
Association Rules Mining for Hospital Readmission: A Case Study


Abstract
:1. Introduction
- We propose the overall framework of ARM in readmission task, which consisted of two processes; data preprocessing and rule mining extraction. The preprocessing stage involved data discretisation, transformation to a binary setting, and handling imbalance data;
- We present the significant rules between input variables on a different setting of readmission durations and basic demographics variables.
2. Related Works
2.1. Data Mining for Hospital Readmission
2.2. The ARM and Its Importance
2.3. The ARM in Medical Application
2.4. Comparison between ARM and Other Methods
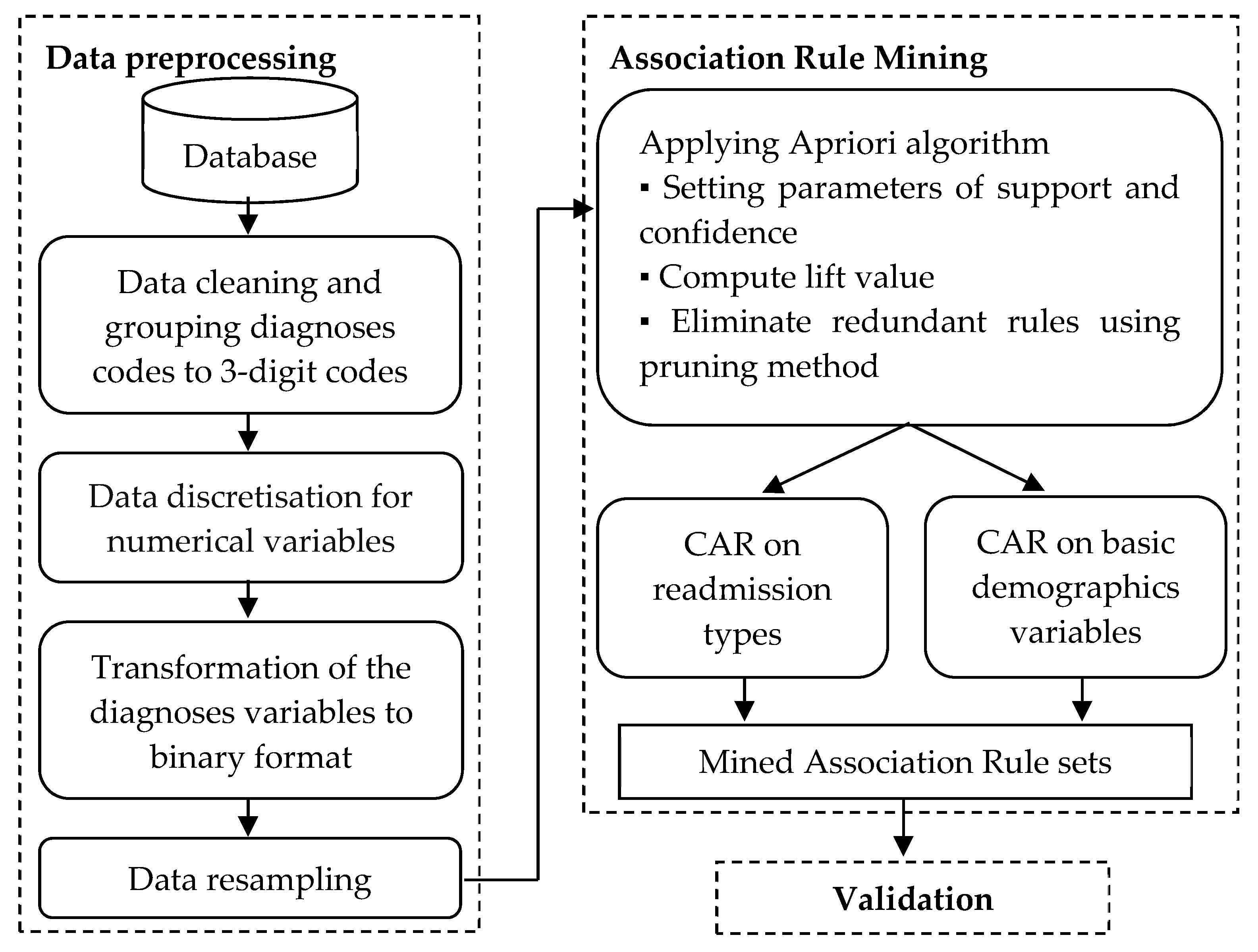
3. Materials and Methods
3.1. Datasets
3.2. Research Framework
3.3. Data Preprocessing
3.4. Association Rule Mining
| Algorithm 1. Apriori algorithm for generating frequent itemsets |
| Require: T, I, minsup Output: F F1 = {f|f ∈ I, F.sup ≥ min sup} for (k = 2; Fk−1 = ∅, k + +) do Ck = generate candidate (Fk−1); for each transaction in the database, t ∈ T do for each candidate, C ∈ Ck, do Increment the count of all candidate those are contained in t end for end for Fk = {c ∈ Ck|c.sup ≥ min sup} end for return F = ⋂k Fk |
4. Experimental Results
4.1. ARM on Different Readmission Lengths
4.2. ARM on Basic Demographics Predictors
4.2.1. ARM on Gender Predictor
4.2.2. ARM on Race Predictor
4.2.3. ARM on Age Group Predictor
4.3. Summary on the Overall ARM
5. Discussion
6. Practical and Managerial Implications
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Golmohammadi, D.; Radnia, N. Prediction modeling and pattern recognition for patient readmission. Int. J. Prod. Econ. 2015, 171, 151–161. [Google Scholar] [CrossRef]
- Kansagara, D.; Englander, H.; Salanitro, A.; Kagen, D.; Theobald, C.; Freeman, M.; Kripalani, S. Risk prediction models for hospital readmission: A systematic review. JAMA 2011, 306, 1688–1698. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ben-Assuli, O.; Padman, R. Analysing repeated hospital readmissions using data mining techniques. Health Syst. 2018, 7, 166–180. [Google Scholar] [CrossRef] [PubMed]
- Artetxe, A.; Beristain, A.; Grana, M. Predictive models for hospital readmission risk: A systematic review of methods. Comput. Methods Programs Biomed. 2018, 164, 49–64. [Google Scholar] [CrossRef]
- Wright, A.; Chen, E.S.; Maloney, F.L. An automated technique for identifying associations between medications, laboratory results and problems. J. Biomed. Inform. 2010, 43, 891–901. [Google Scholar] [CrossRef] [Green Version]
- Liao, S.-H.; Chu, P.-H.; Hsiao, P.-Y. Data mining techniques and applications—A decade review from 2000 to 2011. Expert Syst. Appl. 2012, 39, 11303–11311. [Google Scholar] [CrossRef]
- Sarıyer, G.; Tasar, C.O. Highlighting the rules between diagnosis types and laboratory diagnostic tests for patients of an emergency department: Use of association rule mining. Health Inform. J. 2020, 26, 1177–1193. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tseng, M.-H.; Wu, H.-C. Investigating health equity and healthcare needs among immigrant women using the association rule mining method. Healthcare 2021, 9, 195–208. [Google Scholar] [CrossRef] [PubMed]
- Lee, S.J.; Cartmell, K.B. An association rule mining analysis of lifestyle behavioral risk factors in cancer survivors with high cardiovascular disease risk. J. Pers. Med. 2021, 11, 366–376. [Google Scholar] [CrossRef] [PubMed]
