1. Introduction
The two salient tools of statistical process control (SPC) are memory and memory-less control charts. The memory-less control charts are most suitable for large shift, while the memory-control charts are used to monitor moderate and small shifts. The prominent form of memory-less control chart for location monitoring is the Shewhart
control chart. In general, control charts-irrespective of the magnitude they measure-operate in two phases: phase-I, the prospective stage from which the control limits are obtained; phase-II, where we monitor the process and correct the unnatural causes of variation whenever they occur (cf. [
1]). In phase-I we estimate the control limits using the parameters of the process under study which, in reality, are seldom known. The amount of data employed in phase-I for estimating process parameters varies from one practitioner to the other. As a result, this variability affects the chart performance in the monitoring stage i.e., phase-II. (see for example [
2,
3,
4,
5,
6]).
Furthermore, the amount of data employed in estimating the process parameters does affect the accuracy of the chart, as well as its limits. As we all know, the larger the sample size, the closer we are to the parameter. Therefore, increasing the sample size used for estimating the parameters should be the remedy to this shortcoming, but there is a limit to which we can increase sample sizes in real-life situations. As a result, the Shewhart chart, like any other chart, loses its performance and credibility. The depth of the loss depends on the efficacy of the parameter estimation and sample size employed in phase-I.
The presence of outlying/extreme values in the phase-I dataset can affect the performance of the control chart. The insufficiency of the phase-I estimates could be a result of extreme sample points in the sample, and not necessarily the size of the sample (see [
5,
7]). The easiest remedy for the extreme values is to drop such a sample and pick another one, but this is not appropriate for small sample data. Therefore, there is a need to screen the extreme values to improve the overall performance of the control chart.
Over the years, researchers have studied different types of robust outlier detection models in a series of control charts to enhance their performance. Examples include [
8,
9,
10,
11,
12]. These outlier detectors require the data to be from normal distribution such as the Student-type and Grubbs-type detectors. However, for a non-normal dataset, the Tukey’s and median absolute deviation (MAD) outlier detection models are more accurate and robust since they are independent of mean and standard deviation. (see [
13,
14,
15,
16,
17,
18,
19]). SPC is widely applied and implemented in various sectors; health, industrial, manufacturing and every service-rendering sector. Control charts, however, are most applied in manufacturing industry, with semiconductors as a case study. Semiconductor manufacturing processes are prone to high chances of assignable cause of variations, due to machine breakdown, multiple products, re-entrant flows, batching processes etc. [
20]. Researchers have employed SPC in solving these recurring challenges in this industry (see [
21,
22,
23,
24]). The proposed charts in this study are applied in photolithography, a semiconductor manufacturing process.
In this article, we study the effects of parameter estimation on the Shewhart chart for normal and non-normal environments. We also study the effect of outliers on the reliability of the control charts and the process parameters are estimated. Furthermore, we propose non-parametric outlier detectors, namely: the robust Tukey and MAD outlier detection models in designing the basic control chart structure. A fair comparison between the two-outlier detection models is also made. We achieve all of these using average run length (ARL) and standard deviation run length (SDRL) as the performance measures.
The remainder of this article is as follows: the next Section entails the methodologies employed for the study; briefing the overview of the Shewhart
control chart when the parameters are known and unknown, alongside the performance measure properties adopted in this study; the variability in Shewhart chart performance due to phase-I estimation; a scenario for the presence of outliers in the design structure of Shewhart chart, and its effect; incorporating the Turkey and MAD outlier detection models in the design structure of the Shewhart chart as remedies for rectifying the presence of outliers;
Section 3 gives a concise and precise description of the simulation results. In
Section 4, a detailed comparison of the results is presented; while
Section 5 provides an illustrative example with a real life dataset; finally a concluding remark and future recommendations are given in
Section 6.
2. Methodology
In this section, we give details of the Shewhart control chart for normal and non-normal environments. The known and unknown parameter scenarios, the practitioner–practitioner variation in the estimation stage, the presence of outliers/extreme values in the estimation sample, and incorporating some outlier detection models in the Shewhart chart are all discussed in the following subsections.
2.1. Overview of the Shewhart Control Chart
Let
and
represent a
th observation from
th sample of an ongoing (continuous) process. Further
follows a normal distribution with mean
and variance
i.e.,
. The process is said to be in the in-control (IC) state if
, and out-of-control (OoC) otherwise. A default Shewhart set-up monitors a process by plotting the sample mean (
) of
against the following control chart limits.
where UCL and LCL denote the upper and lower control limits, respectively. Limits in (1) are useful when the parameters (
and
) of the process are known. However, when they are unknown, their respective unbiased estimators from the phase-I are used, and the resulting control chart structures will be in estimated form.
