs, exposed to vast amounts of unfiltered textual data, not only capture linguistic knowledge but also implicitly retain general knowledge present in the data.
- Data size: Pre-training requires a huge quantity of unfiltered data. The system’s statistical engine improves with the quantity of data it processes. As of 28 May 2020, GPT-3 counts 570 GB (300 billion words) of data from CommonCrawl, WebText, English Wikipedia, and two books corpora (Books1 and Books2) [85].
- Data quality: There is no certainty that the pre-training data are correct, as online text is rife with errors, biases, malicious content, and misinformation. In some cases, pre-training data may violate moral and legal laws or contain potentially sensitive information, as discussed by Huang et al. [86] in their analysis of the personal information disclosure tendencies of individuals with PLMs. Consequently, PLMs inherit and perpetuate biases from the training data, resulting in uncontrollable texts with distorted and biased content.
- Tokenization:
- PLMs break the text into tokens, then transform each token into a number and thereafter look for patterns in these tokens. PLMs implicitly capture information about words and their relationships based on the patterns and sequences they observe in the tokens from the data they were trained on. These models are capable of recognizing or generating coherent text, but they do not have explicit knowledge of semantics or the ability to understand concepts in the same way humans do. The model generates contextually appropriate text by predicting the next token in a sequence based on the preceding tokens.
- Semantics:
- Tokenization is performed without considering meanings or semantics. Consequently, these models lack a deep understanding of written language. This implies that the models cannot justify or explain exactly what they emit, which is particularly critical in applications such as healthcare and finance. Furthermore, recognizing ambiguity, both lexical and syntactic, is not straightforward. In general, questions related to the semantic knowledge of a text, such as detecting hidden meanings, remain challenging to resolve.
- Multi-Word Units:
- Multi-word units (MWUs) are “units of meaning” with high semantic value, but processing them is not straightforward.
- MWUs in PLMs: PLMs have no explicit knowledge of multiword units (MWUs) or phrases as atomic entities; they process an MWU as sequences of individual tokens. For example, the phrase “natural language processing” would be tokenized into three separate tokens: “natural”, “language”, and “processing”. Each token is considered independently during the model’s training and inference.
- MWU Size: An MWU can be very long and is composed of any number of simple words, as discussed in Section 3.1. An MWU has no “end unit” symbol (like a space or punctuation for a simple word). In real life, an MWU could theoretically extend to the end of the entire text. In the tokenization process, PLM determines where a “unit of meaning” stops and puts an “end of sentence” token.
- Occurrences of MWUs: In texts, MWUs occur with low frequency compared to single words; therefore, in an overall statistical analysis, they tend to be overlooked. To address this problem, it would be advisable to separate MWU statistics from simple word statistics.
- Spelling:
- Text Flaws: A text, both in the pre-training phase and in the mining phase, could contain spelling errors, typos, misspellings, and features of writing styles. Every word and every little part of a text is important in both the pre-training and mining processes, so a text should be corrected for these issues.
- Pre-processing: Pre-processing cleaning of the input text is necessary, but this is an expensive, time-consuming operation, and often it is not even possible. A pre-processing routine might detect a spelling error, but it might not correct it. Sometimes it may not even detect the error; for example, if there is a word that is lexically but not semantically correct.
- Behavior
- with texts of rare or unknown topics to the model: These models do not work reasonably well on rare or unknown events. LLMs may struggle to provide accurate responses or predictions for rare or unprecedented events due to their heavy reliance on learned patterns from historical data.
- Resource:
- These models, mainly for the pre-training process, require a lot of computational power, resources, and capital investment.
- Management:
- These models could be managed only by very large companies.
8.2. A Comparison between PLMs and AUTOMETA
- Pre-Training
- PL
- Typically, these techniques necessitate a significant initial learning process, often involving the analysis of millions of documents. The system’s statistical engine improves with the quantity of data it processes.
- AU
- In contrast, the proposed system does not require an extensive initial learning process and can recognize the semantic domain of a document without the need to read other documents from the same knowledge domain.
- Pre-processing
- PL
- Natural language texts lack a standard format (refer to Section 7), requiring an effort to make a text as “standard” as possible. Achieving this involves both a syntactic pre-processing phase and a deep understanding of the language, which statistical methods lack. This phase is delicate and time consuming, particularly because simple words, the focus of these methods, are numerous in a text. Probabilistically, they are often not very distinct from each other, making them easily confused. For instance, in a sentence discussing one’s bank, the phrase “my band is far away” might remain unnoticed as a writing error where “band” should have been “bank”. Context investigation is necessary to identify such errors.
