
The Real-Life Application of Differential Evolution with a Distance-Based Mutation-Selection


Abstract
:1. Introduction
Differential Evolution
2. A Novel DE with Distance-Based Mutation-Selection (DEDMNA)
2.1. Proper Mutation Variants for Convergence-Control
2.2. Distance-Based Mutation-Selection Mechanism
2.3. Archive of Historically Good Solutions
2.4. Population Size Adaptation
3. Experimental Settings
3.1. State-of-the-Art Variants in Comparison
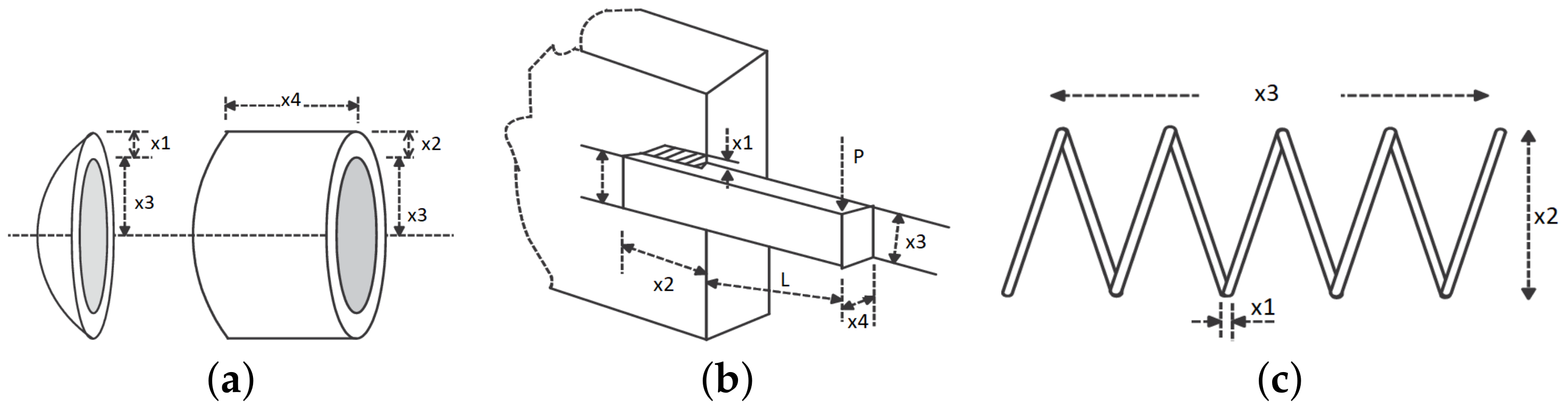
3.2. Well-Known Engineering Problems
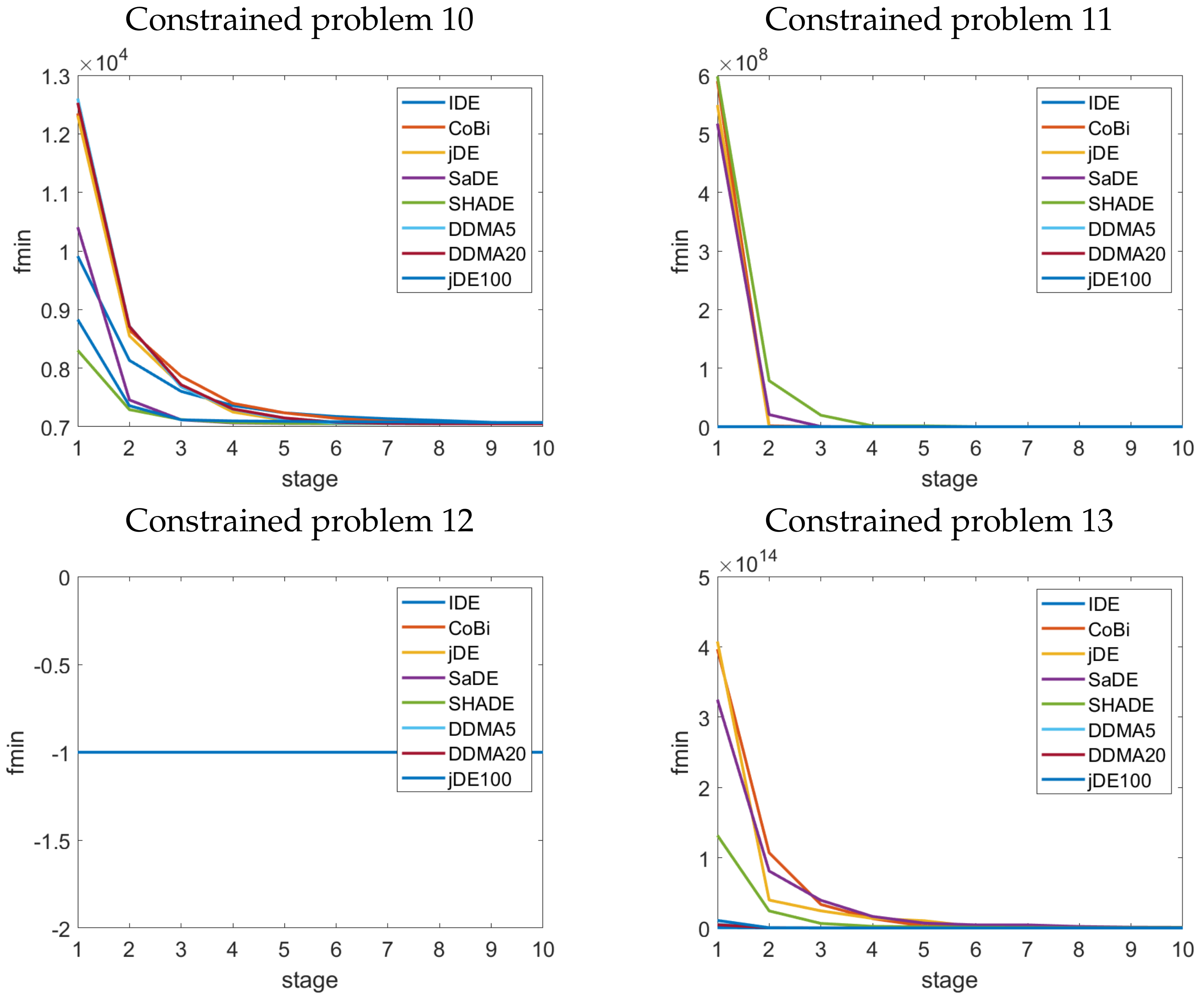
3.3. Constrained Optimisation Problems
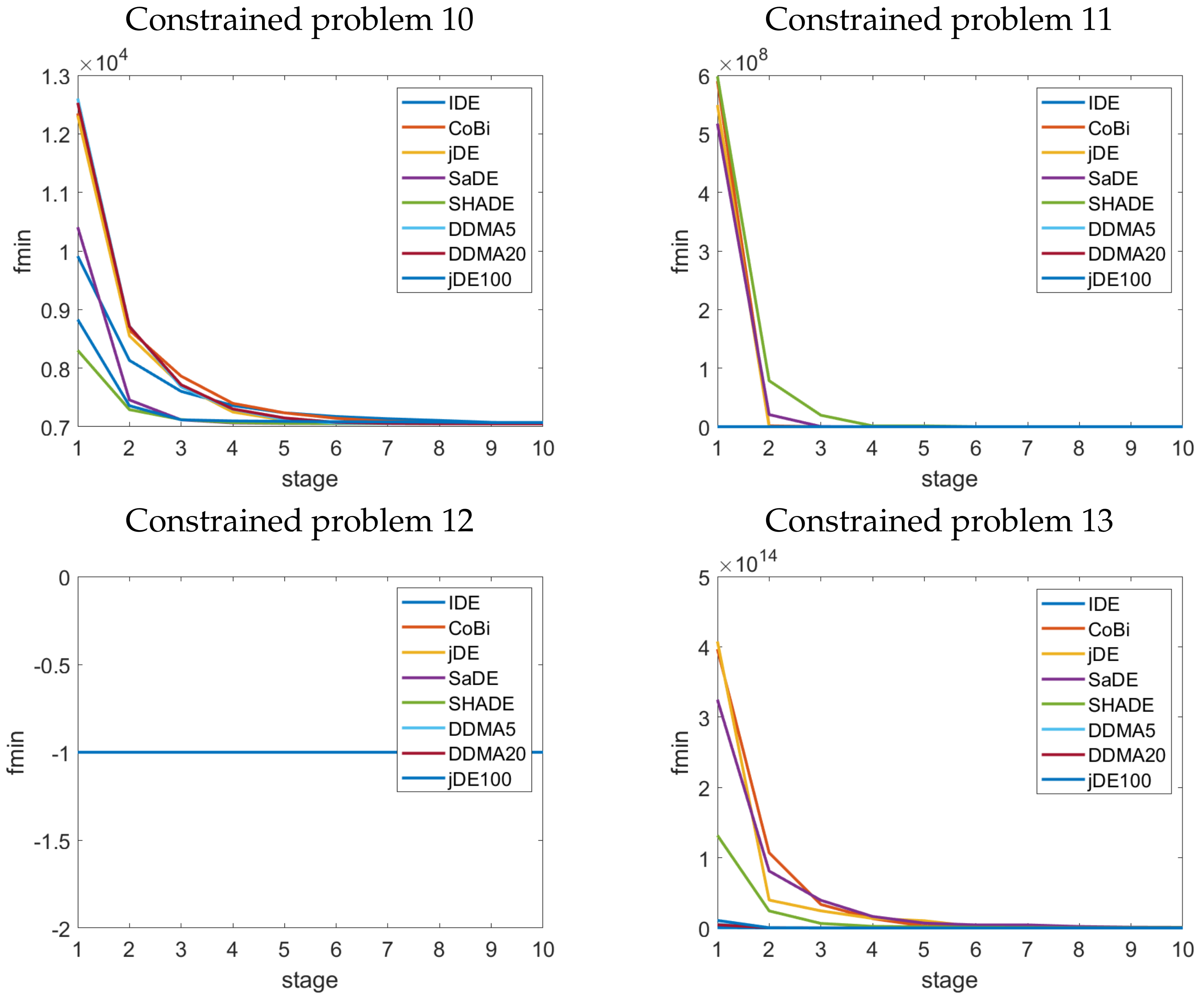
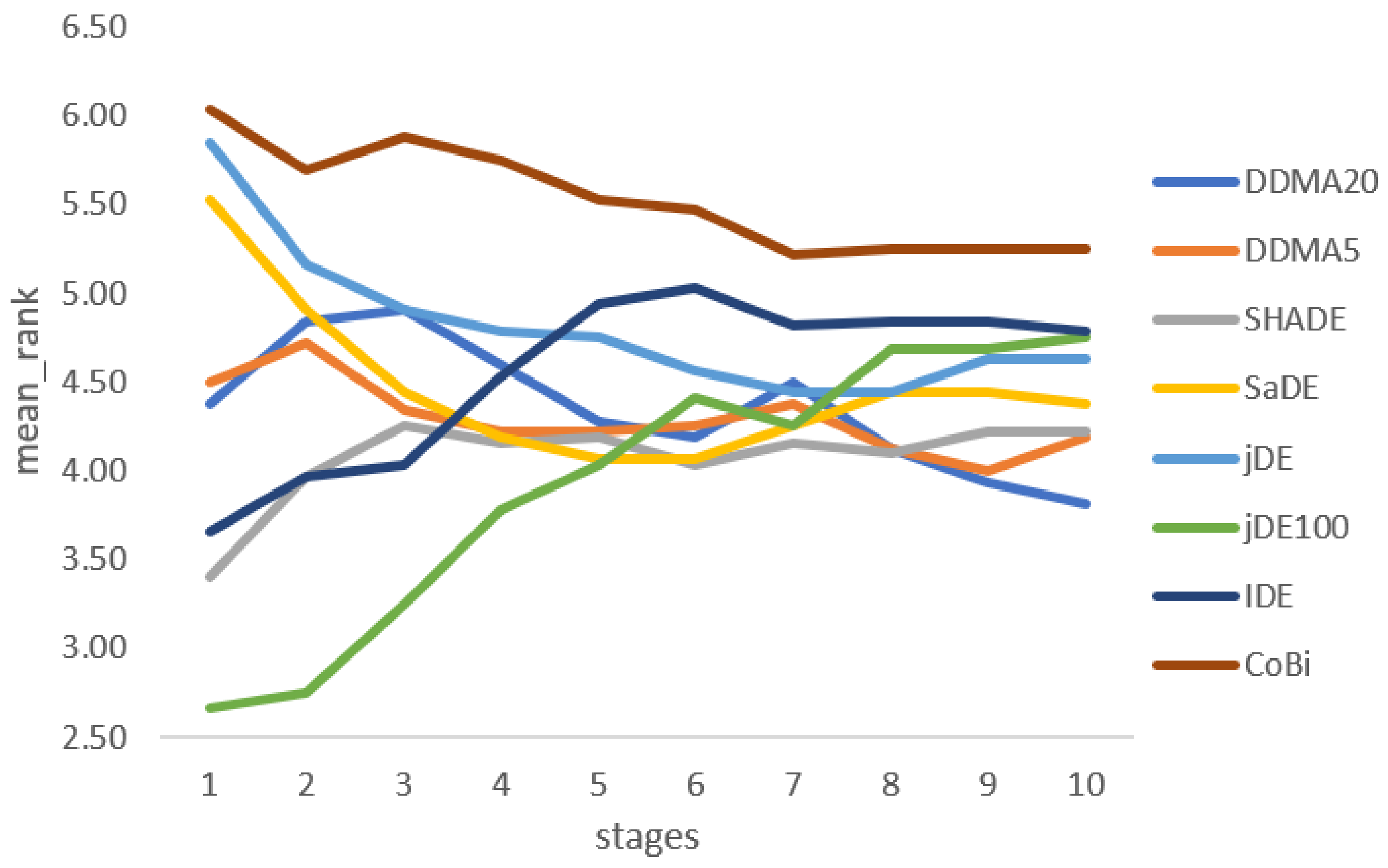
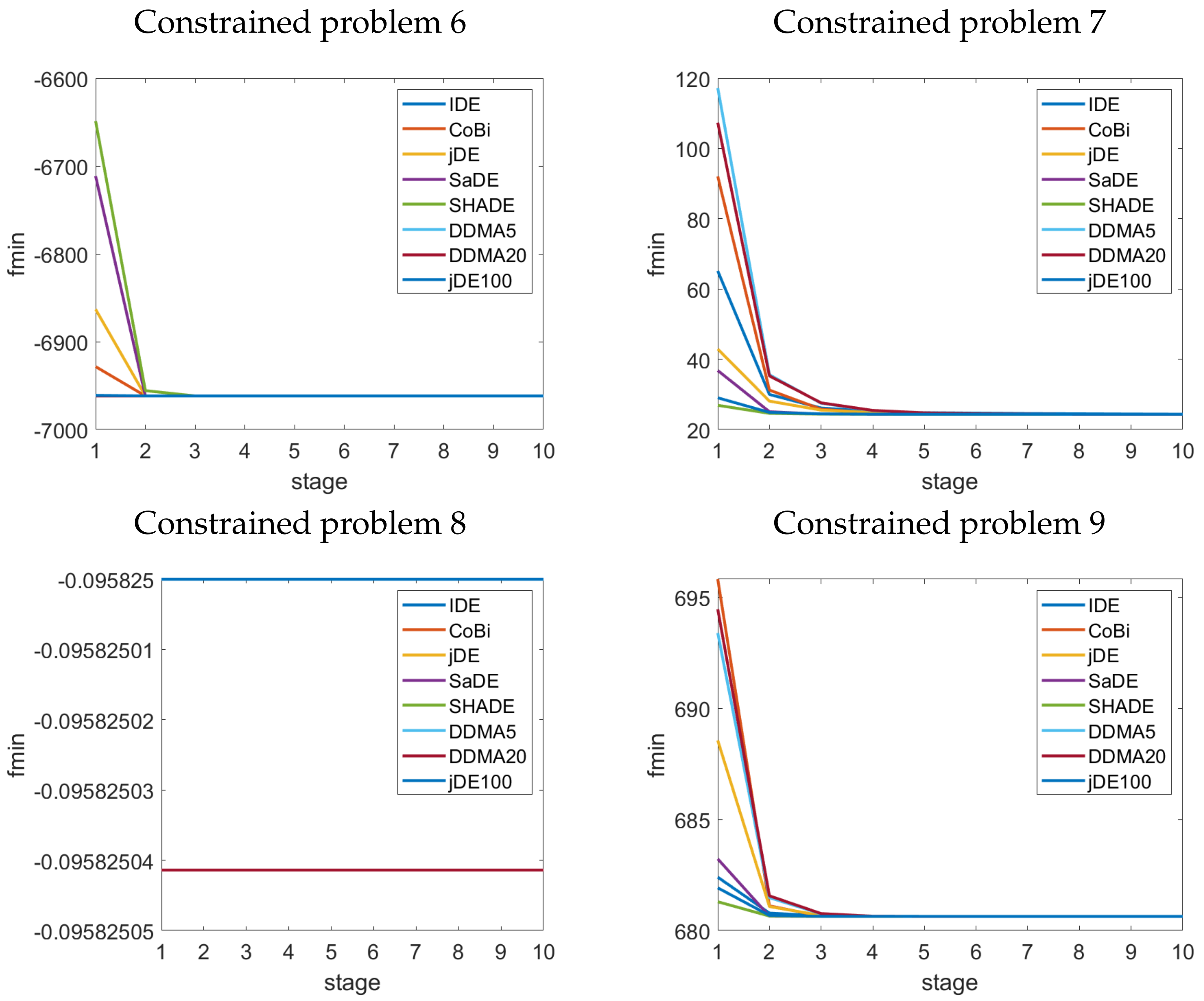
4. Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rhinehart, R.R. Engineering Optimization: Applications, Methods and Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2018. [Google Scholar]
- Fujisawa, K.; Shinano, Y.; Waki, H. Optimization in the Real World: Toward Solving Real-World Optimization Problems; Mathematics for Industry, Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Dosi, G.; Roventini, A. More is Different ... and Complex! The Case for Agent-Based Macroeconomics. J. Evol. Econ. 2019, 29, 1–37. [Google Scholar] [CrossRef] [Green Version]
