
Self-Perceived Health, Life Satisfaction and Related Factors among Healthcare Professionals and the General Population: Analysis of an Online Survey, with Propensity Score Adjustment




Abstract
:1. Introduction
2. Materials and Methods
2.1. Target Population
2.2. Sample
2.3. Variables
- Self-perceived health status (scored on a 5-point Likert scale, ranging from 1 = very bad to 5 = very good)
- Satisfaction with life (scored on a 10-point Likert scale, ranging from 1 = completely unsatisfied to 10 = completely satisfied)
- Alcohol intake (once a day/once a week/once a month/less than once a month/never)
- Tobacco use (never/ex-smoker/occasional smoker/regular smoker)
- Physical activity (none/occasional/regular/intensive)
- Body mass index (BMI), obtained from dividing the weight (in kilograms) by the square of the height (in centimetres) and categorised as low or normal weight (<25 kg/m2), overweight (25–29 kg/m2) and obesity (≥30 kg/m2) [25]
- Hours of sleep per night (numeric)
- Physical, mental or sensorial disability (presence/absence)
- Chronic disease (presence/absence)
- Health problems (none/one/two or more)
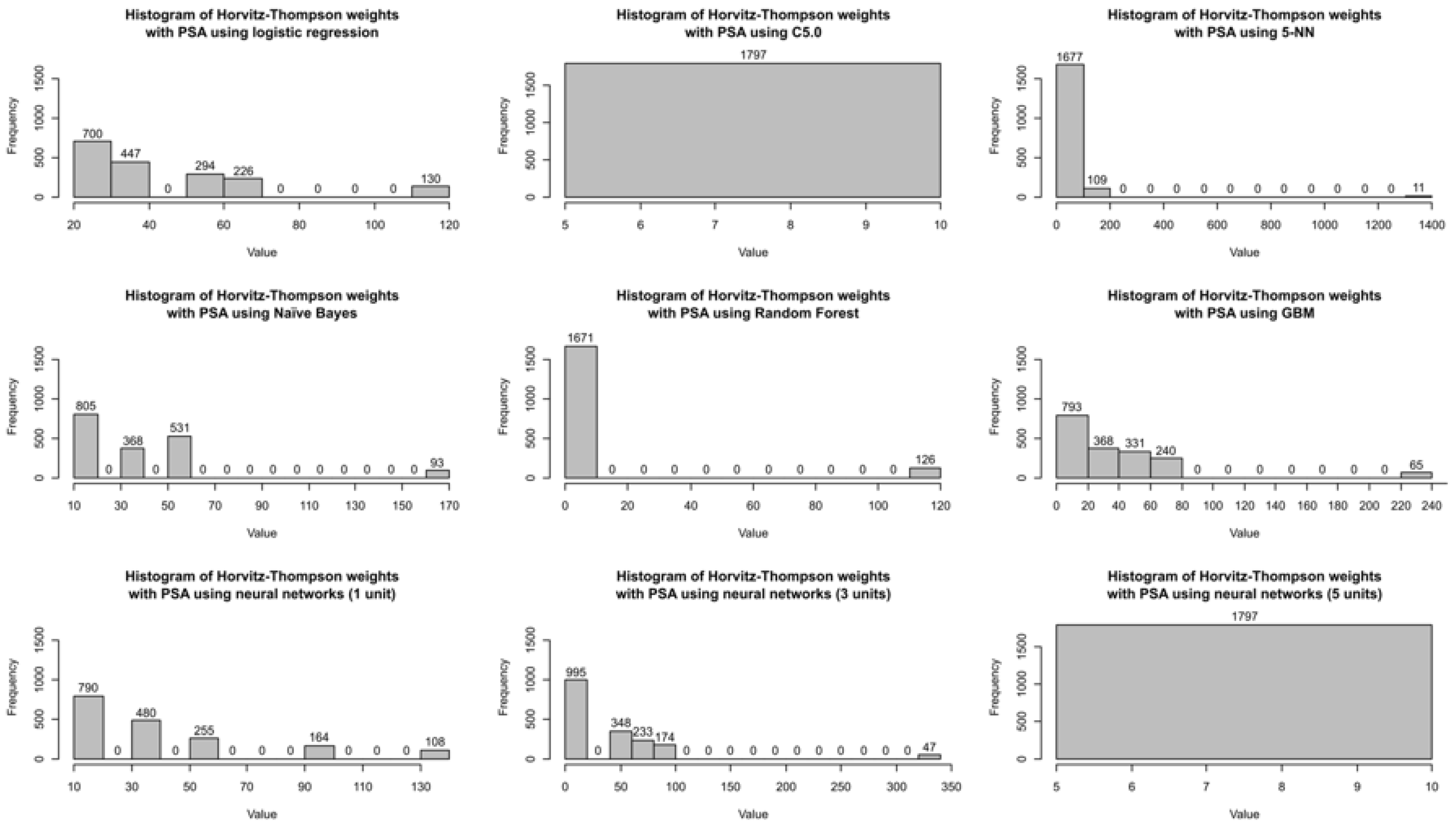
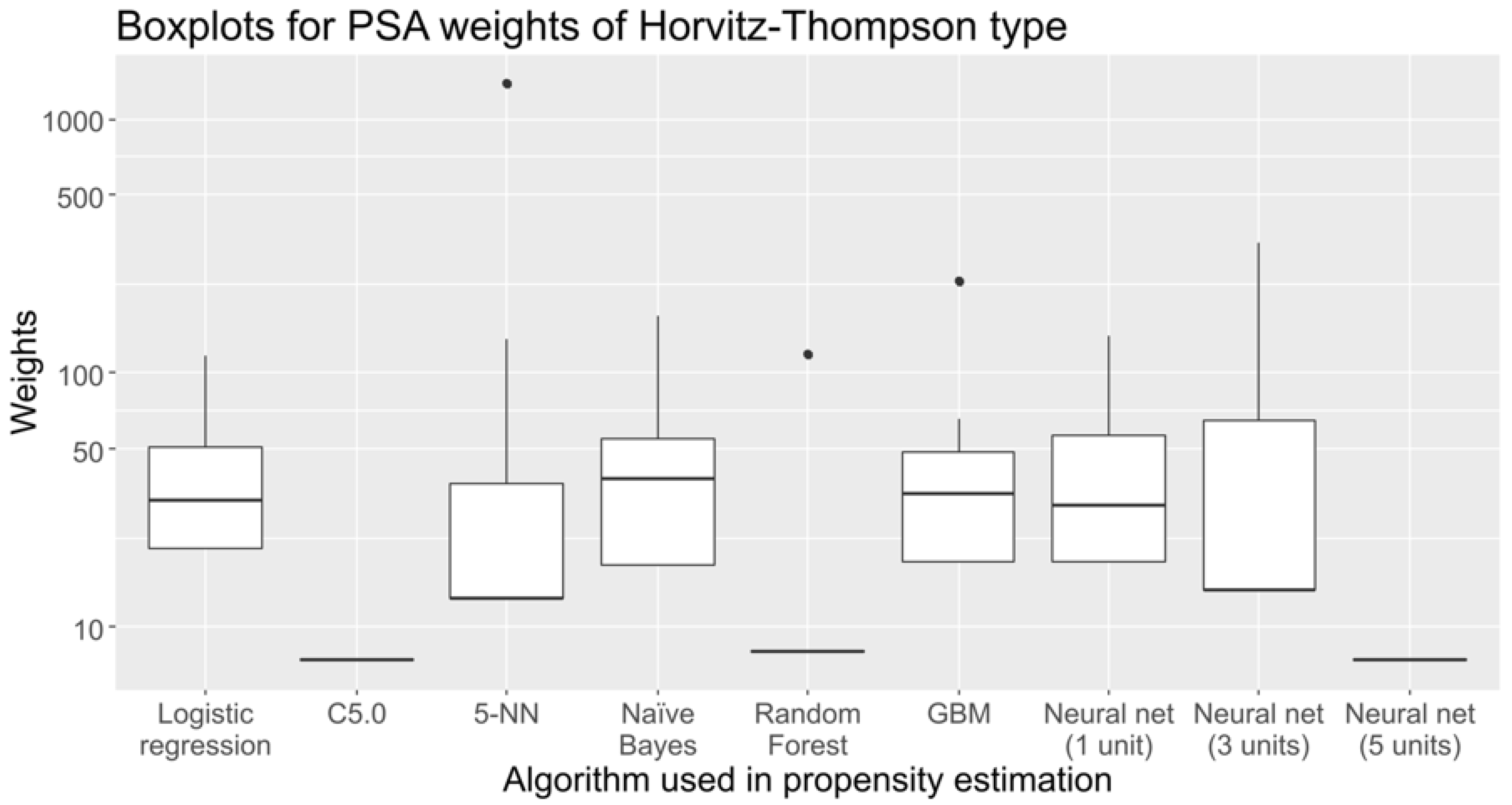
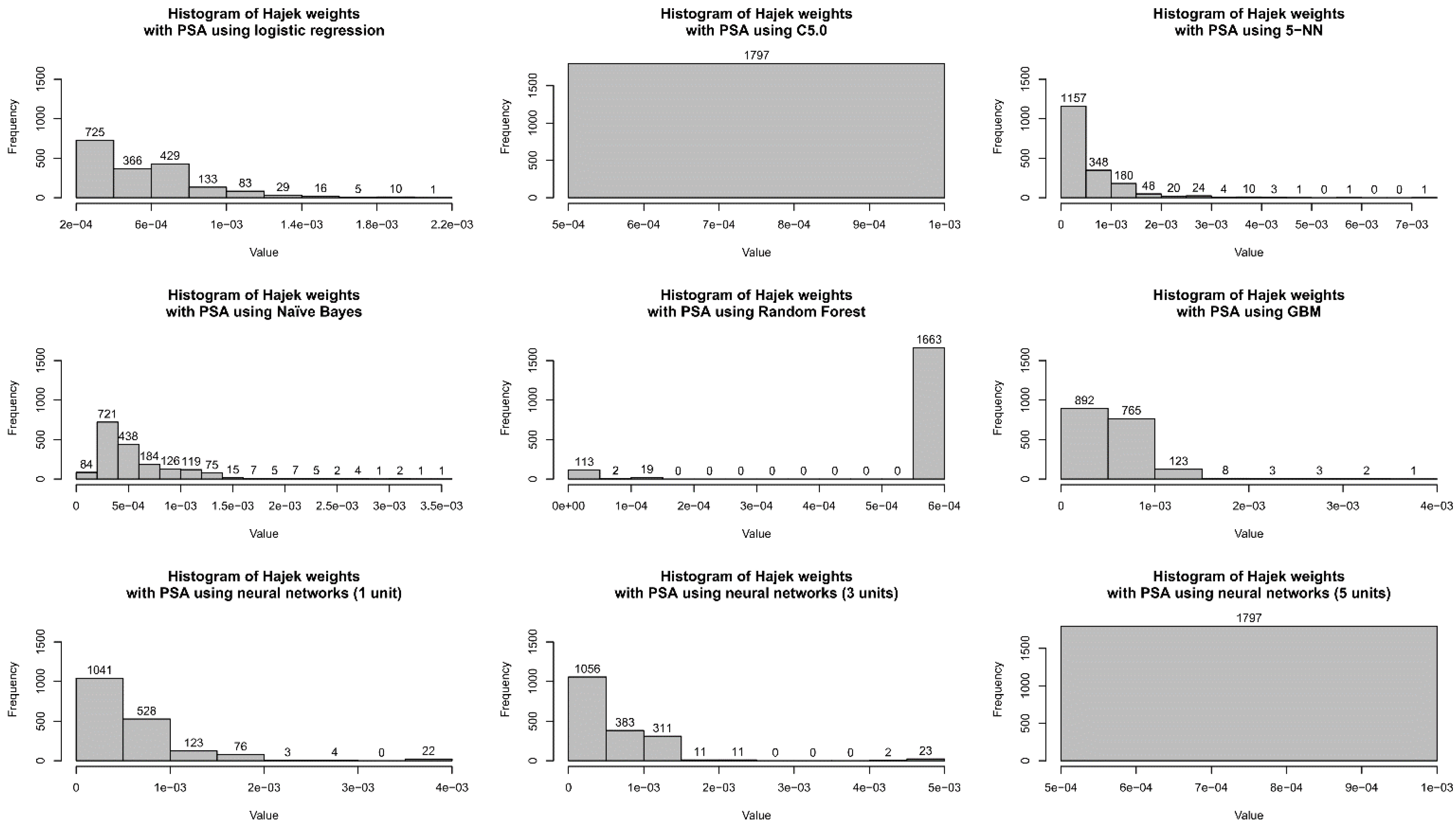
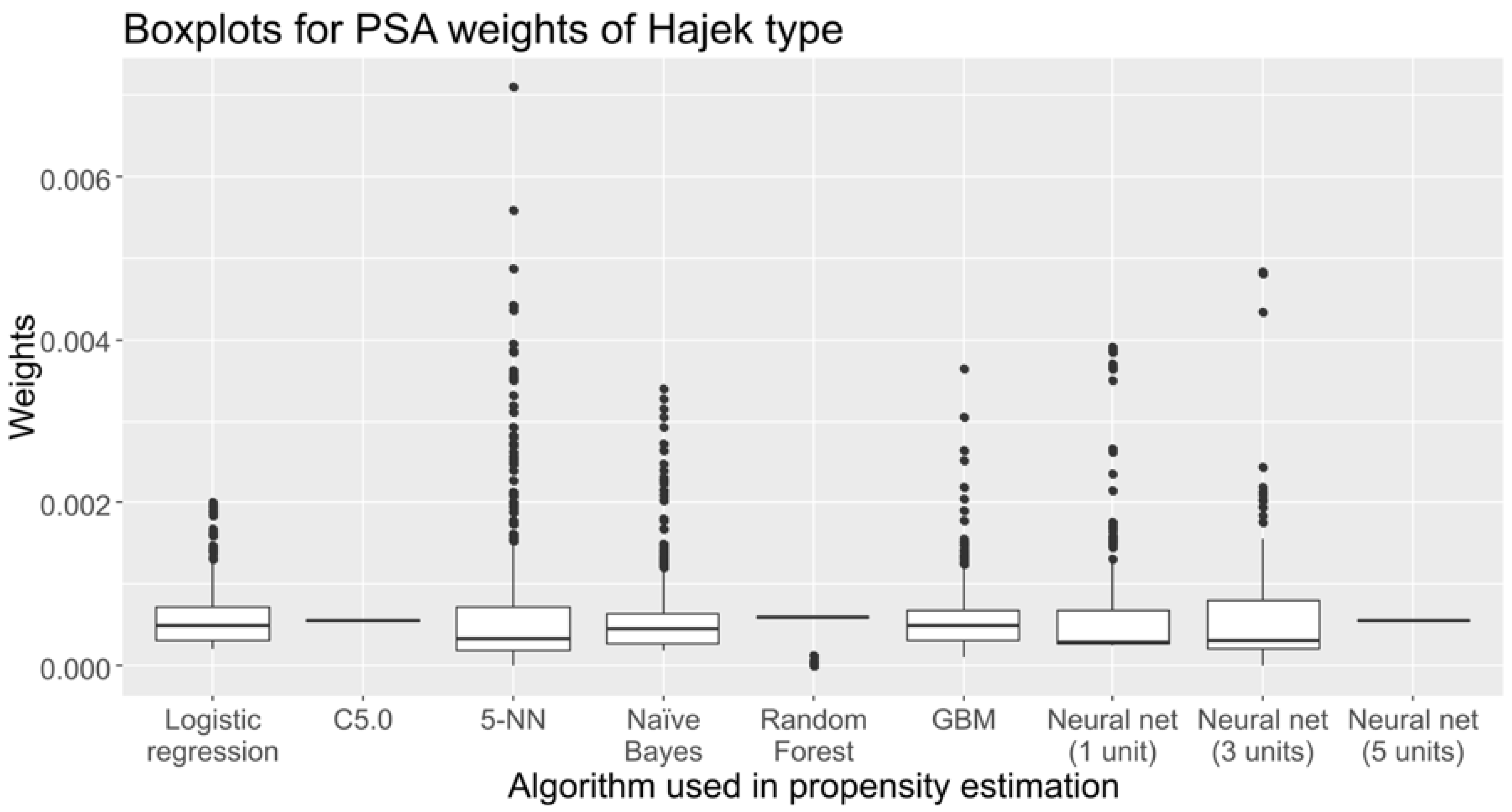
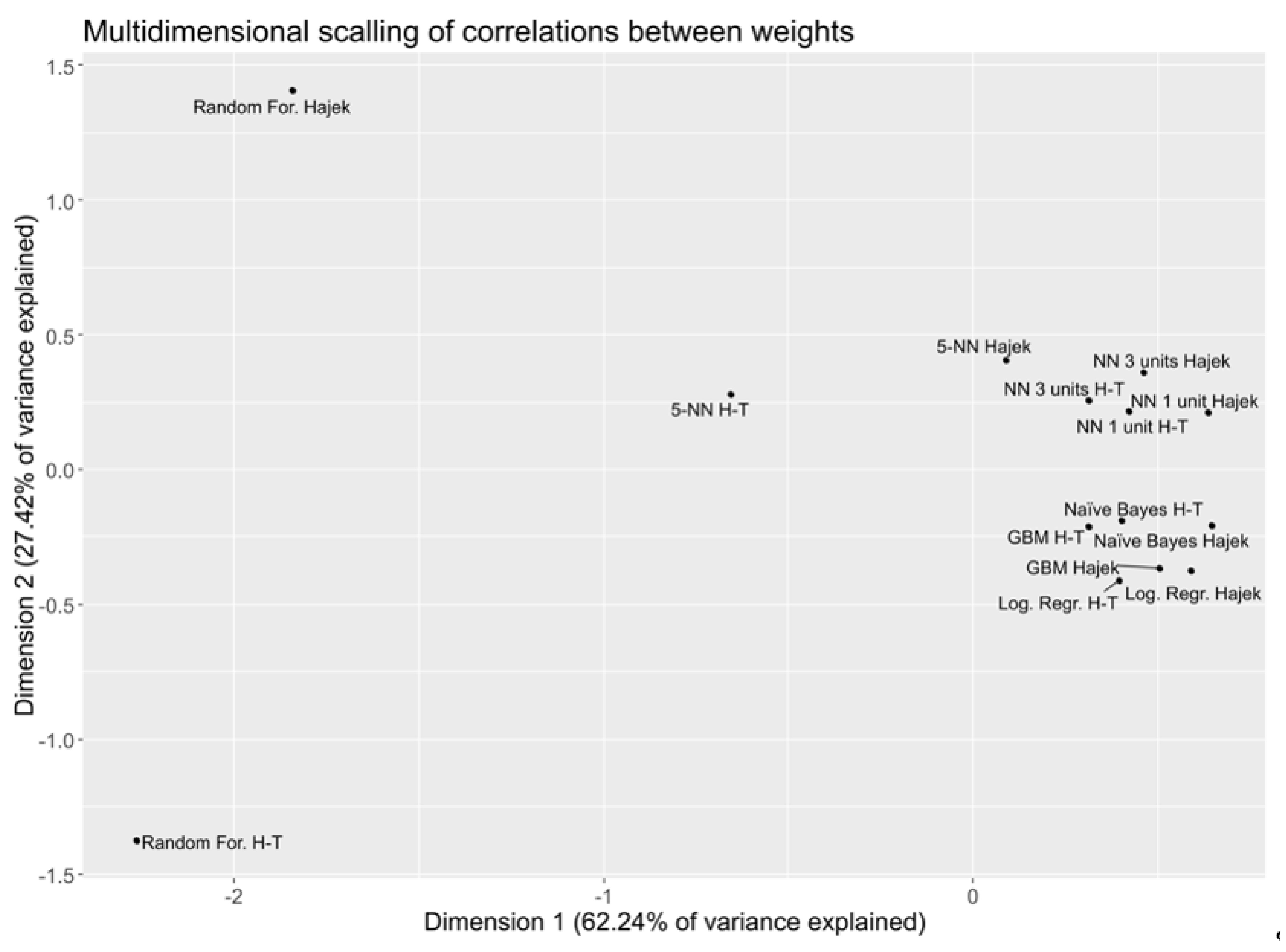
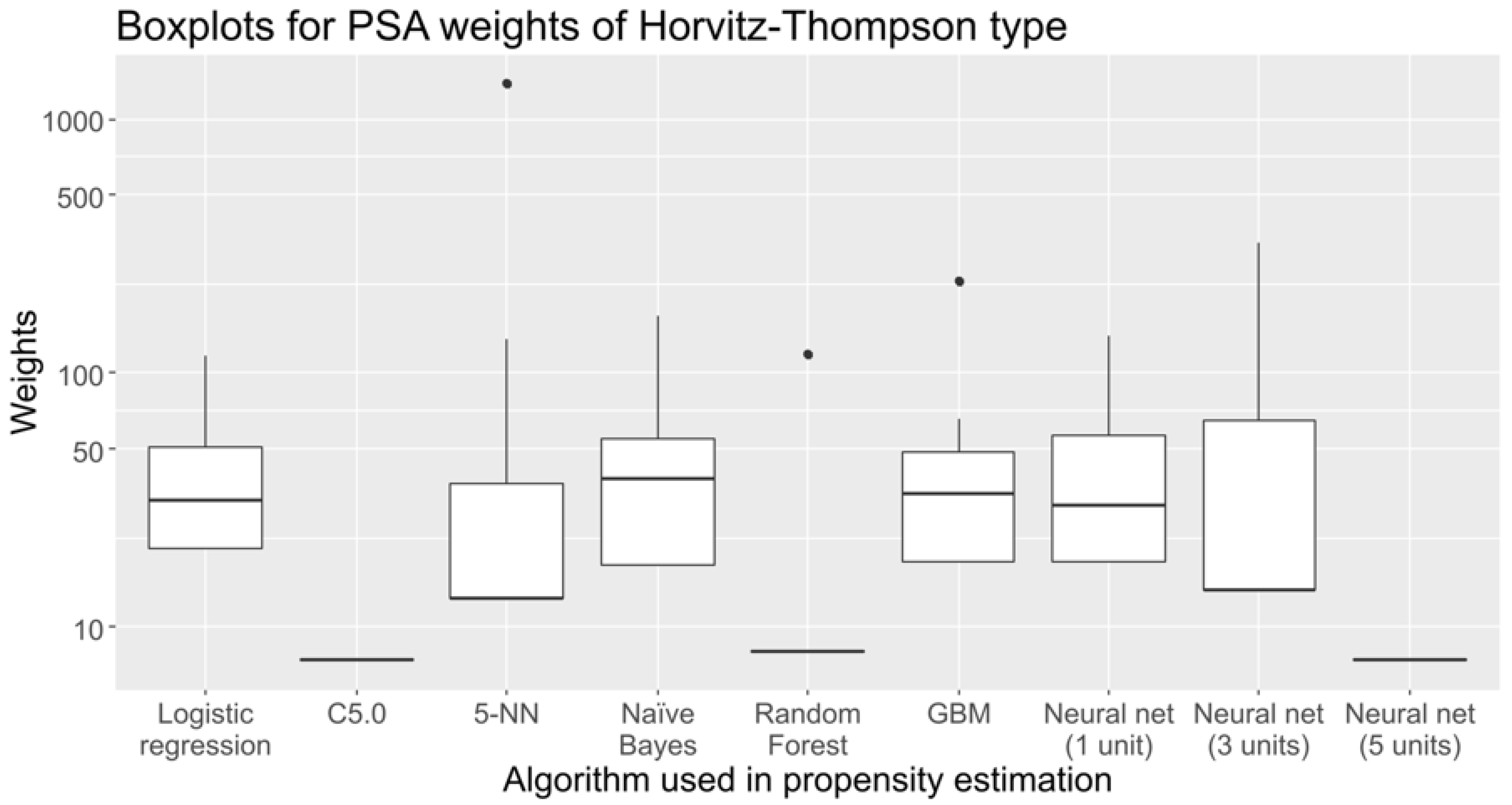
2.4. Sampling Weights
- Logistic regression
- Decision trees (C5.0 algorithm [28])
- The k-nearest neighbours algorithm, with k = 5 (5-NN)
- Naïve Bayes with no Laplace smoothing
- Random forest with 500 trees
- Gradient boosting machine (GBM) with 100 trees, interaction depth of 1 and learning rate of 0.1
- Feed-forward neural networks with one hidden layer, initialising weights to 0 and considering three cases with 1, 3 and 5 units in the hidden layer
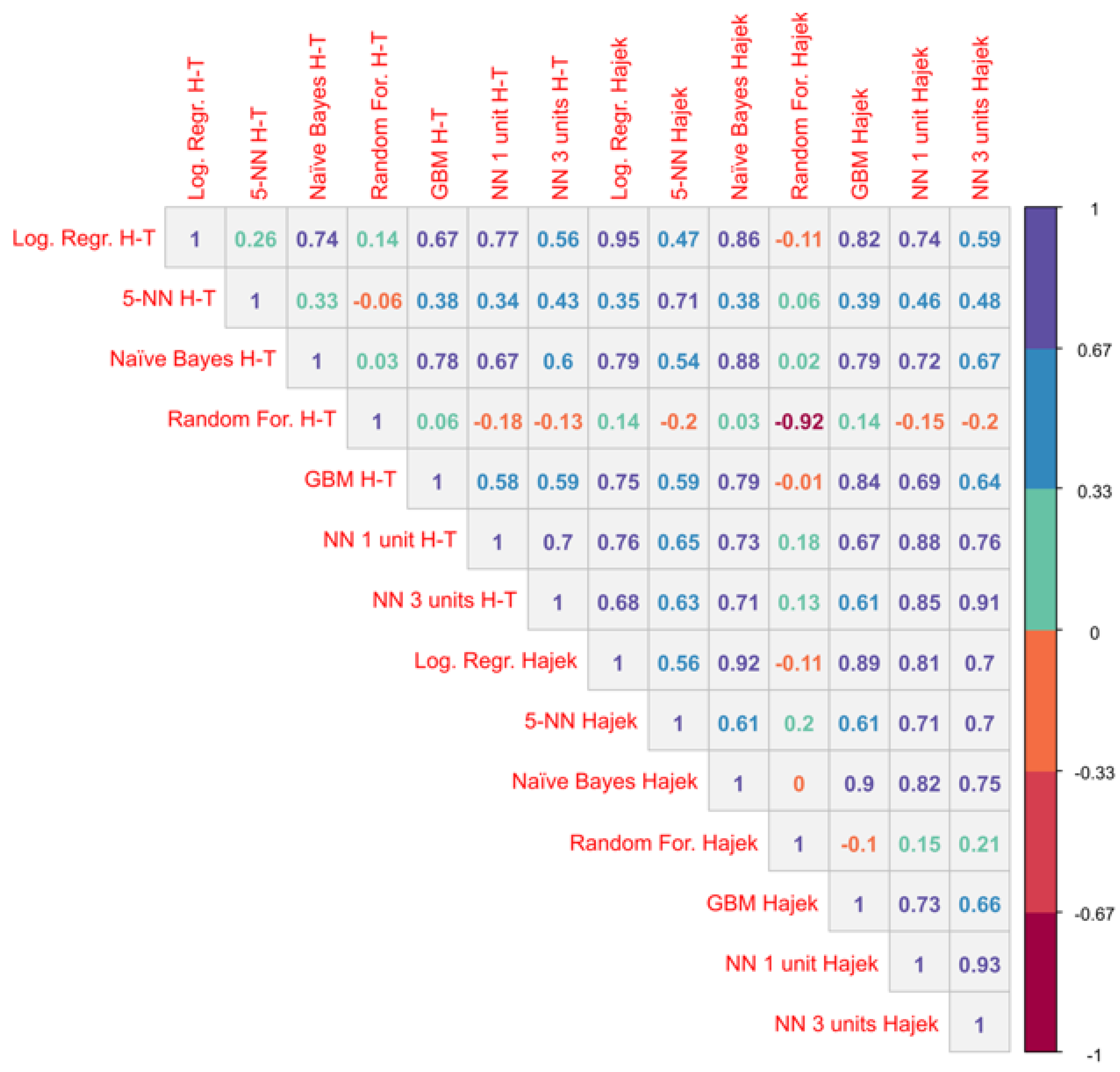
2.5. Statistical Analysis
- Health problems (none/one/two or more)
- Tobacco use (never/ex-smoker/occasional smoker/regular smoker)
- Hours of sleep per night (<7 h/≥7 h)
- Physical activity (none/occasional/regular/intensive)
- Body mass index (BMI), categorised as low or normal weight (<25 kg/m2), overweight (25–29 kg/m2) and obesity (≥30 kg/m2) [25]
- Level of healthcare (Primary/ Other)
- Age in years (numeric)
- Degree (Medicine/Nursing/Other)
3. Results
3.1. Prevalence Estimations
3.2. Regression Modelling
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Logistic Regression | C5.0 | 5-NN | Naïve Bayes | Random Forest | GBM | Neural Net (1 Unit) | Neural Net (3 Units) | Neural Net (5 Units) | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 40.67 | 7.38 | 40.67 | 40.88 | 15.67 | 40.88 | 40.67 | 40.67 | 7.38 |
