Abstract
Probability distributions perform a very significant role in the field of applied sciences, particularly in the field of reliability engineering. Engineering data sets are either negatively or positively skewed and/or symmetrical. Therefore, a flexible distribution is required that can handle such data sets. In this paper, we propose a new family of lifetime distributions to model the aforementioned data sets. This proposed family is known as a “New Modified Exponent Power Alpha Family of distributions” or in short NMEPA. The proposed family is obtained by applying the well-known T-X approach together with the exponential distribution. A three-parameter-specific sub-model of the proposed method termed a “new Modified Exponent Power Alpha Weibull distribution” (NMEPA-Wei for short), is discussed in detail. The various mathematical properties including hazard rate function, ordinary moments, moment generating function, and order statistics are also discussed. In addition, we adopted the method of maximum likelihood estimation (MLE) for estimating the unknown model parameters. A brief Monte Carlo simulation study is conducted to evaluate the performance of the MLE based on bias and mean square errors. A comprehensive study is also provided to assess the proposed family of distributions by analyzing two real-life data sets from reliability engineering. The analytical goodness of fit measures of the proposed distribution are compared with well-known distributions including (i) APT-Wei (alpha power transformed Weibull), (ii) Ex-Wei (exponentiated-Weibull), (iii) classical two-parameter Weibull, (iv) Mod-Wei (modified Weibull), and (v) Kumar-Wei (Kumaraswamy–Weibull) distributions. The proposed class of distributions is expected to produce many more new distributions for fitting monotonic and non-monotonic data in the field of reliability analysis and survival analysis.
1. Introduction
In the field of reliability engineering as well as other related fields, the modeling of lifetime events is of great importance. Generally, numerous probability distributions are available to model such types of lifetime data that are uncertain and complex in nature. However, in many cases, these probability distributions are suitable to model lifetime data.
In the literature, the exponential and Rayleigh distributions are the most popular and widely used distributions in lifetime analysis. However, when the lifetime data sets are complex then these probability distributions are not suitable to represent data accurately. For example, the Exponentiated distribution is concerned with describing data that have a constant failure rate function; on the other hand, the Ray distribution is used to model data that possess an increasing failure rate function. Similarly, the Weibull (Wei) distribution is one of the important lifetime distributions, which has both the characteristic of Exponentiated and Rayleigh distributions and has widely been used in the field of reliability engineering and in other research areas; see, Lee et al. [1]. Although the Wei distribution is widely used in many fields, it is confined to the structure of its HF (hazard function) only increasing, decreasing, and constant. Generally, many significant issues require a flexible range of HF; for instance, human mortality and life cycles of electronic machines and components lifetime events possess a bathtub and unimodal-shaped HF. To overcome these difficulties, we need a more flexible version of the Wei distribution to model reliability data adequately. In this regard, researchers’ efforts have been devoted to deriving new models or families of statistical models to provide a better description of the problem under consideration. Such models have been constructed by inserting one or more new additional parameters to the baseline models to obtain new models that are analytically more flexible and provide better fits to the lifetime events than the other adapted models; see a new modified alpha power (MPA) family of distributions proposed by Hussein et al. [2]; the new exponential-X (NExp-X) family proposed by Shah et al. [3]; the Z-family introduced by Ahmad et al. [4]; the new generalized-X (NG-X) family proposed by Wang et al. [5]; the transmuted alpha power-G (TAP-G) family presented by Eghwerido et al. [6]; the unit extended Weibull (UEx-Wei) families proposed by Guerra et al. [7]; and a new lifetime-X (NLT-X) family introduced by Mohammed et al. [8].
Mudholkar and Srivastava [9] proposed a simple Exponentiated method by inserting an extra parameter into the family of distributions. The CDF (cumulative distribution function) is given by
where is the CDF of any baseline distributions depending on the parameter vector . Cordeiro and de Castro [10] developed a method to incorporate an additional parameter to the baseline distribution, which has the following form,
using Equation (2), Cordiero and de Castro [10] defined four parameters of Kumaraswamy Wei distribution. Moreover, using Equation (2), different researchers extended the classical Wei distribution; see for example ([11,12,13,14]).
Similarly, Marshal and Olkin [15] introduced Marshall–Olkin generated (MO-G) family using the following CDF
using Equation (3), Marshal and Olkin [15] derived two special sub-models, namely, the Marshal–Olkin Exponential (MO-Exp) and Marshal–Olkin Wei (MO-Wei) distributions. Later on, using Equation (3), several probability distributions were proposed in the literature; for instance, see the work given in ([16,17,18]).
