3.1. Q-Learning
In Q-learning, which belongs to the field of reinforcement learning, agents/decision makers try to interact with the environment by learning the behavior of dynamic systems. In this chapter, the agent receives the current state and rewards of the dynamic system, and then performs corresponding actions based on its experience to increase long-term revenue through state transitions. States and rewards represent data the agent receives from the system, while actions are the only input to the system. Unlike supervised learning, in Q-learning, the agent must find the optimal action to maximize the reward while the agent’s actions not only affect the current reward, but also affect future rewards.
A trade-off exists in Q-learning between exploitation and exploration. Unknown actions are investigated in order to avoid missing better candidate actions, but because they are unpredictable, they may worsen network performance. On the other hand, if action is dependent on the present best action choice, it may result in a local optimal solution even when other as yet undiscovered actions might offer more advantages.
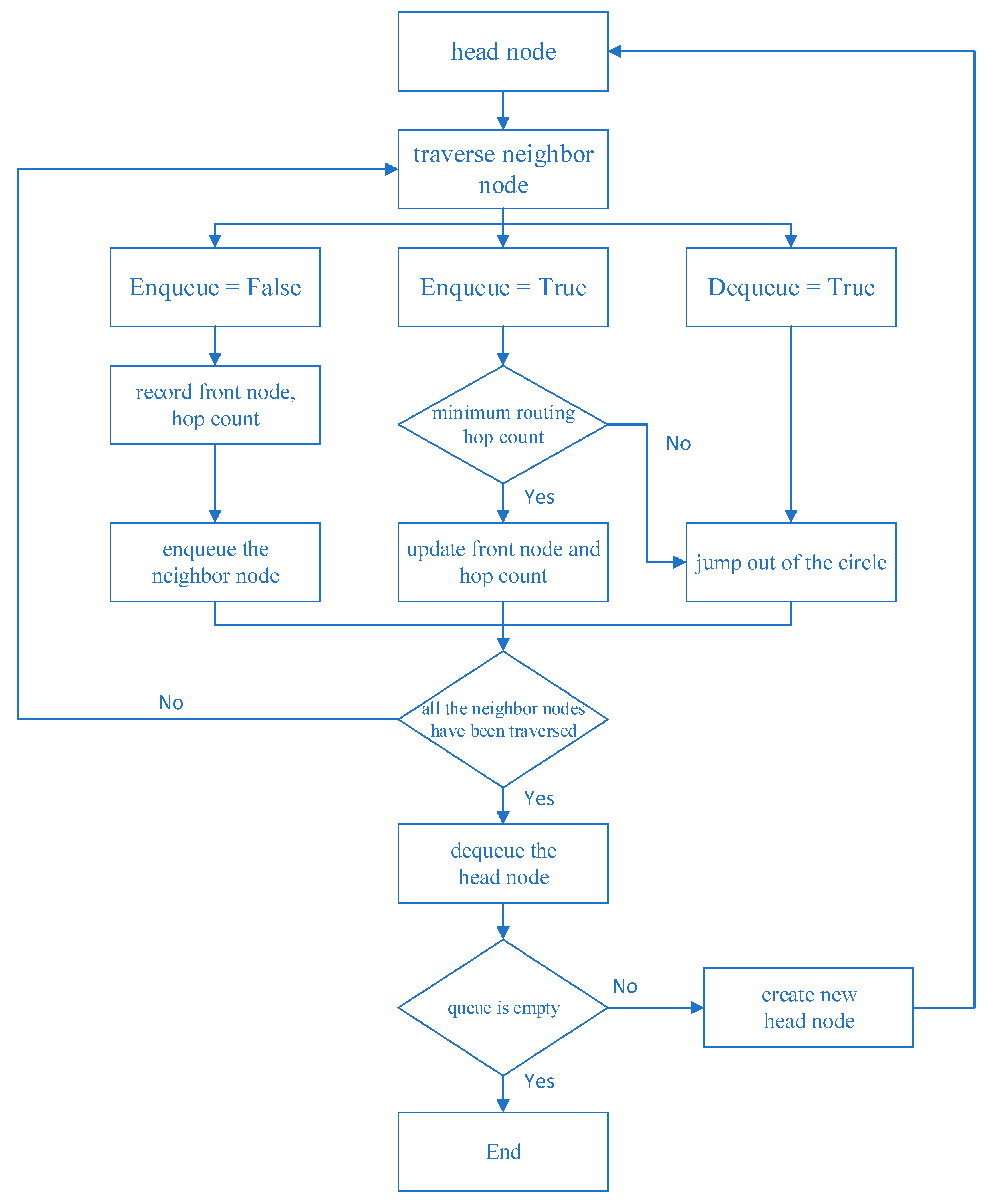
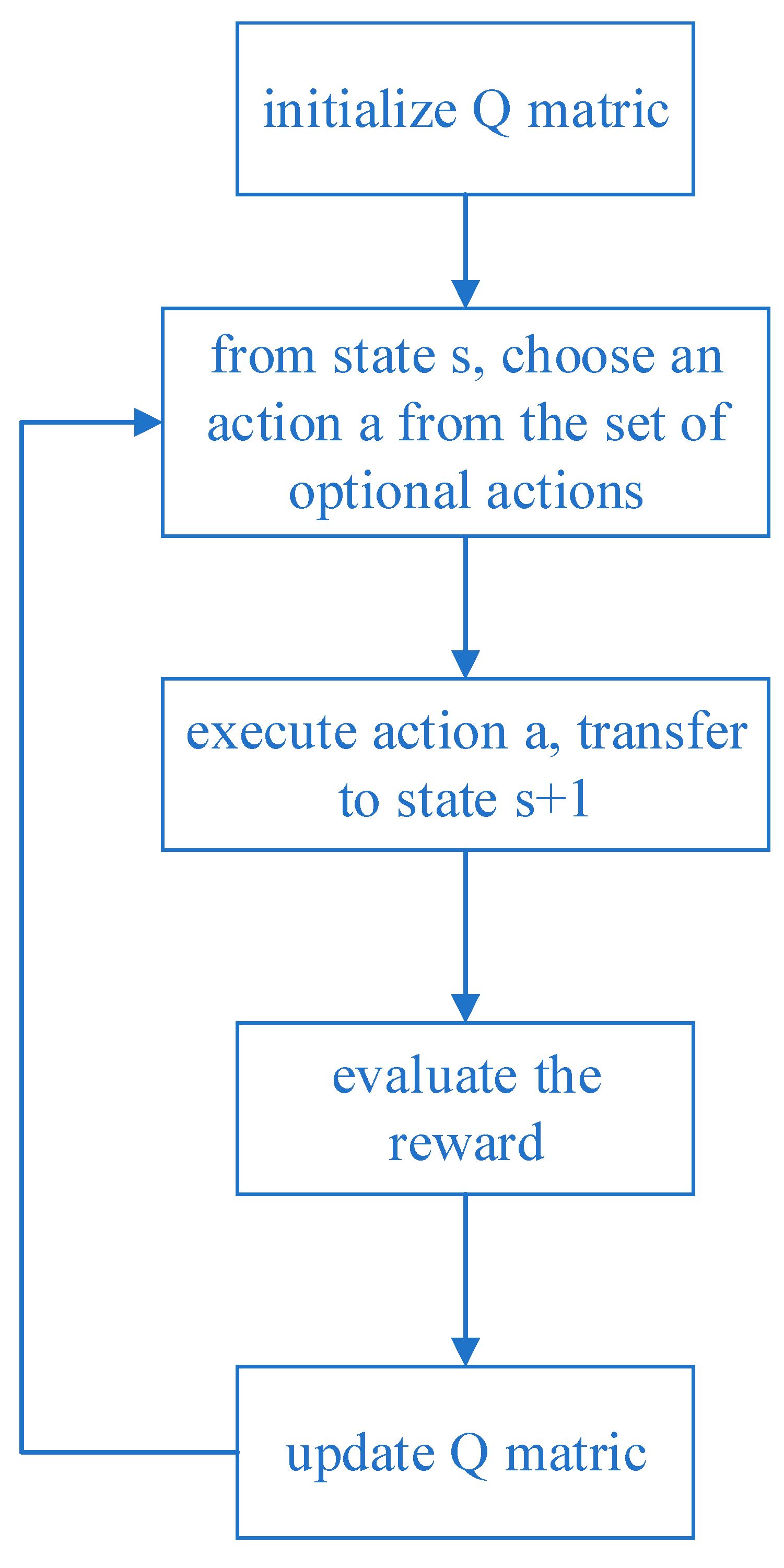
Figure 4 describes the basic Q-learning algorithm flow, and its specific execution steps are described as follows:
Step 1: Initialize the Q value. This stage constructs a Q-table, where the rows represent the state space and the columns represent the action space, and are initialized to 0.
