1. Introduction
Over the last two decades, rapid advancements in information technology have triggered an unprecedented surge in data, creating a storage crisis. Scientific research and social services generate large video datasets, with the proliferation of personalized video creation and sharing on platforms like social networks contributing to this data deluge. In the digital age, video content dominates, constituting 53.72% of global data traffic. Predictions suggest that global data volume will reach
bits by 2040 [
1], exceeding the capacity of existing silicon-based storage, which has a limited lifespan and is unsuitable for long-term (~20 years) storage. Preserving valuable information for future generations requires regular transfers to updated storage media. Hence, there is an urgent need for alternative solutions to address the challenges posed by storing vast amounts of data efficiently [
2,
3,
4].
As a potential solution to the escalating data storage challenges, researchers have turned to DNA (deoxyribonucleic acid), the carrier of biological and genetic information, due to its advantages of significantly higher storage density (1 petabyte per gram of DNA), an extended storage period of centuries, and notably lower maintenance costs [
4,
5]. Unlike traditional magnetic storage, which relies on binary encoding, DNA storage utilizes quaternary encoding, employing specific combinations of A, C, G, and T to encode computer files. The DNA data storage system encompasses several processes [
6,
7,
8,
9], including binarization (transformation of digital data into binary code), encoding (translation of binary code into DNA code), DNA synthesis for data storage, DNA sequencing (to retrieve the nucleobase code), and decoding for the restoration of the original digital data, as depicted in
Figure 1.
The impetus for DNA storage research increased, particularly post-2012, when Harvard University’s Church group successfully stored a 650 KB book in DNA [
10]. In 2013, Goldman [
11] introduced the rotation encoding model, utilizing ternary Huffman compression coding to prevent homopolymer-induced nucleotide repeats in DNA sequences while maintaining a 50% GC content. In 2015, Grass [
12] pioneered the application of Reed–Solomon (RS) error correction codes in DNA storage, introducing a ternary encoding model based on Galois fields. In 2017, Erlich [
13] presented the DNA fountain code, incorporating Luby Transform for XOR operations on binary information with specific random number seeds and selecting sequences meeting biochemical constraints. In 2022, Ping [
14] proposed the Yin-Yang dual encoding model, transforming two binary subsequences into one DNA subsequence based on the “Yin” and “Yang” rotation rules. These innovative models enhance coding density, advancing DNA data storage technology and its practical applications.
Figure 1.
The key stages of DNA data storage system [
14].
Figure 1.
The key stages of DNA data storage system [
14].
Despite these advancements, numerous state-of-the-art encodings [
11,
12,
15] faced errors such as base deletions, mutations, etc., due to the limitations of DNA synthesis and sequencing technologies. To ensure DNA storage reliability [
8], the error correction mechanism plays a crucial role, and researchers have developed various error correction techniques to correct these errors and enhance the stored data’s accuracy and integrity. For instance, Goldman et al. [
11] used quadruple overlapping redundancy, which means that each sequence generates three redundant sequences with 25% overlap. However, this method has a storage density of only 0.33 bits/nt, and the synthesis cost is too high. Bornholt et al. [
15] utilized the method of heterodyne generation of a third sequence using two consecutive binary sequences, which solved the sequence-loss error, but the method has extensive redundancy. Grass et al. [
12] applied error correction techniques from the traditional communication field to DNA storage, using a combination of internal and external codes to improve the robustness of DNA storage; however, the method could not balance the GC content of the sequences. Since then, various error correction codes, such as RS codes [
13,
14,
16,
17,
18,
19], Hamming codes [
20], LDPC codes [
21,
22], etc., have been used to correct base substitution errors within DNA sequences. Among these, RS codes have been applied widely. The error correction capability of these codes is positively correlated with the redundancy level because they are error-corrected at the binary level. Therefore, problems such as biochemical constraints [
23] need to be considered when converting these codes to quadrature. Typically, researchers perform the binary segmentation step by adding RS codes before or after the segment, which are then converted together into DNA sequences. Erlich’s code [
13] can reproduce erroneous sequences with a storage density of 1.57 bits/nt; however, the decoding complexity is high and requires a lot of time for large files. Press et al. [
19] developed “HEDGES” to handle addition and deletion errors in DNA synthesis and sequencing by using RS and convolutional codes for encoding and a tree structure for decoding, but the encoding rate of this method is not sufficient. Therefore, there is still a crucial demand for further improvements in error correction techniques to balance storage density, encoding rate, and time efficiency.
Apart from this crucial scientific problem, this work also emphasizes the types of data stored in DNA. As the source and importance of video data mentioned earlier, video is a data-intensive media type containing many images and sound information. For videos such as historical archives, documentaries, and important news reports, complete preservation can leave a valuable historical and cultural heritage for future generations, and thus, it requires long-term storage. However, traditional storage media usually require regular maintenance and replacement, which consumes many resources. Although DNA storage shows excellent potential, previous research has mainly focused on static data such as text documents and images. To the best of our knowledge, none of the DNA encoding models have efficiently stored the video data so far.
On the one hand, video contains a large amount of data, which requires efficient coding strategies and robust error correction mechanisms to handle the large amount of information, and the existing coding models are less time-efficient [
13,
14]. On the other hand, video needs to ensure continuity. The video quality needs to be maintained during storage and retrieval. The existing research encodes the video files in binary segments [
13,
16,
24]. Due to the continuity of the video data, the binary error in a small segment may lead to catastrophic error propagation such that the video file is corrupted. Therefore, developing a segmentation strategy that guarantees video continuity is crucial.
