1. Introduction
Psychological distress is a state of emotional suffering associated with stressors and demands that are difficult to cope with in daily life [
1], and describes an acute stress disorder caused by a living environment or a mental health disorder. Surveys have shown that psychological distress may lead to emotional instability and interpersonal difficulties, and severe psychological distress can disrupt the body’s biological rhythm, even causing fatal diseases. However, the difficulty in identifying psychological distress is frustrating for patients and health professionals alike. At present, psychological tests or hormone tests are carried out to detect psychological distress, but potential patients with psychological distress seldom take the initiative to undergo any professional testing. Therefore, identifying predictors and reaching a timely diagnosis is beneficial to public mental health.
Considering the current research on the factors influencing psychological distress, some research applied traditional statistical methods to explore the relationship between certain factors and psychological distress. Weaver et al. (1995) examined the relationship between interpersonal violence and psychological distress through the descriptive statistics and statistical tests of the questionnaire data [
2]. Kessler et al. (1998) used survival models to investigate the probability and time association between psychological distress and marital status [
3]. Zabora et al. (2001) determined the prevalence of psychological distress in cancer patients, where univariate and multiple regression analyses were used to examine the relationship between relevant variables and psychological distress [
4]. Additionally, Mirowsky et al. (2017) explored the impact of social stratification on psychological distress [
5]. Drapeau et al. (2012) critically reviewed the empirical evidence on risk and protective factors associated with psychological distress in the general population and in two specific populations by constructing a scale [
6]. Winefield et al. (2017) explored a self-report measure for psychological well-being and used factor analysis to investigate the relationship between mental health and psychological distress [
7]. These studies mainly explored the influence of a certain factor or a class of factors on psychological distress, or only involved certain groups of people; therefore, the scope of the research was relatively limited.
With the rapid development of artificial intelligence, machine learning methods have received increasing attention. Machine learning algorithms are used in a wide variety of applications, such as in medicine and healthcare, where it is difficult or unfeasible to develop conventional algorithms to necessary tasks [
8]. The second important role of machine learning in healthcare is to increase diagnostic accuracy, as machine learning can provide excellent capabilities to predict diseases [
9]. For example, De Silva et al. (2020) used machine learning to identify predictors of prediabetes in a nationally representative sample of the U.S. population. The results demonstrated the value of machine learning in identifying a wide range of predictors that could enhance prediabetes prediction and clinical decision-making [
10]. There are also articles on the use of machine learning methods to study psychological distress. Zhou X et al. (2006) used artificial neural networks and machine learning models to predict the incidence of psychological distress in Alzheimer’s patients and achieved a relatively high prediction accuracy rate [
11]. In Prout TA et al. (2020), a random forest machine learning algorithm was used to identify the strongest predictors of psychological distress during COVID-19, and regression trees were developed to identify individuals at greater risk for anxiety, depression, and post-traumatic stress. The random forest method is able to identify the most important predictors from a large set of potential predictor variables. Moreover, the subsequent regression tree analysis allows for the identification of various interactions between the predictor variables [
12]. Sutter B et al. (2021) aimed to provide a foundation by building a machine learning model across multiple techniques to predict psychological distress from ecological factors alone, and eight different classification techniques were implemented on a sample dataset [
13]. Using machine learning algorithms is likely to enhance a timely diagnosis of psychological distress. However, in these machine learning method studies on psychological distress, the data used were relatively limited, such as only data for certain disease groups or a certain period of time.
In this paper, we used data from the Health Information National Trends Survey (HINTS). The Health Information National Trends Survey (HINTS) is a probability-based and nationally representative survey of the U.S. adult (age 18+) noninstitutionalized population conducted by the NCI. HINTS regularly collects nationally representative data about the American public’s knowledge of, attitudes toward, and use of cancer- and health-related information and provides a rich multidimensional data source for predictive analytics. Moreover, we applied some machine learning algorithms to a nationally representative sample to optimize psychological distress prediction. According to our best knowledge, this is the first study that applied a range of machine learning algorithms to such a large representative sample based on many different factors (predictors of psychological distress). We implemented a combination of machine learning methods and authoritative data. Predictors of psychological distress can be identified based on the results of machine learning methods.
