Abstract
This paper reviews real-time optimization from a reinforcement learning point of view. The typical control and optimization system hierarchy depend on the layers of real-time optimization, supervisory control, and regulatory control. The literature about each mentioned layer is reviewed, supporting the proposal of a benchmark study of reinforcement learning using a one-layer approach. The multi-agent deep deterministic policy gradient algorithm was applied for economic optimization and control of the isothermal Van de Vusse reactor. The cooperative control agents allowed obtaining sufficiently robust control policies for the case study against the hybrid real-time optimization approach.
1. Introduction
Real-time optimization (RTO) is based on a control system that is designed to drive the plant to reach the project decisions made in the planning and scheduling layers (i.e, optimizing the plants’ economic performance as its principal objective). It is an intermediate optimization layer and performs hourly decision-making, providing the reference trajectories for the process and control variables, which hierarchically must be maintained by the supervisory control layer and, then, by the regulatory control layer, as shown in Figure 1 [1,2,3,4].
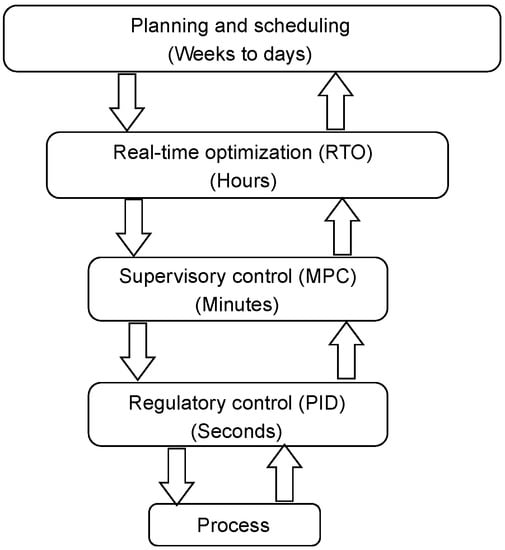
Figure 1.
The typical control and optimization system hierarchy in industry.
Since the 1980s, real-time optimization techniques applied to the process industry have evolved significantly. Mochizuki et al. [5] described the technological achievements that have enabled RTO to grow while simultaneously dropping in cost, which is mainly due to the development of automated and integrated optimization technologies. This is the case for refinery and chemical plants [6], especially as a consequence of the improvement of the mathematical models and of optimization packages with sufficiently robust numerical methods to optimize the economic performance of the plant and help the decision-making of engineers, who do not need to deal with the steps of data reconciliation, the updating of the model parameters, and optimization simultaneously [7].
The main challenge for RTO implementation is the integration of the layers illustrated in Figure 1. The classical two-layer approach deals with the integration of real-time optimization and supervisory control. Steady-state real-time optimization (SSRTO) demands that the plant reach a steady-state for the optimization with a rigorous model to be performed. Until this condition is satisfied, nothing can be done [8]. Model predictive control (MPC) implements control actions in this interval (minute by minute), using a simpler model that captures the process dynamics and drives the design variables to their optimal values. However, this integration can be complex when implementing the set-point resulting from SSRTO because the plant must still be in the original steady-state. In addition, the mismatch model issue must be treated so that the high-level SSRTO sends admissible set-points for the lower-level MPC [8,9,10,11]. Dynamic real-time optimization (DRTO) is an alternative derived from SSRTO, which requires a rigorous dynamic model of the process to eliminate steady-state detection requirements. However, implementing it for large-scale systems is challenging (i.e., regarding its modeling and optimization), even with the computational power currently available [12,13]. A more recent approach combines SSRTO and DRTO, called hybrid real-time optimization (HRTO), which has the modeling effort reduced because the dynamic terms in the model need only to be introduced in the model adaptation step, thus reducing the steady-state waiting time (e.g., [13,14,15,16]).
Alternatively, the one-layer approach has been attempted to circumvent these problems. The objective is to augment the MPC with global plant information (e.g., plant economic objective) to remove the SSRTO layer. Zanin et al. [17,18] applied this methodology to fluid catalytic cracking units, using MPC with an economic factor directly included in the control objective. These studies were precursors for developing a new line of research called economic model predictive control (EMPC) [19,20]. Its main advantage is derived from a controller with better performance in terms of disturbance rejection and economic profits, provided that the control tuning has been correctly performed and the security constraints included. However, the computational burden for the one-layer approach may be huge, especially when it is solved via a global optimization algorithm due to the nonlinearity and non-convexity of the problem [21].
A machine learning approach called reinforcement learning (RL) is showing promising results in several areas of knowledge mainly linked to artificial intelligence (e.g., natural language processing [22], autonomous driving [23], robotics [24,25]). Due to the remarkable results obtained in these areas, which are a consequence of the consolidation of deep neural networks and new reinforcement learning algorithms, this methodology effectively began to be studied by the process control community (e.g., [26,27,28,29,30]). It is characterized by an agent (i.e., control policy) capable of self-learning in the process guided by numerical rewards, following a Markov decision process. Specifically, the agent learns from interactions without relying on a process model (i.e., model-free), and data-driven and simulation information can be used. Thus, reinforcement learning is considered as a promising alternative to replace or complement standard model-based (MPC) approaches for batch process control (e.g., for more details, see [31,32]). At this point, the present article reviews the two-layer and one-layer real-time optimization approaches from the point of view of reinforcement learning. The contribution to the state-of-the-art is twofold: (1) There is a lack of articles covering the subject. To the authors’ knowledge, only Powell et al. [33] implemented RL for the real-time optimization of a theoretical chemical reactor. (2) The research method involves the study of each online optimization layer of the plant-wide structure, explicitly dealing with its conceptualization for reinforcement learning, as well as the challenges for integrating the layers and the problems of the implementation and maintenance of control agents under this point of view.
This review begins in Section 2 with a brief introduction to the reinforcement learning methodology. Section 3 details real-time optimization, supervisory control, and regulatory control for RL. Section 4 proposes a benchmark study of RL using a one-layer approach, evaluating the computational burden and control performance when the disturbance varies with the same plant dynamics, which is a challenge independent of the employed RTO approach. For that purpose, the multi-agent deep deterministic policy gradient algorithm is applied for economic optimization and control of the isothermal Van de Vusse reactor.
2. Reinforcement Learning
The reinforcement learning concept is briefly given in Figure 1. In terms of defining the elements of RL, this self-learning process comprises the interaction of an agent through actions () with the environment, which reaches a new state () guided by a reward (). The first classic example goes back to the theory of animal psychology, exemplified by an animal (i.e., agent) learning how to perform a certain task in a controlled environment, with the reinforcement signal used to guide its learning (e.g., rewards in the form of food) [34]. With the advent of programmable computers, reinforcement learning theory intersected with artificial intelligence. Minsky [35] discussed RL models. Bellman [36,37] founded the theory of optimal control, dynamic programming, and the Markov decision process. Besides these advances, the problems related in Marvin and Seymour [38] about the perceptron network affected the state-of-the-art development in artificial intelligence until the mid-1980s.