- AU
- In contrast, the proposed system involves a “small” pre-processing phase to normalize the formal spelling of words, as multi-word units are few and diverse, minimizing pre-processing and dimensionality reduction. The system recognizes that these tasks are time consuming, error prone, and language specific.
- auto-correction
- PL
- Due to the lexical proximity among simple words, implementing auto-correcting techniques for errors is challenging.
- AU
- In contrast, the proposed system aims to auto-correct as many errors as possible in “useful” but ill-written text.
- polysemic
- PL
- In natural language, simple words are inherently polysemous, belonging to multiple semantic domains.
- AU
- In contrast, the proposed system detects as few “pieces of text” as possible, each carrying a substantial amount of semantic information and having few synonymy relationships.
8.3. A Comparison between AUTOMETA and Other Methods
8.3.1. Different Strategies from AUTOMETA
8.3.2. AUTOMETA
- Independent of the length and number of elementary words in a multi-word unit, it addresses challenges posed by very long units composed of a variable number of simple words.
- The processing time for a text of k characters requires state transitions. The Finite Automaton reads the input text character by character, concurrently identifying all multi-word units from selected ontologies, performing the analysis in linear time.
- Can handle large dictionary sizes without issues.
- Recognizes partially or completely overlapping multi-word units without additional computational effort.
- The entire ontology, stored in a finite automaton in central memory, ensures significantly faster access times compared to secondary memory.
- Ontologies do not need to be sorted, making addition, modification, or deletion of entries virtually computationally cost-free; we simply insert a new word at the end of the ontology or modify or delete a word without touching the others.
- Recognizes multi-word units directly while reading the input text, without providing feedback.
- Efficient for both short and long documents.
- Does not require a pre-training process.
9. Conclusions and Future Research Perspectives
9.1. Conclusions
9.2. Future Research Perspectives
- Ontology Structure Update: Focus on updating existing ontologies and creation of new electronic terminology ontologies for various semantic domains, such as e-government, biomedicine, ecological transition, etc. The flexibility of our approach allows modifications without the need to reorder ontology items.
- Testing and Validation: Conduct of comprehensive testing and validation of existing ontologies by applying them to more extensive corpora.
- Integration into Websites and Portals: Exploration of the integration of ontologies and software tools into websites and portals, allowing for internet users to test the system and provide feedback on its quality and usability.
- Automatic Translation of Multi-Word Units: Investigation of the addition of a translation feature to our approach, enabling the translation of multi-word units from one language to another. This capability is crucial, as translating multi-word units is not always straightforward by translating their individual components, given that a multi-word unit is a whole. The rapid translation feature could address errors in technological and scientific translation caused by the lack of reliable terminological bilingual electronic glossaries/dictionaries.
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, M.; Mao, S.; Liu, Y. Big Data: A Survey. Mob. Netw. Appl. 2014, 19, 171–209. [Google Scholar] [CrossRef]
- Philip Chen, C.; Zhang, C.Y. Data-Intensive Applications, Challenges, Techniques and Technologies: A Survey on Big Data. Inf. Sci. 2014, 275, 314–347. [Google Scholar] [CrossRef]