Overall, previous studies have reported many advanced coding methods; however, when faced with large-volume data such as video, some coding models (Fountain [
13] and Yin-Yang [
14]) require exponential filtering steps, and the time required for coding is too long. In addition, it is critical to answer about how to add error correction codes more efficiently. Although Grass et al. [
12] combined RS code coefficients into the coding process, which improved the efficiency of error correction to a certain extent, the method cannot realize the regulation of GC content when the data volume is large, which triggered more errors.
This study designs and tests a new coding method to deliver an effective solution for Video Storage in DNA (VSD) by addressing the challenges of previous coding methods. The proposed VSD method offers a novel video segmentation strategy that equates videos at certain time intervals to address the problem of error propagation under binary data segmentation. Additionally, VSD develops an innovative quadratic coding model based on RS error-correcting codes to convert video files into hexadecimal codes and DNA sequences, which significantly satisfies the biochemical constraints of DNA coding by derived theorems and improves the computational runtime. Meanwhile, it also introduces an efficient indexing mechanism for random video access. In the experiment, historically significant video data (approximately 300 MB) were used for testing, with an overall encoding density of 1.75 bits/nt and a time efficiency improvement of over 30%, and it performs better than previous works when the base substitution rate is 0.05%. Through simulation sequencing and error correction, the original video is successfully decoded. By extending the capabilities of DNA storage to encompass videos, the proposed VSD opens up new possibilities for reliable video archival and storage applications. The data and codes for this work are available at
https://github.com/jork07/VSD (accessed on 12 March 2024). The significant contributions of this study are summarized as follows:
A novel VSD method that relies on an innovative video segmentation strategy and a quadratic coding model and uses efficient indexing to construct a video-based DNA data storage system is proposed.
The proposed encoding model based on the RS error-correcting code efficiently balances storage density, combinatorial bio-constraints, and time efficiency, reducing overhead costs.
The practicality of the proposed VSD method is evaluated by computer simulation, which reports the significant performance over previous work.
The structure of the remaining paper is as follows:
Section 2 elaborates on the literature work on the overview of DNA storage and MPEG-4 format.
Section 3 introduces the proposed video segmentation strategy and DNA transcoding model,
Section 4 delivers experiments and results evaluations, and
Section 5 concludes this study.
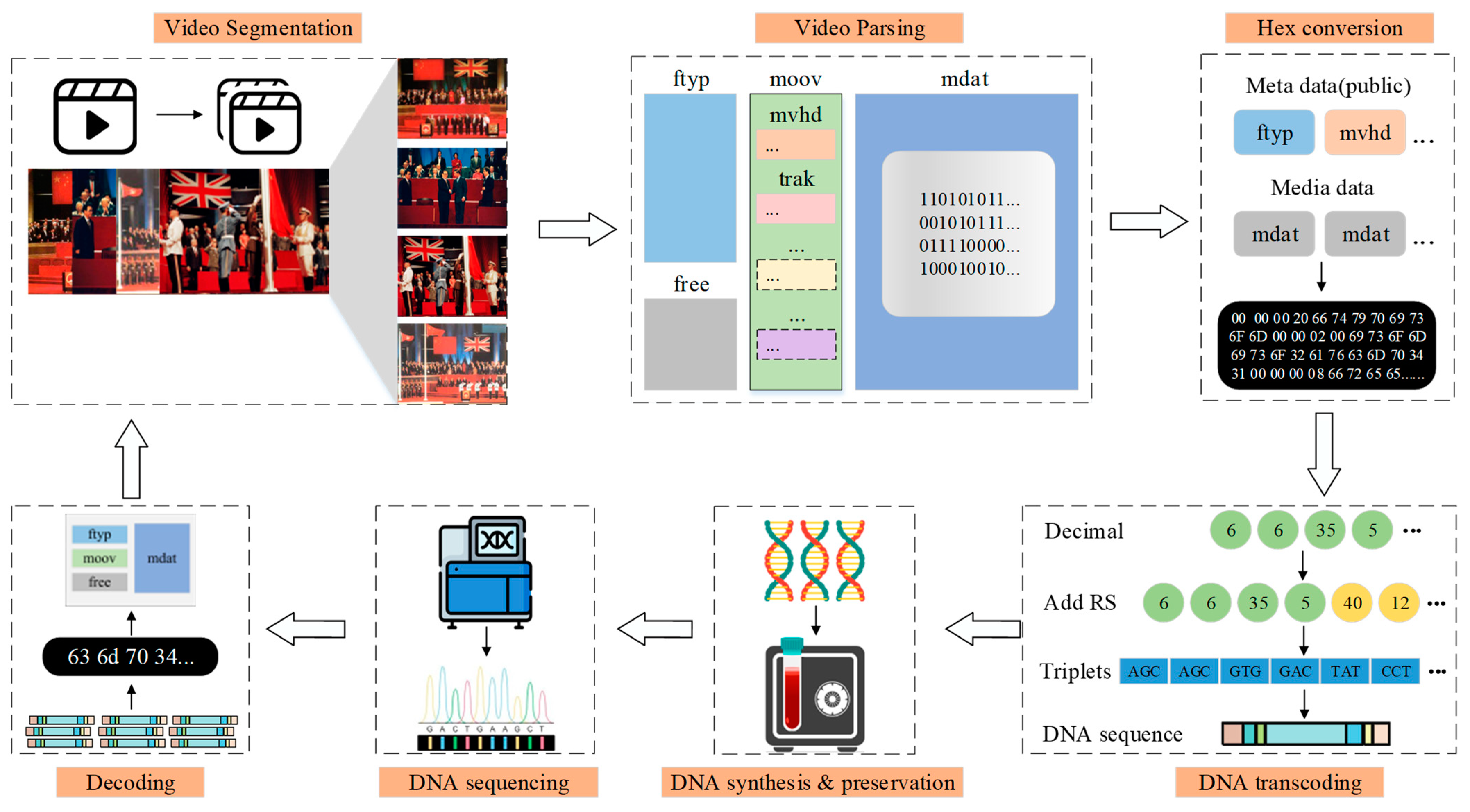
3. Proposed Methodology
In this research endeavor, we present an innovative methodology to address the identified challenges in
Section 2.2. Our approach aims to enhance the practical archival of video data within DNA storage, ensuring metadata integrity, balancing coding density and time efficiency, and satisfying the bio-coding constraints. The structured delineation of our proposed methodology (depicted in
Figure 2), Video Storage in DNA (VSD), unfolds across three pivotal stages.
