4.2.1. A Probabilistic Tabu Search Algorithm
To solve the deterministic CDP, our approach has two phases. In the first one, a tailored method generates a solution based on the type of instance being solved. To do it, we propose two construction methods,
BR-F and
BR-B heuristics, and apply them for a few trials first to select the best one with a reactive mechanism. Then, the selected method is repeatedly applied, following a classic multi-start pattern. The constructed solutions are then submitted to a TS improvement method. We then make use of biased-randomization (BR) techniques to add/remove nodes from an emerging solution. These techniques make use of skewed probability distributions to transform a deterministic heuristic into a probabilistic algorithm able to generate many ‘good-quality’ solutions to the problem in short computational times [
63]. The term ‘forward heuristic’ refers to the constructive method, while the term ‘backward heuristic’ refers to the destructive one. The bias randomized forward heuristic (
BR-F) starts with an empty initial solution
S. The algorithm adds nodes from
V to the solution
S, while the capacity constraint is not satisfied (Algorithm 1). As input parameters, the method requires the instance
I to be solved, the parameter
to balance the distance, and the capacity of the greedy function (
6).
I contains the information about the capacity of each element
i,
, the minimum required level of capacity
B, and the distance between any pair of elements
,
.
S is initialized as an empty solution in step 1. Let
be the list with all the edges in the input graph. In step 2, the algorithm sorts this list of edges in a decreasing order based on the distances between nodes, where the largest edge comes first (we call the ordered list
). We then randomly select one of the edges according to a geometric probability distribution. This biased selection favors the edges with larger distances (i.e., in the first positions in the list). Specifically, in step 3, the edge
is randomly selected from the
. The endpoints of edges
e,
, and
, are added to the partial solution, and their objective functions are initialized in step 5 with the distance between
and
being
. The objective function value
of the partial solution
S is then updated (step 5). The
BR-F performs iterations, adding an element at a time, to reach the required level of service. The while loop in Algorithm 1 shows these iterations (from steps 7–13). In particular, the method first creates a candidate list,
, with all the elements not included in the solution (i.e.,
). The candidate elements in
are evaluated considering both their distance to the elements already in the solution
S, and their capacity. In mathematical terms, for each node
we compute its evaluation
as:
where
is the minimum distance from node
i to the elements in
S, and
is the capacity of elements
i, or
. Both distance and capacity are normalized in order to sum them up. To set up the
parameter, the constructive heuristic is executed 10 times, varying the range of
from 0 to 1 and increasing its value by
in each execution. Subsequently, the
value associated with the best solution found is utilized throughout the entire execution. This parameter in the greedy function oversees the balance between distance and capacity. Once all the elements are computed, they are rearranged by applying a biased-randomized process, so the elements associated with higher values are more likely to be ranked at the top of the list. This process allows us to select the elements in a different order at each iteration of the process, while still preserving the flavor of the original heuristic. In our case, a geometric probability distribution, driven by a single parameter
(
), is used to induce this skewed behaviour. The value of this parameter was set after a quick tuning process over sample of deterministic CPD benchmark instances. Thus, this selection returns the element
of
to be added to the solution (step 9). After adding it to the solution (step 10), the objective function is updated (step 11), and the element is removed from the candidate list (step 12). The algorithm finishes when the capacity level
B is satisfied.
| Algorithm 1 BR-F(I, ) |
- 1:
- 2:
- 3:
- 4:
- 5:
- 6:
- 7:
while
do - 8:
- 9:
- 10:
- 11:
- 12:
- 13:
end while - 14:
return
S
|
In terms of computational complexity, the bias randomized forward heuristic exhibits a Big O notation of . This complexity arises from the necessity to sort the edge list in increasing distance order and the iterative process of selecting and removing nodes based on the geometric probability distribution until the capacity constraint is satisfied. It must be noticed that, since we are solving the stochastic version of the capacity diversity problem, the elements (also called sites) have random capacity variables , and at this stage of the solving method (i.e., when constructing solutions), we are considering their expected value as the input in the algorithm.
