
Tails of the Moments for Sums with Dominatedly Varying Random Summands


{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- Value-at-Risk (VaR) at level :
- Conditional tail expectation (CTE) at level :
2. Definitions and Preliminaries
2.1. Notational Conventions
- if
- if
- if
- if
- if
2.2. Heavy-Tailed Distributions
- A d.f. F supported on is said to be dominatedly varying (belong to class ) if for any (for some) .
- A d.f. F is said to be heavy-tailed (belong to class ) if for any
- A d.f. F is said to be long tailed (belong to class ) if for any .
- A d.f. F supported on is said to be subexponential (belong to class ) if and
- A d.f. F is said to be regularly varying with coefficient (belong to class ) if for any
- A d.f. F is said to be consistently varying (belong to class ) if
2.3. QAI Dependence Structure
- R.v.s with infinite right supports are called pairwise quasi-asymptotically independent (pQAI) if for any , ,
3. Related Results
3.1. Asymptotics of Tail Probabilities
- R.v.s with infinite right supports are called pairwise strongly quasi-asymptotically independent (pSQAI) if for any , ,
- R.v.s with infinite right supports are called pairwise tail quasi-asyptotically independent (pTQAI) if for any , ,
- R.v.s with infinite right supports are called pairwise asymptotically independent (pAI) if for any , ,
3.2. Asymptotics of Tail Expectations
4. Main Results
5. Proofs of Main Results
6. Examples
6.1. Sampling Procedure
- G.i.f. of the Pareto d.f. Consider the regularly varying Pareto d.f. F with parameters , i.e.,
- G.i.f. of the Peter and Paul d.f. Recall that Peter and Paul distribution with parameters , , is defined by the following d.f.
- G.i.f. of d.f. of the Cai–Tang (5) distribution. In Section 2.2, we show that the d.f. of the r.v. with independent and geometric N with parameter , is the following
- Algorithm. Generation of samples from a bivariate distribution characterised by marginal d.f.s , and copula .
- Inverse conditional distribution of bivariate FGM copula.
6.2. Analytic Expressions of Individual Summands’ Tail Expectations