- Tsai, C.W.; Lai, C.F.; Chao, H.C.; Vasilakos, A.V. Big Data Analytics: A Survey. J. Big Data 2015, 2, 21. [Google Scholar] [CrossRef]
- Oussous, A.; Benjelloun, F.Z.; Ait Lahcen, A.; Belfkih, S. Big Data Technologies: A Survey. J. King Saud Univ.-Comput. Inf. Sci. 2018, 30, 431–448. [Google Scholar] [CrossRef]
- Adadi, A. A Survey on Data-efficient Algorithms in Big Data Era. J. Big Data 2021, 8, 24. [Google Scholar] [CrossRef]
- Zhang, H.; Lee, S.; Lu, Y.; Yu, X.; Lu, H. A Survey on Big Data Technologies and Their Applications to the Metaverse: Past, Current and Future. Mathematics 2023, 11, 96. [Google Scholar] [CrossRef]
- Atzori, L.; Iera, A.; Morabito, G. The Internet of Things: A Survey. Comput. Netw. 2010, 54, 2787–2805. [Google Scholar] [CrossRef]
- Tsai, C.W.; Lai, C.F.; Chiang, M.C.; Yang, L.T. Data Mining for Internet of Things: A Survey. IEEE Commun. Surv. Tutor. 2014, 16, 77–97. [Google Scholar] [CrossRef]
- Al-Fuqaha, A.; Guizani, M.; Mohammadi, M.; Aledhari, M.; Ayyash, M. Internet of Things: A Survey on Enabling Technologies, Protocols, and Applications. IEEE Commun. Surv. Tutor. 2015, 17, 2347–2376. [Google Scholar] [CrossRef]
- Qadri, Y.A.; Nauman, A.; Zikria, Y.B.; Vasilakos, A.V.; Kim, S.W. The Future of Healthcare Internet of Things: A Survey of Emerging Technologies. IEEE Commun. Surv. Tutor. 2020, 22, 1121–1167. [Google Scholar] [CrossRef]
- Zhong, Y.; Chen, L.; Dan, C.; Rezaeipanah, A. A Systematic Survey of Data Mining and Big Data Analysis in Internet of Things. J. Supercomput. 2022, 78, 18405–18453. [Google Scholar] [CrossRef]
- Xu, L.D.; He, W.; Li, S. Internet of Things in Industries: A Survey. IEEE Trans. Ind. Inform. 2014, 10, 2233–2243. [Google Scholar] [CrossRef]
- Boyes, H.; Hallaq, B.; Cunningham, J.; Watson, T. The Industrial Internet of Things (IIoT): An Analysis Framework. Comput. Ind. 2018, 101, 1–12. [Google Scholar] [CrossRef]
- Sisinni, E.; Saifullah, A.; Han, S.; Jennehag, U.; Gidlund, M. Industrial Internet of Things: Challenges, Opportunities, and Directions. IEEE Trans. Ind. Inform. 2018, 14, 4724–4734. [Google Scholar] [CrossRef]
- Paniagua, C.; Delsing, J. Industrial Frameworks for Internet of Things: A Survey. IEEE Syst. J. 2021, 15, 1149–1159. [Google Scholar] [CrossRef]
- Akhtar, M.; Neidhardt, J.; Werthner, H. The Potential of Chatbots: Analysis of Chatbot Conversations. In Proceedings of the 21st IEEE Conference on Business Informatics, CBI 2019, Moscow, Russia, 15–17 July 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; Volume 1, pp. 397–404. [Google Scholar] [CrossRef]
- Chaves, A.P.; Gerosa, M.A. How Should My Chatbot Interact? A Survey on Social Characteristics in Human–Chatbot Interaction Design. Int. J. Hum. Comput. Interact. 2021, 37, 729–758. [Google Scholar] [CrossRef]
- Chao, M.H.; Trappey, A.J.C.; Wu, C.T. Emerging Technologies of Natural Language-Enabled Chatbots: A Review and Trend Forecast Using Intelligent Ontology Extraction and Patent Analytics. Complexity 2021, 2021, 5511866. [Google Scholar] [CrossRef]
- Rapp, A.; Curti, L.; Boldi, A. The Human Side of Human-Chatbot Interaction: A Systematic Literature Review of Ten Years of Research on Text-Based Chatbots. Int. J. Hum. Comput. Stud. 2021, 151, 102630. [Google Scholar] [CrossRef]
- Luo, B.; Lau, R.Y.K.; Li, C.; Si, Y.W. A Critical Review of State-of-the-Art Chatbot Designs and Applications. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2022, 12, e1434. [Google Scholar] [CrossRef]
- Zong, C.; Xia, R.; Zhang, J. Text Data Mining; Springer: Singapore, 2021; pp. 1–351. [Google Scholar] [CrossRef]
- Tandel, S.S.; Jamadar, A.; Dudugu, S. A Survey on Text Mining Techniques. In Proceedings of the 2019 5th International Conference on Advanced Computing and Communication Systems, ICACCS 2019, Coimbatore, India, 15–16 March 2019; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2019; pp. 1022–1026. [Google Scholar] [CrossRef]
