

Development and Validation of a Questionnaire to Assess the Radiologists’ Views on the Implementation of Artificial Intelligence in Radiology (ATRAI-14)

 , , and
, , and
Abstract
:1. Introduction
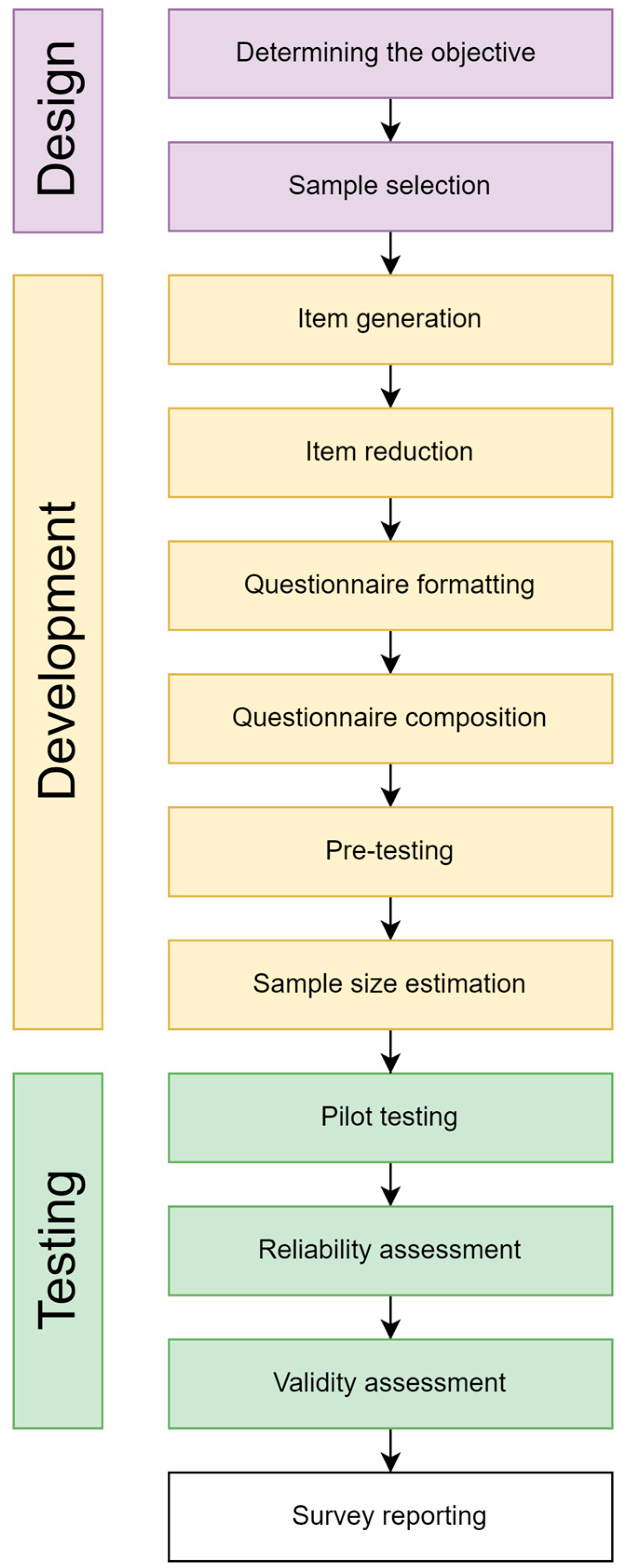
2. Materials and Methods
2.1. Sample Selection
2.2. Research Settings
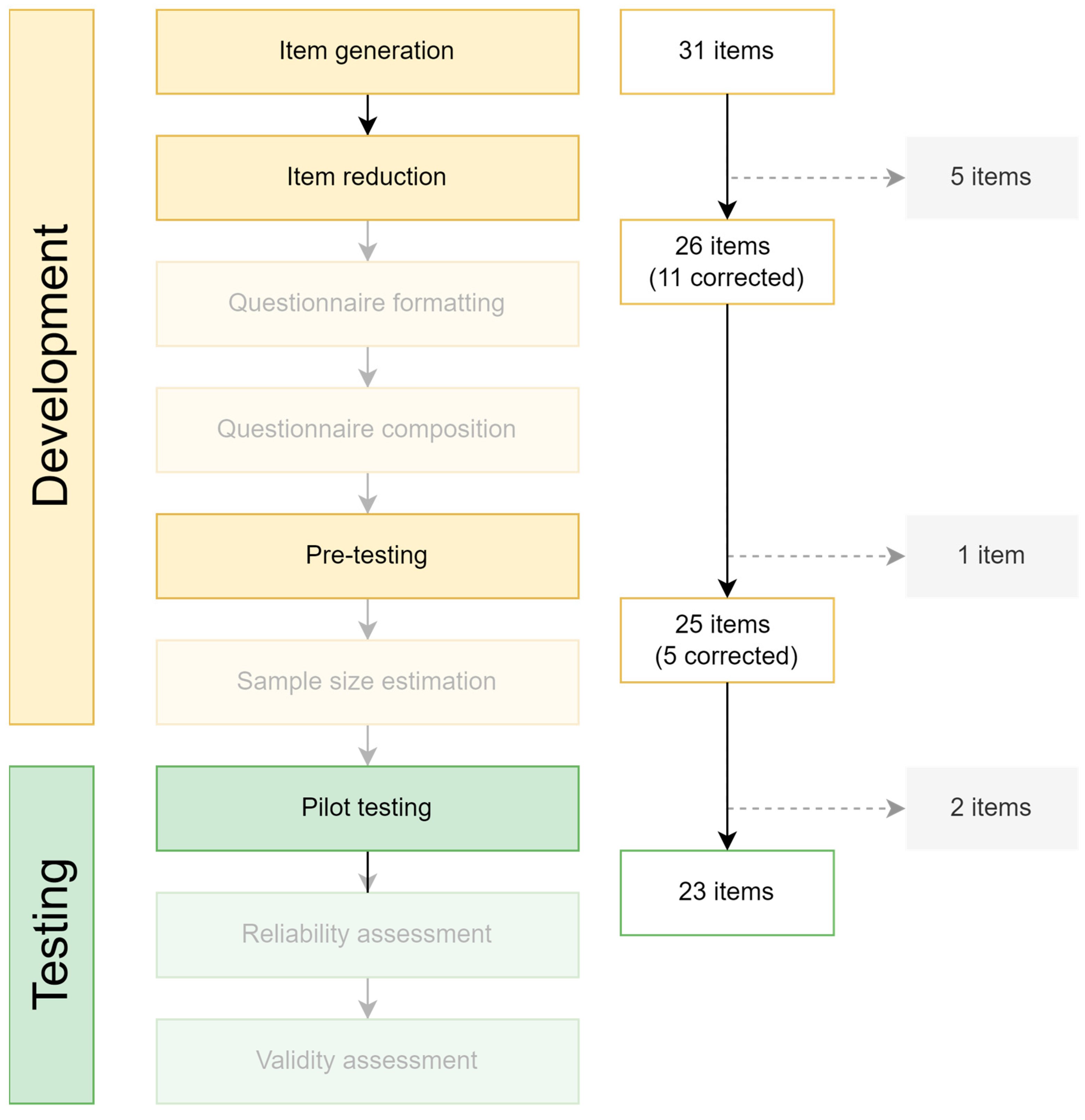
2.3. Item Generation
2.4. Item Reduction
2.5. Questionnaire Formatting
2.6. Questionnaire Composition
2.7. Pre-Testing
2.8. Sample Size Estimation
2.9. Pilot Testing with Reliability and Validity Assessment
2.10. Statistical Data Analysis
3. Results
3.1. Item Generation and Reduction
3.2. Pre-Testing
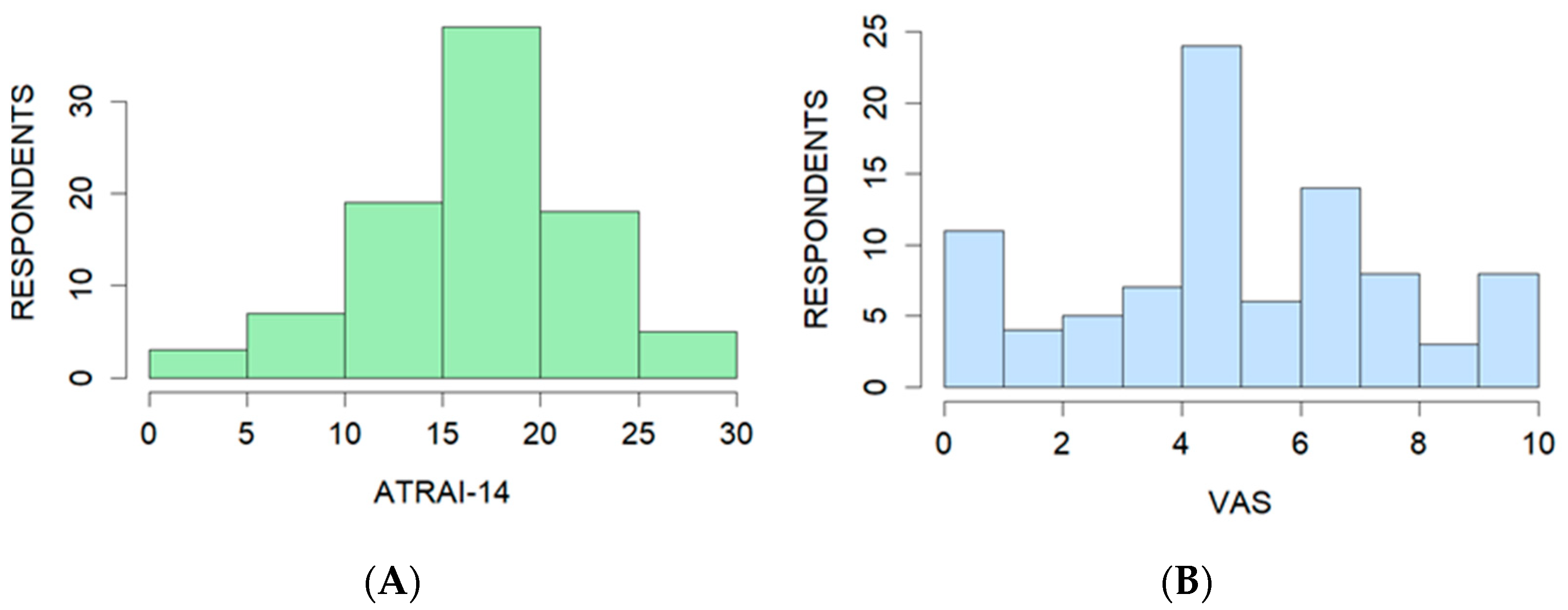
3.3. Pilot Testing
3.4. Validity
3.4.1. Face Validity and Content Validity
3.4.2. Construct Validity
3.4.3. Criterion Validity
3.5. Reliability
