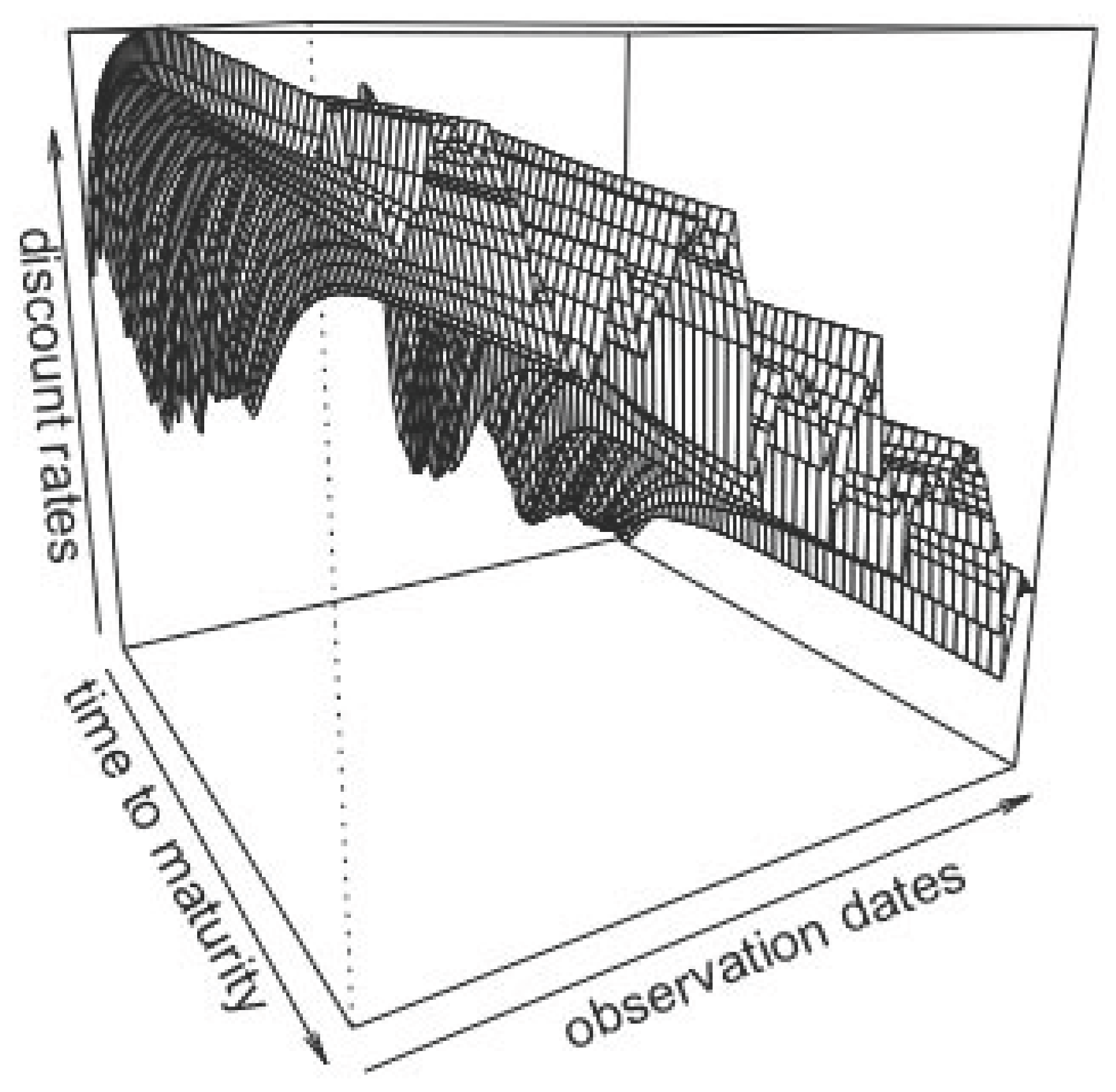
Appendix A.1. Mean Forecast and Confidence Intervals for αi,t, i = 1,…,3 Forecasts
:
alpha1 y_lo80 y_hi80 y_lo95 y_hi95
13 0.7432724 0.6852024 0.8013425 0.6544620 0.8320829
14 0.7357374 0.6776673 0.7938074 0.6469269 0.8245478
15 0.7378042 0.6797342 0.7958742 0.6489938 0.8266147
16 0.7408417 0.6827717 0.7989118 0.6520313 0.8296522
17 0.7407904 0.6827204 0.7988604 0.6519800 0.8296009
18 0.7404501 0.6823801 0.7985201 0.6516396 0.8292605
19 0.7403603 0.6822903 0.7984303 0.6515498 0.8291707
20 0.7403981 0.6823281 0.7984681 0.6515876 0.8292085
21 0.7404788 0.6824087 0.7985488 0.6516683 0.8292892
22 0.7404786 0.6824086 0.7985487 0.6516682 0.8292891
23 0.7404791 0.6824091 0.7985491 0.6516686 0.8292895
24 0.7404758 0.6824058 0.7985458 0.6516654 0.8292863
:
alpha2 y_lo80 y_hi80 y_lo95 y_hi95
13 -1.250640 -1.351785 -1.149495 -1.405328 -1.095952
14 -1.243294 -1.344439 -1.142149 -1.397982 -1.088606
15 -1.241429 -1.342574 -1.140284 -1.396117 -1.086741
16 -1.243868 -1.345014 -1.142723 -1.398557 -1.089180
17 -1.244483 -1.345628 -1.143338 -1.399171 -1.089795
