2. Models Based on the Calculation of Estimates
In the work [
23], the so-called parametric recognition algorithms were considered, such collections of algorithms in which each algorithm is encoded in a one-to-one way by a set of numerical parameters. In these models, the proximity between parts of previously classified objects and the object to be classified was analyzed [
24]. Based on a set of estimates, a general estimate for the object was developed and, according to the introduced decision rule, the belonging of the recognized object to one or another class was determined [
25,
26].
In the article, as the initial model (A), a model was considered that is related to the model for calculating estimates, supplemented by some simple type recognition algorithms: the nearest neighbor algorithm, the average distance algorithm, etc.
A feature of the algorithms of this class is that for calculating estimates that determine the belonging of a recognized object, there are simple analytical formulas that replace complex enumeration procedures that arise when calculating proximity estimates using a system of support sets [
27].
In these models, the division of the algorithm into recognition operators and decision rules was carried out in a natural way [
28,
29,
30,
31,
32].
We will consider only algorithms represented in the form , where B is an arbitrary recognition operator. It turns out that an essential part of the algorithm is the operator—B; decision rule—C can be made standard for all algorithms and programs. Any recognizing vote operator maps task Z to a numeric matrix of votes or scores ; moreover, the value has a clear, meaningful interpretation. This value can be considered as the degree of belonging of the examined object to the class expressed by a number . After introducing appropriate normalizations, the value can also be considered as the value of the membership function of elements of the set .
Before introducing the submodel used in what follows, let us write how the algebra of recognizing operators is constructed [
33,
34]. Let
be a fixed recognition problem with classes
, also let
and
recognize operators,
c is a real number
Then, the sum and product of the operators
and
as well as the multiplication of the operator by a real number is defined as follows
Obviously, all these operations are commutative and associative; moreover, the operation of addition is distributive with respect to the operation of multiplication by a number. Due to these properties, if is the original set of operators, is the closure of the family with respect to the introduced operations (algebraic closure) from can be represented as operator polynomials
Here, —constants and original operators —play the role of variables for ordinary polynomials.
Note that if we have one algorithm for applying the original operators to any problem Z, then it is easy to construct an algorithm for applying the operator polynomial to Z.
For any operator polynomial, the algorithm to be applied to the problem is constructed in a similar way: the original operators are applied to the problem, and then the resulting matrices are multiplied by the corresponding scalars and finally added, as in the example just considered. The evaluation matrix obtained by applying the algorithm
from the closure algebra does not allow such a simple interpretation as the matrix of the number of votes in voting algorithms [
16,
17,
18]. The new recognizing operators are a formal extension of the original space of meaningful operators. Such formal extensions are often used in mathematics; thus, the field of complex numbers is a formal extension of the field of real numbers, for example, the process of formal Galois extensions is known. In the Galois extension, an algebraic equation of any degree is solved elementarily. However, for a long time, no physical interpretation of the Galois expansion was found [
35]. Only in recent years has it been established that the elements of the Galois extension are naturally interpreted in connection with problems of error correction in information transmission.
There is currently no meaningful interpretation for the algebraic extension of the space of operators. However, with the help of these extensions, difficult extremal problems are relatively easily solved, including the problem of synthesizing an error-free algorithm for a given recognition problem [
36].
The degree of an operator polynomial is introduced similarly to the degree of an ordinary polynomial in many variables from the terms:
the term with the largest
K equal, for example, is chosen, and the degree of the polynomial is assumed to be equal to
K. Based on the definition of the degree of polynomials, it is easy to distinguish in the extension
a system of nested extensions
obviously,
the set
is called the
k-th power extension of the original space of operators
. The set is of particular importance
, it consists of all possible linear forms from the original operators
. The elements are represented as:
When forming the elements included in the
operation, the product of operators is not used [
37,
38]. Therefore, this extension is an extension of the original space using the “+” operation, “multiplication by a number”; therefore, the set is
, also commonly denoted as
and is called a linear extension of the set
. And so, let a set of
algorithms be given
, and each
A is represented as
and
the initial model of operators. We take a fixed decision threshold rule
. We introduce a family of algorithms
called, respectively, a linear extension
, an algebraic extension of the
k-th degree
, and an algebraic extension
of a family of algorithms
.
We see that the constructed sets of algorithms consist, in the execution of the corresponding operators, and a fixed threshold decision rule c is applied to the result of the operator’s action .
