Abstract
We focus on two particular aspects of model risk: the inability of a chosen model to fit observed market prices at a given point in time (calibration error) and the model risk due to the recalibration of model parameters (in contradiction to the model assumptions). In this context, we use relative entropy as a pre-metric in order to quantify these two sources of model risk in a common framework, and consider the trade-offs between them when choosing a model and the frequency with which to recalibrate to the market. We illustrate this approach by applying it to the seminal Black/Scholes model and its extension to stochastic volatility, while using option data for Apple (AAPL) and Google (GOOG). We find that recalibrating a model more frequently simply shifts model risk from one type to another, without any substantial reduction of aggregate model risk. Furthermore, moving to a more complicated stochastic model is seen to be counterproductive if one requires a high degree of robustness, for example, as quantified by a 99% quantile of aggregate model risk.
1. Introduction
The renowned statistician George E. P. Box (see Box and Draper (1987)) wrote that “essentially, all models are wrong, but some are useful”. This is certainly true in finance, where many models and techniques that have been extensively empirically invalidated remain in widespread use, not just in academia, but also (perhaps especially) among practitioners. At times, the way models are used directly contradicts the model assumptions: as observed, market prices change, parameters in option pricing models, which are assumed to be time-invariant, are recalibrated, often on a daily basis. Incorrect models and model misuse represent a source of risk that is being increasingly recognised—this is called “model risk”. As a paper by the Board of Governors of the Federal Reserve System put it in 2011 (see Board of Governors of the Federal Reserve System Office of the Comptroller of the Currency (2011)), “the use of models invariably presents model risk, which is the potential for adverse consequences from decisions based on incorrect or misused model outputs and reports”.
In broad terms, one could identify four general classes of model risk that are inherent to the way mathematical models are used in finance, for example, in (but not limited to) option pricing applications:
- Parameter uncertainty (and sensitivity to parameters)—let us call this “Type 0” model risk for short. If model parameters need to be statistically estimated, then they will only be known up to some level of statistical confidence, and this parameter uncertainty induces uncertainty regarding the correctness of the model outputs. Examples of where this type of risk is considered explicitly in the literature include Löffler (2003); Bannör and Scherer (2013) and Kerkhof et al. (2010).
- Inability to fit a model to a full set of simultaneous market observations —this is “calibration error”, let’s call this “Type 1” model risk for short. “Calibration” in this context refers to choosing model parameters in such a way that prices for derivative financial instruments that are implied by the model match market prices at one given point in time. Thus, calibration error on single-time-point (a.k.a. “cross-sectional”) market data means that these data already contradict the model assumptions. The classical example of this is the Black/Scholes implied volatility smile.
- Change in parameters due to recalibration—let us call this “Type 2” model risk for short. Once one moves from one day to the next, this aspect of model risk becomes apparent: in order to again fit the market as closely as possible, it is common practice in the industry to recalibrate models. This recalibration results in model parameters (which the models assume to be fixed) changing from day-to-day, contradicting the model assumptions.
- The “true” dynamics of state variables do not match model dynamics—let us call this violation of model assumptions “Type 3” model risk. The classical example of this is the econometric rejection of the hypothesis that asset prices follow geometric Brownian motion, thus invalidating the key assumption in the seminal model of Black and Scholes (1973). This type of model risk is considered, for example, in Kerkhof et al. (2010), who also relate this to identification risk, which they define as risk that “arises when observationally indistinguishable models have different consequences for capital reserves”. Boucher et al. (2014) present a method for making value-at-risk more robust with respect to this source of model risk by “learning” from the results of model backtesting. Type 3 model risk would impact, in particular, the effectiveness of hedging strategies based on a model, for example Detering and Packham (2016) take the approach of measuring model risk that is based on the residual profit/loss from hedging in a misspecified model.
Note that there is a gradual transition between the different types of model risk and, depending on one’s modelling choices, to a certain extent one can trade off one type of model risk against another. For example,
- Less stringent requirements of an exact fit to market observations (Type 1) allows for less frequent recalibration (Type 2).
- Instead of different model dynamics (Type 3), one could consider a parameterised family of models (Type 2).
- Regime-switching models “legalise” changes in parameters, so Type 2 becomes more like Type 3.
- Adding parameters shifts model risk from Type 1 to Type 2 (or, to a certain extent, to Type 0).
- Adding state variables shifts model risk from Type 2 to Type 3.
