
Enhanced YOLOX with United Attention Head for Road Detetion When Driving


Abstract
:1. Introduction
- This paper proposes a united attention head to precede the YOLO head for extracting scale, location, and contour information. Especially, a spatial self-attention mechanism is designed to obtain spatial similarity through convolutions and pooling.
- Our proposed algorithm, UAH-YOLO, outperforms the compared algorithms in object detection tasks on the BDD100k dataset, including YOLOX, YOLOv3, YOLOv5, EfficientDet, Faster R-CNN, and SSD. It achieves higher detection accuracy on average and has a faster processing speed, surpassing YOLOX [17] by 3.47 frames per second and far outpacing YOLOv3, Faster R-CNN, etc.
- The UAH-YOLO algorithm has been demonstrated to be a superior detection algorithm on the Caltech Pedestrian dataset, accurately identifying pedestrians on both sides of the road when driving.
2. Related Work
2.1. Methodolgy
2.2. Object Detection Research
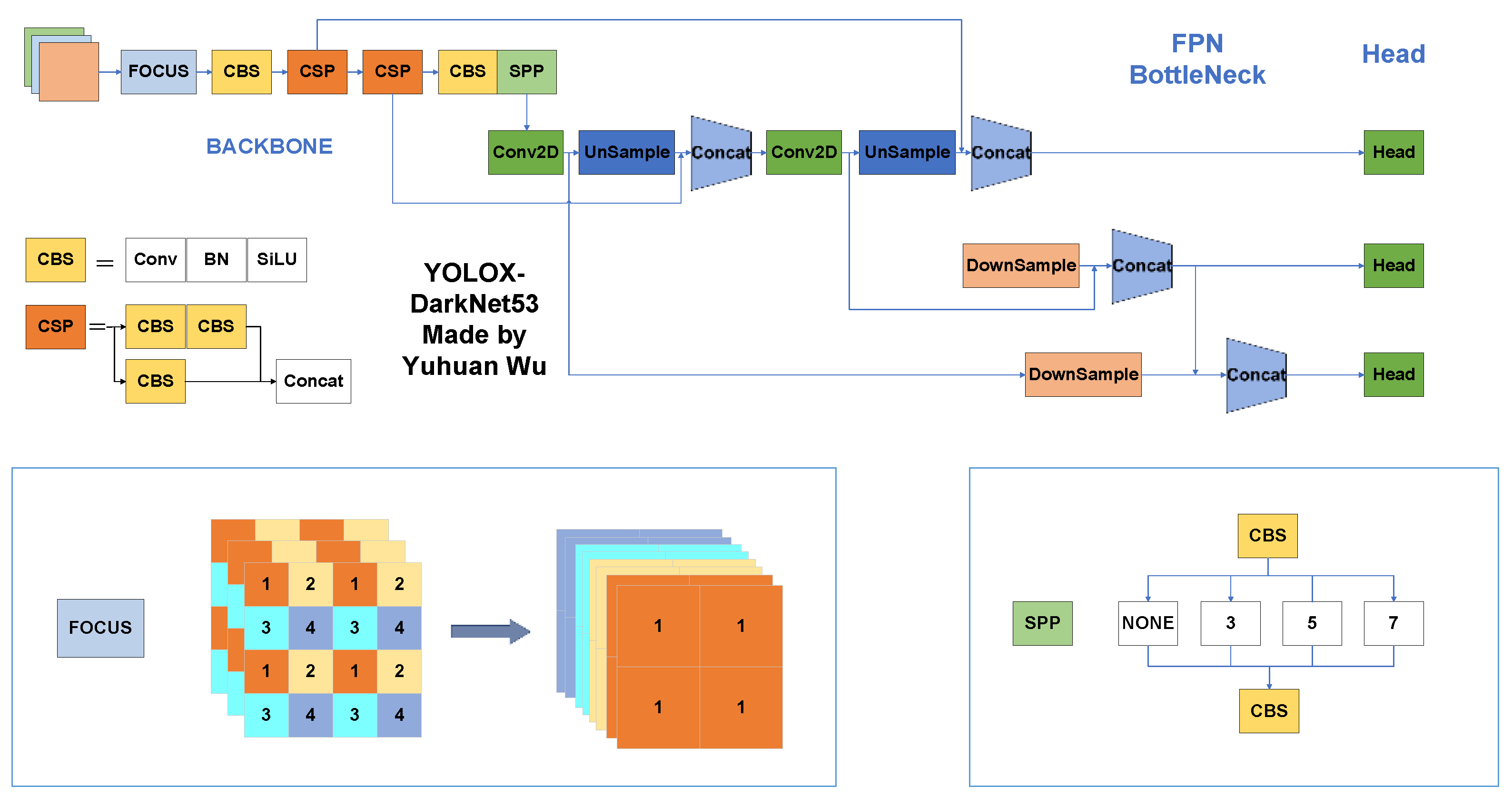
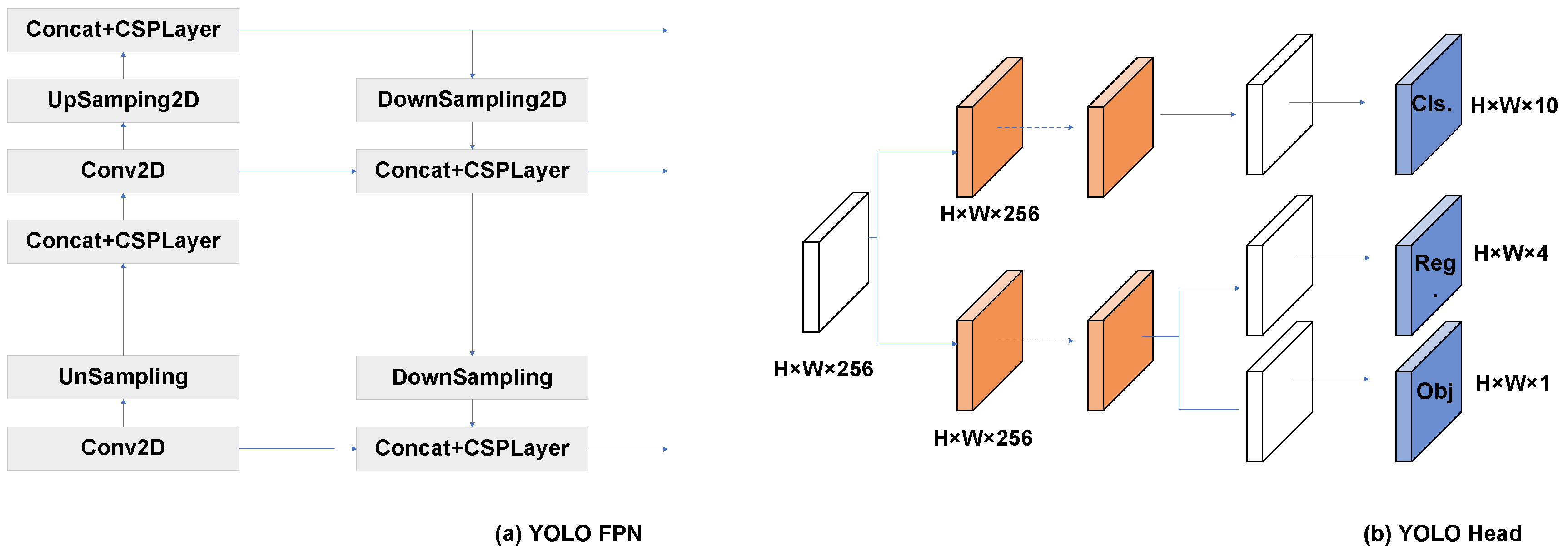
3. Proposed Methods
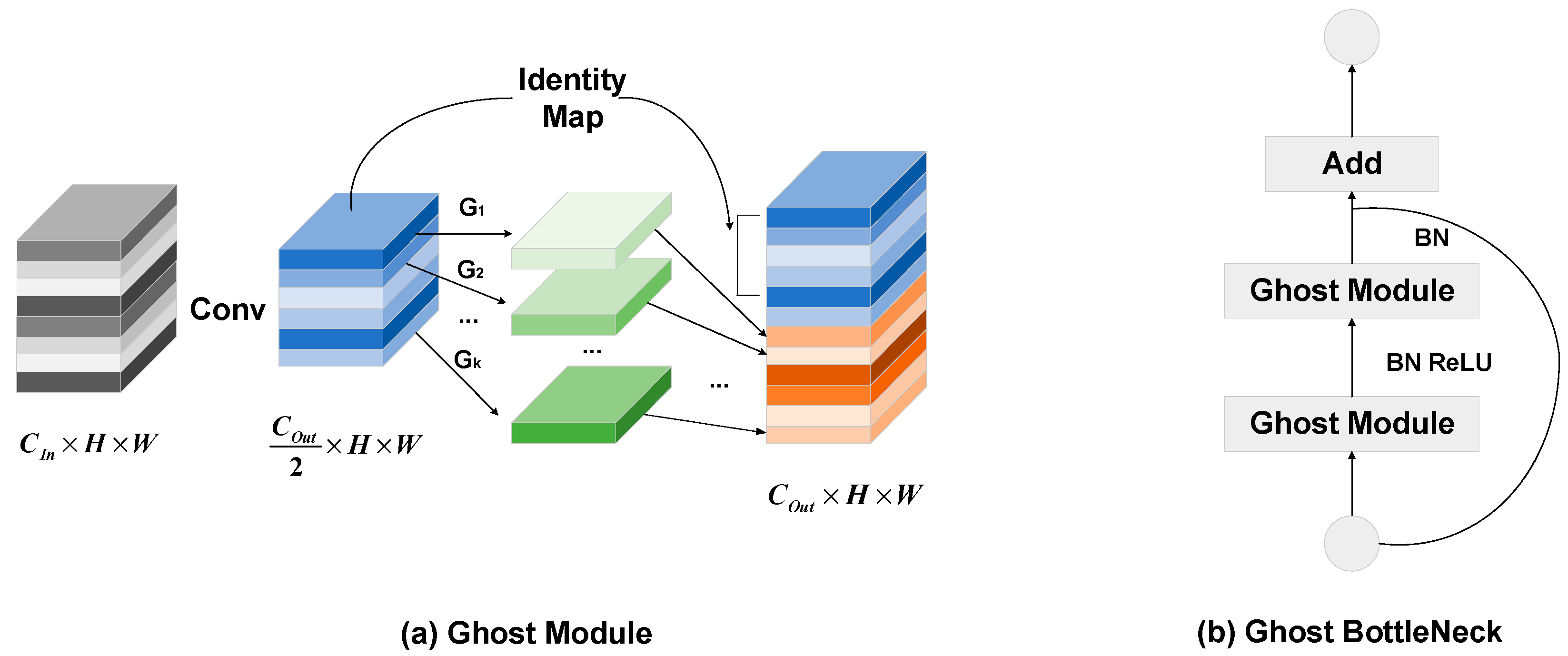
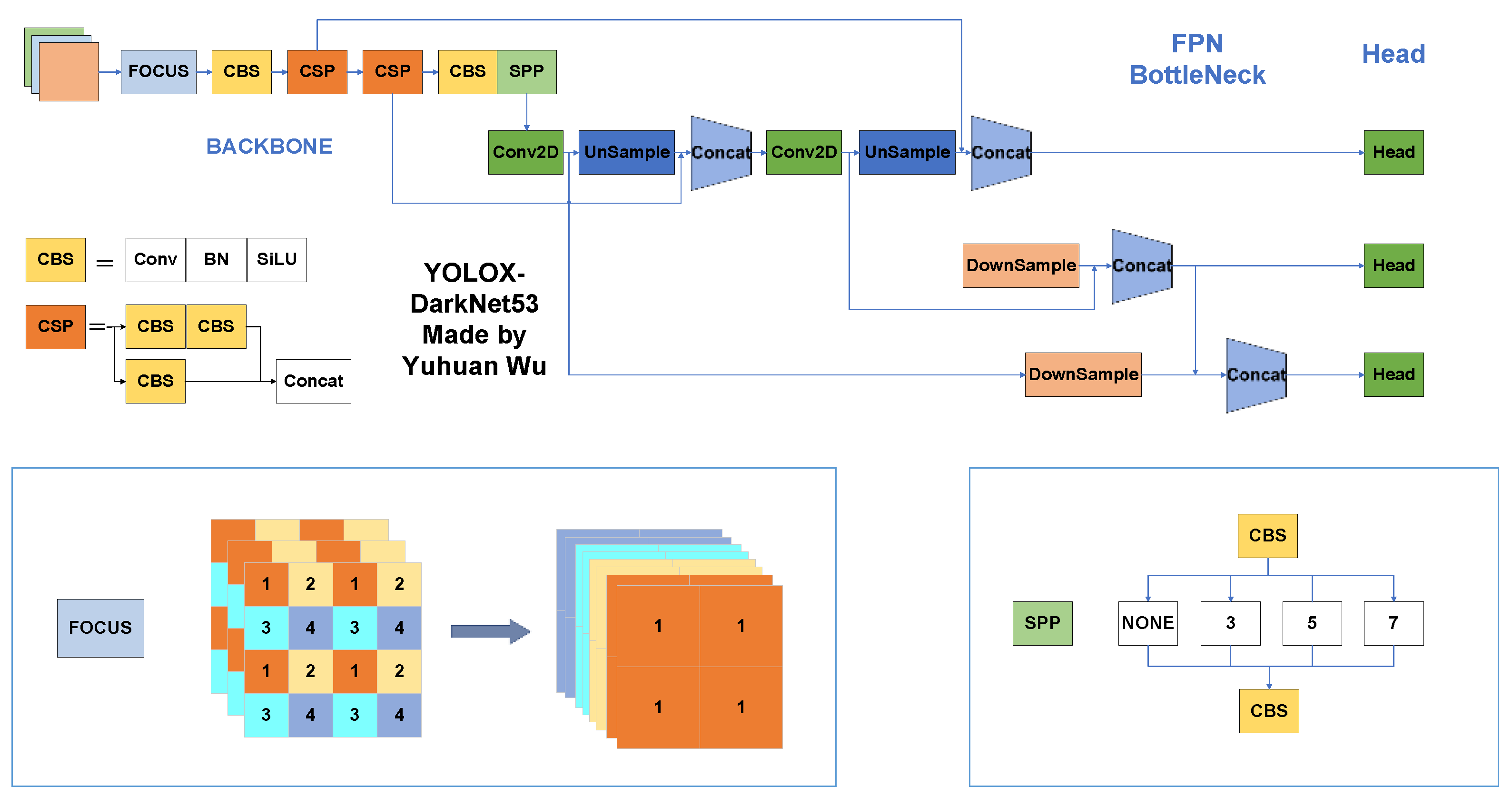
3.1. Backbone
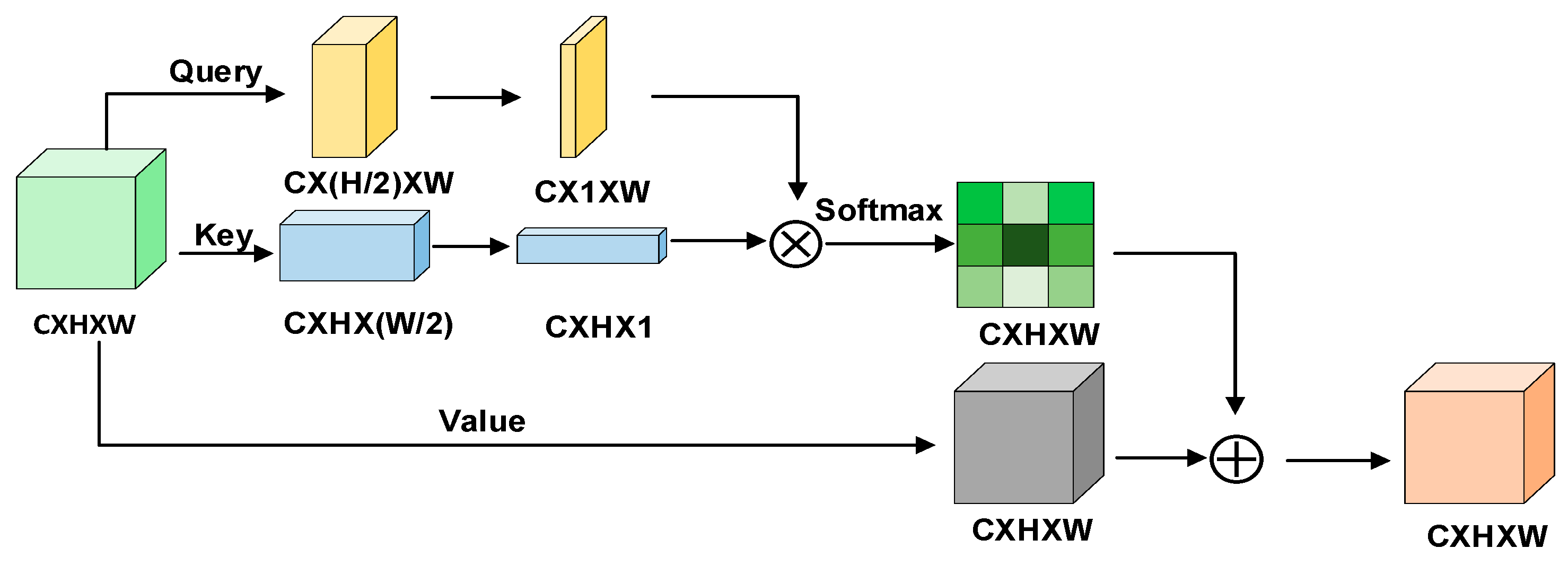
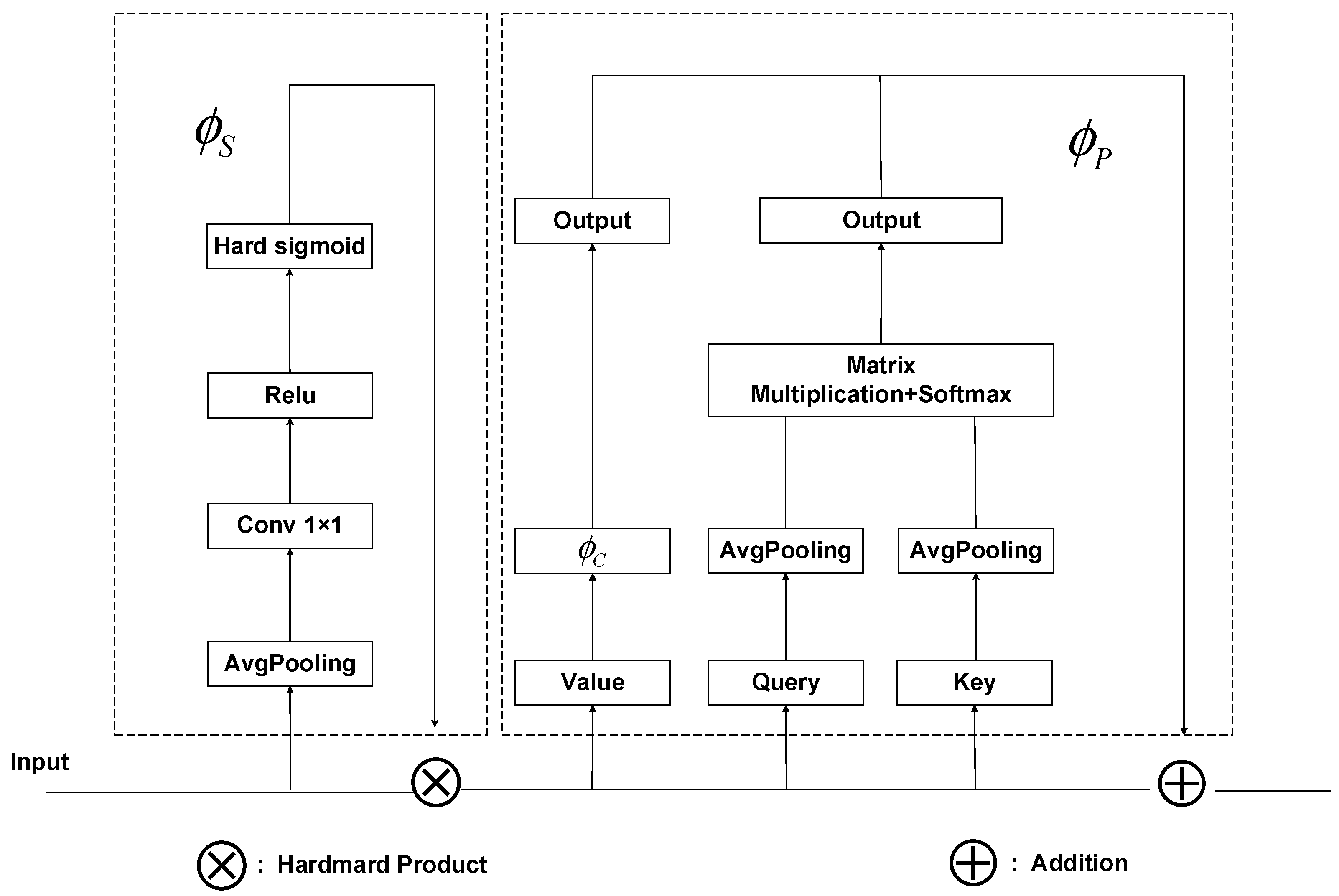
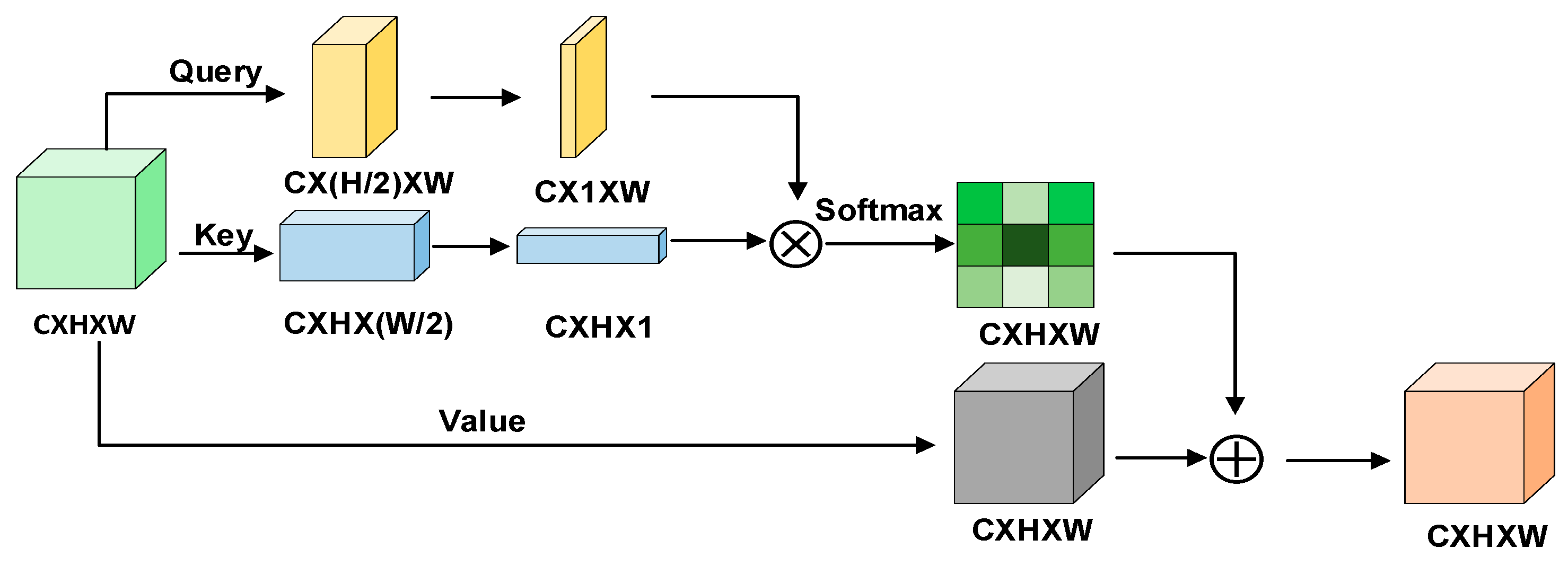
3.2. United Attention Head
3.2.1. Scale-Aware
3.2.2. Position-Aware
3.2.3. Contour-Aware
3.3. CIOU Loss
3.4. Our Model
4. Result and Discussion
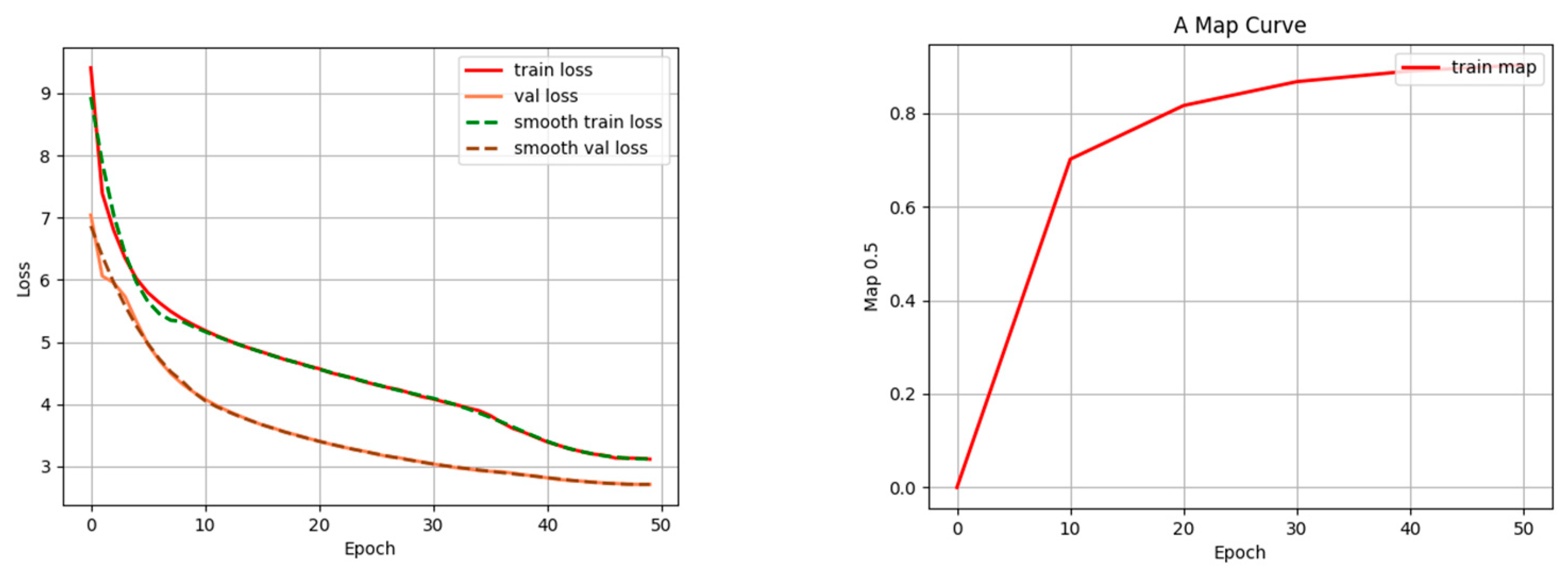
4.1. Implementation Details and Evaluation Metrics
4.2. Experiment Datasets
| Algorithm 1: Without Proposal Boxes, UAH-YOLO Trains Backbone, FPNet, Attention Head for Targets Location, Detection, Classification. |
| Input: Target neural network with parameters groups; ; Training set ; Threshold for convergence: ; Loss function: ; Output: Well-trained network 1: procedure Train 2: repeat 3: sample a mini-batch from training set 4: 5: 6: until 7: end procedure 8: return Trained network |
