A Comparison of Forecasting Mortality Models Using Resampling Methods



Abstract
1. Introduction
2. Fitting and Prediction of the Lee–Carter Models
3. Resampling Methods for Evaluating the Forecasting Abilities of the Models
- Hold-out;
- Repeated hold-out;
- Leave-one-out-CV (Cross Validation); and
- K-fold CV.
3.1. Hold-Out or Out-Of-Sample
3.2. Repeated Hold-Out
3.3. Leave-One-Out Cross-Validation
3.4. K-Fold Cross-Validation
4. Choosing the Optimal Mortality Model
5. Analysis of the Mortality Data from the Human Mortality Database
5.1. Description of the Data
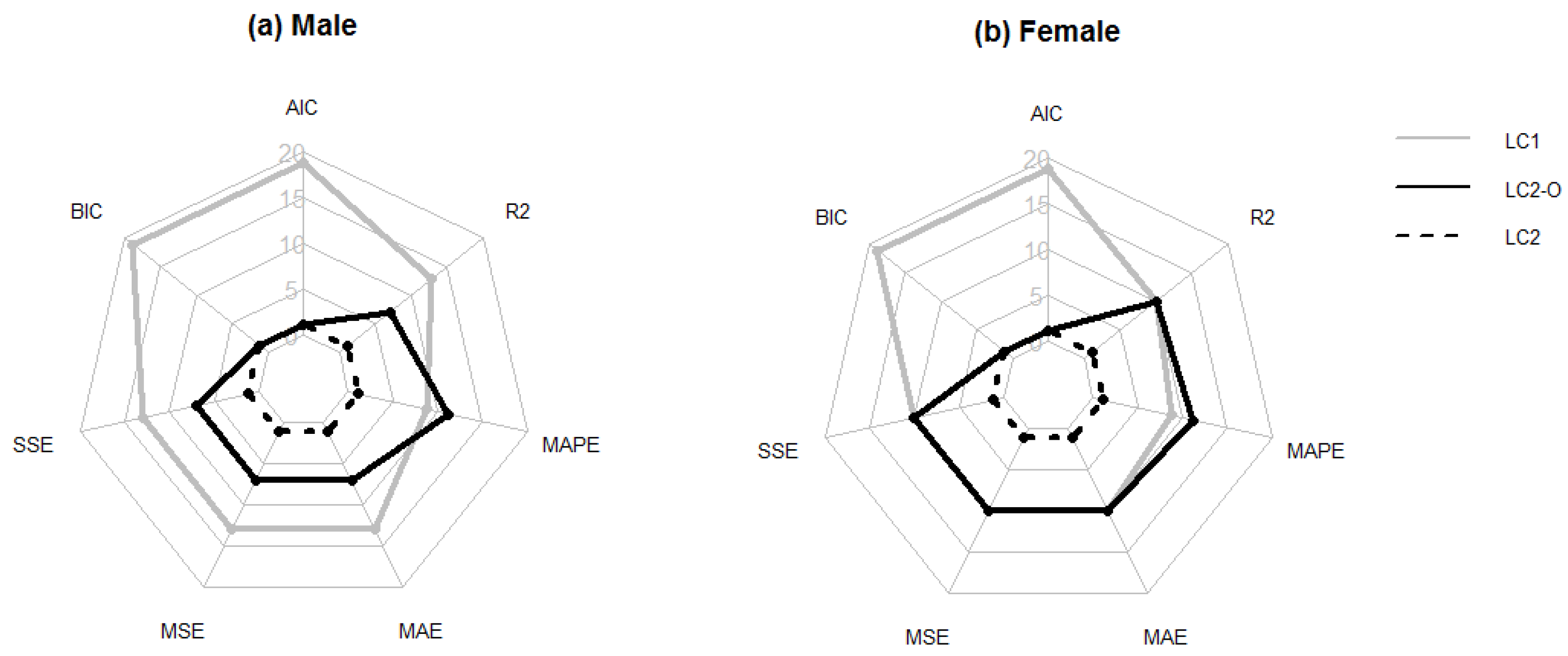
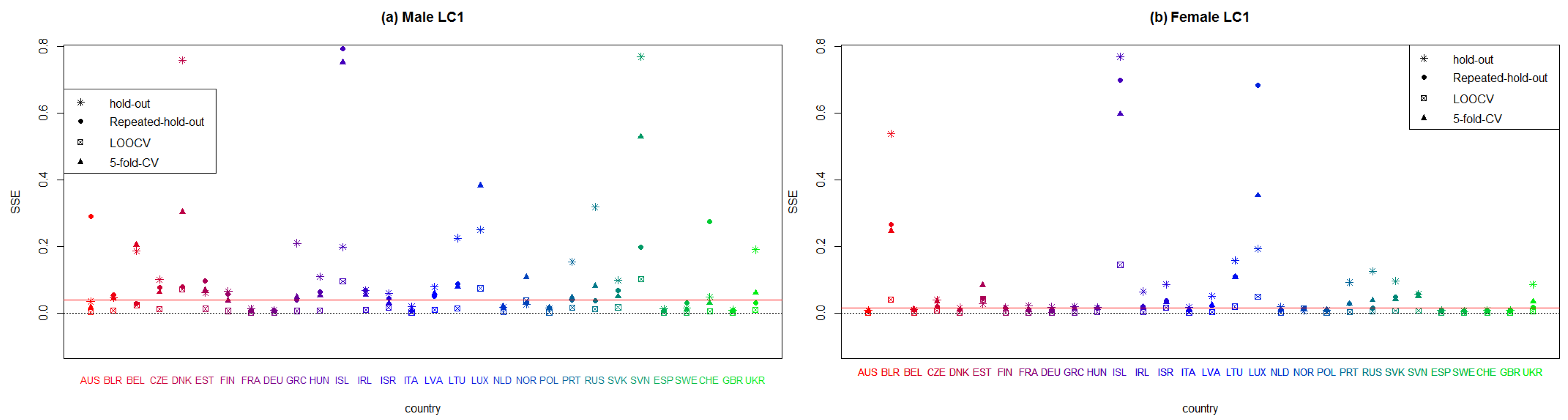
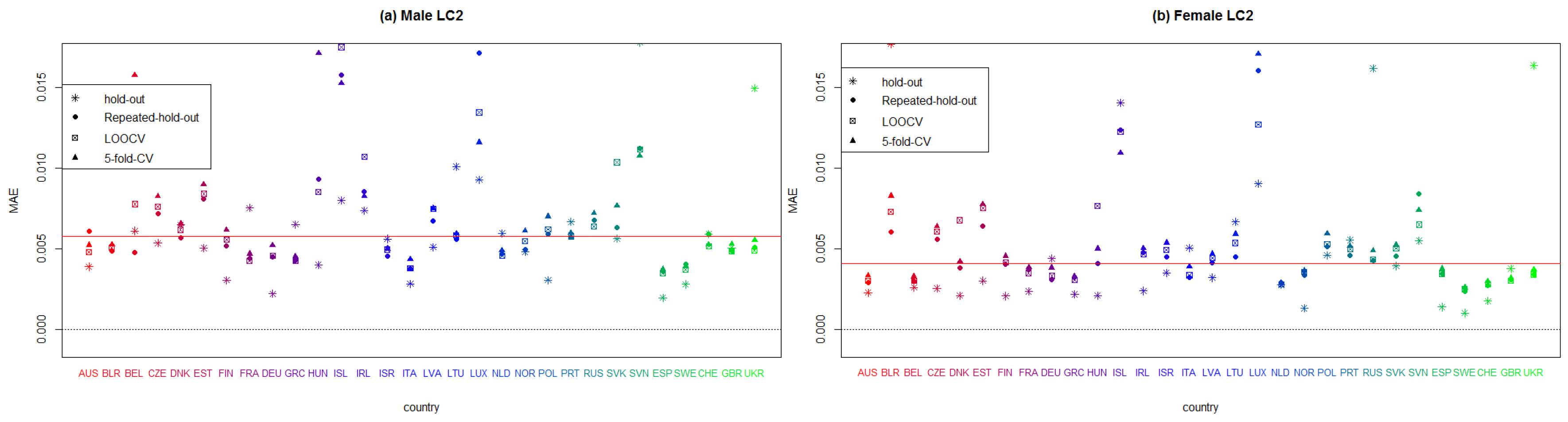
5.2. Forecasting Abilities of the Models
5.3. Hold-Out
- The sample is subdivided into two subsets: the training set contains 75% of the data that correspond to the 1990–2009 period, and the validation set comprises the remaining 25% of the data that cover the 2010–2016 period. The validation set that includes the last years of the sample period is employed to evaluate the forecasting ability of the models.
