1. Introduction
Over the last few decades, there has been a vast increase in actuarial research works focusing on modeling costs of a particular claim type based on various claim severity modeling approaches such as
Furthermore, several works have focused on understanding how the claim severity distribution is influenced by certain risk factors. See, for example, (
Frees 2009;
Laudagé et al. 2019;
Tzougas and Jeong 2021;
Tzougas and Karlis 2020) among many more. However, even if the literature in the univariate setting is abundant, the bivariate, and/or multivariate, extensions of such models have not been explored in depth even if in non-life insurance, the actuary may often be concerned with modeling jointly different types of claims and their associated costs.
In this paper, motivated by a European Motor Third Party Liability (MTPL) insurance data set which is described in
Section 4 we introduce a family of bivariate mixed Exponential regression models for joint modeling the costs from positively correlated bodily injury and property damage claims in terms of covariates. The proposed class of bivariate claim severity regression models is based on a mixing between two marginal Exponential distributions and a unit mean continuous and at least twice differentiable mixing density. The modeling framework we consider can account for the positive dependency between the two claim types in a flexible manner since it allows for a variety of alternative distributional assumptions for the mixing density. Furthermore, depending on the choice of the mixing density the bivariate mixed Exponential model can be used to model both moderate and large bodily injury and property damage claim sizes which can be the result of the same accident. At this point, it is worth noting that modeling positively correlated claims and their associated counts for the same and/or different types of coverage, such as home and auto insurance, bundled together under a single policy, has been explored by many articles. See for example, (
Bermúdez and Karlis 2011,
2012,
2017,
2021;
Shi and Valdez 2014a,
2014b;
Abdallah et al. 2016;
Bermúdez et al. 2018;
Pechon et al. 2018,
2019,
2021;
Bolancé and Vernic 2019;
Denuit et al. 2019;
Fung et al. 2019;
Bolancé et al. 2020;
Jeong and Dey 2021;
Gómez-Déniz and Calderín-Ojeda 2021;
Tzougas and di Cerchiara 2021a,
2021b). Furthermore,
Baumgartner et al. (
2015) and
Oh et al. (
2021) consider shared random effects for capturing possible associations between the frequency and severity and/or among the longitudinal claims. However, with the exception of the bivariate, and/or multivariate Pareto model which have been actively studied in the actuarial literature for the case with and without covariates, see, for instance,
Yang et al. (
2011),
Cockriel and McDonald (
2018) and
Jeong and Valdez (
2020), modeling positively correlated claim sizes based on alternative e bivariate, and/or multivariate, mixed Exponential regression models remains a largely uncharted research territory. Therefore, this is the main contribution of this study from a practical insurance business perspective. Additionally, our contribution from a computational maximum likelihood (ML) estimation standpoint is that we develop an Expectation-Maximization (EM) type algorithm
1 which takes advantage of the stochastic mixture representation of the bivariate mixed Exponential regression model for maximizing its log-likelihood in a computationally efficient and parsimonious manner. For expository purposes, the bivariate Pareto (BPA), or Exponential-Inverse Gamma, and bivariate Exponential-Inverse Gaussian (BEIG) regression models are fitted on the MTPL bodily injury and property damage data set.
Finally, it should be noted that when dealing with different types of claims from different types of coverage, such as motor and home insurance, the regressors on the mean parameters may differ according to different individual and coverage-type risk factors. However, in the case of our MTPL data, both mean parameters of the bivariate mixed Exponential regression model are only modeled using common explanatory variables for both claim types. Thus, we extend the proposed setup by pairing a bivariate Normal copula with the PA and EIG regression models. These copula-based models, which can cope with both positive and negative dependence structures, are compared with the BPA and BEIG regression models using a simulated data set in which we assume that we have different types of claims from different types of cover.
The rest of the paper proceeds as follows.
Section 2 discusses how the bivariate mixed exponential regression model can be constructed and the joint probability density functions (jpdfs) of the BPA and BEIG regression models, which are used for demonstration purposes, are derived.
Section 3 deals with parameter estimation for the proposed model based on the EM algorithm. In
Section 4, the models presented in
Section 2 are fitted to the MTPL bodily injury and property damage claims data set and the comparison based on the simulated data set mentioned in the previous paragraph is presented. Finally, concluding remarks are provided in
Section 5.
2. The Bivariate Mixed Exponential Regression Model
Consider a non-life MTPL insurance which contains bodily injury and property damage claims and their associated costs. Please note that it is possible that there exists a positive correlation between the two types of claims we propose the following family of models.
