4.1. Contribution to the Missing Data Case
A simulation example is presented in this section to emphasize the benefits of the proposed algorithm. The proposed method is compared with the typical PF algorithm, when the complete dataset is available, and the multiple imputation particle filter (MIPF) for
imputations [
8]. The reduction step proposed in [
23] is incorporated in the initial MIPF algorithm for the best possible results to be achieved. The data simulation is based on the state-space model of Equations (
1) and (
2), with two-dimensional vectors
where
,
,
,
,
and
N symbolizes Gaussian distribution. Let
be considered known. Next, concerning missing data, we let
, that is the data are missing completely at random.
particles have been used for every filter. The distributions of noises are also considered known. The weighted mean is used as a point estimator of a hidden state and missing observational errors are substituted by their expected values. All the filters have been repeated for 100 times and their performance concerning their precision and consumed time has been recorded. (The code was written in R project [
24]. Packages
mvnorm [
25], with its corresponding reference book [
26], ggplot [
27], and ggforce [
28] were also used. Simulations were performed on an AMD A8-7600 3.10 GHz processor with 8 GB of RAM.)
The results of the three methods are shown in
Table 1. In the first two columns, the means over the simulations of Root-Mean-Square Errors (RMSE) of the estimators (weighted means) for each component of the hidden states are presented. The mean of the two aforementioned columns is also calculated, as well as the mean time consumed in each approach. In the table, it is shown that the weight estimation with the suggested method outperforms MIPF concerning both precision and time elapsed. The precision of the suggested method supersedes that of MIPF slightly, while the mean required computational time is about
less than the corresponding mean time required for MIPF. The proposed method is also compared with the results of the standard PF algorithm, for which all observations are available, and it seems that, even if the precision is inevitably reduced in the case of missing data, the computational time remains nearly the same. The small differentiation in the mean elapsed time is probably connected with the resampling decision. That is, in this example, the precision of the suggested method slightly supersedes its competitor, while its computational cost is much lower than the cost of its competitor, reaching the levels of the basic filter (which is practically infeasible in the missing data case). In
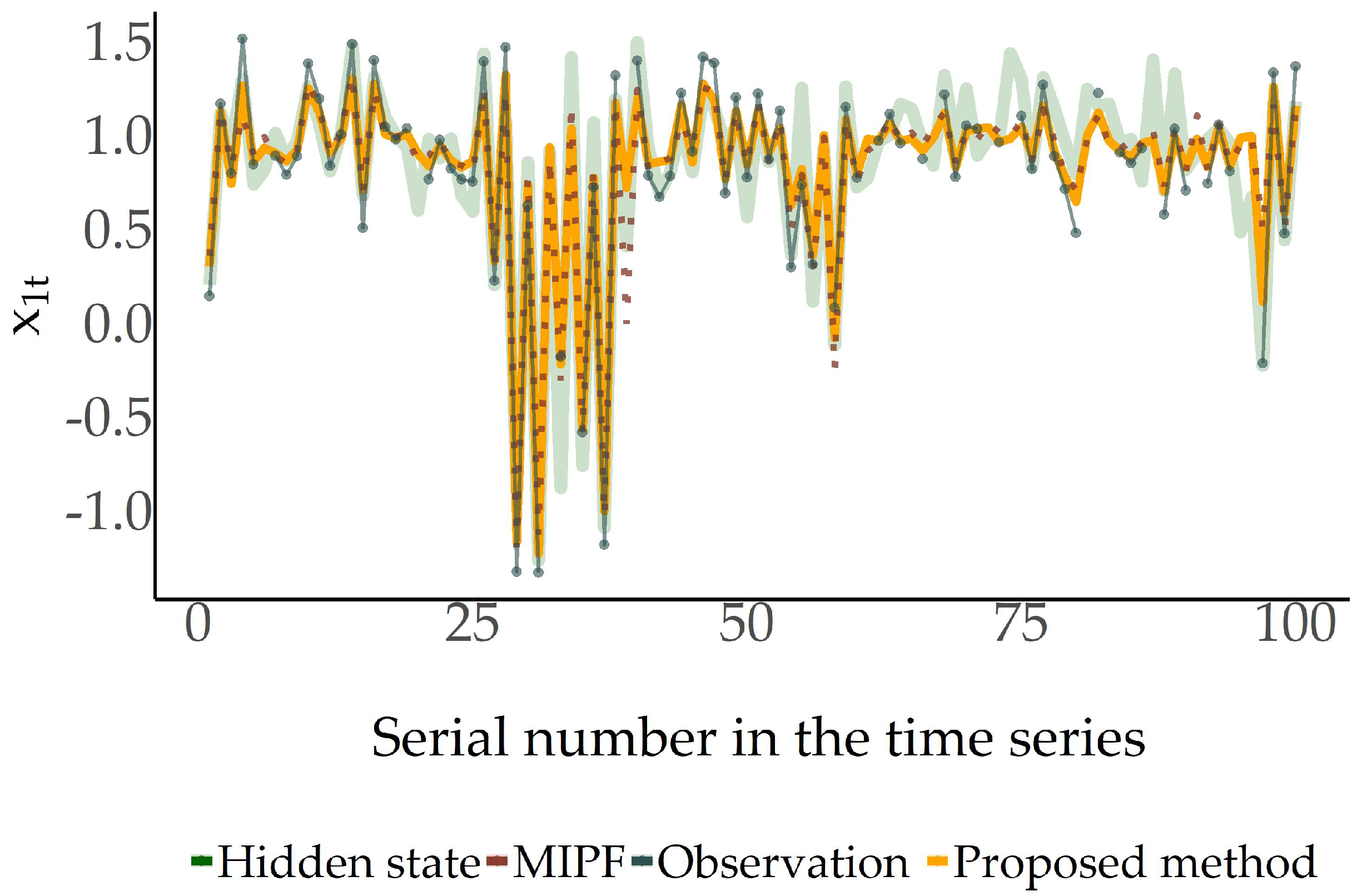
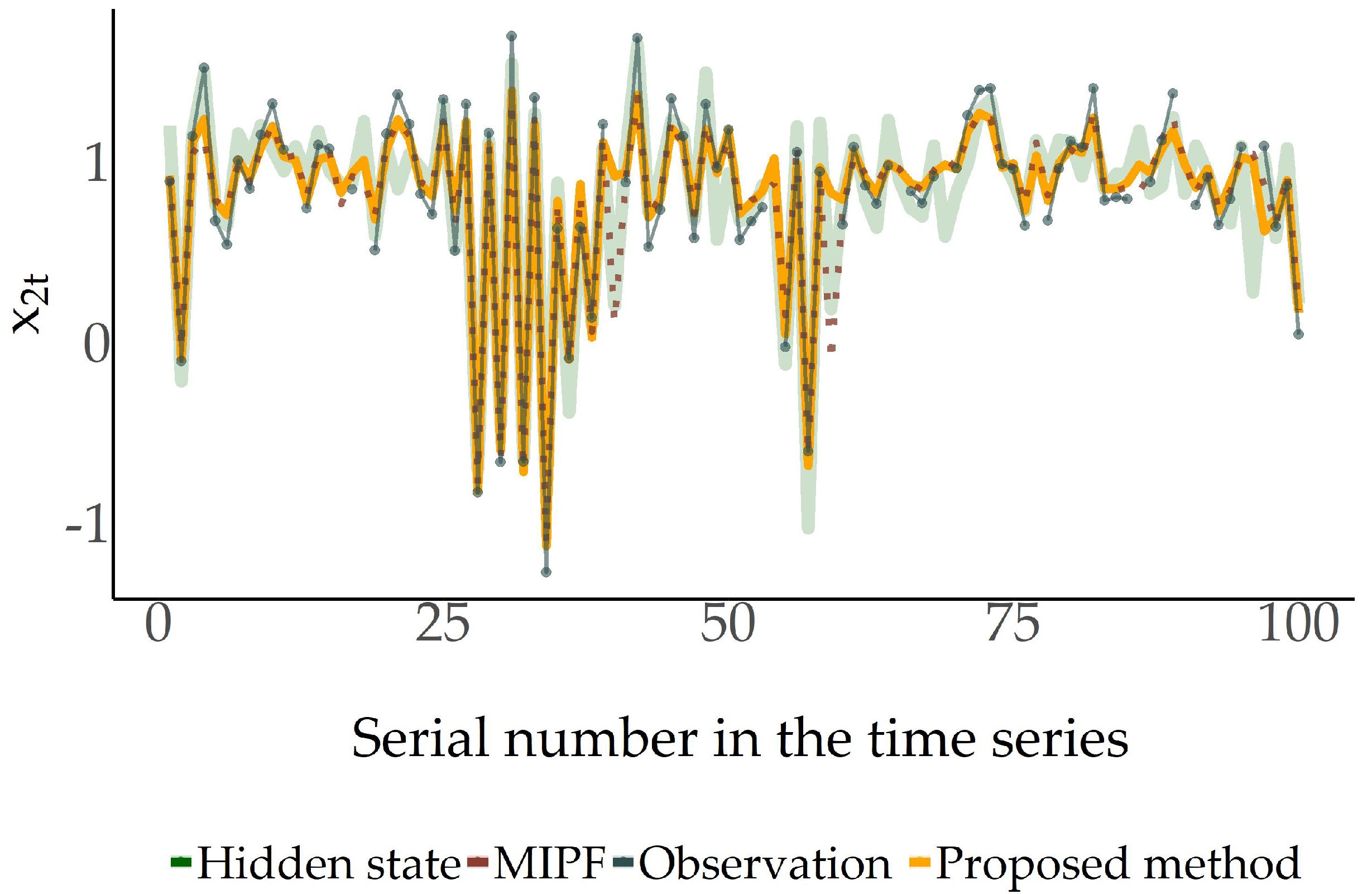
Figure 1 and
Figure 2, the performances of the proposed method and MIPF are depicted for the two components of the state process, respectively, for one iteration of each filter. The estimators (weighted means) of the two approaches are close to each other, tracking the hidden vector satisfactorily. Therefore, in this example, the suggested method appears to provide the best option between the available ones in the missing data case.