For phase-I, let
represents
th observation from
th random sample
and
, regarded to be under statistically IC state. It is good to mention here that the choice of
and
varies from one practitioner-to another. Therefore, it affects the accuracy of the control limits implying an influenced ARL in phase-II. The unbiased estimators for the parameters
and
of an IC process are defined as:
where
,
and
is the bias correction constant. Subsequently, the resulting control limits in (1) are modified to the following:
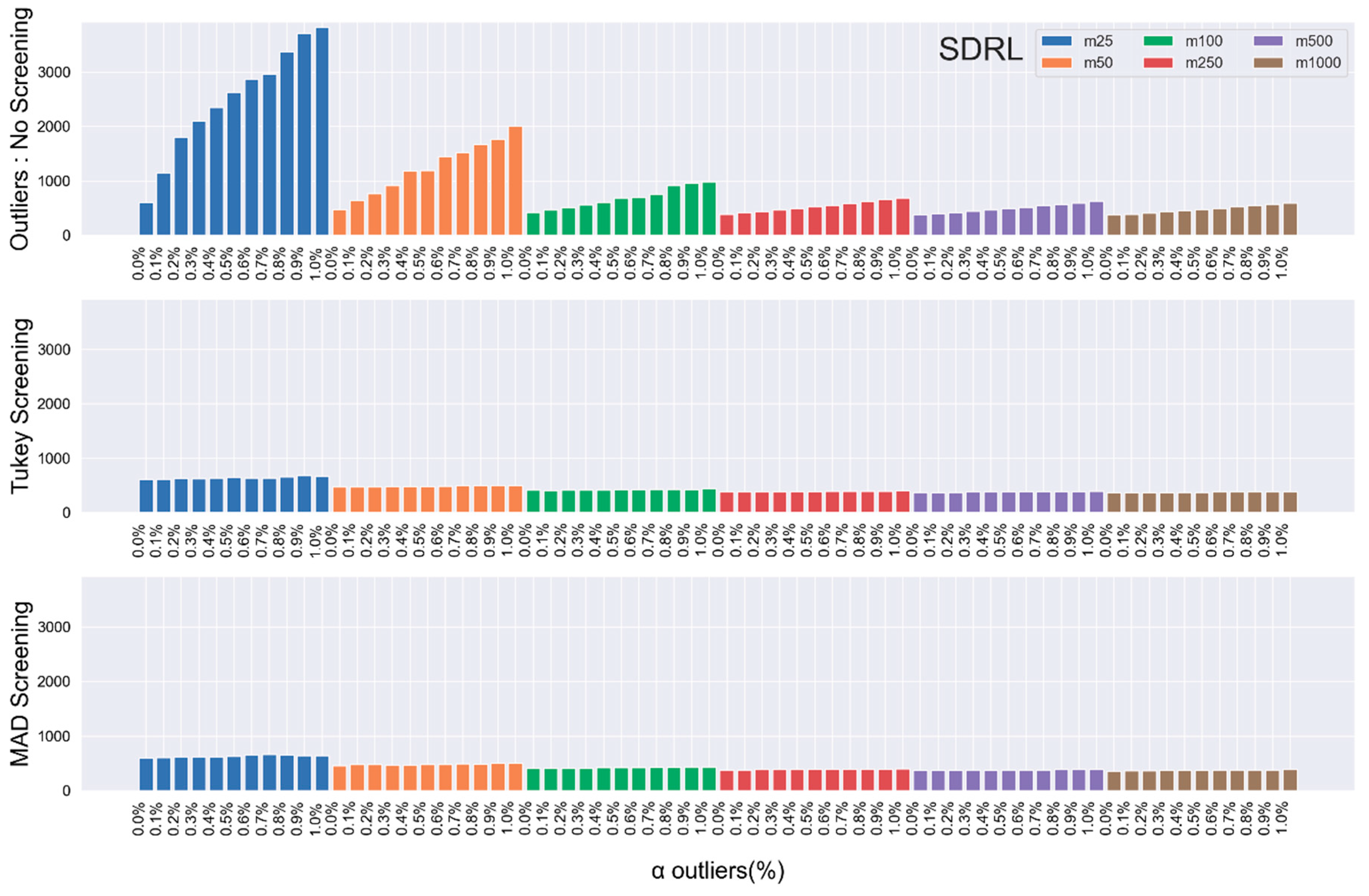
In phase-II, s are plotted against the control limits in (3) and the chart is said to have given an OoC signal if any value of is plotted outside the limits. Here, the sample number at which the statistic is plotted outside the limits is recorded as run length (RL). RL is an important variable in measuring the performance of control charts in general, and the Shewhart is not an exception. The most widely used property of RL is ARL, which is the average number of samples observed before the chart sends an OoC signal. Mathematically, where s is the number of RLs recorded. In addition to ARL, standard deviation of the RL (SDRL) gives more information about the behavior of the RL variable in evaluating the performance of a control chart. Furthermore, the ARL is of two types i.e., the IC ARL, denoted as and the OoC ARL, referred to as. is expected to be sufficiently large enough to avoid false alarms. On the other hand, is anticipated to be sufficiently small to enable the process to send a signal as soon as there is a shift in the process parameter(s).
