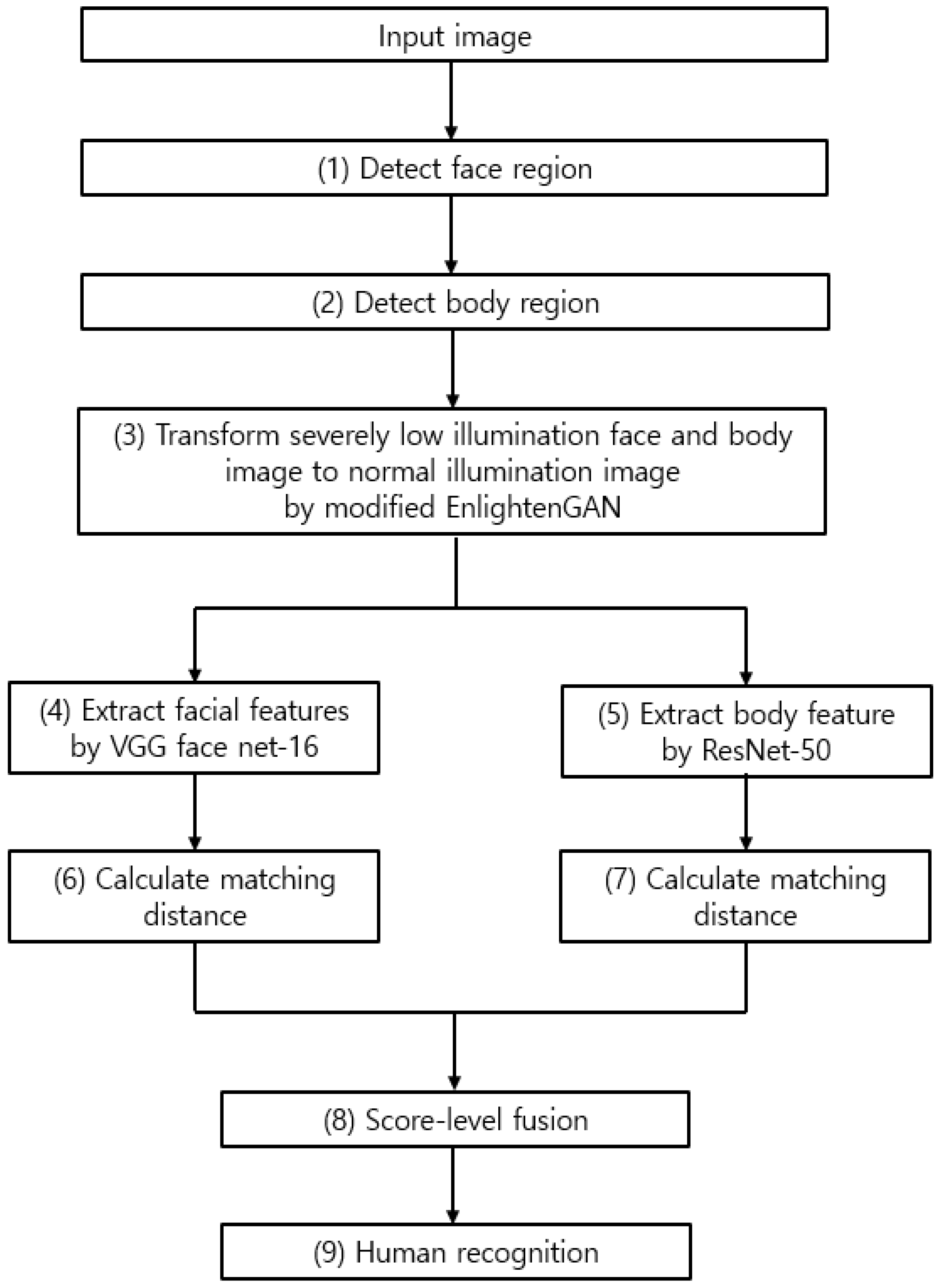
Figure 1.
Overall procedure of proposed method.
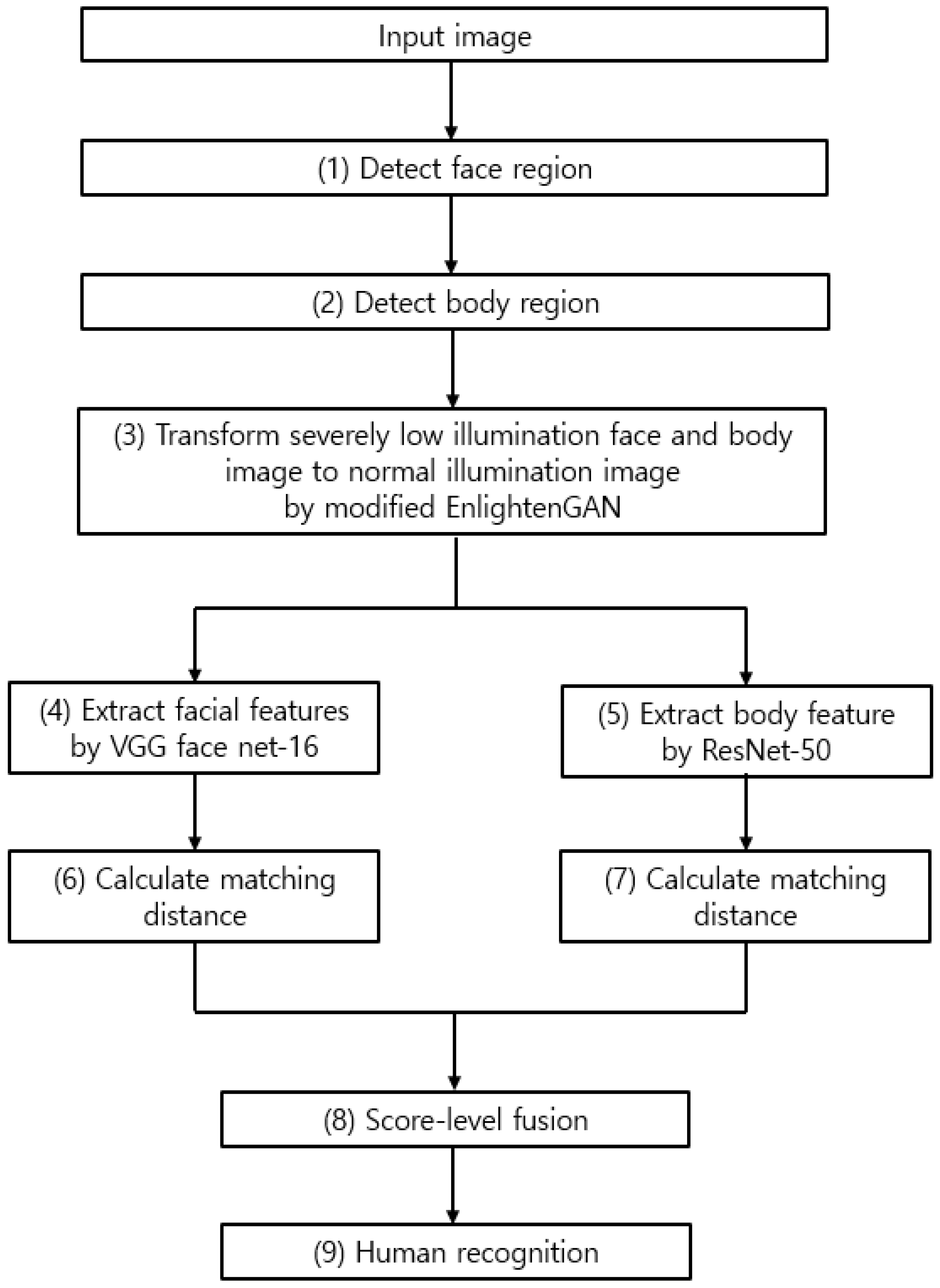
Figure 1.
Overall procedure of proposed method.
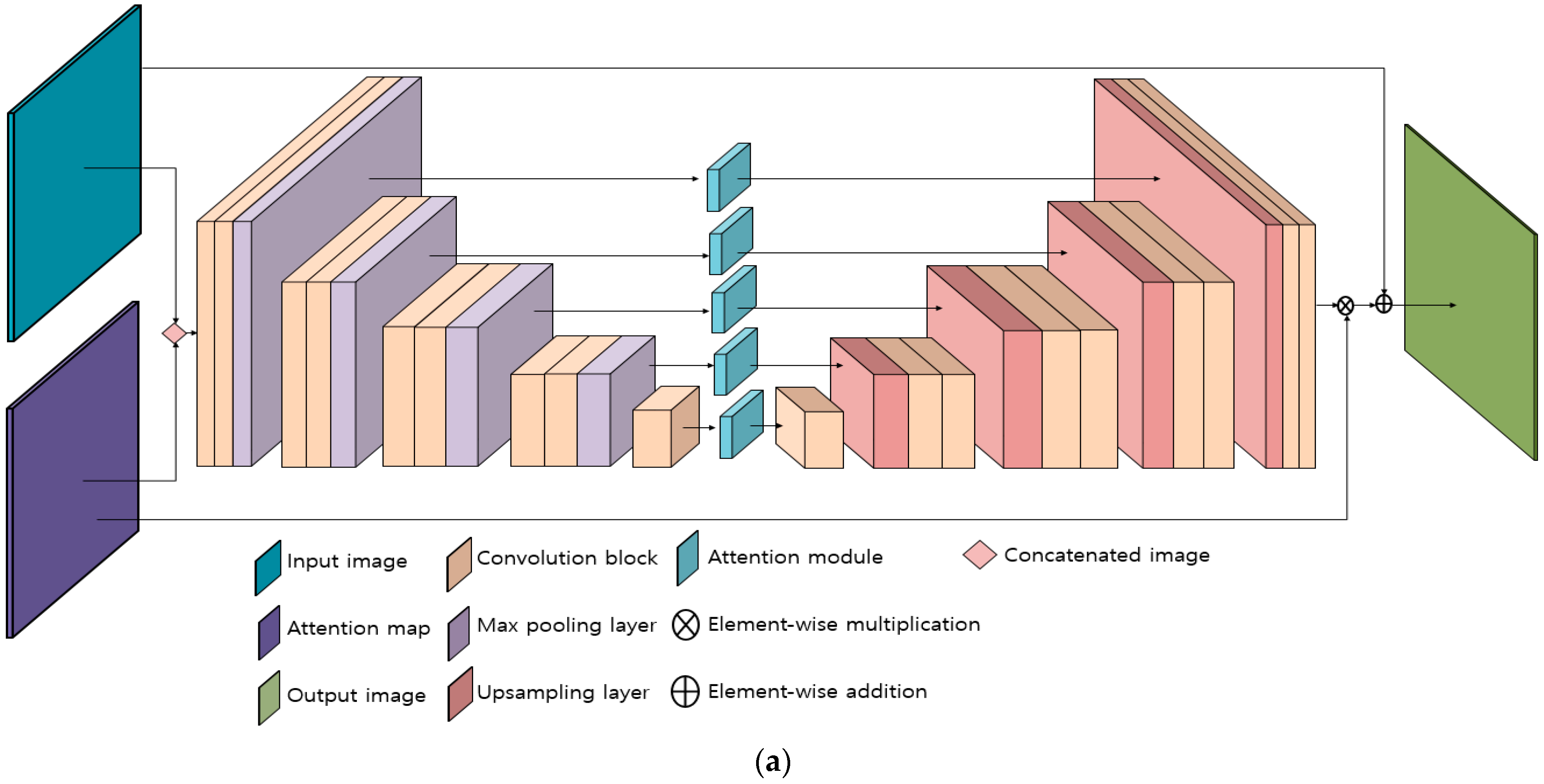
Figure 2.
Architecture of modified EnlightenGAN: (a) generator and (b) discriminator.
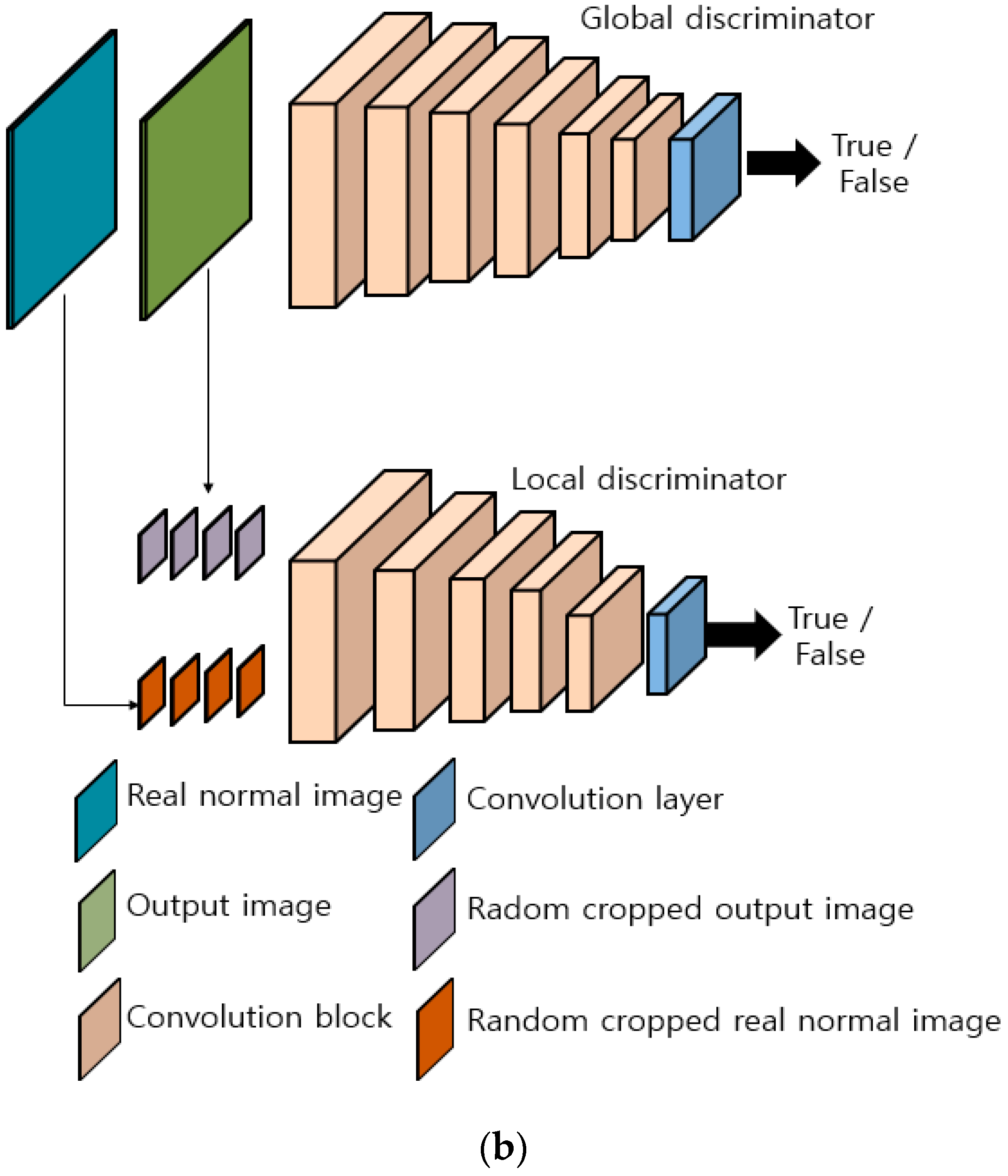
Figure 2.
