
An Agile Super-Resolution Network via Intelligent Path Selection

Abstract
:1. Introduction
- We propose an agile super-resolution network via intelligent path selection (ASRN) for edge computing environments. ASRN adopts a dynamic path selection mechanism that utilizes a policy network to tailor computational pathways based on the real-time data.
- We introduced a smart reward mechanism in ASRN that has been ingeniously crafted to evaluate the policy network’s decisions. By comprehensively assessing the overall performance of the model and the effectiveness of current policy, it directs the policy network towards optimal choices, thereby marking a significant advancement for super-resolution applications in edge-computing scenarios.
- Our extensive experiments across a variety of datasets confirmed the effectiveness of the proposed ASRN. In particular, on the Div2k dataset [20], we reduced the average number of residual blocks by 15.88% and the computational complexity (FLOPS) by 15.68% while maintaining performance close to baseline.
2. Related Work
2.1. Super-Resolution Technology
2.2. Deep Learning Applications in Edge Computing
2.3. Lightweight Model Techniques
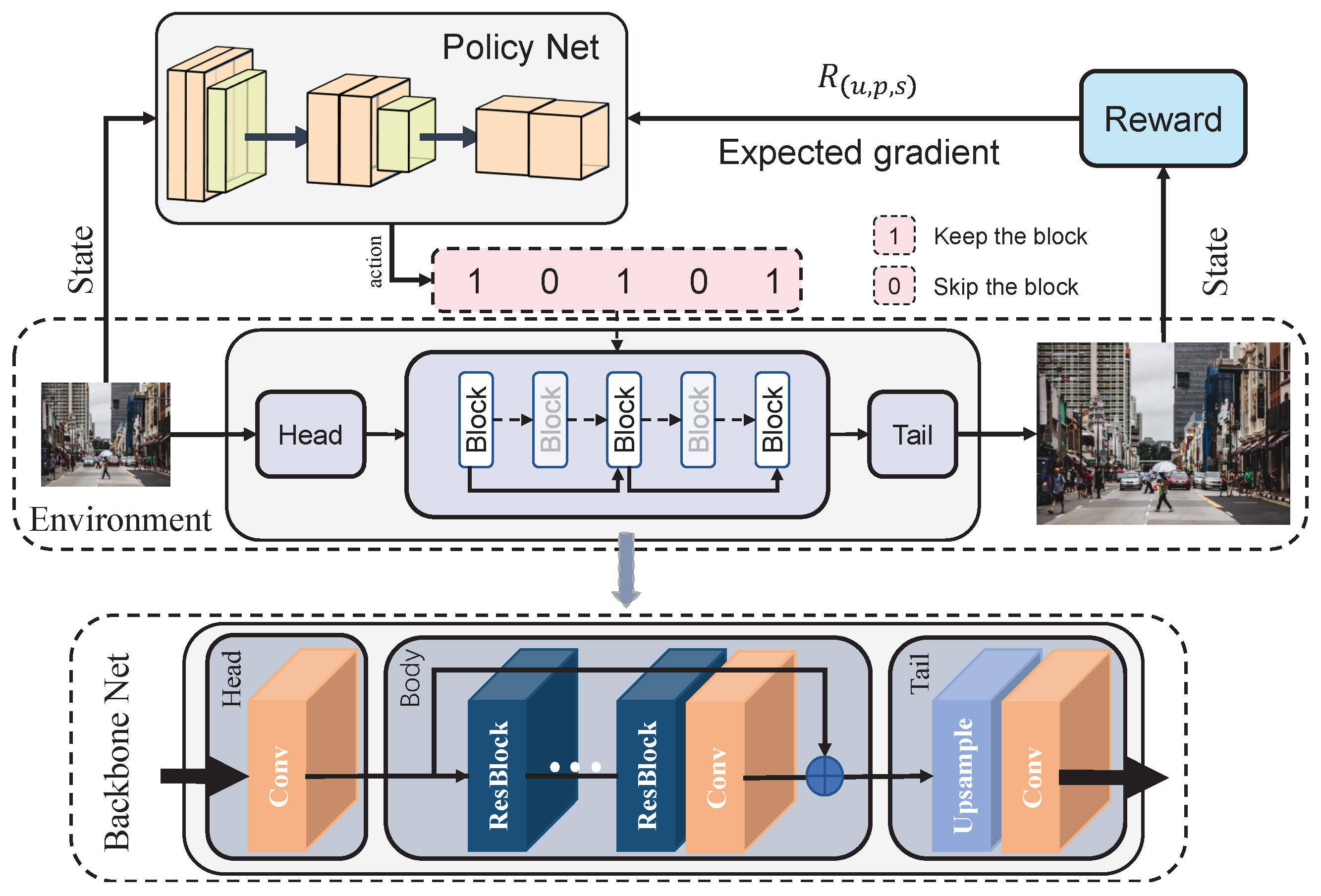
3. Agile Super-Resolution Network via Intelligent Path Selection
3.1. Overall Framework
3.2. Policy Network
3.2.1. Design Principles of the Policy Network
3.2.2. Policy Generation Process
3.2.3. Collaboration of the Policy Network with the Backbone Network
3.2.4. Adaptability to Application Scenarios
3.3. Reward Mechanism
3.4. Optimization of the Policy Network
3.4.1. Optimization Objective
3.4.2. Application of Gradient Optimization Techniques
3.4.3. Policy for Reducing Variance
3.4.4. Incentive Mechanism for Policy Exploration
3.4.5. Parameter Sensitivity Analysis
4. Experiments
4.1. Experimental Setup
4.1.1. Dataset
4.1.2. Network Architecture Components
4.2. Balancing Speed and Quality
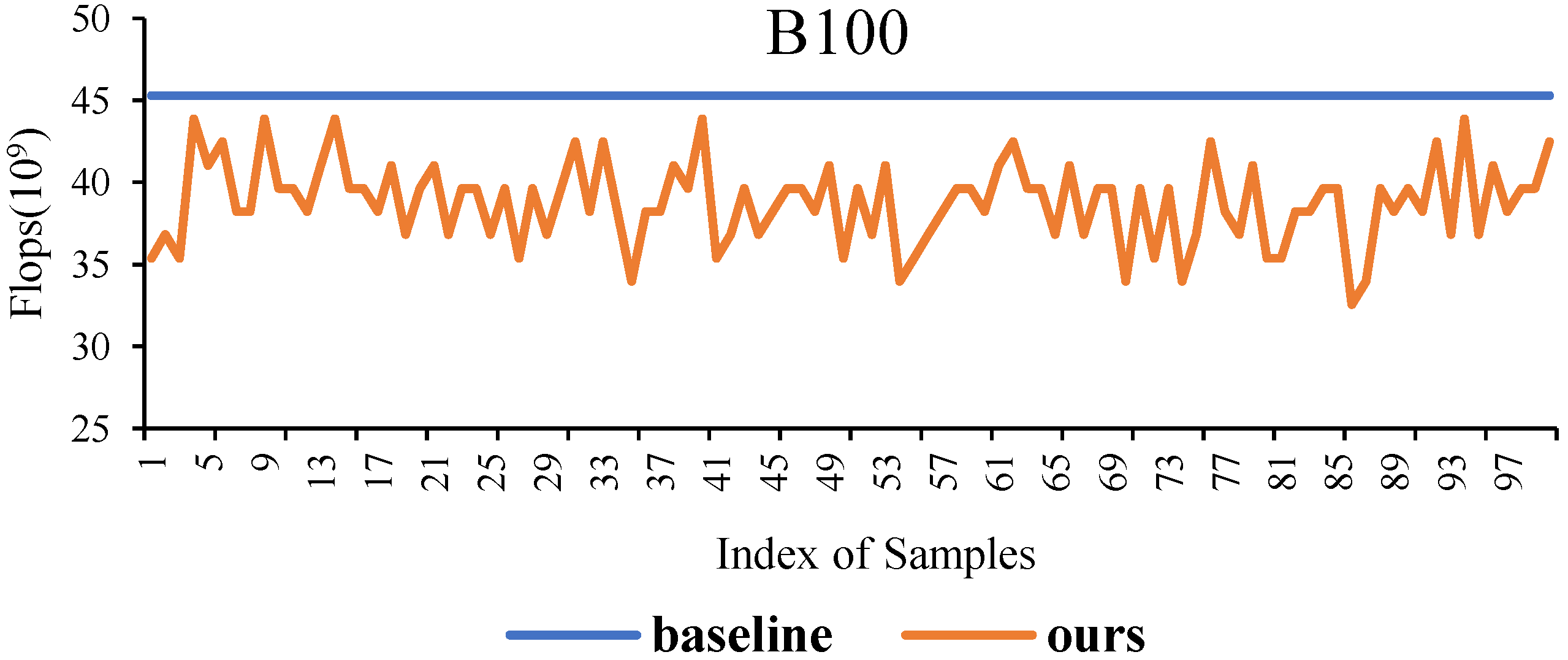
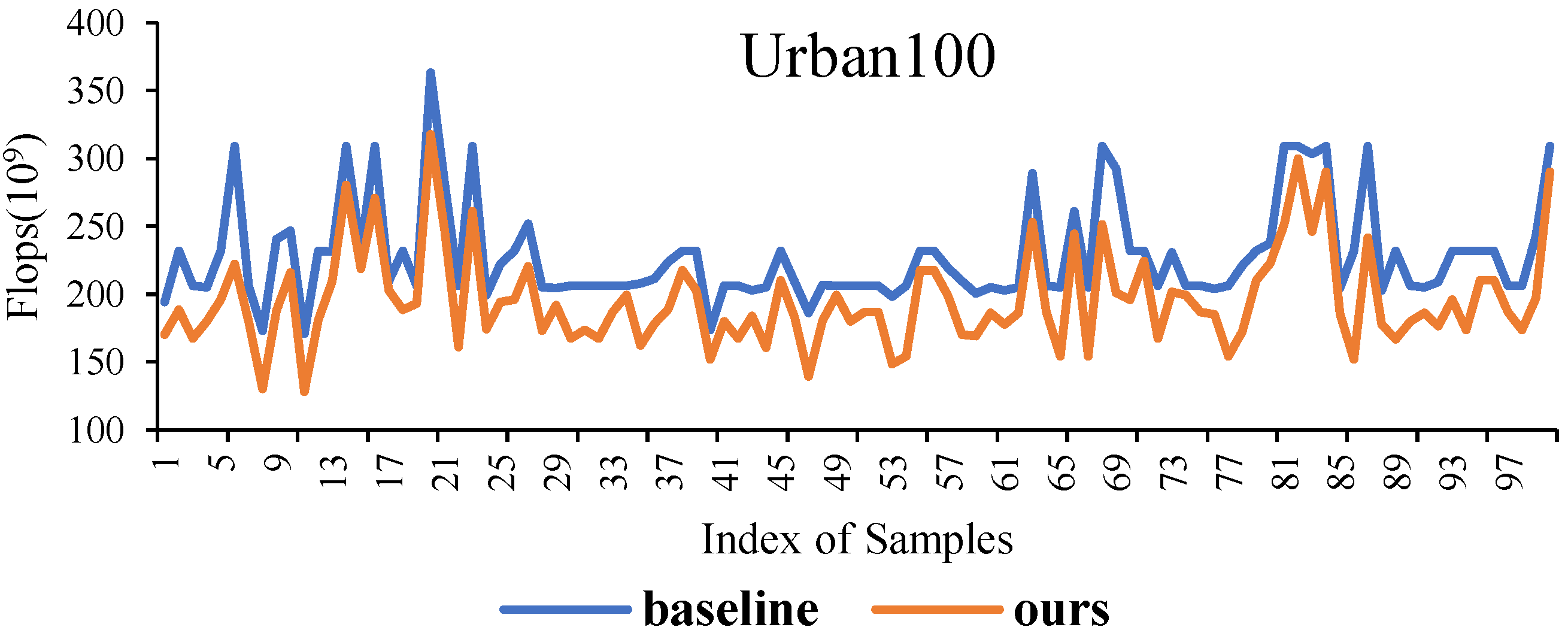
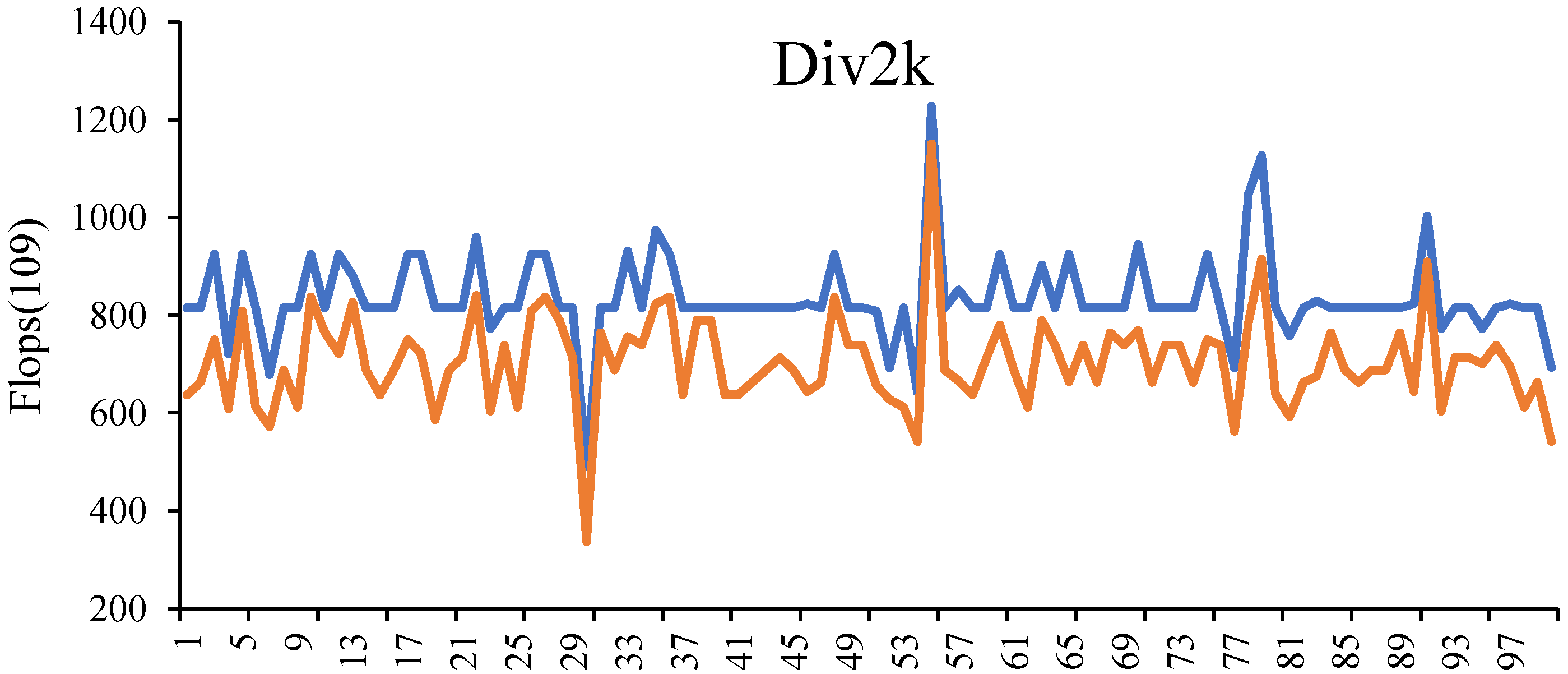
4.2.1. Performance Comparison Analysis
4.2.2. Significant Reduction in Inference Time
4.2.3. Scalability Testing
4.2.4. Application Insights and Future Perspectives
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| PSNR | Peak Signal-to-Noise Ratio |
| SSIM | Structural Similarity Index |
| IoT | Internet of Things |
