1. Introduction
Surveillance systems are a very important and essential part of the built environment due to safety and security. One of the major applications of surveillance is traffic monitoring. Traffic surveillance is an integral part of road safety and security. In terms of security, traffic detection is useful to identify, track, and extract the license plate and behavior of vehicles. Traditional surveillance systems are generally driven by human effort, i.e., a video is captured and people are deployed to examine activity or security risks. However, this approach has disadvantages like high labor costs, lower efficiency, human limitations, and high resource requirements. With the rising trend of artificial intelligence, computer vision and deep learning play a vital role in many advanced applications, ranging from security, medical analysis, sports, military, and general surveillance. These techniques can replace traditional monitoring systems with Intelligent Surveillance Systems (ISSs). This technique takes the input from a camera, i.e., fixed CCTV, drones, or any other imaging source, and helps to identify, track, or classify objects using deep learning algorithms.
For traffic monitoring, road vehicles can be categorized into two main classes: two-wheeled vehicles, and four-wheeled and above vehicles. In developed countries, cars are the most popular means of urban transportation, but in developing nations, the most popular and common means of transportation is motorbikes, mainly because they tend to be more affordable and more easily accessible. However, motorbikes are also more likely to result in fatal road accidents. The World Health Organization (WHO) declared the motorbike as a vulnerable road user (VRU). Motorbikes are one the most venerable road users (VRUs) and are engaged in a large annual number of accidents; therefore, traffic monitoring systems need to detect them in real-time. Once detected, further processing might involve tracking, the detection of rule violations, helmet-wearing compliance, license plate reading, overloading, etc.
Most of the work that has been carried out on road surveillance is for four-wheelers or over (cars, trucks, etc.). Although motorbike detection is equally important, it is much more difficult due to their smaller size, higher occlusion (e.g., often due to the high density of bikes), varying angles of capture, and rider variations. These factors have a high impact on learning algorithms that lead to difficulty in detection. Furthermore, a major difficulty is the unavailability of large datasets. Previous works that have been carried out for motorbike detection have mainly focused on improving the accuracy of bike detection against issues such as occlusion and environmental variations, but they are impractical because of high computation costs, which makes them difficult to deploy in practice. So, the potential challenge that we have identified is in determining how we can make a neural network-based motorbike detection system more cost-efficient for real-time and practical implementation, using off-the-shelf embedded hardware. Regarding bike number plate recognition, it is worth noting that OCR (Optical Character Recognition) is a thoroughly researched technique, as evidenced by numerous studies, e.g., [
1,
2,
3]. While we recognize the potential advantages of integrating number plate detection with OCR capabilities into our research, our primary objective in this study was to enhance motorbike detection using deep learning models specifically designed for edge devices that can be a precursor to OCR-based plate recognition and association to a specific motorbike.
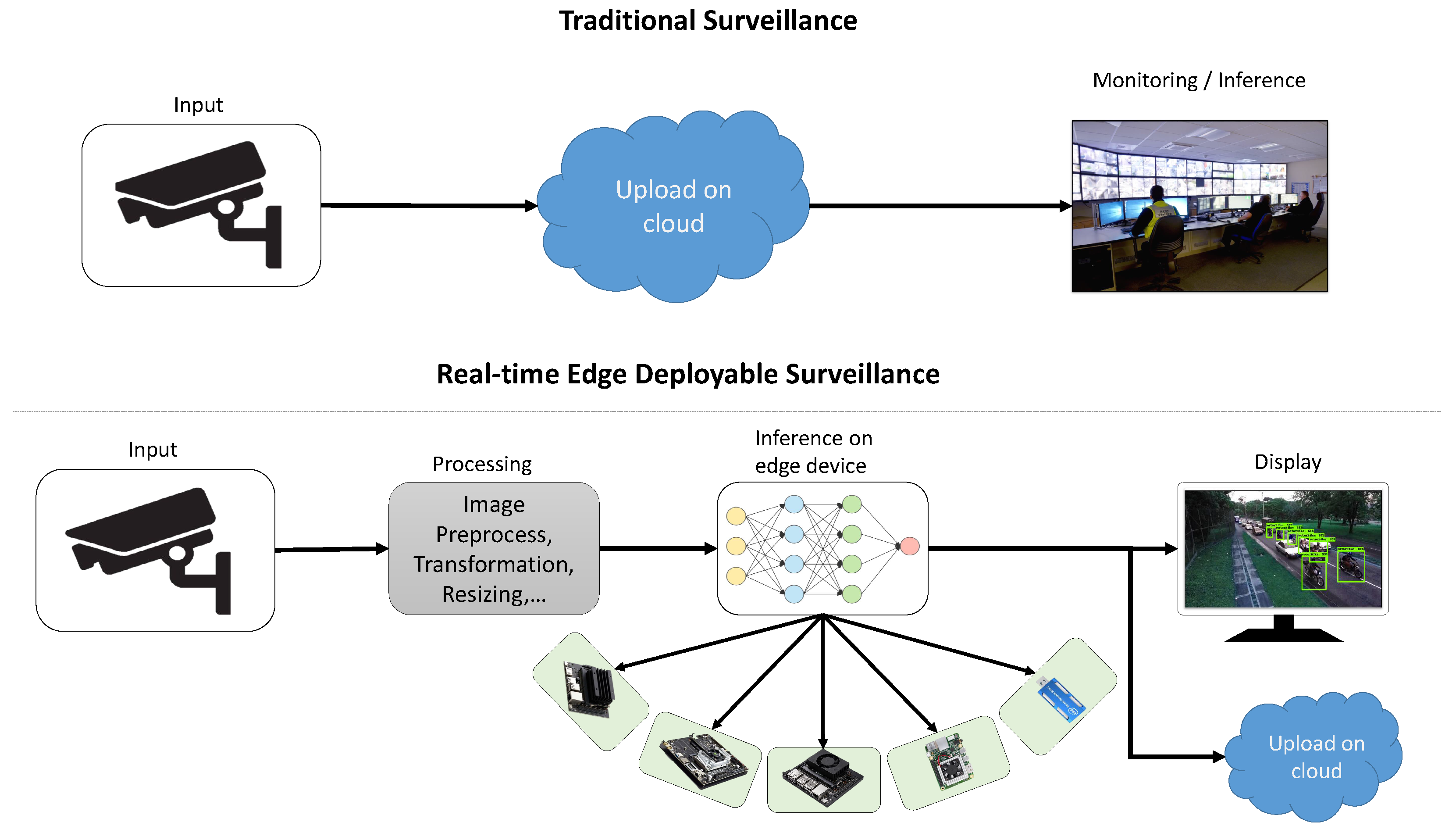
For real-time implementation, a brute force approach with powerful hardware can complete the work, but another critical challenge is how to make the detection system practical. So, an ideal system should be a small form factor embedded solution for using the model in a real-world scenario. Both solutions are shown in
Figure 1.
