Abstract
This paper develops an incipient fault detection and isolation method using the Wasserstein distance, which measures the difference between the probability distributions of normal and faulty data sets from the aspect of optimal transport. For fault detection, a moving window based approach is introduced, resulting in two monitoring statistics that are constructed based on the Wasserstein distance. From analysis of the limiting distribution under multivariate Gaussian case, it is proved that the difference measured by the Wasserstein distance is more sensitive than conventional quadratic statistics like Hotelling’s and Squared Prediction Error (SPE). For non-Gaussian distributed data, a project robust Wasserstein distance (PRW) model is proposed and the Riemannian block coordinate descent (RBCD) algorithm is applied to estimate the Wasserstein distance, which is fast when the number of sampled data is large. In addition, a fault isolation method is further proposed once the incipiently developing fault is detected. Application studies to a simulation example, a continuous stirred tank reactor (CSTR) process and a real-time boiler water wall over-temperature process demonstrate the effectiveness of the proposed method.
1. Introduction
Process monitoring plays a significant role in improving the reliability and safety of modern industrial systems. With the advancement of information and sensor technology, data collection has become more convenient and data processing has become more rapid, which greatly facilitates the developing of data-driven process monitoring methods. Compared with model-based monitoring methods, data-driven technology does not require much prior knowledge, is conceptually simple, and has low implementation costs [1]. Among different kinds of data-driven methods, the most popular is perhaps multivariate statistical based approaches [2], typical analysis methods include principal component analysis (PCA) [3], independent principal component analysis (ICA) [4], and Fisher discriminant analysis (FDA) [5]. The basic idea of multivariate statistical methods is to map the process data onto a low-dimensional space through a specific transformation to obtain latent variables, and construct monitoring statistics like Hotelling’s and squared prediction error (SPE) to determine whether the process data is faulty [6]. Based on multivariate statistical methods, the literature have proposed a series of techniques for monitoring of different kinds of fault types like distributed faults [7], intermittent faults [8], and incipient faults [9].
In recent years, detection of incipiently developing faults has attracted significant research attention, as it is of great benefits for industrial operators to detect and correct an incipient fault at an early stage. A number of techniques have been developed for monitoring of incipient faults, which roughly falls into three categories, namely, methods based on higher-order information, smoothing and denoising based approaches and statistical distance based approaches. Methods based on higher-order information considers the incorporation of higher-order information in the monitoring statistics to cope with incipient faults, including those based on recursive correlative statistical analysis [10], statistical local approach [11], and recursive transform component analysis [12].
The second type of approaches use smoothing and denoising techniques to remove noises and disturbances to enhance the detection sensitivity for incipient faults, such as detrending and denoising based method [13], smoothing based method [14] and non-stationary analysis [15]. Last but not least, statistical distance based approaches use statistical measures that are regarded to be sensitive to small disturbances to perform incipient fault detection. The most widely used statistical distance for incipient fault detection is the Kullback Leibler divergence(KLD). For instance, Harmouche et al. proposed a monitoring method based on KLD under the PCA framework [16], Zeng et al. [9] analyzed the theoretical properties of KLD and proved that KLD is more sensitive than conventional quadratic monitoring statistics, some variants of the KLD have also been developed to accommodate more complicated situations [17,18,19]. Besides, other statistical distances have also been used, such as Jensen-Shannon divergence [20] and Mahalanobis distance [21,22]. To cope with the incipient fault isolation problem, several methods are also proposed, such as probabilistic amplitude estimation method in the framework of KLD [23] and exponential smoothing reconstruction [24]. Deep learning is another very effective method of fault isolation, in which autoencoders and recurrent neural networks have been widely used in process monitoring. In recent work, an improved autoencoder based on sliding-scale resampling strategy is proposed by Yang et al. [25] to isolate incipient fault, Jana et al. [26] proposed convolutional neural networks(CNN) and convolutional autoencoder (CAE) end-to-end framework to reconstructed fault, Sun et al. [27] utilized Bayesian Recurrent Neural Networks (BRNN) with variational dropout for fault detection and combined squared Mahalanobis distance and local density ratio (LDR) to identify Gaussian and non-Gaussian distributed fault variables, respectively.
Despite the research progress on incipient fault detection and isolation, some important issues still remain. First, the recursive methods based on higher-order information [10,11] required to monitor the mass variables at the same time, but some of them cannot be directly obtained; Second, existing method of smoothing techniques [14] improved the detection performance at the cost of detection timeliness, which is not suitable for online monitoring. As for Harmouche et al. [16] and Zeng et al. [9] calculated KLD under the PCA framework, they did not propose effective fault isolation methods. Though Harmouche et al. [23] estimated KLD by a probabilistic way, since KLD has no closed form, the magnitudes of the fault are approximate. Also, the statistical distance method based on Mahalanobis distance [21,22] are calculated by the covariance matrix of the reference data, which is highly demanding on the reference dataset. With regard to deep learning method [25,26,27], they can be effective when there are large number of training sets. However, they may suffer from heavy computation load and are difficult to get sparse fault isolation results.
Motivated by the above discussion, this paper proposes a new incipient fault detection and isolation method based on the Wasserstein distance [28] in the multivariate statical analysis framework, the three main contributions of this article are (1) a novel monitoring approach based on Wasserstein distance with sliding window is developed to detect incipient faults, the limiting distribution and sensitivity analysis of Wasserstein distance are discussed; (2) by introducing the Riemannian block coordinate descent algorithm [29] for estimation of the Wasserstein distance under the non-Gaussian case, an efficient detection method that is suitable for online application is proposed; (3) a fault isolation method based on the Wasserstein distance is designed, resulting in a complete fault detection and isolation framework of incipient faults.