2.2. Variability in the Shewhart Chart Performance
In this section, we explain the effect of the practitioner to practitioner variability on the Shewhart chart, both in normal and non-normal distribution, by using the Monte Carlo simulation approach. See ([
25,
26,
27,
28,
29]) for more information about the effect of sample size and practitioners’ variability. To achieve this aim, we develop an algorithm in R programing language to simulate the Shewhart chart environment, using the standard Shewhart chart as our benchmark and reference point. The
chart has a control limits width determinant
that influences RL properties. We use the standard
, that corresponds to the
(see [
1] for more details). Without any loss of generality, we generate random samples from a standard normal distribution
, each of sample size
, assuming the process parameters are known. While for the non-normal distribution, we considered the
t-distribution with degrees of freedom
and
. Since all the three categories of
exhibit the same pattern, we report only the results for
. In both environments, normal and
t-distributions, we set up the chart limits as given in Equation (1) and plot the sample means against the UCL and LCL. As soon as a value of
is plotted outside the limits, RL is recorded and saved. The process is iterated
times to get ARL and SDRL.
For the unknown parameters, we estimate the parameter from phase-I. The number of samples employed for the estimation differs from on practitioner to another and so does the accuracy of the charts in phase-II. To depict that, we estimated both
and
from different number of in-control phase-I samples i.e.,
and 1000 each of sample size
. The estimated parameters
and
from the phase-I IC stage are, therefore, used in the same algorithm instead of
and
