Abstract
Object detection and segmentation can improve the accuracy of image recognition, but traditional methods can only extract the shallow information of the target, so the performance of algorithms is subject to many limitations. With the development of neural network technology, semantic segmentation algorithms based on deep learning can obtain the category information of each pixel. However, the algorithm cannot effectively distinguish each object of the same category, so YOLOMask, an instance segmentation algorithm based on complementary fusion network, is proposed in this paper. Experimental results on public data sets COCO2017 show that the proposed fusion network can accurately obtain the category and location information of each instance and has good real-time performance.
1. Introduction
Object detection and segmentation based on RGB images are the basis of 6D pose estimation, and it is also the premise of successful robot grasping. Accurate detection and segmentation can improve the accuracy of image recognition, but the traditional method can only extract the shallow information of the target, so it is limited by many conditions. With the development of deep learning in the field of image classification, object detection, semantic segmentation, and instance segmentation based on deep learning have made great achievements [1]. The object detection technology is the basis of the latter two, which mainly includes one-stage methods and two-stage methods. Both semantic segmentation and instance segmentation are used to classify the image at the pixel level, and the instance segmentation model also needs to get the category information and location information of each pixel [2]. Therefore, the instance segmentation algorithm needs higher computational cost. How to maintain high accuracy and real-time performance in complex robot grasping environments is the key problem to be solved in this paper.
At present, there are mainly two frameworks for instance segmentation algorithms based on deep learning [3]. One is to determine the object’s category information and location information through the object detection algorithm, and then segment each instance at the pixel level [4]. The disadvantage of this method is that it cuts off the connection between the pixels inside and outside the bounding box and does not fully consider the context, which leads to the low accuracy of the final segmentation. The other is to cluster the pixels of each instance in the image directly, then the offset of the instance pixels can be calculated according to the distance from the object center to each pixel, and finally, the instance can be segmented without the bounding box [5]. The disadvantage of this method is that it cannot segment the edge information of large-scale objects well. At the same time, most of the instance segmentation algorithms focus on improving the performance of the model while ignoring the real-time requirements in the actual operation process of the robot [6]. Therefore, the goal of this paper is to design an instance segmentation model with balance of accuracy and speed to fill the gap in this aspect.
The essence of instance segmentation is to classify each pixel in the image according to the similar attributes of the instance, such as texture, color, brightness, or distance index [7]. In the early stage of 6D pose estimation, it is necessary to accurately segment the contour information of the object to be captured and, at the same time, to ensure the speed of robot grasping. In this paper, a new instance segmentation algorithm is proposed. In the new model, first, the optimized YOLOv4 (you only look once) algorithm is used to solve the problem of classification and location of salient objects in the image. Then, the semantic segmentation algorithm of dense UNet (U-shaped network) is used to classify the pixels of the objects. Finally, the accurate contour information and location results of the objects are obtained. The architecture adopts dense encoder–decoder structure, which has better spatial connectivity and retains the features learned in the shallow layer of the network, so it can achieve better location and segmentation. Through the experimental verification on public datasets, it is proven that the new algorithm still has good real-time performance under the premise of ensuring the accuracy.
The remainder of the study is arranged as follows: in Section 2, we introduce the related work of image detection and image segmentation. Section 3 focuses on the construction of a neural network that can help to segment each instance in the image. In Section 4, the performance of the proposed neural network is discussed according to the experiment result. Finally, the conclusion that the new method has higher precision and generalizability is given and future research is described.
2. Related Work
In the process of robot grasping, target recognition and location is very important, which is the premise and foundation of later pose estimation. Therefore, how to improve the accuracy and speed of object detection is the key problem of robot grasping applications [8]. According to the timeline, the development of object detection methods can be divided into two historical stages: the traditional mathematical modeling method and the deep learning method. Traditional object detection methods mainly construct image features based on mathematical modeling. The representative features include corner feature descriptor Harris [9], ORB (oriented FAST and rotated BRIEF) [10], SIFT(scale invariant feature transform) [11], SURF (speeded-up robust features) [12], HOG (histogram of oriented gradient), LBP (local binary patterns), and DPM (deformable parts model) [13]. However, the above features mainly extract the shallow information such as color, texture and shape, which have great limitations and are easily disturbed by the external environment.
As Krizhevsky et al. developed the Alexnet algorithm based on deep convolutional neural network, the object detection method can break through the traditional limitations [14]. The methods based on deep learning can process the data by convolution neural networks, extract the high-order semantic features of the image, and improve the robustness of object detection. The idea of object detection algorithms is to find the object and then identify the target category and location, which can be divided into two types of solutions [15]. One is a two-step method, which can recognize the objects in the rectangle based on the target candidate regions. The other is a one-step method, which can obtain the object detection results directly according to the images without searching candidate regions [16].
The original object detection algorithms are mainly based on the selective search method to extract the target candidate box, so there is a bottleneck in the speed. With the development of RPN (Region Proposal Networks) in Fast-RCNN, the end-to-end object detection based on deep learning can be made, and the speed and performance are greatly improved [17]. YOLO and SSD (single shot multibox detector) networks can directly return to the target box position without extracting candidate boxes, so they run faster, but the accuracy is not as good as the former. With the continuous upgrading and optimization of the network, there are mainly four versions of the YOLO algorithm [18].
YOLOv1 first divides the image into several grids and then gives two boundary frames in each grid. The final results are screened according to the probability of the boundary frame containing objects and the NMS (non-maximum suppression) method [19]. The advantage of this version is fast speed and generalization ability, and it is based on an end-to-end network to achieve object detection. However, the problem is that the lower recall rate and the mesh size correspond to only one object, so the detection results for small objects are not good. In order to further improve the accuracy and real-time performance, YOLOv2 adds a BN (batch normalization) layer after each convolution pooling layer and then connects the activation function. By normalizing the processed data, the offset can be eliminated, and the training speed of the model can be greatly improved. The formula of BN is shown as follows:
where is the sampled data, is the mean value of the batch data, and is the variance. The purpose is to evenly distribute the data processed by BN to the definition domain of the activation function so as to maximize the effect of the activation function. In order to solve the problem of slow prediction speed of the boundary frames in the full connected layer, the anchor box structure in Fast-RCNN is used for reference so that each grid can predict five anchor frames, which greatly improves the accuracy of recognition. At the same time, the joint training method is used to expand the dataset and increase the recognizable types of the model so as to improve the recall rate and generalization ability.