This work has studied multiple cost-effective solutions for motor bike detection in real-time as deployable solutions and provides a performance analysis of popular object detection models for this task on different embedded hardware. It has the following contributions:
Improved Baseline Accuracy: Achieved 99% accuracy with custom YoloV5 and augmented dataset, surpassing previous results.
Optimization Analysis: Conducted a comprehensive analysis, comparing motorbike object detection performance on various embedded edge devices, benchmarking results and optimizations.
Edge Deployable Real-Time Systems: Developed real-time motorbike detection models on GPUs, optimized for deployment on NVIDIA, Intel, and Google embedded edge devices.
The rest of the paper is structured as follows:
Section 2 describes related work on real-time motorbike detection models for embedded edge devices.
Section 3 presents the methodology adopted in this study.
Section 4 presents and analyzes the experimental results. Finally,
Section 5 provides the conclusions drawn from the study and outlines potential future work.
2. Related Work
Traditionally, motorbike detection has comprised two main steps. Initially, features are detected, followed by classification to distinguish between motorbikes and non-motorbikes, as well as to identify specific features like helmets and license plates. The Circular Hough Transform (CHT) serves as a valuable tool for localizing regions of interest (ROI), as utilized by Silva et al. [
4] in helmet detection and by Mukhtar et al. [
5] for detecting helmets and headlights on motorbikes. Harr-like features, known for their real-time performance, are employed by Wonghabut et al. [
6] and Gavadi et al. [
7] in motorbike helmet detection. However, Harr-like features are susceptible to factors such as capture angle and proximity, rendering them less robust for surveillance applications. Moreover, Histogram of Oriented Gradient (HOG) feature extraction is employed by Ghonge et al. [
8] to detect license plates of riders without helmets, and also by Dahiya et al. [
9] and Singh et al. [
10] for a comparative analysis of feature extraction techniques in motorbike and helmet detection. At the time of these studies, HOG was considered one of the most effective feature extractors, alongside SWIFT [
11]. In terms of classification, various methods such as Support Vector Machine (SVM), decision trees, random forests, and k-nearest neighbor (KNN) algorithms are employed. Mukhtar et al. [
5] and Barics et al. [
12] explored SVM classifiers. Shuo et al. [
13] utilized SVM with Harr-like features. In contrast, Dupuis et al. [
14] employed decision trees for motorcycle classification, combined with manually labeled blobs to mitigate overfitting. Le et al. [
15] enhanced classification accuracy by combining random forests with other methods to classify different motorbike components. Waranusast et al. [
16] employed K-nearest neighbors (KNNs) for motorcycle classification and helmet detection, while Barics et al. [
12] integrated classifiers with hybrid camera systems to achieve improved accuracy.
The paper [
17] employs a deep learning approach in conjunction with traditional methods for motorbike detection. They combine a Convolutional Neural Network (CNN) with Histogram of Gradient (HOG) and Support Vector Machine (SVM) for classification and detection. To address false detections, they categorize data into four classes, achieving 84% precision. However, their accuracy significantly decreases in occluded scenarios, and the processing time of two minutes per image renders it unsuitable for real-time implementation. Occlusion poses a significant challenge in motorbike detection. In [
18], the authors introduce the annotated dataset MB7500 to handle occlusion, employing a Faster R-CNN-based network with a custom two-layer CNN. Despite these efforts, detection remains irregular, with accuracy dropping to 20% in heavily occluded scenes. The low frame rate per second (fps) of Faster R-CNN makes real-time application challenging. In [
19], a four-layer CNN feature extractor serves as the backbone for Faster R-CNN, augmented with the Markov Decision Process (MDP) for tracking on the MB1000 dataset, achieving 88% mean average precision (mAP) in occluded scenarios. However, the compute-intensive two-step detection process results in high inference time, making it impractical for real-time deployment, especially on edge devices. Addressing false detections, missed detections, and small objects with complex backgrounds, the authors od [
20] propose a customized technique alongside a Fast R-CNN-based deep neural network. Despite achieving high accuracy, reaching 90.8% and 88.6% for low and high difficulty sets, respectively, the computational costs are considerable, prioritizing detection robustness over real-time applicability. In [
21], Faster R-CNN with Inception-ResNet backbone performs well, with the single-stage SSD network with Inception outperforming others in accuracy with preprocessing techniques. However, real-time applications are not considered, posing challenges for embedded solutions. The work in [
22] utilizes deep learning for traffic surveillance, extending to detect traffic violations. They incorporate the “DhakaAI” dataset with their images, enhancing it with 17 vehicle types, including around 4200 motorbike images. While achieving 15–20 fps using YoloV4 and 24–30 with 72.02% mAP using YoloV4-tiny, real-time deployment on edge devices is hindered by low mAP and fps. In [
23], a custom network based on SSD is proposed for detecting complex traffic scenarios, achieving an mAP of 89.05% and an overall speed of 32 fps. While meeting real-time criteria, challenges persist in deployment on embedded platforms. Proposing a methodology for motorbike rider detection with and without helmets, the paper [
24] trains two models using Faster R-CNN with the Inception V2 model, achieving 93.37% accuracy overall. However, the fps is not discussed, suggesting potential difficulties in real-time operation and deployment on embedded platforms.