Let some set of recognition problems be given and the initial set of recognizing operators be chosen in some way . Let also within the framework , not for every problem , there exist an operator and an algorithm , which gives an error-free solution to the problem Z. Then, the scheme for constructing a correct recognition algorithm consists of the following steps:
Stage 1. Some extension is chosen
in which the existence of an error-free solution is guaranteed for each problem
Z from
. In this case, it is natural to find, if possible, the smallest degree of expansion of
K [
39]. The implementation of the first stage in the literature is usually called the study of the completeness of the expansion. The theorems proved in this case are usually analogous to the existence theorem.
Stage 2. In the chosen extension,
for an admissible problem
Z, either an error-free (correct algorithm) is constructed, or, if the former is associated with large computational difficulties, an algorithm for solving with respect to, which is sufficiently acceptable in accuracy
Z. The exact calculation of the minimum degree of
K is a laborious task, which at present can be solved only for relatively narrow classes of problems
, and the original family of algorithms
. Therefore, in the studies carried out for the minimum degree of expansion, an upper estimate is constructed that guarantees the completeness of the expansion. So, for the voting model, such an estimate is
built in [
16].
Here, q is the number of recognizable objects, l is the number of classes, and are the parameters of the threshold decision rule.
For most real problems, this estimate is overestimated, and therefore, the algorithm built in the second stage has computational redundancy. Of particular importance is the fact that the above estimate is constructed for problems with intersecting classes, while the majority of real problems are problems with non-intersecting classes. Later, we will see that for a wide class of problems it is sufficient to consider the degree of 1, that is, to use only a linear closure.
Algorithms of the class for calculating estimates allow solving recognition problems of all types: assigning an object to one of the given classes, automatic classification, choosing a feature system to describe recognition objects, and evaluating their effectiveness.
3. Algebraic Methods for Solving Recognition Problems with Non-Crossing Classes
In [
12], algebraic methods for solving recognition problems with a finite number of intersecting classes were developed. For each recognition problem
Z in terms of algebra over families of heuristic algorithms, a correct algorithm was constructed, e.g., an algorithm that correctly classifies a given finite sample of objects for each of the classes. Due to the fact that the problem with intersecting classes was considered, the algorithm constructed in the above works is rather cumbersome [
40,
41,
42,
43,
44,
45]. The description of the algorithm itself requires the use of large memory (the amount of memory grows proportionally)
, where
q—the number of recognition objects in a given task,
l—the number of classes. It turns out that if we consider only problems with non-intersecting classes, then similar algebraic methods can be used to obtain a much simpler description and a much more effective computational algorithm.
Basic concepts and designations. Let a set of admissible objects be given
and it is known that
can be represented as the sum of a finite number of disjoint subsets
called classes
Objects S are descriptions of some real objects using successive values of a finite number of predefined features . Each attribute i can be associated with its set of values , which we will assume to be a metric space with distance . This paper considers the following sets and metrics .
1. —there is a finite or infinite interval, a half-interval, or a finite segment of the numerical axis. Then, . In this case, the sign i is called numerical.
2. then the sign i is called binary.
3.
—a finite set of integers; then defined by the following
Table 1:
There are zeros on the diagonal in the table, in addition (the table is symmetrical with respect to the main diagonal).
Not every table of the specified type defines a metric. A necessary and sufficient condition for the latter is the fulfillment of inequalities for any such that occurs .
These inequalities ensure that the triangle axiom holds true. Signs are called graded or scalable.
4. finite non-numeric set.
Then
The attribute in this case is called named.
In the future, we will consider only numerical, binary, graded, and named features.
A set is a collection of sets; , such cases will be noted separately.
Consider the predicates . It is easy to notice that for each S, one of these predicates is equal to 1 and the rest are equal to 0.
The task of recognizing Z is to use some information about the sets compute the value of the predicates , for each finite number of objects . In view of the previous remark, this is the same as specifying for each the number of the predicates t such that . The latter distinguishes the recognition problem with non-overlapping classes from the general recognition problem.
For a complete formalization of the description of task Z, it is necessary to determine the initial information .
In this paper, we restrict ourselves to only one type: —consists of an enumeration of reference objects, for each of which the number of the class containing this object is indicated.
For non-overlapping classes, information
can also be in the form of a learning table
, where
n—determines the number of features,
m—the number of objects,
l—the number of classes:
We will use such standard information presented in the form of a table. We will always count:
We introduce important notation for what follows:
The set consists of all reference objects belonging to the class .
In recognition problems with intersecting classes, algorithms A were considered such that where .
These algorithms calculate information vectors for each object
and are called correct for problem
Z.
For problems with intersecting classes, arbitrary binary vectors can be used as information vectors.
