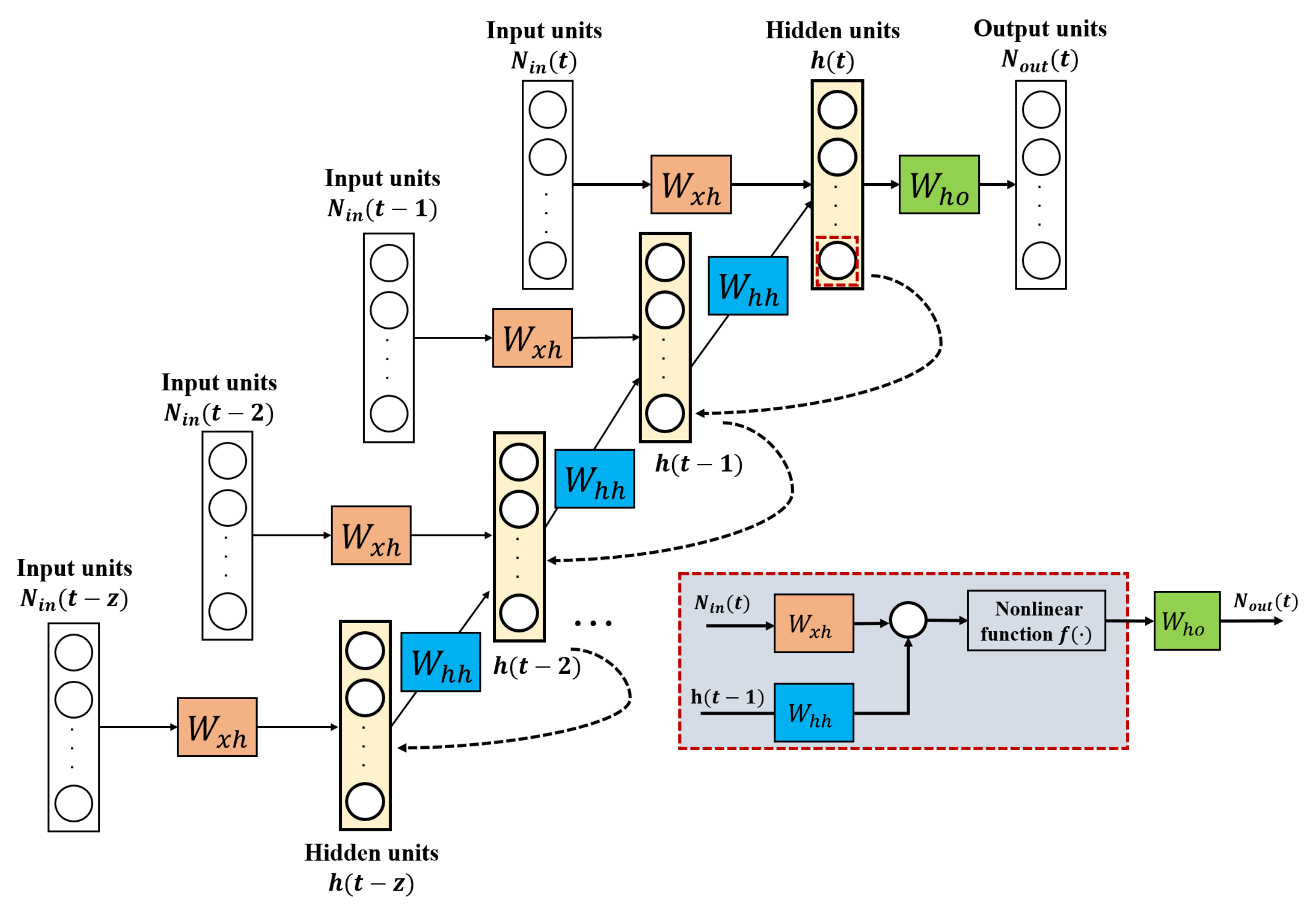
In this section, we introduce the framework of our weight pruning method based on the nonlinear reconstruction error. We aim at effectively removing redundant connections of the whole network, while retaining the control performance of our temperature control system, inspired by the previous neuron pruning by layer-wise and reconstruction methods, which perform pruning operations for every layer connections by minimizing the error between the original and pruned model outputs without any nonlinear activation mapping. These studies focus on effectively compressing the CNN model for visual processing tasks by removing filters or channels until satisfying the given conditions, the optimization problem turns into minimizing the reconstruction error of each layer.