This paper is organized as follows. Section 2, introduced the Wasserstein distance and some of its statistical characteristics as monitoring statistic. The monitoring method of Wasserstein distance of multivariate normal distribution data is studied in Section 3, and we also analyze the sensitivity of Wasserstein distance and Hotelling’s statistics. Section 4, a Wasserstein distance monitoring method for non-Gaussian distributed process data is designed. A fault isolation method based on Wasserstein distance is proposed in Section 5. In Section 6, the proposed method is applied to a simulate example and an industrial boiler that involves an over-temperature fault in the water-wall tube, the effectiveness of the method is proved. The conclusions of this work are presented in Section 7.
2. Preliminaries
This section presents preliminary knowledge involving multivariate statistical based process monitoring framework, the definition of Wasserstein distance and its limiting distribution under multivariate Gaussian case.
2.1. Multivariate Statistical Based Process Monitoring Framework
Assume m measurements of correlated variables have been collected under normal conditions from the process and arranged into a data matrix , . In the multivariate statistical based monitoring framework, the data matrix is often used as a training data set and the following model structure is generally considered.
Here is the dimensional score vector in the projection subspace, is the residual vector, with being the projection matrix, being the loading matrix and being the identity matrix. The projection matrix can be estimated using different techniques, such as principal component analysis, independent component analysis or canonical correlation analysis. On the other hand, another set of n measurements are also collected and arranged as , , which is generally used as the test data set. Similar to Equation (1), the model structure for the test data set can be constructed as follows.
Here is the score vector and the residual vector. The purpose of process monitoring is to investigate whether the score vectors and , as well as the residual vectors and , share the same distribution. This can be achieved by constructing quadratic statistics like Hotelling’s or SPE, which can be defined as follows.
The control limits of the quadratic statistics can be obtained based on the normal samples using statistical analysis. For a specific sample in the test data set, the corresponding statistics can be constructed similar to Equation (3), violation of the control limits of either statistic indicates that a faulty condition arises. Such quadratic statistics, however, have been shown to be not sensitive enough for incipiently developing fault conditions [9]. Instead, the Wasserstein distance is considered alternatively in this paper.
2.2. Definition of Wasserstein Distance
Wasserstein distance is a distance function used to measure the difference between probability distributions [30]. The Wasserstein distance arises from the optimal transportation theory and can be regarded as the minimum cost of transporting when converting one distribution to another. Due to its conceptual simplicity, it has seen a wide range of applications in probability theory, statistics and machine learning [28,31]. Let and be d-dimensional random vectors from a normed vector space , with being the underlying norm, f and being two probability measures, and . The p-Wasserstein distance() between and can be defined as follows [32].
Here, is the set of probability measures on , whose marginal distributions are f and , respectively. For practical application, the underlying norm is generally set as Euclidean norm. In addition, is always considered and becomes the Euclidean distance.
2.3. Limit Distribution of Wasserstein Distance under Multivariate Gaussian Case
In order to be used as a monitoring statistic, the limit distribution of Wasserstein distance should be determined, so that the control limit can be obtained by analyzing its limit distribution. Assume and follow multivariate Gaussian distributions, with , , being the mean vectors and being symmetric, positive covariance matrices. The following Lemma holds.
Lemma 1.
The Wasserstein distance between f and can be computed as follows [33].
Here, denotes the trace of a matrix, denotes the Euclidean norm.
In order to obtain the limit distribution, it is assumed that the probability density function(PDF) f of is known a priori. In contrast, the density of is estimated from a data set and denoted as , with being the k-th i.i.d data point sampled from . Based on , the empirical mean vector and empirical covariance matrix can be calculated as follows.
The Wasserstein distance between f and can be obtained as
For the purpose of clarity, is called the empirical Wasserstein distance and the true Wasserstein distance. Theorem 1 shows that the square of difference between empirical and true Wasserstein distance follows a scaled distribution [34].
Theorem 1.
Let and be two Gaussian distributed random vectors with probability measures and , or , be the empirical density of estimated from Equation (4), the square of difference between empirical and true Wasserstein distance follows a scaled distribution as .
With
Here ⇒ denotes the convergence of the distribution, denotes the eigendecomposition of the symmetric matrix .
Proof.
For multivariate Gaussian distributed data sets, The empirical mean and empirical covariance are related to their true values as follows,
where ∼ and [35]. Here, convergence in the space is understood component wise and is a symmetric random matrix with independent (upper triangular) entries as
Let the mapping of Wasserstein distance of multivariate Gaussian distribution be given by
For and discussed in Equation (11), by fixing and , is Frechet differentiable and its derivative at any point is given as follows.
Based on the delta method [36], the following asymptotic relationship can be obtained:
It should be noticed that has independent Gaussian entries in the upper triangle with mean 0 and variance 1 off-diagonal and variance 2 on the diagonal, the mean of and are both 0, thus, is a real-valued Gaussian variable with mean 0 and a certain variance , and the scaled distribution is described as,
Now, we calculate the variance of the derivative in Equation (13), the first term of Equation (13) involving the means and is computed as follow,
The remaining terms involving the covariance matrices in Equation (13) are given by,
With this we can calculate the second moment and the variance of the centered Gaussian of Equation (17)
The first term in Equation (18) can be rewritten as
Similar derivations can be used for the second and third terms in Equation (18) to obtain and , respectively. Thus, can be described as follows,
3. Wasserstein Distance as a Process Monitoring Statistic
Section 2.3 shows that the distribution of the square of difference between empirical and true Wasserstein distance is a scaled distribution. Hence in Equation (8) can be used as a monitoring statistic to determine whether a set of sample share the same distribution as the reference distribution. This section considers the monitoring method using Wasserstein distance under the multivariate statistical framework and analyzes the sensitivity of the monitoring statistic .