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. ATRAI-14 Questionnaire
Appendix A.1. Questionnaire
- Radiologists’ Views on the Implementation of Artificial Intelligence in Diagnostic Imaging (ATRAI-14).
- P1. State your job title (one answer)
| Resident | ○ | |
| Radiologist | ○ | |
| Head of radiology department | ○ | |
| Other (fill in) | ○ | |
- 2.
- P2. Working place (one answer)
| University Hospital | ○ | |
| Public Hospital | ○ | |
| Teleradiology Center | ○ | |
| Private Hospital | ○ | |
| Other (fill in) | ○ | |
- 3.
- P3. State the type of medical facility you work at/study in (select all that applies)
| Outpatient department | ◻ |
| In-patient department | ◻ |
| Day-case unit | ◻ |
- 4.
- P4. What imaging modalities do you interpret on a daily basis? (select all that applies)
| Radiography | ◻ | |
| Mammography | ◻ | |
| Ultrasound | ◻ | |
| CT | ◻ | |
| MRI | ◻ | |
| Tomosynthesis | ◻ | |
| Nuclear imaging | ◻ | |
| Cone-beam CT | ◻ | |
| Other (fill in) | ◻ | |
- 5.
- P5. What is the age of the patients you interpret studies for? (one answer)
| <18 years old | ○ |
| ≥18 years old | ○ |
| I work with patients of all ages | ○ |
- 6.
- P6. State the anatomical regions/organ systems that you interpret most often (select all that applies)
| I report all anatomical regions/organ systems | ◻ |
| Abdomen | ◻ |
| Thorax | ◻ |
| Breast | ◻ |
| Urogenital | ◻ |
| Musculoskeletal | ◻ |
| Neuroradiology | ◻ |
| Cardiovascular | ◻ |
| Pelvis | ◻ |
| Head and neck | ◻ |
- 7.
- P7. State your total experience, in years, as a radiologist (excluding internship and residency)
- 8.
- P8. Do you partake in scientific research related to your medical activity? (one answer)
| Yes | ○ |
| No | ○ |
- 9.