- Altaf, W.; Shahbaz, M.; Guergachi, A. Applications of association rule mining in health informatics: A survey. Artif. Intell. Rev. 2017, 47, 313–340. [Google Scholar] [CrossRef]
- Jabbar, M.A.; Deekshatulu, B.L.; Chandra, P. Knowledge discovery using associative classification for heart disease prediction. In Intelligent Informatics; Springer: Berlin/Heidelberg, Germany, 2013; pp. 29–39. [Google Scholar]
- Lee, D.G.; Ryu, K.S.; Bashir, M.; Bae, J.-W.; Ryu, K.H. Discovering medical knowledge using association rule mining in young adults with acute myocardial infarction. J. Med. Syst. 2013, 37, 9896. [Google Scholar] [CrossRef] [PubMed]
- Shameer, K.; Perez-Rodriguez, M.M.; Bachar, R.; Li, L.; Johnson, A.; Johnson, K.W.; Glicksberg, B.S.; Smith, M.R.; Readhead, B.; Scarpa, J.; et al. Pharmacological risk factors associated with hospital readmission rates in a psychiatric cohort identified using prescriptome data mining. BMC Med. Inform. Decis. Mak. 2018, 18, 1–11. [Google Scholar] [CrossRef]
- Payus, C.; Sulaiman, N.; Shahani, M.; Bakar, A.A. Association rules of data mining application for respiratory illness by air pollution database. Int. J. Basic Appl. Sci. 2013, 13, 11–16. [Google Scholar]
- Graham, K.L.; Auerbach, A.D.; Schnipper, J.L.; Flanders, S.A.; Kim, C.S.; Robinson, E.J.; Ruhnke, G.W.; Thomas, L.R.; Kripalani, S.; Vasilevskis, E.E. Preventability of early versus late hospital readmissions in a national cohort of general medicine patients. Ann. Intern. Med. 2018, 168, 766–774. [Google Scholar] [CrossRef] [PubMed]
- Braga, P.; Portela, F.; Santos, M.F.; Rua, F. Data mining models to predict patient’s readmission in intensive care units. In Proceedings of the 6th International Conference on Agents and Artificial Intelligence (ICAART 2014), Angers, France, 6–8 March 2014. [Google Scholar]
- Zheng, B.; Zhang, J.; Yoon, S.W.; Lam, S.S.; Khasawneh, M.; Poranki, S. Predictive modeling of hospital readmissions using metaheuristics and data mining. Expert Syst. Appl. 2015, 42, 7110–7120. [Google Scholar] [CrossRef]
- Sawangarreerak, S.; Thanathamathee, P. Detecting and analyzing fraudulent patterns of financial statement for open innovation using discretization and association rule mining. J. Open Innov. Technol. Mark. Complex. 2021, 7, 128–147. [Google Scholar] [CrossRef]
- Kaur, M.; Kang, S. Market basket analysis: Identify the changing trends of market data using association rule mining. Proced. Comput. Sci. 2016, 85, 78–85. [Google Scholar] [CrossRef] [Green Version]
- Apiletti, D.; Pastor, E. Correlating espresso quality with coffee-machine parameters by means of association rule mining. Electronics 2019, 9, 100–118. [Google Scholar] [CrossRef] [Green Version]
- Hang, L.; Kang, S.-H.; Jin, W.; Kin, D.-H. Design and implementation of an optimal travel route recommender system on big data for tourists in Jeju. Processes 2018, 6, 133–152. [Google Scholar] [CrossRef] [Green Version]
- Orama, J.A.; Borras, J.; Moreno, A. Combining cluster-based profiling based on social media features and association rule mining for personalised recommendations of touristic activities. Appl. Sci. 2021, 1, 6512. [Google Scholar] [CrossRef]
- Chen, X.; Deng, H. Research on personalized recommendation methods for online video learning resources. Appl. Sci. 2021, 11, 804. [Google Scholar] [CrossRef]