| Std. Dev. | 26.22 | 0 | 109.39 | 33.7 | 28.07 | 40.65 | 33.44 | 52.35 | 0 |
| CV | 0.64 | 0 | 2.69 | 0.82 | 1.79 | 0.99 | 0.82 | 1.29 | 0 |
| Minimum | 20.19 | 7.38 | 13.02 | 17.52 | 7.96 | 17.93 | 17.87 | 14 | 7.38 |
| Q1 | 20.19 | 7.38 | 13.02 | 17.52 | 7.96 | 17.93 | 17.87 | 14 | 7.38 |
| Median | 31.62 | 7.38 | 13.02 | 38.39 | 7.96 | 33.24 | 30.24 | 14 | 7.38 |
| Q3 | 50.85 | 7.38 | 36.8 | 54.9 | 7.96 | 49 | 56.25 | 64.61 | 7.38 |
| Maximum | 115.89 | 7.38 | 1373.45 | 166.92 | 117.85 | 231.42 | 139.74 | 323.55 | 7.38 |
| MAD | 16.94 | 0 | 0 | 27.75 | 0 | 22.7 | 18.33 | 0 | 0 |
| IQR | 30.66 | 0 | 23.78 | 37.38 | 0 | 31.07 | 38.38 | 50.62 | 0 |
| Skewness | 1.63 | NaN | 11.1 | 2.58 | 3.36 | 3.67 | 1.75 | 4.12 | NaN |
| Kurtosis | 2.15 | NaN | 131.95 | 7.24 | 9.32 | 14.52 | 2.22 | 19.39 | NaN |

| Logistic Regression | C5.0 | 5-NN | Naïve Bayes | Random Forest | GBM | Neural Net (1 Unit) | Neural Net (3 Units) | Neural Net (5 Units) | |
|---|---|---|---|---|---|---|---|---|---|
| Mean | 0.00056 | 0.00056 | 0.00056 | 0.00056 | 0.00056 | 0.00056 | 0.00056 | 0.00056 | 0.00056 |
| Std. Dev. | 0.00030 | 0 | 0.00063 | 0.00040 | 0.00015 | 0.00031 | 0.00052 | 0.00063 | 0 |
| CV | 0.53 | 0 | 1.12 | 0.71 | 0.27 | 0.56 | 0.93 | 1.14 | 0 |
| Minimum | 0.00022 | 0.00056 | 0.00001 | 0.00019 | 0.0000002 | 0.00011 | 0.00025 | 0.0000067 | 0.00056 |
| Q1 | 0.00032 | 0.00056 | 0.00019 | 0.00027 | 0.0005985 | 0.00032 | 0.00027 | 0.000217 | 0.00056 |
| Median | 0.00049 | 0.00056 | 0.00033 | 0.00046 | 0.0005985 | 0.00050 | 0.00028 | 0.0003098 | 0.00056 |
| Q3 | 0.00071 | 0.00056 | 0.00071 | 0.00064 | 0.0005985 | 0.00068 | 0.00069 | 0.0008019 | 0.00056 |
| Maximum | 0.00202 | 0.00056 | 0.00710 | 0.00340 | 0.0005985 | 0.00365 | 0.00392 | 0.0048296 | 0.00056 |
| MAD | 0.00028 | 0 | 0.00027 | 0.00028 | 0 | 0.00027 | 0.00004 | 0.000314 | 0 |
| IQR | 0.00039 | 0 | 0.00052 | 0.00037 | 0 | 0.00036 | 0.00042 | 0.0005849 | 0 |
| Skewness | 1.42 | NaN | 3.28 | 2.28 | −3.26 | 2.57 | 3.51 | 4.28 | NaN |
| Kurtosis | 2.77 | NaN | 16.88 | 8.29 | 8.70 | 14.08 | 16.91 | 25.10 | NaN |
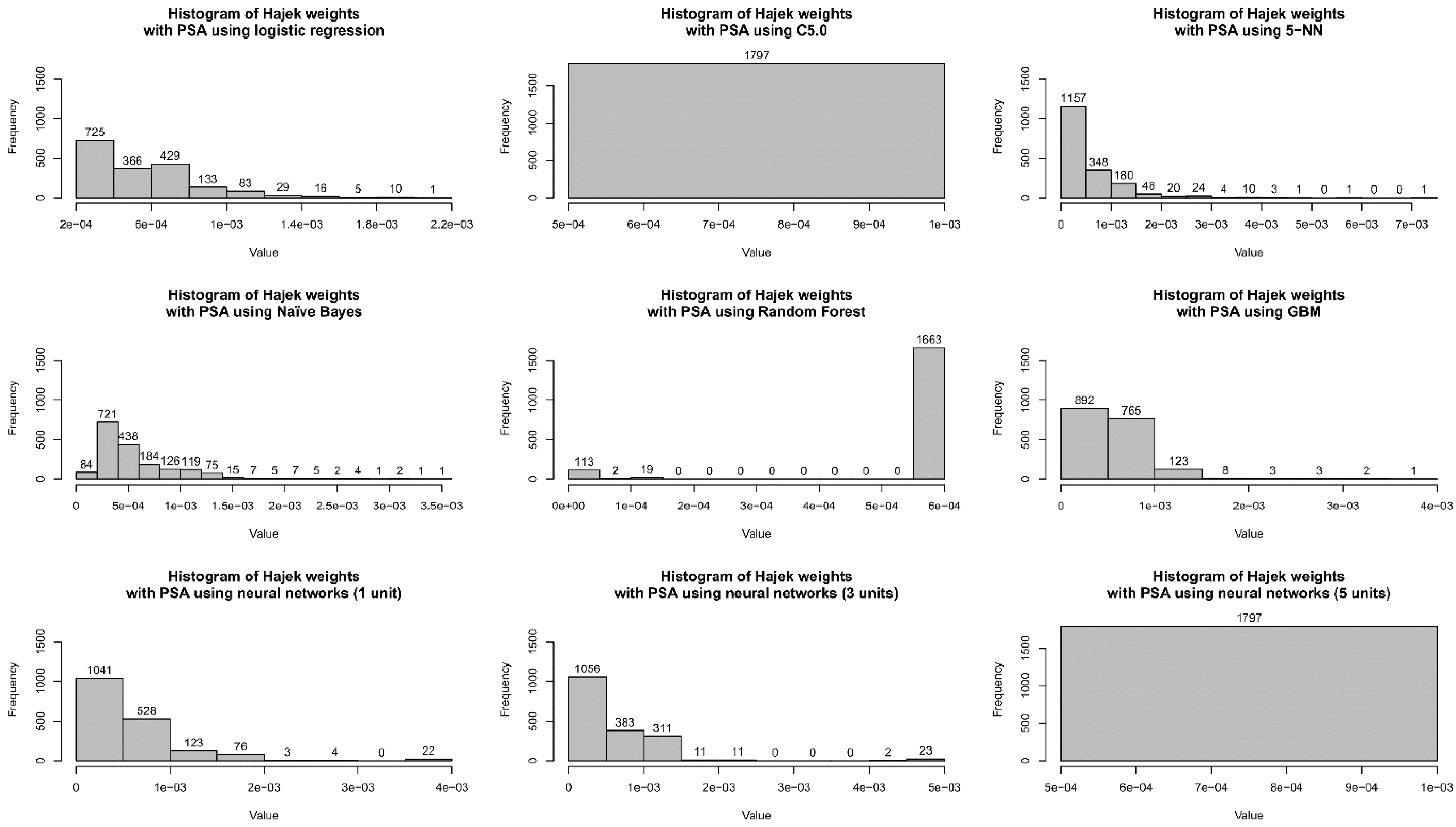

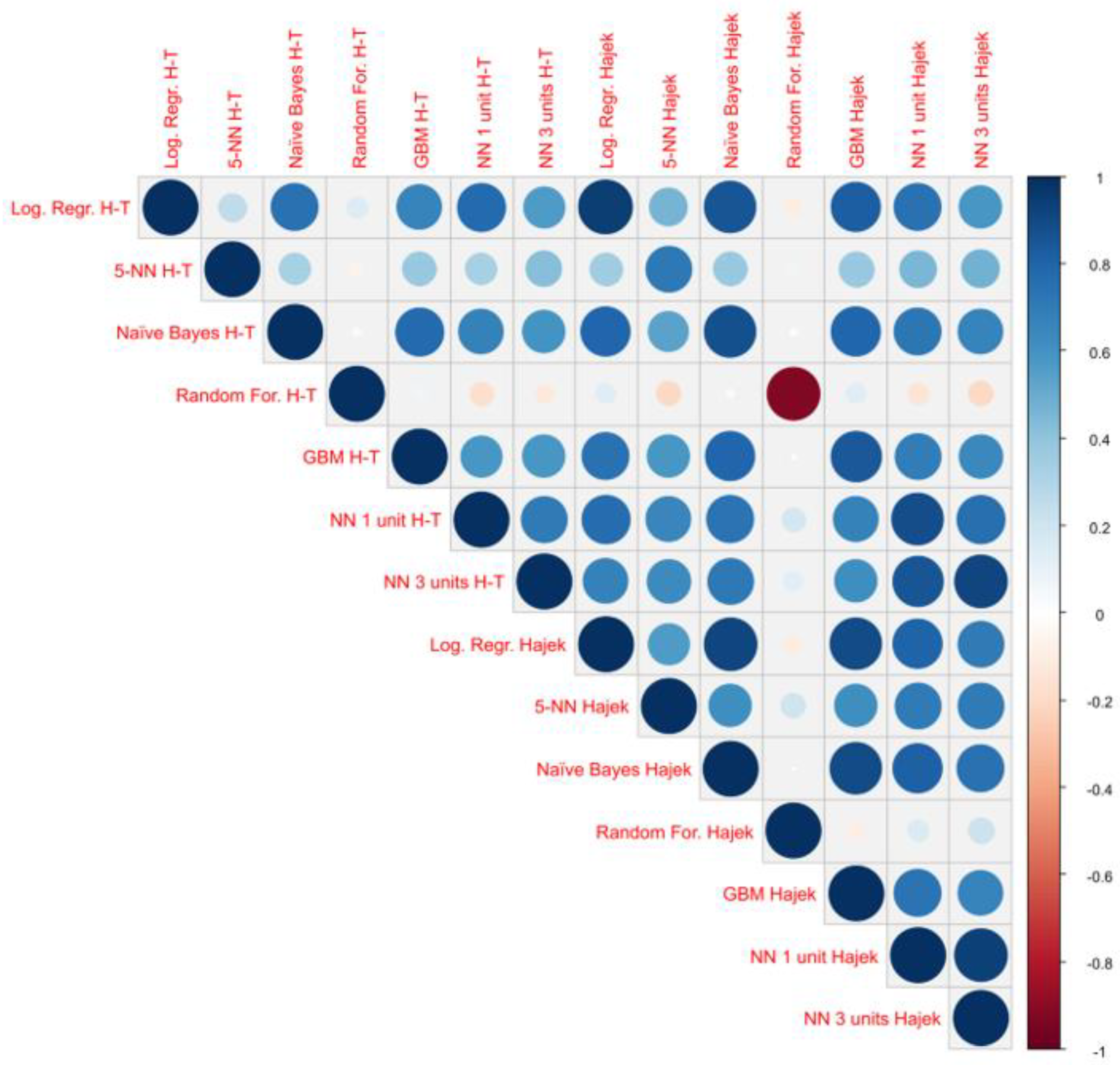
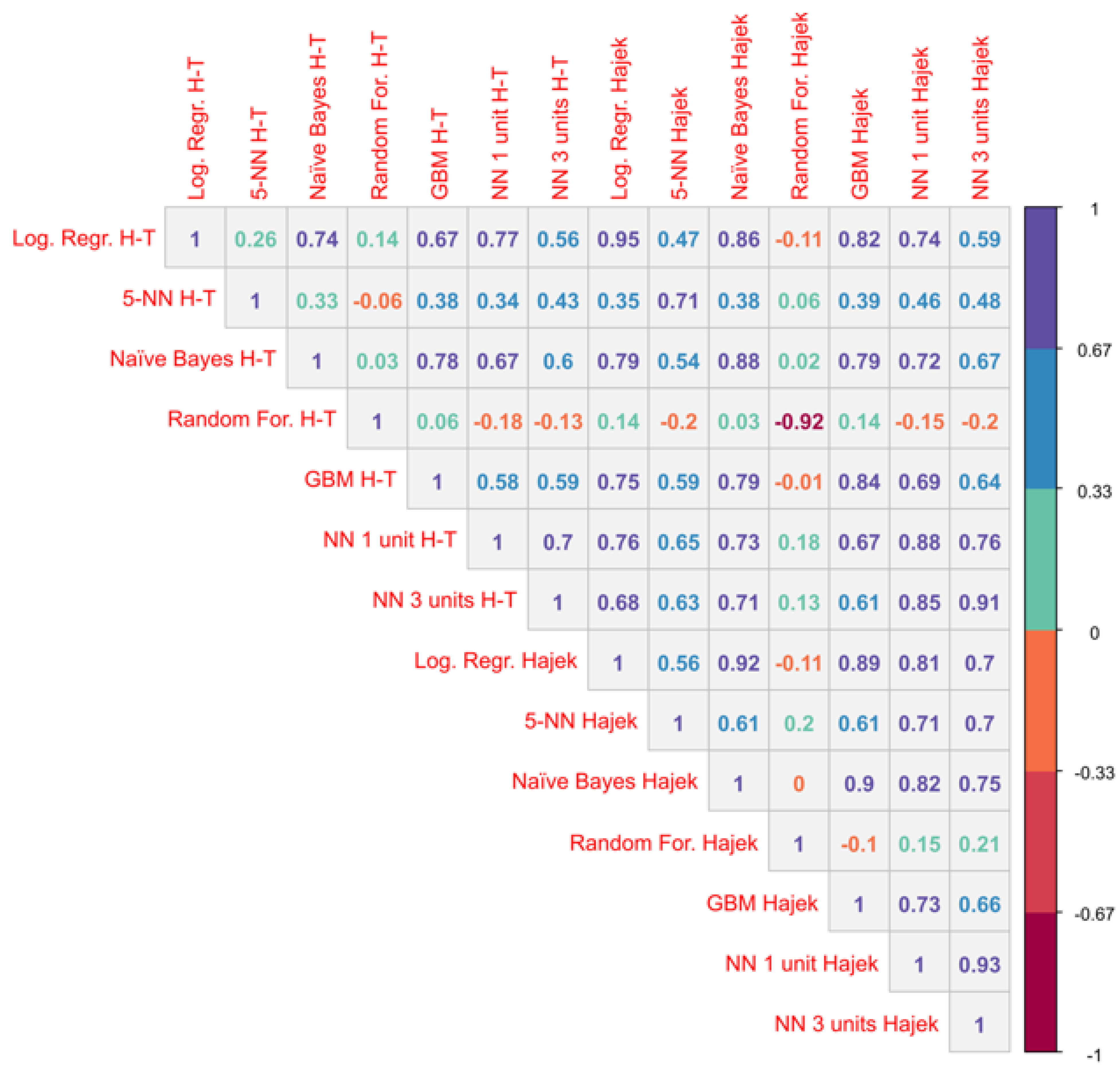

Appendix B
| Algorithm Used in PSA | Poor Self-Perceived Health | Dissatisfied with Life (Score of 6 or Less) | ||||||
|---|---|---|---|---|---|---|---|---|
| Estimate | Variance | Diff. From No Adj. (%) | Estimate | Variance | Diff. From No Adj. (%) | |||
| No adjustment | 0.088 | 0.00014 | Estimate | Variance | 0.1002 | 0.00016 | Estimate | Variance |