4.3. BDD100k Comparison Analysis
4.4. Ablation Studies
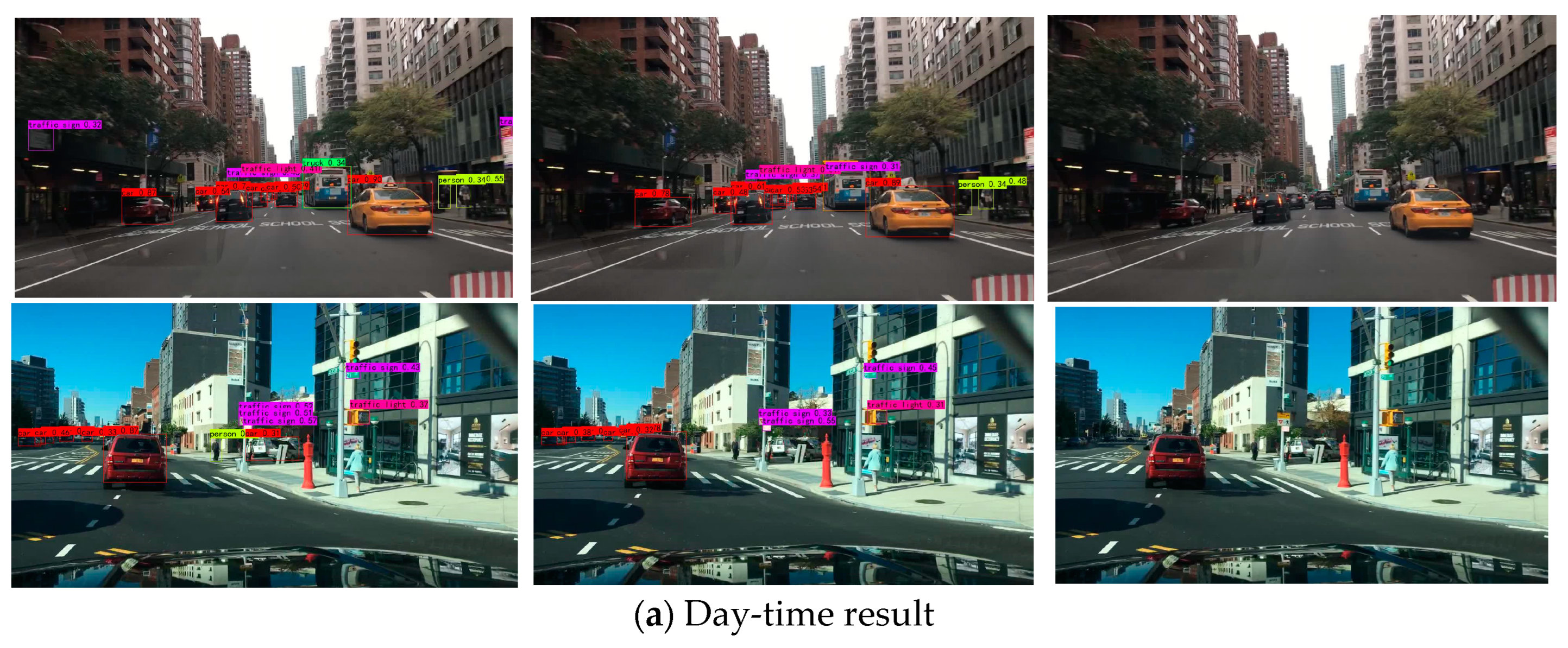
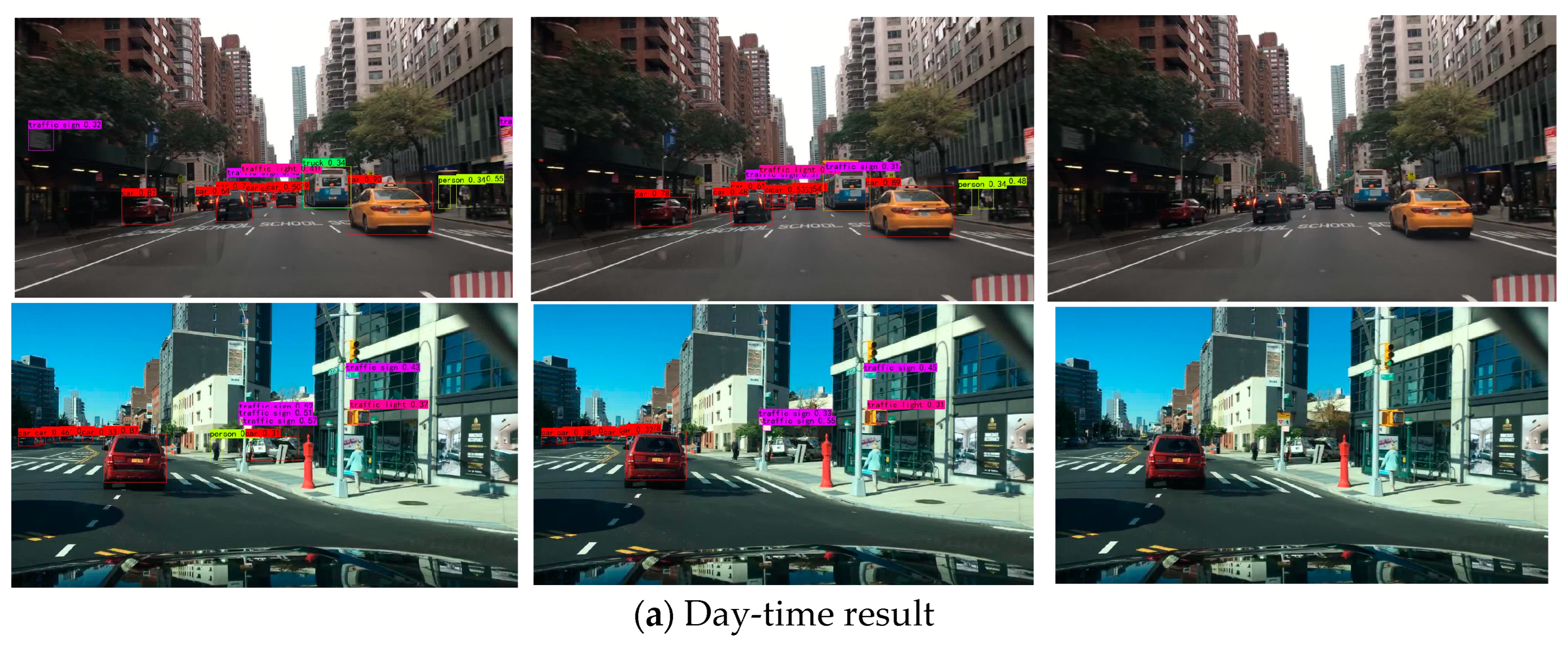
4.5. Visualization of BDD100k Detection Results
4.6. Train on Caltech Pedestrian Dataset
5. Conclusions and Future Scope
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A survey of autonomous driving: Common practices and emerging technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Furda, A.; Vlacic, L. Enabling safe autonomous driving in real-world city traffic using multiple criteria decision making. IEEE Intell. Transp. Syst. Mag. 2011, 3, 4–17. [Google Scholar] [CrossRef]
- Gawande, U.; Hajari, K.; Golhar, Y. Pedestrian detection and tracking in video surveillance system: Issues, comprehensive review, and challenges. In Recent Trends in Computational Intelligence; Books on Demand (BoD): Norderstedt, Germany, 2020; pp. 1–24. [Google Scholar]
