
Decentralized Federated Learning for Private Smart Healthcare: A Survey †

Abstract
1. Introduction
2. Research Method
2.1. Research Questions
2.2. Search Process
2.3. Inclusion and Exclusion Criteria
- The term “decentralized” mentioned in some articles mainly refers to the decentralized approach to data processing and storage, rather than the architecture without a central server. In such articles, it is mainly emphasized that each participating node (hospital) has storage control of its own data and local models, and data processing is completed locally. The central server only aggregates and trains global models. Although the design of the entire system conforms to the principle of decentralization, it is beyond the scope of this article.
- Describe the centralized implementation of FL and cover a topic other than DFL.
- The discussion solely revolves around the blockchain without integration with FL.
- Discussing DFL in non-medical domains (such as industry, communication, etc.).
- Unrelated papers mistakenly returned via the query (Figure 2).
3. Fundamentals and Taxonomy
3.1. Traditional Distributed Methods (TD-FL)
3.2. Blockchain-Based Methods (BC-FL)
3.3. Comparison and Summary of TD-FL and BC-FL
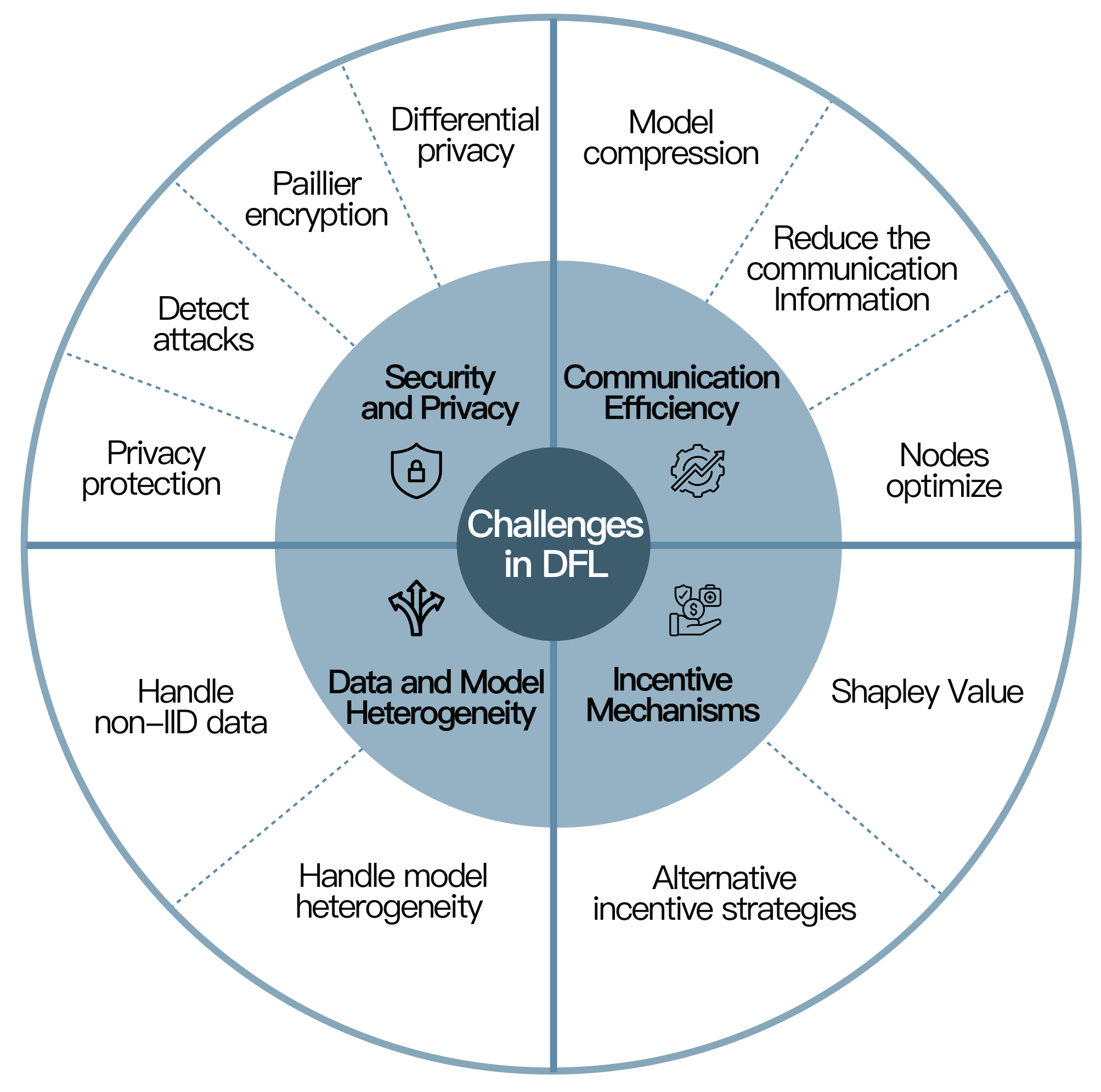
4. Challenges
4.1. Security and Privacy
4.1.1. Differential Privacy
Laplace Mechanism
Gaussian Mechanism
Exponential Mechanism
4.1.2. Paillier Encryption Algorithm
4.1.3. Strategies for Detecting Attacks
4.1.4. Strategies for Privacy Protection
4.2. Communication Efficiency and Cost
4.2.1. Strategies for Model Compression
4.2.2. Strategies for Reducing the Communication Information in Nodes
4.2.3. Strategies for Nodes Optimize
4.3. Data and Model Heterogeneity
4.4. Incentive Mechanisms
5. Case Studies
5.1. Wearable Device Data
5.2. Cardiovascular Diseases
5.3. Neurological Disorders
5.4. Respiratory Diseases
5.5. Cancer
6. Open Issues and Research Directions
6.1. Security and Privacy
6.2. Communication Efficiency and Cost
6.3. Data and Model Heterogeneity
6.4. Incentive Mechanisms
7. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Aceto, G.; Persico, V.; Pescapé, A. Industry 4.0 and health: Internet of things, big data, and cloud computing for healthcare 4.0. J. Ind. Inf. Integr. 2020, 18, 100129. [Google Scholar] [CrossRef]
- Guo, H.; Li, W.; Meese, C.; Nejad, M. Decentralized Electronic Health Records Management via Redactable Blockchain and Revocable IPFS. In Proceedings of the 2024 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE), Wilmington, DE, USA, 19–21 June 2024; pp. 167–171. [Google Scholar]
- Chang, Y.; Fang, C.; Sun, W. A Blockchain-Based Federated Learning Method for Smart Healthcare. Comput. Intell. Neurosci. 2021, 2021, 4376418. [Google Scholar] [CrossRef] [PubMed]
- Carlos Ferreira, J.; Elvas, L.B.; Correia, R.; Mascarenhas, M. Enhancing EHR Interoperability and Security through Distributed Ledger Technology: A Review. Healthcare 2024, 12, 1967. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- de Gomez, M.R.C. A Comprehensive Introduction to Healthcare Data Analytics. J. Biomed. Sustain. Healthc. Appl. 2024, 44–53. [Google Scholar]
- Konečnỳ, J.; McMahan, H.B.; Yu, F.X.; Richtárik, P.; Suresh, A.T.; Bacon, D. Federated learning: Strategies for improving communication efficiency. arXiv 2016, arXiv:1610.05492. [Google Scholar]
- Zhang, Y.; Gai, K.; Qiu, M.; Ding, K. Understanding privacy-preserving techniques in digital cryptocurrencies. In Proceedings of the Algorithms and Architectures for Parallel Processing: 20th International Conference, ICA3PP 2020, New York, NY, USA, 2–4 October 2020; Proceedings, Part III 20. pp. 3–18. [Google Scholar]
- Ran, A.R.; Wang, X.; Chan, P.P.; Wong, M.O.; Yuen, H.; Lam, N.M.; Chan, N.C.; Yip, W.W.; Young, A.L.; Yung, H.W.; et al. Developing a privacy-preserving deep learning model for glaucoma detection: A multicentre study with federated learning. Br. J. Ophthalmol. 2024, 108, 1114–1123. [Google Scholar] [CrossRef]
- Baghersalimi, S.; Teijeiro, T.; Aminifar, A.; Atienza, D. Decentralized federated learning for epileptic seizures detection in low-power wearable systems. IEEE Trans. Mob. Comput. 2023, 23, 6392–6407. [Google Scholar] [CrossRef]
- Heiyanthuduwage, S.R.; Altas, I.; Bewong, M.; Islam, M.Z.; Deho, O.B. Decision trees in federated learning: Current state and future opportunities. IEEE Access 2024, 12, 127943–127965. [Google Scholar] [CrossRef]
- Santhosh, G.; De Vita, F.; Bruneo, D.; Longo, F.; Puliafito, A. Towards trustless prediction-as-a-service. In Proceedings of the 2019 IEEE International Conference on Smart Computing (SMARTCOMP), Washington, DC, USA, 12–15 June 2019; pp. 317–322. [Google Scholar]
- Ma, C.; Li, J.; Ding, M.; Yang, H.H.; Shu, F.; Quek, T.Q.; Poor, H.V. On safeguarding privacy and security in the framework of federated learning. IEEE Netw. 2020, 34, 242–248. [Google Scholar] [CrossRef]
- Zhang, H.; Li, G.; Zhang, Y.; Gai, K.; Qiu, M. Blockchain-based privacy-preserving medical data sharing scheme using federated learning. In Proceedings of the Knowledge Science, Engineering and Management: 14th International Conference, KSEM 2021, Tokyo, Japan, 14–16 August 2021; Proceedings, Part III 14. pp. 634–646. [Google Scholar]