Glasserman and Xu (2014) propose relative entropy as a consistent pre-metric by which to measure model risk from different sources. What matters in the application of mathematical models in finance is the probability distributions tha the models imply, either under a “risk-neutral” probability measure (for applications to relative pricing of financial instruments) or the “physical” (a.k.a. “real-world”) probability measure (for risk management applications such as the calculation of expected shortfall). Breuer and Csiszár (2016) call this distribution model risk. Each type of model risk manifests itself as some form of ambiguity about the “true” probability measures that should be used for these purposes, and being able to quantify different types of model risk in a unified setting while using a pre-metric for the divergence between distributions (like relative entropy) allows for one to make an informed choice about the trade-offs between different sources of model risk. Glasserman and Xu (2014) postulate a “relative entropy budget” defining a set of models that are sufficiently close (in the sense of relative entropy) to a nominal reference model to be considered in an evaluation of model risk expressed as a “worst case” expectation—i.e., a worst-case price or a worst-case risk measure. However, they say little as to how one typically would obtain a specific number for this “relative entropy budget”. In a sense, we invert this problem by noting that higher relative entropy between model distributions indicates higher model risk, and propose a method to jointly evaluate model risk of two types, based on how this model risk manifests itself when option pricing models are calibrated and recalibrated to liquid market instruments.
We focus on the model risk that is inherent in the calibration and recalibration (i.e., in the above terminology, Types 1 and 2) of option pricing models, and to illustrate our approach we consider the models of Black and Scholes (1973) and Heston (1993), thus comparing the most classical option pricing model with its popular extension incorporating stochastic volatility. Clearly, if (as is often the case in practice) one solely focuses on calibration error, more frequent recalibration will always be preferred to less, and Heston (1993) preferred to Black and Scholes (1973). The latter point is due to the fact that the Heston model has more parameters than Black/Scholes (four as opposed to one) and an additional, unobserved state variable (the volatility), thus providing more freedom to fit option prices across different strikes.
We quantify calibration and recalibration risk in both models applied to equity option data, and also explore the trade-off between these two types of model risk, finding that there is no longer a trivial answer to the question which model and recalibration frequency should be preferred when these two sources of model risk are considered in a unified framework.
The rest of the paper is organised, as follows. Section 2 introduces a framework for the joint evaluation of model risk due to calibration error and model recalibration. Section 3 discusses the numerical implementation of the method. Section 4 presents the results that were obtained by applying this method to option price data, and Section 5 concludes.
2. Quantifying Model Risk by Relative Entropy
As noted above, model risk is reflected in the ambiguity with regard to the “correct” probability distribution to use for relative pricing or risk assessment. Following Glasserman and Xu (2014), we quantify this ambiguity while using the divergence between probability measures. In the present context, these can be classified as divergence measures that are defined as a function , satisfying
where S is a space of all probability measures with a common support. More specifically, most divergence measures belong to the class of f-divergence (see e.g., Ali and Silvey (1966); Csiszár (1967) or Ahmadi-Javid (2012)), which gives the divergence between two equivalent measures as:
where f is a convex function of the Radon–Nikodym derivative satisfying . Kullback–Leibler divergence (a.k.a. relative entropy) is the most common f-divergence, which assigns . It is noted that the methodology of this paper applies to all types of statistical distances in principle, athough, in the empirical study, the Kullback–Leibler divergence is adopted due to its simplicity and widespread use.
2.1. Quantifying Calibration Error
If we wish to quantify calibration error (Type 1 model risk) in this fashion, then, in Equations (1)–(3), the probability measure P corresponds to the calibrated model and thus is parametric in some form. The probability measure Q, on the other hand, serves as a reference measure exactly matching observed market option prices at a given point in time, unrestricted by the assumptions of the model under consideration. Note that, if we only consider market prices for European options, then these only constrain the risk-neutral distributions Q for a finite number of (discrete) time horizons and, therefore, the requirement (because we are using f-divergence) that Q and P are equivalent measures is not a material restriction—for example, for a fixed time horizon T, the risk-neutral distribution of the underlying asset price implied by a Black and Scholes (1973) model is a probability measure equivalent to the risk–neutral distribution implied by a Heston (1993) stochastic volatility model, because both distributions have a strictly positive density on the same support.
On calibrating an option pricing model, we may regard the measure Q as some non-parametric risk-neutral measure that fits market option prices. However, in practice, the measure Q is not unique, as the market is usually incomplete. For example, based on the result of Breeden and Litzenberger (1978), in order to obtain Q for a single time horizon completely non-parametrically, one would need option prices for a continuum of strikes, which is clearly never available. Therefore, we define the space of all risk-neutral probability measures that fit market prices by .