Consider nonlinear characteristics of activation function used in our RNN model, the Rectified Linear Unit (ReLU) always outputs the positive input directly and outputs zero for any negative input. Therefore, if we want to minimize the error between the pruned model and the original model output, it is a direct and effective approach to calculate the error between the nonlinear mapping outputs instead of the incoming values before the activation function. Therefore, we extend the layer-wise neuron pruning approach guided by reconstruction error to our RNN-based model for pratical use in the temperature control system. We train the network parameters after removing a certain proportion of redundant elements by minimizing the least square error between the nonlinear outputs of the pruned and unpruned model. Taking the specific structure of RNN with three layers into account, weight pruning starts from the input and hidden layers, first to minimize the reconstruction error between the hidden layer then move to the output layer. During every iteration of pruning, the greedy algorithm is applied for finding the threshold at a given model sparsity, by ranking the importance of parameters and then eliminating those below the threshold. The masks and weights are updated for every iteration. For forward calculation; each mask is applied to the previous weight matrix by element-wise multiplication operator. On the other hand, each pruning mask is also implemented concerning the corresponding gradients for updating weights during the backpropagation period.
3.1. Related Background
To get a more efficient network and be able to deploy it in the hardware devices, effective model compression methods have attracted more attention in recent years, including weight quantization, weight clustering and weight pruning, etc. The quantization technology reduces the original bit size of the connection parameters to the desired lower bit-width without destroying the network accuracy a lot. In some studies, weight parameters quantified to 8-bit or less can also provide the performance equivalent to 32-bit [
51,
52]. This eliminates the multiplications in calculation and makes the network with irregular weight matrices easier to implement into the hardware. Similarly, the weight clustering assigns weight parameters into different pre-defined clusters and keeps the value same in one cluster. Both of them focus on the redundancy in the representations and are hardware friendly in varying degrees [
53,
54]. Different from the quantization and clustering, the weight pruning focuses on the redundancy in the number of parameters and the redundancy of the two different aspects has a large independence. The redundancy in the number of parameters is usually higher than that in the former. Meanwhile, the reductions in bit representations of each parameter will increase inaccuracy. However, the weight pruning eliminates the less important parameters and it is considered as a regularization method for reducing the DNN model complexity to prevent overfitting. In some cases, it can also increase the accuracy which is superior to the weight quantization [
26]. To some extent, therefore, weight pruning enlarges the reduction boundary of the parameters.
In this paper, we focus on the effective weight pruning for our temperature control system rather than the hardware implementation. Compared to other strategies of regularization, such as L2 regularization which makes the connections close to be zero and then pushed the model to be more sparsified, the dropout technique randomly discards the neurons with a certain probability during training [
55,
56,
57]. The pruning technology commonly adopts more reasonable choices for deciding which connections to be discarded, and can be performed in either individual weights or neurons. Hence, we adopt the pruning method to effectively remove the redundant parameters of our pre-trained RNN-based temperature control model. For the neuron pruning method, the layer-wise pruning approach has been performed to obtain higher accuracy than that directly discarding the unimportant connections in many existing neuron pruning experiments [
33,
58].