With the return of interest in artificial intelligence (e.g., with the work of Rumelhart et al. [39] as a landmark), classic RL problems began to be studied again. For example, the pole balancing problem (a benchmark optimal control problem) provided RL-based alternatives to black-box models obtained from neural networks and tabular algorithms. Figure 2 outlines this learning problem, where an agent must keep the pole balanced (when pushing the cart to the right or left) for a defined length of time of the simulation (T), being formulated as a stochastic sequential decision-making problem (more details are given in Section 2.1), in which the optimal policy must maximize the reward sum, known as the return , along the trajectory , as shown in Equation (1). In this equation, corresponds to the discount factor of the return. When , the immediate reward () is prioritized, whereas if , the entire trajectory is considered [40,41,42].
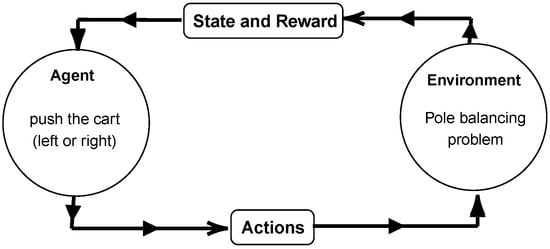
Figure 2.
Simplified outline of the pole balancing problem in the RL framework.
2.1. Markov Decision Process
The Markov decision process (MDP) is defined by the tuple (). , , and correspond to the set of non-terminal states, actions, and rewards. is the probability transition, with and the set of terminal states. As mentioned in Section 2, the MDP is a discrete-time stochastic control process, in which the current state of the system () must contain all the information needed by the agent to decide which action () to take (independent of all previous states and actions), resulting in the subsequent transition to the new state , in order to satisfy the Markov property. Moreover, a policy () must map states to actions and is optimal when it maximizes the return regardless of the initial state chosen () and the obtained trajectory () (Equation (2)) [42,43].
In this equation, denotes the expectation about the trajectory extracted from , and denotes the probability density of observing the trajectory under policy (Equation (3)).
2.2. Algorithms
The main reinforcement learning algorithms can be divided into two main categories [40]. Value-based algorithms obtain the optimal policy by approximating the return value for all possible trajectories. The first proposed alternative considers only the state value function (Equation (4)). The other option considers the value function of the state–action pair (Equation (5)) [41].
An algorithm consolidated in the literature is known as Q-learning and was first described by Watkins [41]. This outstanding work was a watershed for reinforcement learning theory. The main outcome of this study was to replace the tabular methods with parametric approximators to improve generalization and deal with the dimensionality problem. The optimization problem now conforms to Equation (6), and the agent explores the environment until the Bellman optimality condition is reached (i.e., using bootstrapping) (Equation (7)).
The second category includes the policy-based algorithms. Williams [44] developed the first algorithm based on these principles, which is known as REINFORCE and has shown promising results in several fields of research (e.g., [29,30]). Specifically, it uses an auto-parameterized policy () and should maximize the expected return , as shown in Equations (8)–(10).
2.3. Deep Reinforcement Learning
Section 2.2 briefly provided the main RL algorithms described in the literature. There is a consensus that deep neural networks are the best option as parametric approximators due to their ability to deal with big data in terms of generalization, computational processing power, and the invariance dilemma [45]. Another advance concerns the development of stable algorithms to deal with problems demanding high-dimensional state space evaluation and alternatives to improve the offline training of these agents (e.g., [46,47,48]).
The most-employed deep reinforcement learning algorithm in the literature is the actor–critic networks. This is an algorithm that combines ideas from value-based and policy-based algorithms. First, it was described in LeCun et al. [49]. Then, Sutton et al. [50] effectively formulated it for RL, with the guarantee of convergence given by the deterministic policy gradient theorem. Figure 3 illustrates the update of the actor and critic networks. Specifically, the step forward comprises the action selection () and the critic network computation (i.e., value function ). In the backward step, the parameters of both networks are updated with the backpropagation and stochastic gradient descent algorithms. At this point, it is worth mentioning that it is necessary to calculate since the actor network categorizes actions instead of their value, as suggested by Williams [44] and shown in Equation (10). Furthermore, the temporal difference (TD) method is recommended to learn offline directly from experience (i.e., TD-error ()). As the method does not require a model of the environment, it is straightforward to implement and allows bootstrapping, which is an advantage compared to Monte Carlo (MC) methods and dynamic programming. However, its training must be rigorously performed to avoid obtaining unfeasible policies, since the computed Q-value does not consider the return from the entire trajectory as in MC methods [51].
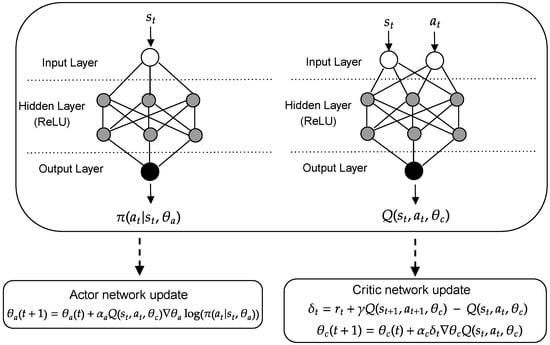
Figure 3.
Diagram describing the update of the actor and critic parameterized by a deep neural network.
This model-free algorithm depends on offline training, where the learning across different episodes can be: (1) off-policy: the learned policy is updated from data obtained from the implementation of other policies. This learning procedure is shown in Figure 4, where is updated from samples of policy roll-out data up to (i.e., ), which are contained in a large buffer. For example, the deep deterministic policy gradient (DDPG) algorithm [47] estimates the Q-values through a greedy policy instead of the behavioral policy, which leads to the TD-error () shown in Equation (11). The second (2) is on-policy: the learned policy is updated from transitions (or data) exclusively taken from the previous policy ; thus, it does not depend on a buffer [42]. For example, the proximal policy optimization (PPO) algorithm [52] estimates the Q-values assuming the current behavioral policy continues to be followed, resulting in the TD-error () shown in Equation (12).
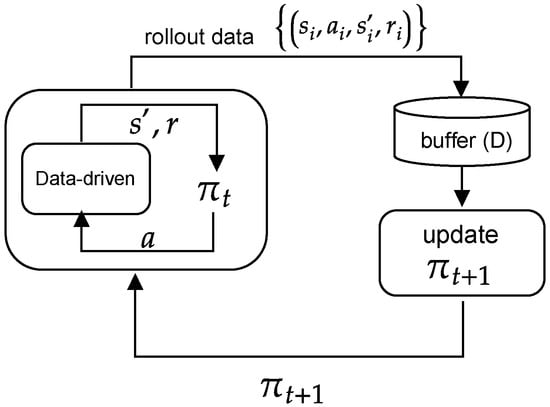
Figure 4.
Off-policy reinforcement learning.
3. Applications
This section details the specific applications of reinforcement learning for real-time optimization, supervisory control, and regulatory control. The main details of these methodologies are also presented. Table 1 summarizes several references for RL in this context, in which the listed algorithms are derived from those shown in Section 2.

Table 1.
Several references for reinforcement learning.
The deep deterministic policy gradient algorithm is actor–critic, off-policy, and deterministic (). This algorithm is an improved version of the deterministic policy gradient algorithm for continuous control. The critic is updated using the Bellman equation (Equation (13)). The actor is updated by applying the chain rule to the expected return (weighed by the critic) with respect to the actor parameter (Equation (14)) [46,47].