- Aggarwal, C.C.; Zhai, C. Mining Text Data; Springer: Boston, MA, USA, 2012; pp. 1–526. [Google Scholar]
- Aggarwal, C.C.; Zhai, C. A Survey of Text Classification Algorithms. In Mining Text Data; Aggarwal, C.C., Zhai, C., Eds.; Springer: Boston, MA, USA, 2012; pp. 163–222. [Google Scholar] [CrossRef]
- Usai, A.; Pironti, M.; Mital, M.; Aouina Mejri, C. Knowledge Discovery out of Text Data: A Systematic Review via Text Mining. J. Knowl. Manag. 2018, 22, 1471–1488. [Google Scholar] [CrossRef]
- Kowsari, K.; Meimandi, K.J.; Heidarysafa, M.; Mendu, S.; Barnes, L.; Brown, D. Text Classification Algorithms: A Survey. Information 2019, 10, 150. [Google Scholar] [CrossRef]
- Kumar, M.; Kumar, S.; Yadav, S.L. Data Mining for the Internet of Things: A Survey; Apple Academic Press: Waretown, NJ, USA, 2023; pp. 93–109. [Google Scholar]
- Navathe, S.B.; Ramez, E. Data warehousing and data mining. In Fundamentals of Database Systems; Pearson Education: Singapore, 2000; pp. 841–872. [Google Scholar]
- Gupta, V.; Lehal, G.S. A survey of text mining techniques and applications. J. Emerg. Technol. Web Intell. 2009, 1, 60–76. [Google Scholar] [CrossRef]
- Liao, S.H.; Chu, P.H.; Hsiao, P.Y. Data Mining Techniques and Applications—A Decade Review from 2000 to 2011. Expert Syst. Appl. 2012, 39, 11303–11311. [Google Scholar] [CrossRef]
- Kusakin, I.; Fedorets, O.; Romanov, A. Classification of Short Scientific Texts. Sci. Tech. Inf. Process. 2023, 50, 176–183. [Google Scholar] [CrossRef]
- Danilov, G.; Ishankulov, T.; Kotik, K.; Orlov, Y.; Shifrin, M.; Potapov, A. The Classification of Short Scientific Texts Using Pretrained BERT Model; IOS Press: Amsterdam, The Netherlands, 2021; pp. 83–87. [Google Scholar] [CrossRef]
- Ongenaert, M.; Van Neste, L.; De Meyer, T.; Menschaert, G.; Bekaert, S.; Van Criekinge, W. PubMeth: A cancer methylation database combining text-mining and expert annotation. Nucleic Acids Res. 2008, 36, D842–D846. [Google Scholar] [CrossRef] [PubMed]
- Cejuela, J.M.; McQuilton, P.; Ponting, L.; Marygold, S.; Stefancsik, R.; Millburn, G.H.; Rost, B. Tagtog: Interactive and text-mining-assisted annotation of gene mentions in PLOS full-text articles. Database 2014, 2014, bau033. [Google Scholar] [CrossRef]
- Baltoumas, F.A.; Zafeiropoulou, S.; Karatzas, E.; Paragkamian, S.; Thanati, F.; Iliopoulos, I.; Eliopoulos, A.G.; Schneider, R.; Jensen, L.J.; Pafilis, E.; et al. OnTheFly2.0: A text-mining web application for automated biomedical entity recognition, document annotation, network and functional enrichment analysis. NAR Genom. Bioinform. 2021, 3, lqab090. [Google Scholar] [CrossRef]
- Chu, C.Y.; Park, K.; Kremer, G.E. A Global Supply Chain Risk Management Framework: An Application of Text-Mining to Identify Region-Specific Supply Chain Risks. Adv. Eng. Inform. 2020, 45, 101053. [Google Scholar] [CrossRef]
- Nota, G.; Postiglione, A.; Carvello, R. Text Mining Techniques for the Management of Predictive Maintenance. In Proceedings of the 3rd International Conference on Industry 4.0 and Smart Manufacturing, ISM 2021, Linz, Austria, 17–19 November 2021; Longo, F., Affenzeller, M.P.A., Eds.; Elsevier: Amsterdam, The Netherlands, 2022; Volume 200, pp. 778–792. [Google Scholar] [CrossRef]
- Kumar, B.S.; Ravi, V. A Survey of the Applications of Text Mining in Financial Domain. Knowl.-Based Syst. 2016, 114, 128–147. [Google Scholar] [CrossRef]
- Gupta, A.; Dengre, V.; Kheruwala, H.A.; Shah, M. Comprehensive review of text-mining applications in finance. Financ. Innov. 2020, 6, 39. [Google Scholar] [CrossRef]
- Kumar, S.; Kar, A.K.; Ilavarasan, P.V. Applications of text mining in services management: A systematic literature review. Int. J. Inf. Manag. Data Insights 2021, 1, 100008. [Google Scholar] [CrossRef]
- Ngai, E.; Lee, P. A review of the literature on applications of text mining in policy making. In Proceedings of the Pacific Asia Conference on Information Systems, PACIS 2016, Chiayi, Taiwan, 27 June–1 July 2016. [Google Scholar]
