1. Introduction
A classic problem in negotiation theory is the problem of fair resource sharing, which is called the pie cutting or the pie sharing problem. The pie sharing problem is relevant to various situations, such as splitting rent among housemates, resolving disputes over land ownership, and allocating work among co-workers. There is a multitude of books [
1,
2] and surveys [
3,
4,
5] dealing with this topic. The situation involves representing a pie as an interval
, with each of the
n agents possessing a value function over the pie. The main aim of the pie-sharing procedure is to divide the pie fairly. The key factors in fairly dividing a pie, as discussed in the literature, are envy-freeness and proportionality. An envy-free allocation ensures that each participant views their share as equal to or better than others’. Meanwhile, a proportional allocation guarantees that each participant receives at least
of the value they place on the pie.
One of the popular approaches to the pie sharing problem is the Rubinstein sequential bargaining game approach [
6]. In this approach, it is assumed that the players take turns suggesting to each other ways to divide a unit size pie, and the process ends as soon as all the players accept some kind of offer. Players can endlessly insist on a solution that is beneficial to themselves. To prevent this from happening, a discounting factor
is introduced, i.e., the pie size at the first step is one; at the second step, it is
; at the third step,
, etc. A subgame perfect equilibrium is chosen as the solution to this game using the backward induction method.
Subsequently, this model was supplemented and improved. In [
7], the authors built a model of multilateral negotiations with a majority rule. There, they demonstrated that a subgame perfect equilibrium exists in a discounted model in the class of stationary strategies. In this case, the player’s choices are made with equal probabilities.
In [
8], a model was proposed in which the players making offers were selected with different probabilities, as well as with different discount coefficients. The uniqueness of the subgame perfect equilibrium in a game with a linear utility functions was proved.
In [
9], the resource-sharing game was expanded to quadratic utility functions. A multidimensional model of sequential bargaining was presented in [
10]. The asymptotic uniqueness of the equilibrium was proved in [
11].
The final decision in bargaining is not necessarily made by the majority rule. The paper [
12,
13] examines a model of pie sharing by generating a random offer and accepting the offer through consensus. In [
14,
15], optimal strategies are considered in the tender competition model, and consensus models are explored in [
16,
17,
18].
A general approach to constructing game-theoretic problems using the theory of mechanism design and the theory of active systems is examined in [
19,
20].
In [
21,
22], Rubinstein’s scheme is used to solve the problem of negotiating the time and venue of the meeting. For the general case, the existence and uniqueness of the subgame perfect equilibrium in the model with unimodal functions is proved. In [
23,
24], the equilibrium was found explicitly.
Depending on the scope of the model, utility functions can take an arbitrary form. For example, in [
25], the problem of water resource allocation is considered using a utility function of the form
, where
are increasing concave functions.
In this paper, we propose a multi-step pie-sharing procedure for two persons, in which the arbitrator makes offers to the players, and the players can agree with this offer or reject it. If there is no consensus, negotiations move on to the next step. The arbitrator, on the other hand, punishes the rejecting player by reducing the amount of the resource in favor of the consenting player. A subgame perfect equilibrium exists in this case.
The article is organized as follows. In
Section 2, we describe the classic pie sharing problem using utility functions, which are the sizes of a player’s piece of the pie that are discounted over time.
Section 3 presents a new design in the pie-sharing procedure, in which, when a player is punished, their share is changed in favor of the other player. In
Section 4, a class of threshold strategies is introduced, and the equilibrium in this game is found in the class of threshold strategies.
Section 5 suggests a matrix method for determining the type of optimal strategies at each step.
Section 6 relates the results of the computer simulation of the pie division in the case where one of the players uses an equilibrium strategy and the other player deviates from the equilibrium strategy.
2. Two-Person Cake-Cutting Problem
Let us consider the problem of dividing a unit-size pie between two persons. We assume that a sequential bargaining design is used for the solution [
1]. With this approach, the players take turns suggesting to each other ways to divide a unit-size pie and the process ends once one of them accepts the other’s offer. For the sake of certainty, let the first player make the offer at the first step and at further odd steps, and the second player at even steps. At each step, the resource is discounted and the discounting factor is
.