- P9. Do you have the opportunity to use artificial intelligence (AI) tools at work to interpret imaging studies? (one answer)
| Yes | ○ |
| No | ○ |
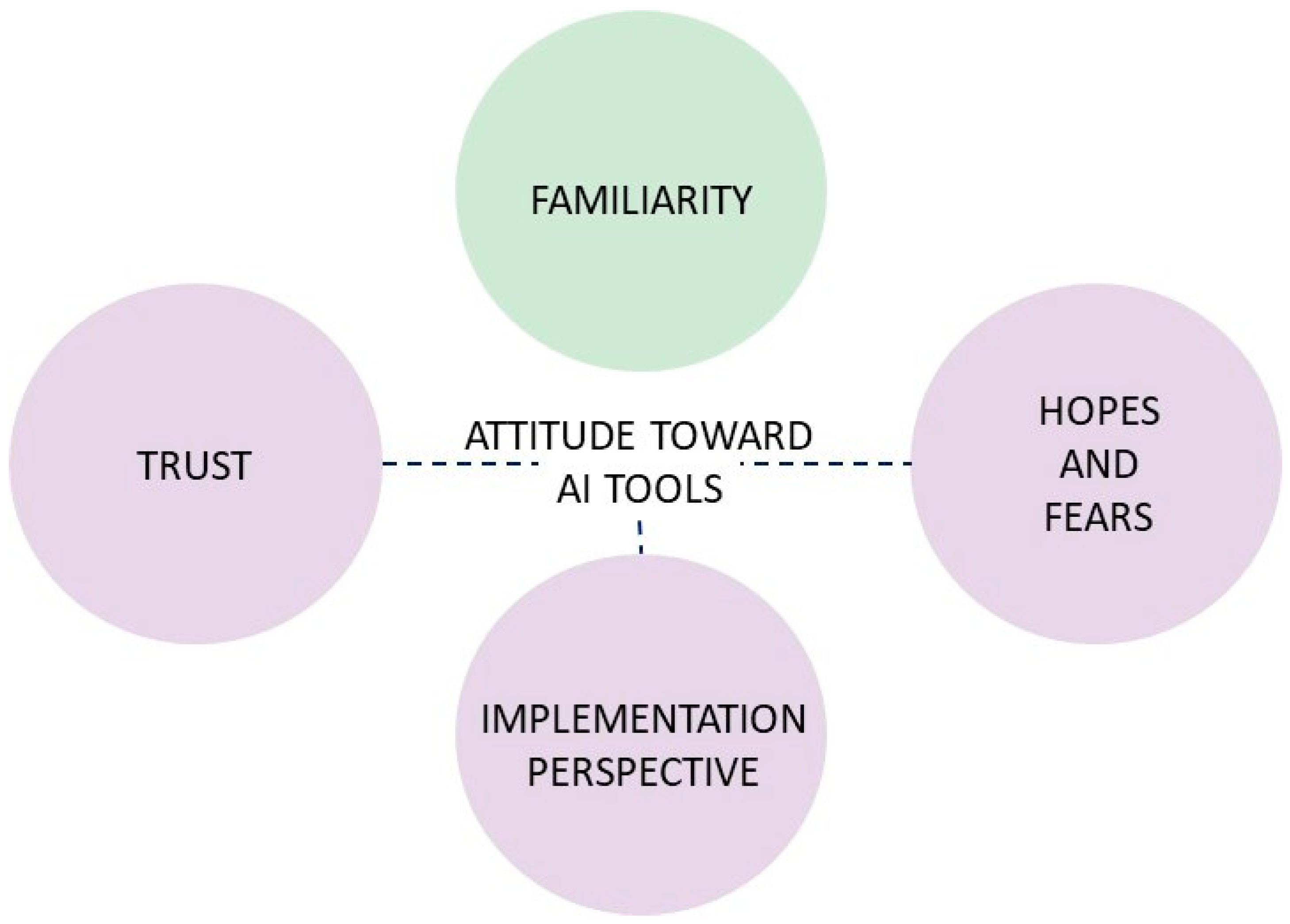
- Familiarity
- 10.
- F1. Do you use AI tools to interpret imaging studies? (one answer)
| Answers: | label | |
| Yes, regularly, for various tasks (example: for routine measurements or incidental findings detection) | ○ | 4 |
| Yes, regularly, a specific AI tool for a single task (example: to measure abdominal aorta diameter) | ○ | 3 |
| Yes, sometimes, depending on the task | ○ | 2 |
| Not yet, but I plan to | ○ | 1 |
| No, and I do not plan to | ○ | 0 |
- 11.
- F4. How often do you participate in AI research projects? (one answer)
| Answers: | label | |
| Very often | ○ | 4 |
| Sometimes | ○ | 3 |
| Participated once or twice | ○ | 2 |
| Not yet, but I would want to | ○ | 1 |
| No, and I do not want to | ○ | 0 |
- Trust
- 12.
- T1. In the next 5 years, do you think you will be comfortable trusting autonomous AI to interpret imaging studies (an AI that acts without radiologist oversight)? (one answer)
| Answers: | label | |
| Yes | ○ | 4 |
| Mostly yes | ○ | 3 |
| Difficult to answer | ○ | 2 |
| Mostly no | ○ | 1 |
| No | ○ | 0 |
- 13.
- T2. Do you trust the work of an AI tool outputting only «pathology present/study unremarkable»? (example: the presence or absence of liver lesions) (one answer)
| Answers: | label | |
| Yes | ○ | 4 |
| Mostly yes | ○ | 3 |
| Difficult to answer | ○ | 2 |
| Mostly no | ○ | 1 |
| No | ○ | 0 |
- 14.
- T3. Do you trust the result of an AI tool outputting only a quantitative indicator (example: aortic diameter, pleural effusion volume, vertebral body height)? (one answer)
| Answers: | label | |
| Yes | ○ | 4 |
| Mostly yes | ○ | 3 |
| Difficult to answer | ○ | 2 |
| Mostly no | ○ | 1 |
| No | ○ | 0 |
- 15.