Dynamic Video Parsing: The dynamic video file is segmented into multiple independent video segments; each video segment is parsed individually to separate the video metadata from the media information,
DNA Quaternary Coding: Hexadecimalizing the data and using a quaternary coding model based on RS codes to encode and decode, and satisfy the constraints with derived theorems,
DNA Synthesis, Storage, and Sequencing: DNA sequences are synthesized using existing techniques and preserved in a suitable environment, and the original sequence is obtained using sequencing techniques.
The comprehensive details are explicitly presented in the following subsections. It must be noted our novelty and primary contribution lie within the initial two stages. The third stage serves the purpose of providing a brief elaboration on end-to-end DNA data storage systems.
3.1. Dynamic Video Parsing
Most existing video data are compressed and stored based on MPEG-4 format. MPEG-4 (Moving Pictures Expert Group 4) is a digital multimedia compression standard designed to provide efficient methods for compressing, transmitting, and storing multimedia content. Compared to previous MPEG standards, MPEG-4 provides excellent compression capabilities and offers diverse functionalities such as multi-view video, transparent video, object recognition and coding, dynamic scene description, interactivity, and more. It makes MPEG-4 widely used in various fields [
25,
26]. In order to store video data efficiently in DNA, the VSD strategy dynamically parses videos, which mainly includes three steps: video segmentation, video parsing, and hexadecimal conversion.
3.1.1. Video Segmentation
Video segmentation is a crucial process in handling large amounts of video data. Traditionally, the video segmentation strategy divides videos into binary information segments [
24,
27]. However, this study proposes a novel approach to video segmentation by leveraging the organizational characteristics of MPEG-4.
Unlike traditional methods [
24,
27], the segmentation strategy employed in this study divides the video into segments based on time. These segments are not binary information segments but rather independently playable small segments akin to clips. By utilizing the inherent structure of MPEG-4, the video is divided into smaller units that retain their playability individually, offering advantages in terms of storage and retrieval. This innovative approach to video segmentation has several benefits: Firstly, it allows for more efficient storage and retrieval of video content. Instead of dealing with a single large file, the video is divided into smaller segments, enabling faster access to specific parts of the video. Additionally, based on the organizational characteristics of MPEG-4, each segmented segment has common information that can be stored only once during the quaternary transcoding process. Each segment can reuse this information, improving storage density and storing videos more efficiently.
Overall, the proposed video segmentation strategy based on MPEG-4 organizational characteristics offers a novel and efficient approach to handling large video data. Dividing the video into independently playable segments enhances the storage and retrieval of video data in DNA.
3.1.2. Video Parsing
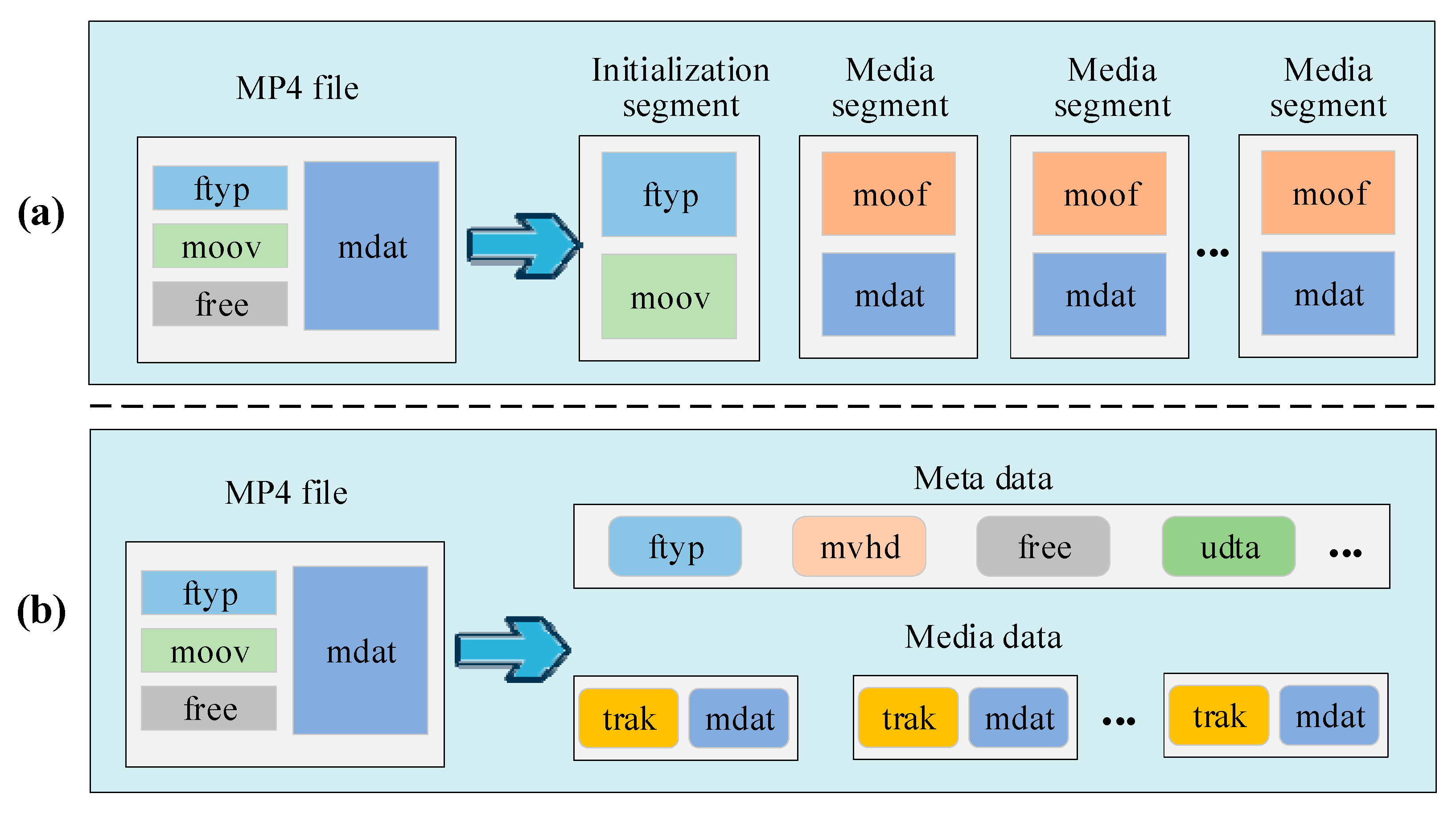
The MPEG-4 format uses a box-based structure where different types of data and metadata are organized into a series of nested boxes or containers, as shown in the left half (MP4 file) of
Figure 3; an MPEG-4 file consists of four main boxes: file type (ftyp), movie fragment (moof), movie (moov), media data (mdat), and free space (free). This structure enables MPEG-4 to package and transmit various media content effectively [
28,
29].
The FMP4 format (Fragmented MP4) is a video streaming format that extends the MPEG-4 Part 12 standard [
30]. In contrast to the traditional MP4 format, the FMP4 format divides media files into several fragments. Each fragment constitutes a complete MP4 file containing media data, metadata, and index information, as illustrated in