respectively. Subsequently the parameter
, changes as the amount of phase-I samples changes. The corresponding
s for the different
are
and
respectively for the normal distribution, and
and
respectively for the
t-distribution of
. These
’s are determined through simulations to obtain
. We carry out the simulation with different level of shifts
ranging from 0 to 5 i.e.,
, as shown in
Table 1 and
Table 2.
2.3. Presence of Outliers in the Shewhart Chart with Estimated Parameters
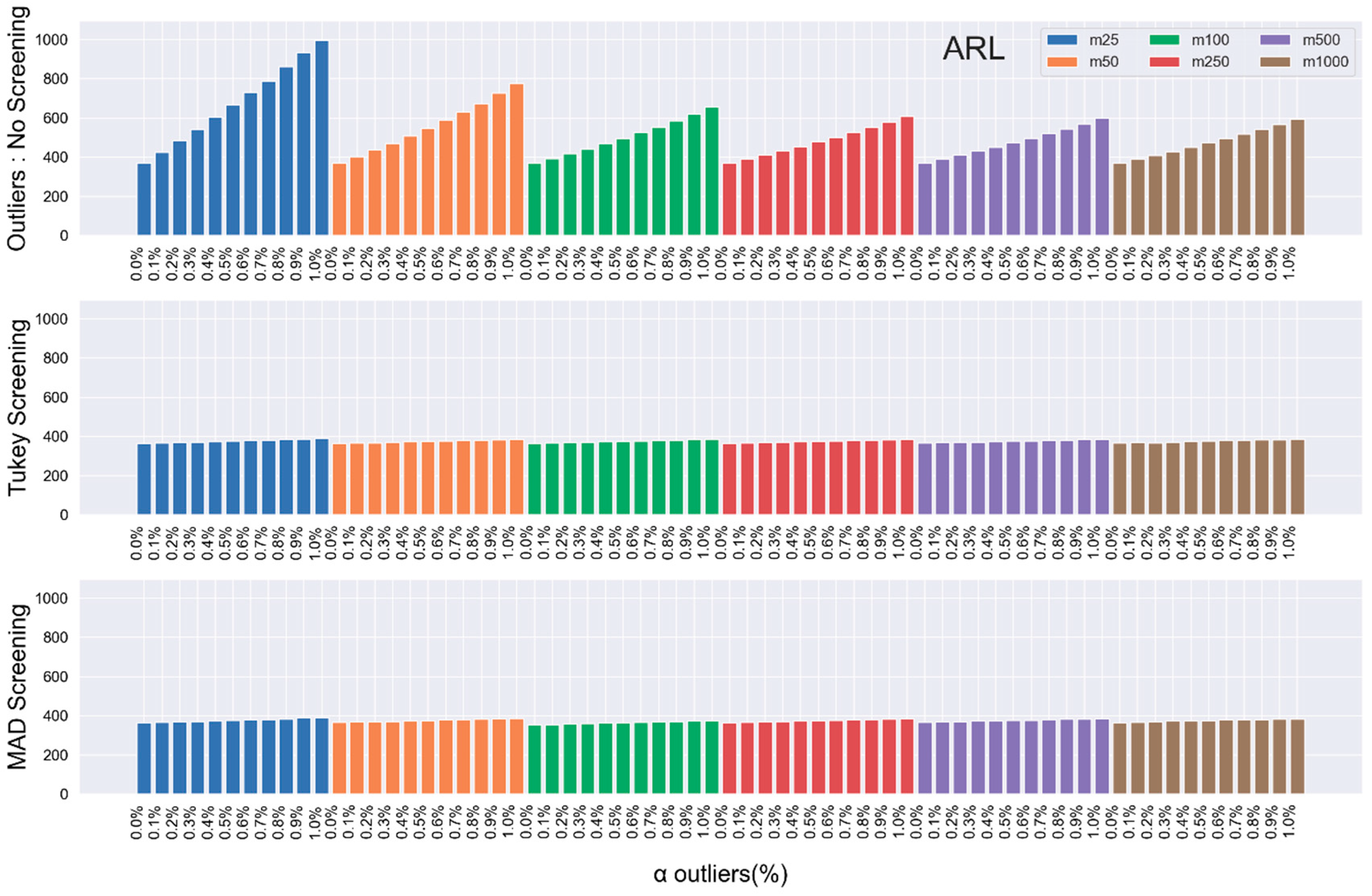
Although the estimation of the unknown parameters in phase-I samples plays its role on the efficiency of the control chart in phase-II. The drop in the efficacy of the chart performance is not limited to this fact alone, rather it extends to presence of outlying/extreme values in the phase-I samples.
In this Section, we study the effect of outliers in the phase-I samples on the performance and accuracy of the Shewhart chart. Here, through Monte Carlo simulation, we generate the
phase-I samples from a mixture distribution i.e.,
from assumed (normal or
t-distribution) and the remaining
from a chi-square distribution with
degrees of freedom denoted by
. Subsequently, the estimated parameters emerging from the
samples have an extreme values effect on the control chart in phase-II. That is, each observation of the phase-I sample is generated from the following expression:
where
, is the probability of having a multiple of
added to the assumed distribution, serving as the outliers in the samples. In addition,
is the magnitude of the outlier. We develop an algorithm from the R language, similar to that in
Section 2.2, but the samples are from the environment described in (4). We set
, and
. We design the Shewhart chart using the same parameters
and
as in
Section 2.2.