Recently, in this regard, Khan et al. [19] proposed an exponentiated odd generalized exponential (OGE2-G) family of distribution using the following CDF
Using Equation (4), Khan et al. [19] also derived a four-parameter exponentiated odd generalized exponential Fréchet (OGE2Fr) distribution.
In this manuscript, we propose a new flexible class family of distributions by implementing the method of the T-X approach together with exponential distribution having density function . The new proposed class is called an NMEPA family of distributions, which capitalizes on the weaknesses of the available distributions in the literature. The main motivations for using the NMEPA method in practice are the following: (i) the method has not been proposed/used so far; (ii) to improve the existing distributions, and numerous new distributions can also be proposed for data modeling in the different phenomenon; (iii) to generalize the existing distributions with a closed form of their distribution functions; (iv) to provide the best fit to real-world data as compared the other distributions having the fever, and same or higher number of parameters; and (v) to provide the best fit to the considered data sets, describing the reliability in engineering. In fact, we conclude empirically that the new modification of the Wei distribution offers the best fit to the considered data sets in comparison to the two, three, and four-parameter competing distributions.
2. The Proposed NMEPA Family
In this section, we introduce a new modified method to derive a new lifetime distribution. The proposed method is introduced by combining the exponential model having PDF (probability density function) with the T-X family proposed by Alzaatreh et al. [20].
Consider a random variable, say T be a baseline random variable with PDF , where [, ] for . Let be a random variable with CDF (cumulative distribution function) depending on the parameter vector . In addition, suppose that be a function of CDF of , satisfying the following three conditions,
- ,
- is differentiable and monotonically increasing,
- as and as .
Then, according to Alzaatreh et al. [20], the CDF of the T-X family is defined by
where satisfies certain conditions given above. The PDF of T-X distribution, corresponding to Equation (5) is given by;
Now, by using and setting in Equation (5), we obtain the CDF of the NMEPA family of distributions, given by
the CDF may also be written in the following form,
where , and is the CDF of the baseline distribution with parameters vector .
The PDF of the NMEPA family associated with Equation (7) is given by
where .
Corresponding to Equations (7) and (8), the SF (survival function) and HF (hazard function) are given as follows:
and
In this article, using Equation (7) we propose a new generalized/extended version of the Wei distribution, namely, an NMEPA-Wei (new modified exponent power alpha Wei) distribution. The NMEPA-Wei model is compared with five other well-known probability distributions including (a) three-parameter APT-Wei (alpha power transformed Wei) [21], (b) Ex-Wei (exponentiated Wei), [9], (c) two-parameter classical Wei [22], (d) Sarhan and Zaindin Mod-Wei (Modified Wei) [23], and (e) four-parameter Ku-Wei (Kumaraswamy Wei) distributions [10], by analyzing two real data sets in the field of reliability engineering. The following Section 2.1, offers the CDF, PDF, SF, HF, and CHF (cumulative hazard function) of the NMEPA-Wei distribution. Furthermore, different PDF and HF behaviors are also presented graphically in the same section. The rest of the work in this study is organized as follows: In Section 3, the statistical properties of the proposed NMEPA family of distributions are also discussed. The method of MLE for the proposed distribution is described in Section 4. In Section 4.1, a brief Monte Carlo simulation study is carried out. The comprehensive analyses using two engineering data sets are discussed in Section 5. Finally, some concluding remarks are given in Section 6.
2.1. The NMEP-Wei Distribution
Consider the CDF and PDF of the classical two-parameter Wei distribution given by
and
where .
Using Equation (11) in Equation (7) yields the CDF of the NMEPA-Wei distribution, which is given by
with PDF
Different plots of the PDF of the NMEPA-Wei distribution are presented in Figure 1a,b for different values of the parameters and . From Figure 1a,b, we can see different PDF patterns including bio-modal, left-skewed, right-skewed, and symmetrical curves.
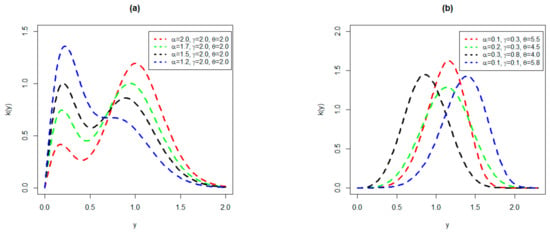
Figure 1.
Plots of (a) bi-modal, and (b) left-skewed, right-skewed, and symmetrical PDF of the proposed NMEPA-Wei distribution.
Furthermore, the SF , HF , and CHF (cumulative hazard function) of the NMEPA-Wei distribution are given by
and
respectively.
