
A Study on Facial Expression Change Detection Using Machine Learning Methods with Feature Selection Technique

 ,
,  , ,
, , 
Abstract
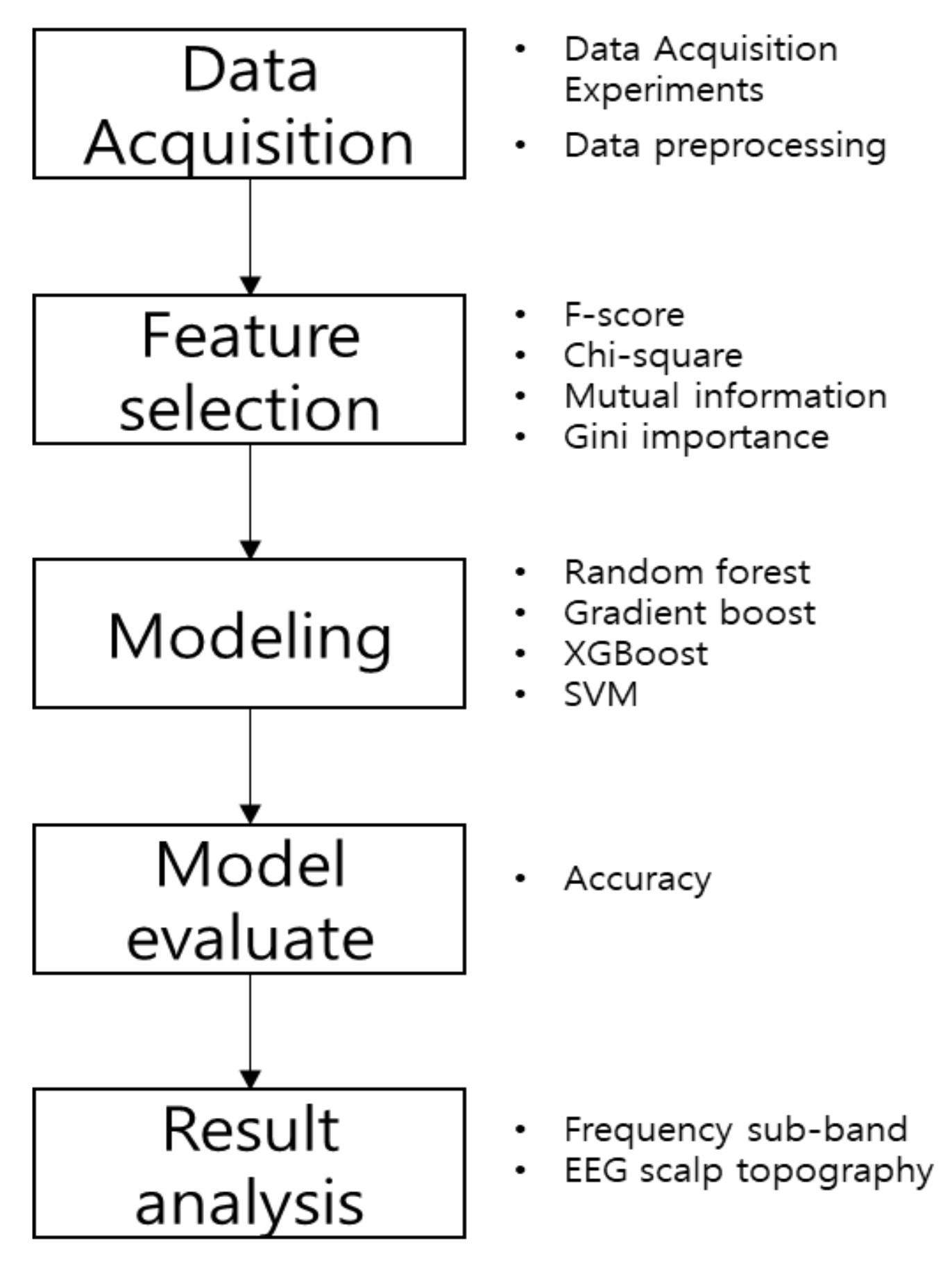
:1. Introduction
2. Methods
2.1. Feature Selection Methods
2.1.1. Fisher Score
2.1.2. Chi-Square
2.1.3. Mutual Information
2.1.4. Gini Importance
2.2. Classifiers
2.2.1. Random Forest
2.2.2. Gradient Boost
2.2.3. XGBoost
2.2.4. SVM
3. Data Analysis
3.1. Data Collection
3.1.1. Participants
3.1.2. Task
3.1.3. EEG Acquisition and Processing
3.2. Feature Selection
3.3. Computing Environment
3.4. Experiment Diagram
3.5. Base Score
4. Results
4.1. Result of Feature Selection
4.1.1. Result of Adding Influential Feature
4.1.2. Result of Feature Subset
4.2. Result of BCI Interaction
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Yang, B.; Li, H.; Wang, Q.; Zhang, Y. Subject-based feature extraction by using fisher WPD-CSP in braincomputer interfaces. Comput. Methods Programs Biomed. 2016, 129, 21–28. [Google Scholar] [CrossRef]
- Pfurtscheller, G.; Müller-Putz, G.R.; Schlögl, A.; Graimann, B.; Scherer, R.; Leeb, R.; Brunner, C.; Keinrath, C.; Lee, F.; Townsend, G.; et al. 15 years of BCI research at Graz University of Technology: Current projects. IEEE Trans. Neural Syst. Rehabil. Eng. 2006, 14, 205–210. [Google Scholar] [CrossRef] [PubMed]
- Dornhege, G.; del RMillán, J.; Hinterberger, T.; McFarland, D.J.; Müller, K.R. Toward Brain-Computer Interfacing; MIT Press: Cambridge, UK, 2007; ISBN 9780262042444. [Google Scholar]
- Daros, A.; Zakzanis, K.; Ruocco, A. Facial emotion recognition in borderline personality disorder. Psychol. Med. 2013, 43, 1953–1963. [Google Scholar] [CrossRef]
- Doma, V.; Pirouz, M. A comparative analysis of machine learning methods for emotion recognition using EEG and peripheral physiological signals. J. Big Data 2020, 7, 7–18. [Google Scholar] [CrossRef] [Green Version]
- Pan, J.; Li, Y.; Wang, J. An EEG-based brain–computer interface for emotion recognition. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016. [Google Scholar] [CrossRef]
- Pantic, M.; Rothkrantz, L.J. Automatic analysis of facial expressions: The state of the art. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1424–1445. [Google Scholar] [CrossRef] [Green Version]
- Shariat, S.; Pavlovic, V.; Papathomas, T.; Braun, A.; Sinha, P. Sparse dictionary methods for EEG signal classifcation in face perception. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing, Kittila, Finland, 29 August–1 September 2010. [Google Scholar] [CrossRef]
- Oskoei, M.A.; Gan, J.Q.; Hu, H. Adaptive Schemes Applied to Online SVM for BCI Data Classification. In Proceedings of the Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Minneapolis, MN, USA, 3–6 September 2010. [Google Scholar] [CrossRef]