Architecture of modified EnlightenGAN: (a) generator and (b) discriminator.
Figure 3.
Example of DFB-DB3 figures obtained from (a) the Logitech C920 camera and (b) the Logitech BCC950 camera. (c) Converted low-illumination figure of DFB-DB3.
Figure 3.
Example of DFB-DB3 figures obtained from (a) the Logitech C920 camera and (b) the Logitech BCC950 camera. (c) Converted low-illumination figure of DFB-DB3.
Figure 4.
Example images for ChokePoint dataset. (
a) Original images of ChokePoint dataset [
34]. (
b) Converted low-illumination image of ChokePoint dataset.
Figure 4.
Example images for ChokePoint dataset. (
a) Original images of ChokePoint dataset [
34]. (
b) Converted low-illumination image of ChokePoint dataset.
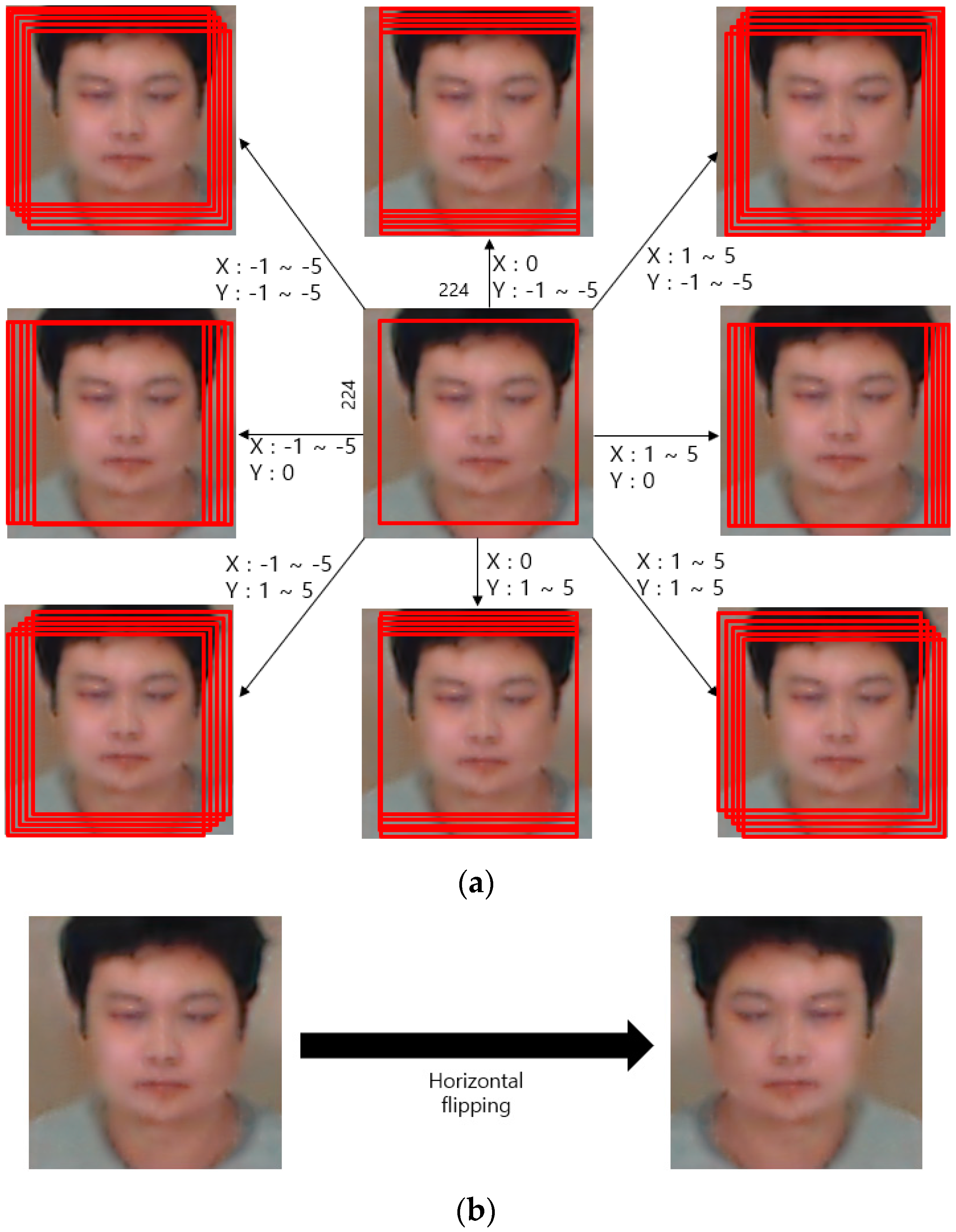
Figure 5.
Method for data augmentation including (a) cropping and image translation, and (b) horizontal flipping.
Figure 5.
Method for data augmentation including (a) cropping and image translation, and (b) horizontal flipping.
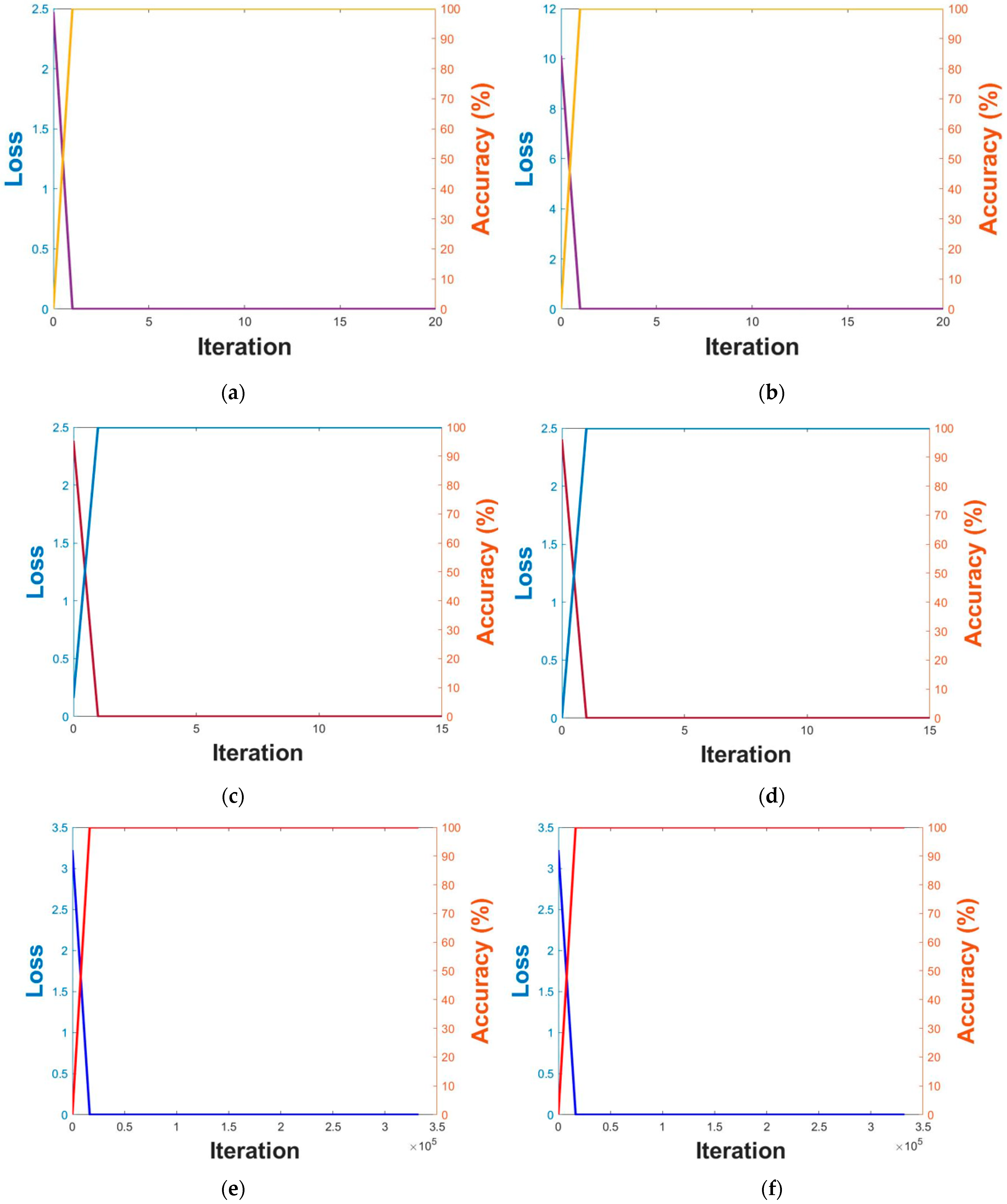
Figure 6.
Graphs illustrating training accuracy and loss of DFB-DB3 (a–d) result and ChokePoint dataset (e–h) result. VGG face net-16 with respect to (a,e) the first fold and (b,f) the second fold. ResNet-50 with respect to (c,g) the first fold and (d,h) the second fold.
Figure 6.
