

Analysis of Production and Failure Data in Automotive: From Raw Data to Predictive Modeling and Spare Parts


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- collect and record information on failures and defects found.
- filter, interpret and analyze all this information.
- obtain the probability curves that represent the reliability behavior of the product.
- predict the trend of future failures over time.
- Materials and Methods: The research begins by gathering and examining data from an automotive Original Equipment Manufacturer (OEM) and a Car Manufacturer (CM). This includes data on original and spare part production, lead times, and vehicle mileage. The study also pays close attention to how data on part failures is collected and analyzed. For estimating the reliability of automotive parts, the study first uses the Kaplan-Meier estimator, a non-parametric method. Then, it shifts to the Weibull model, a parametric method, for predicting when parts might fail over time.
- Results and Discussion: The paper discusses the main outcomes. This includes determining when parts start being used, how the vehicle fleet ages over time, and both non-parametric and parametric estimates of part reliability. It also explores forecasting the need for spare parts and examines how well the methodology works. It also concludes that its approach effectively combines different types of data to predict when automotive parts might fail. The predictions match well with the actual data, although the paper notes some factors that might explain any small differences.
- Comprehensive Data Integration: it integrates data from various sources in the automotive sector, including original and spare part production, vehicle mileage, and failure data. This multi-faceted approach is relatively unique.
- Advanced Statistical Techniques: The use of both non-parametric (Kaplan-Meier estimator) and parametric (Weibull distribution) methods for predicting failures represents an advanced statistical approach, especially outside the use of software tools. This dual method enhances the accuracy and reliability of predictions.
- Real-World Application and Validation: The study is grounded in real-world data, also in the sense that the data are not filtered or corrected to simplify the analysis. This aspect adds significant value to the research, as it demonstrates the applicability of the findings in actual industrial scenarios.
- Methodological Framework: The research outlines a detailed methodological framework that can be replicated or adapted for similar studies in other contexts, making it a valuable reference for future research in the field.
- Multi-Dimensional Analysis: The analysis considers various factors like lead time, production trends, and vehicle usage patterns. This holistic view is relatively novel in automotive reliability research, which often focuses on narrower aspects.
- Consideration of Censored Data: The paper’s approach to handling censored data (by simulating them) in the analysis is methodologically sound and enhances the robustness of the study’s conclusions.
- High Precision in Predictions: The study achieves high precision in its predictive models (over 95% accuracy), which is notable in the field of reliability engineering.
2. Materials and Methods
2.1. Production and Use
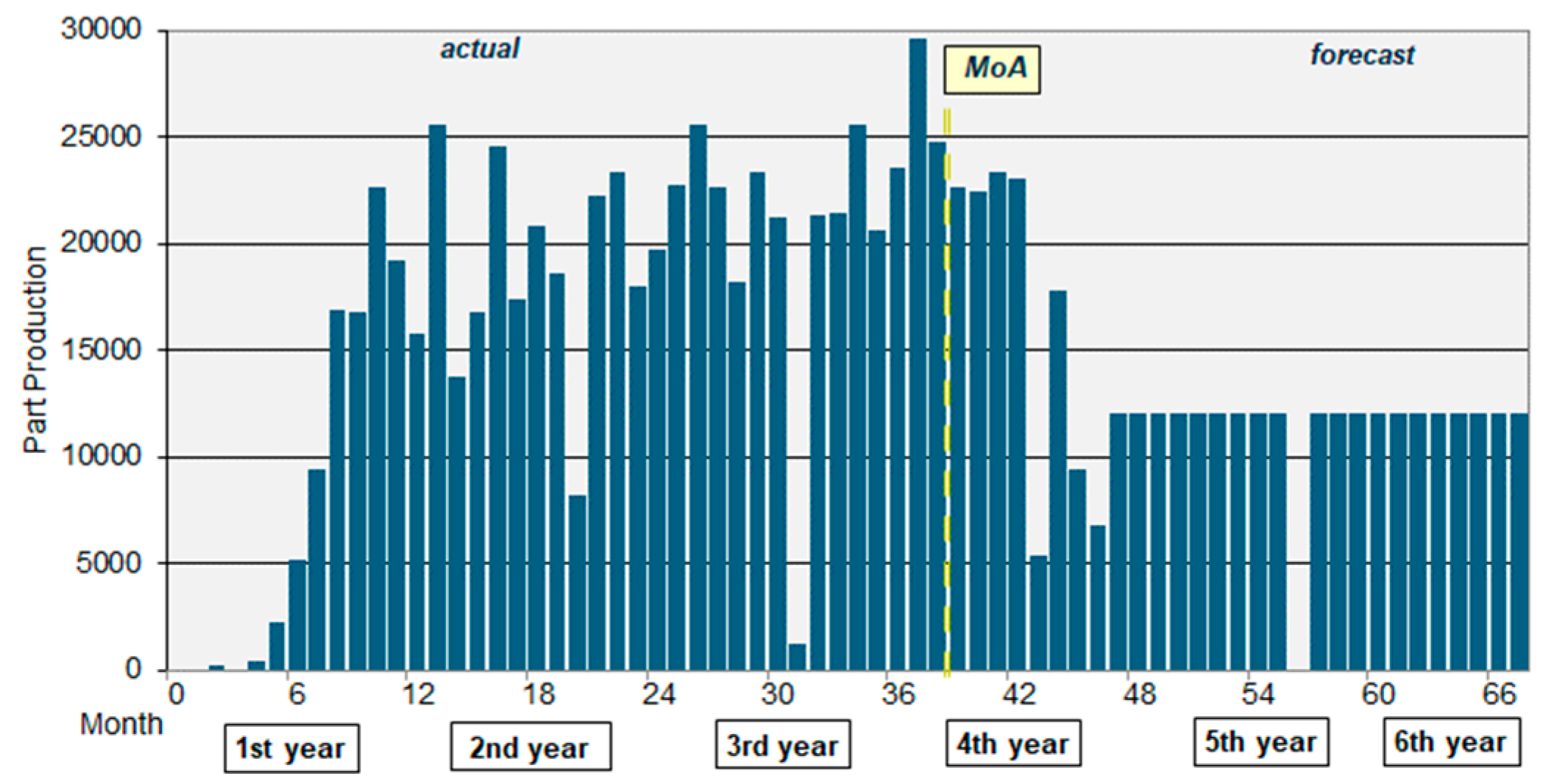
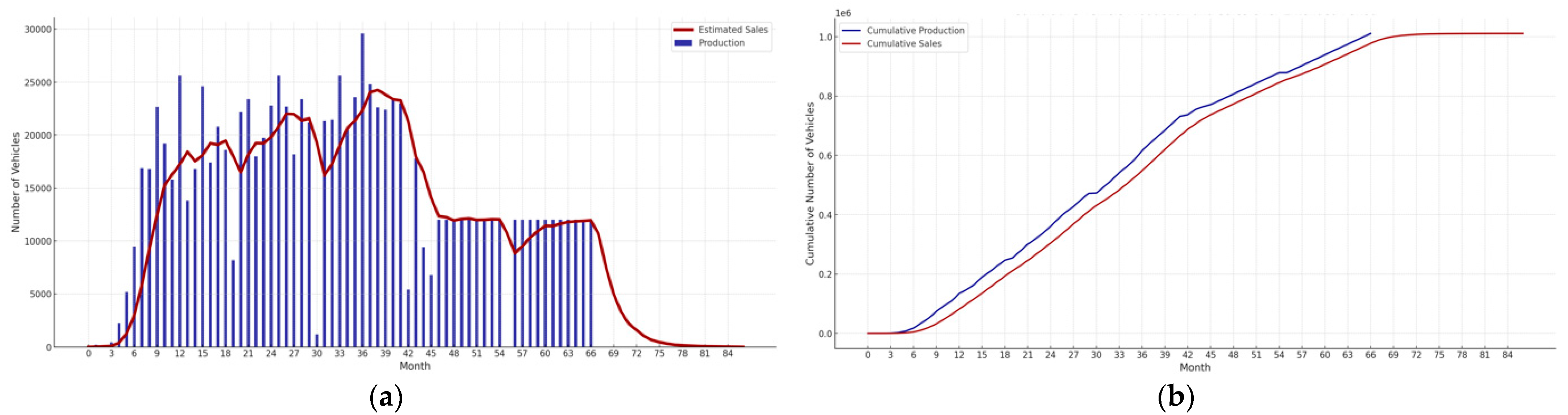
2.1.1. Original Part Production
- an ‘acceleration ramp’ increasing the production rate to 20,000 parts/mo. in ½ year.
