Abstract
In this paper, we propose a novel, highly accurate numerical algorithm for matrix exponentials (MEs). The algorithm is based on approximating Putzer’s algorithm by analytically solving the ordinary differential equation (ODE)-based coefficients and approximating them. We show that the algorithm outperforms other ME algorithms for stiff matrices for several matrix sizes while keeping the computation and memory consumption asymptotically similar to these algorithms. In addition, we propose a numerical-error- and complexity-optimized decision tree model for efficient ME computation based on machine learning and genetic programming methods. We show that, while there is not one ME algorithm that outperforms the others, one can find a good algorithm for any given matrix according to its properties.
MSC:
65L04; 65L08
1. Introduction and Related Work
A matrix exponential (ME) is a function defined as the solution of a system of n linear, homogeneous, first-order, ordinary differential equations (ODEs) with constant coefficients. Equation (1) outlines a formal writing of the ME function:
where is an arbitrary matrix, is a dynamic over time, and is the initial condition of the dynamic system.
An ME is a widely used function [1,2,3,4,5]. For instance, it is used in linear control systems in order to find the state space, as the ME plays a fundamental role in the solution of the state equations [6,7]. In a more general sense, it plays a role in exploring and solving a wide range of dynamical systems represented by a set of ODEs [1]. Due to their usefulness in many applications, MEs have been widely investigated [1,8,9,10,11].
Equation (2) is also known as the naive ME algorithm. It is numerically unstable, slow, and relatively inaccurate when considering floating-point arithmetic [1]. Recently, in the context of modern computer systems, numerical computation of MEs has become more relevant than ever before [1,12]. One of the main challenges associated with computing MEs is the numerical accuracy for any given matrix [9].
One can roughly divide the numerical ME algorithms into two groups: algorithms designed specifically to exploit a property of some groups of matrices (for example, diagonal matrices) and algorithms that are suitable for all matrices. Usually, when one uses an algorithm from the first group, the obtained result is accurate and the computation is stable since the algorithm is explicitly designed to handle the given input matrix. If, for some reason, one uses an inappropriate matrix in such an algorithm, the algorithm more often than not produces a (highly) incorrect result. Algorithms from the second group are usually found in large computational systems as they do not require that the result of the computation, which takes place before the computation of the ME algorithm, satisfies a given condition. This general nature makes these algorithms usable in a wider context [1]. However, each algorithm in this group has a set of matrices that result in large errors or even divergence during computation [1].
One can name several popular examples of such algorithms. First, there is a Taylor series method with a stop condition that is based on Peano’s remainder being smaller than some pre-defined threshold [13]. As a numerical method, it is often slow and inaccurate [1]. Specifically, matrices with small values, in absolute terms, are more likely to produce large errors due to cancellation errors. Second, the Pade-approximation-based algorithm is a two-parameter approximation of the ME Taylor series algorithm, which makes it more robust and well-performing after using scaling and squaring algorithm [1]. However, these algorithms obtain poor results, with the norm of the matrix being large. Third, the Cayley–Hamilton ME algorithm provides another form of approximation of the Taylor series. The coefficients of the decomposition of the input matrix are very sensitive to round-off errors as they generate a large error, specifically when the rank of the input matrix (M) is significantly smaller than that of the diminution of the matrix [8].
Another family of algorithms takes advantage of the eigenvalues of the input matrix. For instance, there are Lagrange-interpolation-based methods [8]. These methods provide very accurate results on average [1]. However, for an input matrix with close but not equal eigenvalues (i.e., ), this method has a significant cancellation error as a result of dividing each iteration by . Matrices with eigenvalues with great algebraic multiplicity will produce significant error and make the algorithm unstable. In a similar manner, the Newton interpolation algorithm is a good example as well. This algorithm is based on a recursive decomposition method of the input matrix and suffers from the same issues as the Lagrange interpolation algorithm.