The claim amounts of both types are denoted as
, which are well-defined when there is at least one claim for each type of claim. Furthermore, we consider that conditional on a random effect
, the random variables
are independent exponential random variables with rates
. The random effect
Z is a continuous random variable with density
which takes positive values only and it mainly controls the variation and correlation of the whole bivariate sequence. To avoid the identifiability problem, we have to restrict the expectation
to be a fixed constant and one usually lets
. On the other hand, to account for the impact of heterogeneity between different policyholders, the rates
are modeled as functions of explanatory variables
such that
, where
and
are the corresponding coefficients. Then, the unconditional joint density function,
, of this bivariate sequence
is given by
In the following, for demonstration purposes, we specialize with two different mixing densities, the Inverse Gamma (IGA) and Inverse Gaussian (IG) distributions, which lead to the bivariate Pareto (BPA) and bivariate Exponential-Inverse Gaussian (BEIG) regression models, respectively.
2.1. Bivariate Pareto Regression Model
The general inverse Gamma density function
is defined as
where the mean and variance are
and
. To avoid the aforementioned identification problem, the mean of this density function has to be one. Then we have the following parametrization by letting
and
,
Under this parametrization, the random variable
Z has a unit mean and variance equal to
for
. This density is denoted as
. Then, the joint density of the bivariate Pareto (BPA) regression model is given by
Here, up to a scaling factor, the integrand is the density function of an
distribution. Therefore, the value of the integral is the reciprocal of the normalizing constant. The mean, variance, covariance and correlation in the case of the BPA model are given by
2.2. Bivariate Exponential-Inverse Gaussian Regression Model
In general, we say that the random variable
X follows a generalized Inverse Gaussian
where
if it has density
where
is the modified Bessel function of the second kind. The random variable X has mean and variance
Then the general inverse Gaussian density
is a special case of Generalized Inverse Gaussian
where the parameter
is fixed. It density function has following form,
Similar to the inverse gamma case, to avoid the identification problem, we have to restrict the mean of
to be one. Then one possible way is to set
. Then the density becomes,
The random effect
Z now has a unit mean and variance
. The unconditional joint density function of the bivariate Exponential-Inverse Gaussian (BEIG) can be derived as follows
The integrand above is, up to a scaling constant, the density of a
. Therefore, the integral value is the reciprocal of the normalizing constant. The mean, variance, covariance and correlation in the case of the BEIG model are given by
3. The EM Algorithm for the Bivariate Mixed Exponential Regression Model
In this Section, an Expectation-Maximization (EM) algorithm is applied to facilitate the maximization likelihood estimation of the bivariate mixed Exponential regression model.
Consider the observed bivariate response sequence
and the corresponding covariates
and
. Furthermore, let
be the parameter space for this model. Then, the log-likelihood function can be written as
The direct maximization of Equation (
10) with respect to parameter space
is complicated. Fortunately, in such cases, the EM algorithm can be used to simplified the maximization problem of Equation (
10). In particular, if we augment the unobserved variable
, then the complete log-likelihood function is given by
The two-steps of EM algorithm are described in what follows.
E-step: The Q-function,
, which is the conditional posterior expectation of Equation (
11), is given by
where
and where the conditional expectation
for any real value function,
, is defined as follows
where the posterior density function is defined as
M-step: After calculating the Q-function, we find its maximum global point, , i.e., we update the parameters by computing the gradient function, , and the Hessian matrix, , of the Q-function. In particular, the Newton–Raphson algorithm is used for maximizing the Q-function and the parameters for the Exponential part and the parameter for the randnom effect part are updated separately as shown below.
- -
For the Exponential part,
where
is the design matrix for
.
- -
For the random effect part, we derive the first and second order derivatives of
and then we take the posterior expectations to construct its gradient functions and the Hessian matrix. In what follows, we derive the derivatives for the IGA and IG densities which were defined in the previous section. Finally, we update
using the one-step ahead Newton iteration
In what follows, we will show how Equation (
11) can be modified in the case of the IGA and IG mixing densities.
4. Empirical Analysis
The study is based on data from automobile policies from a major insurance European company for the underwriting years 2012–2019. This data set contains bodily injury (BI) and property damage (PD) claims and their associated claim costs, denoted by and , respectively, and risk factors that affect both and . An exploratory analysis was conducted so as to select the subset of covariates with the highest predictive power for and . There were 7263 observations in total which met our criteria.