- the saved possibility to boost (by +50%) productive targets, whenever necessary.
- a large variability, ranging from a few parts (in August) to 30,000 units/month.
- 64% of production completed at the Moment of the Analysis (MoA) = 38th month (M38)
- a production trend precisely known only up to a few months beyond this limit (M38)
2.1.2. Spare Part Production
- the spare part production starts late respect to the original part production considering that spare part need is low as long as the vehicles have come a short distance.
- the alignment between original part and spare part productions happens gradually.
- in the meantime, it is possible to establish an initial stockpile (of spare parts) by leveraging those (limited) overproduction situations typical of production processes.
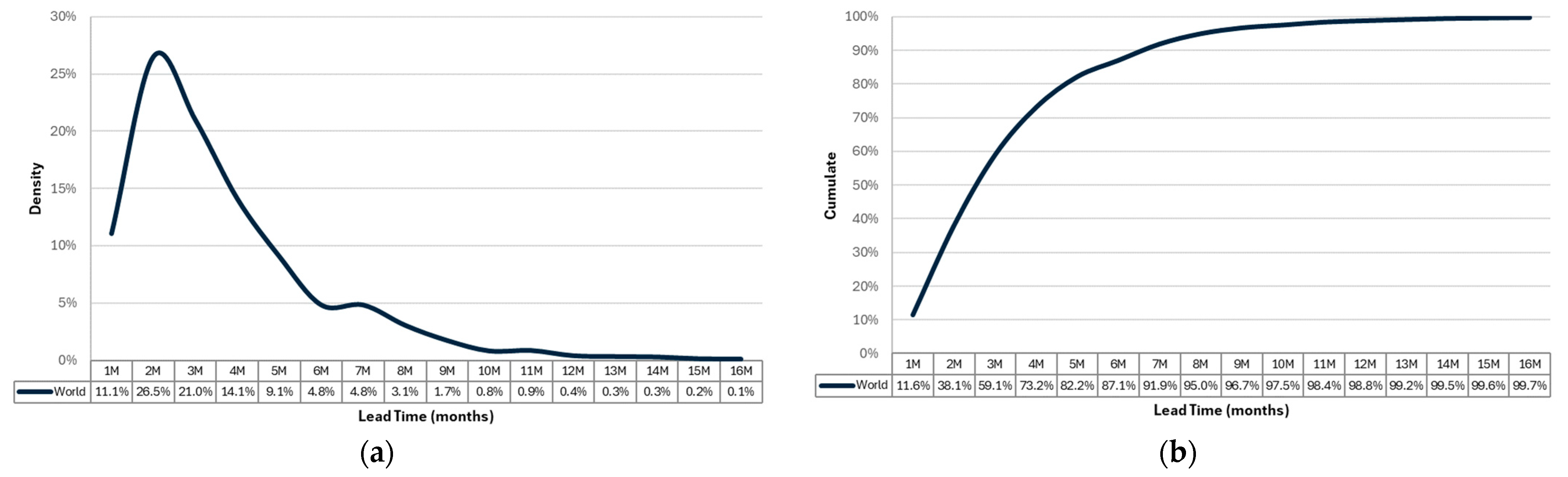
2.1.3. Lead Time
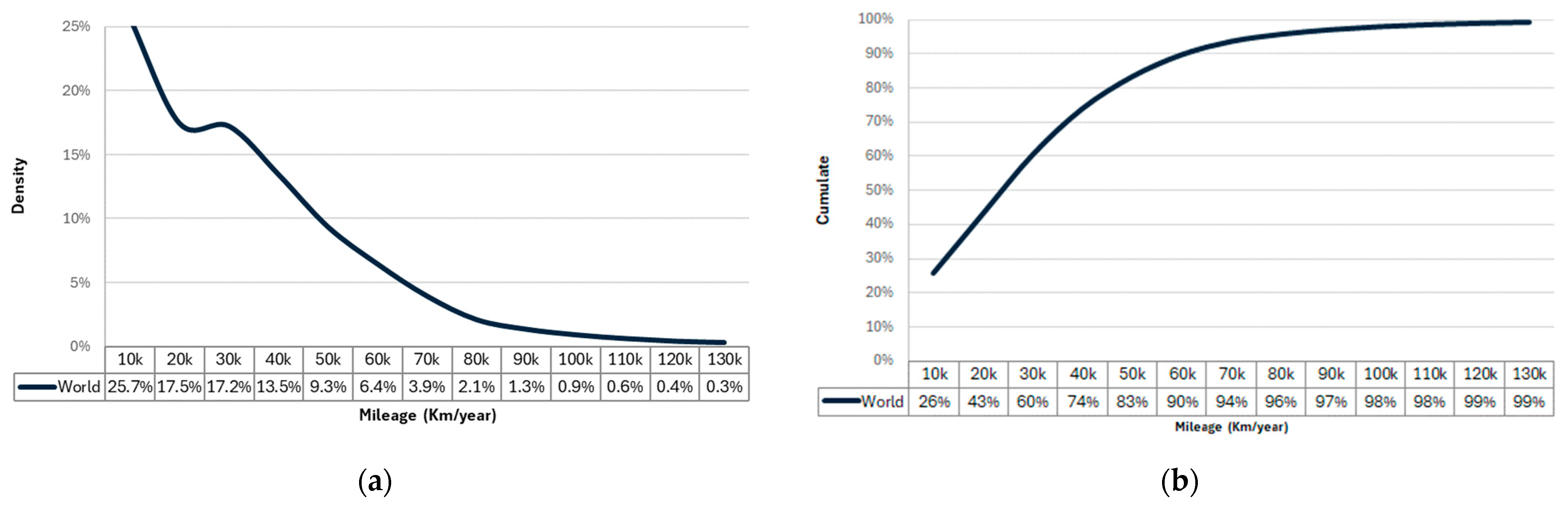
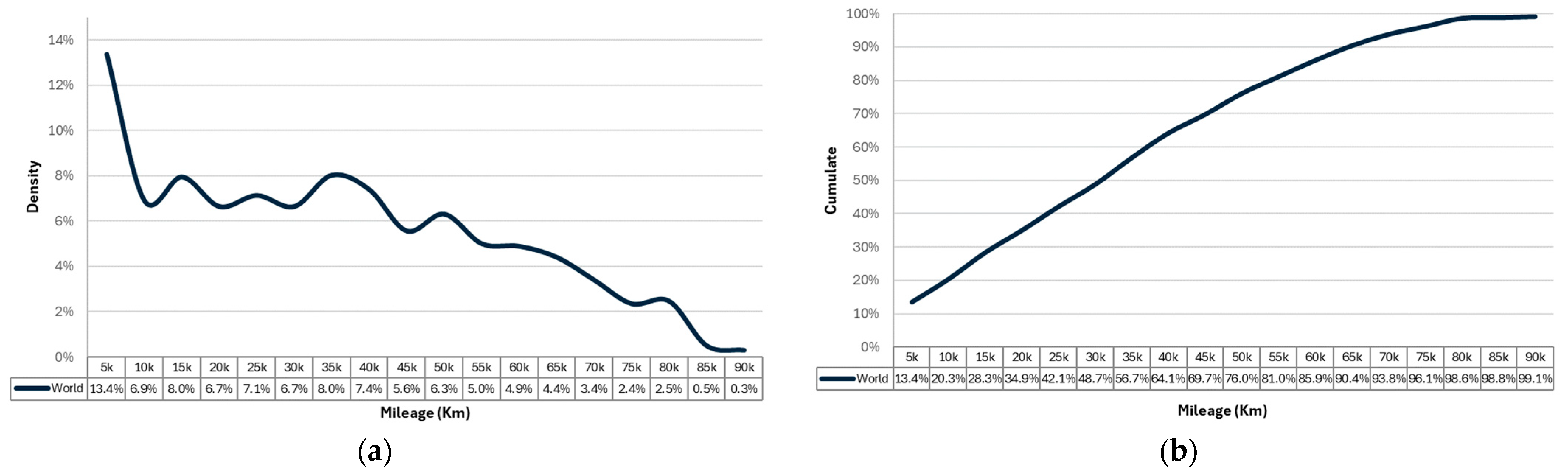
2.1.4. Mileage