The A2C and A3C algorithms [60] are variations of the actor–critic algorithm with agents learning asynchronously, with two or three agents in parallel. The only exception is the proximal policy optimization algorithm, which is an algorithm that learns while interacting with the environment over different episodes (i.e., on-policy). Methodologically, this property comes from another similar algorithm considered more complex (trust region policy optimization (TRPO)), addressing the divergence effect Kullback–Leibler (KL) and surrogate objective functions. Based on this, what is summarized in Table 1 is consistent with the works reported in [61,62,63], with a preference for DDPG and PPO algorithms and their variants as learning algorithms for process control.
3.1. SSRTO
In this review, SSRTO is the only RTO application addressed for three reasons: (1) it remains the most-applied approach in the process industry; (2) it has an extensive literature; (3) to the best of the authors’ knowledge, only Powell et al. [33] used RL in this context. Figure 5 illustrates the steps of SSRTO with model parameter adaptation (MPA). Specifically, MPA updates the rigorous model of the SSRTO layer with steady-state plant information, which must be detected and treated with process data reconciliation before being fed to the parameter estimator. The process disturbances and model uncertainty strongly influence this step. When varying with the same plant dynamics, the former makes it difficult to detect the steady-state. The latter directly affects data reconciliation and parameter estimation. Nevertheless, it is a traditional industry methodology for well-segmented optimization and control steps, facilitating its application and maintenance in the real process. In addition, there are still alternatives to improve parameter estimation by including model and plant derivatives (for more details, see [64,65,66]).
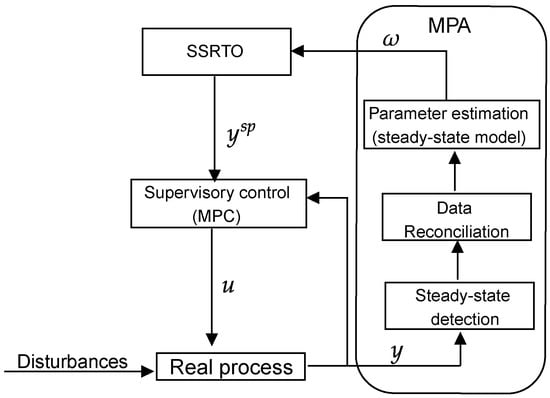
Figure 5.
The classical two-layer approach in the industry. The steps of SSRTO with model parameter adaptation and model predictive control.
For brevity, the optimization details about the MPA approach and SSRTO layer are shown in Equations (15) and (16), respectively, provided that the steady-state detection and data reconciliation steps have been correctly performed. In Equation (15), the parameters of the rigorous model of the process (i.e., ) are updated () based on steady-state reconciled measurements from the plant (), with the values of the manipulated variable (u) received from the supervisory control. In Equation (16), the updated model is used to optimize the plant encompassing the process and economic constraints (). The optimal solution is sent as the set-point to the supervisory control layer, which must drive the plant to these desired values, while rejecting process disturbances [11,13].
Considering RL in the MPA framework, the reformulated problem now comprises offline training, policy transfer, and online policy deployment. Moreover, the elements of RL encompass the current state of the plant , action , and reward . First, extensive offline training based on the randomization of process variables and parameters is required to sample , , , and . To deal with the complexity of offline training, adopting a feasible range for the parameters (i.e., defining the lower bound and upper bound ) and using a replacement model of the rigorous model of the process based on deep neural networks are recommended, which limits the agents’ exploration and exploitation of it. As a result, this allows an adaptive, stochastic and low-computational-cost policy, depending only on the computation of the action by the actor network (). At the end, policy transfer and online policy deployment remain to be addressed by RL. For that purpose, safe RL can guarantee its industrial application in the future (see, for instance, [28]).
SSRTO using RL was addressed by Powell et al. [33], who proposed a methodology to deal with the economic objective and process constraints for a chemical reactor control problem (a continuously stirred tank reactor (CSTR)). Specifically, they simulated data from a rigorous process model. They included process constraints in the reward and the price of reagents and loads (S) as the input to the actor and critic networks. The RL elements encompass the current plant state , action , and reward . For the offline training phase, the vanilla actor–critic algorithm was employed. The training was divided into two stages: (1) the critic network was trained based on the randomization of the process conditions and using cross-validation to obtain an unbiased and generalizing critic network (i.e., ); (2) the actor network was trained around the optimal operating conditions of the plant and the feasible range of the parameters, taking S as known disturbance and adding constraints for the actions, as shown in Equation (17), with adjusting the importance of the magnitude of the action.
After extensive offline training, Powell et al. [33] applied the policy to the real process (i.e., adding white noise and altering S in the simulated process). As a result, the control law was adequate to what would be required by an operator for automatic control or supervision, demanding the evaluation of a function instead of solving the RTO problem. Despite this, the obtained control law generated a smaller economic gain than SSRTO solved by nonlinear programming.
3.2. Supervisory Control
This section focuses on RL’s applications for supervisory control, rather than describing the implications for the development of control theory itself (what can be seen in [62,63]). In Table 1, the listed references comprise RL methodologies applied to the batch process control due to the scarce literature on continuous process control, which mainly combines reinforcement learning and model predictive control to include process constraints and, thus, ensure a level of control stability. Therefore, they guide the discussion throughout this section.
For example, Ma et al. [26] formulated the control problem of a semi-batch polymerization reactor. For MDP sampling (regarding the current process state, action, and reward), extensive offline training was conducted so that the optimal set-points were randomly selected and modified during off-policy learning and the zero-mean Ornstein–Uhlenbeck process was applied to the actions to generate temporally correlated exploration samples (as in the DDPG algorithm). Additionally, the state space was increased by including the difference between the sampled state and the desired set-point (i.e., ). These changes directly influence the obtained reward, as shown in Equation (18), which depends on the time t and parameters , , and c to adjust the importance of reaching the set-point (). To a certain extent, the redefinition of this control problem is close to the approach used for MPC, in which the offline training step would be the model identification. Thereafter, the controller is implemented in a closed loop considering the process constraints and the previously identified model (e.g., [67,68]).
The other listed references and control applications (Table 1) are briefly commented on as they follow an RL methodology similar to the one described above, changing only the type of algorithm used, the addressed control problem, and the definition of the RL elements. Namely, all RL applications depend on extensive offline training based on simulation or real plant data, where the set-point is sampled randomly and has to be reached during the training. Another point for discussion is the lack of validation for industrial processes, as all case studies were restricted to control experiments based on simulation. However, the obtained policies showed superior performance to the model-based ones for all cases (e.g., MPC), which is promising and encourages developing state-of-the-art technologies (RTO using RL). Undoubtedly, safe RL will be essential to ensure such integration in the short term.
Based on this, a parallel is made for continuous processes. Extensive offline training based on the randomization of process conditions is also required to allow MDP sampling. However, a less rigorous model of the process is employed (when compared to that used for SSRTO), and generating simulation data for offline training is costly and complex because the optimal values of the process and control variables need to be maintained minute by minute instead of hourly as in the SSRTO layer. For example, Oh et al. [69] discussed the integration of reinforcement learning and MPC to ensure online policy implementation and fix these issues, suggesting a new approach to Equation (1) (Equation (19)), where the terminal cost is approximated by Q-learning and the cost stage by MPC (e.g., [68,70,71]). This blended receding horizon control approach allows for including constraints on controls and states and incorporating disturbances directly into the optimization problem. It implied in a controller data sampling efficiency much higher than that of model-free RL algorithms, but the challenge is executing online policies continuing to learn about the process and balancing safety and performance.
