1. Introduction
Airborne particulate matter (PM) can have a profound effect on the health of the population. This type of pollution is generally divided into PM2.5 and PM10, based on the diameter of the particles, where PM2.5 indicates a maximum size of 2.5 μm and PM10 indicates a maximum size of 10 μm. PM2.5 tends to remain in the atmosphere for much longer, it tends to be carried far greater distances, and is small enough to penetrate deep within tissue, often leading to serious respiratory disorders. It is for this reason that most research on particulate matter pollution focuses on PM2.5–related issues. There has also been considerable effort in developing methods by which to predict PM2.5 levels in order to prepare the public. Most existing systems rely on extensive monitoring in conjunction with statistical analysis or artificial intelligence technology to perform time-series forecasting [
1]. In statistical analysis, Baur et al. [
2] employed conditional quantile regression to simulate the influences of meteorological variables on ozone concentration in Athens. Sayegh et al. [
3] utilized multiple statistical models, including a multiple linear regression model, a quantile regression model, a generalized additive model, and boosted regression Trees1-way and 2-way to predict PM10 concentrations in Mecca. More recently, Delavar et al. [
4] examined the effectiveness of using geographically weighted regression to predict two different series of data: PM10 and PM2.5 in Tehran. In artificial intelligence, Sun et al. [
5] applied a hidden Markov model to predict 24-h-average PM2.5 concentrations in Northern California. Delavar et al. [
4] used a support vector machine to predict the PM10 and PM2.5 concentrations in Tehran. Various shallow neural networks have also been used to analyze and predict air pollution values. For instance, Biancofiore et al. [
6] employed a recursive neural network to predict PM2.5 concentrations on the Adriatic coast. Zhang and Ding [
7] used an extreme learning machine to predict air pollution values in Hong Kong. Yang and Zhou [
8] recently merged autoregressive moving average models with the wavelet transform to predict the values. Ibrir et al. [
9] used a modified support vector machine to predict the values of PM1, PM2.5, PM4, and PM10. Shafii et al. [
10] used a support vector machine to predict PM2.5 values in Malaysia. Hu et al. [
11] used the random forest algorithm to make numerical predictions of PM2.5 values. Lagesse et al. [
12] and Wang et al. [
13] used shallow neural networks to predict PM2.5 values. Liu and Chen [
14] designed a three-stage hybrid neural network model to enhance the accuracy of PM2.5 predictions. Despite claims pertaining to the efficacy of these methods, there is compelling evidence that they are not as effective at dealing with PM2.5 as for other pollutants. PM2.5 can be attributed to local or external sources. Local sources can be direct emissions or the irregular products of photochemical effects in the atmosphere, which can cause drastic fluctuations in PM2.5 concentrations within a short period of time. In contrast, it is also important to consider external sources. That is, PM2.5 is extremely light and can be easily transported by the monsoon, which creates by the long-term but periodic pollution. The fact that PM2.5 concentrations present gradual fluctuations over the long term, as well as radical changes over the short term, makes it very difficult to make predictions using many methods based on statistics or artificial intelligence.
Numerous researchers have demonstrated the efficacy of deep learning models in formulating predictions [
15,
16,
17]. Freeman et al. [
15] used deep learning models to predict air quality. Huang and Kuo [
16] designed the convolutional neural network-long short-term memory deep learning model to predict PM2.5 concentrations. Tao et al. [
17] merged the concept of 1-dimension conversion with a bidirectional gated recurrent unit in developing a deep learning model aimed at enhancing the accuracy of air pollution forecasts. Pak et al. [
18] recently used a deep learning model to assess spatiotemporal correlations to predict air pollution levels in Beijing. Liu et al. [
19] used attention-based long short-term memory and ensemble-learning to predict air pollution levels. Ding et al. [
20] developed the correlation filtered spatial-temporal long short-term memory model to predict PM 2.5 concentrations. Ma et al. [
21] designed a Bayesian-optimization-based lag layer long short-term memory fully connected network to obtain multi-sequential-variant PM2.5 predictions. Li et al. [
22] used an ensemble-based deep learning model to estimate PM2.5 concentrations over California. Zheng et al. [
23] used micro-satellite images, convolutional neural networks, and a random forest approach to estimate PM2.5 values at the surface. Overall, deep learning models have proven highly in predicting PM2.5 concentrations.
