1. Introduction
The problem of determining the distributions of different functions of random variables is one of the most important problems in statistics and mathematics because the distributions of different functions have wide range of applications in numerous areas in economics, finance, risk management, science, and many other areas (see, for example
Donahue (
1964);
Galambos and Simonelli (
2004);
Springer (
1979)). However, thus far, most studies only focus on independence structure with some common distributions of the functions of random variables (see, for instance
Dettmann and Georgiou (
2009);
Garg et al. (
2016);
Springer and Thompson (
1966,
1970);
Yang and Wang (
2013)). There are few studies on determining distributions for statistical models involving dependence structures of some common distributions for several functions of random variables (see, for example
Ly et al. (
2016,
2019);
Joe (
1997)).
Copula, proposed by Abe Sklar in 1959, is a very important theory in mathematics and statistics. The theory has been gaining attention in the past few decades because it has many applications in many areas including economics, finance, and risk management, especially in modeling financial risk and derivatives (see, for example
Cherubini et al. (
2004);
Frey et al. (
2001);
Joe (
1997);
Tang (
2014);
Tran et al. (
2015,
2017) and references therein). Using copula could enable academics to develop a framework for modeling dependence structures for the distributions of product of dependent random variables. Thus, to bridge the gap in the literature, in this paper, we first apply copula to develop a theory to study both density and distribution functions of the product of two and more dependent and independent random variables via copulas to capture the structures among the variables.
In addition, in this paper, we propose an approach combining Monte Carlo algorithm, graphical approach, and numerical analysis to efficiently estimate both density and distribution when parameters vary because the formula of both density and distribution of the product of dependent random variables are very complicated, and it is very difficult, if not impossible, to obtain their exact forms. Thereafter, we illustrate our approach by examining the shapes of both density and distribution of the product of two log-normal random variables on several different copulas, including Gaussian, Student-t, Clayton, Gumbel, Frank, and Joe Copulas. We find that different types of copulas affect the behavior of the distributions differently. For example, the distributions of the product using Gaussian and Student-t copulas behave similarly while the distributions using Clayton, Gumbel, Frank, and Joe copulas also behave similarly with impacts of different degrees. Our findings are useful to academics, practitioners, and policy makers if they need to study the shapes of both density and distribution functions and some common measures for the product of dependent or independent random variables by using different copulas.
The rest of the paper is organized as follows.
Section 2 discusses the background theory for both density and distribution of the product of the random variables while
Section 3 first briefly discusses some simple copula results on bivariate copula and then discusses the results on the high dimensions copula. In
Section 4, we develop the theory for both density and distribution of the product of two or more random variables. In
Section 5, we examine the behavior of the product of two log-normal random variables by using different copulas. The last section concludes.
2. Background Theory
We first discuss some work on copula methods that is related to the problem studied in this paper. Readers may refer to
Ly et al. (
2016) for more information. For a weighted sum of two dependent random variables with special emphasis on the applications in estimating distortion risk measures and diversification, we assume that a portfolio
Y that is a linear combination of two assets
and
with respect to their weights
and
is expressed as follows:
Let
, and
denote the cumulative distribution functions (CDFs) of
,
, and
Y, respectively. Suppose that investors are interested in estimating risks of the portfolio
Y under distortion risk measure (see
Ly et al. (
2016)), given by
where
g is a
distortion function and
is a survival function of
Y. In this model setting, some academics and practitioners are interested in deriving the distribution of
Y. Recall that, if
and
are independent, then it is well-known that one can use convolution product of two density functions
and
to find the density of
Y, given by
Cherubini et al. (
2011) relaxed the independence assumption and used copulas to define a
C-convolution for the dependence case as expressed in the following:
Ly et al. (
2016) further extended the theory by deriving a more general sum of variables, as stated in the following formula:
where
C is a copula
Nelsen (
2007) which captures the dependence structure of
and
. Furthermore, to deal with credit models,
Frey et al. (
2001) expressed the total loss in terms of the aggregation of products of risk factors. Thus, it is necessary to develop formulas for multiplication case. To do this, this study first uses copula to find the density and distribution of the absolutely continuous random variable
Y that is defined by
or the
n-product
for
. We discuss the latter in the next section.
3. Copulas
In this section, we first briefly discuss the simple theory of bivariate copula, and then discuss the theory of high-dimensional copula
Joe (
1997);
Nelsen (
2007). Letting
be the closed unit interval and
be the closed unit square interval, we define the bivariate copula as follows:
Definition 1. (Copula) A two-dimensional copula is a function C: satisfying the following conditions:
- (i)
for any u and .
- (ii)
and for any u and .
- (iii)
for any , and such that and . We have
The most crucial role in the copula theory is Sklar’s Theorem (1959). Specifically, given that
and
are random variables with absolutely continuous marginal distribution functions
and
, respectively, by Sklar’s Theorem (see
Joe (
1997);
Nelsen (
2007)), there exists a unique copula
C such that
where
denotes density of copula
C,
is probability density function (PDF) of
for
, and
is the joint density function of
and
. The copula
C is used to capture the dependence structure of
and
For example,
and
are independent if and only if
;
and
are comonotonic (that is,
, where
f is strictly increasing) if and only if
; and
and
are countermonotonic (that is,
a.s., where
f is strictly decreasing) if and only if
. Copulas can be used not only to model the dependence structures of the variables, but also to capture the correlation between the variables. Thus, Kendall’s coefficient
can be expressed in terms of copulas as shown in the following:
Readers may refer to
Cherubini et al. (
2004);
Joe (
1997);
Nelsen (
2007) for more details on different families of copulas, the concept of dependence structures and measures of dependence with applications. We now define the copula for higher dimension in the following:
Definition 2. A n-copula is a function satisfying:
- (i)
C is grounded; that is, where such that at least one for .
