Abstract
We introduce an algorithm based on posets and tiled orders to generate emerging images. Experimental results allow concluding that images obtained with these kinds of tools are easy to detect by human beings. It is worth pointing out that the emergence phenomenon is a Gestalt grouping law associated with AI open problems. For this reason, emerging images have arisen in the last few years as a tool in the context of the development of human interactive proofs.
Keywords:
CAPTCHA; emergence; emerging image; matrix problem; human interactive proof; poset; tiled order 1. Introduction
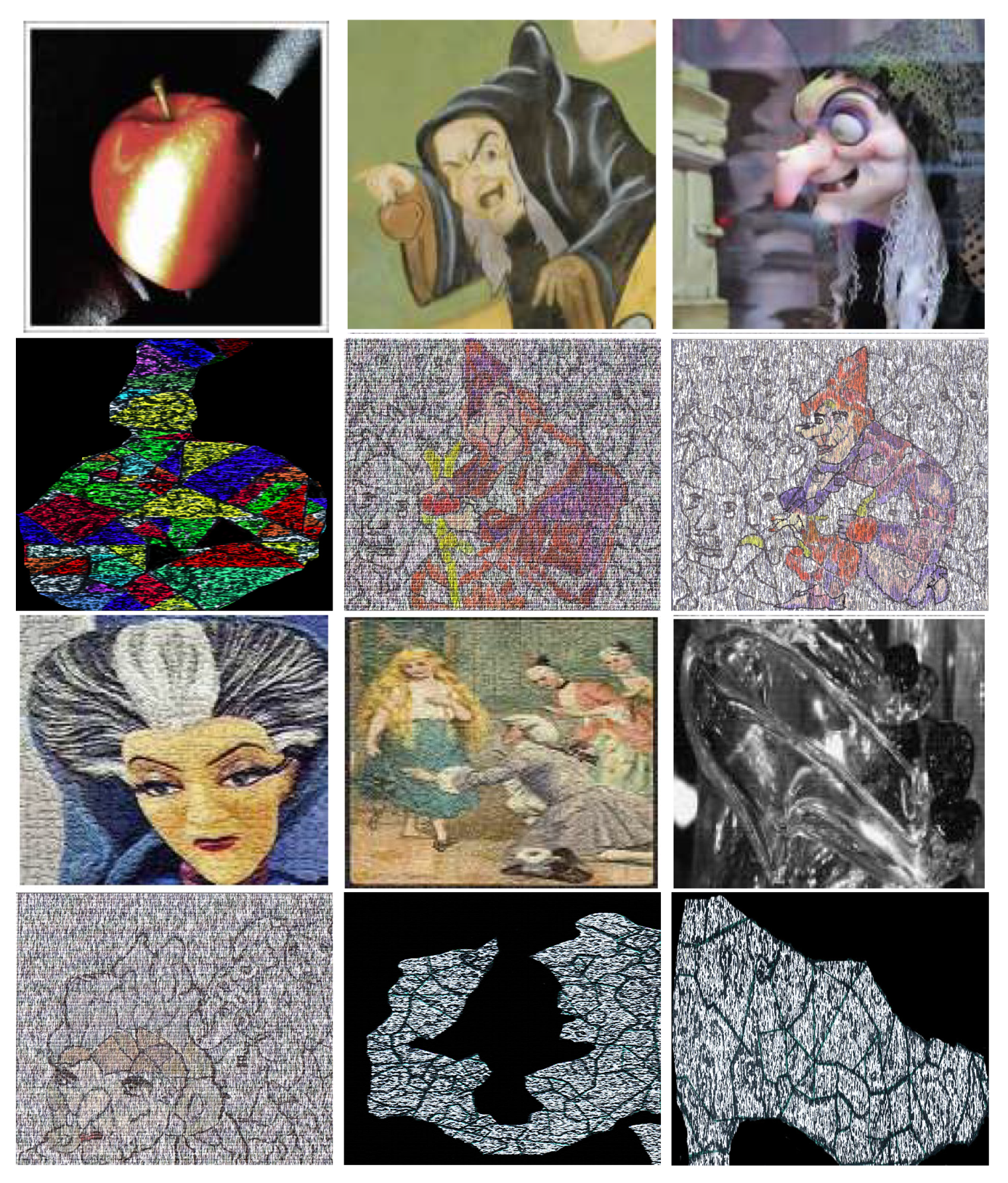
Emergence is one of the grouping laws proposed by Wertheimer, Köhler and Koffka in their Gestalt theory. The main principle in this theory is that the whole (gestalt) is more than the sum of the parts, i.e., the properties of the totality of a given image emerge when the human eye perceives the whole of the objects without paying attention to the elements of the parts constituting it [1,2,3]. Moreover, elements in small local neighborhoods look complex, random, and, therefore, meaningless, however, when observed in its entirety, the elements are aggregated and the main subject in the image suddenly pops out (see Figure 1), i.e., emerges and is thus perceived as a whole [4,5,6].

Figure 1.
Examples of emerging images.
Since its introduction, the notion of emergence associated with images has been the object of study of many investigations, becoming, in this way, one of the most interesting open problems in AI, its generation and recognition being two of the most important questions regarding this subject. For instance, Mitra et al. [7] pointed out that the exact process of how objects within emerging images are perceived is currently unknown, and thus it can be concluded that it is hard to automate the recognition process of this type of image. Therefore, the emergence phenomenon is suitable for the design of human interaction proofs (HIPs), i.e., systems with the main objective of distinguishing between various groups of users through a challenge and response protocol. HIPs protocols can be used to distinguish human versus machine or one person versus another [8,9,10,11].
To tackle the first problem regarding emerging images, Mitra, et al. [7] proposed a synthesis technique to generate emerging images from 3D objects, such images are, in general, detectable by humans but are difficult to recognize by computer vision algorithms. Afterwards, several approaches based on algebras and representations of posets have arisen with the purpose of introducing algorithms that automatically generate emerging images [1,12].
Contributions
We introduce master polygonal meshes (or masters), which simultaneously represent images of different repositories. Images are extracted from the masters with a novel algorithm based on new operations between suitable 0 m-tiled orders known as semi-maximal rings. Among these operations is the completion, which helps to remove noise from an output (model) of an image I. It is worth pointing out that algorithm outputs emerging images that are easy to recognize by human beings. Based on different image repositories, extensive experiments have been conducted to test the accuracy of the proposed algorithms.
The approach allows using only one master to represent models of all images in several repositories, achieving, in this way, memory space-saving. It is worth noting that, currently, there are no known practical applications such as those presented in this paper for the theory of tiled orders and exponent matrices introduced by Zavadskij and Kirichenko.
The following diagram (1) shows the way that some of the main results are related in this paper. Where the symbol Pr stands for proposition, whereas Alg means algorithm.
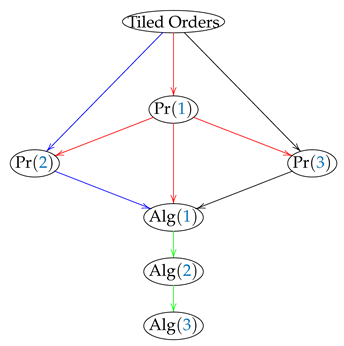
This paper is organized as follows: In Section 2, we present some results regarding CAPTCHAs, posets, tiled orders, and polygonal meshes. In Section 3, we give the main results, in particular, an algorithm is introduced that generates emerging images. Experimental results are given in Section 4. Section 4.3 is devoted to the study of the edges and boundaries of the obtained emerging images with examples of false positives. We see that edge detection algorithms do not give much information about these features. In Section 4.4, we compare the performance of humans and machines recognizing emerging images as those generated by the proposed algorithms. In Section 5, we make some statistical discussions. Finally, in Section 6, we give some conclusions, and it is posed possible future works in line with these investigations.
2. Background and Related Work
In this section, we give definitions and notation to be used throughout the paper. In particular, it is given a brief overview regarding the development of the research of the construction of human interaction proofs (HIPs) and CAPTCHAs, together with the role of emerging images in the advances of these investigations.
2.1. CAPTCHAs
Alan Turing introduced in 1950 the notion of the human interactive proof (HIP) by defining a so-called ”imitation game” [13]. In this scenario, a human judge simultaneously asks questions to a human and a computer located in different rooms. The computer is the winner if the judge is not able to establish what is its location.
It is worth noting that Naor in 1996 introduced without formalisms the concept of human interactive proof [14].
Perhaps completely automated Turing test to tell computers and humans apart (CAPTCHAs) are the most important tests based on human interactive proofs. Von Ahn et al. [8] define a CAPTCHA as a cryptographic protocol of type , which means that at least percent of the population has probability greatest than of passing the test.
According to Blum et al. [8,9,10], among the main characteristics of a CAPTCHA are:
- The test should be easy to solve for humans and hard to solve for machines;
- The test should be automatically graded and generated;
- The test should be resistant to automatic attacks.
To avoid the use of bots by fraudsters, a race for seeking the perfect CAPTCHA has been stimulated. Perhaps, the most significant advances on the subject have been given in the last few years. For instance, in 2014, a Google team solved the famous reCAPTCHA by using a convolutional neural network named DistBelief [15], whereas, in the same year, the Supercomputer Eugene Goostman passed the Turing test. Finally, we recall that in 2020, researchers of the University of Leeds used a generative adversarial network (GAN) based on deep learning to solve any HIP based on text images [16].
2.1.1. Emerging Image Based-CAPTCHAs
In 2009, N. J. Mitra et al. [7] proposed a synthesis technique to generate emerging images of 3D objects. According to them, the special skill that humans have to recognize emerging images can constitute an effective scheme to tell humans and machines apart.
The proposed algorithm is designed in such a way that, locally, the synthesized images divulge little information or cues to assist any segmentation or recognition procedure. The approach allowed to build so-called emerging videos by using frames with very little information of the image reproduced, but when the video is presented, images are easy to recognize by human beings but very difficult to detect by machines.
2.1.2. Moving Image-CAPTCHAs
Based on Mitra’s et al. ideas [7], emerging images have been used to define moving image-CAPTCHAs. For instance, in 2013, Y. Xu et al. [17] (Usenix Security’2012, TDSC’2013) used this type of 2D-images to generate a test named EIMO CAPTCHA, which resists attacks where others fail. Based on the emergence phenomenon, Baird et al. in [11] introduced a dynamic text strings-based CAPTCHA, which is an improvement of NuCAPTCHA considered as one of the most secure and usable CAPTCHAs.
Remark 1.
The main limitation with emerging images seems to be the difficulty to create a large number of recognizable models.
Gao et al. introduced a new class of CAPTCHAs based on the notion of emerging images and dynamic cognitive games. Afterwards, they applied a series of countermeasures, such as pseudo-3D rotation, hidden edge segments, etc., to resist automated object recognition. Gao et al. showed the weakness of 2D EIMO CAPTCHA, and they proposed a different design based on 3D objects and examined its security and usability [18,19].
2.2. Partially Ordered Sets (Posets)
In this section, we introduce some basic definitions and notation regarding posets [20].
Let be a set, then a relation R contained in is said to be a partially order set, if R is obtained from by endowing it with an order ≤, satisfying the following properties:
- For each the pair , which means that ≤ is reflexive;
- If the pairs and for some then , which means that ≤ is antisymmetric;
- If and then , meaning that ≤ is transitive.
If where R is a poset induced by a set and an order ≤ then we will also write . In such a case, elements x and y are called comparable points. Otherwise x and y are incomparable, denoted . If and then we will write .
Henceforth, if no confusion arises we will write or simply to denote the poset defined by a set and a partial order ≤.
If for all , it holds that or then C is said to be a chain or a linearly ordered set. A subset A of a poset is said to be an anti-chain if any pair of different points are incomparable, i.e., if and then .
A relation between two points of a poset is a covering if for any , such that , it holds that either or . In such a case, we will say that x is covered by y.
A poset is finite (infinite) if ( ).
The Hasse diagram is the graphical representation of a finite poset . It is a configuration of the form , where
- For each , is a circle with center at a point and radius . , if . endowed with the usual topology. For each covering in there is a line connecting the circle with the circle ;
- If then , for a suitable , ;
- If is a covering then there exists a point in the boundary of and a point in the boundary of , such that the distance between the circles (as compact sets) and equals the distance . Therefore, there is a unique line connecting with . These are the only points of and connected by ;
- If or a relation is not a covering then there is no line connecting with .
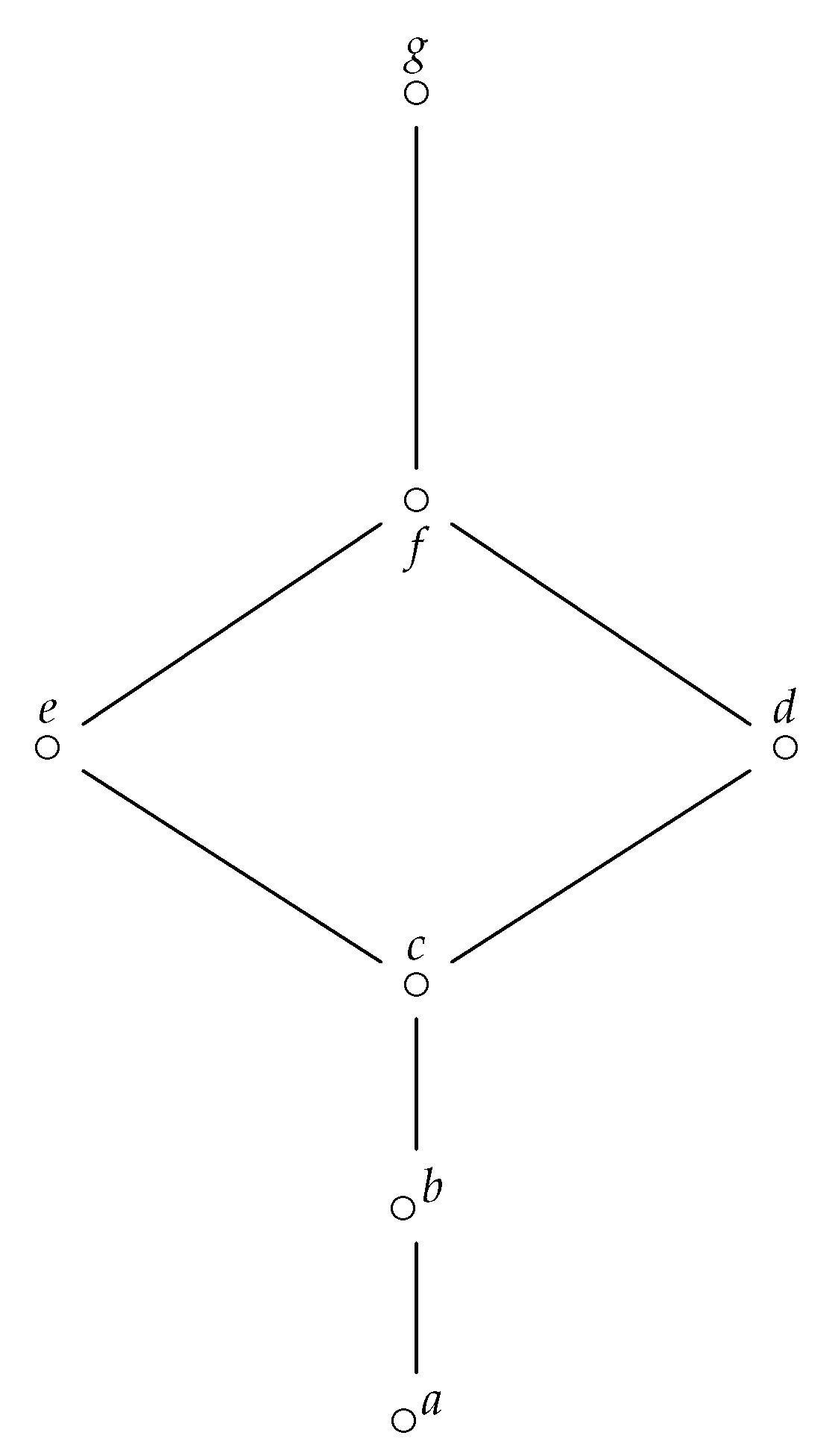
Note that a diagram may be used to define a finite ordered set; an example is given in Figure 2, for a poset , such that , with , .
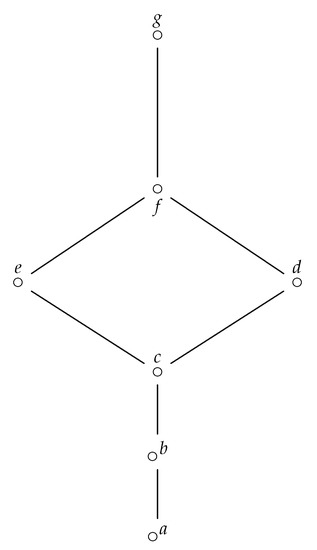
Figure 2.
Hasse diagram of a poset .
The poset dual of a poset is such that if, and only if, . We let denote the poset dual of a poset .
2.3. Tiled Orders
In this section, for the sake of clarity, we recall the notion of semi-maximal ring or tiled order given by Cañadas et al. in [21]. It is worth noting that these types of rings were introduced and classified by Zavadskij and Kirichenko in [22].
A field T is said to be of discrete norm or of discrete valuation if it is endowed with a surjective map
which satisfies the following conditions:
- if, and only if, ;
- ;
- .
We let denote, the normalization ring of the field T, such that
An element , such that is a prime element of . For each , we have that if, and only if, , for some and . Moreover, if, and only if, for some and .
Ring is such that , where is the unique maximal ideal, therefore ideals of generate a chain of the form
A tiled order or semi-maximal ring is a sub-ring of the matrix algebra with the form
consists of all matrices whose entries belong to , in this case the are unit matrices such that (, if , otherwise). Numbers are integers which satisfy the following conditions:
- , for each i;
- for all .
An order is said to be Morita reduced or reduced if it satisfies the additional condition:
For a tiled order (or tiled order) is a tiled order , , where . In particular, if is a -tiled order then has associated a finite poset , where
For instance, the following are the entries of a 01-tiled order associated with a poset :