An additional family of algorithms is the general-purpose ODE solvers. The main idea is that the ME is defined as a solution for a system of ODEs (see Equation (1)). Therefore, it is possible to solve Equation (1) numerically using different approaches such as the Euler, exponential integrator, and Runge–Kutta methods [14,15,16]. The Krylov methods are widely used to solve MEs for which the matrices are large and sparse [17]. These methods are widely adapted due to the fast and accurate results they produce for sparse matrices, which are becoming more common in multiple applications [17,18]. This class of methods is mainly dependent on the norm of the input matrix [19,20]. For cases for which the input matrix is negative definite, the condition number defines the convergence rate and error boundary [17,21]. However, this class of methods does not allow obtaining the ME itself but the product of the ME with a vector. While of interest in multiple applications, in this work, we aim to obtain the ME, as it can be both analyzed by itself and later multiplied with any vector easily.
Moreover, a large body of work investigates the numerical computation of MEs for the transient analysis of continuous-time Markov chains [22]. Multiple numerical algorithms for MEs are proposed: mostly based on the uniformization method [23]. These methods are shown to handle cases for which stiffness occurs. Nonetheless, [22] shows that even modern continuous-time Markov chain solvers are outperformed by Pade approximation combined with scaling and squaring. Recently, further works focused on the computation time and computational memory requirements of ME as matrices grow in size for multiple realistic cases [24,25].
In this study, we propose a novel L-EXPM algorithm that numerically solves MEs with a high level of accuracy. The L-EXPM is designed to tackle the issues of previous methods by combining the advantages of series-based algorithms (for example, Pade) and the eigenvalue-based methods (for example, Newton) by approximating Putzer’s algorithm.
The remainder of the paper is organized as follows. First, we introduce the proposed L-EXPM algorithm with asymptotic complexity and memory consumption analysis and prove it solves MEs. Second, we numerically evaluate the numerical accuracy of the proposed L-EXPM algorithm relative to other ME algorithms on stiff matrices. Third, we propose a complexity- and numerical-accuracy-optimized decision tree model for numerically solving ME. Finally, we conclude the usage of the proposed L-EXPM with a decision tree and suggest future work.
2. The L-EXPM Algorithm
2.1. Algorithm
Numerical computation of MEs using L-EXPM is aimed to reduce the error in computing MEs for any given complex square matrix. L-EXPM is based on Putzer’s algorithm [26] for the decomposition of MEs. L-EXPM handles two steps of the original algorithm from a numerical perspective. First, it finds the eigenvalues of the input matrix (M). This is not a trivial task, especially for large-size matrices. However, recent power methods, such as the Lanczos algorithm [27], are able to obtain the needed eigenvalues with decent accuracy. Second, rather than solving a system of ODEs recursively to obtain the coefficients of the decomposed matrices, the coefficients are iteratively approximated via an analytical solution of the system of ODEs. A schematic view of the algorithm’s structure is shown in Figure 1.

Figure 1.
A schematic view of the algorithm’s structure.
The L-EXPM algorithm takes a square complex (or real) matrix and returns the ME of this matrix. It works as follows: In line 2, the vector of eigenvalues of the input matrix is obtained using some algorithm that finds numerically the eigenvalues of the input matrix. Any algorithm may be used. Specifically, the Lanczos [27] algorithm has been used with the stability extension proposed by Ojalvo and Newman [28] and the spatial bisection algorithm [29]. In line 3, the eigenvalues that are too close to each other are converted to the same eigenvalue, and eigenvalues that are too close to 0 are converted to 0. In lines 4–5, the initial r and P (the input matrix decomposition (P) and its coefficient) from Putzer’s algorithm are initialized. Lines 6–11 are the main loop of the algorithm, with line 8 being the sum of , while in line 9 is an approximation of the shown in [26], as shown in Theorem 1. Specifically, and are the coefficients of the polynomial–exponent representation of , as later described in Equation (10). Line 10 is the iterative calculation of .
In line 3, is a function that replaces every two eigenvalues that satisfy or one eigenvalue , where is an arbitrary small threshold with the same eigenvalue or 0.