2.2. Failure Data
- Chassis number.
- Assembly date.
- Delivery date.
- Claim date.
- Country.
- Age in month.
- Mileage.
- both metrics can conveniently serve for assessing the system reliability. The choice between them depends on the specific nature of the failure under investigation. In this study, given that the failure is related to engine control components, the mileage is chosen as metric for analysis (‘running unit’), as more pertinent for the case.
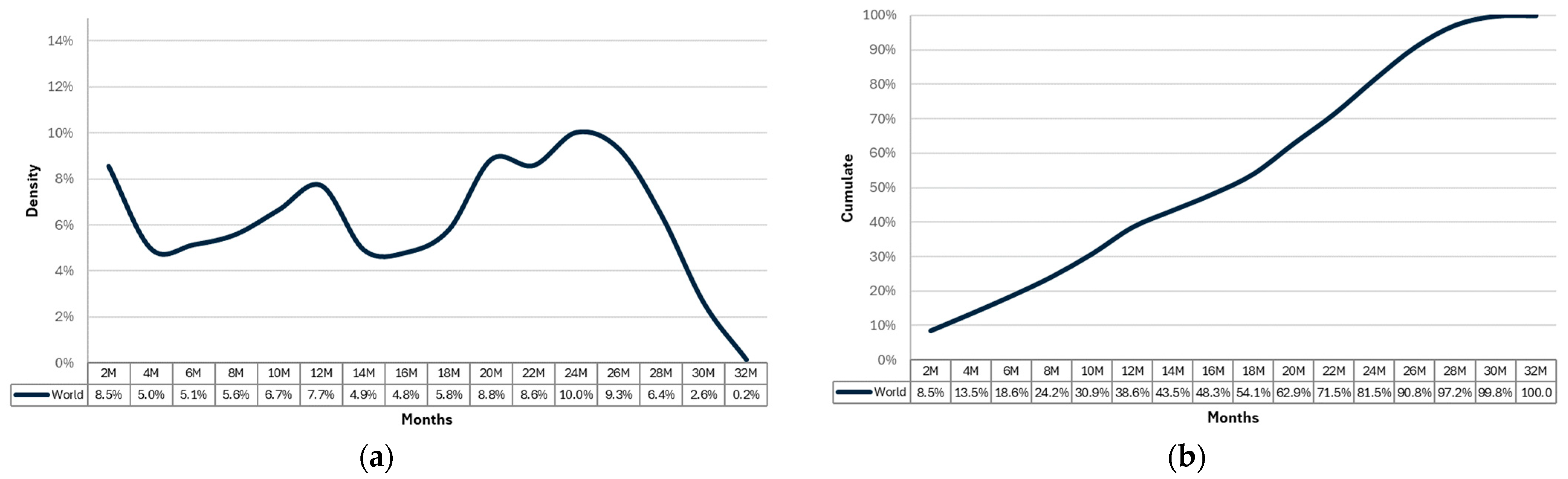
- while the diagrams in Figure 5 and Figure 6 can be used for a preliminary overlook about what is happening in the circulating fleet of cars, they are not able to characterize the reliability behavior as they fail to incorporate essential information such as the “fleet mileage aging”. For instance, Figure 5a highlights 8% of failures between 30,000 and 35,000 km, but it misses to clarify how many cars ended up traveling these mileages.
