Abstract
In this paper, we propose an enhanced version of the Authentication with Built-in Camera (ABC) protocol by employing a deep learning solution based on built-in motion sensors. The standard ABC protocol identifies mobile devices based on the photo-response non-uniformity (PRNU) of the camera sensor, while also considering QR-code-based meta-information. During registration, users are required to capture photos using their smartphone camera. The photos are sent to a server that computes the camera fingerprint, storing it as an authentication trait. During authentication, the user is required to take two photos that contain two QR codes presented on a screen. The presented QR code images also contain a unique probe signal, similar to a camera fingerprint, generated by the protocol. During verification, the server computes the fingerprint of the received photos and authenticates the user if the probe signal is present, the metadata embedded in the QR codes is correct and the camera fingerprint is identified correctly. However, the protocol is vulnerable to forgery attacks when the attacker can compute the camera fingerprint from external photos, as shown in our preliminary work. Hence, attackers can easily remove their PRNU from the authentication photos without completely altering the probe signal, resulting in attacks that bypass the defense systems of the ABC protocol. In this context, we propose an enhancement to the ABC protocol, using motion sensor data as an additional and passive authentication layer. Smartphones can be identified through their motion sensor data, which, unlike photos, is never posted by users on social media platforms, thus being more secure than using photographs alone. To this end, we transform motion signals into embedding vectors produced by deep neural networks, applying Support Vector Machines for the smartphone identification task. Our change to the ABC protocol results in a multi-modal protocol that lowers the false acceptance rate for the attack proposed in our previous work to a percentage as low as 0.07%. In this paper, we present the attack that makes ABC vulnerable, as well as our multi-modal ABC protocol along with relevant experiments and results.
1. Introduction
Rapid advancement of mobile device technology, such as development of high-resolution cameras, contributes to a large volume of data shared across the World Wide Web through social media platforms and other online environments. Moreover, smartphones are now the medium of choice for accessing applications that require strong security, such as banking applications [1], thus making them ideal targets for attackers. While any device carries a minimum of security mechanisms, the information generated by mobile devices can be used in identity forgery attacks [2] or in side-channel attacks such as smudge [3] and reflection [4,5]. To defend against attacks, Zhongjie et al. [6] proposed the Authentication with Built-in Camera (ABC) protocol, based on a special characteristic of the camera sensor, namely the photo-response non-uniformity (PRNU) [7]. The PRNU fingerprint is represented by a noise pattern unique to each camera sensor, which can be determined as detailed in previous research [7,8,9,10,11,12], even from a single photo. The ABC protocol introduced by Zhongjie et al. [6] uses the camera fingerprint as the main authentication factor and is composed of two phases, particularly a registration phase in which the PRNU fingerprint of the device is computed and stored, and secondly, an authentication phase. During authentication, a registered device takes photos of two QR codes presented on a screen and sends them to a server for identification. The server performs a set of tests consisting of QR code metadata validation, camera fingerprint identification and forgery detection.
Photos uploaded on social media platforms offer attackers the possibility to compute PRNU fingerprints of potential victims with the aim of conducting impersonation attacks. To prevent this possibility, in addition to the QR codes, the photos received by the ABC server contain a probe signal, represented by a noise pattern similar to a camera fingerprint. The ABC forgery detection system can determine if an attacker tries to impersonate a legitimate user by testing if the probe signal is missing from the provided QR code images. Zhongjie et al. [6] concluded that, in the process of replacing the attacker’s fingerprint with the victim’s fingerprint, the probe signal is also removed. The ABC protocol supposes that attackers compute fingerprints during the authentication phase, from the photos containing the QR codes. However, as we further detail in this work, the protocol is susceptible to an attack that can easily bypass the ABC forgery detection system.
We present an attack strategy, initially introduced in our preliminary work [13], in which the attacker computes their fingerprint from any other set of photos taken with the device involved in the attack. Hence, when the attacker’s fingerprint is removed from the QR code photos and replaced with the victim’s fingerprint, the probe signal is no longer removed. In this scenario, the forgery detection system will not identify the attacker, rendering the protocol vulnerable to attacks. The proposed attack has a success rate of around . Nevertheless, in this work, we propose a novel method of enhancing the ABC protocol that can prevent the attack strategy described in [13], increasing the overall security level. Our proposal is based on considering motion signals, namely those provided by the gyroscope and the accelerometer sensors, which are typically built-in components of modern smartphones. This results in a passive two-factor (multi-modal) authentication protocol that reduces the attack success rate to .
To learn motion signal patterns specific to the built-in sensors, we propose a deep learning approach that combines features from deep convolutional neural networks (CNNs) [14,15] and convolutional Long Short-Term Memory networks (ConvLSTMs) [16] using an ensemble model based on Support Vector Machines (SVMs) [17]. To demonstrate the effectiveness of our improved ABC protocol, we perform multi-modal experiments using 630 images and corresponding motion signals collected from six different mobile devices. From the 105 examples per device, we use five examples for registration and the rest of 100 examples for authentication experiments. Each device becomes a victim of impersonation attacks throughout our experiments, employing a total of 500 attack sessions from the other five devices. Our experiments on the enhanced multi-modal ABC protocol, consisting in a total of 3000 attacks, indicate a false acceptance rate (successful attack rate) of . Compared to the original ABC protocol [6], which has a false acceptance rate of in the same scenario, our protocol enhancement results in an improvement of . We thus conclude that the multi-modal ABC protocol, enhanced with the authentication based on motion sensors, is more secure, becoming a promising candidate for smartphone device authentication. We emphasize that our additional authentication mechanism based on motion sensors is passive (or implicit), resulting in a seamless experience for the user.
2. Related Work
2.1. Attacks on Authentication Protocols
A recent work [18] proposed attack schemes for machine-to-machine (M2M) authentication protocols [19]. The authors showed that the M2M authentication protocol [19] is vulnerable to Denial-of-Service (DoS) and router impersonation attacks. In a different work, Aghili et al. [20] showed that the untraceable and anonymous three-factor authentication scheme [21] for Heterogeneous Wireless Sensor Networks is vulnerable to user impersonation, de-synchronization and traceability attacks. Aghili et al. [20] also proposed an improved protocol that is resilient to these kinds of attacks.