- (ii)
, .
- (iii)
C is an n-increasing function; that is, where for . Then, we have:where the sum is taken over all vertices of the hyperrectangle B, i.e. or and
We illustrate here how to compute
. This information is useful in deriving Equation (
20). Letting
we get
In the special case in two dimensions such that
, we have
, and thus,
In the three-dimensional case with
we have
, and thus,
4. Theory
In this section, we develop the theorems on the probability distribution of the product of dependent random variables by using copulas. We first study the bivariate case.
4.1. Bivariate Model
We first establish the formulas for both density and distribution functions of the two-dimensional case as shown in the following theorem:
Theorem 1. Suppose that is a vector of two absolutely continuous random variables with marginal distributions and , respectively. Let C be an absolutely continuous copula modeling the dependence structure of the random vector and define Y asthen the density and distribution functions of Y arerespectively, where is an inverse function of , c denotes the density of copula C, and is a sign function such that Proof. Then, the inverse transformation is given by
and the Jacobian is
We note that, since
and
are both continuous random variables,
; that is,
almost surely. Hence, the inverse transformation
always exists with probability 1, and thus, we obtain the following joint density of
and
:
and the density of
The CDF of
can then be determined by
Taking
and since
we have
In addition, because the role of
and
can be exchangeable, the density and CDF of
can be obtained as shown in the following:
Thus, the assertions of Theorem 1 hold. □
In a special case in which
and
are independent, applying Equation (
9), we obtain the following corollary:
Corollary 1. When and are independent, the copula has the density and the density of the product of two independent random variables become This result is well known in the literature.
4.2. Multivariate Model
We now turn to extend Theorem 1 to a vector of more than two random variables as stated in the following theorem:
Theorem 2. Supposing that is a vector of absolutely continuous random variables with the marginal distributions , respectively, C is an absolutely continuous copula modeling dependence structure of , and Y satisfies Then, the density and the distribution function of Y arerespectively, in which ; denotes -Volume of the set A defined byc denotes the density of copula C with being a sign function such thatand Proof. Then, the inverse transformation is
with Jacobian
in which
almost surely because all
are continuous random variables with
. Hence, the joint density of
becomes
and, thus, the density of
can be derived as
Thereafter, we let
for
and
. Then, we obtain
,
, and
The CDF of
can then be obtained as follows:
Taking
, letting
, and denoting its compliment set by
, we get
where
denotes
-volume of the set
A calculated via
—dimensional copula
C. Using the sign function
, we obtain the following result:
Thus, the assertions in Theorem 2 hold. □
From Equation (
20), one could notice that it contains the quantity
. Using this result, we obtain the following corollary:
Corollary 2. For , we have and .
This result can be used for the bivariate model and one could easily apply Corollary 2 to obtain Theorem 1. In addition, we obtain the following corollary:
This result can be used for the trivariate model and one could apply Corollary 3 to obtain the density and distribution functions of .
When
are independent, applying Theorem 2, we obtain the following corollary:
Corollary 4. When are independent, Since Equations (
9), (
10), (
19), and (
20) may not have any close form, in this paper, we propose to use the Monte Carlo (MC) simulation method to obtain the solutions of Equations (
9), (
10), (
19), and (
20). We discuss the issue in the next section.
5. Simulation Study
Because the density and the CDF formula of the product
expressed in both (
9) and (
10) that are in terms of integrals are very complicated, we cannot obtain the exact forms of their density and CDF. To circumvent the difficulty, in this paper, we propose to use numerical analysis and graphical approach to examine the behavior of both density and distribution and the changes of their shapes when parameters are changing.
Let
and
be log-normal random variables denoted by
with the following PDF:
for
. Without loss of generality, we assume
and
. We note that, if
and
are independent, then
. In this paper, we consider several dependence structures of
and
through different copula functions and study the shapes of the corresponding PDF and CDF of
Y. For each copula
, the PDF and CDF of
Y can be plotted on the interval
by using the following steps:
- (i)
For each y belonging to the sequence , generate the uniform random variable U on the unit interval; that is, with the sample size N, say N =10,000.
- (ii)
Estimate the values for
and
by using
in which the density copula
and the derivative
can be obtained by using the packages of
VineCopula in
R language.
- (iii)
Plot and , with .
To estimate the mean, median, standard deviation (sd), skewness, and kurtosis of
Y, we first construct the joint distribution of
by using Sklar’s Theorem, as shown in the following. For each copula
, we first obtain the joint CDF of
We then perform 5000 repetitions, to use the following steps for the computation:
- (1)
For each repetition :
- (i)
Generate
from
of sample size
by using the package
copula in
R language and define
- (ii)
Estimate the mean
, median
, standard deviation
, skewness
and kurtosis
of
Y by using the following formula
- (2)
Finally, take the mean for each of the above quantities by using the following formula:
to obtain the estimates of the mean, median, standard deviation (sd), skewness, and kurtosis for
Y.
We first use the above-mentioned algorithm to examine Gaussian Copula and discuss our analysis in the next subsection.