| FLOPS | Floating Point Operations Per Second |
| GANs | Generative Adversarial Networks |
| CNNs | Convolutional Neural Networks |
References
- Lugmayr, A.; Danelljan, M.; Timofte, R. Unsupervised Learning for Real-World Super-Resolution. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Republic of Korea, 27–28 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3408–3416. [Google Scholar]
- Park, S.C.; Park, M.K.; Kang, M.G. Super-resolution image reconstruction: A technical overview. IEEE Signal Process. Mag. 2003, 20, 21–36. [Google Scholar] [CrossRef]
- Yue, L.; Shen, H.; Li, J.; Yuan, Q.; Zhang, H.; Zhang, L. Image super-resolution: The techniques, applications, and future. Signal Process. 2016, 128, 389–408. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Cheng, Y.; Wang, D.; Zhou, P.; Zhang, T. A survey of model compression and acceleration for deep neural networks. arXiv 2017, arXiv:1710.09282. [Google Scholar]
- Chen, Y.; Fan, H.; Xu, B.; Yan, Z.; Kalantidis, Y.; Rohrbach, M.; Yan, S.; Feng, J. Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3435–3444. [Google Scholar]
- Ayinde, B.O.; Inanc, T.; Zurada, J.M. Redundant feature pruning for accelerated inference in deep neural networks. Neural Netw. 2019, 118, 148–158. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning filters for efficient convnets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Polyak, A.; Wolf, L. Channel-level acceleration of deep face representations. IEEE Access 2015, 3, 2163–2175. [Google Scholar] [CrossRef]
- Yu, R.; Li, A.; Chen, C.F.; Lai, J.H.; Morariu, V.I.; Han, X.; Gao, M.; Lin, C.Y.; Davis, L.S. Nisp: Pruning Networks Using Neuron Importance Score Propagation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9194–9203. [Google Scholar]
- Wu, J.; Leng, C.; Wang, Y.; Hu, Q.; Cheng, J. Quantized convolutional neural networks for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 4820–4828. [Google Scholar]
- Li, H.; De, S.; Xu, Z.; Studer, C.; Samet, H.; Goldstein, T. Training quantized nets: A deeper understanding. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. arXiv 2015, arXiv:1510.00149. [Google Scholar]
- Ioannou, Y.; Robertson, D.; Shotton, J.; Cipolla, R.; Criminisi, A. Training cnns with low-rank filters for efficient image classification. arXiv 2015, arXiv:1511.06744. [Google Scholar]