| Logistic regression | 0.084 | 0.00016 | −4.34% | 17% | 0.1031 | 0.00023 | 2.93% | 45% |
| 5-NN | 0.086 | 0.00029 | −2.29% | 103% | 0.1019 | 0.00041 | 1.68% | 159% |
| Naïve Bayes | 0.081 | 0.00017 | −8.24% | 21% | 0.1049 | 0.00031 | 4.67% | 98% |
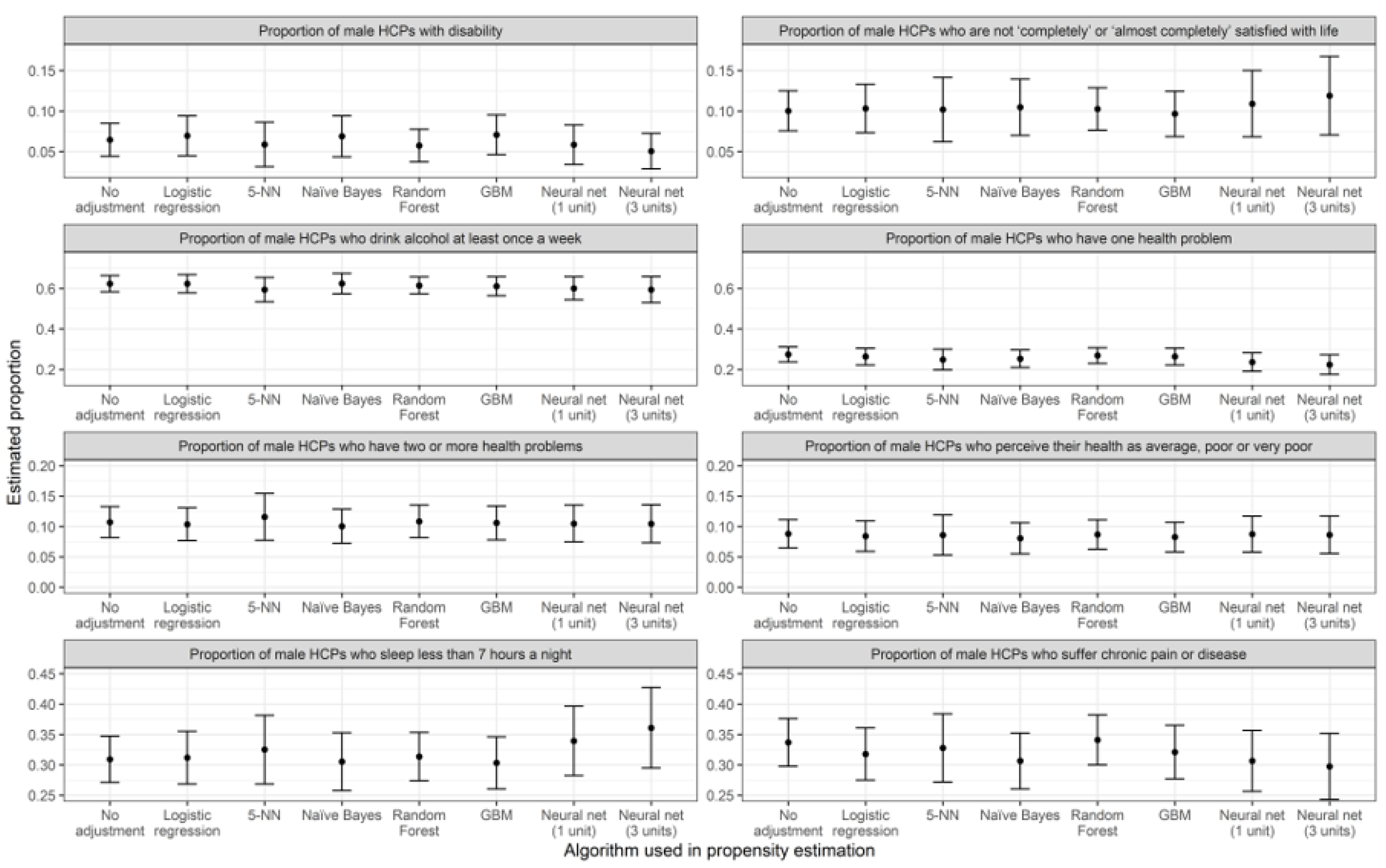
| Random Forest | 0.087 | 0.00015 | −1.12% | 8% | 0.1026 | 0.00018 | 2.38% | 11% |
| GBM | 0.082 | 0.00016 | −6.12% | 11% | 0.0965 | 0.00020 | −3.68% | 28% |
| Neural net (1 unit) | 0.087 | 0.00023 | −0.58% | 62% | 0.1090 | 0.00043 | 8.84% | 174% |
| Neural net (3 units) | 0.086 | 0.00025 | −1.77% | 76% | 0.1190 | 0.00061 | 18.75% | 285% |
| Algorithm used in PSA | Alcohol once a week | <7 h of sleep | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.6232 | 0.00041 | Estimate | Variance | 0.3093 | 0.00038 | Estimate | Variance |
| Logistic regression | 0.6234 | 0.00053 | 0.02% | 29% | 0.3118 | 0.00049 | 0.82% | 30% |
| 5-NN | 0.5940 | 0.00095 | −4.69% | 129% | 0.3252 | 0.00083 | 5.12% | 121% |
| Naïve Bayes | 0.6240 | 0.00066 | 0.12% | 59% | 0.3055 | 0.00059 | −1.25% | 56% |
| Random Forest | 0.6145 | 0.00046 | −1.40% | 10% | 0.3136 | 0.00041 | 1.40% | 10% |
| GBM | 0.6107 | 0.00058 | −2.02% | 40% | 0.3034 | 0.00048 | −1.91% | 27% |
| Neural net (1 unit) | 0.6004 | 0.00085 | −3.66% | 106% | 0.3395 | 0.00085 | 9.76% | 126% |
| Neural net (3 units) | 0.5942 | 0.00109 | −4.67% | 163% | 0.3609 | 0.00114 | 16.69% | 204% |
| Algorithm used in PSA | Disability (physical. mental or sensorial) | Chronic disease | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.0645 | 0.00011 | Estimate | Variance | 0.3369 | 0.00040 | Estimate | Variance |
| Logistic regression | 0.0695 | 0.00016 | 7.74% | 46% | 0.3179 | 0.00048 | −5.63% | 19% |
| 5-NN | 0.0587 | 0.00020 | −8.96% | 81% | 0.3280 | 0.00082 | −2.66% | 104% |
| Naïve Bayes | 0.0688 | 0.00017 | 6.64% | 54% | 0.3065 | 0.00055 | −9.03% | 37% |
| Random Forest | 0.0574 | 0.00011 | −10.98% | −3% | 0.3412 | 0.00044 | 1.27% | 10% |
| GBM | 0.0707 | 0.00016 | 9.51% | 45% | 0.3211 | 0.00050 | −4.70% | 26% |
| Neural net (1 unit) | 0.0584 | 0.00015 | −9.42% | 43% | 0.3065 | 0.00065 | −9.03% | 63% |
| Neural net (3 units) | 0.0506 | 0.00013 | −21.56% | 16% | 0.2974 | 0.00077 | −11.73% | 91% |
| Algorithm used in PSA | One health problem | Two or more health problems | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.2742 | 0.00036 | Estimate | Variance | 0.1072 | 0.00017 | Estimate | Variance |
| Logistic regression | 0.2630 | 0.00044 | −4.09% | 22% | 0.1037 | 0.00019 | −3.23% | 13% |
| 5-NN | 0.2487 | 0.00067 | −9.30% | 89% | 0.1158 | 0.00038 | 8.06% | 128% |
