1. Introduction
The problem of combining two unbiased estimators arises frequently in applied statistics, where it has important implications in a wide range of fields, from quality control in manufacturing to medical research and social sciences [
1,
2,
3]. For instance, in the context of manufacturing, it is essential to ensure that the means of different production lines are within specified quality standards. By using the common mean inference, you can determine whether the means of these production lines are within specified quality standards. If one line’s mean falls outside the acceptable range, it could signal a quality issue. In clinical trials, researchers often need to compare the effectiveness of different treatments or drugs. The common mean approach can help determine whether a particular treatment yields statistically different results in terms of patient outcomes, such as recovery times or symptom alleviation.
The technique of combining and analyzing data from several independent studies on a specific topic or research question is referred to as meta-analysis [
3]. The goal of meta-analysis is to obtain a more accurate and reliable estimate of the overall effect size or treatment effect than what can be achieved by any individual study alone [
3,
4]. It provides a systematic and quantitative approach to synthesizing evidence from various studies, allowing researchers to draw more robust conclusions and make generalizations [
3].
A well-known context of this problem occurred when Meier [
2] was asked to draw inferences about the mean of albumin in plasma protein in human subjects based on results from four experiments [
2], shown in
Table 1.
Another scenario happened when Eberhardt et al. [
5] had results from four experiments about nonfat milk powder and the problem was to draw inferences about the mean Selenium in nonfat milk powder by combining the results from four methods (
Table 2).
Despite the broad applicability of the common mean, , estimating it is not without difficulties. One of the most difficult problems emerges when the population variations are unknown or maybe unequal. Traditional approaches for addressing this issue, such as the two-sample t-test, are insufficient since they assume equal variances and are not designed for combining and analyzing data from several independent studies on a specific topic or research question.
To formulate the present problem, we assume only that there are two normal populations with a common mean, but with unknown and possibly unequal variances
. Let us assume that we have independent and identically distributed (
) observations
from
,
and define
and
are given as
where
,
. Note that these statistics,
, are all mutually independent. Again, it can be noted that
are minimal sufficient statistics for
but are not complete. As a result, one cannot obtain the uniformly minimum-variance unbiased estimator (UMVUE) if it exists using the standard Rao–Blackwell theorem on an unbiased estimator for estimating the common mean
.
The natural meta-analysis question now is the problem of combining several estimates of an unknown quantity to obtain an estimate of improved precision. A similar problem arises in the analysis of incomplete block experiments. The “intra-block” and “inter-block” estimates of varietal means have different variances, and the recovery of “inter-block information” is an attempt to combine these estimates in the most efficient manner. In the case when the two population variances are completely known, the common mean
can easily be estimated as
which is the UMVUE, the best linear unbiased estimator (BLUE), and the maximum likelihood estimator (MLE) with a variance given as
In our present problem, the population variances are unknown and possibly unequal. The most appealing unbiased estimator of
is the Graybill–Deal estimate (GDE) [
6], given as
with
where
For the two-sample case, the GDE [
6] showed first that an unbiased estimator has a smaller variance than either sample mean provided that both sample sizes are greater than 10. Since then, several papers have been written generalizing and extending their findings [
7,
8,
9,
10,
11] and the references therein. On the other hand, Meier [
2] suggested a method for setting an approximate confidence interval for
centered at
. Furthermore, [
12,
13] developed approximate confidence intervals centered at
. The properties of such estimators have received a lot of attention in the literature. We would like to highlight the contributions of Kifle et al. [
1], Sinha et al. [
3], Sinha [
14], Hartung [
15], and Krishnamoorthy and Moore [
16] in particular.
Even though many generalizations of
have been proposed in recent years, it still commonly remains one of the central figures in statistical modeling and methods in meta-analysis due to its natural appeal. We may have prior information that the variances
and
may be equal. Then, we can test the hypothesis
versus
and then estimate the common mean
of these two independent normal populations depending on the outcome of this test. Stein [
17] introduced and thoroughly discussed the preliminary test shrinkage estimator. His work had a profound impact on the field of statistical estimation, particularly for the common mean problem with unknown variances. His approach has inspired various developments and applications in statistics and has become a foundation for the use of shrinkage estimators in modern statistical practice. Thompson [
18] proposed a shrinkage technique, given as
for improving the existing estimator of parameter
and estimating the mean, which lowers the mean square error (MSE) of the UMVUE of the mean of a population, is considered. It was noted that the shrinkage estimator outperforms the usual estimator if the guess value of
q is chosen in a way that aligns with reality. Therefore, rather than considering
q as a fixed constant in the shrinkage estimator, one should consider it as a weight that falls between 0 and 1. In this case,
q can be treated as a continuous function of some relevant statistics, with the expectation that its value will drop monotonically as
increases. Other researchers, like, Walker, Schuurmann, and Raghunathan [
19], also proposed a testimator for the mean of a normal distribution. It was further noted in the literature that when prior information is available, the shrinkage estimators for the parameters of various distributions perform better than the usual estimators in terms of the mean square error when the estimated value is close to the true value [
18,
20,
21].
If we assume that the prior knowledge about population variances
is available and that the variances
and
may be equal, we can test the hypothesis
versus
. The first stage sample is used to test
and if we fail to reject
, we feel comfortable in using prior knowledge (having tested it) to estimate the common mean
. However, if
is rejected, we discard our prior knowledge and obtain a second sample to make up for the loss of the prior knowledge and estimate the common mean
using GDE or MLE. This type of adaptive estimator based on a preliminary test has been used by many researchers [
22,
23].
