
RFID: A Fuzzy Linguistic Model to Manage Customers from the Perspective of Their Interactions with the Contact Center



Abstract
:1. Introduction
2. Related Work
2.1. Customer Service Metrics
2.2. Studies and Uses of the RFM Model
2.2.1. Advantages and Limitations of the RFM Model
2.2.2. An Extension of the RFM Model
2.3. Summary
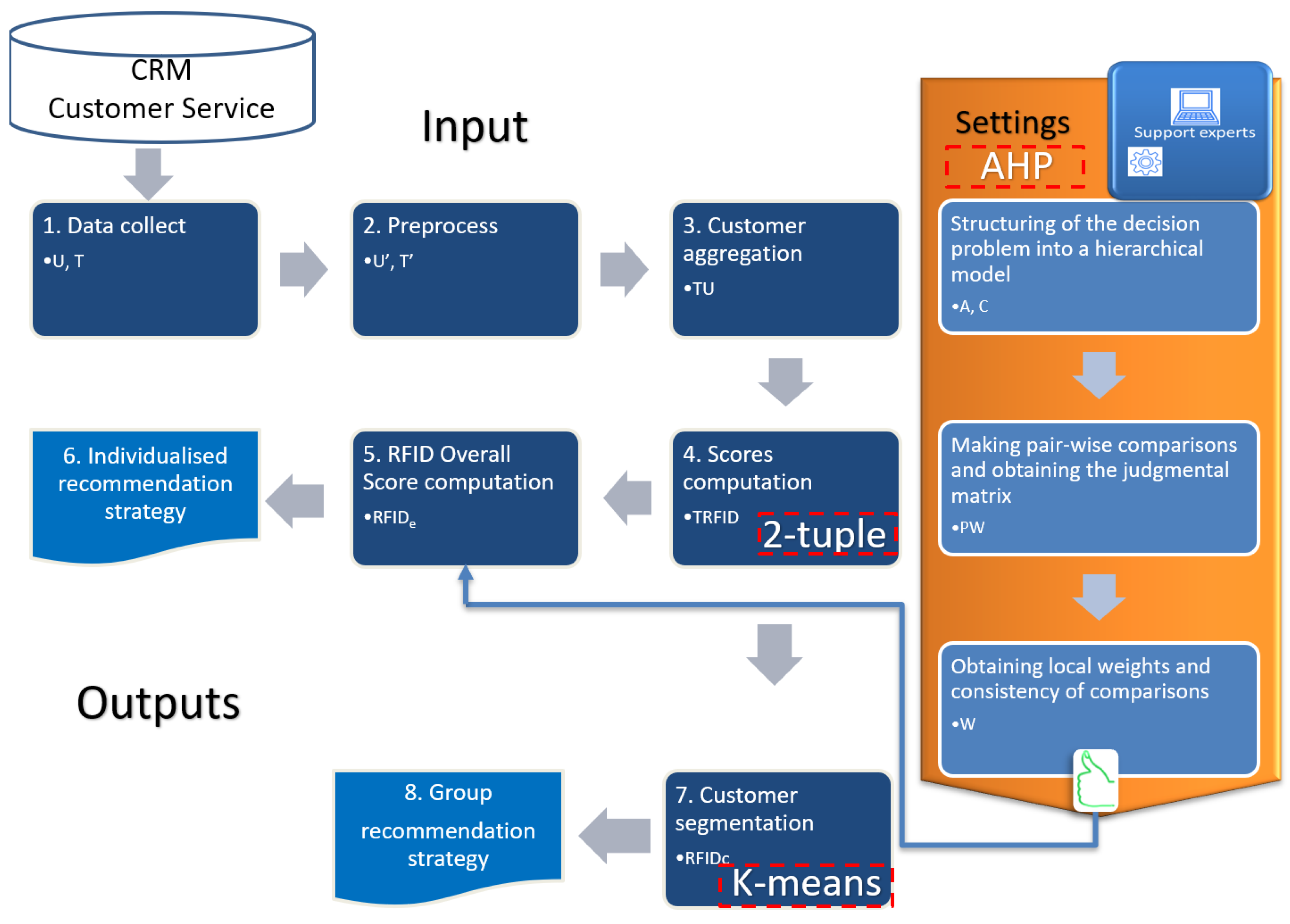
3. Methodology
3.1. The Two-Tuple Fuzzy Linguistic Model
- If , then is less than .
- If , then
- (a)
- If , then and represent the same information.
- (b)
- If , then is less than .
- (c)
- If , then is greater than .
3.2. Two-Tuple RFM Model
- Data collect. Let be the set of customers who have made at least one purchase over a pre-established analysis period. Let bet the details of transactions or purchases made by such customers in that period, where the U, identifies the customer of such a purchase on the date di for the amount of ai.
- Customer aggregation. In this phase, T is aggregated, at customer level, obtaining the set , where re would be the days since the last purchase of such customer ue (using a later fixed reference date for all customer purchases), re is the number of times the customer has purchased, and me contains the total amount of those purchases.
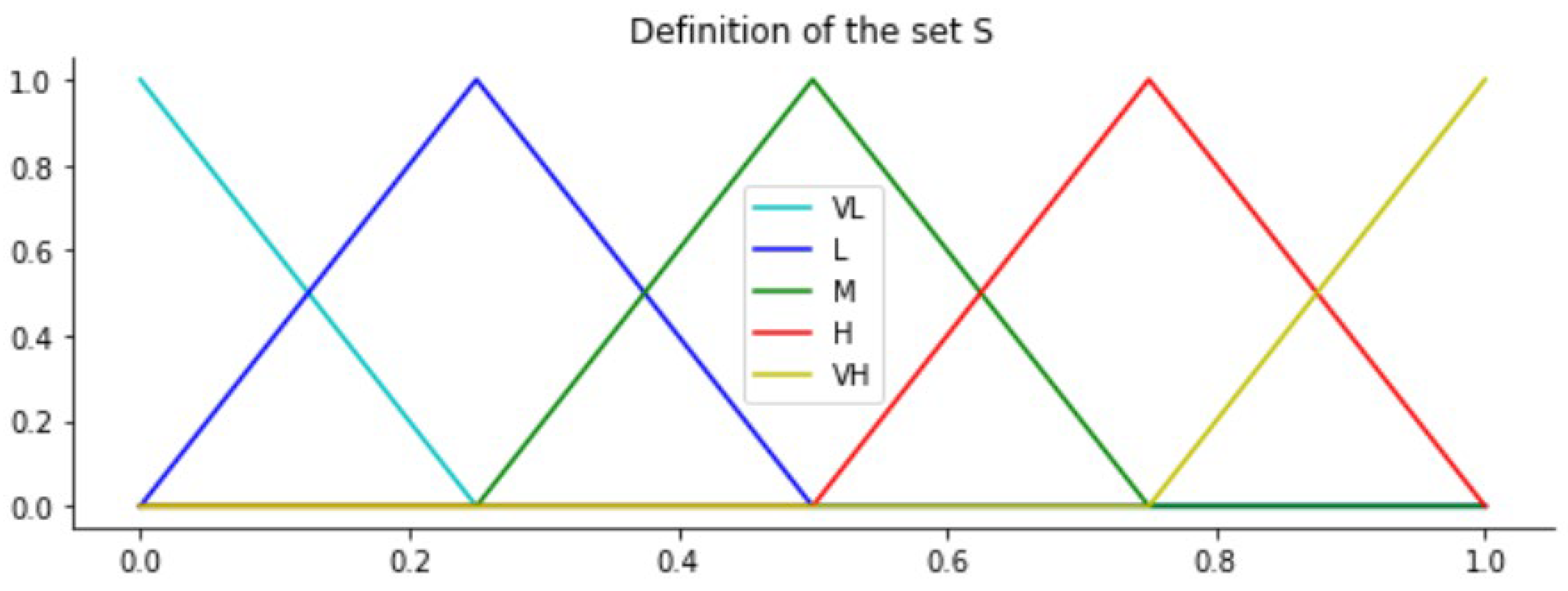
- Score’s computation. Set with the two-tuple RFM scores is obtained. First, a symmetric and uniformly distributed domain S using five linguistic labels is defined. These labels have a semantic meaning for the variables of the RFM model referred:
- RFM Overall Score computation. In this step, the two-tuple , which characterizes together the Re, Fe and Me scores, is calculated for each customer using the Equation (5) as , with the user-defined weights previously defined by the marketing experts.