18 -1.241865 -1.343010 -1.140719 -1.396553 -1.087177
19 -1.240814 -1.341959 -1.139669 -1.395502 -1.086126
20 -1.240371 -1.341516 -1.139226 -1.395059 -1.085683
21 -1.240237 -1.341382 -1.139092 -1.394925 -1.085549
22 -1.240276 -1.341421 -1.139131 -1.394964 -1.085588
23 -1.240329 -1.341474 -1.139184 -1.395017 -1.085641
24 -1.240308 -1.341453 -1.139163 -1.394996 -1.085620
:
alpha3 y_lo80 y_hi80 y_lo95 y_hi95
13 4.584836 4.328843 4.757406 4.215410 4.870840
14 4.546167 4.307253 4.849862 4.163634 4.993482
15 4.527651 4.201991 4.803004 4.042913 4.962082
16 4.513810 4.216525 4.850160 4.048812 5.017874
17 4.517643 4.176214 4.828735 4.003502 5.001446
18 4.523109 4.203064 4.866713 4.027406 5.042371
19 4.522772 4.178489 4.848760 4.001079 5.026170
20 4.521846 4.191833 4.866066 4.013374 5.044524
21 4.521382 4.177560 4.854171 3.998472 5.033259
22 4.521451 4.186714 4.864755 4.007248 5.044222
23 4.521772 4.178995 4.857897 3.999300 5.037591
24 4.521862 4.184734 4.864155 4.004903 5.043987
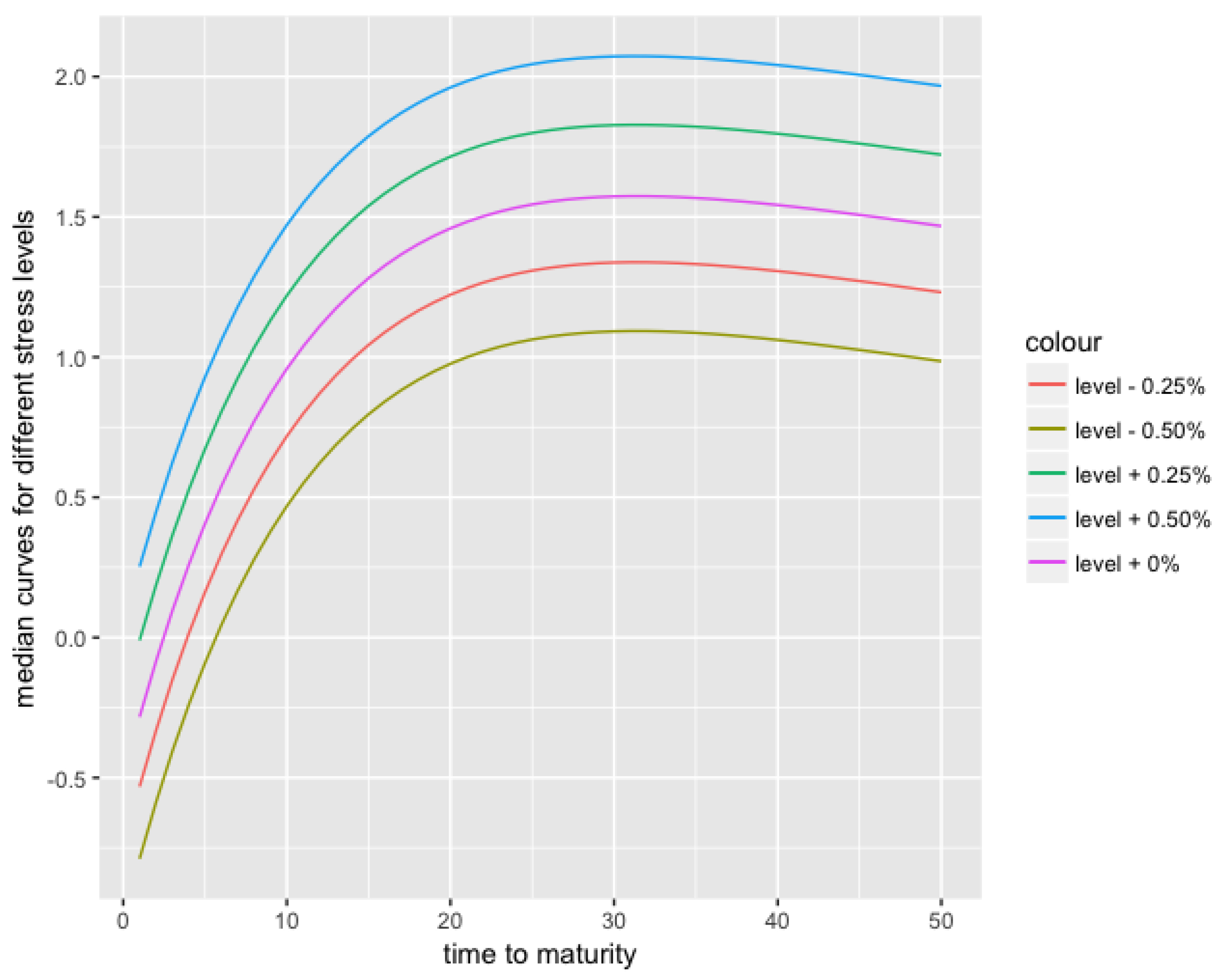