3. Statistical Analysis
This study compared the sociodemographic characteristics and related variables in individuals with or without psychological distress via Chi-squared tests for categorical variables and two-tailed t-tests for continuous variables. Four machine learning algorithms were applied for modeling: logistic regression (linear), random forests (RF) (ensemble), the artificial neural network (ANN) (nonlinear), and gradient boosting (GB) (ensemble). To evaluate the predictive accuracy of the models, we randomly assigned 50% of the dataset to a training set and the remaining 50% to the validation set, reporting the accuracy, precision, recall, F1-score, and AUC of the validation set. The logistic regression model selected predictors by forward selection, backward selection, and stepwise regression. The relative effects of the predictors in the logistic regression model were measured by adjusted odds ratios (ORs), while the variability and significance were assessed by confidence intervals (CIs) and the corresponding p-values. Variable importance values were used in the other three classification algorithms to identify the predictors.
All statistical analyses were performed on R Software version 4.1.2. R is a programming language for statistical computing and graphics created by statisticians Ross Ihaka and Robert Gentleman.The official R software environment is an open-source free software environment within the GNU package, available under the GNU General Public License. The p < 0.05 was considered statistically significant.
4. Measures
4.1. Psychological Distress
Psychological distress is an emotional state associated with intractable stressors and demands in daily life, with depression and anxiety as its manifestations. The variable “Psychological Distress” in this paper was calculated by the HINTS using the following four items. The first two items are for depression screening, with the other two for anxiety screening: Over the past two weeks, how often have you been bothered by any of the following problems? (a) Little interest or pleasure in doing things, (b) Feeling down, depressed, or hopeless, (c) Feeling nervous, anxious, or on edge, and (d) Not being able to stop or control worrying. There were four answer choices for cases (a) to (d): (1) Nearly every day, (2) More than half the days, (3) Several days, and (4) Not at all. We reclassified the answers into two categories, whereby respondents who chose “(4) Not at all” for all cases were classified as “Individuals without Psychological Distress”; on the contrary, respondents who chose choices (1) to (3) for any cases were classified as “Individuals with Psychological Distress”.
4.2. Demographic Variables and Other Related Variables
Demographic variables of interest (dichotomized for analyses) included Gender (Male, Female), Race/Ethnicity (Non-Hispanic white, Racial and ethnic minority), Education (≤High school, >High school), Income Ranges (<$20,000, ≥$20,000), Geographic area (Non-metropolitan, Metropolitan), and Marital status (In marriage, Not in marriage), as well as Numerical demographic variables, including Age (continuous years) and BMI.
For further analysis, we selected as many variables as possible from the HINTS database that might be related to psychological distress by drawing on relevant literature and referring to historical experience. The potential independent variables we extracted were as follows: SeekCancerInfo (Yes, No), UseInternet (Yes, No), WearableDevTrackHealth (Yes, No), Social media user (Yes, No), RegularProvider (Yes, No), AccessOnlineRecord (Yes, No), Caregiving (Yes, No), OwnAbilityTakeCareHealth (Completely confident, Very confident, Somewhat confident, A little confident, Not confident at all), Deaf (Yes, No), TalkHealthFriends (Yes, No), MedConditions_Disease (Yes, No), Drink (Yes, No), Smoke (Yes, No), EverHadCancer (Yes, No), Cancercheck (Yes, No), FreqWorryCancer (Not at all, Slightly, Somewhat, Moderately, Extremely), and ModerateExerciseMinutes (Numerical demographic variables).
Table S1 presents the details of the above variables, including demographic variables and other independent variables, and information on reclassification.
6. Results
The merged datasets from HINTS Cycle 3–Cycle 4 yielded a sample of 5484 respondents, including 2610 respondents without and 2874 respondents with psychological distress.