Graphs illustrating training accuracy and loss of DFB-DB3 (a–d) result and ChokePoint dataset (e–h) result. VGG face net-16 with respect to (a,e) the first fold and (b,f) the second fold. ResNet-50 with respect to (c,g) the first fold and (d,h) the second fold.
Figure 7.
Comparisons of output images by original EnlightenGAN and modified EnlightenGAN. (a) Original normal illumination image. (b) Low-illumination image. Output images by (c) original EnlightenGAN, and (d) modified EnlightenGAN.
Figure 7.
Comparisons of output images by original EnlightenGAN and modified EnlightenGAN. (a) Original normal illumination image. (b) Low-illumination image. Output images by (c) original EnlightenGAN, and (d) modified EnlightenGAN.
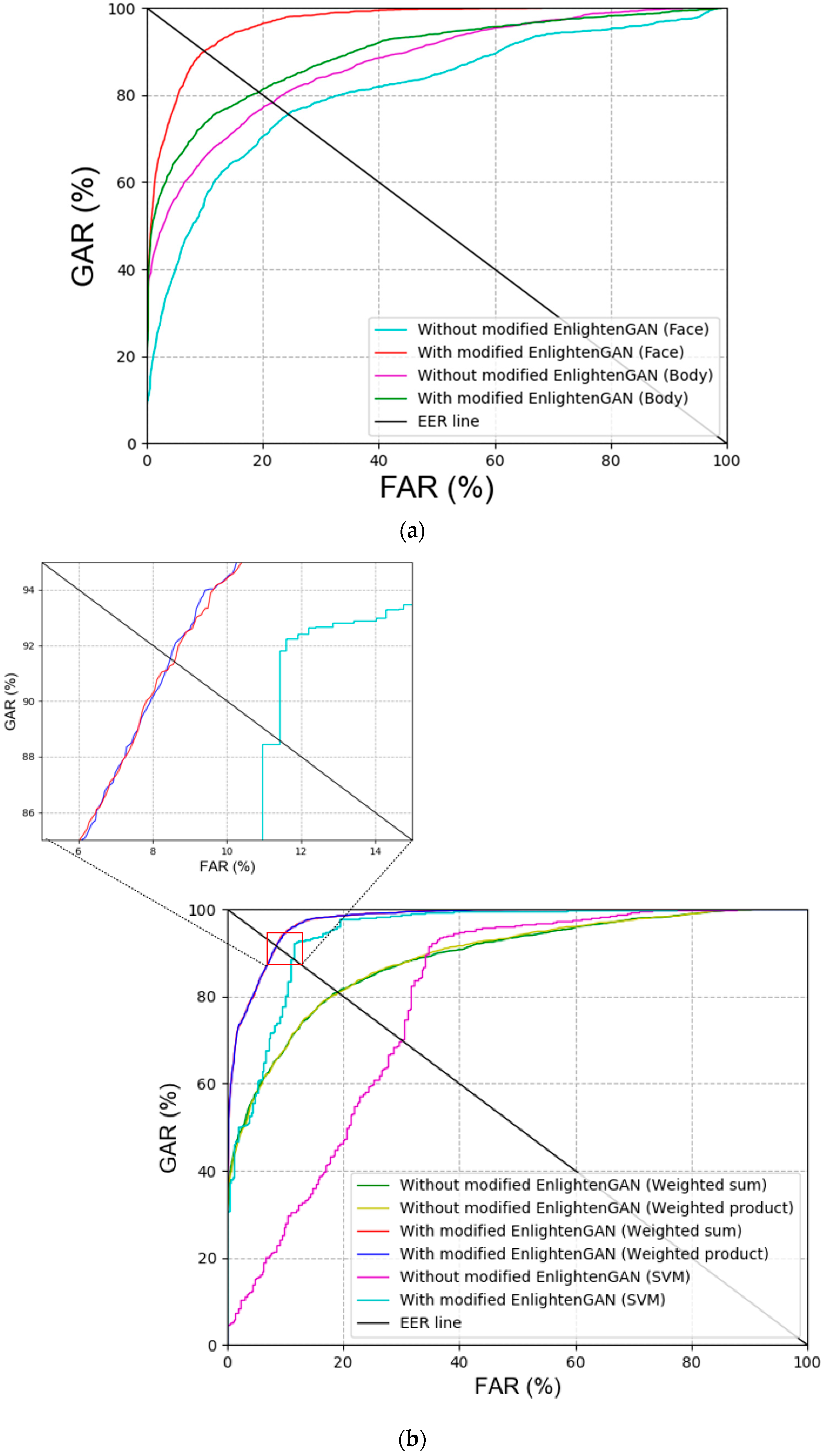
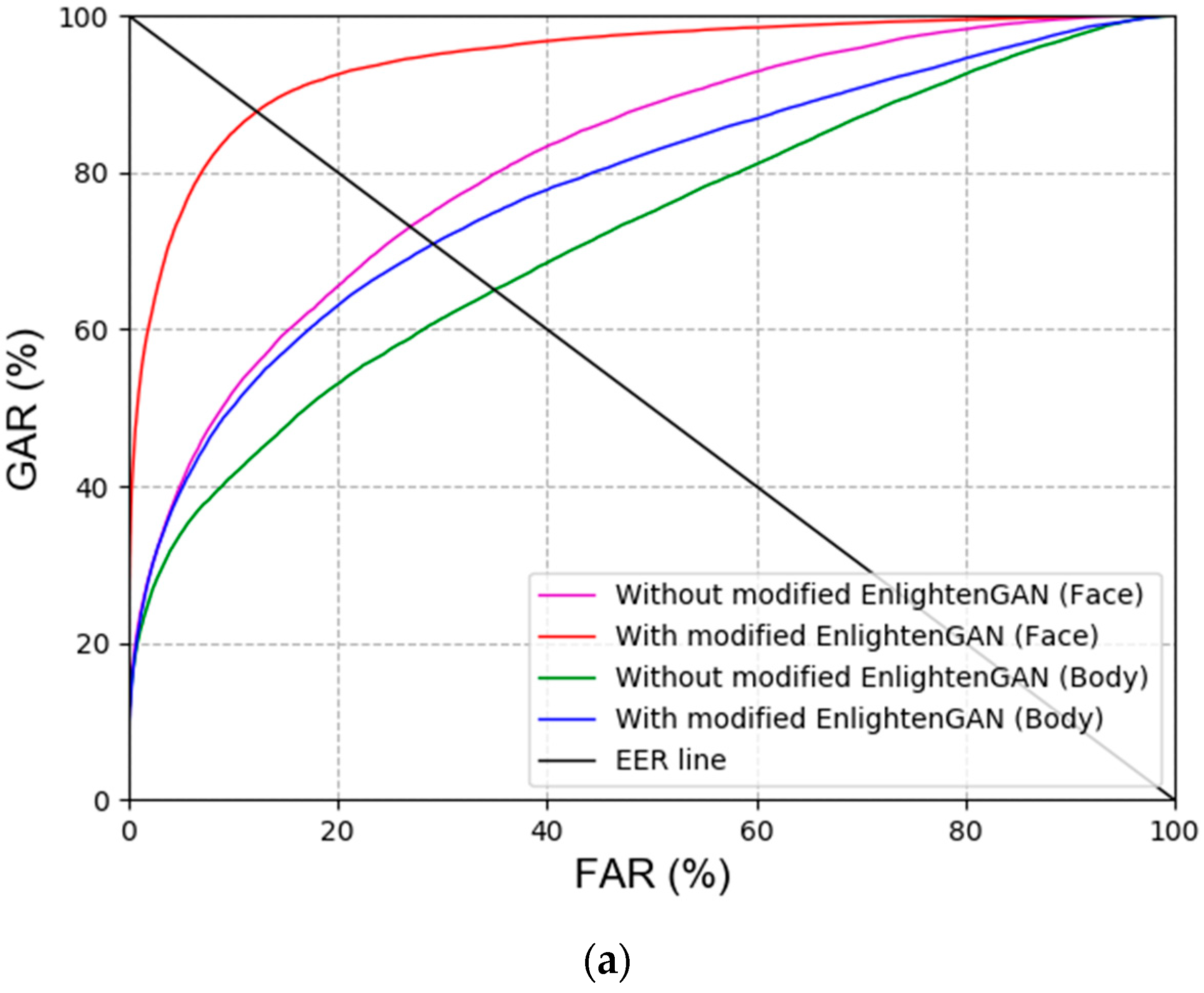
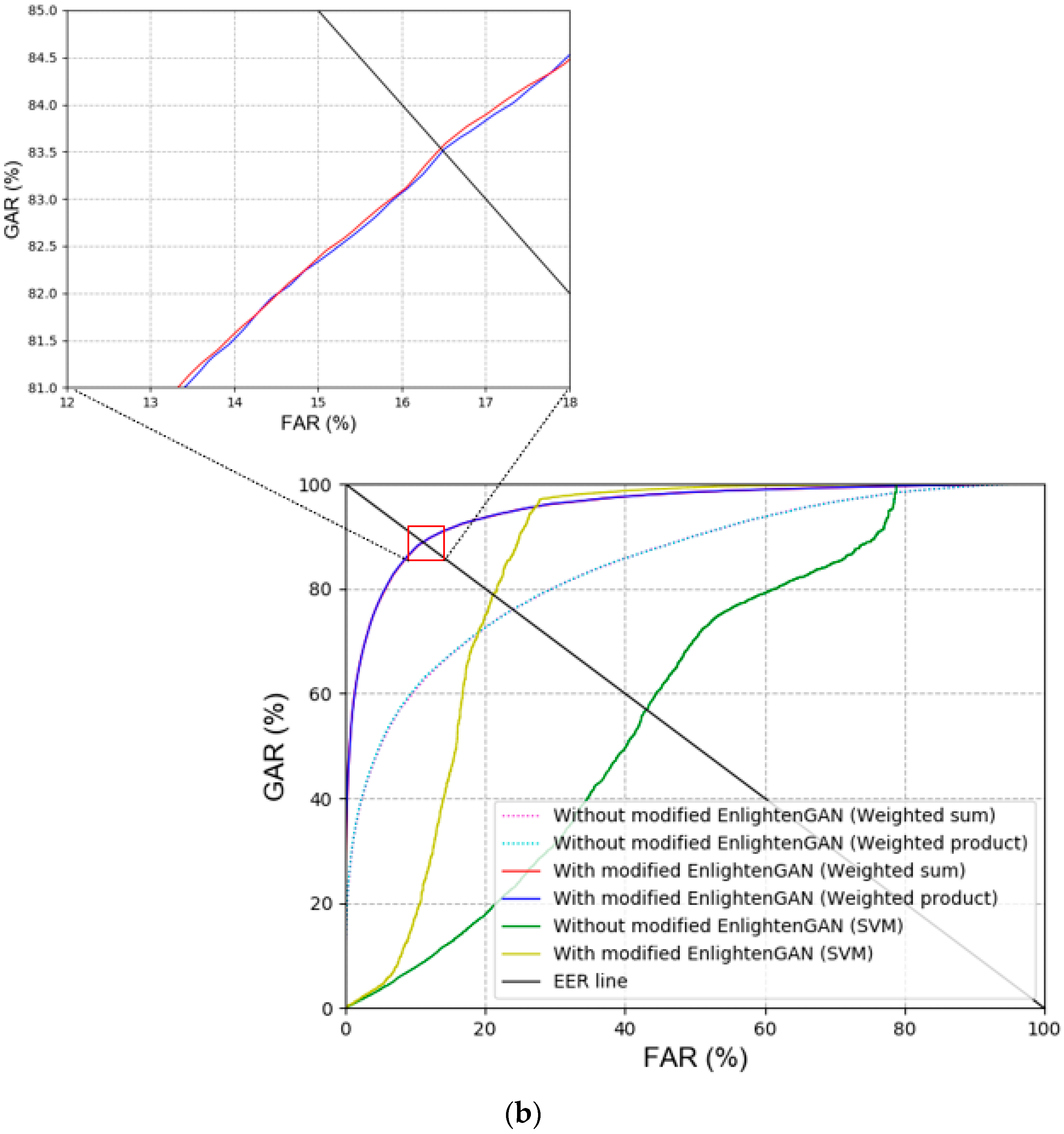
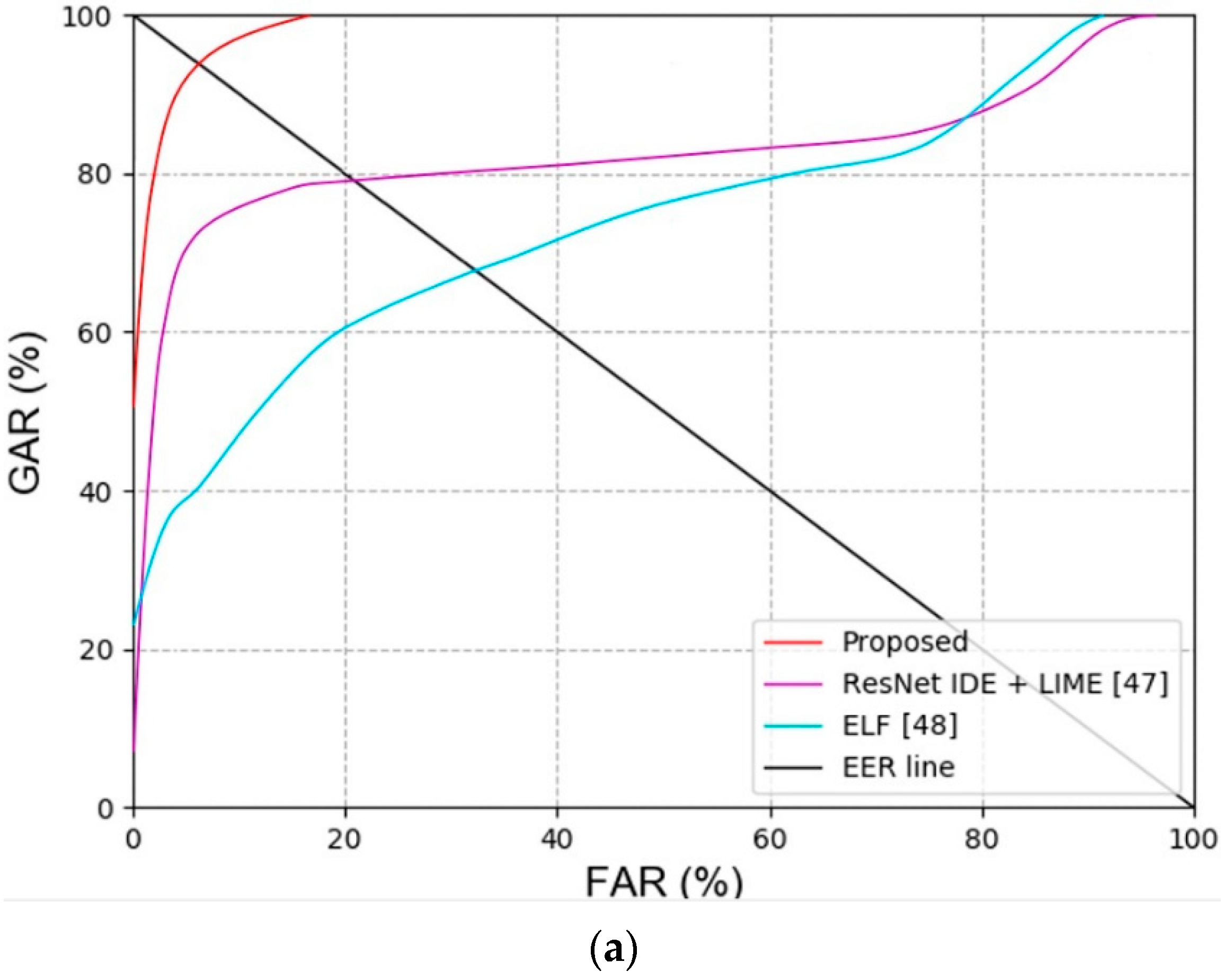
Figure 8.
ROC curves of recognition accuracies with or without modified EnlightenGAN. Results of (a) face and body recognition, and (b) various score-level fusions.
Figure 8.
ROC curves of recognition accuracies with or without modified EnlightenGAN. Results of (a) face and body recognition, and (b) various score-level fusions.
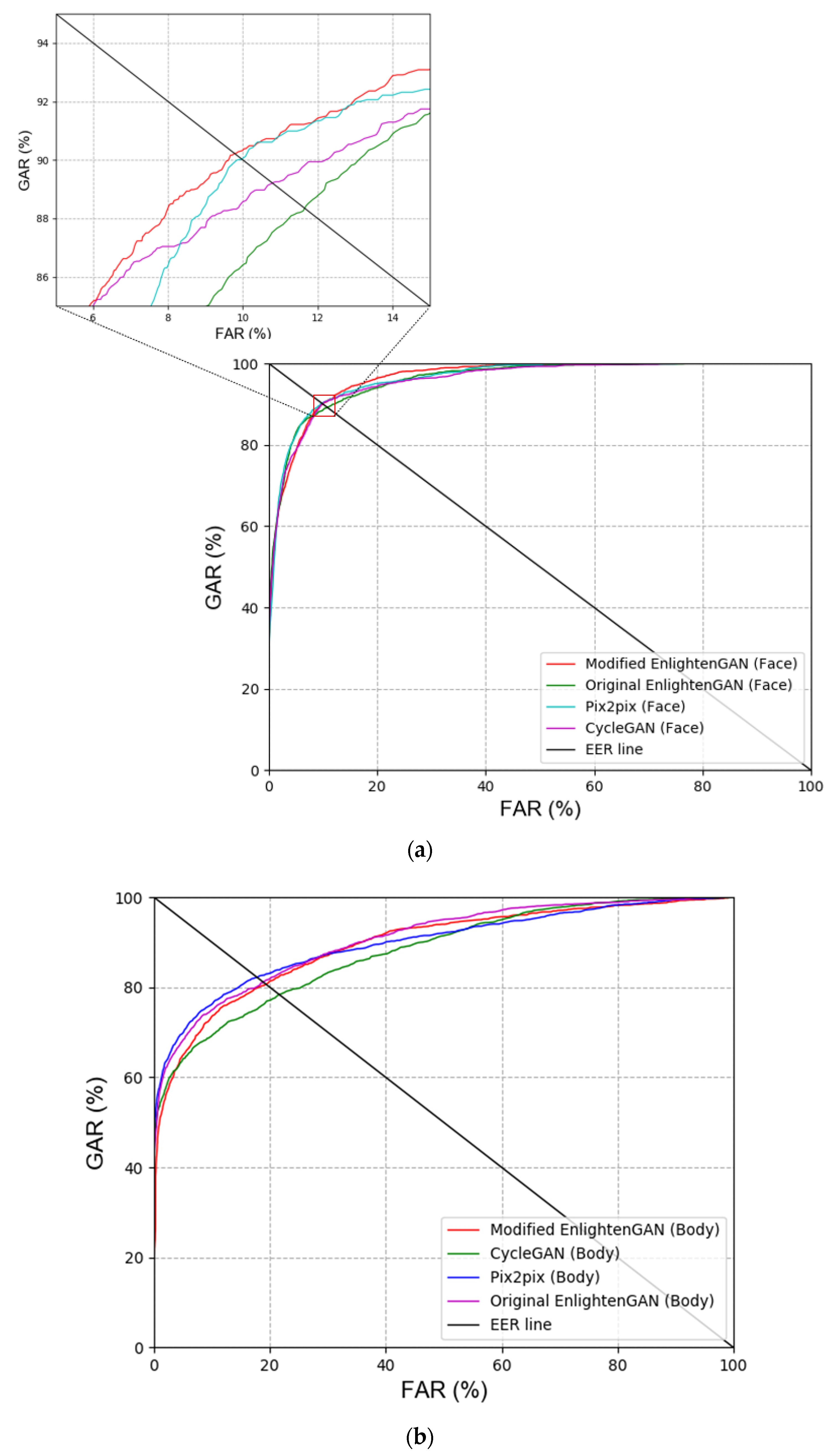
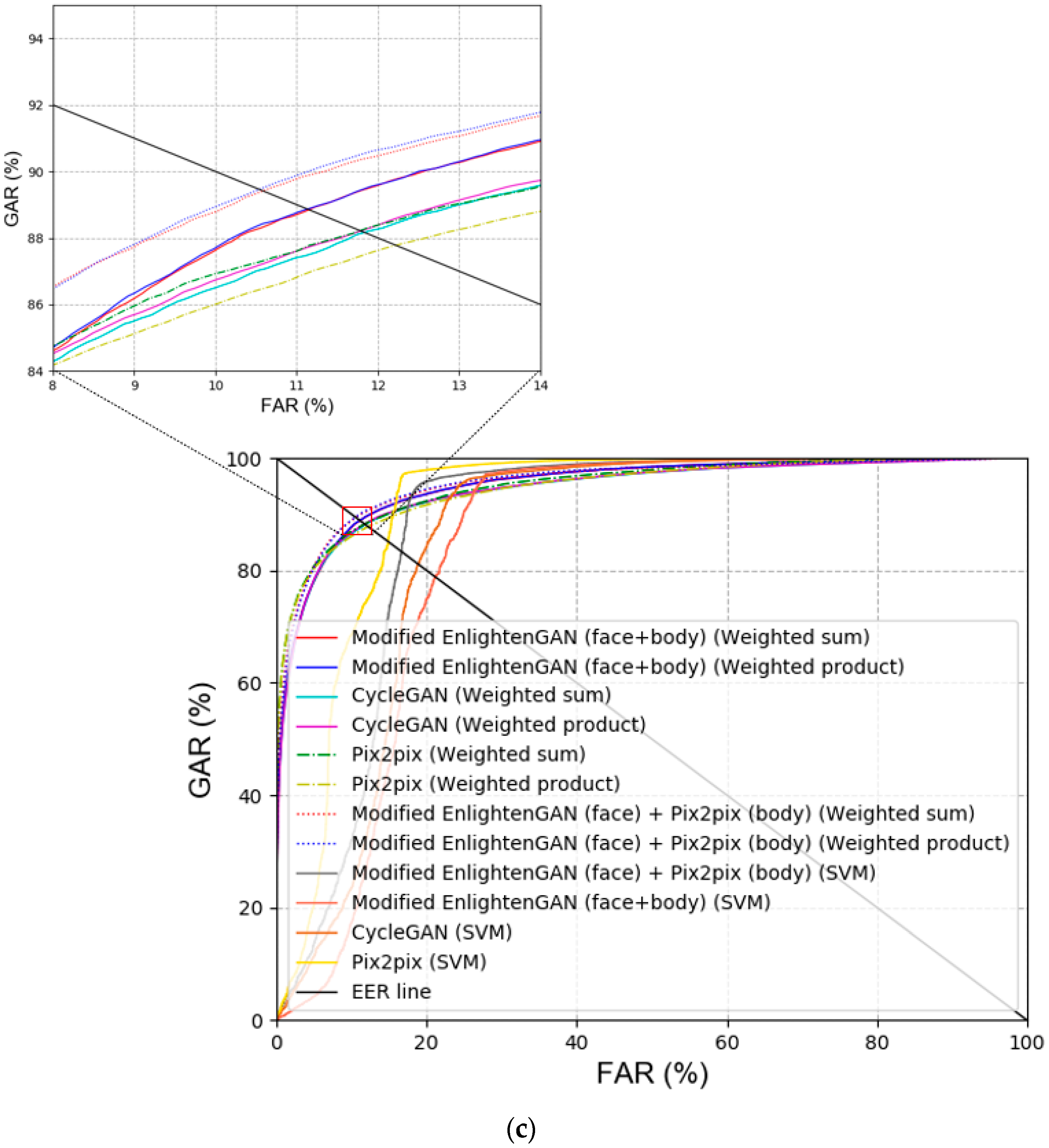
Figure 9.