Regarding datasets, detecting two-wheeled vehicles presents a challenging task, primarily due to the scarcity of comprehensive datasets. Despite the critical nature of this issue, there exists no single dataset that sufficiently covers all aspects and variations essential for benchmarking two-wheeled vehicle detection. This lack of availability of a comprehensive dataset has been underscored by the authors of [
25]. One contributing factor to this scarcity could be the smaller contribution of motorbikes to traffic in developed nations compared to the developing world. Several benchmark datasets include the motorbike category, albeit with various limitations. For instance, the dataset introduced in [
26] comprises five videos and 3880 annotated images, encompassing diverse traffic scenarios. However, it lacks motorbike category annotations and is more suited for autonomous car applications rather than wide-area surveillance. Similarly, the CBCL street scenes database [
27], containing 8000 images with annotations across nine object classes, is relevant for street scene understanding but lacks motorbike images in urban settings. KITTI [
28], renowned in autonomous vehicle research, offers datasets for optical flow, stereo, 3D object detection, tracking, and semantic segmentation. Despite its versatility, KITTI does not include a motorbike category. The PASCAL VOC dataset, a popular benchmark for detection, segmentation, and classification tasks, includes the motorbike category but with only 713 annotated images by 2012 [
29,
30]. Its limited size raises concerns about overfitting, and its focus on detection makes it less suitable for surveillance applications. The Caltech dataset [
31] features 30,607 images spanning 256 object categories, including the motorbike category with 798 images. However, its limitation lies in the absence of frontal views, rendering it less suitable for surveillance purposes. Some researchers resort to custom datasets, which unfortunately are not publicly available. These include datasets used by [
4,
13,
14,
32,
33,
34,
35,
36,
37]. The public MB7500 dataset, published by the authors of [
38], stands out for its coverage of occlusion and representative surveillance viewpoints, making it a valuable resource for two-wheeled detection datasets. To encapsulate the diverse approaches employed by various authors in motorbike detection, it is evident that different methods and models have been utilized. Among these, the approach outlined by the authors of [
19] stands out prominently, boasting an exceptionally high mean average precision (96%). This work suggests that SSD Mobilenet emerges as the optimal choice for motorbike detection among available methods. Shifting the focus to dataset comparisons, it becomes apparent that MB7500 holds a position of prominence. This dataset stands out as the most suitable for motorbike detection, particularly from a surveillance perspective. Not only is MB7500 publicly accessible, but it also stands as the most frequently utilized dataset for motorbike detection in prior research publications.
4. Results
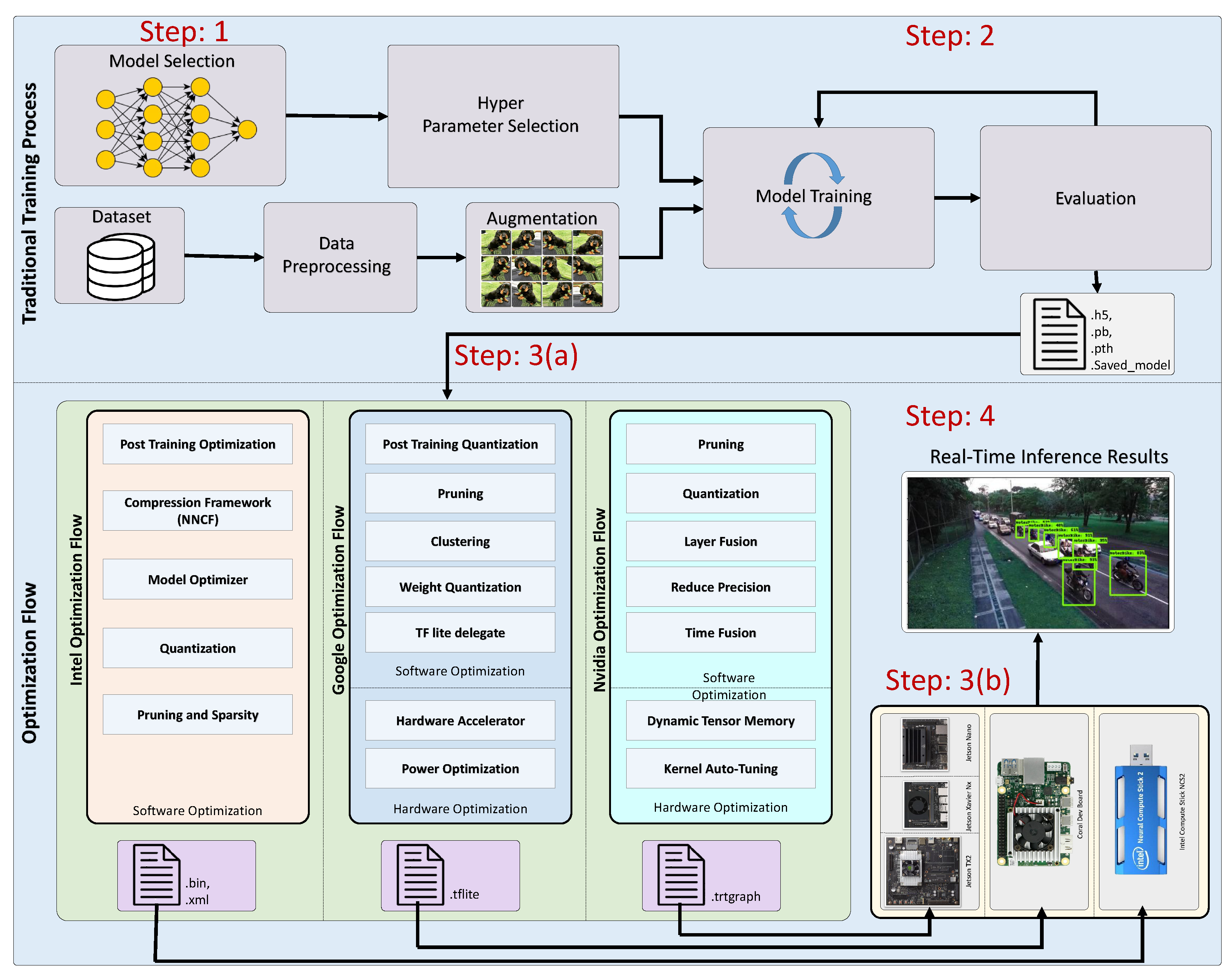
The final optimized network file is copied to the target device to run it for producing predictions. Then, the performance of the optimized network can be measured on the target device. If the desired results are achieved, the solution can be applied in the field. Before proceeding with the results, it is necessary to understand the evaluation metrics, as discussed next.
4.1. Experimental Setup
In this work, the object detection system implemented on the edge devices is coded in Python due to its versatility, ease of development, and compatibility with the selected frameworks and libraries. These choices were made to facilitate comprehensive comparison of the performance of state-of-the-art edge devices with that of a GPU, considering metrics such as mAP (mean average precision), FPS (frames per second), model size after optimization, power consumption, and memory usage. Additionally, two baseline models have been established to mitigate any bias stemming from a particular device on a model.