Step 2: Throughout the lifetime, repeat Step 3–Step 5 until the set number of stop training is reached.
Step 3: Based on the current Q value estimation state, select an action from the optional action space, which involves the trade-off between exploration and exploitation in Q-learning. The most commonly used strategy, for example, , adopts an exploration rate as the random step size. It can be set larger initially, because the Q value in the Q-table is unknown, and a large amount of exploration needs to be performed by randomly selecting actions. Generate a random number and if it is greater than , the action will be selected using known information, otherwise, it will continue to explore. As the agent becomes more confident in the estimated Q value, can be gradually reduced.
Step 4–5: Take action and observe the output state, evaluate the reward, then use the Bellman equation to update the function.
3.2. Q-Learning Routing System Model
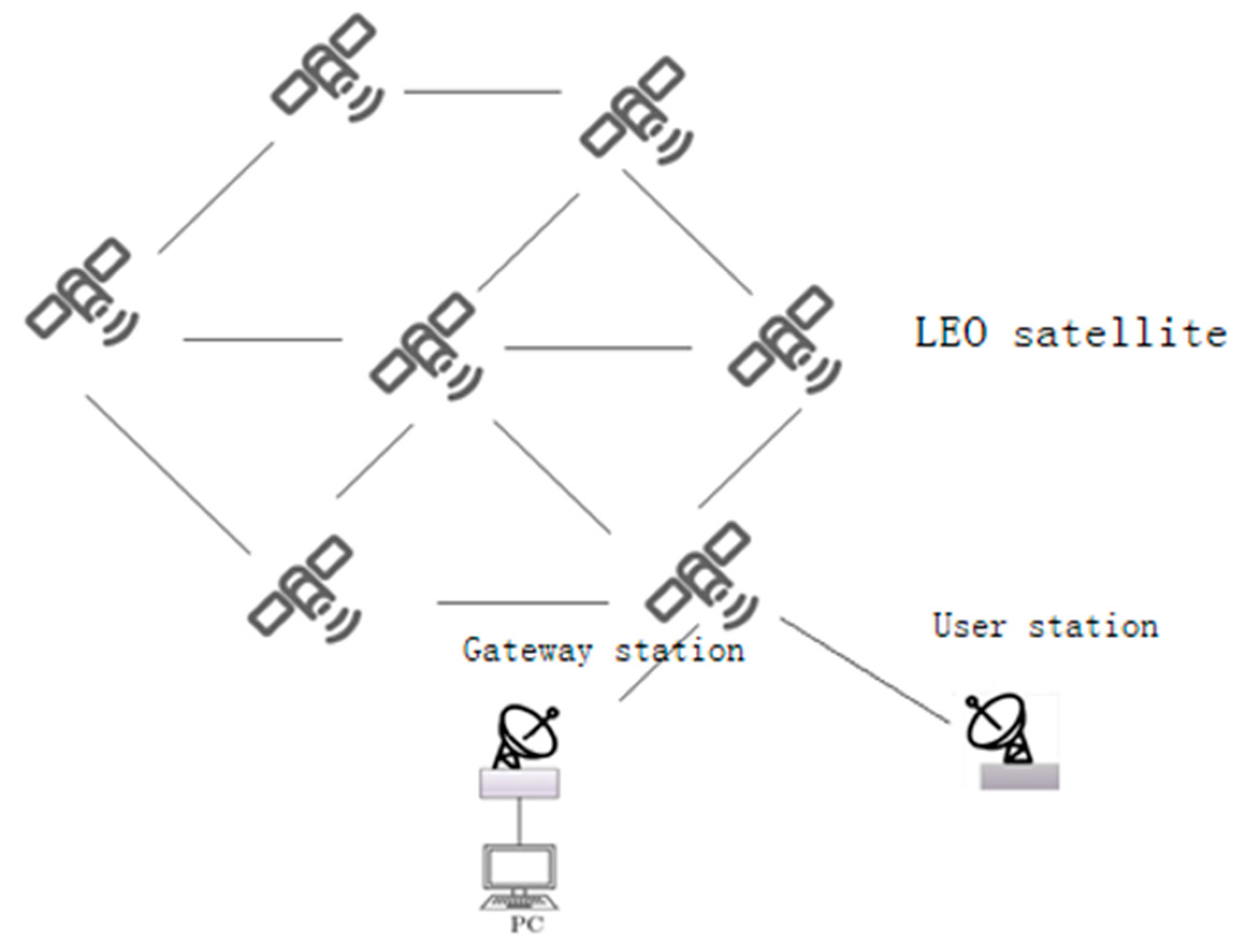
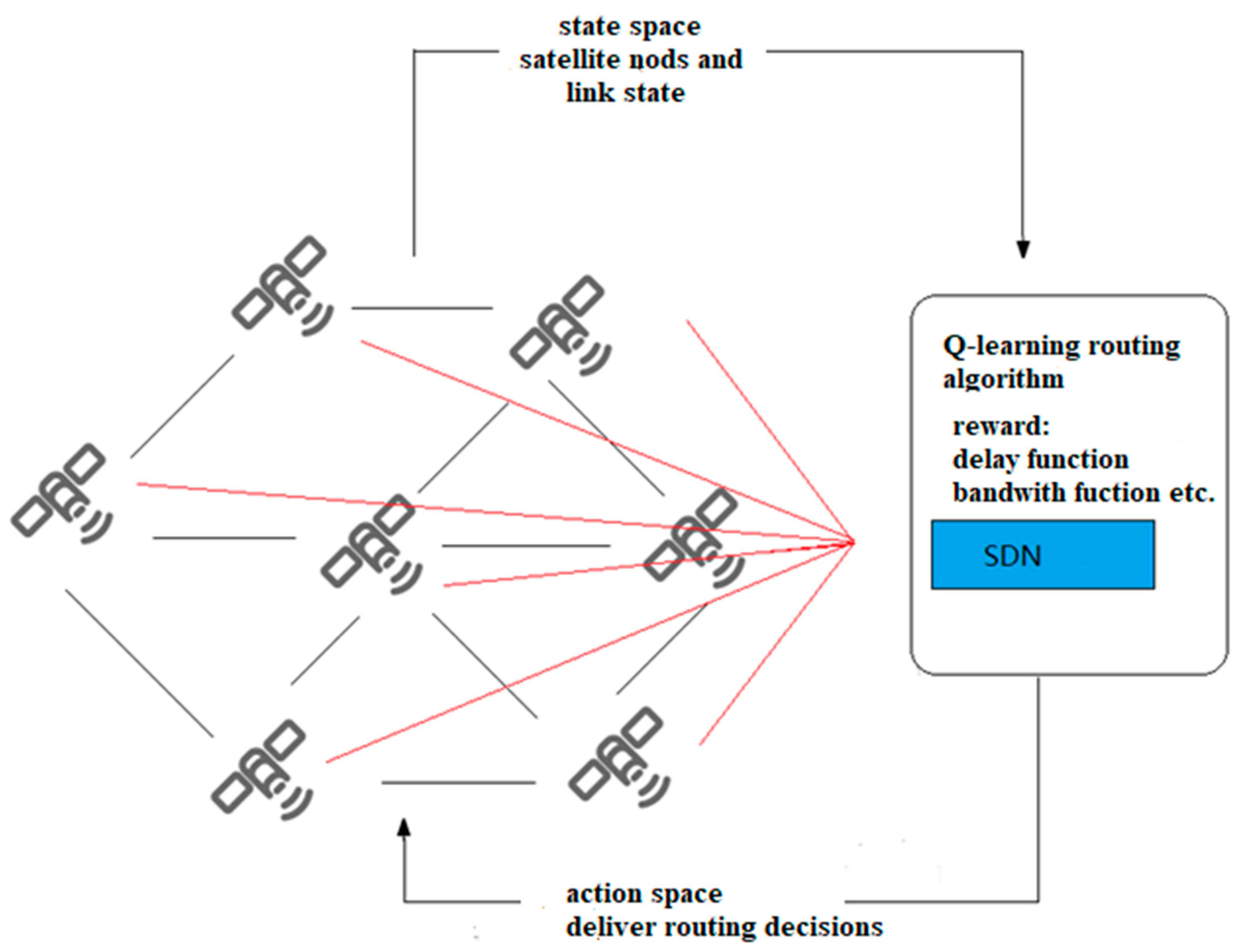
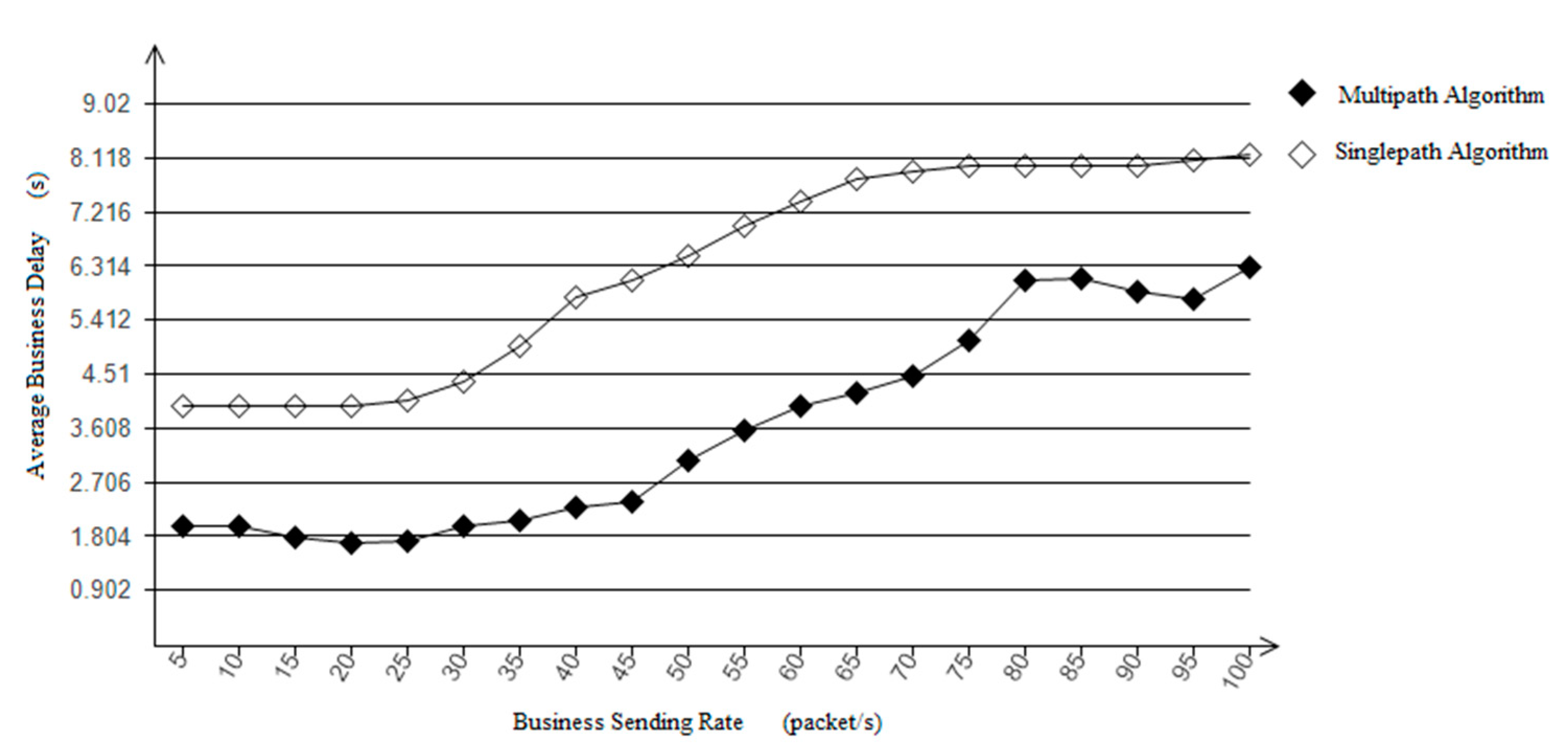
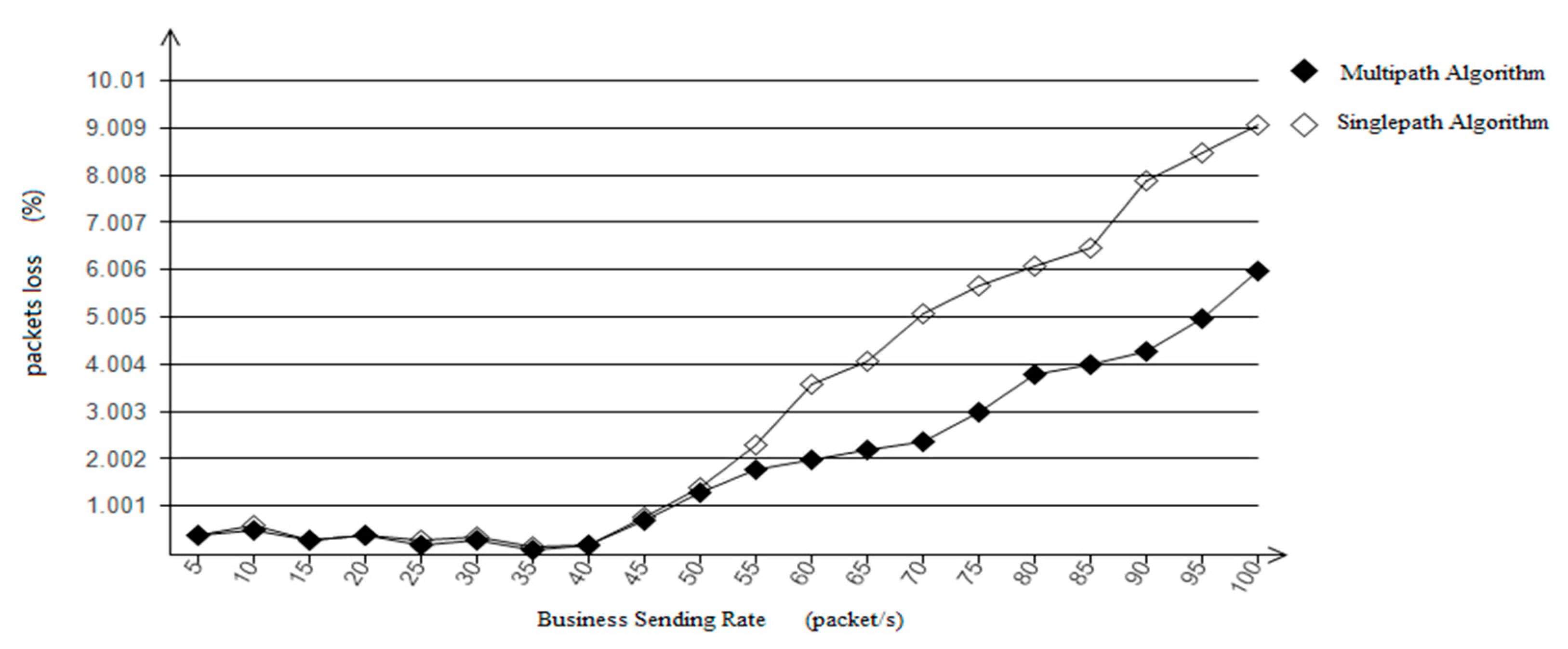
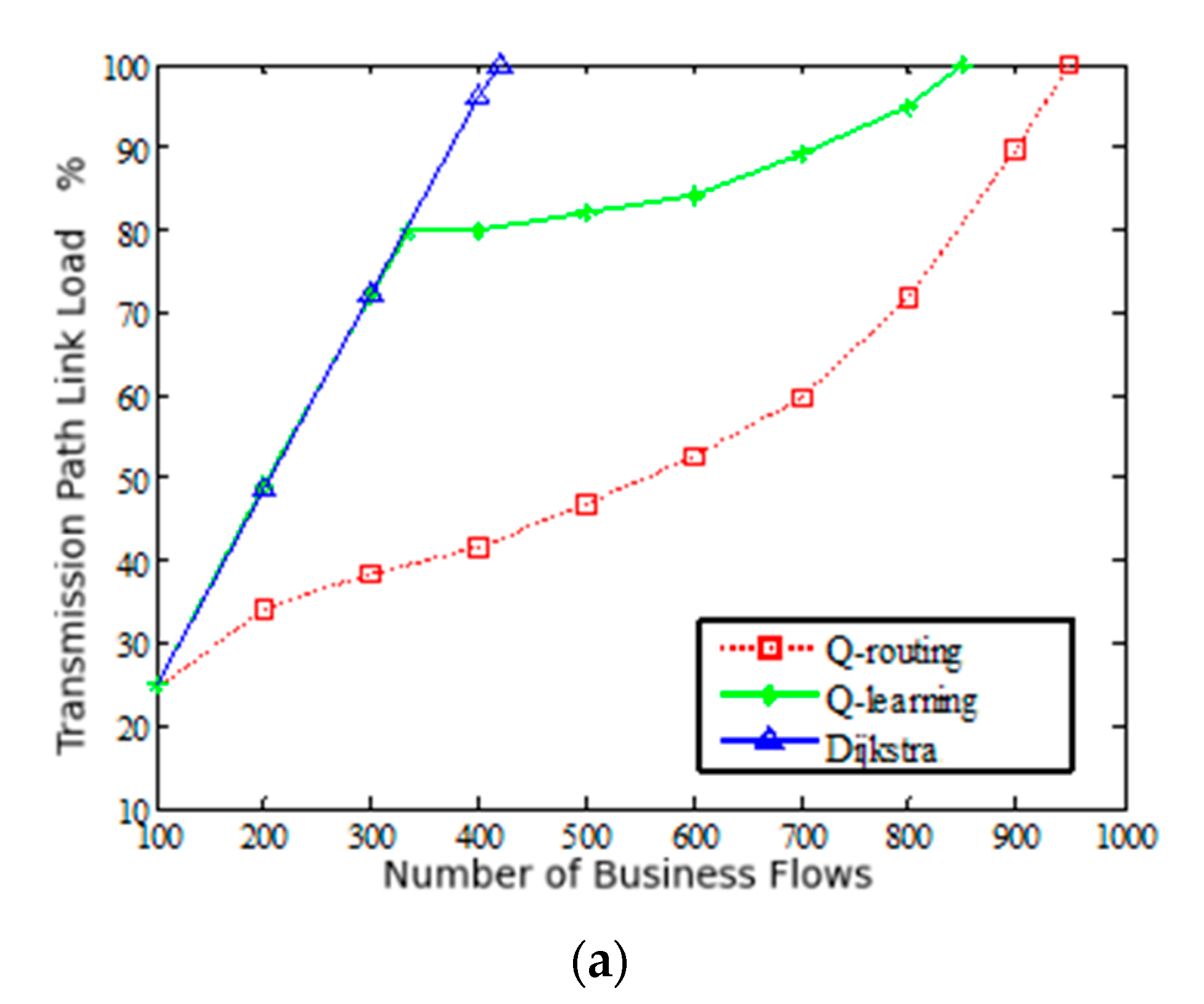
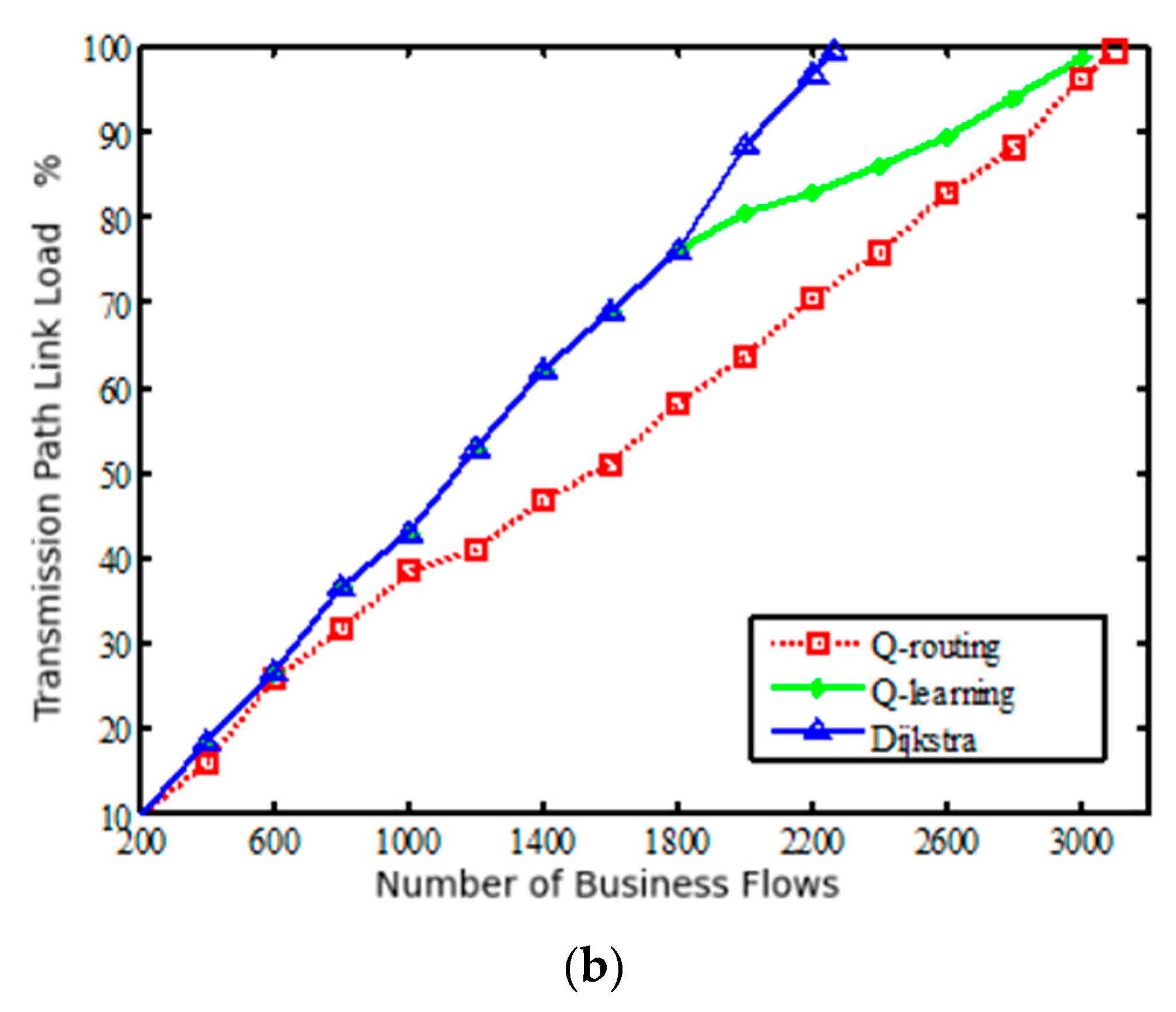
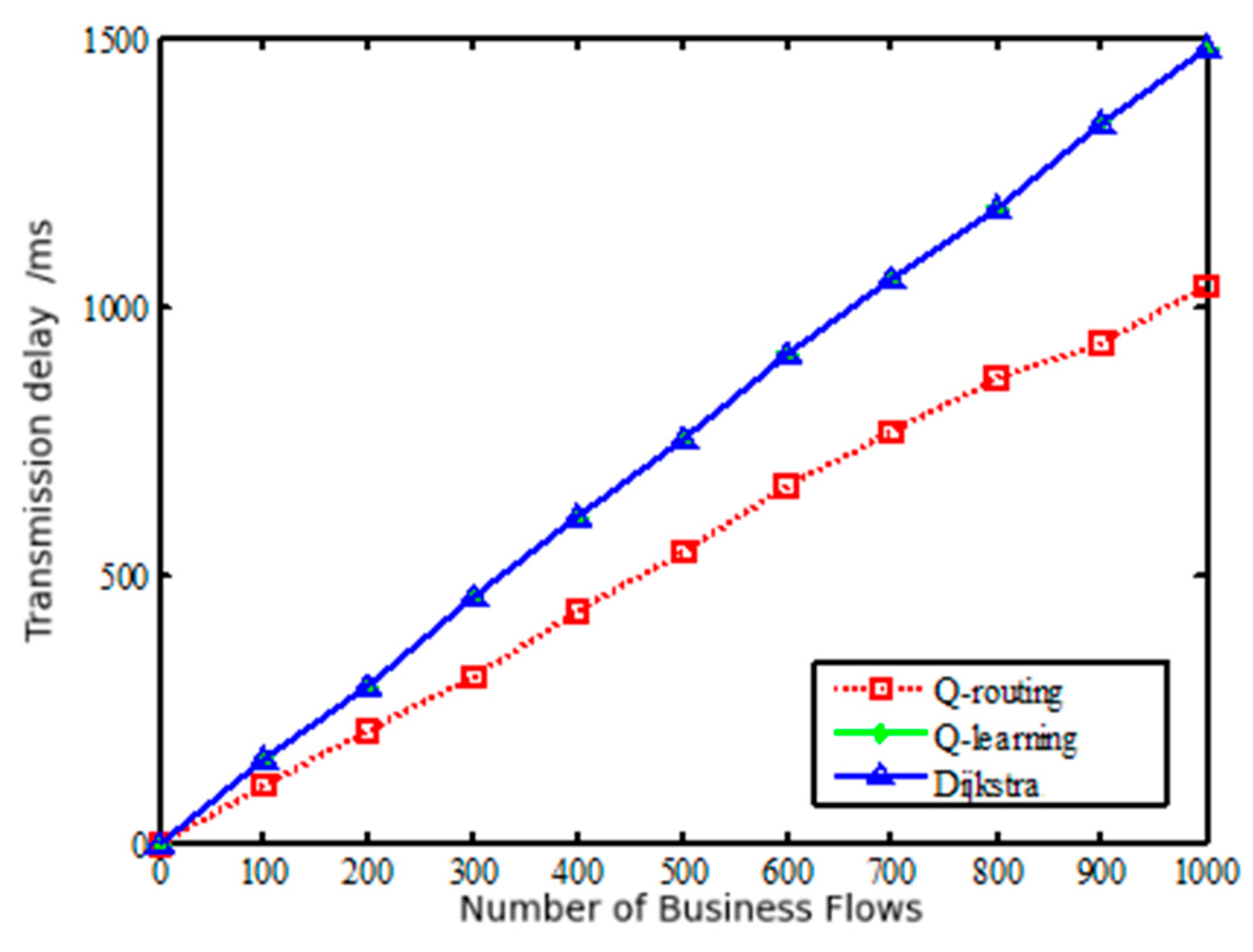
Various services in the satellite network have specific requirements, such as bandwidth, jitter, delay, etc. In order to better meet the QoS requirements of diverse services, intelligent path selection and traffic distribution are crucial. There are multiple optional paths between the source node and the destination node based on service requests, and each path in the network may have different bandwidth and inherent delay. Therefore, the introduction of an SDN controller can intelligently provide a suitable transmission path for each service flow.