3.3. Analytical Hierarchical Process (AHP)
3.3.1. Structuring of the Decision Problem into a Hierarchical Model
3.3.2. Making Pair-Wise Comparisons and Obtaining the Judgmental Matrix
3.3.3. Obtaining Local Weights and Consistency of Comparisons
4. RFID Proposed Model
4.1. Data Collect
- : is a code that uniquely identifies each trouble ticket requested by the customer , with .
- : is the date on which the service was initially required.
- : is a code that identifies the status of the ticket with respect to its management, e.g., initiated, resolved, cancelled, etc.
- : the service required by the customer has a process by which the ticket goes through several states, in this variable the date corresponding to the last state in which the ticket is stored.
- : identifies the type of request, complaint or trouble the customer has.
- : relevance of the ticket which is a standard feature of most CRMs. It is usually expressed on an ordinal and/or linguistic scale of n-values such that the higher the value, the higher the relevance of the ticket. In this article we will consider that the scale has five values very low, low, moderate, high, very high. As it is a linguistic scale, we will consider modelling it with the set S.
4.2. Preprocess
4.3. Customer Aggregation
- re: it is the days since the last request for service of such customer ue (using as a reference the end date of the analysis period). Therefore , where diffdays is a function that returns the difference in days between two dates, and max is a function that return the last date of the different dates of entry.
- fe: it is the number of times the customer has made a service request, i.e., with different ticket codes ticket_idi.
- ie: it is the average importance. As it is a linguistic variable this value is calculated for each customer using the Equation (4) as ie = .
- de: contains the total duration in days of all customer’s tickets. Therefore, .
4.4. Scores Computation
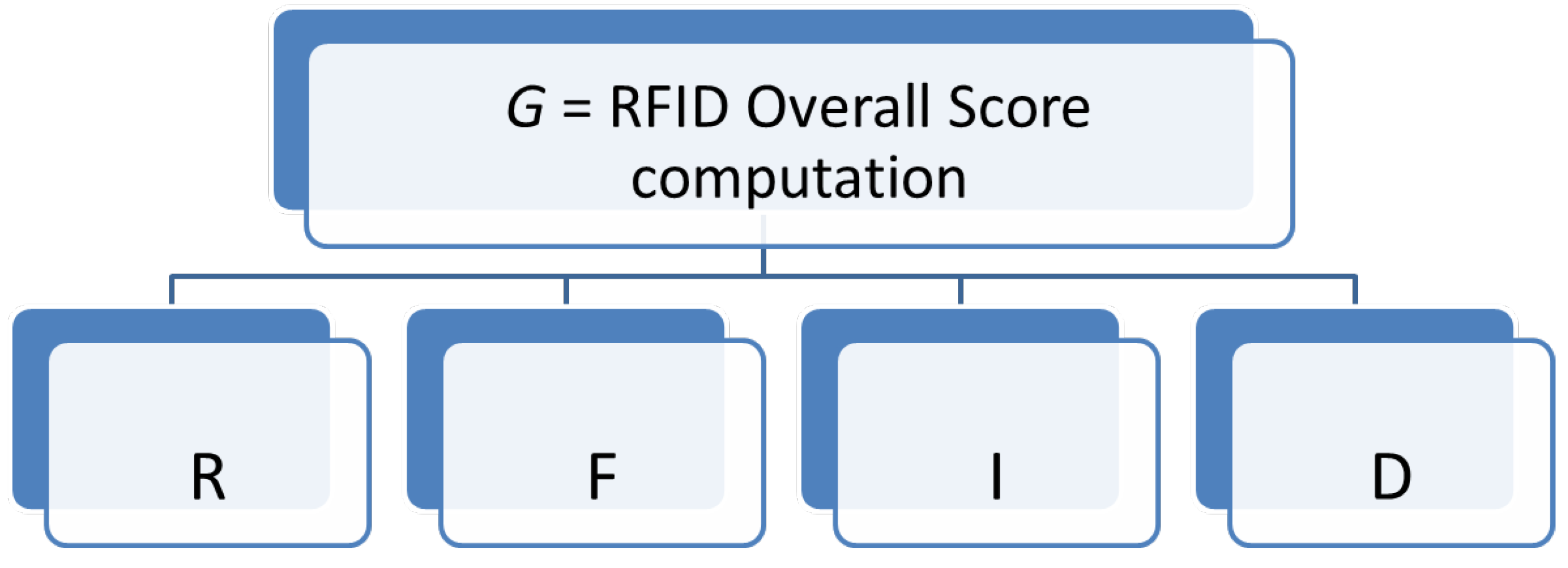
4.5. RFID Overall Score Computation
4.5.1. Structuring of the Decision Problem into a Hierarchical Model
4.5.2. Making Pair-Wise Comparisons
4.5.3. Obtaining Local Weights and Consistency of Comparisons
4.6. Individualized Recommendation Strategy
4.7. Customer Segmentation
4.8. Group Recommendation Strategy
5. Proposed Model Applied to Telecom Industry
5.1. Data Collect
5.2. Preprocess
5.3. Customer Aggregation
5.4. Scores Computation
5.5. RFID Overall Score Computation
5.6. RFID Overall Score Computation
5.7. Customer Segmentation
5.8. Group Recommendation Strategy
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Oztemel, E.; Gursev, S. Literature review of Industry 4.0 and related technologies. J. Intell. Manuf. 2020, 31, 127–182. [Google Scholar] [CrossRef]
- Ali, A. Here’s What Happens Every Minute on the Internet in 2020. 2020. Available online: https://www.visualcapitalist.com/every-minute-internet-2020/ (accessed on 23 July 2021).
- Kumar, V.; Rajan, B.; Gupta, S.; Pozza, I.D. Customer engagement in service. J. Acad. Mark. Sci. 2019, 47, 138–160. [Google Scholar] [CrossRef]
- Lemon, K.N.; Verhoef, P.C. Understanding Customer Experience Throughout the Customer Journey. J. Mark. 2016, 80, 69–96. [Google Scholar] [CrossRef]
- Wei, J.; Lin, S.; Wu, H. A review of the application of RFM model. Afr. J. Bus. Manag. 2010, 4, 4199–4206. [Google Scholar]
- Hughes, A.M. Strategic Database Marketing; Probus Publishing: Chicago, IL, USA, 1994. [Google Scholar]
- Shih, Y.-Y.; Liu, C.-Y. A method for customer lifetime value ranking—Combining the analytic hierarchy process and clustering analysis. J. Database Mark. Cust. Strat. Manag. 2003, 11, 159–172. [Google Scholar] [CrossRef] [Green Version]
- Sohrabi, B.; Khanlari, A. Customer Lifetime Value (CLV) Measurement Based on RFM Model. Iran. Account. Audit. Rev. 2007, 14, 7–20. [Google Scholar]
- Khajvand, M.; Zolfaghar, K.; Ashoori, S.; Alizadeh, S. Estimating customer lifetime value based on RFM analysis of customer purchase behavior: Case study. Procedia Comput. Sci. 2011, 3, 57–63. [Google Scholar] [CrossRef] [Green Version]
- Carrasco, R.A.; Blasco, M.F.; García-Madariaga, J.; Herrera-Viedma, E. A Fuzzy Linguistic RFM Model Applied to Campaign Management. Int. J. Interact. Multimed. Artif. Intell. 2019, 5, 21. [Google Scholar] [CrossRef] [Green Version]
- Bueno, I.; Carrasco, R.A.; Porcel, C.; Kou, G.; Herrera-Viedma, E. A linguistic multi-criteria decision making methodology for the evaluation of tourist services considering customer opinion value. Appl. Soft Comput. 2021, 101, 107045. [Google Scholar] [CrossRef]
- Payne, A.; Frow, P. The role of multichannel integration in customer relationship management. Ind. Mark. Manag. 2004, 33, 527–538. [Google Scholar] [CrossRef]
- Kumar, V.; Reinartz, W. Customer Relationship Management: Concept, Strategy, and Tools LK, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2018; 411p, Available online: https://ucm.on.worldcat.org/oclc/1050446648 (accessed on 2 July 2021).
