

Embedding Secret Data in a Vector Quantization Codebook Using a Novel Thresholding Scheme



Abstract
:1. Introduction
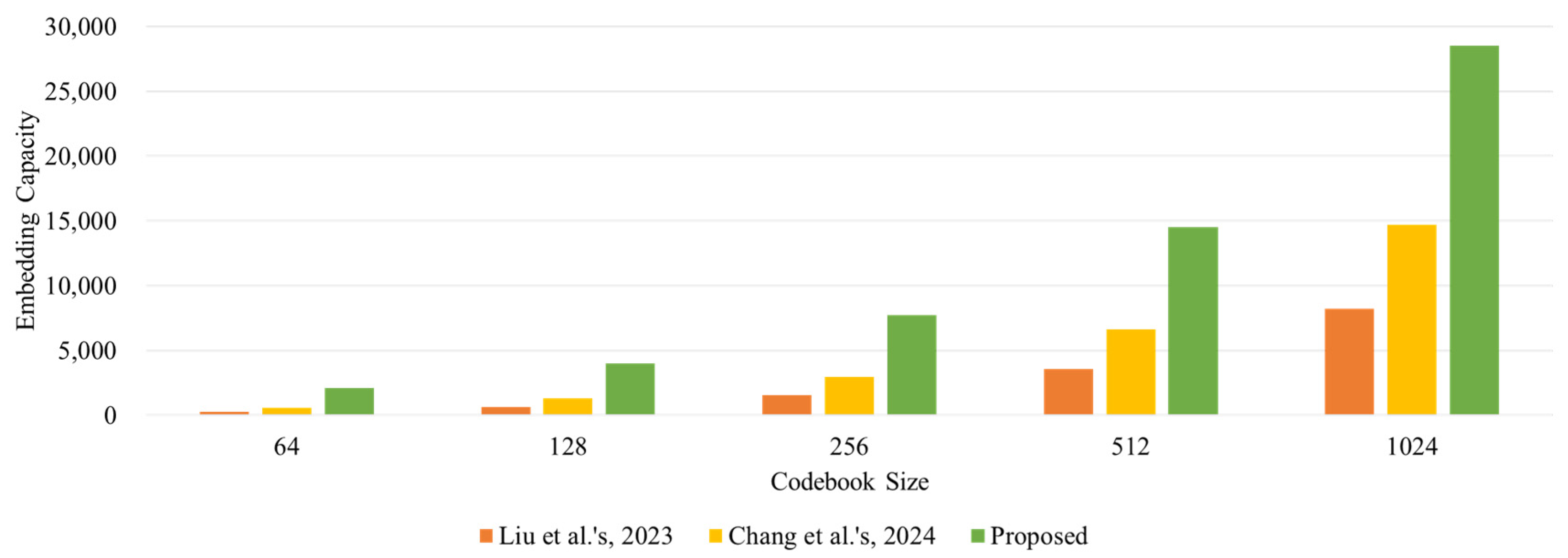
- Compared with a more recent compatible method, the embedding capacity is significantly improved. On a codebook of size 64, the embedding bit rate is 1.8838 bpp, which makes the improvement rate go as high as 223.66%. Even for a codebook of size 1024, the improvement rate can be as high as 85.19%.
- Our proposed scheme provides an adjustable threshold that can be adjusted to suit various requirements and reflects the flexibility of our approach.
- Our proposed scheme can losslessly reconstruct a VQ-compressed image. Achieving a PSNR of +∞ between a VQ-compressed image and the reconstructed VQ-compress image using the original codebook indicates that the two VQ-compressed images are exactly the same.