For problems with non-intersecting classes, only those containing exactly one-unit coordinate are informational, the rest of the coordinates are equal to zero. The last remark will be essential in what follows.
Let A be an arbitrary algorithm that translates the recognition problem Z, with l—classes, into the matrix of answers .
Equality means, respectively, that the algorithm A calculated for the object turns out to be from the calculation of the object’s belonging to the class . If , then this also does not mean that, that is, the algorithm can also make errors in addition to failures.
Such algorithms are called incorrect for problem Z. Obviously, correct algorithms are a special case of incorrect ones.
For arbitrary incorrect algorithms (and hence for correct ones) hold.
Theorem 1. Each algorithm A can be represented as (multiplication means sequential execution), and if that —numerical matrix, .
Theorem 1 [
16] shows that each algorithm
A can be divided into two successive stages. In the 1st stage, task
Z is converted into a numerical matrix of standard sizes
q—rows,
l—columns, the number of rows is equal to the number of recognized objects, and the number of columns is equal to the number of classes.
In the 2nd stage, according to this numerical matrix, answers are finally formed to questions about the belonging of objects to classes .
The value is naturally interpreted as the values of the measures of belonging of objects to classes . Stage B is called the recognition operator, stage C is the decision rule.
In what follows, only threshold decision rules are considered.
The rule is applied element by element. Let
a be a number and
also be numbers (thresholds) and
, then
6. Completeness of Linear Closure of the Second Model Voting
We will consider problems with non-overlapping classes and assume that the information is given in the form of a learning table . The task of recognition will be to classify the final sample .
As before, in what follows, we will assume that in the recognizable sample the objects belong to the class .
The purpose of this section is to single out a set of basic operators of the considered model for calculating estimates, construct their linear closure, and prove the fact that for each class object from the sample these operators form a sufficiently large estimate and for .
All basic operators, as well as operators from the linear closure, will be constructed explicitly.
We will first need a standard condition relating the type of training information and a recognizing sample, namely, we will assume that:
for any two different objects from the collection among the objects included in and belonging to the class K, there is such an object and such a sign, r what .
In this case, it is customary to say that objects from the system are pairwise non-isomorphic.
When proving the completeness of a linear closure, we will rely on the notion of a marked pair. Since in this paper only problems with non-overlapping classes are considered, the notion of a marked pair will be somewhat changed.
Definition 1. Pair is called marked in the operator B if for all S such that .
From the definition of a marked pair, it can be seen that such a pair appears in the operator B if: the estimate for an object by class is large enough, all estimates for the case when the object does not belong to the class are sufficiently small in absolute value.
Let be given in some model such that each pair is marked with at least one operator .
Theorem 2. There is a linear combination such that , C the threshold decision rule algorithm is correct for problem Z.
Proof of Theorem 2. Recall that the threshold decision rule
C is defined by the relation
.
Since every pair , such that is marked by some operator , this operator is worth the evaluation .
All other systems either mark or do not mark this pair. Operators that do not mark a pair
give an estimate that does not exceed an arbitrarily small value in absolute value
; therefore, one can choose
such that
W—number of operators in the system —parameters of the decision rule C.
Consider what estimate the operator will build
for an object
from the class
. The couple
is marked. This means that the operator
constructs an estimate not less than 1. The remaining operators either also construct an estimate for this pair not less than 1, or an estimate less than
and in turn,
inequality Equation (
22) holds. In the worst case, all other operators construct
negative small estimates for to
. Then, if the estimate
for
in the operator
is denoted by
then from Equation (
23) it is easy to obtain the inequality:
Applying the decision rule, we get that , and algorithm A establishes this inclusion.
This is true for any pair such that since all such pairs are marked by some operator from the system .
Now, let be the estimate built by the operator for the object according to the class . Since does not belong, the pair is not marked in any of the operators . Consequently, each of these operators constructs an estimate for the class that does not exceed in absolute value , from the definition of the operator and the estimate that .
It can be seen from the definition of decision rule C that the algorithm establishes the inclusion , this is true for any pair such that .
The theorem has been proven. □
The purpose of further constructions is to find a system of operators that, for an arbitrary problem , mark any pair such that and do not mark any pair
If we manage to find such a system
, then, according to
A, the algorithm correctly solves problem
Z. The correct algorithm for
Z can be written as:
Consider a sample and a system of operators such that all parameters are chosen the same: , where is a sufficiently small number.
In other words, this means that if all pairs are assumed to be small, no restrictions are imposed on the parameters yet.
Let B be an arbitrary operator from and an arbitrary admissible object.