In literature, the use of camera PRNU fingerprint in authentication systems or protocols is studied in a few works [6,22,23]. Zhongjie et al. [6] proposed a protocol based solely on PRNU fingerprint identification, while others [22,23] integrated the PRNU fingerprint in multi-factor authentication systems. However, PRNU-based authentication protocols, such as the ABC protocol studied by Zhongjie et al. [6], have not been thoroughly studied in the presence of attacks. Zhongjie et al. [6] introduced different attack prevention mechanisms, such as an anti-forgery detection system, but the protocol can still be breached through the attack scheme proposed in [13]. Moreover, it is known that camera fingerprints are vulnerable to attacks, e.g., forgery attacks [24,25], thus rendering fingerprints unsafe as a single authentication factor. Hence, in this paper, we propose a multi-modal seamless extension of the ABC protocol. Instead of relying only on the camera fingerprint, we propose to add the joint fingerprint of two additional sensors: the gyroscope and the accelerometer.
Relation to preliminary ACNS 2020 version [13]. Since our current work is an extension of our previous paper [13], we explain the differences in detail. In our previous work [13], we discovered a breach in the design and implementation of the ABC protocol [6]. We provided evidence of an attack scheme that shows how forgery attacks (adversary fingerprint removal) affect the protocol. Different from our preliminary study [13], we introduce an implicit authentication system based on motion sensor data in the ABC protocol, with the aim of improving the overall accuracy and stopping potential forgery attacks. Although in our previous work we tried to model motion sensor data using statistical features [13], the accuracy of the resulting model was far below the requirements of an authentication protocol. Hence, in this work, we propose to employ an ensemble based on neural embeddings derived from two types of deep neural networks, CNNs and ConvLSTMs, concatenated and forwarded as input to an SVM meta-model. To our knowledge, we are the first to propose an ensemble of CNNs and ConvLSTMs for smartphone identification based on motion sensor data. Our improvements lead to a more robust ABC protocol, attaining superior performance in adversarial detection over the preliminary works [6,13].
2.2. Authentication Based on Motion Sensors
Several papers studied user identification on mobile devices based on motion sensor data [26,27,28,29,30,31,32,33,34,35]. Within the wide range of explored approaches, there are studies that perform user recognition based on voice and accelerometer signals [34], as well as studies that perform human movement tracking based on motion sensors [32]. Regarding the considered approach, it is clear that the newest and best-performing methods belong to the category of deep learning approaches [30,36]. Until now, researchers studied recurrent neural networks [30] and convolutional neural networks [36]. To our knowledge, none of the previous works investigated ensemble methods that combine recurrent and convolutional neural networks. We introduce an ensemble that uses an SVM as meta-learner. Different from previous works, we interpret the weights of the meta-learner as a joint fingerprint of the gyroscope and the accelerometer sensors.
3. Method
We first present the ABC protocol [6] and the protection methods implemented in this protocol. We then explain in detail the impersonation attack scheme [13] that is able to bypass the ABC protocol. Finally, we describe our multi-modal ABC protocol that can detect the impersonation attack.
3.1. ABC Protocol
The protocol defined by Zhongje et al. [6] is represented by a two stage authentication system, described as follows. The first stage of the protocol is represented by the registration phase, in which the user’s smartphone is enrolled in the system using an image, denoted as , taken using the built-in camera. The server (verifier) employed in the protocol computes an estimate of the camera PRNU fingerprint from the received image, creating a device profile used for authentication purposes.
In the second stage of the protocol, namely the authentication phase, three sequential actions are executed, as follows: the server generates two QR code images and presents them to the user, the user takes a picture of each QR code and sends the photos back to the server for verification. Each QR code contains embedded information representing the current transaction in progress. In step , along with the embedded metadata, the QR code images produced by the server, contain a probe signal represented by a white Gaussian noise:
In step , the user takes photos of the prompted images on a screen, using a preregistered device. The resulting photos, and , are sent to the server for verification and user identification. The captured images, denoted by , should contain a noise residue composed of the PRNU fingerprint of the user and the probe signal :
where the noise residue is formally defined as follows:
In the last authentication step , the server performs a multi-step user validation and identification, such as QR code integrity check, camera fingerprint verification, forgery detection and probe signal verification, as detailed in [6]. If all integrity checks pass successfully, the user is authenticated by the protocol, otherwise, the system will reject the transaction.
3.2. ABC Protocol Defense Systems
3.2.1. Forgery Detection
Zhongjie et al. [6] propose an anti-forgery system that is able to protect the protocol from attackers that use counterfeit images, in the authentication phase. If an attacker tries to impersonate a victim, his fingerprint can be present in the forged image. Therefore, the protocol computes the noise residue for each of the two received images and compares and , according to the following equation:
where is the Peak-to-Correlation Energy [37]. Furthermore, the PRNU fingerprint computed during user registration is also compared with the noise residue extracted from , the similarity value being given by:
In case of forged images, the similarity between and is higher in comparison with the similarity of the noise residue and the registered PRNU fingerprint . Hence, the ABC protocol uses the following equation to determine whether the images are forged or not:
where t is threshold that eliminates matching by chance due to noise.
An adversary can compute his own fingerprint and remove it from the forged images in order to fool the forgery detection system. To this end, Zhongjie et al. [6] proposed a removal detection system (described below) based on the probe signal embedded in the QR code images.
3.2.2. Removal Detection
During an impersonation attack, the adversary has the aim to remove his fingerprint from the images sent to the verifier. Since the PRNU fingerprint is very similar, in terms of magnitude, to the probe signal embedded in the QR code images, removal of the fingerprint will inherently lead to the removal of the probe signal as well. Thus, when the verifier analyzes the images, the unique pattern noise will not be present. Therefore, the removal detection system will reject the attack. However, Zhonhjie et al. [6] follow the assumption that an adversary computes his fingerprint using the photos captured during the authentication phase, in which the probe signal is embedded. Contrary to their assumption, as we are about to detail further, an adversary can compute his fingerprint from any photo that resulted from the device used in the attack. In consequence, we exploit this vulnerability in our attack described below.
3.3. An Attack for the ABC Protocol
Zhongjie et al. [6] assumed in their work that a potential adversary computes the PRNU fingerprint using photos captured during the authentication phase. We propose an attack that exploits a vulnerability in the assumption of Zhongjie et al. [6], namely that an attacker can compute the camera fingerprint of the device used in the impersonation attack, , at any given time prior to the attack. Thus, we further consider the case in which a pre-computed fingerprint is used within the impersonation attack. In addition, considering that an adversary can gain access to one or a few photos posted on social media platforms by a potential victim, an impersonation attack becomes feasible. In the experiments presented in Section 4, we consider two attack scenarios. The first one uses only one photo to estimate the victim’s PRNU fingerprint, following the same setup considered by Zhongjie et al. [6]. The second one uses five photos to estimate the victim’s PRNU fingerprint, showing that the success rate of our attack can be improved further.