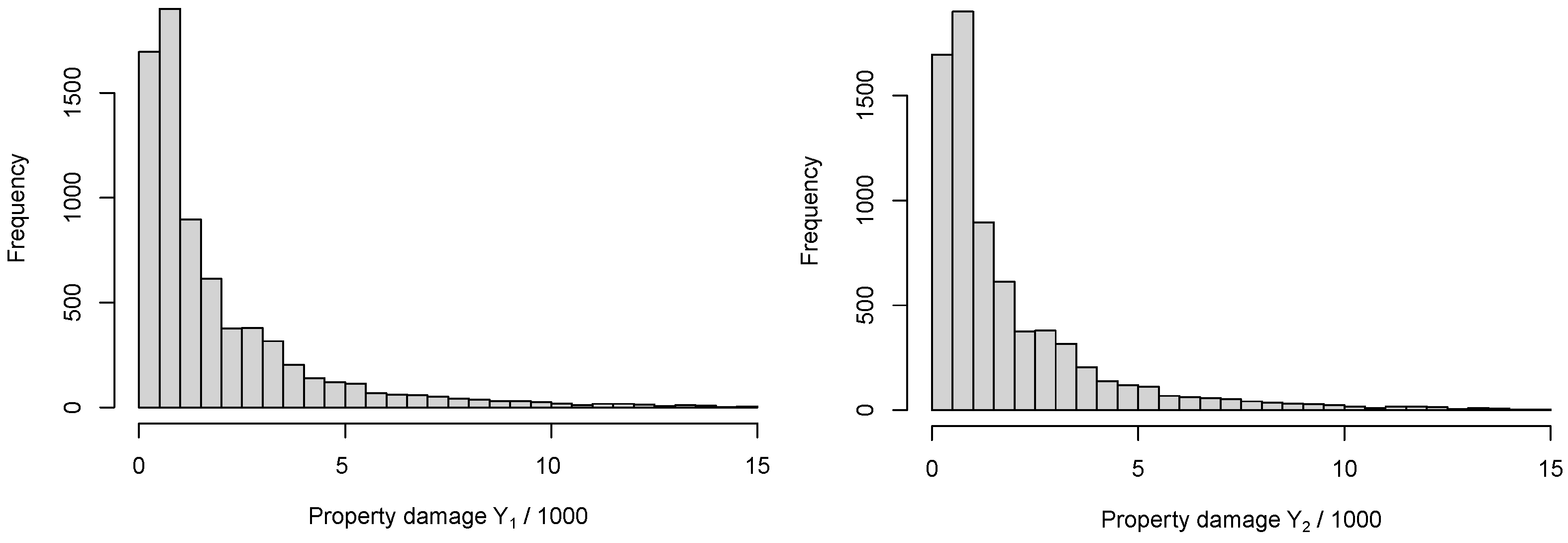
The summary statistics for
and
are shown in
Table 1 and
Figure 1. As was expected, both
and
are positively skewed. Furthermore, the Pearson correlation test indicates that it is appropriate to model both types of claim costs based on a single bivariate model rather than two independent univariate models.
Furthermore, a description of the explanatory variables which we included in the regression analysis for and is provided below.
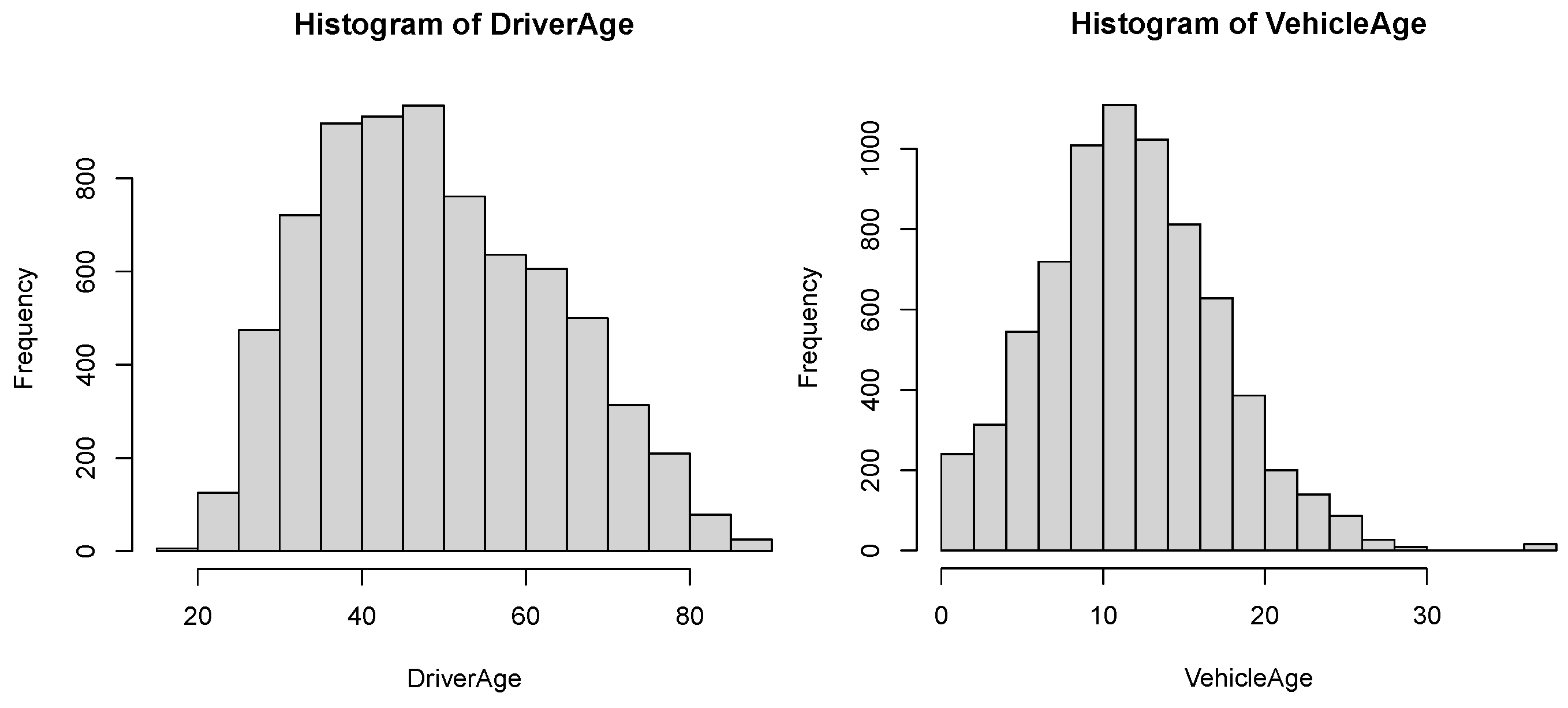
The variable Driver’s age. Policyholders aged 18 to 90 years old.