In practice, the implementation of deep learning models imposes a heavy burden [
24,
25,
26] in constructing the model and obtaining real-time predictions for hundreds of locations every day. Below, we present an example case illustrating the implementation of a deep learning model to predict costs associated with PM2.5 prediction. In this case, the national meteorological bureau is tasked with obtaining forecasts at 500 locations throughout the country. Without loss of generality, we can assume that formulating PM2.5 predictions involves combining five separate long short-term memory (LSTM) outcomes. To maintain prediction accuracy, the agency must retrain all of the LSTMs at intervals of five days based on the most recent data. The meteorological bureau has four deployment options.
Table 1 lists the monetary costs (in 2020 prices) and time costs of the options as follows: (1) Ordinary computer with one central processing unit (CPU) only and no graphics processing unit (GPU) (USD 1000; 10,000 s to train each LSTM), such that 289 days would be required to complete a round of LSTM training at all 500 sites. (2) Mid-range computer with three GPUs (USD 17,000; 11 days required to complete a round of LSTM training at 500 sites (assuming 400 s per iteration). Despite the relatively low hardware cost, the computation time is excessive. (3) Four mid-range computers as above (USD 68,000; 3 days to complete a round of LSTM training at 500 sites. (4) Supercomputer (USD 10,000,000; 0.1 s to train each LSTM, such that 250 s would be required to complete a round of LSTM training). Scenarios (3) and (4) meet the requirements of the meteorological bureau; however, the costs are very high. Note also that the above-mentioned costs are only for a single pollutant. Most monitoring systems must deal with 20 to 30 pollutants as well as conventional forecasting of weather patterns and typhoons. Clearly, the use of deep learning models for the prediction of pollutants and weather systems is far beyond the financial means of many countries, such as Guinea [
27] and Bangladesh [
28]. A new approach to computation is required.
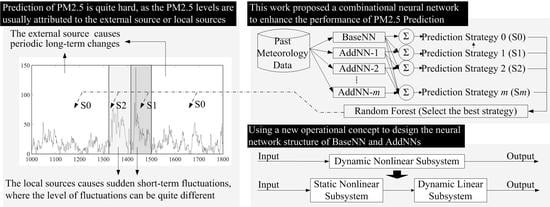
Accordingly, this study proposed a combinational Hammerstein recurrent neural network (CHRNN) to overcome these limitations. The operational concept of the proposed model is shown in
Figure 1. The inputs of the CHRNN include recent meteorological data from a weather observation station, and the output is the predicted value of PM2.5 for a future time point. The CHRNN contains a based-neural network (based-NN) and several add-on neural networks (AddNNs). The former is used to learn long-term changes in PM2.5 data, and the latter is used to learn sudden changes in PM2.5 data. Low-level learning is used for the more common sudden changes, and high-level learning is used for sparsely sudden changes. Considering superimposing the results of the AddNNs layer-by-layer onto the prediction results of the based-NN, the CHRNN can then produce multiple prediction strategies. As shown in
Figure 1, the prediction result of strategy 0 is the output of the based-NN, and the prediction result of strategy 1 is the combined output of the based-NN and AddNN-1. In addition, the CHRNN also includes a random forest that determines the output strategies of the CHRNN based on historical meteorological data, where
Figure 2 can be illustrated as an example. Suppose the PM2.5 value follows usual periodic changes such as those in Section A. Then, the random forest will determine that only strategy 0 is needed for predictions. In contrast, if the PM2.5 values show unusual changes of varying magnitudes, such as shown in Sections B and C, then the random forest will recommend that strategy 1 and strategy 2, respectively, be used to obtain better prediction results. For the framework of the based-NN and AddNNs, we employed the well-known Hammerstein recurrent neural network (HRNN) [
29] into our model. This framework splits a dynamic nonlinear time series data into a static nonlinear module and a dynamic linear module for modeling, respectively, which is shown in
Figure 3. This way, the dynamic behavior in the time series will only be processed by the dynamic linear module, where the nonlinear behavior will only be processed by the static nonlinear module. Therefore, it enhanced the modeling of prediction accuracy [
29,
30]. Furthermore, the CHRNN is modeled based on shallow neural networks, the construction and operation costs of which are far lower than those of deep learning models. In the following, we use the example in
Table 1 to emphasize the merits of employing CHRNN in deep learning models. Assume that the meteorological bureau needs to train 2500 CHRNNs (500 locations × 5 CHRNNs per location) every five days. By only using an ordinary computer (one CPU and no GPUs), the construction of each CHRNN could be completed within 100 s. This means only approximately 25,000 s (3 days) would be required to complete a round of training. This is a considerable improvement over the 289 days and USD 68,000 that would be required under the previous scenario.