The bias randomized backward heuristic (
BR-B) follows the line drawn by destructive heuristics such as
GRASP-D1 [
21]. Similarly to
BR-F, the
BR-B algorithm requires the instance information
I as its input (Algorithm 2). In contrast to
BR-F,
BR-B starts with all elements selected (step 1), and removes nodes from the solution
S as long as it continues to fulfill the capacity constraint (while loop, from steps 3–7). The algorithm creates an edge list sorted in increasing distance order, which we call
(step 2). While the solution remains feasible, the algorithm selects an edge
at random using a geometric probability distribution based on the distances of the edges. Then, the next element to be removed from the solution (step 6) is selected at random from the two nodes of the edge
. The probability of selecting a node
of
is inversely proportional to its capacity, i.e., the lower its capacity, the larger the probability (step 5). To ensure the feasibility of the solution, the last removed element is reinserted after the while loop (step 8).
| Algorithm 2 BR-B(I) |
- 1:
- 2:
- 3:
while
do - 4:
- 5:
- 6:
- 7:
end while - 8:
- 9:
return
S
|
Similar to the BR-F heuristic, the bias randomized backward heuristic also plays a central role in our solution methodology, offering a destructive counterpart to the constructive nature of BR-F. The computational complexity is , attributable to the algorithm’s need to evaluate each node and edge in the process. Both algorithms operate with a loop that continues until a feasible solution is found. This setup implies that, when fewer nodes are needed, the constructive strategy arrives at a solution quicker than its destructive counterpart. In some real-life applications, such as logistics or transportation, a solution with a small fraction of the number of facilities opened usually satisfies the total demand. However, in other applications, such as telecommunications or smart cities with the IoT, the required number of open facilities is usually very large to meet the capacity requirements. This is why we propose two different constructive methods considering the different types of instances to be solved. Notice that, in the first type of applications, a construction method would perform a low number of iterations, but in instances of the second type of applications, it would perform a large number of iterations, and it seems more appropriate to apply a destructive method there. Our BR-F and BR-B heuristics complement each other and together offer a robust solution for any situation.
Algorithm 3 illustrates the pseudocode of our TS for the CDP. The algorithm receives the constructed solution S and the maximum number of iterations without improvement, , as inputs. Let be the best solution, which initially is (step 1). From step 3 to 13, the method sequentially drops the oldest selected element u in S (steps 5 and 6), and adds the element with the maximum–minimum distance from to (step 7). Ties with respect to the max–min value are broken with the element which maximizes the sum of the distances to the elements in (step 8). If the new solution improves the best solution identified so far, , then it is updated (steps 9 to 12). The algorithm ends after iterations without improvement and returns the best solution it found (step 14).
The TS improvement operates with an complexity per iteration, accounting for the management of the tabu list and neighborhood explorations. Consequently, the overall complexity of the probabilisitic tabu search (PTS) algorithm can be succinctly described as , achieving a balance between the initial solution formulation and an efficient TS, where represents the iterations without improvement. As mentioned, the construction can be either the BR-F method, described in Algorithm 1, or the BR-B method, described in Algorithm 2. The method requires three input parameters: the instance I, the parameter obtained from the construction phase, and from the TS algorithm.
4.2.2. Extending the PTS to a Simheuristic Approach
In this section, we extend the PTS using the simheuristic framework [
12], introducing simulation techniques to evaluate the performance of promising solutions in a stochastic environment. As documented in the stochastic literature, good deterministic solutions improve the chances of finding better stochastic solutions. In this vein, we adapt the PTS algorithm to the simheuristic framework, considering its ability to achieve very good outcomes (see
Section 5).
| Algorithm 3 Probabilistic Tabu Search, PTS() |
- 1:
- 2:
- 3:
while
do - 4:
- 5:
- 6:
- 7:
- 8:
- 9:
if then - 10:
- 11:
- 12:
end if - 13:
end while - 14:
return
|
In
Section 3, we described two stochastic variants for the CDP: the stochastic model with a soft constraint (SCDP-SC), and the stochastic model with random capacities and a probabilistic constraint (SCDP-PC). The first model, with soft constraints (Equation (
4)), penalizes the objective function value by selecting more than the required elements (e.g., a
of extra facilities are randomly opened) in scenarios where the soft constraint is not satisfied. In such cases, the penalized objective function value is computed as the minimum distance between all pairs of selected sites. Note that this value is significantly worse (lower) than the original objective function value of the solution. The recourse action of selecting extra elements is a raw strategy but is very effective, as it ensures that a robust solution can be found for different stochastic scenarios. Algorithm 4 illustrates the main steps of our simheuristic approach for the SCDP-SC, which we call
SimTS-SC.
