
Combining Grammatical Evolution with Modal Interval Analysis: An Application to Solve Problems with Uncertainty




Abstract
:1. Introduction
Related Work
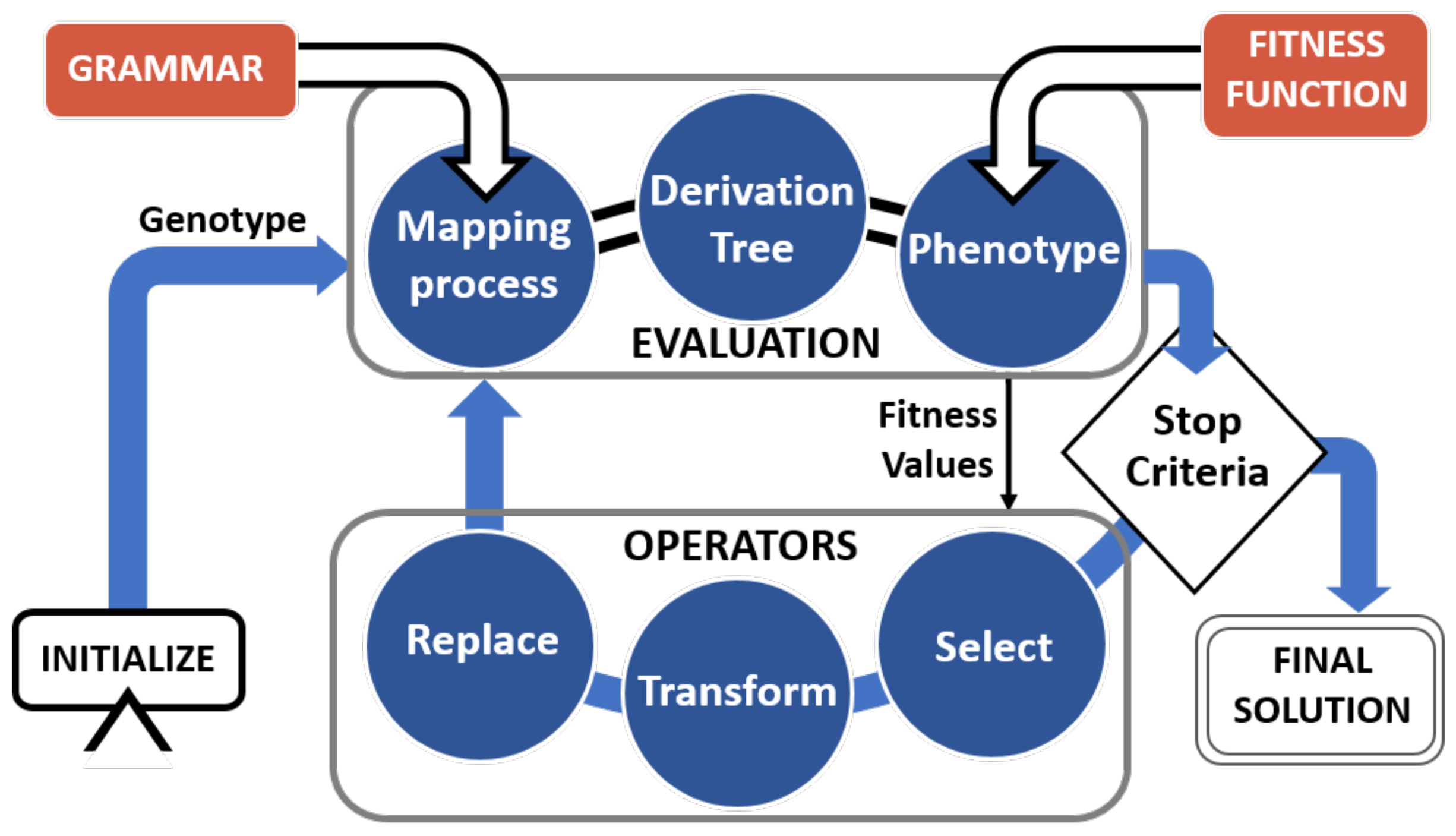
2. Predictive Modeling by Grammatical Evolution
Context-Free Grammar
3. Interval Methods
3.1. Modal Interval Analysis
3.2. Modal Interval Extensions
3.3. Primary Theorems
3.4. Algorithm
4. Interval-Based Grammatical Evolution
4.1. Including Uncertainty in Grammatical Evolution
- Manage intervals as inputs of the system;
- Generate intervals as parameters;
- Compute intervals as basic operations.