- Verhoef, P.C. Understanding the Effect of Customer Relationship Management Efforts on Customer Retention and Customer Share Development. J. Mark. 2003, 67, 30–45. [Google Scholar] [CrossRef]
- Van Dun, Z.; Bloemer, J.; Henseler, J. Perceived customer contact centre quality: Conceptual foundation and scale development. Serv. Ind. J. 2011, 31, 1347–1363. [Google Scholar] [CrossRef]
- Abdullateef, A.O.; Sanuri, S.; Mokhtar, M.; Yusoff, R.Z. The impact of CRM Dimensions on Call Center Performance. OR Spectr. 2010, 10, 184–194. Available online: http://proquest.umi.com/pqdweb?did=669649341&Fmt=7&clientId=65345&RQT=309&VName=PQD (accessed on 23 July 2021).
- Parasuraman, A.; Zeithaml, V.A.; Berry, L.L. A Conceptual Model of Service Quality and Its Implications for Future Research. J. Mark. 1985, 49, 41. [Google Scholar] [CrossRef]
- Reichheld, F.F. The one number you need to grow. Harv. Bus. Rev. 2003, 81, 46–54. Available online: www.hbr.org (accessed on 15 June 2021). [PubMed]
- Dixon, M.; Freeman, K.; Toman, N. Stop trying to delight your customers. Harv. Bus. Rev. 2019, 88, 7–8. [Google Scholar]
- Gupta, S.; Zeithaml, V. Customer Metrics and Their Impact on Financial Performance. Mark. Sci. 2006, 25, 718–739. [Google Scholar] [CrossRef] [Green Version]
- An Doorn, J.; Leeflang, P.S.; Tijs, M. Satisfaction as a predictor of future performance: A replication. Int. J. Res. Mark. 2013, 30, 314–318. [Google Scholar] [CrossRef]
- De Haan, E.; Kannan, P.K.; Verhoef, P.C.; Wiesel, T. The Role of Mobile Devices in the Online Customer Journey; Marketing Science Institute Report No. 15–124; 2015; pp. 1–56. Available online: https://www.msi.org/working-papers/the-role-of-mobile-devices-in-the-online-customer-journey/ (accessed on 16 June 2021).
- De Keyser, A.; Lemon, K.N.; Klaus, P.; Keiningham, T.L. A Framework for Understanding and Managing the CX. Work. Pap. Ser. 2015, 15, 1–47. [Google Scholar]
- Grewal, D.; Levy, M.; Kumar, V. Customer Experience Management in Retailing: An Organizing Framework. J. Retail. 2009, 85, 1–14. [Google Scholar] [CrossRef]
- Morgan, N.A.; Rego, L.L. The Value of Different Customer Satisfaction and Loyalty Metrics in Predicting Business Performance. Mark. Sci. 2006, 25, 426–439. [Google Scholar] [CrossRef] [Green Version]
- Korneta, P. Net promoter score, growth, and profitability of transportation companies. Int. J. Manag. Econ. 2018, 54, 136–148. [Google Scholar] [CrossRef] [Green Version]
- Rocks, B. Interval Estimation for the “Net Promoter Score”. Am. Stat. 2016, 70, 365–372. [Google Scholar] [CrossRef] [Green Version]
- Baehre, S.; O’Dwyer, M.; O’Malley, L.; Lee, N. The use of Net Promoter Score (NPS) to predict sales growth: Insights from an empirical investigation. J. Acad. Mark. Sci. 2021. [Google Scholar] [CrossRef]
- Jahnert, J.R.; Schmeiser, H. The relationship between net promoter score and insurers’ profitability: An empirical analysis at the customer level. Geneva Pap. Risk Insur. Issues Pr. 2021, 1–29. [Google Scholar] [CrossRef]
- Cheng, C.-H.; Chen, Y.-S. Classifying the segmentation of customer value via RFM model and RS theory. Expert Syst. Appl. 2009, 36, 4176–4184. [Google Scholar] [CrossRef]
- Anderson, K.M. A method for customer lifetime value ranking. Prev. Sch. Fail. 1986, 51, 49–51. Available online: https://search.proquest.com/docview/220297257?accountid=12834 (accessed on 16 June 2021).
- Liu, D.-R.; Shih, Y.-Y. Integrating AHP and data mining for product recommendation based on customer lifetime value. Inf. Manag. 2005, 42, 387–400. [Google Scholar] [CrossRef]
- Venkatesan, R.; Kumar, V. A Customer Lifetime Value Framework for Customer Selection and Resource Allocation Strategy. J. Mark. 2004, 68, 106–125. [Google Scholar] [CrossRef]
- Chan, C.C.H. Intelligent value-based customer segmentation method for campaign management: A case study of automobile retailer. Expert Syst. Appl. 2008, 34, 2754–2762. [Google Scholar] [CrossRef]
- Kumar, V.; Venkatesan, R.; Bohling, T.; Beckmann, D. Practice Prize Report—The Power of CLV: Managing Customer Lifetime Value at IBM. Mark. Sci. 2008, 27, 585–599. [Google Scholar] [CrossRef] [Green Version]
- Yeh, I.-C.; Yang, K.-J.; Ting, T.-M. Knowledge discovery on RFM model using Bernoulli sequence. Expert Syst. Appl. 2009, 36, 5866–5871. [Google Scholar] [CrossRef]
- Moro, S.; Cortez, P.; Rita, P. Using customer lifetime value and neural networks to improve the prediction of bank deposit subscription in telemarketing campaigns. Neural Comput. Appl. 2015, 26, 131–139. [Google Scholar] [CrossRef]
- Hamilton, M.; Kaltcheva, V.D.; Rohm, A.J. Social Media and Value Creation: The Role of Interaction Satisfaction and Interaction Immersion. J. Interact. Mark. 2016, 36, 121–133. [Google Scholar] [CrossRef]
- Monalisa, S.; Nadya, P.; Novita, R. Analysis for Customer Lifetime Value Categorization with RFM Model. Procedia Comput. Sci. 2019, 161, 834–840. [Google Scholar] [CrossRef]
- Martínez, R.G.; Carrasco, R.A.; Garcia-Madariaga, J.; Gallego, C.P.; Herrera-Viedma, E. A comparison between Fuzzy Linguistic RFM Model and traditional RFM model applied to Campaign Management. Case study of retail business. Procedia Comput. Sci. 2019, 162, 281–289. [Google Scholar] [CrossRef]