3.1. Moving Window Based Monitoring Strategy
Based on the model structures in Equations (1) and (2), the monitoring problem becomes to investigate whether the samples of and , and are from the same distributions. In order to distinguish between the densities of score vectors and residual vectors, let , , , be the probability density functions, the following monitoring statistics can be constructed.
Here and can be obtained from Equation (9), , are the Wasserstein distance between the true PDFs, which are constants that should be estimated.
When using and for process monitoring, an important issue arises, i.e., it is difficult to know the true densities of , , and . Assume m training samples of and and n test samples of and have been obtained using Equations (1) and (2). In order to get the estimation of these densities, a moving window approach consisting of an offline stage and an online stage can be applied. The purpose of offline stage is to get the estimate of and the expectation of , which is summarized as follows.
- 1.
- Select the first samples of the training data set as the reference set, denoted to be , the remaining samples as the validation set ;
- 2.
- Obtain the estimation of mean vector and covariance matrix of using , and denote the estimated density as ;
- 3.
- Set the moving window length to be , divide the samples in consecutively into sub-windows, estimate the mean vectors and and covariance matrices of the samples in each sub-windows, so that estimated densities can be obtained;
- 4.
- Obtain the Wasserstein distance between and the estimated densities, the expectation of can be calculated as the mean of the Wasserstein distance values.
The estimate of and the expectation of can be obtained in a similar way. For the online stage, whenever a test sample of and is available, the following steps are conducted.
- 1.
- Collect the previous samples of and to construct data windows;
- 2.
- Obtain the estimation of mean vector and covariance matrix of each data window, denote the empirical distributions as and ;
- 3.
- Calculate the Wasserstein distance based monitoring statistics as follows.
Based on the monitoring statistics, it is possible to detect whether a sample is faulty using the moving window approach. This requires the establishment of a control limit for each statistic. For the significance level , if either monitoring statistic exceed the control limit, it means a fault has been detected. Thus, the following inequalities hold if the statistical control limit is not exceeded:
On the other hand, the following holds if the control limit is exceeded.
Here, is the upper quantile of Chi-square distribution .
3.2. Sensitivity Analysis under the Multivariate Statistical Framework
In order to evaluate the potential of Wasserstein distance in detecting incipiently developing faults, this subsection performs sensitivity analysis on the Wasserstein distance based monitoring statistics of and introduced in Equation (22) and compare with the Hotelling’s statistics. For simplicity, sensitivity analysis is performed under the multivariate statistical framework and only is considered. For convenience, a bias fault is considered as follows.
Here is the faulty sample, is the bias, is the unobserved true values.
For convenience, let , and . Under the multivariate statistical framework, a PCA model is applied and the covariance matrix of reduces to identity matrix and the occurrence of fault will cause the monitoring statistic to change as follows.
Here is the density estimated from a window of faulty samples in the principal space, is the l-th column of , the first two terms in Equation (26) correspond to the state under normal conditions and the last term relates to the impact of the fault. In the faulty condition, the monitoring statistic will exceed the control limit and , so that the following inequality holds.
It is easy to see that . Let the last two terms on the right side of Equation (27) be , , it can be seen that . Here, denotes the effect of fault, is the lower boundary of , so that the following corollary holds.
Corollary 1.
reduces in value as increases. In other words the more samples are included the more sensitive monitoring statistics becomes in detecting the considered fault condition.
Similar analysis can be conducted for Hotelling’s statistic:
Seeking expectations on both sides:
Let be , so Where is the lower boundary of , if the fault condition is greater than , fault detected.
Divide the two statistical lower boundaries:
According to Equation (31), the following corollary can be obtained:
Corollary 2.
When the variable number d is fixed, as the window width increases, the ratio of to will become smaller, which means the monitoring statistics are more sensitive than the standard Hotelling’s statistics.
Figure 1 shows the relationship between and , the direction pointed by the arrow represents the increasing of d. Similar to the sensitivity of principal component components, there are the same statistical properties in the residual space.
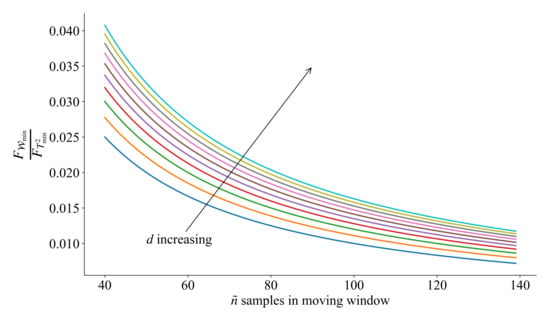
Figure 1.
Sensitivity analysis.
4. Wasserstein Distance for Monitoring Non-Gaussian Process
Section 2 and Section 3 discussed how Wasserstein distance can be used to monitor Gaussian distributed process variables. However, in many industrial processes, process variables are often non-Gaussian distributed, whose PDFs can be difficult to estimate from data. In order to estimate the Wasserstein distance from non-Gaussian distributed data, this Section introduces the Riemannian block coordinate descent(RBCD) method for estimating Wasserstein distance between PDFs of non-Gaussian variables [29,37].
4.1. Riemannian Block Coordinate Descent for Estimation of Wasserstein Distance
This section considers the process monitoring problem under the multivariate statistical analysis framework, as projecting the original data space onto a low-dimensional subspace can effectively alleviate the curse of dimensionality. Let and be the d-dimensional score vectors obtained from non-Gaussian distributed data sources according to Equations (1) and (2). Instead of continuous probability measures, estimation of Wasserstein distance under the non-Gaussian case requires definition of discrete probability measures for and as and , with and being the probability simplex and the Dirac function. According to Ref. [29], computing the Wasserstein distance between and is equivalent to solving an optimal transport problem as follows.