We may further define the space of probability measures that are given by all possible choices of parameter values for the target model by . The new calibration methodology that is proposed here aims to minimise the calibration error, as quantified by the divergence between the two measures P and Q, taken from their respective spaces, i.e.,
This is to say, the new approach attempts to calibrate a model measure (i.e., a set of model parameters ) and non-parametric perfect fit to the market (at a given point in time) , in a fashion that minimises the calibration error that is expressed by
This is not an end in itself—it is required in order to compare model risk due to the calibration error and model risk due to recalibration (as specified in Section 2.2, below) in a unified framework. Here, it is worth reiterating the point that was made in the introduction, that using relative entropy to quantify model risk due to these two sources is motivated by the role of a “relative entropy budget”, as introduced by Glasserman and Xu (2014) in determining worst-case prices or risk measures—i.e., the greater the relative entropy budget, the worse the worst case outcome, with all other things being equal. Furthermore, choosing relative entropy as the divergence pre-metric means that solving (4) corresponds to what Buchen and Kelly (1996) call the “Principle of Minimum Cross-Entropy” for fitting a risk-neutral distribution to market option prices, and given , can be obtained in closed form—this is exploited in the numerical implementation in Section 3, below.
The classical approaches of model calibration, such as minimising the mean-squared error between model and market prices for options, would be inappropriate in this context, as they would lead to unnecessarily high model risk quantities. It is the choice of divergence measure that informs the calibration procedure, which results in a pair of probability measures, , one of which corresponds to the calibrated model while the other provides a consistent reference measure fitting the market exactly.
2.2. Including Model Risk Due to Recalibration
In order to quantify the model risk due to recalibration, let us consider the more specific case where the model is Markovian in a vector of observable state variables X, the model is characterised by a vector of model parameters , and market prices are given for European option prices of a single maturity T. This last assumption of a single maturity T avoids the need to constrain the choice of Q in order to ensure the absence of calendar spread arbitrage between non-parametric risk-neutral measures for different time horizons—parametric models typically ensure this by construction. If we appropriately constrain Q, this assumption could be lifted.
Thus, a “model” in our context is a mapping from parameters and state variables X at a current time (call it ) to a risk-neutral distribution of an underlying asset (or assets) at time horizon T. The two models that are considered below, Black and Scholes (1973) and Heston (1993), both provide such a mapping. Of course, these models also provide more than that, in particular specifying the dynamics of their respective state variables, but that aspect would fall under “Type 3” model risk not considered here.
Suppose that we solved (4) yesterday (at time ) to obtain a —to be as explicit as possible, denote this by
i.e., this is a (conditional) probability measure that is defined on all -measurable events, where the conditioning is on the state variables at time , , and we write in order to express that the time realisations of the state variables are known at the time that these probabilities are evaluated. We write the subscript to express that these probabilities are evaluated in a model with parameters that are calibrated by solving (4) at time . Furthermore, denote the non-parametric measure that results from solving (4) at time by .
Now, if we recalibrate today (at time ) by solving (4), we obtain and
We can then define the model risk quantity due to recalibration, as
which is the divergence between the (conditional) probability measures that were evaluated at time , where one measure is based on the recalibrated parameters and the other is based on the previously calibrated parameters (thus, expressing, in terms of divergence, the inconsistency with the model assumptions due to the fact that we are going “outside of the model” to change parameters in recalibration). The aggregate of calibration error and model risk due to recalibration is then
i.e., the divergence between the non-parametric probability measure obtained by solving (4) at time , and the non-recalibrated parametric probability measure, consisting of probabilities that are conditional on the state at time , but based on model parameters that were obtained by solving (4) at time . However, this approach minimises the divergence between the reference distribution and the recalibrated distribution, thus arguably overstating the divergence to the non-recalibrated (i.e., model-consistent) distribution and, therefore, overstating the aggregate model risk .
Alternatively, we may choose as the non-parametric reference distribution at time
resulting in a lower aggregate model risk of
Note that is still obtained by solving (4), because both and represent non-parametric probability measures that fit observed market prices exactly, so remains the best available parametric fit to the market at time ( is only used to determine minimum divergence of the non-recalibrated model to a measure giving a perfect fit).
In the heuristic schematic shown in Figure 1a, point A represents , being the parametric probability measure “closest” to the set of non-parametric probability measures fitting the market exactly, where point C represents . If we do not recalibrate at time , then we end up with the parametric probability measure (point B), to which (point D) is the “closest” non-parametric probability measure fitting the market exactly. Note that these graphs are for the purpose of heuristic illustration only—in particular, we are not requiring that the two sets of probability measures are convex.
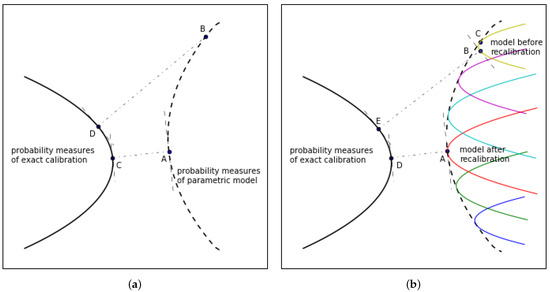
Figure 1.