2.4. Polygonal Meshes
In computer graphics and engineering complex a mesh M of a domain D is a collection of adjacent subsets, such that . The polygonal mesh representation is one of the most general and most used representations of geometric data, however nowadays the idea of using general shapes to construct meshes is widely explored. In this direction, Livesu [23] introduced Cinolib, which is a library for geometric processing. Cinolib supports a wide set of meshes including hexahedral and general polyhedral volumetric meshes.
Perhaps one of the most critical problems regarding the representation of complex shapes consists of finding out algorithms allowing compact storage and fast transmission of meshes (in particular 3D meshes), provided that this type of data consume a large amount of space [24]. Thus, it is necessary to define algorithms for compressing data efficiently.
To save memory space, we introduce some suitable polygonal meshes called masters, whose polygons simultaneously represent images of several repositories.
The Figure 3 shows examples of masters used in this paper to generate emerging images:
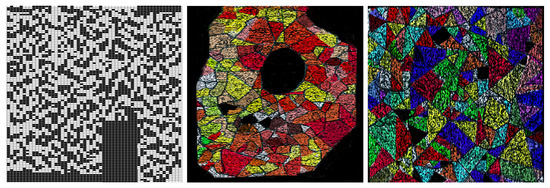
Figure 3.
Examples of masters (polygonal meshes) associated with several image repositories. From left to right, the corresponding master has 5995 polygons and 12,100 vertices, 130 polygons and 219 vertices, and 88 polygons and 121 vertices.
3. Results
In this section, we use tiled orders associated with suitable posets to generate emerging images from fixed templates. Such templates are obtained after applying some novel matrix operations.
3.1. Matrix Operations
In this section, we define algorithms which will allow obtaining emerging images via partially ordered sets.
Given two -tiled orders , and then the joining matrix of and is such that its entries satisfy the following identities (modulo ):
where, denotes that the value of the entry in a matrix is precisely (in matrices, we will write to denote the corresponding entry ). In the case of tiled orders () indicates that points i and j in are comparable (incomparable). and are said to be complementary to each other.
As an example consider the following 01-tiled orders , , and
The following is the identity associated with the corresponding posets.

If is a -tiled order then the completion of is a -tiled order whose entries satisfy the following identities:
For example, if then

The aforementioned definitions of , , and prove the following results.
Proposition 1.
If is the poset of then , where denotes a sub-poset of the poset dual .
Proposition 2.
If Λ is a -tiled order then is a -tiled order for all the possible values of r and s.
The reduction of a -tiled order is defined by the following identities:
As for Propositions 1 and 2, the following result holds by definition.
Proposition 3.
If and Λ is a 01-tiled order then is a -tiled order.
For example, if then

In [12] several templates or masters (see Figure 4) were used in order to generate a repository of emerging images, in this work we obtain such templates by using joining (of tiled orders and shown in Figure 5 and Figure 6), completion and reduction operations.

Figure 4.
Master (polygonal mesh) associated with the joining matrix . We assume that an entry 0 (1) in a tiled order corresponds to a color white (black) in the corresponding models.

Figure 5.
Tiled order as an input of Algorithm 1.

Figure 6.
Tiled order as input of Algorithm 1.
3.2. Emerging Images Associated with Tiled Orders and Posets
According to the present approach, each image I of a repository is modeled by applying joining, completion, reduction, rotation, and suitable filters, in such a way that it is possible to define a map , where is a suitable complementary, and denotes the set of parts of the poset , whereas is a notation for all the transformations required for a visual interpretation of the image . Algorithm 1 defines transformations of type .
| Algorithm 1: The transformation |
|
Following the Cañadas et al. ideas [1,12], some templates are obtained after clustering pixels, so the entries of the joining matrices correspond to suitable clusters with the same pixel value. In some cases, such clusters are polygons, making the template a master, as defined in Section 2.4. The last step has as goal to remove noise to enhance the image quality.
Remark 2.
It is worth noting that, for the sake of applicability, we assume that some polygonal clusters or pixels have been assigned the color black, although the value of the corresponding entry must be 0, such entries are said to be bridges.
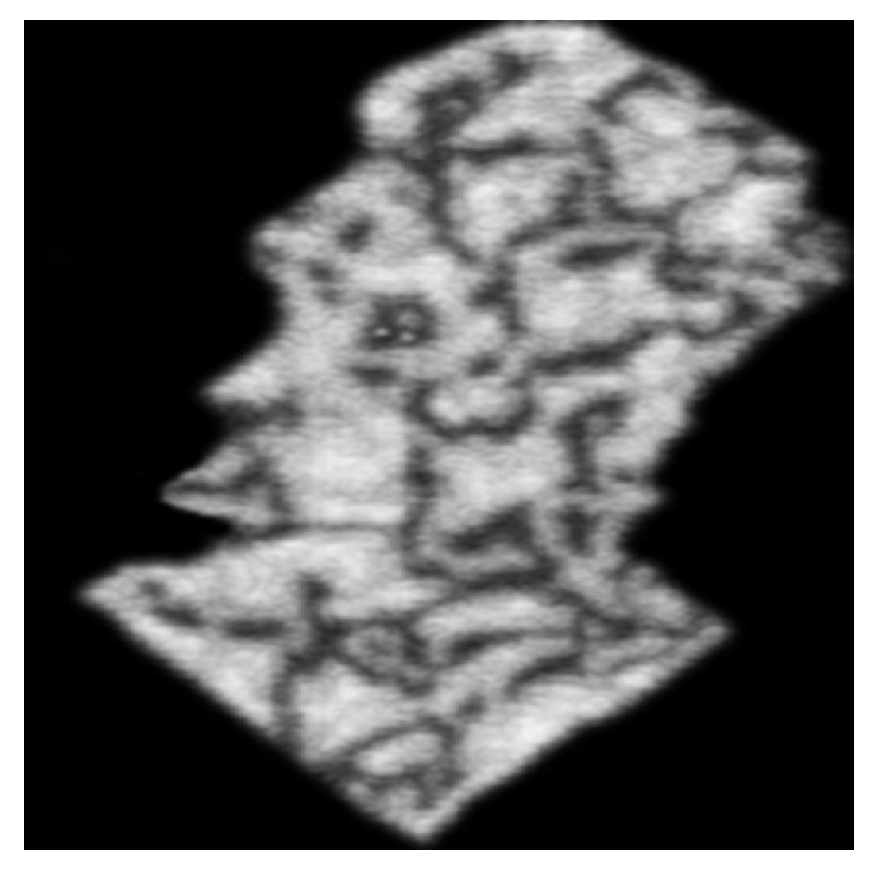
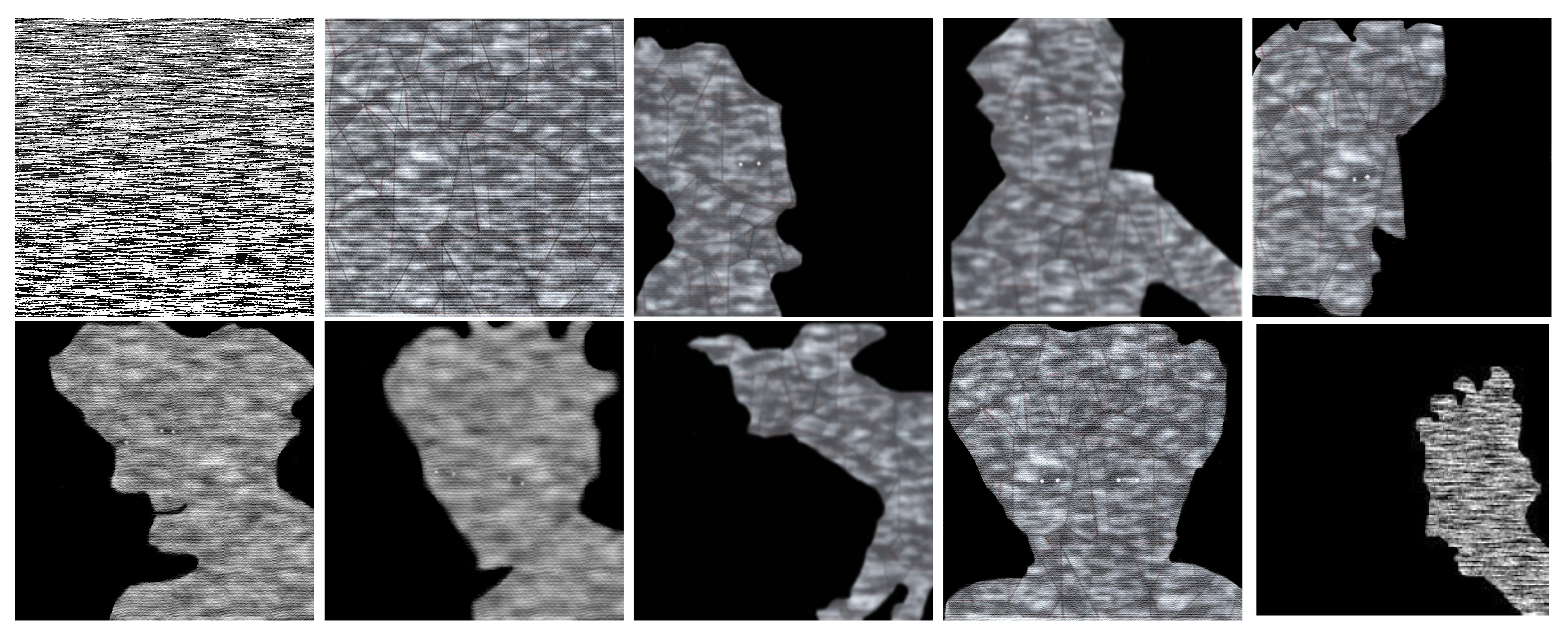
The following Figure 7, Figure 8, Figure 9 and Figure 10 illustrate an application of Algorithm 1 ( is a repository of illustrations of the New Testament realized by different classical painters). Firstly, we fix the target image .
Figure 7.
Target image I in a repository .

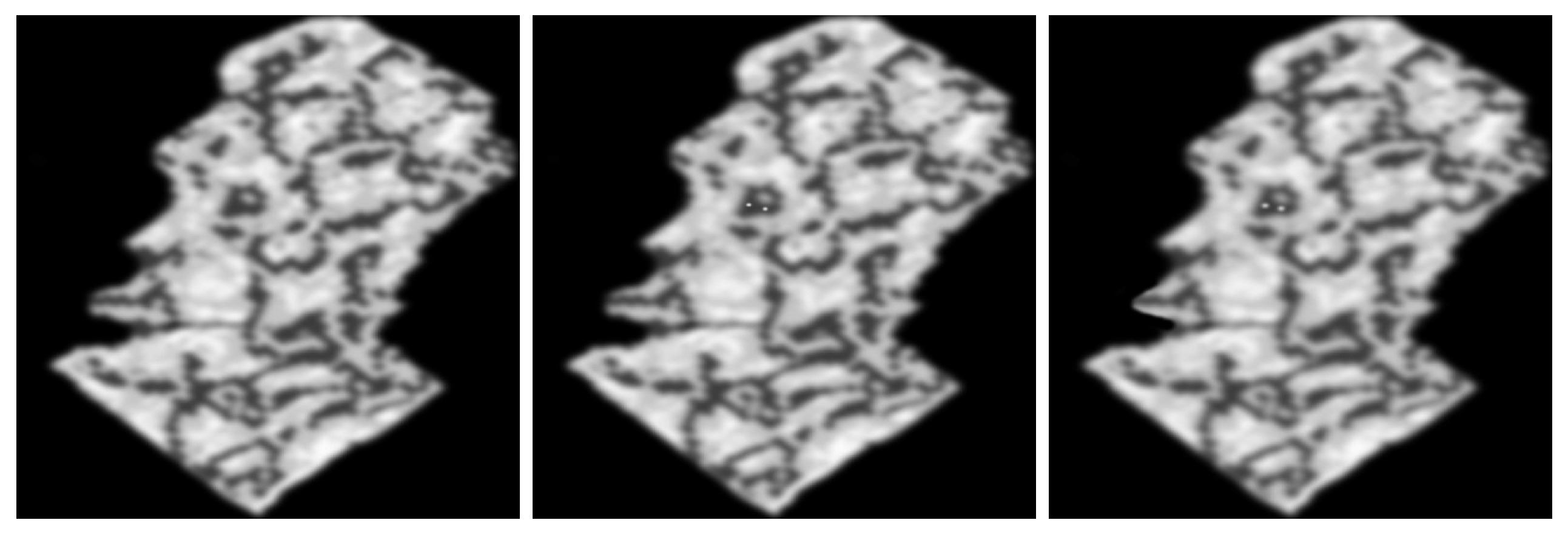
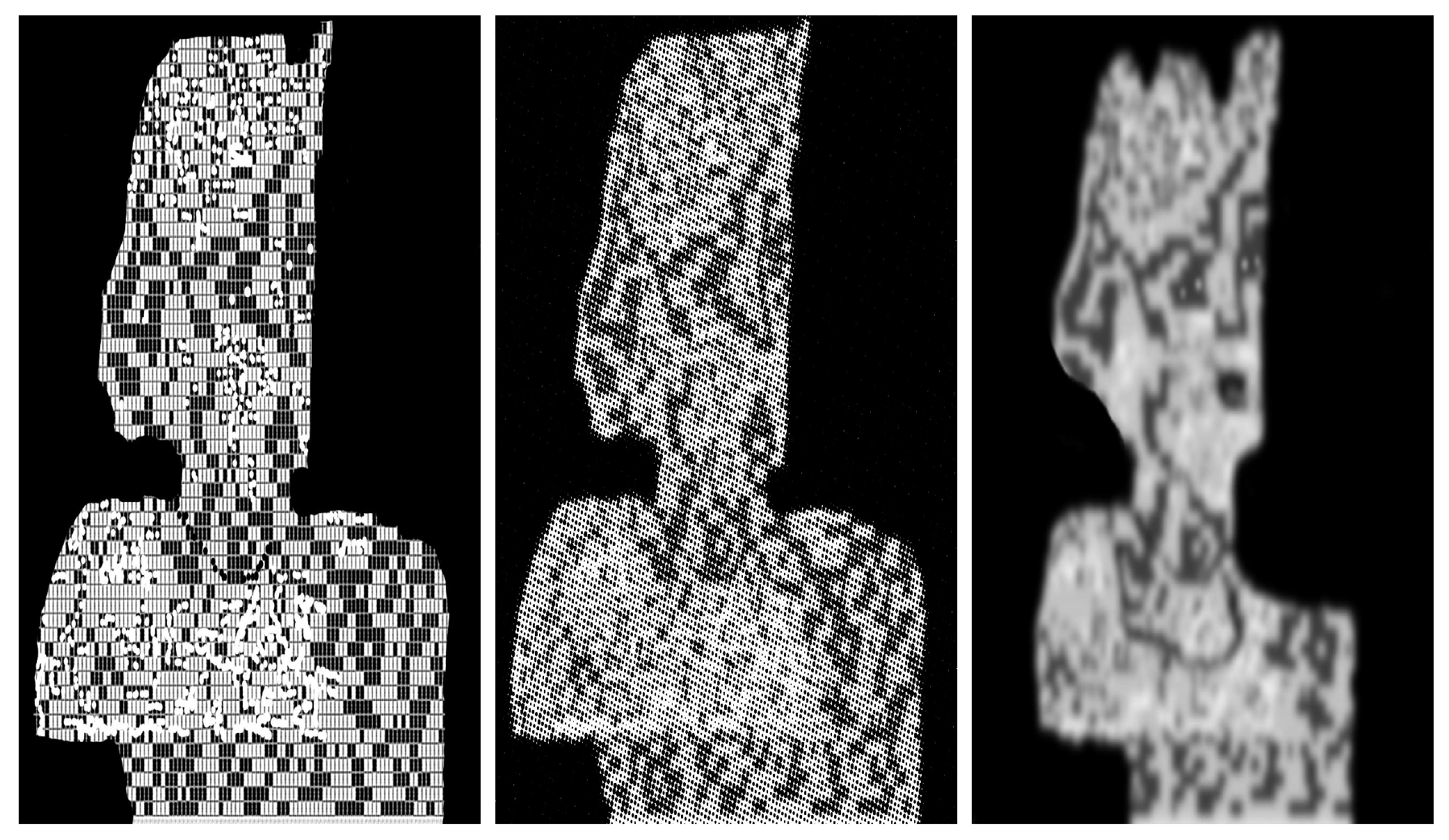
Figure 8.
The first image is obtained after applying reduction to the master (see Figure 4), the third image is obtained after applying completion to the interior of the model. We let , , and denote these images from the left to right.

