1. Introduction
For the past several years, the COVID-19 [
1] pandemic has spread practically all over the globe, resulting in the world’s most critical global health catastrophe that has had a huge effect on humanity and how we see the world and everyday lives [
2]. Consequently, there are health procedures that must be followed to limit the transmission of coronavirus. A few of the norms are either staying at least 2 m apart from other humans or wearing a mask properly, particularly in public places [
3]. In the chaos of the pandemic, there are many circumstances where wearing facemasks can contribute to controlling the transmission of COVID-19, such as migrants in refugee camps, workers taking subways, etc. Hence, authorities have consistently issued statements regarding COVID-19 international guidelines about contact and airborne precautions, including the consideration of utilization of facemasks as an adequate adoption in case of congested human chaos. As a result, it would be desirable if a system could automatically recognize a person who does not appropriately place the mask on his or her face or who does not wear any mask at all. On the other hand, this work employs hybrid deep and classical machine learning models to determine the face coverage area covered by facemasks in an image of a human.
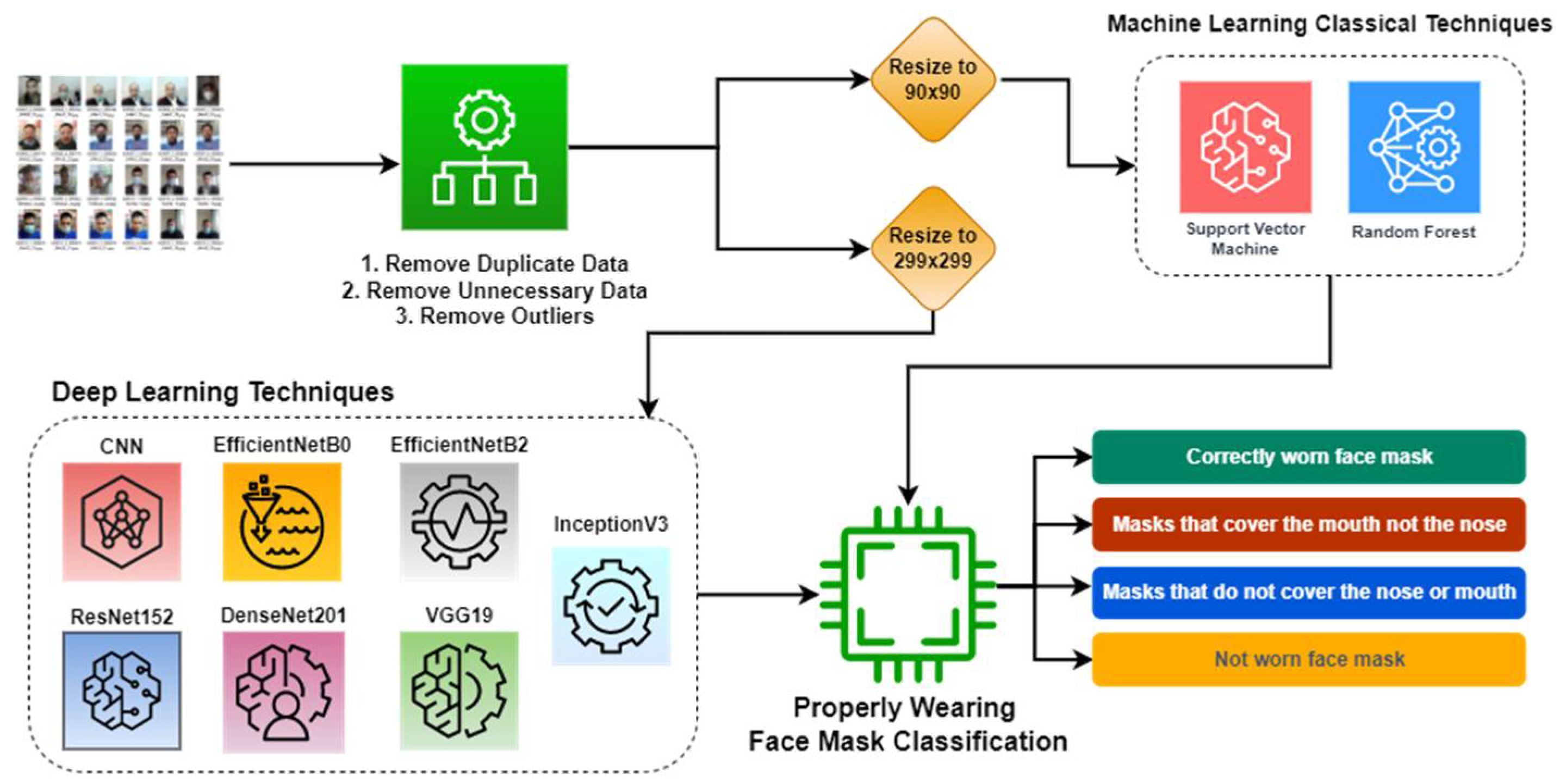
Figure 1 shows the workflow of the proposed scheme. In the first step, the proposed system removes duplicates, outliers, and unnecessary data. Next, it resizes the images according to the classification model. Lastly, it explores seven deep learning-based and two machine learning-based classifiers to classify the given image into four categories that include wearing a mask properly, mask not covering the nose, mask neither covering the nose nor mouth, and not wearing a mask at all.