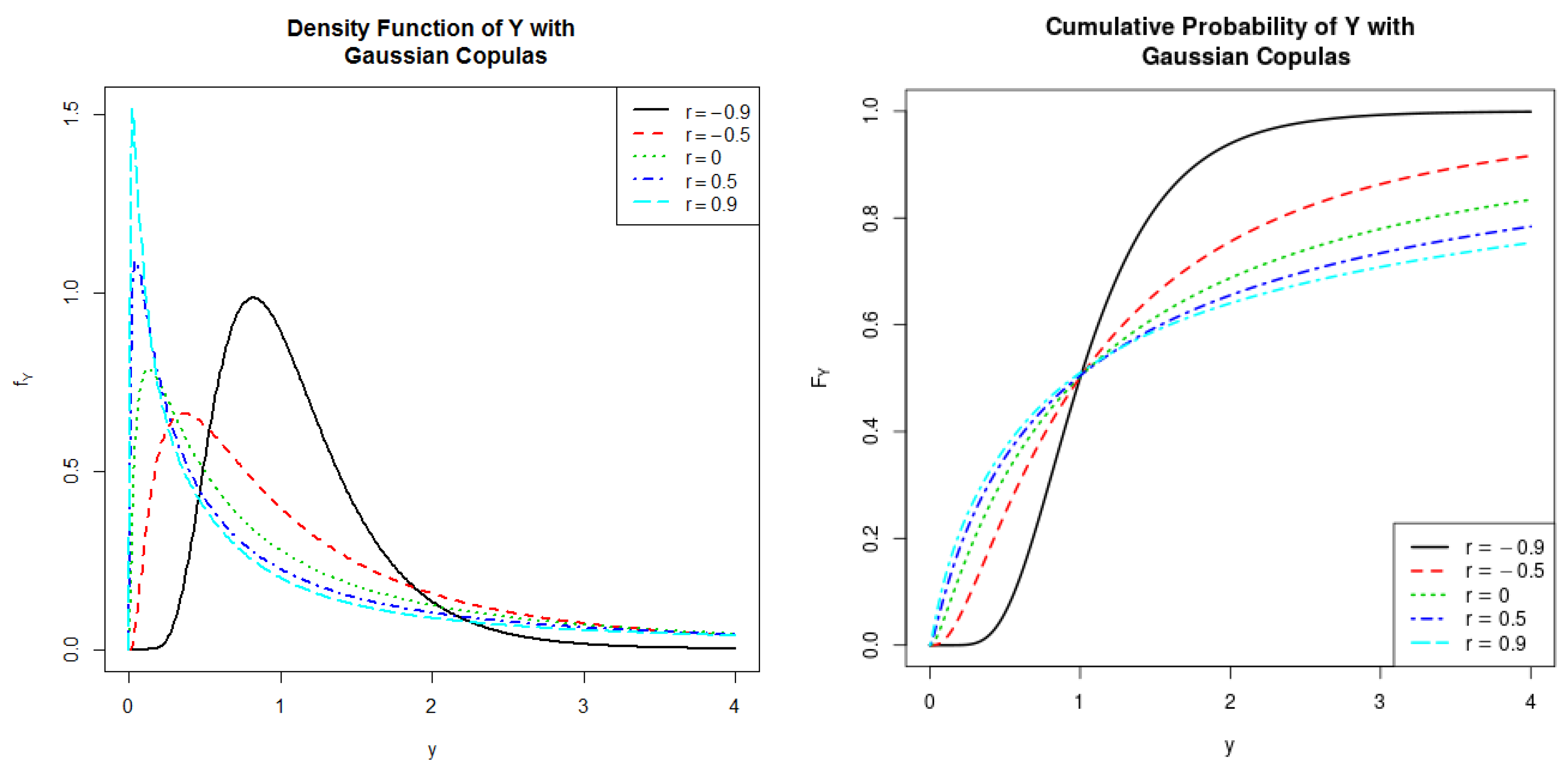
5.1. Gaussian Copula
We first investigate the dependence structure of
and
through the following Gaussian Copula
and observe the shapes of the corresponding distribution for
Y:
where
is the inverse of standard normal CDF and
r is Pearson correlation coefficient between
and
with
. Considering
, and
, we plot both PDFs and CDFs of
Y in
Figure 1 and display some descriptive statistics for
in
Table 1, including the dependence measure Kendall
, mean, median, standard deviation (sd), skewness, and kurtosis. The special case of
corresponds to the situation in which
and
are independent. As can be seen from the graph and table, for parameter
(positive correlation), PDFs of
Y tends to be more right skewed than those from
(negative correlation). When the parameter
r varies from negative values to positive values, one can easily notice that the mean, sd, and kurtosis are all significantly increasing while the median is unchanged.