- Bellomo, N.; Dosi, G.; Knopoff, D.A.; Virgillito, M.E. From particles to firms: On the kinetic theory of climbing up evolutionary landscapes. Math. Model. Methods Appl. Sci. 2020, 30, 1441–1460. [Google Scholar] [CrossRef]
- Storn, R.; Price, K.V. Differential evolution—A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces. J. Glob. Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]
- Das, S.; Mullick, S.; Suganthan, P. Recent advances in differential evolution—An updated survey. Swarm Evol. Comput. 2016, 27, 1–30. [Google Scholar] [CrossRef]
- Das, S.; Suganthan, P.N. Differential Evolution: A Survey of the State-of-the-Art. IEEE Trans. Evol. Comput. 2011, 15, 27–54. [Google Scholar] [CrossRef]
- Neri, F.; Tirronen, V. Recent advances in differential evolution: A survey and experimental analysis. Artif. Intell. Rev. 2010, 33, 61–106. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. No Free Lunch Theorems for Optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Jeyakumar, G.; Shanmugavelayutham, C. Convergence analysis of differential evolution variants on unconstrained global optimization functions. Int. J. Artif. Intell. Appl. (IJAIA) 2011, 2, 116–127. [Google Scholar] [CrossRef]
- Zaharie, D. Differential Evolution: From Theoretical Analysis to Practical Insights. In MENDEL 2012, 18th International Conference on Soft Computing, 27–29 June 2012; University of Technology: Brno, Czech Republic, 2013; pp. 126–131. [Google Scholar]