- T4. Imagine—you read an imaging study and found no pathology, but an AI tool contradicts your opinion. Would this be reason enough for you to double check the study? (one answer)
| Answers: | label | |
| Yes | ○ | 4 |
| Mostly yes | ○ | 3 |
| Difficult to answer | ○ | 2 |
| Mostly no | ○ | 1 |
| No | ○ | 0 |
- 16.
- T6. Which way of interacting with an AI tool would be preferable for you? (one answer)
| Answers: | label | |
| AI autonomously interprets a part of a study | ○ | 4 |
| AI performs routine measurements (diameter, volume, etc.) specified by an radiologist | ○ | 1 |
| AI filters out normal scans; the radiologist, without the help of an AI, analyzes only cases with suspected pathology | ○ | 2 |
| AI filters out normal scans; the radiologist, with the help of an AI, analyzes only cases with suspected pathology | ○ | 3 |
| AI is not included in image interpretation | ○ | 0 |
- Implementation Perspectives
- 17.
- I1. In your opinion, which of the listed functions of AI will be the most useful for radiologist? (select all that applies)
| Answers: | label | |
| Acceleration of the image reconstruction phase | ◻ | A |
| Image acquisition decision support system | ◻ | A |
| Image post-processing (quality improvement, noise reduction) | ◻ | A |
| Collection of quantitative data (size, volume, density/intensity) | ◻ | A |
| Incidental finding detection | ◻ | A |
| Cancer staging (as in TNM system) | ◻ | A |
| Assistance writing a structured report | ◻ | A |
| I don’t think AI can be useful | ◻ | B |
| I don’t think AI would be widely implemented | ◻ | B |
- 18.
- I2. Imagine that usage of an AI is an additional healthcare service for a patient. Who, in your opinion, should pay for it? (one answer)
| Answers: | label | ||
| Universal health care (compulsory medical insurance) | ○ | 4 | |
| A patient’s insurance company | ○ | 1 | |
| Hospital that hosts the AI | ○ | 3 | |
| A patient | ○ | 2 | |
| AI developer | ○ | 1 | |
| I can not imagine such a situation | ○ | 0 | |
| Other (fill in) | ○ | ○ | 2 |
- 19.
- I4. In your opinion, what modalities will be most affected by AI in the next 5 years? (select all that applies)
| Answers: | label | |
| Radiography | ◻ | A |
| Mammography | ◻ | A |
| Ultrasound | ◻ | A |
| CT | ◻ | A |
| MRI | ◻ | A |
| Tomosynthesis | ◻ | A |
| Nuclear imaging | ◻ | A |
| I don’t think AI would have an impact | ◻ | B |
- 20.
- H6. In your opinion, what will be the radiologist’s role in implementation of AI in medical imaging? (select all that applies)
| Answers: | label | |
| Image markup for AI training | ◻ | A |
| Formulating diagnostic tasks for developers | ◻ | A |
| Participation in the development of AI tools (programming, consulting for developers) | ◻ | A |
| Basic usability assessment (DICOM SR and SC) before implementation | ◻ | A |
| Pre-implementation diagnostic performance assessment | ◻ | A |
| Giving feedback on AI tools | ◻ | A |
| Radiologists will not be involved in any way in the development, testing or quality assessment of AI tools | ◻ | B |
| Difficult to say | ◻ | C |
- Hopes and Fears
- 21.
- H1. In your opinion, will the widespread use of AI by the radiologists affect the prestige of their profession in the next 5 years? (one answer)
| Answers: | label | |
| Will not affect/difficult to answer | ○ | 2 |
| Perhaps, the prestige will drop a little | ○ | 1 |
| Yes, the prestige will drop significantly | ○ | 0 |
| Perhaps, the prestige will grow a little | ○ | 3 |
| Yes, the prestige will grow significantly | ○ | 4 |
- 22.
- H4. In your opinion, will the widespread use of AI affect the workload of the radiologists? (one answer)
| Answers: | label | |
| The workload will significantly decrease | ○ | 4 |
| The workload will somewhat decrease | ○ | 3 |
| It will not/difficult to say | ○ | 2 |
| The workload will somewhat increase | ○ | 1 |
| The workload will significantly increase | ○ | 0 |
- 23.
- H5. In your opinion, will the widespread use of AI affect the salary of radiologists in your country in the next 5 years? (one answer)
| Answers: | label | |
| It will not/difficult to say | ○ | 2 |
| The salary will somewhat decrease | ○ | 1 |
| The salary will significantly decrease | ○ | 0 |
| The salary will somewhat increase | ○ | 3 |
| The salary will significantly increase | ○ | 4 |
Appendix A.2. Scoring
- I1: B—0, 1A—1, 2-3A—2, 4-5A—3, 6 or more A—4;
- I4: B or 1A—4, 2-3A—3, 4-5A—2, 6A—1, 7A—0;
- H6: B—0, C—1, 1-2A—2, 3-4A—3, 5-6A—4.