Figure 9.
Applying completion to remove salt and pepper noise. We denote these images , , and from the left to right.

Figure 10.
As an optional final step, we apply a Gaussian filter.
3.3. Boundary Detection
In this section, we introduce an algorithm to detect the boundary of a model associated with a joining of tiled orders.
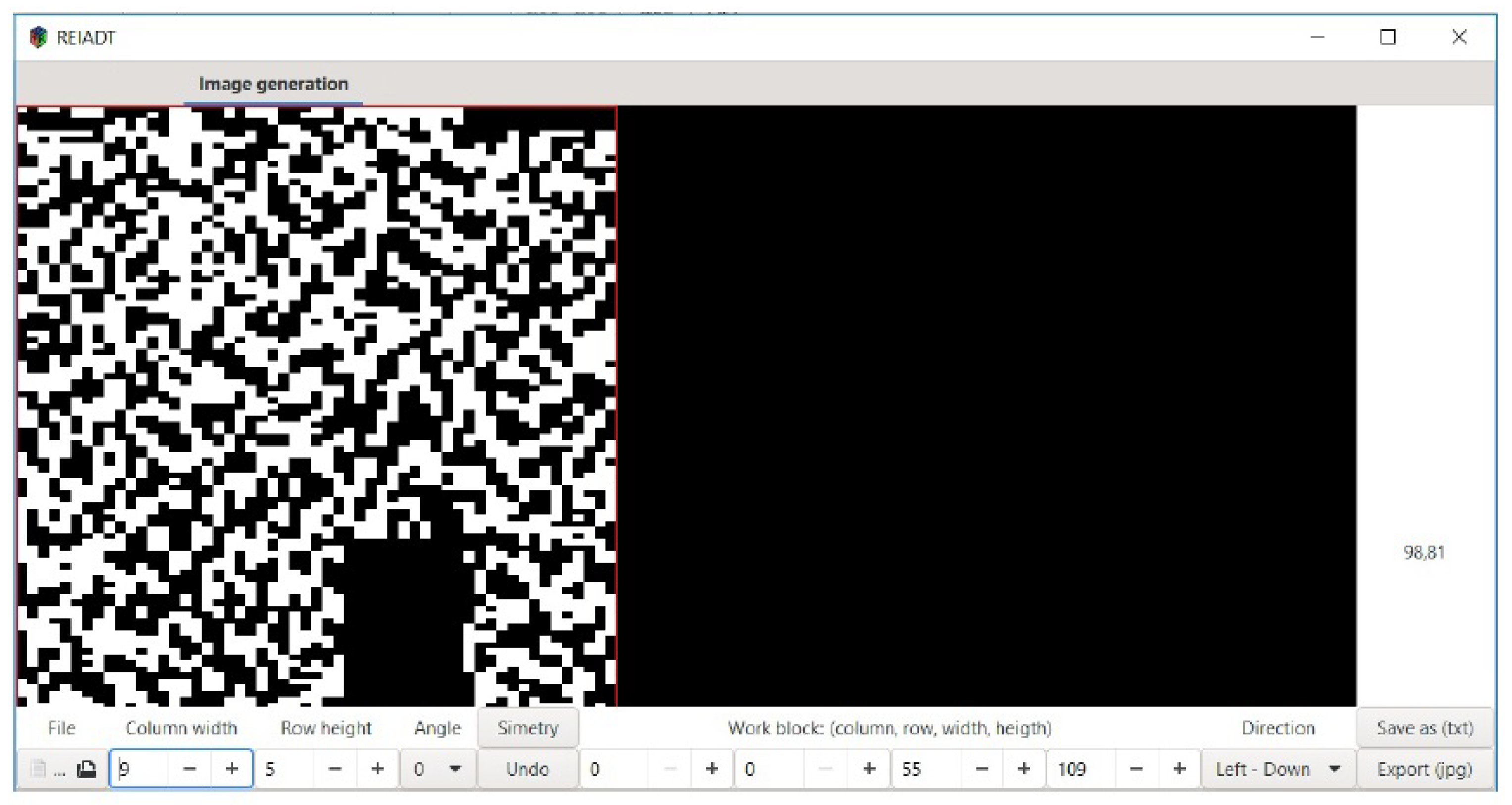
In order to detect the boundary of a model, we have developed a software named REIADT (see Figure 11), which has as its main goal to implement Algorithm 3.
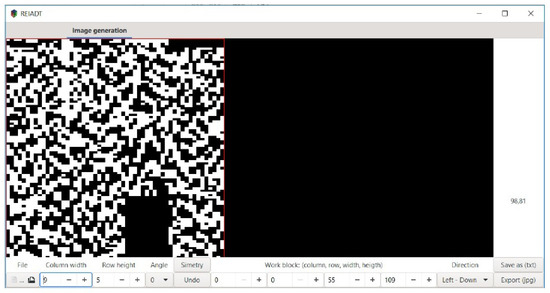
Figure 11.
Computational process representation of emerging images by using admissible transformations (REIADT) created to detect the closure of emerging images.
3.4. The Algorithm ATGEI
The algorithm to generate emerging images (Algorithm ATGEI) embraces Algorithm 1, whose application assumes that a boundary of a model has been already detected. In this section, we introduce an algorithm to detect such a boundary. The starting step consists of fixing some suitable markers, which are clusters with 0 as pixel value (including those after the application of a completion process).
Markers are denoted as , , or . Arrows, in this case denote which clusters in will be changed by using some type of transformation (reduction or completion). For instance, notation () means that any cluster is transformed for any (). We let denote the ordered set of markers associated with a model of an image ().
Algorithm 2 detects clusters in the boundary of . Then applies reduction to any cluster in the direction of the arrow associated with the marker. In this way, the sequence M determines the closure of . Let us describe some details associated with closure recognition.
For the development of the Algorithm 2 the following three procedures are carried out:
- Movement;
- Appendix removal;
- Cropping.
| Algorithm 2: Closure detection |
|
Movement
In this step, Algorithm 2 goes through the array from the markers and it selects a temporal border for the model . By symmetry, it suffices to describe the behavior of the algorithm in vertical direction. We will assume that there is a partition of into suitable blocks denoted , , for some suitable . Thus, . Algorithm 2 is applied block by block.
is arcwise-connected if for any pair of clusters , with pixel values there exists a set of consecutive clusters
With the taxicab distance d, such that for all the possible values of i and v (taking into account the symmetry of the procedure). Henceforth, the set will be called a path. Consecutive clusters in the boundary of a model constitute a path from the initial marker to the (temporal) final marker.
The path , with initial cluster and final cluster , can be written , whereas the set of admissible paths connecting with is denoted as . We let denote the length of .
A cluster with pixel value is said to be a bridge. Bridges allow that the boundary of a model be arcwise-connected.
Note that the application of a movement generates a path . However, such automatic movement does not guarantee the minimality of . That is, it is possible to generate undesired clusters, the process for which such undesired clusters are deleted is called appendix removal. This process can be carried out by a suitable reduction.
Once a movement is applied in a given orientation of a suitable marker, it is necessary to clean the transformed block by deleting all the clusters in the exterior of via reductions. Such a procedure is said to be cropping.
Joining, rotation by suitable angles (of a model ), completion, reduction, and a suitable filtering allow obtaining all the models associated with an image-repository , such a set of models is also a set of emerging images whose parts are given by clusters.
The following Algorithm 3 summarizes the process for which an emerging image based on clusters is obtained.
| Algorithm 3: Algorithm ATGEI |
| 1. Apply steps 1–3 of Algorithm 1. |
| 2. Apply step 4 of Algorithm 1 via Algorithm 2. |
| 3. Apply step 5 of Algorithm 1 (including cropping and appendix removal). |

Figure 12.
Movement, appendix removal, and cropping applied via the system REIADT to a joining matrix associated with an image .