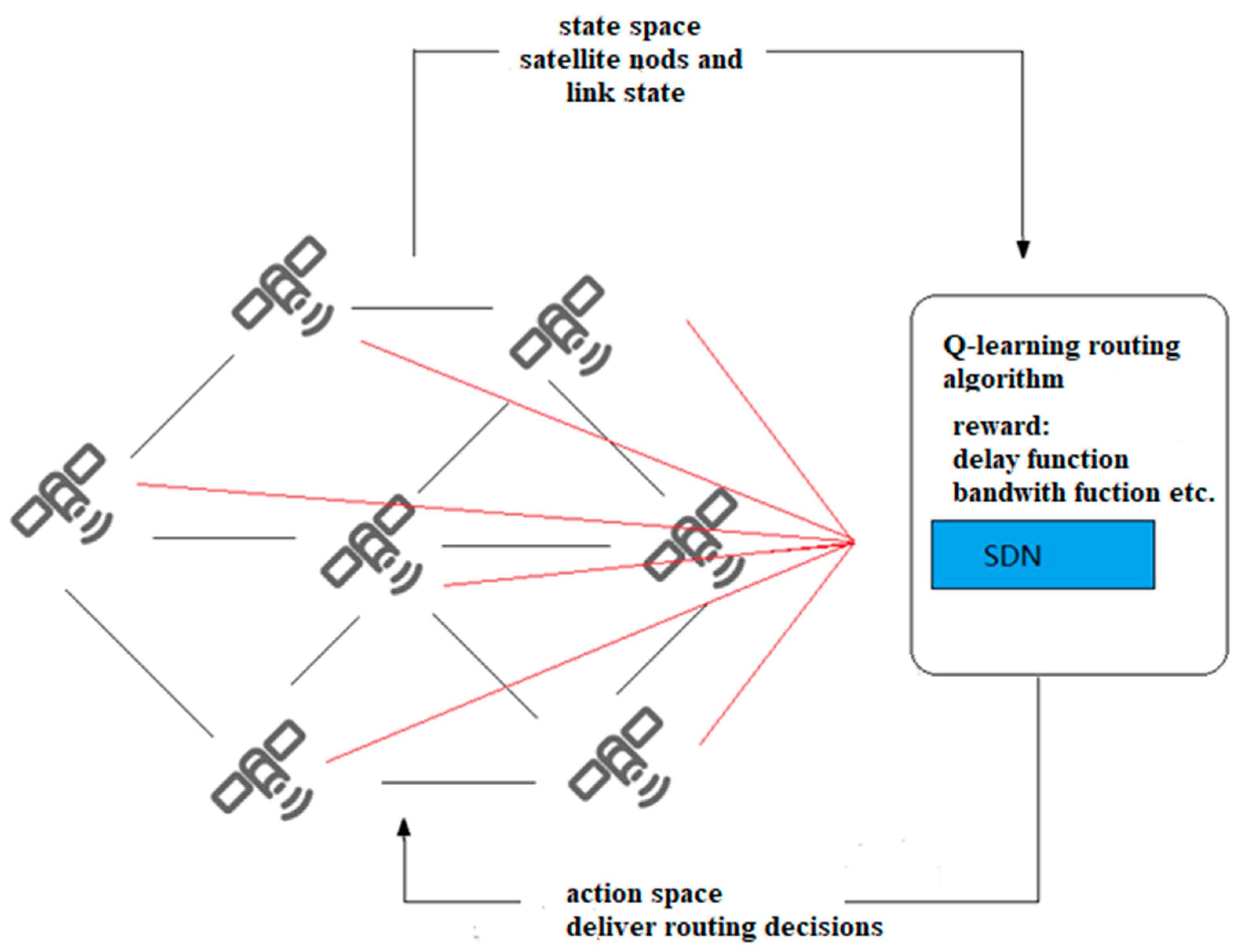
Figure 5 shows the structural framework of SDN based on Q-learning. The SDN control plane contains the intelligent decision-making module of Q-learning. The intelligent decision-making module effectively generates network policies and realizes global, real-time and customizable network control and management. Specifically, when a service request arrives, the SDN controller obtains the global network state, and according to the link state in the current network, coupled with Q-learning action learning, constantly explores various optional paths. Therefore, the intelligent decision-making module generates the optimal path decision, and sends the forwarding rules to the nodes. At this time, the node can forward the data packet according to the routing table. Through this architecture, routing can be intelligently and rationally selected according to network resources to improve network performance.
In this section, the inter-satellite routing model in the SDN network is established to provide the best transmission path for business flows, meet its QoS requirements, and reduce the utilization rate of the link with the highest load and transmission delay in the network as much as possible.
3.2.1. Network Model
The network data plane in SDN is represented as an undirected graph of n nodes, each node represents a satellite, and n nodes are connected by undirected links. The network topology is represented by a graph G = (V, E), where V represents a set of nodes with |V| = n, and E represents a set of links connecting nodes in the network. Assuming that G is a connected graph without any isolated nodes, the link bandwidth capacity, transmission delay and packet loss rate are expressed as , and .
3.2.2. Business Characteristics
The business mainly includes the following characteristics, the source node (the node entering the network), the destination node (the node leaving the network), the bandwidth requirement is set to , other QoS requirements include transmission delay and packet loss rate, which are represented by and , respectively, referring to the highest acceptable delay and packet loss thresholds for this service.
Let denote whether the SDN controller assigns the link to transmit the service flow, if the service flow passes through the link, then set to 1, otherwise it is 0.
The optimization goal is to balance the link load in the network and reduce the transmission delay as much as possible on the basis of ensuring the QoS requirements, that is, to minimize the Formula (2a).
where
is the bandwidth utilization of the link
,
,
denotes the cumulative delay of the selected path, parameter
used to adjust the proportion of link load and delay.
The main constraints under this model are as follows:
Constraint (2b) represents the flow conservation in the traffic network link, Formula (2c) means that the current available bandwidth of the link meets the transmission rate requirements of its business flow, and constraint Formula (2d) means that the traffic carried by the link does not exceed its link bandwidth capacity. The following constraint expression shows that in addition to meeting the transmission rate requirements, other QoS requirements of the business must also be met. Based on the routing framework of SDN, the Q-learning algorithm is further introduced into the routing problem, the reward function is designed, and a dynamic routing algorithm based on Q-learning is proposed.
3.3. Dynamic Routing Algorithm Based on Q-Learning
In this section, a Markov decision process is established for the path selection problem of the inter-satellite link. The arrival and departure of business flows are regarded as random processes, and different types of business flows have different statistical characteristics. We assume that business flow requests arrive independently. Furthermore, the probability of the business type follows a pre-specified Poisson distribution. The SDN controller must make a decision at each discrete time interval to accept or reject new service requests based on the current system state. In the case of acceptance, it is decided to allocate the best transmission path for the traffic flow. If declined, there is no need to allocate resources for it.
The Markov decision process (MDP) provides a mathematical framework for modeling Q-learning systems, represented by a quadruple
, where
represents a finite state set,
a finite action set,
the state transition probability, and R a reward set. The relationship among state, action and reward function can be expressed by Equation (2f). The state transition function:
, where
is the probability distribution for state
, and the reward function returns a reward
after a given action
, where
is the set of available actions for state
. The learning task in MDP is to find the policy
: maximizing the cumulative reward. To maximize the reward received across all interactions, the agent must choose each action according to a strategy that balances exploration (acquisition of knowledge) and exploitation (use of knowledge). Store the value function (or Q value) of each state-action pair in the MDP.
is the expected discounted reward when executing action
in state
following policy
.