- Truncated expectation of the Pareto distribution. Let us consider r.v. having the Pareto distribution with parameters presented in Equation (39). If , then it is obvious that
- Truncated expectation and L-index of Peter and Paul distribution. If r.v. has the generalised Peter and Paul distribution (40) with parameters , , then
6.3. Simulation Procedure and Results
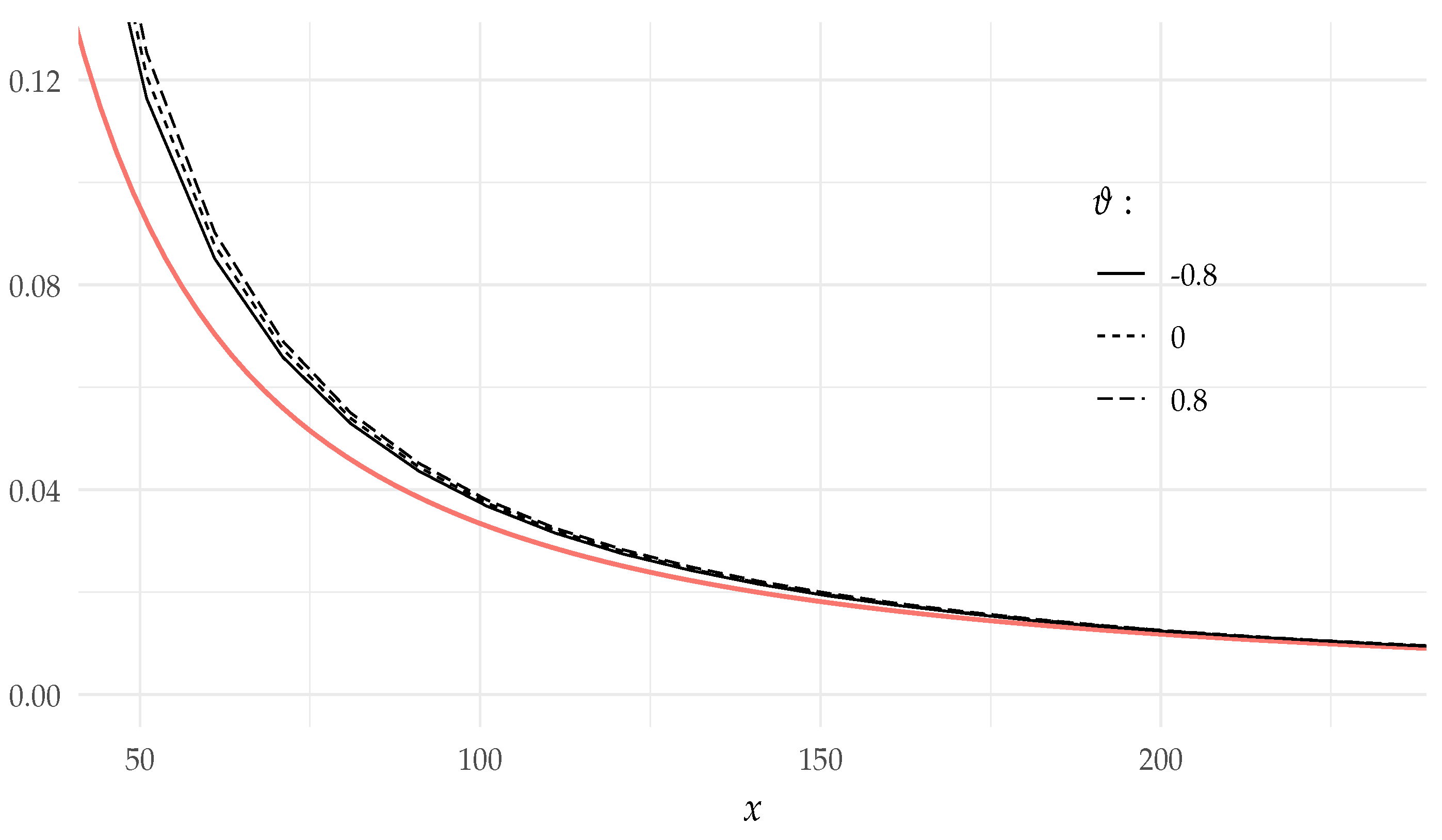
- Under the conditions of Example 3, we get from Theorem 3 thatfor all , according to the expressions of truncated moments derived in Section 6.2. The results of simulated values of together with the values of the derived asymptotic formula are presented in Figure 1.
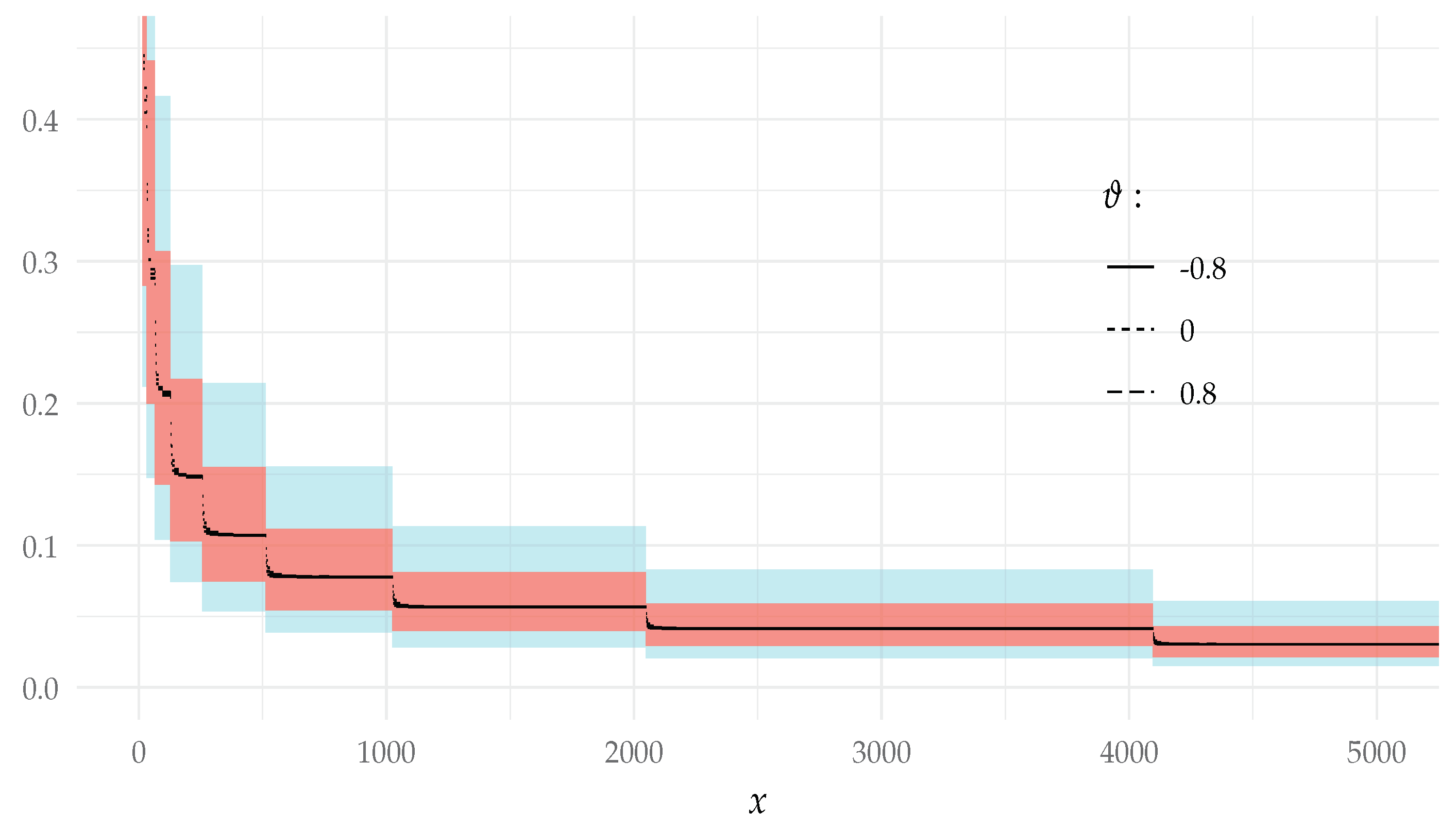
- The conditions of Example 4 and Theorem 3 imply thatdue to the formulas derived in Section 6.2. The results of the simulated values of together with the asymptotic values are presented in Figure 2.
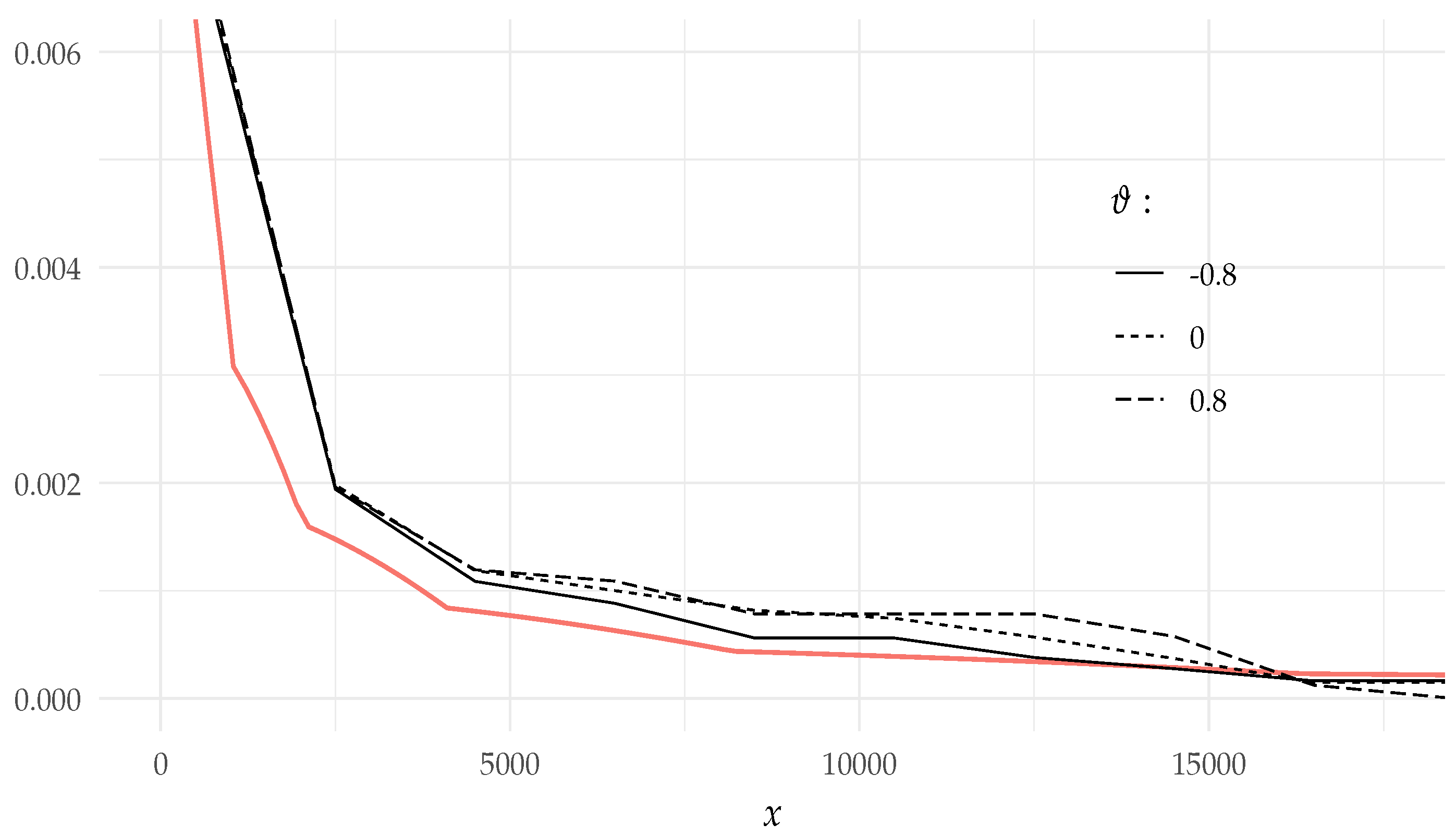
- Under the conditions of Example 5, Theorem 3 implies that can be approximated by sumfor large x and for all three parameter values. The simulated values of and its asymptotic values are presented in Figure 3.
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, Y. A renewal shot noise process with subexponential shot marks. Risks 2019, 7, 63. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Yuen, K.C. Sums of pairwise quasi-asymptotically independent random variables with consistent variation. Stoch. Models 2009, 25, 76–89. [Google Scholar] [CrossRef]
- Cheng, D. Randomly weighted sums of dependent random variables with dominated variation. J. Math. Anal. Appl. 2014, 420, 1617–1633. [Google Scholar] [CrossRef]
- Geluk, J.; Tang, Q. Asymptotic tail probabilities of sums of dependent subexponential random variables. J. Theoret. Probab. 2009, 22, 871–882. [Google Scholar] [CrossRef] [Green Version]
- Goovaerts, M.J.; Kaas, R.; Laeven, R.J.A.; Tang, Q.; Vernic, R. The tail probability of discounted sums of Pareto-like losses in insurance. Scand. Actuar. J. 2005, 2005, 446–461. [Google Scholar] [CrossRef]
- Jaunė, E.; Ragulina, O.; Šiaulys, J. Expectation of the truncated randomly weighted sums with dominatedly varying summands. Lith. Math. J. 2018, 58, 421–440. [Google Scholar] [CrossRef]