Let also
Lemma 1. Let
Proof of Lemma 1. When forming a value, only pairs are considered such that only objects belonging to the class are considered . □
From these pairs, in turn, pairs are selected that are included in the reference set .
Let us denote the number of pairs from through . Obviously, there is an inequality:
Since when comparing the elements a, (the value of the feature in the recognizable object either 0 can be added to the value, if , or the value if .
If from the last assertion, as well as from the inequality, one easily obtains:
Consequence: Let .
Then the elements—
at
satisfy the inequalities:
The proof of the corollary is obtained if we consistently apply Lemma 1 to recognizable objects from the sample .
We see that the operator B from the family constructs numerical matrices in which the elements of all columns except the j-th can be made arbitrarily small with an appropriate choice of the value of . If it is required that , it is enough to put .
Consider now a pair such that , in other words, an object . The pair corresponds to the element in the learning table . In the control sample, as was previously accepted, the objects belong to the class and the rest of the objects do not belong to the class. For brevity, we will assume that the objects that do not belong form the class , and the remaining objects form the class . Consider the values , that is, the distance of the value v-th of the feature on the object , in the learning table to the value of that feature in from .
Let us arrange the objects from in ascending order of value , objects with equal values of elements, arrange among themselves in an arbitrary way.
Let us assign to the objects of the sequence the sign “+” if they belong to the class and
the sign “−” if they belong to the class
. The result might be, for example, the following sequence:
Definition 2. A pair is called stationary if in the constructed sequence the signs “+, −” take place equal to one change of sign, and if the change of sign occurs on the elements then: Otherwise, the pair is called non-stationary.
Let us first consider the case when for each number there is at least one pair stationary. In this case, the basic operators from the family are relatively easy to define, in different ways for the following two cases:
- (A)
The sequence has the form , that is relatively all objects of the class are closer than all objects of class , then the operator is redefined as follows:
The support set is composed of one stationary pair .
other .
otherwise —a fairly small value.
- (B)
The sequence looks like . The operator is searched in the form . As before, in both operators, the support set , is composed of one critical pair other . But:
In operator .
In operator .
Thus, we completely defined the operators .
Let the result of applying the operator to the problem be denoted by .
Lemma 2. If then if then .
Proof of Lemma 2. 1. Consider the first case of defining the operator
. Then, there is a stationary pair
for which the descriptions of the above sequence are as follows:
where
When defining the operator
B, the quantities
are chosen in such a way that the following inequalities are satisfied:
From inequality [
19], it is easy to see that for each object from
Q the proximity function for this
S over the reference set
is equal to 1. Therefore,
.
Similarly, the proximity function for objects from is equal to 0. And therefore, .
2. Consider the second case in the definition of the operator
. In this case, there is a stationary point
and the sequence corresponding to it has the form:
In the operator, the value is chosen in such a way that the proximity function for the reference value is equal to 1 for all objects from the selection .
Therefore, if , then .
In the operator
the value
is chosen in such a way that the proximity function in the reference set
is equal to 1 for objects from
, and is equal to 0 for objects from
Q. That is why
From equality [
21,
22], and also from the fact that
equalities follow:
The Lemma is proven. □
Consider now the operator: and put
In Lemma 2, when applying the operator, , the elements of all columns with the exception of j are not exceeded.
Objects obtain grade N.
Objects obtain grade 0.
Because
by definition of the operator
, then if
Having appropriately chosen the values, and using Theorem 3, we prove the theorem.
Theorem 3. If in the problem Z for each number there is a stationary pair, then the algorithm is correct for problem Z.
Since the operator we have constructed belongs to the linear closure of a model of the type of calculation of estimates, then we proved the completeness of the linear closure of this model for all problems in which for each class there is at least one stationary pair, , and moreover, we wrote this correct algorithm A explicitly.
The verification of the fact that such a stationary pair really exists is not difficult.
For this, enough for each pair , where calculate all and check whether all inequalities of the 1st or 2nd group are fulfilled simultaneously. If all inequalities of groups 1 and 2 are simultaneously satisfied, then the pair is stationary and can be constructed in the same way as was performed in the proof of the theorem.
The conditions for the existence of a stationary pair essentially mean the following:
There is an element and features in the learning table .
1. The distance according to the V attribute from to all elements of the control sample that belong is strictly less than all such distances for objects of the control sample that do not belong to K;
2. The distance according to the V attribute from the object in the control sample that does not belong is less than all such distances for the objects of the control sample that belong to .