YOLOv3 directly solidifies the whole convolution feature extraction network into a complete set of Darknet53 framework; defines convolution block as convolution layer, BN layer, and activation function LeakyReLU (leaky rectified linear unit) layer; and combines the residual module to return a feature graph of the same dimension so as to ensure that the model can still be convergent in the case of many layers. At the same time, the pooling layer is removed, and the convolution step is set to prevent the gradient disappearing after continuous pooling. In the output part, multi-scale prediction structure and binary classification cross entropy are introduced to extract features, detect at different scales, and improve the accuracy and generalization ability of the network [20].
YOLOv4 is the synthesizer of all kinds of algorithms at present. It uses a variety of existing excellent network modules for reference to improve the performance of the algorithm. First, they divide the object detection into three parts: feature extraction network, feature fusion network, and result prediction network. In the feature extraction network, ResNet (residual network) is used as the main deep learning framework, and a better structured DropBlock module is introduced to replace the traditional Dropout so that the network can recognize multiple feature points of the image; at the same time, in order to reduce the cost of computing power, mini-BN is used to replace BN and integrate it into the convolution layer. In feature fusion network, SPP (spatial pyramid pooling) module is used to mix the information of different receptive fields so that different network tendencies can be set according to different datasets. Therefore, the efficiency and strong generalization ability of YOLO algorithm is more helpful to solve the problem of robot grasping in complex environments; therefore, the YOLO algorithm is selected as the sub network of example segmentation in this paper.
Image segmentation is the basis of 6D pose recognition and the key problem of robot grasping. Image segmentation is to divide the object into disjoint regions according to the features of gray, RGB, spatial information, and contour texture and to ensure that the feature information in the same region is consistent. Different from image classification, segmentation is classified at the pixel level, so it can get more accurate information about the target [21]. According to the discontinuity on the boundary of different target regions, the traditional methods are mainly based on threshold, region, and edge to achieve image segmentation. However, traditional methods do not give classification and location information in the process of segmentation, so the representation ability and segmentation effect have certain limitations. With the development of neural network technology, semantic segmentation and instance segmentation algorithms have been proposed to benefit from the strong representation extraction and modeling ability of deep learning [22].
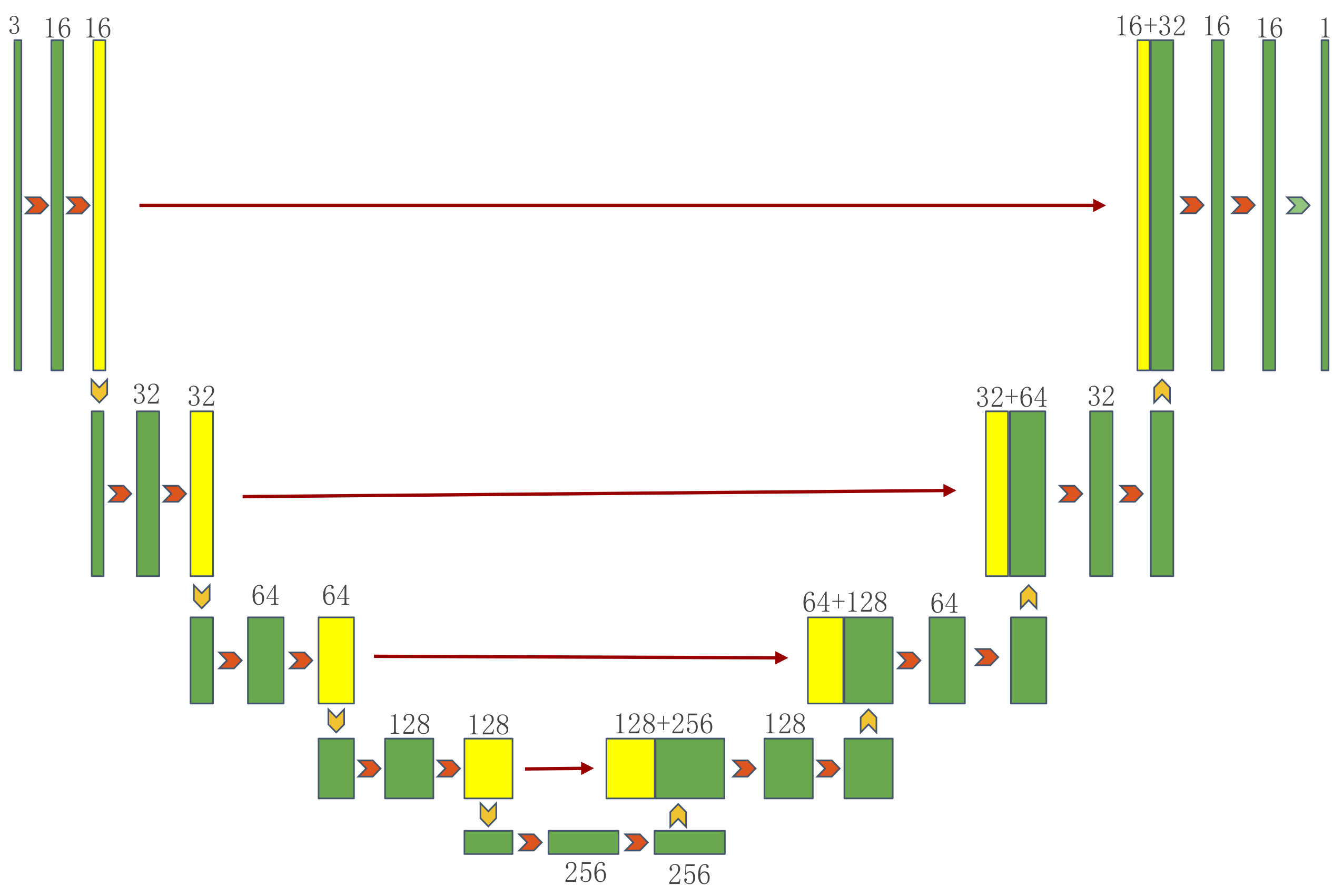
The semantic segmentation algorithm based on deep learning changes the output of the fully connected layer in CNN (convolutional neural network) to that of the convolution layer in FCN (fully convolutional networks) so the category information of pixels can be obtained directly from the extracted features. However, the defect of the FCN model is that it directly upsamples by enlarging and does not make full use of the spatial information of pixels, resulting in a poor image segmentation effect. Then, the improved algorithms Segnet and UNet, based on FCN encoding and decoding structures, have been proposed one after another. The algorithm of UNet directly integrates the multi-scale features of up-sampling and down-sampling, and the network structure is simple and has good robustness. Therefore, many semantic segmentation algorithms are improved by its framework, such as introducing attention mechanisms to improve segmentation effect, introducing hole convolution to increase receptive field, or using cyclic residual convolution to improve model performance. The structure of UNet is shown in Figure 1.