3.3. Regulatory Control
The regulatory control layer is directly in contact with the process. It makes second-scale control decisions to indirectly optimize the plants’ economic performance, depending on the optimal values (for the design variables) from the supervisory control layer. For regulatory control, RL can be understood as an adaptive controller, which is similar to the proportional–integral–derivative (PID) controller (for more details on PID control methods, see Kumar et al. [72]), automating the control decisions while depending on the evaluation of a function (i.e., deep neural network) [62]. Due to these remarkable features and a broad portfolio of bench-scale and industrial-scale control experiments using PID controllers, RL-adapted alternatives also began to be proposed for bench-scale control experiments. The control policy is less conservative and can automate controller tuning to adapt to supervisory control set-point changes.
For example, Lawrence et al. [59] studied an experimental application for PID tuning. They innovated by embedding PID in the RL framework, updating the actor and critic networks (i.e., employing the DDPG algorithm) by directly using PID tuning parameters as parameters of the actor itself (i.e., proportional gain (), integral gain (), and derivative gain ()) such that . They also increased the state space by including time-delayed information on the control action and the difference between the sampled state and the desired set-point (for more details on including historical information for Markov state prediction, see Faria et al. [32]). The authors used this difference as a reward signal and penalized actions with high-magnitude variations (i.e., ). Finally, considering a two-tank system-level control experiment, they compared the results to various tuning parameters (PID controller) based on the internal model control approach and evaluated the nominal performance and stability, among other factors that influenced the response of both controllers. The results showed that the RL-based controller proved efficient for such performance criteria and could follow the set-point and reject perturbations.
The above approach is an extension of the ones seen in the works of Dogru et al. [27] and Ramanathan et al. [56]. Both adapted the control experiment in the RL framework using a more conventional approach than the one proposed by Lawrence et al. [59], similar to the one used for supervisory control. Specifically, instead of updating the PID controller parameters included in the actor network, the actor and critic learn following the approach illustrated in Figure 3. In addition, both increased the state space by including information between the sampled state and the desired set-point (delayed in time) and the immediate reward penalizing large set-point deviations and large magnitude variations of actions. Spielberg et al. [58] focused on the design of the RL agent for regulatory control and rigorously detailed the steps for its implementation considering a control experiment in a simulated environment (using the DDPG algorithm). The resulting control agent followed the set-point for single-input, single-output (SISO) and multiple-input, multiple-output (MIMO) cases. Moreover, a new control experiment evaluated the robustness of the DDPG controller to adapt to abrupt process changes and how this affects its learning performance and convergence. The result was that the controller continues to learn online without the need to restart the offline training.
4. Benchmark Study of Reinforcement Learning
4.1. Offline Control Experiment
To consolidate what was described in this review, a control experiment details the formulation of a control agent based on RL. The proposed control experiment follows an example from the work of Ławryńczuk et al. [73], which evaluated the classical two-layer approach (i.e., RTO plus MPC) for the economic optimization and control of the well-known Van de Vusse reactor.
4.1.1. Dynamic Model of the CSTR
A schematic diagram of the Van de Vusse reactor is shown in Figure 6. The feed inflow contains only cyclopentadiene (component A) with concentration . The volume (V) is maintained constant throughout the reaction. The outflow includes the remainder of cyclopentadiene, the product cyclopentenol, and two unwanted by-products, cyclopentanediol (component C) and dicyclopentadiene (component D), with concentrations of , , , and and constant reaction rates (), characterizing the Van de Vusse reaction (Equation (20)) [73].
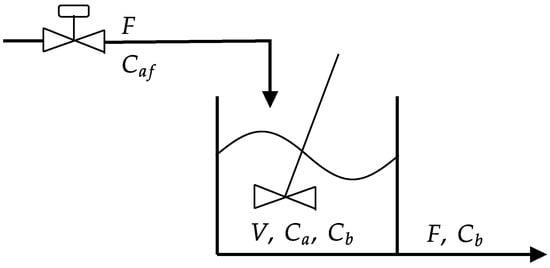
Figure 6.
Van de Vusse reactor.
This process is modeled as an ordinary differential equation (ODE) system with two states ( and ) and one manipulated variable (F), as shown in Equations (21) and (22).
The real-time optimization problem deals with the maximization of the concentration of the component B () by manipulating . It is also assumed that the product should fulfill a purity criterion () regardless of the values of disturbance . Within the classic RTO perspective (Figure 5), corresponds to , the CSTR model () is the same for SSRTO and MPC, and the optimal solution is sent as the set-point to the supervisory control layer (MPC). In the next section, this problem is formulated in the RL framework, according to the one-layer approach. The option is to use a variant of the DDPG algorithm as a learning agent (i.e., multi-agent deep deterministic policy gradient (MADDPG) [74]), which uses cooperative or concurrent control agents to improve the data distribution (i.e., buffer sampling) and to stabilize training, which is a contribution to the literature, following the recommendations of Powell et al. [33] on obtaining an optimal actor and critic given the complex offline training.
4.1.2. RL Framework
The roll-out data sampling was based on the simulation of the Van de Vusse reactor over episodes of size . The RL elements in this framework are illustrated in Figure 7. The current state and the new state are and . The reward is the essential RL element to guide offline learning. Its definition encompasses the economic objective () according to Equation (23), which is maximized only when the required minimum production of is reached (i.e., ), plus the contribution of , with adjusting the importance of reaching such a condition as quickly as possible. When the minimum production is not reached, adjusts the importance of maximizing and and penalizes high variations of (i.e., in the range ). Additionally, the reactor initial conditions are randomly selected according to continuous uniform distribution (i.e., , , where a and b are the minimum and maximum values), with process disturbance also sampled randomly (). They are maintained constant for each episode, and the procedure repeats until the buffer is completely filled ().
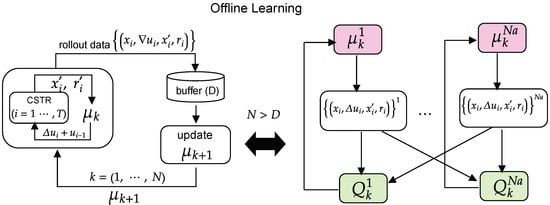
Figure 7.
Offline learning with multi-agent deep deterministic policy gradient, with a buffer of size D, to optimize and control the Van de Vusse reactor.