Consider the 2nd case, when the construction of a correct algorithm in a linear closure is quite simple. As before, we arrange the objects of the control set
in sequence by increasing the distance from some value of the feature u, in the reference
. We put the constructed sequence over the elements of the sequence with the sign “+”, if,
and the sign “−”, if
denoted by
. Let us find in this sequence the last element in order
, this element must also be such that the next element
has the property:
The set of elements of the sequence following the element is denoted by .
We introduce the set
Similarly to the previous one, in each sequence, we select the first element in order , and moreover, such that the inequality holds for the previous element:
Element
in the sequence
is denoted by
. We introduce the set
Definition 3. The problem is called monotonic if for each one of the two equalities is satisfied: The meaning of the monotonicity condition is as follows, an arbitrary reference object is chosen to belong to and an arbitrary feature with number u, in the control sample we select all objects that do not belong to the class and such that, relative to the selected feature, they are farther from than all objects belonging to the class .
The set of all such objects not belonging to the class
is denoted by
. Condition [
17] is that if all elements of the set
are summed up, then all elements from the control sample that do not belong to the class are obtained
.
Construction of operators for a monotonic problem Z.
1. The choice of the reference subset
, since the problem
Z is monotone, then one of the conditions [
17] or [
18] is satisfied, the choice of the reference set is the same in both cases, so we will assume that we have:
The set forms a cover of the set , but this cover may be redundant, in other words, some sets may be removed so that the cover remains a cover. Removing such extra sets, we construct irreducible covers for .
Let the constructed irreducible cover have the form:
Then, .
Choice of options .
All parameters of this group, with the exception of the parameters, are chosen so large that the following inequalities are satisfied: or .
The parameters are chosen so that the following inequalities hold:
In the sequence , we find the last element and the element following it , then or .
This choice of parameters occurs in cases where the relation is satisfied: . If this relation is not satisfied, but the relation .
Then, the operator is sought in the form of a difference , and the values are chosen differently for the operators that make up the difference.
Options . The parameters are assumed to be equal to a sufficiently small value; more precisely, the value will be indicated later for all and also for such numbers of which are not contained in the set . For the rest , we assume: .
Similarly, rest , . The values N are chosen to be sufficiently large; the exact values for N are given later. The operator definition is complete for the case: .
Theorem 4. The operator for calculating estimates defined above marks all objects from the class in the control sample and only them. In other words, if and objects at the remaining objects do not belong to the control sample , then .
Proof of Theorem 4. Threshold parameters and reference sets were chosen in such a way that for each object from the relation was fulfilled in such a way, according to the constructed support set, the proximity function is equal to 1, and the total estimate is not less than .
If the object of the control set does not belong, then it has a mark in the sequences, and therefore there is such a pair (by the definition of a monotone problem) that in the sequence this element is after all elements , then they are chosen so that the corresponding inequality violated. In this case, the proximity function for the object is equal to 0, and .
The evaluation operator constructed in this way puts large estimates for control elements from , and small estimates for elements from . The last assertion easily implies the correctness of the algorithm composed of the previously defined operator and the threshold decision rule.
The Theorem has been proven. □
The proof for the 2nd case of the monotone problem is carried out according to the same principle (see the proof for the stationary problem) only the operator is sought as the difference between two operators.
The simple cases presented by us are an illustration for the proof of the main theorem on the well-posedness of the linear closure. The proof of this theorem is technically more complicated, it is divided into a series of steps; however, each individual step implements a construction of the same type that was used in the last theorems.
When proving the main theorem, in essence, it is the linear closure that is used.
The proof of the linear closure well-posedness theorem will be carried out in two stages. In the first stage, we will introduce one additional constraint on the control objects of the training sample.
Practical tasks really satisfy him. In the first stage, the well-posedness theorem will be proved under this constraint.
Definition 4. Control objects are called consistent with objects if for each pair there is at least one object and attribute W such that .
The lack of consistency in the control sample means that in the control there are objects that are closer in all respects to all objects in the class . In this case, all learning information is collected in such a way as to assign a closer object to a class with greater preference than a more distant object and thereby make a mistake.
We will first consider classes in which there are no such pathological cases, that is, the situation when the control objects are consistent with the training ones.
Let, as before, the objects .
They form learning information J, and the objects belong to the class and do not belong to other classes.
The objects form a control sample and the objects belong to a class and do not belong to other classes.
Operator formation
1. For all pairs such that we assume .
2. Consider an arbitrary control object .
By the definition of a training-consistent control sample, for each there is such a pair .
What
. For the pair
we assume:
Obviously .
Let us include in the support set all pairs for all .
We have defined an auxiliary operator:
Formation of operator B.