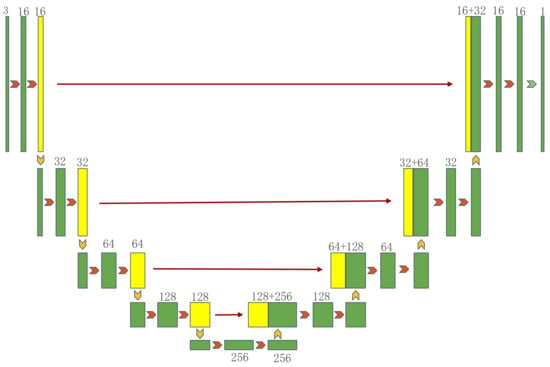
Figure 1.
The architecture of UNet.
It can be seen from Figure 1 that the overall architecture of UNet is similar to the FCN, which is divided into the encoding part of feature extraction and the decoding part of up-sampling, but there is no full connection layer. In the decoding part of UNet, deconvolution is used to improve the space utilization of pixels, and the coding information is directly transmitted to the corresponding decoding unit through the hop connection so as to avoid the loss of image information. The left part of the whole network is a four-stage coding convolution layer, which is used to encode the high-level semantic features of the image. The arrows between the convolution layers represent the average pooling. After four stages of down-sampling, a total of five feature maps can be obtained. The right side represents the decoding part of the network. The shallow features and deep features are fused through the skip layer connection of the red arrow, and then, the segmented mask image with the same resolution as the original image is obtained.
3. Instance Segmentation Network
The previous classic instance segmentation algorithm Mask-RCNN is a case segmentation model based on a two-stage scheme. Its design idea is based on the overall framework of Fast-RCNN, which uses the residual network ResNet as the backbone. After extracting the candidate box in the first stage, the semantic segmentation branch is added in the second stage. Due to the first stage of clipping, a lot of useless information in the image is eliminated, which makes the semantic segmentation task quite accurate. However, the main defect of the Mask-RCNN algorithm is that the network framework of two-stage has too much computation. Although it has high accuracy, it is not suitable for robot grasping with high real-time requirements.
3.1. Network Architecture
To solve this problem, this paper proposes an instance segmentation architecture that combines optimized YOLOv4 and semantic segmentation dense UNet network. First, the object detection network is used to detect the image object, and then, the segmentation network is used to get the accurate contour of the located object. The object detection algorithm optimized YOLOv4 is based on the optimization of the YOLOv4 model, while the semantic segmentation algorithm dense UNet is based on the improvement of the UNet model. The fusion of the two networks can avoid the problem of low real-time multi-stage operation on the premise of ensuring the accuracy of instance segmentation and, finally, obtain the mask and bounding box information of the target at the same time. The overall network architecture is shown in Figure 2.
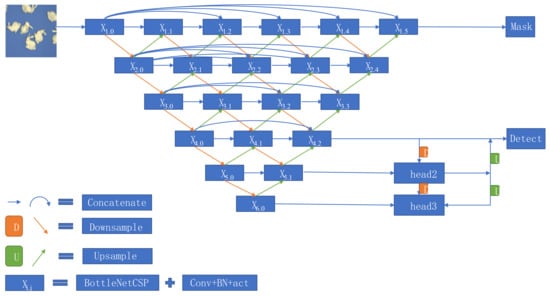
Figure 2.
Network architecture of the proposed algorithm.
The YOLOMask network architecture uses Darknet as the basic feature extraction network and constructs the encoder structure by a layer hopping connection between different depths of Darknet. The FPN (feature pyramid network) and PAN (path aggregation network) are used as feature fusion networks. After the sampling process of FPN, the decoder structure is implemented by adding sampling. ResNets used in the basic network to solve the problem of gradient dispersion. Through the mutual restriction of MaskLoss and ObjLoss, GIOULoss (generalized intersection over union) and ClassLoss, the function of instance segmentation can be realized. The comparison with other examples shows that the new network architecture can accurately obtain the mask map with coordinate location in each instance in complex scenes and is a YOLO improved algorithm based on one-stage, which effectively solves the problem of poor real-time performance of Mask-RCNN. At the same time, the intermediate convolution added in UNet algorithm can be used to make a flexible choice between precision and speed. Because when the network is training, the propagation is positive, the back layer will not affect the results of the front layer.