- Leipus, R.; Šiaulys, J.; Vareikaitė, I. Tails of higher-order moments with dominatedly varying summands. Lith. Math. J. 2019, 59, 389–407. [Google Scholar] [CrossRef]
- Tang, Q.; Tsitsiashvili, G. Precise estimates for the ruin probability in finite horizon in a discrete-time model with heavy-tailed insurance and financial risks. Stoch. Process. Appl. 2003, 108, 299–325. [Google Scholar] [CrossRef]
- Wang, D.; Su, C.; Zeng, Y. Uniform estimate for maximum of randomly weighted sums with applications to insurance risk theory. Sci. China Ser. A 2005, 48, 1379–1394. [Google Scholar] [CrossRef]
- Wang, D.; Tang, Q. Tail probabilities of randomly weighted sums of random variables with dominated variation. Stoch. Models 2006, 22, 253–272. [Google Scholar] [CrossRef]
- Yi, L.; Chen, Y.; Su, C. Approximation of the tail probability of randomly weighted sums of dependent random variables with dominated variation. J. Math. Anal. Appl. 2011, 376, 365–372. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Ignatavičiūtė, E.; Šiaulys, J. Conditional tail expectation of randomly weighted sums with heavy-tailed distributions. Stat. Probab. Lett. 2015, 105, 20–28. [Google Scholar] [CrossRef]
- Fougeres, A.L.; Mercadier, C. Risk measures and multivariate extensions of Breiman’s theorem. J. Appl. Probab. 2012, 49, 364–384. [Google Scholar] [CrossRef] [Green Version]
- Nyrhinen, H. On the ruin probabilities in a general economic environment. Stoch. Process. Appl. 1999, 83, 319–330. [Google Scholar] [CrossRef] [Green Version]
- Tang, Q.; Yuan, Z. Randomly weighted sums of subexponential random variables with application to capital allocation. Extremes 2014, 17, 467–493. [Google Scholar] [CrossRef]
- Wang, S.; Chen, C.; Wang, X. Some novel results on pairwise quasi-asymptotical independence with applications to risk theory. Comm. Stat. Theory Methods 2017, 46, 9075–9085. [Google Scholar] [CrossRef]
- Verrall, R.J. The individual risk model: A compound distribution. J. Inst. Actuaries 1989, 116, 101–107. [Google Scholar] [CrossRef] [Green Version]