To find a solution, we introduce the utility functions of the players, i.e., if bargaining results in a decision , then the players get utilities expressed by the functions and , respectively. We assume that the players take turns offering solutions and the consent of both participants is required to make the decision. At the same time, the utilities get discounted over time, i.e., after each bargaining session, the utility functions of both players will decrease proportionally to . Thus, if the players have not come to a decision before time t, then at time t, their utilities are represented by functions .
In this case, the problem is equivalent to the problem of sharing the pie between two persons. Indeed, if
x is construed as a share of the pie, then the second participant gets the rest of the pie
.
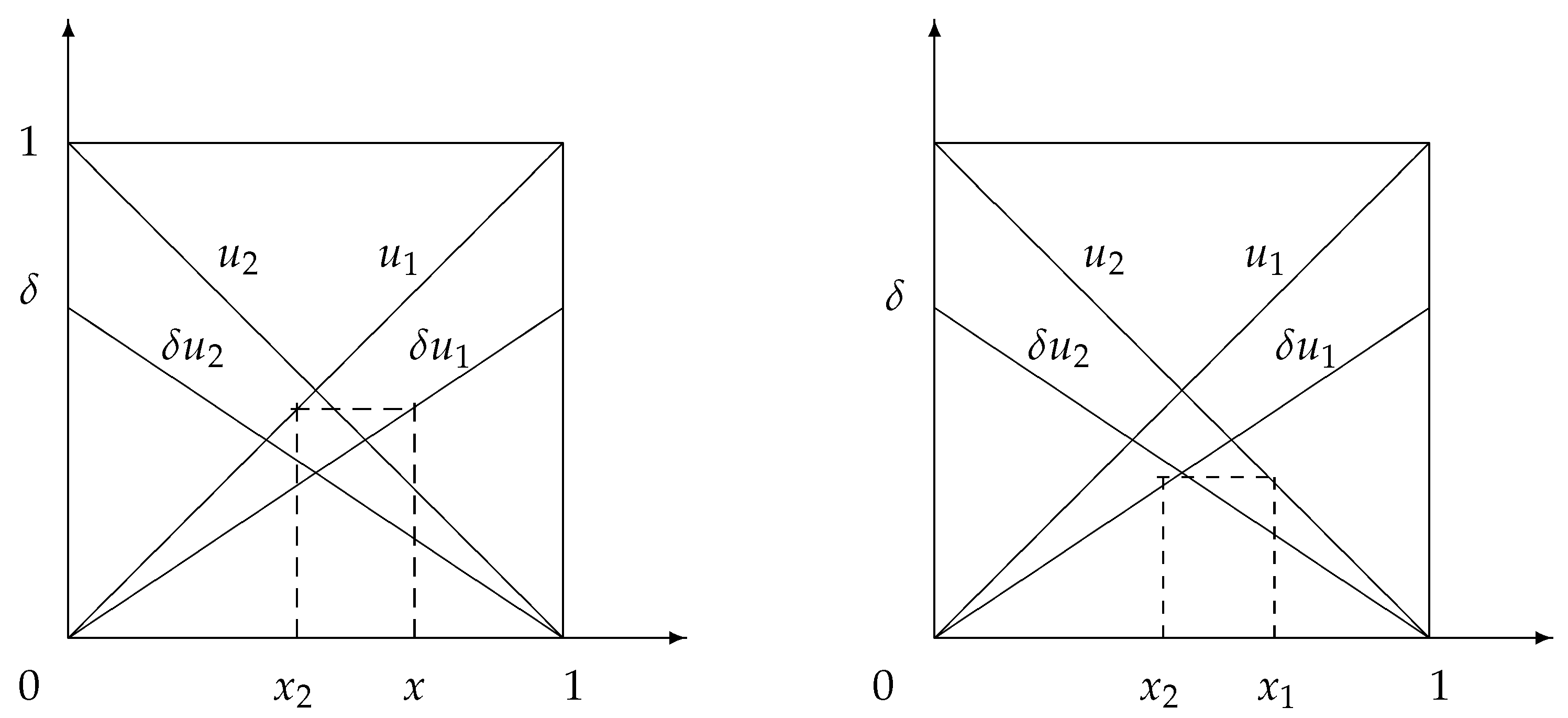
Figure 1 shows utility graphs of
and
and their graphs in the next step, i.e.,
and
.