Here is the projection matrix defined in a Stiefel manifold , is the transportation polytope , is the vector of ones. The purpose of introducing the projection matrix is to reduce the computation load and increase robustness. As can be seen from Equation (32), the optimization problem is nonconvex and difficult to solve. In order to improve the computation efficiency, Lin et al. [37] considered the following entropy-regularized optimization problem.
Here is the entropy regularization term and is the regularization parameter. By introducing the entropy-regularization, Equation (33) can be effectively solved using the Riemannian block coordinate descent(RBCD) method [29] by alternatively estimating and .
Assume is determined, Equation (33) reduces to a convex problem with respect to as follows.
Here and are the Lagrange multipliers of the two equality constraints. Taking the first-order partial derivative of and setting it to zero, it is easy to obtain as follows.
with being the i-th element of and is the k-th element of . The optimization problem in Equation (35) can be easily solved. It should be noted that once is determined, the two discrete probability vectors and can be obtained.
By defining and , Equation (35) is rewritten as follows.
On the other hand, substituting Equation (36) into Equation (33), if is determined, the optimization problem for , and can be defined as follows.
Solution of Equation (37) can be achieved using the RBCD iteration, which performs by updating one parameter each time while fixing other parameters. The detailed Riemannian optimization routines can be referred to Huang et al. [29].
The procedures of alternatively estimating and are conducted until convergence. On convergence, the estimation of Wasserstein distance under non-Gaussian data source can be defined as
4.2. Process Statistics and Null Hypothesis Rejection Region
From the above discussion, the Wasserstein distance of non-Gaussian data can be estimated by RBCD method. Thus, it is necessary to establish corresponding monitoring statistic for fault detection. Since we calculate from Section 4.1, statistic based on Wasserstein distance for non-Gaussian distributed data is given by:
where, k is the sample index. The control limit of the statistic can be estimated by kernel density estimation [38] with the significant level of . By replacing the with and replacing the control limit value with the estimated PDF of under normal condition, the online strategy introduced in Section 3.1 can be used to monitor non-Gaussian processes.
5. Fault Isolation Method Based on the Wasserstein Distance
Once a fault is detected, it becomes extremely important to isolate and identify faulty variables in time to facilitate subsequent correcting operations. Although researchers have made considerable progress in detection of incipient faults, fault isolation remains a problem for non-Gaussian distributed data. This section develops a fault isolation method based on the Wasserstein distance, so that a unified process monitoring framework for incipient faults can be constructed. Consider the fault model introduced in Equation (25), the optimization problem for fault isolation can be defined as follows.
Here, is the estimation of the true fault vector, is the regularization parameter. It should be noted that by introducing the regularization term a sparse faulty variable set can be obtained [39]. The optimization problem in Equation (40) can be divided into a series of sub-problems.
As discussed in Section 4.1, after estimating the Wasserstein distance in a sub-window, and are fixed. Therefore, by denoting as dependent variables, as independent variable and as regression coefficients, Equation (41) can be solved as Lasso regression problem. And the reconstructed fault vector can be described as:
Consequently, obtained by Equation (42) is zero if the lth variable is normal, otherwise it is faulty. It is worth noting that keeps changing as the sliding window moves and the estimation of is related to according to Equation (42), making the results more reliable and robust for dynamically changing data.
6. Application Studies
This section tests the effectiveness of the Wasserstein distance-based process monitoring method using application studies to a simulation example and a real-time boiler water wall over-temperature process.
6.1. Simulation Example
Consider a simulation example generated by the following multivariate process:
Here, . This simulation example involving six input variables defined as , which are linear combination of four multivariate normal distribution data sources , corrupted by Gaussian distributed noises , .
For the purpose of model training, a total of 700 samples are generated as the training set. An additional 300 samples are generated as the test set, which involves a ramp fault on as . For the purpose of process monitoring, PCA is first applied and the Wasserstein distance based monitoring statistics are computed based on Equation (22) for the PCs and residuals. Based on the moving window approach proposed in Section 3.1, a series of monitoring statistics can be calculated. For the proposed method, a window length of 100 is considered and it is found that retaining 3 principal components (PCs) captures more than 95% variance, so that the number of PCs is set as 3. For comparison, PCA based method and an incipient fault detection method based on statistics Mahalanobis distance(SMD) [21] are considered. The window lengths for SMD is also set as 100. In addition, the significance level for all the three methods is set as 0.01 and the monitoring results are shown in Figure 2.
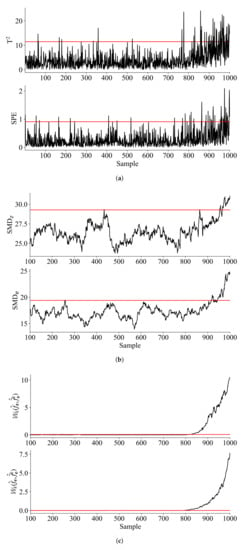
Figure 2.
Monitoring results for the simulation example: (a) PCA (b) SMD (c) Wasserstein distance.
As is observed from Figure 2, the monitoring statistics of conventional PCA and SMD failed to detect the ramp fault in the early stage. In contrast, it can be seen that the ramp fault was successfully detected in both the principle component space and the residual space by the monitoring statistics based on Wasserstein distance. This is expected, as the sensitivity analysis in Section 3.2 shows that the monitoring statistics based on Wasserstein distance show higher sensitivity, indicating that it is suitable for monitoring of incipient faults. In order to further evaluate the performance of the proposed method, Table 1 presents the fault detection rate(FDR) and fault alarm rate(FAR) of the considered methods. Also, to indicate the performance for incipient fault detection, the time of first detection(TFD) is also presented.