- Liang, J.; Qu, B.; Mao, X.; Chen, T. Differential Evolution Based on Fitness Euclidean-Distance Ratio for Multimodal Optimization. In Emerging Intelligent Computing Technology and Applications; Huang, D.S., Gupta, P., Zhang, X., Premaratne, P., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2012; pp. 495–500. [Google Scholar]
- Ghosh, A.; Das, S.; Mallipeddi, R.; Das, A.K.; Dash, S.S. A Modified Differential Evolution With Distance-based Selection for Continuous Optimization in Presence of Noise. IEEE Access 2017, 5, 26944–26964. [Google Scholar] [CrossRef]
- Liang, J.; Wei, Y.; Qu, B.; Yue, C.; Song, H. Ensemble learning based on fitness Euclidean-distance ratio differential evolution for classification. Nat. Comput. 2021, 20, 77–87. [Google Scholar] [CrossRef]
- Bujok, P.; Tvrdík, J. A Comparison of Various Strategies in Differential Evolution. In Proceedings of the MENDEL, 17th International Conference on Soft Computing, Brno, Czech Republic, 14–17 June 2011; pp. 48–55. [Google Scholar]
- Bujok, P. Improving the Convergence of Differential Evolution. In Numerical Analysis and Applications; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2016; pp. 248–255. [Google Scholar]
- Wang, Y.; Cai, Z.; Zhang, Q. Differential Evolution with Composite Trial Vector Generation Strategies and Control Parameters. IEEE Trans. Evol. Comput. 2011, 15, 55–66. [Google Scholar] [CrossRef]
