1. Introduction
Rufus Isaacs [
1] pioneered differential game theory in 1965, and initially applied it to military strategies like pursuit and evasion. This sparked enduring interest in decision-making dynamics. In 1971, Friedman [
2] established key theoretical foundations, revealing value and saddle points. Basar and Olsder [
3] expanded on this, exploring noncooperative games, enriching our understanding of strategic dynamics. Later, Docker et al. [
4] utilized mathematical tools to analyze equilibrium conditions, strengthening the field’s mathematical underpinnings. Overall, research in differential game theory has led to significant advancements in understanding strategic decision making in dynamic systems.
Linear quadratic differential games, a subset of the broader field of differential games, attract both dynamic game theorists and economists exploring policy coordination, resource extraction, and capital accumulation due to their applicability to real-world scenarios and ability to model complex strategic interactions. In 1965, Ho et al. [
5] explored pursuit-evasion games, a key example of linear quadratic differential games, revealing foundational insights into strategic dynamics within this framework. Building on this foundation, Starr and Ho in 1969 [
6] established a crucial condition for closed-loop strategies’ existence, essential for strategic decision making, utilizing the solution of the Riccati equation to provide valuable insights into dynamic optimal strategies. In 1970, Schmitendorf’s work [
7] illuminated a notable aspect of linear quadratic differential games, revealing that the existence of a closed-loop saddle point does not guarantee the presence of an open-loop saddle point, emphasizing the complexities inherent in strategic decision making within dynamic systems. In recent years, scholars have continued to delve into linear quadratic differential games, refining methodologies and uncovering deeper strategic insights, underscoring the enduring relevance and complexity of this specialized area within differential game theory (see, e.g., Bernhard [
8], Delfour et al. [
9] and Delfour [
10]).
In real-world scenarios, the evolution of states in dynamic systems is frequently disrupted by environmental noise, which can infiltrate the state equation or affect players’ observations of the system. When noise follows the Wiener process, stochastic differential equations become essential for characterizing system evolution, thus converting the differential game into a stochastic differential game. Similarly, when noise is shaped by the Liu process, reflecting the uncertainty tied to experts’ belief degrees, uncertain differential equations offer a pivotal means of characterizing system evolution, leading to the emergence of uncertain differential games. Fleming’s seminal contributions [
11] in stochastic control paved the way for solving differential game scenarios with stochastic state dynamics. For instance, in 2006, Mou and Yong [
12] utilized the Hilbert space method to examine open-loop strategies in stochastic linear quadratic differential games, while Sun and Yong [
13] explored both open-loop and closed-loop saddle-point equilibriums in 2014. In uncertain settings, Zhu’s introduction [
14] of uncertain optimal control in 2010 facilitated the analysis of differential games with uncertain state dynamics. Yang and Gao [
15,
16] further advanced this field by proposing uncertain differential games incorporating Liu process noise, establishing conditions for the existence of a feedback Nash equilibrium in 2013 and delving into linear quadratic uncertain differential games in 2016. The integration of chance theory based on subadditive measures addresses systems where both uncertainty and randomness coexist, modeling noise through the Wiener–Liu process and system evolution through uncertain stochastic hybrid differential equations, thus transforming the differential game into a hybrid differential game. Liu’s pioneering work [
17] in 2013 laid the foundation for exploring uncertain stochastic hybrid systems [
18,
19] based on subadditive measures, followed by subsequent research by Fei et al. [
20] in 2014, introducing uncertain stochastic hybrid optimal control and the equation of optimality via uncertain stochastic hybrid differential equations. With the help of uncertain stochastic optimal control, there has been a growing body of literature focusing on uncertain stochastic hybrid differential game systems [
21,
22,
23,
24]. Unlike the models and methods mentioned earlier, this work is the beginning of linear quadratic uncertain stochastic hybrid differential games in finite and infinite horizons.
The structure of this paper is organized as follows.
Section 2 begins by recalling some basic results about the principle of optimality, the HJB equation and the feedback Nash equilibrium of hybrid differential games and so on, and then gives Max–Min Lemma of a two-player zero-sum game, which is essential for our analysis.
Section 3 is devoted to the study of the saddle-point equilibrium strategy for linear quadratic hybrid differential games in continuous time.
Section 4 presents a resource extraction problem and an
control problem. Finally,
Section 5 presents the conclusions.
2. Preliminaries
For any
,
, and any control variable
, where
f,
g, and
h are the given functions, we consider the state equation,
The corresponding cost functional is
where
is the chance expectation,
is a Wiener process and
a Liu process. Define the value function
by
.