Our attack works as follows. In the authentication phase, the attacker uses the built-in camera to capture the two photos generated by the server with the aim of forging and sending them back for verification. The photos taken by the attacker are defined as follows:
Before sending them to the verifier, the images contain the PRNU fingerprint of the adversary instead of the fingerprint of the victim. As described by Zhongjie et al. [6], if the adversary tries to remove his fingerprint using the images defined in Equation (7) which include the probe signal , the attack would be stopped by the ABC Removal Detection system. However, in our approach, the adversary fingerprint is pre-computed using other photos, different from the ones involved in the authentication phase. Hence, the probe signal is only slightly altered but not entirely removed. Furthermore, adding the pre-computed victim’s fingerprint results in a set of forged photos that can bypass the defense systems of the ABC protocol. The forged images are defined as follows:
When the verifier employs Forgery Detection to determine if the images are forged and Removal Detection to assess if the probe signal was removed, the system will find that is included in the received images and the PRNU fingerprint present in the images is the one of the impersonated person. Therefore, the proposed attack scheme bypasses both systems of the ABC protocol. However, due to approximation errors involved in the attack process, the system is able to block about one in every two attacks, as detailed in our experiments below. Still, the attack success rate leaves the standard ABC protocol vulnerable to our attack scheme. Further details about our attack scheme are provided in our preliminary work [13].
3.4. Proposed Multi-Modal ABC Protocol
As noted above, the ABC protocol is vulnerable, being possible to bypass both protection systems of the protocol. We further propose an extension of the protocol which incorporates motion sensor data, as an additional authentication factor that restores the overall protection level of the system. Unlike photos, which are commonly posted on social media platforms, motion sensor signals are not openly posted by smartphone users on the Internet, mainly due to the lack of interest to do such such thing. Therefore, our multi-modal authentication protocol is equipped with an enhanced security mechanism that cannot be exploited by potential attackers. Another advantage of our multi-modal protocol is that the introduction of the second modality does not burden the user with additional steps during authentication, i.e., the second authentication factor is implicit. Our novel protocol is illustrated in Figure 1. The stages involved in our multi-modal ABC protocol are described next.
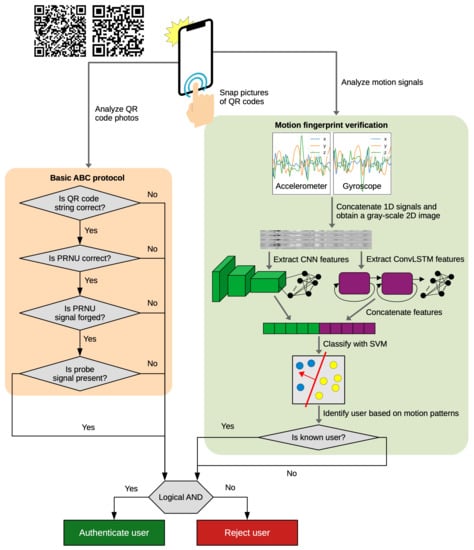
Figure 1.
An overview of the proposed multi-modal ABC protocol. The basic ABC protocol is augmented with a deep learning system that analyzes the motion fingerprint. Best viewed in color.
3.4.1. Motion Signal Recording
In the authentication phase, we collect three-axis motion signals from two sensors, the gyroscope and the accelerometer, while the user is taking photos of the QR codes. A motion sample is formed of six discrete signals. There are three signals for each sensor, such that each signal corresponds to one of the three spatial axes . The signals are continuously recorded at 100 Hz during the whole authentication process, but we only keep the signals recorded within a window of 1.5 s, starting with 0.5 s before the user touches the button that causes the smartphone to take the first photo required for verification. Since each signal is recorded at 100 Hz for 1.5 s, it is composed of roughly 150 values. The recorded signals are associated with the image , being sent together to the server for verification.
3.4.2. Motion Signal Pre-Processing
On the sever side, the collected discrete signals are processed in order to turn them into mono-channel images, enabling us to employ CNNs and ConvLSTMs to learn neural embeddings. Even if, in theory, the motion signals should be recorded at exactly 100 Hz, we observed that, in practice, mobile operating systems (iOS and Android) will not report precisely 100 values per second at perfectly equal time intervals, likely being influenced by the different processes running on each mobile device. Moreover, the accelerometer and gyroscope generate decoupled motion events at a frequency that is close to 100 Hz, but not exactly equal to 100 Hz. Hence, the signals generated by the two independent motion sensors are not necessarily of the same length. To this end, we must normalize all motion signals to a fixed length. As the signals are recorded for 1.5 s at 100 Hz, we start with the assumption that each signal should be formed of exactly 150 discrete values. Thus, we resize the overlength or underlength signals to a fixed length of 150 values through linear interpolation. After resizing a signal, we subtract its minimum magnitude to eliminate negative values. Since the signal corresponding to one axis can have a different magnitude scale than the signals corresponding to other axes, e.g., when the magnitude of the motion along one axis is much higher than the magnitude of the motion along another axis, we rescale each discrete signal using the -norm. Finally, we resample all values to a range between 0 and 1.
3.4.3. Learning Neural Embeddings
To learn discriminative neural embeddings from the motion signals, we consider two neural network architectures, a CNN and a ConvLSTM, which we train on a multi-way user classification task on the HMOG data set [32]. The learning stage is an offline step that needs to be carried out before deploying the multi-modal ABC protocol in testing or production environments.
Our CNN model is composed of three convolutional (conv) layers, followed by two fully-connected (fc) layers and one Softmax classification layer, having a total of six layers. We set the number of filters in the first conv layer to 32. Following AlexNet [15] and VGG [38] architectures, the conv layers get wider as they move farther away from the input. This is because conv layers closer to the input learn low-level features, e.g., edges or corners, which are generally useful for all object classes. Conv layers closer to the output learn high-level features, which are specialized to particular object classes. Hence, our second conv layer is composed of 64 filters, while the third conv layer is composed of 128 filters. Following recent CNN architectures such as ResNet [39], we employ conv filters with a small receptive field of components. The filters are applied at a stride of 1. All activation maps are zero-padded to preserve the spatial dimension. We placed a max-pooling layer after each conv layer. The max-pooling layers have a pool size of and are applied at stride 2. Each fc layer is formed of 256 units with dropout [40] at a rate of , to prevent overfitting. All layers have Rectified Linear Units (ReLU) [41] activations, except for the classification layer. As our neural models must solve a multi-class classification problem, we employ Softmax activation in the last layer, such that the final output provides the probability for each class. We underline that the last layer is formed of 50 neurons, this being the number of classes in our data set. We train the neural networks with the Adam optimizer [42], minimizing the categorical cross-entropy loss.
