1. Introduction
In this work, we are dealing with a
convex minimization problem, which can be formulated as
where
are proper, lower-semicontinuous convex functions and
H is a Hilbert space. Many real world problems, such as signal processing, image reconstruction and compressed sensing, can be described using this model [
1,
2,
3,
4]. Moreover, data classification can also be formulated as (
1); for more information about the importance and development of data classification and its methods see [
5,
6,
7,
8]. Therefore, a convex minimization problem has a wide range of applications, some of which will be studied in this research.
If
f is differentiable then it is well-known that an element
is a solution of (
1) if and only if
where
I is an identity mapping, and
is a subdifferential of
In addition, if
is
L-Lipschitz continuous then the classical
foward–backward algorithm [
9] can be used to solve (
1). It is defined as follows:
where
is a suitable stepsize. This method has been extensively used due to its simplicity, as a result it has been improved by many works, as seen in [
2,
10,
11,
12]. One well-known method that has improved the convergence rate of (
3) significantly is known as the
fast iterative shrinkage-threshodling algorithm or
FISTA. It was proposed by Beck and Teboulle [
13], as seen in Algorithm 1.
| Algorithm 1. FISTA. |
| 1: Input |
| 2: for to k do |
| 3: |
| 4: |
| 5: |
| 6: |
| 7: end for |
| 8: return |
They proved that FISTA has a better convergence rate than (
3), however the convergence theorem of this method was not given. Recently, Laing and Schonlieb [
14] modified FISTA by setting
where
and
and proved its weak convergence theorem.
In the case that
H is an infinite dimension Hilbert space, weak convergence results may not be enough, consequently modifications of some algorithms are needed to obtain strong convergence results. There are several ways to modify the methods for such purpose, for more information see [
15,
16,
17,
18]. One method that caught our attention was the
viscosity-base inertial foward–backward algorithm (
VIFBA) proposed by Verma et al. [
19], as seen in Algorithm 2.
| Algorithm 2. VIFBA. |
1: Input -contractive mapping F,
|
| 2: for to k do |
| 3: |
| 4: , |
| 5: . |
| 6: end for |
| 7: return |
They proved a strong convergence of this algorithm if the following conditions are satisfied for all :
- A1.
and
- A2.
and
- A3.
and
Note that all the methods mentioned above require to be L-Lipschitz continuous, which is quite difficult to find in general. Therefore, some improvements are still desirable.
Very recently, Cruz and Nghia [
20] proposed a linesearch technique which can be used to eliminate the
L-Lipschitz continuous assumption of
and replaced it with weaker assumptions. In their work, the following conditions are needed instead:
- B1.
are proper lower semicontinuous convex functions with
- B2.
f is differentiable on an open set containing and is uniformly continuous on any bounded subset of and maps any a bounded subset of to a bounded set in
The linesearch step is defined as Algorithm 3 as follows.
| Algorithm 3. Linesearch 1. |
| 1: Input , and |
| 2: set |
| 3: while do |
| 4: |
| 5: end while |
| 6: return |
They also proved that
Linesearch 1 stops after finitely many steps, and proposed Algorithm 4 as follows.
| Algorithm 4. |
| 1: Input , and |
| 2: for to k do |
| 3: Linesearch 1 |
| 4: |
| 5: end for |
| 6: return |
They also proved its weak convergence theorem. Again the weak convergence may not be enough in the context of infinite dimension space.
As we know, most of the work related to a convex minimization problem assumes the
L-Lipschitz continuity of
. This restriction can be relaxed using a linesearch technique. So, we are motivated to establish a novel accelerated algorithm for solving a convex minimization problem (
1), which employs a linesearch technique introduced by Cruz and Nghia [
20] together with VIFBA [
19]. The novelty of our proposed method is a suitable combination of the two methods to obtain a fast and efficient method for solving (
1). We improve Algorithm 4 by adding an inertial step, which enhances the performance of the algorithm. We also prove its strong convergence theorem under weaker assumptions on the control conditions than that of VIFBA. More precisely, we can eliminate the assumption A2 and replace A3 with a weaker assumption. As applications, we apply our main result to solve a data classification problem and a regression of a sine function. Then we compare the performance of our algorithm with FISTA, VIFBA, and Algorithm 4.
