Abstract
As a consequence of the application advanced maintenance practices, the theoretical probability of failures occurring is relatively low. However, observations of low levels of market intelligence and maintenance management have been reported. This comprehensive study investigates the determinants of maintenance practices in companies utilising hydraulic machinery, drawing on empirical evidence from a longitudinal questionnaire-based survey across the West-Balkan countries. This research identifies critical predictors of technical and sustainable maintenance performance metrics by employing the CA-AHC (Correspondence Analysis with Agglomerative Hierarchical Clustering) method combined with non-parametric machine learning models. Key findings highlight the significant roles of the number of maintenance personnel employed; equipment size, determined on the basis of nominal power consumption; machinery age; and maintenance activities associated with fluid cleanliness in influencing hydraulic machine maintenance outcomes. These insights challenge current perceptions and introduce novel considerations with respect to aspects such as equipment size, maintenance skills and activities with the aim of preserving peak performance. However, the study acknowledges the variability resulting from differing operational conditions, and calls for further research for broader validation. As large-scale heterogeneous datasets are becoming mainstream, this research underscores the importance of using multidimensional data analysis techniques to better understand operational outcomes.
Keywords:
multidimensional data analysis; correspondence analysis; agglomerative hierarchical clustering; random forest; hydraulic system; machine learning MSC:
90B25; 62H25; 62G08
1. Introduction
Nowadays, companies regard maintenance functions as a strategic move for gaining a competitive advantage [1]. The rise of AI (Artificial Intelligence) and ML (Machine Learning) tools provides a “bright avenue” for the growth of Predictive Maintenance (PdM) [2,3]. However, data-driven and sustainable PdM practices face serious difficulties [4], mainly because most systems still rely on RAM (Reliability, Availability and Maintainability) [5] metrics. Additionally, many believe that adopting PdM will significantly reduce downtime [6], improve production flows, and enhance performance [7], ultimately resulting in a failure to fulfil these expectations [8]. Such issues can largely be attributed to problems regarding maintenance strategy selection [9], implementation suitability [10], industrial environment [11], asset management risks [12], and other technological and organisational issues, leading to poor decision making.
Moreover, the availability, as an integral part of OEE (Overall Equipment Effectiveness) [13], with MTBF (Mean Time Between Failure) and MTTR (Mean Time To Repair) as core parameters, is usually perceived as, if not necessarily being, the most critical Maintenance Performance Indicator (MPI) [14]. There are a myriad of factors affecting availability metrics; however, most of them strongly depend on the knowledge and skills of maintainers [15], the efficacy of decision making [16,17], the alignment of maintenance practice with organisational policies, the use of advanced techniques in the diagnosis and prognosis of machines [18,19], reliability modelling and optimisation capabilities [20], the quality of maintenance activities [21], and many other aspects. These multiple interrelated issues are primarily addressed as a single entity on a unit, system or company level. Thus, there is a lack of studies comparing MPIs across different industrial domains. The research (case) studies usually encompass smaller companies, with no evidence concerning their large-scale application. Moreover, existing studies usually do not include qualitative data (e.g., lubrication, monitoring), since such information is hard to synthesise, process and maintain over time. This is primarily the case in asset-intensive industries with heavy-duty machinery, such as hydraulic power systems, where maintenance research is concerned mainly with diagnostic and prognostic aspects [22], thus needing more evidence regarding the impact of latent factors on MPIs. (Note: See Abbreviation)
Nevertheless, entering the digitalisation and cloud-computing era, many companies have started to rely on Big Data and Visual Analytics [23] to assess business issues by utilising large-scale multivariate data analysis (MDA) [24]. MDA’s benefits include its ability to incorporate large-scale heterogenous data—unstructured text, categorical data, numerical data, logs, binary data—and project it in a lower-dimensional subspace, which is necessary to be able to investigate the latent indicators [25] impacting operational performance. Although it has been little engaged with respect to maintenance management, visual analytics utilising MDA is being used to map the landscape of other fields, such as business management, disaster management, and many others [26,27]. As such, in this study, MDA is used to allocate features impacting MPIs via a questionnaire-based survey considering companies utilising hydraulic machinery (Figure 1). The survey included closed- and open-ended questions in order to extract the features impacting MPIs. To achieve this, we conducted a Systematic Literature Review (SLR) to extract the items needed for the survey based on the proposed Research Questions (RQs).
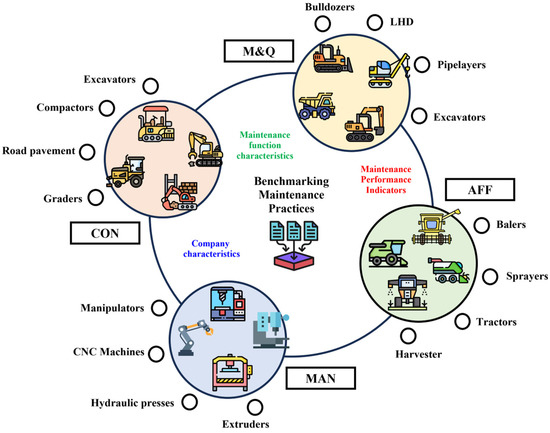
Figure 1.
Infographic of survey data collection from companies utilising hydraulic machinery (Note: CON = Construction; MAN = Manufacturing; AFF = Agriculture, forestry and fishing; M&Q = Mining & Quarrying).
The first research question—RQ1: “What are the most commonly used maintenance performance metrics and/or indicators?”—is used to extract relevant maintenance performance indicators (MPIs) that will be used to build the survey items. The second research question—RQ2: “What are the existing applied maintenance activities under hydraulic systems maintenance practice?”—is designed to extract relevant information regarding the applied maintenance activities, condition monitoring practices, and tools for managing hydraulic machinery. Next, using both open-ended and closed-ended survey questions, since most companies do not have fully implemented CMMSs (Computerised Maintenance Management Systems), it is expected that the responses will include multidimensional data (e.g., text, categorical, numerical). To address these high-dimensional datasets, various dimensionality-reduction techniques must be used to obtain the feature subspace. Finally, the reduced feature subspace is projected against MPIs to allocate the essential features using ML regression algorithms.
The rest of the study is structured as follows. The methodology describes the survey design, including the SLR, the development of the survey items and survey questions, raw data extraction, data wrangling and the ML regression algorithms used to allocate the most critical features impacting the MPIs. The evidence from the longitudinal study, carried out over three years, helped us to gain insights into potential relationships between the MPs (Maintenance Practices) applied and the output results. The third chapter presents the results of the MDA and the extrapolated feature subspace through CA-AHC (Correspondence Analysis with Agglomerative Hierarchical Clustering). Using CA-AHC, we generated components by combining MPs with their associated CFTs (Component Failure Types) and RCFs (Root Causes of Failure) in order to benchmark the MPs. Based on the obtained results, the fourth chapter includes a discussion and analysis of ML post hoc analysis in which features extracted using ML techniques are considered. Finally, the study recapitulates the evidence and provides concluding remarks, describing the implications of this study as well as future research directions.
2. Methodology
2.1. Systematic Literature Review for Extraction of Relevant Performance Indicators
Following the PRISMA (Preferred Reporting Items for Systematic Review and Meta-Analysis) guidelines, we conducted a Systematic Literature Review (SLR) to prepare the items needed to construct the survey. Namely, since we are interested in gathering factors, metrics and/or indicators for measuring the performance of hydraulic machine maintenance, we used the eligibility criteria in Table 1. Based on the eligibility criteria, the search strategy and the obtained search results are given in Table 2. In the following, we briefly describe the SLR and the indicators extracted and used to build the survey items (Figure 2).

Table 1.
Inclusion & Exclusion (I&E) criterias.
Table 2.
Results based on the search strings.
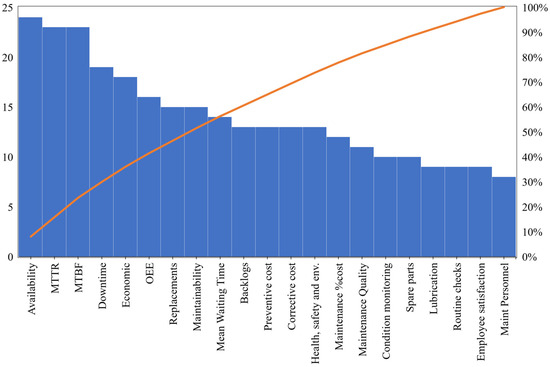
Figure 2.
Maintenance Performance Indicators extracted from the SLR.
After finishing the SLR, the final sample included 27 articles. Based on the retrieved articles, almost all articles, without exception, highlighted Availability, MTTR, and MTBF as the three most essential MPIs (Figure 2). However, MTTR and MTBF are parameters that need to be input in order to derive Availability estimates.
Earlier work [28,29] was mostly dedicated to allocating and benchmarking MPIs using different types of frameworks [30], and was performed by Parida, A. et al. [29,31,32], Kumar, U. et al. [33], and Van Horenbeek and Pintelon, L. [34,35]. Most frameworks are designed as secondary data on the basis of an overview [36] with multicriteria decision-making tools [37] such as AHP (Analytical Hierarchy Process) [38], ANP (Analytical Network Process) [39,40], and ELECTRE [41]. Considering the practical application of the use of MPIs, most of the work is being formed in the context of industrial manufacturing [42,43,44,45,46], business organisations [47], specific production case studies [48], or even in healthcare [49]. Thus, since there is still an ongoing debate regarding framework appropriateness and maintenance practice suitability [50,51] in different types of industry, most of the research still emphasises the availability metric of the maintenance function, since it is an integral part of the OEE (Overall Equipment Effectiveness) [52,53]. Although most of the indicators are concerned with economic and technical evaluation metrics, due to recent environmental concerns, many are incorporating sustainability indicators [53,54] as maintenance indicators.
The recent work on MPIs utilises a broad range of MPIs and performance metrics (Figure 3), presumably due to the computational ability of machine learning techniques that can translate large-scale heterogenous datasets into a low-dimensional feature space. On the basis of the SLR, we used the performance metrics and the performance of associated maintenance activities to derive the information we required to reach a consensus regarding the relationship between maintenance and operation activities and performance. Next, since in the SLR we did not find evidence of addressing specific types of failure or root causes of failure and their overall impact on maintenance performance; we decided to include these output metrics. Finally, as recent work has started utilising sustainability metrics, we also included lubricant waste as one of the essential output metrics regarding the operational performance of hydraulic machinery.