- Brest, J.; Greiner, S.; Boškovič, B.; Mernik, M.; Žumer, V. Self-adapting Control Parameters in Differential Evolution: A Comparative Study on Numerical Benchmark Problems. IEEE Trans. Evol. Comput. 2006, 10, 646–657. [Google Scholar] [CrossRef]
- Tang, L.; Dong, Y.; Liu, J. Differential Evolution With an Individual-Dependent Mechanism. IEEE Trans. Evol. Comput. 2015, 19, 560–574. [Google Scholar] [CrossRef] [Green Version]
- Tanabe, R.; Fukunaga, A.S. Improving the search performance of SHADE using linear population size reduction. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Beijing, China, 6–11 July 2014; pp. 1658–1665. [Google Scholar]
- Brest, J.; Maučec, M.S.; Bošković, B. Single Objective Real-Parameter Optimization: Algorithm jSO. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 1311–1318. [Google Scholar]
- Polakova, R.; Tvrdik, J.; Bujok, P. Differential evolution with adaptive mechanism of population size according to current population diversity. Swarm Evol. Comput. 2019, 50, 100519. [Google Scholar] [CrossRef]
- Qin, A.K.; Huang, V.L.; Suganthan, P.N. Differential Evolution Algorithm With Strategy Adaptation for Global Numerical Optimization. IEEE Trans. Evol. Comput. 2009, 13, 398–417. [Google Scholar] [CrossRef]
