1. Introduction
Flow shop scheduling problems (FSSPs) consist of
jobs that should be processed on
different machines. In the classical FSSP, it is assumed that there exists an unlimited buffer between two successive machines. The no-wait flow shop scheduling problem (NWFSSP) is a special case of the generic FSSP in that each operation of a job has to be processed immediately after the preceding operation, without any delay. Consequently, the problem has a permutation schedule that should be processed on no-buffer machines [
1]. The permutation constraint ensures that all jobs are processed in the same order on the machines [
2]. The NWFSSP is fundamental to applications in real-life production environments, especially for jobs including quick obsolescence risk for manufactured products or their components. Examples are processes of canned food, critical operations of metals while forging, and production with chemical reactions [
3].
Graham et al. [
4] introduced the
notation to define a scheduling problem, where
stands for the machine environment,
denotes any special constraint, and
represents the objective function or functions of the problem. The machine environment shows the shopfloor setup, such as parallel machines, flow shop, and job shop. The constraints present the special cases of processes such as permutation (prmu), no-wait (nwt), blocking (block), and recirculation (rcrc). The last field hosts the objectives, e.g., total completion time, makespan, flow time, earliness, and tardiness. In this study, the NWFSSP is considered to minimize total earliness and tardiness that is denoted by
. NWFSSP problems with
machines have been proven to be NP-hard in the strong sense, where
is higher than 3 [
5]. There are a considerable number of published studies that dealt with the NWFSSP with makespan, total completion time, or only tardiness objectives. Correspondingly, total earliness and tardiness objectives may be encountered in many studies dealing with scheduling problems. In some studies, the due date was also included in the model as a constraint rather than an objective. The survey by Allahverdi [
6] covered over 300 papers in the literature containing no-wait constraints. The problem with the notation
that considers minimizing only total tardiness was recently studied by Aldowaisan and Allahverdi [
7], Liu et al. [
8], and Ding et al. [
9]. However, a relatively small body of literature is concerned with the NWFSSP by minimizing total earliness and tardiness. Some studies [
10,
11,
12,
13,
14,
15,
16] built the problem to minimize multiple objectives by integrating due date constraints and objectives such as makespan, total flow time, and resource consumption. Huang et al. [
17] studied the flexible FSSP to minimize total weighted earliness and tardiness under the due-window constraint. Some of these studies had the goal of minimizing total tardiness and earliness with minor nuances. Arabameri and Salmasi [
18] handled the weighted objective under a sequence-dependent setup time constraint providing a mixed-integer linear programming (MILP) model and a timing algorithm, comparing the performance of the customized particle swarm optimization (PSO) and tabu search (TS) metaheuristics. Schaller and Valente [
19] studied the NWFSSP by minimizing total earliness and tardiness and compared dispatching heuristics. They compared the dispatching heuristics under the additional time-allowed constraint in another study [
20]. Guevara-Guevara et al. [
21] proposed a GA algorithm for the problem under a sequence-dependent setup time constraint and compared it with dispatching heuristics. Zhu et al. [
22] implemented a discrete learning fruit fly algorithm for the distributed NWFSSP with weighted objectives under the common due date constraint and compared it to only iterated greedy with idle time insertion evaluation. Qian et al. [
23] applied the matrix cube-based estimation of distribution algorithm (MCEDA) under sequence-dependent setup time and release time constraints, benchmarked with seven metaheuristic algorithms.
Ingber [
24] addressed the primary shortcoming of the SA algorithm as its time-consuming computational steps. Due to its oscillation during the search for alternative solutions, the algorithm requires extensive time to present reasonable incumbent solutions. Many parallelized versions have been developed to overcome this disadvantage.