- more generally, to correctly evaluate the reliability behavior, it is necessary to incorporate the “censored times”, i.e., survival data, which indicate that certain parts have endured certain operating times. And a simulation is needed for the scope.
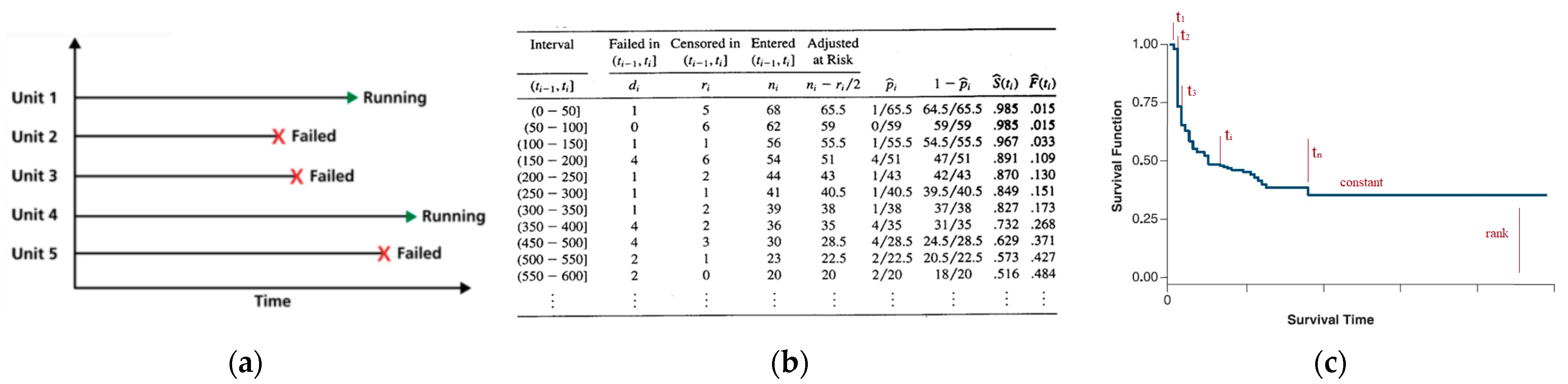
2.3. Survival Non-Parametric Estimation
- Time interval (ti − ti−1), the period (e.g., hours, km, …) over which the data is observed.
- Failed in Interval (di), the number of failures that occurred during each time interval.
- Censored in Interval (ri), the number of censored data points in each time interval, representing units that have not failed but are no longer being observed.
- Entered (ni), the ‘risk set’, equal to the total number of subjects at risk of failure (‘at-risk’) at the beginning of each time i interval.
- Adjusted At Risk (2ni − ri/2), an adjustment to the at-risk number (ni) to better account for censored cases and better reflect the average risk during the interval.
- Failure Risk (pi), the probability of failing through the end of the i interval, calculated as the number of failed (di) by the adjusted number at risk (2ni − ri/2).
- Survival Probability (1 − pi), the probability of surviving without failure through the end of the i interval.
- Survival Function (S(ti)), the product of all previous interval survival probabilities (1 − pi), representing the overall survival probability up to that point in time ti.
- Failure Function (F(ti)), the probability that failure has occurred by time ti, which can be calculated as 1 − S(ti).
2.4. Weibull Reliability Function
- infer the reliability and failure behavior of products or systems,
- estimate their lifetime,
- make decisions about maintenance and warranty.
2.5. Methodological Framework
- 1.
- Input Data
- a.
- Production Trend (from the OEM database)
- b.
- Lead Time Distribution (from the OEM database and CM market data)
- c.
- Mileage Distribution (from CM service data)
- d.
- Failure Data (from CM service data)
- 2.
- Derived Data
- e.
- Sales Trend (combining Production and Lead Time)
- f.
- Fleet Mileage Aging (combining Delivery and Mileages Distribution)
- g.
- Censors (considering the Fleet Mileage Aging at the MoA)
- h.
- Multiple-Censoring Failure Dataset
- i.
- Reliability Non-Parametric Estimation (by Kaplan-Meier Estimator).
- j.
- Reliability Parametric Estimation (by Weibull failure model)
- k.
- Spare Parts Prediction (from Fleet Mileage and Reliability Estimation)
- Production Trend and Lead Time Distribution are combined to obtain the Sales Trend which effectively estimates the moment in which the vehicles entered the operational state and begin to accumulate kilometers. After this, Production Trend and Lead Time Distribution are no longer needed, replaced in subsequent calculations by the Sales Trend.
- Sales Trend and Mileage Distribution are combined to obtain the Fleet Mileage Aging, identified as the distribution of kilometers traveled by vehicles in circulation. This distribution changes over time, moving to ever higher mileages, and is calculated at different times for different scopes.
- As first, the Fleet Mileage Aging is evaluated respect to the exact moment the failure data are updated (MoA). Thus, it is determined the mileage distribution of the vehicles put into circulation, representative of the failures recorded. This distribution allows us to identify the censoring data.
- Failures and censorship data are combined to obtain a multiply censored data from which it is possible to evaluate a (non-parametric) estimation of the reliability/survival function by applying the Kaplan-Meier method.
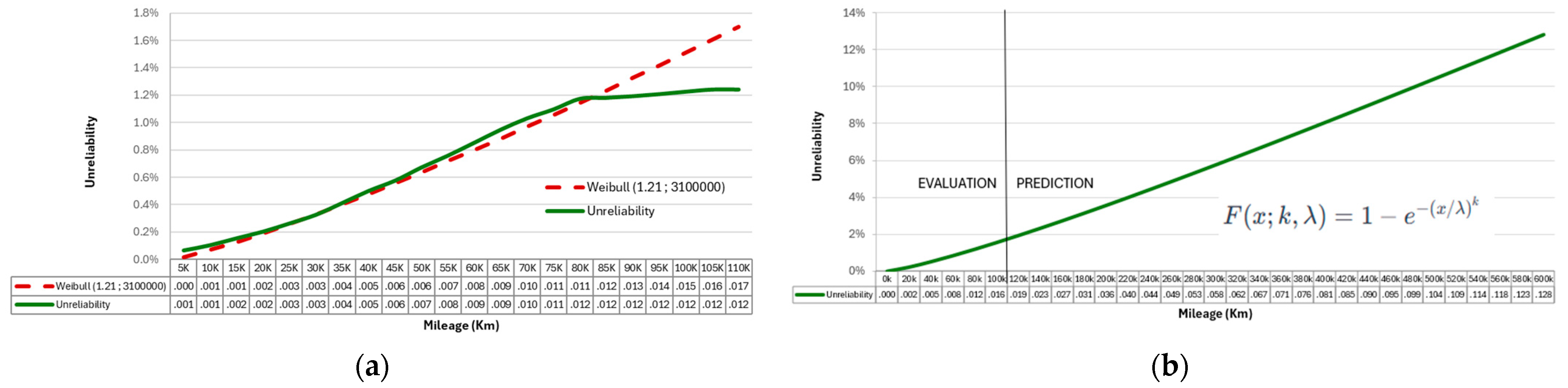
- This initial (non-parametric) estimation is improved using a Weibull model, deriving an analytical formulation for the reliability behavior of the system. The Weibull model is parametric, i.e., it changes shape as the parameters change. In the specific case, the two (shape and scale) parameters are determined to best approximate the values obtained from the (non-parametric) Kaplan-Meier estimator. However, it is worth clarifying the following. Among various potential models (e.g., Exponential, Lognormal), the Weibull model is selected a priori due to its general characteristics, such as flexibility, making it particularly suitable for our purpose. Typically, multiple models are hypothesized and the best fit for the data is chosen. However, in this specific case, the precision achieved with the Weibull model is so high that further refinements are deemed unnecessary.