Table 1.
Comparison of fault detection performance for the simulation example.
Table 1 confirms that the monitoring statistics based on Wasserstein distance outperform those of PCA and SMD. More specifically, the statistic for Wasserstein distance has an FDR of 70.67%. In contrast, the FDRs for PCA based statistics are lower than 5% and those for SMD are lower than 30%.
6.2. Application to a CSTR Process
This section discusses the effectiveness of the proposed method in a CSTR process [40]. The dynamic characteristics of the CSTR process can be described by material conservation and energy conservation respectively,
where is the reactor inlet concentration, C is the outlet concentration, F is the flow rate at the reactor inlet, T is the reaction temperature, is the reactor inlet temperature, is the cooling water temperature and , are independent noise, other variables are described in Table 2, the parameters and conditions of the whole process are the same as in Li et al. [41] and Ji et al. [42].
Table 2.
CSTR process variable description and its initial value.
In order to describe the dynamic and non-linearity of this process, we define , , and , then Equations (44a) and (44b) are normalized using dimensionless variable , , u and [43,44],
where, , , , and , () represents the first derivative with respect to (). Thus, Equations (45)a,b can be regarded as a nonlinear mathematical model. Since we study the ideal CSTR process, it contains the following assumptions [45], (1) composition and temperature are uniform everywhere in the tank; (2) the effluent composition is the same as that in the tank; and (3) the tank operates at steady state.
The sample measured in this system contains six variables, i.e., . Here, C and T are the controlled objects with nomianl values, and F are the controllable variables with feedback from control errors and the negative feedback inputs are added to and F through the transfer function form of the PID controller (P = 1, I = 10, D = 0.1), and are the input variables. The sampling interval of the system is 1 second and 1000 sampling points under normal conditions are collected as training data. In order to verify the validity of the algorithm, a fault is artificially assumed, a sensor bias fault of 5 L/min is applied to the fourth variable F at 1001∼1600 samples, which can be seen as an incipient fault since this bias is small for the initial value.
It is worth noting that the collected data is non-Gaussian distributed and noisy, the proposed method introduced in Section 4 is used, with the learning rate and penalty parameter set as 0.1 and 0.5, also compared with PCA and SMD. It is found that retaining 4 principal components (PCs) is able to capture more than 80% variance, hence the number of PCs is set as 4. The window lengths used for SMD method and the proposed method are both 100. The significance level is set as 0.01 for all the methods and the monitoring results are shown in Figure 3.
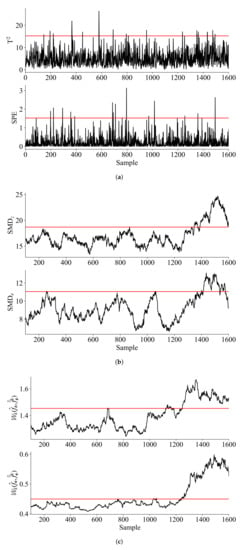
Figure 3.
Monitoring results for the CSTR process: (a) PCA (b) SMD (c) Wasserstein distance.
It can be seen from Figure 3 that the proposed method can detected fault at the early stage, while PCA and SMD failed to detect the fault. Table 3 shows the detailed results of TFD, FDR and FAR for the three methods.
Table 3.
Comparison of fault detection performance on CSTR.
Table 3 confirmed that the monitoring statistics based on Wasserstein distance have better performance for both FDR and FAR. Specifically, the monitoring statistics of Wasserstein distance identified the bias fault at sample No.1027, significantly earlier than the method of SMD.
In order to isolate the bias fault, the method proposed in Section 5 is applied and the regularization parameter is set as 0.001. Also, we compare the proposed method with the BRNN with LDR-based fault isolation method [27]. Figure 4 presents the sample-by-sample fault isolation result, the darker the color in the figure, the greater the fault score of this sampling point and the fault contribution during the process.
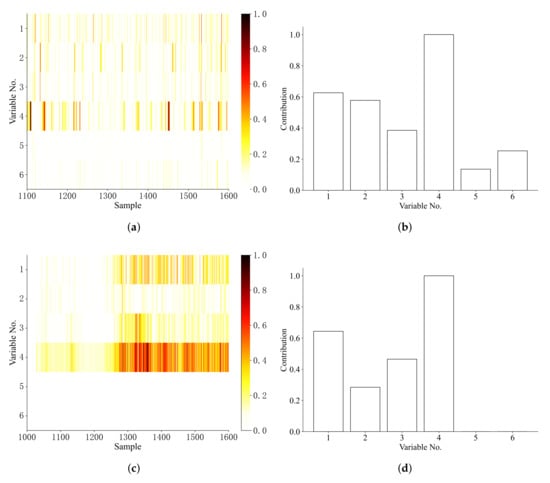
Figure 4.
Fault isolation results for the CSTR process (a) BRNN with LDR isolation (b) BRNN with LDR contribution (c) Wasserstein distance isolation (d) Wasserstein distance contribution.
From Figure 4 is can be seen that the fourth variable was successfully identified as faulty using the Wasserstein distance based fault isolation method, this is in accordance with the previous setting. Though BRNN can identify as the fault variable, it cannot obtain sparse fault isolation results and is not sensitive to the fault.