- Yang, X.; Li, X.; Ye, Y.; Lau, R.Y.; Zhang, X.; Huang, X. Road detection and centerline extraction via deep recurrent convolutional neural network U-Net. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7209–7220. [Google Scholar] [CrossRef]
- Ko, Y.; Lee, Y.; Azam, S.; Munir, F.; Jeon, M.; Pedrycz, W. Key points estimation and point instance segmentation approach for lane detection. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8949–8958. [Google Scholar] [CrossRef]
- Chan, Y.C.; Lin, Y.C.; Chen, P.C. Lane mark and drivable area detection using a novel instance segmentation scheme. In Proceedings of the 2019 IEEE/SICE International Symposium on System Integration (SII), Paris, France, 14–16 January 2019; pp. 502–506. [Google Scholar]
- Teichmann, M.; Weber, M.; Zoellner, M.; Cipolla, R.; Urtasun, R. Multinet: Real-time joint semantic reasoning for autonomous driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 1013–1020. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems 28: Proceedings of the Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015; MIT Press: Cambridg, MA, USA, 2015; Volume 44. [Google Scholar]
- He, K.; Gkioxari, G.; Doll’ar, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Doll’ar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. Centernet: Keypoint triplets for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6569–6578. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. Yolox: Exceeding yolo series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Zheng, Z.; Wang, P.; Ren, D.; Liu, W.; Ye, R.; Hu, Q.; Zuo, W. Enhancing geometric factors in model learning and inference for object detection and instance segmentation. IEEE Trans. Cybern. 2021, 52, 8574–8586. [Google Scholar] [CrossRef] [PubMed]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Tran, D.; Ray, J.; Shou, Z.; Chang, S.F.; Paluri, M. Convnet architecture search for spatiotemporal feature learning. arXiv 2017, arXiv:1708.05038. [Google Scholar]