- Given the reliability function, the Fleet Mileage Aging calculation comes in handy again. For each time of interest (e.g., every 12 calendar months), in fact, the related Fleet Mileage Aging is combined with the Reliability to determine the number of failures that occurred by that date. This provides a tool that allows to evaluate the spare part request month by month.
3. Results and Discussion
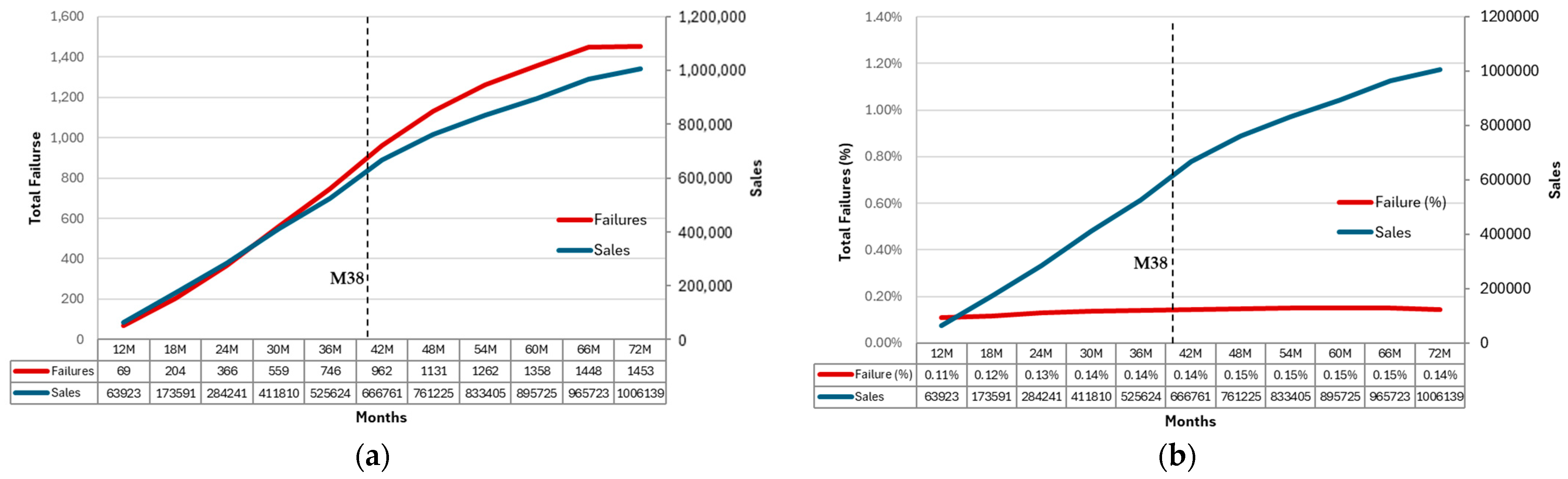
3.1. In Operation
- the application of a lead time (LT) smooths distribution the sales trend.
- their cumulative trends run parallel, with a minimal shift (approx. 1 month).
3.2. Fleet Aging
3.3. Non-Parametric Estimation
3.4. Parametric Estimation
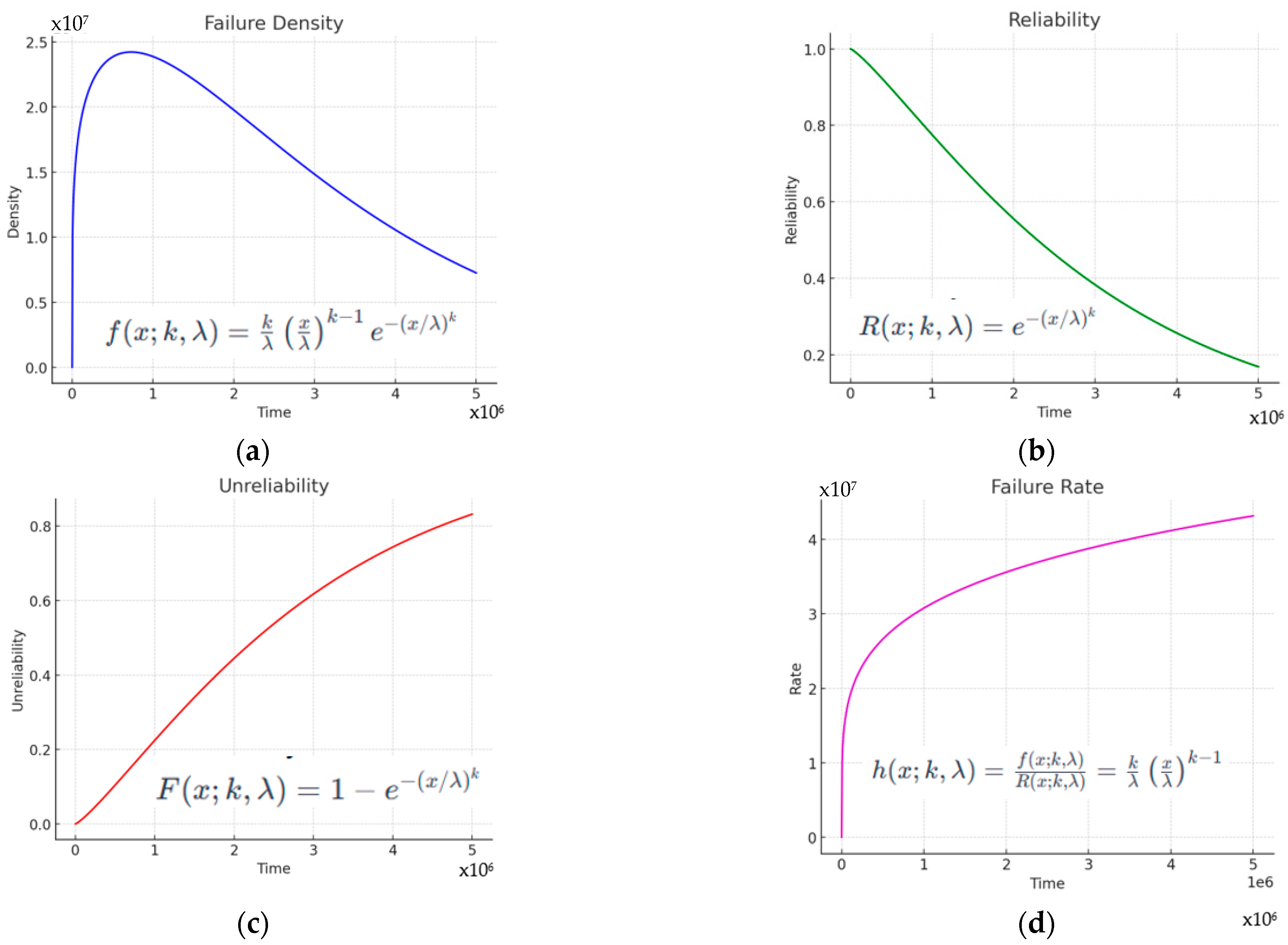
3.5. Failure Model
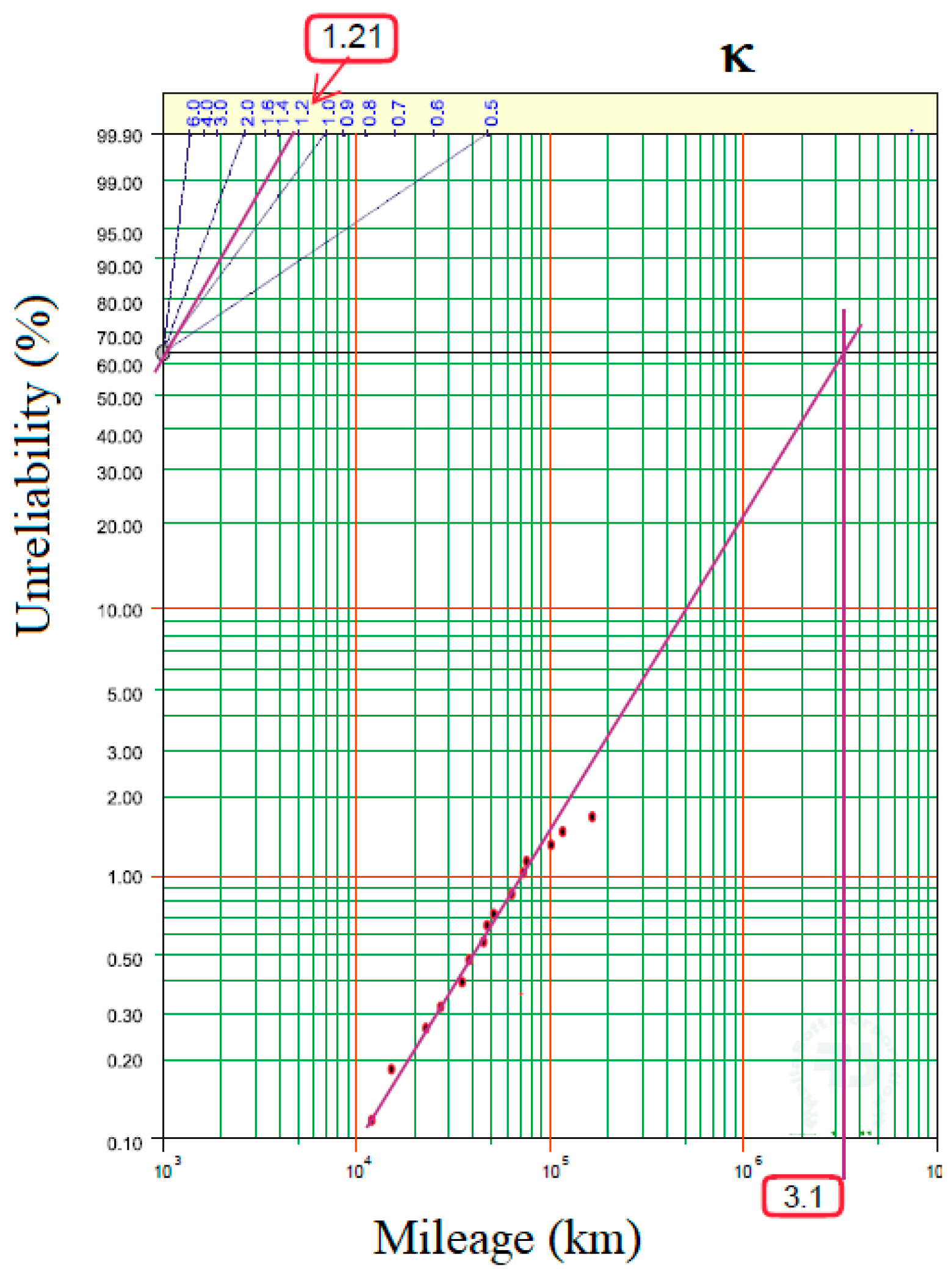
- Failure density shows that the failure probability density starts at zero, increases until it reaches a peak, and then gradually decreases. The peak indicates the point where a failure is most likely to occur. The shape of the graph reflects the fact that with a form factor greater than 1 (1.21 in this case), failures tend to increase with time, suggesting a wear or aging effect.
- Reliability, as expected, starts at 1 (100% reliability) and decreases over time. The curve shows a relatively gradual decrease in reliability, indicating that the probability of failure slightly increases over time.
- Unreliability is the opposite of the reliability graph. It starts from zero and slightly increases over time, indicating that the probability of failure increases with the age of the component or system. The curve reflects an increasing probability of failure, consistent with the increasing failure rate observed in the density plot.
- Mean Time to Failure (MTTF) is ~2,910,000 km,
- Half of the vehicles are expected to fail not before ~2,300,000 km,
- In 80 years, more than half of the systems would still be functioning.