4.2. Contribution to Impoverishment Prediction
As far as estimation of particle distribution one step ahead is concerned, an application for the transition of the particles from time point
to
is presented during one implementation of the suggested PF with single imputation for missing values on the available dataset. In the time interval (0,10], only the first component of observation
is unavailable. In the end of time step
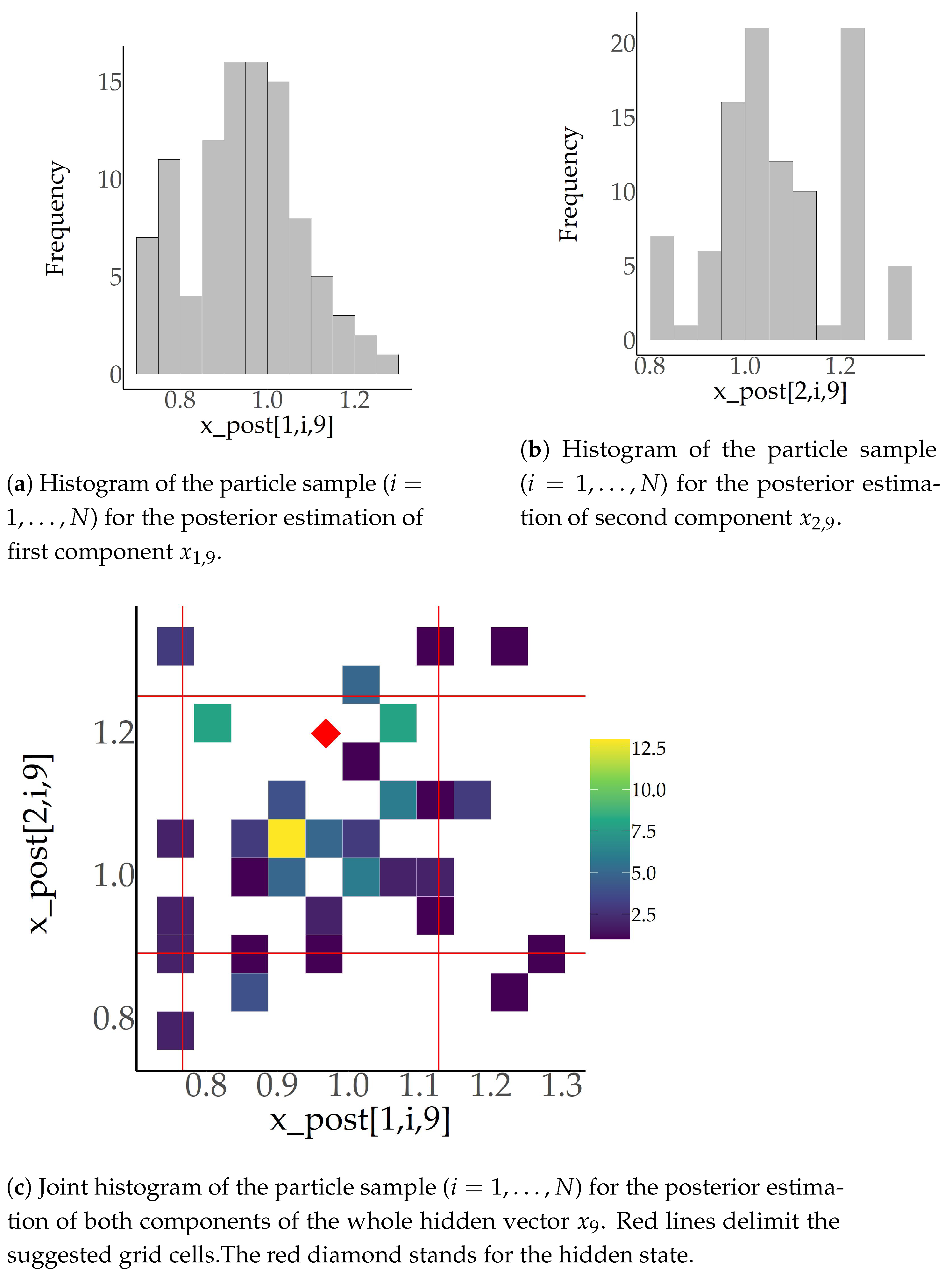
, resampling is implemented and the histograms of the particle sets are exhibited in
Figure 3. The sample mean of the particles is
and the standard deviations of the corresponding components are
and
. According to Equation (
4) and the given parameters of the problem, the random factor needed to be estimated for every particle at the next time step is
where
. Thus, in both dimensions, the following partitions are considered,
so that a grid of nine cells is configured over the two dimensions. The frequency table (
Table 2) exhibits the particle distribution over the grid.