Deep neural networks are capable of performing computer vision tasks and performing cutting-edge image recognition [
4] by taking an input image and distinguishing it by assigning priority, learnable weights, and biases to various sections of the image, for instance [
5,
6]. Furthermore, CNN [
7] is often used to evaluate visual images and needs far less pre-processing than conventional classification techniques. However, classical machine learning algorithms such as RF, decision tree (DT), SVM, k-nearest neighbor (KNN), and many others also have a vast usage in image classification, such as COVID-19 and pneumonia classification systems in [
8,
9].
As facemask detection has become a critical area of study during the COVID-19 pandemic, numerous extensive studies have been conducted to address this issue using a variety of different techniques and strategies, such as the Spartan Face Detection and Identification System suggested in [
10] employed CNN, AlexNet, and long-short-term-memory (LSTM) to handle the primary challenges of mask detection, classification of mask type, classification of mask placements, and identity recognition. Similarly, Ref. [
11] proposes a real-time facemask detection model based on CNN, the computer vision technique, and MobileNet that runs in real-time and recognizes if a person is wearing a facemask; if not, it notifies higher authorities by text message.
To efficiently perform person detection, social distancing infringement detection, face identification, and facemask categorization on surveillance footage datasets, Ref. [
12] presented YOLOv3, clustering of applications with noise based on density, a dual-shot face detector (DSFD), and a binary classifier based on MobileNetV2. Additionally, it included data augmentation strategies to address the community’s data scarcity. To identify the facemask, Ref. [
13] adopted a deep learning algorithm named YOLOv4 to identify the mask in the real-time scenario by deploying the equipment at Politeknik Negeri Batam, Indonesia.
Isunuri et al. proposed a MobileNet block for facemask identification that includes a global pooling [
14]. Their proposed model flattens the feature vector using a global pooling layer and outperforms current models on publicly accessible facemask datasets in terms of critical performance metrics, parameter count, and training time. Yadav [
2] proposed an efficient computer vision-based method for real-time automated monitoring of persons in public areas to detect both safe social separation and face coverings. He used the camera to watch activity and identify violations and developed the model on a raspberry pi4.
Table 1 outlines the techniques and algorithms used in prior facemask detection systems from the literature. Most of these facemask detection systems incorporated deep learning-based pre-trained or transfer-learning models. Moreover, according to our knowledge and research, the literature is full of systems that are capable to identify whether a person is wearing a mask or not; however, no study thus far determines the coverage of a facemask on a human face. The datasets used previously vary from one study to the next, and while the authors may have presented multiple conclusions based on a variety of datasets in a single piece of work, only one of those findings is disclosed.
In this paper, we compared CNN-, RF-, and SVM-based models and several deep learning pre-trained models (InceptionV3, EfficientNetB0, EfficientNetB2, DenseNet201, ResNet152, and VGG19) to detect whether people are wearing a mask or not and whether they are wearing it properly using face images with different types of facemask wearing. The study has the following major contributions:
The proposed scheme checks whether the person wears a mask or not.
It determines the coverage area of the facemask on the human face and classifies the facemask facial image into four categories: appropriately wearing a mask (covering both nose and mouth), partially wearing a mask (covering mouth but not nose), inappropriately wearing a mask (neither covering mouth nor nose), and not wearing a mask at all.
The paper investigates state-of-the-art pre-trained models and analyzes the performance with traditional machine learning and deep learning models for facemask coverage.
The study analyzes the performance of various models with several metrics, such as accuracy, F1-score, precision, and recall.
The application of the proposed system ensures the mask fits and covers essential areas, including the nose, mouth, and chin.
The paper is organized as follows:
Section 2 describes the explored hybrid deep and classical machine learning techniques,
Section 3 presents a detailed discussion of the results, and the paper is concluded in
Section 4.
2. Materials and Methods
The proposed facemask coverage detection scheme used in this study is divided into three stages: pre-processing of data, training the models, and facemask wearing classification. It utilizes several procedures during the pre-processing stage, including deleting duplicate data, removing extraneous data, and downsizing images to 299 × 299 for CNN and pre-trained models, and 50 × 50 for RF and SVM models. The data, which consist of images of people wearing facemasks, are fed into CNN, RF, SVM, and six pre-trained deep learning-based classifiers (InceptionV3, EfficientNetB0, EfficientNetB2, DenseNet201, ResNet152, and VGG19). The study carried out extensive experiments to fine-tune these models to properly determine whether a person is wearing a mask or not or wearing it properly.