Similar in size to the proposed CNN, the architecture of the ConvLSTM is composed of six layers. The first layer of the network is a convolutional LSTM layer containing 64 kernels. The first layer is followed by a second conv LSTM layer with 128 filters and a third conv LSTM layer with 256 filters. All filters have a spatial support of . We underline that a very common practice is to design LSTM architectures having no more than two or three recurrent layers, which are more than enough to capture the temporal aspects of the input signals. Thus, we use only three conv LSTM layers, flattening the activation maps resulting after the last recurrent layer. Then, we have two fc layers, each with 256 neurons. All conv LSTM and fc layers are equipped with ReLU [41] activations. The sixth and last layer provides the final class probabilities, being composed of 50 neurons with Softmax activation (each neuron provides the probability for one user in the multi-class user classification data set). As for our CNN model, we employ the Adam optimizer [42] to minimize the categorical cross-entropy loss.
We underline that the CNN and the ConvLSTM are trained prior to their integration in our multi-modal ABC protocol. After training the CNN and the ConvLSTM models on the multi-class user classification task, we remove the Softmax layer from each architecture, thus using the feature vectors from the last fc layer. Since the fc layers have 256 neurons each, we obtain 256-dimensional feature vectors from each model. Our final neural embeddings are 512-dimensional feature vectors obtained by concatenating the corresponding CNN and the ConvLSTM feature vectors. In the experiments, we show the benefit of combining the CNN and the ConvLSTM embeddings.
3.4.4. Motion Sensor Fingerprints
For the smartphone identification problem based on motion sensors, we utilize a binary SVM classifier, which receives as input the neural embeddings resulted from our pre-trained deep neural networks. We trained an SVM for each smartphone device, using the neural embeddings computed during the registration phase of the respective device as positive examples. Since the SVM requires negative examples as well, we use a pool of negative examples that is independent of all smartphone devices considered in our experiments. This ensures that the SVM models are never trained on examples belonging to attackers, which would lead to unrealistically high accuracy levels.
Formulating our smartphone identification task as a binary classification problem, the SVM learns a linear discriminant function f that outputs the label for an input neural embedding belonging to the registered smartphone and the label for a neural embedding belonging to an adversarial device. The linear function f can be expressed as follows:
where x represents a feature vector, w and b denote the vector of weights and the bias term of the classifier and represents the scalar product. As explained earlier, the feature vector x contains 512 values and is generated by concatenating 256-dimensional neural embeddings from the CNN and the ConvLSTM models, respectively.
An SVM classifier [17] computes the parameters w and b that represent the hyperplane which divides the training examples into two classes with maximum margin. Formally, the SVM model finds the parameters w and b that satisfy the optimization criterion defined below:
where n is the number of examples from the training set, is the label ( or ) associated to the training example , C represents a regularization hyperparameter, and is the -norm.
Let be the discriminant function corresponding to a device j. We interpret the corresponding weights and the bias as a motion sensor fingerprint of the smartphone device j. Upon learning the parameters and by optimizing Equation (10), during authentication, we just need to apply the following equation on a neural embedding x from an unknown a device in order to identify the respective device as device j:
We note that the function is applied in conjunction with the ABC protocol. If the multi-modal sample (composed of two photos and a set of motion sensor signals) collected during an authentication session passes both camera and motion sensor verification layers, then the corresponding smartphone is identified as a legitimate smartphone and authorization takes place. This means that if a sample does not pass one of the verification layers, then the authentication is rejected. Empirical evidence shows that by employing our additional layer of security based on motion sensor signals, we can restore the security level of the multi-modal ABC protocol.
4. Experiments
4.1. Data Sets
To evaluate the success rate of our attack on the standard ABC protocol and on the proposed multi-modal ABC protocol, we collected a multi-modal data set consisting of images and motion signals.
Using six different smartphone devices, we composed a data set consisting of 105 images per device along with the motion sensor data generated during the photo capture session. Based on previous works on PRNU estimation [6,43], we extracted sub-images of pixels, starting from the top left corner, to compute PRNU fingerprints.
For our enhanced ABC protocol, we recorded motion signals for s before and 1 s after pressing the camera shutter. The accelerometer and gyroscope signals, each represented on three axes, are recorded at 100 Hz, resulting in signals of 150 discrete values in the time domain. Each photo in our data set is thus associated with a multi-dimensional motion signal of values, where 6 is the number of motion sensors (accelerometer, gyroscope) multiplied by the number of axes (x, y, z). To allow others to reproduce our results, we will provide our data set for non-commercial use to those who send their request by mail to one of the authors.
Due to the small set of motion signals in our multi-modal data set, we pre-train our CNN and ConvLSTM models on a subset of 50 users from the HMOG data set [32]. Following the experimental settings described in [36], we collect motion signals for 200 tap events per user, generating a data set of 10.000 data samples in total. Employing an 80–20% split of the data, we utilize 8000 samples for training and 2000 for validation.
4.2. Organization of Experiments
Considering our ABC attack scheme [13] as well as the original attack scheme proposed by Zhongjie et al. [6], our first set of experiments aims to test the security level of the ABC protocol. We hereby consider two scenarios.
In the first scenario, we use five images to compute the PRNU fingerprint of each device and 100 images to simulate authentications of a registered user. Furthermore, we use the same set of 100 images to perform simulated impersonation attacks on the other devices. Therefore, we perform 600 valid authentications and 3000 attacks. This scenario is motivated by the fact that attackers can often obtain more than one image (in our scenario, we consider five images) from social media posts to compute a victim’s PRNU fingerprint. Naturally, the attacker is free to use as many photos as necessary (we limit ourselves to five images) to compute his own PRNU fingerprint prior to the attacks.