- Sainath, T.N.; Kingsbury, B.; Sindhwani, V.; Arisoy, E.; Ramabhadran, B. Low-Rank Matrix Factorization for Deep Neural Network Training with High-Dimensional Output Targets. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 6655–6659. [Google Scholar]
- Tai, C.; Xiao, T.; Zhang, Y.; Wang, X. Convolutional neural networks with low-rank regularization. arXiv 2015, arXiv:1511.06067. [Google Scholar]
- Chen, G.; Choi, W.; Yu, X.; Han, T.; Chandraker, M. Learning efficient object detection models with knowledge distillation. Adv. Neural Inf. Process. Syst. 2017, 30, 483. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Romero, A.; Ballas, N.; Kahou, S.E.; Chassang, A.; Gatta, C.; Bengio, Y. Fitnets: Hints for thin deep nets. arXiv 2014, arXiv:1412.6550. [Google Scholar]
- Timofte, R.; Agustsson, E.; Van Gool, L.; Yang, M.H.; Zhang, L. Ntire 2017 challenge on single image super-resolution: Methods and results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 114–125. [Google Scholar]
- Zhang, K.; Tao, D.; Gao, X.; Li, X.; Xiong, Z. Learning multiple linear mappings for efficient single image super-resolution. IEEE Trans. Image Process. 2015, 24, 846–861. [Google Scholar] [CrossRef] [PubMed]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Morel, M.L.A. Single-image super-resolution via linear mapping of interpolated self-examples. IEEE Trans. Image Process. 2014, 23, 5334–5347. [Google Scholar] [CrossRef] [PubMed]
- Ketkar, N.; Moolayil, J.; Ketkar, N.; Moolayil, J. Convolutional Neural Networks. In Deep Learning with Python: Learn Best Practices of Deep Learning Models with PyTorch; Apress: New York, NY, USA, 2021; pp. 197–242. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative adversarial networks: An overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Burt, P.J. Attention Mechanisms for Vision in a Dynamic World. In Proceedings of the 9th International Conference on Pattern Recognition, Valletta, Malta, 22–24 February 2020; IEEE Computer Society: Piscataway, NJ, USA, 1988; pp. 977–978. [Google Scholar]
- Kawulok, M.; Benecki, P.; Piechaczek, S.; Hrynczenko, K.; Kostrzewa, D.; Nalepa, J. Deep learning for multiple-image super-resolution. IEEE Geosci. Remote. Sens. Lett. 2019, 17, 1062–1066. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Part II 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Bai, S.; Chen, J.; Shen, X.; Qian, Y.; Liu, Y. Unified Data-Free Compression: Pruning and Quantization without Fine-Tuning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 5876–5885. [Google Scholar]