In addition to agents/decision makers and dynamic systems, Q-learning also includes decision functions, value functions, long-term rewards, etc. [
18]. The decision function refers to the policy that the agent will take, which maps from the perceived system state to the corresponding action, guiding the action of Q-learning. The exploration strategy we use in this chapter is
, where the probability of choosing a random action (exploration) is
and choosing the best action (exploitation) is
. In this way, at the beginning, maintain a high exploration rate, and each subsequent episode
will decrease according to
.
The state-action value function characterizes the value of a state-action pair, indicating the difference between the current state and the stable state. The Q value function is updated as shown in Formula (2g).
is the learning factor of Q-learning, which represents the rate of the newly acquired training information covering the previous training, and
is the reward at time t.
is the discount factor that determines the importance of future rewards. In Equation (2g), specifically, at time t, the agent performs action
on the current state
of the routing optimization model and then reaches state
, and at the same time, the feedback loop will report the reward function
to the agent, and update the action value function
and Q matrix accordingly. Then, the agent repeats the above operation for the state
, and so on until the optimal action value
is reached, the agent selects the optimal strategy
according to the rewards of each strategy in
, and the optimal strategy can be expressed as Formula (2h);
Long-term rewards indicate the total reward an agent can expect to accumulate over time for each system state.
The key to planning a path for a service flow is to select an appropriate path for packet forwarding according to the service requirements and the real-time status of each link in the network. The key to flexible selection of the best transmission path is that there are multiple optional paths in the network, and the states of links are different. In order to avoid data traffic congestion during inter-satellite network communication, data packets re-plan another optional path. This optional path may not be the shortest, but its link utilization rate is low, while for delay-sensitive services, the impact of link delay cannot be ignored, so the reward function is set as an index of comprehensive link states as shown in Formula (2i), in which are the adjustment factors of link bandwidth, delay and packet loss rate respectively.
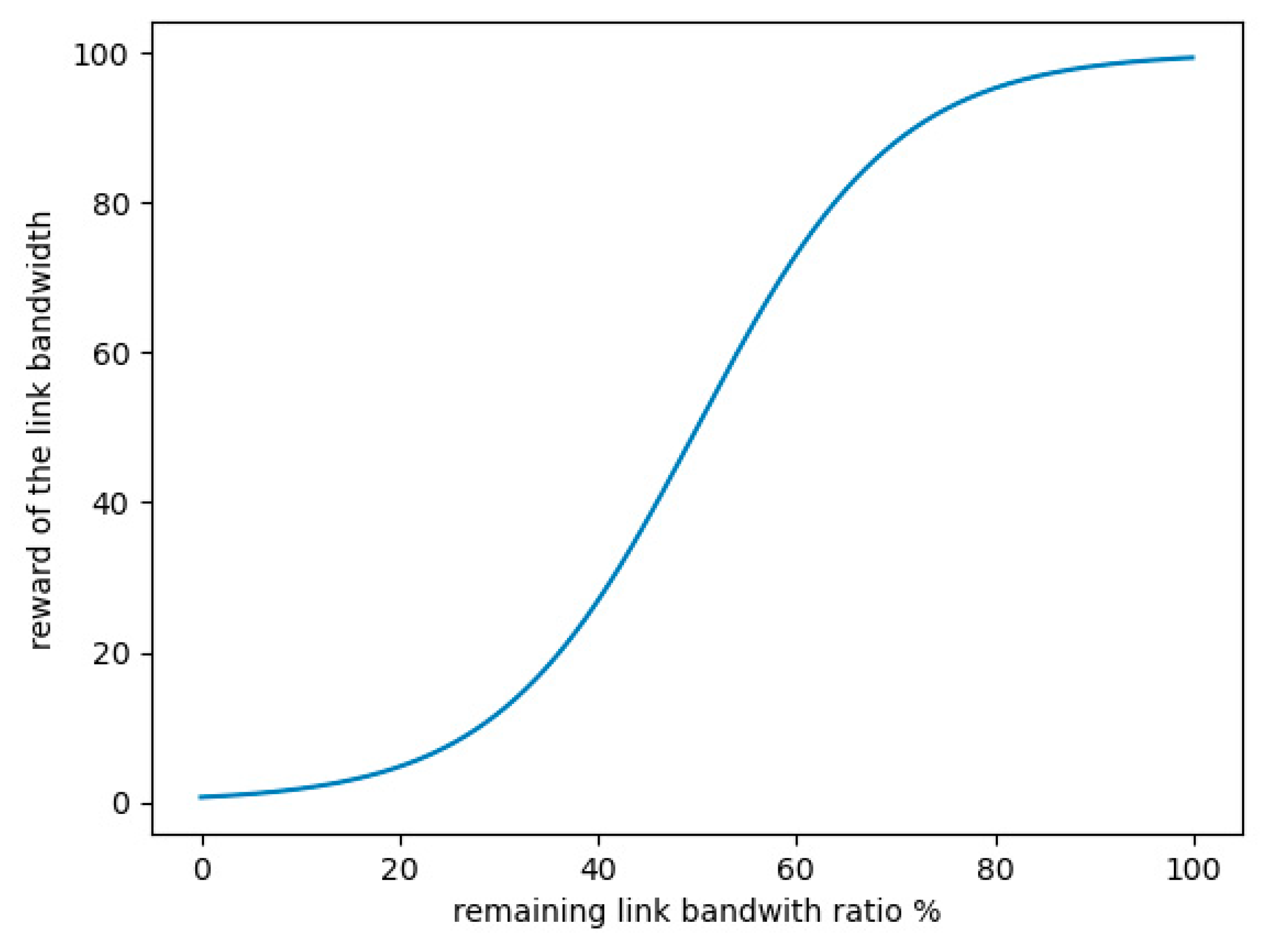
In this chapter, we divide the link bandwidth into three levels, the link load above 80% is regarded as excessive use, the link between 30% and 80% is regarded as moderate load, and the rest is less than 30% as the link load is light. In this way, the state set is roughly classified, but considering that there are differences in link utilization at each level, for example, it is obviously unreasonable to directly regard 40% and 70% link bandwidth utilization as the same level, so when designing the bandwidth part of the reward function R of Q-learning, the link load of the moderate level ([30–80%]) is divided more finely to reflect the difference.
According to the above analysis, the bandwidth part of the reward function is set based on the sigmoid function, as shown in
Figure 6. The abscissa represents the remaining link bandwidth ratio (inversely proportional to the link load), while the ordinate represents the immediate reward of the link bandwidth part
. It is characterized in that when the link utilization rate is overloaded, the reward value of the bandwidth part tends to almost 0, and the mid-term transition is smooth, but the gradient value is getting higher and higher, until the link is idle (occupancy rate is lower than 30%), its reward value approaches 100.
and
represent the ratio of the delay and packet loss rate of link
to the maximum delay and packet loss in the global link, respectively, thus, the values are all between (0,100]. Finally, the reward function is shown in formula (2i). Specifically, if the selected link is in a better state, the reward value will be greater after the agent acts.
