Abstract
Multiple graph and semi-supervision techniques have been successfully introduced into the nonnegative matrix factorization (NMF) model for taking full advantage of the manifold structure and priori information of data to capture excellent low-dimensional data representation. However, the existing methods do not consider the sparse constraint, which can enhance the local learning ability and improve the performance in practical applications. To overcome this limitation, a novel NMF-based data representation method, namely, the multiple graph adaptive regularized semi-supervised nonnegative matrix factorization with sparse constraint (MSNMFSC) is developed in this paper for obtaining the sparse and discriminative data representation and increasing the quality of decomposition of NMF. Particularly, based on the standard NMF, the proposed MSNMFSC method combines the multiple graph adaptive regularization, the limited supervised information and the sparse constraint together to learn the more discriminative parts-based data representation. Moreover, the convergence analysis of MSNMFSC is studied. Experiments are conducted on several practical image datasets in clustering tasks, and the clustering results have shown that MSNMFSC achieves better performance than several most related NMF-based methods.
1. Introduction
In the era of big data, more and more high-dimensional data have been encountered in various practical application fields. Generally speaking, most of the original data is noisy, and many features in the data are not useful in real-world tasks. In this case, how to discover the low-dimensional data representation in the massive data is critical, since the obtained data representation used in practical applications can efficiently enhance the performance of learning algorithm than the original data. In recent decades, the matrix factorization technique, as one of the popular data representation techniques, has gained much attention because of its advantages for learning superior data representation. The commonly used matrix factorization methods include the singular value decomposition [1], nonnegative matrix factorization [2], independent component analysis (ICA) [3], deterministic column-based matrix decomposition [4], principal component analysis [5] and so on. Among these methods, NMF has shown good performances due to its ability of producing a parts-based representation. Therefore, NMF-based methods have widely used in numerous actual tasks such as document analysis, bioinformatics, information retrieval and so on [6,7,8,9,10,11].
The standard NMF decomposes the nonnegative matrix into a nonnegative basis matrix and a nonnegative coefficient matrix , , such that the product of and can approximate the original matrix as close as possible. During the decomposing procedure one can observe that the nonnegative constraints are enforced into the decomposed factors, NMF often can result in a parts-based data representation [2]. Usually, the advantages of the parts-based representation in NMF have been proved in different fields, and they also have significant improvements for the performance of NMF-based methods in many real-world applications [12,13]. Although the standard NMF model has obtained much attentions in recent decades [14], it still has some critical defects. For instance, it entirely ignores the geometrical structure information, and cannot exploit any supervisory information to increase the quality of decomposition of NMF [12,15,16]. Furthermore, the basic NMF method lacks some extra constraints such as sparse constraint to ensure the sparse parts-based representation, which will have an obvious improvement for the performance of NMF-based algorithms [17].
To enhance the performance of the original NMF method, much new research approaches have been developed in recent years [18,19,20,21,22]. For example, the graph regularization–based NMF methods have been proposed [23,24,25], which consider the intrinsic geometry structure information of data (or feature) space, and incorporate the single (or dual) graph regularization for enhancing the performance. Moreover, the limited supervisory information is used in semi-supervised NMF (SSNMF) methods for further capturing better low-dimensional data representation in practical tasks, since the usage of the prior knowledge can effectively improve performance [16,26,27]. In addition, to ensure the decomposed results are the sparse representation, the sparse and orthogonal NMF methods with different constraints such as sparse constraint and orthogonal constraint, respectively, have also been proposed in [28,29,30,31] for simplifying the computation complexity and ensuring the sparse parts-based representation. However, up to now, the SSNMF method including the multiple graph regularization and the sparse constraint has not been studied yet.