Appendix A.2. Stressed Forecast (α1,t + 0.5%) and Confidence Intervals for αi,t, i = 1,…,3 Forecasts
:
alpha1 y_lo80 y_hi80 y_lo95 y_hi95
13 1.25 1.19193 1.30807 1.16119 1.33881
14 1.25 1.19193 1.30807 1.16119 1.33881
15 1.25 1.19193 1.30807 1.16119 1.33881
16 1.25 1.19193 1.30807 1.16119 1.33881
17 1.25 1.19193 1.30807 1.16119 1.33881
18 1.25 1.19193 1.30807 1.16119 1.33881
19 1.25 1.19193 1.30807 1.16119 1.33881
20 1.25 1.19193 1.30807 1.16119 1.33881
21 1.25 1.19193 1.30807 1.16119 1.33881
22 1.25 1.19193 1.30807 1.16119 1.33881
23 1.25 1.19193 1.30807 1.16119 1.33881
24 1.25 1.19193 1.30807 1.16119 1.33881
:
alpha2 y_lo80 y_hi80 y_lo95 y_hi95
13 -1.222568 -1.323713 -1.121423 -1.377256 -1.067880
14 -1.219401 -1.320546 -1.118256 -1.374089 -1.064713
15 -1.211361 -1.312506 -1.110216 -1.366049 -1.056673
16 -1.216213 -1.317358 -1.115068 -1.370901 -1.061525
17 -1.215266 -1.316411 -1.114121 -1.369954 -1.060578
18 -1.211474 -1.312619 -1.110329 -1.366162 -1.056786
19 -1.210329 -1.311474 -1.109183 -1.365017 -1.055640
20 -1.209610 -1.310755 -1.108465 -1.364298 -1.054922
21 -1.209648 -1.310793 -1.108503 -1.364336 -1.054960