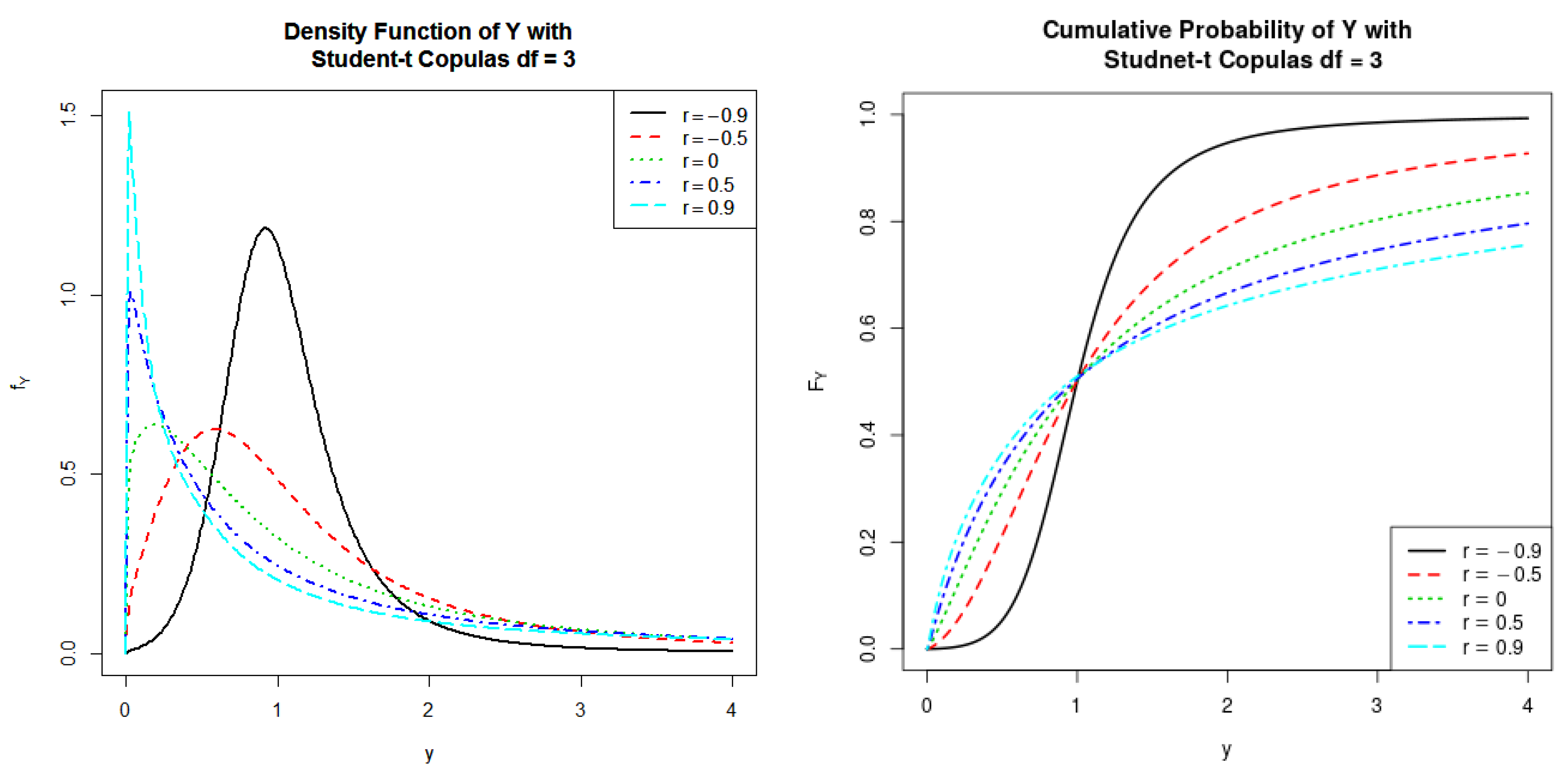
5.2. Student-t Copula
We turn to study the dependence structures of
and
through the following Student-t Copula
:
and investigate the shape of the distribution for
where
is the inverse of Student CDF with
degrees of freedom and
r is the Pearson correlation coefficient between
and
with
and the degree of freedom
.
We illustrate our proposed approach by examining
, and
with
. To do so, we first plot both PDFs and CDFs of
Y in
Figure 2 and exhibit some descriptive statistics for
in
Table 2. Similar to the case of Gaussian copula,
is for the case in which there is no linear correlation. We find that the more positive
r is, the higher the mean and higher the variance of
Y tend to be. However, different from the Gaussian case, Student t-copula can capture the tail dependence between
and
that yields larger kurtosis and larger skewness for
Y than for the case of Gaussian copula.
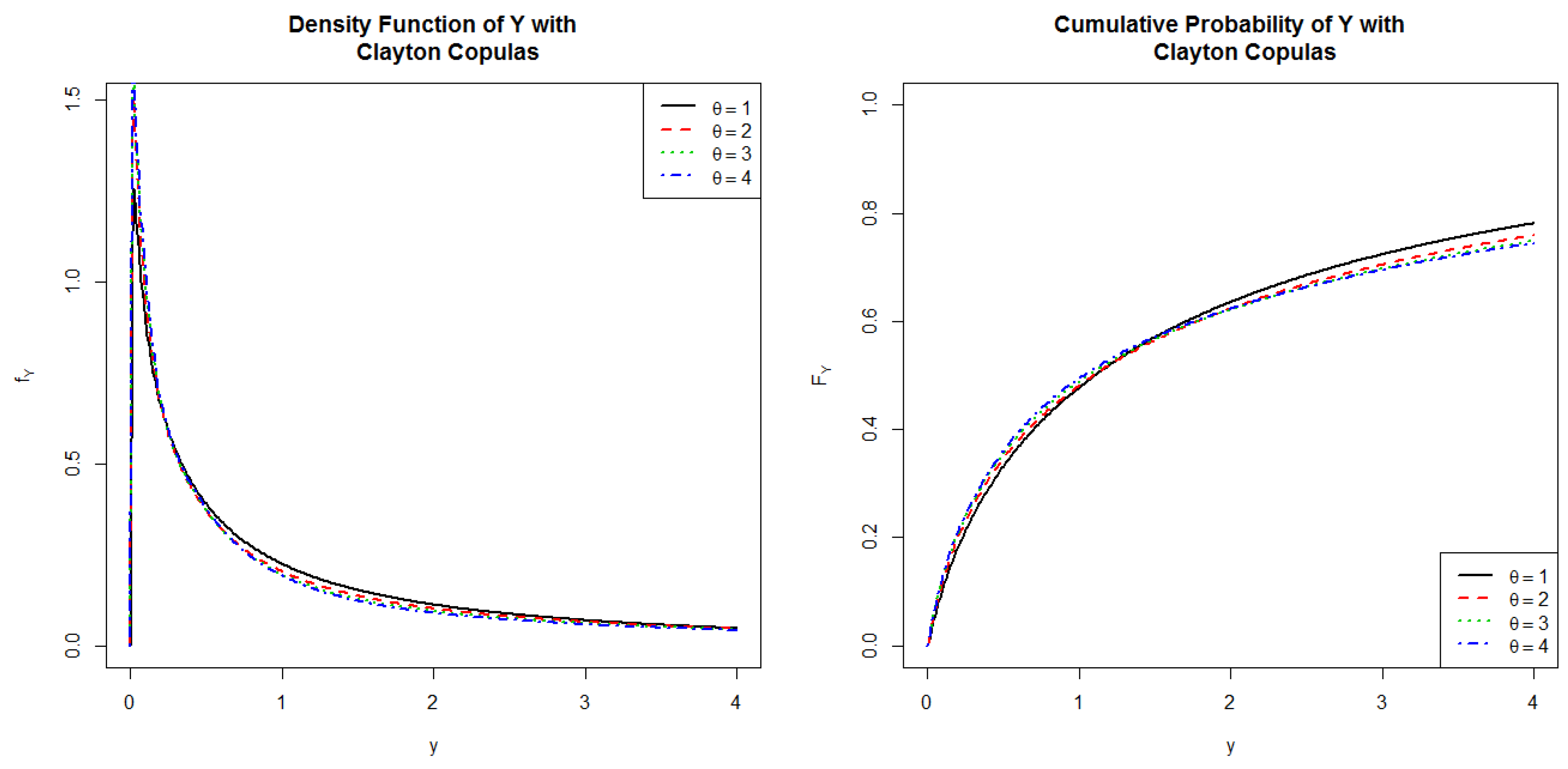
5.3. Clayton Copula
We now investigate the dependence structures of
and
through the following Clayton Copula
:
and examine the shape of the distribution for
Y.