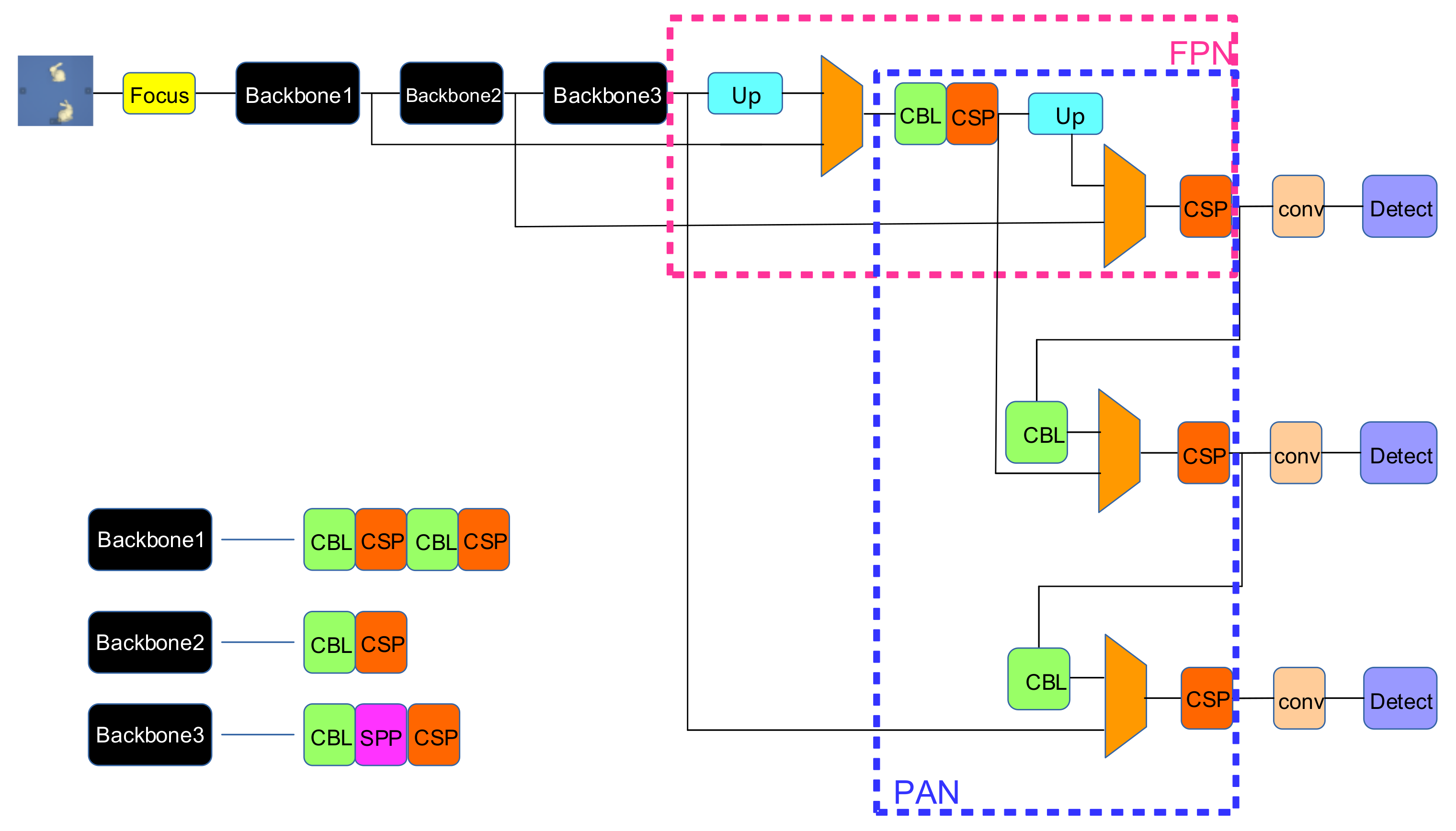
3.2. Optimized YOLOv4
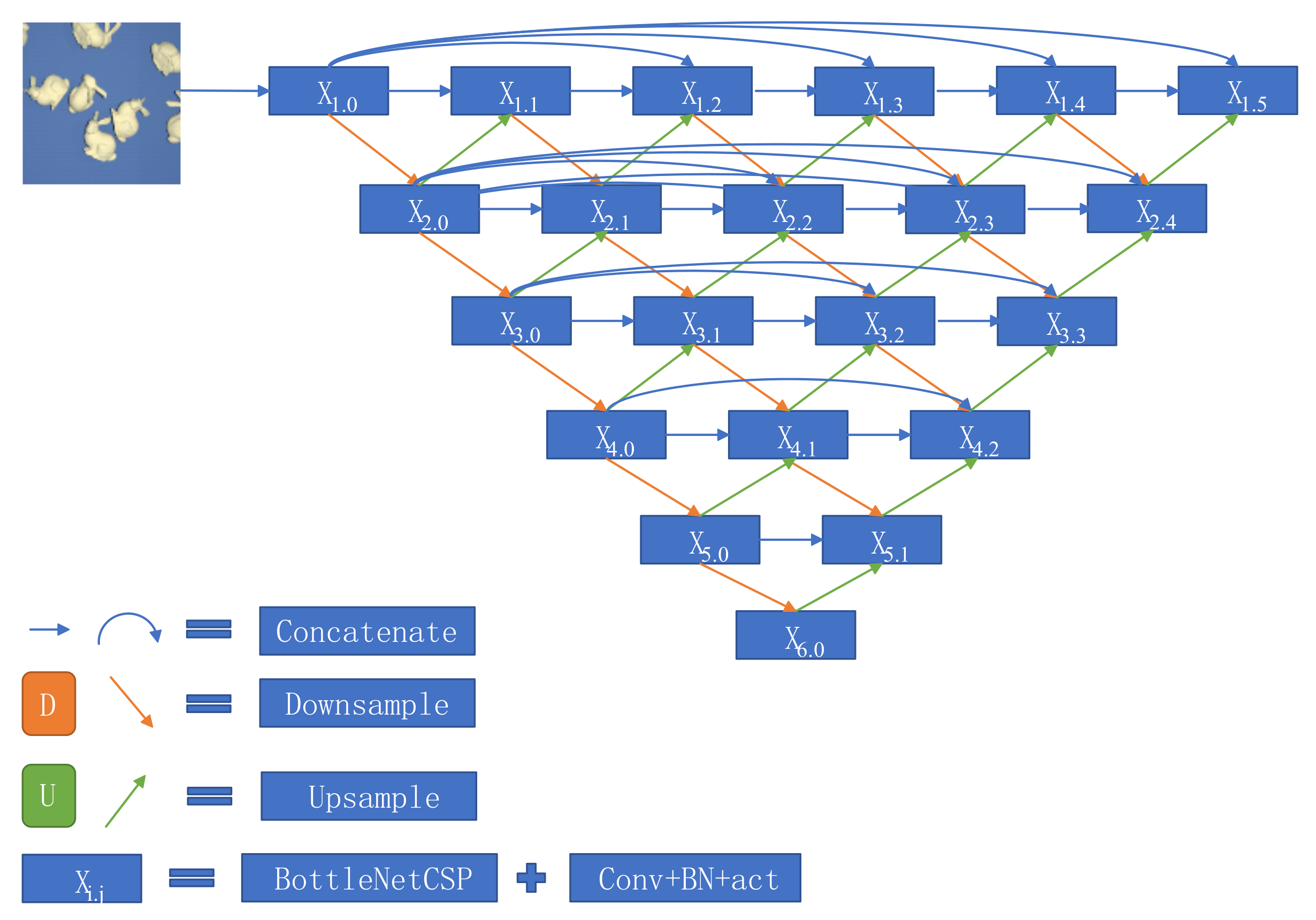
In the actual robot grasping process, the detection of the object to be grasped is very important, which is the basis of instance segmentation. With the development of deep learning in the field of object detection, the algorithm has made great progress in activation function, data augmentation, and network structure. The optimized YOLOv4 algorithm is optimized on the basis of YOLOv4, which improves the real-time performance of the algorithm on the premise of ensuring the accuracy to meet the requirements and makes the balance of detection accuracy and running speed. The overall network structure is shown in Figure 3. The existing object detection algorithms choose FPN to extract features, which can solve the problem of spatial information loss and image resolution loss of multi-scale targets. However, the defect of FPN is that it does not get the location information of the target, so the new algorithm adds a bottom-up PAN to transfer the low-level location information.