2.1. Dataset
The dataset used to train the models comprises 40,000 images belonging to 4 distinct classes (ways of wearing the masks). Moreover, for better testing, we also used images from the downloaded dataset, a few of which are depicted in
Figure 2, where persons are wearing masks in three different ways or not wearing a mask at all. The dataset was downloaded from a public repository [
20]. After removing duplicate and unnecessary images, we were left with a total of 11,536 images for the 4 different types of masks worn: correctly worn masks that cover the nose and mouth, masks that cover the mouth but not the nose, masks that are worn but do not cover the nose and mouth, and faces without facemasks.
Table 2 lists the further division of the dataset for each class. All images acquired in this repository use Toloka.ai’s crowdsourcing platform and are verified by TrainingData.ru. To train and evaluate our models, we separated the dataset into training and test sets with 70/30 ratios. After successful training, the accuracy was computed using all images from the test dataset in each iteration.
2.2. CNN Model Architecture
To identify the facemask and its coverage area, we constructed a CNN model that consists of three convolutional layers, three pooling layers, one dropout layer, one flattened layer, and a fully connected (dense) layer. However, each of the convolutional and pooling layers produced a three-dimensional (3D) form tensor as an output (height, width, channels). The max-pooling layer was then utilized to reduce the output volume’s spatial dimensions. The dropout layer contributes to overfitting reduction by randomly changing input units to 0 at a frequency of the rate during the training period. The SoftMax layer normalizes the preceding layer’s output to include the probability of the actual input image conforming to designated classes.
2.3. Machine Learning Classical Algorithms
To accomplish and test the facemask coverage categorization system using machine learning classical algorithms, we have fed our data to two classical algorithms: RF and SVM. The proposed scheme performed some pre-processing on the data before feeding it into these classifiers. This included resizing the data to a ratio of 50 × 50 and shuffling the data to rearrange the order in which the components appear. After that, it reshaped the value distribution by using the standard scaler to make the mean of the observed values equal to zero and the standard deviation equal to one. Each of these explored classical machine learning algorithms is briefly described below.
2.3.1. Random Forest
The RF approach [
21] is an algorithm usually employed for supervised classification. It extends the idea of DTs and has been effectively utilized in a wide variety of scientific fields to reduce high-dimensional and multi-source data. Self-learning DTs are used by RF, based on a training dataset, and these trees automatically construct rules at each node. The RF is capable of effectively handling huge datasets to generate accurate forecasting that is simple to understand.
2.3.2. Support Vector Machine
SVM is a method that is widely used for pattern recognition and image categorization [
22]. It does this by generating the most efficient separating hyperplanes on the premise of a kernel function. SVM offers two major benefits over other algorithms in terms of speed and performance with a small number of samples. This makes the approach ideal for classification tasks, where access to a dataset of just a few thousands of labeled samples is frequent.
2.4. Deep Neural Network Models
To perform facemask coverage categorization, we fine-tuned InceptionV3, EfficientNetB0, EfficientNetB2, DenseNet201, ResNet152, and VGG19 models. For these, the scheme used an input shape of (299, 299, 3) and added a final dense layer with four outputs and a SoftMax activation function since our data were separated into four classes. Each of these pre-trained models is briefly described below.
2.4.1. InceptionV3
The InceptionV3 [
23] is a 48-layer deep learning model based on CNN used to classify images. The inceptionV3 model is an upgraded version of the InceptionV1 model, which was introduced in 2014 as GoogLeNet. It is a commonly used image recognition model with a demonstrated accuracy of more than 78.1% on the ImageNet dataset. Additionally, it is meant to work well under severe memory and computational resource constraints. The inception layer combines the 1 × 1, 3 × 3, and 5 × 5 convolutional layers, concatenating their output filter banks into a uniform output vector that serves as the subsequent stage’s input.
2.4.2. EfficientNetB0 and EfficientNetB2
EfficientNet [
24] is a scaling technique that uses a compound coefficient to scale all depth, resolution, and breadth parameters uniformly. The EfficientNetB0 base network is based on MobileNetV2’s inverted bottleneck residual blocks, as well as squeeze-and-excite blocks, and consists of 237 layers composed of five modules. EfficientNets substantially outperform other convolutional networks in various tasks. AutoML MNAS created the baseline network, EfficientNetB0, and the subsequent networks, EfficientNetB1 through B7, by scaling up the baseline network. However, the most recent version of EfficientNet, EfficientNetB7, reached an unprecedented top 1 accuracy of 84.3%.