4.2. Uncertainty in Context-Free Grammars
4.3. Intervalized Fitness Functions
4.4. Predictive Modeling Solutions
5. Implementation, Results, and Discussions
5.1. Illustrative Example
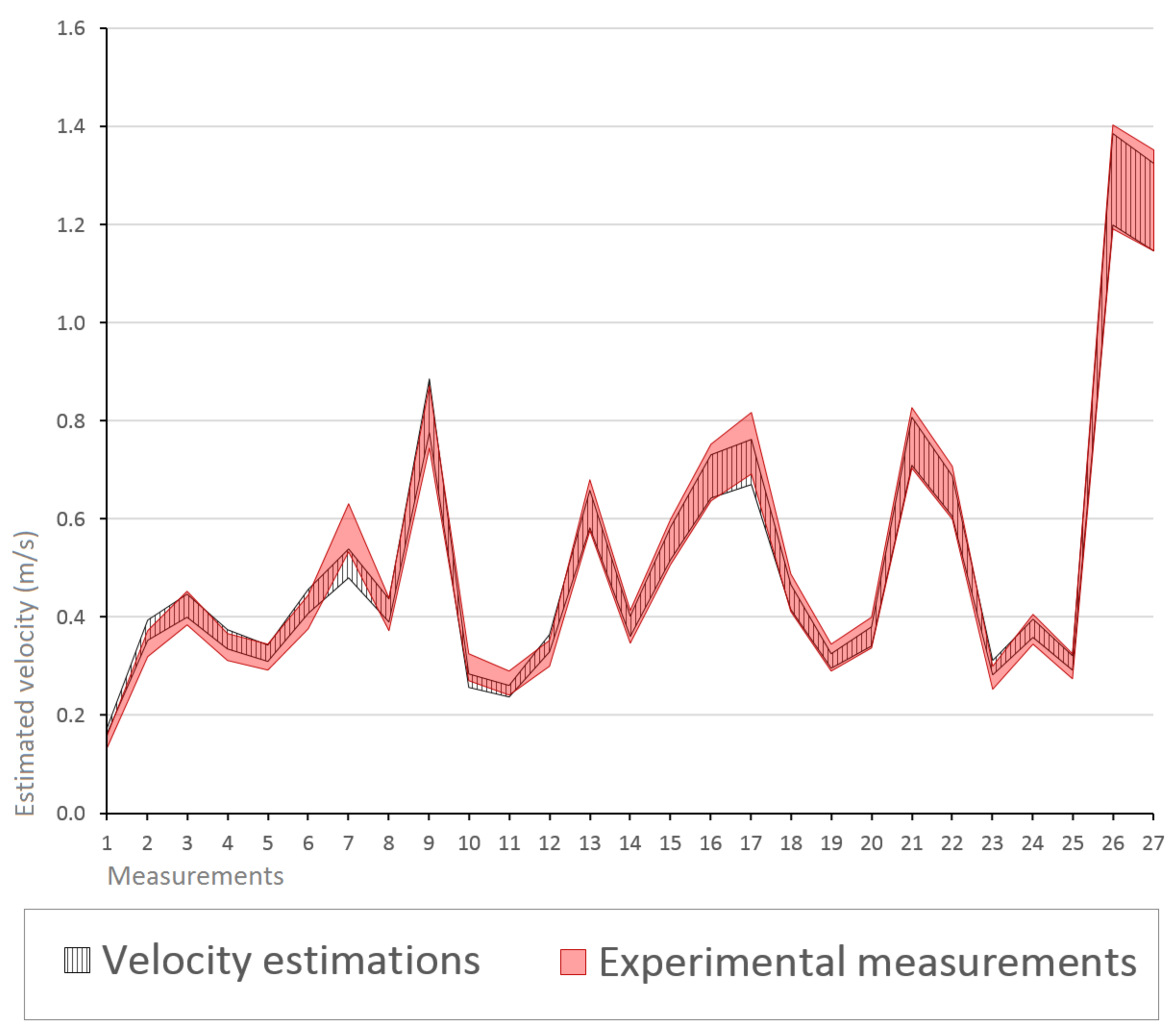
5.2. Modeling River Velocity
| Algorithm 1: Context-free grammar used in our case study, where [Constant] is a non-terminal that generates real constants following a classical implementation via digit concatenation. |
| [Expression] → [Term] | [Term][OperatorSimple][Expression] [Term] → ([Interval] [OperatorB] [OperatorComplex] (Bed Slope∧[Constant])) | ([Interval] [OperatorB] [OperatorComplex] (Flow Rate∧[Constant])) [OperatorComplex] → sqrt | sin | log | pow | [Constant]∧ | cos | [OperatorComplex][OperatorComplex] | [] [OperatorSimple] → [OperatorA] | [OperatorB] [OperatorA] → + | - [OperatorB] → * | ÷ |
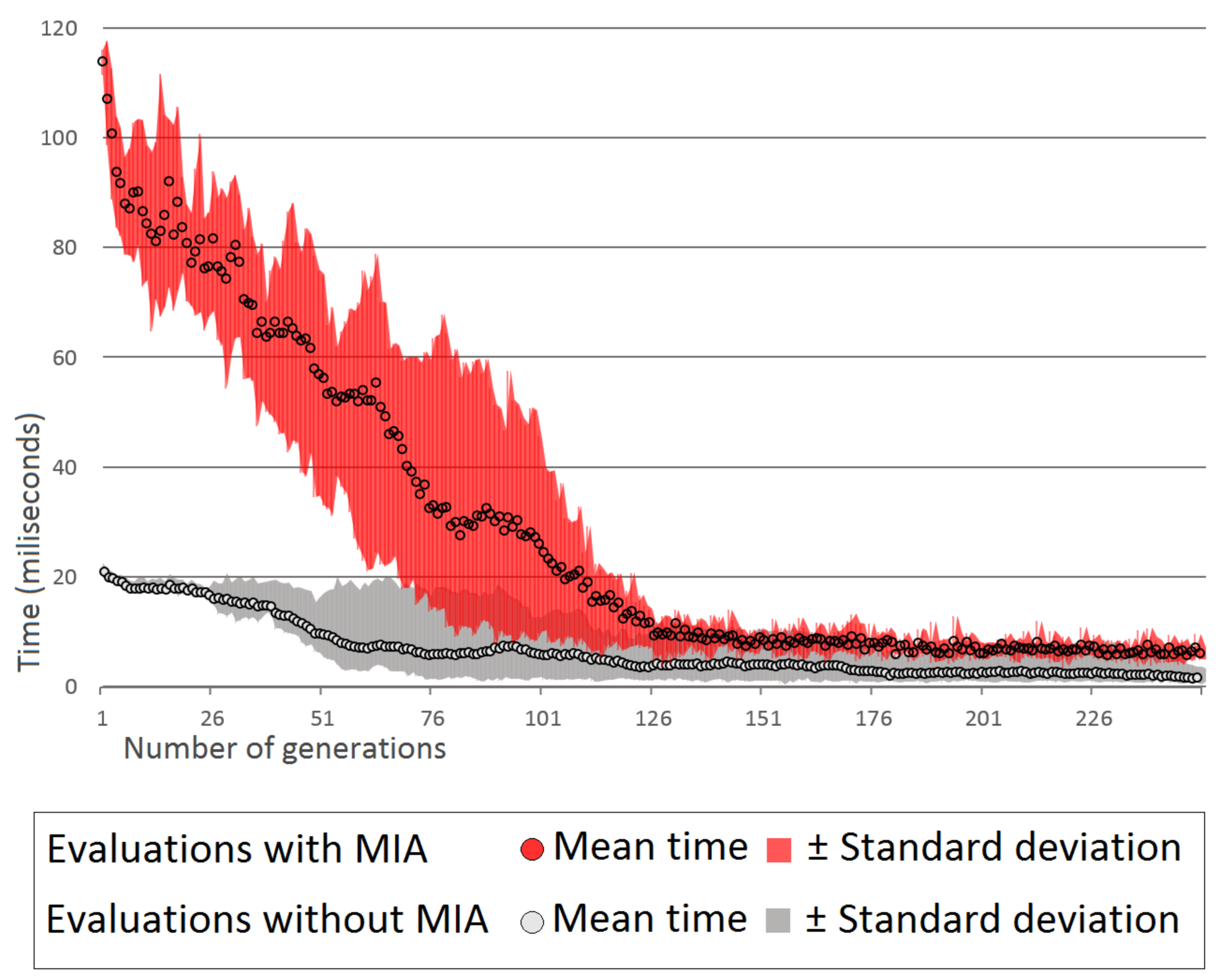
5.3. Results
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Edla, D.R.; Lingras, P.; Venkatanareshbabu, K. Advances in Machine Learning and Data Science Recent Achievements and Research Directives; Springer: Berlin, Germany, 2018. [Google Scholar]
- Grote, G. Management of Uncertainty: Theory and Application in the Design of Systems and Organizations; Springer: Berlin, Germany, 2009. [Google Scholar]
- Bailey, T.S.; Chang, A.; Christiansen, M. Clinical accuracy of a continuous glucose monitoring system with an advanced algorithm. J. Diabetes Sci. Technol. 2015, 9, 209–214. [Google Scholar] [CrossRef] [Green Version]
- Contreras, I.; Oviedo, S.; Vettoretti, M.; Visentin, R.; Vehí, J. Personalized blood glucose prediction: A hybrid approach using grammatical evolution and physiological models. PLoS ONE 2017, 12. [Google Scholar] [CrossRef] [Green Version]
- Sainz, M.A.; Armengol, J.; Calm, R.; Herrero, P.; Jorba, L.; Vehi, J. Modal Interval Analysis: New Tools for Numerical Information; Springer: Berlin, Germany, 2014; Volume 2091. [Google Scholar]
- Zadeh, L. The role of fuzzy logic in the management of uncertainty in expert systems. Fuzzy Sets Syst. 1983, 11, 199–227. [Google Scholar] [CrossRef]
- Korb, K.B.; Nicholson, A.E. Bayesian Artificial Intelligence; CRC Press: Boca Raton, FL, USA, 2011; p. 463. [Google Scholar]