- Shen, W.; Wang, W.; Zhu, J.; Zhou, H.; Wang, S. Pruning-and Quantization-Based Compression Algorithm for Number of Mixed Signals Identification Network. Electronics 2023, 12, 1694. [Google Scholar] [CrossRef]
- Zhang, S.; Sohrabizadeh, A.; Wan, C.; Huang, Z.; Hu, Z.; Wang, Y.; Cong, J.; Sun, Y.; Lin, Y. A Survey on Graph Neural Network Acceleration: Algorithms, Systems, and Customized Hardware. arXiv 2023, arXiv:2306.14052. [Google Scholar]
- Zeng, Z.; Sapatnekar, S.S. Energy-efficient Hardware Acceleration of Shallow Machine Learning Applications. In Proceedings of the 2023 Design, Automation & Test in Europe Conference & Exhibition (DATE), Antwerp, Belgium, 17–19 April 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–6. [Google Scholar]
- Anwar, S.; Hwang, K.; Sung, W. Structured pruning of deep convolutional neural networks. Acm J. Emerg. Technol. Comput. Syst. (JETC) 2017, 13, 1–18. [Google Scholar] [CrossRef]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1389–1397. [Google Scholar]
- Lin, S.; Ji, R.; Yan, C.; Zhang, B.; Cao, L.; Ye, Q.; Huang, F.; Doermann, D. Towards Optimal Structured cnn Pruning via Generative Adversarial Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2790–2799. [Google Scholar]
- Liu, Z.; Sun, M.; Zhou, T.; Huang, G.; Darrell, T. Rethinking the value of network pruning. arXiv 2018, arXiv:1810.05270. [Google Scholar]
- Gholami, A.; Kim, S.; Dong, Z.; Yao, Z.; Mahoney, M.W.; Keutzer, K. A survey of quantization methods for efficient neural network inference. In Low-Power Computer Vision; Chapman and Hall/CRC: Boca Raton, FL, USA, 2022; pp. 291–326. [Google Scholar]
- Nagel, M.; Fournarakis, M.; Amjad, R.A.; Bondarenko, Y.; Van Baalen, M.; Blankevoort, T. A white paper on neural network quantization. arXiv 2021, arXiv:2106.08295. [Google Scholar]
- Xu, S.; Huang, A.; Chen, L.; Zhang, B. Convolutional Neural Network Pruning: A Survey. In Proceedings of the 2020 39th Chinese Control Conference (CCC), Shenyang, China, 27–29 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 7458–7463. [Google Scholar]
- Zhang, Y.; Xiang, T.; Hospedales, T.M.; Lu, H. Deep mutual learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4320–4328. [Google Scholar]