We anticipate that the CHRNN will improve the accuracy and lower the costs of PM2.5 predictions. However, we encountered two difficulties: (1) The first difficulty includes the selection of features to predict PM2.5 values, which may also have a time-delay terms problem. That is, how far into the past, should we go to collect the data for applying these features? This has been considered by many researchers and consequently has been the focus of a wide variety of discussions. Past approaches can be roughly divided into two categories: (i) based on professional knowledge regarding air pollution, several meteorological items are chosen as features [
2,
4,
31], or (ii) correlations between all data items, and the output is first examined before the most relevant items are chosen as features [
6,
15,
17]. Note that the former may result in the selection of unsuitable features, thereby producing poor prediction accuracy. However, while the latter may lead to the selection of more suitable features, the issue of time-delay terms is seldom taken into account, which also affects prediction accuracy. This study developed the modified false nearest neighbor method (MFNNM) to overcome it. (2) The second difficulty we encountered is to determine a means of enabling the based-NN to learn the periodic long-term changes in PM2.5 concentrations and the AddNNs to learn the sudden short-term variations in PM2.5 concentrations. We developed the usual case emphasizing normalization (UCENormalization) method to address this issue. Finally, we conducted simulations using real-world datasets of a one-year period from Taichung, Taiwan. These experiments verified that the proposed approach might achieve greater prediction accuracy than deep learning models at lower costs.
The proposed method provides predictive accuracy superior to that of existing machine-learning methods for a given construction cost. In other words, the proposed method makes it possible to achieve the accuracy of advanced deep learning models without having to invest any more than would be required to establish a machine learning system.
The remaining chapters of this paper include
Section 2, which introduces the datasets and their cleaning,
Section 3, which describes our research method,
Section 4, which presents our experiment simulations; and
Section 5, which contains our conclusions and future work.
3. Study Area, Dataset and Data Preprocessing
The meteorological data collected in this study comprised hourly data collected in 2018 by three air-quality monitoring stations run by the Environmental Protection Administration (DaLi, FengYuan, and ChungMing) in Taichung, Taiwan. The locations of the monitoring stations are shown in
Figure 4. We considered these three stations because they are situated in areas where air pollution is the most severe and the population is the densest. From each station, we collected 12 types of data associated with air pollution, including levels of PM2.5, PM10, CO, O3, SO
2, NO, and NO
2, wind speed, hourly wind speed, relative humidity, temperature, and rainfall. Note that although general meteorological observatories provide air quality index (AQI) values, we opted not to consider AQI values in the current paper. AQI values are derived from particulate matter concentrations as well as carbon monoxide, sulfur dioxide, and nitrogen dioxide, and tropospheric ozone levels. From a mathematical perspective, AQI values are highly dependent on at least one of the above values. Thus, even if we input AQI in addition to the five above-mentioned values, the corresponding improvement in prediction accuracy would be negligible due to overlap. Furthermore, entering AQI values would greatly increase computational overhead by increasing the dimensionality of the data. Of course, it would be possible to formulate predictions based solely on AQI values; however, this would not adequately reflect the variations in the five pollution values. The exclusive use of AQI values for prediction would reduce the scope of the five pollution values, leading to a corresponding decrease in prediction accuracy.