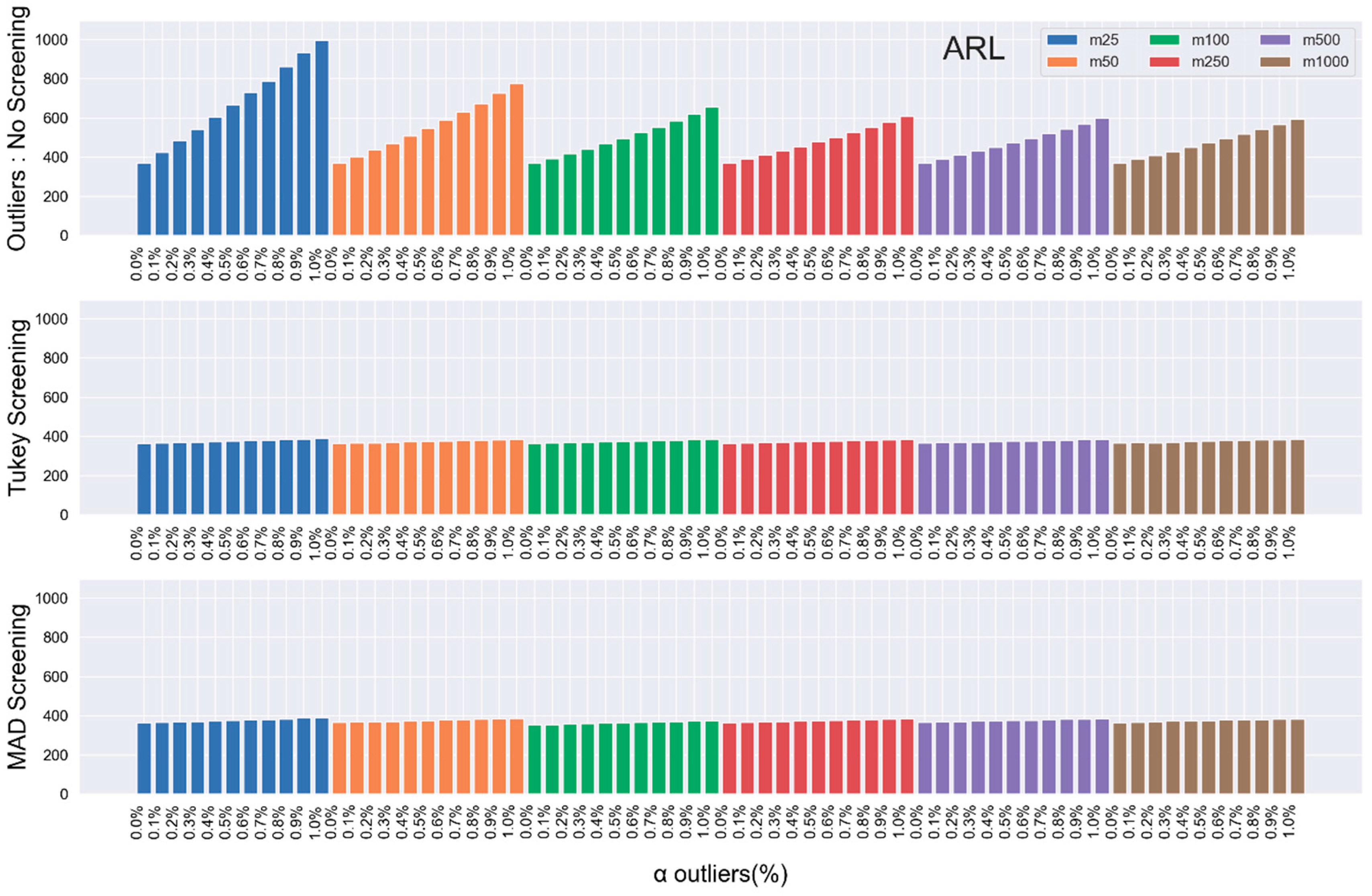
In general, the pattern exhibited by the RL properties implies the following:
Increasing the phase-I samples in the presence of outliers, gets the’s closer to the theoretical values.
Reducing the value of, the percentage of outliers present in the samples also brings the’s closer to the theoretical values.
Unfortunately, neither of the two suggested remedies is practicable in real life. Thus, we propose outliers detecting structures through the robust Turkey and MAD detection models.
2.4. Shewhart Chart with Outlier Detection Models
In the section, we propose two outlier-detecting models as remedy to the issues raised in
Section 2.2 and
Section 2.3. The Tukey and the MAD model-based Shewhart charts. Their procedures applied in parallel to the Shewhart chart are described in the sub sections below:
2.4.1. The Tukey Shewhart Control Chart
For the phase-I samples,
be the median of all
observations. For any observation
if
, then
is declared an outlier. Here
is the inter-quartile range of the sample.
and
are the third and first quartiles, respectively, of all
phase-I observations. The constant
on the other hand is the confidence factor of the Tukey’s detector, commonly chosen between 1.5 and 3.0. The confidence factor should be carefully chosen, and not too small, to avoid over detection. Also it should not be too large, to prevent under detection [
18]. In this study, we choose
. Applying the same algorithm, parameters and limits employed in
Section 2.2, we incorporate the Tukey outlier-detector model on the phase-I samples to screen out the extreme values present there in. Then we compute the IC ARL and SDRL values for the Shewhart chart based on the Tukey model in phase-II, when the parameters are estimated.