Figure 13.
Model detected without applying additional filtering.
The following are markers and bridges used to obtain Figure 13:
, , , ,, ,, , , , , , , , ,, , , , , , , , , , .
4. Experimental Results
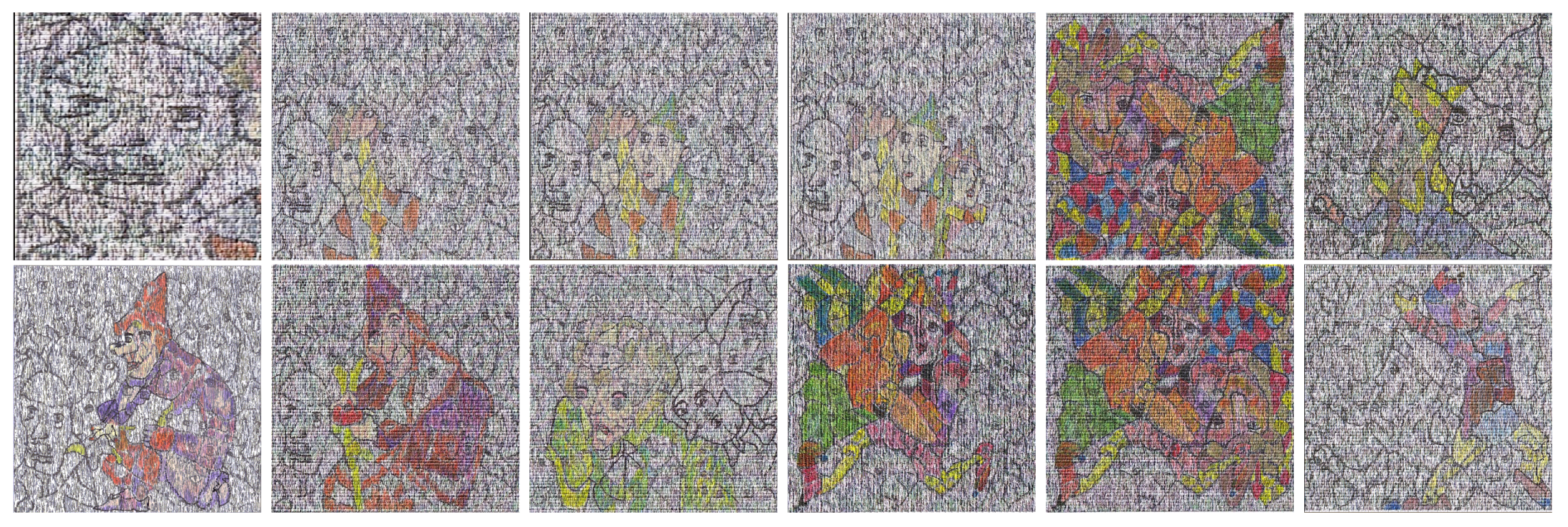
In this section, we apply the Algorithm 3 to obtain emerging images. We model and encode JPEG images of pixels into three masters. As in previous works [1], target images arise from repositories containing illustrations of circus acts [25], fairy tales, Bible classic books (e.g., the New Testament and the book of Esther) and Leonardo da Vinci’s drawings [26] (see Figure 14, Figure 15, Figure 16, Figure 17, Figure 18, Figure 19 and Figure 20). In this paper, the processed images arise from the movies One Night with the King (2006) [27], and The Book of Esther (2013) [28], directed by Michael O. Sajbel and David A.R. White, respectively. Fairy tales images arise from the movies Snow White (1937) [29], Cinderella (1940) [30], and Pinocchio (1940) [31], all of them produced by Walt Disney. Processed images of the Chinese calendar and the Zodiac can be found in the overview [32] on the exhibition ”Zodiac Heads” by the Chinese artist Ai Weiwei and the manuscript [33] ”The Leiden Aratea Ancient Constellations in a Medieval Manuscript” by R. Katzenstein and E. Savage-Smith, respectively.
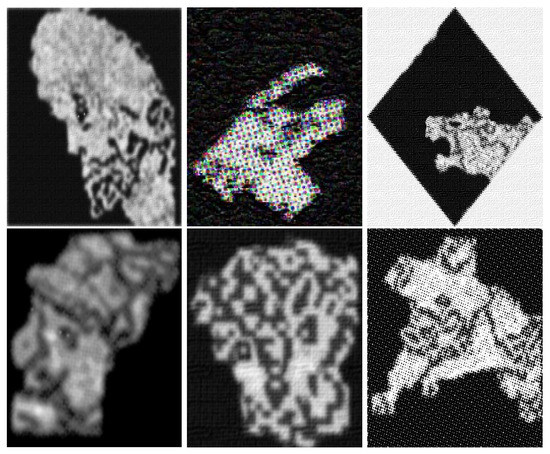
Figure 14.
Images of three repositories and sharing the same space (master Time, see Figure 4).
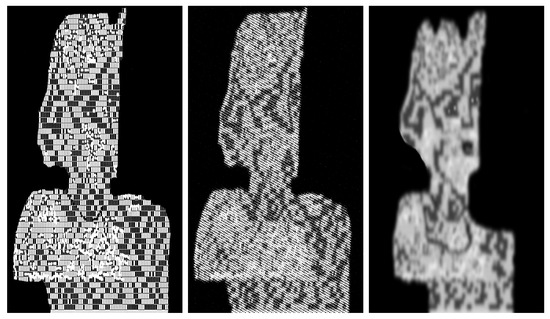
Figure 15.
Sequence of models extracted from the master shown in Figure 4 via Algorithm 3. In this case, reductions have been applied in the interior of the model.
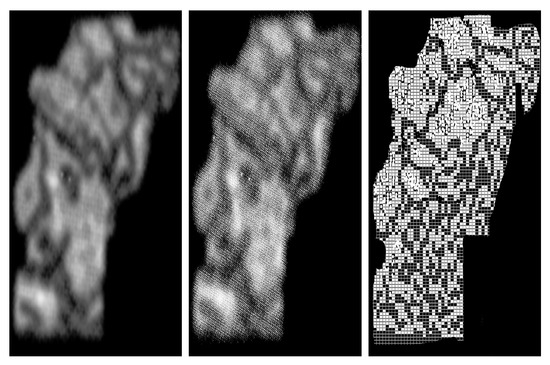
Figure 16.
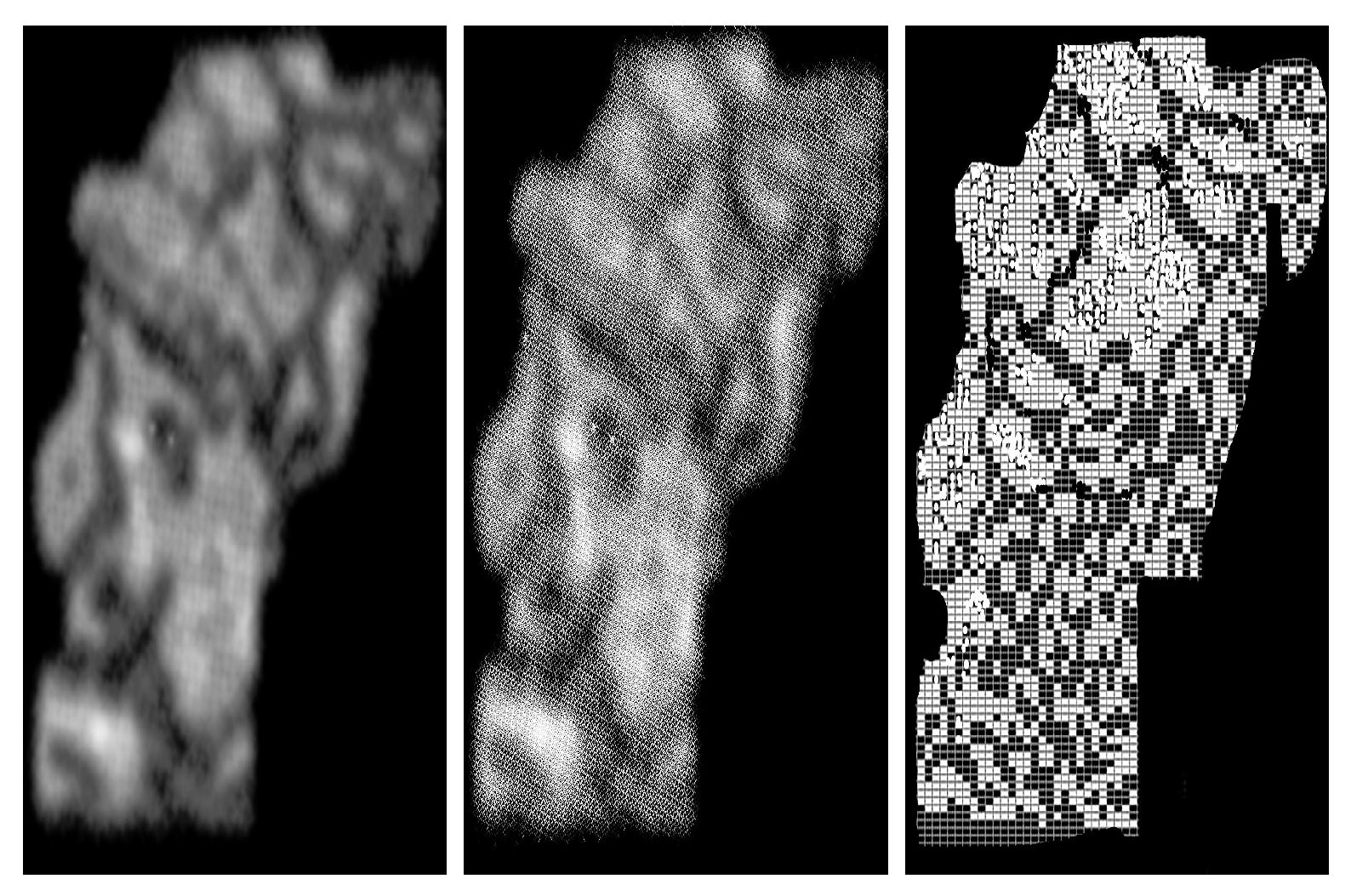
Another application of Algorithm 3, at the left the target image and models obtained after completions, reductions and a suitable filtering (see the central image).
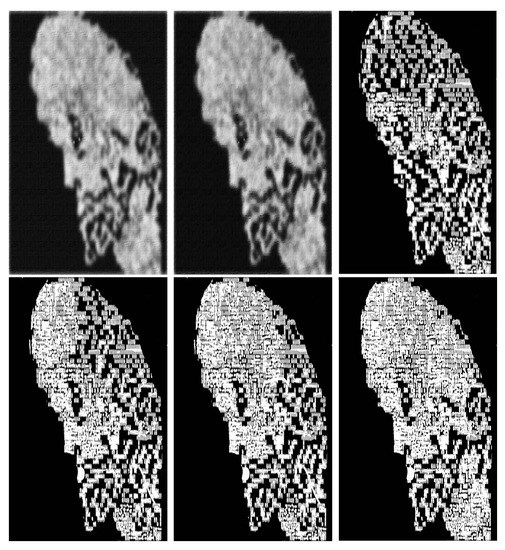
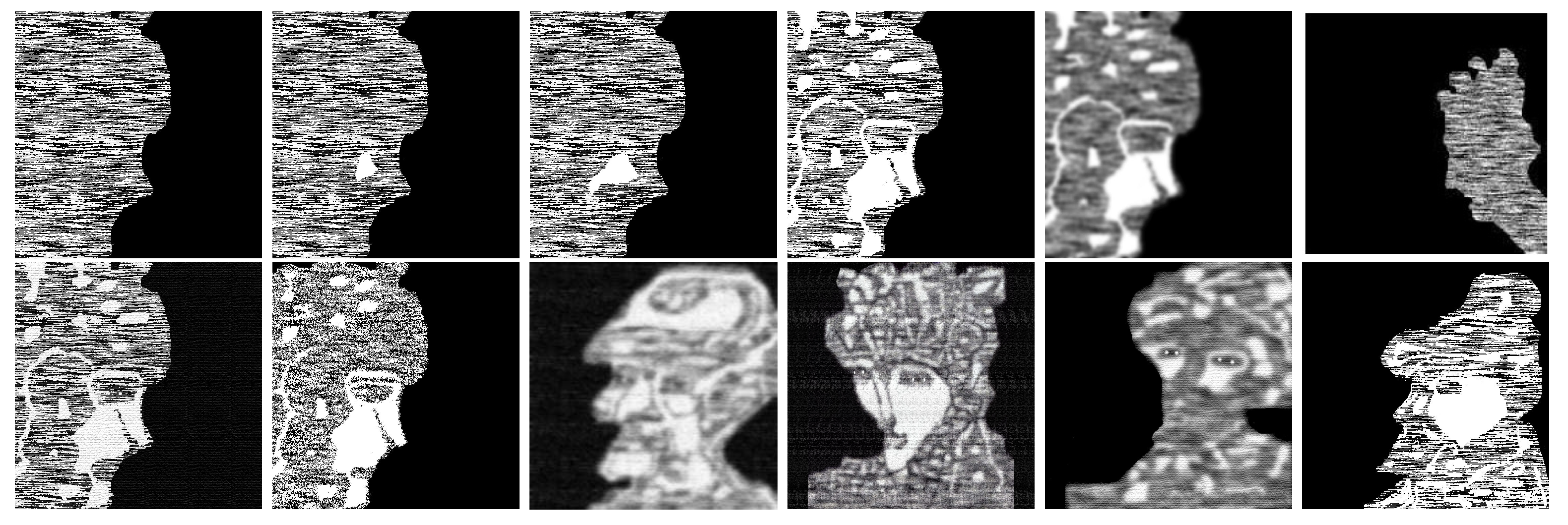
Figure 17.
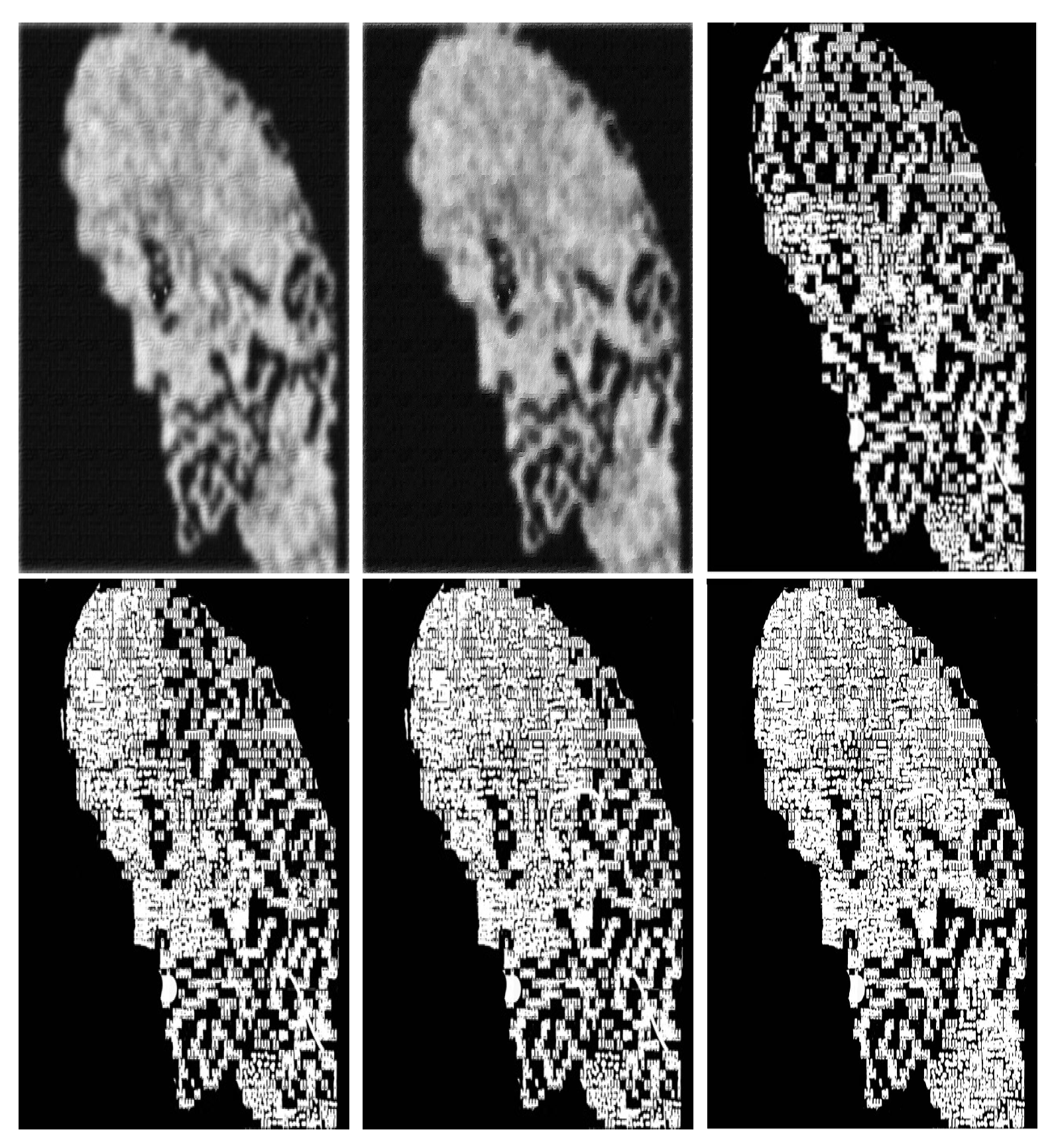
On the left, a target image and the model obtained after applying reductions and completions. We let , and denote the noisy images, see Table 2.

Figure 18.
Examples of targets and models (associated with repository ) obtained after applying Algorithm 3 to a rotation of the master (Figure 4) and a suitable filtering.

Figure 19.
This sequence shows how to use Algorithm 3 to obtain models of illustrations of objects in repository .

Figure 20.
Models arising from illustrations of repositories (zodiacal signs) and (Chinese lunisolar calendar).
4.1. Storage Capacity
In this section, we show the capacity that the master (see Figure 4, which we also called Time) has to storage models of different repositories. Such joining is used to save models of illustrations which commonly are accepted as representations of time measures, e.g., BC or AC for centuries, in such a case there is a repository with classical illustrations of the New Testament, it is our first repository . Zodiacal signs (our second repository ) often are used to illustrate months. Finally, our third repository is the Chinese lunisolar calendar, which commonly is used to represent years.
The following Table 2 shows how the noise is removed via completions.