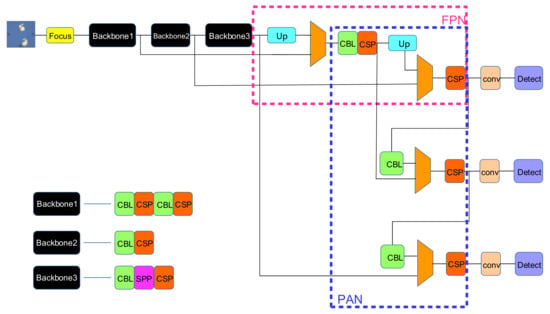
Figure 3.
Schematic diagram of optimized YOLOv4 network structure. The algorithm implements the classification of each object in the original image by transferring the highly compressed semantic information down. Then, the information is transmitted upward again to gradually lock the position of the target in the image, which greatly improves the object detection ability of the network.
As can be seen from Figure 3, FPN structure transfers the highly compressed semantic information downward, then can implement the classification of each target in the original image. After the PAN structure is added, the determined structure will transfer information downward again and gradually lock the position of the target in the image, which greatly improves the object detection ability of the network. The feature extraction network CBL in the three backbones is the abbreviation of the smallest module of the YOLO algorithm, which consists of convolution layer, batch regularization, and LeakyReLU activation function. In the structure diagram, the image goes through the focus module before it is input to the backbone network, and the adjacent down-sampling is made by slicing the image. Finally, the size of the image becomes half of the original size, and the number of channels becomes four times the original size. The advantage of focus is to maximize the use of all information of the image, although the number of FLOPs (floating point operations per second)of the algorithm is much higher than that of ordinary convolution, as shown in Equation (2).
According to the above equation, although the number of parameters obtained is four times that of ordinary convolution, in fact, with the subsequent CSP (cross stage partial) structure, it can perfectly make up for the defect of focus. CSP in Figure 3 is based on the Darknet53 network of the YOLOv3 algorithm and the structure proposed by CSPNet. In the channel dimension, one part combines CBL with the residual module to extract features, and the other part maps directly to features as residuals and then concatenates with the features of the upper part.
Therefore, in order to reduce the weight gap between different channels, the feature map can be compressed into global compressed features by global average pooling, and the global compressed feature quantity of the current feature map can be obtained, that is, each channel can represent the global features of the layer image. The excitation operation can establish the relationship between channels through the two-layer fully connected bottleneck structure. Here we choose the sigmoid form of gating mechanism, as shown in Equation (3).
The two fully connected layers can reduce the complexity of the model and enhance the generalization ability. The first fully connected layer is used to reduce dimension, and then the LeakyReLU function is used to activate the model. The final fully connected layer can be restored to the original dimension. Finally, the learned activation value is used as the weight of each channel and then multiplied by the original feature as the input of the next layer network, as shown in Equation (4).
When the attention mechanism is not added, the heat of the image is very scattered, and the model can be directly located near the target after adding the attention mechanism so as to achieve more effective detection. At the same time, considering that the traditional IOU (intersection over union) cannot solve the problem that two targets are too far away and objects overlap each other, an improved loss function CIOU (complete-IOU) is proposed, as shown in Equation (5).
This loss function can fully consider the location scene of each target and greatly improve the detection ability of the network in the case of object occlusion. Some engineering techniques, such as changing contrast, brightness, and cross combination, are also used in the proposed algorithm, which plays an important role in improving the generalization and detection ability of the network.