Theorem 1 ([
20])
. (Principle of optimality.) For any , we have Theorem 2 ([
20])
. (HJB equation.) Let denote all functions on that are continuously differentiable in time k and continuously twice differentiable in z. If , define operators byThen, V is a solution of the following terminal problem of an HJB equationwith the terminal condition A differential game is a class of decision problems in which the evolution of the state is described by a differential equation. The players act throughout a time interval
and aim to maximize their payoffs. In the general n-person differential game model, player
i optimizes the objective
subject to
where
is the state variable,
is the given initial state,
is the control variable of player
i, and
is a compact metric space. The function
is the transient payoff function of player
i at time
is the terminal reward function of player
i at terminal time
and
is a vector function. All functions mentioned are differentiable.
In the true essence of the game, the state evolution is inevitably disturbed by environmental noise. This noise may may occur directly within the state equations or indirectly through the players’ observations of the system’s condition. In a vector-valued n-person uncertain stochastic hybrid differential game model, player
i optimizes the objective
A vector-valued hybrid differential equation, which delineates the evolution of the state and
n objective functions (3), provides a more suitable framework for analyzing differential games with uncertain stochastic noise driven by the Wiener–Liu process:
where
represents the chance expectation operator performed at time
,
represents the state variables,
is the control of player
is an
l-dimensional Wiener–Liu process, similar to refs. [
18,
19], and
is the given initial state.
For the subsequent analysis, the following assumptions are presented:
and
which satisfy the Lipschitz condition and linear growth condition and possess continuous partial derivatives.
For
, the admissible feedback control denotes:
where
A feedback Nash equilibrium of the hybrid differential game (3)–(4) can be defined as follows.
Definition 1. A set of strategies is called a feedback Nash equilibrium for the n-person hybrid differential game (3)–(4), and is the corresponding state trajectory, if there exist real-valued functions satisfying the following relations for each where on the time interval : Remark 1. If an n-pair establishes a feedback Nash equilibrium for an n-person differential game, as defined in Equations (3)–(4), over the duration , then its restriction to the time interval also constitutes a feedback Nash equilibrium, just as Docker et al. [4] described. Importantly, the feedback Nash equilibrium depends solely on the the current state value and time variable k, not on any prior history (including the initial state ). Next, we give sufficient conditions guaranteeing that is a feedback Nash equilibrium for the game (3)–(4).
Lemma 1. An n-tuple of strategies provides a feedback Nash equilibrium to the n-player uncertain differential game (3)–(4) if there exist real-valued functions satisfying the partial differential equations: Proof. The result can be readily derived from Theorem 2 and the definition of the feedback Nash equilibrium. By holding the strategies of all players fixed at their equilibrium choices, except for the ith player’s, we transform the scenario into a hybrid optimal control problem as described by Theorem 2. □
Now, let us delve into The “Max–Min Lemma” of the two-player zero-sum hybrid differential game.
Lemma 2. (Max–Min Lemma): A pair of strategies provides a feedback Nash equilibrium solution (called a saddle-point Nash equilibrium) to the two-player zero-sum of the game (3)–(4) if there exists a real-valued function satisfying the partial differential equations:
Proof. As a special case of Lemma 1, the result can be easily obtained by taking and in which case and the Max–Min Lemma is completed. □
3. Main Results
Notation: in the following, denote by the set of n-dimensional Euclidean spaces, the set of all matrices, the set of all real symmetric matrices, and the set of all positive definite matrices. denotes , denotes the transpose of a matrix or vector, , and k is the time. For a Hilbert space and an interval I, let be the space of all bounded and measurable functions from I to , that is, , , where or . Now, we discuss two-player zero-sum hybrid differential games in finite and infinite horizons.
3.1. The Case of Finite Horizons
Fix
. Let
and
be two standard independent Wiener–Liu processes in the chance space over
with
almost surely. Let
be the set of
-valued square integrable processes adapted with the
-field generated by
respectively. Associated with each
is a quadratic cost
. The performance index function is defined as:
where
z is the solution to the following equation
and
symbolizes the chance expectation.
and
are matrix functions,
Assumption 1. We assume that and in (5)–(6) satisfy Hybrid differential game problem 1: for the hybrid system described by (6), find the feasible control
and ensure that the following holds:
Theorem 3. The two-player zero-sum linear quadratic hybrid differential game (5)–(6) has a saddle-point Nash equilibrium solution if the following differential Riccati equation has a solution
where
,
, and
are defined as
and the saddle point and the optimum value are
and
Proof. Let
be the solution of Equation (7) and
be the solution of Equation (6) corresponding to control
Using the fundamental theorem of calculus and Itô–Liu formula in ref. [
20], applied to
, we obtain
Taking integrations on
and chance expectation, we obtain
Substituting (8) into (5),
can be be reduced to
While, by the following equality
we can obtain that
The theorem is proved. □
Theorem 4. If linear feedback controls are optimal for the two-player zero-sum linear quadratic hybrid differential game (5)–(6), then the Riccati Equation (7) must have a solution . Moreover, .
