Abstract
A classical reduced order model (ROM) for dynamical problems typically involves only the spatial reduction of a given problem. Recently, a novel space–time ROM for linear dynamical problems has been developed [Choi et al., Space–tume reduced order model for large-scale linear dynamical systems with application to Boltzmann transport problems, Journal of Computational Physics, 2020], which further reduces the problem size by introducing a temporal reduction in addition to a spatial reduction without much loss in accuracy. The authors show an order of a thousand speed-up with a relative error of less than for a large-scale Boltzmann transport problem. In this work, we present for the first time the derivation of the space–time least-squares Petrov–Galerkin (LSPG) projection for linear dynamical systems and its corresponding block structures. Utilizing these block structures, we demonstrate the ease of construction of the space–time ROM method with two model problems: 2D diffusion and 2D convection diffusion, with and without a linear source term. For each problem, we demonstrate the entire process of generating the full order model (FOM) data, constructing the space–time ROM, and predicting the reduced-order solutions, all in less than 120 lines of Python code. We compare our LSPG method with the traditional Galerkin method and show that the space–time ROMs can achieve to relative errors for these problems. Depending on parameter–separability, online speed-ups may or may not be achieved. For the FOMs with parameter–separability, the space–time ROMs can achieve online speed-ups. Finally, we present an error analysis for the space–time LSPG projection and derive an error bound, which shows an improvement compared to traditional spatial Galerkin ROM methods.
1. Introduction
Many computational models for physical simulations are formulated as linear dynamical systems. Examples of linear dynamical systems include, but are not limited to, the Schrödinger equation that arises in quantum mechanics, the computational model for the signal propagation and interference in electric circuits, storm surge prediction models before an advancing hurricane, vibration analysis in large structures, thermal analysis in various media, neuro-transmission models in the nervous system, various computational models for micro-electro-mechanical systems, and various particle transport simulations. These linear dynamical systems can quickly become large scale and computationally expensive, which prevents fast generation of solutions. Thus, areas in design optimization, uncertainty quantification, and control where large parameter sweeps need to be done can become intractable, and this motivates the need for developing a Reduced Order Model (ROM) that can accelerate the solution process without loss in accuracy.
Many ROM approaches for linear dynamical systems have been developed, and they can be broadly categorized as data-driven or non data-driven approaches. We give a brief background of some of the methods here. For the non data-driven approaches, there are several methods, including: balanced truncation methods [1,2,3,4,5,6,7,8,9], moment-matching methods [10,11,12,13,14], and Proper Generalized Decomposition (PGD) [15] and its extensions [16,17,18,19,20,21,22,23,24,25]. The balanced truncation method is by far the most popular method, but it requires the solution of two Lyapunov equations to construct bases, which is a computationally expensive task in large-scale problems using dense solvers. However, the fast and memory-efficient low rank solvers presented in [26,27] can be applied to the large-scale Lyapunov equations. On the other hand, this expensive task can be bypassed by various data-driven empirical and non-intrusive approaches [3,28,29,30,31]. Moment matching methods were originally developed as non data-driven, although later studies developed ideas to benefit from the data. They provide a computationally efficient framework using Krylov subspace techniques in an iterative fashion where only matrix–vector multiplications are required. The optimal tangential interpolation for nonparametric systems [11] is also available. Proper Generalized Decomposition was first developed as a numerical method for solving boundary value problems. It utilizes techniques to separate space and time for an efficient solution procedure and is considered a model reduction technique. For the detailed description of PGD, we refer to a short review paper [32]. Many data driven ROM approaches have been developed as well. When datasets are available either from experiments or high-fidelity simulations, these datasets can contain rich information about the system of interest and utilizing this in the construction of a ROM can produce an optimal basis. Although there are some data-driven moment matching works available [33,34], two popular methods are Dynamic Mode Decomposition (DMD) and Proper Orthogonal decomposition (POD). DMD generates reduced modes that embed an intrinsic temporal behavior and was first developed by Peter Schmid [35]. The method has been actively developed and extended to many applications [36,37,38,39,40,41,42,43]. For a more detailed description about DMD, we refer to this preprint [44] and book [45]. POD utilizes the method of snapshots to obtain an optimal basis of a system and typically applies only to spatial projections [46,47,48,49,50,51,52,53,54,55,56,57,58,59,60,61].
Although the data-driven ROMs have brought many benefits, such as speed-ups and accuracy, they have been mainly the reduction of the complexity on spatial domains. However, reducing the temporal domain complexity brings even more speed-ups for time dependent problems. Therefore, we focus on building a space–time ROM, where both spatial and temporal projections are applied to achieve an optimal reduction. Several space–time ROMs have been developed, including, but not limited to, the ones derived from the corresponding space–time full order models [62,63,64,65], the spectral POD and resolvent modes-based ones [66,67,68], and the ones that take advantage of the right singular vectors [69,70,71]. In particular, a space–time ROM for large-scale linear dynamical systems has been recently introduced [72]. The authors show a speed-up of greater than 8000 with good accuracy for a large-scale transport problem. However, the space–time ROM in [72] was limited to Galerkin projection, which can cause stability issues [22,73,74] for nonlinear problems. It is well-studied that the LSPG ROM formulation [75] brings various benefits, such as better stability, over Galerkin projection with some known issues, such as structure preservation [76]. Furthermore, it is not clear if the space–time least-squares Petrov–Galerkin (LSPG) brings any advantage over the space–time Galerkin approach for a linear dynamical system. The current manuscript addresses this aspect.
In this work, we present several contributions on the space–time ROM development for linear dynamical systems:
- We derive the block structures of least-squares Petrov–Galerkin (LSPG) space–time ROM operators for linear dynamical systems for the first time and compare them with the Galerkin space–time ROM operators.
- We present an error analysis for LSPG space–time ROMs for the first time and demonstrate the growth rate of the stability constant with the actual space–time operators used in our numerical results.
- We compare the performance between space–time Galerkin and space–time LSPG reduced order models on several linear dynamical systems.
- For each numerical problem, we cover the entire space–time ROM process in less than 120 lines of Python code, which includes sweeping a wide parameter space and generating data from the full order model, constructing the space–time ROM, and generating the ROM prediction in the online phase.
We note that the first two bullet points above are minor but useful contributions by making the block structure and error analysis readily available. Additionally, we hope that, by providing full access to the Python source codes, researchers can easily apply space–time ROMs to their linear dynamical problem of interest. Furthermore, we have curated the source codes to be simple and short so that it may be easily extended in various multi-query problem settings, such as design optimization [77,78,79,80,81,82,83], uncertainty quantification [84,85,86], and optimal control problems [87,88,89].
The paper is organized in the following way: Section 2 describes a parametric linear dynamical systems and space–time formulation. Section 3 introduces linear subspace solution representation in Section 3.1 and space–time ROM formulation using Galerkin projection in Section 3.2 and LSPG projection in Section 3.3. Then, both space–time ROMs are compared in Section 3.4. Section 4 describes how to generate space–time basis. We investigate block structures of space–time ROM basis in Section 5.1. We introduce the block structures of Galerkin space–time ROM operators derived in [72] in Section 5.2. In Section 5.3, we derive LSPG space–time ROM operators in terms of the blocks. Then, we compared Galerkin and LSPG block structures in Section 5.4. We show computational complexity of forming the space–time ROM operators in Section 5.5. The error analysis is presented in Section 6. We demonstrate the performance of both Galerkin and LSPG space–time ROMs in two numerical experiments in Section 7. Finally, the paper is concluded with summary and future works in Section 8. Appendix A presents six Python codes with less than 120 lines that are used to generate our numerical results.
2. Linear Dynamical Systems
We consider the parameterized linear dynamical system shown in Equation (1):
where denotes a parameter vector, denotes a time dependent state variable function, denotes an initial state, and denotes a time dependent input variable function. The operators and are real valued matrices that are independent of state variables.
Although any time integrator can be used, for the demonstration purpose, we choose to apply a backward Euler time integration scheme shown in Equation (2):
where is the identity matrix, is the kth time step size with and , and and are the state and input vectors at the kth time step where . The Full Order Model (FOM) solves Equation (2) for every time step, where its spatial dimension is and the temporal dimension is . Each time step of the FOM can be written out and put in another matrix system shown in Equation (3). This is known as the space–time formulation.
where
The space–time system matrix has dimensions , the space–time state vector has dimensions , the space–time input vector has dimensions , and the space–time initial vector has dimensions . Although it seems that the solution can be found in a single solve, in practice, there is no computational saving gained from doing so since the block structure of the space–time system will solve the system in a time-marching fashion anyways. However, we formulate the problem in this way since our reduced order model (ROM) formulation can reduce and solve the space–time system efficiently. In the following sections, we describe the parametric Galerkin and LSPG ROM formulations.
3. Space–Time Reduced Order Models
We investigate two projection-based space–time ROM formulations: the Galerkin and LSPG formulations.
3.1. Linear Subspace Solution Representation
Both the Galerkin and LSPG methods reduce the number of space–time degrees of freedom by approximating the space–time state variables as a smaller linear combination of space–time basis vectors:
where with and . The space–time basis, is defined as
where , . Substituting Equation (8) into the space–time formulation in Equation (3) gives an over-determined system of equations:
This over-determined system of equations can be closed by either the Galerkin or LSPG projections.
3.2. Galerkin Projection
In the Galerkin formulation, Equation (10) is closed by the Galerkin projection, where both sides of the equation of multiplied by . Thus, we solve following reduced system for the unknown generalized coordinates, :
For notational simplicity, let us define the reduced space–time system matrix as , reduced space–time input vector as , and reduced space–time initial state vector as .
3.3. Least-Squares Petrov–Galerkin (LSPG) Projection
In the LSPG formulation, we first define the space–time residual as
where . Note Equation (12) is an over-determined system. To close the system and solve for the unknown generalized coordinates, , the LSPG method takes the squared norm of the residual vector function and minimize it:
For notational simplicity, let us define the reduced space–time system matrix as
reduced space–time input vector as , and reduced space–time initial state vector as .
3.4. Comparison of Galerkin and LSPG Projections
The reduced space–time system matrices, reduced space–time input vectors, and reduced space–time initial state vectors for Galerkin and LSPG projections are presented in Table 1.

Table 1.
Comparison of Galerkin and LSPG projections.
4. Space-Time Basis Generation
In this section, we repeat Section 4.1 in [72] to be self-contained.
A data set for space–time basis generation is chosen by the method of snapshots introduced by Sirovich [90]. This data set is called a snapshot matrix. By solving full order model problems at each of parameters in a parameter set , we obtain a full order model solution matrix at a certain parameter , i.e.,
where is a solution at a time step . Concatenating all the solution matrices for the every parameter yields the snapshot matrix, which is given by
To generate the spatial basis , Proper Orthogonal Decomposition (POD) is used [49]. The POD procedure seeks the reduced dimensional subspace that optimally represents the solution snapshot, . The spatial POD basis is obtained by solving the following minimization problem:
where denotes the Frobenius norm and is the identity matrix with . Then, the solution to the minimization problem is obtained by choosing the leading columns of the left singular matrix of Singular Value Decomposition (SVD) of the snapshot matrix :
where and are orthogonal matrices and is a diagonal matrix with singular values on its diagonal with .
Equation (19) can be written in the summation form
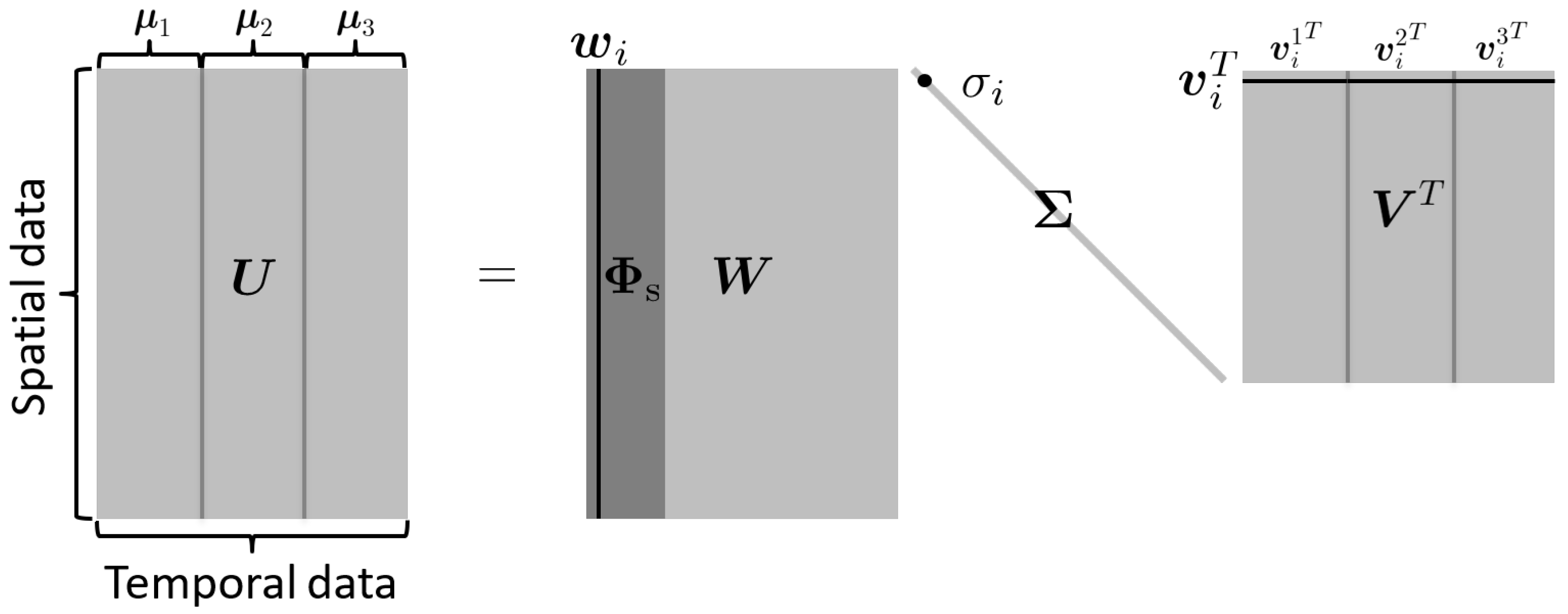
where is the ith singular value, and are the ith left and right singular vectors, respectively. Here, different temporal behavior of are represented by , e.g., , , and describe three different temporal behavior of a certain basis vector in Figure 1. Now, let us set to be a temporal snapshot matrix associated with the ith spatial basis vector , where for , where is the jth component of the vector . Then, applying SVD on gives us
Leading vectors of the left singular matrix become the temporal basis which describes a temporal behavior of the ith column of spatial basis . Finally, we construct a space–time basis vector given in Equation (9) as
where ⊗ denotes Kronecker product, is the ith column of the spatial basis and is the jth column of the temporal basis .
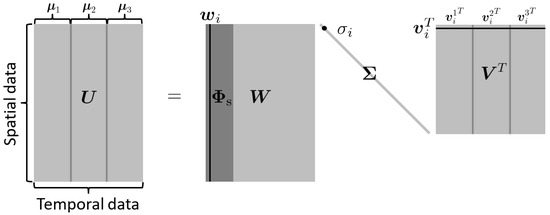
Figure 1.
Illustration of spatial and temporal bases construction, using SVD with . The right singular vector, , describes three different temporal behaviors of a left singular basis vector , i.e., three different temporal behaviors of a spatial mode due to three different parameters that are denoted as , , and . Each temporal behavior is denoted as , , and .
5. Space-Time Reduced Order Models in Block Structure
We avoid building the space–time basis vector defined in Equation (22) because it requires a lot of memory for storage. Instead, we can exploit the block structure of the matrices to save computational cost and storage of the matrices in memory. Section 5.2 introduces such block structures for the space–time Galerkin projection, while Section 5.3 shows block structures for the space–time LSPG projection. First of all, we introduce common block structures that appear both in the Galerkin and LSPG projections.
5.1. Block Structures of Space–Time Basis
Following [72]’s notation, we define the block structure of the space–time basis to be:
where the kth time step of the temporal basis matrix is a diagonal matrix defined as
where is the kth element of .
5.2. Block Structures of Galerkin Projection
As shown in Table 1, the reduced space–time Galerkin system matrix, is:
Now, we define the block structure of this matrix as:
so that we can exploit the block structure of these matrices such that we do not need to form the entire matrix. By inserting Equations (4) and (23) to Equation (25), we derive that the th block matrix is:
The reduced space–time Galerkin input vector is
Again, utilizing the block structure of matrices, we compute the jth block vector to be:
Finally, the space–time Galerkin initial vector, , can be computed as:
where the jth block vector, , is:
5.3. Block Structures of LSPG Projection
In Section 3.3, the reduced space–time LSPG system matrix, is defined as
Then, the block structure of this matrix can be defined as
where the size of each block matrix is . Instead of forming the directly from Equation (32), each block matrix is computed and put into its location. Inserting Equations (4) and (23) to Equation (32) gives us and the th block of this matrix is derived as
The reduced space–time LSPG input vector is given by
where the jth block vector is computed as
Lastly, the space–time LSPG initial vector is
By exploiting the block structure of the vector, we compute the jth block vector to be:
5.4. Comparison of Galerkin and LSPG Block Structures
The block structures of space–time reduced order model operators are summarized in Table 2.
Table 2.
Comparison of Galerkin and LSPG block structures.
5.5. Computational Complexity of Forming Space–Time ROM Operators
To show computational complexity of forming the reduced space–time system matrices and , input vectors and , and initial state vectors and for Galerkin and LSPG projections, we assume that is a band matrix with the bandwidth, b and is an identity matrix of size in Equation (1). The band structure of is often seen in mathematical models because of local approximations to derivative terms. The structure of that is formed with backward Euler scheme is lower triangular matrix with bandwidth . We also assume that the spatial basis vectors and temporal basis vectors are given.