4.1.1. Dataset
As pointed out before, there is a general lack of suitable datasets to train motorbike detection models [
25]. Although no comprehensive dataset is available, we have selected the MB7500 open-source dataset, contributed by Espinosa et al., because it is focused on motorbikes with surveillance-like views. Although it would have been possible to use KITTI, it is mainly aimed at autonomous driving and mobile robotics as the camera is mounted on a car, facing forward. Nevertheless, it also does not include a separate class of motorbikes.
The data was collected for MB7000 using a Phantom 4 drone with a video camera. The dataset consists of 7500 annotated images of motorbikes in urban occluded scenarios with a size of 640 × 364, including 60% of occluded scenarios. The dataset is split into a 60–40 ratio to avoid overfitting. The dataset is collected using a drone with an angle similar to a CCTV camera. This dataset covers the occluded scenario very efficiently. However, this dataset does not address the problem of diversity, i.e., lightning conditions, weather conditions, angle problems, and the diversity in shape, place, and number of riders.
4.1.2. Evaluation Metrics
In a normal classification-based task, the performance of a network is defined in terms of accuracy, and this is sufficient to justify the impact of the method. However, in an object detection-based task, performance is better evaluated based on mAP, which further depends on ROI (region of interest) and prediction accuracy. The actual region of interest is the area on the image where the actual object exists. The area on the image that is predicted by the model in which it believes that some object is identified can be referred to as the predicted region of interest. A correct detection is measured as the overlap (typically 50%) between the predicted region of interest and the actual region of interest, given that the object identified in that area is the same as the actual label. This is the performance criteria for object detection-based tasks. To evaluate the performance of an object detection model in real-time, further metrics are used such as frames per second or inference time per frame. However, further metrics are required to demonstrate the performance of such object detection-based tasks on small, embedded edge devices. For that, we are using model size, power consumption, and memory usage, where the latter two are monitored during the runtime. This gives us insight into the real-time performance of different devices against different optimization flows, for the common task and neural network architecture.
4.2. Result and Analysis
This section presents a detailed analysis of the performance of SSD Mobilenet V2 and YoloV5 models for real-time motorbike detection on various embedded edge devices and a standard GPU. Although YoloV8 is a recent introduction, potential deployment in the field is limited due to licensing costs, and we selected YoloV5 for comparison due to its relevance to our research objectives and full availability at the time of the study. We begin by measuring the baseline performance of SSD Mobilenet V2 on a normal GPU, serving as a reference for comparison. This section highlights the mean average precision (mAP) scores and frames per second (FPS) achieved by each device, offering insights into their computational power and real-time capabilities. Additionally, we explore the impact of model size on the trade-off between accuracy and speed for edge devices. Furthermore, we present inference results of SSD Mobilenet V2 on both the GPU and edge devices, showcasing the detection performance with predicted bounding boxes. Then, we present the evaluation of YoloV5 with and without dataset augmentation, along with various input tensor sizes. A comparison of YoloV5 with other state-of-the-art models and custom networks is provided based on parameter count, mAP, and FPS on the GPU. Overall, the results reveal the advantages and drawbacks of utilizing these models for real-time motorbike detection tasks on different embedded edge devices and a standard GPU.