- Zhao, Y.; Zhang, C.; Zhang, Y.; Wang, Z.; Li, J. A review of data mining technologies in building energy systems: Load prediction, pattern identification, fault detection and diagnosis. Energy Build Environ. 2020, 1, 149–164. [Google Scholar] [CrossRef]
- Shi, Y.; Wu, B.; Chen, N.; Chen, A.; Li, J.; Li, H. Determination of effective management strategies for scenic area emergencies using association rule mining. Int. J. Disaster Risk Reduct. 2019, 39, 101208. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Data Classification: Algorithms and Applications; CRC Press: New York, NY, USA, 2015. [Google Scholar]
- Li, J.; Fu, A.W.-C.; Fahey, P. Efficient discovery of risk patterns in medical data. Artif. Intell. Med. 2009, 45, 77–89. [Google Scholar] [CrossRef]
- Stilou, S.; Bamidis, P.D.; Maglaveras, N.; Pappas, C. Mining association rules from clinical databases: An intelligent diagnostic process in healthcare. Stud. Health Technol. Inform. 2001, 2, 1399–1403. [Google Scholar]
- Dos Santos, B.S.; Steiner, M.T.A.; Fenerich, A.T.; Lima, R.H.P. Data mining and machine learning techniques applied to public health problems: A bibliometric analysis from 2009 to 2018. Comput. Ind. Eng. 2019, 138, 106120. [Google Scholar] [CrossRef]
- Pazhanikumar, K.; Arumugaperumal, S. Association rule mining and medical application: A detailed survey. Int. J. Comput. Appl. 2013, 80, 10–19. [Google Scholar] [CrossRef] [Green Version]
- Kulkarni, A.R.; Mundhe, D. Data mining technique: An implementation of association rule mining in healthcare. Int. Adv. Res. J.Sci. Eng. Technol. 2017, 4, 76–85. [Google Scholar] [CrossRef]
- Ramezankhani, A.; Pournik, O.; Shahrabi, J.; Azizi, F.; Hadaegh, F. An application of association rule mining to extract risk pattern for type 2 diabetes using tehran lipid and glucose study database. Int. J. Endocrinol. Metab. 2015, 13, e25389. [Google Scholar] [CrossRef] [Green Version]
- Nahar, J.; Imam, T.; Tickle, K.S.; Chen, Y.-P.P. Association rule mining to detect factors which contribute to heart disease in males and females. Expert Syst. Appl. 2013, 40, 1086–1093. [Google Scholar] [CrossRef]
- Nahar, J.; Tickle, K.S.; Ali, A.S.; Chen, Y.-P.P. Significant cancer prevention factor extraction: An association rule discovery approach. J. Med. Syst. 2011, 35, 353–367. [Google Scholar] [CrossRef] [PubMed]
- Cheng, C.-W.; Chanani, N.; Venugopalan, J.; Maher, K.; Wang, M.D. icuARM—An icu clinical decision support system using association rule mining. IEEE J. Transl. Eng. Health Med. 2013, 1, 4400110. [Google Scholar] [CrossRef] [PubMed]
- Harahap, M.; Husein, A.; Aisyah, S.; Lubis, F.; Wijaya, B. Mining association rule based on the diseases population for recommendation of medicine need. J. Phys. Conf. Ser. 2018, 1007, 012017. [Google Scholar] [CrossRef]
- Chaves, R.; Ramirez, J.; Gorriz, J.; Puntonet, C.G. Association rule-based feature selection method for alzheimer’s disease diagnosis. Expert Syst. Appl. 2012, 39, 11766–11774. [Google Scholar] [CrossRef]
- Said, I.U.; Adam, A.H.; Garko, A.B. Association rule mining on medical data to predict heart disease. Int. J. Sci. Technol. Manag. 2015, 4, 26–35. [Google Scholar]
- Li, J.; Fu, A.W.-C.; He, H.; Chen, J.; Jin, H.; McAullay, D.; Williams, G.; Sparks, R.; Kelman, C. Mining risk patterns in medical data. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 770–775. [Google Scholar]