Proof. By Theorem (2), the value function
satisfies the HJB equation
Take the following value equation
So, substituting (10) into (9), and by the assumption that
, we can obtain that
So, we obtain that
and
The proof is complete. □
3.2. The Case of Infinite Horizons
Fix
. Let
and
be two standard independent Wiener–Liu processes in a chance space over
with
almost surely. Let
be the set of
-valued square integrable processes (denote by
) adapted with the
-field generated by
respectively. Associated with each
is a quadratic cost
. The performance index function is defined as:
where
z is the solution to the following equation
and
represents the expectation of the enclosed uncertain random variable.
and
are matrix functions,
and they also satisfy Assumption 1.
Hybrid differential game problem 2: for the hybrid system described by the given Formula (11), find the feasible control
and ensure that the following holds:
For this problem, we introduce the following generalized Riccati equation (GRE)
where
is an unknown matrix, and
,
, and
are defined as
Since we are considering the hybrid differential game problem in an infinite horizon, we need the concept of mean-square stabilizability.
Definition 2. (i) An open-loop control is called (mean-square) stabilizing if the corresponding state of (12) with the initial state satisfies . A feedback control , where is a constant matrix, is called stabilizing if for every initial state , the solution of the following equationsatisfies . (ii) The system (12) is called (mean-square) stablizable if there exists a mean-square stabilizing feedback control of the form , where is a constant matrix.
Mean-square stabilizability is pivotal in this paper. We now introduce the equivalent conditions for verifying stabilizability, both analytically and computationally.
Lemma 3. is mean-square stabilizable if and only if there exist a matrix K and such that Proof. For any
matrix
K, define an operator
by
If
satisfies the feedback Equation (14) (under the feedback gain
K), then by Itô–Liu’s formula, the matrix
satisfies the differential matrix system
. Applying the result in ref. [
25], we have the equivalence between the mean-square stabilizability and (15). □
Remark 2. Lemma 3 gives the equivalent conditions of mean-square stabilizability, which provides a theoretical basis for the hypothesis of Theorem 5.
Theorem 5. Suppose the system (14) is mean-square stabilizable. If the GRE (13) exists and , then hybrid differential game problem 2 is solvable; moreover, the saddle point and the optimum value of the performance index function areandthat is, satisfies . Then, we have Proof. Suppose
,
is the solution of (14). For
, denote
Similar to the proof of Theorem 3, we have
Because
, then
. Therefore,
The proof is complete. □
Remark 3. Unlike refs. [8,9,10] concerning stochastic differential games and refs. [15,16], the models in this paper have a wider range of applications and cover these models as well. 