We need to study what numeric matrix the operator B translates into task Z, with a training sample and a control sample . The evaluation of the elements of this matrix will be performed sequentially by the steps of constructing the operator B. The first step is to form the operator .
Let .
Lemma 3. If that .
Proof of Lemma 3. The formation of estimates with respect to the class is carried out for some of the pairs such that for each such pair the term included in the estimate does not exceed: .
The total number of pairs is obviously .
From this, it easily follows that .
The Lemma is proven. □
Lemma 4. If , that .
Proof of Lemma 4. In the base set of the operator for each element there is a pair such that .
By choosing the parameters , as shown above, we obtain .
According to the definition of the proximity function for the unique support set of the operator , for the object it is equal to 0. Therefore, , which proves the Lemma. □
Lemma 5. .
Proof of Lemma 5. For each pair included in the base set of the operator, the parameter , is chosen so that . Due to inequality, the proximity function in the base set of the operator is equal to 1; therefore,
The Lemma is proven. □
Let
By definition of the operator
.
Using the matrix
and Equation (
41), we obtain the following inequalities:
True
for others
.
Because .
And is the matrix into which the operator transforms the problem, then .
Lemmas 3–5 clearly imply the following inequalities at .
For everyone else : .
is a decision rule; then, we can choose the values in such a way that the algorithm will give correct answers for all elements across all classes .
Recall that the decision rule is applied to numerical matrices element by element, that is, and
From the definition of the decision rule and inequalities, it is clear that the parameter N must be chosen so that the inequality .
Therefore, one can put .
With this choice of the parameter N, each of the objects will be assigned by the algorithm A to the class .
It follows from the definition of the threshold decision rule and inequalities that the parameter can be chosen so that the inequality .
Therefore, it suffices to take as any positive quantity satisfying the inequalities
In this case, each of the objects will not be assigned to the class
We have proven.
Theorem 5. with threshold decision rule C and operator B. Operators are operators for calculating estimates, correct for the problem .
Each of the operators is specified by a set of numerical parameters where . m—the number of objects in the learning sample, n—the number of features participating in the description of objects, that is, a set of numerical parameters.
From all that has been said above, it follows that with the described choice of parameters N, the matrix , into which the problem Z is converted by the algorithm .