The variable Vehicle’s age. Vehicles aged 0 to 60 years old.
The variable Car cubism, ’CC’, consists of four categories. Vehicles with horse power ’0–1299 cc’ (C1), ’1300–1399 cc’ (C2), ’1400–1599 cc’ and ’greater or equal 1600 cc’ (C3).
The variable ’PT’ consisted of three types of policy, ’Economic type which includes only MTPL coverage’ (C1) , ’Middle type which includes apart from MTPL coverage other types of coverage’ (C2), and ’Expensive type—Own coverage’ (C3).
The variable ’Region’ consisted of three board regions, ’Capital city’ (C1), ’province cities of the mainland’ (C2), and ’province cities of the island area’ (C3).
Additionally, the empirical distributions of the categorical and continuous explanatory variables are shown in
Table 2 and
Figure 2, respectively.
The BPA and BEIG regression models were fitted to the claim costs
. All computing was made using the
R software. The vector of parameters
was estimated using the EM algorithm which was presented in
Section 3 and their standard deviations were obtained through expressions that were directly produced by the EM algorithm for the observed information matrix of each model. The fit of the competing models was compared by employing the classic hypothesis/specification tests Akaike information criterion (AIC) and Bayesian information criterion (BIC). The results are presented in
Table 3. We see that the values of the estimated regression coefficients of the variables Driver’s Age, Vehicle’s Age and Region have a a similar effect (positive and/or negative) and are almost identical for both response variables in the case of the bivariate claim size models. Furthermore, we observe that the best fitting performances are provided by the BEIG regression models since according to a very well known rule of thumb, two models can be considered to be significantly different if the difference in their respective AIC and SBC values is greater than ten and five, respectively, see
Anderson and Burnham (
2004) and
Raftery (
1995), respectively.
Finally, we consider an extension of the proposed framework using copulas. In particular, the Gaussian copula is paired with the PA and EIG regression models. The copula-based models are compared to the BPA and BEIG regression models using two simulated datasets. The probability density functions of the univariate PA and EIG have similar definitions as those their bivariate counterparts. In particular, we have that
where
for two marginals,
for different policyholders and
are the regression parameters which have the same definition as in
Section 2. Two random samples of size
are generated from the bivariate Gaussian copula which is paired with the PA and EIG marginals, respectively. Then we consider two sets of explanatory variables
that determine the size of
for two marginals. In particular, we assume that
take integer values within the ranges (18–75) and (0–20), respectively. The rest of the variables are considered to be categorical. In particular, we let
have two categories while
has three. Then, we consider that
and
have three and four categories, respectively. All the explanatory variables are generated from the uniform distribution with length
n. The fitting results are shown in
Table 4 and
Table 5, respectively.
5. Concluding Remarks
In this paper, we developed a class of bivariate mixed Exponential regression models which can approximate moderate and large claim costs in an efficient manner based on the choice of mixing density. We illustrated our approach by fitting the BPA and BEIG regression models on MTPL data which were provided by a European insurance company. The proposed family of models can accommodate the positive correlation between MTPL bodily injury and property damage claims and their associated costs, when explanatory variables for each type of claims are taken into account through regression structure for their mean parameters.
The main achievement is that we developed an EM-type algorithm which is computationally efficient. This was demonstrated by obtaining reliable estimates when applying the models to the read data. Finally, the standard errors of estimated parameters were easily produced as byproducts of the algorithm.








{kind=link}
{kind=link}