- Isa, N.E.M.; Amir, A.; Ilyas, M.Z.; Razalli, M.S. Motor imagery classification in Brain computer interface (BCI) based on EEG signal by using machine learning technique. Bull. Electr. Eng. Inform. 2019, 8, 269–275. [Google Scholar] [CrossRef]
- Ewan, S.N.; Philippa, J.K.; David, B.G.; Dean, R.; Freestone, A. Generalizable Brain-Computer Interface (BCI) Using Machine Learning for Feature Discovery. PLoS ONE 2015, 10, e0131328. [Google Scholar] [CrossRef] [Green Version]
- Acı, Ç.İ.; Kaya, M.; Mishchenko, Y. Distinguishing mental attention states of humans via an EEG-based passive BCI using machine learning methods. Expert Syst. Appl. 2019, 134, 153–166. [Google Scholar] [CrossRef]
- Abraham, A.; Pedregosa, F.; Eickenberg, M.; Gervais, P.; Mueller, A.; Kossaifi, J.; Gramfort, A.; Thirion, B.; Varoquaux, G. Machine Learning for Neuroimaging with Scikit-Learn. Front. Neuroinform. 2014, 8, 14. [Google Scholar] [CrossRef] [Green Version]
- Tan, P.; Sa, W.; Yu, L. Applying Extreme Learning Machine to classification of EEG BCI. In Proceedings of the IEEE International Conference on Cyber Technology in Automation, Control and Intelligent Systems (CYBER), Chengdu, China, 19–22 June 2016. [Google Scholar] [CrossRef]
- Kaper, M.; Meinicke, P.; Grossekathoefer, U.; Lingner, T.; Ritter, H. BCI competition 2003-data set IIb: Support vector machines for the P300 speller paradigm. IEEE Trans. Biomed. Eng. 2004, 51, 1073–1076. [Google Scholar] [CrossRef]
- Patil, A.R.; Chang, J.; Leung, M.; Kim, S. Analyzing high dimensional correlated data using feature ranking and classifiers. Comput. Math. Biophys. 2019, 7, 98–120. [Google Scholar] [CrossRef] [Green Version]
- Thaseen, S.; Kumar, C.A.; Ahmad, A. Integrated Intrusion Detection Model Using Chi-Square Feature Selection and Ensemble of Classifiers. Arab. J. Sci. Eng. 2019, 44, 3357–3368. [Google Scholar] [CrossRef]
- Hoque, N.; Bhattacharyya, D.; Kalita, J. MIFS-ND: A mutual information-based feature selection method. Expert Syst. Appl. 2014, 41, 6371–6385. [Google Scholar] [CrossRef]
- Genuer, R.; Poggi, J.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef] [Green Version]
- Ding, S. Feature Selection based F-score and ACO Algorithm in Support Vector Machine. Int. Symp. Knowl. Acquis. Model. 2009, 1, 19–23. [Google Scholar] [CrossRef]
- Jlmaz, E.Y. An Expert System Based on Fisher Score and LS-SVM for Cardiac Arrhythmia Diagnosis. Comput. Math. Methods Med. 2013, 2013, 849674. [Google Scholar] [CrossRef]
- Gu, Q.; Li, Z.; Han, J. Generalized Fisher Score for Feature Selection. arXiv 2012, arXiv:1202.3725. [Google Scholar]