We examine the L-EXPM algorithm’s storage requirements and complexity (Algorithm 1). Analyzing the worst-case scenario, asymptotic complexity, and memory consumption can be performed by dividing the algorithm into two parts: lines 2–5 and 6–11. Assuming that the worst complexity and memory consumption of the algorithm that finds the eigenvalues of the input matrix are ) and , respectively, and that the input matrix is n-dimensional, then it is easy to see that has complexity and memory consumption as it compares every two values in a vector. Lines 4 and 5 are the initialization of two matrices, so complexity and memory consumption are required. Therefore, this part of the algorithm results in complexity and memory consumption.
| Algorithm 1 L-EXPM |
|
Regarding lines 7–11, we repeat the inner loop n times. Inside the inner loop at line 8, there is addition between two matrices, which has complexity and memory consumption. In line 9, there are three sums, each bounded by n. In addition, in the inner sum, there is a factorial, which is naively calculated in in each loop and can be bounded by overall, and therefore, in the worst case, it can be calculated as complexity and memory consumption. Nevertheless, calculating the size of the factorial and storing it in a vector of size n reduces the complexity of line 9 to . In line 10, the more expensive computation is the matrix multiplication, which is bounded by complexity and memory consumption. Therefore, the algorithm’s complexity is bounded by complexity and memory consumption. The values of and are determined during the run time as shown in the Proof of Lemma 1.
2.2. Proof of Soundness and Completeness
In this section, we provide analytical proof for the soundness and completeness of the L-EXPM algorithm. The proof outlines how to reduce the formula proposed in L-EXPM, lines 8–19, to the formula used in Putzer’s algorithm [26].
Theorem 1.
For any given matrix , algorithm L-EXPM solves Equation (1).
Proof.
Consider the following equation:
First, one needs to obtain the eigenvalues of the input matrix M. It is possible to find the biggest eigenvalue of M using the Lanczos algorithm [27]. Using Ojalvo and Newman’s algorithm, this process is numerically stable [28]. The result of their algorithm is a tridiagonal matrix , which is similar to the original matrix M. The eigenvalues of can be obtained with an error as small as needed using spectral bisection [29].
According to the Putzer algorithm [26], a solution to the ME takes the form:
where are the eigenvalues of M ordered from the absolute largest eigenvalue to the smallest one. The solution for for any is a case of a non-heterogeneous linear ODE with a constant coefficient and, therefore, takes the form:
Regarding , it is possible to obtain given using the formula:
because
Equation (1) may diverge if : then for and . In general, this calculation has only precision errors. It may have a significant cancellation error when .
Now, one needs to show that the solution for takes the form shown in line 9 of the L-EXPM algorithm.
Lemma 1.
, where are polynomials and are constants.
Proof of Lemma 1.
Induction on j. For , , which satisfies the condition. Assume the condition is satisfied for , and we show has satisfied the condition. Now, according to Equation (4):
The second term is the multiplication of a constant by an exponent and therefore satisfies the condition. Now, we examine the first term. Based on the assumption, it takes the form:
Integration of the sum is equal to the sum of the integrations, so we can write:
Therefore, it is enough to show that satisfies the condition, because a sum of sums of elements that satisfy the condition also satisfies the condition. Now, is a polynomial, and therefore it is possible to obtain:
As a result, if one shows that satisfies the condition, the whole term satisfies the condition. Now,
As this integral is the incomplete gamma function, it is possible to approximate it as follows:
Since the Putzer algorithm [26] solves Equation (1), it is enough to show that it is possible to obtain using line 9 because the L-EXPM algorithm is an approximation of the Putzer algorithm and therefore solves Equation (1).
Now, for , . According to Lemma 1, takes the form:
where are constants. It is known that , so by setting in Equation (12), one obtains:
This process repeats itself for any . □
3. Numerical Algorithm Evaluation
In comparison with other algorithms, L-EXPM’s storage requirements and complexity are asymptotically equal to the ones of the algorithms with the lowest storage requirements and complexity [8]. To evaluate the performance of L-EXPM compared to the state-of-the-art ME algorithms, a general case matrix may be required. Nevertheless, since ME algorithms provide large errors if the given matrix has a specific property, several families of stiff and non-stiff matrices should be used to obtain a general case analysis of the algorithm’s performance.
3.1. Artificial Stiff Matrices Analysis
We evaluate the performance of L-EXPM with respect to four state-of-the-art ME algorithms: Taylor, Pade, Newton, and Lagrange. For each algorithm, the parameters and tolerances are obtained using the grid search method [30]. Namely, for the Taylor algorithm, the number of terms is determined. In a similar manner, for the Pade algorithm, the fixed degrees combined with scaling and squaring [31,32] and the tolerance parameter are determined using the grid search method. The evaluation of the algorithms is performed using their MATLAB implementations (version 2020b). Since all five algorithms handle random, non-stiff matrices, we compared these algorithms on seven types of stiff matrices:
- Matrices for which the difference between the eigenvalues of the matrix is small but not negligible: we randomly pick a value () and an amplitude () and generate matrices with eigenvalues that are in the range ().