Algorithm 4 takes the maximum number of iterations
without improvement and the maximum time
as inputs, and consists of three main phases.
Table 2 summarizes the parameters and symbols used in this method. In the initial phase, the algorithm generates a feasible solution that is improved with the TS algorithm (step 1). This initial solution
is the best solution known so far. Then, a fast simulation is performed to obtain the average value of the objective function (minimum distance) of the simulations performed over that solution, denoted as
, i.e., the stochastic objective function evaluation (step 2). The pool of best stochastic solutions
is initialized with the best solution
(step 3). In the second phase, a while loop is executed to generate new solutions (step 5). They are obtained by applying the PTS algorithm to the instance with expected values. Then, only a short number of simulations runs are conducted on the promising solutions (steps 6 and 7) to evaluate the quality of each of these solutions in a stochastic environment. In each iteration, if the new promising solution shows a higher stochastic objective function value than the current best solution, it is updated and inserted into the set of best stochastic solutions
(step 10). Finally, in the third phase, an extended simulation experiment is conducted on the best stochastic solutions found (steps 14–19), which provides a more accurate estimate of the expected objective function value. Furthermore, this intensive simulation also provides relevant statistics to analyze the reliability of each solution in
, and the best one is returned by the algorithm (step 20).
| Algorithm 4 SimTS-SC(I, , , ) |
- 1:
- 2:
- 3:
- 4:
while
do - 5:
- 6:
if then - 7:
- 8:
if then - 9:
- 10:
- 11:
end if - 12:
end if - 13:
end while - 14:
for
do - 15:
- 16:
if then - 17:
- 18:
end if - 19:
end for - 20:
return
|
The SimTS-SC algorithm, incorporating the PTS, exhibits a computational complexity of
. The inclusion of short-term simulations adds a complexity of
due to the evaluation of each node being included in the solution, resulting in an overall complexity of
. In the second stochastic model SCDP-PC—see Equation (
3)—the objective function remains unchanged with variations in the expected capacity values across different scenarios. However, the stochastic nature of the model arises from the probabilistic constraint, which assesses the probability of the solution satisfying the capacity constraint. The simheuristic algorithm for the SCDP-PC, denoted as
SimTS-PC, follows the main steps outlined in Algorithm 4. However, it differs in two aspects related to construction and evaluation, which are adapted to accommodate the stochastic nature of the problem. When constructing a solution using the
PTS algorithm, the iterative process of adding elements to the solution (opening facilities) terminates when the probabilistic constraint is satisfied. Additionally, instead of evaluating the objective function
, which remains constant in this model, the simulation process provides an estimation of the reliability level, denoted as
, associated with the current solution
S (steps 2, 7, and 15 in Algorithm 4). As explained before, the reliability level of a solution
S represents the probability that the solution
S is feasible when a scenario occurs.