This work is organized as follows: In
Section 2, we recall some useful concepts related to the topic. In
Section 3, we provide a new algorithm and prove its strong convergence to a solution of (
1). In
Section 4, we conduct some numerical experiments with a data classification problem and a regression of a sine function and compare the performance of each algorithm (FISTA, VIFBA, Algorithms 4 and 5). Finally, the conclusion of this work is in
Section 5.
3. Main Results
In this section, we assume the existence of a solution of (
1) and denote
the set of all such solutions. It is known that
is closed and convex. We propose a new algorithm, by combining a linesearch technique (
Linesearch 1) with VIFBA, as seen in Algorithm 5. A diagram of this algorithm can be seen in
Figure 1.
| Algorithm 5: |
1: Input -contractive mapping
number of iterations. |
| 2: for to k do |
| 3: |
| 4: , |
| 5: Linesearch 1, |
| 6: . |
| 7: end for |
| 8: return |
We prove a strong convergence result of Algorithm 5 in Theorem 1 as follows.
Theorem 1. Let H be a Hilbert space, proper lower-semicontinuous convex, proper convex differentiable with being uniformly continuous on any bounded subset of Suppose the following holds:
- C1.
- C2.
Then a sequence generated by Algorithm 5 converges strongly to
Proof. Since
is closed and convex, a mapping
yields a fixed point. Let
by the definition of
and
, we obtain the following, for all
:
for some
The following also holds:
Next, we prove the following
Indeed, from (
4) and the definition of
we obtain
Hence, by using the above inequalities and the definition of
, we have
Since
Furthermore, it follows from
that
Next, we show that
is bounded. Indeed, from (
7) and (
9), we obtain
Inductively, we have
and hence
is bounded. Furthermore, by using (
5) and (
6),
and
are also bounded. To show the convergence of
we divide the proof into two cases.
Case 1 There exists
such that
for all
. So
for some
From (
5) and (
6), and the fact that
we have
Using (
9), we have
Since
is bounded, there exists a subsequence
of
such that
for some
and the following holds:
We claim that
In order to prove this, we need to consider two cases of
The first case, if
for finitely many
Then, without loss of generality, we can assume that
for all
. From the definition of
we have
The uniform continuity of
implies that
We know that
Since is demiclosed, we can have that and hence
The second case, there exists a subsequence
of
such that
for all
Let
=
and
From the definition of
, we have
Moreover, from Lemma 1 we have
which implies that
. Since
is uniformly continuous, we also have
as
Combining this with (
10), we obtain
as
Again, we know that
The demiclosedness of
implies that
and hence
Therefore
Using (
8), (
9), and Lemma 2, we have
for some
We set and in Lemma 4. Since and we have Consequently, Lemma 4 is applicable and hence that is converges strongly to
Case 2 There exists a subsequence
of
such that
for all
From Lemma 3, there exists a nondecreasing sequence
of
such that
and the following holds, for all sufficiently large
From the definition of
and (
8) we have, for all
for some
Combining with (
9), we obtain
So,
as
Since
is bounded, there exists a subsequence
such that
for some
and
Using the same argument as in case 1, we have that
and
Moreover, it follows from (
11) that
Consequently,
Hence,
Thus, we can conclude that converges strongly to , and the proof is complete. □
Remark 1. We observe that we can prove our main result, Theorem 1, without the condition and use the weaker condition instead of while VIFBA requires all of these conditions.