2.4.3. DenseNet201
DenseNet-201 [
25] is a 201-layer CNN network. The pre-trained models are capable of accurately categorizing photos into 1000 different item categories. It is a dense convolutional network as it uses a technique that links each layer to every other layer using a feed-forward approach. DenseNets overcome the vanishing gradients issue, enhance feature reuse, and boost feature propagation, while needing much fewer parameters than general CNN networks, as they do not need to acquire any superfluous feature mappings.
2.4.4. ResNet201
ResNet is the abbreviation for the Residual Network. This breakthrough neural network was first reported by He, Zhang, Ren, and Sun in their 2015 computer vision study [
26]. ResNet152 learns the residual representation functions rather than the signal analysis directly, resulting in an extremely deep network with up to 152 layers. ResNet uses skip connections (also known as shortcut connections) to fit input from one layer to another without modifying the input.
2.4.5. VGG19
Karen Simonyan and Andrew Zisserman, two academics from the University of Oxford, came up with the idea of the VGGNet design [
27] in 2014. The VGG19 is a variation of the VGG network that has 19 weight layers. These weight layers are made up of a total of 16 convolutional layers, 3 layers that are completely linked, and 5 pooling layers. It has 2 fully connected layers, each with 4096 nodes, and one more fully connected layer having 1000 nodes to predict 1000 labels.
3. Results and Discussion
To obtain satisfactory results with the proposed CNN, RF, and SVM models for the detection of images of people wearing facemasks correctly, we performed several experiments and used a variety of hyperparameters to fine-tune these models. The hyperparameters for the models that performed better than the models with different hyperparameters are shown in
Table 3 and
Table 4.
Table 3 lists the hyperparameters for the proposed CNN model while
Table 4 outlines the parameters of the RF model. The CNN model incorporates an Adam optimizer with 100 epochs, 120 batch sizes, and a learning rate of 0.000001. The RF model has a maximum depth of 3 with 20 estimators, as listed in
Table 4.
To evaluate the usefulness and effectiveness of the models, we used 8075 images of humans, with 4 different labels for the training and 4 metrics (f1-score, accuracy, precision, and recall) that were measured for each individual. Following the completion of the model training, each model was tested with 3461 test images as well as a few unseen data. The performance metrics obtained by each model on the test data are shown in
Table 5.
Moreover, for better visual understanding, the study also plotted various performance curves. Thus, after successful training, the model computed the accuracy and loss using all images from the test dataset in each iteration.
Figure 3 shows the visualization of both training and validation accuracy curves for each model (CNN, InceptionV3, EfficientNetB0, EfficientNetB2, DenseNet201, ResNet152, VGG19), whereas
Figure 4 depicts training and testing loss curves for all exploited models.
It is worth noting that prior well-established studies majorly focused on detecting whether a person is wearing a mask or not. The majority of those used pre-trained deep learning networks and attained reasonable results at that time. However, only a few previously published studies in well-reputed journals attained an accuracy of more than 98% for the two-class classification task. Another study [
28] also explored several pre-trained models, including InceptionV3, to handle a six-class classification problem for detection of the coverage area. They used a small dataset, and thus exploited the data augmentation technique, however they still just managed to achieve an accuracy of 83.4% on a test set that has less than a few hundred samples. However, they used a limited dataset, which may result in overfitting or underfitting issues. Contrarily, our study widened the approach by presenting a system for a four-class classification task and reasonably competes with prior studies, as shown in
Table 6.
4. Conclusions
Humanity can be protected in a crisis such as the COVID-19 pandemic by properly wearing masks to minimize the virus transmission. Thus, ensuring the implementation of such rules requires widespread monitoring, but this can be achieved with help of intelligent systems and smart cameras. Therefore, this study proposed an intelligent facemask detection system. The proposed system is widened by analyzing facial features using classical machine learning classifiers and advanced pre-trained deep learning networks to predict whether a person is wearing a mask properly (fully), partially, substantially depleted, or not wearing one at all. The study investigated random forest (RF), support vector machine (SVM), convolutional neural network (CNN), and six CNN-based pre-trained networks (InceptionV3, EfficientNetB0, EfficientNetB2, DenseNet201, ResNet152, and VGG19). For this, 40,000 images were utilized to train and test these models. The dataset was split into training and test sets with 70/30 ratios. The experimental results revealed that VGG19 performed the worst, attaining an overall accuracy of 24.65% and F1-score of 24.60%, while InceptionV3 and EfficientNetB2 accomplished a remarkable performance by reaching an overall accuracy of 98.40% and 98.35%, and F1-scores of 98.30% and 98.40%, respectively. In the future, it is planned to investigate the performance of traditional machine learning classifiers on a given dataset when exploited along with computer vision and histogram analysis techniques.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}