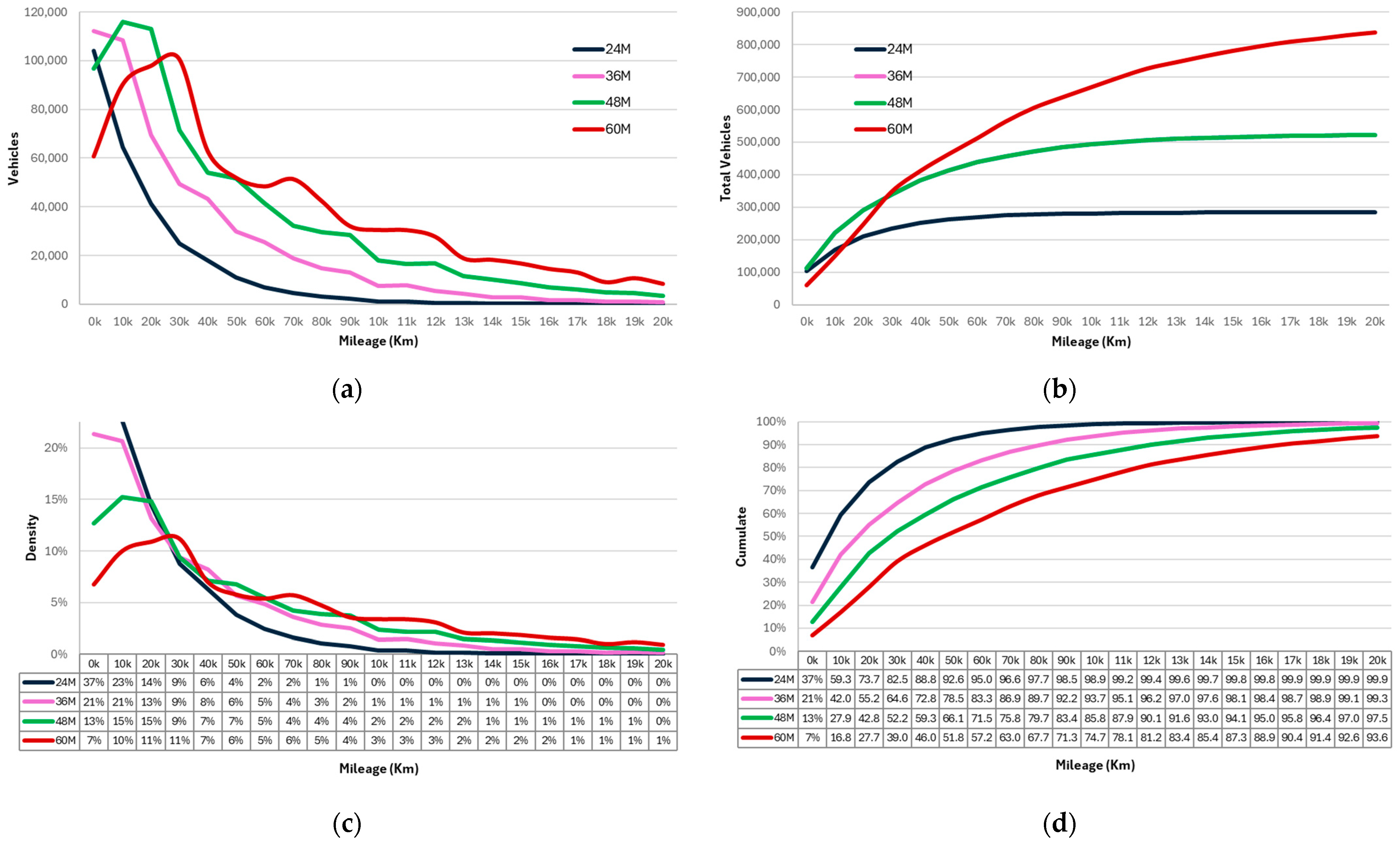
3.6. Fleet Mileage Aging
- the trend widens and moves towards higher kilometers (e.g., the median moves to 58,000 km in 60 months).
- a peak emerges, becomes more and more pronounced, and it progressively moves to greater kilometers (e.g., the mode to 28,000 km in 60 months).
- an increasingly larger portion leaves the interval under observation (0–210,000 km): from 0.06% after 24 months to 6.43% at 60 months.
3.7. Spare Part Prediction
3.8. Validation, Uncertainties, and Unpredictability
- the systems are subject to frequent redesigns, often occurring ‘behind the scenes’, with the aim of enhancing performance and reliability. Consequently, data inputs could concern products not necessarily identical as supposed. Such ‘in progress’ changes improves when defects occur. Here, e.g., starting from the 30th month, a new design solution is introduced to definitely solve several specific emerged criticalities. Regarding the reliability estimation, given that it is based on data updated to the 38th month, it can be estimated that 25–30% of parts is characterized by the new design, with a growing impact, affecting up to 56% of systems.
- it is important to distinguish when failures result from a process issue, typically transient, or an overall design weakness. In the former case, a specific production batch need to be considered, excluding large part of the population with significant impact on prediction. In the present case, no evidence of being in the presence of a ‘defective batch’ has been identified.
- the way draft data is collected and processed, finally, have to be better considered sometimes. This attention includes, e.g., the way data is classified into discrete intervals, the truncation of distribution tails, and much more. For instance, when the mileages are grouped in intervals (e.g., 10,000 km, as in the present case), it is hard to investigate phenomena under this interval (as early failures, typically occurring in the first 5/8,000 km). And it is not a coincidence that Weibull distribution here determined is not dissimilar from an Exponential function (they coincide in the case of k = 1, instead of =1.2). It identifies a constant hazard rate, representative of occasional failures, not related to early failures or aging.
- a deeper attention to the data classification can be fundamental sometimes, as it could directly impact on accuracy. Among others, geographic-based categories are usually necessary. For example, in the present case, the average annual mileage in (Northern) Europe (34,945) is ~6500 km higher than in North America (27,056). With this difference (~22.8%), the European fleet, just after over four years, is effectively ‘one year older’ (Figure 19). In opposition, the introduction of more categorizations results in less data being available for the analysis, with a consequent loss in accuracy.
- as frequently happens, multiple concomitant failure causes can overlap, each with its own reliability behavior. The use of a single model (e.g., Weibull) can be too approximate. In the case, a subgroup of 122 failed parts is collected and analyzed in laboratory, identifying 6 main failure causes and 50% not trouble found (NTF).
- when the RDA does not identify any issue that seem particularly concerning, the most common car manufacturer’s respond is to close the case, ceasing to commit resources to data acquisition (which may not always be complete and automatic).
- experiencing multiple failures (of the same type)
- scrapped from the system due to accidents, permanent breakdowns, or personal choices. This phenomenon commonly starts to be significant around 100/150,000 km, becoming predominant over 250/300,000 km [25].