- Haggerty, C.M.; Damrauer, S.M.; Levin, M.G.; Birtwell, D.; Carey, D.J.; Golden, A.M.; Hartzel, D.N.; Hu, Y.; Judy, R.; Kelly, M.A.; et al. Genomics-First Evaluation of Heart Disease Associated with Titin-Truncating Variants. Circulation 2019, 140, 42–54. [Google Scholar] [CrossRef]
- Mahdiraji, H.A.; Zavadskas, E.K.; Kazeminia, A.; Kamardi, A.A. Marketing strategies evaluation based on big data analysis: A CLUSTERING-MCDM approach. Econ. Res. Ekon. Istraž. 2019, 32, 2882–2898. [Google Scholar] [CrossRef] [Green Version]
- Vilaginés, J.A. Predicting customer behavior with Activation Loyalty per Period. From RFM to RFMAP. ESIC Mark. Econ. Bus. J. 2020, 51, 609–637. [Google Scholar] [CrossRef]
- Heldt, R.; Silveira, C.S.; Luce, F.B. Predicting customer value per product: From RFM to RFM/P. J. Bus. Res. 2021, 127, 444–453. [Google Scholar] [CrossRef]
- Rahim, M.A.; Mushafiq, M.; Khan, S.; Arain, Z.A. RFM-based repurchase behavior for customer classification and segmentation. J. Retail. Consum. Serv. 2021, 61, 102566. [Google Scholar] [CrossRef]
- Zong, Y.; Xing, H. Customer stratification theory and value evaluation—Analysis based on improved RFM model. J. Intell. Fuzzy Syst. 2021, 40, 4155–4167. [Google Scholar] [CrossRef]
- Hsieh, N.-C. An integrated data mining and behavioral scoring model for analyzing bank customers. Expert Syst. Appl. 2004, 27, 623–633. [Google Scholar] [CrossRef]
- King, S.F. Citizens as customers: Exploring the future of CRM in UK local government. Gov. Inf. Q. 2007, 24, 47–63. [Google Scholar] [CrossRef]
- Lumsden, S.-A.; Beldona, S.; Morrison, A.M. Customer Value in an All-Inclusive Travel Vacation Club: An Application of the RFM Framework. J. Hosp. Leis. Mark. 2008, 16, 270–285. [Google Scholar] [CrossRef]
- Li, Y.-M.; Lin, C.-H.; Lai, C.-Y. Identifying influential reviewers for word-of-mouth marketing. Electron. Commer. Res. Appl. 2010, 9, 294–304. [Google Scholar] [CrossRef]
- Van Vlasselaer, V.; Bravo, C.; Caelen, O.; Eliassi-Rad, T.; Akoglu, L.; Snoeck, M.; Baesens, B. APATE: A novel approach for automated credit card transaction fraud detection using network-based extensions. Decis. Support Syst. 2015, 75, 38–48. [Google Scholar] [CrossRef] [Green Version]
- Mohammadzadeh, M.; Hoseini, Z.Z.; Derafshi, H. A data mining approach for modeling churn behavior via RFM model in specialized clinics Case study: A public sector hospital in Tehran. Procedia Comput. Sci. 2017, 120, 23–30. [Google Scholar] [CrossRef]
- Perisic, A.; Pahor, M. Extended RFM logit model for churn prediction in the mobile gaming market. Croat. Oper. Res. Rev. 2020, 11, 249–261. [Google Scholar] [CrossRef]
- Stormi, K.; Lindholm, A.; Laine, T.; Korhonen, T. RFM customer analysis for product-oriented services and service business development: An interventionist case study of two machinery manufacturers. J. Manag. Gov. 2019, 24, 623–653. [Google Scholar] [CrossRef] [Green Version]
- Hwang, S.; Lee, Y. Identifying customer priority for new products in target marketing: Using RFM model and TextRank. Innov. Mark. 2021, 17, 125–136. [Google Scholar] [CrossRef]
- Wu, J.; Shi, L.; Lin, W.-P.; Tsai, S.-B.; Li, Y.; Yang, L.; Xu, G. An Empirical Study on Customer Segmentation by Purchase Behaviors Using a RFM Model and K-Means Algorithm. Math. Probl. Eng. 2020, 2020, 1–7. [Google Scholar] [CrossRef]
- McCarty, J.A.; Hastak, M. Segmentation approaches in data-mining: A comparison of RFM, CHAID, and logistic regression. J. Bus. Res. 2007, 60, 656–662. [Google Scholar] [CrossRef]
- Herrera, F.; Martinez, L. A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. Fuzzy Syst. 2000, 8, 746–752. [Google Scholar] [CrossRef] [Green Version]
- Saaty, T.L. The Analytic Hierarchy Process: Planning, Priority Setting, Resource Allocation; McGraw-Hill International Book Co: New York, NY, USA, 1980; 287p, Available online: https://ucm.on.worldcat.org/oclc/911278091 (accessed on 15 January 2021).
- Saaty, T.L. The Modern Science of Multicriteria Decision Making and Its Practical Applications: The AHP/ANP Approach. Oper. Res. 2013, 61, 1101–1118. [Google Scholar] [CrossRef]
- Khaira, A.; Dwivedi, R.K. A State of the Art Review of Analytical Hierarchy Process. Mater. Today Proc. 2018, 5, 4029–4035. [Google Scholar] [CrossRef]
- Ishizaka, A.; Labib, A. Review of the main developments in the analytic hierarchy process. Expert Syst. Appl. 2011, 38, 14336–14345. [Google Scholar] [CrossRef] [Green Version]
- Saaty, T.L. A scaling method for priorities in hierarchical structures. J. Math. Psychol. 1977, 15, 234–281. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, F.; García-Madariaga, J.; Pedreño-Santos, A.; Herrera-Viedma, E. A Model to Obtain a Servperf Scale Evaluation of the Crm Customer Complaints: An Application to the 4g Telecommunications Sector. Technol. Econ. Dev. Econ. 2018, 24, 1606–1629. [Google Scholar] [CrossRef]
- Kotler, P. Marketing Management; Pearson Education Limited: Harlow, UK, 2016; Available online: https://www.pearson.com/uk/educators/higher-education-educators/program/Kotler-Marketing-Management-3rd-edn-3rd-Edition/PGM1093412.html (accessed on 20 July 2021).