3.3. Dense UNet
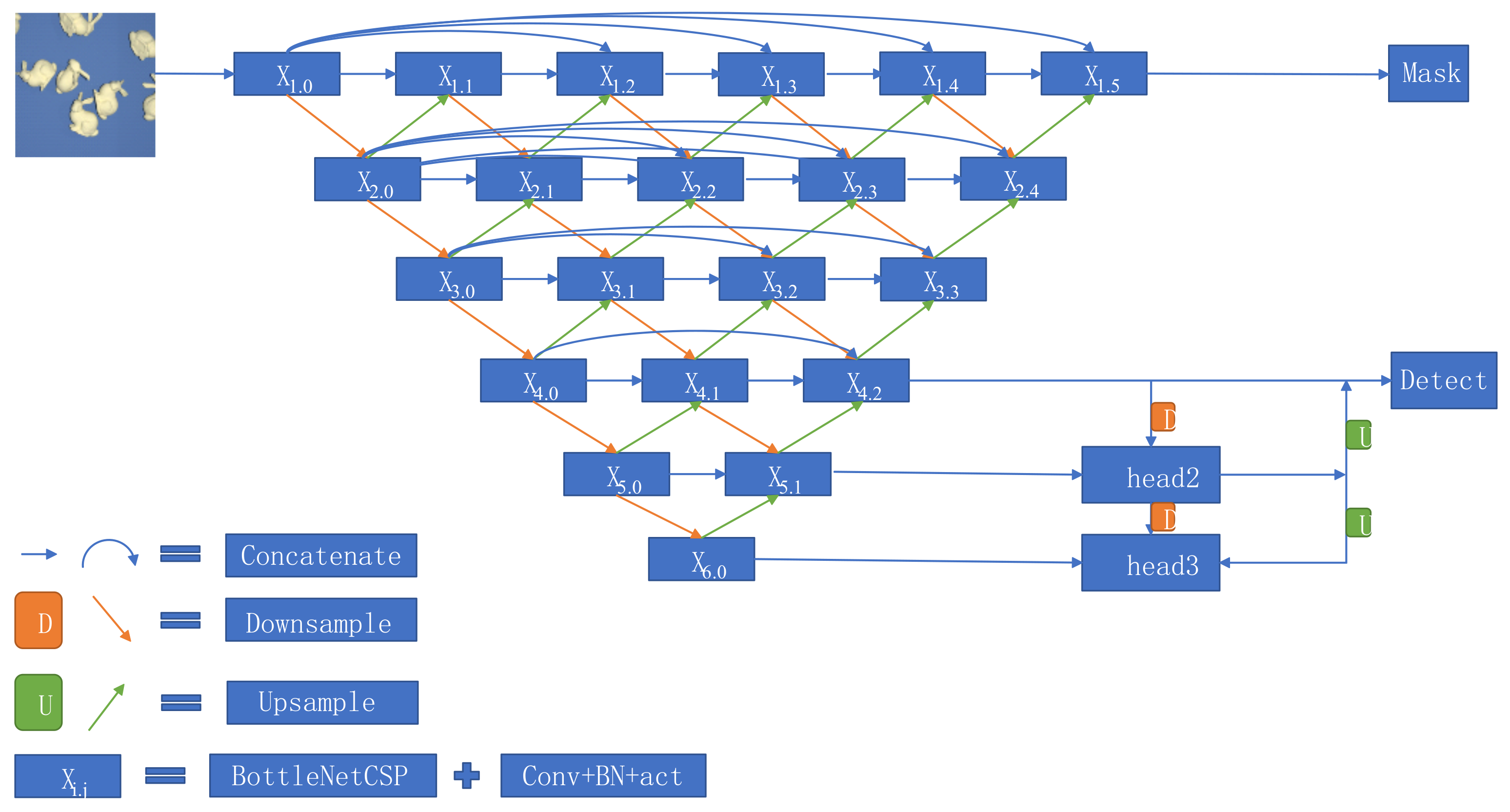
In order to ensure the real-time performance of the robot grasping system, the first thing to do is to segment the object from the image. However, the current instance segmentation algorithm cannot meet the requirements of the robot grasping application in terms of accuracy and real-time. The object detection algorithms based on deep learning are all based on the pixel information of the object to get a boundary box so as to complete the classification and coordinate location. However, in the process of 6D pose estimation, a lot of information in the bounding box is redundant, and the introduction of mixed background and noise will interfere with the accurate pose recognition. The pure target information obviously needs semantic segmentation algorithm, because it can be classified at the pixel level so as to determine the object boundary more clearly. Compared with other segmentation methods, the algorithm of UNet can adjust the depth of the network according to the actual needs and then fully mine the information of the data to obtain better segmentation results. However, in the process of concatenation, there are semantic differences between shallow features and deep features, and direct fusion will increase the difficulty of e-learning. In view of this, we propose a fast object segmentation method named dense UNet based on RGB information. Referring to the hop layer connection module of residual network, we propose a dense residual structure at each down-sampling stage to reduce semantic differences. The overall network structure is shown in Figure 4.
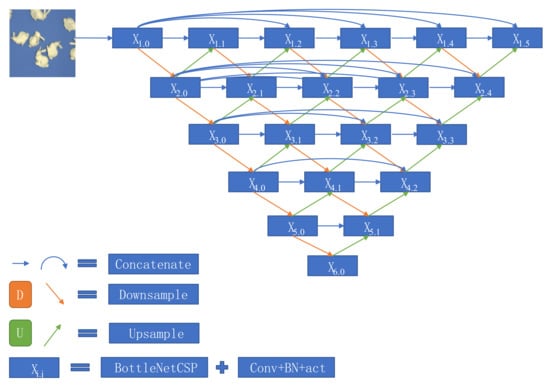
Figure 4.
Structure diagram of dense UNet network. The semantic gap between shallow feature coding and deep feature decoding can be reduced, and the segmentation accuracy can be improved by adding a step-by-step skip layer connection.
As can be seen from Figure 4, compared with the original UNet algorithm, a step-by-step skip layer connection is added between the shallow feature coding and the deep feature decoding that can reduce the semantic gap between features and further improve the segmentation accuracy of the algorithm. The update principle of each unit is shown in Equation (6).
where represents the convolution layer and is the up-sampling layer. In the semantic segmentation process of the previous UNet algorithm, the detailed information of large-scale objects and small-scale objects is easy to be lost, resulting in inaccurate segmentation results. The optimized dense UNet algorithm can effectively perceive multi-scale objects and reuse features by extracting different levels of features for fusion, which can significantly improve the segmentation ability of the model. The principle is shown in Equations (2)–(6).
4. Experiment Result and Discussion
The proposed network is different from the previous instance segmentation algorithm that is based on sparse and location prior information to achieve classification. Our method got the prediction template of each instance via image features, and then combined with multiple templates to achieve multi-target classification of dense pixels. ResNet50-FPN, as the basic structure of experimental training, runs on 1080Ti GPU. After the pre-training of the model, the experiment selects three groups of test data to test the segmentation effect of single class object, multi-class object, and complex background. The detection effect of the proposed network on single class targets is shown in Figure 5.

Figure 5.
Detection results of single target. The detection effect of the network is very good for the single class target in the simple background, and the detection effect is also good in the case of occlusion when multiple objects in the single class are mixed into one image.
It can be seen from Figure 5 that the detection effect of the proposed network for single class objects in simple background is very good, and after mixing multiple objects of a single class into one picture, the detection effect in the case of occlusion is only slightly reduced. However, it also shows that the algorithm is not strict in the process of drawing the mask. For example, in the last picture, the tail of the cat in the lower right corner should be light red, but it turns to white at the bottom. Therefore, the order of drawing mask in occluded scene should start from the bottom background and then select the upper target in order to avoid the mask of the object being covered by the mask of other objects. This is the model test effect of a single class target. This paper also tests the instance segmentation effect of the algorithm for multi-class targets, as shown in Figure 6.