The selected time period was chosen because there is a considerable number of preceding steps that permits a relatively good adaptation of the particle samples over the hidden states and the samples have not yet collapsed to a tiny neighborhood around a single point (utter impoverishment). This argument is evinced in
Figure 3c and
Table 2, where the distribution of the particles is presented in connection with the hidden state and the suggested grid. The produced particles are both close to the hidden state, as most of them are less than one standard deviation
from it, and sparse enough for the existence of particles outside the central cell of the grid. Thus, the condition of the sample during these time points configures a typical example of filter implementation before its collapse. Such time points may be suitable starting points for the introduction of control (which exceeds the limits of this study) as the subject sample is in a good condition concerning both impoverishment and accuracy over hidden variable estimation.
For the next time step, a prior estimation for hidden vector
is implemented. For the formation of the new grid, the existing particles are moved according to the deterministic part of Equation (
9), resulting in
, the mean of the new particle set. This quantity constitutes a prior point estimator of the hidden state. Thus, the grid of
is shifted by
to a new grid, as shown it
Table 3, the central cell of which is
The movement of all the particles according to the deterministic part of Equation (
9) results in the frequency table in
Table 3, where it is shown that all the new particles belong to the central cell. Even though the particles are identically distributed, with the addition of the process noise to the particles, the probabilities for particles to move from the central cell to random ones defer from particle to particle, as the particles have different distances form the grid lines initially. This fact is in contrast to the theoretical background of MS, according to which population members have a common transition probability matrix
P to move during a time step. For this reason, the probabilities of particles to move to a cell with the addition of the random noise are approximated by the probabilities of the point estimation
to move to a random cell with the addition of noise. These probabilities (rounded values) are provided in
Table 4. Thus, the expected numbers of particles over the grid cells are
and the expected distribution of the particles over the grid is presented in
Table 5. Concerning the expected posterior distribution of the particles, the expected observational errors are zero, so that particle weights are expected to remain the same. Thus, no further change is expected in their distribution in cells even if resampling is decided to take place, as all weights are equal after resampling in the previous time step.