Figure 3a. Specifically, the initialization segment includes fundamental video information such as ftyp and moov, while subsequent multiple media segments encapsulate individual video streams, encompassing moof (movie fragment) and mdat boxes. Drawing inspiration from this format, our study proposes a novel strategy for parsing video data for DNA storage. Our aim is to bolster the resilience of video data storage and enhance data access efficiency.
Specifically, after the segmentation in the previous stage, each small segment is parsed into the form of the left half (MP4 file) of
Figure 3. These segments all contain initialization information for the original video, so some metadata remain consistent. Storing these metadata (e.g., ftyp, mvhd (movie header), udat (user data), etc.) only once is sufficient to decode and access these small segments, even the original video. In order to increase the coding density, all the small segments are divided into metadata and media data, as shown in
Figure 3b, which are converted into hexadecimal data to be applied to the subsequent coding process.
3.1.3. Hexadecimal Conversion
Hexadecimal conversion is a common practice when working with MPEG-4 files, as it provides an intuitive way to observe the structure and content of the video files. Representing MPEG-4 data in hexadecimal format allows easy identification of file headers, data blocks, metadata, and other components. By examining the hexadecimal representation of a file, researchers and developers can analyze its features, parse data structures, and perform further processing and operations.
In the context of this study, we first perform hexadecimal conversion on the source data of the MPEG-4 video. Let
X be the source binary data of the MPEG-4 video. The hexadecimal representation
H(X) is obtained by converting the binary data
X to hexadecimal as follows:
This conversion transforms the binary data into a hexadecimal representation, making it easier to identify specific elements. For example, let
denote the
box identifiers through hexadecimal representation. The hexadecimal identifier for each box is denoted by
,
By using hexadecimal identifiers, such as “66 74 79 70” for “ftyp”, we can locate different boxes within each video segment. If
represents the metadata data and
represent the media data within the
segment, the separation can be represented as:
Identifying these boxes through their hexadecimal representations can effectively separate the metadata and media data within each segment. The metadata and media data are separated and segmented into fixed lengths for subsequent DNA quaternary transcoding. The segmented metadata and media data are denoted by
and
, respectively, where
represents the
segment within
segment.
where
is the fixed length for segmentation.
3.2. DNA Quaternary Coding
This study improves the mapping rules from digital data to bases based on Grass et al.’s encoding and decoding method. It addresses the issue of the previously uncontrolled GC content by achieving similar coding density. In the original encoding process, a 16-bit binary bit sequence from every 2 bytes was converted into a numeric sequence in a base-47 system
). Then, a simple mapping between the base-47 sequence and triplet bases was used to transform the binary bit sequence into a DNA sequence. This study first redesigned the mapping rules for triplet bases to maintain a constant GC content in the base sequence as much as possible.
Table 1,
Table 2 and
Table 3 illustrate the partitioning of the original set of 48 triplets.
Table 1 collects triplets with an equal count of A and T, while
Table 2 includes triplets with an equal count of G and C. Moreover, this study switched to using Reed–Solomon (RS) error correction codes based on the Galois field GF(41) for encoding [
31]. The choice of GF(41) was motivated by two reasons. Firstly, 41 is the nearest prime number to 40, which is the total number of elements in the AT and GC tables. This allows for a cross-mapping between the AT and GC (
Table 1 and
Table 2) to control the GC content of the DNA sequence around 50%. Secondly, GF(41) satisfies
, ensuring that two bytes can still be represented by three base-41 numbers while maintaining the same coding density.