In this paper, a new sparse approach, namely, the multiple graph adaptive regularized SSNMF with sparse constraint (MSNMFSC), is proposed for exploiting good data representation. In particular, MSNMFSC combines together the multiple graph adaptive regularization, the limited supervised information and the dual sparse constraints for the basis and coefficient matrices, to guarantee part-based representation and improve the clustering performance. The multiplicative update algorithm is used to solve the optimization problems of MSNMFSC and obtain the multiplicative update rules of MSNMFSC. The convergence of MSNMFSC is analyzed. Extensive clustering experiments have shown the effectiveness of MSNMFSC on seven real-world image datasets, in comparison to several related NMF methods. The key contributions of our work are:
- This paper proposes the MSNMFSC method, which incorporates the multiple graph adaptive regularization, the limited supervisory information and the sparse constraint into the original NMF model for learning superior low-dimensional data representation.
- The multiplicative update rules of MSNMFSC are derived by solving the optimization problem using the multiplicative update algorithm.
- The convergence of MSNMFSC is analyzed theoretically, and the objective function will monotonically decrease under the update rules of MSNMFSC.
The rest of this paper is organized as follows. Section 2 introduces the preliminaries. Section 3 derives the MSNMFSC method in details. Section 4 analyzes the convergence of the MSNMFSC method. Section 5 gives the clustering experimental results. Finally, Section 6 draws the conclusion of this paper.
2. Preliminaries
2.1. Notations
Notations in this paper are defined as follows: uppercase boldface letters (e.g., ), lowercase boldface letters (e.g., ) represent the matrices and vectors, respectively; and represent the i-the column and row vector of , respectively; (or ) is the -th entry of . and are the trace and the transpose operator of a matrix, respectively. denotes the Frobebius norm of the matrix.
2.2. Related Works
NMF has become a popular matrix factorization technique, and is widely used in data mining, pattern recognition and so on. Inspired by previous work (i.e., positive matrix factorization in [32]), Lee and Seung firstly proposed the NMF model, and then developed a multiplicative update algorithm to solve the optimization problem of NMF [2]. Owing to its competitiveness and interpretation, the improved NMF methods from different aspects have been presented in recent decades. The following will introduce the most related NMF-based methods.
Cai et al. first proposed the graph regularized nonnegative matrix factorization (GNMF), which constructed an affinity graph to encode the geometrical information and got more discriminating power than orginal NMF [15]. Then Sun et al. developed the sparse dual graph-regularized NMF(SDGNMF) by incorporating the dual graph-regularized and sparse constraints to discover the geometrical information of the data space and feature space [17]. In order to improve the robustness of NMF, Peng et al. proposed the correntropy-based dual graph regularized NMF with local coordinate constraint (LCDNMF) which was robust to the noisy data contaminated by outliers [12]. After that, Peng et al. further proposed the correntropy-based orthogonal nonnegative matrix tri-factorization (CNMTF) algorithm which not only applied correntropy to NMTF to measure the similarity, but also preserved double orthogonality conditions and dual graph regularization [18]. Usually, it is difficult to select a suitable graph model for the single graph regularized NMF methods. Hence, Shu et al. proposed the parameter-less auto-weighted multiple graph regularized NMF (PAMGNMF), which could automatically obtain an optimal weight for each graph and is easily to be applied to practical problems [25].
In recent years, several SSNMF methods have been proposed, since the obtained supervised information has great contribution for gaining the performance in clustering tasks. For instance, Li et al. developed the semi-supervised graph-based discriminative NMF (GDNMF) method, which incorporated the label information of data into the graph-based NMF to enhance the discriminative abilities of clustering representations [33]. Meng et al. proposed the semi-supervised dual graph regularized NMF (SDNMF) method with sparse and orthogonal constraints which added dual-graph model into semi-supervised NMF to improve the clustering performance [23]. Different with the above semi-supervised NMF methods, Wang et al. presented the SSNMF method with pairwise constraints(CPSNMF), which first propagated the constraints from constrained samples to unconstrained samples to obtain the constraint information of the entire dataset. Therefore, CPSNMF can fully utilize the constraint information [26]. After that, Peng et al. proposed the correntropy-based SSNMF (CSNMF) method, which both used the pointwise and pairwise constraints simultaneously to improve the effectiveness of NMF, and also adopted a correntropy-based loss function to improve the robustness [16]. Recently, the MSNMF method was presented in our previous work, which combined the supervised information with multiple graph regularization to obtain better clustering results [34].