Here, different plots of the HF of the NMEP-Wei distribution are presented in Figure 2a,b. From Figure 2a, we can see increasing and decreasing HF , while in Figure 2b, we can see uni-modal HF . Similarly, from Figure 3, we can see bathtub HF of the NMEPA-Wei distribution.

Figure 2.
Plots of (a) increasing, and decreasing, and (b) unimodal HF of the NMEPA-Wei distribution.
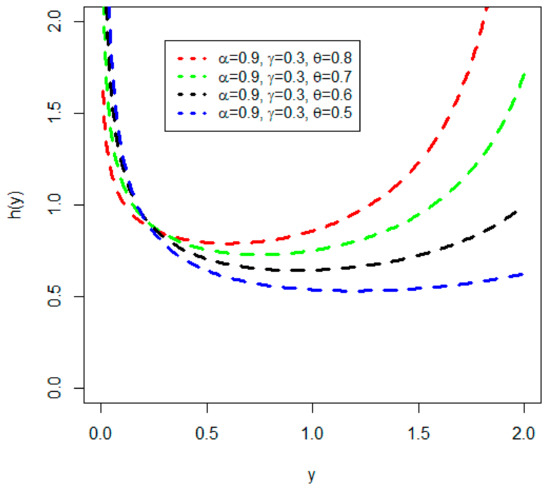
Figure 3.
Plots of different bathtub shapes of HF of the proposed NMEPA-Wei distribution.
3. Statistical Properties of NMEPA Family
In this section, various mathematical properties of the proposed family of distributions such as QF (quantile function), and ordinary moments that can further be used to obtain some important characteristics of the model are discussed. In addition to these properties, the MGF (moment generating function) and OS (order statistics) are also derived.
3.1. Quantile Function
The QF also called IDF (inverse distribution function) is an important statistical characteristic used to generate random numbers (RNs). The QF of the NMEPA distribution is a function that satisfies the following nonlinear equation
where . By using Equation (7) and after some algebraic manipulation the QF is derived as
where u is the solution of the nonlinear equation . The expression (18) can also be used to measure the effect of parameters on Skewness and Kurtosis. Hence, the formulas for Skewness and Kurtosis are the following expression
and
The mean, variance, skewness, and kurtosis for 1, and different values of and , of the NMEPA-Wei distribution, are sketched in Figure 4.

Figure 4.
Different plots of (a) mean, (b) variance, (c) skewness, and (d) kurtosis of the NMEPA-Wei model.
3.2. rth Moments
The rth moment is an important and useful statistical tool to obtain certain characteristics and features of a model. These characteristics are known as (i) central tendency, which deals with the mean point of distribution; (ii) dispersion, which measures the variance of a model; (iii) skewness, which describes the tail behavior of the model; and (iv) kurtosis, which helps in studying the peakedness of the distribution. Let be a random variable that follows the NMEPA-Wei distribution, then its rth moment can be expressed as follows,
Using Equation (8) in Equation (18), we have
Using the following series
and using in Equation (20), we obtain
In addition, using the following series representation for Equation (22)
Using in Equation (23), we obtain
again using series representation in Equation (23), and replacing , we obtain
By inserting Equation (25) in Equation (20), we obtain the following expression
where , from Equation (26), we have
where , , and .
Furthermore, the MGF (moment generating function), say of the NMEPA family of distribution, is derived as follows
By using Equation (27) in Equation (28), we can easily obtain the MGF of the NMEPA family of distributions.
3.3. Order Statistics
In distribution theory, order statistics has great significance and it makes its appearance in reliability analysis, problems of estimation theory, and life testing in different ways. It can characterize the lifetimes of elements or components of a reliability system.
Let be a random sample of observations chosen from the NMEPA family of distributions with CDF and PDF given by (7) and (8), respectively. Then, the density function of is given by
We express the 1st order statistic as and the qth order statistic as Since for . We utilize the binomial expansion of as follows:
Using Equation (30) in Equation (29), we obtain
Using Equations (7) and (8), in Equation (31), we obtain the DF (density function) of .
4. Estimation of Parameters and Monte Carlo Simulation
This section provides a detailed description of the maximum likelihood estimation implemented for estimating unknown parameters of the proposed NMEPA family of distribution. Furthermore, we conduct a comprehensive Monte Carlo simulation study for assessing the performance of these estimators. The same section also provides an assessment of the efficacy of the proposed method in modeling reliability engineering problems.
4.1. Maximum Likelihood Estimation
Several methods for estimating the parameters have been introduced in the literature. MLE is one of the most frequently used methods. This method furnishes estimators with several important properties and can be used in the construction of confidence intervals as well as other tests for checking statistical significance. For further details about MLEs, see [24]. This sub-section provides a discussion on the MLEs approach for estimating the parameters of the NMEPA family of distributions.