Table 2.
The lowest values of the PSNR show the most significant differences between noisy images in Figure 17.
4.2. Additional Experimental Results
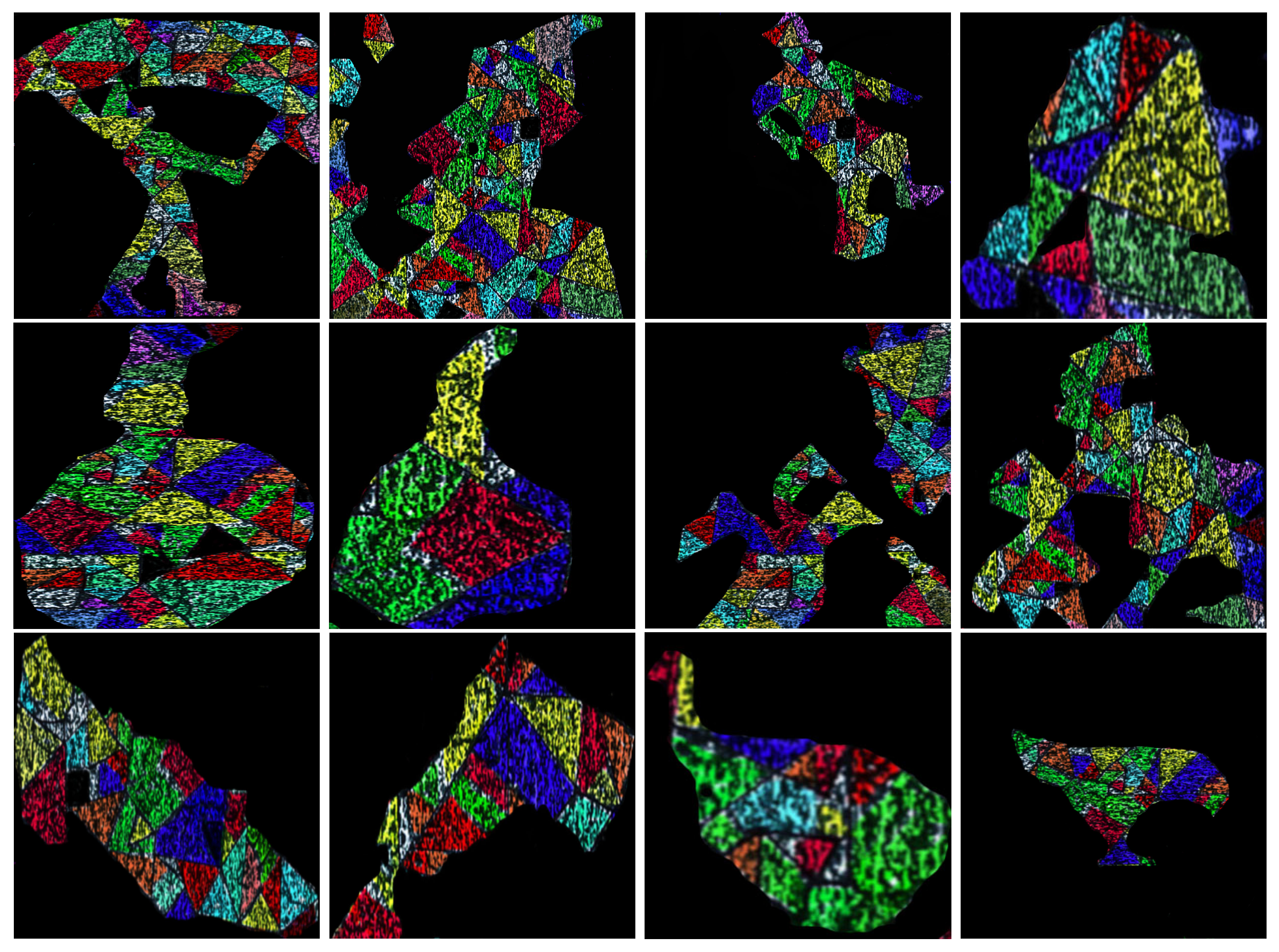
In this section, we use Algorithm 3 in order to generate models (emerging images) associated with illustrations of fairy tales, classical books (such as the Book of Esther), circus acts and the alphabet. In some cases, clusters are colored polygons to avoid the use of completion in the interior of the models, see Figure 21, Figure 22, Figure 23, Figure 24, Figure 25, Figure 26, Figure 27, Figure 28, Figure 29, Figure 30, Figure 31 and Figure 32.

Figure 21.
Example of the application of Algorithm 3 to a master associated with a joining. In this case, the emerging image is obtained without using completions. Thus, internal noise is not removed.

Figure 22.
In this example, it is shown how to recover several emerging images after applying a sequence of steps of Algorithm 3.

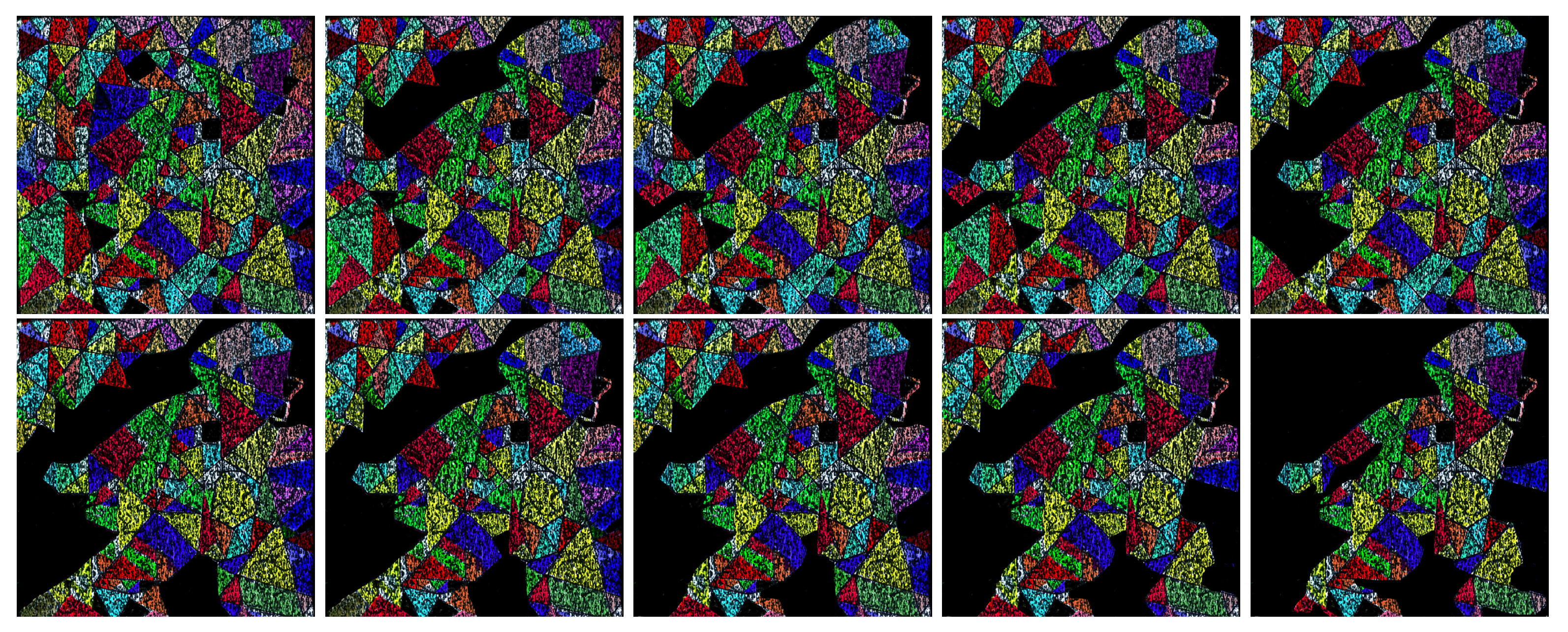
Figure 23.
In this figure, we emphasize how the images in a template master are interrelated to each other. We denote these images – from the left to right.
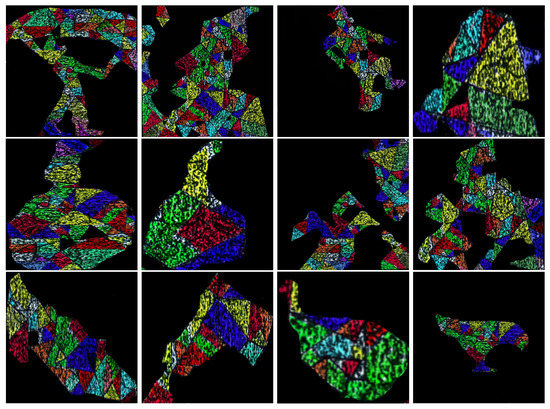
Figure 24.
Models of illustrations of circus acts [25] and fairy tales obtained with Algorithm 3.
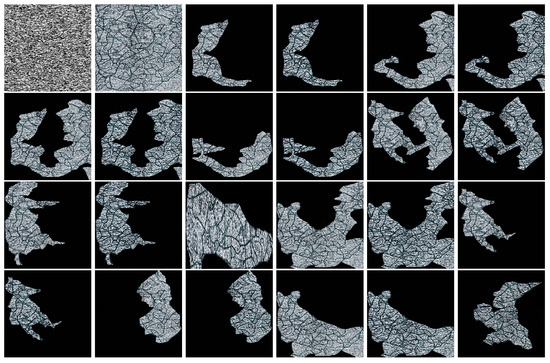
Figure 25.
A master associated with a joining with a sequence of models of illustrations of fairy tales. Models are obtained without applying completions. Instead, it is applied a suitable filtering.
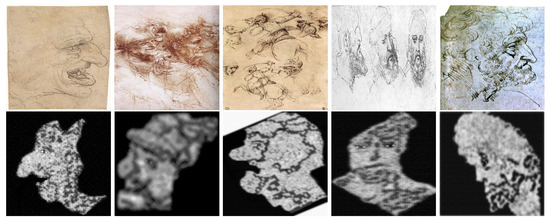
Figure 26.
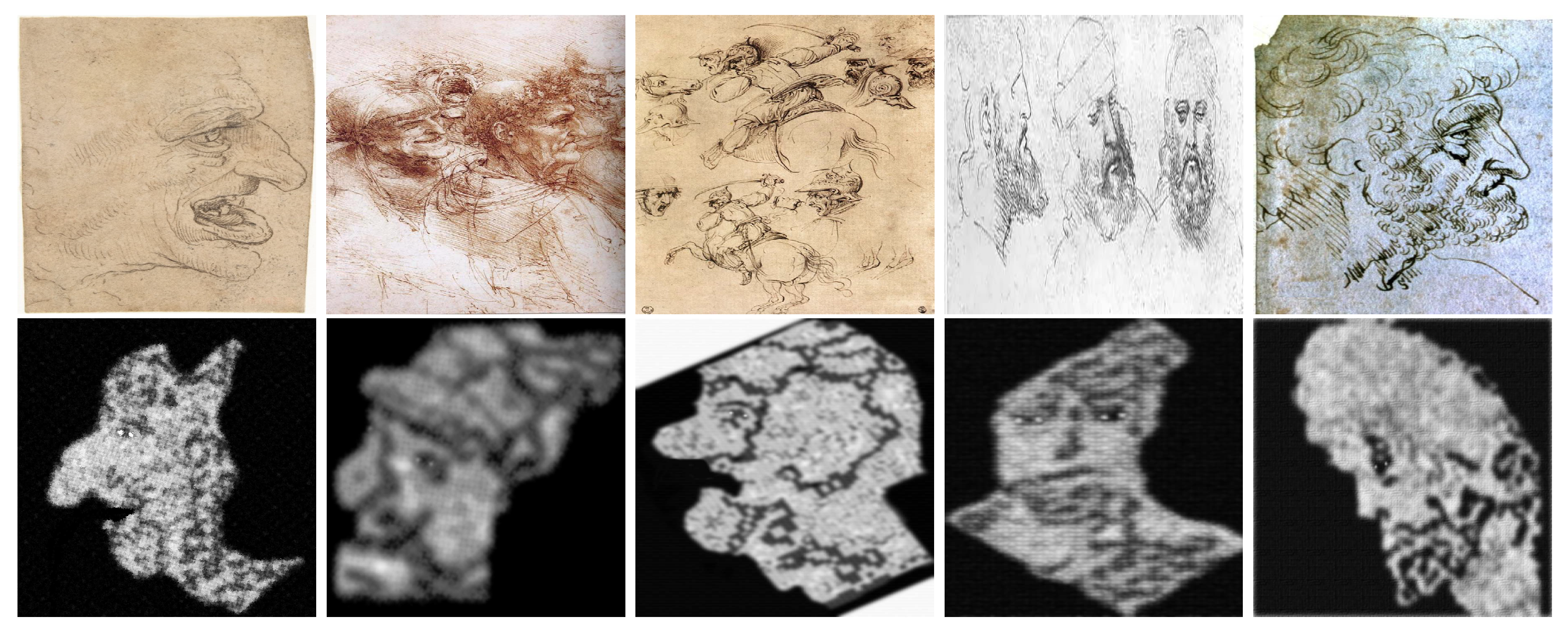
Leonardo da Vinci’s drawings [26,34] related with some outputs of Algorithm 3.
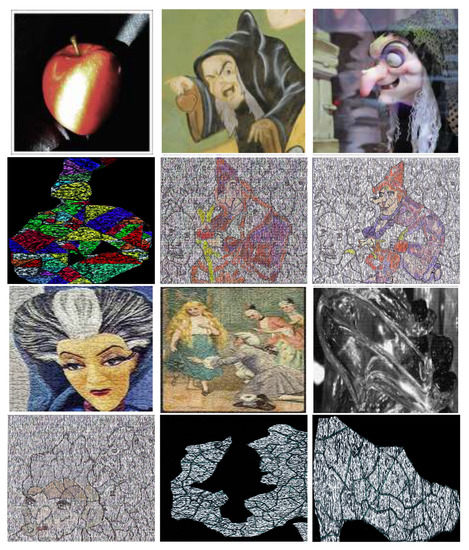
Figure 27.
Outputs of Algorithm 3 related with images extracted from repositories of fairy tales [35,36,37,38,39,40].
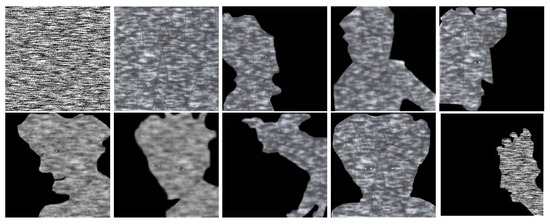
Figure 28.
A sequence of models obtained as outputs of Algorithm 3. In this case, we start by applying a Gaussian filter to . Then it is defined a suitable master.
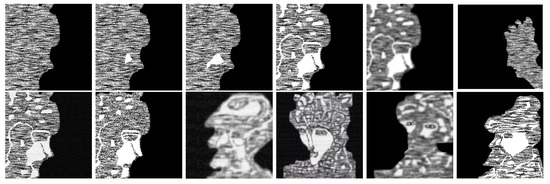
Figure 29.
A sequence of completions applied to a model of an image of the book of Esther and some targets arising from the same book. Note that in the last image no filter has been applied.

Figure 30.
The images shown above describe images from a repository [41,42,43,44] and corresponding models (outputs of Algorithm 3) regarding the book of Esther. Note that the model obtained from the first image arises by applying only reductions.

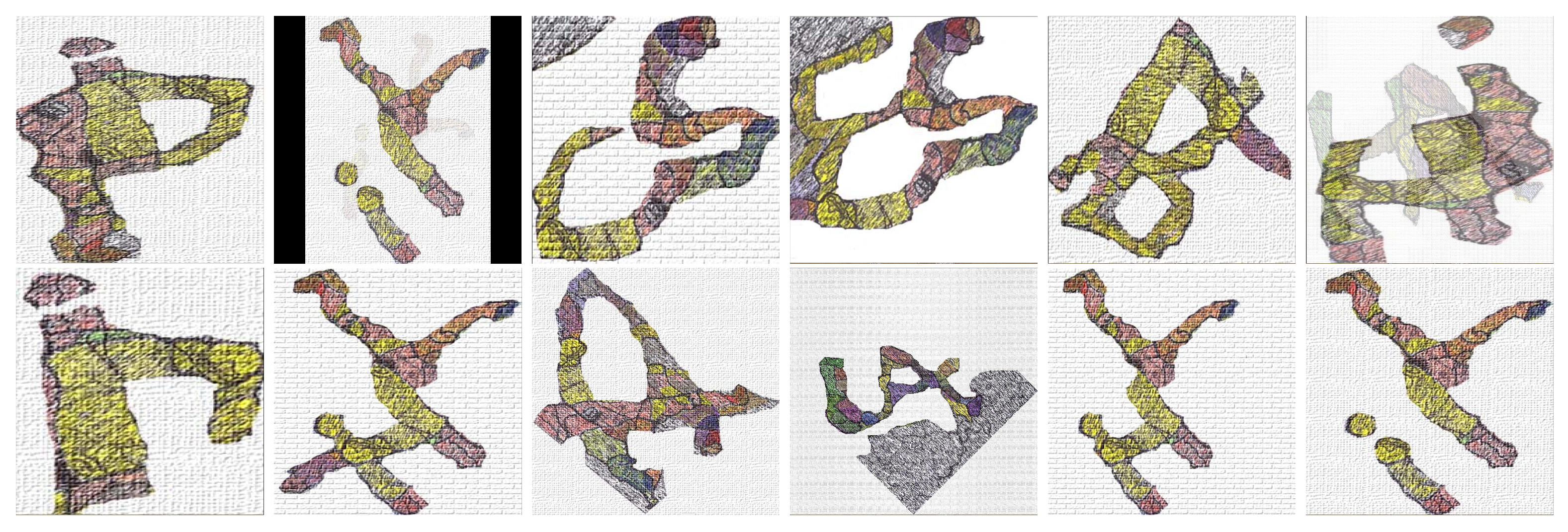
Figure 31.
A sequence of letters arising from the application of Algorithm 3 to the joining shown in Figure 28 associated with images of the Book of Esther.