- Kumar, V.; Reinartz, W. Strategic Customer Relationship Management Today. In Customer Relationship Management; Springer: Berlin/Heidelberg, Germany, 2012; pp. 3–20. [Google Scholar] [CrossRef]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Lu, W. Improved K-Means Clustering Algorithm for Big Data Mining under Hadoop Parallel Framework. J. Grid Comput. 2019, 18, 239–250. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Forero, L.N.; López, S.X.; Herrera-Viedma, E.; Porcel, C. Using the AHP model to improve the measurement of satisfaction in the ICT sector. Front. Artif. Intell. Appl. 2018, 303, 299–311. [Google Scholar] [CrossRef]
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef] [Green Version]
- Andrade, R.; Moazeni, S.; Ramirez-Marquez, J.E. A systems perspective on contact centers and customer service reliability modeling. Syst. Eng. 2019, 23, 221–236. [Google Scholar] [CrossRef]
- Zeithaml, V.A.; Berry, L.L.; Parasuraman, A. The Behavioral Consequences of Service Quality. J. Mark. 1996, 60, 31. [Google Scholar] [CrossRef]
- Parasuraman, A.; Zeithaml, V.A.; Berry, L.L. SERVQUAL: A multiple-item scale for measuring consumer perceptions of service quality. J. Retail. 1988, 64, 12–40. [Google Scholar]
- Hilken, T.; Heller, J.; Chylinski, M.; Keeling, D.I.; Mahr, D.; De Ruyter, K. Making omnichannel an augmented reality: The current and future state of the art. J. Res. Interact. Mark. 2018, 12, 509–523. [Google Scholar] [CrossRef]
- Carrasco, R.A.; Blasco, F.; Herrera-Viedma, E. A 2-tuple Fuzzy Linguistic RFM Model and Its Implementation. Procedia Comput. Sci. 2015, 55, 1340–1347. [Google Scholar] [CrossRef] [Green Version]
- Kumar, V.; Aksoy, L.; Donkers, B.; Venkatesan, R.; Wiesel, T.; Tillmanns, S. Undervalued or Overvalued Customers: Capturing Total Customer Engagement Value. J. Serv. Res. 2010, 13, 297–310. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Studies |
|---|
| Customer engagement in service [3]; |
| Understanding customer experience throughout the customer journey [4]; |
| The one number you need to grow [18]; |
| Stop trying to delight your customers [19]; |
| Customer metrics and their impact on financial performance [20]; |
| Satisfaction as a predictor of future performance: a replication [21]; |
| The role of mobile devices in the online customer journey [22]; |
| A framework for understanding and managing the CX [23]; |
| Customer experience management in retailing: an organizing framework [24]; The value of different customer satisfaction and loyalty metrics in predicting business performance [25]; Net promoter score, growth, and profitability of transportation companies [26]; Interval estimation for the “net promoter score” [27]; The use of net promoter score (NPS) to predict sales growth: insights from an empirical investigation [28]; The relationship between net promoter score and insurers’ profitability: an empirical analysis at the customer level [29]. |
| Studies |
|---|
| A method for customer lifetime value ranking. Preventing school failure [31]; |
| Integrating AHP and data mining for product recommendation based on customer lifetime value [32]; |
| Framework for customer selection [33]; |
| Customer lifetime value (CLV) measurement based on RFM model [8]; |
| Intelligent value-based customer segmentation method for campaign management: A case study of automobile retailer [34]; |
| The power of CLV: managing customer lifetime value at IBM [35]; |
| Knowledge discovery on RFM model using Bernoulli sequence [36]; |
| Estimating customer lifetime value based on RFM analysis of customer purchase behavior: case study [9]; |
| Using customer lifetime value and neural networks to improve the prediction of bank deposit subscription in telemarketing campaigns [37]; |
| Social media and value creation: the role of interaction satisfaction and interaction immersion [38]; |
| Analysis for customer lifetime value categorization with RFM model, [39] |
| A comparison between fuzzy linguistic RFM model and traditional RFM model applied to campaign management. Case study of a retail business [40]; |
| Genomics-first evaluation of heart disease associated with titin-truncating variants [41]; |
| Marketing strategies evaluation based on big data analysis: a CLUSTERING-MCDM approach [42]; |
| Predicting customer behavior with activation loyalty per period. From RFM to RFMAP [43]; |
| A review of the application of RFM model [5]; |
| Predicting customer value per product: From RFM to RFM/P [44]; |
| RFM-based repurchase behavior for customer classification and segmentation [45]; |
| Customer stratification theory and value evaluation-analysis based on improved RFM model [46]. |
| Industry | Studies |
|---|---|