In the second scenario, the experiments are conducted using one image for PRNU fingerprint estimation for both victims and attackers, precisely following the setting described by Zhongjie et al. [6]. Here, our aim is to demonstrate that our attack scheme can bypass the ABC protocol, without any change with respect to the introductory work [6]. The only difference with respect to our first scenario is the number of images used for PRNU estimation in the registration phase. Thus, as in the first scenario, we utilize the same number of devices and images during authentication, resulting in 600 valid sessions and 3000 impersonation attacks.
To test our enhanced ABC protocol, our second and last set of experiments employs deep learning models for user classification based on motion sensors. Upon training the deep learning models in the same setting as in our previous work [36], our aim is to test the efficiency of the proposed attack scheme [13] on our multi-modal data set. Noting that we need to fit a machine learning model on several (more than one) motion signals, we employ the same setting as in the first scenario, considering five images (and associated motion signals) to compute the PRNU (and motion sensor) fingerprints. This limits our multi-modal ABC protocol to use a mandatory lower bound (five) on the number of registration sessions. Nonetheless, this limitation fades away in front of the benefit, namely resistance to impersonation attacks.
4.3. Evaluation Details
4.3.1. Evaluation Measures
We report the number of successful attacks (false acceptances) as well as the false acceptance rate (FAR), which is typically defined as the ratio of the number of false acceptances divided by the number of authentication attempts. A false acceptance is an instance of a security system, in our case the original or the multi-modal ABC protocols, incorrectly verifying an unauthorized person, e.g., an impersonator. We underline that our attack does not impact the false rejection rate (FRR) of the ABC protocol, i.e., the FRR is similar to that reported in [6]. For the multi-class user classification experiments on HMOG, we report the classification accuracy rate. For the multi-modal ABC protocol, we report the accuracy, FAR and FRR values, respectively.
4.3.2. Evaluation Protocol
The main goal of the first two sets of experiments is to validate the attack scheme proposed in [13]. While reporting the FAR values for our attack is necessary, we also have to validate that the forgery detection (FD) system and the removal detection (RD) system of the ABC protocol work properly. For this reason, we need to perform attacks as described in [6]. Our aim is to show that the protection systems of the ABC protocol are indeed able to reject the attacks specified in [6], while not being able to detect our own attack.
When testing the ABC protocol or the multi-modal ABC protocol against attacks, each of the n smartphone devices takes turn in being considered as the victim’s device. In order to perform attacks, the remaining devices are considered to belong to adversaries. Each adversary performs 100 attacks. Given that our data set consists of devices, we obtain a number of 3000 () attacks. For each attack, we determine if it passes undetected by the Forgery Detection system and by the Removal Detection system. We consider a successful attack only if it succeeds to cross both Forgery Detection and Removal Detection systems. We count the number of successful attacks and compute the corresponding FAR at different PCE thresholds between 10,000 and 50,000, using a step of 100. We note that the threshold values are generally higher than those used in [6], because we compute the PRNU fingerprints on larger images. We determine the optimal threshold as the threshold that provides a FAR of roughly for the attack scheme detailed in [6], because Zhongjie et al. [6] report a FAR of in their paper. We note that they selected the threshold that corresponds to equal FAR and FRR.
4.4. Attacking the ABC Protocol
4.4.1. Results with Five Images for PRNU Estimation
In Figure 2, we show the number of false acceptances generated by our attack scheme [13] in comparison with the attack described by Zhongjie et al. [6]. Both attacks employ five images for fingerprint estimation, results being compared using multiple PCE thresholds between 10,000 and 50,000. Attacks that bypass the ABC protocol defense systems, such as Forgery Detection and Removal Detection, are counted as valid authentications. Our attack scheme obtains a FAR of at a threshold of 22,500, similar to what Zhongjie et al. [6] obtained in their experiments. Thus, we consider this value as being the optimal threshold. However, we emphasize that for all thresholds between 10,000 and 50,000, our attack scheme is significantly more successful.
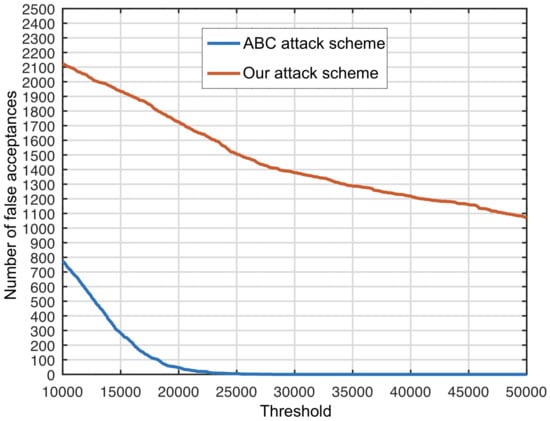
Figure 2.
Number of false acceptances (on the vertical axis) bypassing both Forgery Detection and Removal Detection systems of the original ABC protocol, for the attack scheme proposed in [13] versus the attack scheme detailed in [6], when five images are used for PRNU estimation. False acceptances are counted for multiple PCE thresholds (on the horizontal axis) between 10,000 and 50,000, with a step of 100. Best viewed in color.
Table 1 compares our attack scheme to the attack scheme of Zhongjie et al. [6], for different thresholds between 10,000 and 50,000. At the selected optimal threshold of 22,500, our attack scheme achieves a FAR equal to (1624 successful attacks) while the ABC protocol attack scheme described in [6] achieves a FAR of . To further prove that the results are consistent with the numbers reported in [6], we compute the False Rejection Rate (FRR) by doing 600 authentications with registered devices, obtaining a similar FRR (under ). Our FAR and FRR show that half of the attacks are successful. Therefore, the ABC protocol is unsafe when an attacker has access to a victim’s photos.

Table 1.
False acceptance rates (FAR) and number of successful attempts (in parentheses) for the attack scheme proposed in [13] versus the attack scheme detailed in [6], when five images are used for PRNU estimation in the standard ABC protocol. False acceptance rates are computed for five PCE thresholds between 10,000 and 50,000. Results (highlighted in bold) for the optimal PCE threshold (22,500) are also included. For each attack scheme, we report the false acceptance rates for the Forgery Detection (FD) system, the Removal Detection (RD) system and both (FD + RD).
While our attack can bypass the Removal Detection system with a much higher FAR than the attack scheme considered in [6], it gives slightly lower FAR values in trying to bypass the Forgery Detection system, because the attacker’s PRNU fingerprint is computed on a different set of images than the two QR code images used during authentication. More specifically, the lower FAR rates are generated by the approximation errors between the PRNU estimation and the actual PRNU fingerprint found in the QR code images. Nevertheless, our proposed attack generates higher false acceptance rates even when both systems are considered together. Therefore, the results presented in Table 1 strongly indicate that our attack scheme is very powerful against the ABC protocol, succeeding in one of every two attacks.