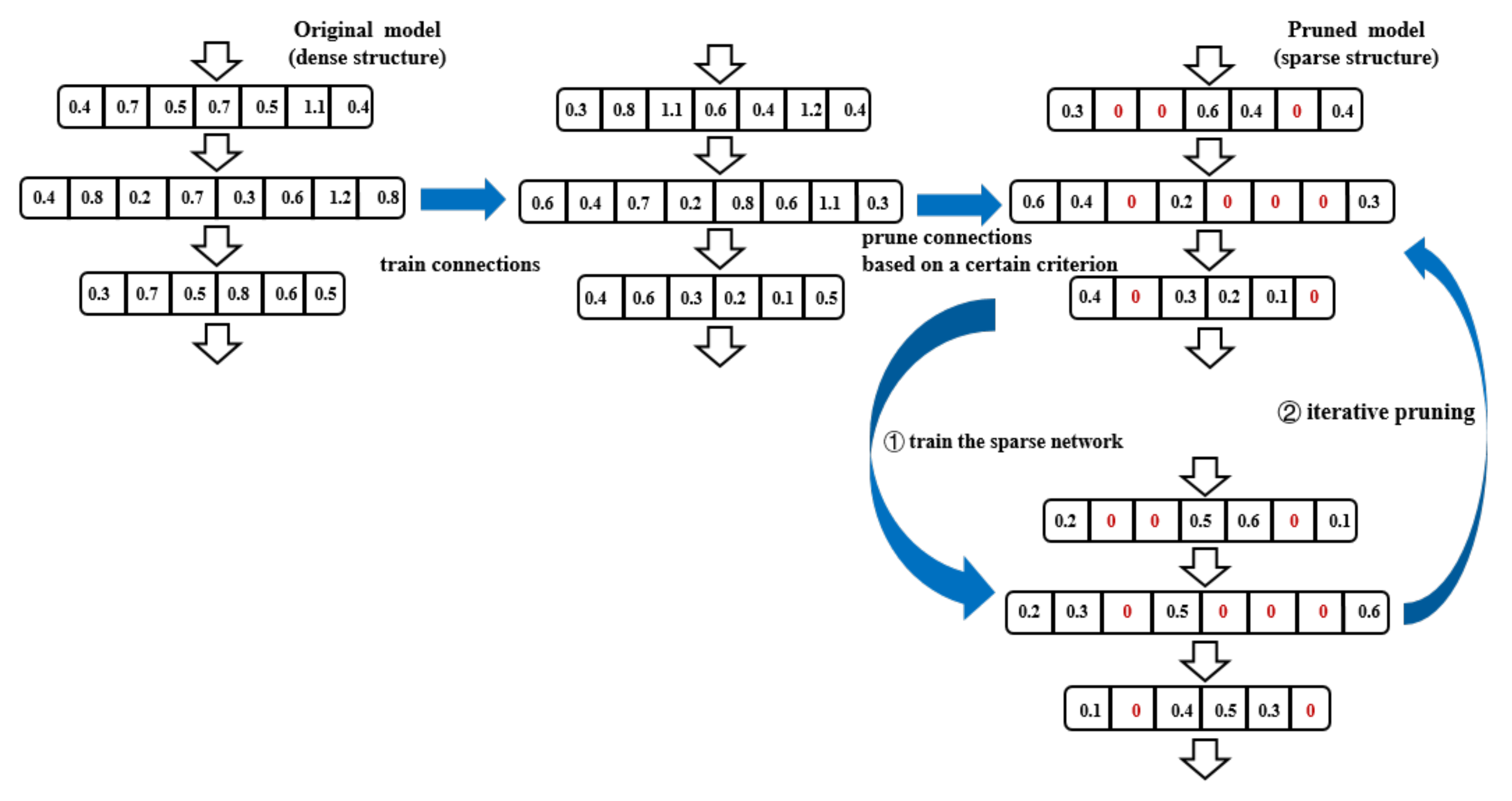
Specifically, whether it is the neuron (channel, filter) pruning or weight pruning of a dense network, the pruning process can be divided into one-shot pruning and iterative pruning. The former first evaluates the importance of connection parameters in the pre-trained model. After that, all unimportant parameters of a certain percentage are directly cut off (by calculated thresholds or other constraints) at once. On the contrary, the iterative pruning flow usually steps up from a low ratio to the targeted compression ratio gradually. Meanwhile, after the pruning operation, the network is usually fine tuned to compensate for lost accuracy, retraining the sparse network with unremoved parameters. The common iterative pruning procedure can be described as in
Figure 7. Those zero values marked in red denote the discarded values.