Graph for ROC curves acquired using our method and the previous GAN-based techniques. (a,b) Recognition results for face and body images, and (c) score-level fusion result.
Figure 9.
Graph for ROC curves acquired using our method and the previous GAN-based techniques. (a,b) Recognition results for face and body images, and (c) score-level fusion result.
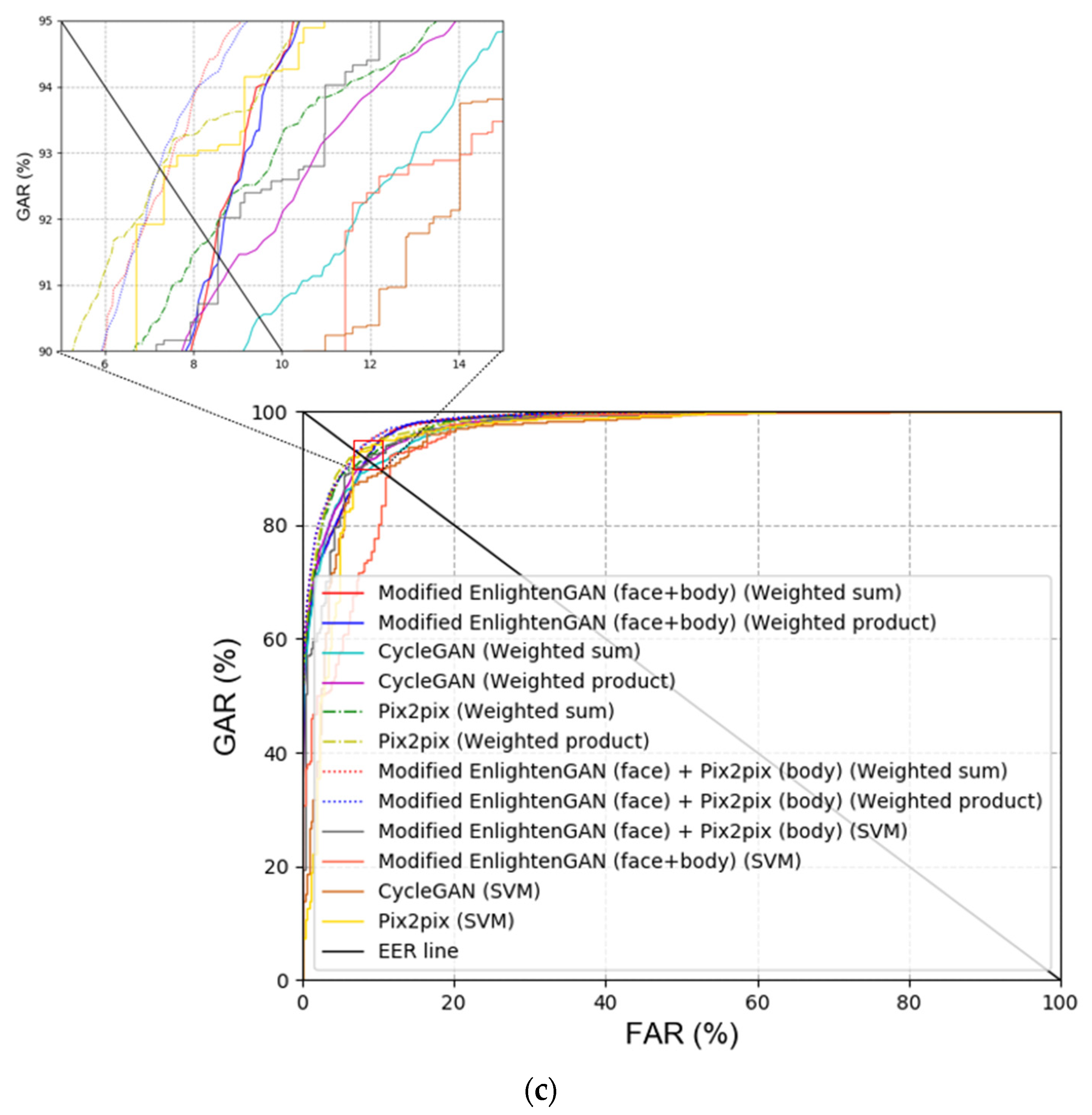
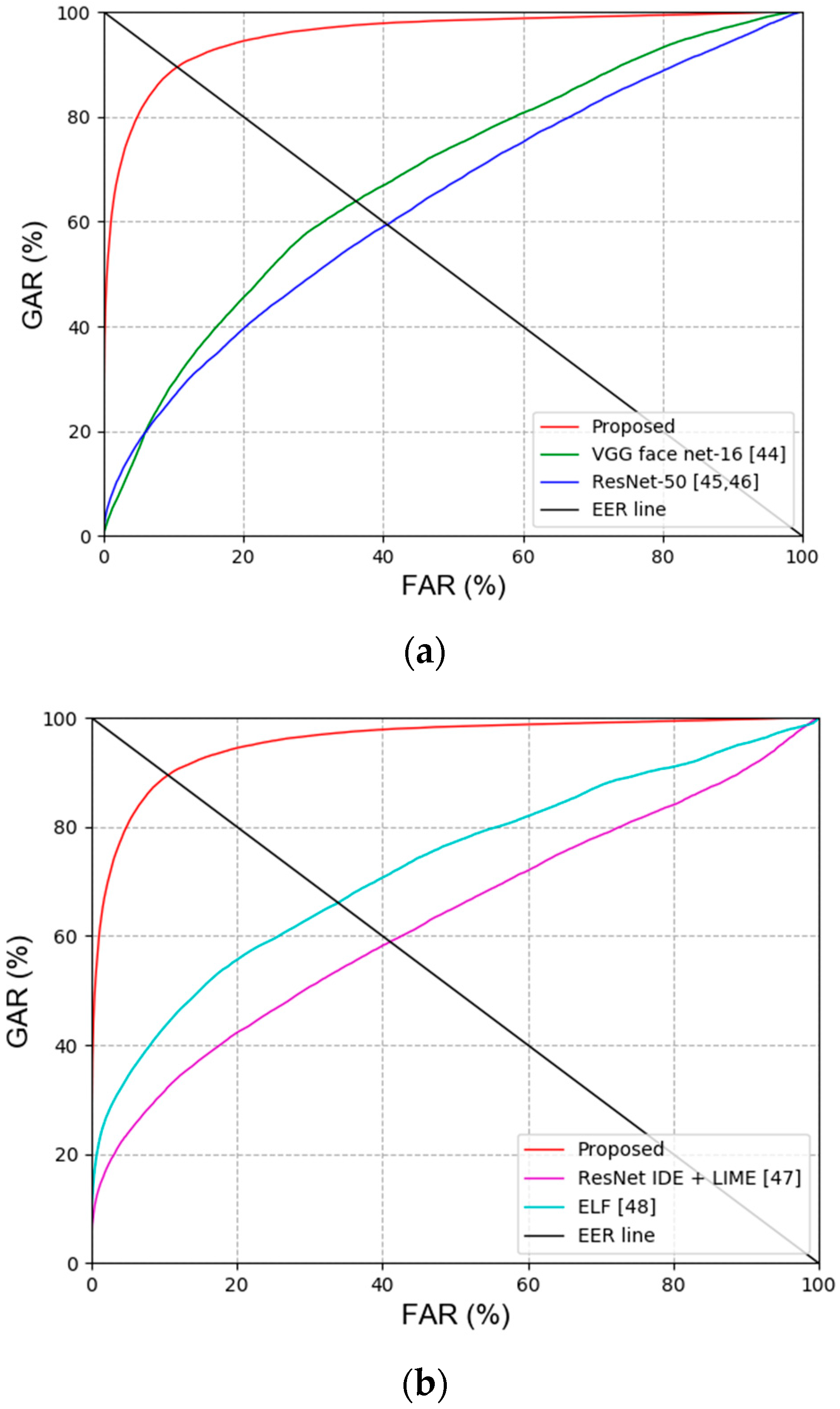
Figure 10.
ROC curves acquired by the previous methods and proposed method. (a) Recognition results for face image, and (b) recognition results for body and face image.
Figure 10.
ROC curves acquired by the previous methods and proposed method. (a) Recognition results for face image, and (b) recognition results for body and face image.