- Shen, T.; Zhang, J.; Jia, X.; Zhang, F.; Huang, G.; Zhou, P.; Kuang, K.; Wu, F.; Wu, C. Federated mutual learning. arXiv 2020, arXiv:2006.16765. [Google Scholar]
- Gupta, S.; Hoffman, J.; Malik, J. Cross Modal Distillation for Supervision Transfer. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2827–2836. [Google Scholar]
- Afouras, T.; Chung, J.S.; Zisserman, A. Asr is all you need: Cross-modal distillation for lip reading. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Las Vegas, NV, USA, 26 June–1 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2143–2147. [Google Scholar]
- Liu, K.; Da Costa, J.P.C.; So, H.C.; Huang, L.; Ye, J. Detection of number of components in CANDECOMP/PARAFAC models via minimum description length. Digit. Signal Process. 2016, 51, 110–123. [Google Scholar] [CrossRef]
- Phan, A.H.; Tichavskỳ, P.; Cichocki, A. CANDECOMP/PARAFAC decomposition of high-order tensors through tensor reshaping. IEEE Trans. Signal Process. 2013, 61, 4847–4860. [Google Scholar] [CrossRef]
- Jang, J.G.; Kang, U. D-Tucker: Fast and Memory-Efficient Tucker Decomposition for Dense Tensors. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1850–1853. [Google Scholar]
- Ahmadi-Asl, S.; Abukhovich, S.; Asante-Mensah, M.G.; Cichocki, A.; Phan, A.H.; Tanaka, T.; Oseledets, I. Randomized algorithms for computation of Tucker decomposition and higher order SVD (HOSVD). IEEE Access 2021, 9, 28684–28706. [Google Scholar] [CrossRef]
- Jia, L.; Hu, Y.; Tian, X.; Luo, W. Fast Super-Resolution Network via Dynamic Path Selection. In Proceedings of the 2023 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Chengdu, China, 3–5 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1093–1099. [Google Scholar]
- Sutton, R.S.; Barto, A.G. The reinforcement learning problem. In Reinforcement learning: An introduction; MIT Press: Cambridge, MA, USA, 1998; pp. 51–85. [Google Scholar]
- Barthélemy, J.; Suesse, T. mipfp: An R package for multidimensional array fitting and simulating multivariate Bernoulli distributions. J. Stat. Softw. 2018, 86. [Google Scholar] [CrossRef]
- Fraiman, R.; Moreno, L.; Ransford, T. A quantitative Heppes theorem and multivariate Bernoulli distributions. J. R. Stat. Soc. Ser. B Stat. Methodol. 2023, 85, 293–314. [Google Scholar] [CrossRef]