Graphic illustration of the mathematical definitions of model risks for (a) observable state variable, (b) latent state variable.
In the case of Kullback–Leibler divergence, if Type 1 (calibration error) and 2 (recalibration) model risk involve independent Radon–Nikodym derivatives, then, in the first case considered above, the aggregate model risk equals the sum of the two components. In fact, the Radon–Nikodym derivatives, as random variables, take the key role in evaluating the two types of model risk. At the time the model is recalibrated, we again consider the optimisation (4), with now changed to reflect the change in observed market prices, so we have the following Radon–Nikodym derivatives:
Abbreviating as P and
as , the aggregate risk can be expressed in terms of and , as
If and are independent, then . The total model risk is equal to the sum of the calibration risk and recalibration risk. In our empirical exploration in Section 4, below, we found that this equality is followed quite well by the Black–Scholes model. However, it typically does not hold in the Heston model, suggesting substantial dependence (of Radon–Nikodym derivatives) between the calibration error and model risk due to recalibration. This already foreshadows the clear trade-off between calibration error and model risk, due to recalibration in the model that is better able to calibrate to option prices across different strikes (i.e., the Heston model) due to its larger number of parameters. If this greater freedom to fit the market reduces calibration error, but effectively only pushes the model risk from Type 1 to Type 2, this dependence between and is to be expected.
2.3. The Treatment of Latent State Variables
A model may also involve one or more latent state variables. An example of that is the class of stochastic volatility models where the volatility is taken as a latent state variable, rather than a model parameter (in the empirical examples in Section 4 below, we specifically consider the model of Heston (1993), which falls into this category). Under the framework of a single stochastic volatility state variable, a model that is specified by a given set of parameters forms a one-dimensional manifold (Figure 1b) for possible realisations of the state variable, rather than a point in the Black/Scholes world (Figure 1a).
Thus, the model that we are now considering is Markovian in a vector of state variables , where the state variables X are observable and the state variables V are latent (unobservable). Subsequently, the initial calibration problem (4) becomes
where and are the sets of legitimate values of the state variables and the parameters, respectively. is the set of model parameters calibrated to the market, and is the best estimate of the latent state variables under the calibrated model. This effectively treats the latent (unobserved) state variable as an additional parameter to be calibrated, but the recalibration of which does not contribute to (Type 2) model risk, due to recalibration, because it is consistent with the model assumptions for this latent state variable to evolve stochastically. This does shift Type 2 model risk to Type 3, the risk that the state variable dynamics are not (econometrically) consistent with the dynamics that are assumed in the model. However, in the present paper, we deliberately set aside Type 3 model risk for the purposes of our analysis, leaving the integration of all four types of model risk for future research.
The notation in (6) is amended to
At time , we have, for the calibration error,
The model risk due to recalibration is
The aggregate model risk while using from and from in (18) is
or, alternatively, using and determined analogously to (10), i.e.,
which results in
We then have the following Radon–Nikodym derivatives:
Note that the key difference between (12)–(14) and (25)–(27) is that the change in v, being permitted by the model assumptions, does not contribute to the model risk quantities. In (4) and (18), we are deliberately prioritising the minimisation of calibration error, as this is congruent to the (often exclusive) focus of practitioners on calibration error (with little or no regard to model risk due to recalibration). If desired, one could reformulate this approach in order to prioritise the minimisation of aggregate model risk or of model risk due to recalibration.
3. Numerical Implementation
In this section, we outline the numerical scheme for solving the minimisation problems that arise when taking into account calibration error and model risk, due to recalibration in the manner that is described in the previous section, including problems of the type (4) involving the optimal choice of two probability measures. In this case, an iterative process is required, optimising two probability measures Q and P, in turn, until convergence, in the following manner:
- (1)
- Produce from a parametric model that is based on an initial guess of the model parameters (and latent state variables, where required).
- (2)
- Solve, for , via Lagrange multipliers for the constrained problem that minimises .
- (3)
- Solve, for , to obtain model parameters for the that minimises .
- (4)
- Iterate steps 2 and 3: until convergence.
3.1. Step 1
In Step 1, the initial guess may be obtained in several different ways. A common way is to minimise the mean-squared error between model and market option prices at all available strikes (see e.g., Cui et al. (2017)). We opted for the Broyden/Fletcher/Goldfarb/ Shanno (BFGS) algorithm for conducting this initial calibration of the model parameters and (where required) latent state variables. In practice, the particular choice of the initial guess in Step 1 appears to have little impact in our implementation, as Step 4 converged quite quickly.