- Baraldi, P.; Podofillini, L.; Mkrtchyan, L.; Zio, E.; Dang, V.N. Comparing the treatment of uncertainty in Bayesian networks and fuzzy expert systems used for a human reliability analysis application. Reliab. Eng. Syst. Saf. 2015, 138, 176–193. [Google Scholar] [CrossRef] [Green Version]
- Sowinski, R.; Stefanowski, J. Handling Various Types of Uncertainty in the Rough Set Approach. In Rough Sets, Fuzzy Sets and Knowledge Discovery; Springer: London, UK, 1994; pp. 366–376. [Google Scholar] [CrossRef]
- Basso, P. Optimal search for the global maximum of functions with bounded seminorm. J. Numer. Anal. 1985, 9, 888–903. [Google Scholar] [CrossRef]
- Zuche, S.; Neumaier, A.; Eiermann, M. Solving minimax problems by interval methods. BIT 1990, 30, 742–751. [Google Scholar]
- Wolfe, M. Interval methods for global optimization. Appl. Math. Comput. 1996, 75, 179–206. [Google Scholar]
- Markov, S.; Popova, E.; Ullrich, C. On the solution of linear algebraic equations involving interval coefficients. Iterative Methods in Linear Algebra. Ser. Comput. Appl. Math. 1996, 3, 216–225. [Google Scholar]
- Shary, S. Solving the linear interval tolerance problem. Math. Comput. Simul. 1995, 39, 145–149. [Google Scholar] [CrossRef]
- Jaulin, L.; Kieffer, M.; Didrit, O.; Walter, E. Applied Interval Analysis: With Examples in Parameter and State Estimation, Robust Control and Robotics; Springer: Berlin, Germany, 2001. [Google Scholar]
- Hladík, M. Optimal value range in interval linear programming. Fuzzy Optim. Decis. Mak. 2009, 8, 283–294. [Google Scholar] [CrossRef]
- Treanta, S. Efficiency in uncertain variational control problems. Neural Comput. Appl. 2020. [Google Scholar] [CrossRef]
- Leibig, C.; Allken, V.; Ayhan, M.S.; Berens, P.; Wahl, S. Leveraging uncertainty information from deep neural networks for disease detection. Sci. Rep. 2017, 7. [Google Scholar] [CrossRef] [Green Version]
- Azar, A.T.; Vaidyanathan, S. Computational Intelligence Applications in Modeling and Control; Springer International Publishing: Cham, Switzerland, 2009; Volume 575. [Google Scholar] [CrossRef]
- Contreras, I.; Vehi, J. Artificial Intelligence for Diabetes Management and Decision Support: Literature Review. J. Med. Internet Res. 2018, 20, e10775. [Google Scholar] [CrossRef]