- Morison, K.; Wang, L.; Kundur, P. Power system security assessment. IEEE Power Energy Mag. 2004, 2, 30–39. [Google Scholar] [CrossRef]
- Forman, G. An extensive empirical study of feature selection metrics for text classification. J. Mach. Learn. Res. 2003, 3, 1289–1305. [Google Scholar]
- Ali, S.I. A Feature Subset Selection Method based on Conditional Mutual Information and Ant Colony Optimization. Int. J. Comput. Appl. 2012, 60, 5–10. [Google Scholar]
- Jović, A.; Brkić, K.; Bogunović, N. A review of feature selection methods with applications. In Proceedings of the 38th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 25–29 May 2015. [Google Scholar] [CrossRef]
- Anju, N.; Sharma. Survey of Boosting Algorithms for Big Data Applications. Int. J. Eng. Res. Technol. (IJERT) 2017, 5. [Google Scholar]
- Bentéjac, C.; Csörgȍ, A.; Martínez-Mu˜noz, G. A Comparative Analysis of XGBoost. arXiv 2019, arXiv:1911.01914. [Google Scholar]
- Rahman, S.; Irfan, M.; Raza, M.; Ghori, K.M.; Yaqoob, S.; Awais, M. Performance Analysis of Boosting Classifiers in Recognizing Activities of Daily Living. Int. J. Environ. Res. Public Health 2020, 17, 1082. [Google Scholar] [CrossRef] [Green Version]
- Wang, X.; Chen, J.; Wang, P.; Huang, Z. Infrared Human Face Auto Locating Based on SVM and A Smart Thermal Biometrics System. Int. Conf. Intell. Syst. Des. Appl. 2006, 2, 1066–1072. [Google Scholar] [CrossRef]
- Ganapathiraju, A.; Hamaker, J.E.; Picone, J. Applications of support vector machines to speech recognition. IEEE Trans. Signal Process. 2004, 52, 2348–2355. [Google Scholar] [CrossRef]
- Ha, H.; Shim, E.-J. Differences in Facial Emotion Recognitions According to Experiences of Childhood Maltreatment. Korean Stud. 2018, 29, 97–123. [Google Scholar] [CrossRef]
- Delorme, A.; Makeig, S. EEGLAB: An open source toolbox for analysis of single-trial EEG dynamics including independent component analysis. J. Neurosci. Methods 2004, 134, 9–21. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, S.P. Preprocessing of EEG. Comput. EEG Anal. 2018, 15–33. [Google Scholar] [CrossRef]
- Pion-Tonachini, L.; Kreutz-Delgado, K.; Makeig, S. ICLabel: An automated electroencephalographic independent component classifier, dataset, and website. Neuroimage 2019, 198, 181–197. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abhang, P.A.; Gawali, B.W.; Mehrotra, S.C. Technical aspects of brain rhythms and speech parameters. Introd. EEG-Speech-Based Emot. Recognit. 2016, 51–79. [Google Scholar] [CrossRef]
- Kropotov, J.D. Quantitative EEG, Event-Related Potentials and Neurotherapy; Academic Press: Cambridge, MA, USA, 2010. [Google Scholar] [CrossRef]