Suppose are the observed values from the PDF given in Equation (8). Then, the LLF (Log-likelihood function) corresponding to Equation (8) is
Generally, the LLF (log-likelihood function) can be maximized either directly by using the R package (Adequacy Model), Ox program (subroutine Max BFGS), or SAS (PROC NLMIXED) (for further details, see Doornik, [25]), or by solving the nonlinear log-likelihood equations. Here, we obtain the partial derivative of Equation (32), on behalf of parameters and it is given as follows:
and
Equating Equation (33) and Equation (34) to zero, and solving simultaneously, yield the MLEs of .
4.2. Simulation Study
In this sub-section, a simulation is performed to study the behavior of , and of the NMEPA-Wei distribution. The random numbers are successfully generated from PDF by using the inverse CDF approach. We are assumed to have three sets (Set 1, Set 2, and Set 3) of parameter combination values, given by (i) Set 1: 1.4, 1.0, 1.6, (ii) Set 2: 2.4, 1.7, 1.5, and (iii) Set 3: 0.5, 1.2, 1.6.
To evaluate the performance of the , and , two statistical measures (i) MSE (mean square error), and (ii) Bias are considered. The formula of mean square error (MSEs) and bias (Bias) of the parameters are, respectively, computed as
and
The above process is also repeated for .
Simulation results on estimated parameters in terms of MSEs and Bias values are reported in Table 1, while graphically the results are displayed in Figure 5, Figure 6, Figure 7, Figure 8, Figure 9 and Figure 10.

Table 1.
Simulation results for NMEPA-Wei distribution of MLEs, MSEs, and Biases for Set 1, Set 2, and Set 3.
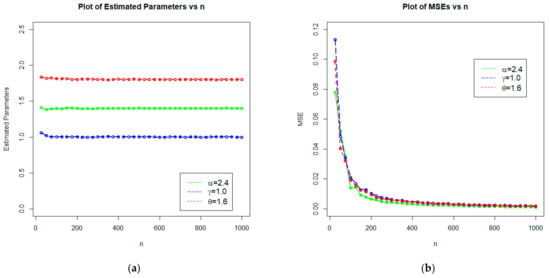
Figure 5.
Plots of (a) estimated parameters vs. n, and (b) MSEs vs. n for Set 1: 1.4, 1.0, 1.6.
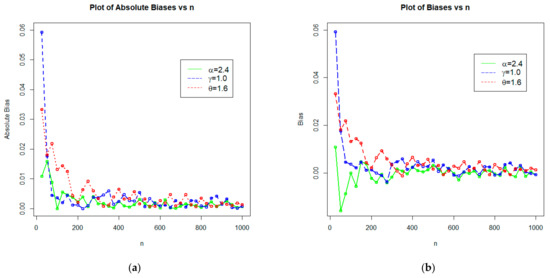
Figure 6.
Plots of (a) absolute biases vs. n, and (b) biases vs. for Set 1: 1.4, 1.0, 1.6.

Figure 7.
Plots of (a) estimated parameters vs. n, and (b) MSEs vs. n for Set 2: 2.4, 1.7, 1.5.

Figure 8.
Plots of (a) absolute biases vs. n, and (b) biases vs. for Set 2: 2.4, 1.0, 1.6.
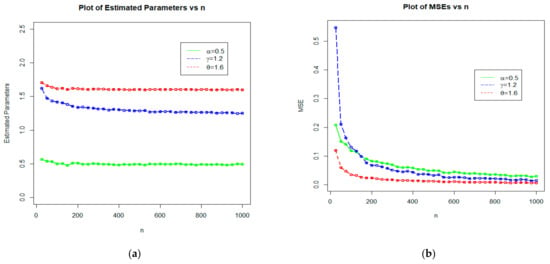
Figure 9.
Plots of (a) estimated parameters vs. n, and (b) MSEs vs. n for Set 3: 0.5, 1.2, 1.6.

Figure 10.
Plots of (a) absolute biases vs. n, and (b) bias vs. n for Set 3: 0.5, 1.2, 1.6.
From Table 1, we can see that as the sample size increase:
- The estimated values of , , and tend to be stable.
- The MSE of , , and decreases.
- The biases of , , and become smaller.
In conclusion, it is apparent that the MLEs perform reasonably well in estimating the model parameters of the NMEPA family of distributions.