Table 1 presents the frequencies and proportions of the variables. The Chi-squared test of categorical variables and the
t-test of continuous variables showed significant differences in some variables between individuals with and without psychological distress (
p < 0.05). Among the categorical variables, respondents choosing the following options comprised a significantly higher proportion (
p < 0.05) in the group without psychological distress: “males,” “had more than
$20,000 annual income,” “in marriage,” “completely confident about self-health care,” “ever had cancer,” “never worry about getting cancer.” For example, in this group, males accounted for 48.08% of the respondents, while in the group with psychological distress, the percentage decreased to 38.31%. The same was true for the other variables mentioned above: “had more than
$20,000 annual income” (89.39% vs. 83.23%), “in marriage” (63.10% vs. 53.93%), “completely confident about self-health care” (31.61% vs. 16.95%), “ever had cancer” (7.62% vs. 6.26%), and “never worry about getting cancer” (24.79% vs. 12.91%). However, those choosing “ever looked for information about cancer” (50% vs. 58.28%), “using social media” (74.14% vs. 83.86%), “ever accessed online medical records” (44.14% vs. 46.49), “caring for or making healthcare decisions for someone” (14.06% vs. 18.20%), “self-health evaluation as good” (6.44% vs. 18.65%), “deaf” (5.36% vs. 7.34%), “had high blood pressure or other diseases” (53.68% vs. 69.31%), and “smoke” (35.71% vs. 44.64%) were significantly higher (
p < 0.05) in the group with psychological distress. Among numeric variables, mean values of age and the average number of minutes of moderate daily exercise were significantly higher (
p < 0.05) in the group without psychological distress, while BMI was significantly higher (
p < 0.05) in the group with psychological distress. The Chi-squared test of categorical variables also showed no significant difference (
p > 0.05) in some variables between individuals with and without psychological distress. In other words, the proportions of those variables were similar in the two groups. As for education, most individuals (approximately 81%) had above high school education in both groups.
The variables in the logistic regression were screened by three methods: forward selection, backward selection, and stepwise regression. The results obtained by the three variable selection methods were consistent. According to the variable
p-value,
Table 2 only retains the variables that were significant in the regression, and the crude odds ratios (ORs) and 95% CI are calculated to elucidate the effect of each variable on the psychological distress. Based on sociodemographic variables, relatively younger age (OR = 0.96, 95% CI: 0.96–0.97), unmarried (married OR = 0.65, 95% CI 0.54–0.78), non-Hispanic white (OR = 1.24, 95% CI: 1.03–1.48), and female (male OR = 0.68, 95% CI: 0.57–0.81) groups were more likely to have psychological distress. According to other research variables, those who searched for cancer-related information (OR = 1.34, 95% CI: 1.12–1.60), used social media (OR = 1.40, 95% CI: 1.11–1.77), were currently caring for or making health care decisions for someone with a medical, behavioral, disability, or other condition (OR = 1.34, 95% CI: 1.06–1.68), and believed they were in poor health (healthy OR = 0.55, 95% CI: 0.40–0.75) were more likely to experience psychological distress. Likewise, individuals who were more likely to experience psychological distress tended to be those who had hearing impairments (OR = 2.63, 95% CI: 1.82–3.79), had been told by a doctor or another health professional that they had health problems (OR = 2.27, 95% CI: 1.88–2.74), did not exercise (OR = 0.9978, 95% CI: 0.9961–0.9995), or smoked (OR = 1.33, 95% CI: 1.11–1.59). According to the multicategory variables (OwnAbilityTakeCareHealth and FreqWorryCancer), individuals who were less confident about taking care of their own bodies and more anxious about cancer were more likely to have psychological distress.
Table 2 shows significant predictors of psychological distress in the logistic regression, including SeekCancerInfo, Social media user, Caregiving, GeneralHealth, OwnAbilityTakeCareHealth, Deaf, MedConditions_Disease, ModerateExerciseMinutes, Smoke, FreqWorryCancer, Age, Marital status, Race, and Gender. According to different variable importance criteria, the random forests, ANN, and XGB can give the importance order of the relevant variables for predicting psychological distress.
Table 3 lists the top 15 important predictors obtained under the random forests, ANN, and XGB, respectively. The three methods identified 20 different predictors, including 14 important predictors identified by the logistic regression model, and another 6 predictors, namely, AccessOnlineRecord, Area, BMI, Drink, Income, and UseInternet.
The essence of this paper is a binary classification problem of judging whether an individual has psychological distress based on the set of inputs like SeekCancerInfo, Social media user, etc. Therefore, we evaluated the four machine learning methods covered in this article using a series of commonly used evaluation metrics for classification algorithms.
Table 4 presents the accuracy, precision, recall, F1-score, and AUC values of the four machine learning methods on the validation set.