The steps for its implementation are similar to the DDPG algorithm and are shown in Algorithm 1. However, the dimension of the buffer is increased since the critic network update () will also depend on collected experiences, actions , states , state transitions , and rewards , from the other agents. Regarding the case study, the first step is selecting the number of agents (), which directly influences the amount of acquired experience and the computational burden. At each execution of the algorithm (), the initial condition () is sampled at random (uniformly) for each agent and kept constant for . The aim is to expose each agent to various experiences, continuing to learn to maximize rewards () regardless of the initial state ( and ) and process disturbance (). This procedure follows the behavioral policy and the Ornstein–Uhlenbeck process to generate temporally correlated exploration samples (), and thus obtain the rewards (Equation (23)) and reach the new state (Equations (21) and (22)), which compose a buffer that stores and replays uniformly the roll-out data (). With a sufficient number of samples (i.e., if ), the update step for each agent effectively begins. The tuple () of size K is sampled at random (uniformly) to compute the TD-error () increased with actions implemented by each agent, which leads to updating the critic and actor networks. Finally, updating the actor and critic networks with delayed (or filtered) copies of the original DNN is an alternative, as in DDPG algorithms, to stabilize training.
| Algorithm 1: MADDPG algorithm. |
 |
4.1.3. Validation of the Control Experiment
The parameters used in the offline control experiment are summarized in Table 2. The selected hyperparameters’ values (i.e., K, , and ) followed the recommendations of Lillicrap et al. [47] and Lowe et al. [74]. The number of episodes (N), the buffer size (D), the number of agents (), the size of the episode time horizon (T), and the parameters , , and were selected by trial and error. The selected actor network must be more conservative than the critic network, according to the recommendations from Faria et al. [32]. Furthermore, the actor and critic learning rates decay by every 1000 episodes (i.e., when ) to stabilize stochastic gradient descent optimization. The definition of the process conditions, except for the control action limit () between −20 and 20, followed the example of Ławryńczuk et al. [73]. Namely, , , , , , , , and the control experiment lasting two hours, with the control action taken at each time interval of duration of 0.025 h (), totaling 80 time steps (i.e., ). Finally, the control experiment was performed on an ACER Aspire A315-23G computer with 12 GB RAM. The system of Equations (21) and (22) was integrated using CVODES [75] (suite of differential algebraic equation solvers implemented in Casadi). Moreover, Pytorch [76] was employed for the actor and critic networks’ definition and offline training.
Table 2.
The MADDPG algorithm’s hyperparameters.
The offline learning of the four agents following the RL framework is illustrated in Figure 8 and Figure 9. In Figure 8, all agents resulted in an actor that maximized the policy gradient, having a magnitude compatible with that computed by the critic network (Figure 9) and independent of the initial conditions of the reactor. This means that all agents learned decision-making policies that maximized the rewards over the episodes. At this point, it was expected to obtain an actor and a critic sufficiently generalizing and robust to adapt to new process conditions. However, Agent 3 had an oscillatory behavior, which can make its online use unfeasible, and Agent 4 may have reached a sub-optimal state.
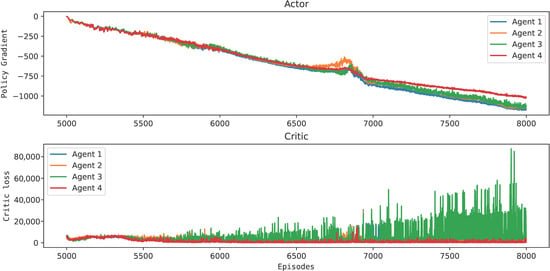
Figure 8.
Actor and critic update to Van de Vusse reactor economic optimization and control.
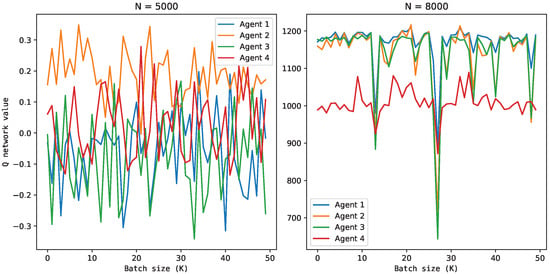
Figure 9.
Q-network value considering the action taken from a continuous uniform distribution () and the action with the MADDPG algorithm ().
Validation for Process Condition 1
To validate these results, a new process condition not tested offline was performed: the training time was extended to 5 h; the dynamics of process disturbance was a sine wave, which exhibited a smooth, periodic oscillation (Figure 10); the steady-state condition was , and .
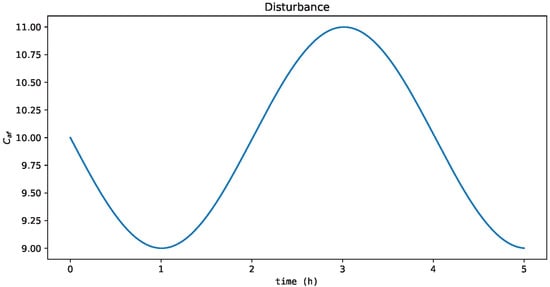
Figure 10.
Process disturbance with sine wave dynamics outside the range used in the offline training.
In Figure 11, when evaluating the dynamics of , Agents 1 and 4 had the least-oscillatory behavior, did not exceed the process constraint, and took adequate control actions for process disturbances, as illustrated in Figure 12. These results corroborate what was expected given the oscillatory behavior of Agents 2 and 3 in the offline training phase to update the actor and critic networks. Agent 3 resulted in a sub-optimal actor with saturated control actions at the upper limit of F. Agent 2 did not find a suitable actor to deal with process disturbances, resulting in an oscillatory and divergent control policy. These results denote one of the main features of the MADDPG algorithm (mentioned in [77]), as it allows using cooperative control agents that have increased learning (Agents 1 and 4) when collecting experiences of sub-optimal policies (Agents 2 and 3). Although Agents 2 and 3 resulted in unfeasible policies, the possibility of using each agent in parallel improved the robustness of the methodology (compared to DDPG), especially considering its implementation in the real process, which could discard Agents 2 and 3 and directly employ Agents 1 and 4 or even combine them. These claims were evaluated by comparing the performance of all agents with respect to the two-layer approach. Specifically, the HRTO approach with the set of parameters based on Matias and Le Roux [14] was chosen. Agents 1 and 4 rejected the disturbances and reached the set-point as in HRTO (Figure 13), which employed the extended Kalman filter (EKF) and estimated (online) for the model adaptation step of RTO and MPC. The EKF suitably estimated the disturbance (Figure 13b) so that MPC achieved the set-points resulting from the RTO layer (Figure 13a,c).
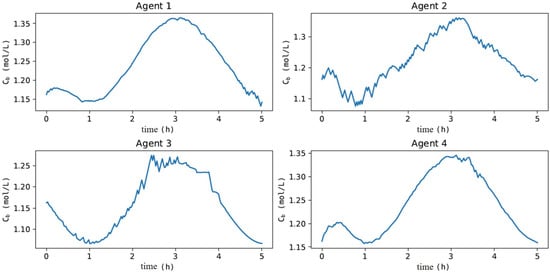
Figure 11.
Dynamics of when subjected to process disturbances of Figure 10 over a 5 h control experiment.
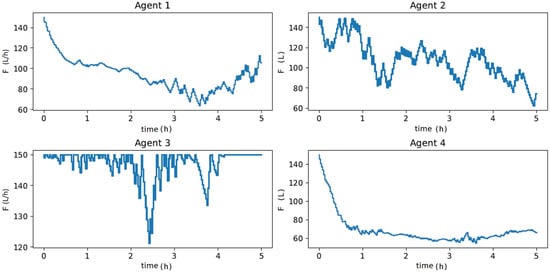
Figure 12.