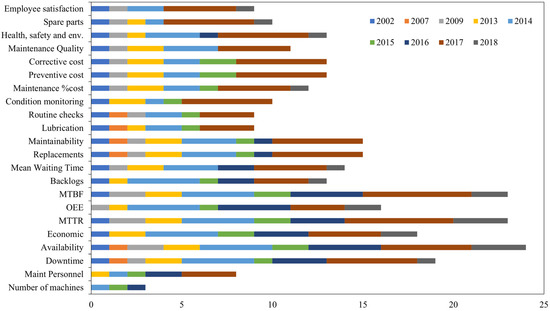
Figure 3.
Maintenance Performance Indicators synthesised on the basis of an SLR study.
2.2. Study Design and Data Wrangling
The study design consists of three parts: (1) survey design; (2) survey raw data processing and data wrangling; and (3) feature subspace extraction and data analysis (Figure 4). The survey design consists of the SLR-based extraction of MPIs (Figure 4a); the survey realisation workflow (Figure 4b); the geographical representation of the survey results (Figure 4c); company characteristics (Figure 4d); strategic and operational level of maintenance activities (Figure 4e); maintenance performance metrics and indicators extracted (Figure 4f); CA considering feature subspace (Figure 4g); AHC clustering (Figure 4h); extraction of features by importance using ML (Machine Learning) algorithms considering output MPIs (Figure 4i). The survey design was performed over the course of several iterations with respect to organisational, maintenance management and performance structures and characteristics. After the survey had been adjusted and was deemed suitable, the CA and Agglomerative Hierarchical Clustering (AHC) models were used to generate a feature subspace based on the extracted raw data. By using MPs and failure-associated characteristics, clusters were created, which were then used to allocate features in consideration of output maintenance metrics. Finally, selected clusters were subjected to output metrics to isolate the features, including maintenance programs, factors and activities via ML algorithms.
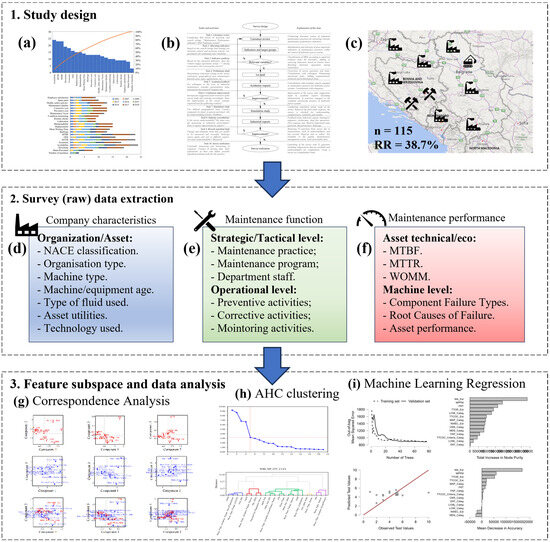
Figure 4.
Study design and data wrangling process.
2.3. Survey Design and Realisation
The design of survey items (Figure 5) started with an SLR (Task 1) regarding keywords and search strings (Table 2). After the SLR, the authors individually synthesised papers (Task 2) based on the eligibility criteria. The extraction of MPIs to be included in the survey was performed on the basis of interrater agreement using Cohens’ K > 0.7 (K = 0.89). The final list included 33 indicators that satisfied the criterion (Task 3). However, in the preliminary draft of the survey targeting companies utilising hydraulic applications in the West Balkan Peninsula, several MPIs were removed (Task 4). This is primarily because different types of maintenance policy and databases had different MPIs, most of which were unavailable for disclosure to the public (e.g., maintenance costs) or were not recored (e.g., injuries, backlogs). The first draft contained 77 survey questions. Next, consultations were carried out with academic experts in the field (Task 5), who considered some survey questions to be redundant, and could be merged or split into subquestions. In addition, other survey questions were deemed irrelevant, such as those covering stoppages that were consequences of non-hydraulic failure events (e.g., structural failures, mechanical failures, electrical failures). This resulted in the elimination of several unrelated questions, merging some and splitting others into subquestions (Task 6). The first version of the survey was sent to the sample of 5 companies as a mini (pilot) survey study in order to gather information and insights regarding the understandability, completeness, reliability, and validity of the open- and closed-ended items of the questionnaire (Task 7).
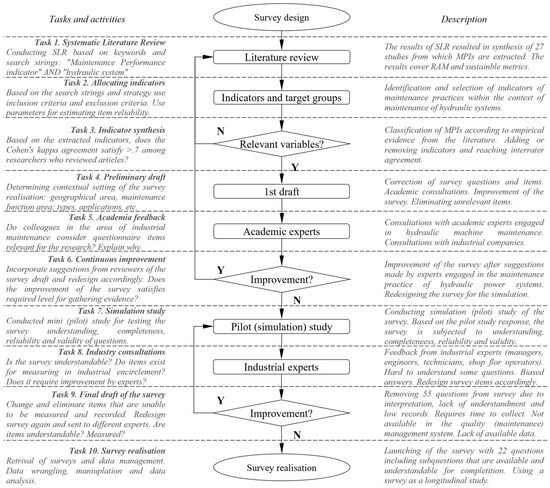
Figure 5.
Survey design workflow.
After administrating the survey to the companies, minimicking the conditions of the target group companies that utilise hydraulic machinery, the results showed that the survey questions regarding the maintenance policies, programs and maintenance activities needed to be clarified. Namely, 4/5 companies still required specifically designed and recorded maintenance policies rather than maintenance procedures in the context of a quality management system. Hence, we reformulated questions regarding maintenance policies into questions about maintenance practices, since some practices included several different activities (e.g., time-based, corrective, and opportunity-based activities) within a given procedure. Additionally, some maintenance activities for replacing parts were not recorded in backlogs; thus, output metrics regarding spare parts management, work order logs, replacements, and preventive and corrective costs were removed, and only availability metrics (MTBF, MTTR) were left. Additionally, the provision of datasets regarding the exact energy consumption of each hydraulic machine was eliminated, since none of the companies had measurements of each hydraulic system’s energy consumption. Instead, nominal working pressure and nominal working flows were used as measures for describing the size of the equipment. However, all of the respondents were able to provide information regarding the most common failure causes and root causes of failure. Regarding the MTBF and MTTR metrics, 3/5 companies had a log of failure times in the pilot study. In contrast, others did not have a complete record, which resulted in the formulation datasets for the extraction of failure times using range values (e.g., 100–200 h TBF). From a sustainability perspective, the waste hydraulic fluid data were available for extraction using the survey. None of the questions were found to be offensive.
Furthermore, the feedback from the industrial experts, maintenance managers and engineers on a strategic level (Task 8) resulted in the elimination of survey items mostly on the basis of the time required to complete the survey, the public disclosure of costs and energy consumption data per machine, and the lack of records and procedures for documenting activities via logbooks or data management systems. Additionally, some companies incorporate a centralised top maintenance management level, including a manager or a director. Here, the responsibility falls under the technical department, whether or not its management is the director’s responsibility. Next, as was later confirmed, some companies still employ a maintenance department or section that is responsible for maintaining and keeping records of hydraulic machine failures. In some of these cases, some or all maintenance management, including diagnosis and prognosis, were outsourced. In such instances, data records were requested from the companies to which the tasks were outsourced or from the experts conducting in-house maintenance activities, and they were asked to provide records and fill out the survey. This helped improve the questions related to maintenance diagnosis and prognosis, and the survey options were extended with external experts and outsourced maintenance activities.
After redesigning and preparing the final draft of the survey (Task 9), the surveyed companies and industrial experts agreed that the survey of 22 questions (with 5 sub-questions) included all information necessary for the analysis. Therefore, the first realisation phase started in September 2019 (Task 10) and lasted until May 2021. In the first run, 81 samples, which included most of the companies in Serbia, were collected. Since the sample size was still small, we conducted a longitudinal study. Thus, in the second run (September 2020–June 2021), 100 companies participated. Next, considering that some companies changed their initial practices on the basis of insights derived from their previous state, we thought that data could be biased due to discrepancies between initial and follow-up (second-run) results. Therefore, we decided to include a third and final run, which ultimately led to results being gathered from 115 companies, from which data were synthesised and subjected to analysis. The obtained results proved compelling, complete and valid, since, based on the first (11% missing data) and second run (4% missing data), only 1.3% of data were missing. The missing data were later excluded from the analysis or replaced by the mean average value to reduce the bias/variance tradeoff. The complete survey is presented in Supplementary Material File S1.
2.4. Survey Items and Data Extraction
The survey design (Figure 5) started in February 2019 and lasted until June 2019. The survey questions were segmented into three facets, namely: (i) organisational characteristics; (ii) characteristics of maintenance functions; and (iii) output data as performance metrics. The organisational facet included questions regarding organisational structure and asset characteristics. Organisational and asset characteristics include information regarding the company and its associated hydraulic machinery (e.g., age, type). The maintenance characteristics include the department’s size, the staff and their qualifications, the condition monitoring tools (e.g., sensors, instruments) available, and preventive/corrective activities performed (e.g., filter replacement time, time to complete oil change). The output performance metrics measured include MTBF (Mean Time Between Failures), MTTR (Mean Time To Repair); CFTs (Component Failure Types), RCFs (Root Causes of Failure); and WOMM (Wasted Oil per Machine-Month). A complete list of the survey questions is provided in Appendix A.