- Bai, L.; Hu, H.; Ye, Q.; Li, H.; Wang, L.; Xu, J. Membership Inference Attacks and Defenses in Federated Learning: A Survey. ACM Comput. Surv. 2024, 57, 1–35. [Google Scholar] [CrossRef]
- Yang, L.; Lu, Y.; Cao, J.; Huang, J.; Zhang, M. E-tree learning: A novel decentralized model learning framework for edge ai. IEEE Internet Things J. 2021, 8, 11290–11304. [Google Scholar] [CrossRef]
- Kang, H.S.; Chai, Z.Y.; Li, Y.L.; Huang, H.; Zhao, Y.J. Edge computing in Internet of Vehicles: A federated learning method based on Stackelberg dynamic game. Inf. Sci. 2025, 689, 121452. [Google Scholar] [CrossRef]
- Li, H.; Ge, L.; Tian, L. Survey: Federated learning data security and privacy-preserving in edge-Internet of Things. Artif. Intell. Rev. 2024, 57, 130. [Google Scholar] [CrossRef]
- Stripelis, D.; Saleem, H.; Ghai, T.; Dhinagar, N.; Gupta, U.; Anastasiou, C.; Ver Steeg, G.; Ravi, S.; Naveed, M.; Thompson, P.M.; et al. Secure neuroimaging analysis using federated learning with homomorphic encryption. In Proceedings of the 17th International Symposium on Medical Information Processing and Analysis, Campinas, Brazil, 17–19 November 2021; Volume 12088, pp. 351–359. [Google Scholar]
- Kalra, S.; Wen, J.; Cresswell, J.C.; Volkovs, M.; Tizhoosh, H.R. Decentralized federated learning through proxy model sharing. Nat. Commun. 2023, 14, 2899. [Google Scholar] [CrossRef] [PubMed]
- Ben Shoham, O.; Rappoport, N. Federated learning of medical concepts embedding using behrt. JAMIA Open 2024, 7, ooae110. [Google Scholar] [CrossRef]
- Babar, M.; Qureshi, B.; Koubaa, A. Review on Federated Learning for digital transformation in healthcare through big data analytics. In Future Generation Computer Systems; Elsevier: Amsterdam, The Netherlands, 2024. [Google Scholar]
- Cong, R.; Ye, Y.; Wu, J.; Li, Y.; Chen, Y.; Bian, Y.; Tago, K.; Nishimura, S.; Ogihara, A.; Jin, Q. A Trustworthy Decentralized System for Health Data Integration and Sharing: Design and Experimental Validation. In Proceedings of the International Conference on Human-Computer Interaction, Copenhagen, Denmark, 23–28 July 2023; pp. 125–134. [Google Scholar]
- Pavlova, E.; Melnikov, G.; Yanovich, Y.; Frolov, A. Unlocking potential of open source model training in decentralized federated learning environment. In Blockchain: Research and Applications; Elsevier: Amsterdam, The Netherlands, 2025; p. 100264. [Google Scholar]
- Samikwa, E.; Di Maio, A.; Braun, T. DFL: Dynamic federated split learning in heterogeneous IoT. IEEE Trans. Mach. Learn. Commun. Netw. 2024, 2, 733–752. [Google Scholar] [CrossRef]
- Gabrielli, E.; Pica, G.; Tolomei, G. A survey on decentralized federated learning. arXiv 2023, arXiv:2308.04604. [Google Scholar]
- Arthi, N.T.; Mubin, K.E.; Rahman, J.; Rafi, G.; Sheja, T.T.; Reza, M.T.; Alam, M.A. Decentralized federated learning and deep learning leveraging xai-based approach to classify colorectal cancer. In Proceedings of the 2022 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 18–20 December 2022; pp. 1–6. [Google Scholar]
- Yuan, L.; Wang, Z.; Sun, L.; Philip, S.Y.; Brinton, C.G. Decentralized federated learning: A survey and perspective. IEEE Internet Things J. 2024, 11, 34617–34638. [Google Scholar] [CrossRef]
- Beltrán, E.T.M.; Pérez, M.Q.; Sánchez, P.M.S.; Bernal, S.L.; Bovet, G.; Pérez, M.G.; Pérez, G.M.; Celdrán, A.H. Decentralized federated learning: Fundamentals, state of the art, frameworks, trends, and challenges. IEEE Commun. Surv. Tutorials 2023, 25, 2983–3013. [Google Scholar] [CrossRef]
- Liu, Y.; Ai, Z.; Sun, S.; Zhang, S.; Liu, Z.; Yu, H. Fedcoin: A peer-to-peer payment system for federated learning. In Federated Learning: Privacy and Incentive; Springer: Berlin/Heidelberg, Germany, 2020; pp. 125–138. [Google Scholar]
- Van Truong, V.; Quan, P.K.; Park, D.H.; Kim, T. Performance Evaluation of Decentralized Federated Learning: Impact of Fully and K-Connected Topologies, Heterogeneous Computing Resources, and Communication Bandwidth. IEEE Access 2025, 13, 32741–32755. [Google Scholar] [CrossRef]
- Xiao, Y.; Ye, Y.; Huang, S.; Hao, L.; Ma, Z.; Xiao, M.; Mumtaz, S.; Dobre, O.A. Fully decentralized federated learning-based on-board mission for UAV swarm system. IEEE Commun. Lett. 2021, 25, 3296–3300. [Google Scholar] [CrossRef]
- Chung, W.C.; Lin, Y.H.; Luo, J.A. Ring-Based Decentralized Federated Learning with Cosine Similarity Grouping. In Proceedings of the 2024 International Conference on Consumer Electronics-Taiwan (ICCE-Taiwan), Taichung, Taiwan, 9–11 July 2024; pp. 113–114. [Google Scholar]
- Iansiti, M.; Lakhani, K.R. The truth about blockchain. Harv. Bus. Rev. 2017, 95, 118–127. [Google Scholar]
- Wang, M.; Zhu, T.; Zuo, X.; Ye, D.; Yu, S.; Zhou, W. Blockchain-based gradient inversion and poisoning defense for federated learning. IEEE Internet Things J. 2023, 11, 15667–15681. [Google Scholar] [CrossRef]
- Qu, Y.; Uddin, M.P.; Gan, C.; Xiang, Y.; Gao, L.; Yearwood, J. Blockchain-enabled federated learning: A survey. ACM Comput. Surv. 2022, 55, 1–35. [Google Scholar] [CrossRef]
- Andrew, J.; Isravel, D.P.; Sagayam, K.M.; Bhushan, B.; Sei, Y.; Eunice, J. Blockchain for healthcare systems: Architecture, security challenges, trends and future directions. J. Netw. Comput. Appl. 2023, 215, 103633. [Google Scholar]