5. Applications of NMEPA-Wei to Engineering Data
In order to demonstrate the usefulness of the NMEPA-Wei distribution for modeling, in this section, we analyzed two real data sets. The first data set is taken from Merovci et al. [26] and also used by Dey et al. [21], consisting of 63 observations of the strength of 1.5 cm glass fibers that were originally obtained by workers in the UK (National Physical Laboratory). While the second data set initially presented by Barlow et al. [27], was later on studied by Andrews and Herzberg [28], and then, later on, was also used by Dey et al. [21], represents the life of a fatigue fracture of Kevlar 373/epoxy that is subject to constant pressure at the 90 stress level until all had failed. For both data sets, see Table 2.
Table 2.
The engineering data sets.
The comparison of the proposed distribution is made with five well-known lifetime probability distributions, such as APT-Wei (Alpha Power Transformed Wei) proposed by Dey et al. [21], Ex-Wei (Exponentiated Wei) of Medholkar and Srivastava [3], classical Weibull (Wei) [14], Sarhan and Zaindin Modified Wei (Mod-Wei) [15], and Kumaraswamy Wei (Ku-Wei) distribution of Cordeiro et al. [16]. The CDFs of the competitor distributions are as follows:
- The APT-Wei distribution
- The Ex-Wei distribution
- The classical Wei distribution
- Sarhan and Zaindin Mod-Wei distribution
- The Ku-Wei distribution
Next, we consider different goodness of fit measures to examine which competitor is the best fit for the considered data sets. These goodness of fit measures include: CM (Cramer–von Misses) test statistic, AD (Anderson–Darling) test statistic, KS (Kolmogorov–Smirnov) test statistic, AIC (Akaike Information Criterion), BIC (Bayesian Information Criterion), corrected Akaike information criterion (CAIC), and HQIC (Hannan–Quinn information criterion) as well as p-values. The mathematical formulae of these measures are given by:
- The CM test statistic calculated as
- The AD test statistics computed as
- The KS test statistic derived as
- The AIC test statistics obtained as
- The BIC test statistics derived as
- The CAIC test statistics calculated as
- The HQIC test statistics computed as
5.1. Data 1
Corresponding glass fiber data set (Data 1), some basic measures of statistics for the first data set are the following: Minimum = 0.550, 1st Quartile = 1.375, Median = 1.590, Mean = 1.507, 3rd Quartile = 1.685, Maximum = 2.240, variance = 0.1050575, Range = 1.69, Skewness = −0.8999263, and Kurtosis = 3.923761. Corresponding to Data 1, some basic plots including histogram, Kernel density plot, TTT plot, Violin plot, and box plot for the first data set are presented in Figure 11. From Figure 11, it is clear that the data are negatively skewed and suffer from an increasing hazard rate. Thus, the proposed NMEPA-Wei model can be used to model HF of the first data set.

Figure 11.
The (a) Histogram, (b) Kernel density plot, (c) TTT plot, (d) Violin plot, and (e) box plot for Data 1.
Furthermore, the values of , , , , , and of the NMEPA-Wei and other competing models are reported in Table 3. While the numerical values of analytical and discrimination measures (taken to select the nice model) are presented in Table 4 and Table 5. The theoretical and empirical PDFs and CDFs plots of the NMEPA-Wei and other competitor models are displayed in Figure 12. The probability–probability plots of the proposed and competing models are displayed in Figure 13. Similarly, for the same data, the quantile–quantile (Q-Q) plots for the proposed and all the other competing models are presented in Figure 14.
Table 3.
The values of , , , , , and of the competitive models using glass fiber data set (Data 1).
Table 4.
The goodness of fit CM, AD, and KS measures, and p-value of the competitive models for glass fiber data set (Data 1).
Table 5.
The discrimination AIC, BIC, CAIC, and HQIC measures of competitive models using glass fiber data set (Data 1).

Figure 12.
Plots of (a) estimated PDFs, and (b) estimated CDFs of competitive models for Data 1.

Figure 13.
Probability–probability (PP) plots of (a) NMEPA-Wei, (b) APT-Wei, (c) Ex-Wei, (d) Wei, (e) Mod-Wei, and (f) Ku-Wei for Data 1.
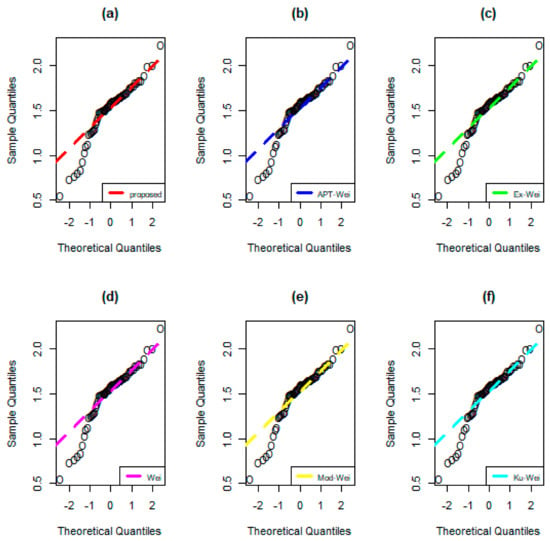
Figure 14.