- The three mortality models are fitted by using the training set, and the corresponding estimations of parameters , and are obtained for each model.
- Once the values are estimated with the training set data, we proceed to fit an ARIMA model to forecast the values of the validation set (2010–2016). The particular ARIMA model is selected according to the AIC, as explained in Section 2.
- Forecasted life tables are obtained for each model, and then, the forecasting ability of each model is obtained by using the goodness-of-fit measures described in Section 4 that are calculated with the validation dataset.
5.4. Repeated Hold-Out
- We randomly subdivide the sample into two subsets. Of the total data, 75% are used as the training subset, and the remaining 25% are the validation subset. Here, the data that correspond to the years 1990, 1991, 1992, 1993, 1994, 1995, 1996, 1998, 1999, 2000, 2001, 2002, 2003, 2005, 2006, 2009, 2011, 2013, 2014 and 2016 are used as the training set, and the data that correspond to the years 1997, 2004, 2007, 2008, 2010, 2012 and 2015 form the validation set.
- The three models are fitted with the training data set that obtains the corresponding estimates , and .
- Since the training set does not contain serialized data, we use the na.kalman function from the imputeTS library of [70] to estimate the missing values by using ARIMA time series models and obtain the values that corresponds to the years included in the validation set.
- Finally, we obtain the forecasted life tables of the years included in the validation set; then, the forecasting ability of the model is obtained by using the goodness-of-fit measures described in Section 4 that are applied to the validation dataset.
5.5. Leave-One-Out CV
- We use the first three years of the sample (1990, 1991 and 1992) as the training set. According to the tsCV function of the forecast library developed by [50], three is the minimum number of years necessary to fit the mortality models used in this study.
- We obtain the estimations of , and .
- By using the ARIMA model that best fits the values, a single forecast is obtained for the that correspond to the year 1993.
- Once these data are projected for 1993, we obtain the corresponding forecasted probabilities of death for all ages (from zero to 109 years), countries and populations, and we then proceed to calculate the forecasting ability measures with the 1993 data as the validation set.
5.6. The 5-Fold CV
- We proceed to subdivide the sample into six equally sized subsets, that include subset data from four consecutive years. The first subset consists of data from 1990 to 1994 and is used only as a training set. The second subset contains data from 1995 to 1998, the third subset contains data from 1999 to 2002, the fourth subset contains data from 2003 to 2006, the fifth subset contains data from 2007 to 2011 and the sixth subset contains data from 2012 to 2016.
- With the data that correspond to the period from 1990 to 1994, we obtain the estimations of , and .
- We fit the ARIMA model to the values of by obtaining projections for the values that correspond to the second subset (from 1995 to 1998) that is used as the validation set.