Figure 32.
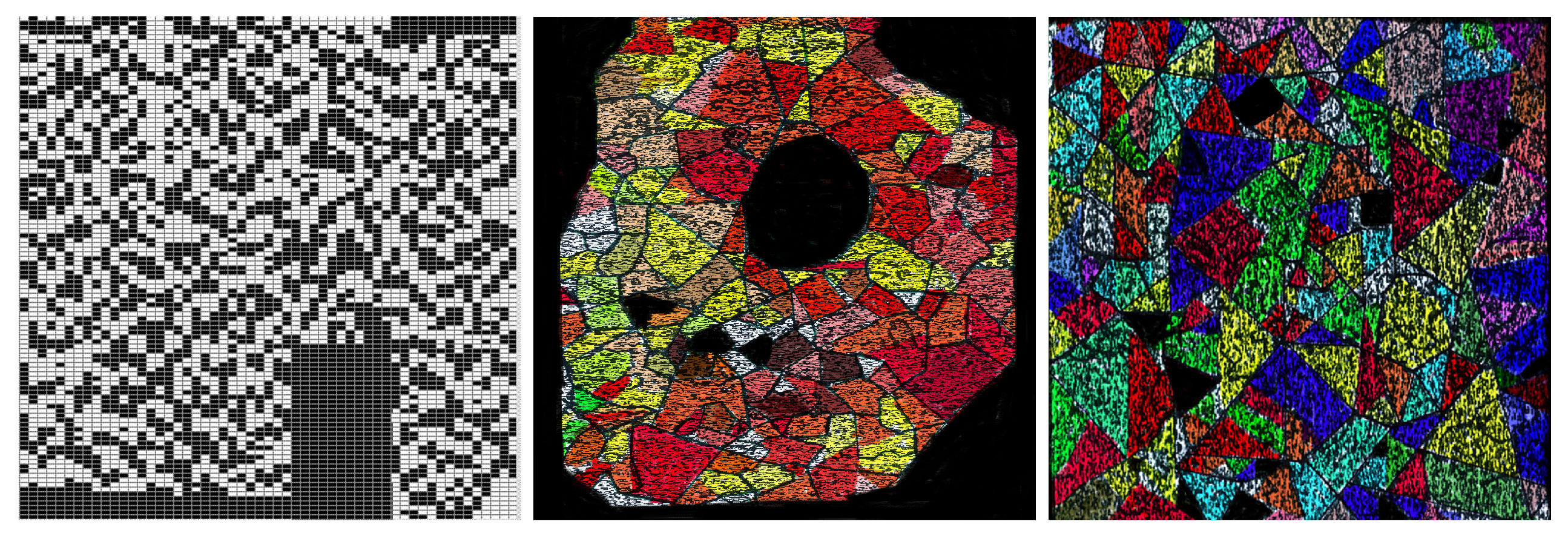
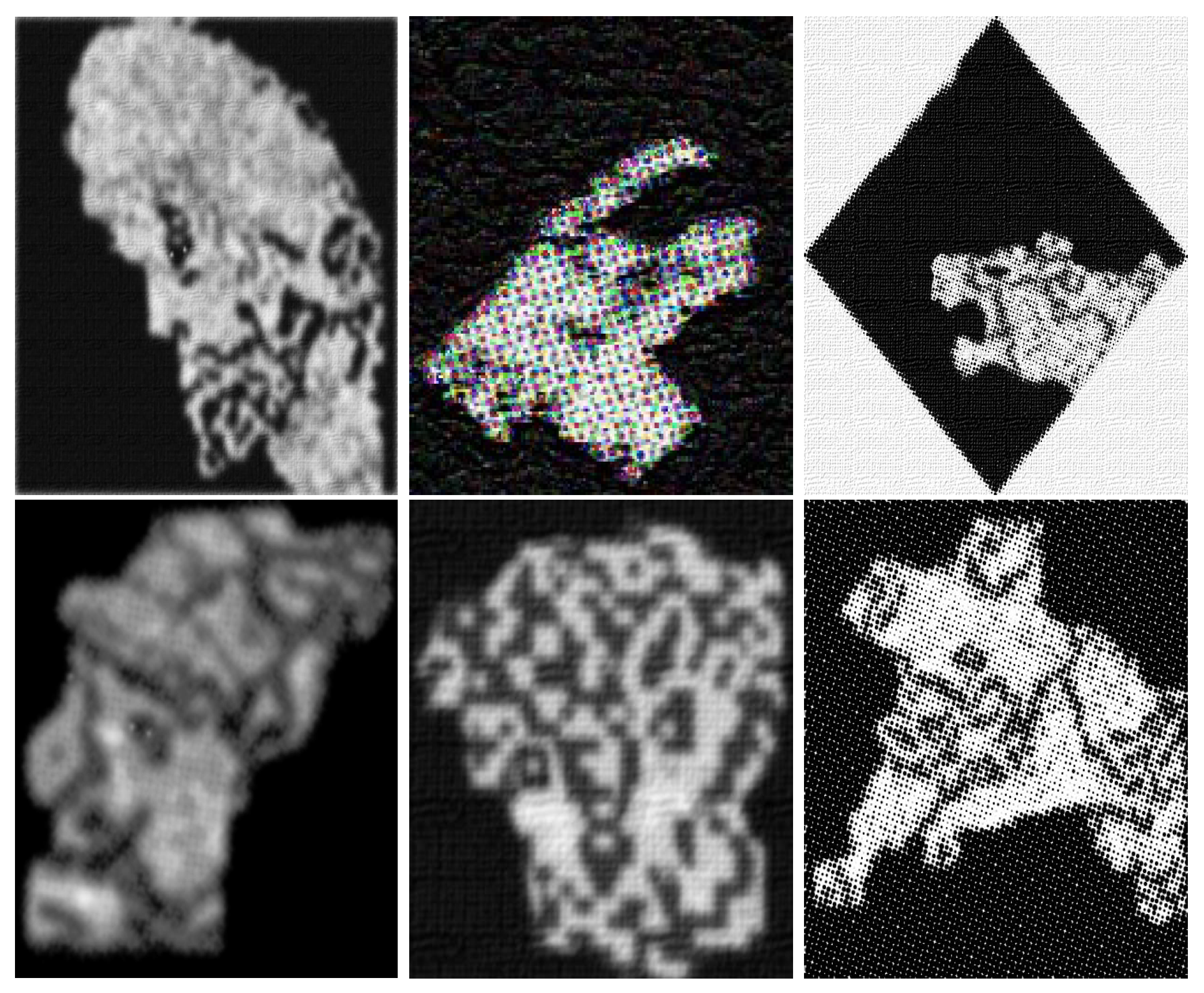
This figure shows models extracted from a master and corresponding edges detected by the Roberts, Prewitt, Sobel, and Canny algorithms. Note that no relevant information is giving by the outputs generated by these algorithms.
4.3. Edge Detection
This section observes that edge detection algorithms do not give information on the models saved by the masters; as we pointed out before, such models are emerging images recognized easily by humans.
We obtain no information on the boundary of the images saved by masters – (see Figure 23) after applying Sobel, Canny, Prewitt, and Roberts algorithms (see Figure 32). To establish such a statement, Table 3 shows the entropy of their outputs. On the other hand, it was observed no significant changes of these images after applying the wavelet transformation to remove noise.
Table 3.
Entropy of outputs generated by the wavelet transformation and the edge detectors algorithms, Roberts, Prewitt, Sobel, and Canny (see Figure 23). According to these data, there are no relevant changes in the amount of information obtained from the images after applying the wavelet transformation, nor significant information arises from the outputs of the edge detector algorithms.
False Positives
False positives occur with a bad assignation of markers. However, these erroneous outputs can be considered emerging images (see Figure 33). Thus, suitable for HIPs.

Figure 33.
Examples of false positives.
4.4. Face Detection: Human vs. Machine
In this section, we explore the accuracy of the Viola–Jones algorithm recognizing faces of models obtained with Algorithm 3 [45,46]. Such an algorithm is one of the most used methods to detect objects on images. It is based on a sliding window principle and uses the Adaboost machine learning method to determine threshold levels and selected particular Haar features. It works by creating strong classifiers from weak ones.
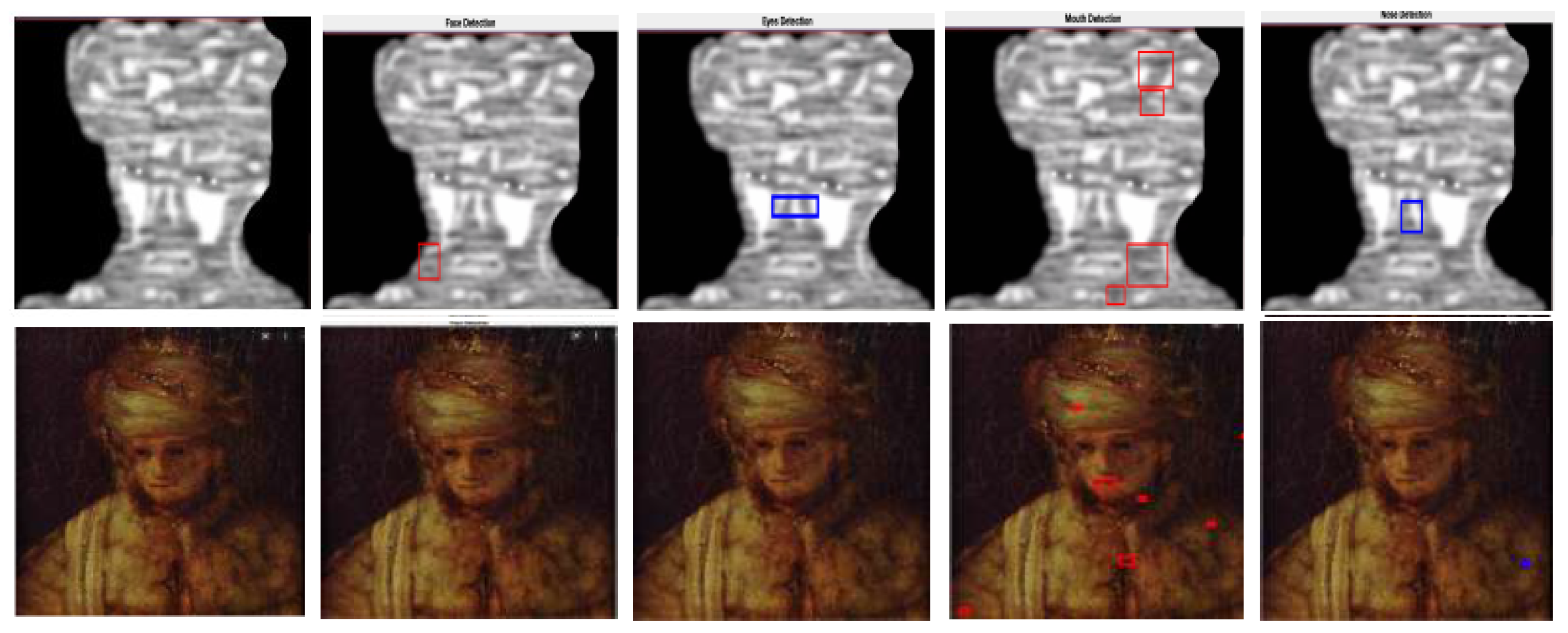
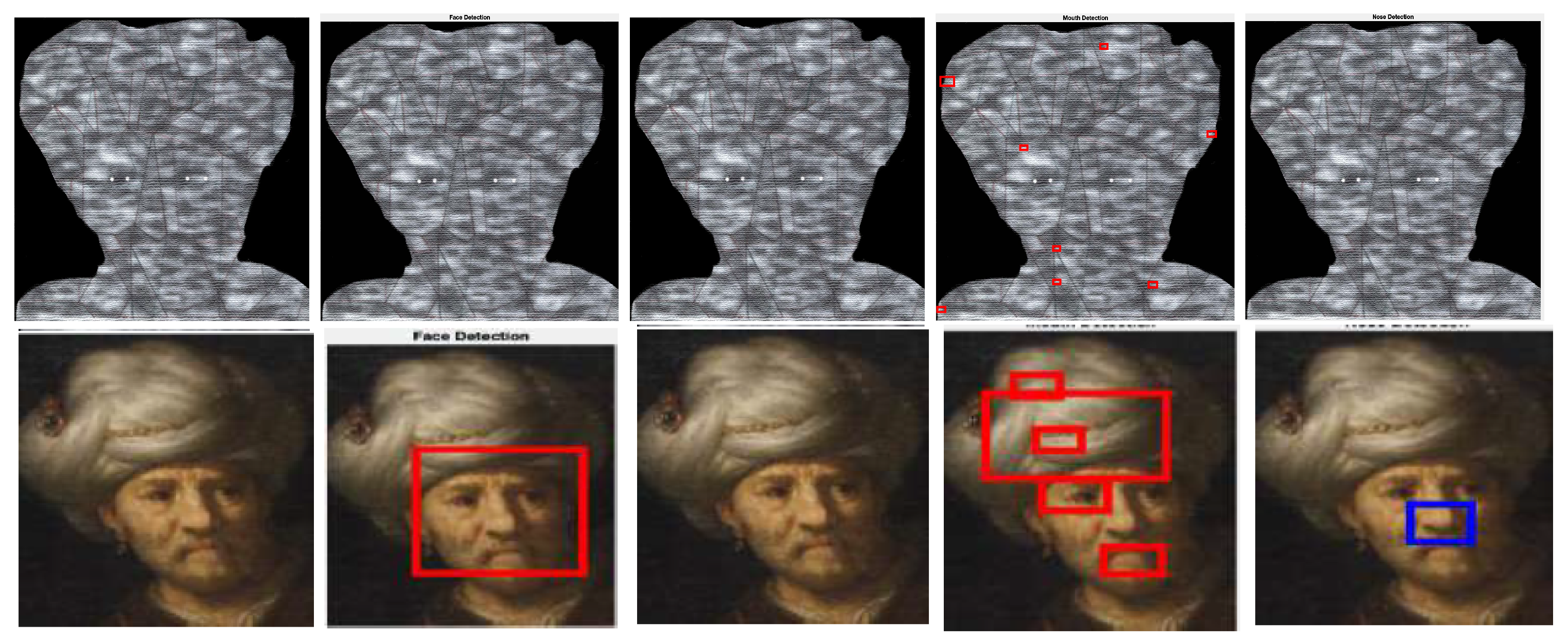
For comparisons, we selected 1200 faces and their corresponding models (outputs of Algorithm 3) from Leonardo da Vinci’s notebooks [26] and the movies, The Book of Esther [28] and One Night with the King [27]. The Figure 34, Figure 35, Figure 36 and Figure 37 give examples of these kind of comparisons.

Figure 34.
This example shows how the Viola–Jones algorithm outputs false positives when detecting the mouths of the original image [41,42] and the corresponding models. Note that, in the third case, the Viola–Jones algorithm does not recognize the face of the original image whereas, it positively detects the face features of its model.
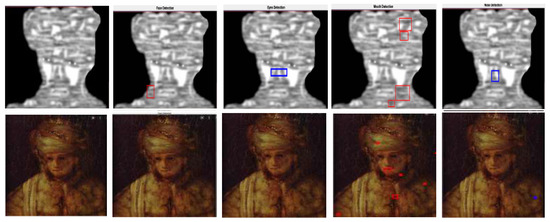
Figure 35.
Examples of how the Viola–Jones method detects faces in an image of the repository [43] and its corresponding model obtained via Algorithm 3.
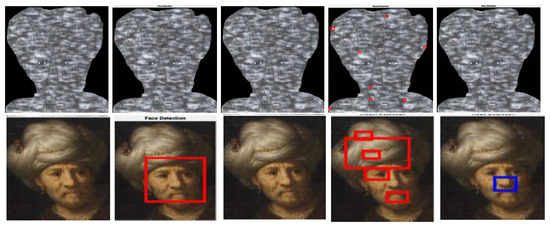
Figure 36.
Another example of objects detected in an image of the repository [44] and its corresponding model. Note that as in Figure 34, the Viola–Jones algorithm outputs many false positives when detecting mouths.