- Park, S.H.; Jang, S.Y.; Kim, H.; Lee, S.W. An association rule mining-based framework for understanding lifestyle risk behaviors. PLoS ONE 2014, 9, e88859. [Google Scholar] [CrossRef]
- Lemon, S.C.; Roy, J.; Clark, M.A.; Friedmann, P.D.; Rakowski, W. Classification and regression tree analysis in public health: Methodological review and comparison with logistic regression. Ann. Behav. Med. 2003, 26, 172–181. [Google Scholar] [CrossRef]
- Deschepper, M.; Eeckloo, K.; Vogelaers, D.; Waegeman, W. A hospital wide predictive model for unplanned readmission using hierarchical ICD data. Comput. Methods Programs Biomed. 2019, 173, 177–183. [Google Scholar] [CrossRef]
- Dorajoo, S.R.; See, V.; Chan, C.T.; Tan, J.Z.; Tan, D.S.Y.; Razak, S.M.B.A.; Ong, T.T.; Koomanan, N.; Yap, C.W.; Chan, A. Identifying potentially avoidable readmissions: A medication-based 15-day readmission risk stratification algorithm. Pharmacother. J. Hum. Pharmacol. Drug Ther. 2017, 37, 268–277. [Google Scholar] [CrossRef]
- Greenwald, J.L.; Cronin, P.R.; Carballo, V.; Danaei, G.; Choy, G. A novel model for predicting rehospitalization risk incorporating physical function, cognitive status, and psychosocial support using natural language processing. Med. Care 2017, 55, 261–266. [Google Scholar] [CrossRef]
- Imamura, T.; Matsumoto, S.; Kanagawa, Y.; Tajima, B.; Matsuya, S.; Furue, M.; Oyama, H. A technique for identifying three diagnostic findings using association analysis. Med. Biol. Eng. Comput. 2007, 45, 51–59. [Google Scholar] [CrossRef] [PubMed]
- Jaafar, S.; Noh, K.M.; Muttalib, K.A.; Othman, N.H.; Healy, J. Malaysian Health System Review; WHO: Geneva, Switzerland, 2012. [Google Scholar]
- Kaboudarahangi, M.; Tahir, O.M.; Kamal, M. Malaysia’s three major ethnic group preferences in creating a malaysian garden identity. Aust. Geogr. 2014, 44, 197–213. [Google Scholar] [CrossRef]
- Yorulmaz, M.; Mohamed, N.N. Malaysia health system review: Overviews and opinions. Int. J. Health Adm. Educ. Congr. (Sanitas Magisterium) 2019, 5, 45–57. [Google Scholar]
- Berry, J.G.; Gay, J.C.; Maddox, K.J.; Coleman, E.A.; Bucholz, E.M.; O’Neill, M.R.; Blaine, K.; Hall, M. Age trends in 30 day hospital readmissions: US national retrospective analysis. BMJ 2018, 360, k497. [Google Scholar] [CrossRef] [Green Version]
- Jain, S.; Khera, R.; Mortensen, E.M.; Weissler, J.C. Readmissions of adults within three age groups following hospitalization for pneumonia: Analysis from the nationwide readmissions database. PLoS ONE 2018, 13, e0203375. [Google Scholar] [CrossRef] [PubMed]
- Swift, H.J.; Abrams, D.; Drury, L.; Lamont, R.A. Categorization by age. Encycl. Evol. Psychol. Sci. 2018. [Google Scholar] [CrossRef]
- Ahn, G.; Park, Y.-J.; Hur, S. A membership probability—Based undersampling algorithm for imbalanced data. J. Classif. 2021, 38, 2–15. [Google Scholar] [CrossRef]
- Guo, H.; Li, Y.; Shang, J.; Gu, M.; Huang, Y.; Bing, G. Learning from class imbalanced data: Review of methods and applications. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar]
- Mahmood, S.; Shahbaz, M.; Guergachi, A. Negative and positive association rules mining from text using frequent and infrequent itemsets. Sci. World J. 2014, 2014. [Google Scholar] [CrossRef]
- Nguyen, L.T.; Vo, B.; Nguyen, T.-N.; Nguyen, A. Mining class association rules on imbalanced class datasets. J. Intell. Fuzzy Syst. 2019, 37, 7131–7139. [Google Scholar] [CrossRef]