- Finally, we forecast the life tables for each country according to sex and age from 1995 to 1998, and we can then proceed to determine the different measures of the forecasting ability of the mortality models employed in this study.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A






References
- Lee, R.D.; Carter, L.R. Modeling and forecast US mortality. J. Am. Stat. Assoc. 1992, 87, 659–671. [Google Scholar]
- Booth, H.; Maindonald, J.; Smith, L. Applying Lee—Carter under conditions of variable mortality decline. Popul. Stud. 2002, 56, 325–336. [Google Scholar] [CrossRef] [PubMed]
- Brouhns, N.; Denuit, M.; Vermunt, J.K. A Poisson log—Bilinear regression approach to the construction of projected lifetables. Insur. Math. Econ. 2002, 3, 373–393. [Google Scholar] [CrossRef]
- Lee, R.; Miller, T. Evaluating the performance of the Lee—Carter method for forecasting mortality. Demography 2001, 38, 537–549. [Google Scholar] [CrossRef] [PubMed]
- Cairns, A.J.G.; Blake, D.; Dowd, K. A two-factor model for stochastic mortality with parameter uncertainty: Theory and calibration. J. Risk Insur. 2006, 73, 687–718. [Google Scholar] [CrossRef]
- Cairns, A.J.G.; Blake, D.; Dowd, K.; Coughlan, G.D.; Epstein, D.; Ong, A.; Balevich, I. A quantitative comparison of stochastic mortality models using data from England and Wales and the United States. N. Am. Actuar. J. 2009, 13, 1–35. [Google Scholar] [CrossRef]
- Renshaw, A.E.; Haberman, S. Lee—Carter mortality forecasting with age-specific enhancement. Insur. Math. Econ. 2003, 33, 255–272. [Google Scholar] [CrossRef]
- Renshaw, A.E.; Haberman, S. A cohort-based extension to the Lee—Carter model for mortality reduction factors. Insur. Math. Econ. 2006, 38, 556–570. [Google Scholar] [CrossRef]
- Hainaut, D. A neural-network analyzer for mortality forecast. ASTIN Bull. J. IAA 2018, 48, 481–508. [Google Scholar] [CrossRef]
- Levantesi, S.; Pizzorusso, V. Application of machine learning to mortality modeling and forecasting. Risks 2019, 7, 26. [Google Scholar] [CrossRef]
- Pascariu, M.D.; Lenart, A.; Canudas-Romo, V. The maximum entropy mortality model: Forecasting mortality using statistical moments. Scand. Actuar. J. 2019, 2019, 661–685. [Google Scholar] [CrossRef]
- Śliwka, P.; Socha, L. A proposition of generalized stochastic Milevsky—Promislov mortality models. Scand. Actuar. J. 2018, 8, 706–726. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning: With Application in R; Springer: New York, NY, USA, 2013. [Google Scholar]
- Lyons, M.B.; Keith, D.A.; Phinn, S.R.; Mason, T.J.; Elith, J. A comparison of resampling methods for remote sensing classification and accuracy assessment. Eur. Actuar. J. 2008, 208, 145–153. [Google Scholar] [CrossRef]
- Molinaro, A.M.; Simon, R.; Pfeiffer, R.M. Prediction error estimation: A comparison of resampling methods. Bioinformatics 2005, 21, 3301–3307. [Google Scholar] [CrossRef] [PubMed]
- Arlot, S.; Celisse, A. A survey of cross-validation procedures for model selection. Stat. Surv. 2010, 4, 40–79. [Google Scholar] [CrossRef]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B (Methodol.) 1974, 36, 111–133. [Google Scholar] [CrossRef]
- Bergmeir, C.; Hyndman, R.J.; Koo, B. A note on the validity of cross-validation for evaluating autoregressive time series prediction. Comput. Stat. Data Anal. 2018, 120, 70–83. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics: New York, NY, USA, 2009. [Google Scholar]
- Efron, B. Bootstrap methods: Another look at the jackknife. Ann. Stat. 1979, 7, 1–26. [Google Scholar] [CrossRef]
- Brouhns, N.; Denuit, M.; Van Keilegom, I. Bootstrapping the Poisson log-bilinear model for mortality forecasting. Scand. Actuar. J. 2005, 3, 212–224. [Google Scholar] [CrossRef]
- D’Amato, V.; Haberman, S.; Piscopo, G.; Russolillo, M. Modelling dependent data for longevity projections. Insur. Math. Econ. 2012, 51, 694–701. [Google Scholar] [CrossRef]
- Debón, A.; Martínez-Ruiz, F.; Montes, F. Temporal evolution of mortality indicators: Application to spanish data. N. Am. Actuar. J. 2012, 16, 364–377. [Google Scholar] [CrossRef]