References
- Huang, A.A.; Huang, S.Y. Technical Report: Machine-Learning Pipeline for Medical Research and Quality-Improvement Initiatives. Cureus 2023, 15, e46549. [Google Scholar] [CrossRef] [PubMed]
- Vasilev, Y.A.; Tyrov, I.A.; Vladzymyrskyy, A.V.; Arzamasov, K.M.; Shulkin, I.M.; Kozhikhina, D.D.; Pestrenin, L.D. Double-reading mammograms using artificial intelligence technologies: A new model of mass preventive examination organization. Digit. Diagn. 2023, 4, 93–104. [Google Scholar] [CrossRef]
- Muehlematter, U.J.; Daniore, P.; Vokinger, K.N. Approval of artificial intelligence and machine learning-based medical devices in the USA and Europe (2015–2020): A comparative analysis. Lancet Digit. Health 2021, 3, e195–e203. [Google Scholar] [CrossRef] [PubMed]
- Park, Y.; Jackson, G.P.; A Foreman, M.; Gruen, D.; Hu, J.; Das, A.K. Evaluating artificial intelligence in medicine: Phases of clinical research. JAMIA Open 2020, 3, 326–331. [Google Scholar] [CrossRef] [PubMed]
- Herman, G.T.; Axel, L.; Bajcsy, R.; Kundel, H.; LeVeen, R.; Udupa, J.K.; Wolf, G. Model-driven visualization of coronary arteries. Radiat. Med. 1983, 1, 112–116. [Google Scholar] [PubMed]
- U. S. Food and Drug Administration. Artificial Intelligence and Machine Learning (AI/ML)-Enabled Medical Devices. Available online: https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-aiml-enabled-medical-devices (accessed on 30 September 2024).
- Aggarwal, R.; Sounderajah, V.; Martin, G.; Ting, D.S.W.; Karthikesalingam, A.; King, D.; Ashrafian, H.; Darzi, A. Diagnostic accuracy of deep learning in medical imaging: A systematic review and meta-analysis. NPJ Digit. Med. 2021, 4, 65. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Liang, G.; Zhang, Y.; Blanton, H.; Bessinger, Z.; Jacobs, N. Inconsistent Performance of Deep Learning Models on Mammogram Classification. J. Am. Coll. Radiol. 2020, 17, 796–803. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500–510. [Google Scholar] [CrossRef]
- Peter, D.; Robert, F.; Jeremy, G.; Tristan, M.; Jon, M.; Andy, M.; David, R. The AI Maturity Roadmap: A Framework for Effective and Sustainable AI in Health Care. NEJM AI Spons. 2024. [Google Scholar] [CrossRef]
- Morozov, S.; Vladzymyrskyy, A.; Ledikhova, N.; Andreychenko, A.; Arzamasov, K.; Omelyanskaya, O.; Reshetnikov, R.; Gelezhe, P.; Blokhin, I.; Turavilova, E.; et al. Diagnostic accuracy of artificial intelligence for analysis of 1.3 million medical imaging studies: The moscow experiment on computer vision technologies. medRxiv 2023. [Google Scholar] [CrossRef]
- Center of Diagnostics and Telemedicine. AI Services in Radiology. Available online: https://mosmed.ai/en/ (accessed on 30 September 2024).