These datasets contained many missing values or errors, and the errors may have continued for varying amounts of time. We employed the linear interpolation method used [
15] to replace the missing values or correct the abnormalities. The interpolation method depended on how long the missing values or errors continued. If they continued for less than 24 h, we used the values of the time periods before and after the period in question for interpolation. This way, the calibration results would best correspond to the conditions of that day. In addition, if the values that needed to be replaced covered more than 24 h, then we used the average supplementing value of the 24 h periods before and after the period in question for interpolation. With such a large range of missing values or errors, it may produce difficulty for us to recover the conditions on the day in question. Therefore, we could only use the conditions of the previous and subsequent days to simulate the possible air quality conditions during the same time of the day.
Figure 5 displays the PM2.5-time series results after data cleaning, and
Table 2 presents the value distributions in the datasets. As shown in
Table 2, the PM2.5 values at each location can fluctuate drastically within a two-hour period, at the most exceeding half the range of the dataset. Furthermore, the mean + 3× standard deviation of the three datasets is around 60 ppm, which means that 95% of the data points in these datasets are lower than 60 ppm, and only about 5% of the data are over 60 ppm. Such widely fluctuating and unbalanced data makes predictions using conventional recursive neural networks difficult to model. Hence, a new approach is needed.
4. Research Methods
The PM2.5 prediction process designed in this study includes several parts. It is shown in
Figure 6, including (1) using modified false nearest neighbor method (MFNNM) to identify suitable predictive features in the datasets and their time-delay terms; (2) using the usual case emphasizing normalization (UCENormalization) to normalize the PM2.5 time series values to help the based-NN learn the long-term changes in PM2.5 concentrations; (3) constructing the based-NN; (4) constructing several AddNNs based on the modeling results of the based-NN; and (5) constructing a random forest to recommend CHRNN usage strategies for different time points. The details of these five parts are as follows:
4.1. Modified False Nearest Neighbour Method (MFNNM)
The MFNNM can extract suitable predictive features from air-quality data and the corresponding time-delay terms for each feature. The method is grounded on the concepts of the false nearest neighbor method [
46,
47], which can determine the optimal time-delay terms for features when the features are fixed. However, it cannot be used to select suitable predictive features. Therefore, we modified this method to meet the needs of this study. We first develop the mathematical model of the system under analysis, then introduce the operational concept of MFNNM based on said system, and finally discuss each step of MFNNM.
For each multiple-input single-output (MISO) time series modeling problem, suppose we have already collected a set of input features
u1(
•),
u2(
•), …,
up(
•) and the corresponding output value
y(
•). Then, we can express the prediction system as
where
p denotes the number of features, and
m is the optimal value of time-delay terms for all features used for prediction. Below, we discuss three concepts underpinning the MFNNM. The first two originate from the theory of the false nearest neighbor method [
46,
47], while the third is our extended concept. To facilitate our explanation, let the input vector of system
f(
•) at time
t in Equation (1) be
X(
t) and the predicted value be
y(
t + 1). (1) If the changes in
y(
i) consist of all the factors in
X(
i) at any time point
i and
X(
j) and
X(
k) at time points
j and
k have a short Euclidean distance between them, then the values of
y(
j) and
y(
k) must also be close to each other. Hereafter, we refer to
X(
t) as the optimal input vector of the system. (2) If input vector
X’(
t) is missing some key factors comparing to
X(
t), then the values of
y(
j) and
y(
k) may not be close to each other even if
X’(
j) and
X’(
k) at time points
j and
k have a short Euclidean distance between them. In this case, a false nearest neighbor (FNN) appears, and the MFNNM can continuously add new factors to
X’(
t) to reduce the appearances of FNNs. Once the factors in the new
X’(
j) highly overlap those in
X(
j), the appearances of FNNs will drop drastically close to 0. (3) If input vector
X″(
t) has more key factors than
X(
t), then the values of
y(
j) and
y(
k) may not be close to each other even if
X″(
j) and
X″(
k) at time points
j and
k have a short Euclidean distance between them. In this case, an FNN appears, and the MFNNM can continuously eliminate factors within
X″(
t) to reduce the appearance of FNNs. When factors that are less correlated with the output are eliminated, the appearance of FNNs will drop even more drastically. We can then estimate the importance of each factor to the prediction system based on the changes in FNN appearance after each factor is eliminated. The MFNNM uses these three concepts to select a suitable input vector to prevent FNN appearance.