- Debón, A.; Montes, F.; Mateu, J.; Porcu, E.; Bevilacqua, M. Modelling residuals dependence in dynamic life tables: A geostatistical approach. Comput. Stat. Data Anal. 2008, 52, 3128–3147. [Google Scholar] [CrossRef]
- Koissi, M.C.; Shapiro, A.F.; Högnäs, G. Evaluating and extending the Lee—Carter model for mortality forecasting: Bootstrap confidence interval. Insur. Math. Econ. 2006, 38, 1–20. [Google Scholar] [CrossRef]
- Liu, X.; Braun, W.J. Investigating mortality uncertainty using the block bootstrap. J. Probab. Stat. 2010, 2010, 813583. [Google Scholar] [CrossRef]
- Efron, B.; Tibshirani, R.J. An Introduction to the Bootstrap. Monogr. on Stat. and Appl. Probab. 1993, 57, 1–436. [Google Scholar]
- Nordman, D.J.; Lahiri, S.N.; Fridley, B.L. Optimal block size for variance estimation by a spatial block bootstrap method. Indian J. Stat. 2007, 69, 468–493. [Google Scholar]
- Härdle, W.; Horowitz, J.; Kreiss, J.P. Bootstrap methods for time series. Int. Stat. Rev. 2003, 71, 435–459. [Google Scholar] [CrossRef]
- Bergmeir, C.; Benítez, J.M. On the use of cross-validation for time series predictor evaluation. Inf. Sci. 2012, 191, 192–213. [Google Scholar] [CrossRef]
- Debón, A.; Montes, F.; Sala, S. A comparison of parametric models for mortality graduation. Application to mortality data of the Valencia region (Spain). SORT Stat. Oper. Res. Trans. 2005, 29, 269–288. [Google Scholar]
- Booth, H.; Hyndman, R.J.; Tickle, L.; de Jong, P. Lee—Carter mortality forecasting: A multi-country comparison of variants and extensions. Demogr. Res. 2006, 15, 289–310. [Google Scholar] [CrossRef]
- Delwarde, A.; Denuit, M.; Eilers, P. Smoothing the Lee—Carter and Poisson log-bilinear models for mortality forecasting: A penalized log-likelihood approach. Stat. Model. 2007, 7, 29–48. [Google Scholar] [CrossRef]
- Debón, A.; Montes, F.; Puig, F. Modelling and forecasting mortality in Spain. Eur. J. Oper. Res. 2008, 189, 624–637. [Google Scholar] [CrossRef][Green Version]
- Currie, I.D.; Durban, M.; Eilers, P.H.C. Smoothing and forecasting mortality rates. Stat. Model. 2004, 4, 279–298. [Google Scholar] [CrossRef]
- Chen, K.; Liao, J.; Shang, X.; Li, J.S.H. Discossion of “A Quantitative Comparison of Stochastic Mortality Models Using Data from England and Wales and the United States”. N. Am. Actuar. J. 2009, 13, 514–520. [Google Scholar] [CrossRef]
- Plat, R. On stochastic mortality modeling. Insur. Math. Econ. 2009, 45, 393–404. [Google Scholar] [CrossRef]
- Debón, A.; Martínez-Ruiz, F.; Montes, F. A geostatistical approach for dynamic life tables: The effect of mortality on remaining lifetime and annuities. Insur. Math. Econ. 2010, 47, 327–336. [Google Scholar] [CrossRef]
- Yang, S.S.; Yue, J.C.; Huang, H.C. Modeling longevity risks using a principal component approach: A comparison with existing stochastic mortality models. Insur. Math. Econ. 2010, 46, 254–270. [Google Scholar] [CrossRef]
- Haberman, S.; Renshaw, A. A comparative study of parametric mortality projection models. Insur. Math. Econ. 2011, 48, 35–55. [Google Scholar] [CrossRef]
- Mitchell, D.; Brockett, P.; Mendoza-Arriaga, R.; Muthuraman, K. Modeling and forecasting mortality rates. Insur. Math. Econ. 2013, 52, 275–285. [Google Scholar] [CrossRef]
- Cadena, M. Mortality Models based on the Transform log(−log x). arXiv 2015, arXiv:1502.07199. [Google Scholar]
- Danesi, I.L.; Haberman, S.; Millossovich, P. Forecasting mortality in subpopulations using Lee—Carter type models: A comparison. Insur. Math. Econ. 2015, 62, 151–161. [Google Scholar] [CrossRef]
- Yang, B.; Li, J.; Balasooriya, U. Cohort extensions of the Poisson common factor model for modelling both genders jointly. Scand. Actuar. J. 2016, 2, 93–112. [Google Scholar] [CrossRef]
- Neves, C.; Fernandes, C.; Hoeltgebaum, H. Five different distributions for the Lee—Carter model of mortality forecasting: A comparison using GAS models. Insur. Math. Econ. 2017, 75, 48–57. [Google Scholar] [CrossRef]
- Human Mortality Database. University of California, Berkeley (USA), and Max Planck Institute for Demographic Research (Germany). Available online: www.mortality.org (accessed on 7 August 2020).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 19 November 2019).