- Vasilev, Y.A.; Kozhikhina, D.D.; Vladzymyrskyy, A.V.; Shumskaya, Y.F.; Mukhortova, A.N.; Blokhin, I.A.; Suchilova, M.M.; Reshetnikov, R.V. Results of the work of the Reference center for diagnostic radiology with using telemedicine technology. Health Care Russ. Fed. 2024, 68, 102–108. [Google Scholar] [CrossRef]
- Mello-Thoms, C.; Mello, C.A.B. Clinical applications of artificial intelligence in radiology. Br. J. Radiol. 2023, 96, 20221031. [Google Scholar] [CrossRef]
- European Society of Radiology (ESR). Impact of artificial intelligence on radiology: A EuroAIM survey among members of the European Society of Radiology. Insights Imaging 2019, 10, 105. [Google Scholar] [CrossRef]
- Huisman, M.; Ranschaert, E.; Parker, W.; Mastrodicasa, D.; Koci, M.; de Santos, D.P.; Coppola, F.; Morozov, S.; Zins, M.; Bohyn, C.; et al. An international survey on AI in radiology in 1041 radiologists and radiology residents part 1: Fear of replacement, knowledge, and attitude. Eur. Radiol. 2021, 31, 7058–7066. [Google Scholar] [CrossRef] [PubMed]
- Huisman, M.; Ranschaert, E.; Parker, W.; Mastrodicasa, D.; Koci, M.; de Santos, D.P.; Coppola, F.; Morozov, S.; Zins, M.; Bohyn, C.; et al. An international survey on AI in radiology in 1041 radiologists and radiology residents part 2: Expectations, hurdles to implementation, and education. Eur. Radiol. 2021, 31, 8797–8806. [Google Scholar] [CrossRef] [PubMed]
- Morozov, S.P.; Vladzymyrskyy, A.V.; Ledikhova, N.V.; Andrejchenko, A.E.; Arzamasov, K.M.; Balanjuk, E.A.; Gombolevskij, V.A.; Ermolaev, S.O.; Zhivodenko, V.S.; Idrisov, I.M.; et al. Moscow experiment on computer vision in radiology: Involvement and participation of radiologists. Vrach I Inf. Tehnol. 2020, 4, 14–23. [Google Scholar] [CrossRef]
- Ce’, M.; Ibba, S.; Cellina, M.; Tancredi, C.; Fantesini, A.; Fazzini, D.; Fortunati, A.; Perazzo, C.; Presta, R.; Montanari, R.; et al. Radiologists’ perceptions on AI integration: An in-depth survey study. Eur. J. Radiol. 2024, 177, 111590. [Google Scholar] [CrossRef] [PubMed]
- Eaden, J.; Mayberry, M.K.; Mayberry, J.F. Questionnaires: The use and abuse of social survey methods in medical research. Postgrad. Med. J. 1999, 75, 397–400. [Google Scholar] [CrossRef]
- Boynton, P.M.; Greenhalgh, T. Selecting, designing, and developing your questionnaire. BMJ 2004, 328, 1312–1315. [Google Scholar] [CrossRef]
- Burns, K.E.; Duffett, M.; Kho, M.E.; Meade, M.O.; Adhikari, N.K.; Sinuff, T.; Cook, D.J.; for the ACCADEMY Group. A guide for the design and conduct of self-administered surveys of clinicians. Can. Med Assoc. J. 2008, 179, 245–252. [Google Scholar] [CrossRef]
- Vasilev, Y.; Vladzymyrskyy, A.; Mnatsakanyan, M.; Omelyanskaya, O.; Reshetnikov, R.; Alymova, Y.; Shumskaya, Y.; Akhmedzyanova, D. Questionnaires Validation Methodology; State Budget-Funded Health Care Institution of the City of Moscow “Research and Practical Clinical Center for Diagnostics and Telemedicine Technologies of the Moscow Health Care Department”: Moscow, Russia, 2024; Volume 133. [Google Scholar]
- Cane, J.; O’connor, D.; Michie, S. Validation of the theoretical domains framework for use in behaviour change and implementation research. Implement. Sci. 2012, 7, 37. [Google Scholar] [CrossRef]
- Collins, D. Pretesting survey instruments: An overview of cognitive methods. Qual. Life Res. 2003, 12, 229–238. [Google Scholar] [CrossRef]
- The Scientific Research Institute of the Health Care Organization and Medical Management Department of the Moscow City Health Department. Staffing by Radiologists of Medical Organizations in Moscow. Available online: https://niioz.ru/news/obespechennost-vrachami-rentgenologami-meditsinskikh-organizatsiy-moskvy/?ysclid=ly49aem2en293951322 (accessed on 30 September 2024).
- Arifin, W.N. A Web-based Sample Size Calculator for Reliability Studies. Educ. Med. J. 2018, 10, 67–76. [Google Scholar] [CrossRef]
- Diamond, I.R.; Grant, R.C.; Feldman, B.M.; Pencharz, P.B.; Ling, S.C.; Moore, A.M.; Wales, P.W. Defining consensus: A systematic review recommends methodologic criteria for reporting of Delphi studies. J. Clin. Epidemiol. 2014, 67, 401–409. [Google Scholar] [CrossRef]
- Brown, T.A. Confirmatory Factor Analysis for Applied Research; Guilford publications: New York, NY, USA, 2015. [Google Scholar]
- Schober, P.; Mascha, E.J.; Vetter, T.R. Statistics From A (Agreement) to Z (z Score): A Guide to Interpreting Common Measures of Association, Agreement, Diagnostic Accuracy, Effect Size, Heterogeneity, and Reliability in Medical Research. Anesth. Analg. 2021, 133, 1633–1641. [Google Scholar] [CrossRef]
- Revelle, W. psych: Procedures for Psychological, Psychometric, and Personality Research. Available online: https://CRAN.R-project.org/package=psych (accessed on 30 September 2024).