4. Conclusions and Further Work
Funding
Data Availability Statement
Conflicts of Interest
Nomenclature
| 1k, 2k, … | 1000; 2000, … |
| CDF | Cumulative Probability Function |
| CM | Car Manufacturer |
| f(x) | Failure Density Function |
| F(x) | Unreliability |
| h(x) | Failure Rate/Hazard Rate |
| KM | Kaplan-Meier (non-parametric) Estimator |
| LT | Lead Time |
| M38 | 38th month (Moment of the Analysis) |
| mo. | Months |
| MoA | Moment of the Analysis |
| MTTF | Mean Time to Failure |
| n. | Number |
| OEM | Original Equipment Manufacturer |
| Probability Density Function | |
| R(x) | Reliability |
| RDA | Reliability Data Analysis |
| W(x) | Weibull density function |
References
- Fragassa, C.; Pavlovic, A.; Massimo, S. Using a Total Quality Strategy in a new Practical Approach for Improving the Product Reliability in Automotive Industry. Int. J. Qual. Res. 2014, 8, 297–310. [Google Scholar]
- Sabbagha, O.; Ab Rahman, M.N.; Ismail, W.R.; Hussain, W.M.H.W. Impact of quality management systems and after-sales key performance indicators on automotive industry: A literature review. Proc.-Soc. Behav. Sci. 2016, 224, 68–75. [Google Scholar] [CrossRef]
- Zhu, X.; Jiao, C.; Yuan, T. Optimal decisions on product reliability, sales and promotion under nonrenewable warranties. Reliab. Eng. Syst. Saf. 2019, 192, 106268. [Google Scholar] [CrossRef]
- Lewis, E.E. Introduction to Reliability Engineering, 2nd ed.; McGraw-Hill: New York, NY, USA, 1994. [Google Scholar]
- Dhillon, B.S. Maintainability, Maintenance and Reliability for Engineers; Taylor & Francis Group, LLC: Boca Raton, FL, USA, 2006. [Google Scholar]
- O’Connor, P.; Kleyner, A. Practical Reliability Engineering; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Bertsche, B. Reliability in Automotive and Mechanical Engineering: Determination of Component and System Reliability; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Guida, M.; Pulcini, G. Automotive reliability inference based on past data and technical knowledge. Reliab. Eng. Syst. Saf. 2002, 76, 129–137. [Google Scholar] [CrossRef]
- Zhang, C.W.; Pan, R.; Goh, T.N. Reliability assessment of high-Quality new products with data scarcity. Int. J. Prod. Res. 2021, 59, 4175–4187. [Google Scholar] [CrossRef]
- Ulbrich, D.; Selech, J.; Kowalczyk, J.; Jóźwiak, J.; Durczak, K.; Gil, L.; Pieniak, D.; Paczkowska, M.; Przystupa, K. Reliability Analysis for Unrepairable Automotive Components. Materials 2021, 14, 7014. [Google Scholar] [CrossRef] [PubMed]
- Ndlovu, B.N.; Ayomoh, M. Reliability Analysis of the Functional Capabilities of an Autonomous Vehicle. Int. J. Math. Eng. Manag. Sci. 2023, 8, 943. [Google Scholar] [CrossRef]
- Zou, T.; Mahadevan, S.; Mourelatos, Z.; Meernik, P. Reliability analysis of automotive body-door subsystem. Reliab. Eng. Syst. Saf. 2002, 78, 315–324. [Google Scholar] [CrossRef]
- Ibrahim, M.; EA, E.A.; Yousof, H.M. A new distribution for modeling lifetime data with different methods of estimation and censored regression modeling. Stat. Optim. Inf. Comput. 2020, 8, 610–630. [Google Scholar] [CrossRef]
- Meeker, W.Q.; Escobar, L.A.; Pascual, F.G. Statistical Methods for Reliability Data; John Wiley & Sons: Hoboken, NJ, USA, 2022. [Google Scholar]
- Lawless, J.F. Statistical Models and Methods for Lifetime Data; John Wiley & Sons, Inc.: New York, NY, USA, 1982. [Google Scholar]
- Deshpande, J.V.; Purohit, S.G. Lifetime Data: Statistical Models and Methods; World Scientific Publishing Company: Singapore, 2015; Volume 16. [Google Scholar]
- Kaplan, E.L.; Meier, P. Nonparametric estimation from incomplete observations. J. Am. Stat. Assoc. 1958, 53, 457–481. [Google Scholar] [CrossRef]
- Weibull, W. A statistical distribution function of wide applicability. Appl. Mech. 1951, 18, 293–297. [Google Scholar]
- Fréchet, M. Sur la loi de probabilité de lécart maximum. Ann. Soc. Pol. Math 1927, 6, 93–116. [Google Scholar]
- Nelson, W. Weibull analysis of reliability data with few or no failures. J. Qual. Technol. 1985, 17, 140–146. [Google Scholar] [CrossRef]
- Guo, J.; Kong, X.; Wu, N.; Xie, L. Weibull parameter estimation and reliability analysis with small samples based on successive approximation method. J. Mech. Sci. Technol. 2023, 37, 5797–5811. [Google Scholar] [CrossRef]
- Elmahdy, E.E. Modelling reliability data with finite weibull or lognormal mixture distributions. Appl. Math. Inf. Sci. 2017, 11, 1081–1089. [Google Scholar] [CrossRef]
- Nelson, W. Applied Life Data Analysis; Addison-Wesley: Boston, MA, USA, 1982. [Google Scholar]
- Genschel, U.; Meeker, W.Q. A Comparison of maximum likelihood and median-rank regression for Weibull estimation. Qual. Eng. 2010, 22, 236–255. [Google Scholar] [CrossRef]
- Brighi, F.; Fragassa, C.; Verratti, L.; Vianello, M. How the Phenomenon of Vehicles Dismantling Influences Reliability Predictions in the Automotive Field. In Proceedings of the 3rd International IMEKO—Youth Symposium on Experimental Solid Mechanics, Porretta Terme, Italy, 12–15 May 2004. [Google Scholar]







Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fragassa, C. Analysis of Production and Failure Data in Automotive: From Raw Data to Predictive Modeling and Spare Parts. Mathematics 2024, 12, 510. https://doi.org/10.3390/math12040510
Fragassa C. Analysis of Production and Failure Data in Automotive: From Raw Data to Predictive Modeling and Spare Parts. Mathematics. 2024; 12(4):510. https://doi.org/10.3390/math12040510
Chicago/Turabian StyleFragassa, Cristiano. 2024. "Analysis of Production and Failure Data in Automotive: From Raw Data to Predictive Modeling and Spare Parts" Mathematics 12, no. 4: 510. https://doi.org/10.3390/math12040510
APA StyleFragassa, C. (2024). Analysis of Production and Failure Data in Automotive: From Raw Data to Predictive Modeling and Spare Parts. Mathematics, 12(4), 510. https://doi.org/10.3390/math12040510