| Naïve Bayes | 0.2527 | 0.00048 | −7.83% | 35% | 0.1003 | 0.00020 | −6.43% | 21% |
| Random Forest | 0.2684 | 0.00038 | −2.12% | 8% | 0.1084 | 0.00019 | 1.12% | 10% |
| GBM | 0.2634 | 0.00045 | −3.95% | 26% | 0.1059 | 0.00020 | −1.23% | 20% |
| Neural net (1 unit) | 0.2361 | 0.00054 | −13.90% | 51% | 0.1048 | 0.00024 | −2.22% | 41% |
| Neural net (3 units) | 0.2235 | 0.00062 | −18.49% | 74% | 0.1044 | 0.00025 | −2.58% | 51% |
| Algorithm Used in PSA | Poor Self-Perceived Health | Dissatisfied with Life (Score of 6 or Less) | ||||||
|---|---|---|---|---|---|---|---|---|
| Estimate | Variance | Diff. from No Adj. (%) | Estimate | Variance | Diff. from No Adj. (%) | |||
| No adjustment | 0.0839 | 0.00006 | Estimate | Variance | 0.1205 | 0.00009 | Estimate | Variance |
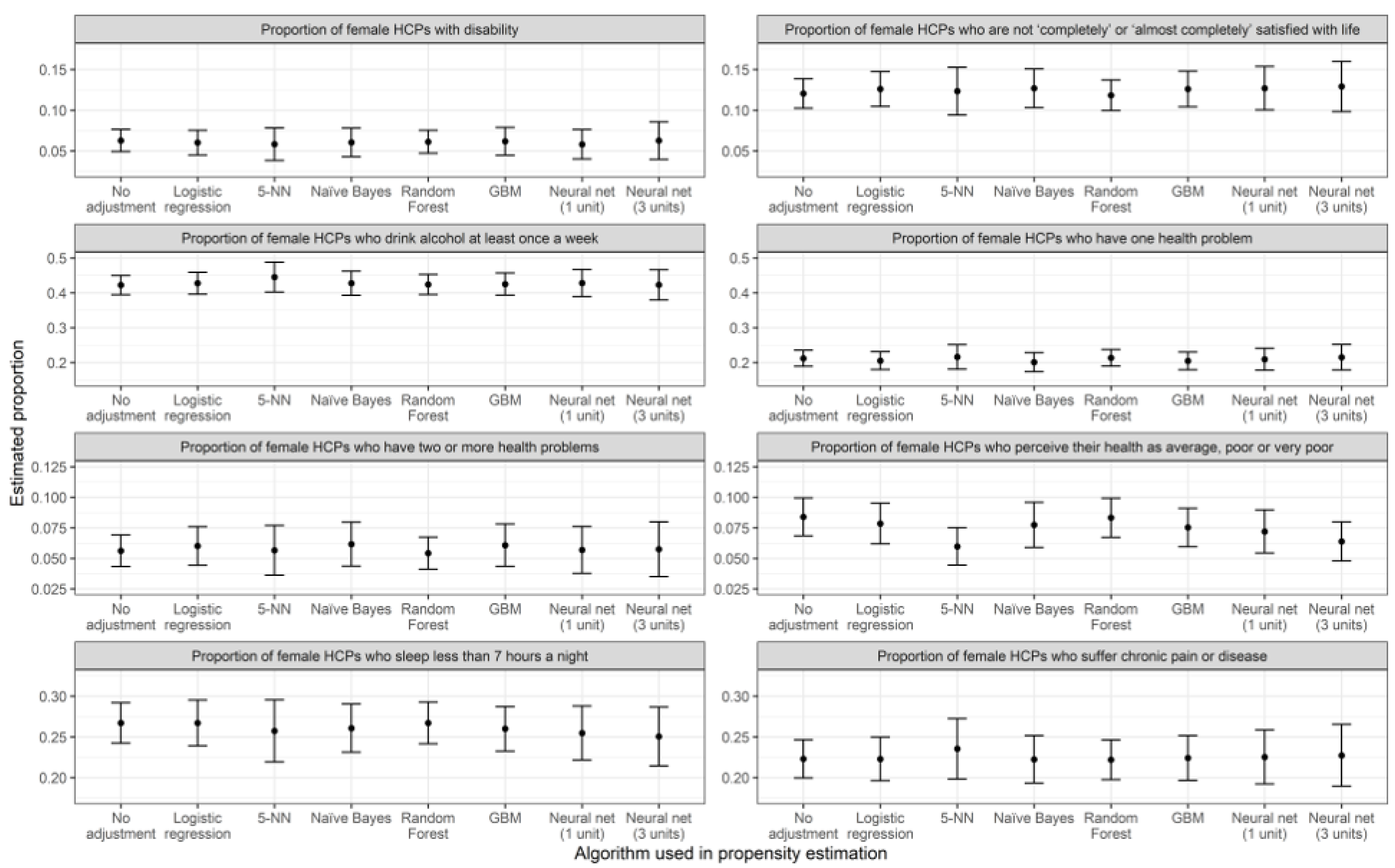
| Logistic regression | 0.0784 | 0.00007 | −6.49% | 15% | 0.1261 | 0.00012 | 4.61% | 39% |
| 5-NN | 0.0597 | 0.00006 | −28.78% | −3% | 0.1234 | 0.00022 | 2.41% | 158% |
| Naïve Bayes | 0.0774 | 0.00009 | −7.71% | 41% | 0.1270 | 0.00015 | 5.34% | 68% |
| Random Forest | 0.0833 | 0.00007 | −0.74% | 7% | 0.1183 | 0.00009 | −1.82% | 6% |
| GBM | 0.0753 | 0.00006 | −10.22% | 3% | 0.1261 | 0.00013 | 4.62% | 45% |
| Neural net (1 unit) | 0.0720 | 0.00008 | −14.21% | 29% | 0.1270 | 0.00019 | 5.36% | 114% |
| Neural net (3 units) | 0.0638 | 0.00007 | −23.90% | 6% | 0.1292 | 0.00025 | 7.16% | 187% |
| Algorithm used in PSA | Alcohol once a week | <7 h of sleep | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.4223 | 0.00020 | Estimate | Variance | 0.2671 | 0.00016 | Estimate | Variance |
| Logistic regression | 0.4275 | 0.00026 | 1.23% | 30% | 0.2670 | 0.00021 | −0.03% | 29% |
| 5-NN | 0.4451 | 0.00048 | 5.42% | 139% | 0.2574 | 0.00038 | −3.65% | 138% |
| Naïve Bayes | 0.4277 | 0.00031 | 1.28% | 56% | 0.2607 | 0.00023 | −2.40% | 43% |
| Random Forest | 0.4239 | 0.00021 | 0.38% | 8% | 0.2671 | 0.00017 | 0.02% | 8% |
| GBM | 0.4251 | 0.00026 | 0.67% | 33% | 0.2599 | 0.00020 | −2.70% | 23% |
| Neural net (1 unit) | 0.4281 | 0.00039 | 1.39% | 95% | 0.2547 | 0.00028 | −4.64% | 79% |
| Neural net (3 units) | 0.4227 | 0.00049 | 0.12% | 144% | 0.2503 | 0.00034 | −6.27% | 113% |
| Algorithm used in PSA | Disability (physical. mental or sensorial) | Chronic disease | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.0628 | 0.00005 | Estimate | Variance | 0.2230 | 0.00014 | Estimate | Variance |
| Logistic regression | 0.0602 | 0.00006 | −4.14% | 23% | 0.2228 | 0.00019 | −0.05% | 29% |
| 5-NN | 0.0583 | 0.00010 | −7.10% | 114% | 0.2353 | 0.00036 | 5.55% | 151% |