2.5. Correspondence Analysis (CA)
Since the survey contains mostly categorical data, contingency tables are formed and χ2 distance metrics are used for CA. The contingency table(s) consider I categories (rows) of variable V1, where i = 1, 2… I, and j categories (columns) of variable V2, where j = 1, 2…J. The value xi,j corresponds to the values of a variable with i rows and j columns, with n instances. Using contingency tables, we first calculate the probabilities as follows:
where the sum of rows equals the marginal probability:
and for the sum of columns, the marginal probability:
The relationship between selected variables is measured using the the χ2 distance:
where nfij is the observed probability and nfi.f.j is the theoretical probability, and factoring n out of Equation (4), we get the total inertia Φ2:
The CA is described as point clouds, as proposed in [55], alongside mathematical formulations [56,57]. Considering the number of row profiles i, we obtain a cloud of profiles NI. With the generated point cloud, we add the point GI, depicting the centre of gravity with coordinate f.j. GI can be considered a centre of gravity if we associate each point i with the weight proportional to its marginal value (fi.). The space then compares profile i with GI using a measure of distance. As stated, the distance between i and i′ is defined as follows:
Although this could suggest Euclidian distance, the χ2 compares the sum of differences, where each dimension J is associated with a weight 1/f.j. Therefore, the centre of gravity GI corresponds to the mean profile as follows:
The same principles are used for estimating the distances in the column profile. A column profile is a set of I values in ℝI dimensional space. The coordinates of the jth point are fij/f.j, and all of the j points together form the Nj cloud. The central point, i.e., the centre of gravity GJ, is added to the coordinate fi. in the Ith dimension. GI is the centre of gravity as long as we assign a column profile j a weight corresponding to its marginal probability f.j. Next, we estimate the distances d between points j and j′ using the χ2 distance metric as follows:
and the centre of gravity GJ is estimated as follows:
If independence exists, the conditional probability is equal to the marginal probability for all i (f.j = fij/fi.), meaning that all profiles are the same as the mean, i.e., NI becomes GI. As such, we measure the inertia using Equation (5), as follows:
The same holds for NJ: Inertia(NJ/GJ) = Inertia(NI/GI). Therefore, Φ2 represents the strength of the link. The CA proceeds, for all components (i.e., factors), by projecting NI to axes C1 and C2, forming a plane P. Finding the plane P is determined by the criteria of maximum inertia, such that:
is maximal and is used to determine the Mi point that corresponds to the Ith profile on the plane P, where OHi represents the distance to the origin GI = O. The plane P is the sum of the inertia, such that the projected Hi overall i is maximal. The C1 and C2 axes (components) represent maximal inertia such that C2⊥C1, and as a result, we obtain plane P. The inertia λs of the sth axis is then:
and λs represents the eigenvalue of the Cs. Calculating fi. on Cs (the same as for the column) over the total inertia of the λs is performed as follows:
where summation leads to the inertia of Cs, and we determine the quality (Qual) of the representation as follows:
where OMi is the distance between the Mi point and the origin O. The numerator represents the inertia of NI on the axis Cs, and the denominator is the total Inertia(NI) = Φ2. Calculating the position on the plot of rows and columns, we use transitional formulas to determine the coordinates of row i on the sth axis (Fs) as follows:
where Gs(j) is the coordinate of the column j on the sth axis, and λs is the inertia of the sth axis. Permuting Gs and Fs, we obtain the same outcome for the different barycentre. Intuitively, the number of axes that contain non-zero inertia is S ≤ min(J − 1, I − 1). Estimating the Φ2 points of the axes gives us:
2.6. Clustering CA Components Using Agglomerative Hierarchical Clustering (AHC)
Agglomerative Hierarchical Clustering (AHC) is added to replace the inability of CA to project data in more than three dimensions. The two important measures of the AHC are distance and linkage. The AHC assumes that each point x is a singleton [58]. The algorithm creates a collection of higher-level clusters ci by merging the point(s) (singletons) into a new cluster ci’. In order to measure the distances between points, the Euclidian distance is used [59]:
where p and q are coordinates of c. For the cluster linkage, we use Ward’s method [60]. The method is imputed by the Lance–Williams algorithm [59] and calculated as:
where agglomeration factors are estimated by the Lance–Williams dissimilarity:
such that ǀiǀ represents the number of objects in cluster i, and g represents the centre coordinates estimated as:
After obtaining the distance metrics and performing the clustering of principal components, the CA-AHC is performed.
2.7. Machine Learning Algorithms and Evaluation Metrics
The obtained AHC-CA clusters are then subjected to the machine learning regression algorithms, where independent variables consider maintenance performance indicators, specifically MTBF, MTTR and WOMM. Next, algorithm selection is performed by considering algorithms that can handle categorical (e.g., nominal and ordinal) and continuous/numeric (scale and metric) data as predictors. Next, for selecting between parametric and non-parametric ML algorithms, we used the Shapiro–Wilk test (p < 0.05) to test the normality assumption. As it turned out, the normality assumption was violated, and the non-parametric counterpart ML algorithms were selected. The ML algorithms used for the analysis include the SVR (Support Vector Regression) [60], kNN (k-Nearest Neighbour) [61], DT (Decision Tree) [62] and RF (Random Forest) [63] regression algorithms. The reader should not know that although SVR is generally a parametric algorithm, we used an RBF (Radial Basis Function), as it is the most frequently applied Kernel trick in the literature [61].
The evaluation metrics used include the following. The MSE (Mean Squared Error):
as well as the RMSE:
and the MAE:
where yi is the actual value, is the predicted value, and n is the number of observations. The R2 coefficient of determination is calculated as:
which represents the proportion of variance in the dependent variable predicted by independent variables. Finally, the analysis is performed using the open-source software JASP. JASP is built using R packages for DT (rpart), RF (randomForest), SVM (e1071), and kNN (kknn). Under each category, feature importance is established by relative importance and mean decrease in accuracy provided by JASP, from which the results are obtained.
3. Research Results
3.1. Survey Insights and Descriptions
From the sample of 297 companies, 7.41% (22 companies) of respondents strongly underscored that they were unwilling to participate in the study. Then, 19.53% (58 companies) of respondents were willing to participate in the survey, but no results were obtained, even after contacting them three times. Next, 34.3% of respondents (102 companies) did not respond. The final dataset comprises 115 companies (38.72% response rate).
The sample includes large (51.3%), medium (37.4%), and small (11.3%) companies. According to the NACE (Nomenclature of Economic Activities), the respondents consisted of 8.7% AFF (Agriculture, forestry, and fishing), 19.1% CON (Construction), 47.0% MAN (Manufacturing) and 25.2% M&Q (Mining and Quarrying) companies. Considering these asset characteristics, the average distribution of HMA (Hydraulic Machinery Age) across classes is presented in Table 3. The NoM (Number of Machines) was the greatest in M&Q. The MPPM (Maintenance Personnel per Machine) was the highest in MAN (0.75), and the lowest in CON (0.45).
Table 3.
Descriptive statistics of survey results.
The CFT (Component Failure Type) item is used to construct categories based on text mining. Therefore, the most frequently reported failures include “hoses OR pipes”, 85.65%; pumps, 71.3%; “actuators OR cylinders” OR “linear OR rotary”, 53.05%; sensors, 23.48%; “servo OR proportional”, 21.6%; “pressure OR flow OR check OR regulation valves”, 4.35%; accumulators, 3.48%; “ice OR internal combustion engine” OR “em OR electrical motor”, 3.48%; and other, 3.4%. These categories are divided into ten categories for the analysis. In terms of RCFs (Root Causes of Failure), the most-reported RCFs were those related to seals (92.2%), leakage (64.35%), overload (42.61%), temperature (24.35%), technician and operator mistakes (23.48%), air and water contamination (10.43%), “wear OR fatigue” (4.35%), particle contamination (3.48%), and other stoppages (27.83%).
It should be noted that most companies do not use a single MP, but rather a combination of different MPs, and for the sake of understanding, we use curly brackets to report cases in which companies utilise MP variants. For instance, in cases where a company itilises OM, CBM and PdM practices, this will be noted as “{OM. CBM. PdM.}”. Finally, the CA-AHC analysis is performed in MINITAB v17.0.
3.2. Relationship between MPs and CFTs Using CA-AHC
The obtained results show that the total inertia is Φ2 = 1.435, with the first two components accounting for 50% of the total inertia (Table 4). Among the mentioned MPs, {OM} and {PM. CBM. PdM.} alone account for >0.95 of the quality (Table 5). On the other hand, it can be seen that {PdM} accounts for significantly less of the inertia λPdM = 0.05; however, with the three proposed axes, the Qual{PdM} = 0.568, showing high interpretability.
Table 4.
Quality of interpretation using MPs and CFTs.
Table 5.
Overview of row components of MPs and CFTs.
Considering the association between MPs and the components of CA, the data suggest that {CBM} and {OM} are correlated with C1, while {FBM. PM. CBM.}, {PM. CBM.}, and {PM. CBM. PdM.} are correlated with C2. When considering the third component, C3, of CA, it can be observed that only {OM} has a higher tendency to associate with this component, suggesting that {OM} differs significantly, i.e., that it has a higher inertia from the centre of the CA. Conversely, {PM}, as the most common MP applied, does not seem to correlate with other components of CA, which is why it is positioned as the centre of gravity on the CA biplot.
In CA analysis (Figure 6), interpreting and making conclusions solely on the basis of the biplot can be insufficient. For instance, the points on the left ({PM. DM.}; {CBM}; {FBM. PM. OM.}; {FBM. PM.}) cluster, while same can be said for ({FBM}; {FBM.PM.CBM.}; {PM. CBM.}). However, looking at the points, it cannot be confirmed that {FBM} and {PM. CBM.} cluster, even when their similarity might suggest an association between the two. Looking at {PM. CBM.} and {PM. CBM. PdM.}, the results imply no association between the two. However, interpreting the results in Table 4, coordinates of C1{PM. CBM.};coord = 1.092 and C3{PM. CBM.};coord = −0.343 are closely associated with C1{PM. CBM. PdM.};coord = 0.945 and C3{PM. CBM. PdM.};coord = −0.760.