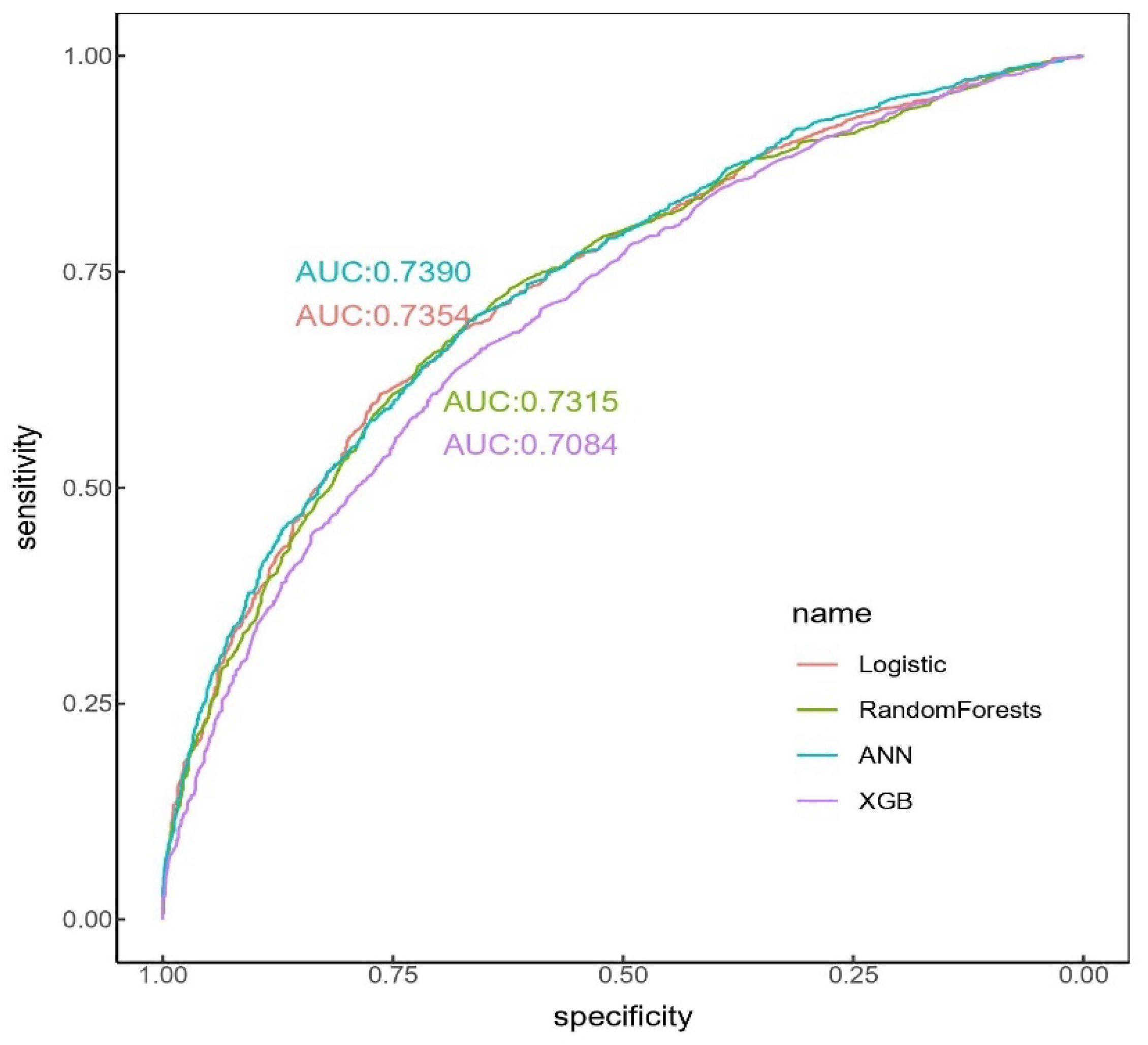
Figure 1 shows the ROC curves and AUC values of four automated machine learning methods. Accuracy is a metric of a classification model that measures the number of correct classifications as a percentage of the total number of classifications made. Precision is the proportion of all positive classifications that are correctly classified, while recall is the proportion of total positive classifications that are correctly classified. The F1-score is the harmonic mean of precision and recall. According to the accuracy, recall, and F1-score values, the optimal model was random forests, with an accuracy of 67.83%, a recall of 72.70%, and an F1-score of 70.24%. However, from the perspective of the precision and AUC indicators, the optimal model was the ANN, with a precision of 70.02% and an AUC of 73.90%. AUC is not affected by the classification threshold and data distribution, and thus reflects the overall classification power of the model. Therefore, in general, this study preferred to choose the ANN as the optimal model to predict the risk of psychological distress.