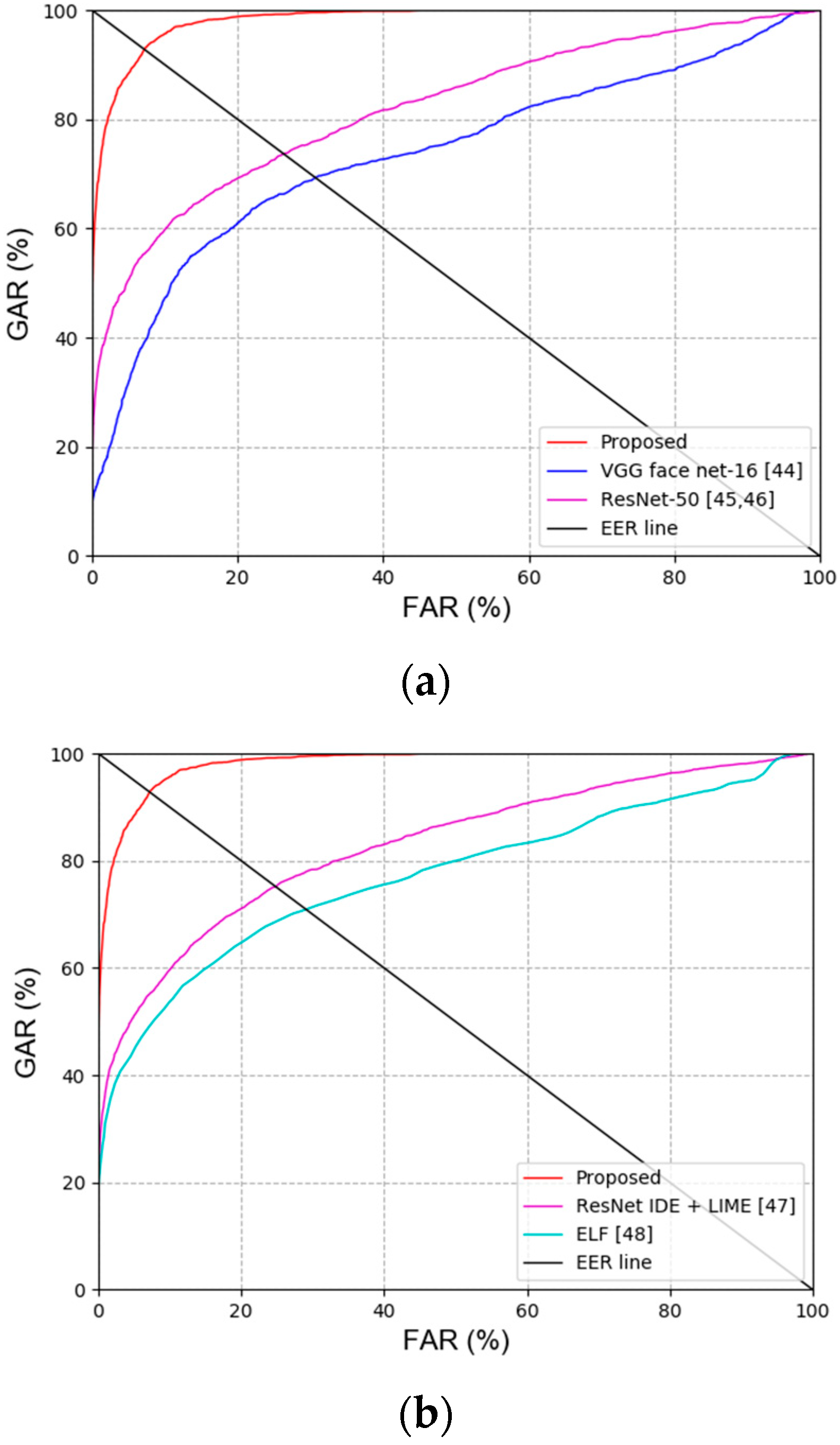
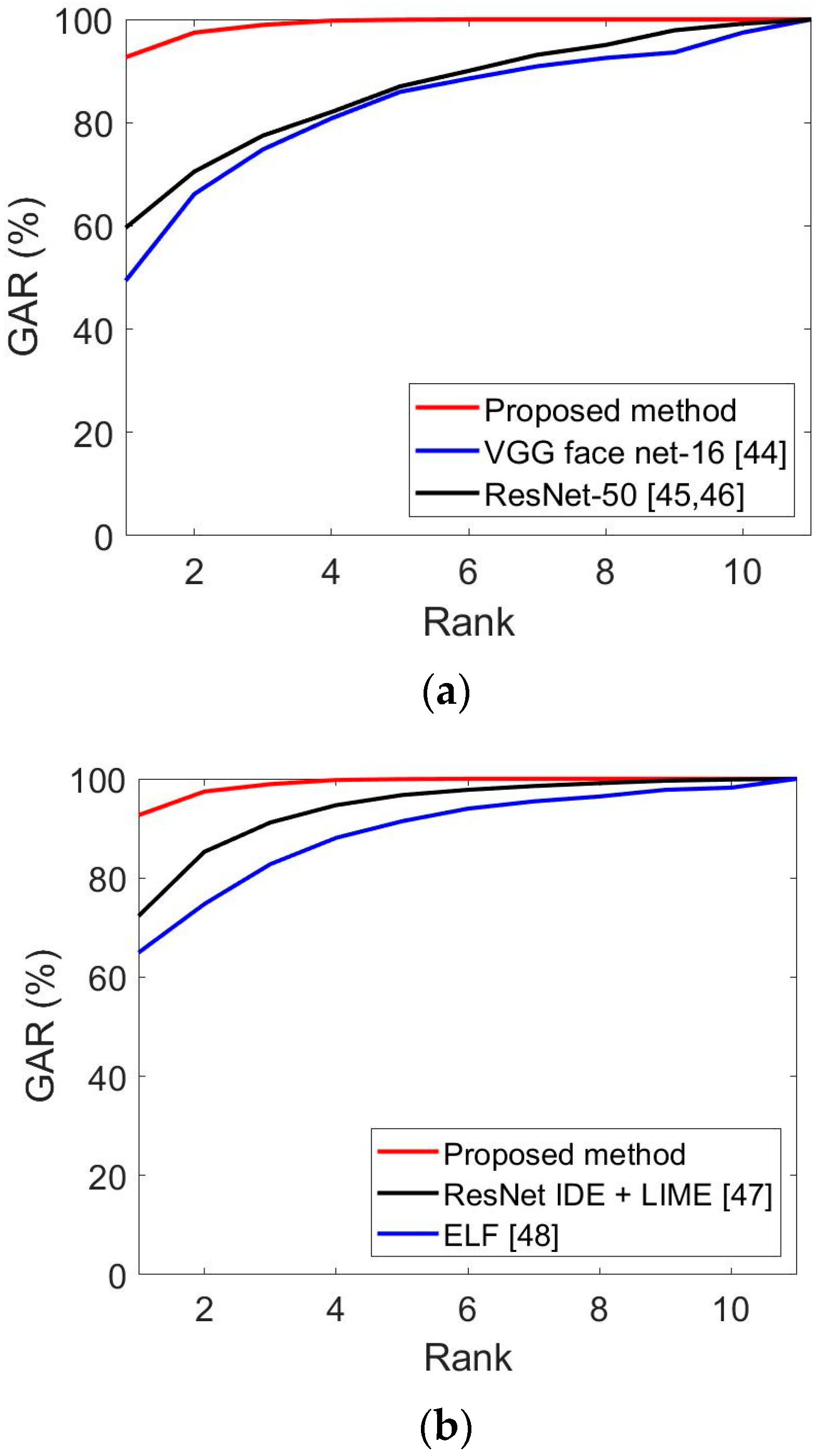
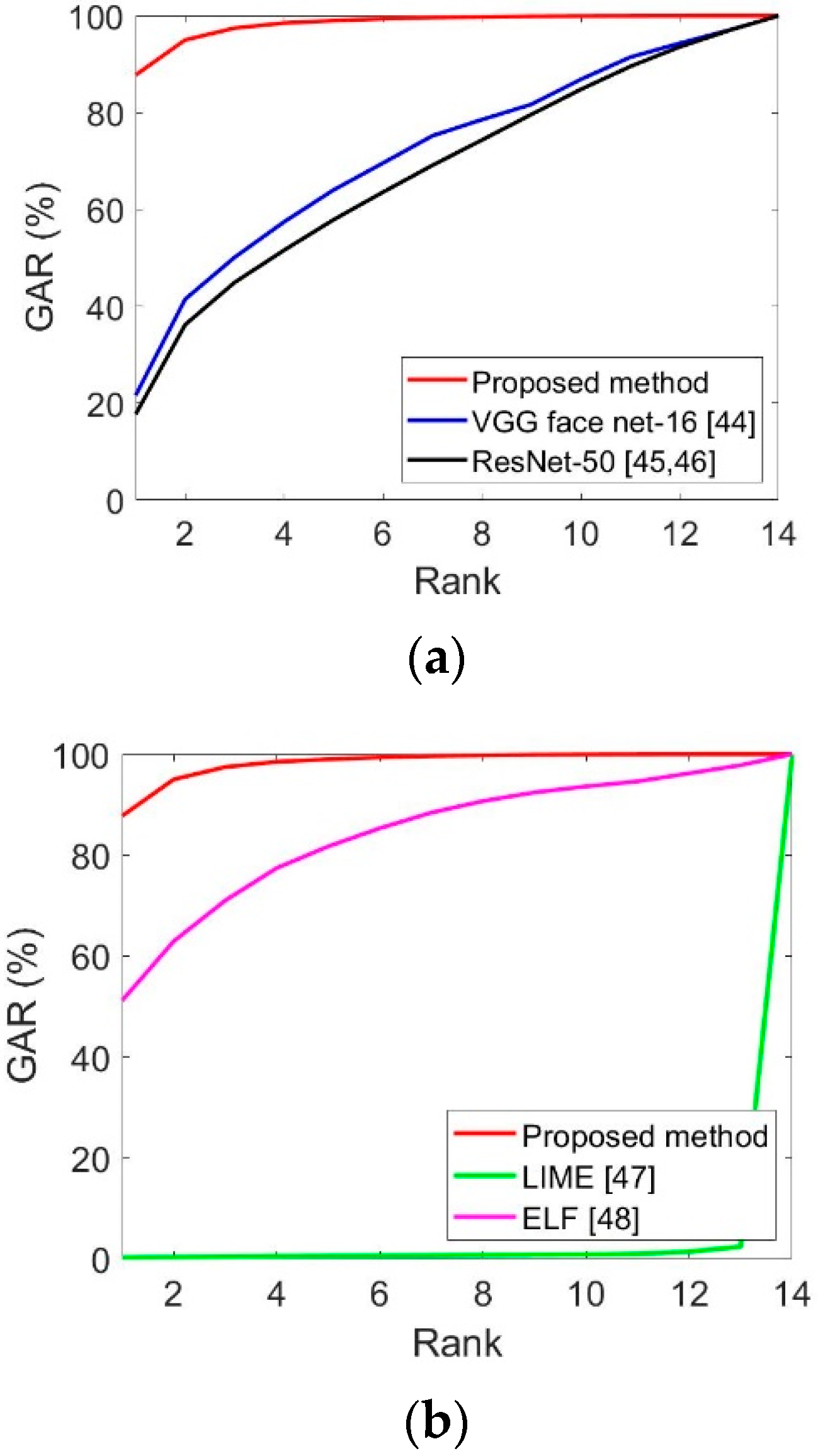
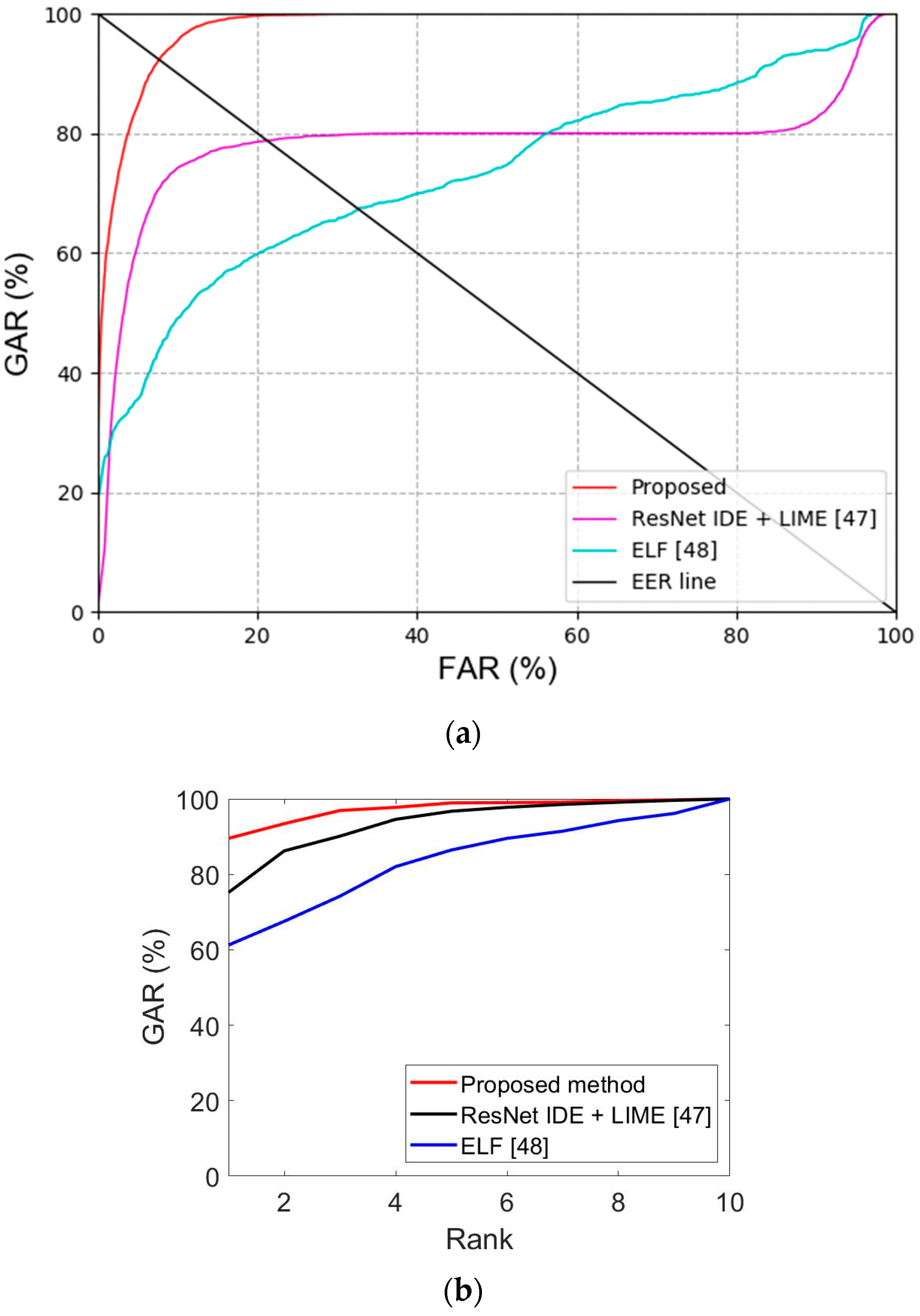
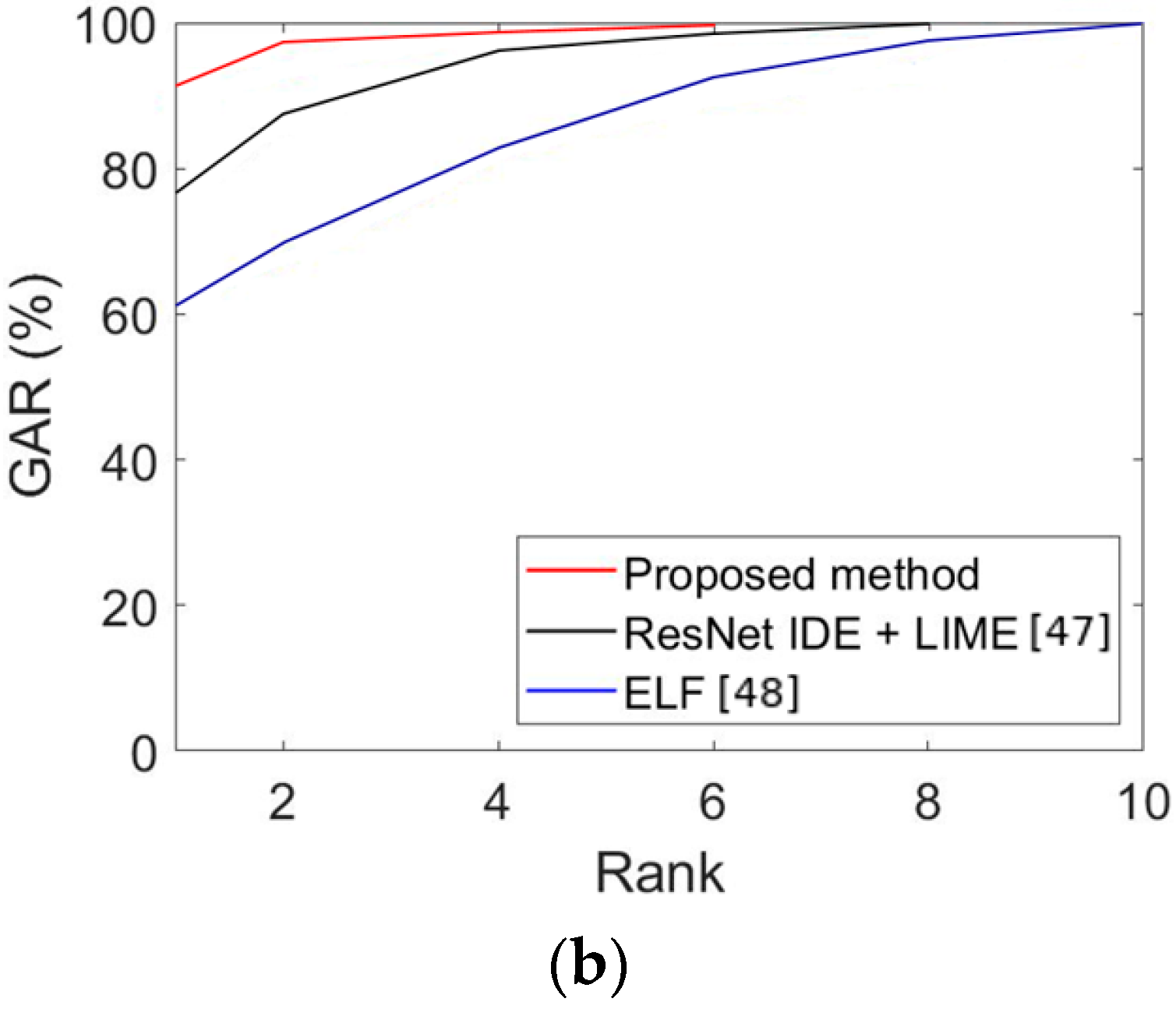
Figure 11.
CMC curves of the proposed and state-of-the-art methods. (a) Face recognition results obtained by the proposed and state-of-the-art methods, and (b) face and body recognition results obtained by the proposed and state-of-the-art methods.
Figure 11.
CMC curves of the proposed and state-of-the-art methods. (a) Face recognition results obtained by the proposed and state-of-the-art methods, and (b) face and body recognition results obtained by the proposed and state-of-the-art methods.