In this chapter, the routing system based on Q-learning is composed of SDN controller and satellite nodes. The SDN controller acts as an agent to interact with the environment and obtain three signals: state, action and reward. Among them, the state space is represented by the traffic matrix of the nodes and the links between the nodes, which represents the current network link traffic load. The agent takes which node to forward the data packet to as an action space. The reward function is related to the type of business. If a business is delay-sensitive, the reward function will increase the weight of the delay part, so that the agent can change the path of the data flow, and the corresponding flow table will be sent to the corresponding nodes. The reward function R for the agent to perform an action is related to the operation and maintenance strategy of the satellite network. It can be a single performance parameter, such as delay, throughput, or comprehensive parameters [
19].
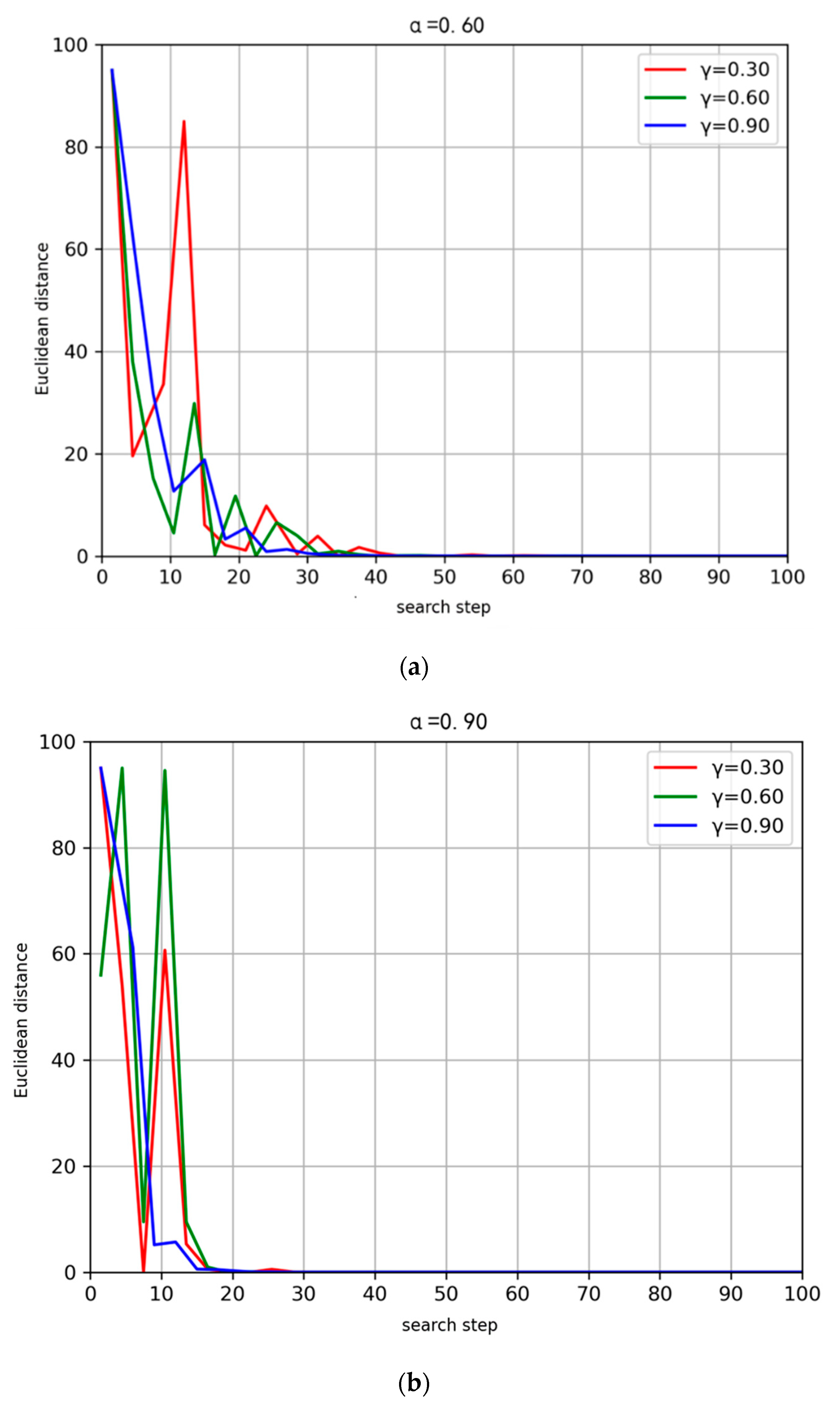
The routing algorithm proposed in this chapter is based on the classic reinforcement learning technique Q-learning for finding the optimal state-action policy for MDP. Under certain conditions, Q-learning has been shown to be optimal [
20]. On the other hand, in the Q-routing algorithm, the decision strategy
is a reasonable exploration and utilization strategy, which also meets the requirement of optimality, so the Q-routing algorithm proposed in this chapter can converge and approach the optimal solution. Regarding the convergence efficiency, it has been proved in [
21] that Q-learning will sufficiently converge to the
neighborhood of the optimal value after
iterations, where N represents the number of states in the MDP, which also ensures that the algorithm proposed in this chapter can converge in a finite number of steps.
In this chapter, the routing problem is reduced to let the agent learn a path from the source node to the destination node. In the routing problem, according to the established strategy , the agent can get a path connecting the source node to the destination node. Next, we introduce the Q-routing algorithm proposed in this chapter in detail.
When the SDN controller plans the transmission path for the business flow, it will search the global space to obtain the best action. The MDP model is as follows: any switch node in the SDN network can be regarded as a state . Each state has an optional action set , which is composed of links connecting the state of , and the reward function is given in the previous section.
The SDN network contains many loops. In order to reduce the search step of the algorithm from the source node to the destination node as much as possible, the maximum execution time of the agent’s action is set to
. Therefore, the SDN controller is required to plan an optimal path for the service flow within a time interval
, otherwise the path allocation is terminated. Although the termination search strategy belongs to the invalid strategy set
, it is still used as an option for the agent (SDN controller) to search for actions. On this basis, the feasible strategy set under the algorithm is defined as
, where M represents the current time interval, and
indicates the total amount of policies from the source node to the destination node. Correspondingly, the invalid strategy set is defined as
, where
represents the current time interval,
is the sum of all strategies from source node to node
. Then the set of all possible strategies is
. Algorithm 1 gives the pseudo cod e of this algorithm.
| Algorithm 1 Dynamic Routing Algorithm Based on Q-learning (Q-routing) |
Input: Network topology information G = (V, E), Business request information
Output: Q matric, Path policy
- 1.
Initialize
- 2.
learning factor , discount factor , maximum execution time ,
set Q matric to 0, reward - 3.
for in business set S
- 4.
while ≤
- 5.
current state
- 6.
for all optional actions in the state , form the action set ;
- 7.
while
- 8.
choose an action based on , shift to next state
- 9.
calculate the reward and feedback it to the agent
- 10.
if state == Goal state
- 11.
;
- 12.
else
- 13.
proceed to step 6 to select the action for the next moment
- 14.
update Q matric based on the formula 4.8
- 15.
end if
- 16.
end while
- 17.
t = t + 1, update learning factor
- 18.
end while
- 19.
end for
|




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}