| Naïve Bayes | 0.0605 | 0.00008 | −3.67% | 64% | 0.2224 | 0.00022 | −0.27% | 54% |
| Random Forest | 0.0612 | 0.00005 | −2.44% | 5% | 0.2219 | 0.00015 | −0.48% | 7% |
| GBM | 0.0618 | 0.00008 | −1.51% | 56% | 0.2241 | 0.00020 | 0.52% | 37% |
| Neural net (1 unit) | 0.0581 | 0.00008 | −7.46% | 74% | 0.2253 | 0.00029 | 1.05% | 99% |
| Neural net (3 units) | 0.0627 | 0.00014 | −0.06% | 183% | 0.2273 | 0.00038 | 1.94% | 162% |
| Algorithm used in PSA | One health problem | Two or more health problems | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.2122 | 0.00014 | Estimate | Variance | 0.0562 | 0.00004 | Estimate | Variance |
| Logistic regression | 0.2056 | 0.00017 | −3.13% | 22% | 0.0601 | 0.00006 | 6.95% | 50% |
| 5-NN | 0.2164 | 0.00032 | 1.95% | 133% | 0.0566 | 0.00011 | 0.65% | 150% |
| Naïve Bayes | 0.2013 | 0.00019 | −5.16% | 39% | 0.0616 | 0.00008 | 9.63% | 96% |
| Random Forest | 0.2136 | 0.00015 | 0.66% | 8% | 0.0542 | 0.00004 | −3.58% | 3% |
| GBM | 0.2047 | 0.00017 | −3.56% | 21% | 0.0607 | 0.00008 | 8.08% | 81% |
| Neural net (1 unit) | 0.2095 | 0.00025 | −1.26% | 83% | 0.0568 | 0.00010 | 1.17% | 123% |
| Neural net (3 units) | 0.2152 | 0.00034 | 1.41% | 150% | 0.0575 | 0.00013 | 2.26% | 205% |
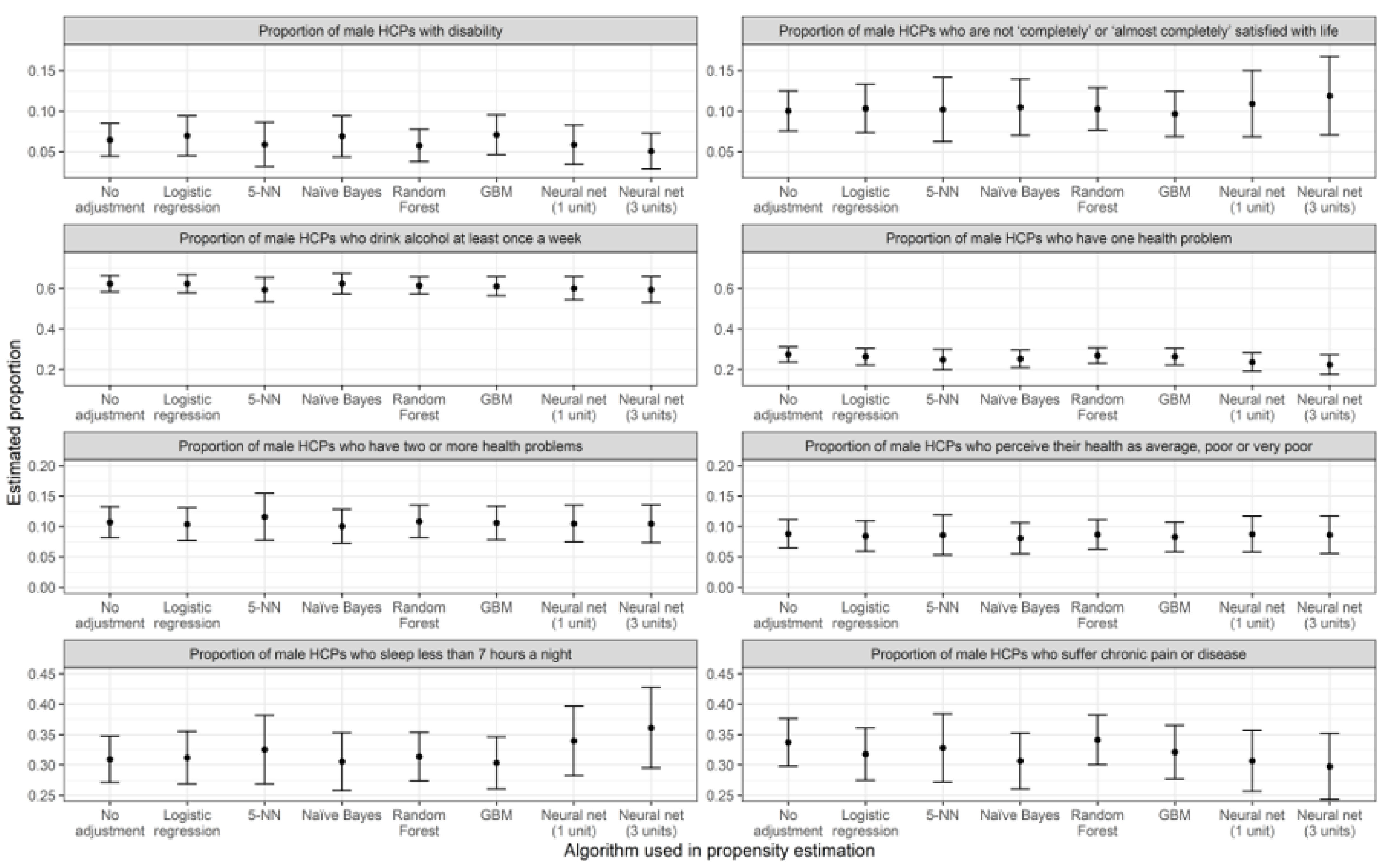
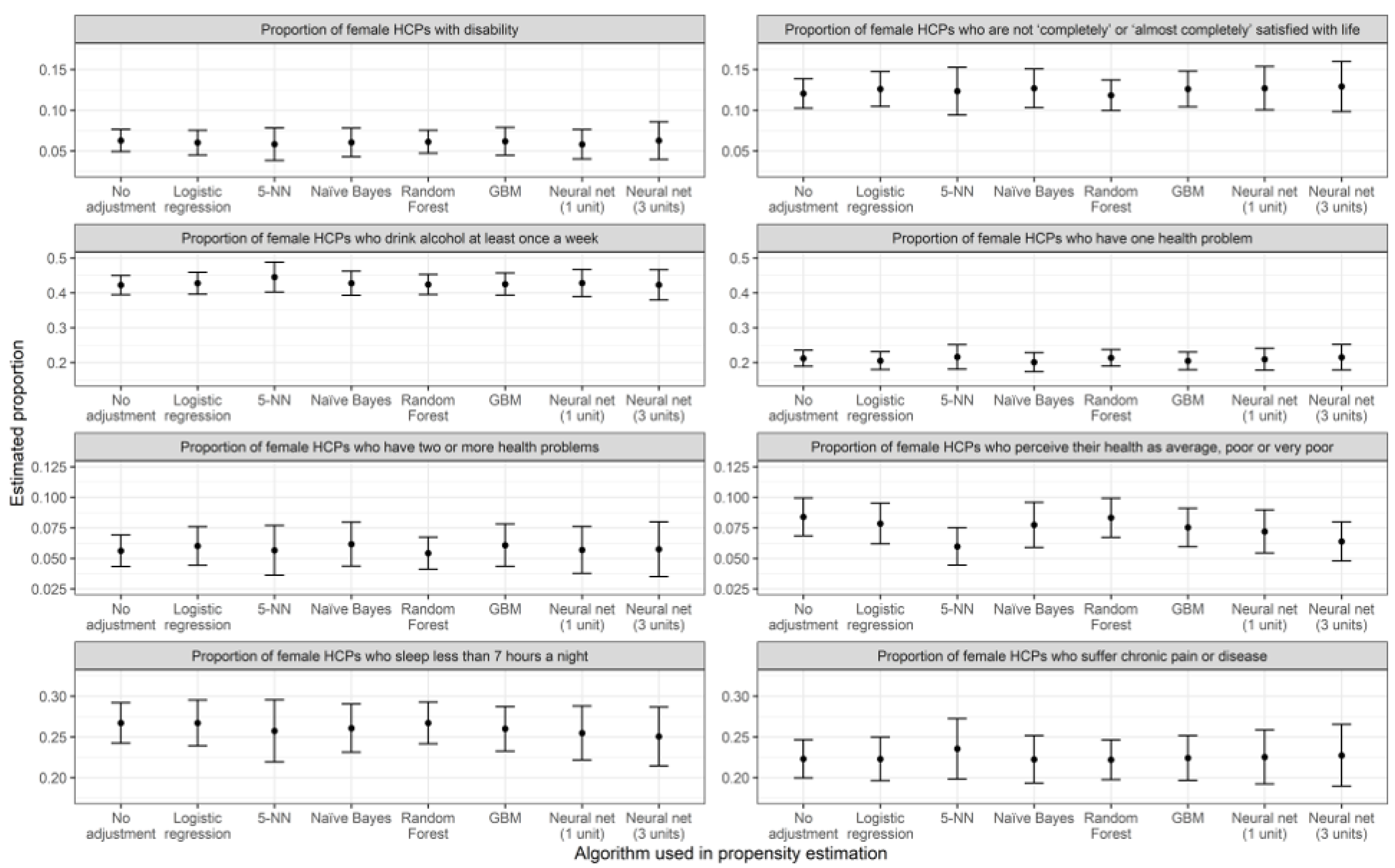
References
- Parsa-Parsi, R.W. The revised Declaration of Geneva: A modern day physician’s pledge. J. Am. Med. Assoc. 2017, 318, 1971–1972. [Google Scholar] [CrossRef] [PubMed]
- Hall, L.H.; Johnson, J.; Watt, I.; Tsipa, A.; O’Connor, D.B. Healthcare staff wellbeing, burnout, and patient safety: A systematic review. PLoS ONE 2016, 11, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Jadad, A.R.; Jadad Garcia, T.M. From a digital bottle: A message to ourselves in 2039 2. J. Med. Internet Res. 2019, 21, e16274. [Google Scholar] [CrossRef]
- Albuquerque, J.; Tulk, S. Physician suicide. Can. Med. Assoc. J. 2019, 191, E505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mumba, M.; Kraemer, K. Substance use disorders among nurses in medical-surgical, long-term care, and outpatient services. Medsurg. Nurs. 2019, 28, 118. [Google Scholar]
- Angie, C.C.; Leung, T. Substance use disorders. In The Art and Science of Physician Wellbeing: A Handbook for Physicians and Trainees; Weiss Roberts, L., Trockel, M., Eds.; Springer International Publishing: Berlin, Germany, 2019. [Google Scholar]
- World Medical Association. WMA Statement on Physicians Well-Being. Adopted by the 66th WMA General Assembly, Moscow, 2015. Available online: https://www.wma.net/policies-post/wma-statement-on-physicians-well-being/ (accessed on 27 November 2019).