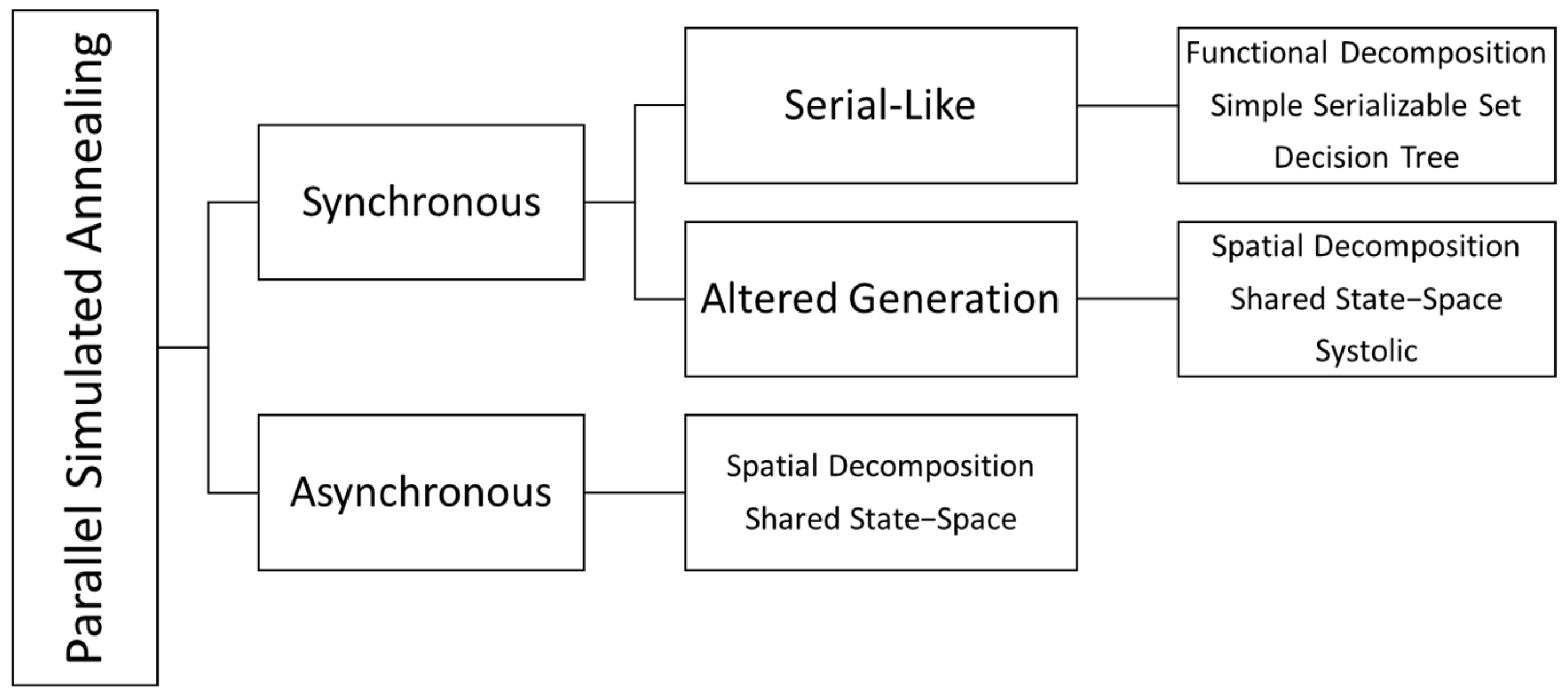
Figure 1 includes the taxonomy by Greening [
25] that was produced during his doctoral dissertation.
Greening [
25] divided parallel simulated annealing (PSA) algorithms into two main categories. Synchronous algorithms share information during runtime, while asynchronous algorithms have limited or no communication. Synchronous algorithms calculate the same cost function. Asynchronous algorithms work faster by ignoring synchronization and allowing errors but result in lower outcome quality. Synchronous algorithms are divided into two subcategories: serial-like and altered generation. Serial-like algorithms generate new states as applied in a sequentially running algorithm. Altered generation applies different strategies for state generation.
In the past years, many studies have been proposed to overcome the disadvantages of the SA algorithm. Fast simulated annealing (FSA) by Szu and Hartley [
26] and very fast simulated reannealing (VFSA) by Ingber [
27] are among the prominent studies that altered the cooling process for more rapid convergence to the global minimum. Malek et al. [
28] proposed a parallel SA strategy to solve the TSP problem in which parallel algorithms compare their solutions at a certain timepoint and restart with the initial temperature with the incumbent solution. On the basis of these studies, Yao [
29] proposed a new simulated annealing algorithm (NSA) that is exponentially faster compared to VFSA. With a different approach, Roussel-Ragot and Dreyfus [
30] suggested a general parallel form with two different temperature regimes. In this approach, parallel processors are in touch to update the approved current solution globally when a move is accepted. Mahfoud and Goldberg [
31] integrated SA into the genetic algorithm to enrich the population at each iteration. Lee and Lee [
32] evaluated various types of moving schemes for parallel synchronous and asynchronous SA strategies with multiple Markov chains. Wodecki and Bożzejko [
33] implemented a parallel SA version considering the flow shop problem with a makespan objective in which parallel threads run simultaneous searches. In this implementation, incumbent solutions of all threads are changed to new ones if a thread finds a better solution than the current best solution. As a similar approach to this study, Bożejko and Wodecki [
34] developed a procedure that runs a master thread and multiple slave threads. The slave threads iteratively search for better solutions. Upon finding a better incumbent solution, a thread tries intensification iterations and reports the result. All slave threads run again on the new incumbent solution with different temperatures. The results of the study demonstrated average values away from the optimum solution even for 20 jobs. The possible root cause of this failure could be premature convergence due to the greedy intensification of threads inconsistent with the cooling process of the SA algorithm. Czapiński [
35] worked on the permutation flow shop problem in order to reduce total flow time. The study included master and worker nodes. Worker nodes obtain feedback on their results after a certain number of iterations to the master node. The incumbent solution is updated by the best solution shared with the master node. Worker nodes run again with the updated incumbent solution as the initial solution. Ferreiro et al. [
36] implemented parallel-running asynchronous graphics processing unit (GPU) threads beginning with the same instructions but different initial solutions. Sonuc et al. [
37] coded another GPU algorithm on the Compute Unified Device Architecture (CUDA) platform that runs independent threads to solve the binary knapsack problem. Richie and Ababei [
38] provided a synchronous methodology with a managing thread that distributes the calculations to the worker threads. Turan et al. [
39] suggested the multithread simulated annealing (MTSA) algorithm with master and slave threads. The created slave thread continues running until the defined number of non-improving iterations. Non-improving indicates that the global best solution cannot be improved. Upon completion of the thread runs, solutions are gathered into the pool. Vousden [
40] compared the performances of asynchronous and synchronous SA implementations with regard to race conditions. Zhou et al. [
41] benchmarked multiple threads of SA without communication initialized with different solutions. Coll et al. [
42] built synchronous GPU threads that communicate in predefined time intervals and resume their runs on the best incumbent solution so far. Yildirim [
43] deployed a multithread methodology with a hybrid structure where SA is fed by optimizer sub-threads. Even though many further studies are present in the literature, this review covered most of the parallelization approaches.