Q-Q (quantile–quantile) plots of (a) NMEPA-Wei, (b) APT-Wei, (c) Ex-Wei, (d) Wei, (e) Mod-Wei, and (f) Ku-Wei distributions for Data 1.
Based on the numerical results, obtained in Table 4 and Table 5, we can see that the NMEPA-Wei model has the lowest values of the analytical and discrimination measures. The values of the analytical measures for the NMEPA-Wei distribution are: AIC = 27.1435, BIC = 33.5729, CAIC = 27.5503, HQIC = 29.6722, CM = 0.0497, AD = 0.3355, KS = 0.1221, with p-value = 0.8685. In terms of AIC, BIC, CAIC, HQIC, and p-value, the second-best model is the APT-Wei distribution. The values of these measures for the APT-Wei distribution are given by 32.9483, 39.3772, 33.3553, 35.4773, and 0.2993. Whereas the second-best model in terms of CM, AD, and KS is the Mod-Wei distribution. For the Mod-Wei distribution, the CM, AD, and KS values are given by 0.1385, 0.7985, and 0.1332, respectively.
In support of numerical illustrations in Table 4 and Table 5 and the above discussion, we observed that the NMEPA-Wei distribution is the optimum choice for glass fiber data (Data 1). According to Figure 12, Figure 13 and Figure 14, it is observed that the NMEPA-Wei distribution fits the glass fiber data quite well.
5.2. Data 2
Corresponding fatigue fracture of Kelvar 373/epoxy data set (Data 2), some basic measures of statistics for the second data set are the following: minimum = 0.0251, 1st Quartile = 0.9048, median = 1.7362, mean = 1.9592, 3rd Quartile = 2.2959, maximum = 9.0960, variance = 2.477415, range = 9.0709, Skewness = 1.979558, and Kurtosis = 8.160792. Corresponding to Data 2, some basic plots including histogram, Kernel density plot, TTT plot, Violin plot, and box plot for the second fatigue fracture data set are presented in Figure 15. From Figure 15, it is clear that the data are positively skewed and suffer from an increasing hazard rate. Thus, the proposed NMEPA-Wei model can be used to model HF of the second data set.

Figure 15.
The (a) Histogram, (b) Kernel density plot, (c) TTT plot, (d) Violin plot, and (e) box plot for Data 2.
Furthermore, the values of , , , , , and of the NMEPA-Wei and other competing models are reported in Table 6. Whereas the numerical values of analytical and discrimination measures (taken to select the nice model) are presented in Table 7 and Table 8. The theoretical and empirical PDFs and CDFs plots of the NMEPA-Wei and other competitor models are displayed in Figure 16. The P-P (probability–probability) plots of the proposed and competing models are displayed in Figure 17. Similarly, for the same data, the Q-Q (quantile–quantile) plots for the proposed and all the other competing models are sketched in Figure 18.
Table 6.
The values of , , , , , and of the competitive models using fatigue fracture data set (Data 2).
Table 7.
The values of CM, AD, and KS measures and p-value of the competitive models for fatigue fracture data set (Data 2).
Table 8.
The discrimination measures values of AIC, BIC, CAIC, and HQIC measures of competitive models using fatigue fracture data set (Data set 2).

Figure 16.
Plots of (a) estimated PDFs, and (b) estimated CDFs of competitive models for Data 2.

Figure 17.
Probability–probability (PP) plots of (a) NMEPA-Wei, (b) APT-Wei, (c) Ex-Wei, (d) Wei, (e) Mod-Wei, and (f) Ku-Wei for Data 2.
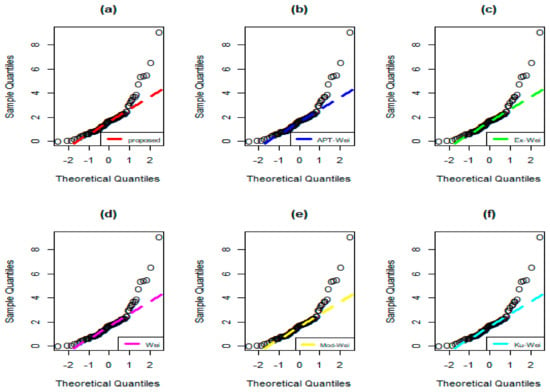
Figure 18.