Dynamics of control actions () when subjected to process disturbances of Figure 10 over a 5 h control experiment, to maximize .
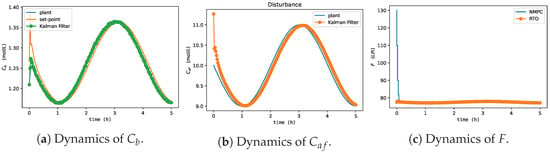
Figure 13.
HRTO approach to Van de Vusse reactor economic optimization and control concerning process disturbances of Figure 10.
In Table 3, the average yield of and the CPU time for each agent are summarized. Agents 1 and 4 were an interrelated alternative to HRTO as they demand to compute a function rather than solve a sequence of nonlinear optimization problems, despite less economic profit. These results were also seen in Powell et al. [33]. However, using multiple agents guarantees learning from sub-optimal policies and parallel implementation.
Table 3.
Average yield and online experiment time for each agent.
Validation for Process Condition 2
Another process condition is proposed to evaluate the generalization of agents when subjected to process disturbances that they were not exposed to during offline training, i.e., has process dynamics according to Figure 14.
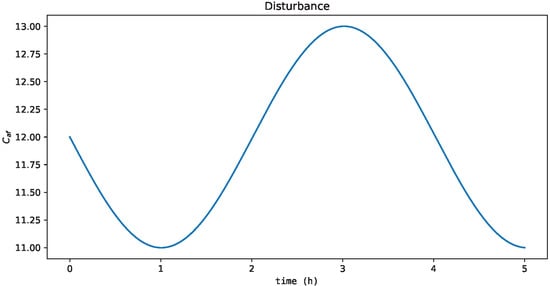
Figure 14.
Process disturbance with sine wave dynamics outside the range used in the offline training.
All learning agents showed a more oscillatory behavior, as shown in Figure 15. This was expected as they were not exposed to these conditions in offline training. Despite this, they managed to capture the dynamic behavior of adequately, again with Agents 1 and 4 taking control actions closer to those considered optimal, as shown in Figure 16 (i.e., concerning HRTO (Figure 17)) and with a CPU time equal to the condition tested before and summarized in Table 3. These results were due to the networks’ ability to generalize to other process conditions, which demonstrated the robustness of the MADDPG controller to adapt to abrupt process changes, as detailed in Spielberg et al. [58] for the DDPG controller, without the need to restart the offline training.
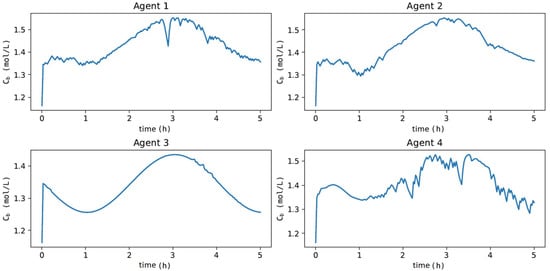
Figure 15.
Dynamics of when subjected to process disturbances of Figure 14 over a 5 h control experiment.
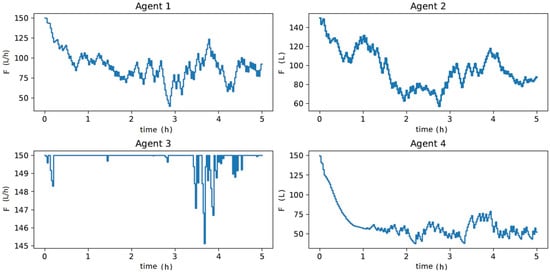
Figure 16.
Dynamics of control actions () when subjected to process disturbances of Figure 14 over a 5 h control experiment, to maximize .
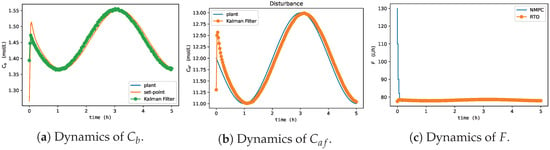
Figure 17.
HRTO approach to Van de Vusse reactor economic optimization and control concerning process disturbances of Figure 14.
5. Conclusions
This review outlined guidelines for real-time optimization using reinforcement learning approaches. The analysis of specific applications for real-time optimization, supervisory control, and regulatory control allowed us to make some general conclusions about it:
- There are a huge number of RL applications not considering the economic optimization of the plant;
- Almost all applications are restricted to validation with bench-scale control experiments or based on simulation;
- There is a consensus in the literature that extensive offline training is indispensable to obtain adequate control agents regardless of the process;
- The definition of the reinforcement signal (reward) must be rigorously performed to adequately guide the agents’ learning, which must be penalized when it is far from the condition considered ideal or when it results in impossible or unfeasible state transitions;
- The benchmark study of RL confirmed the hypothesis that cooperative control agents based on the MADDPG algorithm (i.e., one-layer approach) could be an option for the HRTO approach;
- Learning with cooperative control agents improved the learning rate (Agents 1 and 4) through the collection of experiences of sub-optimal policies (Agents 2 and 3);
- The parallel implementation with MADDPG is possible;
- The benefits of the collection of experiences with MADDPG depend on a trustworthy process simulation;
- Learning with MADDPG is fundamentally more difficult than the single agent (DDPG), especially for large-scale processes due to the dimensionality problem;
- It is necessary to develop RL algorithms to handle security constraints to ensure control stability and investigate applications for small-scale processes.
Author Contributions
As the article’s main author, R.d.R.F. participated in all steps of the research method: conceptualization, methodology, writing—original draft preparation. Review and editing, all authors; conceptualization and supervision, B.D.O.C., A.R.S. and M.B.d.S.J. All authors have read and agreed to the published version of the manuscript.
Funding
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—Brasil (CAPES)—Finance Code 001. Professor Maurício B. de Souza Jr. is grateful for the financial support from CNPq (Grant No. 311153/2021-6) and Fundação Carlos Chagas Filho de Amparo à Pesquisa do Estado do Rio de Janeiro (FAPERJ) (Grant No. E-26/201.148/2022).