- Howell, R.T.; Rodzon, K.S.; Kurai, M.; Sánchez, A.M. A validation of well-being and happiness surveys for administration via the Internet. Behav. Res. Methods 2010, 42, 775. [Google Scholar] [CrossRef] [PubMed]
- Ekman, A.; Klint, A.; Dickman, P.W.; Adami, H.; Litton, J. Optimizing the design of web-based questionnaires—Experience from a population-based study among 50,000 women. Eur. J. Epidemiol. 2007, 22, 293. [Google Scholar] [CrossRef] [PubMed]
- Beaumont, J.F.; Rao, J.N.K. Pitfalls of making inferences from non-probability samples: Can data integration through probability samples provide remedies? Surv. Stat. 2021, 83, 11–22. [Google Scholar]
- Castro-Martín, L.; Rueda, M.; Ferri-García, R. Combining Statistical Matching and Propensity Score Adjustment for inference from non-probability surveys. J. Comput. Appl. Math. 2021, 113414. [Google Scholar] [CrossRef]
- Erens, B.; Burkill, S.; Couper, M.P.; Conrad, F.; Clifton, S.; Tanton, C.; Phelps, A.; Datta, J.; Mercer, C.H.; Sonnenberg, P.; et al. Nonprobability Web surveys to measure sexual behaviors and attitudes in the general population: A comparison with a probability sample interview survey. J. Med. Internet Res. 2014, 16, e276, PMCID:PMC4275497. [Google Scholar] [CrossRef] [PubMed]
- Rosenbaum, P.R.; Rubin, D.B. The central role of the propensity score in observational studies for causal effects. Biometrika 1983, 70, 41–55. [Google Scholar] [CrossRef]
- Lee, S. Propensity score adjustment as a weighting scheme for volunteer panel web surveys. J. Off. Stat. 2006, 22, 329–349. [Google Scholar]
- Lee, S.; Valliant, R. Estimation for volunteer panel web surveys using propensity score adjustment and calibration adjustment. Sociol. Method Res. 2009, 37, 319–343. [Google Scholar] [CrossRef]
- Copas, A.; Burkill, S.; Conrad, F.; Couper, M.P.; Erens, B. An evaluation of whether propensity score adjustment can remove the self-selection bias inherent to web panel surveys addressing sensitive health behaviours. BMC Med. Res. Methodol. 2020, 20, 1–10. [Google Scholar] [CrossRef] [PubMed]
- Flouris, A.D.; Duffy, J. Applications of artificial intelligence systems in the analysis of epidemiological data. Eur. J. Epidemiol. 2006, 21, 167–170. [Google Scholar] [CrossRef] [PubMed]
- Keil, A.P.; Edwards, J.K. You are smarter than you think: (super) machine learning in context. Eur. J. Epidemiol. 2018, 33, 437–440. [Google Scholar] [CrossRef] [PubMed]
- Naimi, A.I.; Balzer, L.B. Stacked generalization: An introduction to super learning. Eur. J. Epidemiol. 2018, 33, 459–464. [Google Scholar] [CrossRef] [PubMed]
- Bentley, R.; Baker, E.; Simons, K.; Simpson, J.A.; Blakely, T. The impact of social housing on mental health: Longitudinal analyses using marginal structural models and machine learning-generated weights. Int. J. Epidemiol. 2018, 1414–1422. [Google Scholar] [CrossRef]
- Mayr, A.; Weinhold, L.; Hofner, B.; Titze, S.; Gefeller, O.; Schmid, M. The betaboost package—A software tool for modelling bounded outcome variables in potentially high-dimensional epidemiological data. Int. J. Epidemiol. 2018, 1383–1388. [Google Scholar] [CrossRef] [Green Version]
- Torres, J.M.; Rudolph, K.E.; Sofrygin, O.; Glymour, M.M.; Wong, R. Longitudinal associations between having an adult child migrant and depressive symptoms among older adults in the Mexican Health and Aging Study. Int. J. Epidemiol. 2018, 1432–1442. [Google Scholar] [CrossRef] [PubMed]
- Ferri-García, R.; Rueda, M.D.M. Propensity score adjustment using machine learning classification algorithms to control selection bias in online surveys. PLoS ONE 2020, 15, e0231500. [Google Scholar] [CrossRef] [PubMed]
- Castro-Martín, L.; Rueda, M.D.M.; Ferri-García, R. Inference from non-probability surveys with statistical matching and propensity score adjustment using modern prediction techniques. Mathematics 2020, 8, 879. [Google Scholar] [CrossRef]
- WHO. Body Mass Classification; World Health Organization: Geneva, Switzerland, 2015; Available online: https://www.who.int/news-room/fact-sheets/detail/obesity-and-overweight (accessed on 1 April 2021).
- Cabrera-León, A.; Cantero-Braojos, M.; Garcia-Fernandez, L.; de Hoyos Guerra, J.A. Living with disabling chronic pain: Results from a face-to-face cross-sectional population-based study. BMJ Open 2018, 8, e020913. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Schonlau, M.; Couper, M. Options for conducting web surveys. Stat. Sci. 2017, 32, 279–292. [Google Scholar] [CrossRef]
- Quinlan, R. C4.5: Programs for Machine Learning; Morgan Kaufmann: San Francisco, CA, USA, 1993. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 1 April 2021).
- Tillé, Y.; Matei, A. Sampling: Survey Sampling; R Package Version 2.7; R Foundation for Statistical Computing: Vienna, Austria, 2015; Available online: http://CRAN.R-project.org/package=sampling (accessed on 1 April 2021).
- Lumley, T. Survey: Analysis of Complex Survey Samples, R package version 3.30; R Foundation for Statistical Computing: Vienna, Austria, 2014. [Google Scholar]
- Kuhn, M.; Quinlan, R. C50: C5.0 Decision Trees and Rule-Based Models. R Foundation for Statistical Computing: Vienna, Austria, 2018. Available online: https://CRAN.R-project.org/package=C50 (accessed on 1 April 2021).
- Liaw, A.; Wiener, M. Classification and regression by random forest. R News 2002, 2, 18–22. [Google Scholar]
- Greenwell, B.; Boehmke, B.; Cunningham, J.; Developers, G. Package ‘gbm’. R Foundation for Statistical Computing: Vienna, Austria, 2018. Available online: https://cran.r-project.org/web/packages/gbm/gbm.pdf (accessed on 1 April 2021).
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F. e1071: Misc Functions of the Department of Statistics (e1071); R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://cran.rproject.org/web/packages/e1071 (accessed on 1 April 2021).
- Kuhn, M. Caret: Classification and Regression Training. Available online: https://cran.rproject.org/web/packages/caret/index.html (accessed on 1 April 2021).
- Venables, W.N.; Ripley, B.D. Modern Applied Statistics with S, 4th ed.; Springer: New York, NY, USA, 2002; ISBN 0-387-95457-0. [Google Scholar]
- Quenouille, M.H. Notes on bias in estimation. Biometrika 1956, 43, 353–360. [Google Scholar] [CrossRef]
- Tibshirani, R.; Leisch, F. Bootstrap: Functions for the Book “An Introduction to the Bootstrap”. 2017. Available online: https://cran.r-project.org/web/packages/bootstrap/index.html (accessed on 1 April 2021).
- Stine, R.A. Graphical interpretation of variance inflation factors. Am. Stat. 1995, 49, 53–56. [Google Scholar]
- Hair, J.F.; Black, W.C.; Babin, B.; Anderson, R.E. Multivariate Data Analysis, 7th ed.; Prentice Hall: Hoboken, NJ, USA, 2010. [Google Scholar]
- Edwards, B.; Pollock, P. Poliscidata: Datasets and Functions Featured in Pollock and Edwards, An R Companion to Essentials of Political Analysis. 2018. Available online: https://CRAN.R-project.org/package=poliscidata (accessed on 1 April 2021).
- Wickham, H. ggplot2—Elegant Graphics for Data Analysis, 2nd ed.; Springer: Berlin/Heidelberg, Germany, 2016; Available online: https://github.com/hadley/ggplot2-book (accessed on 1 April 2021).
- Lim, R.; Aarsen, K.; Van Aarsen, K.; Gray, S.; Rang, L.; Fitzpatrick, J.; Fischer, L. Emergency medicine physician burnout and wellness in Canada before COVID19: A national survey. Can. J. Emerg. Med. 2020, 22, 603–607. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Vinson, A.E. Physician well-being in practice. Anesth. Analg. 2020, 131, 1359–1369. [Google Scholar] [CrossRef] [PubMed]
- López-Cabarcos, M.Á.; López-Carballeira, A.; Ferro-Soto, C. New ways of working and public healthcare professionals’ well-being: The response to face the covid-19 pandemic. Sustainability 2020, 12, 8087. [Google Scholar] [CrossRef]