- Qu, Y.; Pokhrel, S.R.; Garg, S.; Gao, L.; Xiang, Y. A blockchained federated learning framework for cognitive computing in industry 4.0 networks. IEEE Trans. Ind. Inform. 2020, 17, 2964–2973. [Google Scholar] [CrossRef]
- Lin, F.; Xia, S.; Qi, J.; Tang, C.; Zheng, Z.; Yu, X. A parking sharing network over blockchain with proof-of-planned-behavior consensus protocol. IEEE Trans. Veh. Technol. 2022, 71, 8124–8136. [Google Scholar] [CrossRef]
- Qin, Z.; Yan, X.; Zhou, M.; Deng, S. BlockDFL: A blockchain-based fully decentralized peer-to-peer federated learning framework. In Proceedings of the ACM Web Conference 2024, Virtual, 13–17 May 2024; pp. 2914–2925. [Google Scholar]
- Jin, H.; Dai, X.; Xiao, J.; Li, B.; Li, H.; Zhang, Y. Cross-cluster federated learning and blockchain for internet of medical things. IEEE Internet Things J. 2021, 8, 15776–15784. [Google Scholar] [CrossRef]
- Zhou, X.; Huang, W.; Liang, W.; Yan, Z.; Ma, J.; Pan, Y.; Kevin, I.; Wang, K. Federated distillation and blockchain empowered secure knowledge sharing for internet of medical things. Inf. Sci. 2024, 662, 120217. [Google Scholar] [CrossRef]
- Zhaofeng, M.; Xiaochang, W.; Jain, D.K.; Khan, H.; Hongmin, G.; Zhen, W. A blockchain-based trusted data management scheme in edge computing. IEEE Trans. Ind. Inform. 2019, 16, 2013–2021. [Google Scholar] [CrossRef]
- Ray, P.P.; Chowhan, B.; Kumar, N.; Almogren, A. BIoTHR: Electronic health record servicing scheme in IoT-blockchain ecosystem. IEEE Internet Things J. 2021, 8, 10857–10872. [Google Scholar] [CrossRef]
- Gilad, Y.; Hemo, R.; Micali, S.; Vlachos, G.; Zeldovich, N. Algorand: Scaling byzantine agreements for cryptocurrencies. In Proceedings of the 26th Symposium on Operating Systems Principles, Shanghai, China, 28–31 October 2017; pp. 51–68. [Google Scholar]
- Weng, J.; Weng, J.; Zhang, J.; Li, M.; Zhang, Y.; Luo, W. Deepchain: Auditable and privacy-preserving deep learning with blockchain-based incentive. IEEE Trans. Dependable Secur. Comput. 2019, 18, 2438–2455. [Google Scholar] [CrossRef]
- Kim, H.; Park, J.; Bennis, M.; Kim, S.L. Blockchained on-device federated learning. IEEE Commun. Lett. 2019, 24, 1279–1283. [Google Scholar] [CrossRef]
- Feng, L.; Zhao, Y.; Guo, S.; Qiu, X.; Li, W.; Yu, P. BAFL: A blockchain-based asynchronous federated learning framework. IEEE Trans. Comput. 2021, 71, 1092–1103. [Google Scholar] [CrossRef]
- Jatain, D.; Singh, V.; Dahiya, N. Blockchain Base Community Cluster-Federated Learning for Secure Aggregation of Healthcare Data. Procedia Comput. Sci. 2022, 215, 752–762. [Google Scholar] [CrossRef]
- Wang, Z.; Hu, Y.; Xiao, J.; Wu, C. Efficient ring-topology decentralized federated learning with deep generative models for industrial artificial intelligent. arXiv 2021, arXiv:2104.08100. [Google Scholar]
- Feng, C.; Liu, B.; Yu, K.; Goudos, S.K.; Wan, S. Blockchain-empowered decentralized horizontal federated learning for 5G-enabled UAVs. IEEE Trans. Ind. Inform. 2021, 18, 3582–3592. [Google Scholar] [CrossRef]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R.; et al. Advances and open problems in federated learning. Found. Trends® Mach. Learn. 2021, 14, 1–210. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated learning: Challenges, methods, and future directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Shayan, M.; Fung, C.; Yoon, C.J.; Beschastnikh, I. Biscotti: A blockchain system for private and secure federated learning. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1513–1525. [Google Scholar] [CrossRef]
- Lu, Y.; Huang, X.; Dai, Y.; Maharjan, S.; Zhang, Y. Blockchain and federated learning for privacy-preserved data sharing in industrial IoT. IEEE Trans. Ind. Inform. 2019, 16, 4177–4186. [Google Scholar] [CrossRef]
- Kuo, T.T.; Pham, A. Detecting model misconducts in decentralized healthcare federated learning. Int. J. Med. Inform. 2022, 158, 104658. [Google Scholar] [CrossRef] [PubMed]
- Cui, L.; Qu, Y.; Xie, G.; Zeng, D.; Li, R.; Shen, S.; Yu, S. Security and privacy-enhanced federated learning for anomaly detection in IoT infrastructures. IEEE Trans. Ind. Inform. 2021, 18, 3492–3500. [Google Scholar] [CrossRef]
- Wan, Y.; Qu, Y.; Ni, W.; Xiang, Y.; Gao, L.; Hossain, E. Data and model poisoning backdoor attacks on wireless federated learning, and the defense mechanisms: A comprehensive survey. IEEE Commun. Surv. Tutorials 2024, 26, 1861–1897. [Google Scholar] [CrossRef]
- Gholami, A.; Torkzaban, N.; Baras, J.S. Trusted decentralized federated learning. In Proceedings of the 2022 IEEE 19th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 8–11 January 2022; pp. 1–6. [Google Scholar]
- Yang, Z.; Shi, Y.; Zhou, Y.; Wang, Z.; Yang, K. Trustworthy federated learning via blockchain. IEEE Internet Things J. 2022, 10, 92–109. [Google Scholar] [CrossRef]
- Li, Z.; Yu, H.; Zhou, T.; Luo, L.; Fan, M.; Xu, Z.; Sun, G. Byzantine resistant secure blockchained federated learning at the edge. IEEE Netw. 2021, 35, 295–301. [Google Scholar] [CrossRef]
- Dwork, C.; McSherry, F.; Nissim, K.; Smith, A. Calibrating noise to sensitivity in private data analysis. In Proceedings of the Theory of Cryptography: Third Theory of Cryptography Conference, TCC 2006, New York, NY, USA, 4–7 March 2006; Proceedings 3. pp. 265–284. [Google Scholar]