- Tanabe, R.; Fukunaga, A.S. Success-history based parameter adaptation for Differential Evolution. In Proceedings of the IEEE Congress on Evolutionary Computation (CEC), Cancun, Mexico, 20–23 June 2013; pp. 71–78. [Google Scholar]
- Zhang, J.; Sanderson, A.C. JADE: Adaptive Differential Evolution With Optional External Archive. IEEE Trans. Evol. Comput. 2009, 13, 945–958. [Google Scholar] [CrossRef]
- Wang, Y.; Li, H.X.; Huang, T.; Li, L. Differential evolution based on covariance matrix learning and bimodal distribution parameter setting. Appl. Soft Comput. 2014, 18, 232–247. [Google Scholar] [CrossRef]
- Bujok, P.; Tvrdík, J. Enhanced individual-dependent differential evolution with population size adaptation. In Proceedings of the 2017 IEEE Congress on Evolutionary Computation (CEC), Donostia, Spain, 5–8 June 2017; pp. 1358–1365. [Google Scholar]
- Brest, J.; Maučec, M.S.; Bošković, B. The 100-Digit Challenge: Algorithm jDE100. In Proceedings of the 2019 IEEE Congress on Evolutionary Computation (CEC), Wellington, New Zealand, 10–13 June 2019; pp. 19–26. [Google Scholar] [CrossRef]
- Hedar, A.R. Global Optimization Test Problems. Available online: http://www-optima.amp.i.kyoto-u.ac.jp/member/student/hedar/Hedar_files/TestGO_files/Page422.htm (accessed on 30 June 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MR | DDMA | DDMA | SHA | SaDE | jDE | jDE100 | IDE | CoBi | Sig. |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 4.38 | 4.50 | 3.41 | 5.53 | 5.84 | 2.66 | 3.66 | 6.03 | *** |