Figure 37.
Examples of detected objects (eyes, nose, and mouth) by the individuals in the conducted survey.
A survey was conducted among 700 people aged 12–70 to establish if humans recognize the faces of the presented models. In this case, we selected a random sample of 360 models divided into 30 one-minute videos with 12 models each. Such videos were randomly chosen for each individual in the survey. Then, we asked for the location of the presented image’s, eye, nose, and mouth. The Table 4, Table 5 and Table 6 summarize the obtained results.
Table 4.
This table measures the performance of the Viola–Jones algorithm detecting 1200 faces extracted from the Leonardo da Vinci’s notebooks [26] and the movies, The Book of Esther [28] and One Night with the King [27]. Letters E, N, M, and F stand for eyes, nose, mouth, and face, respectively. Coordinates of the vectors (E,N,M,F) correspond to the percentage of the detected objects associated with the selected threshold.
Table 5.
This table shows that the Viola–Jones algorithm fails in detecting faces as outputs of Algorithm 3.
Table 6.
This table allows us to infer that face models as outputs of Algorithm 3 are easy to detect by humans.
5. Additional Statistical Discussion
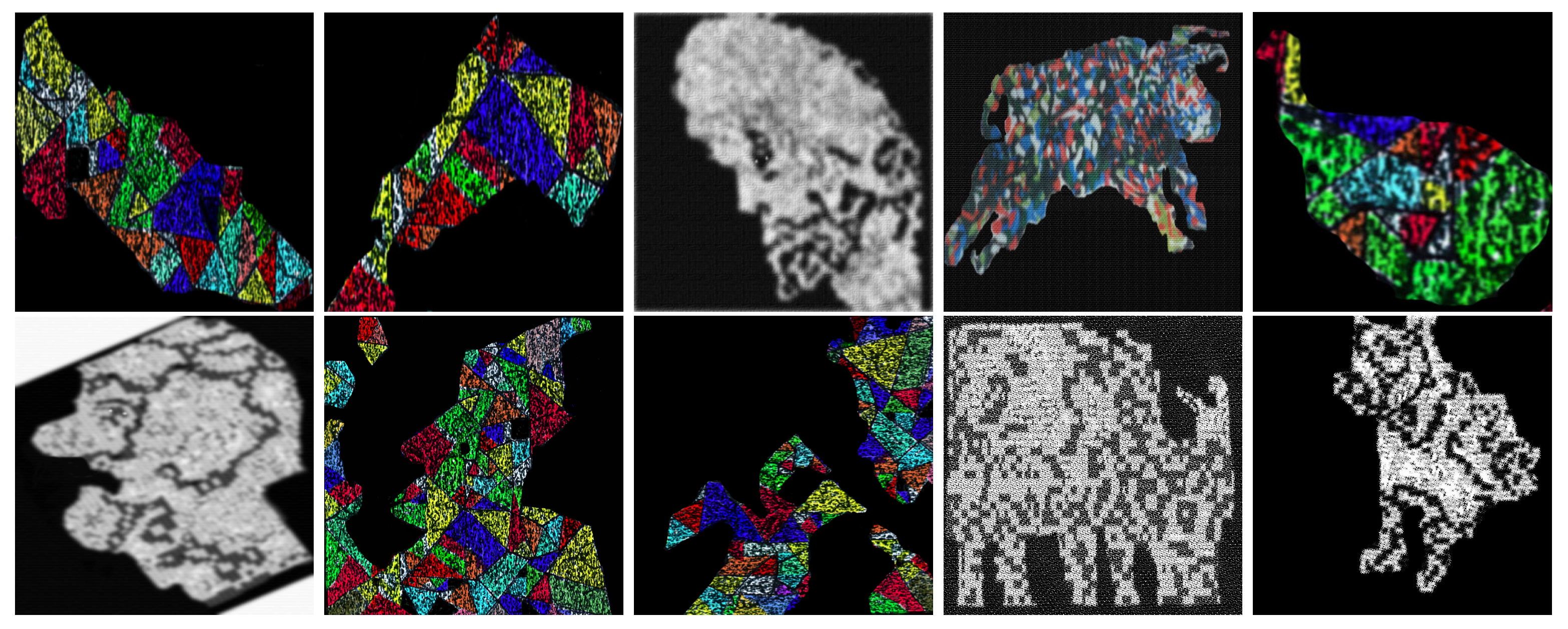
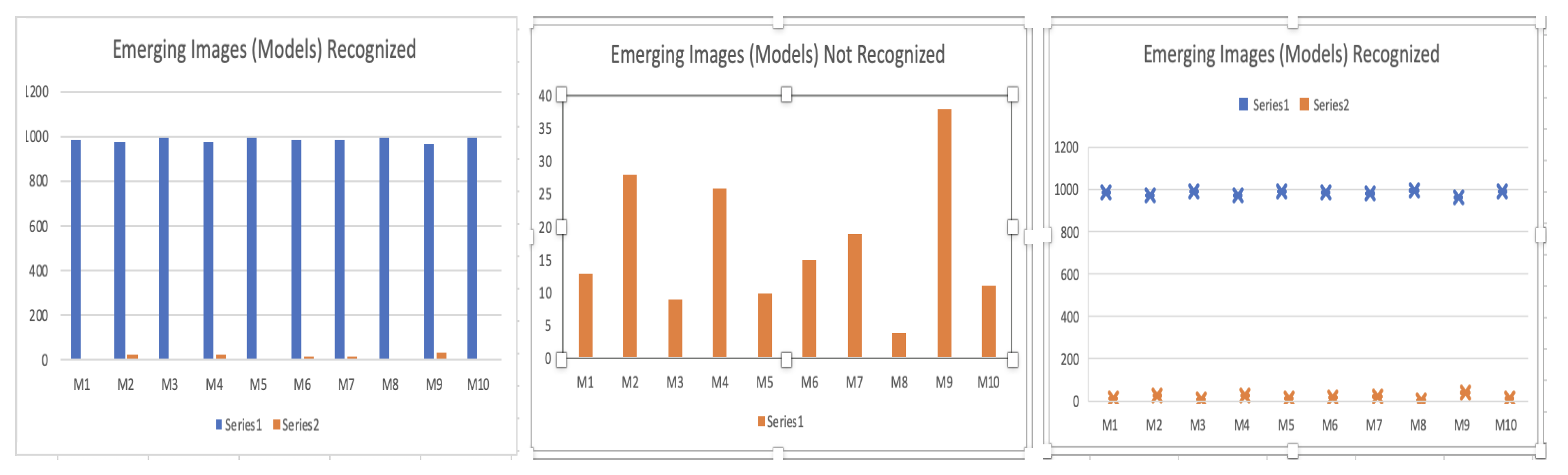
In this section, we discuss results of a survey conducted among 1000 people aged 7–70 to know if models (or emerging images) obtained by applying the Algorithm 3 are easy to detect by human beings. We use four types of categories, objects, animals, activity and faces in order to qualify the image detection accuracy (see Figure 38, Figure 39, Figure 40, Figure 41 and Figure 42).
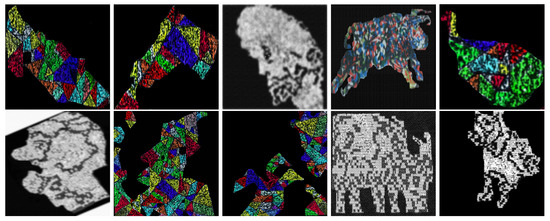
Figure 38.
Models used in the survey from the left to the right, shoe (M1), horse (M2), old man (M3), bull (M4), apple (M5), soldier (M6), clown (M7), duck (M8), cow (M9), and dog (M10).
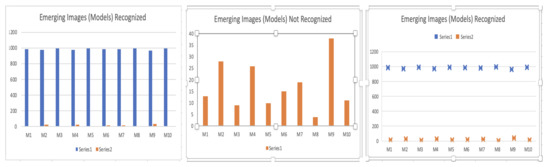
Figure 39.
According to these diagrams, it is possible to infer that models used in the survey are easy to detect. Provided that between 95% and 99% of the people recognize the models in at most 5 s.
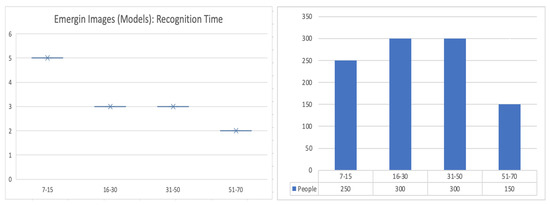
Figure 40.
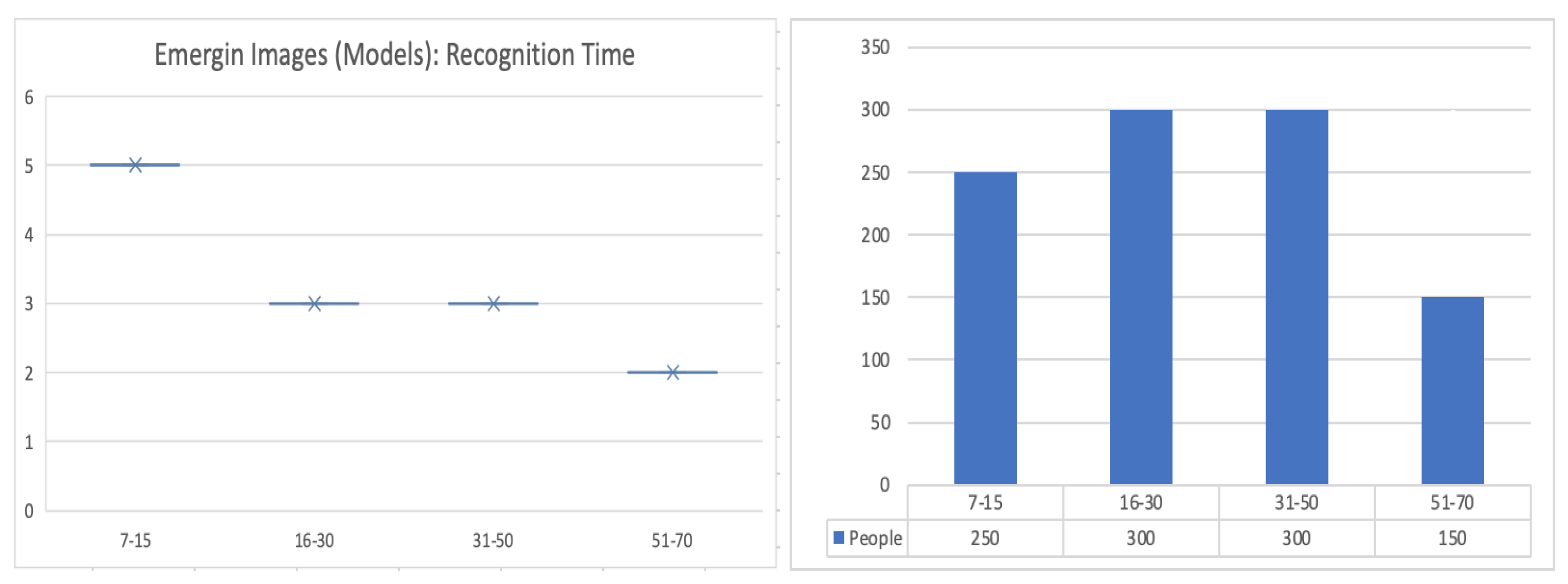
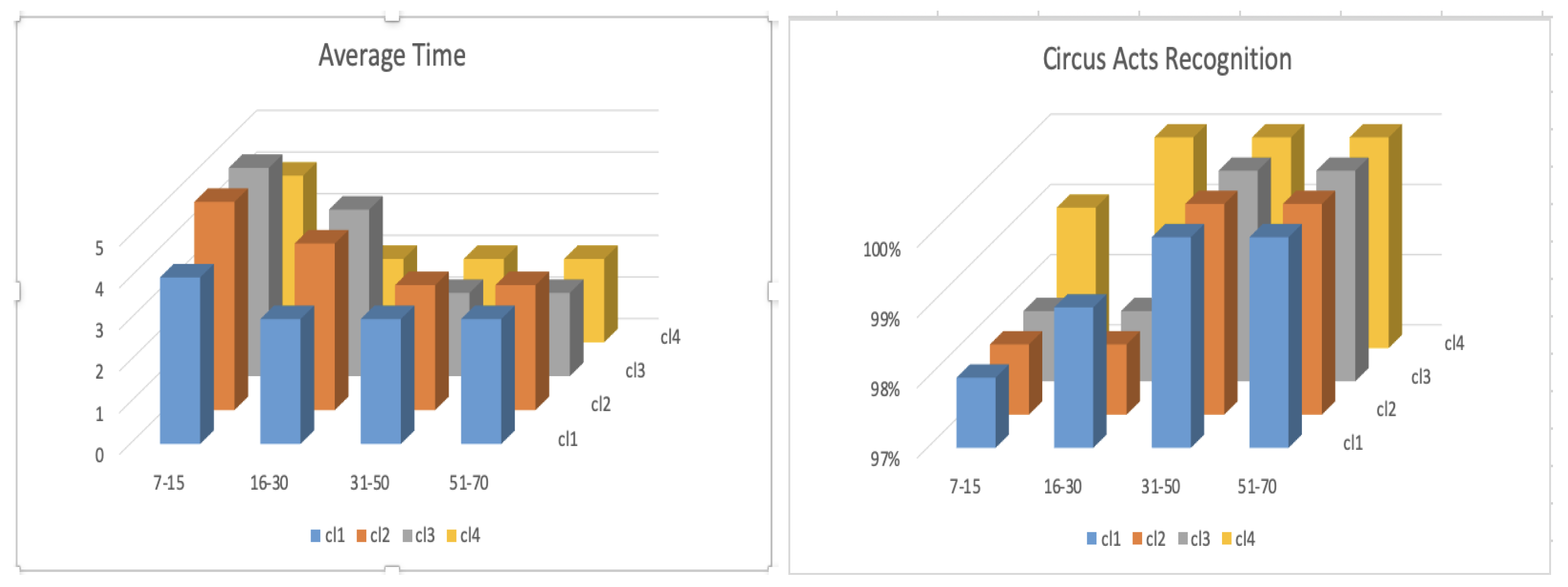
The experience matters.The diagram at the left shows the average time (in seconds) that people took to recognize the models presented. Young people needed more time than people between 16 and 70 years old to make the recognition.
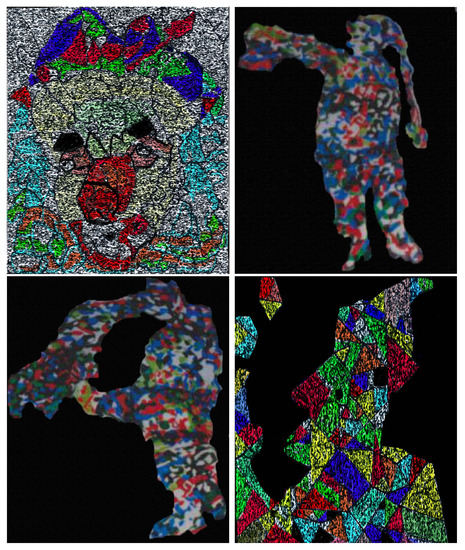
Figure 41.
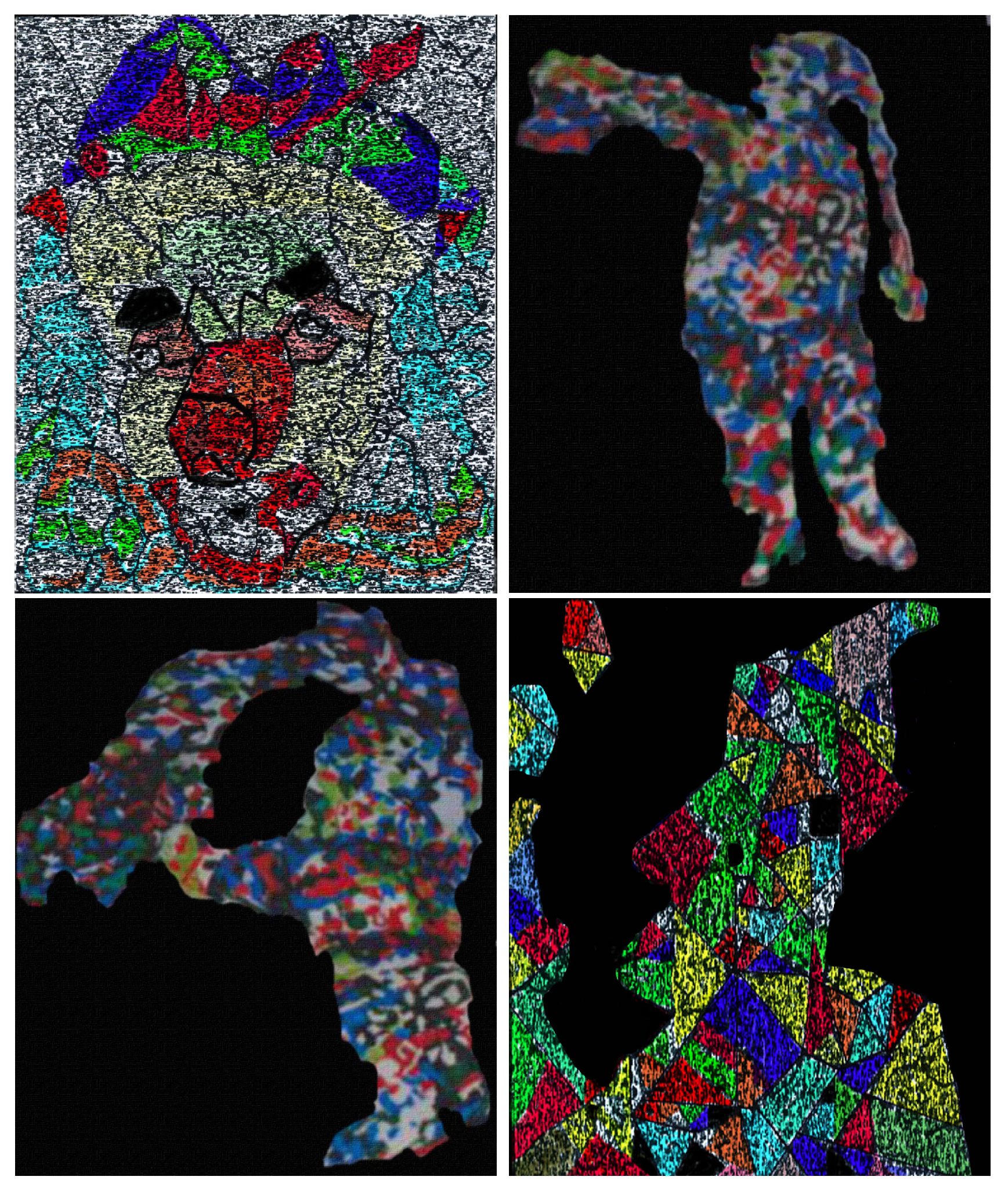
The context matters. In the survey at least 98% percent of the people recognized (in at most 5 s) clowns (activity: circus acts), when a set of models as shown in this figure was presented. We denote these images , , , and , from the left to right (see the diagrams in Figure 42).
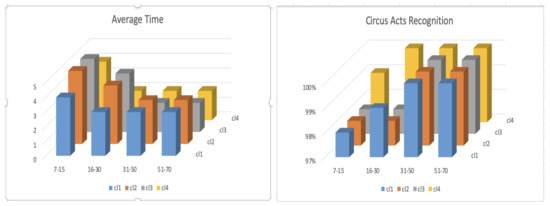
Figure 42.
These diagrams show the average time (in seconds) and the percentage of people who recognized the images shown in Figure 41 as the representation of a clown.
6. Concluding Remarks and Future Work
Given repositories of images illustrating fairy tales, circus acts, the Book of Esther, the New Testament, and Leonardo da Vinci’s drawings, it is possible to build emerging images easy to detect by human beings by using tiled orders and posets. To do that, novel matrix transformations called joining, reduction and completion are introduced by using tiled orders also known as semi-maximal rings. In this context, incomparability in a poset associated with a model (of an image of a given repository) is interpreted as salt and pepper noise, which can be removed via the completion procedure (or by adding new relations in the poset). These transformations are applied to suitable matrices named joining matrices and polygonal meshes called masters. Such masters constitute templates, where all models of different repositories arise, giving us an alternative way of saving memory storage space.
Building emerging images by using deep learning methods and designing new types of CAPTCHAs based on this type of emerging images are interesting tasks for the future.
Author Contributions
Writing—review & editing, M.A.O.A., A.M.C. and I.D.M.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| ATGEI | Algorithm to Generate Emerging Images |
| CAPTCHA | Completely Automated Public Turing Test to Tell Computers and Humans Apart |
| EI | Emerging Image |
| EIMO | Emerging-Image Moving-Object |
| GAN | Generative Adversarial Network |
| HIP | Human Interaction Proof |
| POSET | Partially Ordered Set |
| PSNR | Peak Signal-to-Noise Ratio |
| REIADT | Representation of Emerging Images by Using Admissible Transformations |
References
- Cañadas, A.M.; Vanegas, N.P. Representations of posets to generate emerging images. Far East J. Math. Sci. 2013, 2013 Pt II, 139–152. [Google Scholar]
- Lehar, S. Gestalt isomorphism and the primacy of subjective conscious experience: A Gestalt Bubble model. Behav. Brain Sci. 2003, 26, 375–443. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Moore, P.; Fitz, C. Using Gestalt Theory to Teach Document Design and Graphics. Tech. Commun. Q. 1993, 2, 389–410. [Google Scholar] [CrossRef]
- Desolneux, A.; Moisan, L.; Morel, J.-M. From Gestalt Theory to Image Analysis; Interdisciplinary Applied Mathematics, 34; Springer: New York, NY, USA, 2008. [Google Scholar]
- Kanizsa, G. Gramatica del Vedere. Saggi su Percezione e Gestalt; Società Editrice Il Mulino: Bolonia, Italy, 1980. [Google Scholar]
- Koffka, K. Principles of Gestalt Psychology; Harcourt, Brace and Company: New York, NY, USA, 1935. [Google Scholar]
- Mitra, N.J.; Chu, H.K.; Lee, T.Y.; Wolf, L.; Yeshurun, H.; Cohen-Or, D. Emerging Images. ACM Trans. Graph. 2009, 28, 1–8. [Google Scholar]
- Von Ahn, L.; Blum, M.; Hopper, N.J.; Langford, J. CAPTCHA: Using hard AI problems for security. In Advances in Cryptology—EUROCRYPT 2003; Lecture Notes in Comput. Sci., 2656; Springer: Berlin, Germany, 2003; pp. 294–311. [Google Scholar]
- Von Ahn, L.; Blum, M.; Langford, J. Telling humans and computers apart automatically. Commun. ACM 2004, 47, 56–60. [Google Scholar] [CrossRef] [Green Version]
- Von Ahn, L.; Maurer, B.; McMillen, C.; Abraham, D.; Blum, M. reCAPTCHA: Human-based character recognition via web security measures. Science 2008, 321, 1465–1468. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baird, H.S.; Moll, M.A.; Wang, S.Y. ScatterType: A legible but hard-to-segment CAPTCHA. In Proceedings of the 8th International Conference on Document Analysis and Recognition, Seoul, Korea, 31 August–1 September 2005; pp. 935–939. [Google Scholar]