We follow the common practice to use
that leads to the following formula
For
, and 4, we plot both PDFs and CDFs of
Y in
Figure 3. From the results in the figure, we confirm that Clayton copula can be used to model left tail dependence; that is, dependency at small values. We also find that, when parameter
, it becomes more positive dependence and yields higher mean and higher standard deviation for
Y but makes both the right skewness and the fatness of tail (kurtosis) smaller for
Y (see
Table 3).
5.4. Gumbel Copula
We turn to study the dependence structure of
and
through the following Gumbel Copula
:
and investigate the shape of the distributions for
Y.
We plot both PDFs and CDFs of
Y in
Figure 4 for
, and 4. For Gumbel copula,
is for the case in which
and
are independent. In contrast to Clayton, Gumbel copula is used to capture dependency at large values (right tail dependence). Hence, it makes
Y to get bigger mean, higher variance, more right skewness, and heavier tail (kurtosis). However, in this case, the median is clearly smaller than that in the case of Clayton copula (see
Table 4).
5.5. Frank Copula
We next examine the dependence structure of
and
through the following Frank Copula
:
and study the shape of the distribution for
Y.
We plot both PDFs and CDFs of
Y in
Figure 5 for
, and 4 and display some descriptive statistics in
Table 5. For Frank copula, the parameter
is for the case in which the two variables are independent. In addition, the structure becomes more monotonic when
and becomes counter monotonicity when
. Comparing with both Clayton and Gumbel, Frank copula cannot capture left or right tail dependence. It does not affect the median as in the case of both Gaussian and Student-t copulas. However, the mean and the standard deviation are higher and both skewness and fatness are smaller when the value of the parameter increases.
5.6. Joe Copula
Finally, we study the dependence structure of
and
through the following Joe Copula
:
and examine the shape of the distribution for
Y.
We plot both PDFs and CDFs of
Y in
Figure 6 for
, and 4 and display some descriptive statistics in
Table 6. From the results in the figure and table, we find that the dependency captured by Joe Copula is similar to that captured by Gumbel Copula in the way that the variables are independence for
and becomes more monotonic when
. We also find that the variations of all other measures are changing in a similar manner.
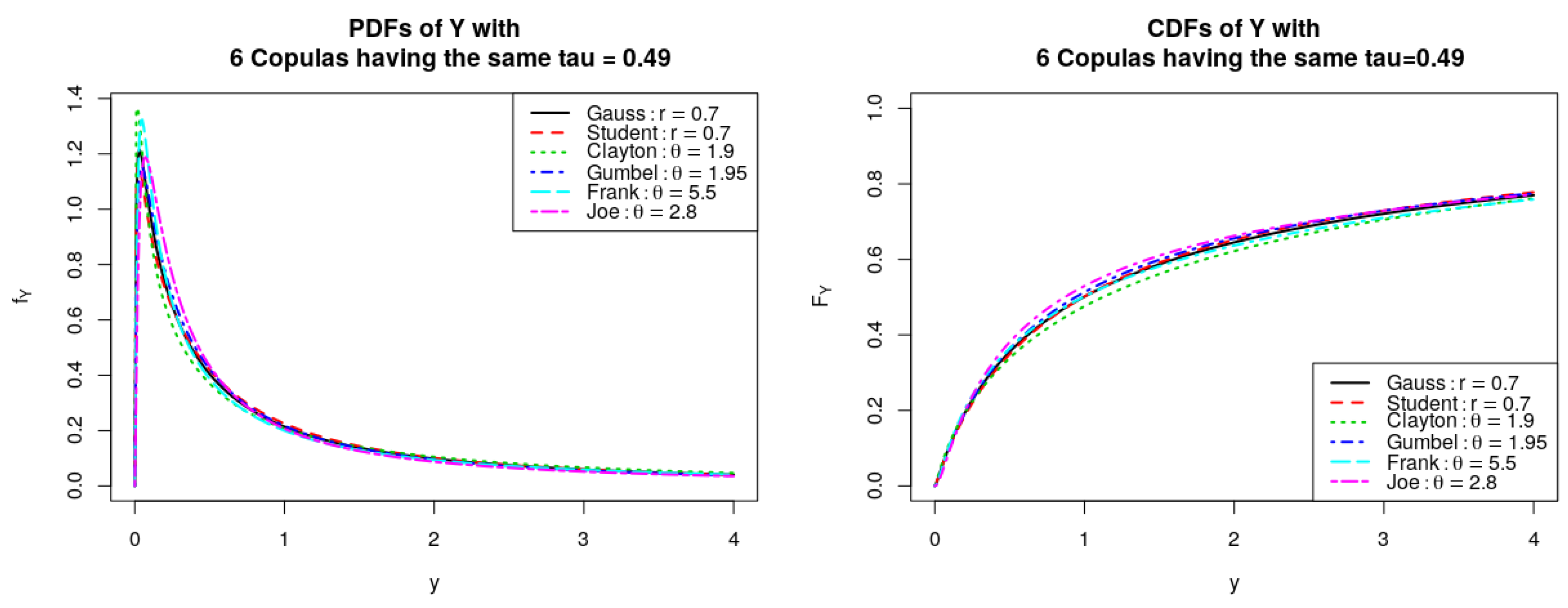
5.7. Comparison of Copulas for the Same Measure of Dependence
In this section, we investigate the effects of the six copulas families as discussed above on the shapes of different distributions for the random variable
when they have the same measure of dependence—the Kendall’s coefficient
. Here, the parameters are chosen to each copula to correspond to Kendall
. We exhibit the corresponding CDFs and PDFs of
Y in
Figure 7, estimate the mean, median, standard deviation, skewness, and kurtosis, and display the values in
Table 7. As can be seen on the table and figure,
Y attains the largest mean (6.84) and standard deviation (44.67) but the smallest median (0.87) when it follows Joe copula. In contrast, Clayton copula produces the smallest mean (0.39) and standard deviation (10.27) but attains the largest median (1.13). Using Student-t copula gets the largest skewness (33.58) and fatness (1876.99), followed by using Gumbel and Joe copulas. On the other hand, using Frank copula gets the lowest skewness (12.59) and the lowest fatness (362.17) for
Y and Gaussian copula is ranked the fourth by mean, sd, skewness, and kurtosis.
6. Conclusions
Determining distributions of the functions of random variables is one of the most important problems in statistics and applied mathematics because it has wide range of applications in numerous areas including economics, finance, risk management, science, and many other areas, especially in modeling financial risk and derivatives. However, most studies only focus on structure for independent variables with some common distributions of the functions for the variables. There are few studies on determining distributions for statistical models involving dependence structure. Nonetheless, to the best of our knowledge, the problem of determining distribution function of product for two or more dependent random variables using copulas has not been studied. Thus, to bridge the gap in the literature, in this paper, we develop the theory to establish the formulas of both density and distribution functions for the product of two and more dependent and independent random variables via copulas to capture the structure among the variables.