- Fenza, G.; Orciuoli, F.; Peduto, A.; Postiglione, A. Healthcare Conversational Agents: Chatbot for Improving Patient-Reported Outcomes. Lect. Notes Netw. Syst. 2023, 661, 137–148. [Google Scholar] [CrossRef]
- Cheerkoot-Jalim, S.; Khedo, K.K. A systematic review of text mining approaches applied to various application areas in the biomedical domain. J. Knowl. Manag. 2020, 25, 642–668. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, I.; Rodríguez, J.V.; Shirvanizadeh, N.; Ortiz, A.; Pardo-Quiles, D.J. Applications of artificial intelligence, machine learning, big data and the internet of things to the COVID-19 pandemic: A scientometric review using text mining. Int. J. Environ. Res. Public Health 2021, 18, 8578. [Google Scholar] [CrossRef]
- Abbe, A.; Grouin, C.; Zweigenbaum, P.; Falissard, B. Text mining applications in psychiatry: A systematic literature review. Int. J. Methods Psychiatr. Res. 2016, 25, 86–100. [Google Scholar] [CrossRef]
- Drury, B.; Roche, M. A Survey of the Applications of Text Mining for Agriculture. Comput. Electron. Agric. 2019, 163, 104864. [Google Scholar] [CrossRef]
- Irfan, R.; King, C.K.; Grages, D.; Ewen, S.; Khan, S.U.; Madani, S.A.; Kolodziej, J.; Wang, L.; Chen, D.; Rayes, A.; et al. A Survey on Text Mining in Social Networks. Knowl. Eng. Rev. 2015, 30, 157–170. [Google Scholar] [CrossRef]
- Salloum, S.A.; Al-Emran, M.; Monem, A.A.; Shaalan, K. A Survey of Text Mining in Social Media: Facebook and Twitter Perspectives. Adv. Sci. Technol. Eng. Syst. 2017, 2, 127–133. [Google Scholar] [CrossRef]
- Ferreira-Mello, R.; André, M.; Pinheiro, A.; Costa, E.; Romero, C. Text Mining in Education. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1332. [Google Scholar] [CrossRef]
- Postiglione, A. Text Mining with Finite State Automata via Compound Words Ontologies; Lecture Notes on Data Engineering and Communications Technologies; Springer Nature: Berlin, Germany, 2024; Volume 193, pp. 1–12. [Google Scholar]
- Gross, M. Lexicon-Grammar and the Syntactic Analysis of French. In Proceedings of the 10th International Conference on Computational Linguistics, COLING 1984 and 22nd Annual Meeting of the Association for Computational Linguistics, ACL 1984, Stanford, CA, USA, 2–6 July 1984; pp. 275–282. [Google Scholar]
- Gross, M. The construction of electronic dictionaries; [La construction de dictionnaires électroniques]. Ann. Télécommun. 1989, 44, 4–19. [Google Scholar] [CrossRef]
- Gross, M. The Use of Finite Automata in the Lexical Representation of Natural Language. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 1989, 377, 34–50. [Google Scholar] [CrossRef]
- Monteleone, M. NooJ for Artificial Intelligence: An Anthropic Approach. Commun. Comput. Inf. Sci. 2021, 1389, 173–184. [Google Scholar] [CrossRef]
- Aho, A.V.; Corasick, M.J. Efficient String Matching: An Aid to Bibliographic Search. Commun. ACM 1975, 18, 333–340. [Google Scholar] [CrossRef]
- Boyer, R.S.; Moore, J.S. A Fast String Searching Algorithm. Commun. ACM 1977, 20, 762–772. [Google Scholar] [CrossRef]
- Crochemore, M.; Hancart, C.; Lecroq, T. Algorithms Strings; Cambridge University Press: Cambridge, UK, 2007; Volume 9780521848992, pp. 1–383. [Google Scholar] [CrossRef]
- Hakak, S.I.; Kamsin, A.; Shivakumara, P.; Gilkar, G.A.; Khan, W.Z.; Imran, M. Exact String Matching Algorithms: Survey, Issues, and Future Research Directions. IEEE Access Pract. Innov. Open Solut. 2019, 7, 69614–69637. [Google Scholar] [CrossRef]
- Postiglione, A.; Monteleone, M. Towards Automatic Filing of Corpora. In Proceedings of the 18ème COLLOQUE INTERNATIONAL “Lexique et Grammaires Comparçs”, Parco Scientifico e Tecnologico Di Salerno e Delle Aree Interne Della Campania, Salerno, Italy, 6–9 October 1999; pp. 1–9. [Google Scholar]