- Yin, C.; Xi, J.; Sun, R.; Wang, J. Location privacy protection based on differential privacy strategy for big data in industrial internet of things. IEEE Trans. Ind. Inform. 2017, 14, 3628–3636. [Google Scholar] [CrossRef]
- Hallaji, E.; Razavi-Far, R.; Saif, M.; Wang, B.; Yang, Q. Decentralized federated learning: A survey on security and privacy. IEEE Trans. Big Data 2024, 10, 194–213. [Google Scholar] [CrossRef]
- McSherry, F.; Talwar, K. Mechanism design via differential privacy. In Proceedings of the 48th Annual IEEE Symposium on Foundations of Computer Science (FOCS’07), Providence, RI, USA, 21–23 October 2007; pp. 94–103. [Google Scholar]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; pp. 223–238. [Google Scholar]
- Gouissem, A.; Abualsaud, K.; Yaacoub, E.; Khattab, T.; Guizani, M. Robust decentralized federated learning using collaborative decisions. In Proceedings of the 2022 International Wireless Communications and Mobile Computing (IWCMC), Dubrovnik, Croatia, 30 May–3 June 2022; pp. 254–258. [Google Scholar]
- Kalapaaking, A.P.; Khalil, I.; Yi, X. Blockchain-based federated learning with SMPC model verification against poisoning attack for healthcare systems. IEEE Trans. Emerg. Top. Comput. 2023, 12, 269–280. [Google Scholar] [CrossRef]
- Kang, J.; Wen, J.; Ye, D.; Lai, B.; Wu, T.; Xiong, Z.; Nie, J.; Niyato, D.; Zhang, Y.; Xie, S. Blockchain-empowered federated learning for healthcare metaverses: User-centric incentive mechanism with optimal data freshness. IEEE Trans. Cogn. Commun. Netw. 2023, 10, 348–362. [Google Scholar] [CrossRef]
- Pennisi, M.; Salanitri, F.P.; Bellitto, G.; Spampinato, C.; Palazzo, S.; Casella, B.; Aldinucci, M. Experience Replay as an Effective Strategy for Optimizing Decentralized Federated Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 3376–3383. [Google Scholar]
- Chen, Y.; Lin, F.; Chen, Z.; Tang, C.; Jia, R.; Li, M. Blockchain-based Federated Learning with Contribution-Weighted Aggregation for Medical Data Modeling. In Proceedings of the 2022 IEEE 19th International Conference on Mobile Ad Hoc and Smart Systems (MASS), Denver, CO, USA, 20–22 October 2022; pp. 606–612. [Google Scholar]
- Roy, S.; Bera, D. A blockchain-based Verifiable Aggregation for Federated Learning and Secure Sharing in Healthcare. In Proceedings of the 2023 IEEE International Conference on Advanced Networks and Telecommunications Systems (ANTS), Jaipur, India, 17–20 December 2023; pp. 165–170. [Google Scholar]
- Moulahi, W.; Jdey, I.; Moulahi, T.; Alawida, M.; Alabdulatif, A. A blockchain-based federated learning mechanism for privacy preservation of healthcare IoT data. Comput. Biol. Med. 2023, 167, 107630. [Google Scholar] [CrossRef] [PubMed]
- El Rifai, O.; Biotteau, M.; de Boissezon, X.; Megdiche, I.; Ravat, F.; Teste, O. Blockchain-based federated learning in medicine. In Proceedings of the Artificial Intelligence in Medicine: 18th International Conference on Artificial Intelligence in Medicine, AIME 2020, Minneapolis, MN, USA, 25–28 August 2020; Proceedings 18. pp. 214–224. [Google Scholar]
- Wang, Z.; Hu, Y.; Yan, S.; Wang, Z.; Hou, R.; Wu, C. Efficient ring-topology decentralized federated learning with deep generative models for medical data in ehealthcare systems. Electronics 2022, 11, 1548. [Google Scholar] [CrossRef]
- Wang, C.; Wang, S.; Zhao, C.; Wang, W.; Hu, B.; Wang, Y.; Wang, L.; Chen, Z. Decentralized Reinforced Anonymous FLchain: A Secure Federated Learning Architecture for the Medical Industry. In Proceedings of the 2023 IEEE 47th Annual Computers, Software, and Applications Conference (COMPSAC), Torino, Italy, 26–30 June 2023; pp. 396–405. [Google Scholar]
- Rahman, M.A.; Hossain, M.S.; Islam, M.S.; Alrajeh, N.A.; Muhammad, G. Secure and provenance enhanced internet of health things framework: A blockchain managed federated learning approach. IEEE Access 2020, 8, 205071–205087. [Google Scholar] [CrossRef] [PubMed]
- Li, W.; Feng, C.; Zhang, L.; Xu, H.; Cao, B.; Imran, M.A. A scalable multi-layer PBFT consensus for blockchain. IEEE Trans. Parallel Distrib. Syst. 2020, 32, 1146–1160. [Google Scholar] [CrossRef]
- Lu, S.; Zhang, Y.; Wang, Y. Decentralized federated learning for electronic health records. In Proceedings of the 2020 54th Annual Conference on Information Sciences and Systems (CISS), Princeton, NJ, USA, 18–20 March 2020; pp. 1–5. [Google Scholar]
- Singh, M.B.; Singh, H.; Pratap, A. Energy-Efficient and Privacy-Preserving Blockchain Based Federated Learning for Smart Healthcare System. IEEE Trans. Serv. Comput. 2023, 17, 2392–2403. [Google Scholar] [CrossRef]
- Nguyen, T.; Dakka, M.; Diakiw, S.; VerMilyea, M.; Perugini, M.; Hall, J.; Perugini, D. A novel decentralized federated learning approach to train on globally distributed, poor quality, and protected private medical data. Sci. Rep. 2022, 12, 8888. [Google Scholar] [CrossRef]
- Tedeschini, B.C.; Savazzi, S.; Stoklasa, R.; Barbieri, L.; Stathopoulos, I.; Nicoli, M.; Serio, L. Decentralized federated learning for healthcare networks: A case study on tumor segmentation. IEEE Access 2022, 10, 8693–8708. [Google Scholar] [CrossRef]
- Zhang, W.; Li, P.; Wu, G.; Li, J. Privacy-Preserving Deep Learning in Internet of Healthcare Things with Blockchain-Based Incentive. In Proceedings of the International Conference on Knowledge Science, Engineering and Management, Singapore, 6–8 August 2022; pp. 302–315. [Google Scholar]