7. Discussion
We conducted a comprehensive evaluation of the effects of individual sociodemographic characteristics, lifestyle, and behavioral habits on psychological distress. Although the generalization of the factors affecting individuals’ psychological distress was difficult, based on the survey data, this study selected some variable sets with realistic and interpretable significance, demonstrating that an individual’s psychological distress is related to their sociodemographic characteristics such as age and gender, lifestyle, behavioral habits, attention to health problems, etc.
Psychological distress is defined as the unpleasant feelings or emotions that a person may have when feeling overwhelmed. These emotions and feelings can interfere with daily routines and affect how the affected individual reacts to others. High levels of psychological distress indicate impaired mental health and may reflect common mental disorders, like depressive and anxiety disorders [
18]. Psychological distress occurs when an individual faces stressors that they cannot cope with, including traumatic experiences, major life events, and everyday stressors such as workplace stress, family stress, interpersonal relationships, health issues, etc. Therefore, it is crucial to understand the factors contributing to psychological distress. This study provided ideas for predicting psychological distress based on personal behavior characteristics.
Self-report rating scales like the General Health Questionnaire [
19] or MHI-5, derived from the RAND-36 questionnaire [
20], are usually used to measure psychological distress levels. Based on the National Cancer Institute’s 2019–2020 Health Information National Trends Survey (HINTS), we used the question “Over the past two weeks, how often have you been bothered by any of the following problems? (a) Little interest or pleasure in doing things, (b) Feeling down, depressed, or hopeless, (c) Feeling nervous, anxious, or on edge, and (d) Not being able to stop or control worrying” to determine whether a person suffers from psychological distress. Our analysis showed that approximately 52.41% of the population in the 5484 survey samples had symptoms of anxiety or depression.
Previous studies have mainly focused on sociodemographic differences in self-reported psychological distress or have divided individuals into different categories according to their characteristics to study some factors that affect their psychological distress. However, they have neglected the individual characteristics that generally affect psychological distress. To the best of our knowledge, this is the first study to apply a range of machine learning algorithms to a nationally representative sample to optimize psychological distress classification.
This study used four machine learning algorithms (logistic regression (linear), random forests (RF) (ensemble), the artificial neural network (ANN) (nonlinear), and gradient boosting (GB) (ensemble)) to identify and investigate factors affecting individuals’ psychological distress. Twenty influencing variables concerning psychological distress were selected based on the coefficient significance in the logistic regression model and the variable importance indicators in the other three methods. Many well-established determinants were also identified as proof of concept for our analytical approach, such as sociodemographic characteristics [
21]. While nonlinear and ensemble algorithms may exhibit better predictive performance than traditional parametric models, they are less interpretable [
22]. Therefore, predictors determined by such algorithms should be evaluated in conjunction with relevant research evidence.
This study showed that sociodemographic indicators such as age, gender, education, marital status, race, area, and BMI significantly impacted psychological distress, while personal income did not significantly affect the prediction of psychological distress. In addition, predictors involving personal lifestyle and behavioral habits, such as smoking, drinking, exercise time, social network usage, etc., also play essential roles in predicting psychological distress. Finally, individuals’ health status and their level of health concern were also associated with psychological distress. Generally speaking, people tend to be more prone to anxiety and psychological distress if they think they are unhealthy or have been told by a doctor that they have a medical condition.
The present research can provide a theoretical basis for screening individual mental health status and conducting mental health counseling. For example, the identified significant predictors can be used in psychiatric screening or electronic medical records, based on which machine learning algorithms can be applied to assess the likelihood of developing psychological distress. In this way, individuals who may have psychological distress can be identified in advance so to undergo mental health tests, thereby providing assistance to psychologists and other personnel.
There were some limitations in this study. Firstly, there were certain subjective factors in selecting candidate predictor sets related to psychological distress, and the relevant variables included might not have been comprehensive enough. Secondly, the relationship between the selected variables was not further studied, and there might be some collinearity in the screened important predictors. If used for linear regression analysis, there might be multicollinearity problems. Thirdly, the data were obtained using a self-report questionnaire. Therefore, we did not obtain detailed information on psychological distress, and self-report bias might have affected the results. Finally, the classification accuracy obtained by the machine learning method used in this paper should be further improved. In addition, the interpretability of the methods was poor. Further research is necessary to combine other methods to reveal the correlation or causal relationship between each predictor and psychological distress.




 and
and 

{kind=link}