- Bui-Thi, D.; Meysman, P.; Laukens, K. Clustering association rules to build beliefs and discover unexpected patterns. Appl. Intell. 2020, 50, 1943–1954. [Google Scholar] [CrossRef]
- Yang, D.H.; Kang, J.H.; Park, Y.B.; Park, Y.J.; Oh, H.S.; Kim, S.B. Association rule mining and network analysis in oriental medicine. PLoS ONE 2013, 8, e59241. [Google Scholar] [CrossRef] [Green Version]
- Habal, M.V.; Garan, A.R. Long-term management of end-stage heart failure. Best Pract. Res. Clin. Anaesthesiol. 2017, 31, 153–166. [Google Scholar] [CrossRef] [PubMed]
- Maas, A.H.E.M.; Appelman, Y.E.A. Gender differences in coronary heart disease. Neth. Heart J. 2010, 18, 598–603. [Google Scholar] [CrossRef]
- Bozkurt, B.; Khalaf, S. Heart failure in women. Methodist DeBakey Cardiovasc. J. 2018, 13, 216–223. [Google Scholar] [CrossRef]
- Chamberlain, R.S.; Sond, J.; Mahendraraj, K.; Lau, C.S.; Siracuse, B.L. Determining 30-day readmission risk for heart failure patients: The readmission after heart failure scale. Int. J. Gen. Med. 2018, 11, 127. [Google Scholar] [CrossRef] [Green Version]
- Hummel, S.L.; Katrapati, P.; Gillespie, B.W.; DeFranco, A.C.; Koelling, T.M. Impact of prior admissions on 30-day readmissions in medicare heart failure inpatients. Mayo Clin. Proc. 2014, 89, 623–630. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hoang-Kim, A.; Parpia, C.; Freitas, C.; Austin, P.C.; Ross, H.J.; Wijeysundera, H.C.; Tu, K.; Mak, S.; Farkouh, M.E.; Sun, L.Y. Readmission rates following heart failure: A scoping review of sex and gender based considerations. BMC Cardiovasc. Disord. 2020, 20, 1–19. [Google Scholar] [CrossRef] [PubMed]
- Woz, S.; Mitchell, S.; Hesko, C.; Paasche-Orlow, M.; Greenwald, J.; Chetty, V.; O’Donnell, J.; Jack, B. Gender as risk factor for 30 days post-discharge hospital utilisation: A secondary data analysis. BMJ Open 2012, 2, e000428. [Google Scholar] [CrossRef] [Green Version]
- Chopra, I.; Wilkins, T.L.; Sambamoorthi, U. Hospital length of stay and all-cause 30-day readmissions among high-risk medicaid beneficiaries. J. Hosp. Med. 2016, 11, 283–288. [Google Scholar] [CrossRef] [Green Version]
- Kitakata, H.; Kohno, T.; Kohsaka, S.; Shiraishi, Y.; Parizo, J.T.; Niimi, N.; Goda, A.; Nishihata, Y.; Heidenreich, P.A.; Yoshikawa, T. Prognostic implications of early and midrange readmissions after acute heart failure hospitalizations: A report from a japanese multicenter registry. J. Am. Heart Assoc. 2020, 9, e014949. [Google Scholar] [CrossRef] [PubMed]
- Sud, M.; Yu, B.; Wijeysundera, H.C.; Austin, P.C.; Ko, D.T.; Braga, J.; Cram, P.; Spertus, J.A.; Domanski, M.; Lee, D.S. Associations between short or long length of stay and 30-day readmission and mortality in hospitalized patients with heart failure. JACC Heart Fail. 2017, 5, 578–588. [Google Scholar] [CrossRef] [PubMed]
- Moriyama, H.; Kohno, T.; Kohsaka, S.; Shiraishi, Y.; Fukuoka, R.; Nagatomo, Y.; Goda, A.; Mizuno, A.; Fukuda, K.; Yoshikawa, T. Length of hospital stay and its impact on subsequent early readmission in patients with acute heart failure: A report from the wet-hf registry. Heart Vessel. 2019, 34, 1777–1788. [Google Scholar] [CrossRef]
- Carey, K.; Lin, M.-Y. Hospital length of stay and readmission: An early investigation. Med. Care Res. Rev. 2014, 71, 99–111. [Google Scholar] [CrossRef]