6.3. Application to a Boiler Water Wall Over-Temperature Process
This section discusses the effectiveness of the proposed method on a real-time boiler water wall data. The water wall is an important part of the boiler system, which is a neatly arranged metal pipe that clings to the inside of the furnace. Its function is to absorb the radiant heat of the high temperature flame or flue gas in the furnace, generate steam or hot water in the tube, and reduce the temperature of the furnace wall to protect the furnace wall. Due to its material properties, the water wall has a corresponding limit to withstand temperature. In this example, the limit temperature is 460 ℃, which is provided by the boiler producer according to their design specifications. Working above the limit temperature for long will lead to the severe accident of burnout of tubes. So, it is also important to keep the absolute temperature of water wall tubes below the limit temperature to ensure safety. In order to minimize the losses caused by the overtemperature of the water wall, it is necessary to monitor the variables that affect the temperature of the water wall. The temperature of the water wall in this case rises slowly, which can be considered as an incipient fault in the industrial process.
Figure 5 shows the process flow chart of coal-fired power plant. It can be seen from the figure that after the coal enters the coal box, it is sent to the coal mill to be ground into pulverized coal and the air is preheated after entering the blower, and then divided into primary air and secondary air, the primary air contains air and pulverized coal. The primary air and secondary air enter the boiler for combustion after passing through the baffle, and the boiler feed water is heated to generate superheated steam to drive the generator to generate electricity. After combustion, coal ash and waste gas are removed from the system.
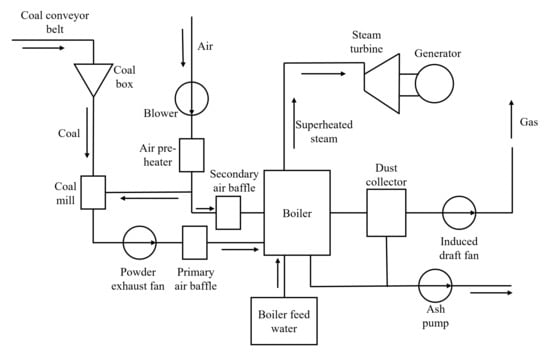
Figure 5.
Process flow chart of coal-fired power plant.
In this process, a total of 10 variables are considered and listed in Table 4. Samples are collected every 15 seconds for each variable, and a total 1100 sample points are collected, including 600 normal samples and 500 faulty samples. The fault occurs when the positional deviation of the secondary air baffle causes the deviant combustion of the flame, and the primary wind speed deviation causes the flame to brush the wall. In addition, the sample data is non-Gaussian, and there is no obvious correlation between variables in a long sampling period.
Table 4.
Variables and description for boiler water wall over-temperature process.
Similar to Section 6.1, PCA is first applied and the Wasserstein distance based monitoring statistics are computed using the RBCD algorithm in Section 4, with the learning rate and penalty parameter set as 0.1 and 1.6. It is found that retaining 4 principal components (PCs) captures more than 85% variance so that the number of PCs is set as 4. The window lengths used for SMD method and the proposed method are both 100. The significance level is equally set as 0.01 for all the methods and the monitoring results are shown in Figure 6.
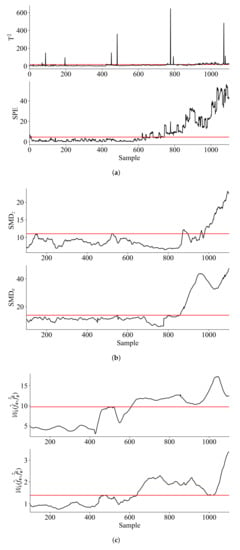
Figure 6.
Monitoring results for the boiler water wall over-temperature process: (a) PCA (b) SMD (c) Wasserstein distance.
Figure 6 shows that the fault is successfully detected by all the three methods at the later stage. However, at the early stage, PCA and SMD failed to detect the fault, indicating they are not sensitive enough for this fault. In contrast, the monitoring statistics based on Wasserstein distance successfully detected the fault at an earlier stage. Table 3 shows the comparison results of TFD, FDR and FAR for the three methods.
From Table 5 it can be seen that the monitoring statistics based on Wasserstein distance shows much higher FDR than other methods. A closer inspection also shows that the monitoring statistic of Wasserstein distance identified the fault at the earliest stage at sample No.607, which further verified the previous results on sensitivity analysis.
Table 5.
Comparison of fault detection performance on boiler water wall over-temperature process.
As for fault isolation, the regularization parameter is set as 0.02 in our method. Also, we compare the proposed method with the BRNN with LDR-based fault isolation method [27]. Figure 6 and gives the sample-by-sample fault isolation results and the fault contribution during the process.
It can be seen from Figure 7 that Wasserstein distance based method can isolate faulty variable and at an early stage and The fault contribution values of and are the largest. This indicates that the failure of the position of the secondary air baffle position and the primary wind speed caused the overtemperature of the water wall, which is consistent with the actual situation. While BRNN with LDR-based method can isolate successfully, the fault scores of is not that significant comparing to other variables.
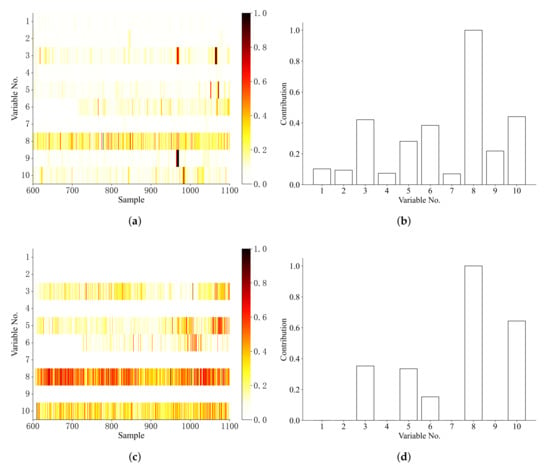
Figure 7.
Fault isolation results for the boiler over-temperature process (a) BRNN with LDR isolation (b) BRNN with LDR contribution (c) Wasserstein distance isolation (d) Wasserstein distance contribution.