Q-Q (quantile–quantile) plots of (a) NMEPA-Wei, (b) APT-Wei, (c) Ex-Wei, (d) Wei, (e) Mod-Wei, and (f) Ku-Wei distributions for Data 2.
Again, if we look at the numerical results obtained in Table 7 and Table 8, it is obvious that the NMEPA-Wei model has the lowest values of the analytical measures and the highest p-value. The values of the analytical measures for the NMEPA-Wei distribution are: AIC = 247.9672, BIC = 254.9594, CAIC = 248.3005, HQIC = 250.7616, CM = 0.0563, AD = 0.3335, KS = 0.0798, with p-value = 0.6872. In terms of AIC, CAIC, CM, AD, KS, and p-value, the second-best model is also the APT-Wei distribution. The values of these measures for the APT-Wei distribution are given by 248.7293, 249.0623, 0.0901, 0.5378, 0.0821, and p-value = 0.6533. Whereas the second-best model in terms of BIC and HQIC is the classical Wei distribution. For the Wei distribution, the BIC, and HQIC values are given by 253.7108, and 250.9123, respectively.
From the numerical illustrations given in Table 7 and Table 8 and the above discussion, we can conclude that the NMEPA-Wei distribution is a good choice for analyzing or examining the fatigue fracture of Kelvar 373/epoxy data (Data 2). According to Figure 16, Figure 17 and Figure 18, it is also observed that the NMEPA-Wei distribution fits the fatigue fracture of Kelvar 373/epoxy data quite well.
6. Conclusions
In the present work, we have presented a new family of distributions called the New Modified Exponent Power Alpha family (NMEPA). A three-parameter special sub-case of the proposed class by employing the Weibull distribution as a baseline distribution is studied in detail. The special sub-case is named as NMEPA-Wei (new modified exponent power Alpha Wei) distribution. The PDF (probability density function) of the derived model is positively skewed, negatively skewed, symmetrical, and also bimodal depending upon parameter values. Moreover, the HF (hazard function) can have non-monotonically increasing, decreasing, uni-model, and bathtub shapes. General expressions, for different statistical properties of the proposed family, have been derived including quantile function, moments, moments generating function, and order statistics. The Maximum Likelihood method has been used for estimating the unknown parameters, and in addition, a Monte Carlo simulation study is carried out to assess the performance of the proposed model estimators. Based on analytical measures and graphical illustration, it is observed that the proposed NMEPA-Wei distribution is the best competitor for modeling the reliability of engineering data sets. We hope that this novel improvement in the field of distributions theory will provide more attractive applications in the reliability of engineering and other related fields.
Author Contributions
Conceptualization, Z.S., D.M.K. and Z.K.; methodology, D.M.K.; software, Z.S., D.M.K. and Z.K.; validation, D.M.K.; M.S. and J.-G.C.; formal analysis, Z.S., D.M.K. and Z.K.; investigation, D.M.K., M.S. and J.-G.C.; resources, M.S. and J.-G.C.; data curation, D.M.K., M.S. and J.-G.C.; writing—original draft preparation, Z.S. and Z.K.; writing—review and editing, D.M.K., M.S. and J.-G.C.; visualization, Z.S. and Z.K. supervision, D.M.K.; project administration, D.M.K.; funding acquisition, M.S. and J.-G.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All the datasets used in this article are available in the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lee, C.; Famoye, F.; Olumolade, O. Beta-Weibull distribution: Some properties and applications to censored data. J. Mod. Appl. Stat. Methods 2007, 6, 17. [Google Scholar] [CrossRef]
- Hussein, M.; Elsayed, H.; Cordeiro, G.M. A new family of continuous distributions: Properties and estimation. Symmetry 2022, 14, 276. [Google Scholar] [CrossRef]
- Shah, Z.; Ali, A.; Hamraz, M.; Khan, D.M.; Khan, Z.; EL-Morshedy, M.; Al-Bossly, A.; Almaspoor, Z. A New Member of TX Family with Applications in Different Sectors. J. Math. 2022, 2022, 1453451. [Google Scholar] [CrossRef]