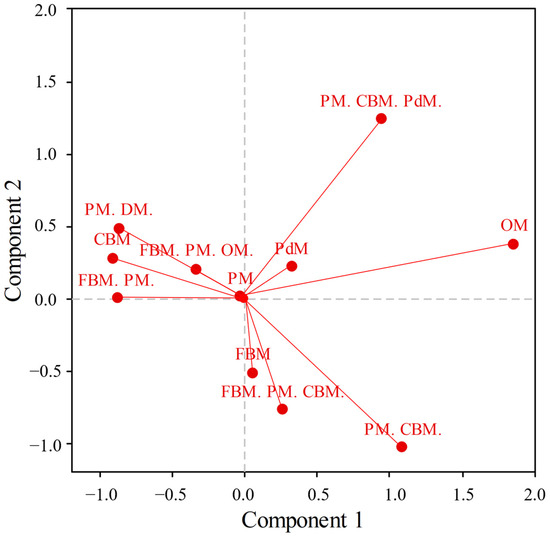
Figure 6.
MP biplot of C1 and C2 components of the MP-CFT analysis.
Observing the column profiles, the results show that {Hoses. Pipes. Pumps.}, λHPP = 0.236, followed by {Hoses. Pipes. Sensors.}, λHPS = 0.211, and {Pressure. Flow. Contr.-Regulation. Valves}, λPFCR = 0.181, account for most of the explained inertia. However, {Hoses. Pipes. Actuators.} are indicated to have higher quality QualHPA = 0.851 > QualPFCR = 0.686.
Looking at the left side of C1 (Figure 7), there is a discrepancy between the frequency and variety of failures, while on the right side of the C1-axis (positive), there is an increase in the number of sensor failures. This is a valuable insight for detecting associations with MPs and for better interpretation of the biplot.
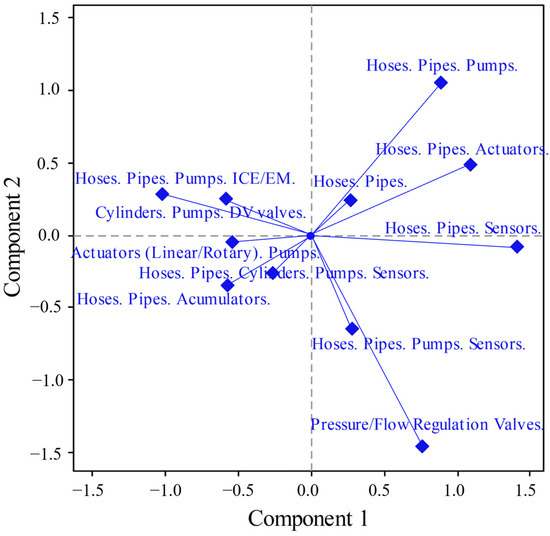
Figure 7.
CFT biplot of C1 and C2 components of the MP-CFT analysis.
Although CA (Figure 8) provides different ways of interpreting the association between categories, post hoc analysis can be misleading if the quality of the visualisations is neglected. Looking at the row profile (Table 5) and column profile (Table 6) tables, it can be seen that only 8/20 components possess a quality of representation > 0.70. Therefore, at least 80.8% of inertia must be preserved; consequently, the fourth component is added.
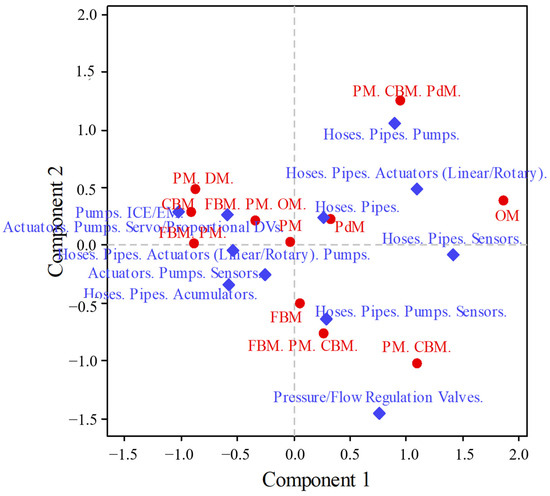
Figure 8.
MP and CFT biplot.
Table 6.
Overview of column components of MP and CFT.
The results (Figure 9) show that the first cluster (blue), consisting of {CBM} and {PM. DM.}, reports a variety of failures, alongside the second (red), where {FBM} and {PM. CBM.} report a smaller variety of failures. The third cluster (green) presents a higher association among the MPs. The fourth cluster (yellow) shows the smallest distance between the MPs {PM. CBM. PdM.} and the failures {Hoses. Pipes. Pumps.}, suggesting the best performance among the applications. Finally, the last cluster (purple) shows small distances between {OM} and ({Hoses. Pipes. Sensors.} and {Hoses. Pipes. Actuators}).
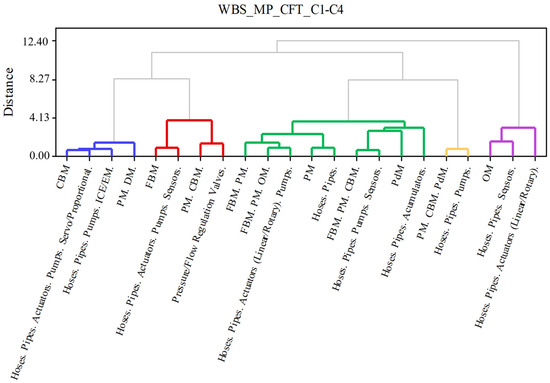
Figure 9.
Dendrogram of MPs and CFTs.
3.3. Relationship between MPs and RCFs Using CA-AHC
In terms of the RCF variable, the category of {Leakage. Seals. Operator and Maintenance mistakes.} was the most dominant. With regard to the frequency of the root causes reported, the highest-frequency fij association was that among {PdM} and OST {Overload. Seals. Temperature.} (fPdM.OST = 0.667). Aside from failures associated with leakage and seals, operator/maintenance personnel mistakes were dominant in {PM. DM.} and {OM}.
The results show a statistically significant value (Table 7) of χ2 = 85.769 (p = 0.016), which suggests the existance of a relationship between the categories. Compared to the previous case, the total inertia of Φ2 = 0.746 with components C1-3 (75.7%) suggests better interpretability than MPs and CFTs (69.3%).
Table 7.
Quality of interpretation using MPs and RCFs.
Observing the inertia of the row profiles (Table 8), the selected components (dimensions) show that {OM} provides the highest percentage of variation λOM = 0.127 (17%), followed by {PM. CBM. PdM.} λPM.CBM.PdM = 0.116 (15.6%), and {FBM. PM.} λFBM.PM = 0.095 (12.7%). Looking at the Qual of the interpretation, it can be seen that for the suggested categories of row profiles, the selected components contributed greatly (Qual > 0.80) to the inertia.
Table 8.
Row profile inertia of MPs and RCFs.
Looking at the inertia by individual components (Figure 10), {OM} seems not to be associated with the previous points. Although {PM. CBM. PdM.} and {PdM} were closely associated in the previous analysis, the points here repel each other on C1. The biplot (Figure 10) provides significant insight without the explicit use of data.
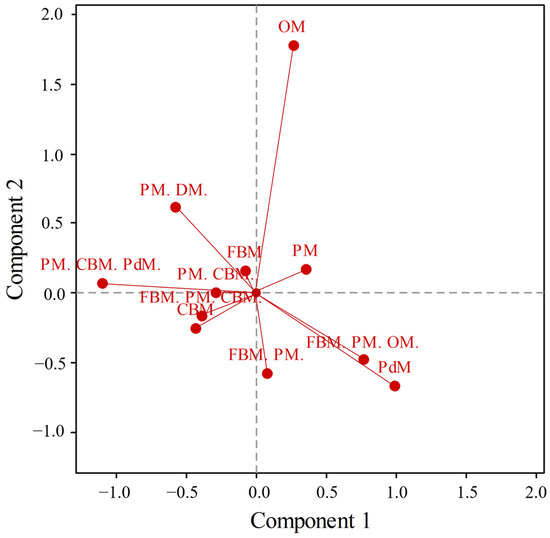
Figure 10.
MP biplot of C1 and C2 components of the MP-RCF analysis.
The data (Table 9) suggest that within the dimensions C1-3, {AWCS} has the highest inertia, λAWCS = 0.149, followed by {OST}, λAWCS = 0.136, and {LS}, λAWCS = 0.120. The Qual metric suggests that AWCS {Air contamination. Water contamination. Seals.} contains enough information for to be visualised (QualAWCS = 0.950).
Table 9.
Column profile inertia of MPs and RCFs.
The graph (Figure 11) shows that C1 (the positive side) suggests that failures are associated with contamination, while the left side of C1 (the negative side) is associated with failures due to operator/maintenance mistakes. The results presented in the biplot (Figure 12) suggest a high association between {OM} and {Air/Water contamination. Seals.}. The positive sides of the C1-C2 components suggest an association among practices in which failures are reported due to contamination, while the centre and negative sides report a variety of failures.
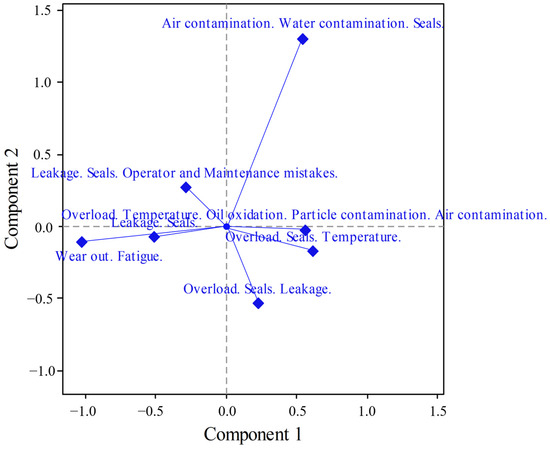
Figure 11.
RCF biplot of C1 and C2 components of the MP-RCF analysis.
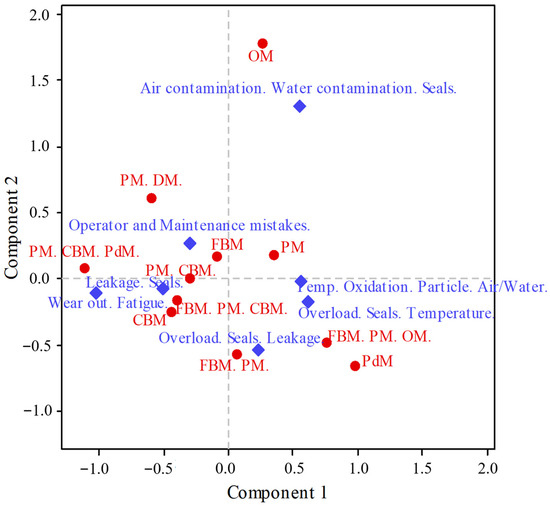
Figure 12.