22 -1.209601 -1.310746 -1.108456 -1.364289 -1.054913
23 -1.209688 -1.310833 -1.108542 -1.364376 -1.055000
24 -1.209653 -1.310798 -1.108508 -1.364341 -1.054965
:
alpha3 y_lo80 y_hi80 y_lo95 y_hi95
13 4.500390 4.244398 4.672961 4.130964 4.786394
14 4.482948 4.244035 4.786643 4.100415 4.930263
15 4.441841 4.116182 4.717194 3.957103 4.876272
16 4.441744 4.144459 4.778094 3.976746 4.945808
17 4.439609 4.098181 4.750701 3.925469 4.923413
18 4.447151 4.127105 4.790755 3.951448 4.966412
19 4.446164 4.101881 4.772152 3.924471 4.949562
20 4.445421 4.115407 4.789641 3.936949 4.968099
21 4.445411 4.101589 4.778200 3.922501 4.957289
22 4.445491 4.110754 4.788795 3.931287 4.968262
23 4.445937 4.103160 4.782062 3.923465 4.961756
24 4.446012 4.108885 4.788306 3.929053 4.968137
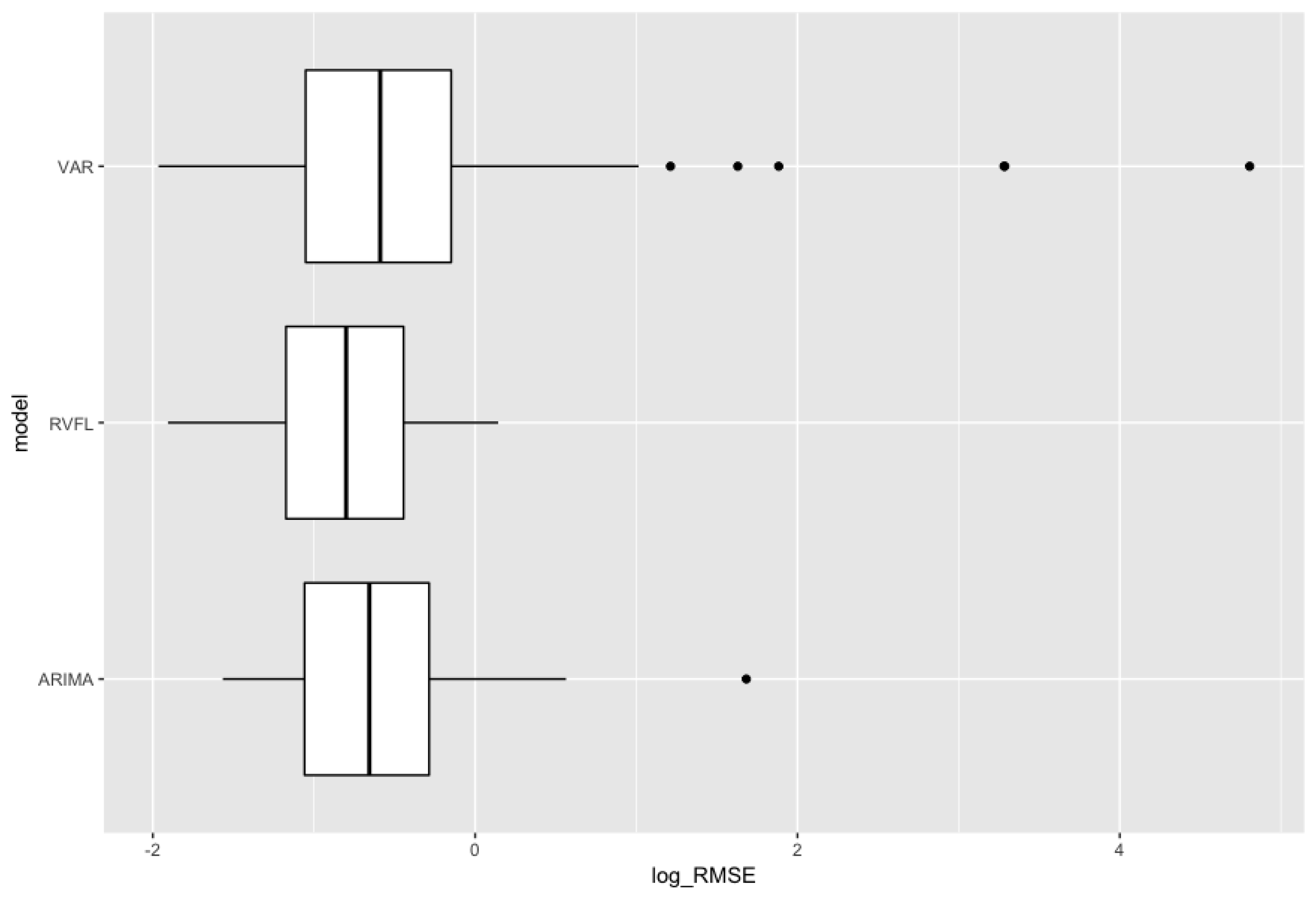
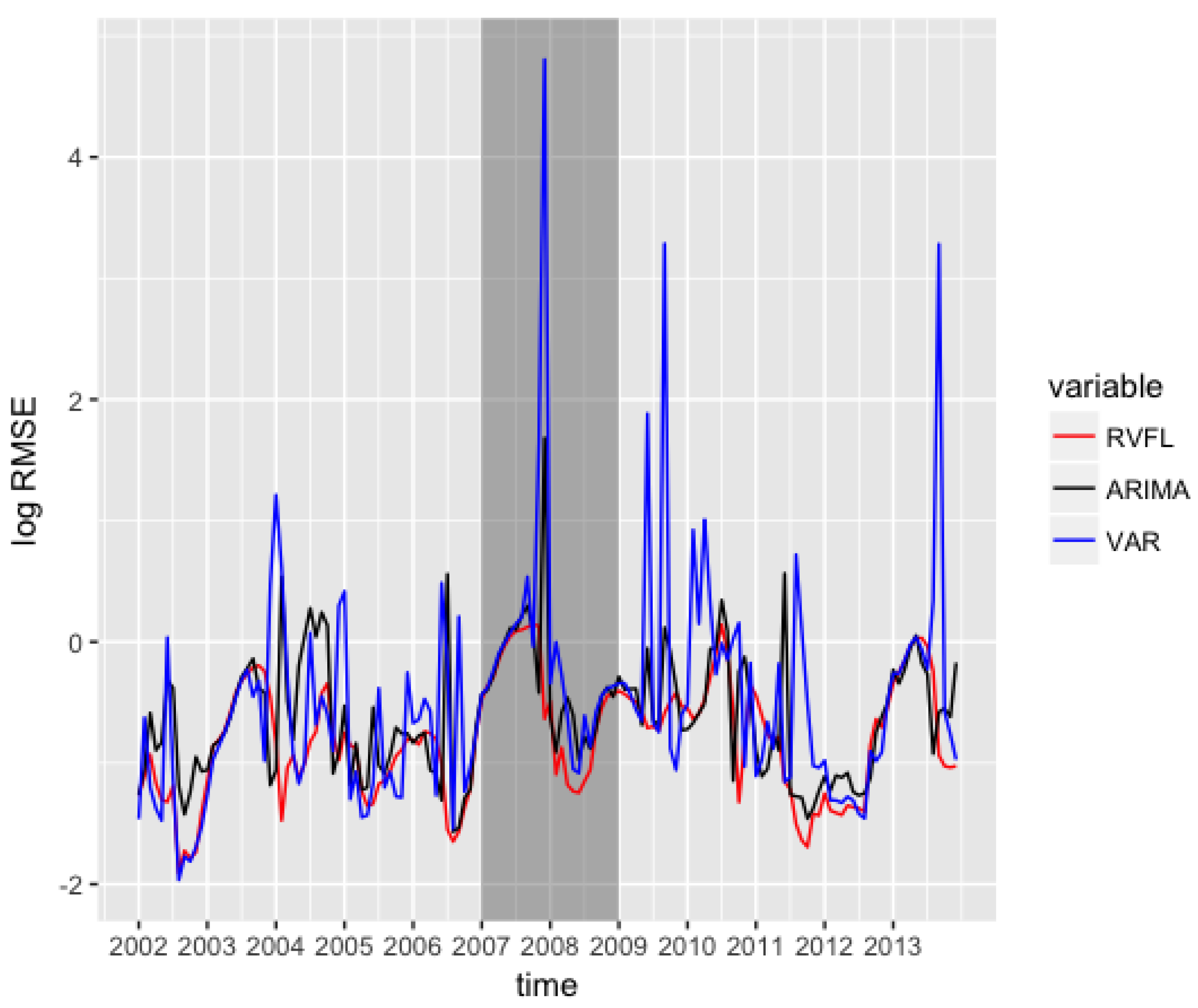
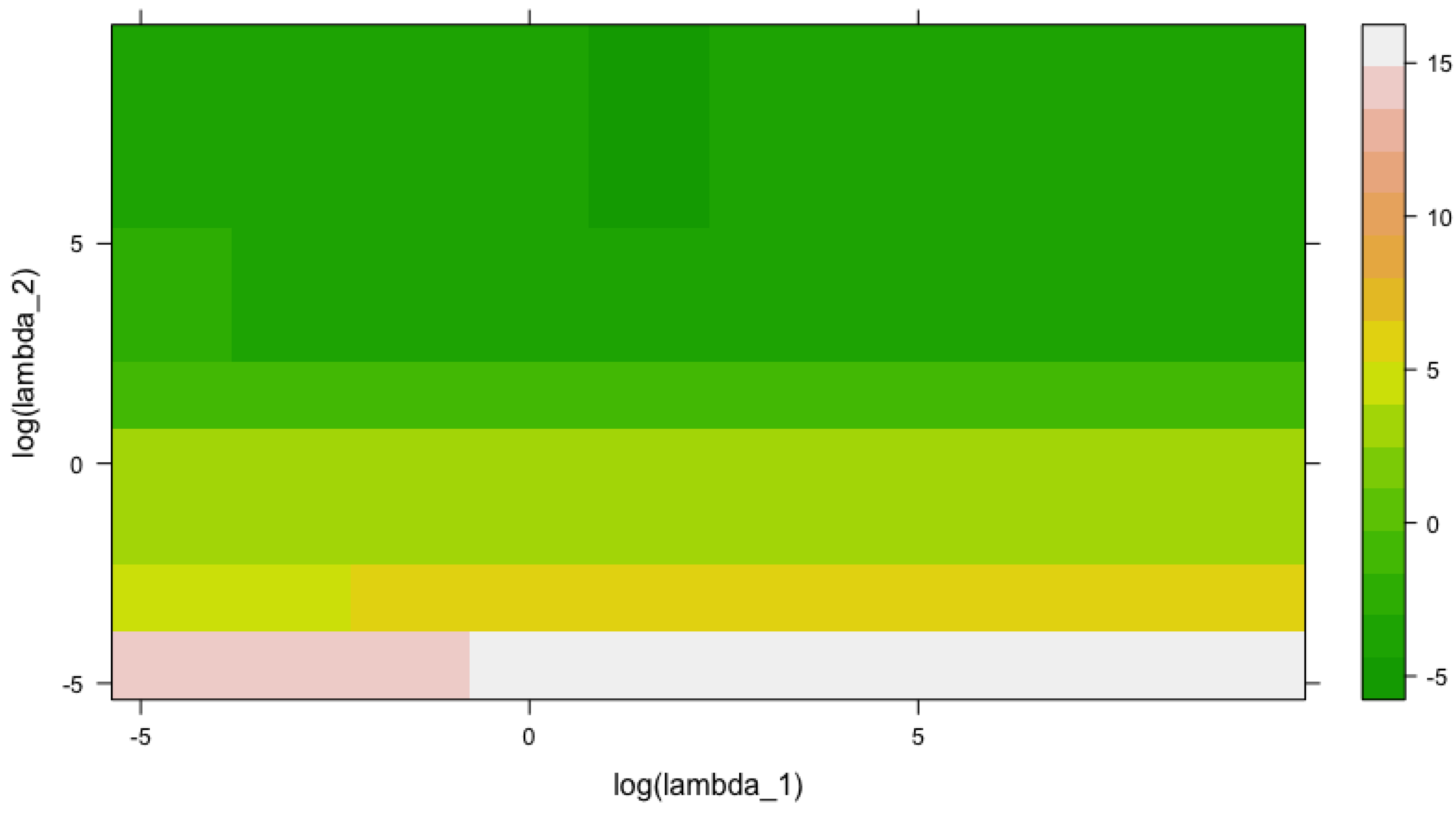
Appendix A.3. Out-of-Sample log(RMSE) as a Function of log(λ1) and log(λ2)
log_lambda1 log_lambda2 log_error
1 -4.605170 -4.605170 13.5039336
2 -3.070113 -4.605170 14.3538621