Figure 6.
Detection results of multi-class targets. For the mixed multi-class target instance, it can be segmented well, and the segmentation effect of the algorithm can be significantly improved without increasing the amount of computation.
It can be seen from Figure 6 that the proposed algorithm can still maintain high clarity for instance segmentation of mixed multi-class objects, and because the model has some data augmentation in data preprocessing, it can significantly improve the segmentation effect of the algorithm without increasing the amount of calculation, which plays a certain enlightening role for follow-up research. In the application scenario of robot capture, it may face a variety of complex scenes, and there are many types of objects. Therefore, this paper also needs to test the segmentation effect of the algorithm for multi-class target instances on a complex background, as shown in Figure 7.

Figure 7.
Detection results of multiple targets in complex background. The left column is the original image, the middle column is the detection effect of the object detection network, and the right column is the detection effect of the proposed algorithm, which proves that the effect of the fusion network is better than that of the single object detection.
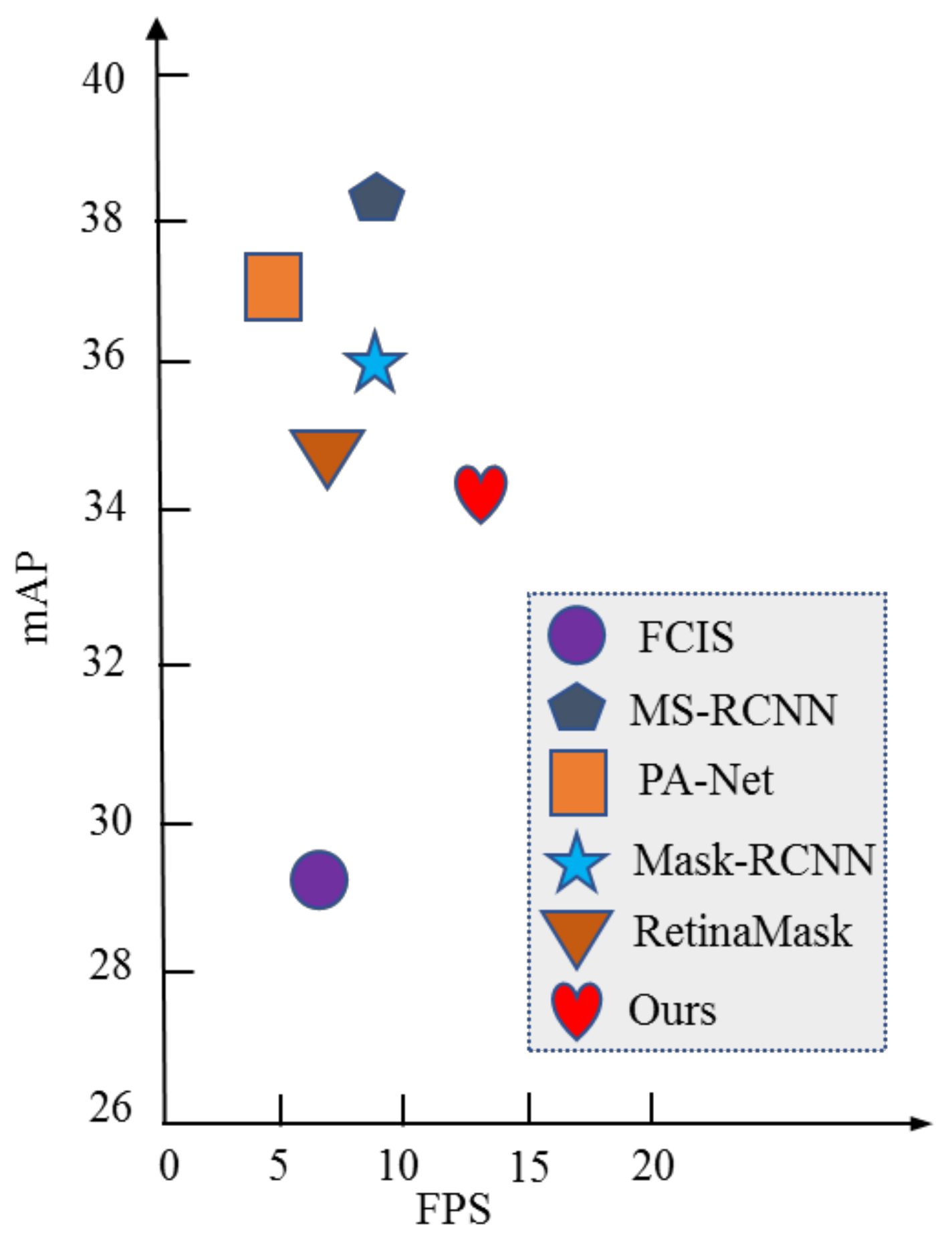
It can be seen from Figure 7 that in the complex scene, for the objects with small number and size in the dataset, such as mouse, knife, and fruit, the segmentation effect is slightly reduced, but it can still maintain a high level. Additionally, for objects with occlusion, the proposed algorithm can still achieve instance segmentation well. At the same time, this experiment also tests the object detection effect based on optimized YOLOv4. According to the detection results, it can be found that the overall detection effect is better than the single object detection effect after combining with semantic segmentation network. The overall map and real-time performance of the algorithm are shown in Figure 8.
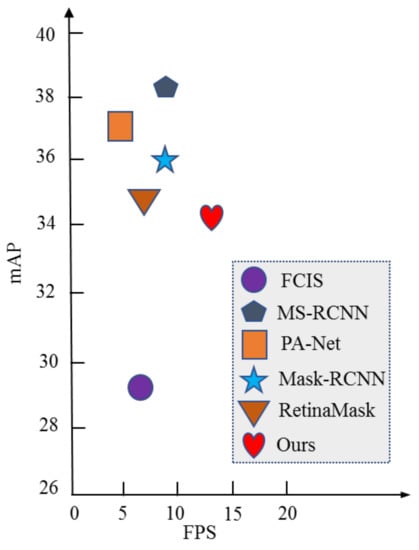
Figure 8.
Performance and real-time performance comparison of segmentation algorithms for each instance on coco dataset.