The pseudo-code for the quaternary coding process is presented in Algorithm 1, which has the following significant steps:
Step 1: The video data, divided in the previous stage, are converted into a hexadecimal sequence data . To control the length of the DNA sequence, these sequence data are divided into several equally sized segments of hexadecimal sequences .
Step 2: For each , starting from the beginning, every 4 hexadecimal digits are converted into 3 base-41 numbers by performing a modulo operation, resulting in a base-41 sequence .
Step 3: RS error correction blocks are added to the base-41 sequence . The error-correcting capability of the sequence is determined by , which means the sequence can tolerate errors.
Step 4: Calculate the median of the base-41 sequence
and use that median as the
. Define boolean indicator variables
and
. Set up the triplet
,
,
, and
. Define the default mapping
Table 4.
Step 5: For each element in the base-41 sequence , if , perform alternating mapping using an indicator variable to add additional base triplet or to the result sequence ’s end, we have designed an integrated Algorithm 2, which can be stated as follows:
When the is 0, if equals 0, perform alternating mapping using the indicator variable to add additional base triplet or to the end of ; if belongs to the range , add the -th element from table to the end of . Otherwise, add the th element from table to the end of .
When the is less than 20, if belongs to the range , add the nth element from table to the end of . If belongs to the range , add the th element from table to the end of . Otherwise, add the th element from table to the end of .
When the is greater than 20, if belongs to the range , add the th element from table to the end of . If belongs to the range , add the -th element from table to the end of . Otherwise, add the th element from table to the end of .
When the is 20, if belongs to the range , add the -th element from table to the end of . Otherwise, add the th element from table to the end of .
Step 6: Process the by adding the -th element from the default mapping table D to the end of the result sequence . Output the resulting sequence
| Algorithm 1. DNA encoding method. |
Input: Video hexadecimal data , RS error correction blocks
Output: DNA sequence set of one video .
1 for do
2 for do
3 convert 4 hexadecimal numbers to a decimal number.
4 perform 3 remainder operations on n over 41 to obtain 3 residues .
5 add 3 residues to the decimal list in order.
6 end for
7 add k RS error correction blocks for .
8 .
9 .
10
11 end for
12 return S |
| Algorithm 2. Mapping triplet algorithm. |
Input: Decimal list , odd triplet table AT, even triplet table GC, default triplet table D, odd extra triplet , even extra triplet , odd zero triplet , even zero triplet , extra flag , zero flag .
Output: DNA sequence set s.
1 for each number in do
2 if then
3 if then
4 else
5 else
6 if then
7 if then
8 if then
9 else
10 else if then
11 else
12 else if then
13 if then
14 else if then
15 else
16 else if then
17 if then
18 else if then
19 else
20 else
21 if then
22 else
23 end for
24 s.append(
25 return . |
The computational complexity of the proposed VSD strategy is (n*m), where n is the number of hexadecimal data sequences H, and m is the number of 4-digit hexadecimal numbers in each sequence.
3.2.1. Integration of RS Codes
Our study’s proposed DNA quaternary coding uses RS codes to add redundancy and facilitate error correction. The use of RS codes based on the Galois field GF(41) allows for efficient mapping between the digital data and the four nucleotides of DNA while maintaining a balanced GC content. Our method encodes the data into hexadecimal form, then decimal, and finally into residues of 41 to comply with the RS code over GF(41). The core idea of RS codes is to encode data into polynomials over a finite field (also known as a Galois field). The key parameters of an RS code are denoted as
with
symbols, meaning that the encoder takes
data symbols and adds
parity symbols to make an
-symbol codeword. Each symbol can be seen as a base-41 value, and therefore, the RS code operates over GF(41). A
-symbol message is represented as a polynomial
of degree
[
32]:
where each coefficient
represents a symbol from the field GF(41).
The generator polynomial
is used to encode the message and is of degree
:
where
are called the roots of the generator polynomial and are chosen from the field GF(41).
The encoding process involves creating a generator polynomial, which is multiplied by
raised to the power of
(to make space for the parity symbols) and then divided by the generator polynomial
.
where the resulting polynomial
represents the encoded message.
When errors occur during transmission, the received polynomial
differs from the transmitted polynomial
. The decoder uses various methods, such as the Berlekamp–Massey algorithm [
33] or the Euclidean algorithm [
34], to correct the error locations. The decoder calculates the syndrome polynomial
by evaluating
at the roots of the generator polynomial:
By finding the roots of the syndrome polynomial, the decoder identifies the error locations and corrects the received polynomial accordingly. Finally, the errors are corrected, and the original message is recovered.
3.2.2. DNA Coding Constraints
Furthermore, the generated DNA sequences undergo validation based on biological coding constraints, specifically focusing on GC and homopolymer constraints in our study. We applied newly derived theoretical models from our previous work [
23], emphasizing the limitations of GC content
within the range of 40–60% and homopolymer
based on benchmark studies [
35,
36,
37,
38]. Analogously, GC can be represented as
for the four nucleobases, ensuring that all DNA segments adhere to the desired code
and constraints. The ensuing lower bounds constraints for constructing the DNA library are articulated in Theorem 1 [
23,
39], incorporating variables for sequence length
and Hamming distance
. The concise proof is provided in this work due to these variables.