Because the density and distribution of the product for dependent random variables are in terms of integrals, the forms of both density and distribution are very complicated, and, thus, it is very difficult, if not impossible, to obtain the exact forms of the density and distribution. To circumvent the problem, in this paper, we propose using Monte Carlo algorithm, graphical approach, and numerical analysis to efficiently compute their complicated integrals and examine the behaviors of both density and distribution and the changes of their shapes when parameters vary.
We illustrated our proposed approaches by using simulation and graphical approaches to study the behavior of the distribution for the product of two log-normal random variables on several different copulas, including Gaussian, Student-t, Clayton, Gumbel, Frank, and Joe Copulas. We found that different types of copulas have different impact on the behaviors of distributions. For example, since both Gaussian and Student-t copulas belong to elliptical family, their distributions of the product behave similarly. On the other hand, because Clayton, Gumbel, Frank, and Joe copulas belong to Archimedean family, their distributions of the product behave similarly but with impacts of different degrees. Furthermore, we found that there are some differences on location, variance, skewness, fatness of tail, and others when the values of the parameters vary.
In this paper, we derive formulas for both density and cumulative probability functions of the product of
n random variables for
. We also propose a Monte Carlo algorithm to compute both density and cumulative probability functions. The Monte Carlo algorithm we proposed enables academics and practitioners to obtain both density and cumulative probability functions easily. Furthermore, we drawn some useful information on the product of two lognormal-distributed random variables. Our results are the foundations of any further study that relies on the density and cumulative probability functions of the product of
n random variables. We note that, although the theory we developed in our paper is not difficult to derive, as far as we know, our findings are new and there is no study obtaining similar results as our findings. Readers may read
Cherubini et al. (
2004);
Nelsen (
2007) for all related theories. Thus, the theory we developed in this paper is new, useful, and the contribution of our paper is important in the literature.
Our findings are useful to academics if studying the shapes and basic measures of both density and distributions of the product of dependent or independent random variables by using different copulas is their interest. Because the product of dependent or independent random variables by using different copulas are widely used in many empirical applications in economics, finance, and many other areas, our findings are useful to practitioners and policy makers in economics, finance, and many other areas if they need to study the shapes of both density and distribution functions for the product of dependent or independent random variables by using different copulas.
Author Contributions
Writing–original draft preparation, S.L. (Sel Ly) and K.H.P.; writing–review and editing, W.K.W.; visualization, S.L. (Sel Ly) and S.L. (Sal Ly).
Funding
This research has been supported by Ton Duc Thang University, Asia University, China Medical University Hospital, Hang Seng University of Hong Kong, Research Grants Council (RGC) of Hong Kong (project number 12500915), and Ministry of Science and Technology (MOST, Project Numbers 106-2410-H-468-002 and 107-2410-H-468 -002-MY3), Taiwan.