- Ratliff, N.; Zucker, M.; Bagnell, J.A.; Srinivasa, S. CHOMP: Gradient Optimization Techniques for Efficient Motion Planning. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 489–494. [Google Scholar]
- Metropolis, N.; Ulam, S. The monte carlo method. J. Am. Stat. Assoc. 1949, 44, 335–341. [Google Scholar] [CrossRef] [PubMed]
- Bielajew, A.F. History of monte carlo. In Monte Carlo Techniques in Radiation Therapy; CRC Press: Boca Raton, FL, USA, 2021; pp. 3–15. [Google Scholar]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Mu Lee, K. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 136–144. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2012, 25. [Google Scholar] [CrossRef]
- Bevilacqua, M.; Roumy, A.; Guillemot, C.; Alberi-Morel, M.L. Low-Complexity Single-Image Super-Resolution Based on Nonnegative Neighbor Embedding. In Proceedings of the 23rd British Machine Vision Conference (BMVC), Surrey, UK, 3–7 September 2012. [Google Scholar]
- Zeyde, R.; Elad, M.; Protter, M. On Single Image Scale-Up Using Sparse-Representations. In Proceedings of the Curves and Surfaces: 7th International Conference, Avignon, France, 24–30 June 2010; Revised Selected Papers 7. Springer: Berlin/Heidelberg, Germany, 2012; pp. 711–730. [Google Scholar]
- Martin, D.; Fowlkes, C.; Tal, D.; Malik, J. A Database of Human Segmented Natural Images and Its Application to Evaluating Segmentation Algorithms and Measuring Ecological Statistics. In Proceedings of the Eighth IEEE International Conference on Computer Vision, ICCV 2001, Vancouver, BC, Canada, 7–14 July 2001; IEEE: Piscataway, NJ, USA, 2001; Volume 2, pp. 416–423. [Google Scholar]
- Huang, J.B.; Singh, A.; Ahuja, N. Single Image Super-Resolution from Transformed Self-Exemplars. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5197–5206. [Google Scholar]
- Timofte, R.; De Smet, V.; Van Gool, L. A+: Adjusted anchored neighborhood regression for fast super-resolution. In Proceedings of the Computer Vision–ACCV 2014: 12th Asian Conference on Computer Vision, Singapore, 1–5 November 2014; Revised Selected Papers, Part IV 12. Springer: Berlin/Heidelberg, Germany, 2015; pp. 111–126. [Google Scholar]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning a Deep Convolutional Network for Image Super-Resolution. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Part IV 13. Springer: Berlin/Heidelberg, Germany, 2014; pp. 184–199. [Google Scholar]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using Very Deep Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1646–1654. [Google Scholar]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| t | PSNR | Blocks Used | |