- Elia, A.; Monteleone, M.; Postiglione, A. Cataloga: A Software for Semantic-Based Terminological Data Mining. In Proceedings of the 1st International Conference on Data Compression, Communication and Processing, Palinuro, Italy, 21–24 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 153–156. [Google Scholar] [CrossRef]
- Elia, A.; Postiglione, A.; Monteleone, M.; Monti, J.; Guglielmo, D. CATALOGA: A Software for Semantic and Terminological Information Retrieval. In Proceedings of the ACM International Conference Proceeding Series, Wuhan, China, 13–14 August 2011; pp. 1–9. [Google Scholar] [CrossRef]
- Postiglione, A.; Monteleone, M. Semantic-Based Bilingual Text-Mining. In Proceedings of the Second International Conference on Data Compression, Communication, Processing and Security (CCPS 2016), Cetara, Italy, 22–23 September 2016; pp. 1–4. [Google Scholar]
- Hadi, M.U.; Tashi, Q.A.; Qureshi, R.; Shah, A.; Muneer, A.; Irfan, M.; Zafar, A.; Shaikh, M.B.; Akhtar, N.; Wu, J.; et al. Large Language Models: A Comprehensive Survey of its Applications, Challenges, Limitations, and Future Prospects. Authorea Prepr. 2023. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent Advances in Natural Language Processing via Large Pre-trained Language Models: A Survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Wu, J.; Yang, S.; Zhan, R.; Yuan, Y.; Wong, D.F.; Chao, L.S. A Survey on LLM-generated Text Detection: Necessity, Methods, and Future Directions. arXiv 2023, arXiv:cs.CL/2310.14724. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 2017, pp. 5999–6009. [Google Scholar]
- Qiu, X.; Sun, T.; Xu, Y.; Shao, Y.; Dai, N.; Huang, X. Pre-trained models for natural language processing: A survey. Sci. China Technol. Sci. 2020, 63, 1872–1897. [Google Scholar] [CrossRef]
- Silva Barbon, R.; Akabane, A.T. Towards Transfer Learning Techniques—BERT, DistilBERT, BERTimbau, and DistilBERTimbau for Automatic Text Classification from Different Languages: A Case Study. Sensors 2022, 22, 8184. [Google Scholar] [CrossRef]
- Onita, D. Active Learning Based on Transfer Learning Techniques for Text Classification. IEEE Access 2023, 11, 28751–28761. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the NAACL HLT 2019—2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A primer in bertology: What we know about how bert works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Kaliyar, R.K. A multi-layer bidirectional transformer encoder for pre-trained word embedding: A survey of BERT. In Proceedings of the Confluence 2020—10th International Conference on Cloud Computing, Data Science and Engineering, Noida, India, 29–31 January 2020; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2020; pp. 336–340. [Google Scholar] [CrossRef]
- Xia, P.; Wu, S.; van Durme, B. Which *BERT? A survey organizing contextualized encoders. In Proceedings of the EMNLP 2020—2020 Conference on Empirical Methods in Natural Language Processing, Virtual, 16–20 November 2020; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2020; pp. 7516–7533. [Google Scholar]
- Mohammed, A.H.; Ali, A.H. Survey of BERT (Bidirectional Encoder Representation Transformer) types. J. Phys. Conf. Ser. 2021, 1963, 012173. [Google Scholar] [CrossRef]
- Aftan, S.; Shah, H. A Survey on BERT and Its Applications. In Proceedings of the 20th International Learning and Technology Conference, Jeddah, Saudi Arabia, 26 January 2023; Institute of Electrical and Electronics Engineers Inc.: Piscataway, NJ, USA, 2023; pp. 161–166. [Google Scholar] [CrossRef]
- Zhou, C.; Li, Q.; Li, C.; Yu, J.; Liu, Y.; Wang, G.; Zhang, K.; Ji, C.; Yan, Q.; He, L. A Comprehensive Survey on Pretrained Foundation Models: A History from Bert to Chatgpt. arXiv 2023, arXiv:2302.09419. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training. OpenAI Blog 2018, 1–12. Available online: https://www.mikecaptain.com/resources/pdf/GPT-1.pdf (accessed on 3 February 2024).