- Hughes, L.D.; Witham, M.D. Causes and correlates of 30 day and 180 day readmission following discharge from a medicine for the elderly rehabilitation unit. BMC Geriatr. 2018, 18, 197. [Google Scholar] [CrossRef] [Green Version]


{kind=link}
{kind=link}
| Readmission Type | Duration from the Previous Discharge | Total (%) |
|---|---|---|
| Nor readmitted | - | 37,380 (76.93) |
| Readmission category A | From 0 to 30 days | 3092 (6.36) |
| Readmission category B | From 31 to 90 days | 2563 (5.27) |
| Readmission category C | From 91 to 180 days | 1780 (3.66) |
| Readmission category D | From 181 to 360 days | 1652 (3.40) |
| Readmission category E | More than 360 days | 2126 (4.38) |
| Variables | Total Input | List of Input | Notation |
|---|---|---|---|
| Gender | 2 | Male, female | Gender = {M, F} |
| Race | 4 | Malay, Chinese, Indian, others | Race = {Mal, Chi, Ind, O} |
| Age group | 7 | Infant (less than two years), children (three to eleven years old), teenagers (12 to 18 years old), young adult (19 to 30 years old), middle-aged adult (31 to 45 years old), old adult (46 to 64 years old) and elderly (more than 64 years old) | Age = {I, C, T, YA, MA, OA, E} |
| Admitting discipline of care | 9 | General medical, paediatric, general surgery, orthopaedics, gynaecology, cardiology, cardiothoracic surgery, others, without classification | Admit_disp = {GEN, PAE, SUR, OTH, GYN, CAR, CTS, O, NOC} |
| The discipline of care to be discharged from | 9 | Disc_disp = {I10, I25, E14, J18, I48, E87, J44, I20, N18, V89, DHF, OD} | |
| Other related diagnoses | 12 | I10, I25, E14, J18, I48, E87, J44, I20, N18, V89, decompensated heart failure (DHF), other diagnoses | Each of the codes represented as binary variables of yes or no |
| Length of stay | 7 | 1–5 days, 6–10 days, 11–15 days, 16–20 days, 21–25 days, 26–30 days, more than 30 days | LOS = {1–5 days, 6–10 days, 11–15 days, 16–20 days, 21–25 days, 26–30 days, Above 30 days} |
| Past admission | 6 | No, one, two, three, four, more than four | Past_adm = {N, 1, 2, 3, 4, above 4} |
| Total visit past 360 days | 6 | TV_360days = {N, 1, 2, 3, 4, above 4} | |
| Total other diagnoses | 6 | TOD = {N, 1, 2, 3, 4, above 4} | |
| Total underlying cause | 4 | No, one, two, more than two | TC = {N, 1, 2, above 2} |
| Total external cause of trauma | 4 | TE = {N, 1, 2, above 2} | |
| Surgery experience | 2 | Yes, no | SE = {Y, N} |
| Readmission Type | Condition | Support | Confidence | Lift |
|---|---|---|---|---|
| Not readmitted | {Past_adm = N, TOD = N, TE = N, Race = Mal, Admit_disp = GEN, Disc_disp = GEN} | 0.0144 | 0.6590 | 3.9539 |
| {LOS = 1–5 days, past_adm = N, TOD = N, Race = Mal} | 0.0722 | 0.3230 | 1.9378 | |
| {LOS = 1–5 days, past_adm = N, TOD = N, Gender = F} | 0.0503 | 0.3130 | 1.8783 | |
| {Past_adm = N, Race = Mal, Gender = F, E14 = N, J18 = N, I48 = N, E87 = N, DHF = N} | 0.0503 | 0.3048 | 1.8286 | |
| Readmission category A (0–30 days) | {Past_adm = above 4, TE = N, E87 = N} | 0.0109 | 0.3661 | 2.1966 |
| {TV_360days = 2, TE = N, Gender = M, E14 = N, J18 = N, I20 = N} | 0.0102 | 0.3311 | 1.9869 | |
| {TV_360days = 2, SE = N, TE = N, Race = Mal, underlying cause I25 = N, J18 = N, E87 = N, N18 = N} | 0.0104 | 0.3249 | 1.9495 | |
| {Age = OA, TE = N, external cause V89 = N, J18 = N, E87 = N} | 0.0670 | 0.1702 | 1.0213 | |