- Hunt, A.; Blake, D. Identifiability in age/period/cohort mortality models. Ann. Actuar. Sci. 2020. forthcoming. [Google Scholar] [CrossRef]
- Turner, H.; Firth, D. Generalized Nonlinear Models in R: An Overview of the Gnm Package. 2018. Available online: https://cran.r-project.org/package=gnm (accessed on 12 January 2020).
- Hyndman, R.J.; Khandakar, Y. Automatic time series forecasting: The forecast package for R. J. Stat. Softw. 2008, 26, 1–22. [Google Scholar]
- Lachenbruch, P.A.; Mickey, M.R. Estimation of error rates in discriminant analysis. Technometrics 1968, 10, 1–11. [Google Scholar] [CrossRef]
- Kohavi, R. A study of cross-validation and bootstrap for accuracy estimation and model selection. In Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 20–25 August 1995; Morgan Kaufmann: San Francisco, CA, USA, 1995; pp. 1137–1143. [Google Scholar]
- Torgo, L. Data mining with R: Learning with case studies. In Data Mining and Knowledge Discovery Series; Chapman and Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Tashman, L.J. Out-of-sample tests of forecasting accuracy: An analysis and review. Int. J. Forecast. 2000, 16, 437–450. [Google Scholar] [CrossRef]
- Diaz, G.; Ana, D.; Giner-Bosch, V. Mortality forecasting in Colombia from abridged life tables by sex. Genus 2018, 74, 15. [Google Scholar] [CrossRef]
- Ahcan, A.; Medved, D.; Olivieri, A.; Pitacco, E. Forecasting mortality for small populations by mixing mortality data. Insur. Math. Econ. 2014, 54, 12–27. [Google Scholar] [CrossRef]
- Atance, D.; Balbás, A.; Navarro, E. Constructing dynamic life tables with a single factor model. In Documentos de trabajo IAES; Instituto Universitario de Análisis Económico y Social Universidad de Alcalá: Madrid, Spain, 2019; Volume 9, pp. 1–45. [Google Scholar]
- Forsythe, A.; Hartigan, J.A. Efficiency of confidence intervals generated by repeated subsample calculations. Biometrika 1970, 57, 629–639. [Google Scholar] [CrossRef]
- Burman, P. A comparative study of ordinary cross-validation, v-fold cross-validation and the repeated learning-testing methods. Biometrika 2002, 76, 503–514. [Google Scholar] [CrossRef]
- Shao, J. Linear model selection by cross-validation. J. Am. Stat. Assoc. 1993, 88, 486–494. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Li, H.; O’Hare, C. Mortality Forecasting: How far back should we look in time? Risks 2019, 7, 22. [Google Scholar] [CrossRef]
- Breiman, L.; Spector, P. Submodel selection and evaluation in regression: The X-random case. Int. Stat. Rev. 1992, 60, 291–319. [Google Scholar] [CrossRef]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 6, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. [Google Scholar] [CrossRef]
- Hunt, A.; Blake, D. A general procedure for constructing mortality models. N. Am. Actuar. J. 2014, 18, 116–138. [Google Scholar] [CrossRef]
- Riffe, T. Reading Human Fertility Database and Human Mortality Database Data into R; TR-2015-004; MPIDR: Rostock, Germany, 2015. [Google Scholar]
- Hyndman, R.J.; Booth, H.; Tickle, L.; Maindonald, J. Demography: Forecasting Mortality, Fertility, Migration and Population Data. R Package Version 1.21; 2010; Available online: http://CRAN.R-project.org/package=demography (accessed on 12 January 2020).
- Nakazawa, M. fmsb: Functions for Medical Statistics Book with Some Demographic Data. R Package Version 0.6.3; 2018; Available online: https://CRAN.R-project.org/package=fmsb (accessed on 12 January 2020).