Let us start to show the computational complexity without use of block structures as presented in Table 1. Space–time basis is constructed by Equation (22), and it involves times Kronecker product of vector of size and vector of size . Thus, it costs . For Galerkin projection, the reduced space–time system matrix involves matrix multiplication twice. The first operation is matrix multiplication of matrix and lower triangular matrix with bandwidth . Then, the second one is matrix multiplication of matrix and matrix. Thus, the cost of computing the reduce space–time system matrix, is . The input vector requires matrix and vector multiplication, resulting in . The initial state vector requires matrix and vector multiplication. Considering that the contains zero values except the first components, the computational cost is . Keeping the dominant terms leads to . For LSPG projections, we first compute which is going to be re-used, resulting in . Then, computing the reduced space–time system matrix requires multiplication of precomputed matrix and its transpose matrix, resulting in . The input vector is computed by multiplication between precomputed matrix and vector with operation counts. Constructing initial state vector costs because of precomputed matrix and vector whose components except first components are zero. Summing operation counts and keeping the dominant terms gives us . With the assumption of , the computational cost without use of block structures for both Galerkin and LSPG projections is .
Now, let us show the computational complexity with the use of block structures. For Galerkin projection, we first compute which will be reused, resulting in . Then, we compute blocks for the reduced space–time system matrix. Each block requires times multiplication between diagonal matrices of size and times multiplication by diagonal matrices of size on the left and right of the precomputed matrix, which takes . Thus, it costs to compute the reduced space–time system matrix . For the reduced space–time input vector , blocks are needed. Each block is computed by matrix and vector multiplication followed by the diagonal matrix of size and vector multiplication, resulting in . Thus, the cost of computing the reduced space–time input vector is . Computing the reduced space–time initial vector requires matrix and vector multiplication followed by diagonal matrix of size and vector multiplication. Its cost is . Summing each computational cost for Galerkin projection gives us . Keeping the dominant terms and taking off coefficient 2 lead to . For LSPG projection, we compute which will be re-used, resulting in . Then, we compute , using precomputed matrix and its transpose matrix. Its computational cost is . Similarly, when we compute , the precomputed matrix is multiplied by matrix, resulting in computational complexity of . Now, we compute blocks for the reduced space–time system matrix . Each block involves times multiplication by diagonal matrices of size on the left and right side of precomputed matrices and multiplication between diagonal matrices of size , which gives us computational cost of . Thus, it costs to compute the reduced space–time system matrix . For the reduced space–time input vector, blocks are needed and each block requires times matrix and vector multiplication followed by diagonal matrix of size and vector multiplication. The computational cost of computing each block is . Thus, it takes to compute the reduced space–time input . Computing the reduced space–time initial vector costs because we multiply the precomptued matrix by a vector of size ; then, a diagonal matrix of size is multiplied on the left. Summing computational cost of , , and yields . Keeping the dominant terms and taking off coefficients 2 and 6 lead to . With the assumptions of , , and , we have a computational cost of for both Galerkin and LSPG projections with use of block structures.
In summary, the computational complexities of forming space–time ROM operators in the training phase for Galerkin and LSPG projections are presented in Table 3. We observe that a lot of computational costs are reduced by making use of block structures for forming space–time reduced order models.
Table 3.
Comparison of Galerkin and LSPG computational complexities.
6. Error Analysis
We present error analysis of the space–time ROM method. The error analysis is based on [72]. An a posteriori error bound is derived in this section. Here, we drop the parameter dependence for notational simplicity.
Theorem 1.
We define the error at the kth time step as where denotes FOM solution, denotes approximate solution, and . Let be the space–time system matrix, be the residual computed using FOM solution at the kth time step, and be the residual computed using approximate solution at the kth time step. For example, and after applying the backward Euler scheme with the uniform time step become
with . Then, the error bound is given by
where denotes the stability constant.
Proof.
Let us define the space–time residual as
with . Then, we have
where is the space–time FOM solution, and is the approximate space–time solution. Subtracting Equation (44) from Equation (43) gives
where . Inverting yields
Taking norm and Hölders’ inequality gives
We can rewrite this in the following form:
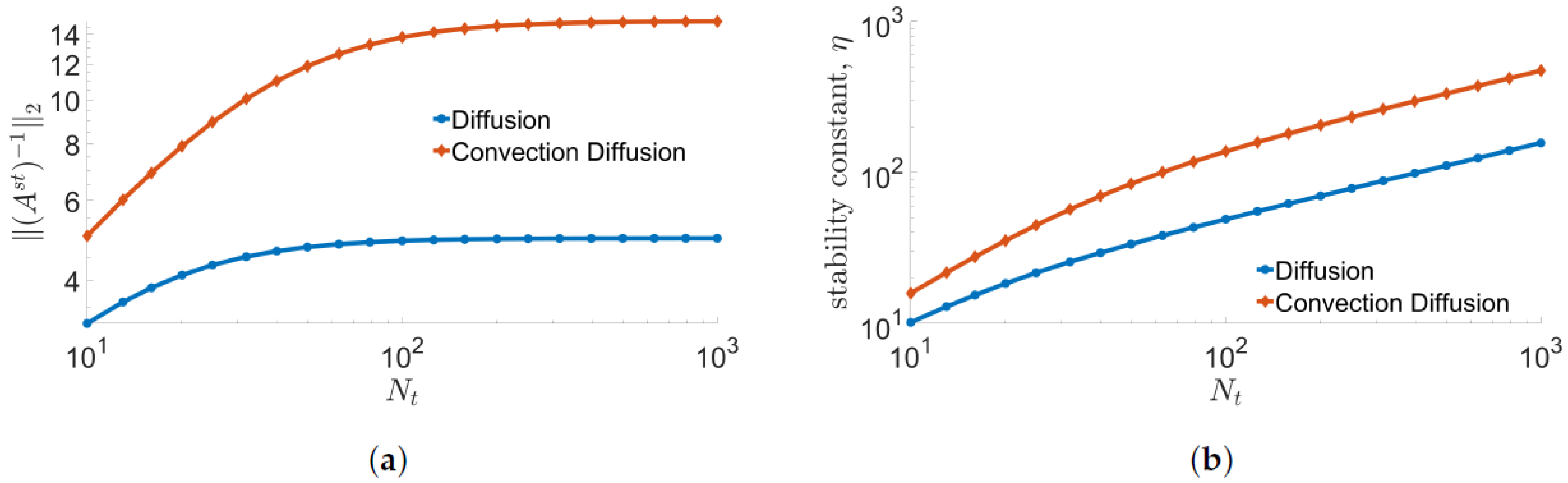
A numerical demonstration with space–time system matrices, , that have the same structure as the ones used in Section 7.1 and Section 7.2.1 shows the magnitude of increases linearly for small , while it becomes eventually flattened for large as shown in Figure 2a for the backward Euler time integrator with uniform time step size. Combined with , the stability constant growth rate is shown in Figure 2b. This error bound shows much improvement against the ones for the spatial Galerkin and LSPG ROMs, which grows exponentially in time [72].
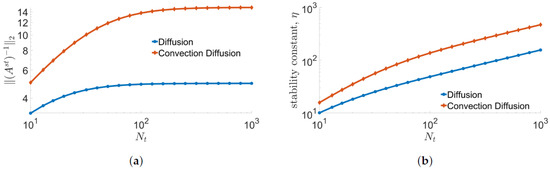
Figure 2.
Growth rate of stability constant in Theorem 1. Backward Euler time stepping scheme with uniform time step size, is used. (a): in inequality (41), (b): Stability constant, in inequality (41).
7. Numerical Results
In this section, we apply both the space–time Galerkin and LSPG ROMs to two model problems: (i) a 2D linear diffusion equation in Section 7.1 and (ii) a 2D linear convection-diffusion equation in Section 7.2. We demonstrate their accuracy and speed-up. The space–time ROMs are trained with solution snapshots associated with train parameters in a chosen domain. Then, the space–time ROMs are used to predict the solution of a parameter that is not included in the trained parameter domain. We refer to this as the predictive case. The accuracy of space–time ROM solution is assessed from its relative error by:
and the norm of space–time residual:
The computational cost is measured in terms of wall-clock time. The online phase includes all computations required to solve a problem with a new parameter. The online phase of FOM includes assembly of the FOM operators and time integration (i.e., FOM solving), and the online phase of the ROM consists of assembly of the ROM operators and time integration (i.e., ROM solving). The offline phase includes all computations that can be computed once and re-used for a new parameter. The offline phase of the FOM consists of computations that are independent of parameters. The offline phase of the ROM includes FOM snapshot generation, ROM basis generation, and parameter-independent ROM operator generation. Note that the parameter-independent ROM operators can be pre-computed during the offline phase only for parameter-separable cases. Then, the online speed-up is evaluated by dividing the wall-clock time of the FOM runtime by the online phase of the ROM. For the multi-query problems, total speed-up is evaluated by dividing the sum of runtime of all FOMs by the sum of elapsed time of the online and offline phase of all ROMs. All calculations are performed on an Intel(R) Core(TM) i9-10900T CPU @ 1.90 GHz and DDR4 Memory @ 2933 MHz.
In the following subsections, the backward Euler with uniform time step size is employed as a time integrator. For spatial differentiation, the second order central difference scheme for the diffusion terms and the first order backward difference scheme for the convective terms are implemented with uniform mesh size.
We conduct two kinds of tests for each model problem. In the first case, we compare relative errors, space–time residuals, and speed-ups of Galerkin and LSPG projections when the number of spatial basis vectors and temporal basis vectors are varied with the target parameter being fixed. We show the singular value decay of solution snapshot and temporal snapshot matrix for each problem.
We also show the accuracy (i.e., relative error) of the reduced order models versus the number of reduced basis. This clearly shows that the number of reduced basis affects the accuracy of the reduced order models, depending on the singular value decay. We observe that the relative errors of Galerkin projection are slightly smaller, but the space–time residual is slightly larger than LSPG projection. This is because LSPG space–time ROM solution minimizes the space–time residual as formulated in Section 3.3. However, the Galerkin and LSPG methods give very similar performance both in terms of accuracy and speed-up.
Secondly, we investigate the generalization capability of both Galerkin and LSPG ROMs by solving several predictive cases. We see that, as the parameter points go beyond the train parameter domain, the accuracy of the Galerkin and LSPG ROMs start to deteriorate gradually. This implies that the Galerkin and LSPG ROMs have a trust region. Its trust region should be determined by the application space. We also see that the Galerkin and LSPG space–time ROMs achieve total speed-up in Section 7.2 by taking advantage of parameter–separability but both space–time ROMs are not able to achieve total speed-up in Section 7.1 because we cannot take advantage of parameter–separability, which plays an important role in efficient parametric reduced order models.
7.1. 2D Linear Diffusion Equation
We consider a parameterized 2D linear diffusion equation with a source term
where , and . The boundary condition is
and the initial condition is
In Equation (54), the parameters are nonlinearly used in terms of operators, i.e., fractional, so we cannot take advantage of parameter–separability for efficient formation of the reduced order model.
The uniform time step size is given by where we set . The space domain is discretized into and uniform meshes in x and y directions, respectively. Excluding boundary grid points, we have 4761 spatial degrees of freedom. Multiplying and gives us free degrees of freedom in space–time.
For training phase, we collect solution snapshots associated with the following parameters:
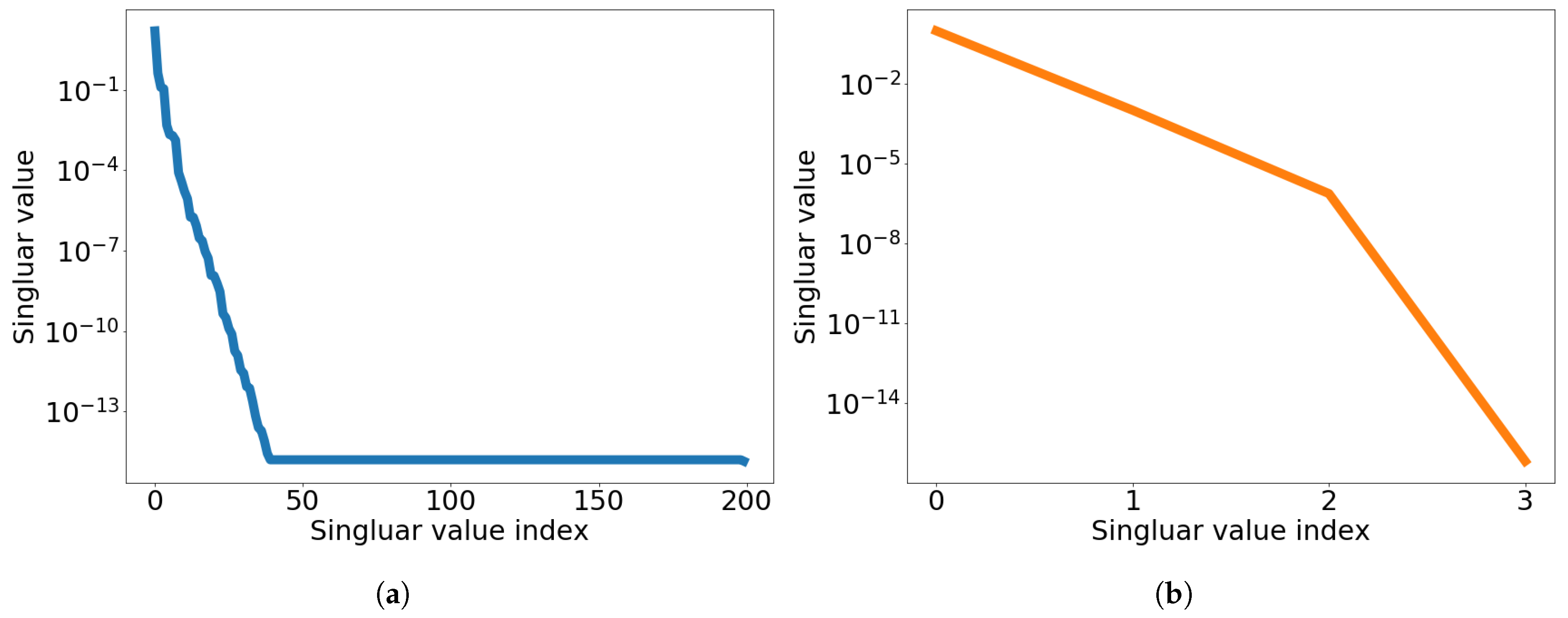
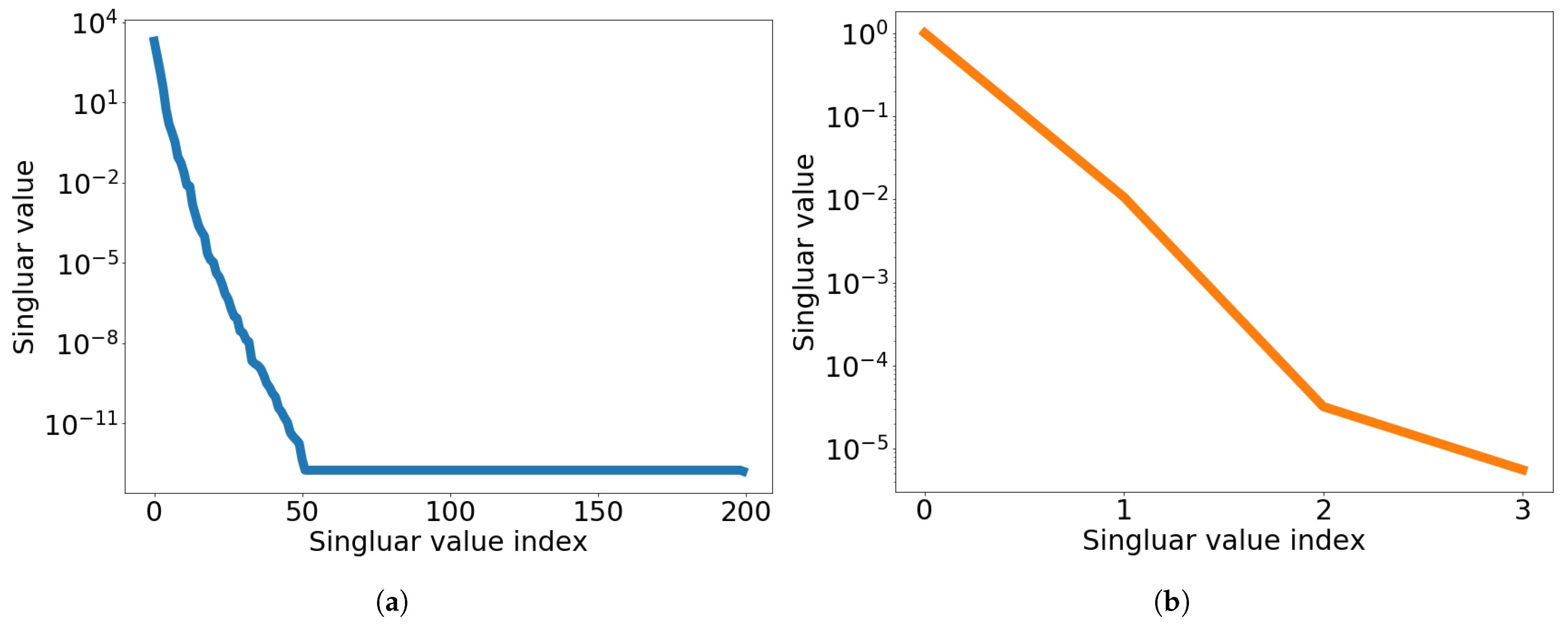
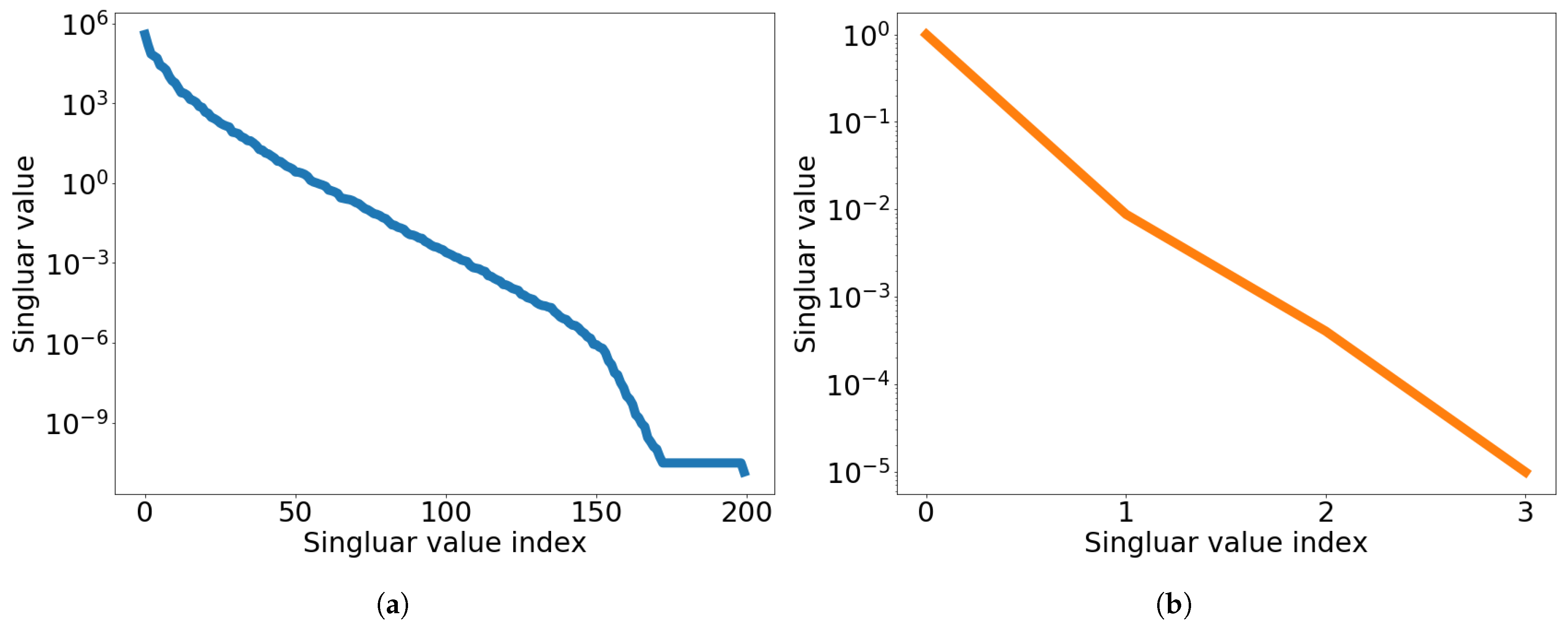
at which the FOM is solved. The singular value decays of the solution snapshot and the temporal snapshot are shown in Figure 3.