- Lian, Z.; Wang, W.; Han, Z.; Su, C. Blockchain-based personalized federated learning for internet of medical things. IEEE Trans. Sustain. Comput. 2023, 8, 694–702. [Google Scholar] [CrossRef]
- Jiang, S.; Firouzi, F.; Chakrabarty, K. Low-overhead clustered federated learning for personalized stress monitoring. IEEE Internet Things J. 2023, 11, 4335–4347. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Xiong, J.; Bi, R.; Zhou, Z.; Bhuiyan, M.Z.A. Robust and privacy-preserving decentralized deep federated learning training: Focusing on digital healthcare applications. IEEE/ACM Trans. Comput. Biol. Bioinform. 2023, 21, 890–901. [Google Scholar] [CrossRef]
- Lian, Z.; Yang, Q.; Wang, W.; Zeng, Q.; Alazab, M.; Zhao, H.; Su, C. DEEP-FEL: Decentralized, efficient and privacy-enhanced federated edge learning for healthcare cyber physical systems. IEEE Trans. Netw. Sci. Eng. 2022, 9, 3558–3569. [Google Scholar] [CrossRef]
- Zhang, W.; Lu, Q.; Yu, Q.; Li, Z.; Liu, Y.; Lo, S.K.; Chen, S.; Xu, X.; Zhu, L. Blockchain-based federated learning for device failure detection in industrial IoT. IEEE Internet Things J. 2020, 8, 5926–5937. [Google Scholar] [CrossRef]
- Peng, Z.; Xu, J.; Chu, X.; Gao, S.; Yao, Y.; Gu, R.; Tang, Y. Vfchain: Enabling verifiable and auditable federated learning via blockchain systems. IEEE Trans. Netw. Sci. Eng. 2021, 9, 173–186. [Google Scholar] [CrossRef]
- Hu, C.; Jiang, J.; Wang, Z. Decentralized federated learning: A segmented gossip approach. arXiv 2019, arXiv:1908.07782. [Google Scholar]
- Hinton, G. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Mou, T.; Jiang, X.; Li, J.; Yan, B.; Chen, Q.; Zhang, T.; Huang, W.; Gao, C.; Chen, Y. FedTAM: Decentralized Federated Learning with a Feature Attention Based Multi-teacher Knowledge Distillation for Healthcare. In Proceedings of the 2023 IEEE 29th International Conference on Parallel and Distributed Systems (ICPADS), Danzhou City, China, 17–21 December 2023; pp. 1246–1253. [Google Scholar]
- Ratwani, R.M.; Sutton, K.; Galarraga, J.E. Addressing AI algorithmic bias in health care. JAMA 2024, 332, 1051–1052. [Google Scholar] [CrossRef]
- Veeramachaneni, V. Edge Computing: Architecture, Applications, and Future Challenges in a Decentralized Era. Recent Trends Comput. Graph. Multimed. Technol. 2025, 7, 8–23. [Google Scholar]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; y Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Ng, D.; Lan, X.; Yao, M.M.S.; Chan, W.P.; Feng, M. Federated learning: A collaborative effort to achieve better medical imaging models for individual sites that have small labelled datasets. Quant. Imaging Med. Surg. 2021, 11, 852. [Google Scholar] [CrossRef]
- Shapley, L.S. A value for n-person games. Contrib. Theory Games 1953, 2, 307–317. [Google Scholar]
- Zhan, Y.; Li, P.; Qu, Z.; Zeng, D.; Guo, S. A learning-based incentive mechanism for federated learning. IEEE Internet Things J. 2020, 7, 6360–6368. [Google Scholar] [CrossRef]
- Kosta, A.; Pappas, N.; Angelakis, V. Age of information: A new concept, metric, and tool. Found. Trends® Netw. 2017, 12, 162–259. [Google Scholar] [CrossRef]
- Wei, M.; Yang, J.; Zhao, Z.; Zhang, X.; Li, J.; Deng, Z. Defedhdp: Fully decentralized online federated learning for heart disease prediction in computational health systems. IEEE Trans. Comput. Soc. Syst. 2024, 11, 6854–6867. [Google Scholar] [CrossRef]
- Piao, C.; Zhu, T.; Wang, Y.; Baldeweg, S.E.; Taylor, P.; Georgiou, P.; Sun, J.; Wang, J.; Li, K. Privacy Preserved Blood Glucose Level Cross-Prediction: An Asynchronous Decentralized Federated Learning Approach. arXiv 2024, arXiv:2406.15346. [Google Scholar]
- Chetoui, M.; Akhloufi, M.A. Peer-to-peer federated learning for COVID-19 detection using transformers. Computers 2023, 12, 106. [Google Scholar] [CrossRef]
- Chai, H.; Huang, Y.; Xu, L.; Song, X.; He, M.; Wang, Q. A decentralized federated learning-based cancer survival prediction method with privacy protection. Heliyon 2024, 10, e31873. [Google Scholar] [CrossRef]
- Adeniran, I.A.; Efunniyi, C.P.; Osundare, O.S.; Abhulimen, A.O. Data-driven decision-making in healthcare: Improving patient outcomes through predictive modeling. Eng. Sci. Technol. J. 2024, 5, 59–67. [Google Scholar]
- Wong, E.S.; Choy, R.W.; Zhang, Y.; Chu, W.K.; Chen, L.J.; Pang, C.P.; Yam, J.C. Global retinoblastoma survival and globe preservation: A systematic review and meta-analysis of associations with socioeconomic and health-care factors. Lancet Glob. Health 2022, 10, e380–e389. [Google Scholar] [CrossRef]
- Xie, H.; Zhang, Y.; Zhongwen, Z.; Zhou, H. Privacy-Preserving Medical Data Collaborative Modeling: A Differential Privacy Enhanced Federated Learning Framework. J. Knowl. Learn. Sci. Technol. 2024, 3, 340–350. [Google Scholar]
- Chen, R.; Xia, H.; Wang, K.; Xu, S.; Zhang, R. KDRSFL: A knowledge distillation resistance transfer framework for defending model inversion attacks in split federated learning. Future Gener. Comput. Syst. 2025, 166, 107637. [Google Scholar] [CrossRef]
- Liu, H.; Wei, J.; Xu, Z.; Zhao, Z. Authentication and Traceability for Federated Learning Models via Group Signatures. 2024. Available online: https://www.researchsquare.com/article/rs-4867383/v1 (accessed on 30 March 2025).