Here, the operator B in terms of elementary operators has the form that is, the operator B belongs to the linear closure of the previously introduced families of estimation algorithms.
Significant memory is required to write code B; however, when solving real applied problems, the operator code can be placed in the RAM of modern computers. So, if , that is, the training material consists of 50 objects described by 100 features, and it is required to store numbers in memory.
In the future, we will consider methods that make it possible to more economically encode the operator B, which will reduce the required memory and more efficiently use the constructed correct algorithms for solving applied problems.
Summarizing all the above, we can state that we have proved the theorem.
Theorem 6. Algorithmwith an operator from the linear closure of the score, the calculation model is correct for problem Z, and the operator is the sum of q operators from the score calculation model and is described by a set of numerical parameters. The only condition for constructing a correct rule is the consistency of the training control sample.
7. Results
In [
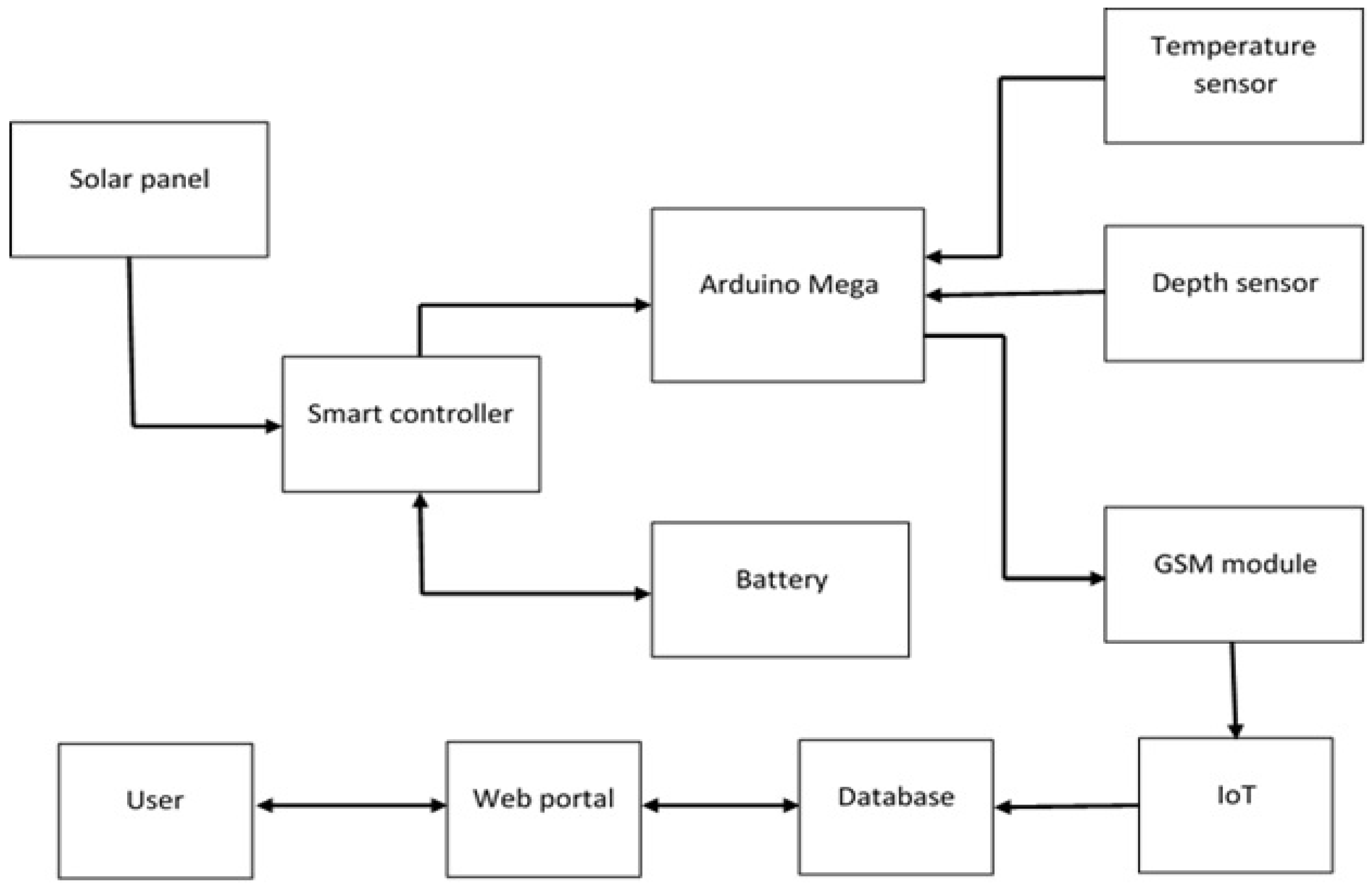
15], the use of Internet of Things technologies in ecology (using the example of the Aral Sea region) as a system is proposed (
Figure 1). The system was developed as a website. The Django framework was used to develop the server side of the system and Vue.js was used to develop the client side as a single page application (SPA) using the Quasar GUI framework. To start the system, you need to open this website
ecoaral.uz in one of the modern browsers. After this, the main window of the system will be reflected on the browser page.
In this article, to identify input information flows, we considered the so-called parametric recognition algorithms, i.e., such sets of algorithms in which each algorithm is one-to-one encoded by a set of numerical parameters. These models analyze the proximity between parts of previously classified objects and the object to be classified. Based on a set of assessments, a general assessment of the object is generated and, according to the introduced decision rule, the belonging of the recognized object to one or another class is determined.
In this article, as the initial model (A), we consider a model related to the model for calculating estimates, supplemented with some simple recognition algorithms such as the nearest neighbor algorithm, the average distance algorithm, etc.
The peculiarity of algorithms of this class is that in order to calculate estimates that determine the identity of a recognized object, there are simple analytical formulas that replace complex enumeration procedures that arise when calculating proximity estimates using a system of support sets.
In these models, the division of the algorithm into recognition operators and decision rules is carried out in a natural way.