3.2. Step 2
In Step 2, we solve the following constrained minimisation problem whlie using Lagrange multipliers:
Note that, here, we specify the constraints in the form of expectations under the measure Q, where these expectation are the model prices for our calibration instruments for the model that is based on the non-parametric reference distribution Q. In general, , , and are vectors; thus, (29) is a “stack” of inequality constraints representing observed market prices. Additionally, notice that, for generality, we “relax” each equality constraint into two inequality constraints. This is in order to account for the bid-ask spread of each option traded on the market. The vector denotes a list of bid prices, while the vector contains ask prices. In a simplified scenario, where exact option prices are given, we may set . denotes the vector of discounted option payoffs. By introducing vectors of Lagrange multipliers and , we convert the constrained problem to an unconstrained dual problem,
In the case of Kullback–Leibler divergence, solving the inner problem corresponds to the “Principle of Minimum Cross-Entropy” in Buchen and Kelly (1996). By Equation (11) in that paper, the probability density function of is given in terms of the density of , by
If , then the last term vanishes, representing the problem with exact market prices. If (component-wise) , then the last term reflects a penality on the objective function that is proportional to the difference of the two Lagrange multipliers. Therefore, we may transform the Lagrange multipliers by
and the objective function becomes
Because only appears in the final, negative term, maximising (39) implies that must be as small as possible, so we can set , and the objective function becomes
We can numerically solve the maximization problem by taking its gradient with respect to ,
where the element-wise sign function assigns 1, −1, or 0 to each element of . However, due to the discontinuouity of the sign, function (41) cannot be solved directly in a stable way. In order to bypass this problem, we approximate the sign function with a continuous step function:
We use Powell’s hybrid method in order to solve the multidimensional Equations (41), where controls the steepness of the function and choosing this value is critical for a fast and stable convergence of the method, i.e., with a careful choice of , Step 2 converges quickly.
3.3. Steps 3 and 4
In Step 3, we use the L-BFGS-B algorithm to minimise the divergence with respect to model parameters (or latent variables or both). This step corresponds to the quite standard process of calibrating a parametric option pricing model, and it does not result in any difficulties in obtaining convergence. Step 2 and Step 3 are repeated until convergence. The convergence criterion that is adopted here is that all of the percentage changes of parameters after one iteration do not exceed a certain threshold, say 0.1%. On this “outer” convergence, in practice we did not encounter any difficulties either, which may be due to the convexity of the sets constraining P and Q.
4. Examining the Trade-Off between Calibration Error and Model Risk Due to Recalibration
As an application example of the method that is described in the previous two sections, we consider historical data that consist of daily market prices for call options on Apple (AAPL) and Google (GOOG) stock over a period from 6 January 2004 to 19 December 2008 for AAPL and 4 January 2005 to 19 December 2008 for GOOG. This gives us a reasonably straightforward application example that is free of extraneous complications, while still reasonably covering liquid options and including a period of “interesting” market volatility (August 2007): although these options are of the American type, i.e., permitting early exercise, AAPL and GOOG did not pay any dividends during this period. Thus, the possibility of early exercise may be ignored (see Merton (1973)).
From these data, we remove options that are very far away from the money, restricting the range of strikes from delta 2.5% to delta 97.5%. Furthermore, we remove prices of options that had zero trading volume on a given day, in order to avoid using prices that are likely to be stale.
On these data, we consider two parametric models, Black and Scholes (1973) and Heston (1993)—arguably the two most popular option pricing models available, where the latter introduces a latent variable for stochastic volatility. The unified methodology, quantifying calibration error, model risk due to recalibration, and the aggregate of the two allows for us to explore the trade-off between calibration error (which is, unsurprisingly, reduced by moving from Black and Scholes (1973) to Heston (1993)) and model risk due to recalibration (which has hitherto been largely ignored) when moving from one parametric model to another, as well as when changing the frequency with which the model is recalibrated.
We start by evaluating the calibration, recalibration, and aggregated model risk quantities under a Black/Scholes model, i.e., where the underlying asset price is assumed to follow geometric Brownian motion, with dynamics under the risk-neutral measure that is given by
where r is the continuously compounded risk-free rate of interest and is a constant volatility parameter. In Appendix A, we note that, in the Black/Scholes model, we obtain a simple closed form expression for the recalibration model risk quantity that is defined in (8):
where is the correctly recalibrated Black/Scholes volatility parameter and is the parameter value that was obtained in a previous calibration. This formula is a consequence of the log-normal distribution of returns assumed in the Black/Scholes model.
We can express the aggregate model risk as the sum of the calibration error, the recalibration risk, and a residual. The residual is zero if the likelihood ratios that are involved in the calibration and recalibration risks are two independent random variables, as noted in Equation (15). In practice, the residual usually takes a small non-zero value. In Figure 2, we demonstrate the decomposition of the total model risk into the three components. Unsurprisingly (as it is well documented that the Black/Scholes model cannot fit the implied volatility “smile” observed in most options markets), we see that calibration error typically predominates.