- Azimi-Abarghouyi, S.M.; Fodor, V. Quantized hierarchical federated learning: A robust approach to statistical heterogeneity. arXiv 2024, arXiv:2403.01540. [Google Scholar]
- Zheng, S.; Hu, J.; Min, G.; Li, K. Mutual Knowledge Distillation based Personalized Federated Learning for Smart Edge Computing. IEEE Trans. Consum. Electron. 2024, 1. [Google Scholar] [CrossRef]
- Qu, Y.; Ding, M.; Sun, N.; Thilakarathna, K.; Zhu, T.; Niyato, D. The Frontier of Data Erasure: A Survey on Machine Unlearning for Large Language Models. Computer 2025, 58, 45–57. [Google Scholar] [CrossRef]
- Ye, M.; Fang, X.; Du, B.; Yuen, P.C.; Tao, D. Heterogeneous federated learning: State-of-the-art and research challenges. ACM Comput. Surv. 2023, 56, 1–44. [Google Scholar] [CrossRef]
- Shi, Y.; Zhang, Y.; Xiao, Y.; Niu, L. Optimization strategies for client drift in federated learning: A review. Procedia Comput. Sci. 2022, 214, 1168–1173. [Google Scholar] [CrossRef]
- Mu, X.; Shen, Y.; Cheng, K.; Geng, X.; Fu, J.; Zhang, T.; Zhang, Z. FedProc: Prototypical contrastive federated learning on non-IID data. Future Gener. Comput. Syst. 2023, 143, 93–104. [Google Scholar] [CrossRef]
- Liu, X.; Deng, Y.; Nallanathan, A.; Bennis, M. Federated learning and meta learning: Approaches, applications, and directions. IEEE Commun. Surv. Tutorials 2023, 26, 571–618. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
| Notations | Descriptions |
|---|---|
| Pr | The probability distributions of the query result |
| S | The subset of possible outputs for the query result |
| The privacy budget | |
| The sensitivity of the query function | |
| The noise value | |
| p | The probability density |
| Sampling from a Laplace distribution with a mean of 0 and a scale parameter of | |
| The tolerance parameter that controls the probability of privacy failure | |
| The standard deviation | |
| The sensitivity of the scoring function, indicating the impact of a single-data-point’, s, change in the data set on the scoring function. | |
| x and | The adjacent data sets |
| O | The set of candidate outputs, which includes all possible outputs |
| o | The particular output selected from the candidate output set O |
| Another candidate output from the set, O, used for normalization | |
| The private key | |
| Least common multiple | |
| The set of all integers that are relatively prime to | |
| m | Plaintext message |
| c | Ciphertext |
| The Shapley value of node k | |
| The subset S of all nodes, excluding node k | |
| ! | The number of permutations of the nodes in coalition S |
| ! | The total number of permutations of all nodes |
| N | The number of total clients |
| The utility function of coalition S, which represents the total value obtained via the nodes in coalition S when cooperating |
| Ref. | Challenges | Solutions | ML Methods | Metrics | Compared to the Baseline Algorithms | Framework |
|---|---|---|---|---|---|---|
| [3] | Model parameters are stolen by attackers to infer the original private clinical data | (1) Adaptive differential privacy algorithm (2) A consensus protocol based on the gradient validation | CNN | Accuracy | BlockFL Original FL | Blockchain-based FL method |
| [20] | Privacy disclosure | Differential privacy stochastic gradient descent (DP-SGD) | LeNet5 MLP CNN | Accuracy A macro-average accuracy | FedAvg FML-proxy | Proxy-based FL (ProxyFL) |
| [23] | Privacy disclosure | (1) Blockchain provides a tamper-proof recording and verification mechanism for data operations (2) The ciphertext-policy attribute-based encryption (CP-ABE) encryption method that allows cryptors to define who can decrypt the ciphertext ensures that only authorized users have access to sensitive data | NA | NA | NA | A novel model of individual-initiated auditable access control (IIAAC) |
| [42] | Privacy disclosure | Federated distillation | NN | Loss Accuracy | FedAtt DS2PM FedAvg | Federated distillation and blockchain-empowered secure knowledge sharing (FDBC-SKS) |
| [56] | Model misconduct, such as submitting incorrect or tampered models | A framework with three components, auditing, coefficient, and performance detectors, that detects model misconduct by comparing models with historical data | Logistic regression | Precision Recall F1-score Execution time | NA | The model misconduct detection framework |
| [67] | Byzantine attack | Dual-way updating mechanism to isolate malicious nodes | NN | Accuracy | Cyclic institutional incremental learning (CIIL) | Robust DFL (RDFL) |
| [68] | Poisoning attack | Using secure multi-party computation (SMPC) encryption inference to exclude malicious models before model aggregation | ResNet18 | Accuracy Time cost | NA | Secure multi-party computation (SMPC) |
| [69] | Data tampering | A practical Byzantine fault-tolerant (PBFT) consensus algorithm is used in a hierarchical cross-chain architecture | NA | Accuracy | NA | Cross-chain-empowered FL framework |
| [70] | Privacy disclosure | The generative adversarial network (GAN) is used to generate synthetic data to simulate the statistical properties of the real data without exposing the raw data | GAN | Accuracy | FedAvg FedProx FedBN | A DFL strategy using experience replay and GANs |
| Ref. | Challenges | Solutions | ML Methods | Metrics | Compared to the Baseline Algorithms | Framework |
|---|---|---|---|---|---|---|
| [10] | (1) A large number of increased clients leads to higher communication costs (2) Resource limitations for the client side (wearables) | Knowledge distillation reduces the complex teacher model to a student model to run on wearable devices | DNN | Sensitivity (Sen) Specificity (Spe) Geometric mean (Gmean) | FedAvg | Real-time decentralized FL framework |
| [14] | (1) The growing size of the blockchain affects its scalability (2) Blockchain storage performance is limited by a single node | Upload the trained local model to the InterPlanetary File System (IPFS) | CNN | Accuracy | Training with individual nodes | Blockchain-Based Privacy-Preserving Medical Data Sharing Scheme (MPBC) |
| [42] | (1) Node load (2) Consensus process lacks efficiency | Selecting the master node based on node load, filtering nodes capable of participating in consensus in blockchain through reinforcement learning | NN | Loss Accuracy | FedAtt DS2PM FedAvg | Federated distillation and blockchain-empowered secure knowledge sharing (FDBC-SKS) |