MP and RCF biplot.
Considering an inertia of 75.7%, the representation shows that Qual > 0.70 contains 12/18 categories, while with the extension to the fourth component, all except {PM. DM.} have Qual > 0.70. Thus, interpretation using only three components (75.7% inertia) was sufficient. The first cluster (blue) on the dendrogram (Figure 13) had the most significant association between the MPs and failures associated with {Leakage. Seals. Operator and Maintenance Mistakes}, especially {FBM}. The second cluster (green) shows the smallest distance between {FBM. PM. CBM.} and {Leakage. Seals.}. The third (red) cluster shows similarity between {FBM. PM.} and {Overload. Seals. Leakage.}. The fourth (purple) cluster shows similarities among different applied MPs and failures related to overload and temperature. Finally, the last cluster (yellow) shows similarity between {OM} and {Air contamination. Water contamination. Seals.}.

Figure 13.
Dendrogram of MP and RCF.
3.4. Clusters and Performance Metrics
The obtained clusters (MP-CFT in Table 10 and MP-RCF in Table 11) were benchmarked against performance metrics, including both technical (i.e., MTTR, MTBF) and sustainability-related (e.g., WOMM) metrics. Although there was no significant variation among MTTR values with respect to clusters, the MTBF metric showed differences among the metrics. Namely, in both cases, clusters 2, 3, and 4 outperformed the other clusters, where the second cluster showed the best performance for the mean value of MTBF. Considering the WOMM metric, the results indicate that the second, third and fourth clusters possessed lower average WOMM. Note: The cluster 0* (n = 21) includes the respondents that were not clustered, and were left out of the analysis.
Table 10.
MP-CFT clusters and performance metrics.
Table 11.
MP-RCF clusters and performance metrics.
3.5. Machine Learning Feature Importance
To select machine learning algorithms, we checked the normality of data using the Shapiro–Wilk test. The test showed that the normality assumption was violated; thus, we used non-parametric ML algorithms including RF (Random Forest), SVM (Support Vector Machine), kNN (k-Neirest Neighbour) and DT (Decision Tree). The results of ML regression analysis for response MPIs of MTTR (Table 12), MTBF (Table 13) and WOMM (Table 14) are provided in the following. Additionally, the reason for selecting these non-parametric regression algorithms is that they can be used with continuous and categorical predictors. Finally, we used feature importance from the obtained results to allocate the most important predictors.
Table 12.
Performance results of MTTR.
Table 13.
Performance results of MTBF.
Table 14.
Performance results of WOMM.
The results show that RF outperformed the other models. The out-of-bag MSE did not change significantly (Figure 14), and up to approximately 10 trees were enough to reduce the discrepancy between training and testing. However, a significant error existed in all cases due to the low prediction accuracy. The regression (Figure 14) showed significant variation in the validation (predicted vs. observed values). Feature perturbations were conducted to measure the mean decrease in accuracy, showing that MDS (Maintenance Department Staff), NWEC (Nominal Working Energy Consumption), TTCOC (Time To Complete Oil Change), MPPM, and FAP were the most essential features (Figure 14). Conversely, the increase in node purity (Figure 14) showed that NWEC, MPPM, and TTOR (Time To Oil Refilling) were the main contributors to the homogeneity of the output, i.e., the reduction in variance. In addition, negative features such as CMS (Condition Monitoring Sensor), TTCOC, and MA suggest noise and/or overfitting, calling into question their suitability for modelling, since they do not seem to contribute positively to prediction.
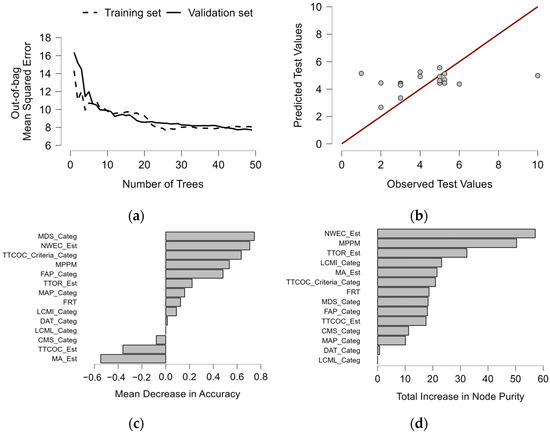
Figure 14.
Results of clusters considering the MTTR metric via (a) OOB-MSE error; (b) predicted versus observed test value; (c) mean decrease in accuracy; and (d) total increase in node purity of features.
Considering the MTBF (Figure 15) metric, the evidence suggests that machine age has the highest impact on MTBF. This is also supported by empirical evidence [21], as equipment age contributes significantly to the reduction of MTBF. Additionally, MPPM, TTOR, TTCOC, MAP (Maintenance Analysis Program), and FRT (Filter Replacement Time) are the most critical indicators of MTBF. This suggests that hydraulic fluid condition significantly affects the MTBF of hydraulic machinery.
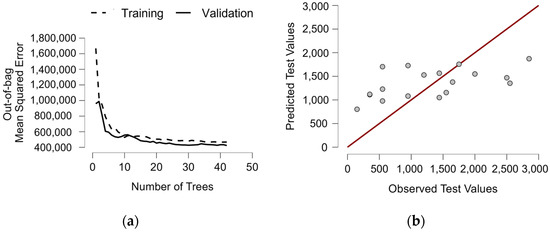
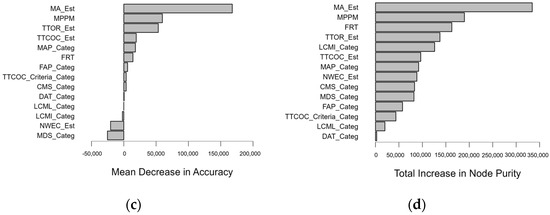
Figure 15.
Results of clusters considering the MTBF metric via (a) OOB-MSE error; (b) predicted versus observed test value; (c) mean decrease in accuracy; and (d) total increase in node purity of features.
Observing the sustainability metric of WOMM, it can be seen that MPPM, TTCOC, NWEC, MDS, and FRT are the most impactful factors for fluid waste (Figure 16), with respect to both the reduction of MSE and the decrease in variance. To better understand this, we used the ranking of feature importance to establish essential features (Figure 17). The ranking showed that the number of maintenance personnel per machine played a vital role in hydraulic system maintenance, followed by time to oil refilling, the equipment size measured by nominal working energy consumption, machinery age, filter replacement time, etc. Surprisingly, although only 9.6% of the companies applied data analysis tools in hydraulic machine maintenance, only slight improvements were noticeable considering the output metrics. This is also for the case for the laboratory analysis of hydraulic oil, which showed no significant impact on the output metrics.
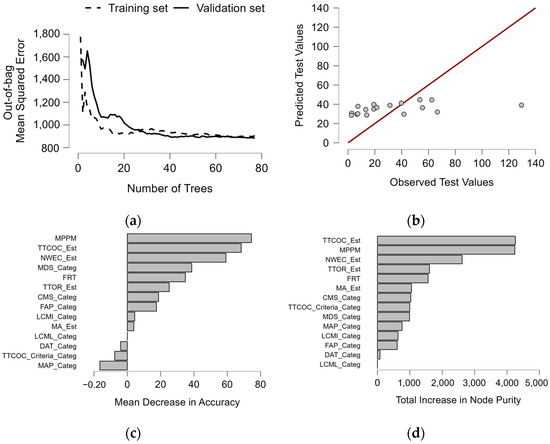
Figure 16.
Results of clusters considering the WOMM metric via (a) OOB-MSE error; (b) predicted versus observed values; (c) mean decrease in accuracy; and (d) total increase in node purity of features.
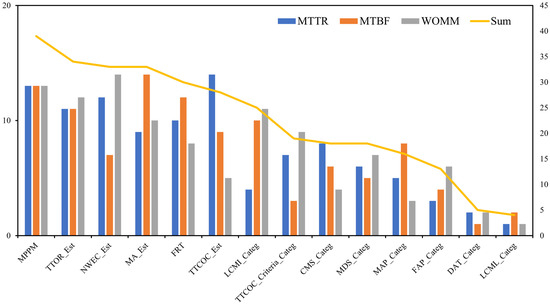
Figure 17.
RF Feature Importance scores summarised by rankings with respect to the performance metrics MTTR, MTBF and WOMM.
4. Discussion
4.1. Research Results from the Analysis of MPs and CFTs
The results show a high association between the investigated variables of MPs and CFTs, χ2 = 165.021, with a p-value < 0.001. Looking at the categories of MPs, {PM} is the most frequently applied MP, while among CFTs, it is suggested that {Hoses. Pipes. Actuators. Pumps. Servo/Proportional valves.} is the most frequently reported category of component failures.
The results obtained show that the first cluster, {CBM} and {Pipes. Actuators. Pumps. DV (Servo/Proportional) valves.} with {Hoses. Pipes. Pumps. ICE/EM.}, suggests the poor performance of MPs. Namely, filtering {CBM} using different items, it turns out that companies that report using {CBM} strictly had the lowest MTBFCBM = 835 h, and in that sense had the worst performance when considering this metric. The results show that maintenance activities behind {CBM} mostly included visual inspection (56%), while in up to 75% of the cases in which condition monitoring instruments like PFT (Pressure/Flow/Temperature) were used, they were not used for maintenance decision making. Considering data analysis, the results show that only 7% of {CBM} respondents report using data analysis tools. This also poses a question as to whether maintenance practitioners truly apply CBM and at what level. The second (red) and third (green) clusters show mixed MPs and a variety of reported failures, although with less severity and variation than in the first cluster. The fourth (yellow) and fifth (purple) clusters show presumably better performance in terms of reducing the severity of the failures of major components.