Let us assume that player 2 knows the solution
x that player 1 will choose in the next step. To ensure that a decision is made, she/he needs to offer the first player a solution
y such that their utility
is not less than the utility in the next step, i.e.,
(see
Figure 1). This leads to the inequality
, and the utility of player 2 herself/himself is maximized at
. Thus, her/his optimal response to the first player’s strategy
x will be
. Next, we assume that the first player knows the second player’s strategy
in the next step. Then, in order for her/his offer at this step to be accepted by player 2, she/he must propose a solution
y such that the utility of the second player
is not less than her/his utility at the next step, i.e.,
, which is equivalent to the inequality
or
.
It follows that the best response of the first player at this step is
. The solution
x produces an equilibrium in the bargaining if
or
, wherefore
which coincides with the classical solution.
3. Bargaining over a Time-Varying Resource
This paper proposes a new bargaining design for the pie sharing problem. There are still two players who want to divide a unit-size pie between themselves, but now an arbitrator is introduced into the game. The bargaining solution is
. The utility functions of players 1 and 2 are equal, respectively, to the following:
Utility functions will not change under this approach. Instead, the resource itself will change.
Negotiations are sequential in time. At each step, the arbitrator makes an offer to the players. Her/his offer at step
t is modeled by a random variable having a uniform distribution on the unit interval
. The players, on the other hand, agree to this offer (action
A) or reject it (action
R). If both players agree at step
t, the game ends and the players get payoffs of
If at least one of the players rejects the offer, the game moves on to the next step, and the interval is reduced by
times, the penalty being imposed on the rejecting player. Here,