| [75] | There is a redundancy when the data transfer between the nodes | (1) The large-scale data processing tasks are decomposed into small parts and processed in parallel on multiple processing nodes in the map-reduce framework (2) The Ring-All Reduce algorithm in parallel computing optimizes communication | GAN | Inception score (IS) Earth mover’s distance (EMD) | Traditional centralized FL methods Decentralized FL frameworks that utilize gossip algorithms | Ring-topology DFL (RDFL) |
| [70] | Concept drift | Experience replay method | GAN | Accuracy | FedAvg FedProx FedBN | A DFL strategy using experience replay and GANs |
| [79] | The parameter exchange between nodes causes a communication burden | Decentralized stochastic gradient tracking (DSGT) through the gradient-tracking mechanism maintains the global gradient tracking at each node, reducing the overall communication frequency | NN | Optimality gap Accuracy Communication rounds | Traditional FL (FL) FL with DSGD FL with DSGT | NA |
| [80] | The device in a wireless body area network (WBAN) consumes energy while transmitting | The Stable WBAN-Miner Association (WMA) heuristic algorithm maximizes the utility function of the entire system | QNN | Test loss Energy consumption | BlockFL HFEL BFL schemes | Efficient and privacy-preserving blockchain-based FL framework |
| [81] | Network communication burden | Knowledge distillation | ResNet18 ResNet50 DenseNet121 | Balanced accuracy Class-specific accuracy Log loss | NA | Decentralized AI training algorithm (DAITA) |
| [82] | Communication and computational latency between the distributed nodes | The asynchronous consensus mechanism is integrated to handle changes in communication and computational delays between distributed nodes. | U-Net model | Dice similarity coefficient (DSC) Training time | Traditional centralized learning Federated averaging Consensus-driven fully DFL | NA |
| [83] | Miner disconnections during consensus execution in blockchain | A robust consensus based on PoS improvement that a robust proof of stake (RPoS) allows nodes participating in the consensus to go offline or enter during the execution of the consensus | CNN | Accuracy Convergence speed | Traditional FL without blockchain integration FL with PoW consensus mechanisms | Blockchain-Enabled Secure FL Architecture |
| [84] | (1) Differences in communication capacity between different nodes (2) Network heterogeneity leads to communication difficulties | (1) Edge servers with greater computing power are the nodes instead of mobile devices (2) Lin–Kernighan–Helsgaun (LKH) algorithm-based bottleneck traveling salesman problem (BTSP) solver | CNN | Accuracy Training time | Traditional decentralized ring-based FL as DFL | Decentralized, efficient, and privacy-enhanced federated edge learning (DEEP-FEL) |
| [85] | The heterogeneity of the data leads to inefficient model training | A dynamic clustering mechanism that groups clients based on data similarity | ClusterGAN CNN LSTM | Accuracy Training runtime | Dynamic clustering algorithm Dynamic-Fusion FL algorithm | A “Low-Overhead Clustered FL” approach |
| [86] | Differences in communication capacity between different nodes | Data-sharing scheme based on Ring-Allreduce | NA | Accuracy | FedAvg Gossip learning | Robust and privacy-preserving decentralized deep FL (RPDFL) |
| Ref. | Challenges | Solutions | ML Methods | Metrics | Compared to the Baseline Algorithms | Framework |
|---|---|---|---|---|---|---|
| [10] | Data heterogeneity | Adaptive ensemble learning | DNN | Sensitivity (Sen) Specificity (Spe) Geometric mean (Gmean) | FedAvg | Real-time decentralized FL framework |
| [20] | Model heterogeneity | Each participant uses a private model trained independently in a proxy model; a publicly available proxy model acts as a medium for information exchange | LeNet5 MLP CNN | Accuracy, macro-average accuracy | FedAvg FML-proxy | Proxy-based FL (ProxyFL) |
| [23] | Individual users are reluctant to share data | Provide personalized feedback to the data owners who share the data; personalized feedback includes the results of comparative analysis with peer users or a group of users | NA | NA | NA | A novel model of individual-initiated auditable access control (IIAAC) |
| [71] | Lack of incentive | Staged reward mechanism | NN | Accuracy Loss | Federated average algorithm (FL-AVG) | FL with contribution-weighted aggregation (FL-CWA) |
| [69] | In the case of client information asymmetry, no consideration is given to motivate users to contribute fresh sensing data | An incentive mechanism based on contract theory with data freshness | NA | Accuracy | NA | Cross-chain-empowered FL framework |
| [70] | Data heterogeneity | The thetic data generated via GAN enhance data diversity and allow the model to learn from diverse data | GAN | Accuracy | FedAvg FedProx FedBN | A DFL strategy using experience replay and GANs |
| [79] | Data heterogeneity | Decentralized stochastic gradient tracking (DSGT) algorithm | NN | Optimality gap Accuracy Communication rounds | Traditional FL (FL) FL with DSGD FL with DSGT | NA |
| [92] | Assessing the quality of client features to determine which features should contribute more during the distillation process | Cyclic model transfer and feature attention-based multi-teacher knowledge distillation | AlexNet CNN LeNet5 | Accuracy | FedAvg FedProx FedBN FedAP | FedTAM |
| Category | Ref. | Data Set | Performance | Summary |
|---|---|---|---|---|
| Wearable Device Data | [23] | Health-related data from wearable devices(private) | NA | The health data-sharing system supported via DFL provides personal feedback to users through data analysis, and shared models |
| [92] | Physical activity monitoring (PAMAP2) | The average accuracy over multiple standard data sets is better than traditional FL methods | FedTAM combined recurrent model transfer and feature attention mechanism to customize personalized models for customers in environments with non-iid personal health monitoring data distribution | |
| [85] | Wearable stress and affect detection (WESAD) | Higher accuracy, reduced training runtime compared to baseline methods | A personalized, low-overhead clustered FL algorithm for stress level identification that improves accuracy and reduces training time | |
| [80] | MIT-BIH arrhythmia | The proposed scheme outperforms BlockFL, HFEL, and BFL, achieving 15.1%, 9.03%, and 15.35% more utility on average; consumes 12.87%, 7.6%, and 13.18% less energy on average than that of BlockFL, HFEL, and BFL, respectively | The algorithm based on the blockchain-supported FL model uses the wireless body area network (WBAN) to use the physiological sensor data collected via local devices to monitor the real-time health indicators of patients | |