In addition, various kinds of constraint conditions, especially the sparse constraint, have been enforced into the standard NMF to improve the performance. For example, Hoyer et al. first incorporated the sparse constraints into NMF to improve the parts-based representations [28]; Alberto et al. proposed the nonsmooth nonnegative matrix factorization (nsNMF), which represented sparseness in the form of nonsmoothness, and got advantages in reconstructing the original data faithfully [29]; and Yang et al. developed the fast NsNMF (FNsNMF), which designed a Lipschitz constant-based proximal function and got a nonlinear convergence rate, which was much faster than the former nonsmooth nonnegative matrix factorization [35].
2.3. Constraint Propagation Algorithm (CPA)
For most of the existing semi-supervised NMF, it is hard to use the supervised information completely. In order to make full use of the limited supervised information, the CPA [26] is presented to obtain a new weight matrix with the pairwise constraint supervisory information of all data points, so the limited supervised information can be used effectively. In CPA [26,34], assuming that and are the labels of data and , then the initial pairwise constraints matrix is defined as follows:
The propagated pairwise constraints matrix is defined as , when then , if , then , denotes the confidence score of for a must-link constraint () or a cannot-link constraint (), similarly, is the vertical propagation of and is the horizontal propagation, then the constraint propagation algorithm(CPA) is described as follows [26,34]:
- Construct the pairwise constraints matrix by Formula (1), compute the Laplacian matrix , in which is the diagonal matrix with and is the input weight matrix;
- Make vertical propagating by repeating until convergence, is the balance parameter;
- Make horizontal propagating by repeating until convergence, is the limit of ;
- Obtain the final propagated pairwise constraints matrix , is the limit of ;
- Calculate the new weight matrix by
Up to now, there is no technique which combines together multiple graph regularization, supervised information and sparse constraint to solve clustering problems. Therefore, we proposal a novel SSNMF method with multiple graph adaptive regularization and sparse constraint in next section.
3. The Proposed MSNMFSC
Although multiple graph regularization and semi-supervision techniques have been successfully introduced into the NMF model, the existing methods do not consider the sparse constraint which can enhance the parts-based representation and obtain better clustering performance. So in this work, we combine the multiple graph adaptive regularization, the limited supervised information and the sparse constraint together, then propose the MSNMFSC algorithm accordingly.
3.1. Objective Function
Here we give the object function of MSNMFSC step by step. Firstly, the object function of original NMF is given, and the square of Euclidean distance (SED) is used as the similarity measure to calculate the similarity of the original data matrix and the reconstructed matrix. The SED-based object function of original NMF is expressed as follows [34]:
where , , , .
In order to capture the geometrical structure information of data, the graph regularization [15,34] is given by:
where , and are the edge weight matrix, the diagonal matrix with and the graph Laplacian of the data graph, respectively. is the graph regularization parameter. Previous studies have illustrated that the multiple graph regularized methods usually outperform the single graph regularized method. According to [25], based on (3) and (4), the object function of the NMF method containing multiple graph regularization [34] is as follows:
where Q is the number of graphs, is the weight value of the qth graph, , and have the same meaning as (4). Supervised information including label information and pairwise constraints is a great help to enhance the performance. Therefore, the CPA [26] described in Section 2.3 is used in our work to reconstruct the new , so the object function of the semi-supervised NMF with multiple graph regularization is as follows [34].
Here , in which , and have the same meaning as that in (5) but contain supervised information.
Apparently, the object function in (6) fails to consider the sparse constraint which can increase the clustering performance by enhancing parts learning ability [28]. So, here we incorporate the sparse constraint into the object function in (6). L0-norm, L1-norm and Frobenius norm are commonly used to measure the sparseness, however, the optimization procedure under L0-norm has been proved to be a NP-hard problem [36], and the L1-norm-based methods require the original signals to be highly sparse and will be ineffective in some situations [36,37]. In this situation, we choose the Frobenius norm as the measure method due to its advantages such as simplicity and effectiveness, and impose the sparse constraints into the object function in (6), then the object function of MSNMFSC can be derived as follows:
where and are the sparseness parameters of U and V, respectively, the ranges of and are both in .