|---|---|---|---|
| −100 | 30 | 37.364 | 28 |
| −50 | 30 | 37.380 | 27 |
| −10 | 30 | 37.450 | 26 |
| −100 | 100 | 37.415 | 30 |
| −100 | 50 | 37.402 | 29 |
| −100 | 10 | 37.421 | 25 |
| Image ID | Baseline | Ours | Reduction | Speedup |
|---|---|---|---|---|
| 33 | 45.3 | 42.47 | 2.83 | 6.35% |
| 38 | 45.3 | 41.05 | 4.25 | 9.38% |
| 43 | 45.3 | 39.64 | 5.66 | 12.49% |
| 74 | 45.3 | 33.97 | 11.33 | 25.00% |
| 35 | 45.3 | 32.56 | 12.74 | 28.12% |
| Image ID | Baseline | Ours | Reduction | Speedup |
|---|---|---|---|---|
| 43 | 202.94 | 183.91 | 19.03 | 9.38% |
| 50 | 205.96 | 180.21 | 25.75 | 12.50% |
| 58 | 209.58 | 170.28 | 39.3 | 18.75% |
| 67 | 205.35 | 154.01 | 51.34 | 25.00% |
| 86 | 231.93 | 152.2 | 79.73 | 34.38% |
| Image ID | Baseline | Ours | Reduction | Speedup |
|---|---|---|---|---|
| 10 | 924.09 | 837.46 | 86.63 | 9.37% |
| 42 | 815.80 | 662.84 | 152.96 | 18.75% |
| 78 | 1046.82 | 785.11 | 261.71 | 25.00% |
| 19 | 815.80 | 586.35 | 229.54 | 28.13% |
| 30 | 490.92 | 337.51 | 153.41 | 31.25% |
| Evaluation (avg.) | Set5 | Set14 | B100 | Urban100 | Div2k | |
|---|---|---|---|---|---|---|
| PSNR/SSIM | Baseline Ours | 38.11/0.9601 38.02/0.9586 | 33.92/0.9195 33.74/0.9166 | 32.32/0.9013 32.24/0.9018 | 32.93/0.9351 32.28/0.9274 | 35.03/0.9695 34.73/0.9676 |
| BLOCKS | Baseline Ours Speedup | 32 28.99 9.41% | 32 28.13 12.09% | 32 27.48 14.14% | 32 27.46 14.19% | 32 26.90 15.93% |
| FLOPS (109) | Baseline Ours Speedup | 33.47 30.33 9.37% | 67.86 58.64 13.58% | 45.3 38.86 14.21% | 228.59 195.70 14.39% | 836.09 704.57 15.73% |
| Dataset | Block Usage | Scale | Bicubic | A+ | SRCNN | VDSR | Ours | EDSR | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | PSNR | SSIM | |||
| Set5 | 90.59% | X2 | 33.66 | 0.9229 | 36.54 | 0.9544 | 36.66 | 0.9542 | 37.53 | 0.9587 | 38.02 | 0.9586 | 38.11 | 0.9601 |
| X3 | 30.39 | 0.8682 | 32.58 | 0.9088 | 32.75 | 0.9090 | 33.66 | 0.9213 | 34.59 | 0.9263 | 34.65 | 0.9282 | ||
| X4 | 28.42 | 0.8104 | 30.28 | 0.8603 | 30.48 | 0.8628 | 31.35 | 0.8838 | 32.37 | 0.8945 | 32.46 | 0.8968 | ||
| Set14 | 87.91% | X2 | 30.24 | 0.8688 | 32.28 | 0.9056 | 32.42 | 0.9063 | 33.03 | 0.9124 | 33.74 | 0.9166 | 33.92 | 0.9195 |