The original untrained model with a dense structure is first trained to be converged, then iteratively pruning and training operations are applied for achieving the satisfactory performance at a given pruning rate. Therefore, pruning can learn useful connections, while storing the sparse network will help reduce computational burden and storage size with some specific storage formats.
Commonly, the selection for less important parameters to be removed usually rely on a certain criterion calculation, learning which connections are unimportant and then discarding them. Some studies suggested that the impact of parameter changes on the loss function should be evaluated. It is a relatively expensive, time consuming task to compute the loss after eliminating each parameter. The earlier work Optimal Brain Damage and Optimal Brain Surgeon proposed to calculate the Taylor expansion of the gradient of the optimization objective with respect to the weight parameters, which need to compute the Hessian matrices containing the second-order terms or its approximation [
59,
60]. Intuitively, the contribution of each connection in the entire network can be estimated by itself concerning magnitude and smaller numerical value together with a smaller contribution to the entire network performance. Hence, magnitude-based pruning (e.g., absolute values) is the more widely recognized and used method concerning the criteria for selecting unimportant elements to be removed.
3.2. Pruning Implementation
Our pruning procedure is combined with three binary mask matrices in different layers, expressed by , which are in the form of a binary mask, with the same size as the individual weight matrices W with l∈ in our RNN model. They will fix the less important parameters to be zero by ⊙, where ⊙ denotes the element-wise product operation.
We use the symbol
, which denotes the parameters connecting the layer
l with
j units to the last layer
with
i units. The unimportant connections to be removed can be determined by ranking the magnitude-based values of the model; the threshold for discarding those lowest values is calculated for the given pruning rates. For each layer, every connection parameter after the mask operations is expressed as
and can be formulated as:
The detailed procedure of the weight pruning operation for our well-trained RNN-based temperature model is summarized as follows:
Step 1: From the pre-trained model, we extract the input and hidden layers containing weight connections and and put them together to rank these connections based on absolute magnitudes of them. Then the threshold of which values to be removed at the given pruning rate are obtained.
Step 2: Guided by the threshold, the mask vectors for the connection
and
are updated and the unimportant connections removed from the weight matrices are as in Equation (
12), those preserved as 1 and pruned as 0. Then the extracted input–hidden layer performs the forward calculation with the pruned weight matrices and gets the hidden output
.
Step 3: Calculate the least square loss
between the model outputs of original
and
with masked connections, as expressed in Equation (
13), where
represents the
-norm. Modify a standard calculation formulation as written in Equation (
14), the network follows Equation (
15) to do backpropagation (BP) computation with the masked weight vectors
and
.
Step 4: The updated parameters are imported into the network for inferencing and fine tuning the preserved parameters until the network converges.
Step 5: After pruning the connections of input layer and hidden layer, trained parameters and mask vectors are preserved for the output layer pruning, the optimization problem of output layer backs to the objective function (
5); the weights of output layer is removed by the threshold calculated at the pruning rate.