- Schubring, D.; Schupp, H.T. Emotion and brain oscillations: High arousal is associated with decreases in alpha-and lower beta-band power. Cereb. Cortex 2021, 31, 1597–1608. [Google Scholar] [CrossRef]
- Berntsen, M.B.; Cooper, N.R.; Romei, V. Emotional valence modulates low beta suppression and recognition of social interactions. J. Psychophysiol. 2019, 34, 235–245. [Google Scholar] [CrossRef]
- Kostandov, E.A.; Cheremushkin, E.A.; Yakovenko, I.A.; Ashkinazi, M.L. The role of the context of cognitive activity in the recognition of facial emotional expressions. Neurosci. Behav. Physiol. 2012, 42, 293–301. [Google Scholar] [CrossRef]
- Gelastopoulos, A.; Whittington, M.A.; Kopell, N.J. Parietal low beta rhythm provides a dynamical substrate for a working memory buffer. Proc. Natl. Acad. Sci. USA 2019, 116, 16613–16620. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, W.; Lu, J.; Liu, X.; Fang, H.; Li, H.; Wang, D.; Shen, J. Event-related synchronization of delta and beta oscillations reflects developmental changes in the processing of affective pictures during adolescence. Int. J. Psychophysiol. 2013, 90, 334–340. [Google Scholar] [CrossRef]
- Cooper, N.R.; Simpson, A.; Till, A.; Simmons, K.; Puzzo, I. Beta event-related desynchronization as an index of individual differences in processing human facial expression: Further investigations of autistic traits in typically developing adults. Front. Hum. Neurosci. 2013, 7, 159. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buschman, T.J.; Miller, E.K. Top-down versus bottom-up control of attention in the prefrontal and posterior parietal cortices. Science 2007, 315, 1860–1862. [Google Scholar] [CrossRef] [Green Version]
- Maksimenko, V.A.; Kuc, A.; Frolov, N.S.; Khramova, M.V.; Pisarchik, A.N.; Hramov, A.E. Dissociating Cognitive Processes During Ambiguous Information Processing in Perceptual Decision-Making. Front. Behav. Neurosci. 2020, 14, 95. [Google Scholar] [CrossRef] [PubMed]
- Dauwels, J.; Vialatte, F.; Musha, T.; Cichocki, A. A comparative study of synchrony measures for the early diagnosis of Alzheimer’s disease based on EEG. Neuroimage 2010, 49, 668–693. [Google Scholar] [CrossRef] [Green Version]
- Sampath, V.; Maurtua, I.; Aguilar Martín, J.J.; Gutierrez, A. A survey on generative adversarial networks for imbalance problems in computer vision tasks. J. Big Data 2021, 8, 27. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Item | Specification |
|---|---|---|
| Hardware | CPU | Intel Core i7-8700 |
| GPU | GeForce GTX 1060 3 GB | |
| RAM | 16 GB | |
| Library | Pandas | 1.1.3 |
| Numpy | 1.19.2 | |
| Scikit-learn | 0.23.2 | |
| Language | Python | 3.8.5 |
| Data | Random Forest | Gradient Boost | XGBoost | SVM | Ensemble |