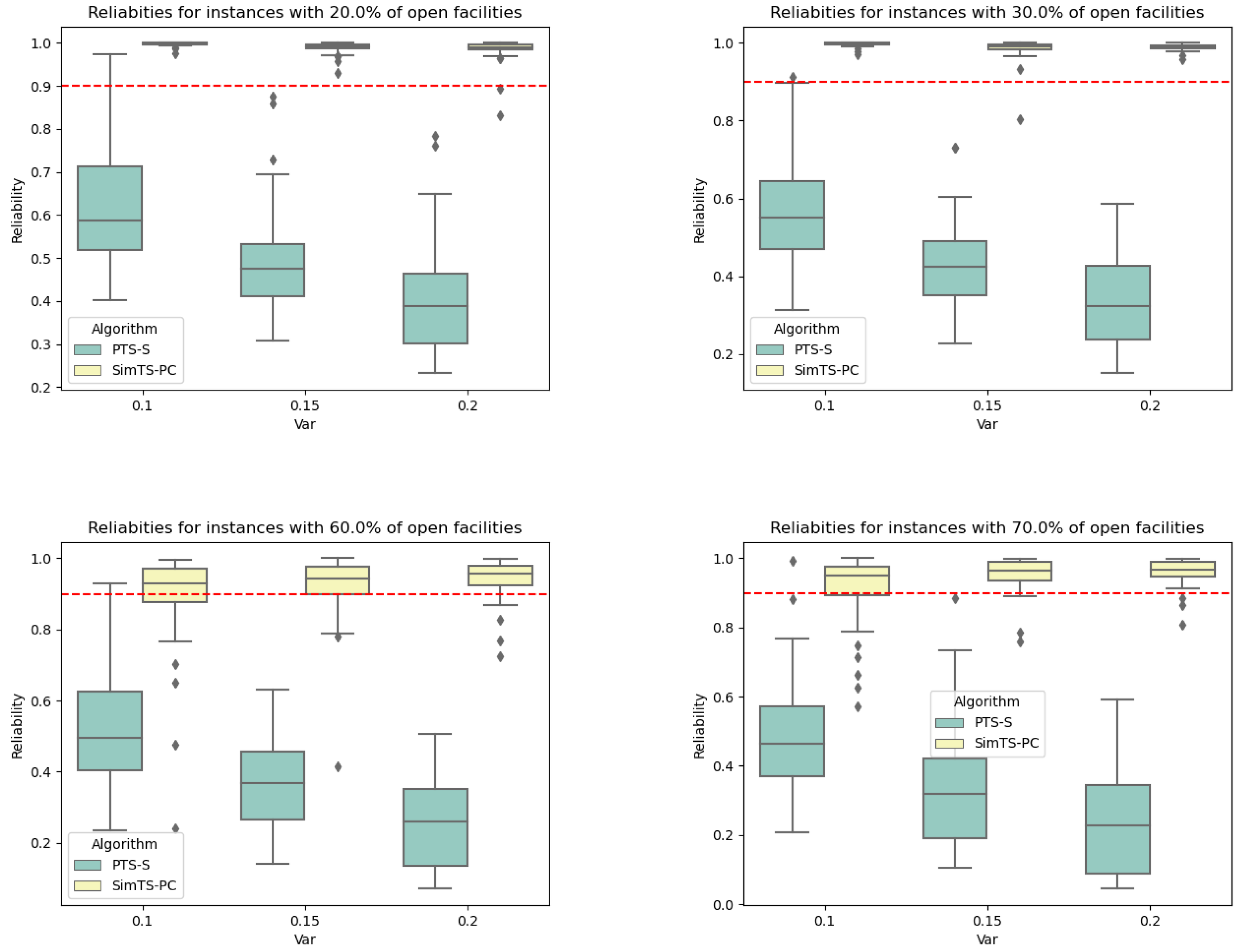
Figure 2 presents a multi-dimensional comparison between two methodologies: PTS and SimTS. The chart assesses each methodology across six distinct performance metrics: optimality, speed, flexibility, uncertainty, scalability, and reliability. Each axis corresponds to one of these metrics, extending outward from the center where the lowest value is located, and higher values are depicted further from the center. The performance of SimTS is depicted by the green line, whereas the performance of PTS is illustrated by the black line.
SimTS demonstrates a superior performance in handling uncertainty and ensuring reliability, thanks to the simulations integrated into the algorithm. These simulations also result in significant computational times. Consequently, there is a relative decrease in speed and optimality under the deterministic conditions compared to the PTS algorithm. Therefore, in terms of scalability, SimTS may face challenges with larger instances where PTS excels. Nonetheless, SimTS exhibits greater flexibility, allowing it to effectively manage more dynamic and variable environments.










{kind=link}
{kind=link}
{kind=link}
{kind=link}