| Readmission category B (31–90 days) | {Past_adm = above 4, SE = N, I48 = N, I20 = N} | 0.0101 | 0.3356 | 2.0134 |
| {Age = OA, SE = N, TE = N, Admit_disp = GEN, Disc_disp = GEN, J18 = N, I48 = N, DHF = N} | 0.0503 | 0.1804 | 1.0824 | |
| {SE = N, TE = N, Admit_disp = GEN, Gender = M, external cause V89 = N, J18 = N, I48 = N, DHF = N} | 0.0709 | 0.1795 | 1.0768 | |
| Readmission category C (91–180 days) | {LOS = 1–5 days, TV_360 days = 1, TOD = N, TC = N, Race = Mal, Admit_disp = GEN, underlying cause I25 = N} | 0.0101 | 0.3049 | 1.8293 |
| {LOS = 1–5 days, Age = E, TV_360 days = 1, Disc_disp = GEN, external cause V89 = N, I10 = N, J44 = N, N18 = N} | 0.0101 | 0.3021 | 1.8127 | |
| {TC = N, TE = N, Race = Mal, Admit_disp = GEN, underlying cause I25 = N, E14 = N, N18 = N, OD = N | 0.0638 | 0.1827 | 1.0963 | |
| Readmission category D (181–360 days) | {LOS = 1–5 days, TOD = 2, SE = N, I25 = N, I48 = N, I20 = N, DHF = N} | 0.0101 | 0.2653 | 1.5915 |
| {LOS = 1–5 days, age = OA, SE = N, Race = Mal, Admit_disp = GEN, Gender = F, I25 = N, J44 = N} | 0.0121 | 0.2564 | 1.5385 | |
| {Age = OA, Admit_disp = GEN, Disc_disp = GEN, I25 = N, I48 = N, J44 = N, N18 = N} | 0.0520 | 0.1935 | 1.1608 | |
| Readmission category E (More than 360 days) | {Past_adm = N, TOD = 2, SE = N, E14 = N, J44 = N, N18 = N} | 0.0101 | 0.2924 | 1.7544 |
| {LOS = 1–5 days, past_adm = N, TC = N, Admit_disp = GEN, Disc_disp = GEN, E14 = N, J44 = N, N18 = N} | 0.0672 | 0.2212 | 1.3271 |
| Data Classification | Rules | Support | Confidence | Lift |
|---|---|---|---|---|
| All patient data | {Age = OA, TC = N, TE = N, Race = Chi, adm_disp = GEN, disc_disp = GEN, external cause V89 = N, DHF = N} → {Gender = M} | 0.0279 | 0.7181 | 1.2968 |
| {LOS = 1–5 days, age = OA, TC = N, TE = N, Race = Chi, external cause V89 = N, I48 = N, DHF = N} → {Gender = M} | 0.0277 | 0.7179 | 1.2964 | |
| {Age = E, past_adm = N, TE = N, Race = Ind, J18 = N, E87 = N, J44 = N, OD = N} → {Gender = F} | 0.0216 | 0.5854 | 1.3118 | |
| {LOS = 6–10 days, age = E, TV_360days = N, TC = N, external cause V89 = N, I25 = N, E14 = N, J44 = N, N18 = N} → {Gender = F} | 0.0503 | 0.5231 | 1.1722 | |
| Readmitted patient data | {LOS = 1–5 days, TC = N, E14 = N, E87 = N, J44 = Y, I20 = N, N18 = N} → {Gender = M} | 0.0106 | 0.9154 | 1.5359 |
| {Age = OA, TV_360days = 1, SE = N, TC = N, TE = N, J18 = N, N18 = N, OD = N} → {Gender = M} | 0.0503 | 0.6989 | 1.1726 | |
| {LOS = 1–5 days, Age = OA, past_adm = N, TE = N, Race = Ind, J44 = N, DHF = N, OD = N} → {Gender = F} | 0.0107 | 0.6218 | 1.5390 | |
| {LOS = 1–5 days, Age = E, past_adm = N, TE = N, Race = Ind, I10 = N, I25 = N, J44 = N} → {Gender = F} | 0.0107 | 0.6218 | 1.5390 |
| Data Classification | Rules | Support | Confidence | Lift |
|---|---|---|---|---|
| All patient data | {Age = OA, admit_disp = NOC, disc_disp = NOC, Gender = F, E14 = N, J18 = N, E87 = N, OD = N} → {Race = Mal} | 0.0101 | 0.9440 | 1.5436 |
| {LOS = 1–5 days, admit_disp = NOC, disc_disp = NOC, Gender = F, I10 = N, E14 = N, E87 = N, OD = N} → {Race = Mal} | 0.0180 | 0.9439 | 1.5434 | |
| {Age = E, TV_360days = N, TOD = N, admit_disp = CAR, disc_disp = CAR, I10 = N, J44 = N, OD = N} → {Race = Chi} | 0.0117 | 0.4863 | 2.6473 | |
| {LOS = 1–5 days, Age = E, past_adm = N, TOD = N, TE = N, underlying cause I25 = N, external cause V89 = N, I10 = N, J44 = N} → {Race = Chi} | 0.0659 | 0.2562 | 1.3950 | |