Taking a practical standpoint regarding the association between MPs and CFT using CA-AHC analysis, the results suggest that advanced maintenance practices, such as CBM and PdM, seem to result in a smaller variety of failures being reported, while at the same time there is an increased frequency of sensor failures. This can be attributed to the fact that sophisticated monitoring technology and instruments can avoid some serious failures. On the other hand, when applying traditional practices, such as FBM and PM, stoppages are primarily associated with failures associated with actuators and power units. This can suggest poor maintenance skills and the lack of the competence required to prevent this type of failure. The absence of such abilities leads to severe failures and a drop in productivity. Overall, the use of CA-AHC analysis in our case proved compelling due to its ability to transform categorical data into a feature subspace that can then be used for extracting relevant predictors against MPIs.
4.2. Results from the Analysis of MPs and RCFs
The results show the existence of a relationship between MPs and RCFs, χ2 = 85.769 (p < 0.05). While {PM} was reported to be the most applied practice, {Leakage. Seals. Operator and Maintenance personnel mistakes.} was the most reported category of RCF, with leakage and seals being the most reported root causes of failure across categories.
The clusters obtained from the CA-AHC analysis suggest the following. The first (blue) cluster (Figure 13) shows similarity mostly between {CBM}, {PM. CBM.}, and {FBM}, and failures associated with {Leakage. Seals. Operator and Maintenance mistakes.} on one side, while at higher distances among categories of the same cluster, {PM. CBM. PdM.} and {PM. DM.} show an association with {Wear out. Fatigue.} of hydraulic components. Compared to other items from the survey considering quantitative data, the highest value of MTBF was indeed reported for {Wear out. Fatigue.}, where MTBF{Wear out. Fatigue} = 2080 h.
Looking at the qualitative items, 60% of cases show the utilisation of Pressure/Flow/Temperature/Contamination sensors, suggesting that failures were avoided using an effective maintenance program. The second (green) cluster reports failures, mainly {Leakage. Seals.}, and displays similarity with {FBM. PM. CBM.}. Looking at the analysis of MPs and CFTs, these types of of practices show a small distance from {Hoses. Pipes. Pumps. Sensors}, suggesting CM practice; however, failures associated with leakage/seals could not be prevented. Unlike the previous cases, the third (red) and fourth (purple) clusters are similar to the failures associated with overload. This also justifies the failures associated with temperature, since overload leads to the transformation of power into heat and its subsequent dissipation. Finally, the last (yellow) cluster shows the similarity between {OM} and {Air/Water contamination. Seals.}, suggesting that these failures are associated with constant inspections and activities (e.g., filter replacements, oil refilling). Indeed, looking at quantitative data, MTTR{AirWater cont.} = 6.13 h, which is the second-highest value (with operator/maintenance mistakes being the highest), which suggests that the long time required to perform a repair leaves the system exposed to the environment. The time required to complete an oil change was 3995 h on average, while usual practice and equipment manufacturers suggest approximately 2000 h. Additionally, the activity of TTOR, which is the application of usual maintenance activity to “refresh” the oil properties, is 191.7 h. This practice of trying to compensate for the loss of fluid properties (e.g., viscosity) and, consequently, system response by constantly adding fluid into the system is associated with oxidation and particle/air contamination.
Taken together, several conclusions can be derived. Firstly, the component failures and root causes of failure in hydraulic systems can be clustered into three categories: (1) Random events—these typically include failures of components such as pipes and hoses. This can also be said for failures associated with leakage and seals, since over 90% of companies report these failures. (2) Non-random events—these typically include degradational events under advanced maintenance practices. For instance, the failure of pumps and actuators for which pressure, flow and temperature indicators can explain or indicate degradational behaviour. Looking at RCF, non-random effects include failures associated with contamination in which instruments (e.g., particle counters) can be implemented to monitor and reduce the severity of wear. (3) Human-related events—the obtained evidence suggests a lack of industrial maintenance personnel, especially with respect to advanced data analytics and specialists in the domain of hydraulic system maintenance.
4.3. Feature Importance Considering Performance Metrics
The generated CA-AHC feature subspaces of the devised categories were used with the RF algorithm to extract relevant predictors, i.e., features related to MPIs. From an asset and machine perspective, equipment size (i.e., NWEC) and machine age seem to be the most important predictors. Introducing the NWEC variable for measuring the maintenance performance proved significant, and has not previously been reported in the literature, to the best of the authors’ knowledge. From a maintenance perspective, the number of maintenance personnel per machine, i.e., MPPM, has the greatest impact on the prediction properties of RF regression overall. This is also a vital remark since, to the best of the authors’ knowledge, no empirical evidence has been presented in the literature. Considering maintenance activities, TTOR, FRT, TTCOC, and TTCOC_Criteria, are the most essential features. Hence, considering the fact that fluid contamination is one of the most common causes of failure, the constant refilling of hydraulic oil and frequent complete oil changes in the system, presumably by overhaul, reduces the probability of failure, increasing MTBF and, at the same time, reducing the MTTR of the hydraulic machinery. From a technological perspective, LCMI (Lubricant Condition Monitoring Instruments) is the most critical feature overall; however, the impact on MTTR is questionable, unlike MTBF and WOMM, where it has a significant impact. Additionally, the CMS and LCML (Lubricant Condition Monitoring Laboratory) analyses show poor or negative predictive properties with respect to the performance metrics used in our analysis.
The allocated features that show a negative or poor contribution to the regression model suggest that the existing maintenance of hydraulic systems shows low technological and digital readiness levels. Namely, the fact that 45.2% of MDS consist only of operators and technicians calls into question whether companies perceive maintenance as a “strategic move”, or still see it as a “necessary evil”. Rhetorically, companies utilising advanced PdM solutions have faced difficulties in managing their assets, and as a result have reported a variety of failures. This, however, proved to be a business opportunity for companies and maintenance experts willing to engage with and provide outsourced maintenance services using in-house solutions, which is why many engage with MaaS (Maintenance as a Service) concepts [61]. Additionally, the results show that 13.1% of companies outsource their maintenance activities, while 50.4% rely on external experts or companies to perform equipment failure analysis. Moreover, confounding statistics regarding the application of data analysis show that only 9.6% of companies apply statistical or data analysis tools in hydraulic machine maintenance, which is why no actual contribution to the prediction properties was observed.
Important notice should be given to the ML algorithms used. Namely, considering that non-parametric regression ML algorithms were mainly chosen, with the violation of normality (Shapiro–Wilk p value > 0.05) and their ability to handle mixed data (categorical and continuous) being given as the rationale for their selection. However, other algorithms like gradient boosting machines (XGBoost and LightGBM) or even some neural networks can be used if the data are sufficient. Next, although we used RF feature importance to isolate important predictors, in complex models, tools like SHAP (SHapley Additive exPlanations) would also be of interest for explaining the performance outputs. Nevertheless, given the constraints of our dataset, we limited our exploration of other powerful parametric methods that might yield different insights when applied to different samples. This study relied heavily on data obtained from a questionnaire-based survey, which might inherently have some biases based on respondents applying day-to-day maintenance practices. Finally, deep learning methods that require extensive amounts of data for training were not considered due to the limited size of our dataset. With a more extensive dataset, the exploration of neural networks might provide additional insights through the benchmarking of existing maintenance practices.
5. Conclusions
This paper presented an extensive and in-depth study of features affecting the maintenance performance of companies utilising hydraulic machines. The study used empirical evidence and data synthesised from a questionnaire-based survey disseminated throughout the territory of the West-Balkan countries. Since extensive data were gathered, the study used correspondence analysis in combination with agglomerative hierarchical clustering to generate a feature subspace, after which components were used to identify the predictors impacting maintenance performance metrics, such as MTBF, MTTR and WOMM. The evidence shows that maintenance personnel, machine age, equipment size measured by nominal working energy consumption level, filter replacement time and time required to complete an oil change are the highest-ranked predictors, as established using the random forest algorithm.
Although the obtained evidence represents a significant contribution to the body of knowledge regarding hydraulic system maintenance, the study has limitations. Namely, the obtained results include a variety of companies under different NACE classifications; thus, the environmental conditions and working regimes can differ. Next, the results obtained via non-parametric ML algorithms due to violation of normality need to be further verified using a larger sample size. Additionally, further analysis needs to be conducted to verify and validate the impact of features on operational performance.
In the future, we plan to conduct a study regarding the impact of maintenance features on maintenance performance metrics, considering both categorical and numerical data. Specifically, we will include measuring the impact of outsourced versus in-house maintenance and the impact of data analysis tools in hydraulic machine maintenance. The underlying reason for this is the obvious barrier between preventive and predictive maintenance. The evidence also supports the need for more success in implementing advanced maintenance practices in this domain.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/math11183816/s1, File S1.