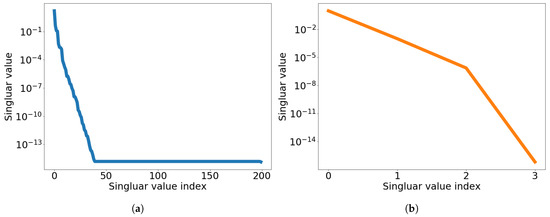
Figure 3.
2D linear diffusion equation. Graph of singular value decay. (a): Singular value decay of solution snapshot, (b): Singular value decay of temporal snapshot for the first spatial basis vector.
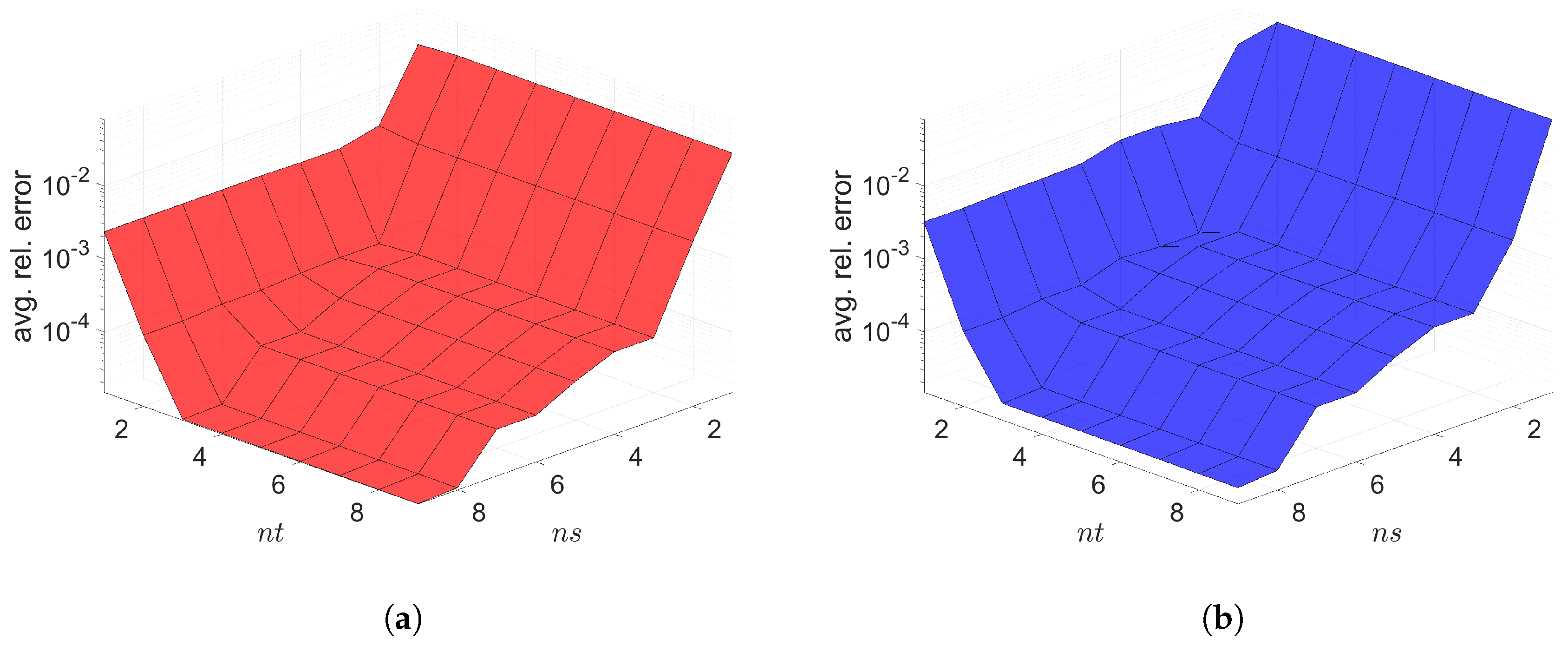
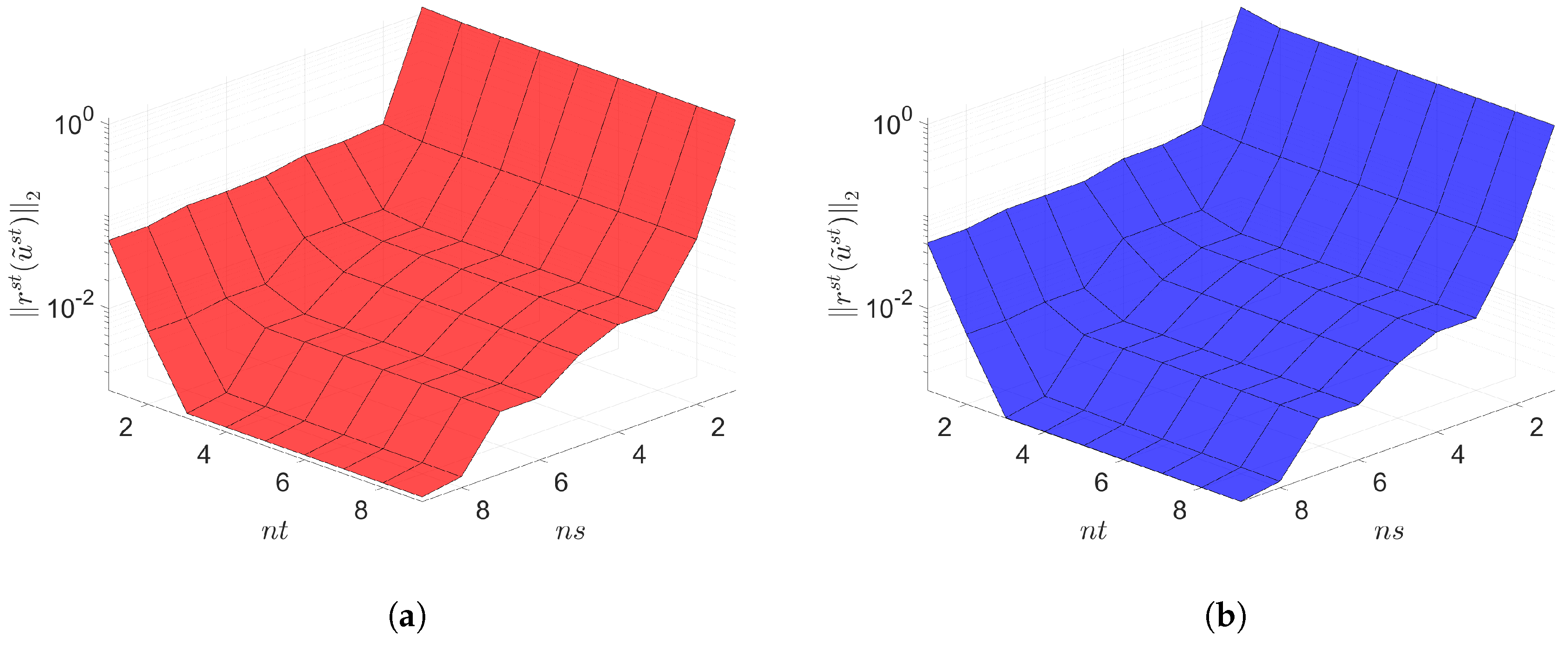
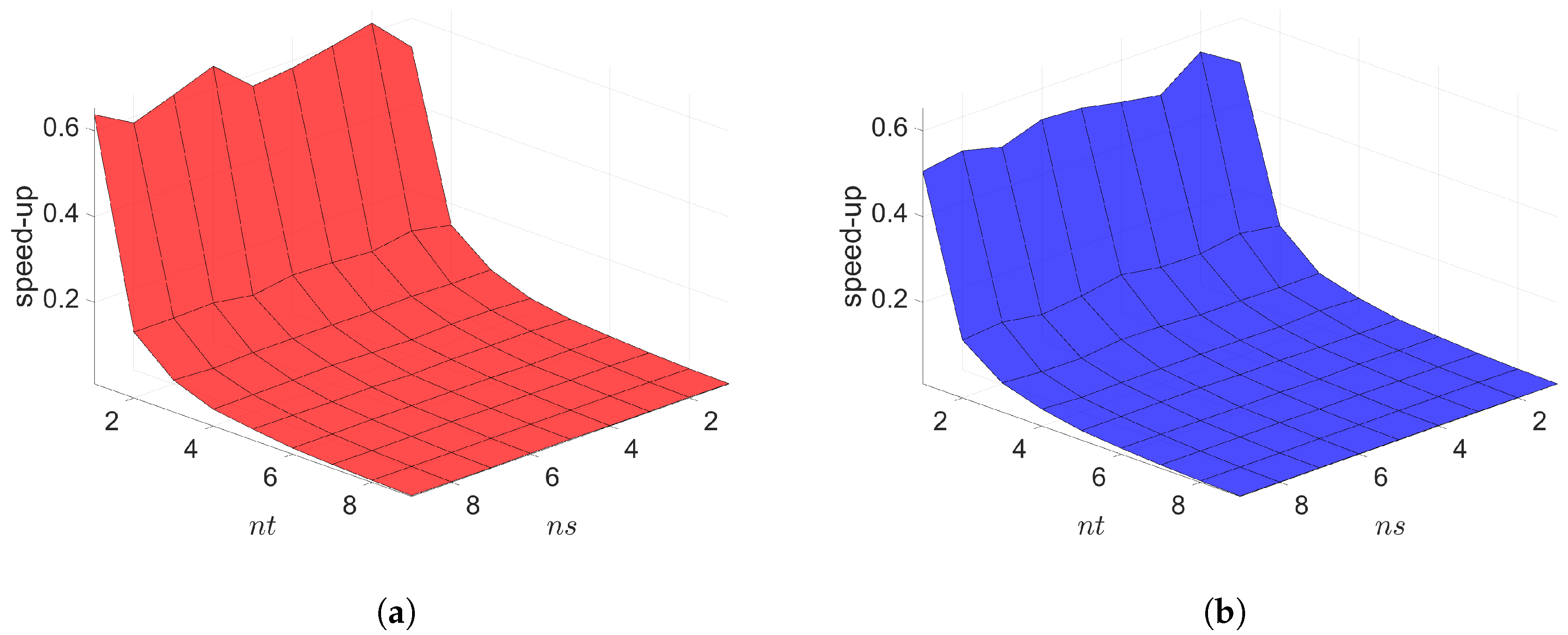
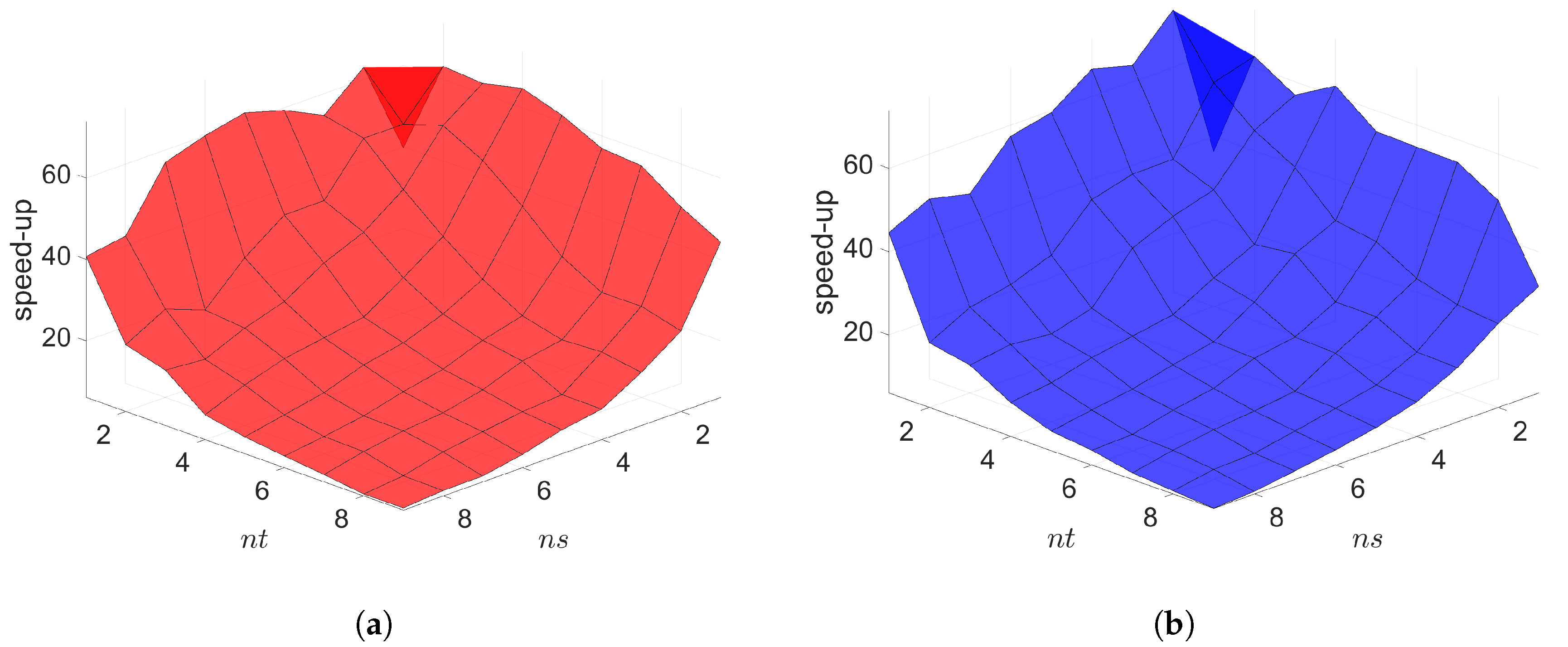
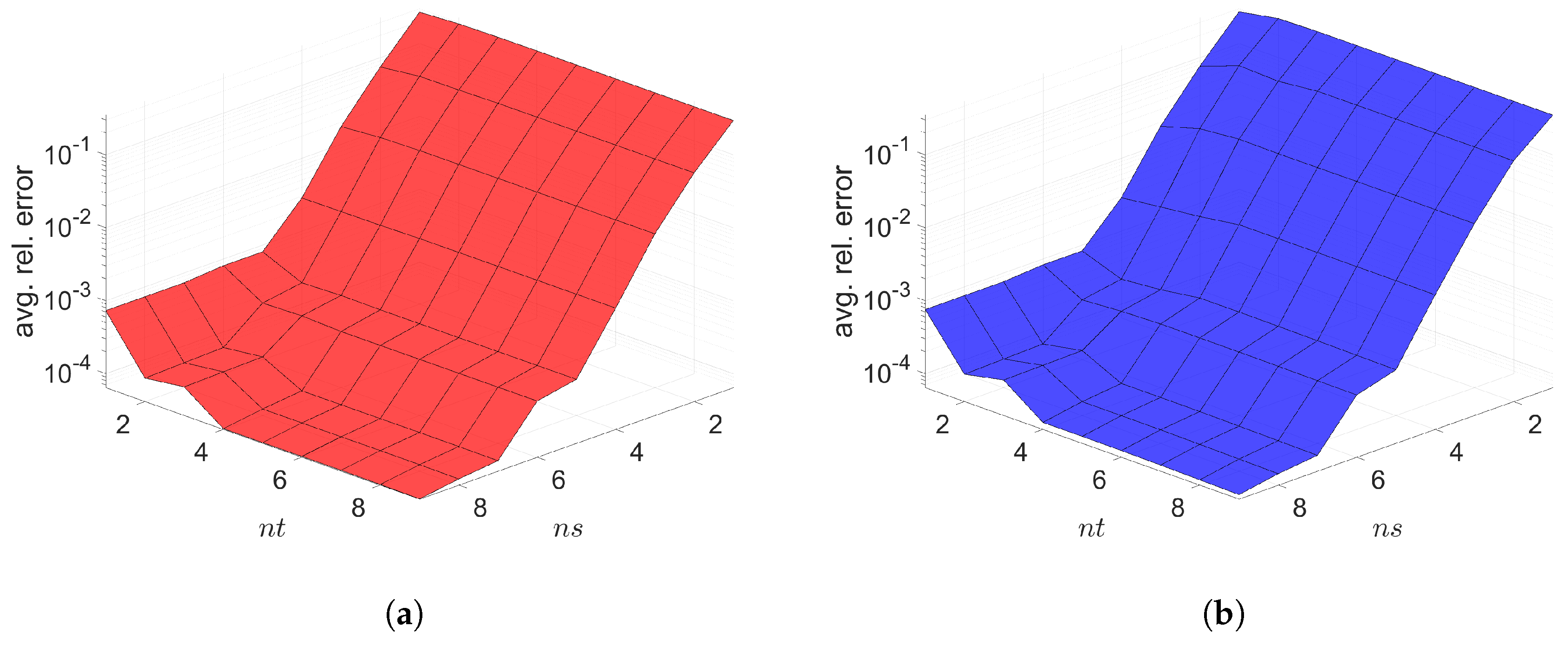
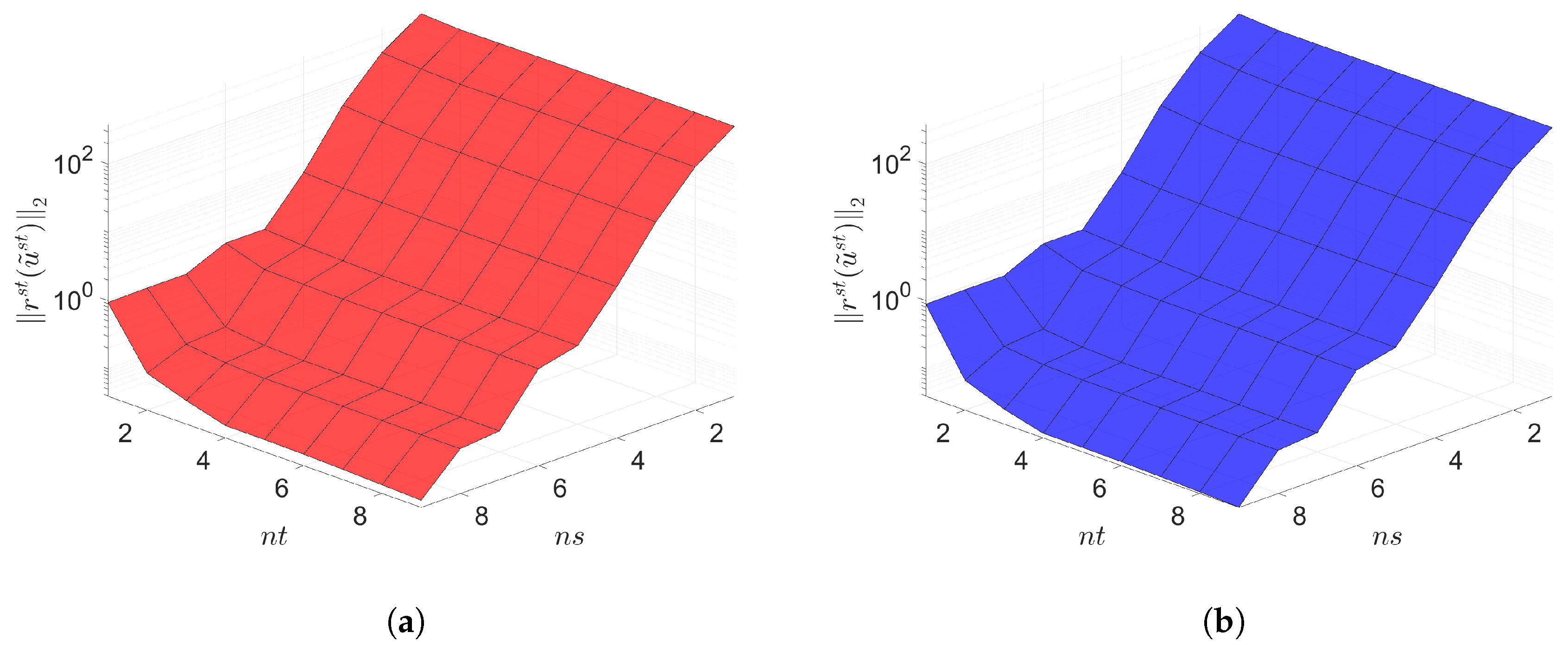
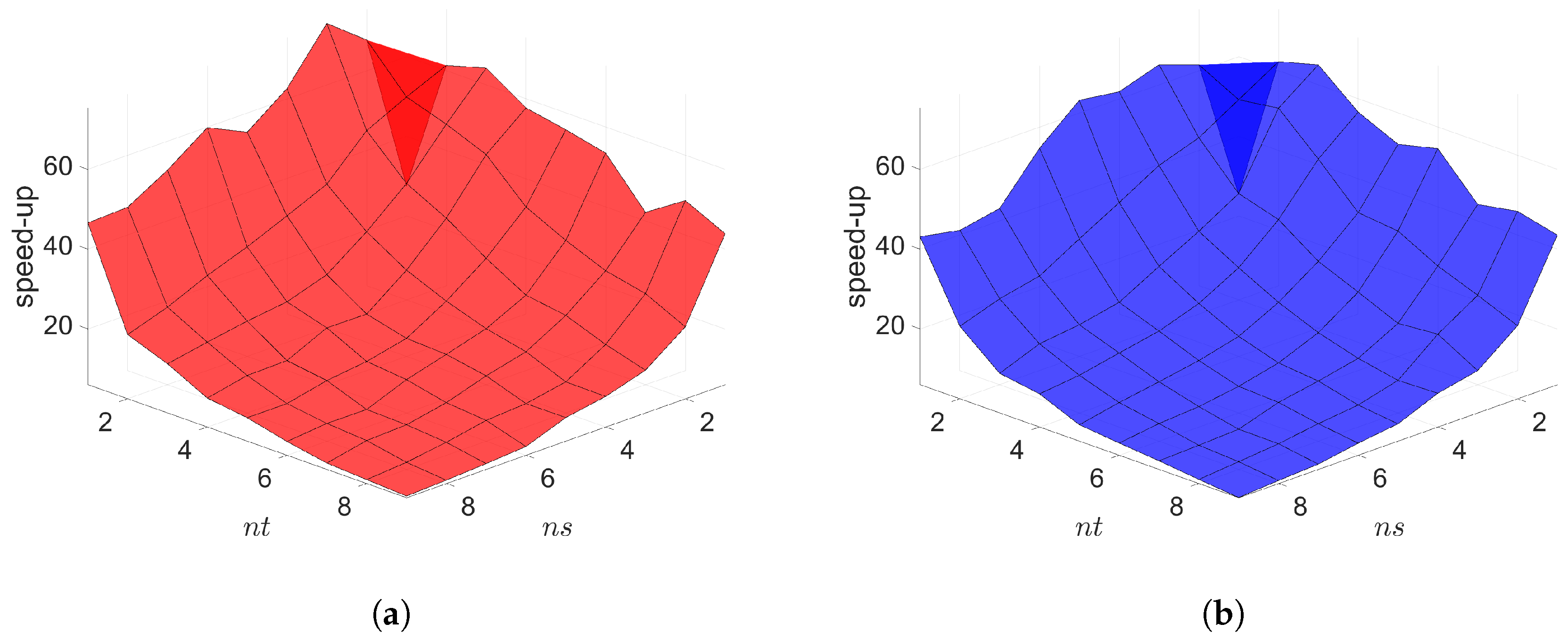
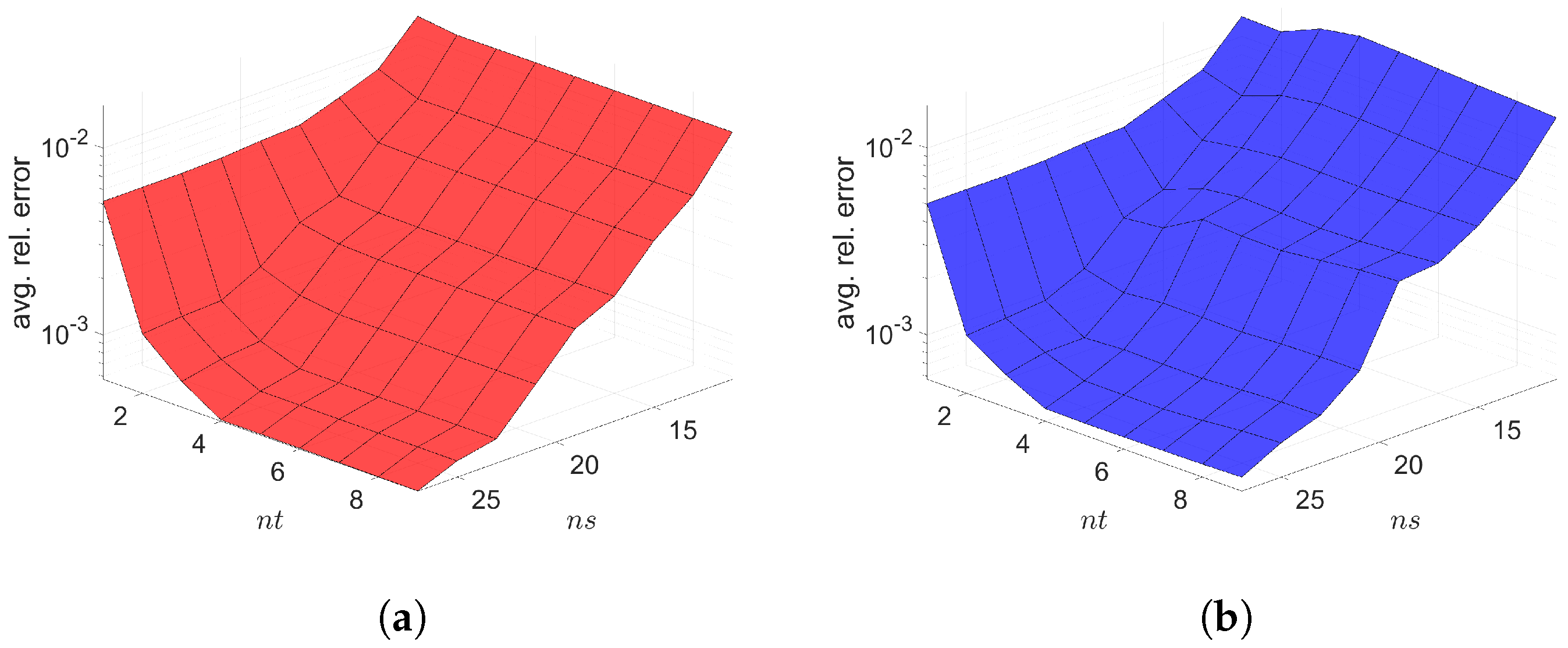
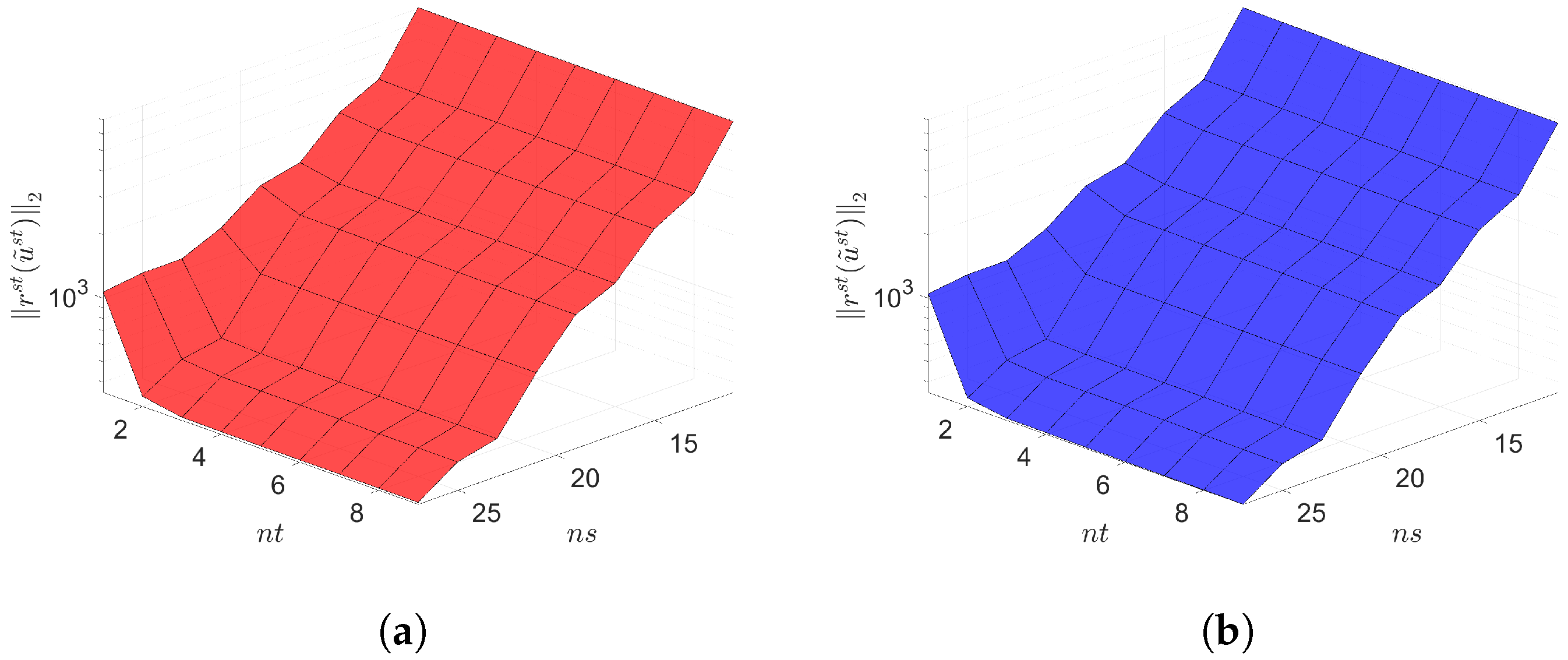
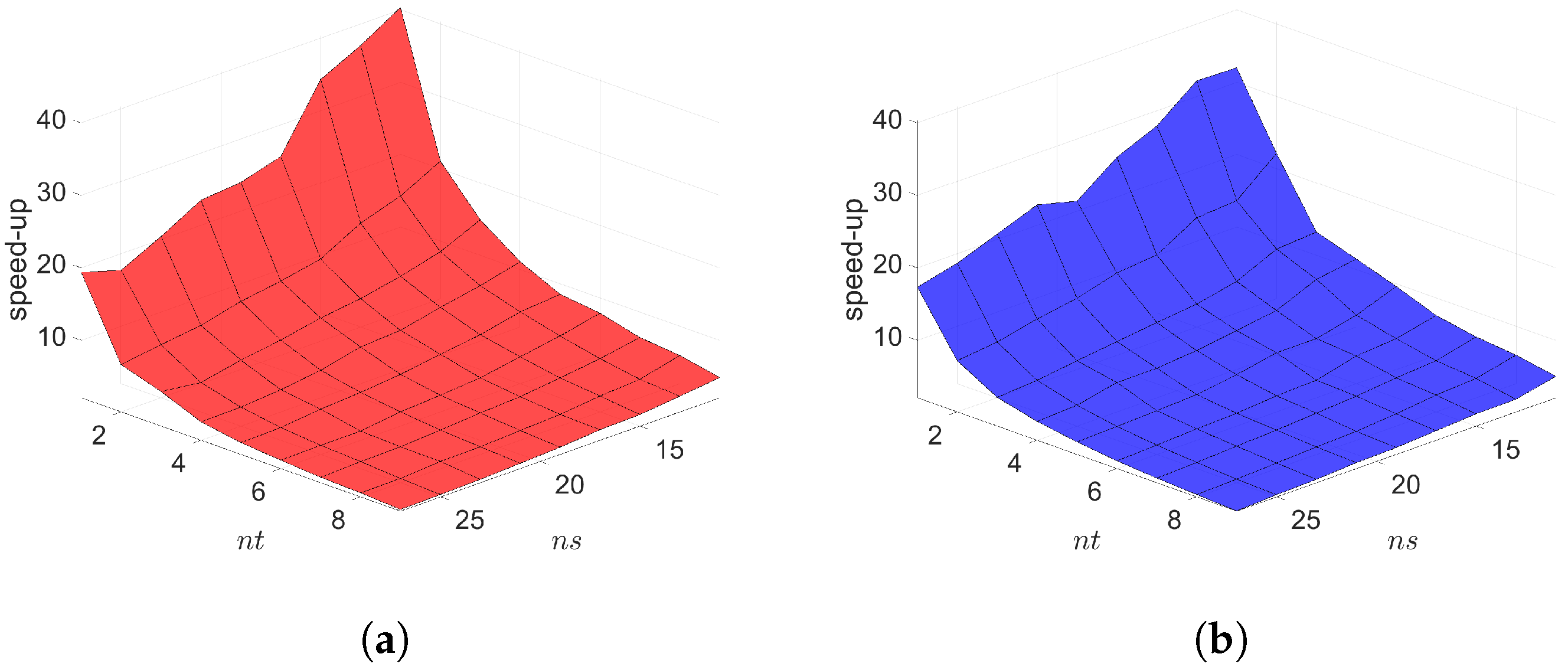
The Galerkin and LSPG space–time ROMs solve the Equation (54) with the target parameter . Figure 4, Figure 5 and Figure 6 show the relative errors, the space–time residuals, and the online speed-ups as a function of the reduced dimension and . We observe that both Galerkin and LSPG ROMs with and achieve a good accuracy (i.e., relative errors of and , respectively). However, they are not able to achieve an online speed-up (i.e., and , respectively) because parameter–separability cannot be made use of. For such problems, local ROM operators can be constructed; then, we can use an interpolation to obtain ROM operator at a certain parameter point. For a detailed description of the local ROM interpolation method, please see [81]. By doing so, online speed-up can be achieved. Excluding assembly time of the FOM and ROM operators from the online phase yields solving speed-ups as shown in Figure 7. The Galerkin space–time ROM gives slightly lower relative error than the LSPG space–time ROM (see Figure 4), while the LSPG method gives a slightly lower space–time residual norm than the Galerkin method (see Figure 5), as we repeatedly stated in Section 7.