The MFNNM follows two phases. The first phase follows the suggestions of [
46,
47] and, based on concepts (1) and (2), involves gradually increasing the time-delay terms of a fixed number of features to increase the number of factors in the input vector and obtain the optimal time-delay terms. The second phase is based on the concept (3) and, with the optimal time-delay terms known, involves eliminating different features to reduce the number of factors in the input vector to understand the correlation between each feature and the output. Finally, the most suitable features for predictions are selected based on their correlation with the output. The steps of the MFNNM are described in detail in the following:
Step 1: Collect the system input and output values of the prediction model at k time points: the output is y(t + i) and the input vector is Xm(t + i), m denotes the delay times of the features, and 1 ≤ I ≤ k.
Step 2: Under the settings
m = 1 and
I = 1, find a time point
j with a minimum Euclidean distance between
Xm(
t +
i) and
Xm(
t +
j). Next, check whether an FNN appears using Equation (2):
where
R is a threshold value given by the user. If Equation (2) is not supported, then an FNN appears.
Step 3: Add 1 to i and repeat Step 2 until I = k. Then, calculate Perfnn, which is the probability of an FNN appearing at the k time points with the current m.
Step 4: Repeat Steps 2 and 3, adding 1 to m each time to record the Perfnn. When m finally reaches the set value given by the user, the minimum Perfnn is picked among all m values is the optimal time-delay mfinal, and the corresponding Perfnn is named Perfnn_final.
Having found the optimal time-delay terms of the features, we next explain the approach to seeking the optimal predictive features. First, the input vectors are defined under mfinal as Xmfinal(t + i). Next, we check the impact of each feature on the number of FNNs, beginning with the input factor u1 all the way to input factor up, ultimately determining the importance of each feature.
Step 5: From the original input vector Xmfinal(t + i), eliminate the factor of feature l, and the new vector becomes Xmfinal-l(t + i). Next, repeat the process from Step 2 to Step 4 and calculate Perfnn-l.
Step 6: Repeat Step 5. It is decided to add 1 to l each time and recording the corresponding Perfnn-l until l = p. The features are ultimately ranked in ascending order based on the results of |Perfnn_final–Perfnn-l|. The smaller the difference, the more correlation the feature is to the output, and the more it should be considered during modeling. Next, users can choose the features that will be used in the subsequent steps based on the conditions they have set, such as a required number of features or a required degree of feature impact.
4.2. Usual Case Emphasizing Normalization Method
The UCENormalization uses normalization to enhance the learning effectiveness of the based-NN, considering the long-term changes in a PM2.5 time series while reducing the impact of abnormal values on based-NN modeling. The fundamental concept is that the normal conditions in a PM2.5 time series are normalized to cover a wider range in [−1, 1], while the abnormal conditions occupy a smaller range. This way, the based-NN can more easily find the optimal solution for normal conditions, and prediction accuracy is increased. The remaining abnormal conditions are left for the AddNNs to learn. Then,
Figure 7 is an example to explain the concept.