is the discount factor.
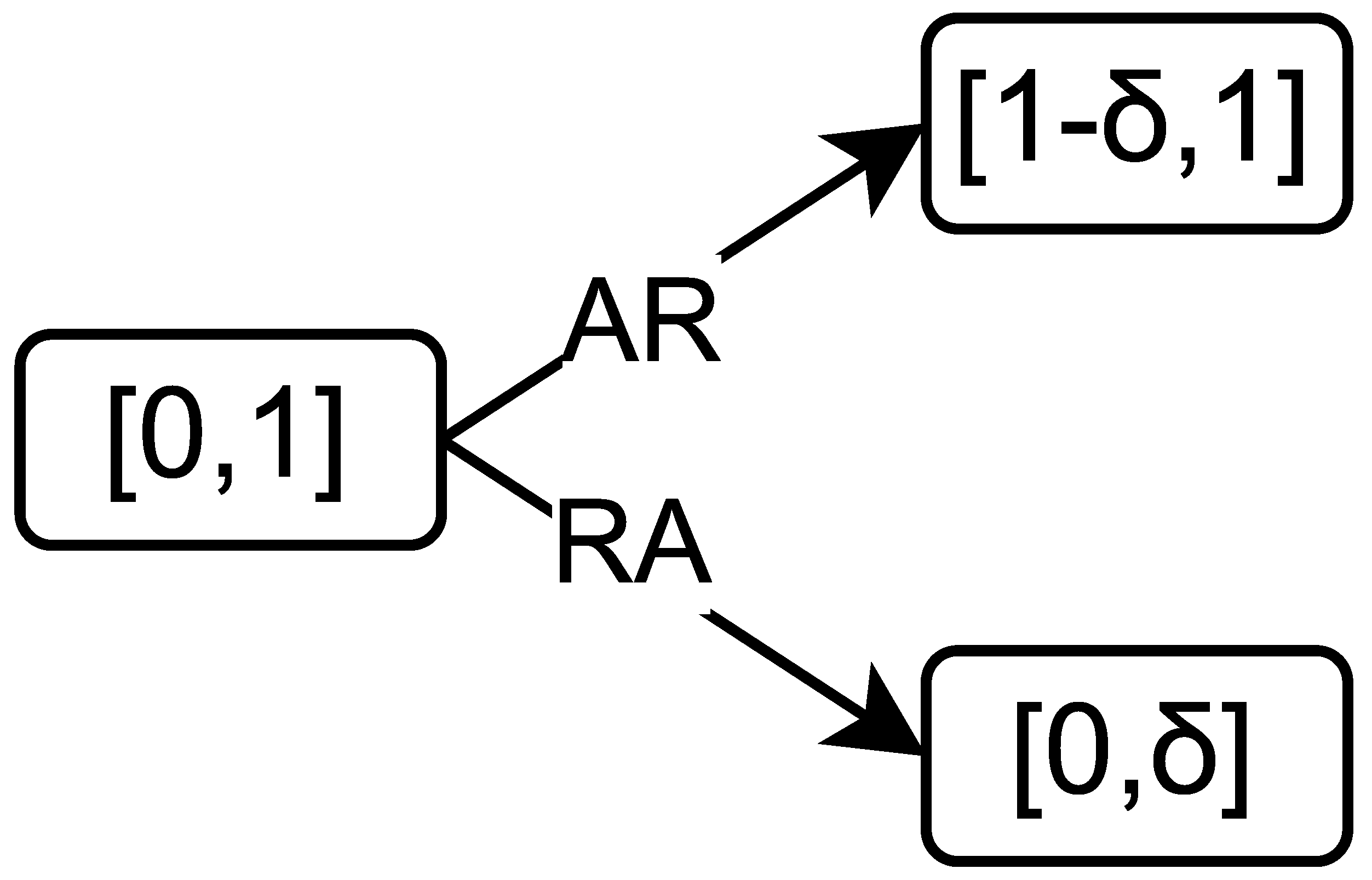
The punishment is carried out as follows (see
Figure 2). If the first player refuses (situation (
)), the initial interval
is changed in the next step to the interval
. Thus, the maximum utility of player 1 becomes smaller. If the second player refuses (the situation (
)), the initial interval
is changed to the interval
, i.e., the maximum utility of player 2 becomes smaller.
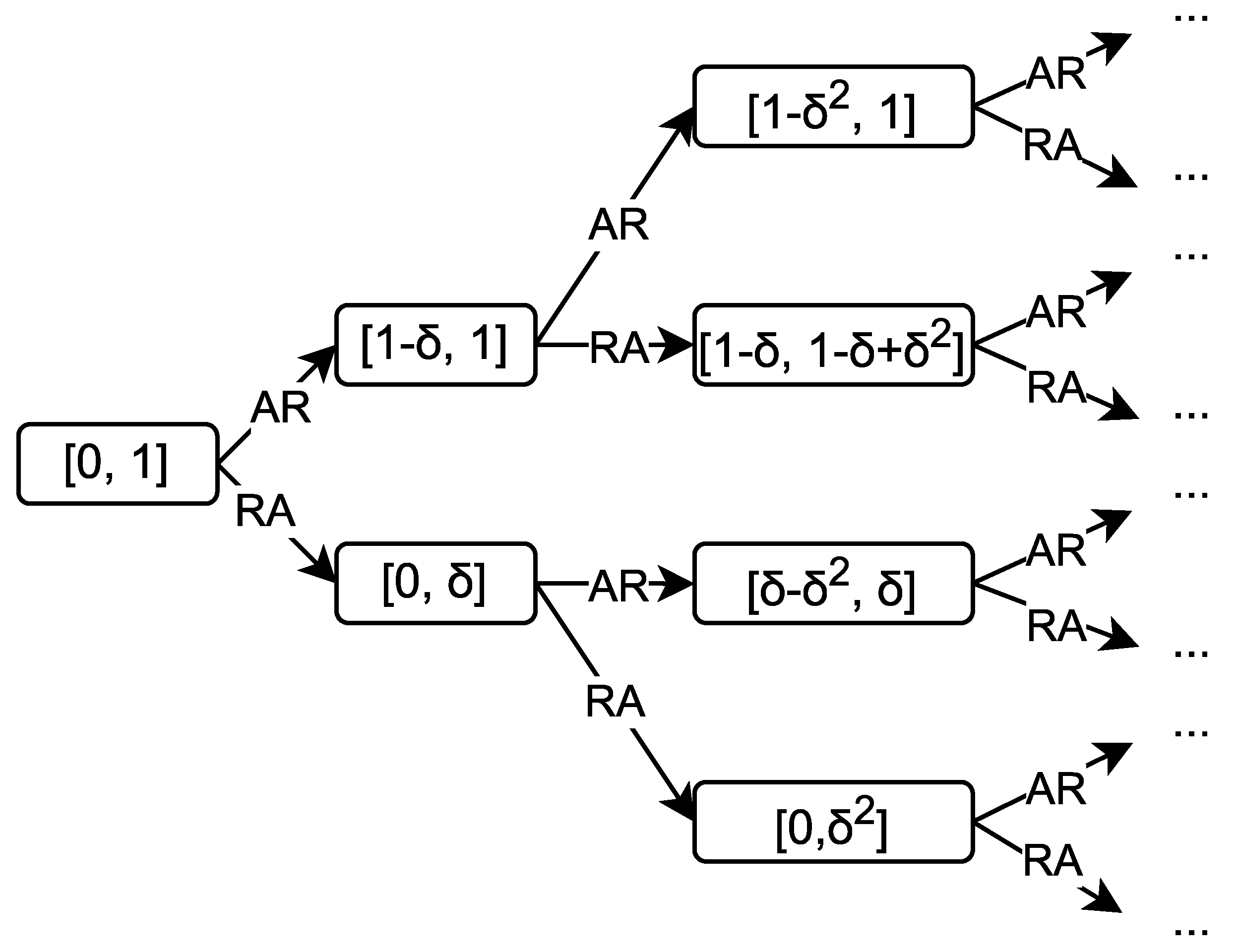
At subsequent steps, the situation recurs (see
Figure 3), where, at step
t, the interval for the offers has the form
. If the first player rejects the offer at step
, the interval
takes the form
. If the second player refuses, the interval
takes the form
.
In the situation , when both players refuse, we suppose that the players are penalized equally, and the interval becomes .
For clarity, we substitute . Large values of show that players are patient and are willing to play the game for a long time. If the first player refuses, the interval becomes . If the second player refuses, then the interval at the second move becomes .
Let us now substitute . Small values indicate that the players are impatient and wish to finish the game as quickly as possible. If the first player refuses, the interval becomes . If the second player refuses, the interval at the second move is .
Each of the players is interested in maximizing their utility function. Based on the form of these functions, the first player wants to settle on an offer close to 1, and the second player would like to settle on an offer close to 0. The interval for the offers changes over time, so the players’ strategies must be time-dependent. Let us denote the players’ strategies as
. The equilibrium strategies of the players
are defined by the conditions
4. Threshold Strategies
We look for a solution in the class of threshold strategies of the following form:
For the first player, the strategy is determined by a threshold . If the referee’s offer is , the first player accepts the offer; otherwise, she/he rejects it.