- Moritz, S.; Bartz-Beielstein, T. imputeTS: Time Series Missing Value Imputation in R. R J. 2017, 9, 207–2018. Available online: https://journal.r-project.org/archive/2017/RJ-2017-009/index.html (accessed on 12 January 2020). [CrossRef]
- Holt-Lunstad, J.; Smith, T.B.; Layton, J.B. Social relationships and mortality risk: A meta-analytic review. PLoS Med. 2010, 7, e1000316. [Google Scholar] [CrossRef]
- Thai, M.T.; Wu, W.; Xiong, H. Big Data in Complex and Social Networks; Chapman and Hall/CRC Press: London, UK, 2016. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Measure of Goodness Fit | Mortality Models | Selected Model |
|---|---|---|---|
| [31] | Gompertz–Makeham | Logit–Gompertz–Makeham | |
| MAPE | Logit–Gompertz–Makeham | ||
| Heligman–Pollard–2law | |||
| [32] | MAE | LC1/LM | BMS with small differences |
| ME | BMS/HU | ||
| LC-smooth | |||
| [33] | AIC | LC1-Negative Binomial | LC1-Negative Binomial |
| BIC | LC1-Poisson | ||
| [24] | MAPE | LC1-Logit/LC2-Logit | MP |
| MSE | Median Polish (MP) | ||
| [34] | MAPE | LC1-SVC/LC1-GLM | LC2 |
| MSE | LC1-ML/LC2-SVD | ||
| LC2-GLM/LC2-ML | |||
| [6] | BIC | LC1/LC2-Cohort | LC2-Cohort |
| APC/M5 | M8 | ||
| [35] | |||
| M6/M7/M8 | |||
| [36] | SSE | M5-Logit | M5-Logit |
| M5-Log/M5-Probit | |||
| [37] | BIC | [37] model | [37] model |
| LC1/M7/M5 | |||
| LC2-Cohort | |||
| [35] model | |||
| [38] | Deviance | LC1/LC1-res | LC-APC |
| MSE | LC2/LC2-res | ||
| MAPE | LC-APC/LC-APC-res | ||
| MP/MP-res | |||
| MP-APC/MP-APC-res | |||
| [39] | MAPE | LC1/APC1 | [39] model |
| BIC | APC2/CBD | ||
| [39] model | |||
| [40] | AIC | LC1/ | M7/M8/ |
| BIC | M/LC2 | ||
| HQC | M5/M6 | ||
| M7/M8 | |||
| [41] | RSSE | [41] model | RH |
| LC1/RH | [41] | ||
| BIC | / | ||
| [37] model | |||
| [42] | MSE | LC1/CBD | [42] model |
| MAPE | [42] model | ||
| [43] | MAPE | P-Double-LC2/M-Double-LC2 | P-Common-LC2 |
| AIC | P-Common-LC2/M-Common-LC1 | ||
| BIC | P-Simple-LC1/M-Simple-LC1 | ||
| MAPE | P-Division-LC1/M-Division-LC1 | ||
| P-One-LC1/M-One-LC1 | |||
| [44] | BIC | PCFC | PCFC |
| MAPE | PCFM | ||
| [45] | AIC | GAS Poisson/GAS Binomial | GAS Negative Binomial |
| MAPE | GAS Negative Binomial | ||
| GAS Gaussian/GAS Beta |
| Label Model | Parameter Constraints | Formula |
|---|---|---|
| LC | ||
| LC2 | ||
| LC2-O | ||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Atance, D.; Debón, A.; Navarro, E. A Comparison of Forecasting Mortality Models Using Resampling Methods. Mathematics 2020, 8, 1550. https://doi.org/10.3390/math8091550
Atance D, Debón A, Navarro E. A Comparison of Forecasting Mortality Models Using Resampling Methods. Mathematics. 2020; 8(9):1550. https://doi.org/10.3390/math8091550
Chicago/Turabian StyleAtance, David, Ana Debón, and Eliseo Navarro. 2020. "A Comparison of Forecasting Mortality Models Using Resampling Methods" Mathematics 8, no. 9: 1550. https://doi.org/10.3390/math8091550
APA StyleAtance, D., Debón, A., & Navarro, E. (2020). A Comparison of Forecasting Mortality Models Using Resampling Methods. Mathematics, 8(9), 1550. https://doi.org/10.3390/math8091550