Acknowledgments
The authors are grateful to Chia-Lin Chang and Michael McAleer, the Guest Editors, and anonymous referees for substantive comments that have significantly improved this manuscript. The fourth author would like to thank Robert B. Miller and Howard E. Thompson for their continuous guidance and encouragement.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bohrnstedt, George W., and Arthur S. Goldberger. 1969. On the exact covariance of products of random variables. Journal of the American Statistical Association 64: 1439–42. [Google Scholar] [CrossRef]
- Cherubini, Umberto, Elisa Luciano, and Walter Vecchiato. 2004. Copula Methods in Finance. Hoboken: John Wiley & Sons. [Google Scholar]
- Cherubini, Umberto, Sabrina Mulinacci, and Silvia Romagnoli. 2011. A copula-based model of speculative price dynamics in discrete time. Journal of Multivariate Analysis 102: 1047–63. [Google Scholar] [CrossRef]
- Dettmann, Carl P., and Orestis Georgiou. 2009. Product of n independent uniform random variables. Statistics & Probability Letters 79: 2501–3. [Google Scholar]
- Donahue, James D. 1964. Products and Quotients of Random Variables and Their Applications. Technical Report. Fort Collins: MARTIN CO DENVER CO. [Google Scholar]
- Frey, Rüdiger, Alexander J. McNeil, and Mark Nyfeler. 2001. Copulas and credit models. Risk 10: 111–4. [Google Scholar]
- Galambos, Janos, and Italo Simonelli. 2004. Products of Random Variables: Applications to Problems of Physics and to Arithmetical Functions. Boca Raton: CRC Press. [Google Scholar]
- Garg, Mridula, Ajay Sharma, and Pratibha Manohar. 2016. The distribution of the product of two independent generalized trapezoidal random variables. Communications in Statistics-Theory and Methods 45: 6369–84. [Google Scholar] [CrossRef]
- Glen, Andrew G., Lawrence M. Leemis, and John H. Drew. 2004. Computing the distribution of the product of two continuous random variables. Computational Statistics & Data Analysis 44: 451–64. [Google Scholar]
- Joe, Harry. 1997. Multivariate Models and Multivariate Dependence Concepts. Boca Raton: Chapman and Hall/CRC. [Google Scholar]
- Lomnicki, Z. A. 1967. On the distribution of products of random variables. Journal of the Royal Statistical Society Series B (Methodological) 29: 513–24. [Google Scholar] [CrossRef]
- Ly, Sel, Hoang-Uyen Pham, and Radim Briš. 2016. On the distortion risk measure using copulas. In Applied Mathematics in Engineering and Reliability. Boca Raton: CRC Press, p. 309. [Google Scholar]
- Ly, Sel, Kim-Hung Pho, Sal Ly, and Wing-Keung Wong. 2019. Distribution of quotient of dependent and independent random variables using copulas. Journal of Risk and Financial Management. First revision. [Google Scholar]
- Maller, Ross A. 1981. A theorem on products of random variables, with application to regression. Australian Journal of Statistics 23: 177–85. [Google Scholar] [CrossRef]
- Nelsen, Roger B. 2007. An Introduction to Copulas. Berlin: Springer Science & Business Media. [Google Scholar]
- Salo, Jari, Hassan M. El-Sallabi, and Pertti Vainikainen. 2006. The distribution of the product of independent Rayleigh random variables. IEEE Transactions on Antennas and Propagation 54: 639–43. [Google Scholar] [CrossRef]
- Springer, Melvin Dale, and W. E. Thompson. 1966. The distribution of products of independent random variables. SIAM Journal on Applied Mathematics 14: 511–26. [Google Scholar] [CrossRef]
- Springer, Melvin Dale, and W. E. Thompson. 1970. The distribution of products of beta, gamma and Gaussian random variables. SIAM Journal on Applied Mathematics 18: 721–37. [Google Scholar] [CrossRef]
- Springer, Melvin Dale. 1979. The Algebra of Random Variables, 1st ed. Hoboken: Wiley. [Google Scholar]
- Tang, Jiechen, Songsak Sriboonchitta, Vicente Ramos, and Wing-Keung Wong. 2014. Modelling dependence between tourism demand and exchange rate using copula-based GARCH model. Current Issues in Method and Practice 19: 1–19. [Google Scholar] [CrossRef]
- Tran, Duy-Hien, Hoang-Uyen Pham, Sel Ly, and Trung Vo-Duy. 2015. A new measure of monotone dependence by using Sobolev norms for copula. In International Symposium on Integrated Uncertainty in Knowledge Modelling and Decision Making. Belin: Springer, pp. 126–37. [Google Scholar]
- Tran, Duy-Hien, Hoang-Uyen Pham, Sel Ly, and Trung Vo-Duy. 2017. Extraction dependence structure of distorted copulas via a measure of dependence. Annals of Operations Research 256: 221–36. [Google Scholar] [CrossRef]
- Yang, Yang, and Yuebao Wang. 2013. Tail behavior of the product of two dependent random variables with applications to risk theory. Extremes 16: 55–74. [Google Scholar] [CrossRef]
Figure 1.
PDFs and CDFs of the product of two log-normal distributed random variables having Gaussian Copulas.
Figure 1.
PDFs and CDFs of the product of two log-normal distributed random variables having Gaussian Copulas.
Figure 2.
PDFs and CDFs of the product of two log-normal distributed random variables having Student t-Copulas .
Figure 2.
PDFs and CDFs of the product of two log-normal distributed random variables having Student t-Copulas .
Figure 3.
PDFs and CDFs of the product of two log-normal distributed random variables having Clayton Copulas.
Figure 3.
PDFs and CDFs of the product of two log-normal distributed random variables having Clayton Copulas.
Figure 4.
PDFs and CDFs of the product of two log-normal distributed random variables having Gumbel Copulas.