- Rosseel, Y. lavaan: An R Package for Structural Equation Modeling. J. Stat. Softw. 2012, 48, 1–36. [Google Scholar] [CrossRef]
- Rizopoulos, D. ltm: An R Package for Latent Variable Modeling and Item Response Theory Analyses. J. Stat. Softw. 2006, 17, 1–25. [Google Scholar] [CrossRef]
- Wolak, M.E.; Fairbairn, D.J.; Paulsen, Y.R. Guidelines for estimating repeatability. Methods Ecol. Evol. 2011, 3, 129–137. [Google Scholar] [CrossRef]
- Radiologists’ Perceptions on the Use of AI in Diagnostic Imaging (ATRAI-14). Available online: https://forms.yandex.ru/cloud/66a0f2a502848f1509eae07c/ (accessed on 30 September 2024).
- Irving, L.H.; Smith, C.T. Measure what you are trying to predict: Applying the correspondence principle to the Implicit Association Test. J. Exp. Soc. Psychol. 2020, 86, 103898. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Method | Threshold Values |
|---|---|---|
| Test–retest reliability | Interclass Correlation Coefficient, ICC | <0.5—poor 0.5–0.75—moderate 0.75–0.9—good >0.9—excellent [23] |
| Internal consistency | Cronbach’s alpha | ≤0.5—unacceptable >0.5—poor >0.6—questionable >0.7—acceptable >0.8—good >0.9—excellent [23] |
| Face validity | Experts evaluate whether the questionnaire measures what it intends to measure. | More than 75% of experts [28] |
| Content validity | Experts evaluate whether questionnaire content accurately assesses all fundamental aspects of the topic. | More than 75% of experts [28] |
| Construct validity | Confirmatory factor analysis | Comparative Fit Index (CFI) ≥ 0.9 Root Mean Square Error of Approximation (RSMEA) < 0.08 Standardized Root Mean Squared Residual (SRMR) < 0.08 Tucker–Lewis Index (TLI) ≥ 0.9 [29] |
| Criterion validity | Correlation with visual analogue scale | <0.10—negligible correlation 0.10–0.39—weak correlation 0.40–0.69—moderate correlation 0.70–0.89—strong correlation ≥0.90—very strong correlation [30] |
| Item | Standardized Factor Loadings (SE) | p-Value | |||
|---|---|---|---|---|---|
| Factor 1 Familiarity | Factor 2 Trust | Factor 3 Implementation Perspective | Factor 4 Hopes and Fears | ||
| F1 | 0.71 (0.16) | - | - | - | <0.001 |
| F4 | 0.75 (0.18) | - | - | - | <0.001 |
| T1 | - | 0.86 (0.11) | - | - | <0.001 |
| T2 | - | 0.82 (0.12) | - | - | <0.001 |
| T3 | - | 0.95 (0.12) | - | - | <0.001 |
| T4 | - | 0.79 (0.13) | - | - | <0.001 |
| T6 | - | 0.6 (0.1) | - | - | <0.001 |
| I1 | - | - | 0.88 (0.13) | - | <0.001 |
| I2 | - | - | 0.56 (0.19) | - | 0.003 |
| I4 | - | - | 0.86 (0.11) | - | <0.001 |
| H6 | - | - | 0.75 (0.14) | - | <0.001 |
| H1 | - | - | - | 0.67 (0.17) | <0.001 |
| H4 | - | - | - | 0.35 (0.15) | 0.022 |
| H5 | - | - | - | 0.71 (0.16) | <0.001 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vasilev, Y.A.; Vladzymyrskyy, A.V.; Alymova, Y.A.; Akhmedzyanova, D.A.; Blokhin, I.A.; Romanenko, M.O.; Seradzhi, S.R.; Suchilova, M.M.; Shumskaya, Y.F.; Reshetnikov, R.V. Development and Validation of a Questionnaire to Assess the Radiologists’ Views on the Implementation of Artificial Intelligence in Radiology (ATRAI-14). Healthcare 2024, 12, 2011. https://doi.org/10.3390/healthcare12192011
Vasilev YA, Vladzymyrskyy AV, Alymova YA, Akhmedzyanova DA, Blokhin IA, Romanenko MO, Seradzhi SR, Suchilova MM, Shumskaya YF, Reshetnikov RV. Development and Validation of a Questionnaire to Assess the Radiologists’ Views on the Implementation of Artificial Intelligence in Radiology (ATRAI-14). Healthcare. 2024; 12(19):2011. https://doi.org/10.3390/healthcare12192011
Chicago/Turabian StyleVasilev, Yuriy A., Anton V. Vladzymyrskyy, Yulya A. Alymova, Dina A. Akhmedzyanova, Ivan A. Blokhin, Maria O. Romanenko, Seal R. Seradzhi, Maria M. Suchilova, Yuliya F. Shumskaya, and Roman V. Reshetnikov. 2024. "Development and Validation of a Questionnaire to Assess the Radiologists’ Views on the Implementation of Artificial Intelligence in Radiology (ATRAI-14)" Healthcare 12, no. 19: 2011. https://doi.org/10.3390/healthcare12192011