- Ahmad, Z.; Mahmoudi, E.; Kharazmi, O. On modeling the earthquake insurance data via a new member of the TX family. Comput. Intell. Neurosci. 2020, 2020, 7631495. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Ahmad, Z.; Kharazmi, O.; Ampadu, C.B.; Hafez, E.H.; Mohie El-Din, M.M. New generalized-x family: Modeling the reliability engineering applications. PLoS ONE 2021, 16, e0248312. [Google Scholar] [CrossRef]
- Eghwerido, J.T.; Efe-Eyefia, E.; Zelibe, S.C. The transmuted alpha power-G family of distributions. J. Stat. Manag. Syst. 2021, 24, 965–1002. [Google Scholar] [CrossRef]
- Guerra, R.R.; Peña-Ramírez, F.A.; Bourguignon, M. The unit extended Weibull families of distributions and its applications. J. Appl. Stat. 2021, 48, 3174–3192. [Google Scholar] [CrossRef]
- Mohammed, H.S.; Ahmad, Z.; Abdulrahman, A.T.; Khosa, S.K.; Hafez, E.H.; Abd El-Raouf, M.M.; El-Din, M.M.M. Statistical modelling for Bladder cancer disease using the NLT-W distribution. AIMS Math. 2021, 6, 9262–9276. [Google Scholar] [CrossRef]
- Mudholkar, G.S.; Srivastava, D.K. Exponentiated Weibull family for analyzing bathtub failure-rate data. IEEE Trans. Reliab. 1993, 42, 299–302. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; de Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 2011, 81, 883–898. [Google Scholar] [CrossRef]
- Nofal, Z.M.; Afify, A.Z.; Yousof, H.M.; Granzotto, D.C.; Louzada, F. Kumaraswamy transmuted exponentiated additive Weibull distribution. Int. J. Stat. Probab. 2016, 5, 78–99. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
- El-Damcese, M.A.; Mustafa, A.; El-Desouky, B.S.; Mustafa, M.E. The Kumaraswamy flexible Weibull extension. Int. J. Math. Appl. 2016, 4, 1–14. [Google Scholar]
- Selim, M.A.; Badr, A.M. The Kumaraswamy generalized power Weibull distribution. Math. Theo. Model 2016, 6, 110–124. [Google Scholar]
- Marshall, A.W.; Olkin, I. A new method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Biometrika 1997, 84, 641–652. [Google Scholar] [CrossRef]
- Ghitany, M.E.; Al-Hussaini, E.K.; Al-Jarallah, R.A. Marshall–Olkin extended Weibull distribution and its application to censored data. J. Appl. Stat. 2005, 32, 1025–1034. [Google Scholar] [CrossRef]
- Gui, W. Marshall-Olkin extended log-logistic distribution and its application in minification processes. Appl. Math. Sci. 2013, 7, 3947–3961. [Google Scholar] [CrossRef]
- Saboor, A.; Pogány, T.K. Marshall–Olkin gamma–Weibull distribution with applications. Commun. Stat. Theory Methods 2016, 45, 1550–1563. [Google Scholar] [CrossRef]
- Khan, S.; Balogun, O.S.; Tahir, M.H.; Almutiry, W.; Alahmadi, A.A. An alternate generalized odd generalized exponential family with applications to premium data. Symmetry 2021, 13, 2064. [Google Scholar] [CrossRef]
- Alzaatreh, A.; Lee, C.; Famoye, F. A new method for generating families of continuous distributions. Metron 2013, 71, 63–79. [Google Scholar] [CrossRef]
- Dey, S.; Sharma, V.K.; Mesfioui, M. A new extension of Weibull distribution with application to lifetime data. Ann. Data Sci. 2017, 4, 31–61. [Google Scholar] [CrossRef]
- Weibull, W.A. Statistical distribution function of wide applicability. J. Appl. Mech. 1951, 18, 293296. [Google Scholar] [CrossRef]
- Sarhan, A.M.; Zaindin, M. Modified Weibull distribution. Appl. Sci. 2009, 11, 2336. [Google Scholar]
- Dong, B.; Ma, X.; Chen, F.; Chen, S. Investigating the differences of single-vehicle and multivehicle accident probability using mixed logit model. J. Adv. Transp. 2018, 2018, 2702360. [Google Scholar] [CrossRef]
- Doornik, J.A. An Object-Oriented Matrix Programming Language Ox 6; University of Oxford: Oxford, UK, 2009. [Google Scholar]
- Merovci, F.; Khaleel, M.A.; Ibrahim, N.A.; Shitan, M. The beta Burr type x distribution properties with applications. Springer Plus 2016, 5, 697. [Google Scholar] [CrossRef]
- Paul, D.R.; Barlow, J.W. A binary interaction model for miscibility of copolymers in blends. Polymer 1984, 25, 487–494. [Google Scholar] [CrossRef]
- Andrews, D.F.; Herzberg, A.M. Data: A Collection of Problems from Many Fields for the Student and Research Worker; Springer: Berlin/Heidelberg, Germany, 2012. [Google Scholar]


















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).