- Matrices for which the eigenvalues are approaching 0: we generate matrices with eigenvalues that satisfy the following formula: .
- Matrices with large diameters: we generate matrices with eigenvalues that satisfy the formula, where a and b are picked randomly such that .
- Matrices that have a large condition number: we generate matrices with eigenvalues that satisfy the formula , such that .
- Matrices that have eigenvalues with significant algebraic multiplicity: we generate matrices with eigenvalues with an algebraic multiplicity of at least two.
- Matrices with a single eigenvalue: we generate matrices with a single eigenvalue picked at random.
- Matrices with complex eigenvalues with a large imaginary part: we generate matrices with eigenvalues that satisfy the formula , where is a random number.
The matrices are generated as follows. First, a Jordan matrix (J) with the required eigenvalues is randomly generated. Then, a random matrix P with the same size of J is generated such that the condition number of P is less than two, and its determinant . The random matrix used in the analysis is obtained by computing . For each type of matrix, we examine the performance of each algorithm on matrices with sizes and to determine the growth of the error as a function of the matrix’s size. Each value is obtained as the average of repetitions, and the values of the matrices are generated using a normal distribution with mean and standard deviation .
The numerical relative error is calculated using the distance between the analytically obtained (ground truth) ME matrix and the numerically obtained one: , where A is a numerical ME algorithm. The ground truth ME is obtained analytically by calculating the ME of the J matrix to obtain . While is a closed form, it is not guaranteed to be exact since the matrix is a product of performing finite arithmetic. However, matrix is computed as an ME of a diagonal matrix, which is formed by computing exactly the exponential of a floating point number and is assumed to be an accurate computation (up to -machine), and the multiplication with a random matrix with a small condition number (smaller than 2) is numerically stable [33]. Therefore, while the matrix is not guaranteed to be exact, it is close enough to the ground truth for any applied purpose. The results of this analysis are shown in Table 1.

Table 1.
Numerical relative error from four numerical ME algorithms and the L-EXPM ME algorithm of seven stiff cases of matrices for matrix sizes and . The results are the average of random matrices in each case. Err indicates an error in the computation due to stack overflow.
Based on the results shown in Table 1, we compare the average relative error across the seven types of matrices of each algorithm divided by the matrix sizes, as shown in Figure 2, where each point is the mean value of each row in Table 1. The x-axis is the matrix’s size (i.e., dimension), and the y-axis is the numerical error as computed by the norm metric between the analytically and numerically obtained matrices. Unsurprisingly, all five algorithms present monotonically increasing numerical error with respect to the input’s matrix size.
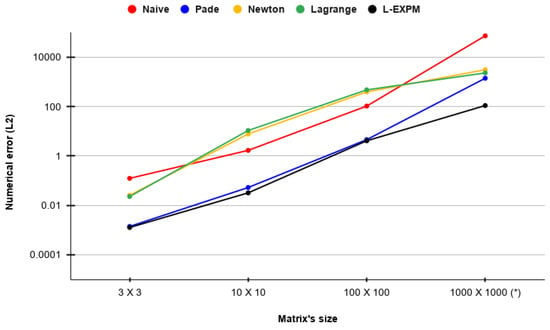
Figure 2.
Average relative numerical error of the five ME algorithms across the five types of matrices divided by matrix size. * The values for the () case are the average of the matrices from types 1 and 6 (see Table 1) rather than all seven types.
3.2. Control System’s Observability Use Case
One usage of MEs is linear control systems, wherein one records the output of a control system over time and wishes to obtain the input of the control system, which is known as the observability problem [34]. Formally, one observes the output from the system:
where over a finite period of time , and we aim to compute . Analytically, this problem is solved by [35] and requires computing the ME of A and C (see [34] for more details). Based on the glucagon–glucose dynamics linear control system for the regulation of artificial pancreas solution in type 1 diabetes [36], we simulated A and C matrices of sizes , , , and that follow the same distribution. In particular, we introduce Gaussian noise with a mean of and standard deviation of for all non-zero values in the matrix to simulate measurement error. This way, one obtains realistic samples of matrices that one can find in clinical settings. We used a dedicated server with an Ubuntu 18.04.5 operating system. The server had an Intel Core i7-9700K CPU and 64 GB RAM. All experiments were conducted in a linear fashion, and no other programs were executed on the device except for the operating system. This was to ensure the computation time was measured accurately. Each matrix’s size was computed with 100 different samples obtained by using the different seeds for the pseudo-random process. The results are shown as mean ± standard deviation in Table 2.