3.2. Solving Optimization Problem
Although the objective function in (7) is not convex with respect to U and V at the same time, it is convex with respect to single U or single V. So, in most cases, one can have a local minimum of (7). Here, we use the multiplicative update algorithm to obtain the update rules of and for MSNMFSC, the optimization problem of MSNMFSC in (7) is given as follows:
3.2.1. Updating
Here, is the Lagrange multiplier for , so we have the Lagrange function :
Then we obtain its partial derivative with respect to :
According to the Karush–Kuhn–Tucker (KKT) conditions [38], i.e., , so
Finally, we derive the update rule of U:
3.2.2. Updating
Similarly, we can derive the update rule of V. Assuming that is the Lagrange multiplier for , the Lagrange function for is as follows:
Then we obtain its partial derivative with respect to :
According to the KKT conditions, i.e., , so
At last, we derive the update rule for as follows:
3.2.3. Computing the Weight Value
Inspired by [25,39], in this work, we use the same method in [34] to calculate weight value of the qth graph, which is:
Finally, the proposed MSNMFSC algorithm is summarized in Algorithm 1.
| Algorithm 1: MSNMFSC Algorithm. |
| Input: Data matrix , label information , parameters , p, , and . Output: . |
4. Convergence of MSNMFSC
Here we use the auxiliary function method [15,34] to analyze the convergence of MSNMFSC. Considering the update rules in (12) and (16), we derive Theorem 1 as follows:
Here, we just give the proof that is nonincreasing under the update rules (16), because the proof procedure of is nonincreasing under (12) is similar; therefore, in this work, we omit it. First, we define the auxiliary function and Lemma 1:
Definition 1
([34]). If function G satisfies and , then is an auxiliary function for .
Lemma 1
([34]). F is nonincreasing under the update steps in (18), here G is an auxiliary function of F:
Proof.
So, Lemma 1 is proved. □
According to Lemma 1, if we can obtain the same update rule as (16) when minimizing the auxiliary function G of , we can prove that is nonincreasing under (16). Here, is the corresponding entry of , and is the part which only involves the term in . Then, we derive the following partial derivatives:
Next, is nonincreasing under (16) needs to be proved.
Lemma 2.
The function (21) below is an auxiliary function of .
Proof.
Because , so we just require to prove . Then we give the Taylor series expansion of as follows:
Due to and ,
and
and
So is proved. The function (21) is an auxiliary function of . □
Next we will prove Theorem 1 on the base of Lemmas 1 and 2.
5. Experiments Results
Here, we give the experiment results on seven image datasets to illustrate the advantage of MSNMFSC, in comparison to GDNMF [33], SDNMF [23], CPSNMF [26], LCDNMF [12], MGNMF [24], PAMGNMF [25] and MSNMF [34].
5.1. Settings for the Experiments
We choose seven real-world image datasets including two handwritten datasets (Optdigits with 10 classes and MNIST with 10 classes), two object datasets (COIL20 with 20 classes and COIL100 with 100 classes ) and three face datasets (CMU PIE with 68 classes, UMIST with 20 classes and MSRA25 with 12 classes) for the clustering experiments. Particularly, we format every image dataset as a M by N data matrix, in which N is the number of samples, M is the number of dimensions of each sample, which is equal to the product of the sample image’s length and width, so the Optdigits, MNIST, COIL20, COIL100, CMU PIE, UMIST and MSRA25 datasets are formatted as , , , , , and matrices, respectively. Each column of the data matrix which represents a sample is normalized to have unit Euclidean length. We also use three typical evaluation metrics including accuracy, normalized mutual information (NMI) and purity to evaluate the clustering performance. Here, we omit the detailed definitions of these used metrics since they are described in [16].