- Herrero, P.; Sainz, M.A.; Veh, J.; Jaulin, L. Quantified set inversion algorithm with applications to control. Reliab. Comput. 2005, 11, 369–382. [Google Scholar] [CrossRef] [Green Version]
- Vehí, J.; Rodellar, J.; Sainz, M.; Armengol, J. Analysis of the robustness of predictive controllers via modal intervals. Reliab. Comput. 2000, 6, 281–301. [Google Scholar] [CrossRef]
- Fan, J.M.; Wang, Q.S.; Zou, J.X.; Shen, Y.; Zhang, M.S. Application of Modal Intervals in the Diagnosis of Liquid-propellant Rocket Engine. J. Harbin Inst. Technol. 2006, 38, 1406–1409. [Google Scholar]
- Calm, R.; García-Jaramillo, M.; Bondia, J.; Sainz, M.A.; Vehí, J. Comparison of interval and Monte Carlo simulation for the prediction of postprandial glucose under uncertainty in type 1 diabetes mellitus. Comput. Methods Programs Biomed. 2011, 104, 325–332. [Google Scholar] [CrossRef]
- Flórez, J.; Sbert, M.; Sainz, M.A.; Vehí, J. Improving the interval ray tracing of implicit surfaces. Adv. Comput. Graph. 2006, 655–664. [Google Scholar] [CrossRef]
- Adillon, B.; Jorba, L. Financial Applications of Modal Interval Analysis. In Statistical and Soft Computing Approaches in Insurance Problems; Nova Science Publishers, Inc.: Hauppauge, NY, USA, 2013; pp. 113–122. [Google Scholar]
- Dempsey, I.; O’Neill, M.; Brabazon, A. Foundations in Grammatical Evolution for Dynamic Environments; Springer: Berlin, Germany, 2009; Volume 194, pp. 163–169. [Google Scholar] [CrossRef]
- Brabazon, A.; O’Neill, M. Evolving technical trading rules for spot foreign-exchange markets using grammatical evolution. CMS 2004, 1, 311–327. [Google Scholar] [CrossRef]
- Gong, D.; Sun, J.; Miao, Z. A Set-Based Genetic Algorithm for Interval Many-Objective Optimization Problems. IEEE Trans. Evol. Comput. 2018, 22, 47–60. [Google Scholar] [CrossRef]
- Bhunia, A.K.; Samanta, S.S. A study of interval metric and its application in multi-objective optimization with interval objectives. Comput. Ind. Eng. 2014, 74, 169–178. [Google Scholar] [CrossRef]
- Gong, D.; Qin, N.; Sun, X. Evolutionary algorithms for optimization problems with uncertainties and hybrid indices. Inf. Sci. 2011, 181, 4124–4138. [Google Scholar] [CrossRef]