4. Applications to Data Classification and Regression Problems
As mentioned in the literature, many real world problems can be formulated in the form of a convex minimization problem. So, in this section, we illustrate the reformulation process of some problems in machine learning, namely classification and regression problems, into a convex minimization problem, and apply our proposed algorithm to solve such problems. We also show that our proposed method is more efficient than some methods mentioned in the literature.
First, we give a brief concept of extreme learning machine for data classification and regression problems, then we apply our main result to solve these two problems by conducting some numerical experiments. We also compare the performance of FISTA, VIFBA, Algorithms 4 and 5.
Extreme learning machine (ELM). Let
be a training set of
N distinct samples, then
is an
input data and
is a
target. For any single hidden layer of ELM, the output of the
i-th hidden node is
where
G is an activate function,
and
are parameters of the
i-th hidden node. The output function of ELM for SLFNs with
M hidden nodes is
where
is the output weight of the
i-th hidden node. The hidden layer output matrix
is defined as follows:
The main goal of ELM is to find such that where is the training data. In some cases, finding , where is the Moore–Penrose generalized inverse of maybe a difficult task when does not exist. Thus, finding such solution by means of convex minimization can overcome such difficulty.
In this section, we conduct some experiments on regression and classification problems, the problem is formulated as the following convex minimization problem:
where
is a regularization parameter. This problem is called the
least absolute shrinkage and selection operator (LASSO) [
26]. In this case
and
. We note that, in our experiments, FISTA and VIFBA can be used to solve the problems, since the
L-Lipschitz constants of the problems exist. However, FISTA and VIFBA fail to solve problems in which
L-Lipschitz constants do not exist, while Algorithms 4 and 5 succeed.
4.1. Regression of a Sine Function
Throughout
Section 4.1 and
Section 4.2, all parameters are chosen to satisfy all the hypotheses of Theorem 1. All results are performed on Intel Core i5-7500 CPU with 16GB RAM and GeForce GTX 1060 6GB GPU.
As seen in
Table 1, we create randomly 10 distinct points
which value between
, then we create the training set
and a graph of a sine function on
as the target. The activation function is sigmoid, number of hidden nodes
and regularization parameter
We use FISTA, VIFBA, Algorithms 4 and 5 to predict a sine function with 10 training points.
The first experiment is to compare the performance of Algorithm 5 with different
c-contractive mapping
so we can observe if
F affects the performance of Algorithm 5. We use
mean square error (MSE) as a measure defined as follows:
By setting
and the inertial parameter
and MSE
as the stopping criteria, we obtain the results as seen in
Table 2.
We observe that Algorithm 5 performs better when c is closer to 1.
In the second experiment, we compare the performance of Algorithm 5 with different inertial parameters
in Theorem 1, namely
It can be shown that
and
satisfy C2. By setting
and MSE
as the stopping criteria, we obtain the results, as seen in
Table 3.
We can clearly see that significantly improves the performance of Algorithm 5. Although, converges to 0 as , we observe that the behavior of is different form and at the first few steps of the iteration, i.e., is extremely close to 1 while and are far away from 1. Based on this experiment, we choose as our default inertial parameter for later experiments.
The third experiment, we compare the performance of FISTA, VIFBA, Algorithms 4 and 5. As in
Table 4, we set the following parameters for each algorithm:
By setting MSE
as the stopping criteria, we obtain the results, as seen in
Table 5.
We observe that Algorithm 5 takes only 129 iterations while FISTA, VIFBA and Algorithm 4 take a higher number of iterations, and Algorithm 5 uses a training time less than Algorithm 4.
Next, we compare each algorithm at the 3000th iteration with different kinds of measures, namely
mean absolute error (MAE) and
root mean squared error (RMSE) defined as follows:
The results can be seen in
Table 6.