- Valliant, R.; Dever, J.A. Estimating propensity adjustments for volunteer web surveys. Sociol. Method Res. 2011, 40, 105–137. [Google Scholar] [CrossRef]
- Ferri-García, R.; Rueda, M. Efficiency of propensity score adjustment and calibration on the estimation from non-probabilistic online surveys. SORT Stat. Oper. Res.Trans. 2018, 42, 159–182. [Google Scholar]
- Chen, Y.; Li, P.; Wu, C. Doubly robust inference with nonprobability survey samples. J. Am. Stat. Assoc. 2020, 115, 2011–2021. [Google Scholar] [CrossRef] [Green Version]
- Weber, A.; Jaekel-Reinhard, A. Burnout syndrome: A disease of modern societies? Occup. Med. 2000, 50, 512–517. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Campbell, S.; Delva, D. Physician do not heal thyself. Survey of personal health practices among medical residents. Can. Fam. Phys. 2003, 49, 1121–1127. [Google Scholar]
- Robert Koch-Institut. Gesundheitstrends Bei Erwachseneninin Deutschland Zwischen 2003 und 2012. In DatenundFakten: Ergebnisse der Studie ‘Gesundheit in Deutschland Aktuell 2012’; Beiträge zur Gesundheitsberichterstattung des Bundes; Robert Koch-Institut, Ed.; RKI: Berlin, Germany, 2014; pp. 13–33. [Google Scholar]
- Domagała, A.; Bała, M.M.; Storman, D.; Peña-Sánchez, J.N.; Świerz, M.J.; Kaczmarczyk, M.; Storman, M. Factors associated with satisfaction of hospital physicians: A systematic review on european data. Int. J. Environ. Res. Public Health 2018, 15, 2546. [Google Scholar] [CrossRef] [PubMed] [Green Version]

| Variable | Web Survey (%) | Census (%) |
|---|---|---|
| Sex | ||
| Male | 31.66 | 33.12 |
| Female | 68.34 | 66.88 |
| Age1 | ||
| ≤25 | 1.11 | 2.16 |
| 26–35 | 21.09 | 26.96 |
| 36–45 | 34.78 | 25.74 |
| 46–55 | 32.78 | 24.50 |
| >55 | 10.24 | 20.65 |
| Healthcare area | ||
| Specialised | 50.97 | 66.74 |
| Primary | 49.03 | 33.26 |
| Degree subject area | ||
| Medicine | 43.80 | 40.44 |
| Nursing | 44.46 | 52.86 |
| Other | 11.74 | 6.69 |
| Valid sample | n = 1797 | n = 73,465 |
| Algorithm Used in PSA | Poor Self-Perceived Health | Dissatisfied with Life (Score of 6 or Less) | ||||||
|---|---|---|---|---|---|---|---|---|
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.088 | 0.00014 | Estimate | Variance | 0.1002 | 0.00016 | Estimate | Variance |
| Logistic regression | 0.084 | 0.00016 | −4.34% | 17% | 0.1031 | 0.00023 | 2.93% | 45% |
| Neural net (1 unit) | 0.087 | 0.00023 | −0.58% | 62% | 0.1090 | 0.00043 | 8.84% | 174% |
| Algorithm used in PSA | Alcohol once a week | <7 h of sleep | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.6232 | 0.00041 | Estimate | Variance | 0.3093 | 0.00038 | Estimate | Variance |
| Logistic regression | 0.6234 | 0.00053 | 0.02% | 29% | 0.3118 | 0.00049 | 0.82% | 30% |
| Neural net (1 unit) | 0.6004 | 0.00085 | −3.66% | 106% | 0.3395 | 0.00085 | 9.76% | 126% |
| Algorithm used in PSA | Disability (physical. mental or sensorial) | Chronic disease | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.0645 | 0.00011 | Estimate | Variance | 0.3369 | 0.00040 | Estimate | Variance |
| Logistic regression | 0.0695 | 0.00016 | 7.74% | 46% | 0.3179 | 0.00048 | −5.63% | 19% |
| Neural net (1 unit) | 0.0584 | 0.00015 | −9.42% | 43% | 0.3065 | 0.00065 | −9.03% | 63% |
| Algorithm used in PSA | One health problem | Two or more health problems | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.2742 | 0.00036 | Estimate | Variance | 0.1072 | 0.00017 | Estimate | Variance |
| Logistic regression | 0.2630 | 0.00044 | −4.09% | 22% | 0.1037 | 0.00019 | −3.23% | 13% |
| Neural net (1 unit) | 0.2361 | 0.00054 | −13.90% | 51% | 0.1048 | 0.00024 | −2.22% | 41% |
| Algorithm Used in PSA | Poor Self-Perceived Health | Dissatisfied with Life (Score of 6 or Less) | ||||||
|---|---|---|---|---|---|---|---|---|
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.0839 | 0.00006 | Estimate | Variance | 0.1205 | 0.00009 | Estimate | Variance |
| Logistic regression | 0.0784 | 0.00007 | −6.49% | 15% | 0.1261 | 0.00012 | 4.61% | 39% |
| Neural net (1 unit) | 0.0720 | 0.00008 | −14.21% | 29% | 0.1270 | 0.00019 | 5.36% | 114% |
| Algorithm used in PSA | Alcohol once a week | <7 h of sleep | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.4223 | 0.00020 | Estimate | Variance | 0.2671 | 0.00016 | Estimate | Variance |
| Logistic regression | 0.4275 | 0.00026 | 1.23% | 30% | 0.2670 | 0.00021 | −0.03% | 29% |
| Neural net (1 unit) | 0.4281 | 0.00039 | 1.39% | 95% | 0.2547 | 0.00028 | −4.64% | 79% |
| Algorithm used in PSA | Disability (physical. mental or sensorial) | Chronic disease | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.0628 | 0.00005 | Estimate | Variance | 0.2230 | 0.00014 | Estimate | Variance |
| Logistic regression | 0.0602 | 0.00006 | −4.14% | 23% | 0.2228 | 0.00019 | −0.05% | 29% |
| Neural net (1 unit) | 0.0581 | 0.00008 | −7.46% | 74% | 0.2253 | 0.00029 | 1.05% | 99% |
| Algorithm used in PSA | One health problem | Two or more health problems | ||||||
| Estimate | Variance | Diff. from no adj. (%) | Estimate | Variance | Diff. from no adj. (%) | |||
| No adjustment | 0.2122 | 0.00014 | Estimate | Variance | 0.0562 | 0.00004 | Estimate | Variance |
| Logistic regression | 0.2056 | 0.00017 | −3.13% | 22% | 0.0601 | 0.00006 | 6.95% | 50% |
| Neural net (1 unit) | 0.2095 | 0.00025 | −1.26% | 83% | 0.0568 | 0.00010 | 1.17% | 123% |
| Study Variables | General Population | Healthcare Professionals (Weighted with Propensity Score Adjustment Using Logistic Regression) | |||
|---|---|---|---|---|---|
| % | 95% CI | % | 95% CI | ||
| Poor self-perceived health (fair/bad/very bad) in the last 12 months | Total | 14.8 | (13.5; 16) | 8.1 | (6.7; 9.5) |
| Men | 12.1 | (10.6; 14) | 8.4 | (5.9; 1.,9) | |
| Women | 17.5 | (15.6; 19) | 7.8 | (6.2; 9.5) | |
| Dissatisfied with life (6 or less on a scale from 1 to 10) | Total | 17.8 | (16.2; 20) | 10.7 | (9.2; 12.3) |
| Men | 16.3 | (14.6; 18) | 10.3 | (7.3; 13.3) | |
| Women | 19.2 | (17.1; 21) | 12.6 | (10.5; 14.8) | |
| Alcohol consumption (at least once in a month) | Total | 49.5 | (47; 52) | 66.4 | (63.9; 68.8) |
| Men | 62.5 | (59.9; 65) | 79.8 | (76.1; 83.5) | |
| Women | 37.1 | (33.7; 41) | 60.0 | (56.9; 63.1) | |
| Less than 7 h of sleep | Total | 20 | (17.8; 22) | 27.9 | (25.6; 30.3) |
| Men | 17.7 | (15.3; 20) | 31.2 | (26.8; 35.5) | |
| Women | 22.1 | (19.7; 25) | 26.7 | (23.9; 29.5) | |
| Presence of a chronic disease | Total | 40.7 | (38.6; 43) | 26.6 | (24.2; 28.9) |
| Men | 35.9 | (33.6; 38) | 31.8 | (27.5; 36.1) | |
| Women | 45.3 | (42.7; 48) | 22.3 | (19.6; 25) | |
| Physical, mental or sensorial disability | Total | 3.54 | (2.94; 4) | 6.0 | (4.8; 7.2) |
| Men | 3.95 | (3.16; 5) | 7.0 | (4.5; 9.4) | |
| Women | 3.16 | (2.45; 4) | 6.0 | (4.5; 7.5) | |
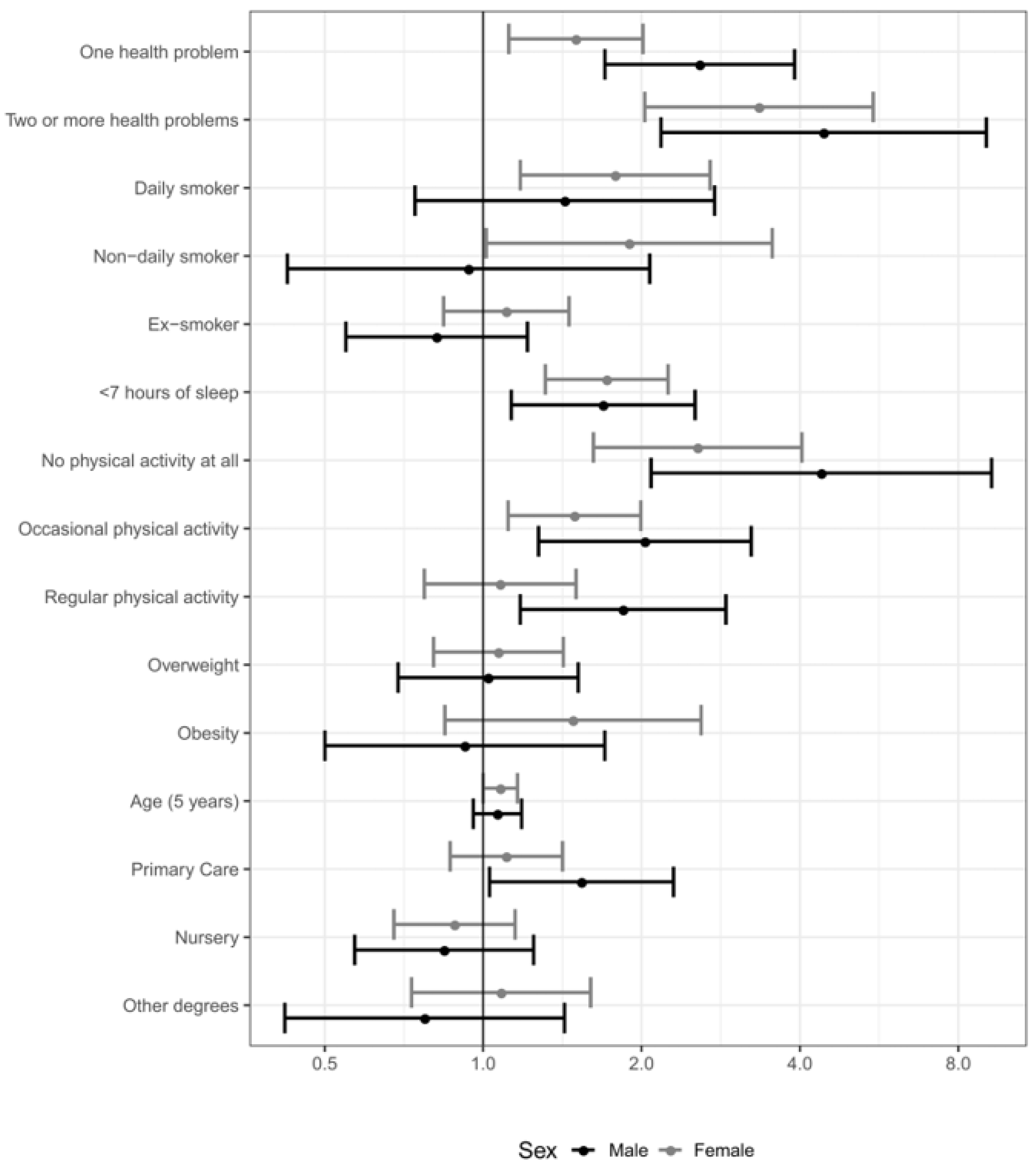
| No PSA Adjustment | PSA with Logistic Regression | PSA with Neural Net (1 Unit) | ||||
|---|---|---|---|---|---|---|
| Predictors | Odds ratio | 95% CI | Odds ratio | 95% CI | Odds ratio | 95% CI |
| 1|2 intercept | 7.44 | 2.71–20.4 | 9.43 | 3.26–27.3 | 10.15 | 2.90–35.5 |
| 2|3 intercept | 279.11 | 249–313 | 331.25 | 289–380 | 314.56 | 264–375 |
| 3|4 intercept | 2411.0 | 1733–3354 | 2979.3 | 2078–4273 | 3151.0 | 2100–4728 |
| 4|5 intercept | 5792.5 | 2086–16,085 | 7636.5 | 2635–22,132 | 6489.2 | 1890–22,276 |
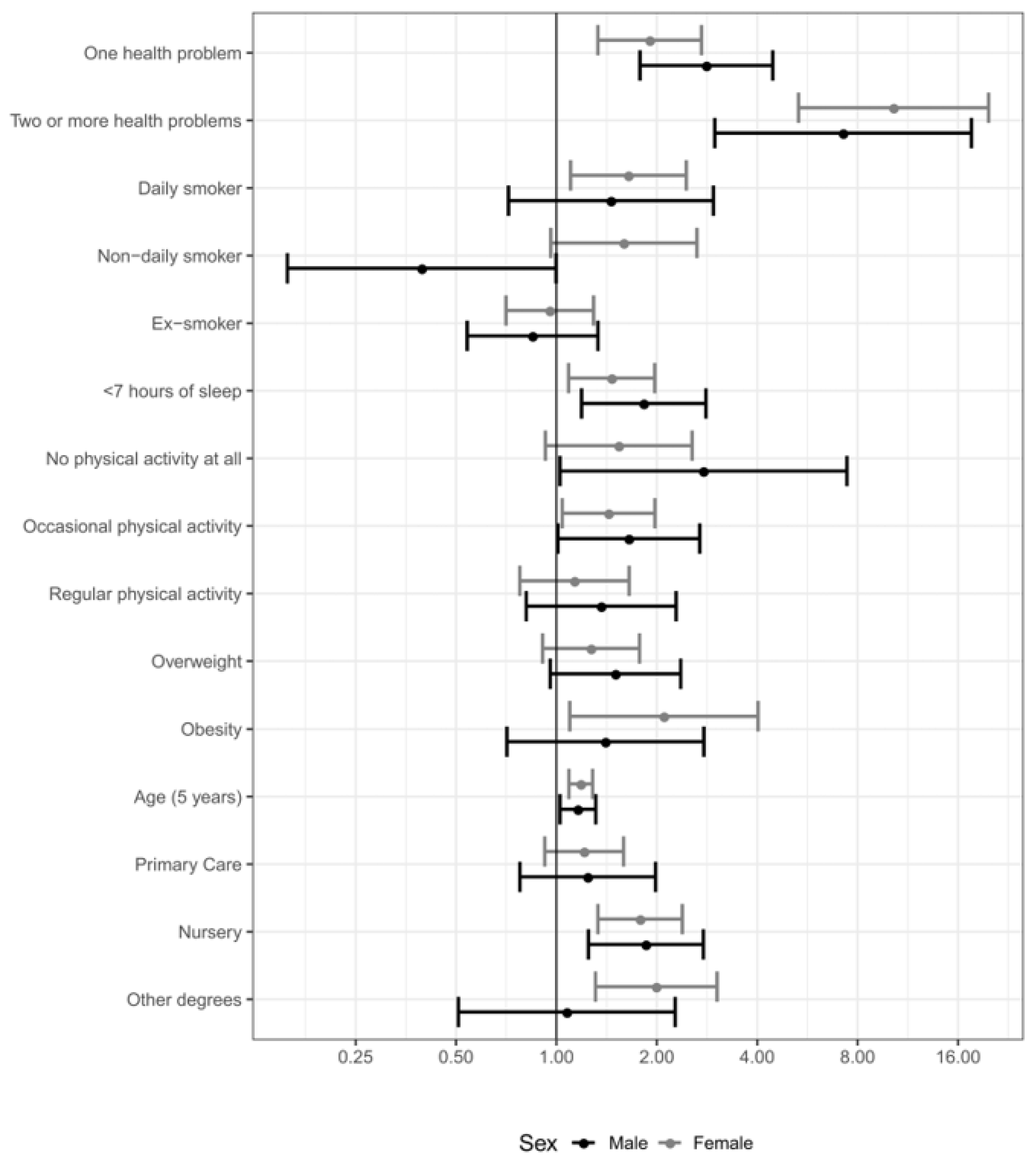
| One health problem | 3.23 | 2.14–4.86 | 2.82 | 1.78–4.45 | 2.59 | 1.53–4.38 |
| Two or more health problems | 8.31 | 4.11–16.8 | 7.24 | 2.99–17.6 | 7.18 | 1.79–28.9 |
| Daily smoker | 1.30 | 0.66–2.58 | 1.46 | 0.72–2.96 | 1.43 | 0.67–3.05 |
| Non-daily smoker | 0.45 | 0.18–1.12 | 0.39 | 0.16–1.00 | 0.19 | 0.07–0.50 |
| Ex-smoker | 0.88 | 0.59–1.31 | 0.85 | 0.54–1.33 | 0.60 | 0.34–1.05 |
| <7 h of sleep | 1.78 | 1.23–2.59 | 1.83 | 1.19–2.81 | 1.95 | 1.17–3.26 |