- Zhang, C.; Zhang, C.; Zheng, S.; Qiao, Y.; Li, C.; Zhang, M.; Dam, S.K.; Thwal, C.M.; Tun, Y.L.; Huy, L.L.; et al. A Complete Survey on Generative AI (AIGC): Is ChatGPT from GPT-4 to GPT-5 All You Need? arXiv 2023, arXiv:cs.AI/2303.11717. [Google Scholar]
- Kalyan, K.S. A survey of GPT-3 family large language models including ChatGPT and GPT-4. Nat. Lang. Process. J. 2024, 6, 100048. [Google Scholar] [CrossRef]
- Calzolari, N.; Fillmore, C.J.; Grishman, R.; Ide, N.; Lenci, A.; MacLeod, C.; Zampolli, A. Towards Best Practice for Multiword Expressions in Computational Lexicons. In Proceedings of the 3rd International Conference on Language Resources and Evaluation, LREC 2002, Las Palmas, Spain, 27 May–2 June 2002; pp. 1934–1940. [Google Scholar]
- Sag, I.A.; Baldwin, T.; Bond, F.; Copestake, A.; Flickinger, D. Multiword Expressions: A Pain in the Neck for NLP. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2002, 2276, 1–15. [Google Scholar] [CrossRef]
- Constant, M.; Eryiğit, G.; Monti, J.; Van Der Plas, L.; Ramisch, C.; Rosner, M.; Todirascu, A. Multiword Expression Processing: A Survey. Comput. Linguist. 2017, 43, 837–892. [Google Scholar] [CrossRef]
- Zhang, M.; Li, J. A commentary of GPT-3 in MIT Technology Review 2021. Fundam. Res. 2021, 1, 831–833. [Google Scholar] [CrossRef]
- Schramowski, P.; Turan, C.; Andersen, N.; Rothkopf, C.A.; Kersting, K. Large pre-trained language models contain human-like biases of what is right and wrong to do. Nat. Mach. Intell. 2022, 4, 258–268. [Google Scholar] [CrossRef]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems, Virtual, 6–12 December 2020; Volume 2020-December. [Google Scholar]