| 2 | 4.84 | 4.72 | 3.97 | 4.91 | 5.16 | 2.75 | 3.97 | 5.69 | * |
| 3 | 4.91 | 4.34 | 4.25 | 4.44 | 4.91 | 3.25 | 4.03 | 5.88 | ≈ |
| 4 | 4.59 | 4.22 | 4.16 | 4.19 | 4.78 | 3.78 | 4.53 | 5.75 | ≈ |
| 5 | 4.28 | 4.22 | 4.19 | 4.06 | 4.75 | 4.03 | 4.94 | 5.53 | ≈ |
| 6 | 4.19 | 4.25 | 4.03 | 4.06 | 4.56 | 4.41 | 5.03 | 5.47 | ≈ |
| 7 | 4.50 | 4.38 | 4.16 | 4.25 | 4.44 | 4.25 | 4.81 | 5.22 | ≈ |
| 8 | 4.13 | 4.13 | 4.09 | 4.44 | 4.44 | 4.69 | 4.84 | 5.25 | ≈ |
| 9 | 3.94 | 4.00 | 4.22 | 4.44 | 4.63 | 4.69 | 4.84 | 5.25 | ≈ |
| 10 | 3.81 | 4.19 | 4.22 | 4.38 | 4.63 | 4.75 | 4.78 | 5.25 | ≈ |
| Fun | DDMA | IDE | CoBi | jDE | SaDE |
|---|---|---|---|---|---|
| preved | 5885.333 | 5885.3328 | 5885.333 | 5885.333 | 5885.33 |
| (≈) | (≈) | (≈) | () | ||
| welded | 2.218151 | 2.218151 | 2.218151 | 2.218151 | 2.21815 |
| (≈) | (≈) | (≈) | () | ||
| tecost | 0.012665 | 0.012665 | 0.012665 | 0.012665 | 0.012665 |
| () | () | (≈) | () | ||
| p1 | −15 | −14.99 | −15 | −15 | −15 |
| (+++) | (≈) | (≈) | (≈) | ||
| p2 | −0.8049 | −0.792 | −0.754 | −0.803 | −0.804 |
| (+++) | (+++) | (+) | (≈) | ||
| p3 | −0.02377 | −0.25338 | −1.04 × 10 | −3.00 × 10 | −5.00 × 10 |
| () | (+++) | (+++) | (+++) | ||