2. Related Work
2.1. Vector Quantization Codebook Training
- (a)
- Pick a random sample point
- (b)
- Let the distance between and a VQ centroid be
- (c)
- Find the VQ centroid with the shortest distance
- (d)
- Repeat
2.2. VQ Codeword Index Reordering
2.2.1. Codebook Sorting
2.2.2. VQ Codebook Data Embedding
2.2.3. VQ Codebook Data Extraction
2.3. Extended Run-Length Encoding
3. Proposed Scheme
3.1. Preprocessing Phase
3.2. Data Embedding Phase
| Algorithm 1 Data Embedding | |
| Input | Preprocessed codebook , index table , secret , and threshold . |
| Output | Stego codebook and reordered index table . |
| Step 1 | Preserve reference pixels and pixels causing overflow. Hide secret data in pixels flagged by indicators according to encoding rules. Record all indicators. ; for for Obtain the label according to the encoding rules. if or ; else if ; if indicator ; else indicator ; end if ; end if end if end for end for |
| Step 2 | Compress the indicator sequence using the ERLE algorithm to obtain compressed auxiliary information. |
| Step 3 | Similar to Step 1, but here, is first used for auxiliary information. Any remaining space can be used to embed the secret. for for Obtain the label according to the encoding rules. if or ; else if ; end if end if end for end for |
| Step 4 | Utilize reordering for additional data embedding. Embed any remaining auxiliary information not fully embedded in Step 3, and use available spaces to embed secret data. |
| Step 5 | Output stego codebook and reordered index table . |
3.3. Data Extraction and Image Recovery Phase
| Algorithm 2 Data Extraction | |
| Input | Stego codebook , reordered index table , and threshold . |
| Output | Secret and reordered codebook . |
| Step 1 | Use reordering of the stego codebook to extract data. |
| Step 2 | Keep reference pixels unchanged and recover the pixels that can be directly known to be embedded and extract data. for for if ; else if ; ; Obtain the data according to the encoding rules. end if end if end for end for |
| Step 3 | Similar to Step 2, the situation of needs to be judged based on the indicator. for for if ; else if if ; else ; ; Obtain the data according to the encoding rules. end if Obtain the secret and the reordered preprocessed codebook . end if end if end for end for |
| Step 4 | Post-processing for reordered preprocessed codebook for for if ; else ; end if end for end for Obtain the recovered codebook . |
| Step 5 | Output secret and recovered codebook . |
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sahu, A.K.; Umachandran, K.; Biradar, V.D.; Comfort, O.; Sri Vigna Hema, V.; Odimegwu, F.; Saifullah, M.A. A study on content tampering in multimedia watermarking. SN Comput. Sci. 2023, 4, 222. [Google Scholar] [CrossRef]
- Ramesh, R.K.; Dodmane, R.; Shetty, S.; Aithal, G.; Sahu, M.; Sahu, A.K. A Novel and Secure Fake-Modulus Based Rabin-3 Cryptosystem. Cryptography 2023, 7, 44. [Google Scholar] [CrossRef]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible data hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar]
- Chang, C.C.; Kieu, T.D.; Chou, Y.C. A high payload steganographic scheme based on (7, 4) hamming code for digital images. In Proceedings of the 2008 International Symposium on Electronic Commerce and Security, Guangzhou, China, 3–5 August 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 16–21. [Google Scholar]
- Zhang, X. Reversible data hiding in encrypted image. IEEE Signal Process. Lett. 2011, 18, 255–258. [Google Scholar] [CrossRef]
- Huang, C.T.; Weng, C.Y.; Shongwe, N.S. Capacity-Raising Reversible Data Hiding Using Empirical Plus–Minus One in Dual Images. Mathematics 2023, 11, 1764. [Google Scholar] [CrossRef]
- Zhang, Q.; Chen, K. Reversible Data Hiding in Encrypted Images Based on Two-Round Image Interpolation. Mathematics 2023, 12, 32. [Google Scholar] [CrossRef]
- He, D.; Cai, Z. Reversible Data Hiding for Color Images Using Channel Reference Mapping and Adaptive Pixel Prediction. Mathematics 2024, 12, 517. [Google Scholar] [CrossRef]
- Gray, R. Vector quantization. IEEE Assp Mag. 1984, 1, 4–29. [Google Scholar] [CrossRef]
- Linde, Y.; Buzo, A.; Gray, R. An algorithm for vector quantizer design. IEEE Trans. Commun. 1980, 28, 84–95. [Google Scholar] [CrossRef]