Remark 3. The expected values of observational errors are zero. Nevertheless, the prior estimation of their distribution according to relation (4) and model parameters, where the variances of the errors are presented, evinces the increased uncertainty for them, as while . The results of the implementation of PF at time step
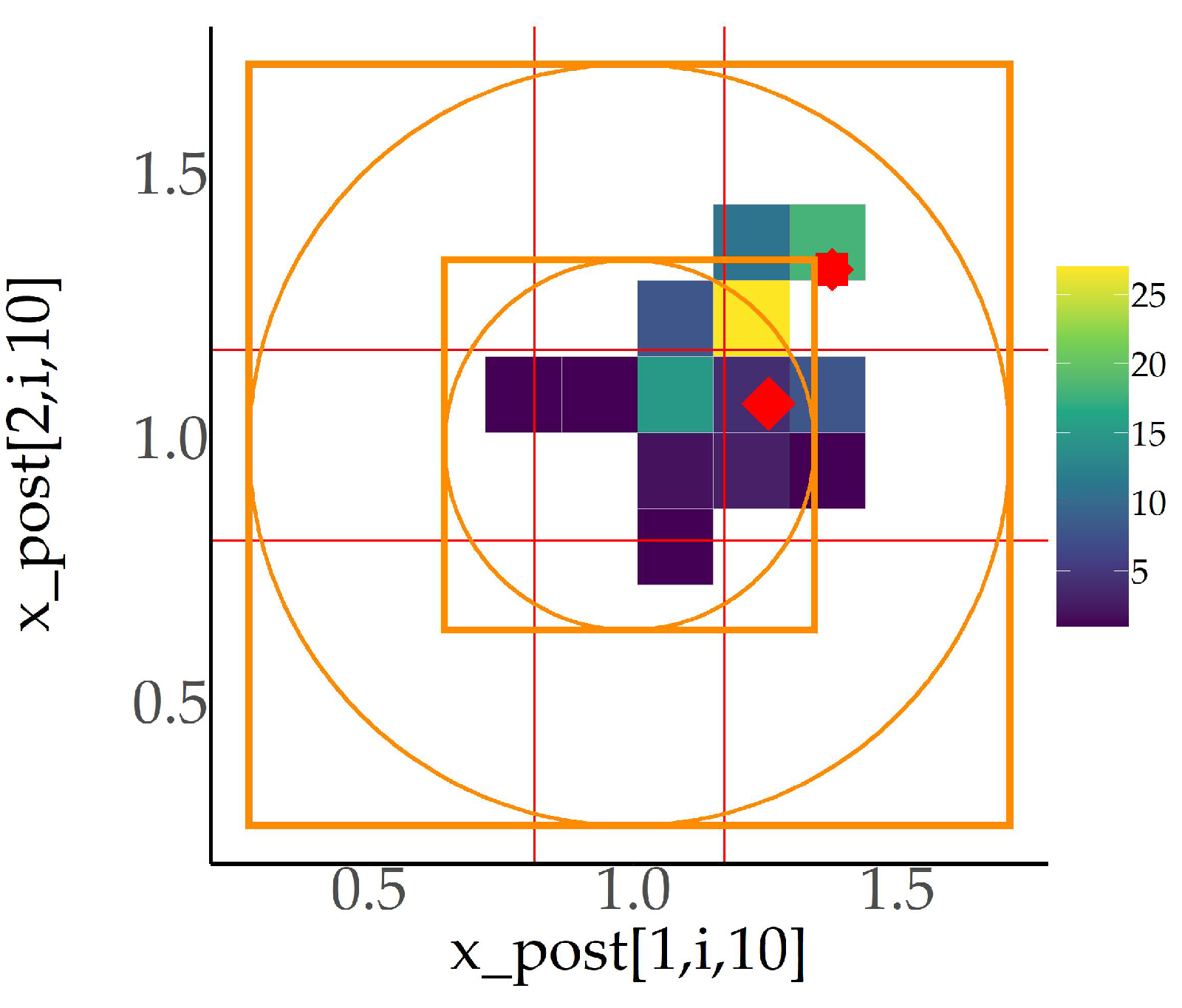
are also exhibited. Resampling has taken place at this time step as well. The joint histogram of the posterior sample over both dimensions (
Figure 4) indicates that the majority of the particles do not belong to the central cell. This fact is reasonable, as the length of the sides of the central cell equals only one standard deviation
, so that prior probabilities for the particles to be placed outside of the central cell at this time point are considerably big according to the Empirical Rule (68-95-99.7) for normal distribution. For the consolidation of these results towards this rule, the orange squares are drawn in
Figure 4 for the corresponding areas of the rule to be defined for each separate dimension, while the orange circles are the corresponding standard deviation circles (and not ellipses, generally, as the two components have the same variance
) of the whole vector. Thus, questions on the suitability of the proposed grid structure are raised for future study. Nevertheless, it should be mentioned that a grid with a central cell of double side length would have classified all particles to the central cell during time step
, rendering further study on the issue meaningless. Additionally, a new grid of nine cells is also constructed around the mean of this posterior particle set, the central cell of which also has length
. The distribution of the particles in the new grid is quoted in
Table 6. In comparison with
Table 2, it seems that the number of particles in the central cell is increased in
Table 6.
Remark 4. In the present example, the transitions of the particles according to the deterministic function led all particles to a single cell (Table 3), so that the result of the addition of process noise was handled as a result of a multinomial trial. In the case that the deterministic function leads the particles to more than one cell, then it is suggested that different means be found for each cell as well as corresponding transition probabilities, so that the final result can be considered the sum of results of multinomial trials for the transitions to every cell. 







{kind=link}
{kind=link}
{kind=link}
{kind=link}