The second player’s strategy is determined by the threshold . The second player accepts the arbitrator’s offer if and rejects is otherwise. Let us assume . This assumption can be made without any loss of generality; if we suppose , then the second player could change their strategy by adjusting the threshold to . Depending on the step number t, we denote the strategy profile by . These numbers indicate the extreme values that players will agree on.
The recurrence relations for the thresholds depending on the step number are as follows. Suppose at step t of the game the negotiation interval is . At the next step, depending on the players’ decision, the negotiation interval will change.
If the situation
occurs, then the boundaries of the interval at the next step can be found by the formula
If the players’ solution is
, then the boundaries are found by the formula
In the matrix form, relations (1) and (2) can be written, respectively, as
where the matrices
and
have the form
Lemma 1. At step n, if the history of the game iswhere , then the boundaries of the negotiation interval can be expressed aswhere the matrices and have the form (3). Seeking to find the optimal behavior of the players, we use mathematical induction. Suppose that at step n the players decided to end the game and accept the arbitrator’s offer. If the interval for negotiation was , then the average value for the first player’s chosen offer will be .
Let us find the optimal strategies of the players at the previous step
. Suppose that at this step the negotiation interval is
, and let the players choose the threshold strategies with thresholds
. Then, the first player’s payoff is
The saddle point of function (4) has the form
Substituting it into the payoff function (4), we obtain
Thus, under optimal behavior, the payoff at each step t represents the midpoint of the interval . Applying induction, we obtain the following proposition.