| p4 | −30665.5 | −30665.5 | −30665.5 | −30665.5 | −30665.5 |
| (≈) | (+++) | (≈) | (+++) | ||
| p5 | 1.19 × 10 | 1.19 × 10 | 1.19 × 10 | 1.19 × 10 | 1.19 × 10 |
| (≈) | () | (≈) | () | ||
| p6 | −6961.81 | −6961.81 | −6961.81 | −6961.81 | −6961.81 |
| (≈) | (+++) | (≈) | (+++) | ||
| p7 | 24.30697 | 24.35218 | 24.307 | 24.30798 | 24.3064 |
| (+++) | (≈) | (++) | () | ||
| p8 | −0.09583 | −0.09583 | −0.095825 | −0.09583 | −0.095825 |
| (≈) | (+++) | (≈) | (+++) | ||
| p9 | 680.6301 | 680.63007 | 680.63 | 680.6301 | 680.63 |
| (+++) | () | (≈) | () | ||
| p10 | 7049.42 | 7059.31 | 7054.68 | 7049.43 | 7049.41 |
| (+++) | (+++) | (≈) | (≈) | ||
| p11 | 0.7499 | 0.7499 | 0.7499 | 0.7499 | 0.9656 |
| (≈) | (≈) | (≈) | (+++) | ||
| p12 | −1 | −1 | −1 | −1 | −1 |
| (≈) | (≈) | (≈) | (≈) | ||
| p13 | 4.1 × 10 | 0.95456 | 3.25 × 10 | 1.44 × 10 | 8.95 × 10 |
| () | (+) | (++) | (+++) | ||
| 5/8/3 | 7/6/3 | 4/12/0 | 6/4/6 |
| Fun | DDMA | SHADE | DDMA | jDE100 |
|---|---|---|---|---|
| preved | 5885.333 | 5885.3328(≈) | 5885.3328(≈) | 5885.330() |
| welded | 2.218151 | 2.2181509(≈) | 2.2181509(≈) | 2.21815() |
| tecost | 0.012665 | 0.012666(+++) | 0.012665(+) | 0.012665(≈) |
| p1 | −15 | −15(≈) | −15(≈) | −15(≈) |
| p2 | −0.80359 | −0.8036() | −0.8036(≈) | −0.79256(+++) |
| p3 | −0.02377 | −0.0004899(+++) | −0.02249(≈) | −0.00268(+++) |