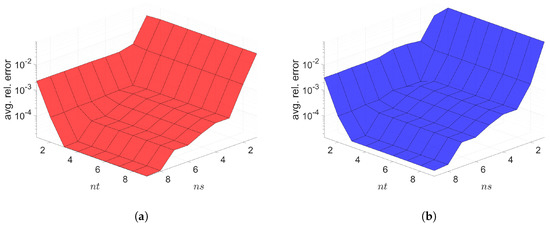
Figure 4.
2D linear diffusion equation. Relative errors vs. reduced dimensions. Note that the scales of the z-axis, i.e., the average relative error, are the same both for Galerkin and LSPG. Although the Galerkin achieves slightly lower minimum average relative error values than the LSPG, both Galerkin and LSPG show comparable results. (a): Relative errors vs. reduced dimensions for Galerkin projection, (b): Relative errors vs. reduced dimensions for LSPG projection.
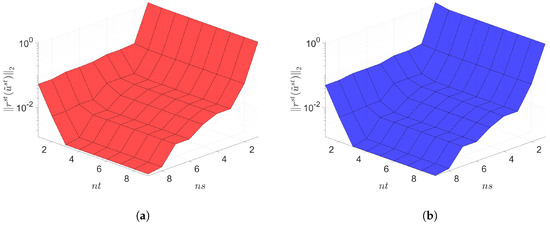
Figure 5.
2D linear diffusion equation. Space-time residuals vs. reduced dimensions. Note that the scales of the z-axis, i.e., the residual norm, are the same both for Galerkin and LSPG. Although the LSPG achieves slightly lower minimum residual norm values than the Galerkin, both Galerkin and LSPG show comparable results. (a): Space-time residuals vs. reduced dimensions for Galerkin projection, (b): Space-time residuals vs. reduced dimensions for LSPG projection.
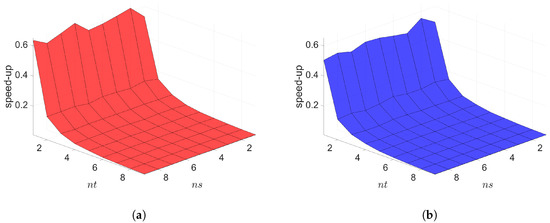
Figure 6.
2D linear diffusion equation. Online speed-ups vs. reduced dimensions. Both Galerkin and LSPG show similar speed-ups. (a): Online speed-ups vs. reduced dimensions for Galerkin projection, (b): Online speed-ups vs. reduced dimensions for LSPG projection.
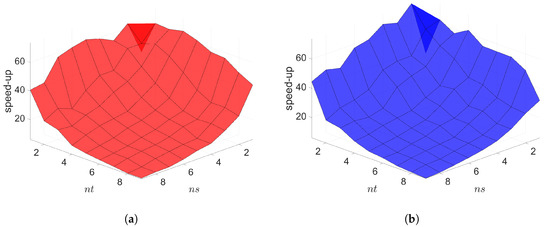
Figure 7.
2D linear diffusion equation. Solving speed-ups vs. reduced dimensions. (a): Solving speed-ups vs. reduced dimensions for Galerkin projection, (b): Solving speed-ups vs. reduced dimensions for LSPG projection.
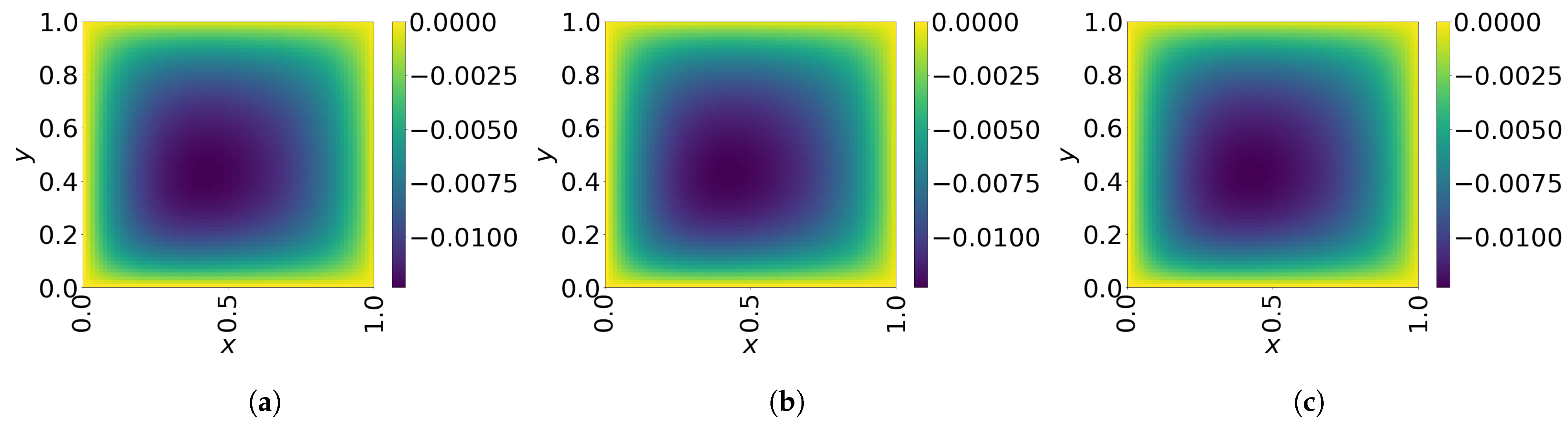
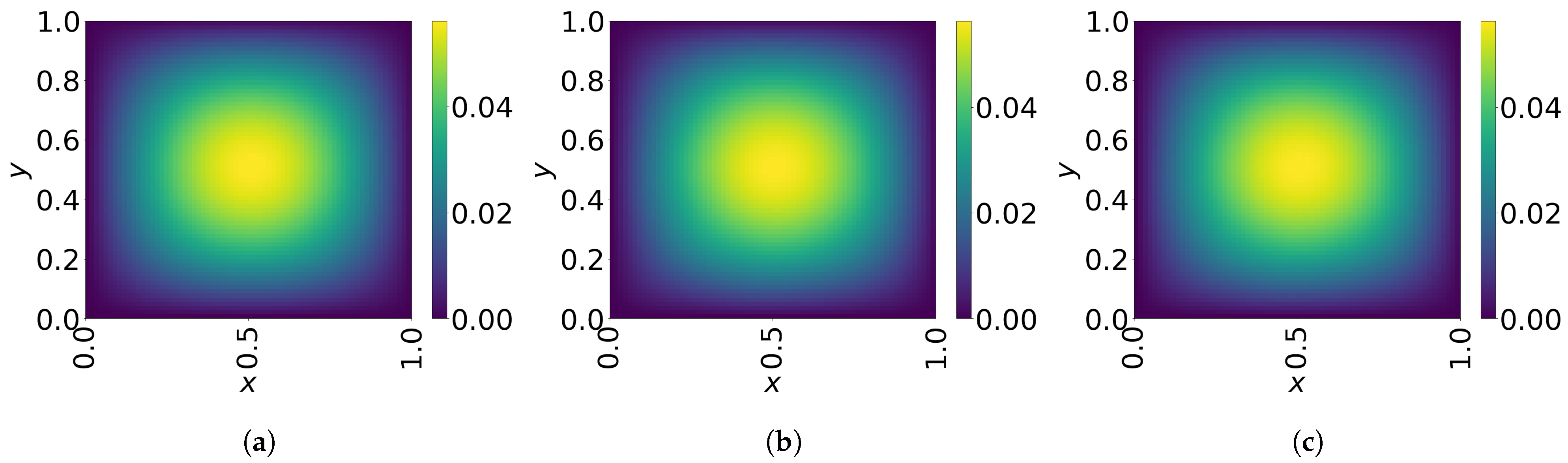
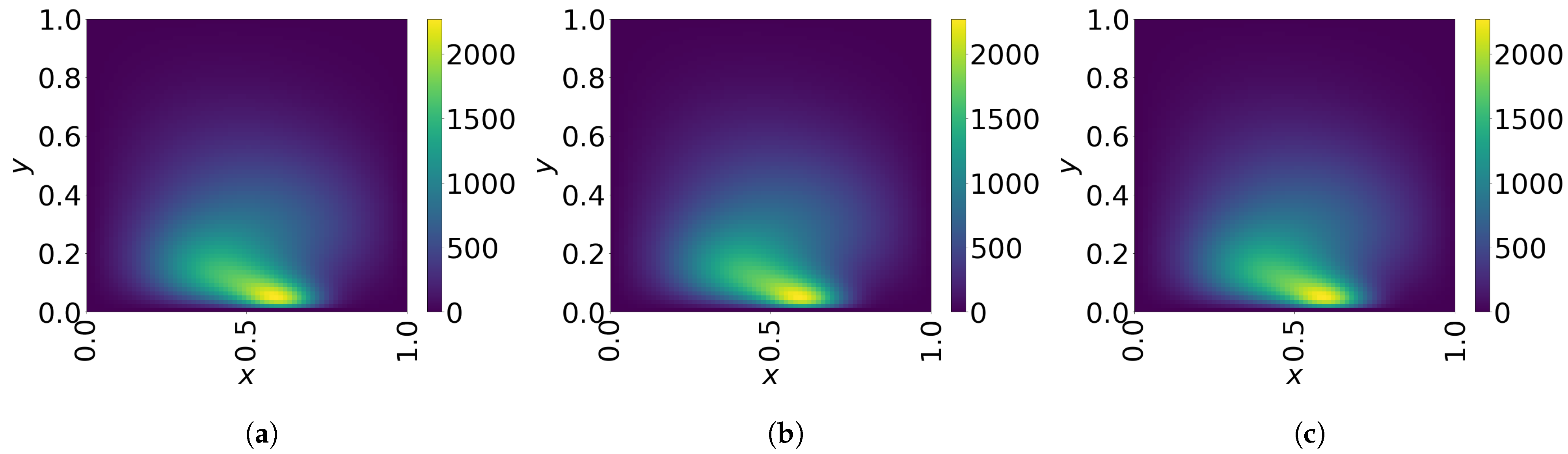
The final time snapshots of FOM, Galerkin space–time ROM, and LSPG space–time ROM are seen in Figure 8. Both ROMs have a basis size of and , resulting in a reduction factor of . For the Galerkin method, the FOM and space–time ROM simulation with and take an average time of and s, respectively, resulting in online speed-up of . For the LSPG method, the FOM and space–time ROM simulation with and take an average time of and s, respectively, resulting in speed-up of . For accuracy, the Galerkin method results in % relative error and space–time residual norm, while the LSPG results in % relative error and space–time residual norm.
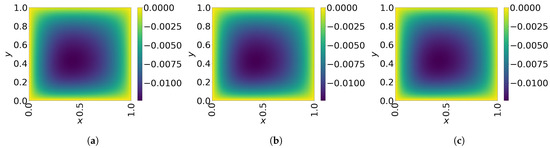
Figure 8.
2D linear diffusion equation. Solution snapshots of FOM, Galerkin ROM, and LSPG ROM at . (a): FOM, (b): Galerkin ROM, (c): LSPG ROM.
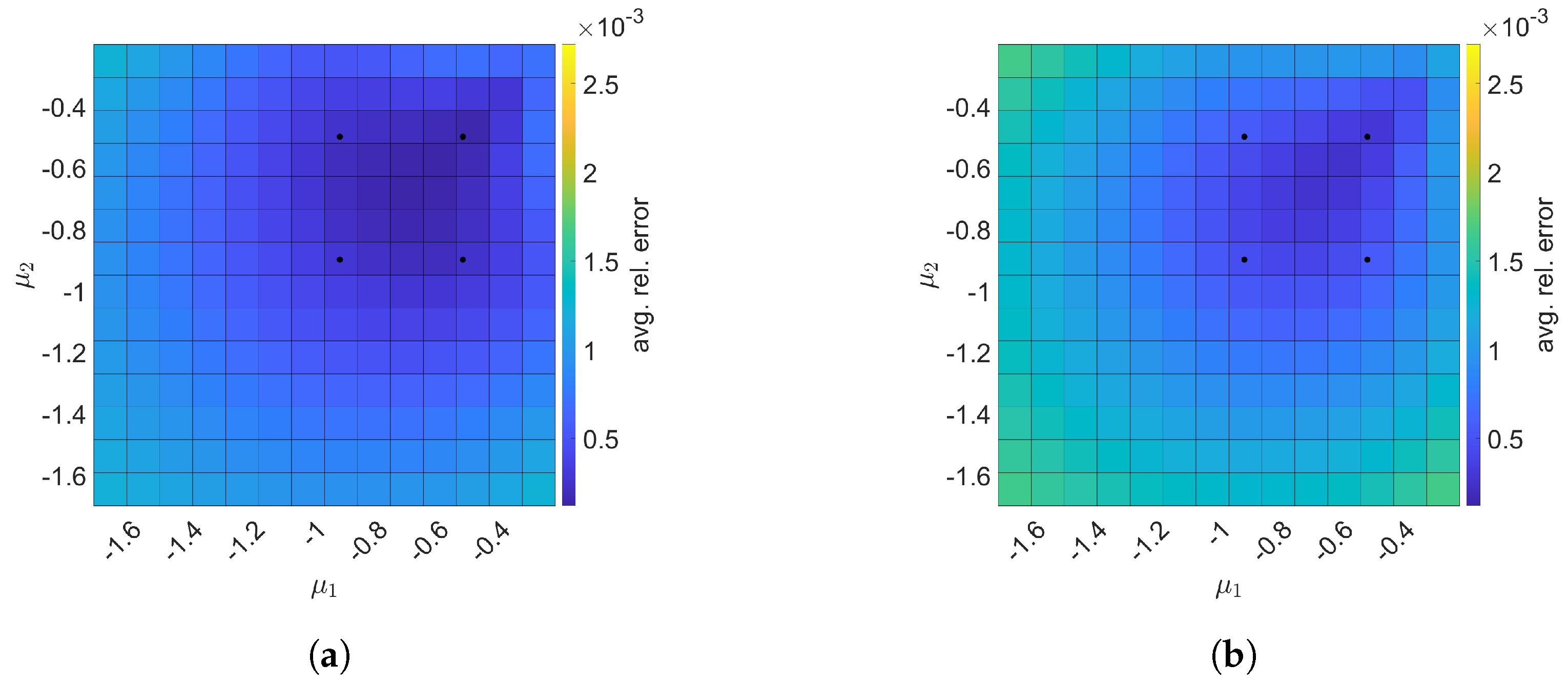
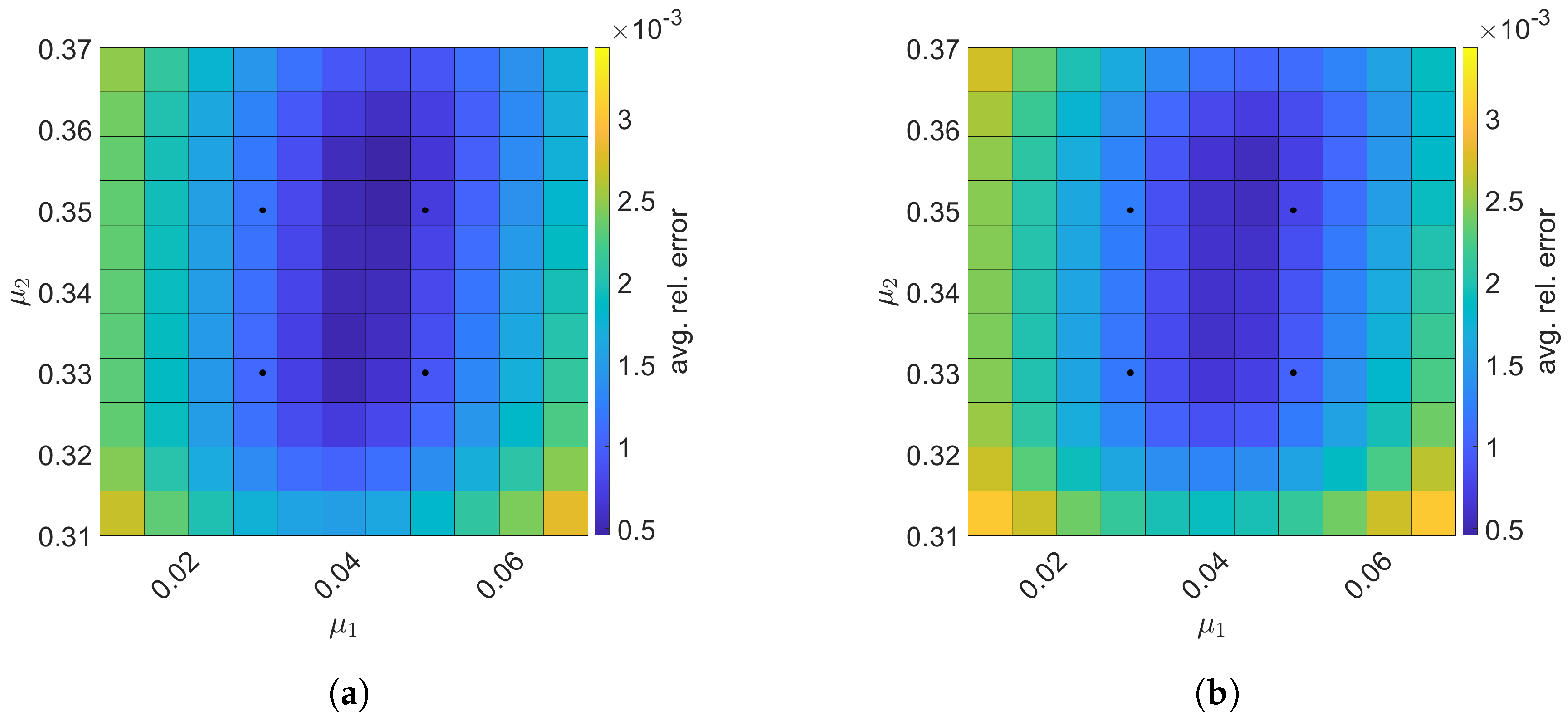
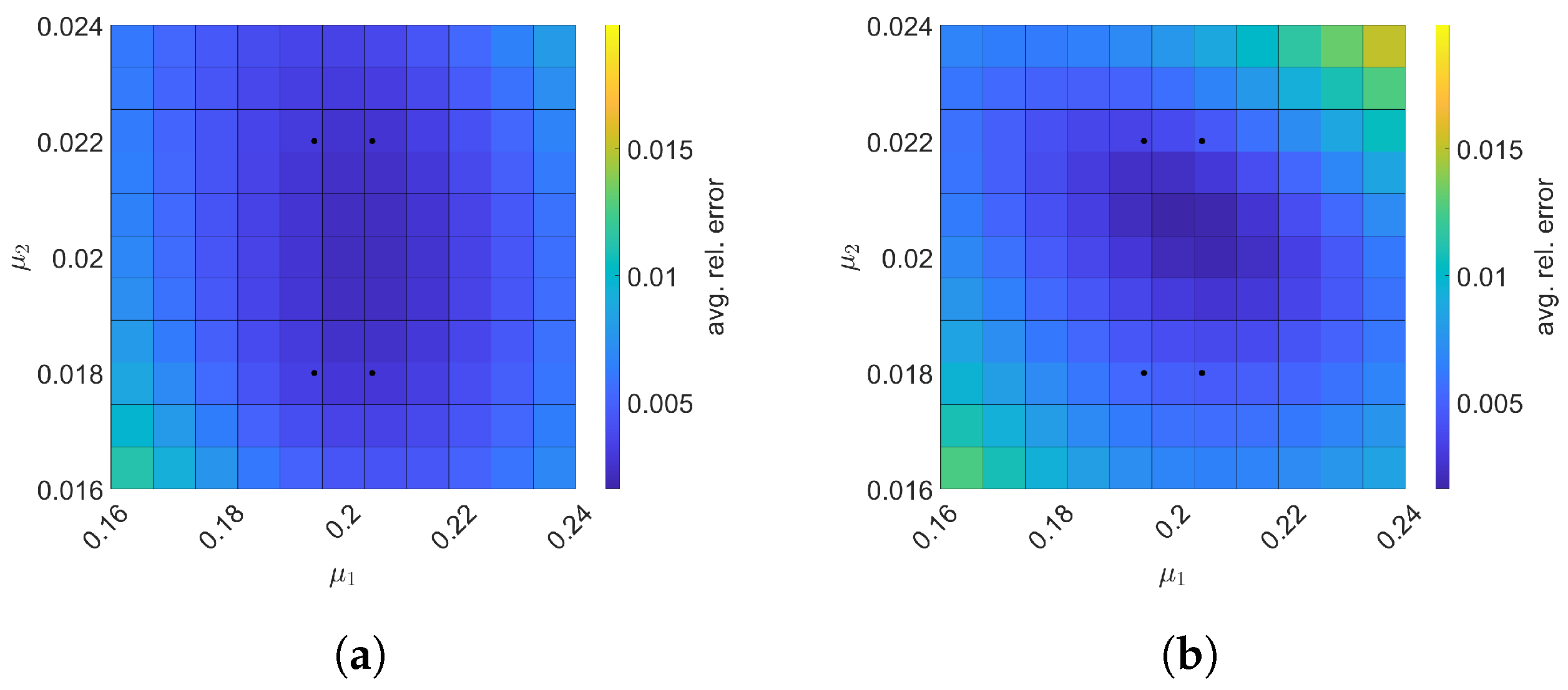
Next, we construct space–time ROMs with a basis of and using the same train parameter set given in Equation (57) for solving the predictive cases. The test parameter set is . Figure 9 shows the relative errors over the test parameter set. The relative errors of both projection methods are the lowest within the rectangular domain defined by the train parameter points, i.e., . For Galerkin ROM, online speed-up is about in average and total time for ROM and FOM are and s, respectively, resulting in total speed-up of . The total time for the ROM consists of of FOM snapshot generation, of ROM basis generation, of ROM operator assembly, and of time integration. For LSPG ROM, online speed-up is about in average and total time for ROM and FOM are and s, respectively, resulting in total speed-up of . The breakdown of the total time for the ROM is as follows: of FOM snapshot generation, of ROM basis generation, of ROM operator assembly, and of time integration.
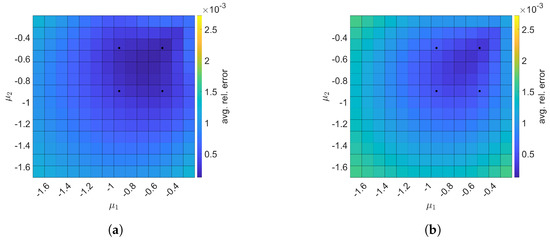
Figure 9.
2D linear diffusion equation. The comparison of the Galerkin and LSPG ROMs for predictive cases. The block dots indicate the train parameters. (a): Galerkin, (b): LSPG.
7.2. 2D Linear Convection Diffusion Equation
7.2.1. Without Source Term
We consider a parameterized 2D linear convection diffusion equation
where , and . The boundary condition is given by
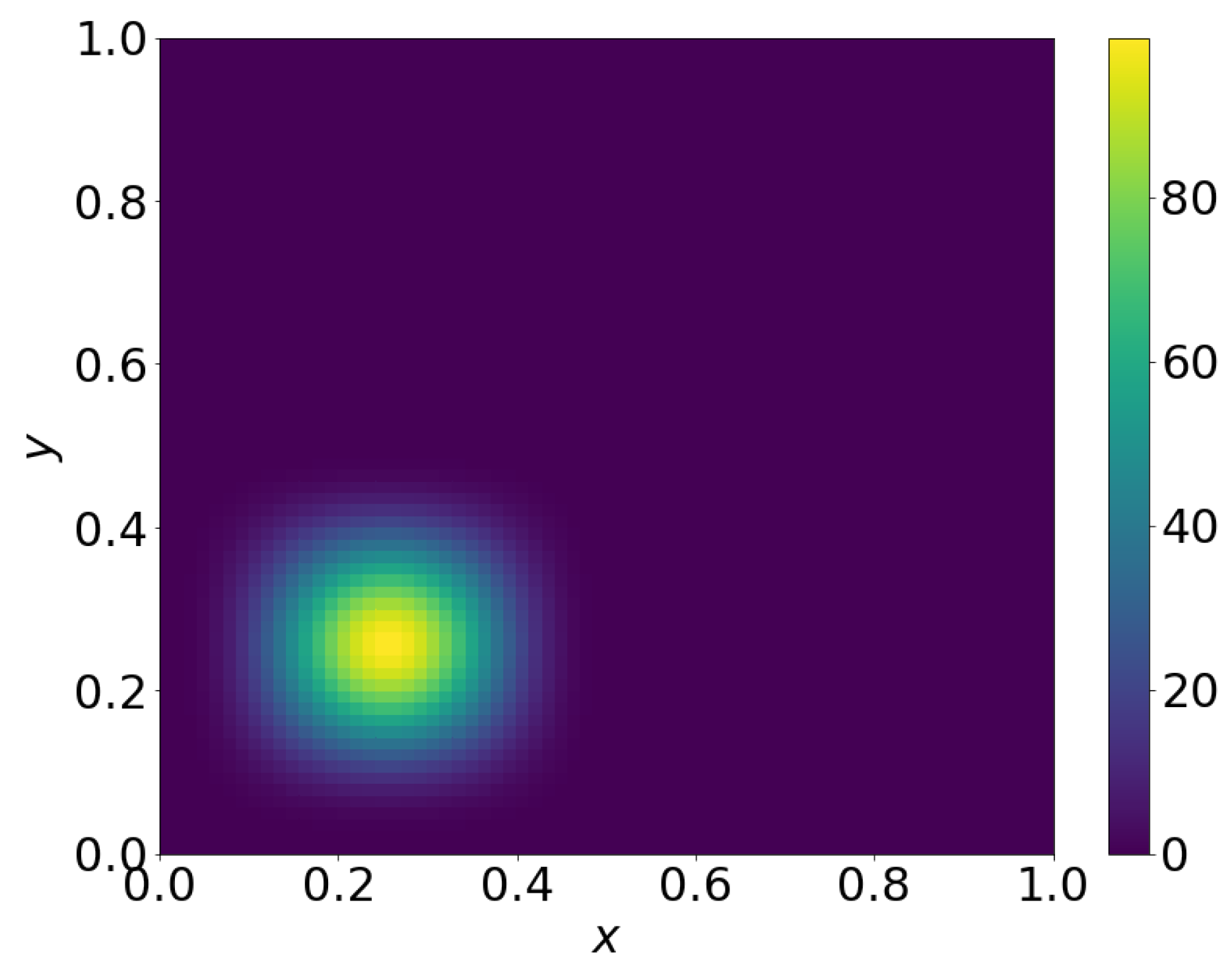
The initial condition is given by
and shown in Figure 10.
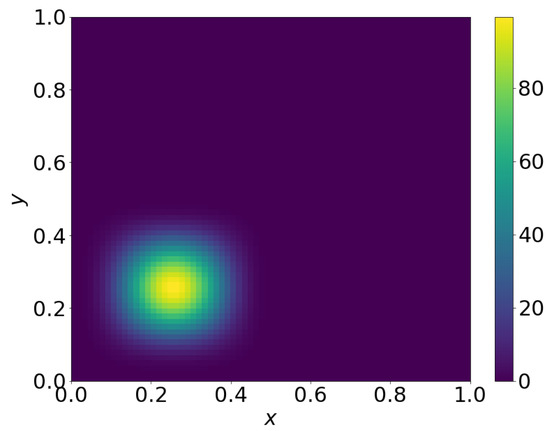
Figure 10.
Plot of Equation (60).
In this example, the parameters are used linearly in terms of operators, thus we can take advantage of parameter–separability for efficient projection of the full order model.
The time domain is discretized with the the uniform time step size with . Discretizing the space domain into and uniform meshes in x and y directions, respectively and excluding boundary grid points give us 4761 grid points. As a result, there are 238,050 free degrees of freedom in space–time.
For the training phase, we collect solution snapshots associated with the following parameters:
at which the FOM is solved. Figure 11 shows the singular value decay of the solution snapshot and the temporal snapshot.