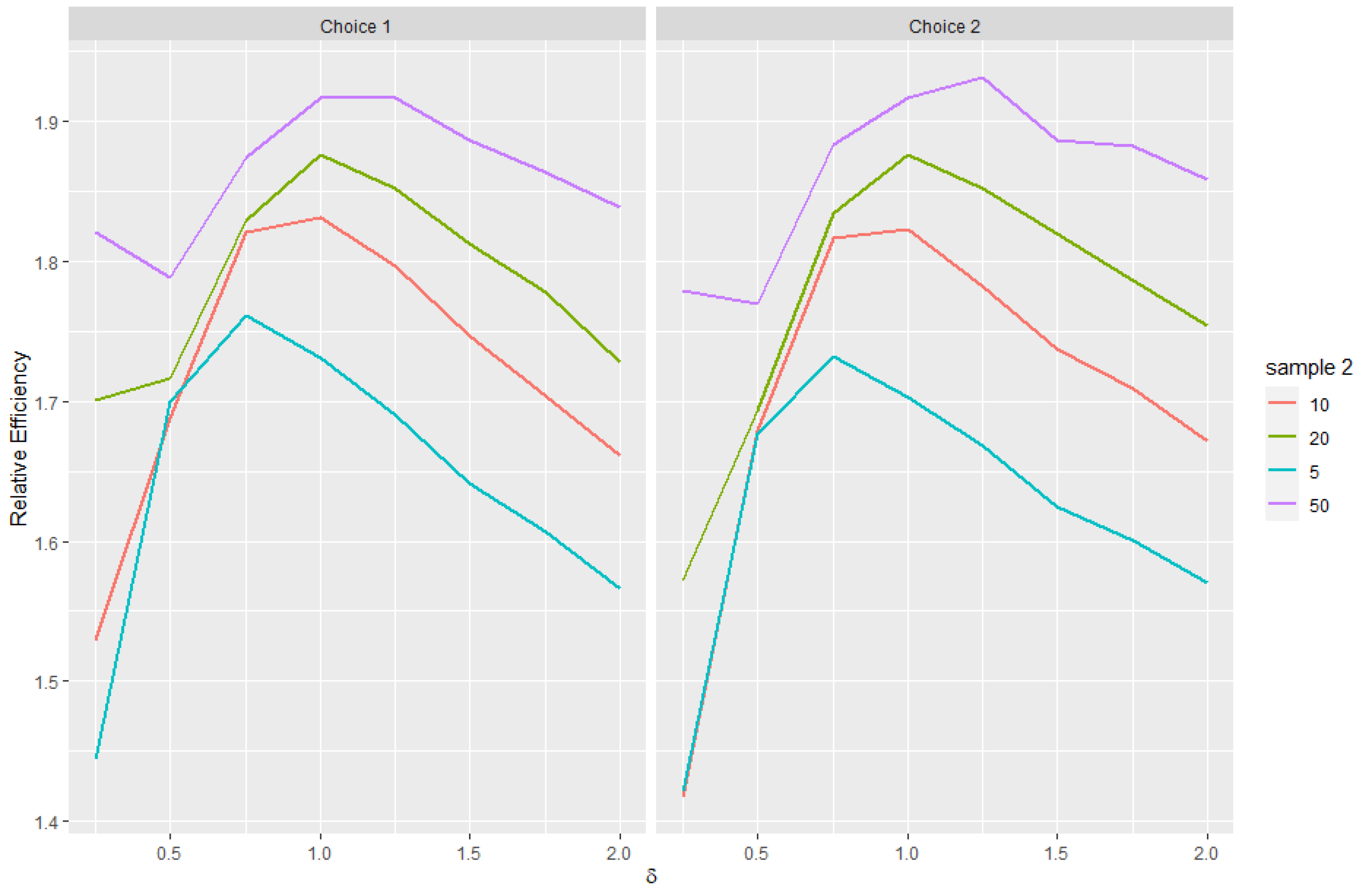
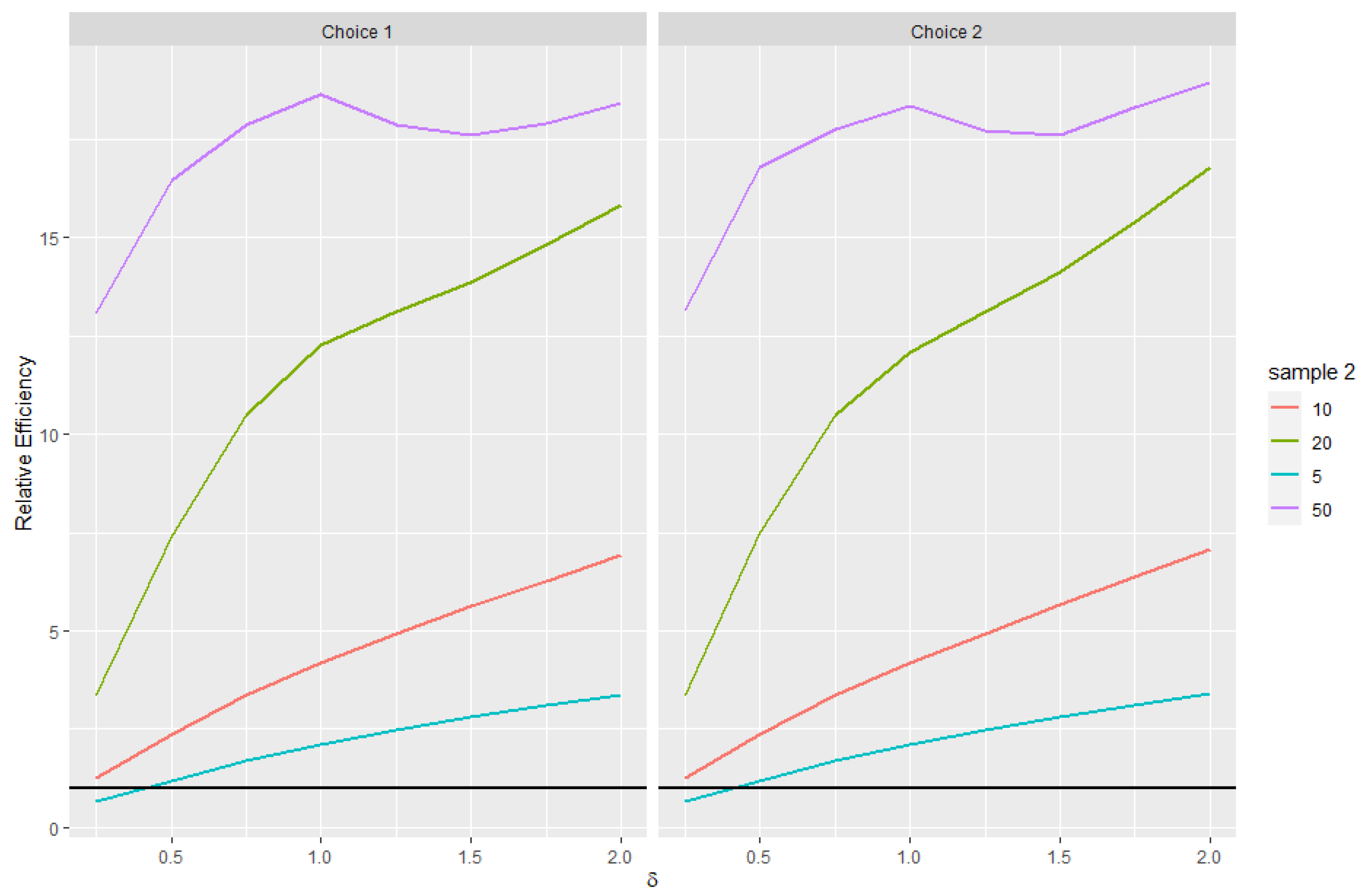
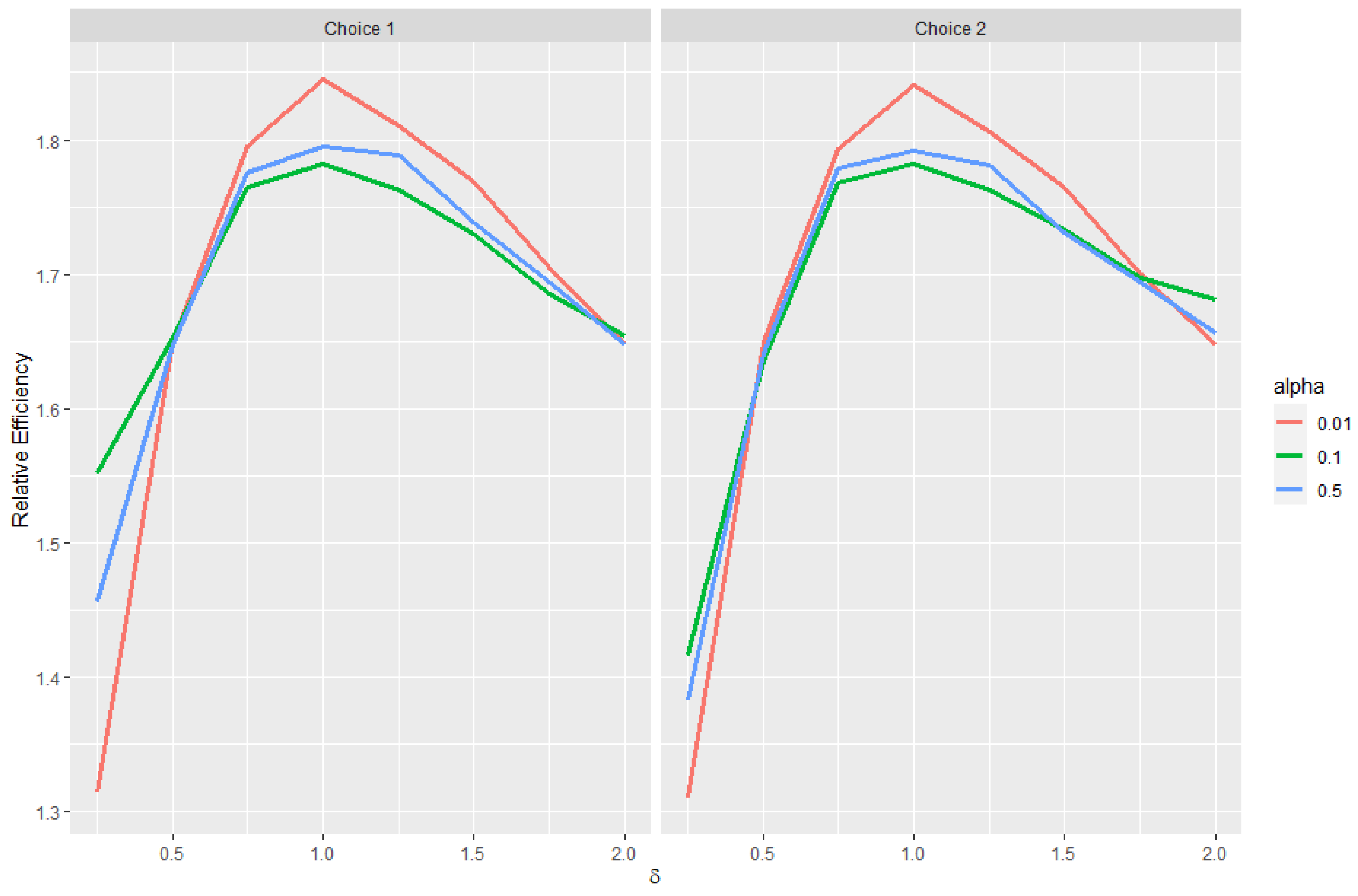
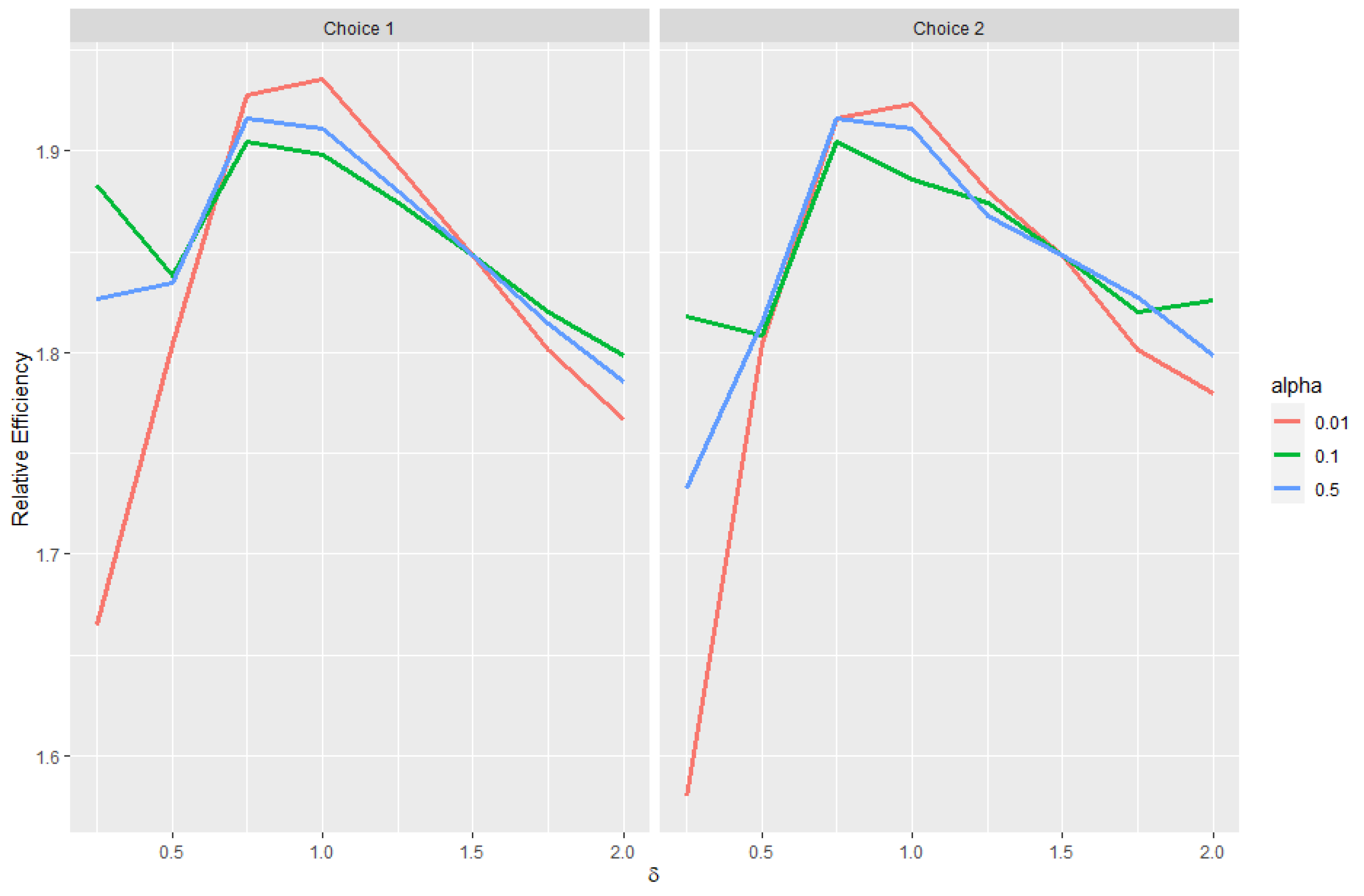
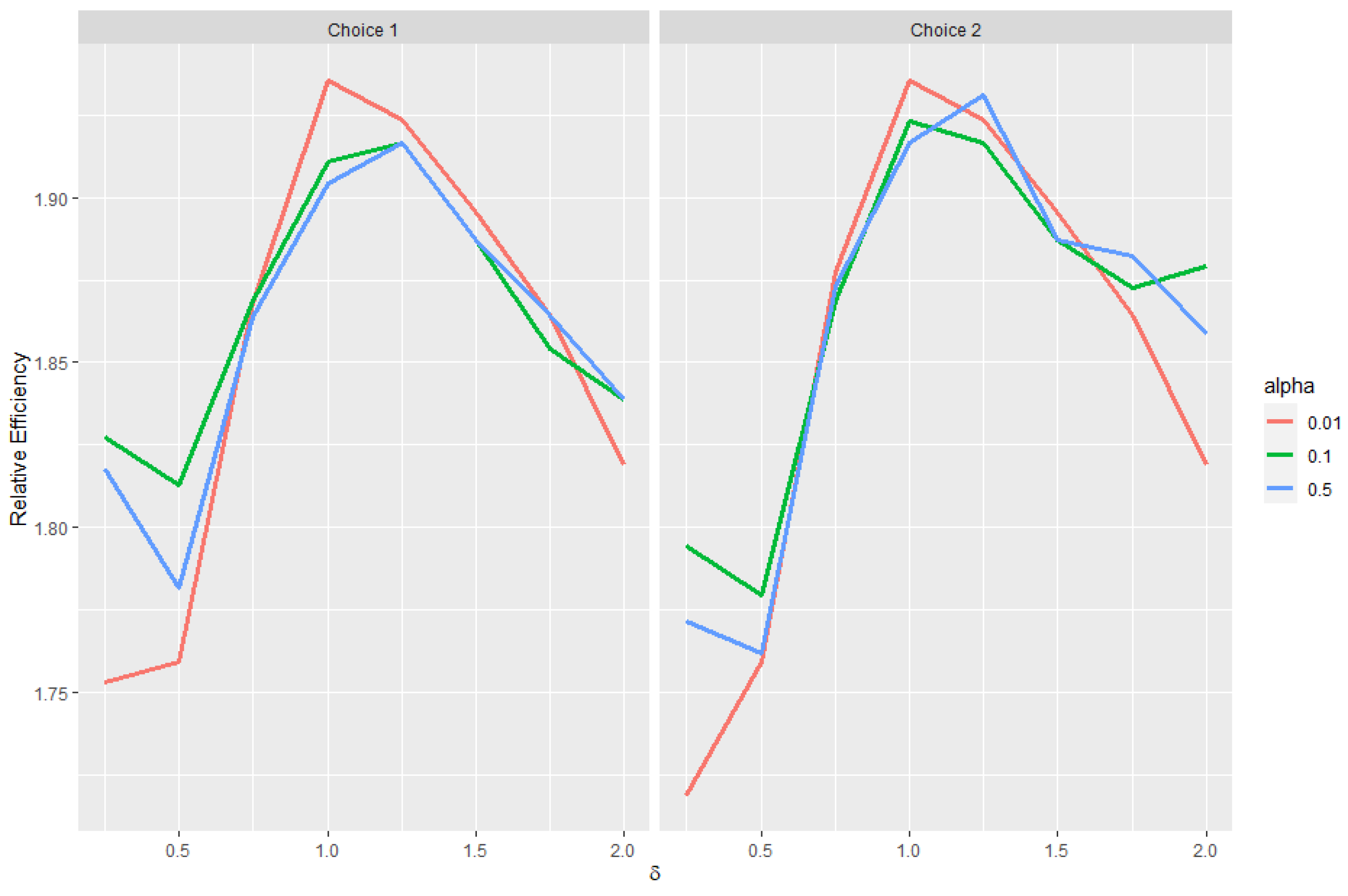
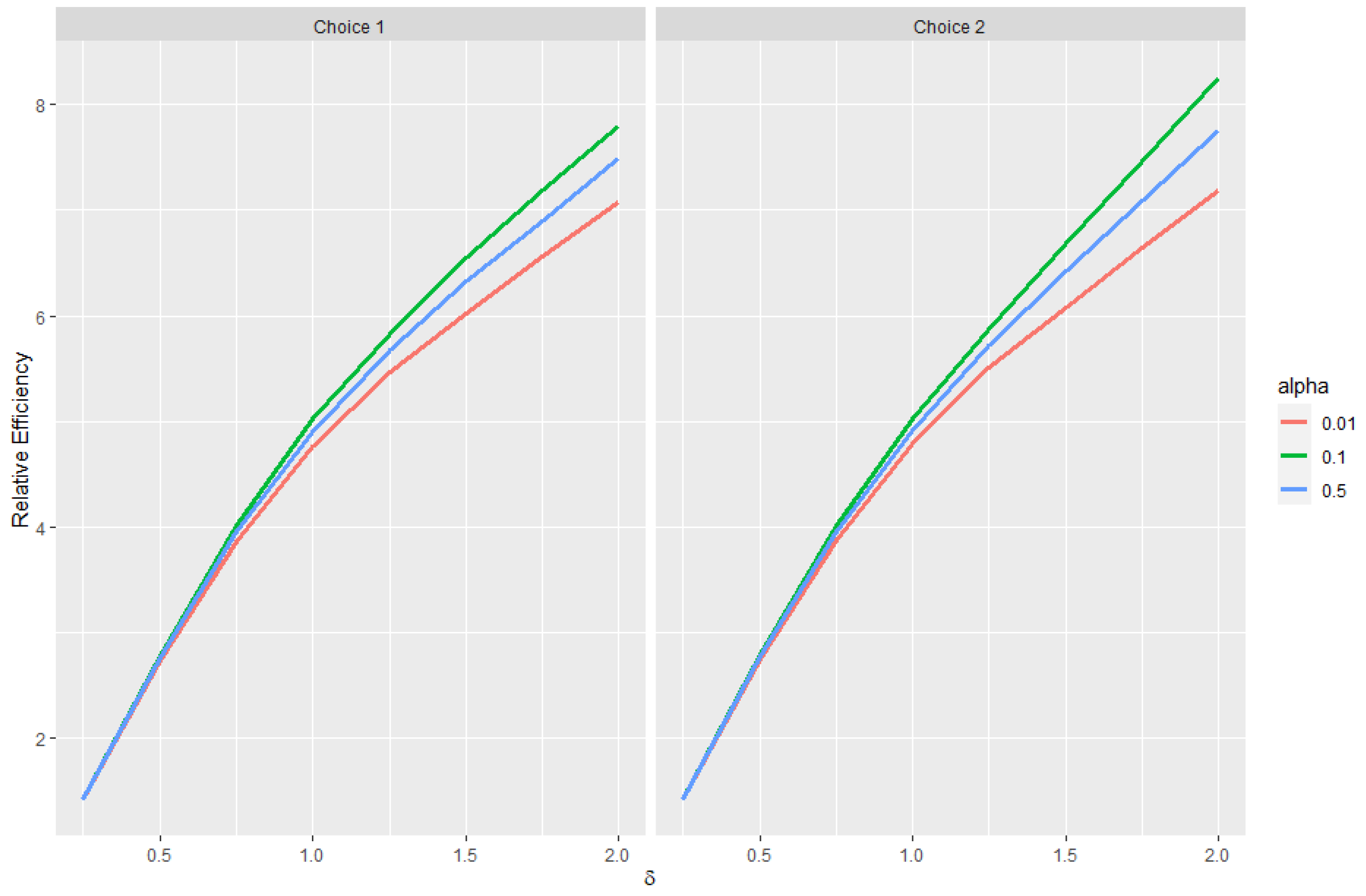
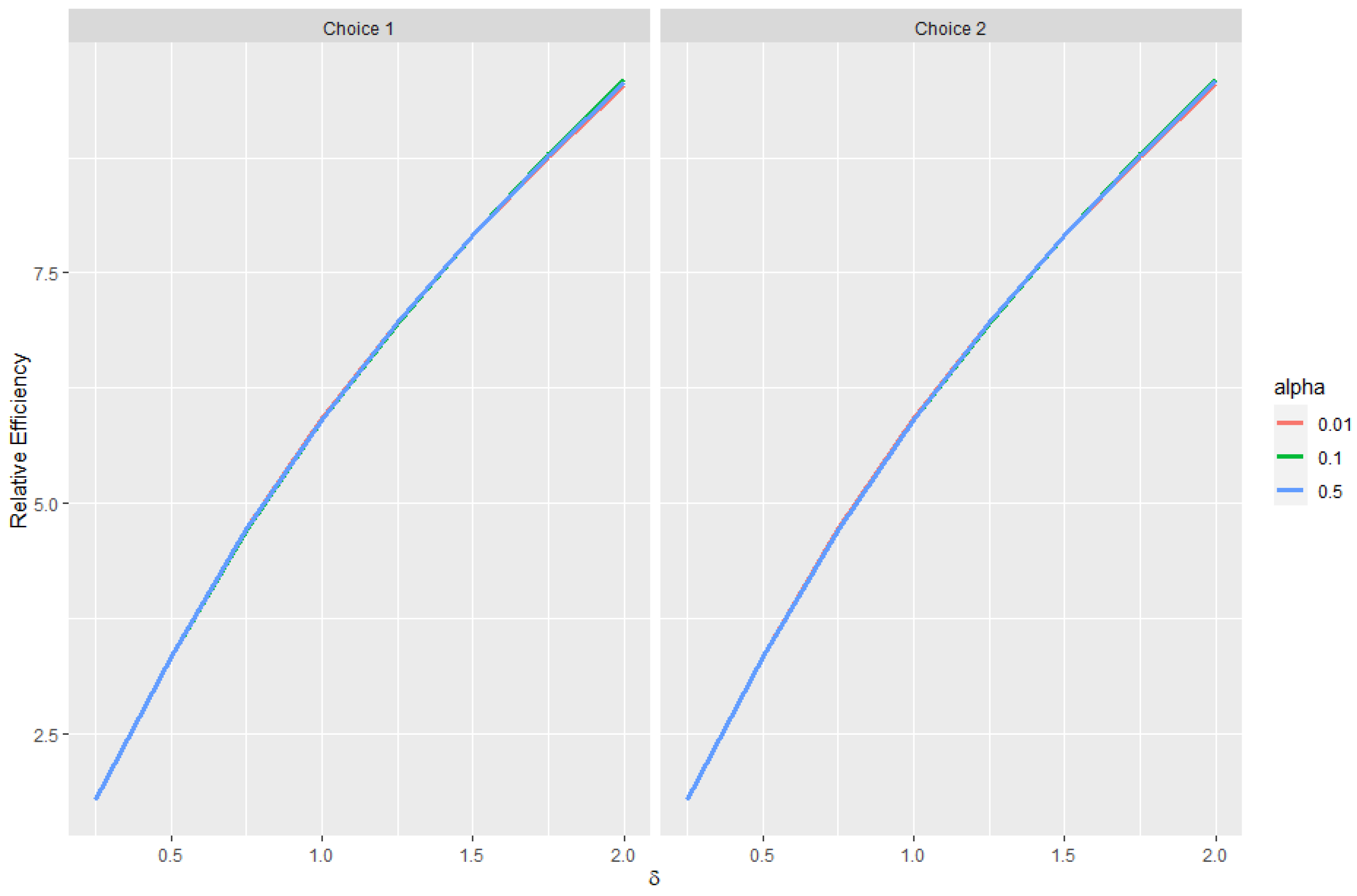
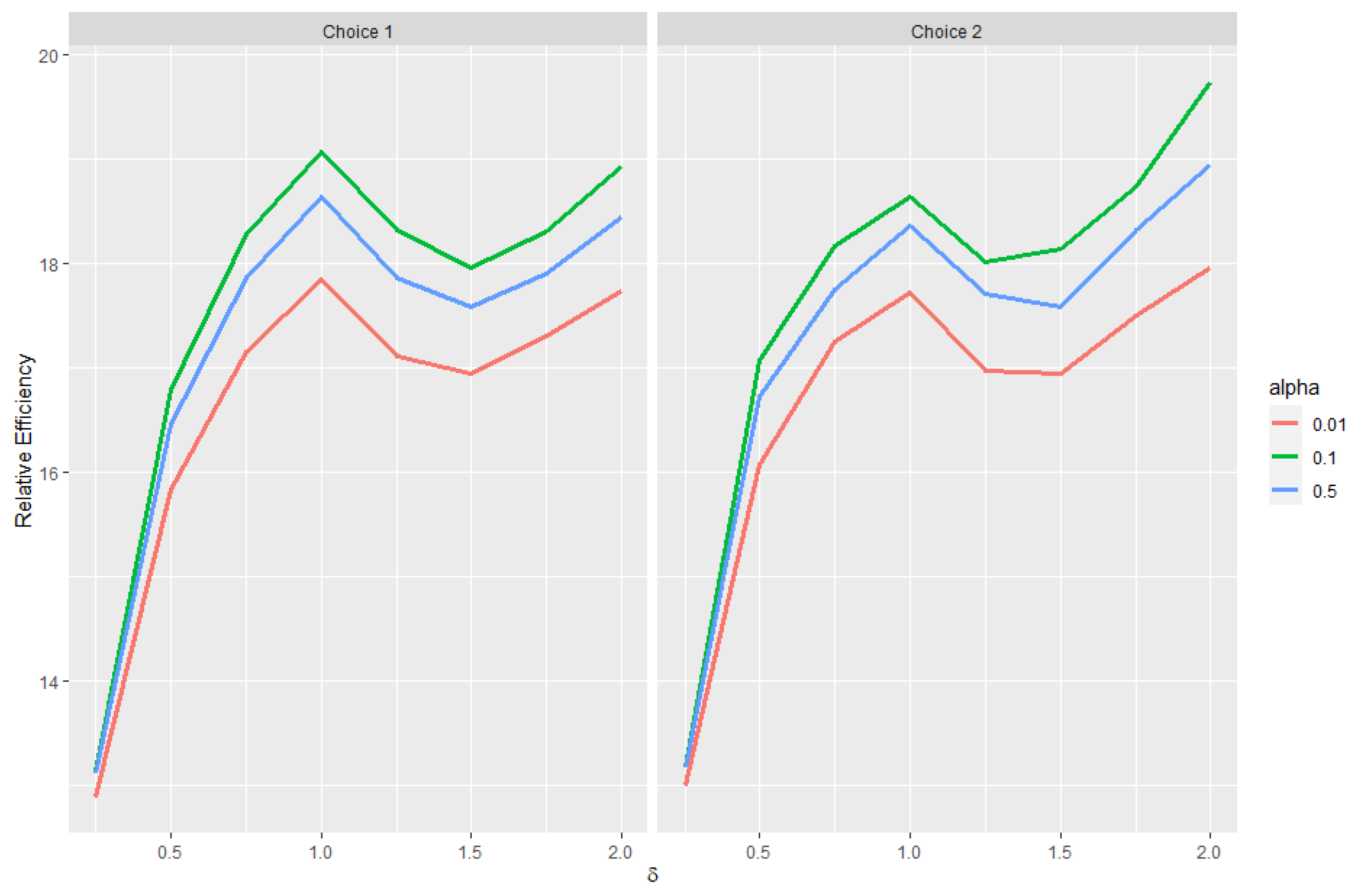
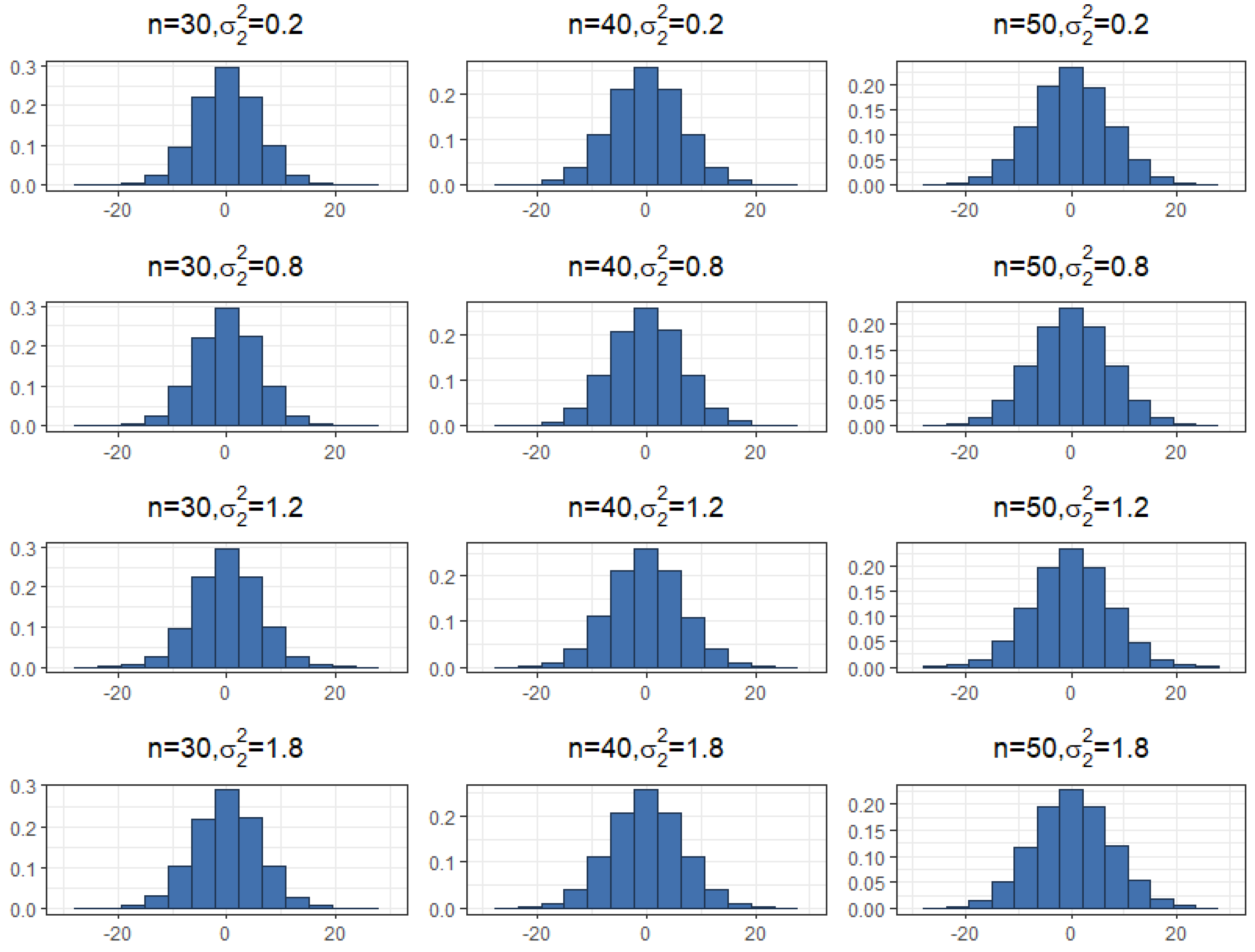
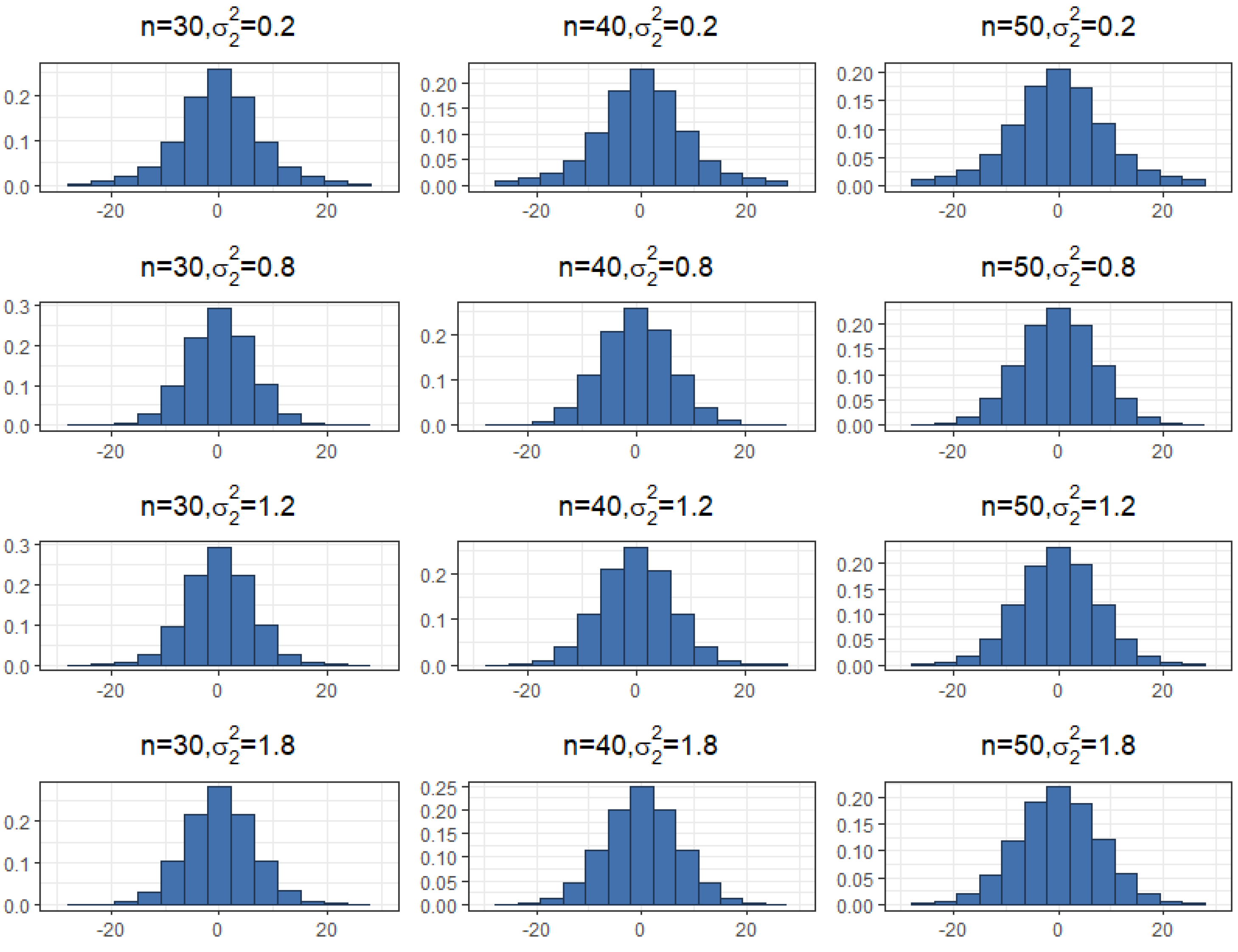