We will only consider algorithms that can be represented in the form , where B is an arbitrary recognition operator. It turns out that an essential part of the algorithm is the operator—B; the decisive rule is that C can be made standard for all algorithms and programs. Any voting recognition operator maps task Z into a numeric matrix of votes or ratings
Moreover, the value
has a clear, meaningful interpretation. This value can be considered as the degree of belonging of the examined object
to class
, expressed as a number. Let
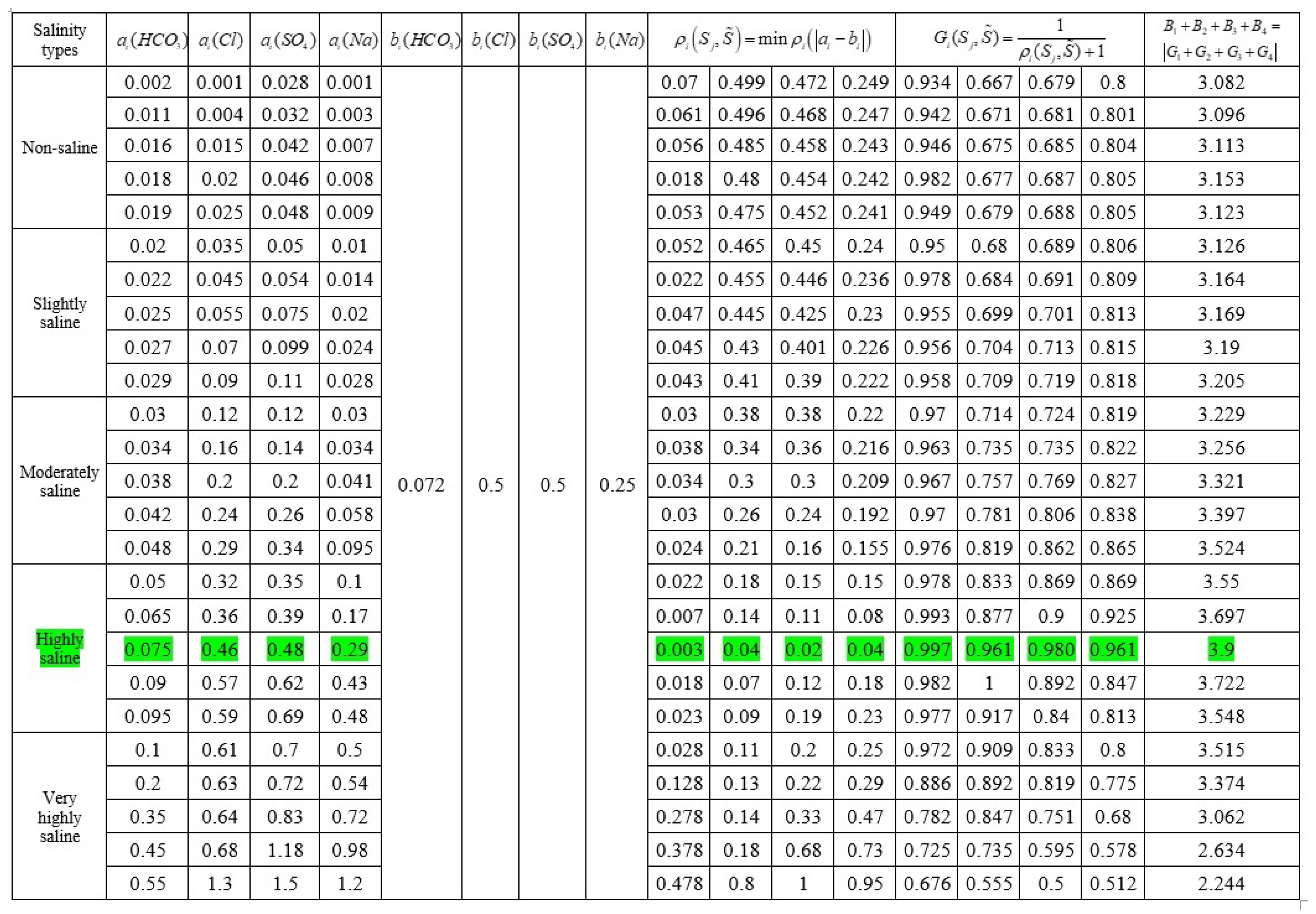
—these are sensor data,
—salinity class parameters. Sensor data in
Table 2:
(bicarbonate),
(chlorine),
(sulfuric acid),
(calcium),
(magnesium),
(sodium) in
Table 3 and
Table 4: Salinity is divided into five classes (non-saline, slightly saline, moderately saline, highly saline, and very highly saline), and each class consists of 10 points.
If the sensor receives data
and it checks the value
if the given condition completed, and indicates which salinity class it belongs to. If the
values correspond to more than one salinity class, then the information was intercepted somewhere (see
Figure 2).
To solve the problem of comparative classification in an information system in electronic resources based on an algorithm for calculating estimates, a correct algorithm was used
The work of the recognition algorithm in this case is based on the analysis of the data structure and its importance for classification purposes. With this approach, reliability is assessed by the quality of work of the recognition algorithm on control material. In other words, the algorithm carries out a classification and its results are compared with those that are known a priory. Obviously, with a sufficiently large volume of control, the results reflect the quality of the algorithm. It was this approach that was implied and incorporated into the software package, the application of which to the initial information made it possible to obtain the following: relative weights of feature groups , vote formula and the sum of operators .
Example for :







{kind=link}
{kind=link}