Compared with other segmentation algorithms, such as Mask R-CNN, FCIS, and PANet, the proposed algorithm has some shortcomings in the performance index map, but it has obvious improvement in real-time performance. When the depth and width of the model network are complex to a certain extent, the burden of the graphics card will become very heavy. On a 1080Ti graphics card, you can only train with batchsize = 8. However, it also highlights another problem, the algorithm needs more epoch to adjust parameters, so the model will gradually converge with a fluctuating training trend.
5. Conclusions
Image detection and segmentation are the basis of 6D pose estimation and the key factors to accomplish successful robot grasping. At present, the main idea of object detection algorithms based on deep learning is to obtain the target’s bounding box information from pixel information, but a lot of them in the box is redundant for 6D pose estimation, therefore, it will interfere with accurate recognition.
Although the previous instance segmentation algorithms can obtain the accurate outline of the target, the computational load of the model is too large, and the real-time performance is not good. In order to accurately locate and segment objects in complex scenes, an instance segmentation algorithm based on a complementary fusion network is proposed in this paper. The model classifies and locates salient objects in the image by optimizing the YOLOv4 algorithm, which effectively improves the algorithm’s speed. Then, the dense linking function is added to the UNet algorithm that can improve the accuracy of semantic segmentation.
The final fusion network can generate accurate contour information and location results of the target simultaneously. The experimental results show that the two tasks can establish an internal relationship between object detection and semantic segmentation, and the fused instance segmentation algorithm can effectively improve the real-time performance of the model under the premise of ensuring the accuracy.
Author Contributions
Conceptualization, J.H.; data curation, J.H. and L.Z.; formal analysis, J.H.; funding acquisition, L.Z.; investigation, J.H. and T.H.; methodology, J.H. and T.H.; supervision, L.Z. and G.Y.; validation, L.Z. and G.Y.; writing—original draft, J.H.; writing—review and editing, J.H. and L.Z. All authors have read and agreed to the published version of the manuscript.
Funding
The authors would like to acknowledge the support from the National Natural Science Foundation of China (grant no. 51975425).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Please contact Jiang Hua (huajiang@wust.edu.cn).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ali, W.; Abdelkarim, S.; Zahran, M.; Zidan, M.; Sallab, A.E. YOLO3D: End-to-End Real-Time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud. arXiv 2018, arXiv:1808.02350. [Google Scholar]
- Cao, J.; Cholakkal, H.; Anwer, R.M.; Khan, F.S.; Pang, Y.; Shao, L. D2Det: Towards High Quality Object Detection and Instance Segmentation. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11482–11491. [Google Scholar]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. YOLACT: Real-Time Instance Segmentation. arXiv 2019, arXiv:1904.02689. [Google Scholar]
- Chen, H.; Sun, K.; Tian, Z.; Shen, C.; Huang, Y.; Yan, Y. BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation. arXiv 2020, arXiv:2001.00309. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Bae, S.-H. Object Detection Based on Region Decomposition and Assembly. arXiv 2020, arXiv:1901.08225. [Google Scholar] [CrossRef] [Green Version]
- Hafiz, A.M.; Bhat, G.M. A Survey on Instance Segmentation: State of the Art. Int. J. Multimed. Inf. Retr. 2020, 9, 171–189. [Google Scholar] [CrossRef]
- Liu, L.; Ouyang, W.; Wang, X.; Fieguth, P.; Chen, J.; Liu, X.; Pietikäinen, M. Deep Learning for Generic Object Detection: A Survey. Int. J. Comput. Vis. 2020, 128, 261–318. [Google Scholar] [CrossRef] [Green Version]
- Sipiran, I.; Bustos, B. Harris 3D: A Robust Extension of the Harris Operator for Interest Point Detection on 3D Meshes. Vis. Comput. 2011, 27, 963–976. [Google Scholar] [CrossRef]
- Buch, A.G.; Petersen, H.G.; Krüger, N. Local Shape Feature Fusion for Improved Matching, Pose Estimation and 3D Object Recognition. SpringerPlus 2016, 5, 1–33. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, J.; Xiao, Y.; Cao, Z. Toward the Repeatability and Robustness of the Local Reference Frame for 3D Shape Matching: An Evaluation. IEEE Trans. Image Process. 2018, 27, 3766–3781. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.-W.; Wu, J. UNet 3+: A Full-Scale Connected UNet for Medical Image Segmentation. In Proceedings of the 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–9 May 2020; pp. 1055–1059. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Wang, X.; Kong, T.; Shen, C.; Jiang, Y.; Li, L. SOLO: Segmenting Objects by Locations. arXiv 2020, arXiv:1912.04488. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 9783319464473. [Google Scholar]
- Liu, F.; Fang, P.; Yao, Z.; Fan, R.; Pan, Z.; Sheng, W.; Yang, H. Recovering 6D Object Pose from RGB Indoor Image Based on Two-Stage Detection Network with Multi-Task Loss. Neurocomputing 2019, 337, 15–23. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Rom, H.; Alldrin, N.; Uijlings, J.; Krasin, I.; Pont-Tuset, J.; Kamali, S.; Popov, S.; Malloci, M.; Kolesnikov, A.; et al. The Open Images Dataset V4: Unified Image Classification, Object Detection, and Visual Relationship Detection at Scale. Int. J. Comput. Vis. 2020, 128, 1956–1981. [Google Scholar] [CrossRef] [Green Version]
- Dai, C.; Hu, X. Extracting and Classifying Spatial Muscle Activation Patterns in Forearm Flexor Muscles Using High-Density Electromyogram Recordings. Int. J. Neural Syst. 2019, 29, 1850025. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kobayashi, T. Towards Deep Robot Learning with Optimizer Applicable to Non-Stationary Problems. In Proceedings of the 2021 IEEE/SICE International Symposium on System Integration (SII), Iwaki, Fukushima, Japan, 11–14 January 2021; pp. 190–194. [Google Scholar]
- Caruso, G.; Gattone, S.A.; Fortuna, F.; Di Battista, T. Cluster Analysis for Mixed Data: An Application to Credit Risk Evaluation. Socio-Econ. Plan. Sci. 2021, 73, 100850. [Google Scholar] [CrossRef]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).