| Cardiovascular Diseases | [67] | Physikalisch-Technische Bundesanstalt Database electrocardiogram (PTBDB ECG) | Detection accuracy: above 95% | A server-less FL training mechanism verified the effectiveness in detecting irregular heart rhythms; dual-way update mechanism resisted Byzantine attacks |
| [3] | Pima Indians Diabetes | With the same privacy budget, the accuracy of this method is slightly lower than Original FL, but with enhanced privacy protection | Blockchain-based FL for smart healthcare achieves high model accuracy in acceptable running time in diabetes monitoring while also showing good performance in reducing the privacy budget consumption and resisting poisoning attacks | |
| [100] | UCI Heart Disease Dataset | The DeFedHDP model achieved an accuracy of 90% in heart disease prediction, converging faster than the FedAVG (centralized FL) method to this accuracy | As a fully DFL method, DeFedHDP solves the privacy protection problem in heart disease prediction by introducing a differential privacy mechanism, an online aggregation strategy, and a single-point slot machine feedback strategy | |
| [56] | Edinburgh Myocardial Infarction Dataset (EMIDEC) | DFL framework that generates different types of model misbehaviors through simulators and develops audit, coefficient, and performance detectors to efficiently identify misbehaviors in FL improves the reliability of healthcare modeling | DFL allowed participants to optimize the heart disease risk prediction model through local training, leading to higher accuracy early | |
| [101] | Four distinct T1D data sets—OhioT1DM, ABC4D, CTR3, and REPLACE-BG (all containing CGM records) | The asynchronous architecture with GluADFL addresses data heterogeneity while maintaining prediction accuracy, achieving mean absolute errors 15–20% lower than those of conventional centralized approaches | GluADFL as an asynchronous DFL method for blood glucose prediction, solves the “cold start” problem of patients with type 1 diabetes under privacy protection and demonstrates excellent prediction accuracy on multiple data sets | |
| Neurological Disorders | [10] | (1) EPILEPSIAE (2) TUHEEGSeizureCorpus (TUSZ) | (1) Gmean: 88.72%, higher than FedAvg (2) Gmean: 85.83%, higher than FedAvg | A decentralized FL framework using adaptive ensemble learning and knowledge distillation addresses the non-IID challenge of hospital data and meets the resource constraints of wearable systems |
| [79] | Proprietary data set consisting of patients diagnosed with Alzheimer’s disease (AD) and mild cognitive impairment (MCI) | (1) Decentralized stochastic gradient descent (DSGD) reduces the computational burden compared to centralized GD/SGD processing. (2) Decentralized stochastic gradient tracking (DSGT) offers the advantage of dealing with non-identical data sets compared with (DSGD) | Decentralized non-convex optimization for FL to extract patients’ features from hospital data sets; data privacy could be preserved better than the centralized case | |
| Respiratory diseases | [70] | Tuberculosis classification contains two distinct sources (1) Montgomery County X-ray set (2) the Shenzhen Hospital X-ray set | Classification accuracy: 83.41%, better than FedAvg, FedProx, and FedBN | DFL inspired by experience replay and generative adversarial concepts achieves comparable performance to non-FL in the non-IID medical data scenario |
| [102] | (1) Society for Imaging Informatics in Medicine COVID-19(SIIM-COVID-19) (2) Valencian Region Medical Image Bank COVID-19 (BIMCV COVID-19) | A detection model using vision transformers achieved high AUC scores of 0.92 and 0.99, respectively | A point-to-point FL (P2PFL) framework based on the Vision Transformer (ViT) model to address the classification of COVID-19 versus normal cases in chest X-ray (CXR) images | |
| Cancer | [20] | (1) Kvasir (2) Camelyon-17 | (1) Average accuracy: approximately 83.4% (2) Average accuracy: 81.1%; higher than FedAvg, the FML-proxy | A scheme for DFL called ProxyFL outperforms existing alternatives with much less communication overhead and stronger privacy on cancer diagnostic problems using gigapixel whole-slide histology images |
| [69] | Breast cancer Wisconsin (BCW) | After 25 iterations, the prediction accuracy reaches 93.71% | A privacy-preserving framework based on DFL (FL) enhances privacy protection in the healthcare metaverse | |
| [71] | Breast image data set | FL-CWA achieved slightly higher training accuracy at each learning rate relative to FL-AVG; when the number of attackers increased, FL-CWA could still maintain high training accuracy and achieve low losses, while FL-AVG training accuracy was significant, and the loss gradually increased | Blockchain-based contribution-weighted aggregation FL outperforms centralized learning methods and FL average aggregation in terms of breast image classification model accuracy and system security | |
| [82] | Brain Tumor Segmentation (BraTS) for brain tumor segmentation | Saving 20% of training time compared to synchronous methods | Federated and decentralized learning tools with MQTT protocol show the reliability in brain tumor segmentation and support smart medical diagnosis | |
| [103] | Collect colon, head and neck, liver, and ovarian data from (1) The Cancer Genome Atlas (TCGA) (2) Gene Expression Omnibus (GEO) | AdFed outperforms other FL-based methods, achieving a better performance in cancer survival prediction (AUC = 0.605) compared to the average AUC of 0.554 | AdFed, an integrated framework based on DFL, performs better than traditional FL in evaluating and predicting the survival of cancer patients |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, H.; Qu, Y.; Liu, W.; Gao, L.; Zhu, T. Decentralized Federated Learning for Private Smart Healthcare: A Survey. Mathematics 2025, 13, 1296. https://doi.org/10.3390/math13081296
Cheng H, Qu Y, Liu W, Gao L, Zhu T. Decentralized Federated Learning for Private Smart Healthcare: A Survey. Mathematics. 2025; 13(8):1296. https://doi.org/10.3390/math13081296
Chicago/Turabian StyleCheng, Haibo, Youyang Qu, Wenjian Liu, Longxiang Gao, and Tianqing Zhu. 2025. "Decentralized Federated Learning for Private Smart Healthcare: A Survey" Mathematics 13, no. 8: 1296. https://doi.org/10.3390/math13081296
APA StyleCheng, H., Qu, Y., Liu, W., Gao, L., & Zhu, T. (2025). Decentralized Federated Learning for Private Smart Healthcare: A Survey. Mathematics, 13(8), 1296. https://doi.org/10.3390/math13081296