- Lin, T.Y.; Doll’ar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Yang, M. Research on vehicle automatic driving target perception technology based on improved MSRPN algorithm. J. Comput. Cogn. Eng. 2022, 1, 147–151. [Google Scholar] [CrossRef]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 2021, 70, 4503613. [Google Scholar] [CrossRef]
- Sun, M.; Zhang, H.; Huang, Z.; Luo, Y.; Li, Y. Road infrared target detection with I-YOLO. IET Image Process. 2022, 16, 92–101. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning (PMLR), Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Fang, S.; Zhang, B.; Hu, J. Improved mask R-CNN multi-target detection and segmentation for autonomous driving in complex scenes. Sensors 2023, 23, 3853. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems, Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Curran Associates Inc.: Red Hook, NY, USA, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Car | Traffic Sign | Traffic Light | Truck | Bus | Person | mAP50 | FPS |
|---|---|---|---|---|---|---|---|---|---|
| UAH-YOLO | GhostNet | 0.7604 | 0.6364 | 0.5985 | 0.5989 | 0.6048 | 0.5760 | 62.90% | 40.05 |
| YOLOX | CSPDarkNet53 | 0.7488 | 0.6215 | 0.5802 | 0.6050 | 0.6072 | 0.5682 | 61.20% | 36.68 |
| YOLOv3 | DarkNet | 0.6327 | 0.5641 | 0.4784 | 0.5421 | 0.5589 | 0.5031 | 54.85% | 32.8 |
| YOLOv5-s | CSPDarkNet53 | 0.7254 | 0.6032 | 0.5638 | 0.5788 | 0.5836 | 0.5612 | 58.68% | 34.84 |
| EfficientDet | EfficientNet | 0.7158 | 0.6012 | 0.5704 | 0.5802 | 0.5794 | 0.5608 | 58.98% | 30.28 |
| Faster R-CNN | vgg-16 | 0.5926 | 0.5086 | 0.4462 | 0.495 | 0.5081 | 0.4629 | 51.57% | 10.07 |
| ResNet50 | 0.6012 | 0.5011 | 0.4517 | 0.4812 | 0.5114 | 0.4598 | 51.92% | - | |
| SSD | vgg-16 | 0.5057 | 0.4021 | 0.3766 | 0.4081 | 0.4129 | 0.4012 | 43.04% | - |
| G. | A. | C. | mAP50 | Parameters |
|---|---|---|---|---|
| × | × | × | 61.20 | 9.92 |
| √ | × | × | 61.46 | 6.85 |
| × | √ | × | 61.63 | 10.22 |
| × | × | √ | 61.87 | 9.97 |
| × | √ | √ | 61.98 | 10.27 |
| √ | × | √ | 62.68 | 6.90 |
| √ | √ | × | 62.42 | 7.15 |
| √ | √ | √ | 62.90 | 7.20 |
| Metrics | AP50/% | AP50–95/% | AR50–95/% |
|---|---|---|---|
| UAH-YOLO | 90.30 | 50.90 | 56.60 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Wu, Y. Enhanced YOLOX with United Attention Head for Road Detetion When Driving. Mathematics 2024, 12, 1331. https://doi.org/10.3390/math12091331
Wu Y, Wu Y. Enhanced YOLOX with United Attention Head for Road Detetion When Driving. Mathematics. 2024; 12(9):1331. https://doi.org/10.3390/math12091331
Chicago/Turabian StyleWu, Yuhuan, and Yonghong Wu. 2024. "Enhanced YOLOX with United Attention Head for Road Detetion When Driving" Mathematics 12, no. 9: 1331. https://doi.org/10.3390/math12091331
APA StyleWu, Y., & Wu, Y. (2024). Enhanced YOLOX with United Attention Head for Road Detetion When Driving. Mathematics, 12(9), 1331. https://doi.org/10.3390/math12091331