4.4.2. Results with One Image for PRNU Estimation
By using only one image for PRNU estimation and the same PCE thresholds between 10,000 and 50,000, Figure 3 shows the number of false acceptances generated by our proposed attack scheme in comparison to the attack scheme considered by Zhongjie et al. [6]. With only one image to compute both the adversary’s and the victim’s PRNU fingerprints, this setting is more difficult and less likely to succeed. We carry out this experiment to have an apples-to-apples comparison to Zhongjie et al. [6].
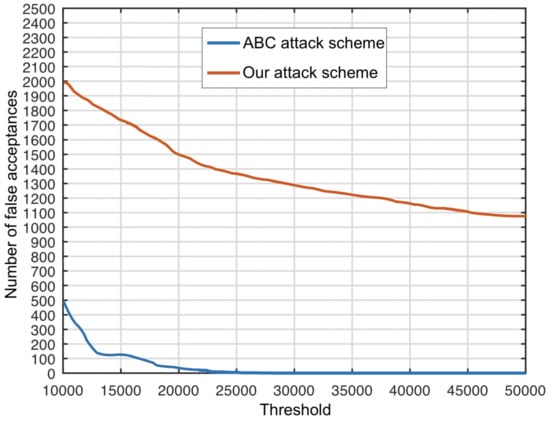
Figure 3.
Number of false acceptances (on the vertical axis) bypassing both Forgery Detection and Removal Detection systems of the original ABC protocol, for the attack scheme proposed in [13] versus the attack scheme proposed in [6], when one image is used for PRNU estimation. False acceptances are counted for multiple PCE thresholds (on the horizontal axis) between 10,000 and 50,000, with a step of 100. Best viewed in color.
Comparing Figure 2 and Figure 3, we can draw two conclusions. First, the number of attacks that bypass the ABC protocol defense systems is lower when utilizing one image compared to the setting in which we use five images. Second, we can see that even in the harder setting, the number of successful attacks is large. Therefore, our attack scheme still represents a great threat for the ABC protocol. Considering the optimal threshold value of 22,500, the number of successful attacks is 1430 (representing a FAR of ). The empirical results show that the ABC protocol is still vulnerable, regardless of the total number of images considered for PRNU estimation.
We thus conclude that the protection systems of the ABC protocol, namely the Forgery Detection and Removal Detection systems, do not suffice to prevent our attack scheme proposed in [13].
4.5. Multi-Way Classification Results with Deep Models
In our multi-way user classification experiments on HMOG, we trained the CNN model on mini-batches of 32 samples. The model is optimized for a maximum 50 epochs using a learning rate of . However, in order to prevent overfitting, we applied early stopping at around 40 epochs. We employ the same hyperparameters for the ConvLSTM model, namely a learning rate of and mini-batches of 32 samples. The ConvLSTM is also trained for a maximum of 50 epochs, but the optimization is halted after 20 epochs due to early stopping. We also consider an ensemble that employs an SVM as meta-leaner on top of concatenated CNN and ConvLSTM neural embeddings. The SVM uses for regularization and is based on the RBF kernel. As baseline, we add a model based on invariant handcrafted features, as proposed by Shen et al. [31]. The corresponding results are presented in Table 2. We observe that the CNN model attains an accuracy of , while the ConvLSTM performs slightly worse, attaining an accuracy of . By merging the two deep models, we obtain superior results, attaining an accuracy of . We underline that our final results are very good, considering that the baseline based on handcrafted features attains an accuracy of only on the 50-way user classification task.
Table 2.
Multi-way user classification accuracy rates on the HMOG data set, obtained by a baseline model based on handcrafted features versus our CNN and ConvLSTM models and their combination represented by an ensemble that merges the two models.
4.6. Attacking the Multi-Modal ABC Protocol
We further present the empirical results obtained after using our attack scheme on the multi-modal ABC protocol, which combines PRNU and motion sensor fingerprints. We conducted the experiments using five samples to estimate the fingerprints during the attacks, irrespective of the modality. As shown earlier, this scenario is more difficult (the attack exhibits a higher penetration rate) than using a single image for fingerprint estimation (see Figure 2 and Figure 3).
We considered three options to enhance the ABC protocol with motion sensor fingerprints: using SVM classifiers on top of CNN embeddings, using SVM classifiers on top of ConvLSTM embeddings or using SVM classifiers on top of joint CNN and ConvLSTM embeddings. Throughout our experiments, we utilized two kernels for our SVM models, either linear or RBF, and two alternative values for the regularization parameter C, 10 or 100. For the RBF kernel, the parameter is automatically scaled with respect to the number of features. The corresponding results are shown in Table 3.
Table 3.
Accuracy, FAR and FRR of the multi-modal ABC protocol for the attack scheme proposed in [13], when five images and motion signals are used during registration and authentication. Results are reported for binary SVM classifiers based on neural embeddings from a CNN, a ConvLSTM or both. For each neural embedding type, we consider two kernels and different values for the regularization parameter C. All reported metrics represent average values computed for six smartphone devices, with 100 authentic sessions and 500 attack sessions per device. For each neural embedding type, the best results are highlighted in bold.
4.6.1. Results with CNN Embeddings
By extending the ABC protocol with motion sensor fingerprints based on CNN neural embeddings, we attain a top average accuracy of for the linear kernel and the regularization parameter . In this case, the multi-modal ABC protocol successfully rejects our attack scheme with a false acceptance rate of and a false rejection rate of , as shown in Table 3. However, the smallest false acceptance ratio that can be obtained with CNN embeddings is , using the RBF kernel and the regularization parameter . In this case, the model is not very well balanced, the false rejection rate being . We note that the accuracy of the multi-modal ABC protocol based on CNN embeddings is around , irrespective of the kernel type or the regularization parameter value. Overall, the best SVM configuration for the CNN embeddings seems to be the one based on the linear kernel and the regularization .
4.6.2. Results with ConvLSTM Embeddings
The best accuracy attained by the multi-modal ABC protocol based on ConvLSTM embeddings is , while the best false acceptance rate and the best false rejection rate are and , respectively. However, these values are not attained with the same kernel and regularization parameter configuration. We are undecided regarding the best SVM configuration for the ConvLSTM embeddings. While the optimal regularization parameter is , it appears that the linear and the RBF kernel produce equally good results for . Another important remark is that the CNN embeddings seem to produce better motion sensor fingerprints than the ConvLSTM embeddings. With one exception (the configuration given by the RBF kernel and the regularization ), the differences in favor of the CNN embeddings are rather small.