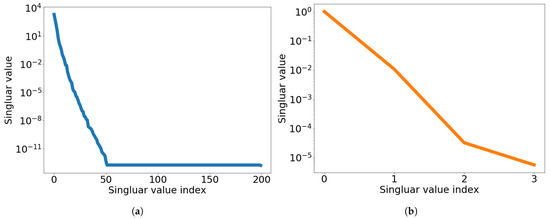
Figure 11.
2D linear convection diffusion equation. Graph of singular value decay. (a): Singular value decay of solution snapshot, (b): Singular value decay of temporal snapshot for the first spatial basis vector.
The Galerkin and LSPG space–time ROMs solve the Equation (58) with the target parameter . Figure 12, Figure 13 and Figure 14 show the relative errors, the space–time residuals, and the online speed-ups as a function of the reduced dimension and . We observe that both Galerkin and LSPG ROMs with and achieve a good accuracy (i.e., relative errors of and , respectively) and speed-up (i.e., and , respectively). Although the relative errors and space–time residuals are similar, the relative error of Galerkin space–time ROM is slightly lower than the LSPG space–time ROM as shown in Figure 12. On the other hand, Figure 13 shows that the space–time residual of the LSPG method is lower than the Galerkin method.
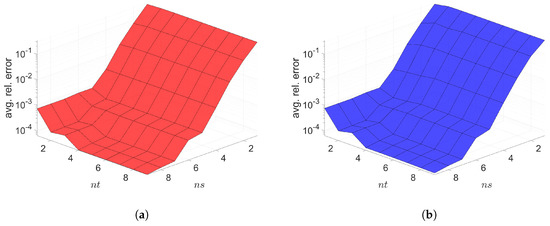
Figure 12.
2D linear convection diffusion equation. Relative errors vs. reduced dimensions. Note that the scales of the z-axis, i.e., the average relative error, are the same both for Galerkin and LSPG. Although the Galerkin achieves slightly lower minimum average relative error values than the LSPG, both Galerkin and LSPG show comparable results. (a): Relative errors vs. reduced dimensions for Galerkin projection, (b): Relative errors vs. reduced dimensions for LSPG projection.
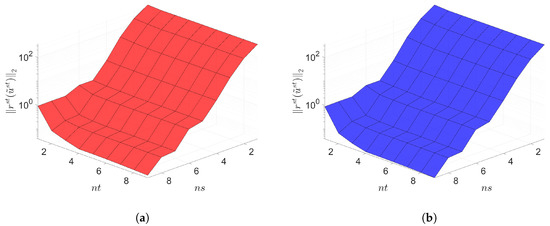
Figure 13.
2D linear convection diffusion equation. Space-time residuals vs. reduced dimensions. Note that the scales of the z-axis, i.e., the residual norm, are the same both for Galerkin and LSPG. Although the LSPG achieves slightly lower minimum residual norm values than the Galerkin, both Galerkin and LSPG show comparable results. (a): Space-time residuals vs. reduced dimensions for Galerkin projection, (b): Space-time residuals vs. reduced dimensions for LSPG projection.
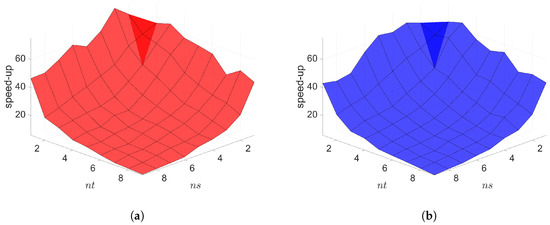
Figure 14.
2D linear convection diffusion equation. Online speed-ups vs. reduced dimensions. Both Galerkin and LSPG show similar speed-ups. (a): Online speed-ups vs. reduced dimensions for Galerkin projection, (b): Online speed-ups vs. reduced dimensions for LSPG projection.
The final time snapshots of FOM, Galerkin space–time ROM, and LSPG space–time ROM are seen in Figure 15. Both ROMs have a basis size of and , resulting in a reduction factor of 15,870. For the Galerkin method, the FOM and space–time ROM simulation with and takes an average time of and s, respectively, resulting in speed-up of . For the LSPG method, the FOM and space–time ROM simulation with and takes an average time of and s, respectively, resulting in speed-up of . For accuracy, the Galerkin method results in % relative error and space–time residual norm while the LSPG results in % relative error and space–time residual norm.
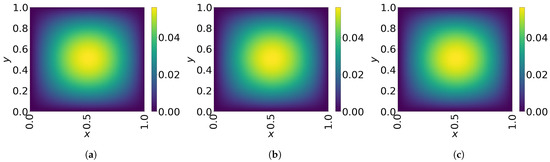
Figure 15.
2D linear convection diffusion equation. Solution snapshots of FOM, Galerkin ROM, and LSPG ROM at . (a): FOM, (b): Galerkin ROM, (c): LSPG ROM.
Now, the space–time reduced order models with and are generated using the same train parameter set given in Equation (61) to solve the predictive cases with the test parameter set, . Figure 16 shows the relative errors over the test parameter set. The Galerkin and LSPG ROMs are the most accurate within the range of the train parameter points, i.e., . For Galerkin ROM, online speed-up is about in average and total time for ROM and FOM are and s, respectively, resulting in total speed-up of . The total time for the ROM is composed of of FOM snapshot generation, of ROM basis generation, of parameter-independent ROM operator generation, of ROM operator assembly, and of time integration. For LSPG ROM, online speed-up is about in average and total time for ROM and FOM are and s, respectively, resulting in total speed-up of . The total time for the ROM breaks down into of FOM snapshot generation, of ROM basis generation, of parameter-independent ROM operator generation, of ROM operator assembly, and time integration.
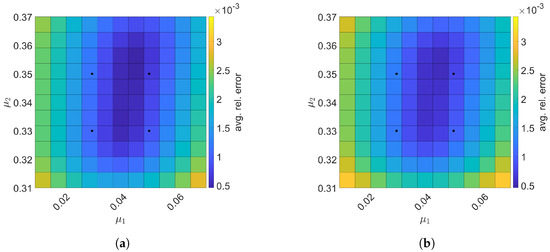
Figure 16.
2D linear convection diffusion equation. The comparison of the Galerkin and LSPG ROMs for predictive cases. The block dots indicate the train parameters. (a): Galerkin, (b): LSPG.
7.2.2. With Source Term
We consider a parameterized 2D linear convection diffusion equation
with the source term which is given by
where , and . The boundary condition is given by
and the initial condition is given by
Note that the parameters can be factored out when forming reduced order model operators in this example. Thus, we can avoid a lot of re-computation for a parametric case.