4.2.1. Results and Analysis Using SSD Mobilenet V2
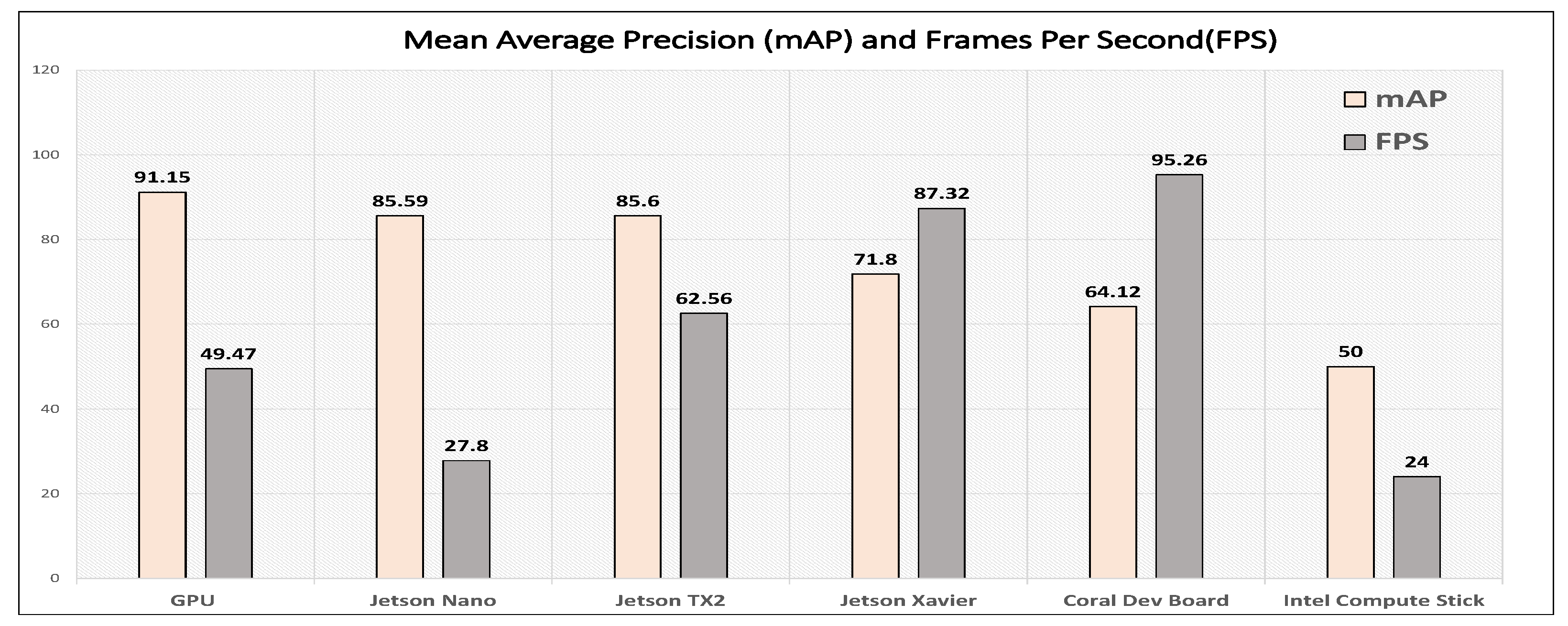
First, we measure the performance of this model on a normal GPU, which gives the baseline performance. From
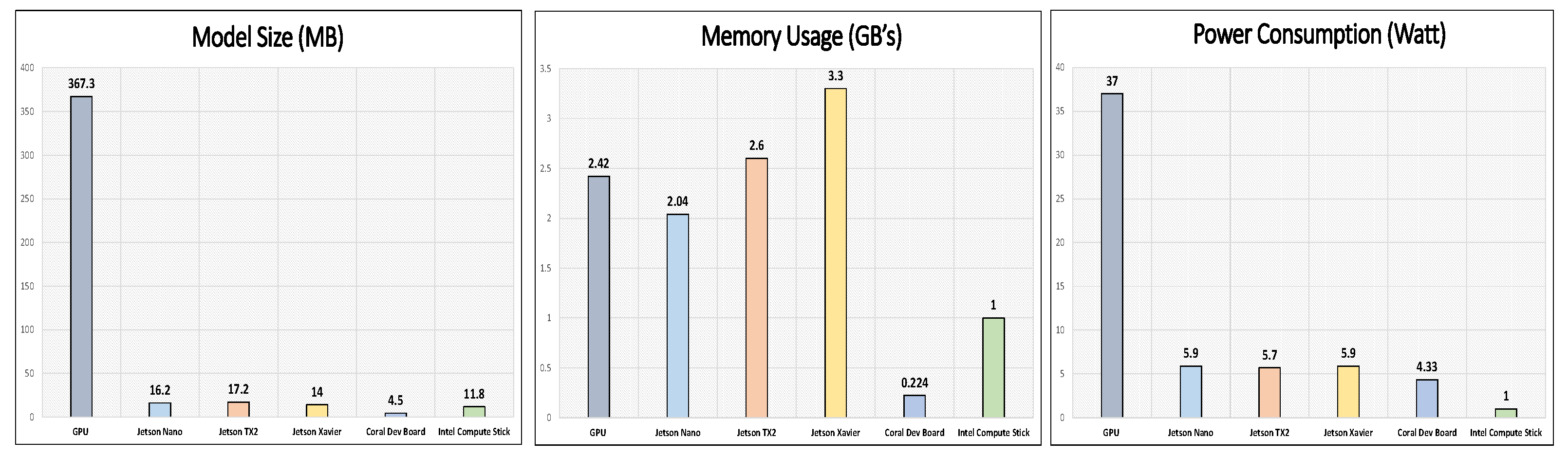
Figure 5, it can be seen that the Single Shot Detection (SSD) Mobilenet V2 gives a 91% mean average precision score, which is higher than all the embedded edge devices but at the cost of high computation power and memory, as shown in
Figure 6. On the other hand, the GPU processes around 49 FPS, which is more than the real-time requirement but is somewhat low compared to most edge devices, given the fact that edge device are very low-power and limited on resources (
Figure 5).