4.6.3. Results with Joint Neural Embeddings
The results presented in Table 3 indicate that concatenating the neural embeddings generated by both CNN and ConvLSTM models gives superior performance levels than using the embeddings individually. By employing the RBF kernel and the regularization parameter , we attain our lowest false acceptance rate of and our highest accuracy of in attack prevention. However, the lowest false rejection rate of is attained with the configuration based on the RBF kernel and the regularization parameter . Overall, the joint CNN and ConvLSTM embeddings attain optimal results with the RBF kernel, irrespective of the value assigned to the regularization parameter.
5. Conclusions
In this paper, we first presented an attack scheme for the ABC protocol proposed by Zhongjie et al. [6]. Our attack scheme exposes a vulnerability in the original formulation of the ABC protocol, raising the false acceptance rate to . Our attack scheme, which was initially proposed in [13], is based on computing the attacker’s camera fingerprint using photos taken outside the ABC protocol, allowing us to remove the fingerprint during impersonation attacks, without drastically altering the probe signal generated by the protocol. This procedure bypasses both protection systems of the original ABC protocol, namely Removal Detection and Forgery Detection.
Furthermore, we proposed a multi-modal ABC protocol based on deep neural networks applied on motion sensor signals, aiming to improve the security of the original ABC protocol. We processed the discrete signals using deep neural networks employed as feature extractors and we experimented with different kernels and embeddings in the meta-learning stage based on SVM. During the experiments, we identified that 512-dimensional neural embeddings, resulted from the concatenation of CNN and ConvLSTM embeddings, provided superior performance levels in attack prevention. Indeed, our multi-modal ABC protocol lowers the false acceptance rate for the attack proposed in [13] to as little as , achieving, in the same time, a false rejection rate of . Since motion sensor signals are not typically shared on social media platforms, we consider our multi-modal ABC protocol as much safer than the original formulation. Moreover, the users perform the exact same authentication steps in both original and multi-modal protocols. Hence, upgrading to the multi-modal ABC protocol does not imply additional authentication steps from the users.
One direction for future work is to turn our attention to transformer models [44]. Transformers recently caught the attention of computer vision scientists [45], as such models seem to have a better capacity of modeling global relations in the input. We believe that this property can lead to similar performance gains in motion signal processing. Another direction for future research is to adjust the proposed protocol to take advantage of the multiple cameras available on the high-end smartphone devices, which could provide a way to further enhance the protocol.
Author Contributions
Conceptualization, R.T.I.; Data curation, C.B.; Funding acquisition, R.T.I.; Investigation, C.B.; Methodology, R.T.I.; Project administration, R.T.I.; Software, C.B.; Validation, C.B.; Writing—original draft, C.B.; Writing—review and editing, R.T.I. All authors have read and agreed to the published version of the manuscript.
Funding
The research leading to these results has received funding from the NO Grants 2014–2021, under project contract no. 24/2020. The article has also benefited from the support of the Romanian Young Academy, which is funded by Stiftung Mercator and the Alexander von Humboldt Foundation for the period 2020–2022.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Readers can contact any author to access the constructed data set for non-commercial use. The HMOG data set is available at http://www.cs.wm.edu/~qyang/hmog.html (accessed on 21 June 2021).
Acknowledgments
The authors thank reviewers for their valuable feedback.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Board of Governors of the Federal Reserve System. Consumers and Mobile Financial Services 2016. Available online: https://www.federalreserve.gov/econresdata/consumers-and-mobile-financial-services-report-201603.pdf (accessed on 21 June 2021).
- Arthur, C. iPhone 5S fingerprint sensor hacked by Germany’s Chaos Computer Club. Guardian News. Np 2013, 23. [Google Scholar]
- Aviv, A.J.; Gibson, K.; Mossop, E.; Blaze, M.; Smith, J.M. Smudge Attacks on Smartphone Touch Screens. In Proceedings of the WOOT, Washington, DC, USA, 11–13 August 2010; pp. 1–7. [Google Scholar]
- Xu, Y.; Heinly, J.; White, A.M.; Monrose, F.; Frahm, J.M. Seeing double: Reconstructing obscured typed input from repeated compromising reflections. In Proceedings of the CCS, Berlin, Germany, 4–8 November 2013; pp. 1063–1074. [Google Scholar]
- Zhang, Y.; Xia, P.; Luo, J.; Ling, Z.; Liu, B.; Fu, X. Fingerprint attack against touch-enabled devices. In Proceedings of the Second ACM Workshop on Security and Privacy in Smartphones and Mobile Devices, Raleigh, NC, USA, 19 October 2012; pp. 57–68. [Google Scholar]
- Zhongjie, B.; Sixu, P.; Xinwen, F.; Dimitrios, K.; Aziz, M.; Kui, R. ABC: Enabling Smartphone Authentication with Built-in Camera. In Proceedings of the 25th Annual Network and Distributed System Security Symposium, NDSS, San Diego, CA, USA, 18–21 February 2018. [Google Scholar]
- Lukáš, J.; Fridrich, J.; Goljan, M. Digital camera identification from sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2006, 1, 205–214. [Google Scholar] [CrossRef]
- Altinisik, E.; Tasdemir, K.; Sencar, H.T. Extracting PRNU Noise from H.264 Coded Videos. In Proceedings of the 26th European Signal Processing Conference (EUSIPCO), Rome, Italy, 3–7 September 2018; pp. 1367–1371. [Google Scholar]
- Akshatha, K.; Karunakar, A.; Anitha, H.; Raghavendra, U.; Shetty, D. Digital camera identification using PRNU: A feature based approach. Digit. Investig. 2016, 19, 69–77. [Google Scholar] [CrossRef]
- Li, C.T. Source camera identification using enhanced sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2010, 5, 280–287. [Google Scholar]