| p4 | −30665.5 | −30665.5387(≈) | −30665.5387(≈) | −30665.5(+++) |
| p5 | 1.19 × 10 | 1.19 × 10(≈) | 1.19 × 10(≈) | 1.19 × 10() |
| p6 | −6961.81 | −6961.81388(≈) | −6961.81388(≈) | −6961.81(+++) |
| p7 | 24.30697 | 24.30625() | 24.30699(≈) | 24.3269(+++) |
| p8 | −0.09583 | −0.095823(≈) | −0.09583(≈) | −0.095825(+++) |
| p9 | 680.6301 | 680.630057(≈) | 680.630057(≈) | 680.633(+++) |
| p10 | 7049.42 | 7049.29() | 7049.55(≈) | 7071.57(+++) |
| p11 | 0.7499 | 0.9401(+++) | 0.7499(≈) | 0.7499(≈) |
| p12 | −1 | −1(≈) | −1(≈) | −1(≈) |
| p13 | 4.1 × 10 | 5.07 × 10(+++) | 0.97026(−) | 0.902() |
| 4/9/3 | 1/14/1 | 8/4/4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bujok, P. The Real-Life Application of Differential Evolution with a Distance-Based Mutation-Selection. Mathematics 2021, 9, 1909. https://doi.org/10.3390/math9161909
Bujok P. The Real-Life Application of Differential Evolution with a Distance-Based Mutation-Selection. Mathematics. 2021; 9(16):1909. https://doi.org/10.3390/math9161909
Chicago/Turabian StyleBujok, Petr. 2021. "The Real-Life Application of Differential Evolution with a Distance-Based Mutation-Selection" Mathematics 9, no. 16: 1909. https://doi.org/10.3390/math9161909
APA StyleBujok, P. (2021). The Real-Life Application of Differential Evolution with a Distance-Based Mutation-Selection. Mathematics, 9(16), 1909. https://doi.org/10.3390/math9161909