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Skogestad, S. Control structure design for complete chemical plants. Comput. Chem. Eng. 2004, 28, 219–234. [Google Scholar] [CrossRef]
- Skogestad, S. Plantwide control: The search for the self-optimizing control structure. J. Process Control 2000, 10, 487–507. [Google Scholar] [CrossRef]
- Forbes, J.F.; Marlin, T.E. Model accuracy for economic optimizing controllers: The bias update case. Ind. Eng. Chem. Res. 1994, 33, 1919–1929. [Google Scholar] [CrossRef]
- Miletic, I.; Marlin, T. Results analysis for real-time optimization (RTO): Deciding when to change the plant operation. Comput. Chem. Eng. 1996, 20, S1077–S1082. [Google Scholar] [CrossRef]
- Mochizuki, S.; Saputelli, L.A.; Kabir, C.S.; Cramer, R.; Lochmann, M.; Reese, R.; Harms, L.; Sisk, C.; Hite, J.R.; Escorcia, A. Real time optimization: Classification and assessment. In Proceedings of the SPE Annual Technical Conference and Exhibition, Houston, TX, USA, 27–29 September 2004. [Google Scholar]
- Bischoff, K.B.; Denn, M.M.; Seinfeld, J.H.; Stephanopoulos, G.; Chakraborty, A.; Peppas, N.; Ying, J.; Wei, J. Advances in Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2001. [Google Scholar]
- Krishnamoorthy, D.; Skogestad, S. Real-Time Optimization as a Feedback Control Problem—A Review. Comput. Chem. Eng. 2022, 161, 107723. [Google Scholar] [CrossRef]
- Sequeira, S.E.; Graells, M.; Puigjaner, L. Real-time evolution for on-line optimization of continuous processes. Ind. Eng. Chem. Res. 2002, 41, 1815–1825. [Google Scholar] [CrossRef]
- Adetola, V.; Guay, M. Integration of real-time optimization and model predictive control. J. Process Control 2010, 20, 125–133. [Google Scholar] [CrossRef]
- Backx, T.; Bosgra, O.; Marquardt, W. Integration of model predictive control and optimization of processes: Enabling technology for market driven process operation. IFAC Proc. Vol. 2000, 33, 249–260. [Google Scholar] [CrossRef]
- Yip, W.; Marlin, T.E. The effect of model fidelity on real-time optimization performance. Comput. Chem. Eng. 2004, 28, 267–280. [Google Scholar] [CrossRef]
- Biegler, L.; Yang, X.; Fischer, G. Advances in sensitivity-based nonlinear model predictive control and dynamic real-time optimization. J. Process Control 2015, 30, 104–116. [Google Scholar] [CrossRef]
- Krishnamoorthy, D.; Foss, B.; Skogestad, S. Steady-state real-time optimization using transient measurements. Comput. Chem. Eng. 2018, 115, 34–45. [Google Scholar] [CrossRef]
- Matias, J.O.; Le Roux, G.A. Real-time Optimization with persistent parameter adaptation using online parameter estimation. J. Process Control 2018, 68, 195–204. [Google Scholar] [CrossRef]
- Matias, J.; Oliveira, J.P.; Le Roux, G.A.; Jäschke, J. Steady-state real-time optimization using transient measurements on an experimental rig. J. Process Control 2022, 115, 181–196. [Google Scholar] [CrossRef]
- Valluru, J.; Purohit, J.L.; Patwardhan, S.C.; Mahajani, S.M. Adaptive optimizing control of an ideal reactive distillation column. IFAC-PapersOnLine 2015, 48, 489–494. [Google Scholar] [CrossRef]
- Zanin, A.; de Gouvea, M.T.; Odloak, D. Industrial implementation of a real-time optimization strategy for maximizing production of LPG in a FCC unit. Comput. Chem. Eng. 2000, 24, 525–531. [Google Scholar] [CrossRef]
- Zanin, A.; De Gouvea, M.T.; Odloak, D. Integrating real-time optimization into the model predictive controller of the FCC system. Control Eng. Pract. 2002, 10, 819–831. [Google Scholar] [CrossRef]
- Ellis, M.; Durand, H.; Christofides, P.D. A tutorial review of economic model predictive control methods. J. Process Control 2014, 24, 1156–1178. [Google Scholar] [CrossRef]
- Mayne, D.Q. Model predictive control: Recent developments and future promise. Automatica 2014, 50, 2967–2986. [Google Scholar] [CrossRef]
- Wang, X.; Mahalec, V.; Qian, F. Globally optimal dynamic real time optimization without model mismatch between optimization and control layer. Comput. Chem. Eng. 2017, 104, 64–75. [Google Scholar] [CrossRef]
- Uc-Cetina, V.; Navarro-Guerrero, N.; Martin-Gonzalez, A.; Weber, C.; Wermter, S. Survey on reinforcement learning for language processing. Artif. Intell. Rev. 2022, 1–33. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep reinforcement learning for autonomous driving: A survey. IEEE Trans. Intell. Transp. Syst. 2021, 23, 4909–4926. [Google Scholar] [CrossRef]
- Peng, X.B.; Andrychowicz, M.; Zaremba, W.; Abbeel, P. Sim-to-real transfer of robotic control with dynamics randomization. In Proceedings of the 2018 IEEE international conference on robotics and automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018; pp. 3803–3810. [Google Scholar]
- Wulfmeier, M.; Posner, I.; Abbeel, P. Mutual alignment transfer learning. In Proceedings of the Conference on Robot Learning. PMLR, Mountain View, CA, USA, 13–15 November 2017; pp. 281–290. [Google Scholar]
- Ma, Y.; Zhu, W.; Benton, M.G.; Romagnoli, J. Continuous control of a polymerization system with deep reinforcement learning. J. Process Control 2019, 75, 40–47. [Google Scholar] [CrossRef]
- Dogru, O.; Wieczorek, N.; Velswamy, K.; Ibrahim, F.; Huang, B. Online reinforcement learning for a continuous space system with experimental validation. J. Process Control 2021, 104, 86–100. [Google Scholar] [CrossRef]
- Mowbray, M.; Petsagkourakis, P.; Chanona, E.A.D.R.; Smith, R.; Zhang, D. Safe Chance Constrained Reinforcement Learning for Batch Process Control. arXiv 2021, arXiv:2104.11706. [Google Scholar]
- Petsagkourakis, P.; Sandoval, I.O.; Bradford, E.; Zhang, D.; del Rio-Chanona, E.A. Reinforcement learning for batch-to-batch bioprocess optimisation. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2019; Volume 46, pp. 919–924. [Google Scholar]
- Petsagkourakis, P.; Sandoval, I.O.; Bradford, E.; Zhang, D.; del Rio-Chanona, E.A. Reinforcement learning for batch bioprocess optimization. Comput. Chem. Eng. 2020, 133, 106649. [Google Scholar] [CrossRef]
- Yoo, H.; Byun, H.E.; Han, D.; Lee, J.H. Reinforcement learning for batch process control: Review and perspectives. Annu. Rev. Control 2021, 52, 108–119. [Google Scholar] [CrossRef]
- Faria, R.D.R.; Capron, B.D.O.; Secchi, A.R.; de Souza, M.B. Where Reinforcement Learning Meets Process Control: Review and Guidelines. Processes 2022, 10, 2311. [Google Scholar] [CrossRef]
- Powell, K.M.; Machalek, D.; Quah, T. Real-time optimization using reinforcement learning. Comput. Chem. Eng. 2020, 143, 107077. [Google Scholar] [CrossRef]
- Thorndike, E.L. Animal intelligence: An experimental study of the associative processes in animals. Psychol. Rev. Monogr. Suppl. 1898, 2, i. [Google Scholar] [CrossRef]
- Minsky, M. Neural nets and the brain-model problem. Unpublished Doctoral Dissertation, Princeton University, Princeton, NJ, USA, 1954. [Google Scholar]
- Bellman, R. A Markovian decision process. J. Math. Mech. 1957, 6, 679–684. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957; Volume 95. [Google Scholar]