Theorem 1. For DNA sequence having the number of segments , with constraint and for the bound, Proof. Equation (9) signifies an equivalence between DNA codes with zero GC content and binary codes . It illustrates that transforming binary codes by replacing 0s with As and 1s with Ts maintains Hamming distance and thus establishes a bijection between these two sets. This transformation establishes a one-to-one correspondence, demonstrating the interchangeability of binary and DNA codes with specific GC content, which is crucial in DNA storage. In Equation (10), the interchange operation is demonstrated to uphold the equality between the sets with different GC-contents ( and . Swapping complementary nucleobases in a DNA sequence preserves the constant GC content, illustrating symmetry within the set of DNA codes. Equation (11) establishes a formula for the count of DNA codes with specific GC-content and Hamming distance of 1 . The proof considers two scenarios:
When and are both even: in this case, the Equation calculates the count of words with GC-content that are their own reverse complements.
When either and is odd: the formula simplifies to , signifying that no DNA codes possess the property of being their own reverse complement.
It succinctly states that when both and are even, there are words with GC content that are their own reverse complements; otherwise, there are none. □
Eventually, we demonstrated an example of quaternary transcoding, in which we define
= TAT,
= CGC,
= ATA,
= GCG;
Figure 4 is illustrated. The original video is segmented into a fixed-length sequence after hexadecimal conversion, using Equation (4). In this sequence, four hexadecimal bits are used as a unit, and each unit is first converted to a decimal number. Then, the remainder of 41 is calculated one by one to obtain three residues. For example, 60223/41 = 1468 (35), 1468/41 = 35 (33), 35/41 = 0 (35), where the remainder is enclosed in parentheses. By analogy, when all units are converted into three residues, RS codes are added later to obtain a base-41 sequence. Next, calculate the median of the sequence as the offset. In the above example, the median is 30 (round down). According to Algorithm 2, number 35 corresponds to line 23 and is therefore converted to a triplet (GTG) with GC table index 15; number 33 conforms to line 25 and is converted to a triplet (CTA) with an AT table index of 4; number 3 conforms to line 24 and is converted to a triplet (GGA) with GC table index 3; number 40 conforms to line 7 and is converted to a triplet
(TAT). Finally, the triad was integrated into a sequence called “GTGTCGGTGCTAGGAGAGCGTCGCTTGATCTTCTCAGAT”, which showed homopolymer
, and a GC content of 54%.
3.3. DNA Synthesis, Storage and Sequencing
Our primary focus is on computer simulations and computational biology, and it is important to clarify that our work does not directly involve the experimental processes of DNA synthesis, storage, and sequencing. Nevertheless, we present a concise overview of these procedures for the benefit of early researchers and readers seeking a general understanding of DNA manipulation techniques.
In the synthesis phase, oligo pools are synthesized by companies to provide DNA gel for subsequent sequencing. When considering storage options, DNA fragments intended for in vivo storage undergo careful segmentation into subfragments and further division into blocks. These blocks consist of synthesized 80-nt oligos and are assembled using polymerase cycling assembly. Subsequently, they are cloned into vectors for Sanger sequencing, validating their sequence accuracy. The sequencing-verified blocks are then further assembled into subfragments using overlap extension PCR. Finally, the complete full-length DNA fragment, approximately 10 MB in size, is obtained by introducing the subfragments into yeast through homologous recombination, enabling in vivo storage.
However, in addition to in vivo storage, an alternative approach is in vitro storage. For in vitro storage, DNA fragments are not transferred into living organisms but instead preserved in laboratory conditions. This method offers advantages such as ease of manipulation and reduced reliance on living systems. In this context, the storage process entails carefully preserving the DNA fragments in a controlled environment, typically using techniques like cryopreservation or freeze-drying. These methods ensure the long-term stability and integrity of the DNA molecules, allowing for extended storage periods without the need for living organisms.
The choice between in vivo and in vitro storage depends on various factors. In vivo storage is preferred when DNA fragments need to be maintained and propagated within a living organism. It allows researchers to utilize the host organism’s cellular machinery, making it useful for studying complex genetic interactions. In contrast, in vitro storage is selected when the primary goal is preserving DNA fragments themselves without immediate utilization in a living system. It offers long-term stability and easy accessibility, enabling straightforward manipulation such as retrieval and amplification. In vitro storage is more suitable for archiving. These methodologies are crucial in genetic research, synthetic biology, and biotechnological applications.
4. Experiments and Results Validation
All experiments were conducted under Windows 10 × 64, Intel Core i7 3.41 GHz, RAM 16 GB, and Python 3.8.13v language. To begin with, the data used in the experiments were obtained from the Internet, and the segmentation and integration of video data were realized using ffmpeg 6.1 (a cross-platform audio/video processing framework) [
40]. Additionally, the data processing involved utilizing two Python packages, codecs (
https://docs.python.org/3/library/codecs.html, accessed on 1 March 2024), and binascii (
https://docs.python.org/3/library/binascii.html, accessed on 1 March 2024), which played a crucial role in data processing tasks. For RS code generation and error correction, we use the galois (
https://galois.readthedocs.io/en/v0.3.6/, accessed on 1 October 2023) package.
In order to evaluate the performance of the proposed VSD method, we first encoded a series of digital files and analyzed the biological constraints on the encoding results. We tested the encoding on video files and other types of files and compared them comprehensively with previous studies. (For other types of files, we apply VSD method without the video segmentation and parsing steps). We have also compared the efficiency of error correction and encoding time efficiency.
4.1. Biological Constraint Validation
Most errors that occur during DNA storage are caused by sequences that do not conform to biological constraints. Researchers are most concerned with homopolymer and GC content among the many biological constraints. For this reason, we performed extensive tests using proposed quaternary coding with computational theorems to satisfy the constraints.