Figure 7a displays the original PM2.5 time series, except for A, B, C, and D, which indicate sudden circumstances in the PM2.5 values, the values all present relatively normal conditions.
Figure 7b displays the results of proportionally normalizing
Figure 7a, and
Figure 7c presents the results of UCENormalization. A comparison of the two figures shows that most of the normal conditions are compressed to [−1, −0.3) in
Figure 7b, while they are compressed to [−1, 0.9) in
Figure 7c. Generally speaking, compression of the normal conditions to a smaller range means that the neural network output will also have a smaller range. In addition, the operational range of the weights will also be reduced, which makes it hard for the neural network to find the optimal solution for each weight and final outputs. As shown in
Figure 8, the
x-axis represents the operational range of each weight in the based-NN, and the
y axis indicates the based-NN output corresponding to said weight. Clearly, the compression of the normal conditions to [−1, 0.3) in
Figure 7b means that the operational range of the weights will also be constricted (
Figure 8a). In contrast, the normalization of the normal conditions to [−1, 0.9) in
Figure 7c means that the operational range of the weights in the based-NN is expanded (
Figure 8b), which will increase the accuracy of based-NN predictions for normal conditions.
Based on the definitions of normal and abnormal conditions in half-normal distributions, the abnormal threshold values of PM2.5 are set as mean +
n standard deviations, where
n is adjusted to normal conditions. The normalization formulas for normal and abnormal conditions are shown in Equations (3) and (4):
where
u(•) is the PM2.5 time series value;
Norm_u(•) is the normalized PM2.5 time series value;
n represents the abnormal threshold value set by the user, and
m is the upper bound of normalized values for normal conditions. Note that the value distribution ranges of normal conditions and sudden circumstances in the original data should be taken into consideration when
m is set. If the value distribution range of sudden circumstances is small, then it is recommended that
m be near 0.9 to increase the accuracy of model learning for normal data. If the value distribution range of sudden circumstances is large, however, then it is recommended that
m be around 0.7 to prevent the values from being overly compressed, which would affect model learning of sudden values. In the end, the results of any PM2.5 time series normalized using Equations (3) and (4) should fall within the range of [−1, 1].
4.3. Construction of Based-NN
For the framework of the based-NN in the CHRNN, we adopted the HRNN [
29,
40], the effectiveness of which has already been demonstrated. As shown in
Figure 9, it contains a total of four layers: the input layer, the hidden layer, the dynamic layer, and the output layer. The only function of neurons in the input layer is to pass on the input data to the hidden layer. Suppose
n features are extracted using MFNNM, and the value of time-delay terms of each feature is
m. Thus, the based-NN has (
n + 1) ×
m inputs, where 1 represents a historical PM2.5 value. Next, the hidden layer is linked to establish the static nonlinear module. The neurons in this layer do not use any recursive items, which means they are static, and the nonlinear tangent sigmoid function serves as the nonlinear function. Then, the dynamic layer and the output layer are responsible for establishing the dynamic linear module. The recursive items of the dynamic layer are responsible for handling the dynamic part, while the linear function of the output layer is responsible for the linear part. The output of the based-NN is the normalized PM2.5 value of the next time point. The mathematical framework of the model is presented in Equations (5)–(7). Among those equations, Equation (5) is the formula from the input layer to the hidden layer, Equation (6) is the formula for the dynamic layer, and Equation (7) is the formula for the output layer. Furthermore, in the neurons in layer
j, we use
Ii(j)(
k) and
oi(j)(
k) to represent the input and output of neuron
i at time
k.
In the formulas above, w is the weight between the input layer and the hidden layer. The d is the bias value; the a indicates the regression weight of the dynamic layer; the b is the weight between the dynamic layer and the hidden layer, and the c is the weight between the dynamic layer and the output layer.
In the based-NN, we recommend that the number of neurons in the hidden layer and the dynamic layer should be set as the
mfinal value calculated using MFNNM. Researchers have demonstrated that setting this value as the number of hidden layers produces optimal modeling results [
48]. The back-propagation algorithm is used to train the HRNN. However, due to the limitation of the paper, please refer to [
29] for further details.