As far as mAP and FPS are concerned, it can be observed from
Figure 5 that the mean average precision score of the edge devices starts to decrease with an increase in FPS. Therefore, the devices offer a straight trade-off between FPS and mean average precision. To maintain a certain FPS and real-time performance, a device has to drop its mAP. This way, despite their small sizes and limited resources, some of these devices can exceed the GPU performance in terms of FPS score, i.e., Coral Dev Board achieves an FPS twice as high as THE GPU, Jetson Xavier achieves 80% higher FPS as compared to the GPU, and Jetson TX2 achieves 63 FPS, which is also considerably higher than the 49 FPS of the GPU.
On the other hand, from
Figure 5, it can be seen that some smaller edge devices lack performance in terms of mean average precision (Intel compute stick); moreover, although their FPS is lower than that of the GPU (Intel compute stick and jetson nano), they are closer at reaching the threshold of real-time performance.
When looking at the impact of model size, since we are using the same model for the evaluation of the performance on all edge devices, the optimized model size can provide a direct measure of the effectiveness of the model optimization flow of a respective vendor that has caused a significant reduction in the computation complexity of a model. One core observation, from
Figure 6, is that a reduction in the computation complexity of a model causes a decrease in mAP while it increases the FPS. Optimization of the Coral Dev Board provides the highest compression in terms of model size, and this in turn provides the highest frame rate.
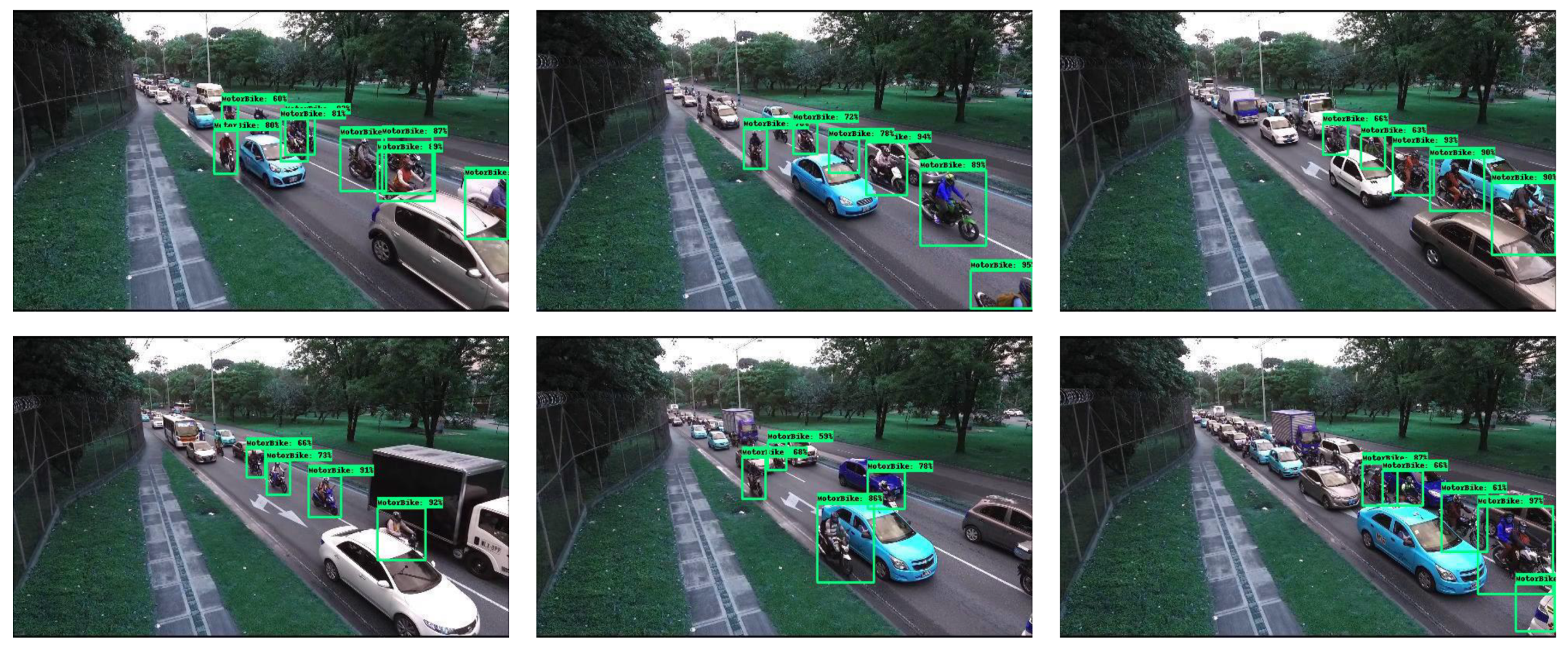
Inference results of different frames of SSD Mobilenet V2 on GPU are shown in
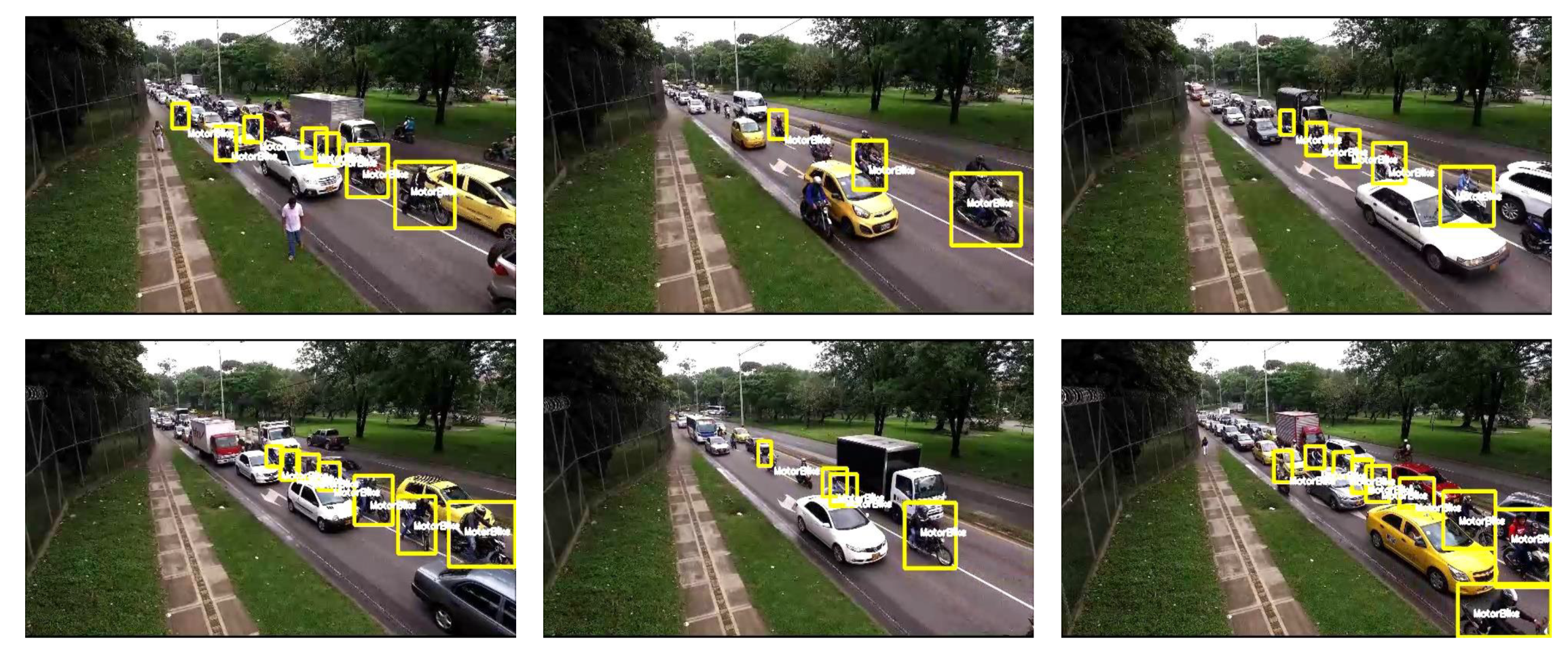
Figure 7. These are the same set of images as depicted during dataset selection but with predicted bounding boxes. For comparison, inference results of embedded devices are also presented in
Figure 8,
Figure 9 and
Figure 10 for TX2, Coral Board, and Xavier, respectively. It can be observed that the highest number of bikes are detected in the GPU-based implementation, but almost the same number of bikes are detected on the edge device-based implementations as well, and with higher FPS.
4.2.2. Results and Analysis of Customized YoloV5
YoloV5 has been trained with two settings, i.e., with and without dataset augmentation and also with different-sized input tensors. The results of YoloV5 on a GPU and the Jetson Xavier are presented in
Table 3. It can be seen that training without augmentation gives around 97 percent mAP, while training with augmentation gives around 99 percent mAP, while in terms of FPS, it gives around 65 FPS on 640 × 364-sized images. When the image size is decreased to 300 × 300, we see some drop in mAP, but the inference rate goes up to over 100 FPS.