Estimating and evaluating hypotheses about the common means of different univariate normal populations is an important problem. This study attempts to propose a preliminary testimator for the common mean with unknown and unequal variances. The preliminary testimator thus produced will be studied for its behavior when the expressions of its bias, MSE, and Relative Efficiency (RE) are determined and their performance will be evaluated. The proposed method incorporates preliminary testing to assess the equality of population variances before estimating the common mean . When significant differences in variances are detected, the preliminary test shrinkage estimator adjusts the weight assigned to each sample mean, shrinking estimates from populations with smaller sample variances towards the overall mean. This is the main motivation behind this revisit to the common mean problem and filling certain gaps analytically as well as computationally while proposing a preliminary test shrinkage estimator.
4. Application
The Environmental Protection Agency (EPA) of the United States provided a data set to evaluate gasoline quality based on Reid vapor pressure (RVP); more information can be found in the article by Yu et al. [
27]. Occasionally, an EPA inspector would visit gas pumps in the city, take gasoline samples of a particular brand, and measure the RVP on the spot, which produced cheap and quick measurements. Once in a while, the inspector, after measuring the RVP at the spot, would ship a gasoline sample to the laboratory for a measurement of presumably higher precision at a higher cost. Two types of RVP measurements were taken,
X, the field measurement, and the lab measurement,
Y, which were referred to as the same chemical (RVP). It was assumed that the measurements
X and
Y had the common mean
.
Table 7 contains two independent samples of RVP measurements:
X, the field measurements, with a sample size of 45, and the lab measurements,
Y, with a sample size of 15.
The Shapiro tests and Q–Q plots were conducted to assess the distribution of the average field (X) and lab (Y) data. The findings showed that both sets of data exhibited a normal distribution, where and . The sample means were calculated as and , with sample variances of and , respectively.
First of all,
,
, and
were found to be very close to each other, indicating that there is probably not much difference between these estimators’ in estimating the common mean
(
Table 8). We do not want to draw any general conclusions here, but our theoretical and simulated results indicate that our proposed preliminary testimator
is viable and could be used for this particular application if we assume that
, as the sample of gasoline of a particular brand is drawn from the same gas pumps in the city.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}