| X3 | 27.55 | 0.7742 | 29.13 | 0.8188 | 29.28 | 0.8209 | 29.77 | 0.8314 | 30.34 | 0.8426 | 30.52 | 0.8462 | ||
| X4 | 26.00 | 0.7027 | 27.32 | 0.7491 | 27.49 | 0.7503 | 28.01 | 0.7674 | 28.64 | 0.7843 | 28.80 | 0.7876 | ||
| B100 | 85.86% | X2 | 29.56 | 0.8431 | 31.21 | 0.8863 | 31.36 | 0.8879 | 31.90 | 0.8960 | 32.24 | 0.9018 | 32.32 | 0.9013 |
| X3 | 27.21 | 0.7385 | 28.29 | 0.7835 | 28.41 | 0.7863 | 28.82 | 0.7976 | 29.08 | 0.8074 | 29.25 | 0.8093 | ||
| X4 | 25.96 | 0.6675 | 26.82 | 0.7087 | 26.90 | 0.7101 | 27.29 | 0.7251 | 27.62 | 0.7363 | 27.71 | 0.7420 | ||
| Urban100 | 85.81% | X2 | 26.88 | 0.8403 | 29.20 | 0.8938 | 29.50 | 0.8946 | 30.76 | 0.9140 | 32.28 | 0.9274 | 32.93 | 0.9351 |
| X3 | 24.46 | 0.7349 | 26.03 | 0.7973 | 26.24 | 0.7989 | 27.14 | 0.8279 | 28.33 | 0.8562 | 28.80 | 0.8653 | ||
| X4 | 23.14 | 0.6577 | 24.32 | 0.7183 | 24.52 | 0.7221 | 25.18 | 0.7524 | 26.24 | 0.7931 | 26.64 | 0.8033 | ||
| Div2k | 84.07% | X2 | 31.01 | 0.9393 | 32.89 | 0.9570 | 33.05 | 0.9581 | 33.66 | 0.9625 | 34.73 | 0.9676 | 35.03 | 0.9695 |
| X3 | 28.22 | 0.8906 | 29.50 | 0.9116 | 29.64 | 0.9138 | 30.09 | 0.9208 | 30.92 | 0.9307 | 31.26 | 0.9340 | ||
| X4 | 26.66 | 0.8521 | 27.70 | 0.8736 | 27.78 | 0.8753 | 28.17 | 0.8841 | 28.97 | 0.8987 | 29.25 | 0.9017 | ||
| Data 0 | Data 1 | Data 2 | Data 3 | Data 4 | Average | |
|---|---|---|---|---|---|---|
| Baseline | 384.626 s | 106.37 s | 92.334 s | 96.162 s | 102.96 s | 156.490 s |
| Ours | 370.942 s | 92.994 s | 73.700 s | 90.772 s | 102.388 s | 146.159 s |
| Data 0 | Data 1 | Data 2 | Data 3 | Data 4 | Average | |
|---|---|---|---|---|---|---|
| Baseline | 153.850 s | 42.548 s | 36.934 s | 38.465 s | 41.184 s | 62.596 s |
| Ours | 148.377 s | 37.198 s | 29.480 s | 36.309 s | 40.955 s | 58.464 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jia, L.; Hu, Y.; Tian, X.; Luo, W.; Ye, Y. An Agile Super-Resolution Network via Intelligent Path Selection. Mathematics 2024, 12, 1094. https://doi.org/10.3390/math12071094
Jia L, Hu Y, Tian X, Luo W, Ye Y. An Agile Super-Resolution Network via Intelligent Path Selection. Mathematics. 2024; 12(7):1094. https://doi.org/10.3390/math12071094
Chicago/Turabian StyleJia, Longfei, Yuguo Hu, Xianlong Tian, Wenwei Luo, and Yanning Ye. 2024. "An Agile Super-Resolution Network via Intelligent Path Selection" Mathematics 12, no. 7: 1094. https://doi.org/10.3390/math12071094