| {LOS = 1–5 days, age = OA, Gender = F, TOD = N, TC = N, disc_disp = GEN, I10 = N, I48 = N} → {Race = Ind} | 0.0136 | 0.1888 | 1.6210 | |
| {Age = OA, TOD = N, SE = N, underlying cause I25 = N, external cause V89 = N, I10 = N, I48 = N, J44 = N, DHF = N} → {Race = Ind} | 0.0501 | 0.1564 | 1.3431 | |
| Readmitted patient data | {Admit_disp = NOC, I10 = N, I25 = Y} → {Race = Mal} | 0.0111 | 0.9843 | 1.5590 |
| {Age = OA, TC = N, disc_disp = NOC, Gender = F, E14 = N, E87 = N} → {Race = Mal} | 0.0109 | 0.9760 | 1.5460 | |
| {Age = E, TOD = N, TE = N, admit_disp = CAR, disc_disp = CAR} → {Race = Chi} | 0.0106 | 0.4146 | 2.3721 | |
| {LOS = 1–5 days, age = E, TE = N, I10 = N, I25 = N, E14 = N, J18 = N, J44 = N, OD = N} → {Race = Chi} | 0.0584 | 0.2488 | 1.4232 | |
| {Age = OA, TV_360days = 1, disc_disp = GEN, I25 = N, J18 = N, I48 = N, I20 = N, OD = N} → {Race = Ind} | 0.0101 | 0.1958 | 1.5971 |
| Data Classification | Rules | Support | Confidence | Lift |
|---|---|---|---|---|
| All patient data | {LOS = 6–10 days, Race = Chi, Gender = F, Dics_disp = GEN, E87 = N, I20 = N} → {Age = E} | 0.0100 | 0.7880 | 1.5810 |
| {TC = N, TE = N, Race = Chi, Gender = F, underlying cause I25 = N, external cause V89 = N, E87 = N, DHF = N, N18 = N} → {Age = E} | 0.0544 | 0.7541 | 1.5130 | |
| {LOS = 1–5 days, SE = N, Race = Ind, Gender = M, external cause V89 = N, J18 = N, I48 = N, J44 = N} → {Age = OA} | 0.0242 | 0.5708 | 1.3831 | |
| {Race = Mal, Gender = M, adm_disp = GEN, external cause V89 = N, I48 = N, J44 = N, N18 = N, OD = N} → {Age = OA} | 0.1010 | 0.4775 | 1.1571 | |
| {Past_adm = N, Gender = M, underlying cause I25 = N, I10 = N, I25 = N, E14 = N, J18 = N, J44 = N} → {Age = MA} | 0.0336 | 0.0782 | 1.1832 | |
| {Past_adm = N, I10 = N, I25 = N, E14 = N, I48 = N, J44 = N, I20 = N} → {Age = YA} | 0.0122 | 0.0154 | 1.1114 | |
| Readmitted patient data | {LOS = 6–10 days, Race = Chi, Gender = F, I10 = N, I20 = N, DHF = N} → {Age = E} | 0.0119 | 0.8261 | 1.7230 |
| {TV_360days = N, TC = N, TE = N, Race = Chi, disc_disp = GEN, E87 = N, OD = N} → {Age = E} | 0.0500 | 0.6361 | 1.3267 | |
| {LOS = 6–10 days, Race = Ind, Gender = M} → {Age = OA} | 0.0108 | 0.6368 | 1.4380 | |
| {TE = N, Race = Mal, admit_disp = O, Gender = M, I25 = N, J44 = N, OD = N} → {Age = OA} | 0.0104 | 0.6158 | 1.3904 | |
| {LOS = 1–5 days, past_adm = N, Race = Mal, Gender = M, I10 = N, E14 = N, J44 = N, I20 = N} → {Age = MA} | 0.0111 | 0.0873 | 1.3859 | |
| {TC = N, I25 = N, E14 = N, I48 = N, J44 = N, I20 = N, DHF = N, N18 = N} → {Age = YA} | 0.0102 | 0.0129 | 1.1772 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Miswan, N.H.; Sulaiman, ‘I.M.; Chan, C.S.; Ng, C.G. Association Rules Mining for Hospital Readmission: A Case Study. Mathematics 2021, 9, 2706. https://doi.org/10.3390/math9212706
Miswan NH, Sulaiman ‘IM, Chan CS, Ng CG. Association Rules Mining for Hospital Readmission: A Case Study. Mathematics. 2021; 9(21):2706. https://doi.org/10.3390/math9212706
Chicago/Turabian StyleMiswan, Nor Hamizah, ‘Ismat Mohd Sulaiman, Chee Seng Chan, and Chong Guan Ng. 2021. "Association Rules Mining for Hospital Readmission: A Case Study" Mathematics 9, no. 21: 2706. https://doi.org/10.3390/math9212706
APA StyleMiswan, N. H., Sulaiman, ‘I. M., Chan, C. S., & Ng, C. G. (2021). Association Rules Mining for Hospital Readmission: A Case Study. Mathematics, 9(21), 2706. https://doi.org/10.3390/math9212706