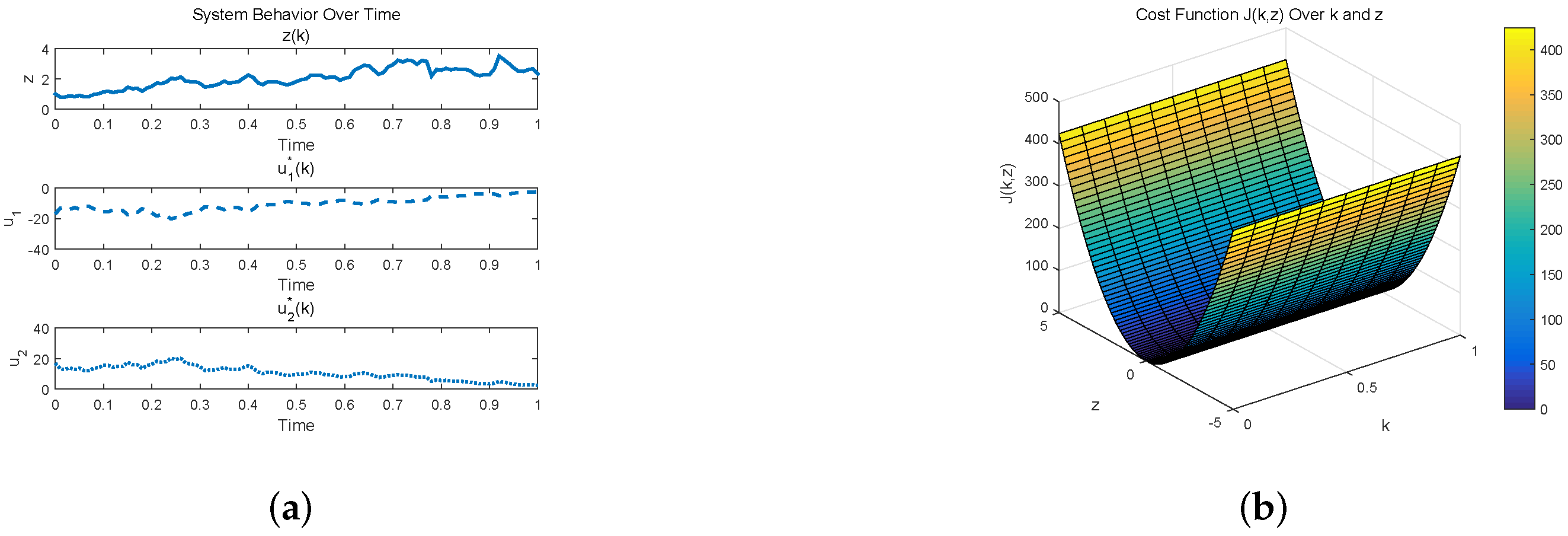{kind=link}
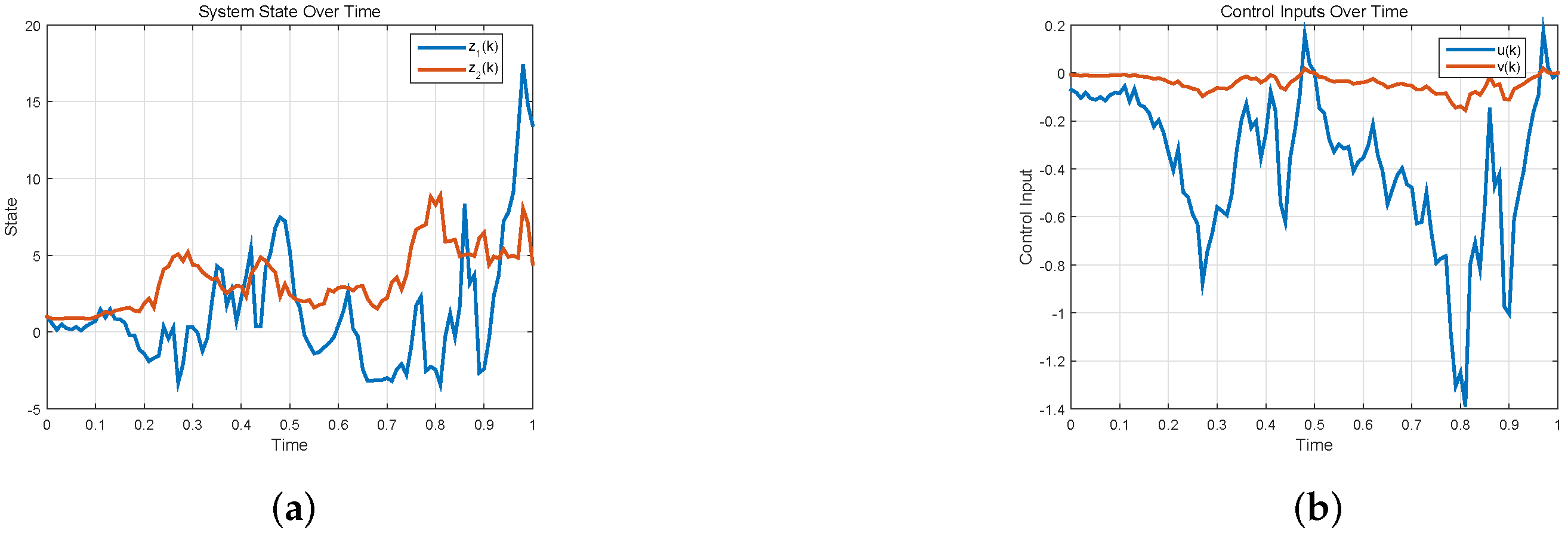{kind=link}