| Financial | An integrated data mining and behavioural scoring model for analyzing bank customers [47]; |
| Customer lifetime value (CLV) measurement based on RFM model [8]; | |
| APATE: A novel approach for automated credit card transaction fraud detection using network-based extensions [51]; | |
| Travel | Customer value in an all-inclusive travel vacation club: an application of the RFM framework [49]; |
| A linguistic multi-criteria decision-making methodology for the evaluation of tourist services considering customer opinion value [11]; | |
| Government | Citizens as customers: exploring the future of CRM in UK local government [48]; |
| Social Marketing | Identifying influential reviewers for word-of-mouth marketing [50]; |
| Identifying customer priority for new products in target marketing: Using RFM model and TextRank [55]; | |
| Gaming | Extended RFM logit model for churn prediction in the mobile gaming market [53]; |
| Health | A data mining approach for modeling churn behavior via RFM model in specialized clinics case study: a public sector hospital in Tehran [52]; |
| Manufacturing | RFM customer analysis for product-oriented services and service business development: an interventionist case study of two machinery manufacturers [54]. |
| Intensity of Importance | Definition | Explanation |
|---|---|---|
| 1 | Equal importance | Two activities contribute equally to the objective |
| 2 | Weak or slight | |
| 3 | Moderate importance | Experience and judgement slightly favour one activity over another |
| 4 | Moderate plus | |
| 5 | Strong importance | Experience and judgement strongly favour one activity over another |
| 6 | Strong plus | |
| 7 | Very strong or demonstrated importance | An activity is favoured very strongly over another; its dominance demonstrated in practice |
| 8 | Very, very strong | |
| 9 | Extreme importance | The evidence favouring one activity over another is of the highest possible order of affirmation |
| Reciprocals of above | If activity i has one of the above non-zero numbers assigned to it when compared with activity j, then j has the reciprocal value when compared with i. |
| u | Ticket_id | Ticket_Date | Status_id | Status_Date | Ticket_Importance |
|---|---|---|---|---|---|
| 21046586 | 155395585 | 25 January 2016 | Closed | 02 April 2019 | M |
| 21046586 | 155402659 | 25 January 2016 | Closed | 02 April 2019 | VL |
| 21046586 | 155418120 | 25 January 2016 | Closed | 04 April 2019 | VL |
| 21046586 | 155520776 | 25 January 2016 | Closed | 04 April 2019 | VL |
| 21046586 | 155887861 | 25 January 2016 | Closed | 08 April 2019 | VL |
| 21046586 | 156171484 | 25 January 2016 | Closed | 13 April 2019 | VH |
| 21334657 | 156206850 | 12 April 2016 | Closed | 13 April 2019 | L |
| 21334657 | 156548471 | 12 April 2016 | Closed | 19 April 2019 | L |
| 21334657 | 156750555 | 12 April 2016 | Closed | 25 April 2019 | VH |
| 2288774 | 155508450 | 12 September 2015 | Closed | 04 April 2019 | M |
| 24583147 | 155628991 | 18 October 2018 | Closed | 06 April 2019 | VL |
| 25860618 | 155670320 | 28 March 2019 | Closed | 06 April 2019 | VL |
| 25860618 | 156085093 | 28 March 2019 | Closed | 12 April 2019 | M |
| 25860618 | 156086410 | 28 March 2019 | Working | 12 April 2019 | M |
| 25860618 | 156345579 | 28 March 2019 | Closed | 15 April 2019 | VH |
| 25860618 | 156345680 | 28 March 2019 | Working | 15 April 2019 | L |
| 25864456 | 155401447 | 29 March 2019 | Closed | 02 April 2019 | VH |
| 25864456 | 155420645 | 29 March 2019 | Closed | 04 April 2019 | VH |
| 26053204 | 157048831 | 27 April 2019 | Closed | 28 April 2019 | VL |
| 26064419 | 157149871 | 29 April 2019 | Closed | 29 April 2019 | L |
| 26064419 | 157214640 | 29 April 2019 | Closed | 29 April 2019 | VL |
| 26064419 | 157215347 | 29 April 2019 | Closed | 29 April 2019 | M |
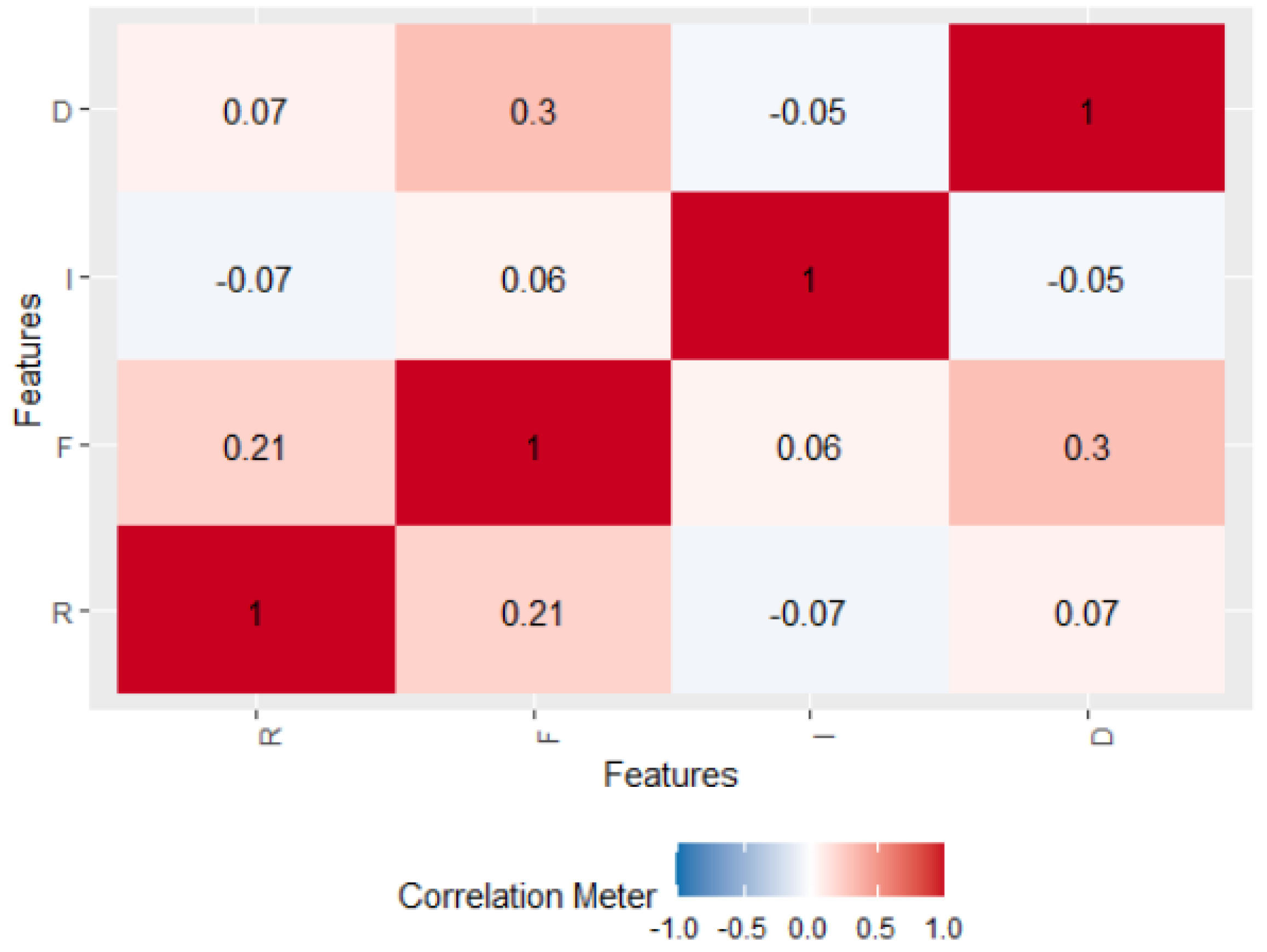
| u | r | f | i | d |
|---|---|---|---|---|
| 21046586 | 17 | 6 | L | 6999 |
| 21334657 | 5 | 3 | M | 3306 |
| 2288774 | 26 | 1 | M | 1300 |
| 24583147 | 24 | 1 | VL | 170 |
| 25860618 | 15 | 5 | (M, −0.05) | 75 |
| 25864456 | 26 | 2 | VH | 10 |
| 26053204 | 2 | 1 | VL | 1 |
| 26064419 | 1 | 3 | L | 0 |
| u | R | F | I | D |
|---|---|---|---|---|
| 21046586 | (M, −0.087) | (VH, −0.035) | L | (VH, −0.002) |
| 21334657 | (H, −0.026) | (H, 0.008) | M | (VH, −0.024) |
| 2288774 | (VL, 0.085) | VL | M | (VH, −0.12) |
| 24583147 | (L, −0.086) | VL | VL | (L, 0.12) |
| 25860618 | (M, −0.003) | (VH, −0.065) | (M, −0.05) | (L, −0.009) |
| 25864456 | (VL, 0.085) | (M, 0.01) | VH | (VL, 0.098) |
| 26053204 | (VH, −0.097) | VL | VL | (VL, 0.038) |
| 26064419 | (VH, −0.025) | (H, 0.008) | L | VL |
| u | RFID |
|---|---|
| 21046586 | (M, 0.062) |
| 21334657 | (H, −0.035) |
| 2288774 | (L, −0.092) |