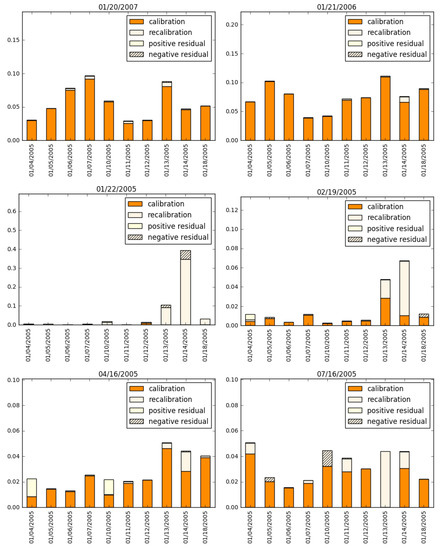
Figure 2.
Decomposition of model risks of Apple (AAPL) options while using the Black/Scholes model as the nominal model, for a selection of option maturity dates (given as the title of each graph). The vertical axis denotes the numerical value of the relative entropy.
In the Heston model, the dynamics (43) are extended in order to allow for stochastic volatility, i.e.,
This model involves two state variables, the underlying asset price and the volatility , and five model parameters: r, , , , and , where is the correlation coefficient between the two Wiener processes:
r is the risk-free rate, and , and relate to the volatility process, with being the rate of mean reversion, the long-run mean, and the volatility of this process.
In our empirical application examples, we take the risk-free rate as one of the financial variables that were observed in the market, but we do not explicitly take the interest rate risk in our empirical analysis into account. For the short-dated options that were considered here, interest rate risk is known to be of relatively little importance—for a discussion of this issue, see e.g., Cheng et al. (2018) and the literature cited therein.
Following Gatheral (2006), Equation (2.13), the risk-neutral probability of exercise of a European call option with strike K in the Heston model is given by
where v is the current value of the volatility state variable , is the time to maturity, and x is the logarithmic forward moneyness of the option, i.e.,
with the time t price of a zero bond maturing in T. Furthermore,
Parameters and are functions of u (Fourier transform variable of x):
It is noted that , since, by definition, is the probability of exercise. Therefore, the probability density function of the risk-neutral measure is obtained:
For simplicity, denotes the ratio of the forward price at t to its spot price at maturity T, i.e., , we derive the risk-neutral probability with respect to y:
can be calculated by fast Fourier transform (FFT). We use this in each step of our iterative procedure, where a risk-neutral probability measure P as a function of the model parameters and state variables is required for the Heston model, i.e., when fitting an initial guess of the model parameters to market option prices in Step 1, when using in Step 2, when solving for in Step 3, and so on.
The decomposition of the total model risk into the three components (the components due to calibration and recalibration, and the positive or negative residual measuring the departure from independence between the first two components) when using the Heston model as the baseline is given in Figure 3. Again, because it is well documented that the Heston model can fit observed option prices better than Black/Scholes, it is unsurprising that, in this case, the relative entropy measuring calibration error is much lower—however, already in this set of example days, it is evident that this comes at the price of increased model risk due to recalibration.
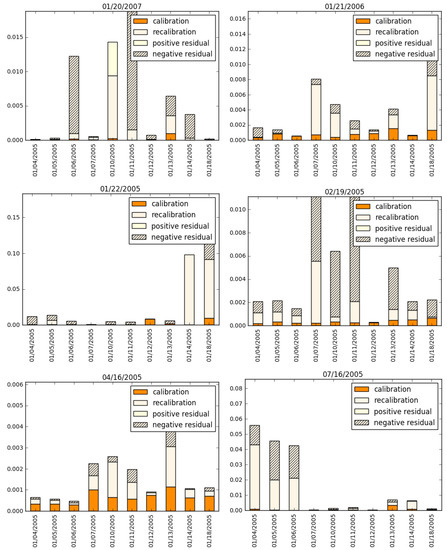
Figure 3.
Decomposition of model risks of Google (GOOG) options while using the Heston model as the nominal model, for a selection of option maturity dates (given as the title of each graph). The vertical axis denotes the numerical value of the relative entropy.