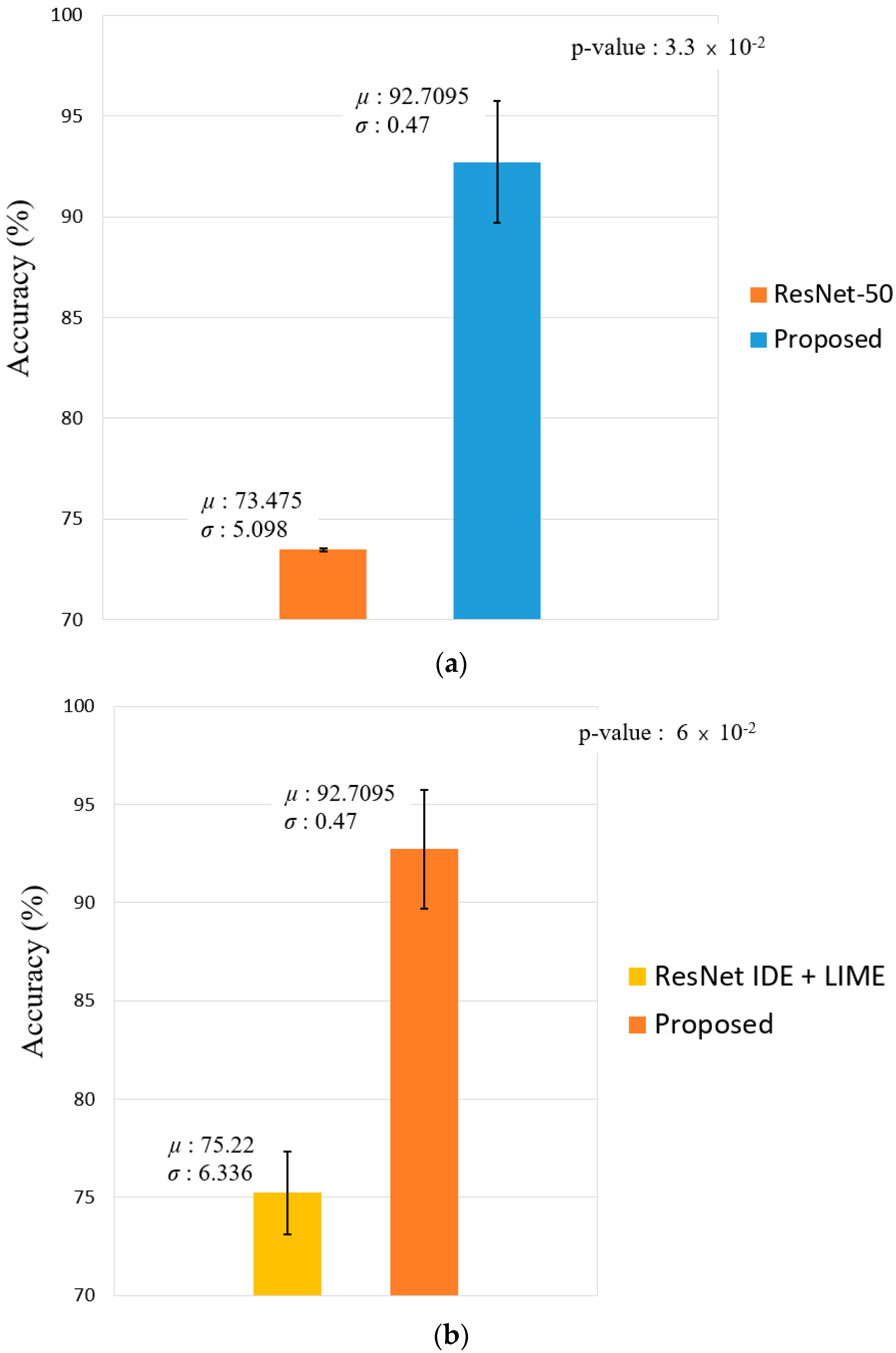
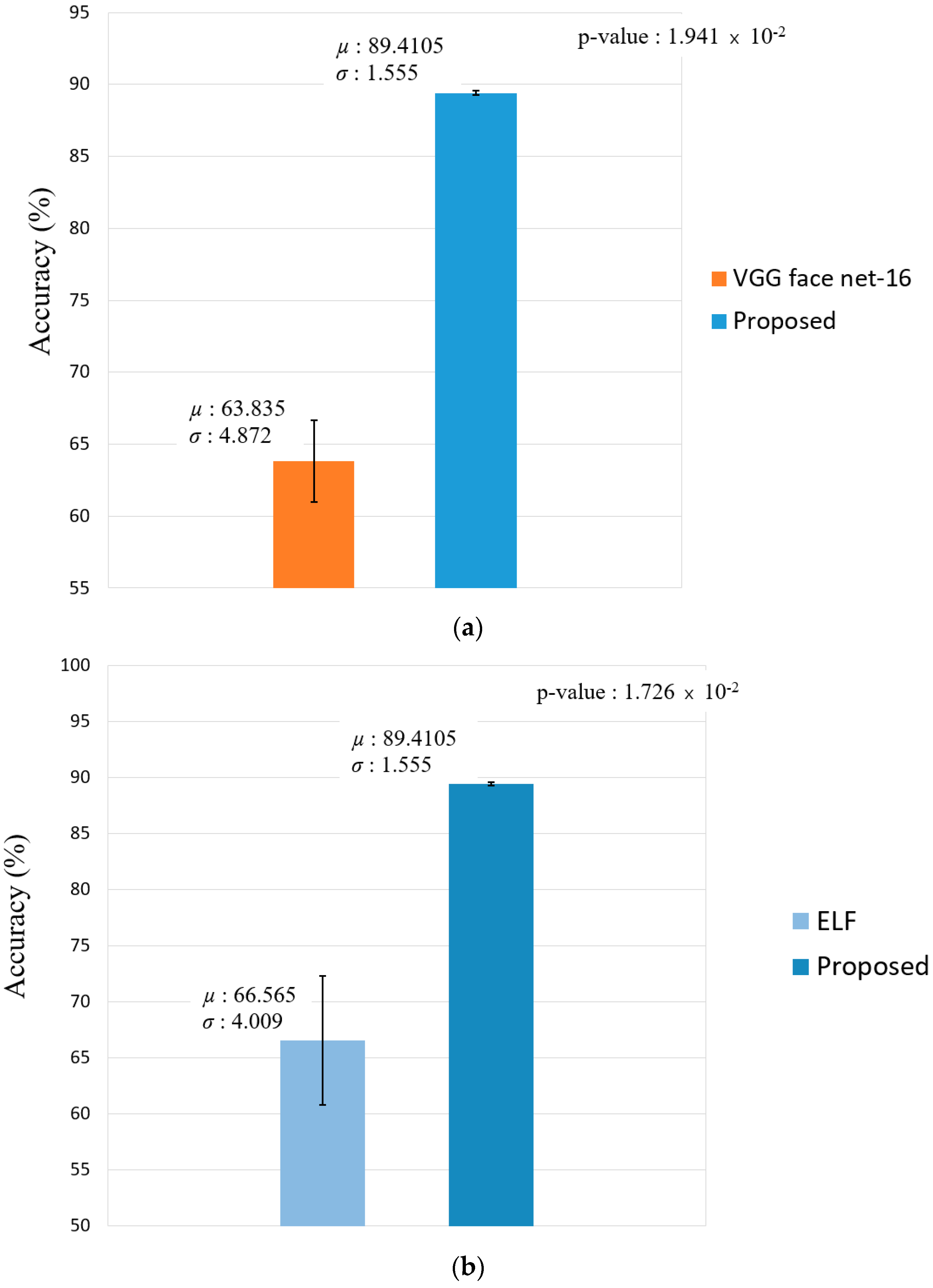
Figure 12.
Graphs for t-test result between the second best model and our proposed method with respect to accuracy of average recognition. (a) Comparison between ResNet-50 and the proposed method, and (b) comparison between ResNet IDE + LIME and the proposed method.
Figure 12.
Graphs for t-test result between the second best model and our proposed method with respect to accuracy of average recognition. (a) Comparison between ResNet-50 and the proposed method, and (b) comparison between ResNet IDE + LIME and the proposed method.
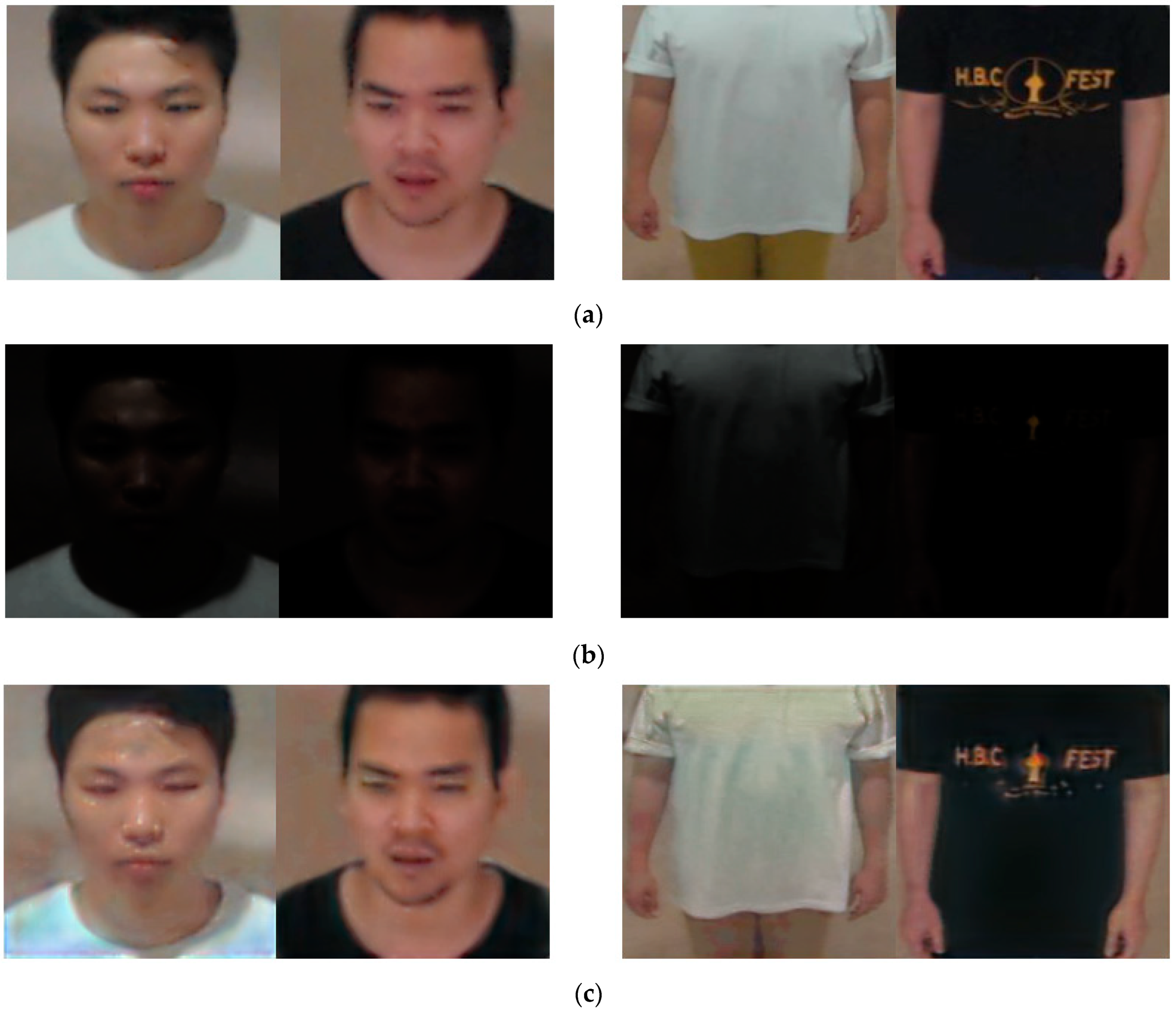
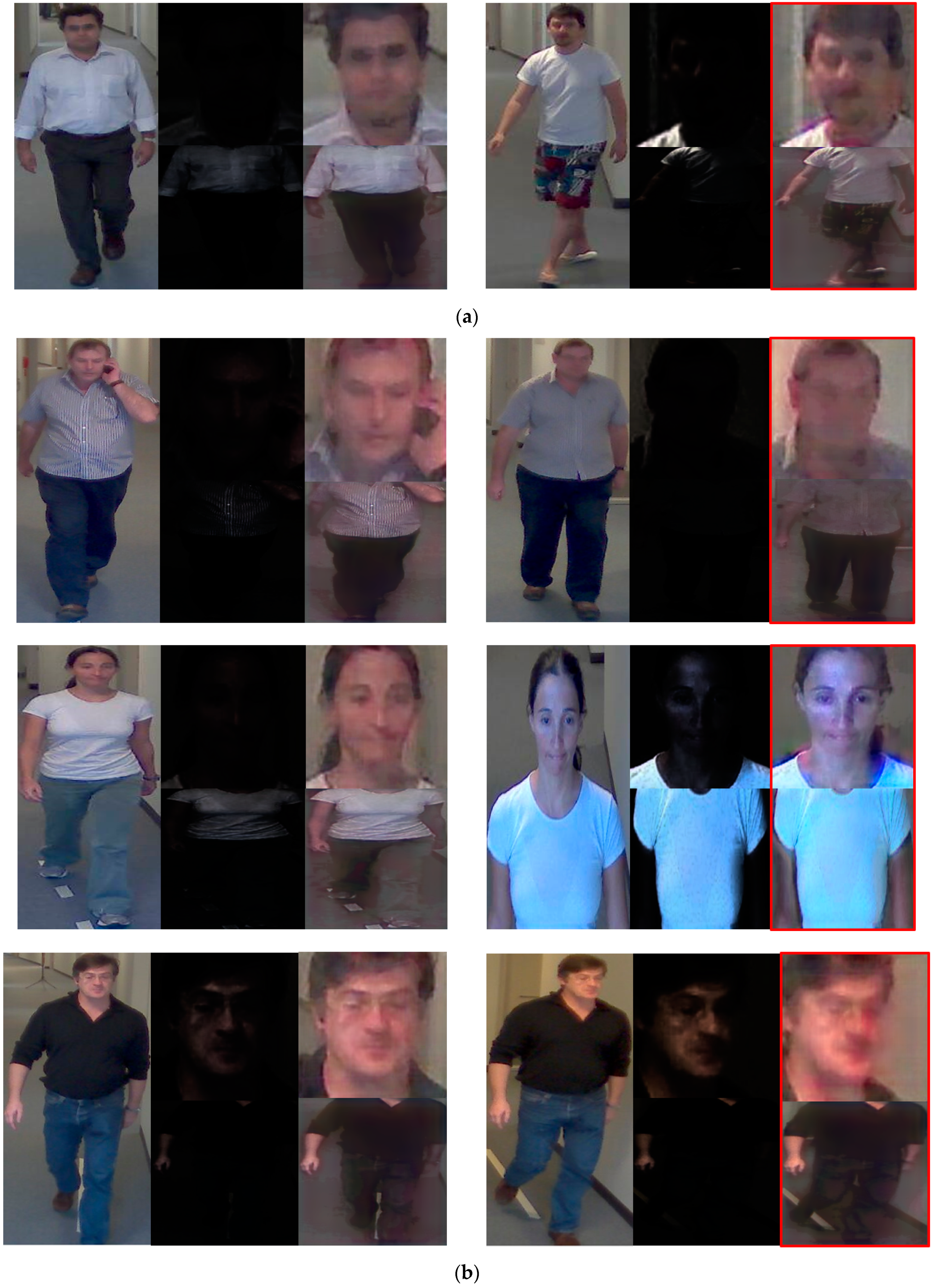
Figure 13.
Cases of FA, FR, and correction recognition. (a) Cases of FA, (b) cases of FR, and (c) correct cases. In (a–c), left and right images are enrolled and recognized images, respectively.
Figure 13.
Cases of FA, FR, and correction recognition. (a) Cases of FA, (b) cases of FR, and (c) correct cases. In (a–c), left and right images are enrolled and recognized images, respectively.