3 -1.535057 -4.605170 14.7912525
4 0.000000 -4.605170 14.8749375
5 1.535057 -4.605170 14.8928025
6 3.070113 -4.605170 14.8962203
7 4.605170 -4.605170 14.8975776
8 6.140227 -4.605170 14.8976494
9 7.675284 -4.605170 14.8976630
10 9.210340 -4.605170 14.8976715
11 -4.605170 -3.070113 3.9701229
12 -3.070113 -3.070113 4.9644144
13 -1.535057 -3.070113 5.2607788
14 0.000000 -3.070113 5.3208833
15 1.535057 -3.070113 5.3326856
16 3.070113 -3.070113 5.3351784
17 4.605170 -3.070113 5.3357136
18 6.140227 -3.070113 5.3358306
19 7.675284 -3.070113 5.3358557
20 9.210340 -3.070113 5.3358610
21 -4.605170 -1.535057 3.6692928
22 -3.070113 -1.535057 3.5643607
23 -1.535057 -1.535057 3.5063072
24 0.000000 -1.535057 3.4942438
25 1.535057 -1.535057 3.4904354
26 3.070113 -1.535057 3.4881352
27 4.605170 -1.535057 3.4888202
28 6.140227 -1.535057 3.4880668
29 7.675284 -1.535057 3.4886911
30 9.210340 -1.535057 3.4886383
31 -4.605170 0.000000 3.6224691
32 -3.070113 0.000000 3.8313407
33 -1.535057 0.000000 3.8518759
34 0.000000 0.000000 3.8163287
35 1.535057 0.000000 3.7993471