These observations are reinforced when we consider aggregate model risk, calibration error, and model risk due to recalibration over the entire sample period, as presented in Table 1 and Table 2. Note that the absolute numbers refer to relative entropy and, thus, lack direct financial interpretation—what matters are the relative values when comparing the model across models and different recalibration frequencies, in particular when considering the aggregate model risk. Here, we consider recalibrating the Black/Scholes and Heston models either daily, every three days, every week, every two weeks, or every quarter year. Thus, for each model and each recalibration frequency, we get a (for example, daily) sequence of model risk quantities for each of the three types (calibration, recalibration, and aggregate). In each column, we report summary statistics of such a sequence, i.e., its mean, median, and the 99%, 95%, 90%, and 75% quantiles. Note that on days on which we do not recalibrate, the model risk, due to recalibration being zero, because (consistent with the model assumptions) we are keeping previously calibrated parameters unchanged—so, on those days, aggregate model risk is entirely due to calibration error (which increases because the fit to market prices deteriorates when we do not recalibrate).

Table 1.
Model risks (in terms of relative entropy) under different models and recalibration frequencies for AAPL.
Table 2.
Model risks (in terms of relative entropy) under different models and recalibration frequencies for GOOG.
We see that recalibrating more frequently has little effect on the aggregate model risk, neither when using the Black/Scholes model nor when using the Heston model. Essentially, recalibrating more frequently simply shifts calibration error into model risk, due to recalibration, highlighting the dangers in the common practice of focusing solely on the calibration of derivative pricing models, at the expense of all other sources of model risk.
In addition, we observe that if we are interested in “robustness” at a high level of confidence (looking at, say, the 99% quantile of aggregate model risk), moving from Black/Scholes to Heston also does not appear to deliver any advantage (it does yield some improvement at lower quantiles, or average or median, aggregate model risk). This means that, when high levels of confidence are required, any gain in calibration accuracy that is delivered by the Heston model is offset by higher model risk due to recalibration. One should note that this last point holds, even before considering Type 3 model risk, which may well be worse when additional state variables are introduced (as in the Heston model). For these results, in Table 1 and Table 2, we calculated the means, medians, and quantiles across all available option maturities. If we only consider particular maturity “buckets” (i.e., considering only subsets of options, with maturities in a particular range), the same qualitative conclusions are evident—Table 3 and Table 4 illustrate this in the case of daily recalibration.
Table 3.
Model risks (in terms of relative entropy) under different models, by maturity buckets, for AAPL (daily recalibration frequency).
Table 4.
Model risks (in terms of relative entropy) under different models, by maturity buckets, for GOOG (daily recalibration frequency).
5. Conclusions
Under our approach, less relative entropy implies less model risk, and we are able to evaluate two hitherto disparate sources of model risk (calibration error and model risk due to recalibration) in a unified fashion, and examine the potential trade-off between the two. We have considered a simple choice between two models, and between different recalibration frequencies. “Putting a number on model risk” by calculating quantiles for the maximum model risk (quantified by relative entropy) over a time series of market data allows for one to assess the added value (if any) of more complicated stochastic models of financial markets.
One should note that, instead of using a relative entropy pre-metric, one could approach quantifying model risk in terms of optimal-transport distance, while using for example Wasserstein distance, which most recently has become popular for this purpose (see Bartl et al. (2020); Blanchet et al. (2018) and Feng and Schlögl (2018)). In the present paper, we have followed the more established approach while using relative entropy, which, in economics, has its roots in the seminal work of Hansen and Sargent (see e.g., Hansen and Sargent (2006)), as well as a long history of application in other fields, such as thermodynamics and information theory.
In our application, we are deliberately prioritising the minimisation of calibration error, as this is congruent to the (often exclusive) focus of practitioners on calibration error (with little or no regard to model risk due to recalibration). Even in this case, we see that, by including recalibration as one of the sources of aggregate model risk, frequently recalibrating a model to a changing market simply interchanges one source of model risk for another, and more complicated stochastic models may well underperform when aggregate model risk is taken into account.
Author Contributions
Conceptualisation, Y.F. and E.S.; Formal analysis, Y.F.; Investigation, Y.F., R.R., C.B., Q.M. and M.M.; Methodology, Y.F. and E.S.; Resources, E.S.; Software, Y.F.; Supervision, E.S.; Visualisation, Y.F.; Writing-original draft, Y.F. and E.S.; Writing-review & editing, E.S. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data was obtained from IVolatility and are available via https://www.ivolatility.com/data/historical_data2.html.