For homopolymers, we encoded several digital files, totaling 177,360 sequences of length 100 nt, and counted the number of repetitions of homopolymers of three different lengths; as shown in
Figure 5, there is no homopolymer of length > 3 in the resultant sequences encoded by the VSD method. In addition, the number of times that homopolymers of length 2 or 3 occur in the four bases does not differ much. The results show that the VSD method can avoid the generation of longer homopolymers.
For GC content, 2000 DNA sequences were randomly selected from the encoding results for comparison.
Figure 6 compares the GC content results of the generated sequences with Grass et al.’s encoding model (a) and VSD encoding model (b). The VSD method exhibits superior regulation of the GC content in the generated DNA sequences when compared to Grass et al.’s encoding model [
6]. This improvement can be attributed to the VSD method’s effective base triplet mapping, which ensures a more balanced distribution of G and C nucleotides throughout the sequences. By avoiding longer homopolymers and achieving a more balanced GC content, the VSD method can reduce non-specific hybridization during DNA sequence synthesis, thereby improving the robustness of DNA storage.
4.2. Encoding Efficiency Validation
The evaluation of the computer simulations (
Table 5) reveals insightful findings regarding the proposed VSD method for video data storage. Notably, the density of DNA sequences, a crucial metric for assessing storage efficiency, exhibits varying trends across different file types and sizes.
In our test video file, the maximum duration of a single video is “Macao1999”, which is 12 min and 18 s. The total duration of all videos is 25 min and 51 s. To our knowledge, there has been no research on encoding videos of this duration. The highest density is observed in the “FoundingCeremony” MP4 file at 1.79 bits/nt, while the lowest density is recorded in the “Les Miserables” TXT file at 1.73 bits/nt. The average density across all files is consistently competitive, showing the robustness of the VSD method. Intriguingly, the results illustrate that density tends to increase with larger file sizes, emphasizing the scalability of the proposed approach. The observed fluctuations in density among different file types underscore the nuanced impact of file format on storage efficiency. The VSD method demonstrates efficacy in achieving favorable density levels, coupled with reduced computational time, affirming its potential as a promising solution for video data storage. This is particularly noteworthy given the method’s unique features, including the novel video segmentation strategy, quadratic coding model, and efficient indexing mechanism, all contributing to improved storage density and computational complexity.
Furthermore, a 3D representation (
Figure 7) offers valuable insights into the intricate relationships between file size, internal complexity, and embedded information across diverse media formats. The graph reveals several intriguing relationships. We observe a general trend of size increasing with density. This suggests that denser files, packing more information per unit space, tend to be larger in size. However, deviations from this trend are also evident. For instance, according to the data in
Table 5, “Mona Lisa” (.JPG) is positioned at the far left on the “Size” axis. Despite having a high density, it occupies minimal space due to its inherent compression efficiency. Interestingly, the sequence values appear unrelated to either size or density. They act as independent identifiers for each file type, potentially encoding specific media formats or internal structures. Further investigation would be needed to uncover the nature and role of these sequence values.
4.3. Error Correction Performance
The realm of DNA data storage faces inherent challenges due to base mutations, predominantly arising during DNA synthesis and sequencing. Factors such as the concentration or temperature of base addition reagents, the quality of DNA templates, and the sequencing instrument’s light source intensity or detection sensitivity, significantly influence the incidence of base mutations. These mutations, particularly base substitutions, can lead to data corruption, posing a substantial obstacle in accurate data decoding. In our VSD method, leveraging RS error correction codes, emerges as a pioneering solution.
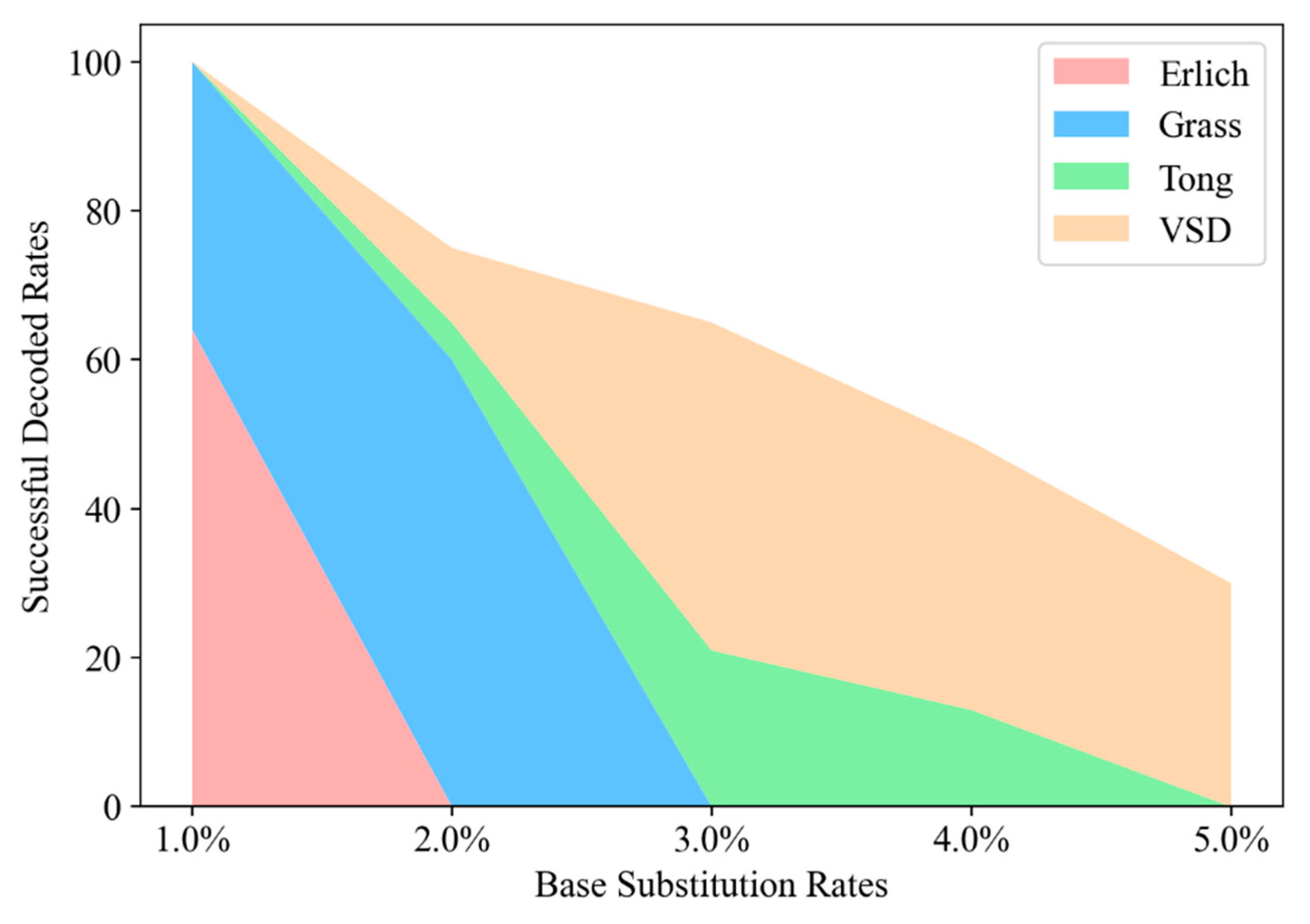