7. Conclusions
This paper proposes an incipient fault detection method based on Wasserstein distance of industrial systems. For both Gaussian and non-Gaussian cases, a theoretical model is proposed and widely show the effectiveness of Wasserstein distance for fault detection. It is found that there is a normally distributed relationship between the empirical estimated value and the true value of Wasserstein distance, a confidence limit based on Wasserstein distance of two Gaussian data sets can be easily obtained. The sensitivity of Wasserstein distance is compared with Hotelling’s statistics, which increases as the number of variable increases. For the source signals do not have a Gaussian distribution, we proposed a RBCD method under the PCA framework. We use PCA to project high-dimensional data into low-dimensional space to establish a projection robust Wasserstein distance model, a Riemannian block coordinate descent algorithm is adopted to speed up the solution of the model and the monitoring method is then test on fault monitoring of a simulation example, a CSTR process and a real-time boiler water wall over-temperature process. After detecting the fault, we proposed a reconstruction method based on Wasserstein distance to isolate fault. The fault detection based on Wasserstein distance is then compared with other fault detection methods and the results show that it has better sensitivity and higher fault detection rate. Future work on the Wasserstein distance-based fault detection method could be extended to nonlinear and time-varying industrial processes.
Author Contributions
Conceptualization, J.Z.; methodology, C.L. and J.Z.; validation, C.L. and J.Z.; formal analysis, C.L.; investigation: C.L.; resources, J.Z., S.L. and J.C.; data curation, J.Z.; writing—original draft preparation, C.L.; writing—review and editing, J.Z.; visualization, C.L.; supervision, J.Z., S.L. and J.C.; project administration, J.Z.; funding acquisition, J.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (Grant Nos. 61673358 and 61973145).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Liu, Y.; Zeng, J.; Bao, J.; Xie, L. A unified probabilistic monitoring framework for multimode processes based on probabilistic linear discriminant analysis. IEEE Trans. Ind. Inform. 2020, 16, 6291–6300. [Google Scholar] [CrossRef]
- Ge, Z. Review on data-driven modeling and monitoring for plant-wide industrial processes. Chemom. Intell. Lab. Syst. 2017, 171, 16–25. [Google Scholar] [CrossRef]
- Jolliffe, I.T.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef] [PubMed]
- Ajami, A.; Daneshvar, M. Data driven approach for fault detection and diagnosis of turbine in thermal power plant using Independent Component Analysis (ICA). Int. J. Electr. Power Energy Syst. 2012, 43, 728–735. [Google Scholar] [CrossRef]
- Zhong, K.; Han, M.; Qiu, T.; Han, B. Fault diagnosis of complex processes using sparse kernel local fisher discriminant analysis. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 1581–1591. [Google Scholar] [CrossRef] [PubMed]
- Yin, S.; Ding, S.X.; Xie, X.; Luo, H. A review on basic data-driven approaches for industrial process monitoring. IEEE Trans. Ind. Electron. 2014, 61, 6418–6428. [Google Scholar] [CrossRef]
- Zhu, J.; Ge, Z.; Song, Z.; Zhou, L.; Chen, G. Large-scale plant-wide process modeling and hierarchical monitoring: A distributed Bayesian network approach. J. Process Control 2018, 65, 91–106. [Google Scholar] [CrossRef]
- Zhao, Y.; He, X.; Zhang, J.; Ji, H.; Zhou, D.; Pecht, M.G. Detection of intermittent faults based on an optimally weighted moving average T2 control chart with stationary observations. Automatica 2021, 123, 109298. [Google Scholar] [CrossRef]
- Zeng, J.; Kruger, U.; Geluk, J.; Wang, X.; Xie, L. Detecting abnormal situations using the Kullback–Leibler divergence. Automatica 2014, 50, 2777–2786. [Google Scholar] [CrossRef]
- Qin, Y.; Yan, Y.; Ji, H.; Wang, Y. Recursive correlative statistical analysis method with sliding windows for incipient fault detection. IEEE Trans. Ind. Electron. 2021, 69, 4184–4194. [Google Scholar] [CrossRef]
- Zeng, J.; Xie, L.; Kruger, U.; Gao, C. Regression-based analysis of multivariate non-Gaussian datasets for diagnosing abnormal situations in chemical processes. AIChE J. 2014, 60, 148–159. [Google Scholar] [CrossRef]
- Shang, J.; Chen, M.; Ji, H.; Zhou, D. Recursive transformed component statistical analysis for incipient fault detection. Automatica 2017, 80, 313–327. [Google Scholar] [CrossRef]
- He, Z.; Shardt, Y.A.; Wang, D.; Hou, B.; Zhou, H.; Wang, J. An incipient fault detection approach via detrending and denoising. Control Eng. Pract. 2018, 74, 1–12. [Google Scholar] [CrossRef]
- Ji, H.; He, X.; Shang, J.; Zhou, D. Incipient fault detection with smoothing techniques in statistical process monitoring. Control Eng. Pract. 2017, 62, 11–21. [Google Scholar] [CrossRef]
- Zhao, C.; Huang, B. Incipient fault detection for complex industrial processes with stationary and nonstationary hybrid characteristics. Ind. Eng. Chem. Res. 2018, 57, 5045–5057. [Google Scholar] [CrossRef]