Figure 4.
PDFs and CDFs of the product of two log-normal distributed random variables having Gumbel Copulas.
Figure 5.
PDFs and CDFs of the product of two log-normal distributed random variables having Frank Copulas.
Figure 5.
PDFs and CDFs of the product of two log-normal distributed random variables having Frank Copulas.
Figure 6.
PDFs and CDFs of the product of two log-normal distributed random variables having Joe Copulas.
Figure 6.
PDFs and CDFs of the product of two log-normal distributed random variables having Joe Copulas.
Figure 7.
PDFs and CDFs of the product of two log-normal distributed random variables with six copulas having the same Kendall coefficient.
Figure 7.
PDFs and CDFs of the product of two log-normal distributed random variables with six copulas having the same Kendall coefficient.
Table 1.
Descriptive Statistics for when follows Gaussian copulas.
Table 1.
Descriptive Statistics for when follows Gaussian copulas.
| r | | Mean | Median | sd | Skewness | Kurtosis |
|---|
| | 1.11 | 1 | 0.52 | 1.51 | 7.30 |
| | 1.65 | 1 | 2.16 | 5.84 | 85.43 |
| 0 | 0 | 2.72 | 1 | 6.77 | 14.27 | 466.41 |
| 0.5 | 0.33 | 4.48 | 1 | 18.21 | 23.23 | 1045.26 |
| 0.9 | 0.71 | 6.68 | 1 | 38.59 | 30.15 | 1585.27 |
Table 2.
Descriptive Statistics for when follows Student-t copulas, .
Table 2.
Descriptive Statistics for when follows Student-t copulas, .
| r | | Mean | Median | sd | Skewness | Kurtosis |
|---|
| | 1.13 | 1 | 1.42 | 3.62 | 2221.42 |
| | 1.92 | 1 | 9.26 | 40.75 | 2562.20 |
| 0 | 0 | 3.30 | 1 | 20.44 | 37.01 | 2182.05 |
| 0.5 | 0.33 | 5.51 | 1 | 32.58 | 34.03 | 1903.21 |
| 0.9 | 0.71 | 6.89 | 1 | 44.09 | 32.31 | 1766.27 |
Table 3.
Descriptive Statistics for when follows Clayton copulas.
Table 3.
Descriptive Statistics for when follows Clayton copulas.
| | Mean | Median | sd | Skewness | Kurtosis |
|---|
| 1 | 0.33 | 3.53 | 1.12 | 8.93 | 13.12 | 403.90 |
| 2 | 0.5 | 4.01 | 1.13 | 10.43 | 12.81 | 389.76 |
| 3 | 0.60 | 4.34 | 1.11 | 11.55 | 12.65 | 379.99 |
| 4 | 0.67 | 4.59 | 1.08 | 12.41 | 12.36 | 359.40 |
Table 4.
Descriptive Statistics for when follows Gumbel copulas.
Table 4.
Descriptive Statistics for when follows Gumbel copulas.
| | Mean | Median | sd | Skewness | Kurtosis |
|---|
| 1 | 0 | 2.72 | 1 | 6.78 | 14.41 | 477.10 |
| 2 | 0.5 | 6.47 | 0.95 | 41.52 | 32.34 | 1756.88 |
| 3 | 0.67 | 7.01 | 0.97 | 44.46 | 31.88 | 1719.80 |
| 4 | 0.75 | 7.19 | 0.98 | 44.83 | 31.66 | 1696.71 |
Table 5.
Descriptive Statistics for when follows Frank copulas.
Table 5.
Descriptive Statistics for when follows Frank copulas.
| | Mean | Median | sd | Skewness | Kurtosis |
|---|
| 1 | 0.11 | 3.10 | 1 | 8.06 | 13.84 | 440.25 |
| 2 | 0.21 | 3.47 | 1 | 9.26 | 13.49 | 419.00 |
| 3 | 0.31 | 3.81 | 1 | 10.35 | 13.07 | 394.79 |
| 4 | 0.39 | 4.11 | 1 | 11.34 | 12.88 | 384.20 |
Table 6.
Descriptive Statistics for when follows Joe copulas.
Table 6.
Descriptive Statistics for when follows Joe copulas.
| | Mean | Median | sd | Skewness | Kurtosis |
|---|
| 1 | 0 | 2.72 | 1.00 | 6.76 | 14.28 | 466.67 |
| 2 | 0.36 | 6.30 | 0.87 | 42.01 | 32.67 | 1789.96 |
| 3 | 0.52 | 6.91 | 0.88 | 44.31 | 31.65 | 1692.84 |
| 4 | 0.61 | 7.11 | 0.90 | 45.01 | 31.79 | 1720.81 |
Table 7.
Descriptive Statistics for in which is modeled with six copulas having the same Kendall coefficient .
Table 7.
Descriptive Statistics for in which is modeled with six copulas having the same Kendall coefficient .
| Copulas | Parameters | | Mean | Median | sd | Skewness | Kurtosis |
|---|
| Gaussian | 0.7 | 0.49 | 5.47 | 1.00 | 26.98 | 27.42 | 1375.98 |
| Student-t | 0.7, | 0.49 | 5.95 | 1.00 | 38.33 | 33.58 | 1876.99 |
| Clayton | 1.90 | 0.49 | 3.97 | 1.13 | 10.27 | 12.74 | 382.27 |
| Gumbel | 1.95 | 0.49 | 6.42 | 0.95 | 41.54 | 32.41 | 1764.93 |
| Frank | 5.5 | 0.49 | 4.47 | 1.00 | 12.58 | 12.59 | 362.17 |
| Joe | 2.8 | 0.49 | 6.84 | 0.87 | 44.67 | 32.37 | 1766.43 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}