Table 2.
Comparison between the Pade approximation algorithm’s and the proposed L-EXPM algorithm’s errors and computation times (seconds) for the observability task.
Taken jointly, the resultsshow that L-EXPM has similar or slightly better numerical stability compared to current state-of-the-art ME algorithms for stiff matrices. For the more general case, L-EXPMs show statistically significant ( with paired two-tailed t-test) better error compared to the Pade algorithm. This outcome comes with a cost of one or two orders of magnitude more computational time.
4. Matrix Exponential Decision Tree
As shown in Table 1, there is no one ME algorithm that “rules them all” and outperforms all other ME algorithms for all cases in terms of numerical error. On top of that, we have neglected the computation time and resources needed to perform these algorithms on different matrices. Therefore, we can take advantage of the decision tree (DT) model. DTs are one of the most popular and efficient techniques in data mining and have been widely used thanks to their relatively easy interpretation and efficient computation time [37,38]. A DT is a mathematical tree graph wherein the root node has all the data, non-leaf nodes operate as decision nodes, and the leaf nodes store the model’s output for a given input that reaches them.
Two types of DTs are important for computational systems: For one, the numerical error is critical to the result such that the resources and computing time are less significant. The second case is where the numerical error is less significant, while the time and resources required to obtain the results need to be minimized.
To find these DTs, we first generate a data set () with 1000 matrices with sizes ranging between 3 and 100 generated for each of the first seven groups and an additional 7000 matrices from the eighth group generated to balance between stiff and non-stiff matrices (14,000 matrices in total). Afterward, the data set is divided into a training cohort and a testing cohort such that 80% of each sub-group of the data set is allocated to the training cohort, and the remaining 20% is allocated to the testing cohort. This process is repeated five times to obtain a five-fold split [39].
We aim to find a DT that is both computationally optimized and with minimal error and, as such, offers an optimal decision algorithm for the ME algorithm for any case while simultaneously taking into consideration computation time and numerical error. Therefore, we first define the available leaves and decision nodes for the DT. Each leaf node is a numerical ME algorithm with its own complexity, and each decision node is a discrete classification function that receives a matrix M and returns a value . The components used to construct the DT are shown in Table 3.
Table 3.
The components that are available for the complexity-optimized DT.
We define a penalty function as the sum of the worst-case complexity of all the computational components (vertices, marked by ) computed during the DT. In addition, to avoid over-fitting the optimization on a too-small DT that does not use anything and uses the algorithm with the least worst-case complexity, a decrease by one order of magnitude (factor of 10) in the relative error is equal to dividing by a linear factor from the worst overall complexity. Formally, one can write the optimization problem as follows:
where is the training set of matrices. We search for a directed acyclic graph (DAG) () for which for any pair of nodes for which there is a path from to satisfying that the asymptotic complexity of is smaller or equal to .
In addition, for the minimal error constraint, we compute the outcome for each one of the decision components shown in Table 3. We then compute the numerical relative error of each of the leaf components shown in Table 3 and store the index of the algorithm.
Based on both the complexity and numerical error data sets, a genetic programming approach has been used to obtain the DT model [41,42]. First, an initial population of DT models is generated as follows: based on the generated numerical related data set, a DT model is trained using the CART algorithm and the gini dividing metric [43]. In addition, the grid search method [30] is used on the DT’s depth (ranging between two and seven levels) to obtain the best depth of the tree. Finally, the Boolean satisfiability-based post-pruning (SAT-PP) algorithm is used to obtain the smallest DT with the same level of accuracy [44]. The population of the DT model differs in two parameters: first, the maximum number of leaves, if the leaf node can be used twice or not, and the minimum samples for dividing a node [30].