The balance parameter , the regularization parameter and the sparseness parameter and are empirically set to be 0.2, 100, 0.4 and 0.2, respectively. The initial values for and are randomly selected, ranging from 0 to 1. Here, we adopt three single p-nearest neighbor graphs with , respectively. Furthermore, we select 10% of the data points in each image dataset as the labeled data points, which are used as the supervised information. Particularly for the compared methods, we use best parameters according to their reference papers.
5.2. Clustering Results
The clustering results for all methods on seven datasets are shown in Table 1, and the bold-faced results represent the best result among all the methods. From the table, one can discover that, compared with other state-of-the-art methods, MSNMFSC has the best clustering results on all image datasets in terms of accuracy and NMI, and has better performance on almost all used datasets except CMU PIE and UMIST in term of purity. For example, compared with the MSNMF method, which usually has the second best clustering performance, MSNMFSC has 5.8%, 3.25% and 0.52% improvements on the MNIST dataset, 1.18%, 0.55% and 1.13% improvements on the COIL100 dataset, 3.22%, 1.77% and 0.8% improvements on the MSRA25 dataset, for three evaluation metrics, respectively. The clustering results illustrate that the proposed MSNMFSC outperforms the compared NMF methods in clustering tasks, that’s because MSNMFSC can take full advantage of the multiple graph adaptive regularization, the limited supervised information and the sparse constraint to obtain more discriminative parts-based data representation and improve the clustering performance.

Table 1.
Clustering results.
5.3. Convergence
In order to validate that in (7) is monotonically nonincreasing under (12) and (16), we give the convergence curves of MSNMFSC on seven image datasets in Figure 1, in which the number of iteration and the value of are represented by the x-axis and the y-axis, respectively. According to Figure 1, we observe that the value of is monotonically nonincreasing under (12) and (16) for all the datasets used in our experiment, which shows Theorem 1 that have been proved in the convergence analysis section is correct.
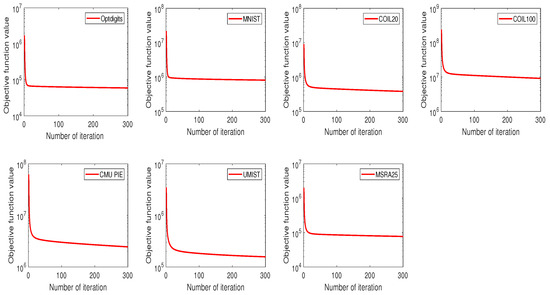
Figure 1.
Convergence curves of MSNMFSC.
6. Conclusions
In this paper, the multiple graph adaptive regularized SSNMF with sparse constraint (MSNMFSC) is developed, which enforces the multiple graph adaptive regularization, the limited supervised information and the sparse constraints into the NMF model for learning the more discriminative parts-based data representation. We derive the multiplicative update rules of MSNMFSC by solving the optimization problem. Moreover, the convergence of MSNMFSC is also analyzed. The extensive experimental results have shown MSNMFSC outperforms the compared NMF approaches on seven image datasets for clustering tasks.
Author Contributions
K.Z.: Conceptualization, methodology, validation, writing—original draft preparation; L.L.: formal analysis, software; J.D.: software, simulation; Y.W.: software, simulation; X.Z.: software; J.Z.: writing—review and editing, supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Henan Center for Outstanding Overseas Scientists (GZS2022011), the Training Program for Young Scholar of Henan Province for Colleges and Universities under Grand (2020GGJS172), the Program for Science and Technology Innovation Talents in Universities of Henan Province under Grand (22HASTIT020).
Acknowledgments
The authors thank the Guest Editor, Assistant Editor, and the reviewers for their valuable comments and constructive suggestions.
Conflicts of Interest
The authors declare that they have no conflict of interest.