- Huang, J.; Shao, H.; Chang, K.C.C. Are Large Pre-Trained Language Models Leaking Your Personal Information? In Findings of the Association for Computational Linguistics: EMNLP 2022; Association for Computational Linguistics (ACL): Stroudsburg, PA, USA, 2022; pp. 2038–2047. [Google Scholar]


{kind=link}
{kind=link}
| Words | Chars | Knowledge Domains |
|---|---|---|
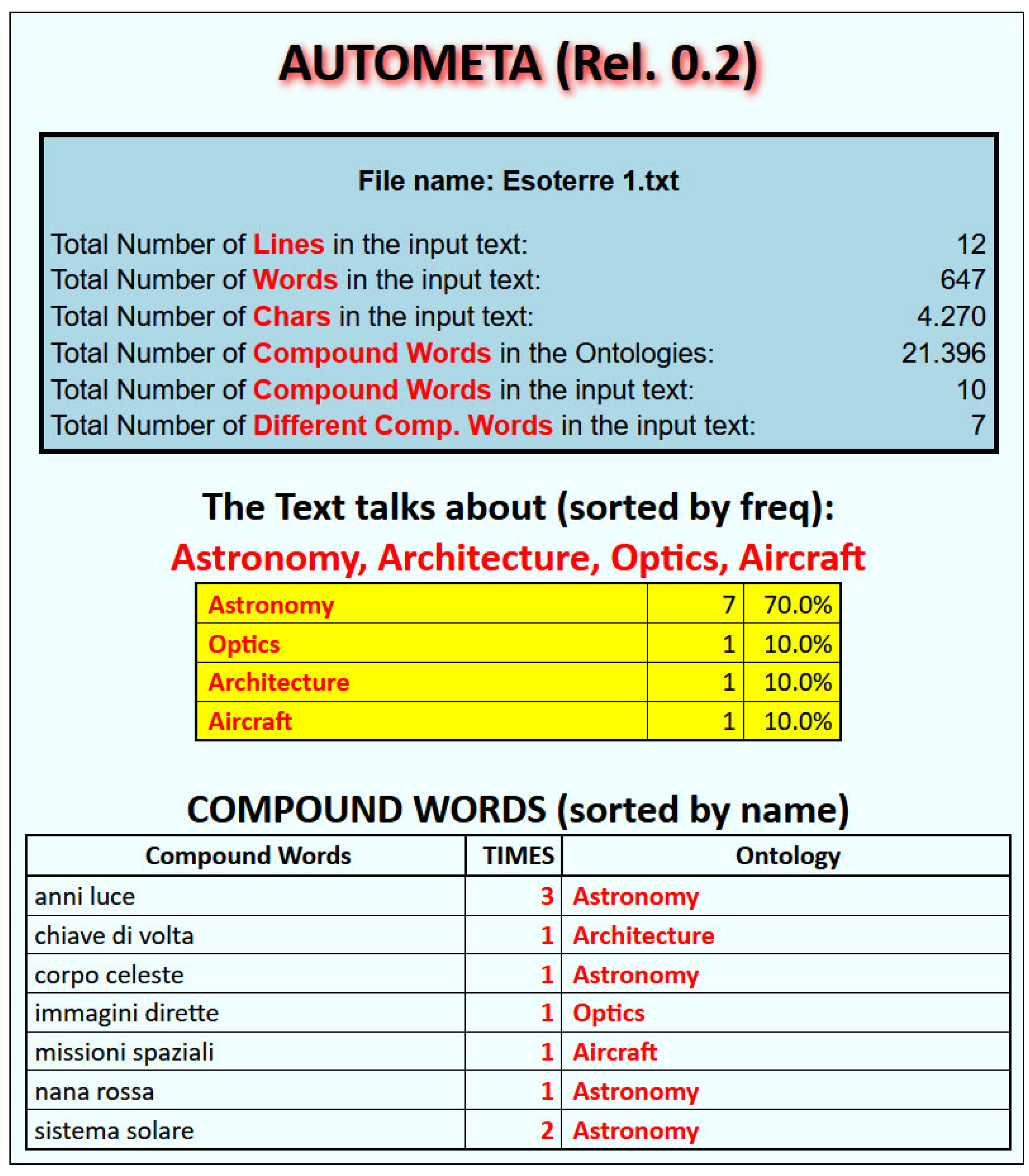
| 647 | 4270 | Astronomy (7), Architecture (1), Aircraft (1), Optics (1) |
| 440 | 2884 | Astronomy (7), Aircraft (1), Optics (1) |
| 168 | 1093 | Astronomy (6) |
| 186 | 1220 | Astronomy (2) |
| 182 | 1178 | Astronomy (3), Architecture (1) |
| Goal | Documents | Avg. Words | Avg. Chars | Avg. Percentage |
|---|---|---|---|---|
| Fully Achieved | 52 | 721.50 | 5279.87 | 93.56% |
| Well Achieved | 31 | 956.93 | 6731.37 | 75.97% |
| Achieved | 8 | 698.25 | 4598.13 | 52.50% |
| Poorly Achieved | 2 | 581.50 | 3687.50 | 37.50% |
| Not Achieved | 7 | 440.71 | 2716.14 | 2.86% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Postiglione, A. Finite State Automata on Multi-Word Units for Efficient Text-Mining. Mathematics 2024, 12, 506. https://doi.org/10.3390/math12040506
Postiglione A. Finite State Automata on Multi-Word Units for Efficient Text-Mining. Mathematics. 2024; 12(4):506. https://doi.org/10.3390/math12040506
Chicago/Turabian StylePostiglione, Alberto. 2024. "Finite State Automata on Multi-Word Units for Efficient Text-Mining" Mathematics 12, no. 4: 506. https://doi.org/10.3390/math12040506
APA StylePostiglione, A. (2024). Finite State Automata on Multi-Word Units for Efficient Text-Mining. Mathematics, 12(4), 506. https://doi.org/10.3390/math12040506