Afterward, in each algorithmic step, each DT model is scored based on Equation (15) (without the optimization term)—performed as the fitness metric. The scores of all models are normalized such that the sum of the values equals 1. The top p percent (p is empirically picked to be 50%) of the population is kept for the next generation. The population is repopulated based on stochastic mutations of the remaining models. The mutation function operates as follows: First, two DT models are picked at random with a distribution corresponding to the fitness score of the models. Both DTs are scanned from the root node using the BFS algorithm [45] such that each node that they have is similarly allocated to the new DT model, and nodes that are different are taken from the first model 33% of the time and from the second model 33% of the time, and the remaining 34% are pruned.
The obtained DT model is shown in Figure 3, wherein each rectangle node is a decision node and each circle node is a leaf node, which is identified by its component name as defined in Table 3.
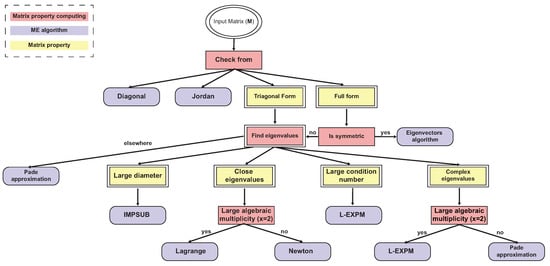
Figure 3.
Numerical-accuracy- and computation-complexity-optimized DT for numerical MEs.
5. Conclusions
This study introduces a novel algorithm for numerically calculating matrix exponentials (MEs) that achieves high accuracy on stiff matrices while maintaining computational and memory efficiency comparable to existing ME algorithms. By combining eigenvalue-based and series-based approaches, the proposed L-EXPM algorithm demonstrates improved robustness against stiff matrices compared to individual methods. Although L-EXPM generally outperforms the Pade approximation algorithm, especially for large matrices, the latter remains preferable for time-sensitive applications due to its shorter computation time. In practical applications, like observability in control systems, L-EXPM shows superior accuracy but with longer computation times than Pade. To address varying matrix characteristics, a decision tree (DT) model integrating Boolean functions and ME algorithms is proposed, and it is optimized using machine learning and genetic programming techniques.
This study is not without limitations. First, an analytical boundary for the error, rather than the numerical one shown in this study, can be theoretically useful. Second, exploring the influence of different eigenvalue computation methods can further improve the numerical performance of L-EXPM. Finally, future research should focus on testing this DT model in diverse engineering contexts, particularly in control systems, to assess its performance across real-world scenarios.
Author Contributions
T.L.: conceptualization, data curation, methodology, formal analysis, investigation, supervision, software, visualization, project administration, and writing—original draft. S.B.-M.: validation and writing—review and editing. All authors have read and agreed to the published version of the manuscript.
Funding
This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Data Availability Statement
All the data that were used were computed.
Conflicts of Interest
The authors have no conflicts of interest to declare that are relevant to the content of this article.
References
- Dunn, S.M.; Constantinides, A.; Moghe, P.V. Chapter 7—Dynamic Systems: Ordinary Differential Equations. In Numerical Methods in Biomedical Engineering; Academic Press: Cambridge, MA, USA, 2006; pp. 209–287. [Google Scholar]
- Van Loan, C. Computing integrals involving the matrix exponential. IEEE Trans. Autom. Control 1978, 23, 395–404. [Google Scholar] [CrossRef]
- Al-Mohy, A.H.; Higham, N.J. Computing the Action of the Matrix Exponential, with an Application to Exponential Integrators. SIAM J. Sci. Comput. 2011, 33, 488–511. [Google Scholar] [CrossRef]
- Aboanber, A.E.; Nahla, A.A.; El-Mhlawy, A.M.; Maher, O. An efficient exponential representation for solving the two-energy group point telegraph kinetics model. Ann. Nucl. Energy 2022, 166, 108698. [Google Scholar] [CrossRef]