| No physical activity at all | 2.94 | 1.36–6.35 | 2.76 | 1.02–7.43 | 1.98 | 0.32–12.3 |
| Occasional physical activity | 1.60 | 1.03–2.46 | 1.65 | 1.01–2.69 | 1.78 | 1–3.17 |
| Regular physical activity | 1.36 | 0.84–2.19 | 1.36 | 0.81–2.28 | 1.45 | 0.78–2.71 |
| Obesity | 1.39 | 0.78–2.49 | 1.40 | 0.71–2.77 | 1.78 | 0.81–3.95 |
| Overweight | 1.50 | 1.01–2.22 | 1.50 | 0.96–2.36 | 1.60 | 0.93–2.75 |
| Age (5 years) | 1.14 | 1.02–1.27 | 1.16 | 1.02–1.31 | 1.17 | 1.00–1.36 |
| Primary care | 1.16 | 0.77–1.75 | 1.24 | 0.78–1.98 | 1.37 | 0.77–2.44 |
| Nursing degree | 1.91 | 1.33–2.74 | 1.85 | 1.25–2.76 | 1.86 | 1.20–2.89 |
| Other degree | 0.92 | 0.46–1.87 | 1.07 | 0.51–2.27 | 1.17 | 0.51–2.67 |
| No PSA Adjustment | PSA with Logistic Regression | PSA with Neural Net (1 Unit) | ||||
|---|---|---|---|---|---|---|
| Predictors | Odds ratio | 95% CI | Odds ratio | 95% CI | Odds ratio | 95% CI |
| 1|2 intercept | 6.96 | 3.65–13.2 | 6.7 | 3.24–13.8 | 7.2 | 2.97–17.5 |
| 2|3 intercept | 252.80 | 234–273 | 242.22 | 222–264 | 253.71 | 230–280 |
| 3|4 intercept | 2705.6 | 2141–3419 | 2481.2 | 1886–3264 | 2252.8 | 1643–3088 |
| 4|5 intercept | 6655.2 | 3093–14,319 | 5758.5 | 2337–14,191 | 4897.8 | 1816–13,210 |
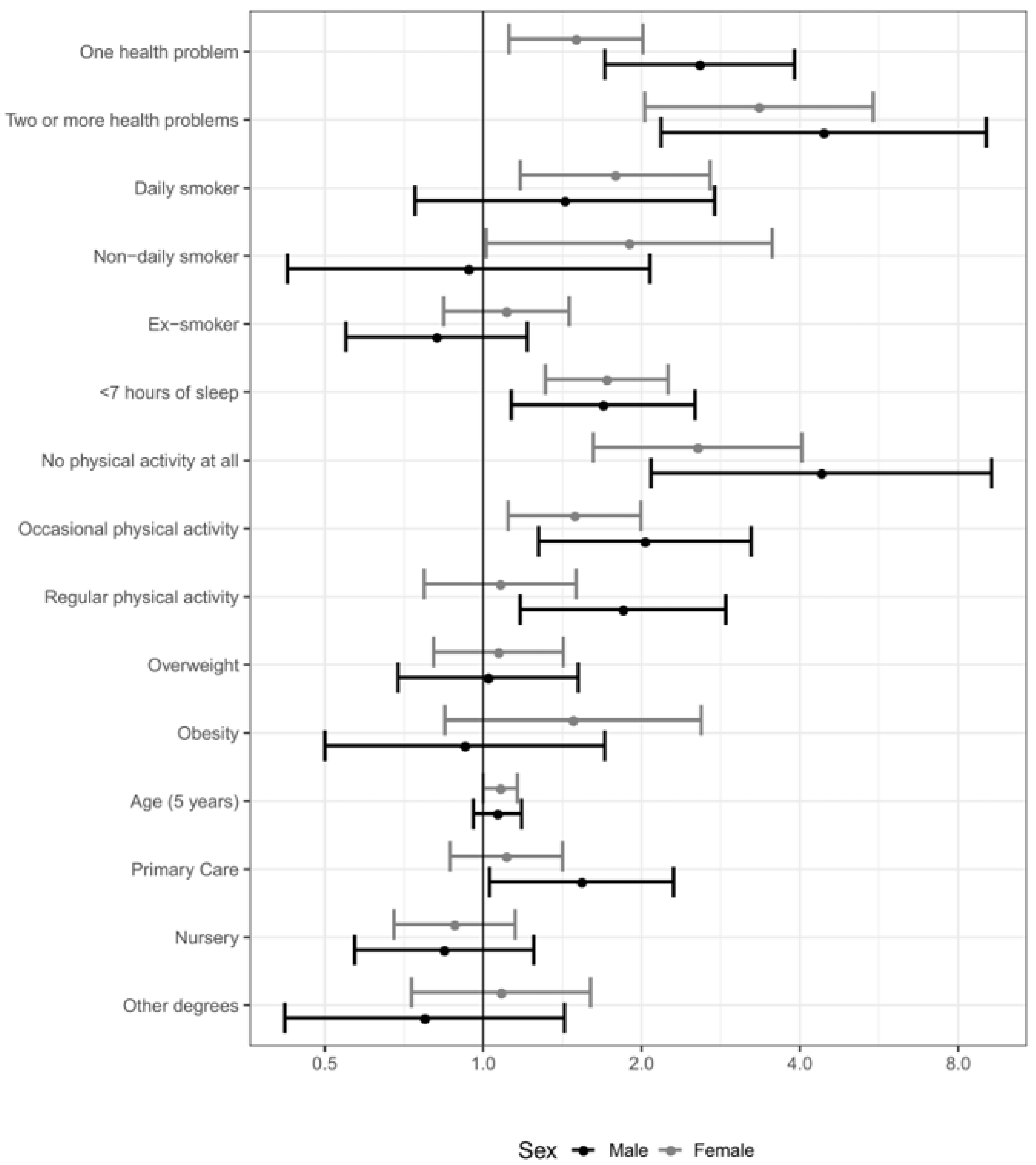
| One health problem | 2.27 | 1.64–3.14 | 1.90 | 1.33–2.72 | 1.76 | 1.15–2.70 |
| Two or more health problems | 10.81 | 6.22–18.8 | 10.25 | 5.32–19.8 | 10.15 | 4.91–21.0 |
| Daily smoker | 1.54 | 1.07–2.23 | 1.64 | 1.10–2.45 | 1.60 | 1.02–2.51 |
| Non-daily smoker | 1.56 | 0.98–2.51 | 1.59 | 0.96–2.64 | 1.46 | 0.83–2.59 |
| Ex-smoker | 0.93 | 0.71–1.22 | 0.96 | 0.71–1.29 | 0.99 | 0.70–1.41 |
| <7 h of sleep | 1.27 | 0.97–1.65 | 1.46 | 1.09–1.97 | 1.53 | 1.10–2.13 |
| No physical activity at all | 1.94 | 1.25–3.00 | 1.54 | 0.93–2.55 | 1.48 | 0.82–2.65 |
| Occasional physical activity | 1.50 | 1.13–2.00 | 1.43 | 1.04–1.97 | 1.47 | 1.02–2.11 |
| Regular physical activity | 1.17 | 0.842–1.64 | 1.13 | 0.78–1.65 | 1.10 | 0.72–1.69 |
| Obesity | 2.14 | 1.23–3.72 | 2.10 | 1.10–4.02 | 1.84 | 0.81–4.20 |
| Overweight | 1.39 | 1.04–1.85 | 1.27 | 0.91–1.77 | 1.16 | 0.81–1.67 |
| Age (5 years) | 1.19 | 1.11–1.28 | 1.18 | 1.09–1.28 | 1.19 | 1.07–1.32 |
| Primary care | 1.24 | 0.95–1.60 | 1.21 | 0.92–1.59 | 1.29 | 0.98–1.70 |
| Nursing degree | 1.67 | 1.29–2.16 | 1.78 | 1.33–2.38 | 1.87 | 1.36–2.56 |
| Other degree | 1.93 | 1.30–2.88 | 1.99 | 1.31–3.03 | 2.20 | 1.45–3.33 |
| No PSA Adjustment | PSA with Logistic Regression | PSA with Neural Net (1 Unit) | ||||
|---|---|---|---|---|---|---|
| Predictors | Oddsratio | 95% CI | Odds ratio | 95% CI | Odds ratio | 95% CI |
| 1|2 intercept | 0.35 | 0.14–0.87 | 0.21 | 0.08–0.57 | 0.24 | 0.07–0.80 |
| 2|3 intercept | 3.05 | 2.60–3.58 | 2.43 | 2.05–2.89 | 3.25 | 2.69–3.93 |
| 3|4 intercept | 18.54 | 16.4–20.9 | 15.01 | 13.1–17.1 | 20.24 | 17.4–23.6 |
| 4|5 intercept | 91.95 | 77.6–109 | 75.94 | 63.1–91.4 | 100.31 | 80.4–125 |
| 5|6 intercept | 227.57 | 162–320 | 180.36 | 121–269 | 255.27 | 156–418 |
| 6|7 intercept | 509.65 | 296–877 | 442.63 | 245–799 | 577.23 | 300–1111 |
| 7|8 intercept | 1597.5 | 776–3290 | 1938.1 | 975–3852 | 2483.3 | 1187–5196 |
| 8|9 intercept | 1597.6 | 612–4175 | 2281.3 | 838–6212 | 2919.1 | 1047–8136 |
| 9|10 intercept | 3223.0 | 790–13,165 | 4045.2 | 853–19,181 | 4846.0 | 993–23,640 |
| One health problem | 2.60 | 1.79–3.77 | 2.58 | 1.70–3.91 | 2.65 | 1.67–4.20 |
| Two or more health problems | 3.98 | 2.13–7.44 | 4.44 | 2.18–9.04 | 3.65 | 1.38–9.70 |
| Daily smoker | 1.53 | 0.84–2.76 | 1.43 | 0.74–2.75 | 1.41 | 0.69–2.89 |
| Non-daily smoker | 0.91 | 0.41–2.03 | 0.94 | 0.43–2.07 | 0.74 | 0.29–1.89 |
| Ex-smoker | 0.81 | 0.57–1.16 | 0.82 | 0.55–1.21 | 0.65 | 0.40–1.07 |
| <7 h of sleep | 1.51 | 1.07–2.14 | 1.69 | 1.13–2.53 | 1.87 | 1.15–3.05 |
| No physical activity at all | 5.10 | 2.73–9.51 | 4.39 | 2.09–9.26 | 3.69 | 1.26–10.8 |
| Occasional physical activity | 1.95 | 1.29–2.96 | 2.03 | 1.27–3.23 | 2.09 | 1.21–3.61 |
| Regular physical activity | 1.94 | 1.30–2.90 | 1.84 | 1.18–2.89 | 1.94 | 1.12–3.35 |
| Obesity | 0.99 | 0.58–1.70 | 0.92 | 0.50–1.70 | 1.03 | 0.52–2.02 |
| Overweight | 1.20 | 0.83–1.73 | 1.02 | 0.69–1.52 | 1.07 | 0.68–1.68 |
| Age (5 years) | 1.08 | 0.98–1.19 | 1.06 | 0.96–1.18 | 1.11 | 0.98–1.27 |
| Primary care | 1.43 | 1.00–2.05 | 1.54 | 1.03–2.30 | 1.42 | 0.89–2.25 |
| Nursing degree | 1.00 | 0.71–1.41 | 0.84 | 0.57–1.25 | 0.75 | 0.49–1.15 |
| Other degree | 0.90 | 0.51–1.60 | 0.77 | 0.42–1.43 | 0.82 | 0.42–1.58 |
| No PSA Adjustment | PSA with Logistic Regression | PSA with Neural Net (1 Unit) | ||||
|---|---|---|---|---|---|---|
| Predictors | Odds ratio | 95% CI | Odds ratio | 95% CI | Odds ratio | 95% CI |
| 1|2 intercept | 0.23 | 0.12–0.42 | 0.24 | 0.12–0.49 | 0.26 | 0.11–0.59 |
| 2|3 intercept | 1.48 | 1.32–1.66 | 1.52 | 1.33–1.72 | 1.58 | 1.37–1.83 |
| 3|4 intercept | 7.20 | 6.62–7.84 | 7.55 | 6.86–8.31 | 7.93 | 7.08–8.88 |
| 4|5 intercept | 32.10 | 28.8–35.8 | 35.79 | 31.7–40.5 | 40.47 | 35.0–46.8 |
| 5|6 intercept | 79.91 | 64.3–99.3 | 81.36 | 63.5–104 | 88.66 | 66.7–118 |
| 6|7 intercept | 177.46 | 127–248 | 185.18 | 127–269 | 194.14 | 127–298 |
| 7|8 intercept | 437.33 | 273–700 | 441.97 | 259–755 | 411.03 | 223–758 |
| 8|9 intercept | 820.65 | 365–1847 | 938.97 | 396–2224 | 949.42 | 385–2344 |
| 9|10 intercept | 2901.2 | 1147–7338 | 2710.6 | 892–8233 | 2447.5 | 690–8684 |
| One health problem | 1.57 | 1.19–2.07 | 1.50 | 1.12–2.01 | 1.55 | 1.13–2.13 |
| Two or more health problems | 3.71 | 2.33–5.92 | 3.34 | 2.03–5.51 | 3.74 | 2.20–6.33 |
| Daily smoker | 1.83 | 1.25–2.66 | 1.78 | 1.18–2.70 | 1.57 | 0.99–2.49 |
| Non-daily smoker | 1.92 | 1.13–3.25 | 1.90 | 1.01–3.54 | 1.40 | 0.71–2.77 |
| Ex-smoker | 1.21 | 0.94–1.54 | 1.11 | 0.84–1.46 | 1.07 | 0.79–1.47 |
| <7 h of sleep | 1.80 | 1.42–2.30 | 1.72 | 1.31–2.25 | 1.86 | 1.34–2.58 |
| No physical activity at all | 2.47 | 1.65–3.70 | 2.56 | 1.62–4.03 | 2.17 | 1.33–3.56 |
| Occasional physical activity | 1.57 | 1.21–2.04 | 1.49 | 1.12–1.99 | 1.28 | 0.93–1.77 |
| Regular physical activity | 1.10 | 0.82–1.50 | 1.08 | 0.77–1.50 | 1.05 | 0.71–1.55 |
| Obesity | 1.54 | 0.94–2.51 | 1.48 | 0.85–2.60 | 1.43 | 0.84–2.43 |
| Overweight | 1.11 | 0.87–1.43 | 1.07 | 0.81–1.42 | 1.13 | 0.82–1.57 |
| Age (5 years) | 1.06 | 0.99–1.13 | 1.08 | 1.00–1.16 | 1.10 | 1.00–1.21 |
| Primary care | 1.10 | 0.87–1.38 | 1.11 | 0.87–1.42 | 1.04 | 0.81–1.34 |
| Nursing degree | 0.88 | 0.70–1.11 | 0.88 | 0.68–1.15 | 0.87 | 0.65–1.16 |
| Other degree | 1.14 | 0.78–1.66 | 1.08 | 0.73–1.60 | 1.08 | 0.71–1.63 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ferri-García, R.; Rueda, M.d.M.; Cabrera-León, A. Self-Perceived Health, Life Satisfaction and Related Factors among Healthcare Professionals and the General Population: Analysis of an Online Survey, with Propensity Score Adjustment. Mathematics 2021, 9, 791. https://doi.org/10.3390/math9070791
Ferri-García R, Rueda MdM, Cabrera-León A. Self-Perceived Health, Life Satisfaction and Related Factors among Healthcare Professionals and the General Population: Analysis of an Online Survey, with Propensity Score Adjustment. Mathematics. 2021; 9(7):791. https://doi.org/10.3390/math9070791
Chicago/Turabian StyleFerri-García, Ramón, María del Mar Rueda, and Andrés Cabrera-León. 2021. "Self-Perceived Health, Life Satisfaction and Related Factors among Healthcare Professionals and the General Population: Analysis of an Online Survey, with Propensity Score Adjustment" Mathematics 9, no. 7: 791. https://doi.org/10.3390/math9070791
APA StyleFerri-García, R., Rueda, M. d. M., & Cabrera-León, A. (2021). Self-Perceived Health, Life Satisfaction and Related Factors among Healthcare Professionals and the General Population: Analysis of an Online Survey, with Propensity Score Adjustment. Mathematics, 9(7), 791. https://doi.org/10.3390/math9070791