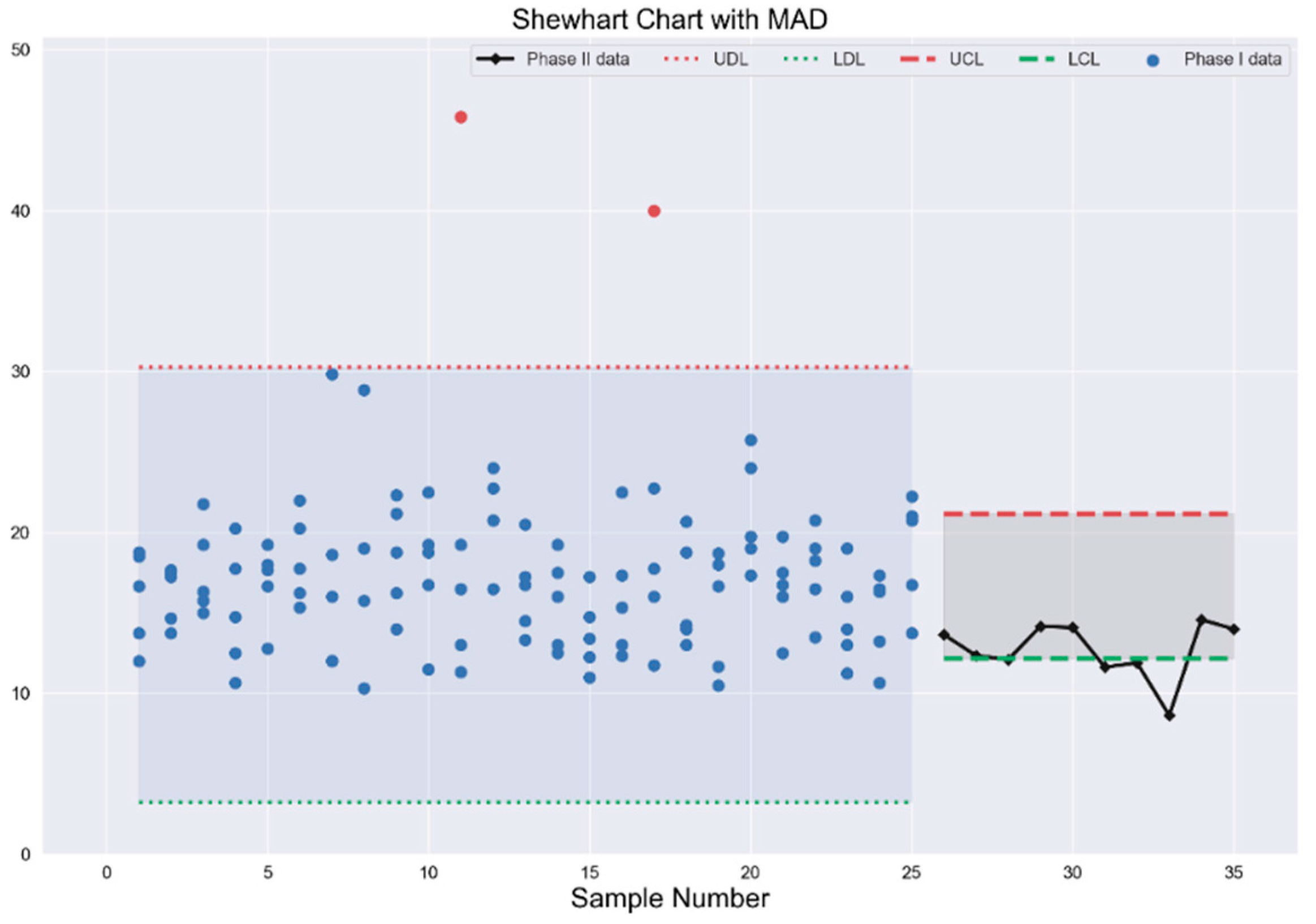
2.4.2. The Median Absolute Deviation (MAD) Shewhart Control Chart
We define median absolute deviation (MAD) as the deviation of the dataset about the median as
. Then it follows, that any observation
from the sample that falls outside the expression
, is declared an outlier. Here
is the outlier detecting constant and chosen
so that the percentage of screening by MAD is the same as Tukey. This has been done to keep the comparison between two outlier detectors valid [
19].