Figure 8 illustrates the efficiency of VSD in comparison to other benchmark studies like Erlich [
13], Grass [
12], and Tong [
41]. The chart distinctly shows VSD’s superior performance in maintaining high successful decoded rates, even at elevated base substitution rates. For instance, at a 0.05% error rate, VSD demonstrates an impressive ability to correct 30% of errors, a feat not mirrored by its counterparts.
The VSD method’s success in DNA data storage is due to its unique blend of video segmentation and encoding, enhanced by robust RS coding. This combination improves error correction, particularly for substitution errors, and strengthens data integrity and reliability. As shown in
Figure 8, VSD demonstrates remarkable error resilience and efficiency, establishing a new standard in the field and addressing key challenges of capacity and accuracy.
4.4. Large-Scale Compatibility
The VSD robustness is assessed with large-scale public video datasets (
https://github.com/VSD/video_data, accessed on 12 March 2024). The experiments are conducted in a high-performance environment compressed with Ubuntu 22.04 system, AMD EPYC 7763@3.53Ghz CPU, 1024 GB memory.
Figure 9 is a compelling visual affirmation of the VSD method’s proficiency, particularly in handling and encoding large-scale video datasets efficiently. The proportional relationship between video file size and processing time, depicted by the ascending bars, evidences the VSD’s adept handling of increased data volumes without significant time penalties. Notably, the density trend, illustrated by a brown line and scaled on a secondary
y-axis, indicates a consistent density increase with video file sizes. This suggests the VSD method’s capability to enhance encoding quality, possibly due to higher video resolutions and bitrates, without sacrificing biochemical compatibility or efficiency. These observations underscore the VSD’s innovative coding model and indexing mechanisms’ success, which notably outstrips prior models in both time efficiency and storage density. The graph thus solidifies the VSD method’s potential for revolutionizing DNA-based video archival systems, aligning with the study’s aim to establish a fast, reliable, and scalable video data storage solution.
4.5. Computational Time
In addition to the aforementioned analysis, we compared the encoding efficiency of the proposed encoding strategy. This evaluation aimed to assess how efficiently the VSD method performs compared to previous research work. The results of this comparison are presented in
Figure 10.
Figure 10 clearly illustrates the encoding time for the proposed VSD method and the encoding methods employed in previous research studies. Upon examining the graph, it becomes evident that the VSD method offers a substantial improvement in terms of encoding efficiency. The encoding time required by the VSD method is significantly lower when compared to the encoding times reported in previous research efforts. For example, Goldman’s model requires 1601 s/min to encode a 100 MB file, while VSD accomplished this task within 373 s/min.
The observed enhancement in encoding efficiency achieved by the VSD method is significant. It implies that the proposed approach outperforms existing encoding techniques [
10,
11,
12,
16] and streamlines the overall encoding process.
4.6. Ablation Studies
The comparison between the proposed VSD method and existing state-of-the-art methods [
10,
11,
12,
13,
14,
16] reveals notable advantages of our approach (
Table 6). It should be noted that the experimental data of each method in the table are based on the video files given in
Table 5 (numbered 1–7). In terms of GC content ratio, the VSD method consistently demonstrates a superior balance, ensuring optimal biochemical compatibility. The innovative quadratic coding model, leveraging RS error-correcting codes, stands out for its effectiveness in converting video files into DNA sequences with enhanced error-correction capabilities. This unique approach not only meets biochemical constraints but also addresses the complexities of computational processing. Furthermore, the VSD method introduces an efficient indexing mechanism for random video access, adding a layer of versatility to the storage system. Through extensive simulations and error correction procedures, the VSD method consistently outperforms existing methods, showing its robustness, efficiency, and success in accurately decoding the original video content.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}