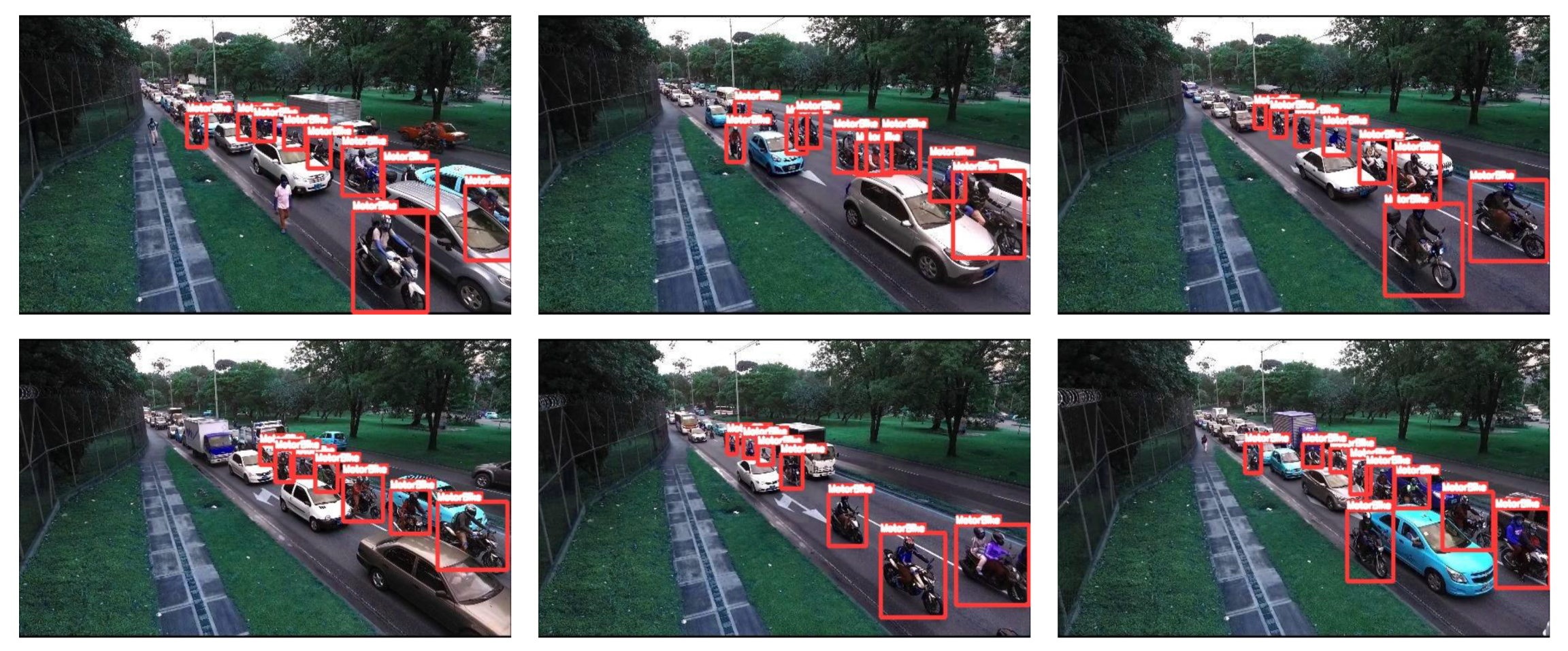
YoloV5 provides around 90 percent mAP on a Jetson Xavier with 27 FPS. This low FPS is due to partial optimization and these results can be further improved with optimal optimization as discussed earlier. There is, however, another way to improve the FPS, i.e., image size reduction. A model has been trained with a 300 × 300 image size, and when this small network is partially optimized for Jetson Xavier, the FPS increases to 51 FPS. This significant boost is due to reduced computation, caused by a small frame size with only a marginal drop in mAP. This suggests that YoloV5 can still be used with partial optimization on a Jetson Xavier with acceptable mAP and FPS. For comparison, the inference results of different frames of YoloV5 on the GPU and on Jetson-Xavier are shown in
Figure 11 and
Figure 12, respectively.
Table 4 provides a comparison of different variants of YoloV5, along with a custom network, based on parameter count, mAP and FPS on a standard GPU. It can be seen that the custom network provides almost the same mAP but has a significantly reduced parameter (size) count.
Table 5 provides a comparison of YoloV5 with other state-of-the-art models used in previous papers. As mentioned earlier, we have trained YoloV5 with and without dataset augmentation. From
Table 5, it can be seen that training without augmentation gives around 97% mAP while training with augmentation gives around 99% mAP. Both these accuracies are better than all other previous baseline accuracies. On the other hand, we obtain around 65 FPS on the GPU with YoloV5, which is also better than the previously reported inference rates. In conclusion, using YoloV5 has the following advantages:
It gives consistently high mean average precision.
It gives higher FPS on GPU.
Model size is very small.
It uses less memory resources.
One drawback of YoloV5 is that its robustness is low compared to SSD Mobilenet. In our observation, SSD Mobilenet trained on one motor bike dataset can be used for other motor bike datasets as well, but YoloV5 does not have such robustness.
5. Conclusions and Future Work
In this paper, we have presented an investigation of motorbike detection on edge devices for real-time applications. We have investigated five different state-of-the-art embedded edge devices from three different vendors, using state-of-the-art SSD Mobilenet and YoloV5. The most important aspect that differentiates between conventional machine learning implementation and edge deployable machine learning is the optimization of the neural network. We have used three different frameworks/toolkits to perform optimization for edge devices. We have demonstrated that with proper optimization, neural networks can be made to run on small, low-power edge devices with some pros and cons. Firstly, model size is significantly reduced by several folds after optimization. Due to this reduced model size, power consumption and memory usage drop significantly. Reduced model size is a direct outcome/indication of reduced computation complexity, which in turn increases inference rate. For some embedded devices, we have achieved inference rates that are twice as high as a GPU. For the Coral Dev Board, the inference rate is 96 FPS; for Nvidia Xaviera, the inference rate is 88 FPS; and for Nvidia Jetson TX2, the inference rate is 63 FPS, which is higher than the standard GPU inference rate of 53 FPS. A boost in inference rate comes at the cost of some decrease in mAP. In this case, this decrement lies in the range of 5 percent of the original baseline accuracy, which is acceptable for most edge devices. On the other hand, we have improved the previous best baseline accuracy of motorbike detection using a custom network based on YoloV5 on a standard GPU-based system. We have achieved 99 percent mAP with 65 FPS, which is around 2–3 percent better than the previous mAP and 15 FPS higher.
One of the possible future directions is related to the unavailability of the dataset. We have used the MB7500 dataset with some custom-labeled images. This is a small dataset in terms of the total number of images. Future work could include collecting much more representative data for motorbike-related analysis, including not only the variability of the motor vehicle, but also the atmospheric conditions, type of riders, and traffic violations. Another useful work would be to investigate and improve the lack of robustness of YoloV5 in “domain shifts”, i.e., when data change in type, camera view, etc. This is a major problem that currently requires the time-consuming manual annotation of additional data.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}