- Cooper, A.J. Improved photo response non-uniformity (PRNU) based source camera identification. Forensic Sci. Int. 2013, 226, 132–141. [Google Scholar] [CrossRef]
- Kang, X.; Li, Y.; Qu, Z.; Huang, J. Enhancing source camera identification performance with a camera reference phase sensor pattern noise. IEEE Trans. Inf. Forensics Secur. 2012, 7, 393–402. [Google Scholar] [CrossRef]
- Benegui, C.; Ionescu, R.T. A breach into the Authentication with Built-in Camera (ABC) Protocol. In Proceedings of the ACNS, Rome, Italy, 19–22 October 2020; pp. 3–20. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based Learning Applied to Document Recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the NIPS, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Xingjian, S.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.K.; Woo, W.C. Convolutional LSTM network: A machine learning approach for precipitation nowcasting. In Proceedings of the NIPS, Montreal, QC, Canada, 7–12 December 2015; pp. 802–810. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Aghili, S.F.; Mala, H. Breaking a Lightweight M2M Authentication Protocol for Communications in IIoT Environment. IACR Cryptol. ePrint Arch. 2018, 2018, 891. [Google Scholar]
- Esfahani, A.; Mantas, G.; Matischek, R.; Saghezchi, F.B.; Rodriguez, J.; Bicaku, A.; Maksuti, S.; Tauber, M.; Schmittner, C.; Bastos, J. A lightweight authentication mechanism for M2M communications in industrial IoT environment. IEEE Internet Things J. 2019, 6, 288–296. [Google Scholar] [CrossRef]
- Aghili, S.F.; Mala, H.; Peris-Lopez, P. Securing Heterogeneous Wireless Sensor Networks: Breaking and Fixing a Three-Factor Authentication Protocol. Sensors 2018, 18, 3663. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Amin, R.; Islam, S.H.; Kumar, N.; Choo, K.K.R. An untraceable and anonymous password authentication protocol for heterogeneous wireless sensor networks. J. Netw. Comput. Appl. 2018, 104, 133–144. [Google Scholar] [CrossRef]
- Amerini, I.; Bestagini, P.; Bondi, L.; Caldelli, R.; Casini, M.; Tubaro, S. Robust smartphone fingerprint by mixing device sensors features for mobile strong authentication. In Proceedings of the Media Watermarking, Security, and Forensics, San Francisco, CA, USA, 14–18 February 2016; pp. 1–8. [Google Scholar]
- Valsesia, D.; Coluccia, G.; Bianchi, T.; Magli, E. User Authentication via PRNU-Based Physical Unclonable Functions. IEEE Trans. Inf. Forensics Secur. 2017, 12, 1941–1956. [Google Scholar] [CrossRef]
- Gloe, T.; Kirchner, M.; Winkler, A.; Böhme, R. Can we trust digital image forensics? In Proceedings of the 15th ACM International Conference on Multimedia, Augsburg, Germany, 25–29 September 2007; pp. 78–86. [Google Scholar]
- Goljan, M.; Fridrich, J.; Chen, M. Defending against fingerprint-copy attack in sensor-based camera identification. IEEE Trans. Inf. Forensics Secur. 2011, 6, 227–236. [Google Scholar] [CrossRef] [Green Version]
- Buriro, A.; Crispo, B.; Delfrari, F.; Wrona, K. Hold and Sign: A Novel Behavioral Biometrics for Smartphone User Authentication. In Proceedings of the IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 22–26 May 2016; pp. 276–285. [Google Scholar]
- Buriro, A.; Crispo, B.; Zhauniarovich, Y. Please Hold On: Unobtrusive User Authentication using Smartphone’s built-in Sensors. In Proceedings of the IEEE International Conference on Identity, Security and Behavior Analysis (ISBA), New Delhi, India, 22–24 February 2017; pp. 1–8. [Google Scholar]
- Ku, Y.; Park, L.H.; Shin, S.; Kwon, T. Draw It As Shown: Behavioral Pattern Lock for Mobile User Authentication. IEEE Access 2019, 7, 69363–69378. [Google Scholar] [CrossRef]
- Li, H.; Yu, J.; Cao, Q. Intelligent Walk Authentication: Implicit Authentication When You Walk with Smartphone. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 1113–1116. [Google Scholar]
- Neverova, N.; Wolf, C.; Lacey, G.; Fridman, L.; Chandra, D.; Barbello, B.; Taylor, G. Learning Human Identity from Motion Patterns. IEEE Access 2016, 4, 1810–1820. [Google Scholar] [CrossRef]
- Shen, C.; Yu, T.; Yuan, S.; Li, Y.; Guan, X. Performance Analysis of Motion-Sensor Behavior for User Authentication on Smartphones. Sensors 2016, 16, 345. [Google Scholar] [CrossRef] [Green Version]
- Sitová, Z.; Šedenka, J.; Yang, Q.; Peng, G.; Zhou, G.; Gasti, P.; Balagani, K.S. HMOG: New Behavioral Biometric Features for Continuous Authentication of Smartphone Users. IEEE Trans. Inf. Forensics Secur. 2016, 11, 877–892. [Google Scholar] [CrossRef]
- Sun, L.; Wang, Y.; Cao, B.; Philip, S.Y.; Srisa-An, W.; Leow, A.D. Sequential keystroke behavioral biometrics for mobile user identification via multi-view deep learning. In Proceedings of the ECML-PKDD, Skopje, Macedonia, 18–22 September 2017; pp. 228–240. [Google Scholar]
- Vildjiounaite, E.; Mäkelä, S.M.; Lindholm, M.; Riihimäki, R.; Kyllönen, V.; Mäntyjärvi, J.; Ailisto, H. Unobtrusive multimodal biometrics for ensuring privacy and information security with personal devices. In Proceedings of the PERVASIVE, Dublin, Ireland, 7–10 May 2006; pp. 187–201. [Google Scholar]
- Wang, R.; Tao, D. Context-Aware Implicit Authentication of Smartphone Users Based on Multi-Sensor Behavior. IEEE Access 2019, 7, 119654–119667. [Google Scholar] [CrossRef]
- Benegui, C.; Ionescu, R.T. Convolutional Neural Networks for User Identification based on Motion Sensors Represented as Images. IEEE Access 2020, 8, 61255–61266. [Google Scholar] [CrossRef]
- Goljan, M. Digital camera identification from images—Estimating false acceptance probability. In Proceedings of the IWDW, Busan, Korea, 10–12 November 2008; pp. 454–468. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the ICLR, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the ICML, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Quiring, E.; Kirchner, M. Fragile sensor fingerprint camera identification. In Proceedings of the IEEE International Workshop on Information Forensics and Security (WIFS), Rome, Italy, 16–19 November 2015; pp. 1–6. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is All You Need. In Proceedings of the NIPS, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. In Proceedings of the ICLR, Virtual, 3–7 May 2021. [Google Scholar]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).