Specifically, for an RNN model at time step
t + 1, the derivation of gradients with respect to the input–hidden
and hidden–hidden
matrices needs to consider the time-step accumulation from t to 0, called backpropagation through time as introduced in Section; we use the chain rule to calculate them at time step
t + 1, written as follows:
3.3. Pruning Results
For various pre-trained ref-model based RNN temperature control models with different size of weight parameters, the same pruning operation is performed to reduce the randomness of results. We perform the same pruning process on the pre-trained networks based on our temperature control system, which consists of 40 hidden units and 120 hidden units, respectively. The weight size of the pre-trained RNN model is
of 40 by 3,
of 40 by 40 and
of 1 by 40; the total weight parameters are 1760. Another is
of 120 by 3,
of 120 by 120 and
of 1 by 120, the total weight parameters are 14,880. The sum of the squared error between the actual temperature output and the proposed ref-model output for the temperature variation (from 100
C–105
C within 10,000 s, containing 20,000 data points) after adding disturbance is calculated as baseline for a comparison between the performance of the pre-trained model and that of the pruned model. The cost values for the pre-trained temperature control models with 40 and 120 hidden units are 2276.8 and 2189.9, respectively. The other basis settings of our pre-trained temperature control models are as described in
Section 2.1.3 above, including the ref-model based RNN model with the initial learning rate of 1.0 × 10
and the Adam optimizer is implemented for adjusting learnable parameters.
First of all, we do the experiments to observe how sensitive each weight matrix of different layers is to the increasing pruning rate. The weight matrices are independently pruned by the increasing pruning rates without retraining and the performances of the pruned model are compared with the initially pre-trained model. The accuracy differences after pruning each weight matrix are plotted in
Figure 8.
The pruning rate indicates what proportion of the original parameters are put away, which set as zero. We do the same pruning operations in the pre-trained model with 40 hidden units and 120 hidden units separately. As
Figure 8a shows, the performance losses after discarding each matrix parameters for given pruning rates are quite different; those of the input–hidden and hidden–hidden layer connections are relatively much higher than those of the hidden–hidden layer. In particular, when the pruning rate for
is greater than about 50% for the network with a 3-40-1 structure, it results in that the performance of the pruned model deteriorates drastically. In contrast, the performance loss of only pruning hidden–hidden layer weights
increased not so significantly as the pruning percentage is higher. Similarly, the performance loss of the network with a 3-120-1 structure after only removing
or
is much bigger than pruning the connections
, as the pruning rate increases over 50%(
Figure 8b). We can find the connections
account for a bigger proportion of all original connections than others initially having more redundancy to reduce. The original model which is more sensitive to the connection
and
decrease with the increasing pruning rates. At the same pruning rates, they result in much more performance loss of the system than
. Therefore, in practice the hidden connection
can be more sharply trimmed than
and
while hurting the system performance less.
Then we do pruning experiments that directly remove the corresponding portion of the overall network parameters and retrain once. It is based on the global measured thresholds corresponding to the pruning rate, which puts all weight connections together and then asseses the importance of each parameter. The control performances of the pruned models with 10, 40 and 120 hidden neurons, respectively, deleting those redundant connections at different pruning rates and results are compared to the initial pre-trained model. Then the accuracies in percentage of the untrimmed model and thresholds with different pruning rates are shown in
Table 4. In addition, the reduced memory overhead of the pruned model can be estimated by the ratio of reduced parameters of each weight matrix. Commonly, the pruned model size with the sparse structure can be saved in compressed sparse row format (CSR) to cut computational expense [
61], the nonzero values can be stored by 32-bit floating-point, 4 bytes, while the row and column indices of each weight parameter are stored as 16-bit, 2 bytes. Hence, the pruned float point operations (FLOPs) with various pruning rates are approximately expressed in kilobyte and listed. The pruning thresholds of different models vary for the original weight distributions.
With the increasing pruning rates, although considering the overall network connections for removing parameter redundancy, it is obvious that the accuracy falls sharply when the pruning rate is over 60% in each model. Because the sparse models can not be directly adaptive to the initial parameters of the pre-trained networks, resulting in the remaining parameters not being able to keep the ideal performance. The damage to a network by deleting a large number of connections at once is not easily remedied. From previous studies [
62,
63], the compressed model obtained by the iterative pruning method is more compact and smaller, although its training cost is higher than that of the one-shot method, which prunes the connections to the desired percentage once. Discarding too many parameters at once can cause irreparable accuracy loss; therefore, it is more reasonable to gradually prune the network connections to the target sparsity.