- Goh, C.K.; Tan, K.C. Handling Noise in Evolutionary Multi-objective Optimization. In Evolutionary Multi-objective Optimization in Uncertain Environments: Issues and Algorithms; Springer: Berlin/Heidelberg, Germany, 2009; pp. 55–99. [Google Scholar] [CrossRef]
- Karshenas, H.; Bielza, C.; Larrañaga, P. Interval-based ranking in noisy evolutionary multi-objective optimization. Comput. Optim. Appl. 2015, 61, 517–555. [Google Scholar] [CrossRef] [Green Version]
- Sun, J.; Ma, Q.; Liu, R.; Wang, T.; Tang, C. A novel multiobjective charging optimization method of power lithium-ion batteries based on charging time and temperature rise. Int. J. Energy Res. 2019, 43, 7672–7681. [Google Scholar] [CrossRef]
- Femia, N.; Spagnuolo, G. True worst-case circuit tolerance analysis using genetic algorithms and affine arithmetic. IEEE Trans. Circuits Syst. Fundam. Theory Appl. 2000, 47, 1285–1296. [Google Scholar] [CrossRef]
- Rocco, C.M.; Moreno, J.A.; Carrasquero, N. Robust design using a hybrid-cellular-evolutionary and interval-arithmetic approach: A reliability application. Reliab. Eng. Syst. Saf. 2003, 79, 149–159. [Google Scholar] [CrossRef]
- Keijzer, M. Improving Symbolic Regression with Interval Arithmetic and Linear Scaling. In Genetic Programming; Ryan, C., Soule, T., Keijzer, M., Tsang, E., Poli, R., Costa, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 70–82. [Google Scholar]
- Gardeñes, E.; Sainz, M.Á.; Jorba, L.; Calm, R.; Estela, R.; Mielgo, H.; Trepat, A. Model Intervals. Reliab. Comput. 2001, 7, 77–111. [Google Scholar] [CrossRef]
- Kaucher, E. Interval Analysis in the Extended Interval Space IR. In Fundamentals of Numerical Computation (Computer-Oriented Numerical Analysis); Alefeld, G., Grigorieff, R.D., Eds.; Springer: Vienna, Austria, 1980; pp. 33–49. [Google Scholar] [CrossRef]
- Herrero, P.; Sainz, M.A. Extended quantified set inversion algorithm with applications to control. J. Comput. Technol. 2017, 22, 4–18. [Google Scholar]
- Herrero, P.; Sainz, M.Á. MIC: Modal Interval Calculator. Version 2.1. 2018. Available online: https://sites.google.com/site/modalintervalcalculator/ (accessed on 15 March 2021).