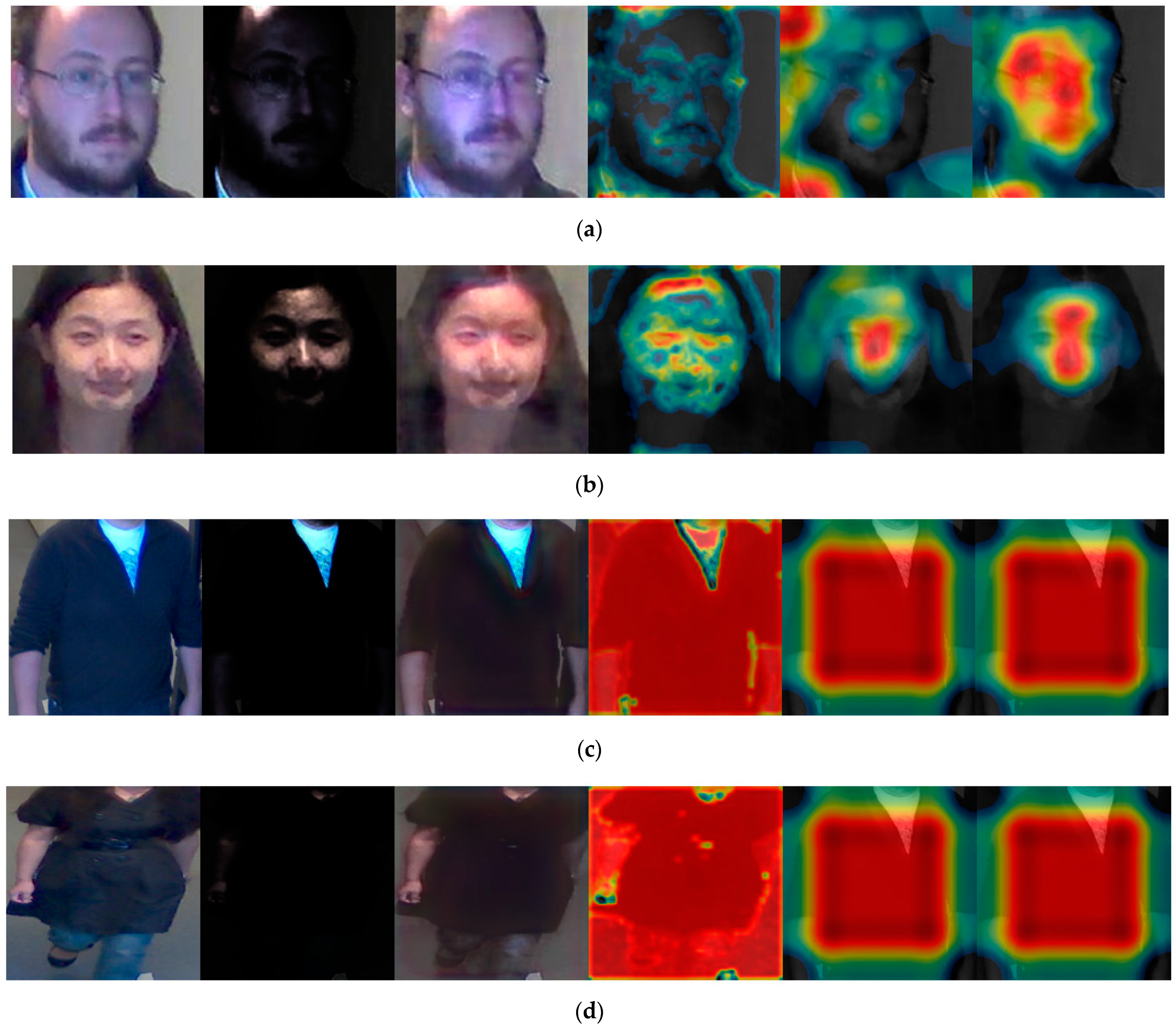
Figure 14.
Results on class activation feature map of DFB-DB3. (a,b) are the activation map results from face images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 7th ReLU layer, result from 12th ReLU layer, and result from 13th ReLU layer of VGG face-net 16. (c,d) are the activation map results from body images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 3rd batch-normalized layer, result from conv5 2nd block, and result from conv5 3rd block of ResNet-50.
Figure 14.
Results on class activation feature map of DFB-DB3. (a,b) are the activation map results from face images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 7th ReLU layer, result from 12th ReLU layer, and result from 13th ReLU layer of VGG face-net 16. (c,d) are the activation map results from body images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 3rd batch-normalized layer, result from conv5 2nd block, and result from conv5 3rd block of ResNet-50.
Figure 15.
ROC curves of recognition accuracies with and without modified EnlightenGAN. Results of (a) face and body recognition, and (b) various score-level fusions.
Figure 15.
ROC curves of recognition accuracies with and without modified EnlightenGAN. Results of (a) face and body recognition, and (b) various score-level fusions.
Figure 16.
ROC curves acquired by our proposed method and previous GAN-based methods. (a,b) Recognition results for face and body images, and (c) score-level fusion result.
Figure 16.
ROC curves acquired by our proposed method and previous GAN-based methods. (a,b) Recognition results for face and body images, and (c) score-level fusion result.
Figure 17.
ROC curves acquired using the proposed method and the previous methods. (a) Results for face recognition, and (b) results for body and face recognition.
Figure 17.
ROC curves acquired using the proposed method and the previous methods. (a) Results for face recognition, and (b) results for body and face recognition.
Figure 18.
CMC curves of the proposed and state-of-the-art methods. (a) Face recognition results obtained by the proposed and state-of-the-art methods, and (b) face and body recognition results obtained by the proposed and state-of-the-art methods.
Figure 18.
CMC curves of the proposed and state-of-the-art methods. (a) Face recognition results obtained by the proposed and state-of-the-art methods, and (b) face and body recognition results obtained by the proposed and state-of-the-art methods.
Figure 19.
Graphs for
t-test result of the second best model and our proposed method with regard to average recognition accuracy. (
a) Comparison of VGG face net-16 [
44] and the proposed method, and (
b) comparison of the proposed method and ELF [
48].
Figure 19.
Graphs for
t-test result of the second best model and our proposed method with regard to average recognition accuracy. (
a) Comparison of VGG face net-16 [
44] and the proposed method, and (
b) comparison of the proposed method and ELF [
48].
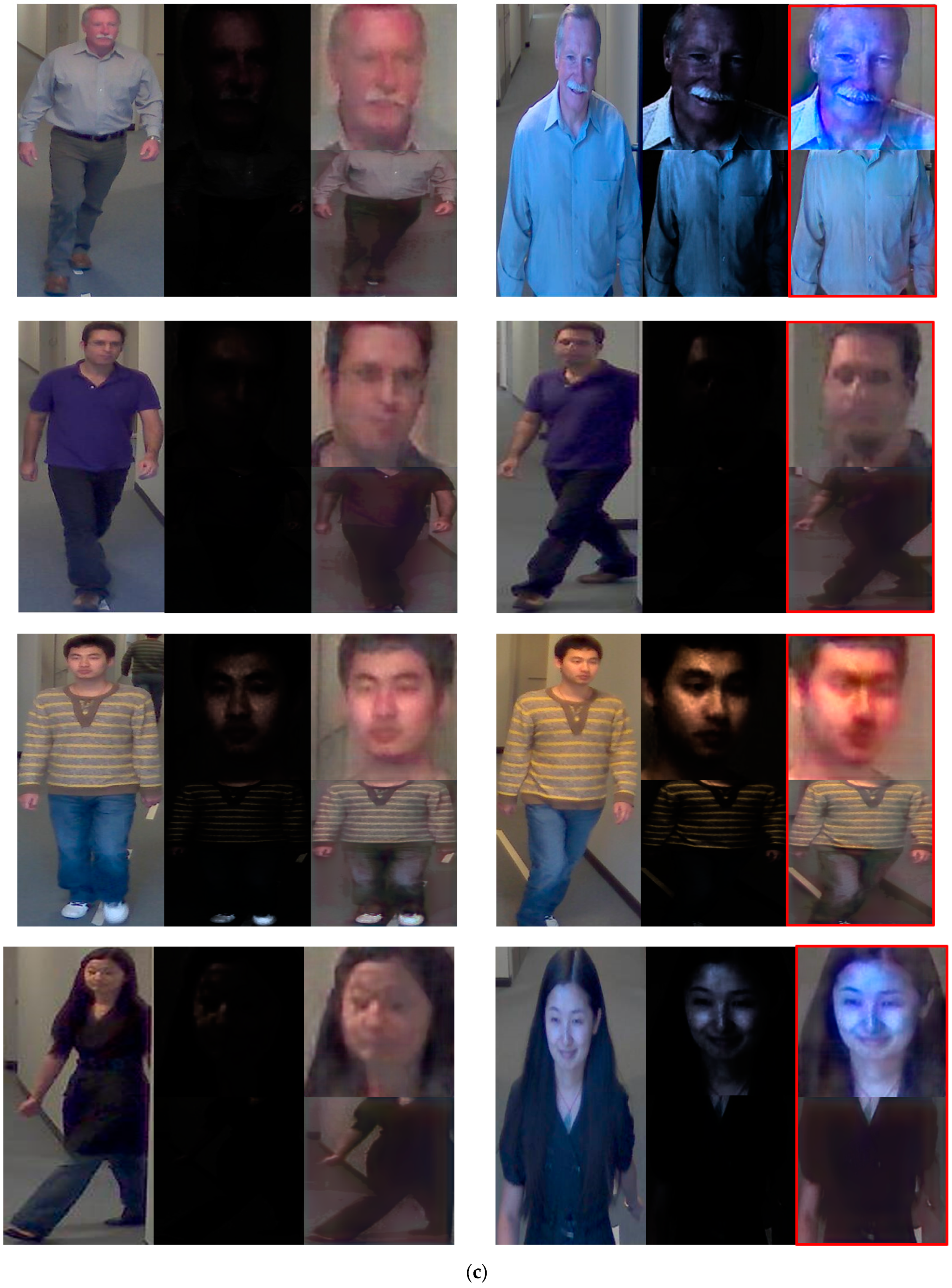
Figure 20.
Cases of FA, FR, and correction recognition on ChokePoint database [
34]. (
a) Cases of FA, (
b) cases of FR, and (
c) correct cases. In (
a–
c), the left and right images are enrolled and recognized images, respectively.
Figure 20.
Cases of FA, FR, and correction recognition on ChokePoint database [
34]. (
a) Cases of FA, (
b) cases of FR, and (
c) correct cases. In (
a–
c), the left and right images are enrolled and recognized images, respectively.
Figure 21.
Results on class activation feature map on ChokePoint dataset [
34]. (
a,
b) are activation map results from face images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 7th ReLU layer, result from 12th ReLU layer, and result from 13th ReLU layer of VGG face-net 16. (
c,
d) are activation map results from body images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 3rd batch-normalized layer, result from conv5 2nd block, and result from conv5 3rd block of ResNet-50.
Figure 21.
Results on class activation feature map on ChokePoint dataset [
34]. (
a,
b) are activation map results from face images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 7th ReLU layer, result from 12th ReLU layer, and result from 13th ReLU layer of VGG face-net 16. (
c,
d) are activation map results from body images. From the left image to the right image: original image, low-illumination image, enhancement image from modified EnlightenGAN, result from 3rd batch-normalized layer, result from conv5 2nd block, and result from conv5 3rd block of ResNet-50.
Figure 22.
Examples of original images captured in real low-light environments.
Figure 22.
Examples of original images captured in real low-light environments.
Figure 23.
Comparisons of (a) ROC and (b) CMC curves obtained by proposed method and state-of-the-art-methods.
Figure 23.
Comparisons of (a) ROC and (b) CMC curves obtained by proposed method and state-of-the-art-methods.
Figure 24.
Example of an original image from an open database captured in a real low-light environment.
Figure 24.
Example of an original image from an open database captured in a real low-light environment.
Figure 25.
Comparisons of (a) ROC and (b) CMC curves obtained by the proposed method and state-of-the-art-methods with an open database.
Figure 25.
Comparisons of (a) ROC and (b) CMC curves obtained by the proposed method and state-of-the-art-methods with an open database.
Figure 26.
Jetson TX2 embedded system.
Figure 26.
Jetson TX2 embedded system.
Table 1.
Overview of the previous studies and the proposed method about low-illumination multimodal human recognition.
Table 1.
Overview of the previous studies and the proposed method about low-illumination multimodal human recognition.
| Type | Techniques | Strength | Weakness |
|---|
| Not considering low-illumination condition | Face recognition | PCA [1] | Good recognition performance when images are captured up close | Recognition performance may be degraded owing to external light |
| SML-MKFC with DA [2] |
| Texture- and shape-based body recognition | S-CNN [3] | Requires less data for recognition compared to gait-based recognition | Recognition performance may be degraded in a low-illumination environment |
| CNN+DDML [4] |
| Gait-based body recognition | Synthetic GEI, PCA + MDA [5] | Recognition performance less affected by low illumination | Requires an extended period of time to obtain gait data |
| Gait-based body and face recognition | HMM/Gabor feature-based EBGM [6] |
| Body and face recognition based on texture and shape | ResNet-50 and VGG face net-16
[7] | Takes relatively less time to acquire data compared to gait-based recognition | Possibility of clothes color being changed owing to lighting changes or losing important facial features |
| Considering low-illumination condition | Face recognition | MPEf and fMPE [10] | Able to perform face recognition in a low-illumination condition | Did not consider face and body recognition in a very low illumination environment |
| FRN [11] |
Gradientfaces
[12,13] |
| DCT and local normalized method [14] |
| DoG filter and adaptive nonlinear function [15] |
| DeLFN [16] |
| Homomorphic filter and image multiplication [17] |
| Face and body recognition | Proposed method | Recognition possible in a very low illumination environment | Requires more time to process face and body recognition data |
Table 2.
Generator of modified EnlightenGAN (all the convolution blocks include one convolutional layer, one Leaky rectified linear unit (ReLU) layer, and one batch normalization layer, except for the last convolution block, which includes one convolutional layer and one Leaky ReLU layer).
Table 2.
Generator of modified EnlightenGAN (all the convolution blocks include one convolutional layer, one Leaky rectified linear unit (ReLU) layer, and one batch normalization layer, except for the last convolution block, which includes one convolutional layer and one Leaky ReLU layer).
| Type of Layer | Feature Map Sizes
(Height × Width × Channel) | Number of Filters | Filter Sizes | Number of Strides | Number of Paddings |
|---|
| Input image layer | 224 × 224 × 3 | | | | |
| Attention map layer | 224 × 224 × 1 | | | | |
| Concatenated layer | 224 × 224 × 4 | | | | |
| Convolution block1 | 224 × 224 × 32 | 32 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block2 | 224 × 224 × 32 | 32 | 3 × 3 | 1 × 1 | 1 × 1 |
| Maxpooling layer1 | 112 × 112 × 32 | | 2 × 2 | 2 × 2 | |
| Convolution block3 | 112 × 112 × 64 | 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block4 | 112 × 112 × 64 | 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Maxpooling layer2 | 56 × 56 × 64 | | 2 × 2 | 2 × 2 | |
| Convolution block5 | 56 × 56 × 128 | 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block6 | 56 × 56 × 128 | 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Maxpooling layer3 | 28 × 28 × 128 | | 2 × 2 | 2 × 2 | |
| Convolution block7 | 28 × 28 × 256 | 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block8 | 28 × 28 × 256 | 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Maxpooling layer4 | 14 × 14 × 256 | | 2 × 2 | 2 × 2 | |
| Convolution block9 | 14 × 14 × 512 | 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block10 | 14 × 14 × 512 | 512 | 3 × 3 | 1 × 1 | 1 × 1 |
| Deconvolution block1 | 28 × 28 × 256 | 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block11 | 28 × 28 × 256 | 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block12 | 28 × 28 × 256 | 256 | 3 × 3 | 1 × 1 | 1 × 1 |
| Deconvolution block2 | 56 × 56 × 128 | 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block13 | 56 × 56 × 128 | 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block14 | 56 × 56 × 128 | 128 | 3 × 3 | 1 × 1 | 1 × 1 |
| Deconvolution block3 | 112 × 112 × 64 | 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block15 | 112 × 112 × 64 | 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block16 | 112 × 112 × 64 | 64 | 3 × 3 | 1 × 1 | 1 × 1 |
| Deconvolution block4 | 224 × 224 × 32 | 32 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block17 | 224 × 224 × 32 | 32 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution block18 | 224 × 224 × 32 | 32 | 3 × 3 | 1 × 1 | 1 × 1 |
| Convolution layer (Output layer) | 224 × 224 × 3 | 3 | 1 × 1 | 1 × 1 | |
Table 3.