- Dhaene, J.; Goovaerts, M.J. On the dependency of risks in the individual life model. Insur. Math. Econom. 1997, 19, 243–253. [Google Scholar] [CrossRef]
- Dickson, D.C.M. Insurance Risk and Ruin; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Acerbi, C. Spectral measures of risks: A coherent representation of subjective risk aversion. J. Bank. Financ. 2002, 26, 1505–1518. [Google Scholar] [CrossRef] [Green Version]
- Artzner, P.; Delbaen, F.; Eber, J.M.; Heath, D. Coherent measures of risk. Math. Financ. 1999, 9, 203–228. [Google Scholar] [CrossRef]
- Asimit, A.V.; Furman, E.; Tang, Q.; Vernic, R. Asymptotics for risk capital allocations based on conditional tail expectation. Insur. Math. Econom. 2011, 49, 310–324. [Google Scholar] [CrossRef] [Green Version]
- Hua, L.; Joe, H. Strength of tail dependence based on conditional tail expectation. J. Multivar. Anal. 2014, 123, 143–159. [Google Scholar] [CrossRef]
- Wang, S.; Hu, Y.; Yang, L.; Wang, W. Randomly weighted sums under a wide type of dependence structure with application to conditional tail expectation. Commun. Stat. Theory Methods 2018, 47, 5054–5063. [Google Scholar] [CrossRef]
- Goldie, C.M. Subexponential distributions and dominated-variation tails. J. Appl. Probab. 1978, 15, 440–442. [Google Scholar] [CrossRef]
- Cai, J.; Tang, Q. On max-sum equivalence and convolution closure of heavy-tailed distributions and their applications. J. Appl. Probab. 2004, 41, 117–130. [Google Scholar] [CrossRef]
- Cline, D.B.H.; Samorodnitsky, G. Subexponentiality of the product of independent random variables. Stoch. Process. Appl. 1994, 49, 75–98. [Google Scholar] [CrossRef] [Green Version]
- Embrechts, P.; Goldie, C.M. On closure and factorization properties of subexponential and related distributions. J. Austral. Math. Soc. Ser. A 1980, 29, 243–256. [Google Scholar] [CrossRef] [Green Version]
- Embrechts, P.; Omey, E. A property of longtailed distributions. J. Appl. Probab. 1984, 21, 80–87. [Google Scholar] [CrossRef]
- Foss, S.; Korshunov, D.; Zachary, S. An Introduction to Heavy-Tailed and Subexponential Distributions, 2nd ed.; Springer: New York, NY, USA, 2013. [Google Scholar]