We observe from
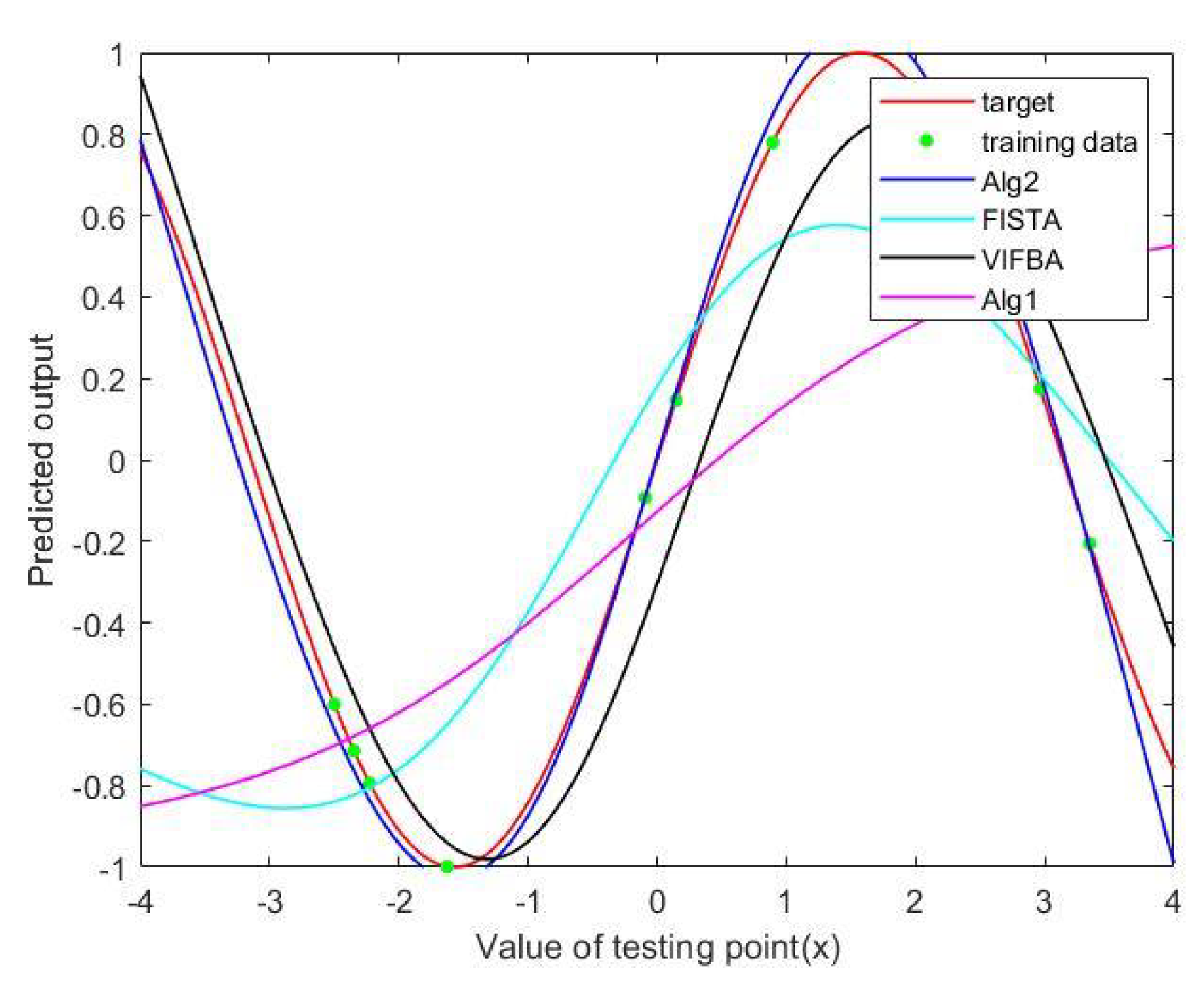
Table 6 that Algorithm 5 has the lowest MAE and RMSE, but takes the longest training time. In
Figure 2, we observe that Algorithm 5 outperforms other algorithms in the regression of a graph of a sine function under the small number of iterations. In
Figure 3, it is shown that Algorithm 5, FISTA and VIFBA have a better performance in the regression of a graph than Algorithm 4 when the number of iterations is higher.