- Yorifuji, T.; Suzuki, E.; Kashima, S. Hourly differences in air pollution and risk of respiratory disease in the elderly: A time-stratified case-crossover study. Environ. Health 2014, 13, 67. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kardelen, F.; Akcurin, G.; Ertug, H.; Akcurin, S.; Bircan, I. Heart rate variability and circadian variations in type 1 diabetes mellitus. Pediatr. Diabetes 2006, 7, 45–50. [Google Scholar] [CrossRef]
- Sainz, M.; Baldasano, J. Modelo Matemático de Autodepuración para el Bajo Ter; Technical Report; Junta de Sanajament, Generalitat de Catalunya: Barcelona, Spain, 1988. [Google Scholar]
- Freckmann, G.; Pleus, S.; Grady, M.; Setford, S.; Levy, B. Measures of Accuracy for Continuous Glucose Monitoring and Blood Glucose Monitoring Devices. J. Diabetes Sci. Technol. 2019, 13, 575–583. [Google Scholar] [CrossRef]
- Schmelzeisen-Redeker, G.; Schoemaker, M.; Kirchsteiger, H.; Freckmann, G.; Heinemann, L.; del Re, L. Time Delay of CGM Sensors. J. Diabetes Sci. Technol. 2015, 9, 1006–1015. [Google Scholar] [CrossRef] [Green Version]
- Basu, A.; Dube, S.; Slama, M.; Errazuriz, I.; Amezcua, J.C.; Kudva, Y.C.; Peyser, T.; Carter, R.E.; Cobelli, C.; Basu, R. Time Lag of Glucose From Intravascular to Interstitial Compartment in Humans. Diabetes 2013, 62, 4083–4087. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hyperparameter | Value |
|---|---|
| Population size | 500 |
| Generations | 100 |
| Crossover prob. | 0.9 |
| Mutation prob. | 0.03 |
| K (weighting factor) | 10 |
| Tournament size | 2 |
| Max. Wraps | 1 |
| Chromosome length | 50 |
| Elitism | 1 |
| N (number of executions) | 20 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Contreras, I.; Calm, R.; Sainz, M.A.; Herrero, P.; Vehi, J. Combining Grammatical Evolution with Modal Interval Analysis: An Application to Solve Problems with Uncertainty. Mathematics 2021, 9, 631. https://doi.org/10.3390/math9060631
Contreras I, Calm R, Sainz MA, Herrero P, Vehi J. Combining Grammatical Evolution with Modal Interval Analysis: An Application to Solve Problems with Uncertainty. Mathematics. 2021; 9(6):631. https://doi.org/10.3390/math9060631
Chicago/Turabian StyleContreras, Ivan, Remei Calm, Miguel A. Sainz, Pau Herrero, and Josep Vehi. 2021. "Combining Grammatical Evolution with Modal Interval Analysis: An Application to Solve Problems with Uncertainty" Mathematics 9, no. 6: 631. https://doi.org/10.3390/math9060631