4.4. Construction of AddNNs
The construction process of the AddNNs is, as shown in
Figure 10. The first step is to calculate the “Base_Error”, which is the error between the based-NN prediction results and the actual PM2.5 values. The second step is to use the Base_Error to train AddNN-1, which also uses HRNN for its framework, but the inputs and output are different. Besides the original inputs of the based-NN, the inputs of AddNN-1 also include the Base_Error values of the past
m time points. The outputs of AddNN-1 are the normalized results of the Base_Error for the next time point. After completing the training of AddNN-1, the program calculate the Add_1_Error, the error between the Base_Error and the AddNN-1 output. Note that we recommend setting the numbers of neurons in the hidden layer and dynamic layer of the AddNNs to the same as the number of input dimensions. This is because the ideal output of the AddNNs is the error, which may only be related to some particular inputs. If each neuron in the hidden layer can independently process the changes in an input neuron, prediction accuracy is enhanced.
The third step is roughly the same as the second step: (1) construct AddNN-k (the AddNN on layer k based on HRNN), (2) set the inputs and outputs of AddNN-k and train them together, and (3) calculate Add_k_Error (the error between Add_k-1_Error and AddNN-k). This process continues until the number of AddNNs reaches the preset upper bound or until the error reduction in the AddNN on each layer becomes limited.
Finally, when all of the AddNNs have been constructed, the study is designed to produce the various strategy results of the CHRNN. Each strategy result is the sum of the outputs of the based-NN and multiple AddNNs, as shown in
Figure 10. For instance, the result of Strategy 0 equals the result of the based-NN alone, the result of Strategy 1 is the sum of the outputs of the based-NN and AddNN-1, and so on.
4.5. Construction of Random Forest to Determine CHRNN Usage Strategies
This section explains how a random forest is constructed to determine the usage strategies of the CHRNN. However, the random forest algorithm is not the focus of this study, so we introduce only the inputs and output of the random forest. For details on the algorithm, please refer to Breiman [
48].
The inputs of the random forest in this paper are identical to those of the based-NN. The reason for this was that these features are identified by the MFNNM as the most correlated with future PM2.5 values and are thus helpful for random forest modeling. The output labels of the random forest represent the optimal strategies of the CHRNN at each time point. The study did not use the smallest error between all of the strategies and the actual values as the output label. We designed a new calculation method. Since the output values of different strategies are often close, using the smallest error among the strategies as the output label would result in relatively small differences among strategy outputs, but the conditions of the output labels at each time point would vary, making random forest training procedure become more difficult.
A buffer variable is generated to overcome this problem. The variable increases the chance that Strategy 0 will be determined as the output label, with Strategy 1, the next most likely, and so on. The reason for this design was that Strategy 0 is used to learn normal conditions and should rationally be the most common. The strategies following Strategy 1 are used to predict abnormal conditions that are less common and should be increasingly less likely to be used, so the probability of them becoming output labels is reduced. We introduce how the output labels are calculated, with Θ denoting the buffer variable. Suppose we want to identify the output label at time i, and the CHRNN has γ AddNNs. Thus, there are γ+1 possible output results for the random forest:
- Case 1
If |Output of Strategy 0-actual value|÷Θ < |Output of Strategy i-actual value|, where 1 ≤ I ≤ γ, then the output label is set as Strategy 0.
- Case 2
If Case 1 does not hold, and |Output of Strategy 1-actual value |÷Θ<|Output of Strategy j-actual value|, where 2 ≤ i ≤ γ, then the output label is set as Strategy 1.
The judgment conditions from Case 3 to Case γ are similar to those of Case 2, so we remove the details here. Case γ + 1 holds when none of the conditions from Case 1 to Case γ hold. Finally, when the output labels have been calculated, it is considered the inputs and output labels at each time point as independent events to train the random forest. After training, the random forest can be used directly.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}