- Konstantinides, D.G. Risk Theory. A Heavy Tail Approach; World Scientific Publishing: Singapore, 2018. [Google Scholar]
- Pitman, E.J.G. Subexponential distribution functions. J. Austral. Math. Soc. Ser. A 1980, 29, 337–347. [Google Scholar] [CrossRef]
- Wang, Y.B.; Wang, K.Y.; Cheng, D.Y. Precise large deviations for sums of negatively associated random variables with common dominatedly varying tails. Acta Math. Sin. (Engl. Ser.) 2006, 22, 1725–1734. [Google Scholar] [CrossRef]
- Yang, Y.; Wang, Y. Asymptotics for ruin probability of some negatively dependent risk models with a constant interest rate and dominatedly-varying-tailed claims. Statist. Probab. Lett. 2010, 80, 143–154. [Google Scholar] [CrossRef]
- Matuszewska, W. On a generalization of regularly increasing functions. Studia Math. 1964, 24, 271–279. [Google Scholar] [CrossRef] [Green Version]
- Bingham, N.H.; Goldie, C.M.; Teugels, J.L. Regular Variation; Cambridge University Press: Cambridge, UK, 1987. [Google Scholar]
- Sklar, M. Fonctions de répartition à n dimensions et leurs marges. Publ. Inst. Stat. Univ. Paris 1959, 8, 229–231. [Google Scholar]
- Nelsen, R.B. An introduction to Copulas, 2nd ed.; Springer: New York, NY, USA, 2006. [Google Scholar]
- Kotz, S.; Balakrishnan, N.; Johnson, N.L. Continuous Multivariate Distributions, 2nd ed.; John Wiley and Sons: New York, NY, USA, 2000; Volume 1. [Google Scholar]
- Ali, M.M.; Mikhail, N.N.; Haq, M.S. A class of bivariate distributions including the bivariate logistic. J. Multivar. Anal. 1978, 8, 405–412. [Google Scholar] [CrossRef] [Green Version]
- Albrecher, H.; Asmussen, S.; Kortschak, D. Tail asymptotics for the sum of two heavy-tailed dependent risks. Extremes 2006, 9, 107–130. [Google Scholar] [CrossRef]
- Fang, H.; Ding, S.; Li, X.; Yang, W. Asymptotic approximations of ratio moments based on dependent sequences. Mathematics 2020, 8, 361. [Google Scholar] [CrossRef] [Green Version]
- Yang, H.; Gao, W.; Li, J. Asymptotic ruin probabilities for a discrete-time risk model with dependent insurance and financial risks. Scand. Actuar. J. 2016, 2016, 1–17. [Google Scholar] [CrossRef]