Here, we adopt the iteratively layer-wise pruning approach to trim the pre-trained models, respectively. For example, if the given pruning rate is 80%, the connections are pruned to 20% based on the overall weights, and the preserved parameters are retrained until the network converges. After that, the model parameters are pruned to a higher pruning rate as the previous steps. The process is repeated until the model reaches the given sparsity. Note that retraining and pruning operations are performed alternately; those preserved connections can be retrained until the model reaches the desired performance concerning the increasing pruning rate. In addition, the learning rate of the pruned model also needs to be reduced relatively for adjusting the sparse network. Following the proposed layer-wise pruning method, we first compare the iteratively pruning and directly pruning (one-shot) experiment results of the original pre-trained model with 10 neurons; the pruning results from 10% to 90% are described in
Table 5.
Comparing the accuracy of the model after discarding the connection W and W by directly pruning and retraining with that preforming iteratively pruning and retraining, from the results, the performances of the two methods are similar when the pruning rate is below 70%. With the pruning rate increasing, the model performance of the iterative pruning clearly outperforms that of directly pruning and retraining. Therefore, although the iterative pruning advantage is less obvious in a low pruning rate, it is useful to hold a higher accuracy in a high rate. For this RNN model in the temperature control system, the overall weight connections can be pruned to 15% without hurting the final performance. However, when the 95% percentage of overall network weights are discarded, the performance shifts down significantly. This demonstrates the limitation of the pruning rate to the pre-trained model; once too many connections are removed, the remaining model underfits the data.
Then, we perform nonlinear reconstruction error pruning and retrain iteratively on the pre-trained control models with 40 and 120 hidden neurons, respectively. The same learning rate of 1.0 × 10
with 50 retraining epochs after every pruning rate is used in our temperature control models; the pruned control models can converge and achieve relatively satisfactory results. The accuracy results of the layer-wise pruned models are shown in
Table 6 and
Table 7.
From the results, we can also find when the pruning rate is below 80%, the performance decrease of the temperature control system is not obvious. The iterative layer-wise pruning results describe the accuracy after pruning each layer connection. However, when the pruning rate is too high such as from 80% to 90%, there is an obvious decrease in the performance of the temperature system. Too many parameters being removed makes it difficult for the models to fit the data. In terms of the percentage concerning weights that are removed, there are a lot of redundant parameters in the hidden layer. The pruning limitation of the pre-trained models with 40 and 120 hidden units is about 85% and 80%, respectively. The current sparse network models reduce a high percentage of hidden layer connections without damaging the system performance, thus effectively saving the plenty of storage space compared to the original pre-trained model. From the results, although we adopt the magnitude-based pruning method for deleting the parameters, the original model with large dimension may lose some important parameters as the pruning rate increases, which are actually related to the remaining parameters in the original model and have a great impact on the final performance of the system, and in practice the lost accuracy is hard to recover within limited epochs.
Finally, to verify the control performance of the pruned models with different hidden units by the layer-wise reconstruction error method, we list the final response characteristics of our temperature system with the disturbance signal under the same conditions of experiments. As
Table 8 shows, the differences between the original pre-trained model and the trimmed model with 10 hidden units in 80% pruning rate are less than 2%. The settling time is 2847 s, which has a slight increase of 1.1%, and the fluctuation of drop and overshoot in temperature are 1.8% and 1.4% compared to the original pre-trained model, respectively. Similarly, the difference between the pruned model with 40 and 120 hidden units has a slight higher percentage deviation within about 5% in the same pruning rate of 80%. The pruned model can also obtain a similar control effect with the remaining parameters.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}