Author Contributions
Conceptualisation, M.O. and D.Š.; methodology, M.O. and D.Š.; formal analysis, M.O.; investigation, M.O. and D.Š.; data curation, M.O. and D.Š.; writing—original draft preparation, M.O. and D.Š.; writing—review and editing, M.O. and D.Š.; visualisation, M.O.; supervision, D.Š. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Data are available upon request.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
A complete list of the abbreviations used in the manuscript is presented below.
| Acron. | Description | Acron. | Description |
| AHC | Agglomerative Hierarchical Clustering | MDM | Maintenance Decision Making |
| AHP | Analytical Hierarchical Process | MDS | Maintenance Department Staff |
| AI | Artificial Intelligence | ML | Machine Learning |
| ANP | Analytical Network Process | MP | Maintenance Practice |
| CA | Correspondence Analysis | MPI | Maintenance Performance Indicators |
| CBM | Condition-Based Maintenance | MPM | Maintenance Performance Metrics |
| CFT | Component Failure Type | MPPM | Maintenance Personnel Per Machine |
| CM | Corrective Monitoring | MSE | Mean Squared Error |
| CMMS | Comput. Maintenance Management | MSS | Maintenance Strategy Selection |
| CMP | Condition Monitoring Plan | MTBF | Mean Time Between Failures |
| CMS | Condition Monitoring Sensors | MTTR | Mean Time To Repair |
| CON | Construction | NOM | Number of Machines |
| DM | Design-out Maintenance | NWEC | Nominal Working Energy Consum. |
| DT | Decision Tree | OEE | Overall Equipment Effectiveness |
| FBM | Failure-Based Maintenance | PdM | Predictive Maintenance |
| FRT | Filter Replacement Time | PM | Preventive Maintenance |
| HMA | Hydraulic Machinery Age | RCF | Root Causes of Failure |
| LCM | Lubricant Condition Monitoring | RF | Random Forest |
| LCML | LCM Laboratory | RMSE | Root Mean Squared Error |
| M&Q | Mining and Quarrying | SVM | Support Vector Machine |
| MaaS | Maintenance as a Service | SVR | Support Vector Regression |
| MAE | Mean Absolute Error | TTCOC | Time To Complete Oil Change |
| MAN | Manufacturing | TTOR | Time To Oil Refilling |
| MDA | Multivariate Data Analysis | WOMM | Wasted Oil Monthly Machine |
Appendix A. West-Balkan Survey Questionnaire
A list of the open-ended questions in the questionnaire. The full survey is in the Supplementary Materials.
| N | Question Description |
| Q1 | What are the characteristics of your company, considering: |
| Q1a | The number of maintenance employees in your company? |
| Q1b | The number of machines employing oil-hydraulic systems? |
| Q2 | What are the characteristics of your maintenance department, considering: |
| Q2a | The number of maintenance personnel employed? |
| Q2b | The number of staff in the maintenance department? |
| Q3 | Who performs diagnostics and prognostics on your hydraulic machinery? |
| Q4 | What type of hydraulic machines are utilised (please name), what is the exact number you employ? |
| Q5 | What are the average nominal pressures within your hydraulic systems? |
| Q6 | What are the average nominal flows within your hydraulic systems? |
| Q7 | What types of hydraulic fluids are you utilising for your hydraulic machinery? |
| Q8 | What types of maintenance policies do you conduct in your company on specific hydraulic machines? |
| Q9 | For your hydraulic machines, what specific maintenance analysis programs are you conducting? |
| Q10 | What monitoring sensors are you utilising? |
| Q11 | What types of instrument are you using for the oil contamination analysis program? |
| Q11a | Oil monitoring instruments? |
| Q11b | If you are using external oil analysis, what type of analysis is used? |
| Q12 | What data analysis tools are you employing for the analysis and maintenance decision making? |
| Q13 | What is the average age of your hydraulic machinery? |
| Q14 | What is the average Time Between Failures (TBF) of your hydraulic machinery? |
| Q15 | What are your hydraulic machinery’s most common component failures? |
| Q16 | What are the most common Root Causes of Failure (RCF) of your hydraulic machinery? |
| Q17 | What is the average period for your filter replacement? |
| Q18 | What is the specific hydraulic fluid viscosity grade that you use in your hydraulic machines? |
| Q19 | How often do you refill the system with hydraulic fluid? |
| Q20 | What is the average time required to complete an oil change, and based on what criteria do you conduct it? |
| Q20a | Average time of complete oil change: |
| Q20b | Criteria: |
| Q21 | What are the characteristics of your hydraulic fluid usage and waste (respond in the following)? |
| Q21a | Average machine hydraulic fluid filling: |
| Q21b | Hydraulic fluid spent monthly (litres/month): |
References
- Simões, J.M.; Gomes, C.F.; Yasin, M.M. A Literature Review of Maintenance Performance Measurement: A Conceptual Framework and Directions for Future Research. J. Qual. Maint. Eng. 2011, 17, 116–137. [Google Scholar] [CrossRef]
- Cachada, A.; Moreira, P.M.; Romero, L.; Barbosa, J.; Leitno, P.; Gcraldcs, C.A.S.; Deusdado, L.; Costa, J.; Teixeira, C.; Teixeira, J.; et al. Maintenance 4.0: Intelligent and Predictive Maintenance System Architecture. In Proceedings of the 2018 IEEE 23rd International Conference on Emerging Technologies and Factory Automation (ETFA), Turin, Italy, 4–7 September 2018; pp. 139–146. [Google Scholar]
- Chen, S.-Z.; Zhang, S.-Y.; Feng, D.-C.; Taciroglu, E. Embedding Prior Knowledge into Data-Driven Structural Performance Prediction to Extrapolate from Training Domains. J. Eng. Mech. 2023; in press. [Google Scholar] [CrossRef]
- Orošnjak, M.; Brkljač, N.; Šević, D.; Čavić, M.; Oros, D.; Penčić, M. From Predictive to Energy-Based Maintenance Paradigm: Achieving Cleaner Production through Functional-Productiveness. J. Clean. Prod. 2023, 408, 137177. [Google Scholar] [CrossRef]
- Soltanali, H.; Garmabaki, A.H.S.; Thaduri, A.; Parida, A.; Kumar, U.; Rohani, A. Sustainable production process: An application of reliability, availability, and maintainability methodologies in automotive manufacturing. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2019, 233, 682–697. [Google Scholar] [CrossRef]
- Wang, J.; Wang, Y.; Fu, Y. Joint Optimization of Condition-Based Maintenance and Performance Control for Linear Multi-State Consecutively Connected Systems. Mathematics 2023, 11, 2724. [Google Scholar] [CrossRef]
- Chui, M.; Henke, N.; Miremadi, M. Most of AI’s Business Uses Will Be in Two Areas. Available online: https://hbr.org/2018/07/most-of-ais-business-uses-will-be-in-two-areas (accessed on 8 February 2023).
- Orosnjak, M. Maintenance Practice Performance Assessment of Hydraulic Machinery: West Balkan Meta-Statistics and Energy-Based Maintenance Paradigm. In Proceedings of the 2021 5th International Conference on System Reliability and Safety (ICSRS), Palermo, Italy, 24–26 November 2021; pp. 108–114. [Google Scholar]
- Avakh Darestani, S.; Palizban, T.; Imannezhad, R. Maintenance Strategy Selection: A Combined Goal Programming Approach and BWM-TOPSIS for Paper Production Industry. J. Qual. Maint. Eng. 2022, 28, 14–36. [Google Scholar] [CrossRef]
- Ding, S.H.; Kamaruddin, S.; Azid, I.A. Maintenance Policy Selection Model—A Case Study in the Palm Oil Industry. J. Manuf. Technol. Manag. 2014, 25, 415–435. [Google Scholar] [CrossRef]
- Muchiri, P.N.; Pintelon, L.; Martin, H.; De Meyer, A.-M. Empirical Analysis of Maintenance Performance Measurement in Belgian Industries. Int. J. Prod. Res. 2010, 48, 5905–5924. [Google Scholar] [CrossRef]
- Piechnicki, F.; Dos Santos, C.F.; De Freitas Rocha Loures, E.; Dos Santos, E.A.P. Data Fusion Framework for Decision-Making Support in Reliability-Centered Maintenance. J. Ind. Prod. Eng. 2021, 38, 1–17. [Google Scholar] [CrossRef]
- Orošnjak, M.; Jocanović, M.; Čavić, M.; Karanović, V.; Penčić, M. Industrial Maintenance 4(.0) Horizon Europe: Consequences of the Iron Curtain and Energy-Based Maintenance. J. Clean. Prod. 2021, 314, 128034. [Google Scholar] [CrossRef]
- Parida, A.; Chattopadhyay, G. Development of a Multi-Criteria Hierarchical Framework for Maintenance Performance Measurement (MPM). J. Qual. Maint. Eng. 2007, 13, 241–258. [Google Scholar] [CrossRef]
- Nunes, P.; Santos, J.; Rocha, E. Challenges in Predictive Maintenance—A Review. CIRP J. Manuf. Sci. Technol. 2023, 40, 53–67. [Google Scholar] [CrossRef]
- Parida, A.; Kumar, U. Maintenance Performance Measurement (MPM): Issues and Challenges. J. Qual. Maint. Eng. 2006, 12, 239–251. [Google Scholar] [CrossRef]
- Dui, H.; Zhang, Y.; Zhang, Y.-A. Grouping Maintenance Policy for Improving Reliability of Wind Turbine Systems Considering Variable Cost. Mathematics 2023, 11, 1954. [Google Scholar] [CrossRef]
- Roosefert Mohan, T.; Preetha Roselyn, J.; Annie Uthra, R.; Devaraj, D.; Umachandran, K. Intelligent Machine Learning Based Total Productive Maintenance Approach for Achieving Zero Downtime in Industrial Machinery. Comput. Ind. Eng. 2021, 157, 107267. [Google Scholar] [CrossRef]
- Dalzochio, J.; Kunst, R.; Pignaton, E.; Binotto, A.; Sanyal, S.; Favilla, J.; Barbosa, J. Machine Learning and Reasoning for Predictive Maintenance in Industry 4.0: Current Status and Challenges. Comput. Ind. 2020, 123, 103298. [Google Scholar] [CrossRef]