|---|---|---|---|---|---|
| BCI_186 | 0.681 | 0.682 | 0.680 | 0.680 | 0.690 |
| Feature Selection & Classification Model | F-Score | Chi-Square | Mutual Information | Gini Importance | Ensemble | |
|---|---|---|---|---|---|---|
| Random Forest | Accuracy | 69.4% | 69.2% | 69.2% | 69.0% | 70.0% |
| The number of features | 38 | 30 | 80 | 111 | 157 | |
| Gradient Boost | Accuracy | 69.6% | 69.0% | 70.0% | 69.2% | 69.2% |
| The number of features | 34 | 41 | 8 | 7 | 129 | |
| XGBoost | Accuracy | 70% | 71.0% | 69% | 70.0% | 70.0% |
| The number of features | 76 | 52 | 6 | 8 | 73 | |
| SVM | Accuracy | 68.3% | 68.3% | 68.3% | 68.3% | 68.3% |
| The number of features | 1 | 1 | 1 | 1 | 1 | |
| Feature Selection and Classification Model | F-Score | Chi-Square | Mutual Information | Gini Importance | Ensemble | |
|---|---|---|---|---|---|---|
| Random Forest | Accuracy | 69.4% | 68.3% | 68.1% | 70.0% | 69.2% |
| Subset of features | 73, 153, 95, 25, 124, 127, 29 | 95, 25, 73, 10, 94, 79 | 11, 2, 90, 137, 180 | 152, 148, 64, 127, 126, 141, 151 | 84, 139, 69, 130, 93, 12, 63 | |
| Gradient Boost | Accuracy | 69.4% | 69.4% | 69.4% | 70.3% | 69.2% |
| Subset of features | 10 | 10 | 23, 50, 2, 90, 137 | 152, 153, 64, 27 | 148, 69, 93, 12 | |
| XGBoost | Accuracy | 69% | 69.0% | 70.0% | 70.0% | 69.4% |
| Subset of features | 73, 95, 29 | 124, 73, 10 | 50, 11, 2, 137 | 152, 153, 64, 27, 151 | 83, 130, 64 | |
| SVM | Accuracy | 68.4% | 68.4% | 68.3% | 68.4% | 68.3% |
| Subset of features | 153, 95, 10 | 153, 95, 10 | 23 | 152, 153 | 84 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sung, S.-H.; Kim, S.; Park, B.-K.; Kang, D.-Y.; Sul, S.; Jeong, J.; Kim, S.-P. A Study on Facial Expression Change Detection Using Machine Learning Methods with Feature Selection Technique. Mathematics 2021, 9, 2062. https://doi.org/10.3390/math9172062
Sung S-H, Kim S, Park B-K, Kang D-Y, Sul S, Jeong J, Kim S-P. A Study on Facial Expression Change Detection Using Machine Learning Methods with Feature Selection Technique. Mathematics. 2021; 9(17):2062. https://doi.org/10.3390/math9172062
Chicago/Turabian StyleSung, Sang-Ha, Sangjin Kim, Byung-Kwon Park, Do-Young Kang, Sunhae Sul, Jaehyun Jeong, and Sung-Phil Kim. 2021. "A Study on Facial Expression Change Detection Using Machine Learning Methods with Feature Selection Technique" Mathematics 9, no. 17: 2062. https://doi.org/10.3390/math9172062
APA StyleSung, S.-H., Kim, S., Park, B.-K., Kang, D.-Y., Sul, S., Jeong, J., & Kim, S.-P. (2021). A Study on Facial Expression Change Detection Using Machine Learning Methods with Feature Selection Technique. Mathematics, 9(17), 2062. https://doi.org/10.3390/math9172062