- Chang, C.C.; Hu, Y.C. A fast LBG codebook training algorithm for vector quantization. IEEE Trans. Consum. Electron. 1998, 44, 1201–1208. [Google Scholar] [CrossRef]
- Hsieh, C.H.; Tsai, J.C. Lossless compression of VQ index with search-order coding. IEEE Trans. Image Process. 1996, 5, 1579–1582. [Google Scholar] [CrossRef] [PubMed]
- Yang, C.H.; Lin, Y.C. Reversible data hiding of a VQ index table based on referred counts. J. Vis. Commun. Image Represent. 2009, 20, 399–407. [Google Scholar] [CrossRef]
- Lee, J.D.; Chiou, Y.H.; Guo, J.M. Lossless data hiding for VQ indices based on neighboring correlation. Inf. Sci. 2013, 221, 419–438. [Google Scholar] [CrossRef]
- Qin, C.; Hu, Y.C. Reversible data hiding in VQ index table with lossless coding and adaptive switching mechanism. Signal Process. 2016, 129, 48–55. [Google Scholar] [CrossRef]
- Rahmani, P.; Dastghaibyfard, G. Two reversible data hiding schemes for VQ-compressed images based on index coding. IET Image Process. 2018, 12, 1195–1203. [Google Scholar] [CrossRef]
- Liu, J.C.; Chang, C.C.; Lin, C.C. Hiding Information in a Well-Trained Vector Quantization Codebook. In Proceedings of the 2023 6th International Conference on Signal Processing and Machine Learning, Tianjin, China, 14–16 July 2023; pp. 287–292. [Google Scholar]
- Chang, C.C.; Liu, J.C.; Chang, C.C.; Lin, Y. Hiding Information in a Reordered Codebook Using Pairwise Adjustments in Codewords. In Proceedings of the 2024 5th International Conference on Computer Vision and Computational Intelligence, Bangkok, Thailand, 29–31 January 2024. [Google Scholar]
- Chen, K.; Chang, C.C. High-capacity reversible data hiding in encrypted images based on extended run-length coding and block-based MSB plane rearrangement. J. Vis. Commun. Image Represent. 2019, 58, 334–344. [Google Scholar] [CrossRef]
- Weber, A.G. The USC-SIPI Image Database: Version 5. 2006. Available online: http://sipi.usc.edu/database/ (accessed on 11 April 2024).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Codebook Size | 64 | 128 | 256 | 512 | 1024 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Image | OI | VI | OI | VI | OI | VI | OI | VI | OI | VI |
| Egretta | 29.6811 | +∞ | 30.4843 | +∞ | 31.1983 | +∞ | 31.9952 | +∞ | 32.7203 | +∞ |
| Elaine | 29.3081 | +∞ | 30.1569 | +∞ | 30.8513 | +∞ | 31.4101 | +∞ | 32.1139 | +∞ |
| Peppers | 28.2237 | +∞ | 29.1556 | +∞ | 30.4569 | +∞ | 31.3893 | +∞ | 32.3213 | +∞ |
| Tiffany | 27.0808 | +∞ | 27.7653 | +∞ | 28.4232 | +∞ | 29.6245 | +∞ | 30.4309 | +∞ |
| Woodland | 31.1364 | +∞ | 32.2857 | +∞ | 33.0819 | +∞ | 33.8991 | +∞ | 34.6139 | +∞ |
| Zelda | 31.8216 | +∞ | 32.8539 | +∞ | 33.6891 | +∞ | 34.5065 | +∞ | 35.2775 | +∞ |
| Codebook Size | 64 | 128 | 256 | 512 | 1024 | |
|---|---|---|---|---|---|---|
| 2 | 1098 | 2206 | 4727 | 9888 | 20,478 | |
| 3 | 1449 | 2819 | 5833 | 12,022 | 24,413 | |
| 4 | 1581 | 3169 | 6470 | 13,312 | 26,846 | |
| 5 | 1745 | 3336 | 6560 | 12,889 | 26,185 | |
| 6 | 1834 | 3545 | 6714 | 13,119 | 26,374 | |
| 7 | 1885 | 3655 | 6943 | 13,456 | 26,809 | |
| 8 | 1929 | 3738 | 7114 | 13,821 | 27,425 | |
| Codebook Size | 64 | 128 | 256 | 512 | 1024 | |
|---|---|---|---|---|---|---|
| EC | Liu et al. [17] | 264 | 649 | 1546 | 3595 | 8204 |
| Chang et al. [18] | 596 | 1433 | 3128 | 6876 | 14,809 | |
| Proposed Scheme | 1929 | 3738 | 7114 | 13,821 | 27,425 | |
| ER | Liu et al. [17] | 0.2578 | 0.3169 | 0.3774 | 0.4388 | 0.5007 |
| Chang et al. [18] | 0.5820 | 0.6997 | 0.7637 | 0.8394 | 0.9039 | |
| Proposed Scheme | 1.8838 | 1.8252 | 1.7368 | 1.6871 | 1.6739 | |
| Improvement Rate | 223.66% | 160.85% | 127.43% | 101.00% | 85.19% | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, Y.; Liu, J.-C.; Chang, C.-C.; Chang, C.-C. Embedding Secret Data in a Vector Quantization Codebook Using a Novel Thresholding Scheme. Mathematics 2024, 12, 1332. https://doi.org/10.3390/math12091332
Lin Y, Liu J-C, Chang C-C, Chang C-C. Embedding Secret Data in a Vector Quantization Codebook Using a Novel Thresholding Scheme. Mathematics. 2024; 12(9):1332. https://doi.org/10.3390/math12091332
Chicago/Turabian StyleLin, Yijie, Jui-Chuan Liu, Ching-Chun Chang, and Chin-Chen Chang. 2024. "Embedding Secret Data in a Vector Quantization Codebook Using a Novel Thresholding Scheme" Mathematics 12, no. 9: 1332. https://doi.org/10.3390/math12091332