- He, Y.; Su, H.; Zio, E.; Peng, S.; Fan, L.; Yang, Z.; Yang, Z.; Zhang, J. A Systematic Method of Remaining Useful Life Estimation Based on Physics-Informed Graph Neural Networks with Multisensor Data. Reliab. Eng. Syst. Saf. 2023, 237, 109333. [Google Scholar] [CrossRef]
- Orošnjak, M.; Delić, M.; Ramos, S. Influence of Maintenance Practice on MTBF of Industrial and Mobile Hydraulic Failures: A West Balkan Study. In Proceedings of the International Conference on Machine and Industrial Design in Mechanical Engineering, Novi Sad, Serbia, 10–12 June 2021; Rackov, M., Mitrović, R., Čavić, M., Eds.; SpringerLink: Cham, Switzerland, 2022; pp. 617–625. [Google Scholar]
- Wang, S.; Xiang, J. A Minimum Entropy Deconvolution-Enhanced Convolutional Neural Networks for Fault Diagnosis of Axial Piston Pumps. Soft Comput. 2020, 24, 2983–2997. [Google Scholar] [CrossRef]
- Cheng, X.; Chaw, J.K.; Goh, K.M.; Ting, T.T.; Sahrani, S.; Ahmad, M.N.; Abdul Kadir, R.; Ang, M.C. Systematic Literature Review on Visual Analytics of Predictive Maintenance in the Manufacturing Industry. Sensors 2022, 22, 6321. [Google Scholar] [CrossRef]
- Zhang, X.; Fujiwara, T.; Chandrasegaran, S.; Brundage, M.P.; Sexton, T.; Dima, A.; Ma, K.-L. A Visual Analytics Approach for the Diagnosis of Heterogeneous and Multidimensional Machine Maintenance Data. In Proceedings of the 2021 IEEE 14th Pacific Visualization Symposium (PacificVis), Tianjin, China, 19–21 April 2021; Volume 2021, pp. 196–205. [Google Scholar]
- Navinchandran, M.; Sharp, M.E.; Brundage, M.P.; Sexton, T.B. Discovering Critical KPI Factors from Natural Language in Maintenance Work Orders. J. Intell. Manuf. 2022, 33, 1859–1877. [Google Scholar] [CrossRef]
- Lu, Y.; Garcia, R.; Hansen, B.; Gleicher, M.; Maciejewski, R. The State-of-the-Art in Predictive Visual Analytics. Comput. Graph. Forum 2017, 36, 539–562. [Google Scholar] [CrossRef]
- Zhang, L.; Stoffel, A.; Behrisch, M.; Mittelstadt, S.; Schreck, T.; Pompl, R.; Weber, S.; Last, H.; Keim, D. Visual Analytics for the Big Data Era: A Comparative Review of State-of-the-Art Commercial Systems. In Proceedings of the 2012 IEEE Conference on Visual Analytics Science and Technology (VAST), Seattle, WA, USA, 19 October 2012; pp. 173–182. [Google Scholar]
- Komonen, K. A Cost Model of Industrial Maintenance for Profitability Analysis and Benchmarking. Int. J. Prod. Econ. 2002, 79, 15–31. [Google Scholar] [CrossRef]
- Parida, A. Study and Analysis of Maintenance Performance Indicators (MPIs) for LKAB. J. Qual. Maint. Eng. 2007, 13, 325–337. [Google Scholar] [CrossRef]
- Qian, Y.; Li, T.; Li, L.; Du, K. A Framework for Identifying Maintenance Performance Metrics and Its Selection Methodology. In Proceedings of the International Conference on Management and Engineering (CME), Shanghai, China, 24–25 May 2014; Destech Publications, Inc.: Shanghai, China, 2014; pp. 813–824. [Google Scholar]
- Åhrén, T.; Parida, A. Maintenance Performance Indicators (MPIs) for Benchmarking the Railway Infrastructure. Benchmarking An. Int. J. 2009, 16, 247–258. [Google Scholar] [CrossRef]
- Parida, A. Maintenance Performance Assessment (MPA) Framework for Engineering Asset. In Proceedings of the 2008 IEEE International Conference on Industrial Engineering and Engineering Management, Singapore, 8–11 December 2008; pp. 1351–1354. [Google Scholar]
- Kumar, U.; Galar, D.; Parida, A.; Stenström, C.; Berges, L. Maintenance Performance Metrics: A State-of-the-art Review. J. Qual. Maint. Eng. 2013, 19, 233–277. [Google Scholar] [CrossRef]
- Van Horenbeek, A.; Pintelon, L.; Muchiri, P. Maintenance Optimization Models and Criteria. Int. J. Syst. Assur. Eng. Manag. 2010, 1, 189–200. [Google Scholar] [CrossRef]
- Van Horenbeek, A.; Pintelon, L. Development of a Maintenance Performance Measurement Framework—Using the Analytic Network Process (ANP) for Maintenance Performance Indicator Selection. Omega 2014, 42, 33–46. [Google Scholar] [CrossRef]
- Contri, P.; Kuzmina, I. An Overview of the Research by EC-JRC/IE on Enhancement of Maintenance Efficiency of Nuclear Power Plants. In Proceedings of the ASME Pressure Vessels and Piping Conference, Prague, Czech Republic, 26–30 July 2009; pp. 545–552. [Google Scholar]
- Ighravwe, D.E.; Oke, S.A. A Fuzzy-Grey-Weighted Aggregate Sum Product Assessment Methodical Approach for Multi-Criteria Analysis of Maintenance Performance Systems. Int. J. Syst. Assur. Eng. Manag. 2017, 8, 961–973. [Google Scholar] [CrossRef]
- Baidya, R.; Ghosh, S.K. Model for a Predictive Maintenance System Effectiveness Using the Analytical Hierarchy Process as Analytical Tool. IFAC-Pap. 2015, 48, 1463–1468. [Google Scholar] [CrossRef]
- Momc, V.; Bojovic, N.; Papic, V.; Vujanovic, D. Expert Systems with Applications Evaluation of Vehicle Fleet Maintenance Management Indicators by Application of DEMATEL and ANP. Expert. Syst. Appl. 2012, 39, 10552–10563. [Google Scholar] [CrossRef]
- Naji, M.A.; Mousrij, A. Maintenance Success Factors Identification Using the Fuzzy AHP. In Proceedings of the 2018 IEEE International Conference on Technology Management, Operations and Decisions (ICTMOD), Marrakech, Morocco, 21–23 November 2018; pp. 107–112. [Google Scholar]
- Gonçalves, C.D.F.; Dias, J.A.M.; Cruz-Machado, V.A. Decision Methodology for Maintenance KPI Selection: Based on ELECTRE I. In Proceedings of the Eighth International Conference on Management Science and Engineering Management: Focused on Computing and Engineering Management, Lisbon, Portugal, 25–27 July 2014; pp. 1001–1012. [Google Scholar]
- Oliveira, M.; Lopes, I.; Rodrigues, C. Use of Maintenance Performance Indicators by Companies of the Industrial Hub of Manaus. Procedia CIRP 2016, 52, 157–160. [Google Scholar] [CrossRef]
- Gandhare, B.S.; Akarte, M.M.; Patil, P.P. Maintenance Performance Measurement—A Case of the Sugar Industry. J. Qual. Maint. Eng. 2018, 24, 79–100. [Google Scholar] [CrossRef]
- Upasani, K.; Bakshi, M.; Pandhare, V.; Lad, B.K. Distributed Maintenance Planning in Manufacturing Industries. Comput. Ind. Eng. 2017, 108, 1–14. [Google Scholar] [CrossRef]
- Carnero, M.C. Asymmetries in the Maintenance Performance of Spanish Industries before and after the Recession. Symmetry 2017, 9, 166. [Google Scholar] [CrossRef]
- Sahoo, S. An Empirical Exploration of TQM, TPM and Their Integration from Indian Manufacturing Industry. J. Manuf. Technol. Manag. 2018, 29, 1188–1210. [Google Scholar] [CrossRef]
- Simões, J.M.; Gomes, C.F.; Yasin, M.M. Changing Role of Maintenance in Business Organisations: Measurement versus Strategic Orientation. Int. J. Prod. Res. 2016, 54, 3329–3346. [Google Scholar] [CrossRef]
- Erkoyuncu, J.A.; Khan, S.; Eiroa, A.L.; Butler, N.; Rushton, K.; Brocklebank, S. Perspectives on Trading Cost and Availability for Corrective Maintenance at the Equipment Type Level. Reliab. Eng. Syst. Saf. 2017, 168, 53–69. [Google Scholar] [CrossRef][Green Version]
- Mahfoud, H.; Abdellah, E.B.; El Biyaali, A. Dependability-Based Maintenance Optimization in Healthcare Domain. J. Qual. Maint. Eng. 2018, 24, 200–223. [Google Scholar] [CrossRef]
- Rijsdijk, C.; Tinga, T. Observing the Effect of a Policy: A Maintenance Case. J. Qual. Maint. Eng. 2016, 22, 277–301. [Google Scholar] [CrossRef]
- Seecharan, T.; Labib, A.; Jardine, A. Maintenance Strategies: Decision Making Grid vs Jack-Knife Diagram. J. Qual. Maint. Eng. 2018, 24, 61–78. [Google Scholar] [CrossRef]
- Ylipää, T.; Skoogh, A.; Bokrantz, J.; Gopalakrishnan, M. Identification of Maintenance Improvement Potential Using OEE Assessment. Int. J. Product. Perform. Manag. 2017, 66, 126–143. [Google Scholar] [CrossRef]
- Sénéchal, O. Research Directions for Integrating the Triple Bottom Line in Maintenance Dashboards. J. Clean. Prod. 2017, 142, 331–342. [Google Scholar] [CrossRef]
- Pires, S.P.; Sénéchal, O.; Loures, E.F.R.; Jimenez, J.F. An Approach to the Prioritization of Sustainable Maintenance Drivers in the TBL Framework. IFAC-Papers 2016, 49, 150–155. [Google Scholar] [CrossRef]
- Husson, F.; Houee-Bigot, M. Correspondence Analysis. Available online: https://husson.github.io/MOOC_GB/CA_course_slides.pdf (accessed on 30 December 2022).
- Husson, F.; Lê, S.; Pagès, J. Computer Science and Data Analysis Series: Exploratory Multivariate Analysis by Example Using R; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: Abingdon, UK, 2017; ISBN 9781138196346. [Google Scholar]
- Le, S.; Josse, J.; Husson, F. FactoMineR: An R Package for Multivariate Analysis. J. Stat. Softw. 2008, 25, 1–18. [Google Scholar] [CrossRef]
- Nielsen, F. Hierarchical Clustering. In Introduction to HPC with MPI for Data Science; Undergraduate Topics in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; pp. 223–239. ISBN 978-3-319-21902-8. [Google Scholar]
- Murtagh, F.; Contreras, P. Algorithms for Hierarchical Clustering: An Overview. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Methods of Hierarchical Clustering. arXiv 2011, arXiv:1105.0121. [Google Scholar]
- Chang, Y.-M.; Hsieh, C.-J.; Chang, K.-W.; Ringgaard, M.; Lin, C.-J. Training and Testing Low-Degree Polynomial Data Mappings via Linear SVM. J. Mach. Learn. Res. 2010, 11, 1471–1490. [Google Scholar]
- Quinlan, J.R. Induction of decision trees. Mach. Learn. 1986, 1, 81–106. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]


















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).