Global discriminator of modified EnlightenGAN (convolution blocks through 1~6 include one convolutional layer and one Leaky ReLU layer).
Table 3.
Global discriminator of modified EnlightenGAN (convolution blocks through 1~6 include one convolutional layer and one Leaky ReLU layer).
| Type of Layer | Feature Map Sizes
(Height × Width × Channel) | Number of Filters | Filter Sizes | Number of Strides | Number of Paddings |
|---|
| Input image layer | 224 × 224 × 3 | | | | |
| Target image layer | 224 × 224 × 3 | | | | |
| Convolution block1 | 113 × 113 × 64 | 64 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block2 | 58 × 58 × 128 | 128 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block3 | 30 × 30 × 256 | 256 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block4 | 16 × 16 × 512 | 512 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block5 | 9 × 9 × 512 | 512 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block6 | 10 × 10 × 512 | 512 | 4 × 4 | 1 × 1 | 2 × 2 |
| Convolution layer | 11 × 11 × 1 | 1 | 4 × 4 | 1 × 1 | 2 × 2 |
Table 4.
Local discriminator of modified EnlightenGAN (convolution blocks through 1~5 include one convolutional layer and one Leaky ReLU layer).
Table 4.
Local discriminator of modified EnlightenGAN (convolution blocks through 1~5 include one convolutional layer and one Leaky ReLU layer).
| Type of Layer | Feature Map Sizes
(Height × Width × Channel) | Number of Filters | Filter Sizes | Number of Strides | Number of Paddings |
|---|
| Layer of input image | 40 × 40 × 3 | | | | |
| Layer of target image | 40 × 40 × 3 | | | | |
| Convolution block1 | 21 × 21 × 64 | 64 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block2 | 12 × 12 × 128 | 128 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block3 | 7 × 7 × 256 | 256 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block4 | 5 × 5 × 256 | 512 | 4 × 4 | 2 × 2 | 2 × 2 |
| Convolution block5 | 6 × 6 × 512 | 512 | 4 × 4 | 1 × 1 | 2 × 2 |
| Convolution layer | 7 × 7 × 1 | 1 | 4 × 4 | 1 × 1 | 2 × 2 |
Table 5.
Overall images of ChokePoint dataset and DFB-DB3.
Table 5.
Overall images of ChokePoint dataset and DFB-DB3.
| | DFB-DB3 | ChokePoint Dataset |
|---|
| Number of Each Fold Class | Number of Testing Images | Number of Augmented Training Images | Number of Each Fold Class | Number of Testing Images | Number of Augmented Training Images |
|---|
| Face | Sub-Dataset1 | 11 | 827 | 200,134 | 14 | 10,381 | 332,192 |
| Sub-Dataset2 | 11 | 989 | 239,338 | 14 | 10,269 | 328,608 |
| Body | Sub-Dataset1 | 11 | 827 | 200,134 | 14 | 10,381 | 332,192 |
| Sub-Dataset2 | 11 | 989 | 239,338 | 14 | 10,269 | 328,608 |
Table 6.
Performance comparisons with enhanced images by modified EnlightenGAN according to the number of patches in the discriminator.
Table 6.
Performance comparisons with enhanced images by modified EnlightenGAN according to the number of patches in the discriminator.
| Method | Number of Patches | Face | Body |
|---|
| SNR | 5 | 15.532 | 14.172 |
| 8 | 19.294 | 15.343 |
| 11 | 11.237 | 11.2 |
| PSNR | 5 | 24.42 | 23.533 |
| 8 | 28.181 | 24.704 |
| 11 | 20.125 | 20.61 |
| SSIM | 5 | 0.78 | 0.703 |
| 8 | 0.896 | 0.769 |
| 11 | 0.727 | 0.697 |
Table 7.
Performance comparisons with enhanced images by original EnlightenGAN or modified EnlightenGAN.
Table 7.
Performance comparisons with enhanced images by original EnlightenGAN or modified EnlightenGAN.
| Method | Original EnlightenGAN [24] | Modified EnlightenGAN |
|---|
| Face | Body | Face | Body |
|---|
| SNR | 19.59 | 18.852 | 19.294 | 15.343 |
| PSNR | 28.478 | 28.213 | 28.181 | 24.704 |
| SSIM | 0.895 | 0.849 | 0.896 | 0.769 |
Table 8.
Comparisons of EER for face and body recognition with or without modified EnlightenGAN (unit: %).
Table 8.
Comparisons of EER for face and body recognition with or without modified EnlightenGAN (unit: %).
| Method | Face | Body |
|---|
| Without modified EnlightenGAN | 1st fold | 20.22 | 22.08 |
| 2nd fold | 29.32 | 21.32 |
| Average | 24.77 | 21.7 |
| With modified EnlightenGAN | 1st fold | 11.21 | 19 |
| 2nd fold | 8.44 | 19.76 |
| Average | 9.825 | 19.38 |
Table 9.
Comparisons of EER for score-level fusion with or without modified EnlightenGAN (unit: %).
Table 9.
Comparisons of EER for score-level fusion with or without modified EnlightenGAN (unit: %).
| Method | Score-Level Fusion |
|---|
| SVM | Weighted Product | Weighted Sum |
|---|
| Without modified EnlightenGAN | 1st fold | 33.62 | 16.979 | 17.077 |
| 2nd fold | 25.73 | 21.605 | 21.345 |
| Average | 29.675 | 19.292 | 19.211 |
| With modified EnlightenGAN | 1st fold | 11.552 | 8.805 | 8.848 |
| 2nd fold | 11.51 | 7.735 | 7.812 |
| Average | 11.531 | 8.27 | 8.33 |
Table 10.
Comparisons of EERs using our proposed method with those using state-of-the-art GAN-based methods (unit: %).
Table 10.
Comparisons of EERs using our proposed method with those using state-of-the-art GAN-based methods (unit: %).
| Method | 1st Fold | 2nd Fold | Average |
|---|
| Face | Modified EnlightenGAN | 11.21 | 8.44 | 9.825 |
| Original EnlightenGAN [24] | 12.51 | 8.53 | 10.52 |
| CycleGAN [23] | 14.2 | 6.47 | 10.335 |
| Pix2pix [22] | 12.26 | 7.7 | 9.98 |
| Body | Modified EnlightenGAN | 19 | 19.76 | 19.38 |
| Original EnlightenGAN [24] | 18.52 | 19.47 | 18.995 |
| CycleGAN [23] | 21.89 | 21.38 | 21.635 |
| Pix2pix [22] | 17.04 | 18.39 | 17.715 |
| Weighted sum | Modified EnlightenGAN (face) + Pix2pix (body) | 7.819 | 7.034 | 7.427 |
| Modified EnlightenGAN (face and body) | 8.848 | 7.812 | 8.33 |
| CycleGAN [23] | 12.067 | 5.866 | 8.967 |
| Pix2pix [22] | 10.466 | 5.506 | 7.986 |
| Weighted product | Modified EnlightenGAN (face) + Pix2pix (body) | 7.623 | 6.958 | 7.291 |
| Modified EnlightenGAN (face and body) | 8.805 | 7.735 | 8.27 |
| CycleGAN [23] | 10.767 | 5.659 | 8.213 |
| Pix2pix [22] | 9.35 | 5.399 | 7.375 |
| SVM | Modified EnlightenGAN (face) + Pix2pix (body) | 9.72 | 7.12 | 8.42 |
| Modified EnlightenGAN (face and body) | 11.552 | 11.51 | 11.531 |
| CycleGAN [23] | 13.32 | 6.57 | 9.945 |
| Pix2pix [22] | 9.08 | 5.9 | 7.49 |
Table 11.
Comparison of EERs using the proposed method and the previous face recognition methods (unit: %).
Table 11.
Comparison of EERs using the proposed method and the previous face recognition methods (unit: %).
| Method | 1st Fold | 2nd Fold | Average |
|---|
| Proposed method | 7.623 | 6.958 | 7.291 |
| VGG face net-16 [44] | 25.21 | 35.59 | 30.4 |
| ResNet-50 [45,46] | 22.92 | 30.13 | 26.525 |
Table 12.
Comparison of EERs using the proposed method and the previous body and face recognition techniques (unit: %).
Table 12.
Comparison of EERs using the proposed method and the previous body and face recognition techniques (unit: %).
| Method | 1st Fold | 2nd Fold | Average |
|---|
| ResNet IDE + LIME [47] | 20.3 | 29.26 | 24.78 |
| ELF [48] | 28.02 | 30.07 | 29.045 |
| Proposed method | 7.623 | 6.958 | 7.291 |
Table 13.
Comparisons of EER for face and body recognition with and without modified EnlightenGAN (unit: %).
Table 13.
Comparisons of EER for face and body recognition with and without modified EnlightenGAN (unit: %).
| Method | Face | Body |
|---|
| Without modified EnlightenGAN | 1st fold | 25.5 | 38.06 |
| 2nd fold | 28.49 | 32.07 |
| Average | 26.995 | 35.065 |
| With modified EnlightenGAN | 1st fold | 13.25 | 28.96 |
| 2nd fold | 11.47 | 25.94 |
| Average | 12.36 | 27.45 |
Table 14.
Comparisons of EER for score-level fusion with and without modified EnlightenGAN (unit: %).
Table 14.
Comparisons of EER for score-level fusion with and without modified EnlightenGAN (unit: %).
| Method | Score-Level Fusion |
|---|
| Weighted Sum | Weighted Product | SVM |
|---|
| Without modified EnlightenGAN | 1st fold | 24.44 | 24.4 | 40.16 |
| 2nd fold | 23.52 | 23.47 | 40.02 |
| Average | 23.98 | 23.935 | 40.09 |
| With modified EnlightenGAN | 1st fold | 12.59 | 12.542 | 23.82 |
| 2nd fold | 19.83 | 19.928 | 17.16 |
| Average | 16.21 | 16.235 | 20.49 |
Table 15.
Comparisons of EERs obtained using our proposed method with those obtained using state-of-the-art GAN-based methods (unit: %).
Table 15.
Comparisons of EERs obtained using our proposed method with those obtained using state-of-the-art GAN-based methods (unit: %).
| Method | 1st Fold | 2nd Fold | Average |
|---|
| Face | Modified EnlightenGAN | 13.25 | 11.47 | 12.36 |
| Original EnlightenGAN [24] | 12.88 | 15.17 | 14.025 |
| CycleGAN [23] | 15.87 | 11.11 | 13.49 |
| Body | Modified EnlightenGAN | 28.96 | 25.94 | 27.45 |
| Original EnlightenGAN [24] | 25.01 | 23.86 | 24.435 |
| CycleGAN [23] | 27.16 | 29.56 | 28.36 |
| Weighted sum | Modified EnlightenGAN (face) + Pix2pix (body) | 11.821 | 9.54 | 10.681 |
| Modified EnlightenGAN (face and body) | 12.59 | 9.92 | 11.255 |
| CycleGAN [23] | 13.69 | 10.32 | 12.005 |
| Pix2pix [22] | 9.835 | 13.43 | 11.633 |
| Weighted product | Modified EnlightenGAN (face) + Pix2pix (body) | 11.689 | 9.49 | 10.59 |
| Modified EnlightenGAN (face and body) | 12.542 | 9.87 | 11.206 |
| CycleGAN [23] | 13.59 | 10.23 | 11.91 |
| Pix2pix [22] | 9.843 | 14.31 | 12.08 |
| SVM | Modified EnlightenGAN (face) + Pix2pix (body) | 17.17 | 15.51 | 16.34 |
| Modified EnlightenGAN (face and body) | 23.82 | 17.16 | 20.49 |
| CycleGAN [23] | 21.15 | 16.83 | 18.99 |
| Pix2pix [22] | 15.86 | 8.76 | 12.31 |
Table 16.
Comparisons of EERs obtained using proposed method and state-of-the-art face recognition methods (unit: %).
Table 16.
Comparisons of EERs obtained using proposed method and state-of-the-art face recognition methods (unit: %).
| Method | 1st Fold | 2nd Fold | Average |
|---|
| Proposed method | 11.689 | 9.49 | 10.59 |
| VGG face net-16 [44] | 32.72 | 39.61 | 36.165 |
| ResNet-50 [45,46] | 39.94 | 41.21 | 40.575 |
Table 17.
Comparisons of EERs obtained using proposed method and state-of-the-art body and face recognition techniques (unit: %).
Table 17.
Comparisons of EERs obtained using proposed method and state-of-the-art body and face recognition techniques (unit: %).
| Method | 1st Fold | 2nd Fold | Average |
|---|
| ResNet IDE + LIME [47] | 30.88 | 49.47 | 40.175 |
| ELF [48] | 36.27 | 30.6 | 33.435 |
| Proposed method | 11.689 | 9.49 | 10.59 |
Table 18.
Comparison of EERs using the proposed method and state-of-the-art body and face recognition methods (unit: %).
Table 18.
Comparison of EERs using the proposed method and state-of-the-art body and face recognition methods (unit: %).
| Method | EER |
|---|
| ResNet IDE + LIME [47] | 21.17 |
| ELF [48] | 32.65 |
| Proposed method | 7.39 |
Table 19.
Comparison of EERs using the proposed method and state-of-the-art face and body recognition methods with an open database (unit: %).
Table 19.
Comparison of EERs using the proposed method and state-of-the-art face and body recognition methods with an open database (unit: %).
| Method | EER |
|---|
| ResNet IDE + LIME [47] | 22.54 |
| ELF [48] | 31.78 |
| Proposed method | 7.32 |
Table 20.
Comparison of desktop computer and Jetson TX2 processing times by EnlightenGAN (unit: ms).
Table 20.
Comparison of desktop computer and Jetson TX2 processing times by EnlightenGAN (unit: ms).
| GAN Model | Jetson TX2 | Desktop Computer |
|---|
| Modified EnlightenGAN | 288.1 | 18.8 |
Table 21.
Comparison of desktop computer and Jetson TX2 processing times by ResNet-50 and VGG face net-16 (unit: ms).
Table 21.
Comparison of desktop computer and Jetson TX2 processing times by ResNet-50 and VGG face net-16 (unit: ms).
| CNN Model | Desktop Computer | Jetson TX2 |
|---|
| VGG face net-16 | 24.6 | 91.7 |
| ResNet-50 | 18.93 | 40.9 |
| Total | 43.53 | 132.6 |







































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}