Proposition 1. A subgame perfect equilibrium in a negotiation game with a time-varying resource has the following form:where thresholds are defined by the relations Note that according to (5), the length of the interval
at step
t is equal to
If the arbitrator’s offer falls within this interval, the players stop playing. The probability of this event is
. This event recurs at each negotiation step. Thus, the probability of taking a final decision within finite time under optimal behavior
equals 1.
Remark 1. According to (5), the optimal strategies in the first step are of the form . If the arbitrator’s offer is , the second player accepts the offer while the first player rejects it. In this case, the game moves on the next step, player 1 is penalized, and the negotiation interval becomes .
If the arbitrator’s offer is , the first player accepts the offer, while the second player rejects it. In this case, the game moves on to the next step, but now player 2 is penalized and the negotiation interval becomes .
If the arbitrator’s offer falls within the interval , the negotiation ends, and the players accept the offer.
5. Optimal Strategies
According to Lemma 1, if the history of the game has the form
where
,
then the boundaries of the negotiation interval at step
n are calculated by the formula
In this case, some of the powers of
may be zero. Note that the eigenvalues of the matrices
and
are equal to 1 and
. In this case, these matrices can be represented in the form
where
Then, (6) can be rewritten in the form
Denoting
and noticing that
, we find the boundaries of the negotiation interval at step
n for history
It follows from statement 1 that the thresholds for optimal strategies at step
n in matrix form have the form
Proposition 2. At the n-th step of the game, when the negotiation history has the formwhere , the thresholds of equilibrium strategies have the formwhere the matrix D has the form For example, if during the bargaining process the situation
occurred twice, the situation
three times, and then again the situation
two times, then the boundaries of the negotiation interval at step 7 have the following form:
whence we get
The optimal thresholds that players should use are found from the relations
and, consequently,
6. Numerical Simulation
Suppose that both players use optimal strategies. The number of games in the experiment is 1000. The notations are
n for the average number of moves per game,
for the average payoff of the first player, and
for the average payoff of the second player. For both payoffs, the confidence interval with a reliability of
is given in parentheses.
Table 1 shows the numerical simulation results.
Consider the line at . The discount factor close to one shows the players’ willingness to bargain for a long time, and, indeed, the average number of moves in the game is 11,420.83. In this case, the payoffs of both players and the confidence intervals are close to the value .
If, for example, , then we observe a decrease in the average number of moves in the game to , i.e., the players will not bargain for a long time. At the same time, for both players, the mean payoffs are , but the confidence intervals for the mean increases. For the first player, the confidence interval widens to , and for the second player to .
Table 2 shows the results of numerical simulations for the situation where the first player uses an equilibrium strategy and the second player uses a strategy with a constant threshold
that does not change throughout the game. A column is added to the table to show the strategy of the second player in the game.
Consider the case for . The second player’s strategy indicates that the player wants to obtain a large payoff, namely, . With such a large value of , the game lasts, on average, moves. However, we see that the second player obtains a payoff of , while the first player obtains a larger payoff, namely, . This shows the effectiveness of the first player’s optimal strategy. If the second player uses a less greedy strategy , their payoff will still be less than the first player’s, namely, .
Now, consider the case of smaller value . When the second player uses the greedy strategy , the average number of moves in the game is . Note that this is almost twice as large as it is when both players use optimal strategies. However, the second player’s payoff is , and even the right-hand boundary of the confidence interval does not go beyond . The use of a less greedy strategy by the second player will only reduce their payoff from to . Thus, we see that the second player’s unwillingness to use the optimal strategy can lead to a significant decrease in their payoff.
7. Conclusions
In this paper, a new design is proposed in the two-person pie sharing problem involving an arbitrator. This is a multi-step procedure, and the solution is reached by consensus. The arbitrator is represented by a random number generator, which is easy to implement in practice. The procedure is fair for both players, and both players are on equal terms. It is demonstrated that deviations from the optimal strategy lead to a decrease in payoff.
This method is described for the two-person pie sharing problem. We plan to transfer this scheme to the case of several players and other utility functions. It is also possible to apply this procedure to the problems of resource allocation and contests.








{kind=link}
{kind=link}
{kind=link}