| 24583147 | (VL, 0.109) |
| 25860618 | (M, 0.092) |
| 25864456 | (L, 0.07) |
| 26053204 | (M, 0.004) |
| 26064419 | (H, 0.022) |
| u | r | f | i | d | R | F | I | D | RFID |
|---|---|---|---|---|---|---|---|---|---|
| 23420561 | 0 | 10 | (M, −0.125) | 3911 | VH | (VH, −0.005) | (M, −0.125) | (VH, −0.013) | (VH, −0.087) |
| 25403001 | 0 | 7 | M | 585 | VH | (VH, −0.018) | M | (H, −0.057) | (VH, −0.088) |
| 23987407 | 1 | 7 | M | 1926 | (VH, −0.025) | (VH, −0.018) | M | (VH, −0.071) | (VH, −0.09) |
| 21858356 | 0 | 4 | M | 3442 | VH | (VH, −0.125) | M | (VH, −0.021) | (VH, −0.101) |
| 22242821 | 0 | 4 | M | 2803 | VH | (VH, −0.125) | M | (VH, −0.031) | (VH, −0.102) |
| 23694383 | 1 | 5 | M | 1689 | (VH, −0.025) | (VH, −0.065) | M | (VH, −0.085) | (VH, −0.103) |
| 23888282 | 1 | 5 | M | 1470 | (VH, −0.025) | (VH, −0.065) | M | (VH, −0.1) | (VH, −0.103) |
| 25972671 | 0 | 5 | (H, −0.1) | 45 | VH | (VH, −0.065) | (H, −0.1) | (L, −0.062) | (VH, −0.104) |
| 2227948 | 1 | 5 | (M, −0.05) | 6626 | (VH, −0.025) | (VH, −0.065) | (M, −0.05) | (VH, −0.003) | (VH, −0.105) |
| 24178272 | 1 | 5 | M | 1120 | (VH, −0.025) | (VH, −0.065) | M | (H, 0.087) | (VH, −0.106) |
| 25905579 | 1 | 9 | (M,0.083) | 117 | (VH, −0.025) | (VH, −0.007) | (M, 0.083) | (L, 0.048) | (VH, −0.107) |
| 2194707 | 1 | 9 | (L,0.056) | 12110 | (VH, −0.025) | (VH, −0.007) | (L, 0.056) | VH | (VH, −0.11) |
| 25962365 | 0 | 4 | (H, −0.062) | 66 | VH | (VH, −0.125) | (H, −0.062) | (L, −0.026) | (VH, −0.113) |
| 23304767 | 0 | 6 | L | 2452 | VH | (VH, −0.035) | L | (VH, −0.046) | (VH, −0.113) |
| 2463879 | 1 | 6 | (L, 0.083) | 7739 | (VH, −0.025) | (VH, −0.035) | (L, 0.083) | (VH, −0.002) | (VH, −0.114) |
| 24128560 | 1 | 7 | (L, 0.071) | 1677 | (VH, −0.025) | (VH, −0.018) | (L, 0.071) | (VH, −0.086) | (VH, −0.115) |
| 2640503 | 0 | 11 | (L, −0.091) | 13764 | VH | (VH, −0.003) | (L, −0.091) | VH | (VH, −0.115) |
| 23640429 | 0 | 11 | (L, −0.091) | 3752 | VH | (VH, −0.003) | (L, −0.091) | (VH, −0.016) | (VH, −0.116) |
| 25410677 | 0 | 6 | (L, 0.083) | 517 | VH | (VH, −0.035) | (L, 0.083) | (H, −0.085) | (VH, −0.116) |
| 25845359 | 0 | 10 | (L, 0.1) | 246 | VH | (VH, −0.005) | (L, 0.1) | (M, −0.041) | (VH, −0.116) |
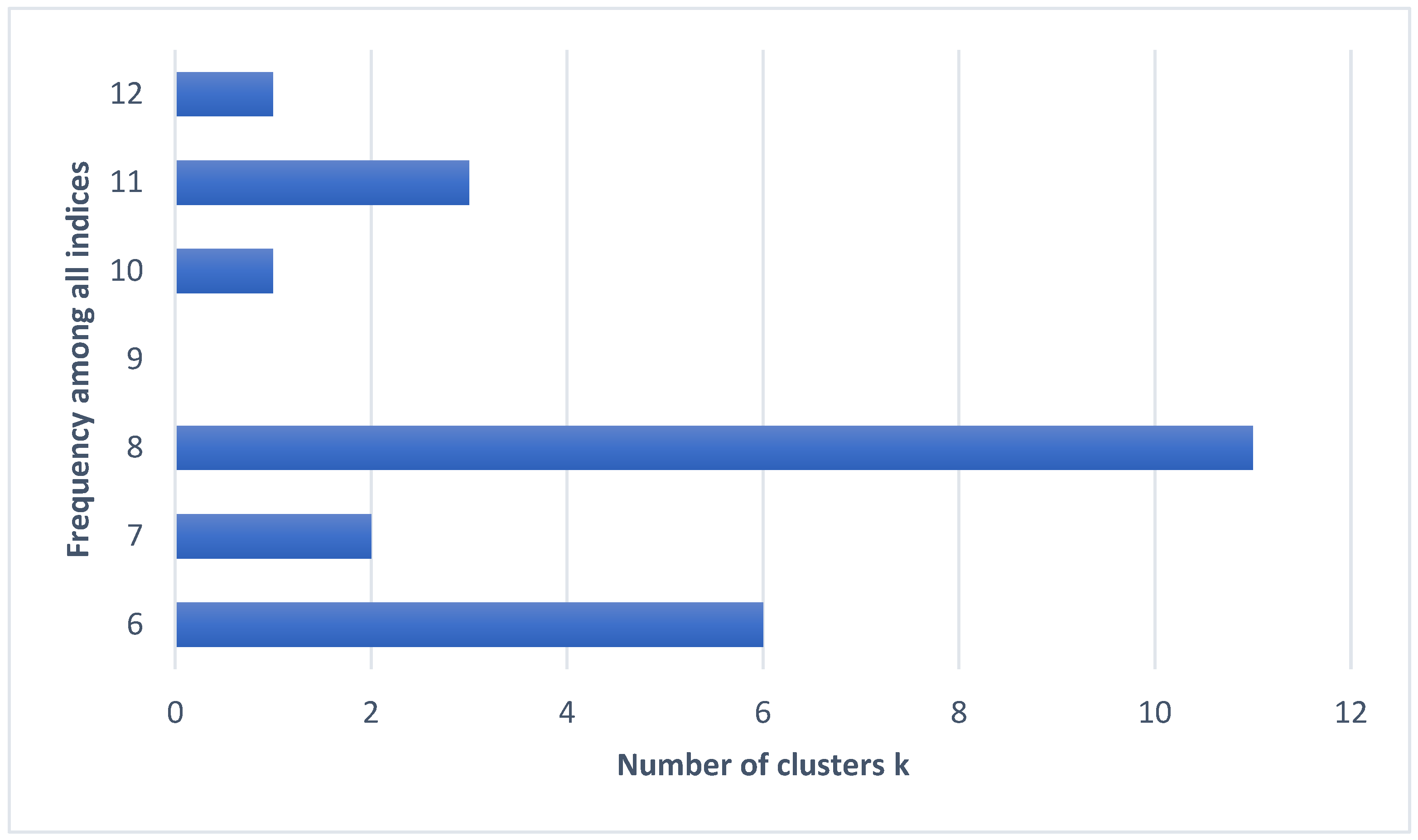
| Index | Number of Clusters | Value Index |
|---|---|---|
| KL | 8 | 57.13 |
| CH | 11 | 682.26 |
| Hartigan | 8 | 272.03 |
| CCC | 12 | 74.13 |
| Scott | 8 | 876.63 |
| Marriot | 8 | 1,477,204.00 |
| TrCovW | 8 | 326.29 |
| TraceW | 8 | 19.57 |
| Friedman | 8 | 15.09 |
| Rubin | 8 | −2.67 |
| Cindex | 10 | 0.26 |
| DB | 7 | 0.92 |
| Silhouette | 8 | 0.39 |
| Duda | 6 | 4.10 |
| PseudoT2 | 6 | −305.40 |
| Beale | 6 | −1.82 |
| Ratkowsky | 6 | 0.33 |
| Ball | 7 | 4.73 |
| PtBiserial | 8 | 0.58 |
| Frey | 6 | 1.04 |
| McClain | 6 | 1.81 |
| Dunn | 11 | 0.03 |
| SDindex | 8 | 4.93 |
| SDbw | 11 | 0.39 |
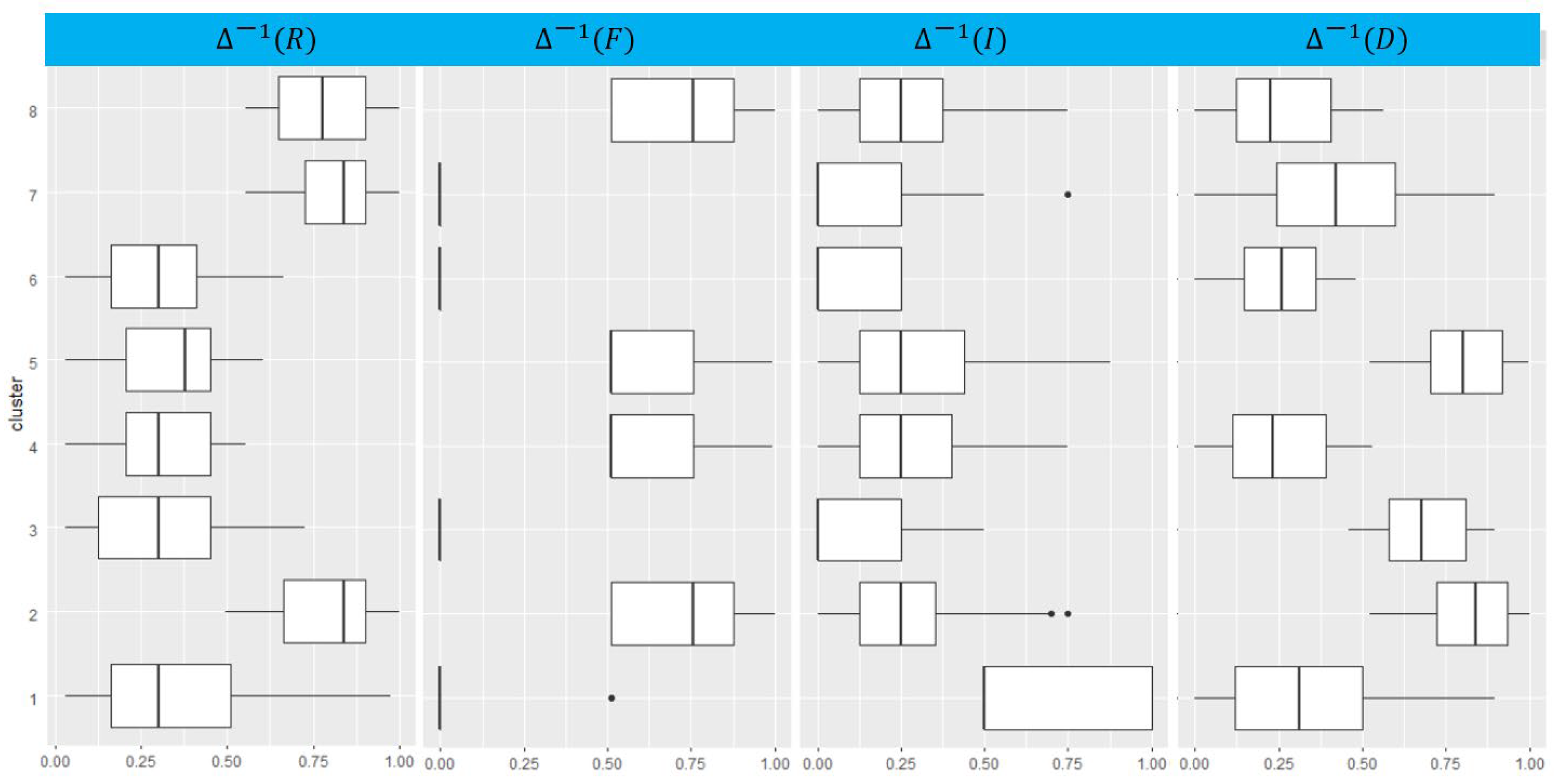
| Cluster c | R vc1 | F vc2 | I vc3 | D vc4 | Number of Customers |
|---|---|---|---|---|---|
| 1 | 0.3468286 | 0.004483071 | 0.64094575 | 0.3294273 | 682 |
| 2 | 0.802829 | 0.728453895 | 0.23999396 | 0.82394 | 1059 |
| 3 | 0.3025948 | 0 | 0.14033457 | 0.6893585 | 807 |
| 4 | 0.3091454 | 0.622837611 | 0.27908176 | 0.2508257 | 645 |
| 5 | 0.3238762 | 0.636744215 | 0.27405076 | 0.7974674 | 892 |
| 6 | 0.2976317 | 0 | 0.09399773 | 0.2478526 | 883 |
| 7 | 0.8238419 | 0 | 0.17406221 | 0.4135224 | 1093 |
| 8 | 0.7944105 | 0.683038143 | 0.26883786 | 0.257423 | 728 |
| Cluster c | R vc1 | F vc2 | I vc3 | D vc4 |
|---|---|---|---|---|
| 1 | (L, 0.097) | (VL, 0.004) | (H, −0.109) | (L, 0.079) |
| 2 | (H, 0.053) | (H, −0.022) | (L, −0.01) | (H, 0.074) |
| 3 | (L, 0.053) | VL | (L, −0.11) | (H, −0.061) |
| 4 | (L, 0.059) | (M, 0.123) | (L, 0.029) | (L, 0.001) |
| 5 | (L, 0.074) | (H, −0.113) | (L, 0.024) | (H, 0.047) |
| 6 | (L, 0.048) | VL | (VL, 0.094) | (L, −0.002) |
| 7 | (H, 0.074) | VL | (L, −0.076) | (M, −0.086) |
| 8 | (H, 0.044) | (H, −0.067) | (L, 0.019) | (L, 0.007) |
| Cluster | Interaction | Recommendation Strategy |
|---|---|---|
| 1 | SelfCustom | Description: A priori these are not very problematic customers, they do not have recurrent or frequent incidents, but the incidents they have had are of some importance. Future interactions: In subsequent customer interactions with the contact centre, the use of bot (faqs, chat, voice) is recommended, and if personalisation is required because the customer demands it, an automatic channel could be changed to a personalised and even specialised one. Campaigns: It is proposed for this type of customer to reward brand loyalty with discount campaigns for permanence. |
| 2 | StrongCustom | Description: Customer considered at high risk of abandonment.