References
- Klema, V.; Laub, A. The singular value decomposition: Its computation and some applications. IEEE Trans. Autom. Control. 1980, 25, 164–176. [Google Scholar] [CrossRef]
- Lee, D.D.; Seung, H.S. Learning the parts of objects by non-negative matrix factorization. Nature 1999, 401, 788. [Google Scholar] [CrossRef] [PubMed]
- Stone, J.V. Independent component analysis: An introduction. Trends Cogn. Sci. 2002, 6, 59–64. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Pang, Y. Deterministic column-based matrix decomposition. IEEE Trans. Knowl. Data Eng. 2009, 22, 145–149. [Google Scholar] [CrossRef]
- Shlens, J. A tutorial on principal component analysis. arXiv 2014, arXiv:1404.1100. [Google Scholar]
- Gan, G.; Ma, C.; Wu, J. Data Clustering: Theory, Algorithms, and Applications; SIAM: Philadelphia, PA, USA, 2020. [Google Scholar]
- Janmaijaya, M.; Shukla, A.K.; Muhuri, P.K.; Abraham, A. Industry 4.0: Latent Dirichlet Allocation and clustering based theme identification of bibliography. Eng. Appl. Artif. Intell. 2021, 103, 104280. [Google Scholar] [CrossRef]
- Pozna, C.; Precup, R.E. Applications of Signatures to Expert Systems Modelling. Acta Polytech. Hung. 2014, 11, 21–39. [Google Scholar]
- Si, S.; Wang, J.; Zhang, R.; Su, Q.; Xiao, J. Federated Non-negative Matrix Factorization for Short Texts Topic Modeling with Mutual Information. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–7. [Google Scholar]
- Seo, H.; Shin, J.; Kim, K.H.; Lim, C.; Bae, J. Driving Risk Assessment Using Non-Negative Matrix Factorization With Driving Behavior Records. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20398–20412. [Google Scholar] [CrossRef]
- Helal, S.; Sarieddeen, H.; Dahrouj, H.; Al-Naffouri, T.Y.; Alouini, M.S. Signal Processing and Machine Learning Techniques for Terahertz Sensing: An overview. IEEE Signal Process. Mag. 2022, 39, 42–62. [Google Scholar] [CrossRef]
- Peng, S.; Ser, W.; Chen, B.; Sun, L.; Lin, Z. Robust nonnegative matrix factorization with local coordinate constraint for image clustering. Eng. Appl. Artif. Intell. 2020, 88, 103354. [Google Scholar] [CrossRef]
- Xing, Z.; Wen, M.; Peng, J.; Feng, J. Discriminative semi-supervised non-negative matrix factorization for data clustering. Eng. Appl. Artif. Intell. 2021, 103, 104289. [Google Scholar] [CrossRef]
- Gillis, N. Nonnegative Matrix Factorization; SIAM: Philadelphia, PA, USA, 2020. [Google Scholar]
- Cai, D.; He, X.; Han, J.; Huang, T.S. Graph regularized nonnegative matrix factorization for data representation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 1548–1560. [Google Scholar]
- Peng, S.; Ser, W.; Chen, B.; Lin, Z. Robust semi-supervised nonnegative matrix factorization for image clustering. Pattern Recognit. 2021, 111, 107683. [Google Scholar] [CrossRef]
- Sun, J.; Wang, Z.; Sun, F.; Li, H. Sparse dual graph-regularized NMF for image co-clustering. Neurocomputing 2018, 316, 156–165. [Google Scholar] [CrossRef]
- Peng, S.; Ser, W.; Chen, B.; Lin, Z. Robust orthogonal nonnegative matrix tri-factorization for data representation. Knowl. Based Syst. 2020, 201, 106054. [Google Scholar] [CrossRef]
- Shang, F.; Jiao, L.; Wang, F. Graph dual regularization non-negative matrix factorization for co-clustering. Pattern Recognit. 2012, 45, 2237–2250. [Google Scholar] [CrossRef]
- Rahiche, A.; Cheriet, M. Variational Bayesian Orthogonal Nonnegative Matrix Factorization Over the Stiefel Manifold. IEEE Trans. Image Process. 2022, 31, 5543–5558. [Google Scholar] [CrossRef]
- Xu, X.; He, P. Manifold Peaks Nonnegative Matrix Factorization. IEEE Trans. Neural Netw. Learn. Syst. 2022. early access. [Google Scholar] [CrossRef]