4.2. Data Classification
In this experiment, we classify the type of Iris plants from
Iris dataset created by Fisher [
27]. As shown in
Table 7, this dataset contains 3 classes of 50 instances and each sample contains four attributes.
With this dataset, we set sigmoid as an activation function, number of hidden nodes
and regularization parameter
We use FISTA, VIFBA, Algorithms 4 and 5 as the training algorithm to estimate the optimal weight
The output data
O of training and testing data are obtained by
see
Table 8 for more detail.
In the first experiment, we use the first 35 instances of each class as training data and the last 15 of each class as testing data, see
Table 9 for detail.
The accuracy of the output data is calculated by:
To compare the performance of FISTA, VIFBA, Algorithms 4 and 5, we choose parameters for each algorithm the same as in
Table 4.
We first compare the accuracy of each method at the 700th iteration, and obtain the following results, as seen in
Table 10.
As we see, from
Table 10, Algorithm 5 obtains the highest accuracy at 700th iterations. We use acc.train and acc.test for the accuracy of the training data set and testing data set, respectively.
Next we compare each method with the stopping criteria as acc.train > 90 and acc.test > 90, the results can be seen in
Table 11.
We observe from
Table 11 that Algorithm 5 performs better than Algorithm 4.
In the next experiment, we use 10-fold stratified cross-validation to set up the training and testing data, see
Table 12 for detail.
We also use
Average ACC and
ERR to evaluate the performance of each algorithm.
where
N is a number of sets considered during cross validation (
),
a number of correctly predicted data at fold i and
a number of all data at fold i.
Let err
= sum of errors in all 10 training sets, err
= sum of errors in all 10 testing sets,
sum of all data in 10 training sets and
sum of all data in 10 testing sets. Define
where err
=
, and err
=
.
We choose the same parameters as in
Table 4. We compare the accuracy at the 1000th iteration of each fold, and obtain the following results, as seen in
Table 13.
We observe from
Table 13 that Algorithm 5 has higher average accuracy than Algorithm 4.
5. Conclusions
In this work, algorithms for solving a convex minimization problem (
1) are studied. Many effective algorithms for solving this problem were proposed, most of them require a Lipschitz continuous assumption of
By combining a linesearch technique introduced by Cruz and Nghia [
20], and an iterative method VIFBA by Verma et al. [
19], we establish a new algorithm that does not require a Lipschitz continuous assumption of
As a result, it can be applied to solve problems in which Lipschitz constants do not exist, while VIFBA and FISTA cannot. Moreover, by viscosity approximation together with the inertial technique, our proposed algorithm has a better convergence behavior than Algorithm 4. A strong convergence of our proposed method is also proven under some control conditions that are weaker than that of VIFBA.
Our algorithm can be used to solve many real world problems such as image and signal processing, machine learning, especially regression and classification problems. To compare the performance of FISTA, VIFBA, Algorithm 4 and our proposed algorithm(Algorithm 5), we conduct numerical experiments on the latter problems. We observe from these experiments that Algorithms 4 and 5 take computational time longer than FISTA and VIFBA at the same number of iterations because the linesearch step (
Linesearch 1) takes a long time to compute. In the experiments with the stopping criteria (
Table 5 and
Table 11), Algorithm 5 converges to a solution with a lower number of iterations than Algorithm 4 and hence performs better in terms of speed. We can also observe that Algorithm 5 performs decently in terms of accuracy, especially when compared with Algorithm 4.
For our future research, since FISTA performs better than Algorithm 5 in terms of speed, in order to compete with FISTA, we aim to find a new linesearch technique that takes less computational time than Linesearch 1 and hence decreases the computational time of Algorithm 5.





{kind=link}
{kind=link}
{kind=link}