Future interactions: In future customer interactions with the contact centre, it is recommended to personalise communication through specialised agents. Campaigns: Campaigns are proposed that tend to raise the customer’s perception of the service and the brand. We recommend listening to the customer, acquiring in-depth knowledge of them, and based on this, proposing discounts, offers and promotions. |
| 3 | SelfCustom | Description: A priori these are not very problematic customers, they do not have recurrent or frequent incidents, but the incidents they have had are of medium to long duration.
Future interactions: In subsequent customer interactions with the contact centre, it is recommended to use bot (faqs, chat, voice), if customisation is required because the customer demands it, it could move from an automatic channel to a customised and even specialised one. Campaigns: It is proposed for this type of customer to reward brand loyalty with discount campaigns for permanence. |
| 4 | Custom | Description: A priori, these are customers who have had frequent incidents and, in the past, possibly problems related to the implementation of the service. Future interactions: In future customer interactions with the contact centre, it is recommended to personalise communication through generalist and, if necessary, specialised agents. Campaigns: Campaigns aimed at strengthening and rewarding customer loyalty, discounts for permanence, etc., are proposed. |
| 5 | Custom | Description: A priori, these are customers who have had frequent incidents in the past, possibly problems derived from the installation, which produced long-lasting incidents. Future interactions: In subsequent customer interactions with the contact centre, it is recommended to personalise communication through generalist and, if necessary, specialised agents. Campaigns: We propose campaigns aimed at strengthening and rewarding customer loyalty, as well as raising the brand image, listening to the customer, and generating valuable content. |
| 6 | Self | Description: A priori these are customers with infrequent incidents in the past, and without much relevance. Future interactions: In future customer interactions with the contact centre it is recommended to use bot (faqs, chat, voice), excessive personalisation is not required, and auto response will be sought in the interaction with the customer. Campaigns: This type of customer could be an excellent brand ambassador, campaigns are proposed that reward their interaction and participation in social networks, in addition to strengthening customer loyalty with discounts associated with permanence. |
| 7 | SelfCustom | Description: Although incidents are not frequent, there is a recency in them, however, the importance and duration are low, they are customers with a low abandonment rate. Future interactions: In future customer interactions with the contact centre it is recommended to use bot (faqs, chat, voice), if personalisation is required because the customer demands it, it could move from an automatic channel to a personalised and even specialised one. Campaigns: Campaigns aimed at strengthening the brand image are proposed, if the customer has been with the brand for some time, complementary strategies that reward loyalty are proposed. |
| 8 | Custom | Description: Frequent and repeated incidents, but without importance. The customer typology may correspond to customers seeking excellence in the brand’s services. Future interactions: In subsequent customer interactions with the contact centre, it is recommended to personalise communication through generalist and, if necessary, specialised agents. Campaigns: Aimed at promoting trust among customers, creating messages of value that can help the customer and understand what the brand does for their benefit. |
| Client_ID | Cluster |
|---|---|
| 21046586 | 5 |
| 21334657 | 2 |
| 2288774 | 3 |
| 24583147 | 6 |
| 25860618 | 4 |
| 25864456 | 1 |
| 26053204 | 7 |
| 26064419 | 8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marín Díaz, G.; Carrasco, R.A.; Gómez, D. RFID: A Fuzzy Linguistic Model to Manage Customers from the Perspective of Their Interactions with the Contact Center. Mathematics 2021, 9, 2362. https://doi.org/10.3390/math9192362
Marín Díaz G, Carrasco RA, Gómez D. RFID: A Fuzzy Linguistic Model to Manage Customers from the Perspective of Their Interactions with the Contact Center. Mathematics. 2021; 9(19):2362. https://doi.org/10.3390/math9192362
Chicago/Turabian StyleMarín Díaz, Gabriel, Ramón Alberto Carrasco, and Daniel Gómez. 2021. "RFID: A Fuzzy Linguistic Model to Manage Customers from the Perspective of Their Interactions with the Contact Center" Mathematics 9, no. 19: 2362. https://doi.org/10.3390/math9192362