- Cañadas, A.M.; Espinosa, P.F.F.; Gaviria, I.D.M. Representations of a tetrad to generate emerging images. Far East J. Math. Sci. 2013, 2013 Pt II, 173–184. [Google Scholar]
- Turing, A.M. Computing machinery and intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Naor, M. Verification of a Human in the Loop or Identification via the Turing Test. Unpublished Notes. 1996. Available online: http://www.wisdom.weizmann.ac.il/~naor/PAPERS/human.pdf (accessed on 27 March 2021).
- Goodfellow, I.J.; Bulatov, Y.; Ibarz, J.; Arnoud, S.; Shet, V. Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks. arXiv 2014, arXiv:1312.6082. [Google Scholar]
- Ye, G.; Tang, Z.; Fang, D.; Zhu, Z.; Feng, Y.; Xu, P.; Chen, X.; Han, J.; Wang, Z. Using Generative Adversarial Networks to Break and Protect Text Captchas. ACM Trans. Priv. Secur. 2020, 23, 1–29. [Google Scholar] [CrossRef]
- Xu, Y.; Reynaga, G.; Chiasson, S.; Frahm, M.; Monrose, F.; Oorschot, P. Security and usability challenges of moving-object CAPTCHAs: Decoding codewords in motion. In Proceedings of the 21st USENIX Conference on Security Symposium, IEEE TDSC, Bellevue, WA, USA, 8–10 August 2012; pp. 49–64. [Google Scholar]
- Gao, S.; Mohamed, M.; Saxena, N.; Zhang, C. Emerging Image Game CAPTCHAs for Resisting Automated and Human-Solver relay Attacks. In Proceedings of the 31st Annual Computer Security Applications Conference, Los Angeles, CA, USA, 7–11 December 2015; pp. 11–20. [Google Scholar]
- Gao, S.; Mohamed, M.; Saxena, N.; Zhang, C. Emerging-Image Motion CAPTCHAs: Vulnerabilities of Existing Designs, and Countermeasures. In IEEE Transactions on Dependable and Secure Computing; IEEE: Piscataway, NJ, USA, 2019; Volume 16, pp. 1040–1053. [Google Scholar]
- Davey, B.A.; Priestley, H.A. Introduction to Lattices and Order, 2nd ed.; Cambridge University Press: New York, NY, USA, 2002. [Google Scholar]
- Cañadas, A.M.; Serna, R.J.; Espinosa, C. On the reduction of some tiled orders. J. Algebr. Number Theory Appl. 2015, 36, 157–176. [Google Scholar]
- Zavadskiĭ, A.G.; Kiričenko, V.V. Semimaximal rings of finite type. Math. USSR Sb. 1977, 103, 323–345. [Google Scholar] [CrossRef]
- Livesu, M. Cinolib: A Generic Programming Header Only C++ Library for Processing Polygonal and Polyhedral Meshes. Trans. Comput. Sci. 2019, 34, 64–76. [Google Scholar]
- Alliez, P.; Gotsman, C. Recent advances in compression of 3D meshes. In Advances in Multiresolution for Geometric Modelling; Mathematics and Visualization; Springer: Berlin, Germany, 2005; pp. 3–26. [Google Scholar]
- Rothengatter, E. Circus Sketches: Acrobats and Circus Animals; Library of Congress, Prints and Photographs Division: Washington, DC, USA, 1920. [Google Scholar]
- Da Vinci, L. The Notebooks of Leonardo Da Vinci; Translated by Richter J. P. 1888; Dover Publications, Inc.: New York, NY, USA, 1970; Volumes I and II. [Google Scholar]
- Sajbel, M. One Night with the King; Film; Gener8Xion Entertainment: Hollywood, CA, USA, 2006. [Google Scholar]
- White, D. The Book of Esther; Film; Pure Flix Entertainment: Scottsdale, AZ, USA, 2013. [Google Scholar]
- Cottrell, W.; Hand, D.; Jackson, W.; Morey, L.; Pearce, P.; Sharpsteen, B. Snow White and the Seven Dwarfs; Film; Walt Disney Pictures: Burbank, CA, USA, 1937. [Google Scholar]
- Geronimi, C.; Jackson, W.; Luske, H. Cinderella; Film; Walt Disney Productions: Burbank, CA, USA, 1950. [Google Scholar]
- Ferguson, N.; Hee, T.; Jackson, W. Pinocchio; Film; Walt Disney Productions: Burbank, CA, USA, 1940. [Google Scholar]
- Weiwei, A. Circle of Animals Zodiac Heads; Somerset House: London, UK, 2011. [Google Scholar]
- Katzenstein, R.; Savage-Smith, E. The Leiden Aratea Ancient Constellations in a Medieval Manuscript; The J. Paul Getty Museum: Malibu, CA, USA, 1988. [Google Scholar]
- Da Vinci, L. The Notebooks of Leonardo Da Vinci. Available online: https://commons.wikimedia.org/w/index.php?search=Leonardo+da+Vinci+grotesque&title=Special:MediaSearch&type=image (accessed on 27 March 2021).
- Brechtbug. Christmas Window Display Saks 5th Ave 2017 NYC 4018. Available online: https://search.creativecommons.org/photos/749e0568-6fbe-4797-83db-9d1f43544fad (accessed on 27 March 2021).
- Modris, P. Cinderella Shoes. Available online: https://commons.wikimedia.org/wiki/File:Cinderella_shoes_-_panoramio.jpg (accessed on 27 March 2021).
- Moggymawee. DFDC Cinderella and Lady Tremaine Doll Set. Available online: https://search.creativecommons.org/photos/a81aa069-3cfa-4b2a-8118-094a6e90162d (accessed on 27 March 2021).
- Nathangibbs. Snow White Attacked by Birds, Dwarfs, Witch and Queen. Available online: https://search.creativecommons.org/photos/d6a85488-29a3-47e2-b43a-4023bbf1af8e (accessed on 27 March 2021).
- Nysrøm, J. Cinderella and the Prince. Available online: https://commons.wikimedia.org/w/index.php?search=Askepot+og+Prinsen&title=Special:MediaSearch&go=Go&type=image (accessed on 27 March 2021).
- Sawyer, K. Photography, Just Another Poisoned Apple. Available online: https://search.creativecommons.org/photos/721b0db0-dd96-44ab-8ea2-5515aeeff3c1 (accessed on 27 March 2021).
- Celesti, A. Esther before King Ahasuerus. Available online: https://commons.wikimedia.org/wiki/File:Andrea_celesti_painting1.jpg (accessed on 27 March 2021).
- Lievens, J. The Feast of Esther. Available online: https://commons.wikimedia.org/wiki/File:The_Feast_of_Esther_-_Jan_Lievens_-_Google_Cultural_Institute.jpg (accessed on 27 March 2021).
- Van Rembrandt, H.R. Ahasuerus, Haman and Esther. Available online: https://commons.wikimedia.org/wiki/File:Rembrandt_Harmensz_van_Rijn_-_Ahasuerus,_Haman_and_Esther_-_Google_Art_Project.jpg (accessed on 27 March 2021).
- Victors, J. Esther en Haman voor Ahasverus. Available online: https://commons.wikimedia.org/wiki/File:Jan_Victors_-_Esther_en_Haman_voor_Ahasverus.jpg (accessed on 27 March 2021).
- Khalil, K. The Effectiveness of Haar Features and Threshold in Multiple Face Detection Systems Based on Adaboost Algorithm. Master’s Thesis, Department of Computer Science, Middle East University, Amman, Jordan, 2011. [Google Scholar]
- Wang, Y.Q. An Analysis of the Viola-Jones Face Detection Algorithm. Image Process. Line 2014, 4, 128–148. [Google Scholar] [CrossRef]


















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).