- Marvin, M.; Seymour, A.P. Perceptrons; MIT Press: Cambridge, MA, USA, 1969. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Sugiyama, M. Statistical Reinforcement Learning: Modern Machine Learning Approaches; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Watkins, C.J.C.H. Learning from Delayed Rewards; King’s College: Oxford, UK, 1989. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement learning: An introduction; MIT Press: London, UK, 2018. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Introduction to Reinforcement Learning; MIT Press: Cambridge, UK, 1998; Volume 135. [Google Scholar]
- Williams, R. Toward a Theory of Reinforcement-Learning Connectionist Systems; Technical Report NU-CCS-88-3; Northeastern University: Boston, MA, USA, 1988. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R.R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Silver, D.; Lever, G.; Heess, N.; Degris, T.; Wierstra, D.; Riedmiller, M. Deterministic Policy Gradient Algorithms. In Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 21–26 June 2014; Volume 32, pp. 387–395. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Fujimoto, S.; Van Hoof, H.; Meger, D. Addressing function approximation error in actor–critic methods. arXiv 2018, arXiv:1802.09477. [Google Scholar]
- LeCun, Y.; Touresky, D.; Hinton, G.; Sejnowski, T. A theoretical framework for back-propagation. In Proceedings of the 1988 Connectionist Models Summer School; CMU, Morgan Kaufmann: Pittsburgh, PA, USA, 1988; Volume 1, pp. 21–28. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 2000, 12, 1057–1063. [Google Scholar]
- Sutton, R.S. Learning to predict by the methods of temporal differences. Mach. Learn. 1988, 3, 9–44. [Google Scholar] [CrossRef]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal policy optimization algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Hwangbo, S.; Sin, G. Design of control framework based on deep reinforcement learning and Monte-Carlo sampling in downstream separation. Comput. Chem. Eng. 2020, 140, 106910. [Google Scholar] [CrossRef]
- Yoo, H.; Kim, B.; Kim, J.W.; Lee, J.H. Reinforcement learning based optimal control of batch processes using Monte-Carlo deep deterministic policy gradient with phase segmentation. Comput. Chem. Eng. 2021, 144, 107133. [Google Scholar] [CrossRef]
- Oh, D.H.; Adams, D.; Vo, N.D.; Gbadago, D.Q.; Lee, C.H.; Oh, M. Actor-critic reinforcement learning to estimate the optimal operating conditions of the hydrocracking process. Comput. Chem. Eng. 2021, 149, 107280. [Google Scholar] [CrossRef]
- Ramanathan, P.; Mangla, K.K.; Satpathy, S. Smart controller for conical tank system using reinforcement learning algorithm. Measurement 2018, 116, 422–428. [Google Scholar] [CrossRef]
- Bougie, N.; Onishi, T.; Tsuruoka, Y. Data-Efficient Reinforcement Learning from Controller Guidance with Integrated Self-Supervision for Process Control. IFAC-PapersOnLine 2022, 55, 863–868. [Google Scholar] [CrossRef]
- Spielberg, S.; Tulsyan, A.; Lawrence, N.P.; Loewen, P.D.; Bhushan Gopaluni, R. Toward self-driving processes: A deep reinforcement learning approach to control. AIChE J. 2019, 65, e16689. [Google Scholar] [CrossRef]
- Lawrence, N.P.; Forbes, M.G.; Loewen, P.D.; McClement, D.G.; Backström, J.U.; Gopaluni, R.B. Deep reinforcement learning with shallow controllers: An experimental application to PID tuning. Control Eng. Pract. 2022, 121, 105046. [Google Scholar] [CrossRef]
- Mnih, V.; Badia, A.P.; Mirza, M.; Graves, A.; Lillicrap, T.; Harley, T.; Silver, D.; Kavukcuoglu, K. Asynchronous methods for deep reinforcement learning. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 1928–1937. [Google Scholar]
- Badgwell, T.A.; Lee, J.H.; Liu, K.H. Reinforcement learning–overview of recent progress and implications for process control. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2018; Volume 44, pp. 71–85. [Google Scholar]
- Buşoniu, L.; de Bruin, T.; Tolić, D.; Kober, J.; Palunko, I. Reinforcement learning for control: Performance, stability, and deep approximators. Annu. Rev. Control 2018, 46, 8–28. [Google Scholar] [CrossRef]
- Nian, R.; Liu, J.; Huang, B. A review on reinforcement learning: Introduction and applications in industrial process control. Comput. Chem. Eng. 2020, 139, 106886. [Google Scholar] [CrossRef]
- Mendoza, D.F.; Graciano, J.E.A.; dos Santos Liporace, F.; Le Roux, G.A.C. Assessing the reliability of different real-time optimization methodologies. Can. J. Chem. Eng. 2016, 94, 485–497. [Google Scholar] [CrossRef]
- Marchetti, A.G.; François, G.; Faulwasser, T.; Bonvin, D. Modifier adaptation for real-time optimization—Methods and applications. Processes 2016, 4, 55. [Google Scholar] [CrossRef]
- Câmara, M.M.; Quelhas, A.D.; Pinto, J.C. Performance evaluation of real industrial RTO systems. Processes 2016, 4, 44. [Google Scholar] [CrossRef]
- Alhazmi, K.; Albalawi, F.; Sarathy, S.M. A reinforcement learning-based economic model predictive control framework for autonomous operation of chemical reactors. Chem. Eng. J. 2022, 428, 130993. [Google Scholar] [CrossRef]
- Kim, J.W.; Park, B.J.; Yoo, H.; Oh, T.H.; Lee, J.H.; Lee, J.M. A model-based deep reinforcement learning method applied to finite-horizon optimal control of nonlinear control-affine system. J. Process Control 2020, 87, 166–178. [Google Scholar] [CrossRef]
- Oh, T.H.; Park, H.M.; Kim, J.W.; Lee, J.M. Integration of reinforcement learning and model predictive control to optimize semi-batch bioreactor. AIChE J. 2022, 68, e17658. [Google Scholar] [CrossRef]
- Shah, H.; Gopal, M. Model-free predictive control of nonlinear processes based on reinforcement learning. IFAC-PapersOnLine 2016, 49, 89–94. [Google Scholar] [CrossRef]
- Recht, B. A tour of reinforcement learning: The view from continuous control. Annu. Rev. Control Robot. Auton. Syst. 2019, 2, 253–279. [Google Scholar] [CrossRef]
- Kumar, V.; Nakra, B.; Mittal, A. A review on classical and fuzzy PID controllers. Int. J. Intell. Control Syst. 2011, 16, 170–181. [Google Scholar]
- awryńczuk, M.; Marusak, P.M.; Tatjewski, P. Cooperation of model predictive control with steady-state economic optimisation. Control Cybern. 2008, 37, 133–158. [Google Scholar]
- Lowe, R.; Wu, Y.; Tamar, A.; Harb, J.; Abbeel, P.; Mordatch, I. Multi-agent actor–critic for mixed cooperative-competitive environments. arXiv 2017, arXiv:1706.02275. [Google Scholar]
- Anderson, C.W. Learning and Problem Solving with Multilayer Connectionist Systems. Ph.D. Thesis, University of Massachusetts at Amherst, Amherst, MA, USA, 1986. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Chen, K.; Wang, H.; Valverde-Pérez, B.; Zhai, S.; Vezzaro, L.; Wang, A. Optimal control towards sustainable wastewater treatment plants based on multi-agent reinforcement learning. Chemosphere 2021, 279, 130498. [Google Scholar] [CrossRef]

















Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).