- Damgaard, P.; Hansen, E.; Plante, L.; Vanhove, P. Classical observables from the exponential representation of the gravitational S-matrix. J. High Energy Phys. 2023, 2023, 183. [Google Scholar] [CrossRef]
- Datta, B.N. Chapter 5—Linear State-Space Models and Solutions of the State Equations. In Numerical Methods for Linear Control Systems: Design and Analysis; Academic Press: Cambridge, MA, USA, 2004; pp. 107–157. [Google Scholar]
- Fadali, M.S.; Visioli, A. State–space representation. In Digital Control Engineering: Analysis and Design; Academic Press: Cambridge, MA, USA, 2020; pp. 253–318. [Google Scholar]
- Moler, C.; Van Loan, C. Nineteen dubious ways to compute the exponential of a matrix, twenty-five years later. SIAM Rev. 2003, 45, 3–49. [Google Scholar] [CrossRef]
- Ward, R.C. Numerical Computation of the Matrix Exponential with Accuracy Estimate. SIAM J. Numer. Anal. 1977, 14, 600–610. [Google Scholar] [CrossRef]
- Zhou, C.; Wang, Z.; Chen, Y.; Xu, J.; Li, R. Benchmark Buckling Solutions of Truncated Conical Shells by Multiplicative Perturbation With Precise Matrix Exponential Computation. J. Appl. Mech. 2022, 89, 081004. [Google Scholar] [CrossRef]
- Wan, M.; Zhang, Y.; Yang, G.; Guo, H. Two-Dimensional Exponential Sparse Discriminant Local Preserving Projections. Mathematics 2023, 11, 1722. [Google Scholar] [CrossRef]
- Najfeld, I.; Havel, T. Derivatives of the Matrix Exponential and Their Computation. Adv. Appl. Math. 1995, 16, 321–375. [Google Scholar] [CrossRef]
- Genocchi, A.; Peano, G. Calcolo Differenziale e Principii di Calcolo Integrale; Fratelli Bocca: Rome, Italy, 1884; Volume 67, pp. XVII–XIX. (In Italian) [Google Scholar]
- Biswas, B.N.; Chatterjee, S.; Mukherjee, S.P.; Pal, S. A Discussion on Euler Method: A Review. Electron. J. Math. Anal. Appl. 2013, 1, 294–317. [Google Scholar]
- Hochbruck, M.; Ostermann, A. Exponential Integrators; Cambridge University Press: Cambridge, UK, 2010; pp. 209–286. [Google Scholar]
- Butcher, J. A history of Runge-Kutta methods. Appl. Numer. Math. 1996, 20, 247–260. [Google Scholar] [CrossRef]
- Wang, H. The Krylov Subspace Methods for the Computation of Matrix Exponentials. Ph.D. Thesis, University of Kentucky, Lexington, KY, USA, 2015. [Google Scholar]
- Dinh, K.N.; Sidje, R.B. Analysis of inexact Krylov subspace methods for approximating the matrix exponential. Math. Comput. Simul. 2017, 1038, 1–13. [Google Scholar] [CrossRef]
- Druskin, V.; Greenbaum, A.; Knizhnerman, L. Using nonorthogonal Lanczos vectors in the computation of matrix functions. SIAM J. Sci. Comput. 1998, 19, 38–54. [Google Scholar] [CrossRef]
- Druskin, V.L.; Knizhnerman, L.A. Krylov subspace approximations of eigenpairs and matrix functions in exact and computer arithemetic. Numer. Linear Algebra Appl. 1995, 2, 205–217. [Google Scholar] [CrossRef]
- Ye, Q. Error bounds for the Lanczos methods for approximating matrix exponentials. SIAM J. Numer. Anal. 2013, 51, 66–87. [Google Scholar] [CrossRef]
- Pulungan, R.; Hermanns, H. Transient Analysis of CTMCs: Uniformization or Matrix Exponential. Int. J. Comput. Sci. 2018, 45, 267–274. [Google Scholar]
- Reibman, A.; Trivedi, K. Numerical transient analysis of markov models. Comput. Oper. Res. 1988, 15, 19–36. [Google Scholar] [CrossRef]
- Wu, W.; Li, P.; Fu, X.; Wang, Z.; Wu, J.; Wang, C. GPU-based power converter transient simulation with matrix exponential integration and memory management. Int. J. Electr. Power Energy Syst. 2020, 122, 106186. [Google Scholar] [CrossRef]
- Dogan, O.; Yang, Y.; Taspınar, S. Information criteria for matrix exponential spatial specifications. Spat. Stat. 2023, 57, 100776. [Google Scholar] [CrossRef]
- Wahln, E. Alternative Proof of Putzer’s Algorithm. 2013. Available online: http://www.ctr.maths.lu.se/media11/MATM14/2013vt2013/putzer.pdf (accessed on 17 February 2021).