Acknowledgments
Part of the initial research for this paper was conducted at the Financial Mathematics Team Challenge 2016 at the University of Cape Town. We would like to thank Sam Cohen and Hardy Hulley for helpful comments on earlier drafts of this paper. The usual disclaimers apply.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Derivation of the Recalibration Model Risk Quantity in the Black/Scholes Model
Denote by the risk–neutral probability density of the stock price at time T given the stock price at time 0, in a Black and Scholes (1973) model with volatility . This is given by
Furthermore, denote by the correctly recalibrated Black/Scholes volatility parameter and by the parameter value obtained in a previous calibration. The model risk quantity due to recalibration defined in (8) then becomes
Therefore,
Combining (A5), (A6) and (A10) gives
References
- Ahmadi-Javid, Amir. 2012. Entropic value-at-risk: A new coherent risk measure. Journal of Optimization Theory and Applications 155: 1105–23. [Google Scholar] [CrossRef]
- Ali, Syed Mumtaz, and Samuel D. Silvey. 1966. A general class of coefficients of divergence of one distribution from another. Journal of the Royal Statistical Society: Series B 28: 131–42. [Google Scholar] [CrossRef]
- Bannör, Karl F., and Matthias Scherer. 2013. Capturing parameter risk with convex risk measures. European Actuarial Journal 3: 97–132. [Google Scholar] [CrossRef]
- Bartl, Daniel, Samuel Drapeau, and Ludovic Tangpi. 2020. Computational aspects of robust optimized certainty equivalents and option pricing. Mathematical Finance 30: 287–309. [Google Scholar] [CrossRef]
- Black, Fischer, and Myron Scholes. 1973. The pricing of options and corporate liabilities. Journal of Political Economy 81: 637–54. [Google Scholar] [CrossRef]
- Blanchet, Jose, Lin Chen, and Xun Yu Zhou. 2018. Distributionally robust mean–variance portfolio selection withWasserstein distances. arXiv, arXiv:1802.04885. [Google Scholar]
- Board of Governors of the Federal Reserve System Office of the Comptroller of the Currency. 2011. Supervisory Guidance on Model Risk Management. Technical Report OCC 2011-12 Attachment. Washington D.C.: Office of the Comptroller of the Currency. [Google Scholar]
- Boucher, Christophe M., Jón Danielsson, Patrick S. Kouontchou, and Bertrand B. Maillet. 2014. Risk models–at–risk. Journal of Banking & Finance 44: 72–92. [Google Scholar]
- Box, George E. P., and Norman R. Draper. 1987. Empirical Model–Building and Response Surfaces. Hoboken: Wiley. [Google Scholar]
- Breeden, Douglas T., and Robert H. Litzenberger. 1978. Prices of state-contingent claims implicit in option prices. Journal of Business 51: 621–51. [Google Scholar] [CrossRef]
- Breuer, Thomas, and Imre Csiszár. 2016. Measuring distribution model risk. Mathematical Finance 26: 395–411. [Google Scholar] [CrossRef]
- Buchen, Peter W., and Michael Kelly. 1996. The maximum entropy distribution of an asset inferred from option prices. Journal of Financial and Quantitative Analysis 31: 143–59. [Google Scholar] [CrossRef]
- Cheng, Benjamin, Christina Sklibosios Nikitopoulos, and Erik Schlögl. 2018. Pricing of long-dated commodity derivatives: Do stochastic interest rates matter? Journal of Banking & Finance 95: 148–66. [Google Scholar]
- Csiszár, Imre. 1967. Information-type measures of difference of probability distributions and indirect observations. Studia Scientiarum Mathematicarum Hungarica 2: 299–318. [Google Scholar]
- Cui, Yiran, Sebastian del Baño Rollin, and Guido Germano. 2017. Full and fast calibration of the Heston stochastic volatility model. European Journal of Operational Research 263: 625–38. [Google Scholar] [CrossRef]
- Detering, Nils, and Natalie Packham. 2016. Model risk of contingent claims. Quantitative Finance 16: 1357–74. [Google Scholar] [CrossRef]
- Feng, Yu, and Erik Schlögl. 2018. Model risk measurement under Wasserstein distance. arXiv, arXiv:1809.03641. [Google Scholar] [CrossRef]
- Gatheral, Jim. 2006. The Volatility Surface: A Practitioner’s Guide. Hoboken: John Wiley & Sons. [Google Scholar]
- Glasserman, Paul, and Xingbo Xu. 2014. Robust risk measurement and model risk. Quantitative Finance 14: 29–58. [Google Scholar] [CrossRef]
- Hansen, Lars Peter, and Thomas J. Sargent. 2006. Robustness. Princeton: Princeton University Press. [Google Scholar]
- Heston, Steven L. 1993. A closed–form solution for options with stochastic volatility with applications to bond and currency options. The Review of Financial Studies 6: 327–43. [Google Scholar] [CrossRef]
- Kerkhof, Jeroen, Bertrand Melenberg, and Hans Schumacher. 2010. Model risk and capital reserves. Journal of Banking & Finance 34: 267–79. [Google Scholar]
- Löffler, Gunter. 2003. The effects of estimation error on measures of portfolio credit risk. Journal of Banking & Finance 27: 1427–53. [Google Scholar]
- Merton, Robert C. 1973. Theory of rational option pricing. The Bell Journal of Economics and Management Science 4: 141–83. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).