- Huang, Q.; Zhang, G.; Yin, X.; Wang, Y. Robust Graph Regularized Nonnegative Matrix Factorization. IEEE Access 2022, 10, 86962–86978. [Google Scholar] [CrossRef]
- Meng, Y.; Shang, R.; Jiao, L.; Zhang, W.; Yang, S. Dual-graph regularized non-negative matrix factorization with sparse and orthogonal constraints. Eng. Appl. Artif. Intell. 2018, 69, 24–35. [Google Scholar] [CrossRef]
- Wang, J.J.Y.; Bensmail, H.; Gao, X. Multiple graph regularized nonnegative matrix factorization. Pattern Recognit. 2013, 46, 2840–2847. [Google Scholar] [CrossRef]
- Shu, Z.; Wu, X.; Fan, H.; Huang, P.; Wu, D.; Hu, C.; Ye, F. Parameter-less auto-weighted multiple graph regularized nonnegative matrix factorization for data representation. Knowl. Based Syst. 2017, 131, 105–112. [Google Scholar] [CrossRef]
- Wang, D.; Gao, X.; Wang, X. Semi-supervised nonnegative matrix factorization via constraint propagation. IEEE Trans. Cybern. 2015, 46, 233–244. [Google Scholar] [CrossRef] [PubMed]
- Wu, W.; Jia, Y.; Kwong, S.; Hou, J. Pairwise constraint propagation-induced symmetric nonnegative matrix factorization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 6348–6361. [Google Scholar] [CrossRef]
- Hoyer, P.O. Non-negative matrix factorization with sparseness constraints. J. Mach. Learn. Res. 2004, 5, 1457–1469. [Google Scholar]
- Pascual-Montano, A.; Carazo, J.M.; Kochi, K.; Lehmann, D.; Pascual-Marqui, R.D. Nonsmooth nonnegative matrix factorization (nsNMF). IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 403–415. [Google Scholar] [CrossRef]
- Ding, C.; Li, T.; Peng, W.; Park, H. Orthogonal nonnegative matrix t-factorizations for clustering. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Philadelphia, PA, USA, 20–23 August 2006; pp. 126–135. [Google Scholar]
- Choi, S. Algorithms for orthogonal nonnegative matrix factorization. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1828–1832. [Google Scholar]
- Paatero, P.; Tapper, U. Positive matrix factorization: A non-negative factor model with optimal utilization of error estimates of data values. Environmetrics 1994, 5, 111–126. [Google Scholar] [CrossRef]
- Li, H.; Zhang, J.; Shi, G.; Liu, J. Graph-based discriminative nonnegative matrix factorization with label information. Neurocomputing 2017, 266, 91–100. [Google Scholar] [CrossRef]
- Zhang, K.; Zhao, X.; Peng, S. Multiple graph regularized semi-supervised nonnegative matrix factorization with adaptive weights for clustering. Eng. Appl. Artif. Intell. 2021, 106, 104499. [Google Scholar] [CrossRef]
- Yang, Z.; Zhang, Y.; Yan, W.; Xiang, Y.; Xie, S. A fast non-smooth nonnegative matrix factorization for learning sparse representation. IEEE Access 2016, 4, 5161–5168. [Google Scholar] [CrossRef]
- Sun, F.; Xu, M.; Hu, X.; Jiang, X. Graph regularized and sparse nonnegative matrix factorization with hard constraints for data representation. Neurocomputing 2016, 173, 233–244. [Google Scholar] [CrossRef]
- Donoho, D.L.; Elad, M. Optimally sparse representation in general (nonorthogonal) dictionaries via L1 minimization. Proc. Natl. Acad. Sci. USA 2003, 100, 2197–2202. [Google Scholar] [CrossRef] [PubMed]
- Boyd, S.; Boyd, S.P.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Nie, F.; Li, J.; Li, X. Parameter-free auto-weighted multiple graph learning: A framework for multiview clustering and semi-supervised classification. In Proceedings of the IJCAI, New York, NY, USA, 9–15 July 2016; pp. 1881–1887. [Google Scholar]

Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).