36 3.070113 0.000000 3.7948073
37 4.605170 0.000000 3.7937787
38 6.140227 0.000000 3.7935546
39 7.675284 0.000000 3.7935063
40 9.210340 0.000000 3.7934958
41 -4.605170 1.535057 -1.2115597
42 -3.070113 1.535057 -1.0130537
43 -1.535057 1.535057 -0.5841784
44 0.000000 1.535057 -0.3802817
45 1.535057 1.535057 -0.3109827
46 3.070113 1.535057 -0.2931830
47 4.605170 1.535057 -0.2891586
48 6.140227 1.535057 -0.2882824
49 7.675284 1.535057 -0.2880932
50 9.210340 1.535057 -0.2880524
51 -4.605170 3.070113 -2.0397856
52 -3.070113 3.070113 -3.1729003
53 -1.535057 3.070113 -3.8655596
54 0.000000 3.070113 -3.9279840
55 1.535057 3.070113 -3.9508440
56 3.070113 3.070113 -4.0270316
57 4.605170 3.070113 -4.0831569
58 6.140227 3.070113 -4.0953167
59 7.675284 3.070113 -4.0979447
60 9.210340 3.070113 -4.0985113
61 -4.605170 4.605170 -2.6779260
62 -3.070113 4.605170 -3.4704808
63 -1.535057 4.605170 -4.0404935
64 0.000000 4.605170 -4.2441836
65 1.535057 4.605170 -4.3657802
66 3.070113 4.605170 -4.3923094
67 4.605170 4.605170 -4.3862826
68 6.140227 4.605170 -4.3830293
69 7.675284 4.605170 -4.3820703