For time domain, we set the uniform time step size with . For spatial domain, the number of uniform meshes in x and y directions are set and , respectively. Considering free spatial degrees of freedom (i.e., excluding boundary grid points), we have grid points. Then, the number of space–time free degrees of freedom becomes 238,050.
For training phase, we collect solution snapshots associated with the following parameters:
at which the FOM is solved. In Figure 17, we can see how the singular values of the solution snapshot and the temporal snapshot decay.
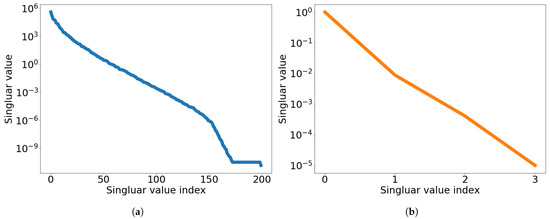
Figure 17.
2D linear convection diffusion equation with source term. Graph of singular value decay. (a): Singular value decay of solution snapshot, (b): Singular value decay of temporal snapshot for the first spatial basis vector.
The Galerkin and LSPG space–time ROMs solve the Equation (62) with the target parameter . Figure 18, Figure 19 and Figure 20 show the relative errors, the space–time residuals, and the online speed-ups as a function of the reduced dimension and . We observe that both Galerkin and LSPG ROMs with and achieve a good accuracy (i.e., relative errors of and , respectively) and speed-up (i.e., and , respectively). From Figure 18 and Figure 19, we find that there is the same observation that the LSPG method gives lower space–time residuals but higher relative errors as in Section 7.1 and Section 7.2.1.
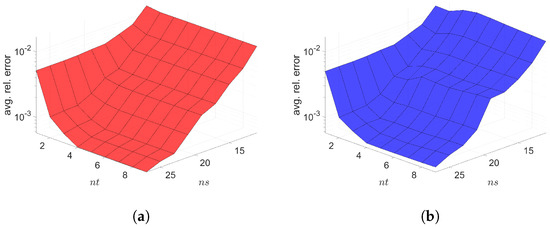
Figure 18.
2D linear convection diffusion equation with source term. Relative errors vs. reduced dimensions. Note that the scales of the z-axis, i.e., the average relative error, are the same both for Galerkin and LSPG. Although the Galerkin achieves slightly lower minimum average relative error values than the LSPG, both Galerkin and LSPG show comparable results. (a): Relative errors vs. reduced dimensions for Galerkin projection, (b): Relative errors vs. reduced dimensions for LSPG projection.
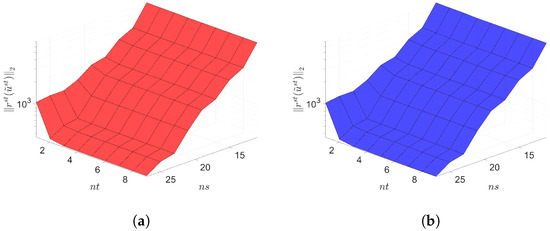
Figure 19.
2D linear convection diffusion equation with source term. Space-time residuals vs. reduced dimensions. Note that the scales of the z-axis, i.e., the residual norm, are the same both for Galerkin and LSPG. Although the LSPG achieves slightly lower minimum residual norm values than the Galerkin, both Galerkin and LSPG show comparable results. (a): Space-time residuals vs. reduced dimensions for Galerkin projection, (b): Space-time residuals vs. reduced dimensions for LSPG projection.
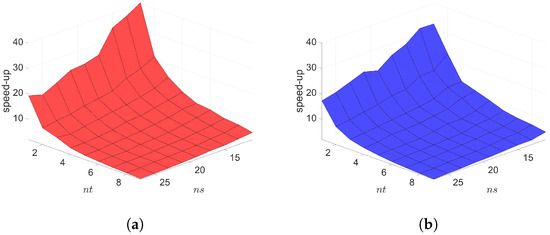
Figure 20.
2D linear convection diffusion equation with source term. Online speed-ups vs. reduced dimensions. Both Galerkin and LSPG show similar speed-ups. (a): Online speed-ups vs. reduced dimensions for Galerkin projection, (b): Online speed-ups vs. reduced dimensions for LSPG projection.
The final time snapshots of FOM, Galerkin space–time ROM, and LSPG space–time ROM are seen in Figure 21. Both ROMs have a basis size of and , resulting in a reduction factor of 4176. For the Galerkin method, the FOM and space–time ROM simulation with and takes an average time of and s, respectively, resulting in speed-up of . For the LSPG method, the FOM and space–time ROM simulation with and takes an average time of and s, respectively, resulting in speed-up of . For accuracy, the Galerkin method results in % relative error and space–time residual norm while the LSPG results in % relative error and space–time residual norm.
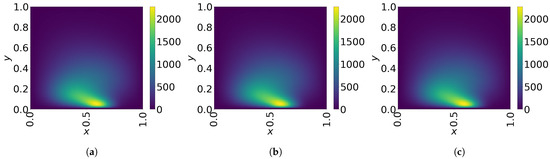
Figure 21.
2D linear convection diffusion equation with source term. Solution snapshots of FOM, Galerkin ROM, and LSPG ROM at . (a): FOM, (b): Galerkin ROM, (c): LSPG ROM.
Next, we set the test parameter set to be . Then, predictive cases with the test parameter set are solved using the space–time ROMs which are generated using the train parameter set given by Equation (66) with and . The relative errors over the test parameter set are shown in Figure 22. We see that the Galerkin and LSPG ROMs are the most accurate inside region of the rectangle defined by the train parameter points, i.e., . For Galerkin ROM, online speed-up is about in average and total time for ROM and FOM are and s, respectively, resulting in total speed-up of . The total time for the ROM breaks down into of FOM snapshot generation, of ROM basis generation, of parameter-independent ROM operator generation, of ROM operator assembly, and of time integration. For LSPG ROM, online speed-up is about in average and total times for ROM and FOM are and s, respectively, resulting in total speed-up of . The total time of the ROM consists of of FOM snapshot generation, of ROM basis generation, of parameter-independent ROM operator generation, of ROM operator assembly, and of time integration.
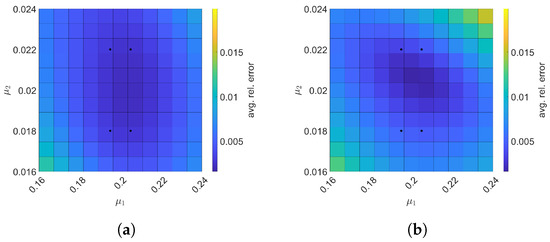
Figure 22.
2D linear convection diffusion equation with source term. The comparison of the Galerkin and LSPG ROMs for predictive cases. The block dots indicate the train parameters. (a): Galerkin, (b): LSPG.
8. Conclusions
In this work, we have formulated Galerkin and LSPG space–time ROMs for linear dynamical systems using block structures which enable us to implement the space–time ROM operators efficiently. We also presented an a posteriori error bound for both Galerkin and LSPG space–time ROMs. We demonstrated that both Galerkin and LSPG space–time ROMs solve 2D linear dynamical systems with parameter–separability accurately and efficiently. Both space–time reduced order models were able to achieve to relative errors with online speed-ups, and their differences were negligible. We also presented our Python codes used for the numerical examples in Appendix A so that readers can easily reproduce our numerical results. Furthermore, each Python code is less than 120 lines, demonstrating the ease of implementing our space–time ROMs.
We used a linear subspace based ROM which is suitable for accelerating physical simulations whose solution space has a small Kolmogorov n-width. However, the linear subspace based ROM is not able to represent advection-dominated or sharp gradient solutions with a small number of bases. To address this challenge, a nonlinear manifold based ROM can be used, and, recently, a nonlinear manifold based ROM has been developed for spatial ROMs [91,92,93]. In future work, we aim to develop a nonlinear manifold based space–time ROM. Another interesting future direction is to build a component-wise space–time ROM as an extension to the work in [94], which is attractive for extreme-scale problems, whose simulation data are too big to store in a given memory.
Author Contributions
Conceptualization and methodology, Y.C.; coding and validation, Y.K. and K.W.; formal analysis and investigation, Y.K. and K.W.; writing—original draft preparation, Y.K., K.W. and Y.C.; writing—review and editing, Y.K., K.W. and Y.C.; visualization, Y.K.; supervision, Y.C.; project administration, Y.C.; funding acquisition, Y.C. All authors have read and agreed to the published version of the manuscript.
Funding
This work was performed at Lawrence Livermore National Laboratory and was supported by the LDRD program (project 20-FS-007).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
All data generated during the current study are available from the corresponding author on reasonable request.
Acknowledgments
We thank four anonymous reviewers whose comments/suggestions helped improve and clarify this manuscript. Youngkyu was supported for this work through generous funding from DTRA. Lawrence Livermore National Laboratory is operated by Lawrence Livermore National Security, LLC, for the U.S. Department of Energy, National Nuclear Security Administration under Contract DE-AC52-07NA27344 and LLNL-JRNL-816093.
Conflicts of Interest
The authors declare no conflict of interest. The funder had a role in the decision to publish the results. The funder had no role in the design of the study, in the collection, analyses, or interpretation of data, or in the writing of the manuscript.
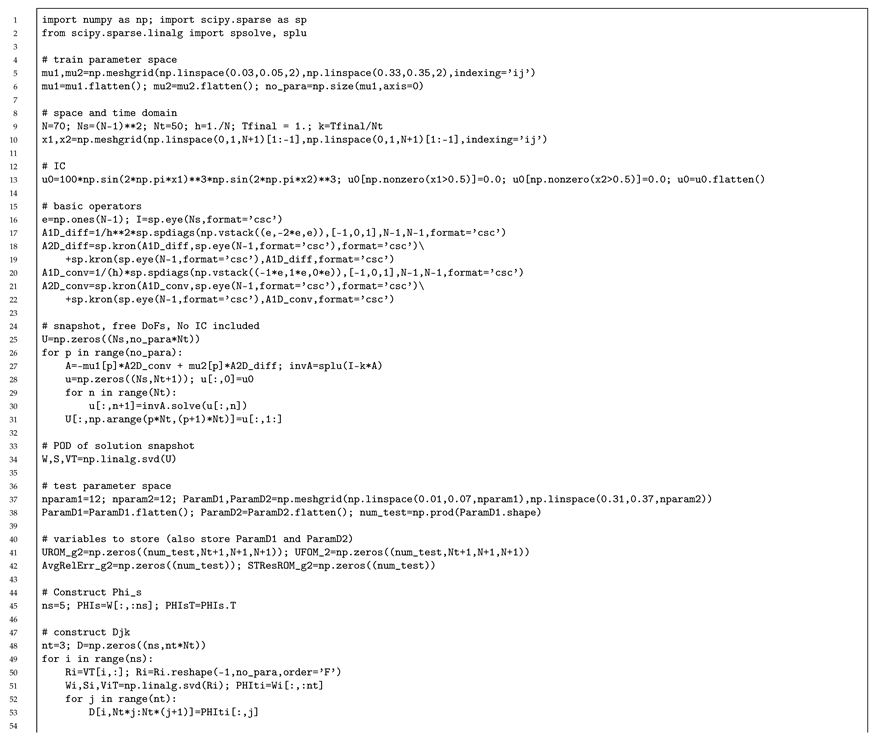
Appendix A. Python Codes in Less than 120 Lines of Code for All Numerical Models Described in Section 7
The Python code used for the numerical examples described in this paper are included in the following pages of the appendix and they are listed below. The total number of lines in each of the files are denoted in the parentheses. Note that we removed print statements of the results:
- 1.
- All input code for the Galerkin Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term (111 lines)
- 2.
- All input code for the LSPG Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term (117 lines)
- 3.
- All input code for the Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation (119 lines)
- 4.
- All input code for the LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation (119 lines)
- 5.
- All input code for the Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term (114 lines)
- 6.
- All input code for the LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term (119 lines)
Appendix A.1. Galerkin Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term


Appendix A.2. LSPG Reduced Order Model for 2D Implicit Linear Diffusion Equation with Source Term



Appendix A.3. Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation

Appendix A.4. LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation



Appendix A.5. Galerkin Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term
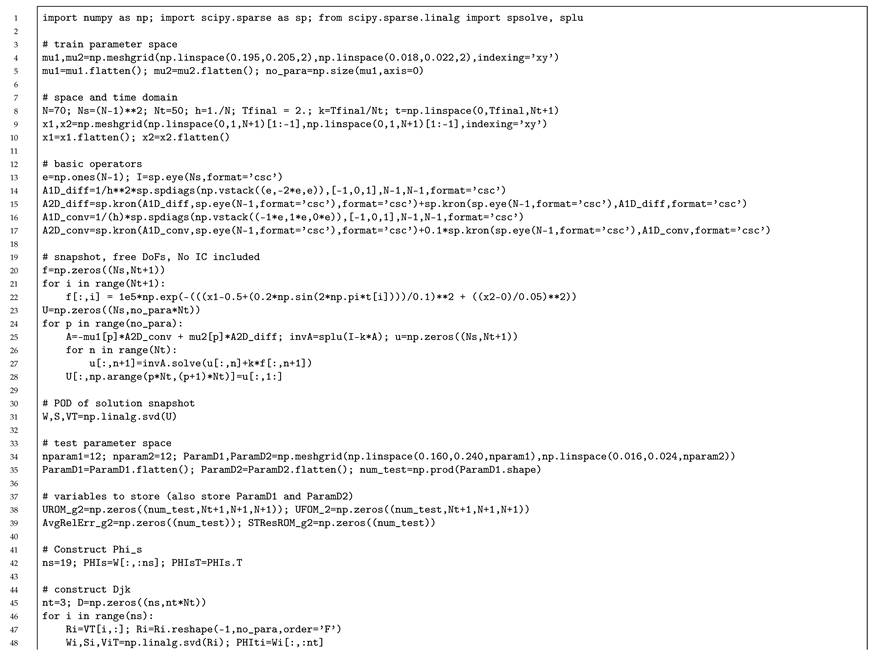

Appendix A.6. LSPG Reduced Order Model for 2D Implicit Linear Convection Diffusion Equation with Source Term


References
- Mullis, C.; Roberts, R. Synthesis of minimum roundoff noise fixed point digital filters. IEEE Trans. Circuits Syst. 1976, 23, 551–562. [Google Scholar] [CrossRef]
- Moore, B. Principal component analysis in linear systems: Controllability, observability, and model reduction. IEEE Trans. Autom. Control 1981, 26, 17–32. [Google Scholar] [CrossRef]
- Willcox, K.; Peraire, J. Balanced model reduction via the proper orthogonal decomposition. AIAA J. 2002, 40, 2323–2330. [Google Scholar] [CrossRef]
- Willcox, K.; Megretski, A. Fourier series for accurate, stable, reduced-order models in large-scale linear applications. SIAM J. Sci. Comput. 2005, 26, 944–962. [Google Scholar] [CrossRef] [Green Version]
- Heinkenschloss, M.; Sorensen, D.C.; Sun, K. Balanced truncation model reduction for a class of descriptor systems with application to the Oseen equations. SIAM J. Sci. Comput. 2008, 30, 1038–1063. [Google Scholar] [CrossRef] [Green Version]
- Sandberg, H.; Rantzer, A. Balanced truncation of linear time-varying systems. IEEE Trans. Autom. Control 2004, 49, 217–229. [Google Scholar] [CrossRef] [Green Version]
- Hartmann, C.; Vulcanov, V.M.; Schütte, C. Balanced truncation of linear second-order systems: A Hamiltonian approach. Multiscale Model. Simul. 2010, 8, 1348–1367. [Google Scholar] [CrossRef] [Green Version]
- Petreczky, M.; Wisniewski, R.; Leth, J. Balanced truncation for linear switched systems. Nonlinear Anal. Hybrid Syst. 2013, 10, 4–20. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Rowley, C.W.; Tadmor, G. Snapshot-based balanced truncation for linear time-periodic systems. IEEE Trans. Autom. Control 2010, 55, 469–473. [Google Scholar]
- Bai, Z. Krylov subspace techniques for reduced-order modeling of large-scale dynamical systems. Appl. Numer. Math. 2002, 43, 9–44. [Google Scholar] [CrossRef] [Green Version]
- Gugercin, S.; Antoulas, A.C.; Beattie, C. H_2 model reduction for large-scale linear dynamical systems. SIAM J. Matrix Anal. Appl. 2008, 30, 609–638. [Google Scholar] [CrossRef]
- Astolfi, A. Model reduction by moment matching for linear and nonlinear systems. IEEE Trans. Autom. Control 2010, 55, 2321–2336. [Google Scholar] [CrossRef]
- Chiprout, E.; Nakhla, M. Generalized moment-matching methods for transient analysis of interconnect networks. In Proceedings of the 29th ACM/IEEE Design Automation Conference, Anaheim, CA, USA, 8–12 June 1992; pp. 201–206. [Google Scholar]
- Pratesi, M.; Santucci, F.; Graziosi, F. Generalized moment matching for the linear combination of lognormal RVs: application to outage analysis in wireless systems. IEEE Trans. Wirel. Commun. 2006, 5, 1122–1132. [Google Scholar] [CrossRef]
- Ammar, A.; Mokdad, B.; Chinesta, F.; Keunings, R. A new family of solvers for some classes of multidimensional partial differential equations encountered in kinetic theory modeling of complex fluids. J. Non-Newton. Fluid Mech. 2006, 139, 153–176. [Google Scholar] [CrossRef] [Green Version]
- Ammar, A.; Mokdad, B.; Chinesta, F.; Keunings, R. A new family of solvers for some classes of multidimensional partial differential equations encountered in kinetic theory modelling of complex fluids: Part II: Transient simulation using space-time separated representations. J. Non-Newton. Fluid Mech. 2007, 144, 98–121. [Google Scholar] [CrossRef] [Green Version]
- Chinesta, F.; Ammar, A.; Cueto, E. Proper generalized decomposition of multiscale models. Int. J. Numer. Methods Eng. 2010, 83, 1114–1132. [Google Scholar] [CrossRef]
- Pruliere, E.; Chinesta, F.; Ammar, A. On the deterministic solution of multidimensional parametric models using the proper generalized decomposition. Math. Comput. Simul. 2010, 81, 791–810. [Google Scholar] [CrossRef] [Green Version]
- Chinesta, F.; Ammar, A.; Leygue, A.; Keunings, R. An overview of the proper generalized decomposition with applications in computational rheology. J. Non-Newton. Fluid Mech. 2011, 166, 578–592. [Google Scholar] [CrossRef] [Green Version]
- Giner, E.; Bognet, B.; Ródenas, J.J.; Leygue, A.; Fuenmayor, F.J.; Chinesta, F. The proper generalized decomposition (PGD) as a numerical procedure to solve 3D cracked plates in linear elastic fracture mechanics. Int. J. Solids Struct. 2013, 50, 1710–1720. [Google Scholar] [CrossRef]
- Barbarulo, A.; Ladevèze, P.; Riou, H.; Kovalevsky, L. Proper generalized decomposition applied to linear acoustic: A new tool for broad band calculation. J. Sound Vib. 2014, 333, 2422–2431. [Google Scholar] [CrossRef] [Green Version]