- Lanczos, C. An iteration method for the solution of the eigenvalue problem of linear differential and integral operators. J. Res. Natl. Bur. Stand. 1950, 45, 225–282. [Google Scholar] [CrossRef]
- Ojalvo, I.U.; Newman, M. Vibration modes of large structures by an automatic matrix-reduction methods. AIAA J. 1970, 8, 1234–1239. [Google Scholar] [CrossRef]
- Barnard, S.T.; Simon, H.D. Fast multilevel implementation of recursive spectral bisection for partitioning unstructured problems. Concurr. Comput. Pract. Exp. 1994, 6, 101–117. [Google Scholar] [CrossRef]
- Liu, R.; Liu, E.; Yang, J.; Li, M.; Wang, F. Optimizing the Hyper-parameters for SVM by Combining Evolution Strategies with a Grid Search. In Intelligent Control and Automation; Springer: Berlin/Heidelberg, Germany, 2006; Volume 344. [Google Scholar]
- Al-mohy, A.H.; Higham, N.J. A New Scaling and Squaring Algorithm for the Matrix Exponential. SIAM J. Matrix Anal. Appl. 2009, 31, 970–989. [Google Scholar] [CrossRef]
- Higham, N.J. The Scaling and Squaring Method for the Matrix Exponential Revisited. SIAM J. Matrix Anal. Appl. 2005, 26, 1179–1193. [Google Scholar] [CrossRef]
- Demmel, J.; Dumitriu, I.; Holtz, O.; Kleinberg, R. Fast matrix multiplication is stable. Numer. Math. 2007, 106, 199–224. [Google Scholar] [CrossRef]
- Poulsen, N.K. The Matrix Exponential, Dynamic Systems and Control; DTU Compute: Kongens Lyngby, Denmark, 2004. [Google Scholar]
- Kailath, T. Linear Systems; Prentice Hall: Upper Saddle River, NJ, USA, 1980. [Google Scholar]
- Farman, M.; Saleem, M.U.; Tabassum, M.F.; Ahmad, A.; Ahmad, M.O. A linear control of composite model for glucose insulin glucagon pump. Ain Shams Eng. J. 2019, 10, 867–872. [Google Scholar] [CrossRef]
- Swain, P.H.; Hauska, H. The decision tree classifier: Design and potential. IEEE Trans. Geosci. Electron. 1977, 15, 142–147. [Google Scholar] [CrossRef]
- Stiglic, G.; Kocbek, S.; Pernek, I.; Kokol, P. Comprehensive Decision Tree Models in Bioinformatics. PLoS ONE 2012, 7, e33812. [Google Scholar] [CrossRef] [PubMed]
- Kohavi, R. A Study of Cross Validation and Bootstrap for Accuracy Estimation and Model Select. In Proceedings of the International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995. [Google Scholar]
- Lu, Y.Y. Exponentials of symmetric matrices through tridiagonal reductions. Linear Algerba Its Appl. 1998, 279, 317–324. [Google Scholar] [CrossRef]
- Koza, J.R.; Poli, R. Genetic Programming. In Search Methodologies: Introductory Tutorials in Optimization and Decision Support Techniques; Springer: New York, NY, USA, 2005; pp. 127–164. [Google Scholar]
- Alexi, A.; Lazebnik, T.; Shami, L. Microfounded Tax Revenue Forecast Model with Heterogeneous Population and Genetic Algorithm Approach. Comput. Econ. 2023. [Google Scholar] [CrossRef]
- Grabmeier, J.L.; Lambe, L.A. Decision trees for binary classification variables grow equally with the Gini impurity measure and Pearson’s chi-square test. Int. J. Bus. Intell. Data Min. 2007, 2, 213–226. [Google Scholar] [CrossRef]
- Lazebnik, T.; Bahouth, Z.; Bunimovich-Mendrazitsky, S.; Halachmi, S. Predicting acute kidney injury following open partial nephrectomy treatment using SAT-pruned explainable machine learning model. BMC Med. Inform. Decis. Mak. 2022, 22, 133. [Google Scholar] [CrossRef] [PubMed]
- Moore, E.F. The shortest path through a maze. In Proceedings of the International Symposium on the Theory of Switching; Harvard University Press: Cambridge, MA, USA, 1959; pp. 285–292. [Google Scholar]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).