- Harmouche, J.; Delpha, C.; Diallo, D. Incipient fault detection and diagnosis based on Kullback–Leibler divergence using principal component analysis: Part I. Signal Process. 2014, 94, 278–287. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Lu, N. An improved incipient fault detection method based on Kullback-Leibler divergence. ISA Trans. 2018, 79, 127–136. [Google Scholar] [CrossRef]
- Xiong, Y.; Chen, T. Abnormality detection based on the Kullback-Leibler divergence for generalized Gaussian data. Control Eng. Pract. 2019, 85, 257–270. [Google Scholar] [CrossRef]
- Cao, Y.; Jan, N.; Huang, B.; Fang, M.; Wang, Y.; Gui, W. Multimode process monitoring based on variational Bayesian PCA and Kullback-Leibler divergence between mixture models. Chemom. Intell. Lab. Syst. 2021, 210, 104230. [Google Scholar] [CrossRef]
- Zhang, X.; Delpha, C.; Diallo, D. Incipient fault detection and estimation based on Jensen–Shannon divergence in a data-driven approach. Signal Process. 2020, 169, 107410. [Google Scholar] [CrossRef]
- Ji, H. Statistics Mahalanobis distance for incipient sensor fault detection and diagnosis. Chem. Eng. Sci. 2021, 230, 116233. [Google Scholar] [CrossRef]
- Yang, J.; Delpha, C. An incipient fault diagnosis methodology using local Mahalanobis distance: Detection process based on empirical probability density estimation. Signal Process. 2022, 190, 108308. [Google Scholar] [CrossRef]
- Harmouche, J.; Delpha, C.; Diallo, D. Incipient fault amplitude estimation using KL divergence with a probabilistic approach. Signal Process. 2016, 120, 1–7. [Google Scholar] [CrossRef][Green Version]
- Ji, H.; He, X.; Zhou, D. Exponential smoothing reconstruction approach for incipient fault isolation. Ind. Eng. Chem. Res. 2018, 57, 6353–6363. [Google Scholar] [CrossRef]
- Yang, J.; Yang, Y.; Xie, G. Diagnosis of incipient fault based on sliding-scale resampling strategy and improved deep autoencoder. IEEE Sens. J. 2020, 20, 8336–8348. [Google Scholar] [CrossRef]
- Jana, D.; Patil, J.; Herkal, S.; Nagarajaiah, S.; Duenas-Osorio, L. Cnn and convolutional autoencoder (cae) based real-time sensor fault detection, localization, and correction. Mech. Syst. Signal Process. 2022, 169, 108723. [Google Scholar] [CrossRef]
- Sun, W.; Paiva, A.R.; Xu, P.; Sundaram, A.; Braatz, R.D. Fault detection and identification using bayesian recurrent neural networks. Comput. Chem. Eng. 2020, 141, 106991. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Huang, M.; Ma, S.; Lai, L. A riemannian block coordinate descent method for computing the projection robust wasserstein distance. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 18–24 July 2021; pp. 4446–4455. [Google Scholar]
- Rüschenorf, L. Wasserstein Metric. In Encyclopedia of Mathematics; Hazewinkel, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2001. [Google Scholar]
- Rudolf, D.; Schweizer, N. Perturbation theory for Markov chains via Wasserstein distance. Bernoulli 2018, 24, 2610–2639. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar]
- Givens, C.R.; Shortt, R.M. A class of Wasserstein metrics for probability distributions. Mich. Math. J. 1984, 31, 231–240. [Google Scholar] [CrossRef]
- Rippl, T.; Munk, A.; Sturm, A. Limit laws of the empirical Wasserstein distance: Gaussian distributions. J. Multivar. Anal. 2016, 151, 90–109. [Google Scholar] [CrossRef]
- Ruymgaart, F.H.; Yang, S. Some applications of Watson’s perturbation approach to random matrices. J. Multivar. Anal. 1997, 60, 48–60. [Google Scholar] [CrossRef]
- Ver Hoef, J.M. Who invented the delta method? Am. Stat. 2012, 66, 124–127. [Google Scholar] [CrossRef]
- Lin, T.; Fan, C.; Ho, N.; Cuturi, M.; Jordan, M.I. Projection robust Wasserstein distance and Riemannian optimization. arXiv 2020, arXiv:2006.07458. [Google Scholar]
- Silverman, B.W. Density Estimation for Statistics and Data Analysis; Routledge: Oxfordshire, UK, 2018. [Google Scholar]
- Yan, Z.; Yao, Y. Variable selection method for fault isolation using least absolute shrinkage and selection operator (LASSO). Chemom. Intell. Lab. Syst. 2015, 146, 136–146. [Google Scholar] [CrossRef]
- Donghua, Z.; Yinzhong, Y. Modern Fault Diagnosis and Fault Tolerant Control; Tsing Hua University Publishing House: Beijing, China, 2000. [Google Scholar]
- Li, G.; Qin, S.J.; Ji, Y.; Zhou, D. Reconstruction based fault prognosis for continuous processes. Control Eng. Pract. 2010, 18, 1211–1219. [Google Scholar] [CrossRef]
- Ji, H.; He, X.; Shang, J.; Zhou, D. Incipient sensor fault diagnosis using moving window reconstruction-based contribution. Ind. Eng. Chem. Res. 2016, 55, 2746–2759. [Google Scholar] [CrossRef]
- Ghaffari, V.; Naghavi, S.V.; Safavi, A. Robust model predictive control of a class of uncertain nonlinear systems with application to typical cstr problems. J. Process Control 2013, 23, 493–499. [Google Scholar] [CrossRef]
- Wu, F. Lmi-based robust model predictive control and its application to an industrial cstr problem. J. Process Control 2001, 11, 649–659. [Google Scholar] [CrossRef]
- Foutch, G.L.; Johannes, A.H. Reactors in process engineering. In Encyclopedia of Physical Science and Technology, 3rd ed.; Meyers, R.A., Ed.; Academic Press: Cambridge, MA, USA, 2003; pp. 23–43. [Google Scholar]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).