- Amsallem, D.; Farhat, C. Stabilization of projection-based reduced-order models. Int. J. Numer. Methods Eng. 2012, 91, 358–377. [Google Scholar] [CrossRef]
- Amsallem, D.; Farhat, C. Interpolation method for adapting reduced-order models and application to aeroelasticity. AIAA J. 2008, 46, 1803–1813. [Google Scholar] [CrossRef] [Green Version]
- Thomas, J.P.; Dowell, E.H.; Hall, K.C. Three-dimensional transonic aeroelasticity using proper orthogonal decomposition-based reduced-order models. J. Aircr. 2003, 40, 544–551. [Google Scholar] [CrossRef]
- Hall, K.C.; Thomas, J.P.; Dowell, E.H. Proper orthogonal decomposition technique for transonic unsteady aerodynamic flows. AIAA J. 2000, 38, 1853–1862. [Google Scholar] [CrossRef]
- Simoncini, V. A new iterative method for solving large-scale Lyapunov matrix equations. SIAM J. Sci. Comput. 2007, 29, 1268–1288. [Google Scholar] [CrossRef] [Green Version]
- Benner, P.; Li, J.R.; Penzl, T. Numerical solution of large-scale Lyapunov equations, Riccati equations, and linear-quadratic optimal control problems. Numer. Linear Algebra Appl. 2008, 15, 755–777. [Google Scholar] [CrossRef]
- Rowley, C.W. Model reduction for fluids, using balanced proper orthogonal decomposition. Int. J. Bifurc. Chaos 2005, 15, 997–1013. [Google Scholar] [CrossRef] [Green Version]
- Ma, Z.; Ahuja, S.; Rowley, C.W. Reduced-order models for control of fluids using the eigensystem realization algorithm. Theor. Comput. Fluid Dyn. 2011, 25, 233–247. [Google Scholar] [CrossRef] [Green Version]
- Lall, S.; Marsden, J.E.; Glavaški, S. A subspace approach to balanced truncation for model reduction of nonlinear control systems. Int. J. Robust Nonlinear Control. IFAC-Affil. J. 2002, 12, 519–535. [Google Scholar] [CrossRef] [Green Version]
- Gosea, I.V.; Gugercin, S.; Beattie, C. Data-driven balancing of linear dynamical systems. arXiv 2021, arXiv:2104.01006. [Google Scholar]
- Chinesta, F.; Ladeveze, P.; Cueto, E. A short review on model order reduction based on proper generalized decomposition. Arch. Comput. Methods Eng. 2011, 18, 395. [Google Scholar] [CrossRef] [Green Version]
- Mayo, A.; Antoulas, A. A framework for the solution of the generalized realization problem. Linear Algebra Its Appl. 2007, 425, 634–662. [Google Scholar] [CrossRef] [Green Version]
- Scarciotti, G.; Astolfi, A. Data-driven model reduction by moment matching for linear and nonlinear systems. Automatica 2017, 79, 340–351. [Google Scholar] [CrossRef]
- Schmid, P.J. Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 2010, 656, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Chen, K.K.; Tu, J.H.; Rowley, C.W. Variants of dynamic mode decomposition: Boundary condition, Koopman, and Fourier analyses. J. Nonlinear Sci. 2012, 22, 887–915. [Google Scholar] [CrossRef]
- Williams, M.O.; Kevrekidis, I.G.; Rowley, C.W. A data—Driven approximation of the koopman operator: Extending dynamic mode decomposition. J. Nonlinear Sci. 2015, 25, 1307–1346. [Google Scholar] [CrossRef] [Green Version]
- Takeishi, N.; Kawahara, Y.; Yairi, T. Learning Koopman invariant subspaces for dynamic mode decomposition. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 1130–1140. [Google Scholar]
- Askham, T.; Kutz, J.N. Variable projection methods for an optimized dynamic mode decomposition. SIAM J. Appl. Dyn. Syst. 2018, 17, 380–416. [Google Scholar] [CrossRef] [Green Version]
- Schmid, P.J.; Li, L.; Juniper, M.P.; Pust, O. Applications of the dynamic mode decomposition. Theor. Comput. Fluid Dyn. 2011, 25, 249–259. [Google Scholar] [CrossRef]
- Kutz, J.N.; Fu, X.; Brunton, S.L. Multiresolution dynamic mode decomposition. SIAM J. Appl. Dyn. Syst. 2016, 15, 713–735. [Google Scholar] [CrossRef] [Green Version]
- Li, Q.; Dietrich, F.; Bollt, E.M.; Kevrekidis, I.G. Extended dynamic mode decomposition with dictionary learning: A data-driven adaptive spectral decomposition of the Koopman operator. Chaos Interdiscip. J. Nonlinear Sci. 2017, 27, 103111. [Google Scholar] [CrossRef]
- Proctor, J.L.; Brunton, S.L.; Kutz, J.N. Dynamic mode decomposition with control. SIAM J. Appl. Dyn. Syst. 2016, 15, 142–161. [Google Scholar] [CrossRef] [Green Version]
- Tu, J.H.; Rowley, C.W.; Luchtenburg, D.M.; Brunton, S.L.; Kutz, J.N. On dynamic mode decomposition: Theory and applications. arXiv 2013, arXiv:1312.0041. [Google Scholar]
- Kutz, J.N.; Brunton, S.L.; Brunton, B.W.; Proctor, J.L. Dynamic Mode Decomposition: Data-Driven Modeling of Complex Systems; SIAM: Philadelphia, PA, USA, 2016. [Google Scholar]
- Choi, Y.; Coombs, D.; Anderson, R. SNS: A solution-based nonlinear subspace method for time-dependent model order reduction. SIAM J. Sci. Comput. 2020, 42, A1116–A1146. [Google Scholar] [CrossRef] [Green Version]
- Hoang, C.; Choi, Y.; Carlberg, K. Domain-decomposition least-squares Petrov-Galerkin (DD-LSPG) nonlinear model reduction. arXiv 2020, arXiv:2007.11835. [Google Scholar]
- Carlberg, K.; Choi, Y.; Sargsyan, S. Conservative model reduction for finite-volume models. J. Comput. Phys. 2018, 371, 280–314. [Google Scholar] [CrossRef] [Green Version]
- Berkooz, G.; Holmes, P.; Lumley, J.L. The proper orthogonal decomposition in the analysis of turbulent flows. Annu. Rev. Fluid Mech. 1993, 25, 539–575. [Google Scholar] [CrossRef]
- Gubisch, M.; Volkwein, S. Proper orthogonal decomposition for linear-quadratic optimal control. Model Reduct. Approx. Theory Algorithms 2017, 5, 66. [Google Scholar]
- Kunisch, K.; Volkwein, S. Galerkin proper orthogonal decomposition methods for parabolic problems. Numer. Math. 2001, 90, 117–148. [Google Scholar] [CrossRef]
- Hinze, M.; Volkwein, S. Error estimates for abstract linear—Quadratic optimal control problems using proper orthogonal decomposition. Comput. Optim. Appl. 2008, 39, 319–345. [Google Scholar] [CrossRef]
- Kerschen, G.; Golinval, J.C.; Vakakis, A.F.; Bergman, L.A. The method of proper orthogonal decomposition for dynamical characterization and order reduction of mechanical systems: An overview. Nonlinear Dyn. 2005, 41, 147–169. [Google Scholar] [CrossRef]
- Bamer, F.; Bucher, C. Application of the proper orthogonal decomposition for linear and nonlinear structures under transient excitations. Acta Mech. 2012, 223, 2549–2563. [Google Scholar] [CrossRef]
- Atwell, J.A.; King, B.B. Proper orthogonal decomposition for reduced basis feedback controllers for parabolic equations. Math. Comput. Model. 2001, 33, 1–19. [Google Scholar] [CrossRef]
- Rathinam, M.; Petzold, L.R. A new look at proper orthogonal decomposition. SIAM J. Numer. Anal. 2003, 41, 1893–1925. [Google Scholar] [CrossRef]
- Kahlbacher, M.; Volkwein, S. Galerkin proper orthogonal decomposition methods for parameter dependent elliptic systems. Discuss. Math. Differ. Inclusions Control Optim. 2007, 27, 95–117. [Google Scholar] [CrossRef] [Green Version]
- Bonnet, J.P.; Cole, D.R.; Delville, J.; Glauser, M.N.; Ukeiley, L.S. Stochastic estimation and proper orthogonal decomposition: Complementary techniques for identifying structure. Exp. Fluids 1994, 17, 307–314. [Google Scholar] [CrossRef]
- Placzek, A.; Tran, D.M.; Ohayon, R. Hybrid proper orthogonal decomposition formulation for linear structural dynamics. J. Sound Vib. 2008, 318, 943–964. [Google Scholar] [CrossRef] [Green Version]
- LeGresley, P.; Alonso, J. Airfoil design optimization using reduced order models based on proper orthogonal decomposition. In Proceedings of the Fluids 2000 Conference and Exhibit, Denver, CO, USA, 19–22 June 2000; p. 2545. [Google Scholar]
- Efe, M.O.; Ozbay, H. Proper orthogonal decomposition for reduced order modeling: 2D heat flow. In Proceedings of the 2003 IEEE Conference on Control Applications, (CCA 2003), Istanbul, Turkey, 25–25 June 2003; Volume 2, pp. 1273–1277. [Google Scholar]
- Urban, K.; Patera, A. An improved error bound for reduced basis approximation of linear parabolic problems. Math. Comput. 2014, 83, 1599–1615. [Google Scholar] [CrossRef] [Green Version]
- Yano, M.; Patera, A.T.; Urban, K. A space-time hp-interpolation-based certified reduced basis method for Burgers’ equation. Math. Model. Methods Appl. Sci. 2014, 24, 1903–1935. [Google Scholar] [CrossRef]
- Yano, M. A space-time Petrov–Galerkin certified reduced basis method: Application to the Boussinesq equations. SIAM J. Sci. Comput. 2014, 36, A232–A266. [Google Scholar] [CrossRef]
- Baumann, M.; Benner, P.; Heiland, J. Space-time Galerkin POD with application in optimal control of semilinear partial differential equations. SIAM J. Sci. Comput. 2018, 40, A1611–A1641. [Google Scholar] [CrossRef] [Green Version]
- Towne, A.; Schmidt, O.T.; Colonius, T. Spectral proper orthogonal decomposition and its relationship to dynamic mode decomposition and resolvent analysis. J. Fluid Mech. 2018, 847, 821–867. [Google Scholar] [CrossRef] [Green Version]
- Towne, A. Space-time Galerkin projection via spectral proper orthogonal decomposition and resolvent modes. In Proceedings of the AIAA Scitech 2021 Forum, San Diego, CA, USA, 3–7 January 2021; p. 1676. [Google Scholar]
- Towne, A.; Lozano-Durán, A.; Yang, X. Resolvent-based estimation of space–time flow statistics. J. Fluid Mech. 2020, 883. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y.; Carlberg, K. Space–Time Least-Squares Petrov–Galerkin Projection for Nonlinear Model Reduction. SIAM J. Sci. Comput. 2019, 41, A26–A58. [Google Scholar] [CrossRef]
- Parish, E.J.; Carlberg, K.T. Windowed least-squares model reduction for dynamical systems. J. Comput. Phys. 2021, 426, 109939. [Google Scholar] [CrossRef]
- Shimizu, Y.S.; Parish, E.J. Windowed space-time least-squares Petrov-Galerkin method for nonlinear model order reduction. arXiv 2020, arXiv:2012.06073. [Google Scholar]
- Choi, Y.; Brown, P.; Arrighi, W.; Anderson, R.; Huynh, K. Space–time reduced order model for large-scale linear dynamical systems with application to Boltzmann transport problems. J. Comput. Phys. 2020, 424, 109845. [Google Scholar] [CrossRef]
- Barone, M.F.; Kalashnikova, I.; Segalman, D.J.; Thornquist, H.K. Stable Galerkin reduced order models for linearized compressible flow. J. Comput. Phys. 2009, 228, 1932–1946. [Google Scholar] [CrossRef]
- Rezaian, E.; Wei, M. A hybrid stabilization approach for reduced-order models of compressible flows with shock-vortex interaction. Int. J. Numer. Methods Eng. 2020, 121, 1629–1646. [Google Scholar] [CrossRef]
- Carlberg, K.; Bou-Mosleh, C.; Farhat, C. Efficient nonlinear model reduction via a least-squares Petrov–Galerkin projection and compressive tensor approximations. Int. J. Numer. Methods Eng. 2011, 86, 155–181. [Google Scholar] [CrossRef]
- Huang, C.; Wentland, C.R.; Duraisamy, K.; Merkle, C. Model reduction for multi-scale transport problems using structure-preserving least-squares projections with variable transformation. arXiv 2020, arXiv:2011.02072. [Google Scholar]
- Yoon, G.H. Structural topology optimization for frequency response problem using model reduction schemes. Comput. Methods Appl. Mech. Eng. 2010, 199, 1744–1763. [Google Scholar] [CrossRef]
- Amir, O.; Stolpe, M.; Sigmund, O. Efficient use of iterative solvers in nested topology optimization. Struct. Multidiscip. Optim. 2010, 42, 55–72. [Google Scholar] [CrossRef]
- Amsallem, D.; Zahr, M.; Choi, Y.; Farhat, C. Design optimization using hyper-reduced-order modelsvd. Struct. Multidiscip. Optim. 2015, 51, 919–940. [Google Scholar] [CrossRef]
- Gogu, C. Improving the efficiency of large scale topology optimization through on-the-fly reduced order model construction. Int. J. Numer. Methods Eng. 2015, 101, 281–304. [Google Scholar] [CrossRef]
- Choi, Y.; Boncoraglio, G.; Anderson, S.; Amsallem, D.; Farhat, C. Gradient-based constrained optimization using a database of linear reduced-order models. J. Comput. Phys. 2020, 423, 109787. [Google Scholar] [CrossRef]
- Choi, Y.; Oxberry, G.; White, D.; Kirchdoerfer, T. Accelerating design optimization using reduced order models. arXiv 2019, arXiv:1909.11320. [Google Scholar]
- White, D.A.; Choi, Y.; Kudo, J. A dual mesh method with adaptivity for stress-constrained topology optimization. Struct. Multidiscip. Optim. 2020, 61, 749–762. [Google Scholar] [CrossRef]
- Najm, H.N. Uncertainty quantification and polynomial chaos techniques in computational fluid dynamics. Annu. Rev. Fluid Mech. 2009, 41, 35–52. [Google Scholar] [CrossRef]
- Walters, R.W.; Huyse, L. Uncertainty Analysis for Fluid Mechanics with Applications; Technical Report; National Aeronautics and Space Administration Hampton va Langley Research Center: Hampton, VA, USA, 2002. [Google Scholar]
- Zang, T.A. Needs and Opportunities for Uncertainty-Based Multidisciplinary Design Methods for Aerospace Vehicles; National Aeronautics and Space Administration, Langley Research Center: Hampton, VA, USA, 2002. [Google Scholar]
- Petersson, N.A.; Garcia, F.M.; Copeland, A.E.; Rydin, Y.L.; DuBois, J.L. Discrete Adjoints for Accurate Numerical Optimization with Application to Quantum Control. arXiv 2020, arXiv:2001.01013. [Google Scholar]
- Choi, Y.; Farhat, C.; Murray, W.; Saunders, M. A practical factorization of a Schur complement for PDE-constrained distributed optimal control. J. Sci. Comput. 2015, 65, 576–597. [Google Scholar] [CrossRef] [Green Version]
- Choi, Y. Simultaneous Analysis and Design in PDE-Constrained Optimization. Ph.D. Thesis, Stanford University, Stanford, CA, USA, 2012. [Google Scholar]
- Sirovich, L. Turbulence and the dynamics of coherent structures. I. Coherent structures. Q. Appl. Math. 1987, 45, 561–571. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Carlberg, K.T. Model reduction of dynamical systems on nonlinear manifolds using deep convolutional autoencoders. J. Comput. Phys. 2020, 404, 108973. [Google Scholar] [CrossRef] [Green Version]
- Kim, Y.; Choi, Y.; Widemann, D.; Zohdi, T. A fast and accurate physics-informed neural network reduced order model with shallow masked autoencoder. arXiv 2020, arXiv:2009.11990. [Google Scholar]
- Kim, Y.; Choi, Y.; Widemann, D.; Zohdi, T. Efficient nonlinear manifold reduced order model. arXiv 2020, arXiv:2011.07727. [Google Scholar]
- McBane, S.; Choi, Y. Component-wise reduced order model lattice-type structure design. Comput. Methods Appl. Mech. Eng. 2021, 381, 113813. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).