Furthermore, it is worth distinguishing between outlying and OoC sample points. The former emerges from
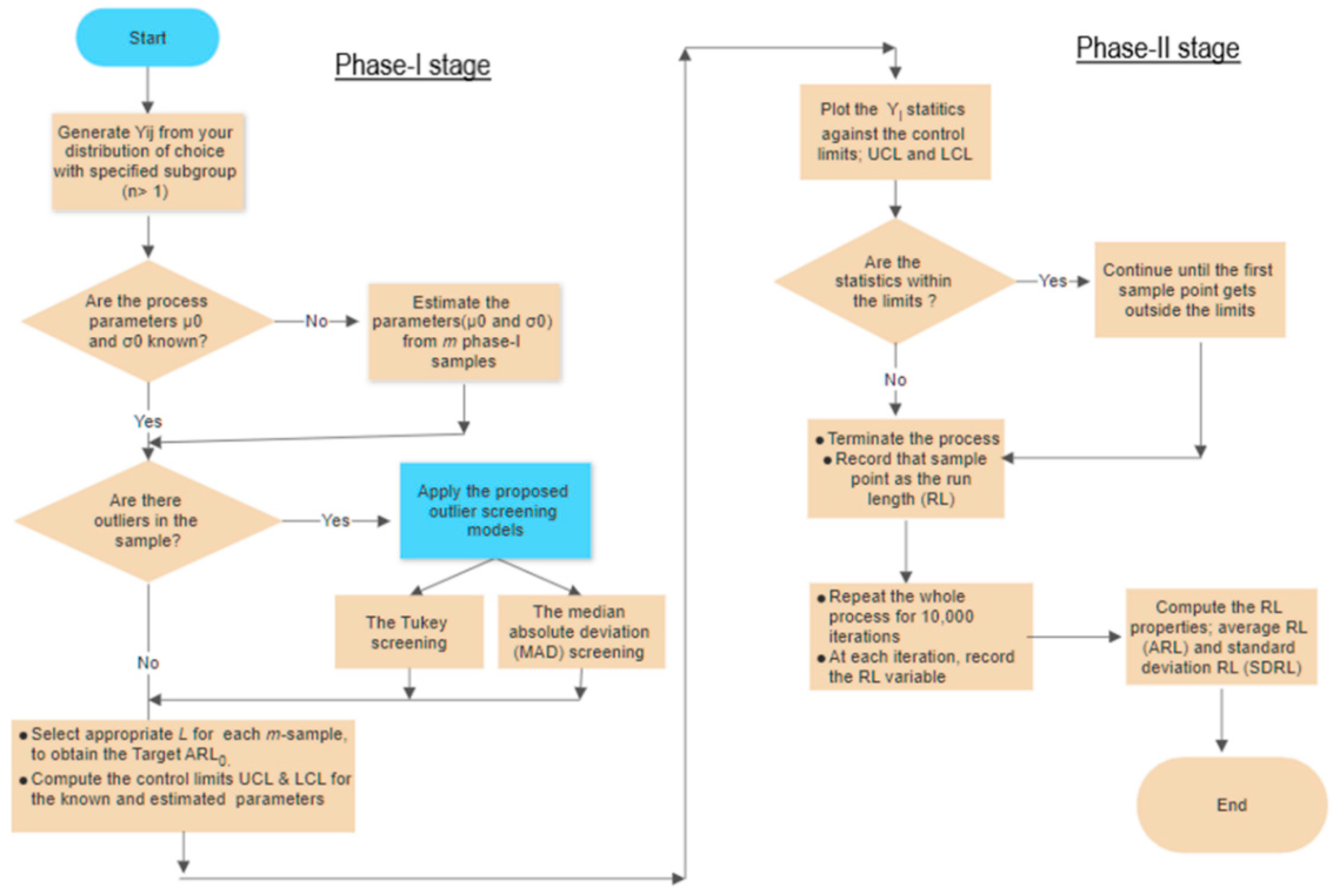
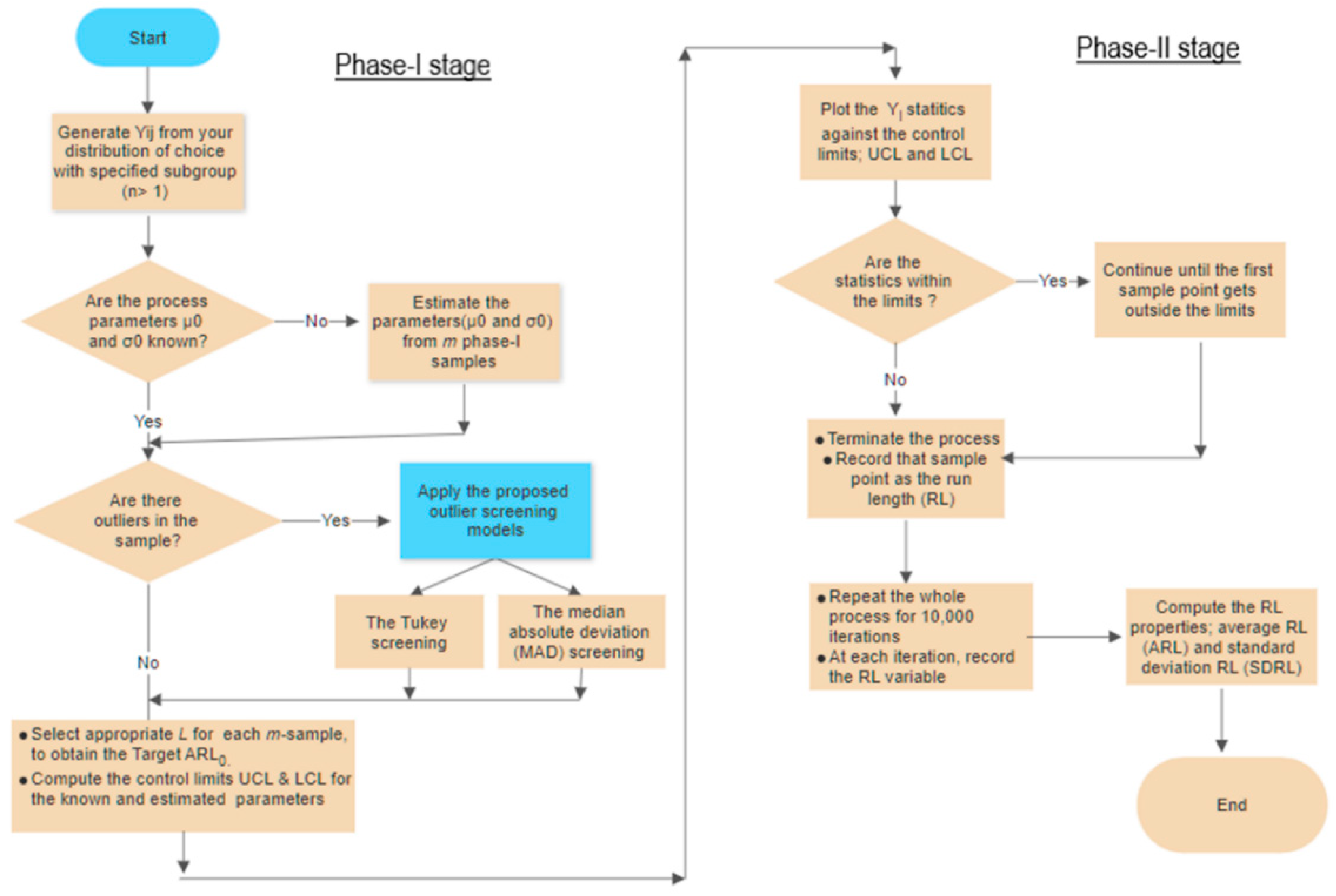
phase-I samples, which are used to construct the control limits for the monitoring stage; phase-II; while the latter are the sample points that fall beyond the control limits in phase-II. Therefore, the presence of outlying sample points in phase-I leads to wider control limits, rendering the control charts less effective. A flowchart summarizing the procedure is depicted in
Figure 1.
6. Conclusions
In this article, we evaluate the performance of the Shewhart control chart for location monitoring with estimated parameters. The study substantiates the effect of estimation error and the variability in the practitioners’ choice of phase-I samples on the chart, especially when the samples are prone to outliers. Increasing the phase-I sample size (although not practicably) will to some extent reduce the gross impact on the Shewhart chart. The results of this study further prove that incorporation of the non-parametric outlier screening models, Tukey and MAD, in the design of the Shewhart chart is more practicable as it requires less phase-I samples and yields better results. Another advantage of this study lies in the simplicity of its design and ease of usage. The study rounds up with an illustrative example with a photolithography real data. A comparison of the two detection models, Tukey and MAD, reveals that duo relatively efficient. The study is limited to operate within the univariate setup, while focusing on multivariate setup will be a great advantage and we plan a future study for that. Also, proposed charts are memory-less, which implies they are suitable for monitoring large shift. However, the idea of the study is not only applicable in Shewhart multivariate setup, but also extendable to other control charts, like exponentially weighted moving average and cumulative sum charts both univariate and multivariate setups.

 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}