70 9.210340 4.605170 -4.3818486
71 -4.605170 6.140227 -3.5007058
72 -3.070113 6.140227 -3.8389274
73 -1.535057 6.140227 -4.1969545
74 0.000000 6.140227 -4.3400025
75 1.535057 6.140227 -4.4179718
76 3.070113 6.140227 -4.3797034
77 4.605170 6.140227 -4.3073100
78 6.140227 6.140227 -4.2866647
79 7.675284 6.140227 -4.2820357
80 9.210340 6.140227 -4.2810151
81 -4.605170 7.675284 -3.7236774
82 -3.070113 7.675284 -4.0057353
83 -1.535057 7.675284 -4.2699684
84 0.000000 7.675284 -4.3569254
85 1.535057 7.675284 -4.4156364
86 3.070113 7.675284 -4.3842360
87 4.605170 7.675284 -4.2759516
88 6.140227 7.675284 -4.2425876
89 7.675284 7.675284 -4.2346514
90 9.210340 7.675284 -4.2328863
91 -4.605170 9.210340 -3.7706268
92 -3.070113 9.210340 -4.0406387
93 -1.535057 9.210340 -4.2776907
94 0.000000 9.210340 -4.3498230
95 1.535057 9.210340 -4.4095778
96 3.070113 9.210340 -4.3860089
97 4.605170 9.210340 -4.2647179
98 6.140227 9.210340 -4.2273624
99 7.675284 9.210340 -4.2183911
100 9.210340 9.210340 -4.2163638












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}