- Li, J. On pairwise quasi-asymptotically independent random variables and their applications. Stat. Probab. Lett. 2013, 83, 2081–2087. [Google Scholar] [CrossRef]
- Embrechts, P.; Hofert, M. A note on generalized inverses. Math. Methods Oper. Res. (Heidelb) 2013, 77, 423–432. [Google Scholar] [CrossRef] [Green Version]
- Rosenblatt, M. Remarks on a multivariate transformation. Ann. Math. Stat. 1952, 23, 470–472. [Google Scholar] [CrossRef]
- Brockwell, A.E. Universal residuals: A multivariate transformation. Stat. Probab. Lett. 2007, 77, 1473–1478. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/ (accessed on 15 December 2020).
- Izrailev, S. Tictoc: Functions for Timing R Scripts, as Well as Implementations of Stack and List Structures. R Package Version 1.0. 2014. Available online: https://CRAN.R-project.org/package=tictoc (accessed on 23 December 2020).
- Sharpsteen, C.; Bracken, C. tikzDevice: R Graphics Output in LaTeX Format. R Package Version 0.12.3.1. 2020. Available online: https://CRAN.R-project.org/package=tikzDevice (accessed on 9 January 2021).
- Vaughan, D.; Dancho, M. Furrr: Apply Mapping Functions in Parallel Using Futures. R Package Version 0.1.0. 2018. Available online: https://CRAN.R-project.org/package=furrr (accessed on 17 January 2021).
- Wickham, H.; Averick, M.; Bryan, J.; Chang, W.; McGowan, L.D.; François, R.; Grolemund, G.; Hayes, A.; Henry, L.; Hester, J.; et al. Welcome to the tidyverse. J. Open Source Softw. 2019, 4, 1686. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dirma, M.; Paukštys, S.; Šiaulys, J. Tails of the Moments for Sums with Dominatedly Varying Random Summands. Mathematics 2021, 9, 824. https://doi.org/10.3390/math9080824
Dirma M, Paukštys S, Šiaulys J. Tails of the Moments for Sums with Dominatedly Varying Random Summands. Mathematics. 2021; 9(8):824. https://doi.org/10.3390/math9080824
Chicago/Turabian StyleDirma, Mantas, Saulius Paukštys, and Jonas Šiaulys. 2021. "Tails of the Moments for Sums with Dominatedly Varying Random Summands" Mathematics 9, no. 8: 824. https://doi.org/10.3390/math9080824