In the remainder of this paper, an MILP model is introduced to define the research problem. A simulated annealing (SA) metaheuristic variant, namely, the simulated annealing multithread (SAMT) algorithm, is proposed to solve the problem. The contributions of this algorithm and study are as follows:
Improving the runtime drawback of the SA algorithm;
Enhancing its robustness to converge to the global optimum solution;
Providing a new solution approach to NWFSSP, minimizing total earliness and tardiness;
Enabling parallel processing without excessive resource allocation.
The motivation behind this study is an aim to contribute to improvements in field optimization, more specifically metaheuristics. Even though metaheuristics were introduced after intense studies and analysis, there are still open issues to be optimized. A good example is the study by Deng et al. [
44], where the authors improved the mutation strategy of the differential evolution algorithm and even compared the novel methodology to the previously improved differential evolution algorithm methodologies. Similarly, Cai et al. [
45] worked on the quantum-inspired evolutionary algorithm to improve multiple shortcomings, such as poor runtime, search capability, and difficulty in assigning rotation angles. With the same focus, this study introduces a novel methodology that improves the original SA without requiring excessive computational resources.
Section 2 of the paper states the research problem and details the proposed and benchmark metaheuristic algorithms.
Section 3 introduces the benchmark results and comparative analysis.
Section 4 includes the discussion, conclusion, and future prospects.
2. Methodology
The NWFSSP imposes processing of the jobs without interruption from the beginning on the first machine until completion on the last machine. Since the objective function also includes minimization of earliness in addition to tardiness, adding a delay between jobs may improve the objective function value (OFV) by avoiding the early completion of a job. However, unforced idleness would not be practical in most cases of the NWFSSP [
46]. The disadvantages may be operational costs, such as machine running costs, setup costs, and buffer costs that exceed any cost incurred due to earliness. As a result, the problem is proposed to have a non-delay schedule. An MILP model is suggested to formulate the problem. To provide integrality, two dummy jobs with zero processing times on all machines should be added to the model as the initial and last jobs. Thus, the MILP model has
jobs and
machines. Each job may be processed only on one machine at a time. Similarly, one machine can process only one job at a time. The proposed MILP model, its parameters, and its decision variables are outlined below.
Parameters:
Decision variables:
= Earliness of .
= Tardiness of .
= Completion time of on .
= 1, if is processed immediately after , and 0 otherwise.
The MILP model on NWFSSP minimizing total earliness and tardiness:
where the objective function in Equation (1) minimizes the sum of total earliness and tardiness; the constraint in Equation (2) ensures that the completion time of a job on a machine is the summation of the completion time of the preceding job, the slack time between these jobs, and the processing time of the job; the constraint in Equation (3) guarantees that the completion time of the first job is its total processing time on all machines; the constraint in Equation (4) calculates the earliness or tardiness by comparing the completion time and due date of each job; and the constraints in Equations (5) and (6) ensure that each job has only one predecessor and successor, respectively. The model consists of
jobs to satisfy the constraints in Equations (5) and (6). Equation (7) is a virtual constraint that assigns the first (dummy) job as the predecessor of the last (dummy) job. It is assumed that each job is processed without any delay once any operation of the predecessor job does not cause any violation for no-wait processing to be aligned with real-world applications. Thus, the values of slack time
are fixed for any consecutive jobs independent from their position in the schedule. The calculation of
is broadly explained by Röck [
47].
2.1. Neighborhood Operations
Neighborhood operations are applied to reveal neighbor solutions for metaheuristic algorithms. The types of neighborhood operations influence the performance of a metaheuristic algorithm. Thus, selecting the appropriate operations is the crucial key to exploring the search space wisely. Three different types are considered in this paper that are implemented in the proposed or benchmark algorithms.
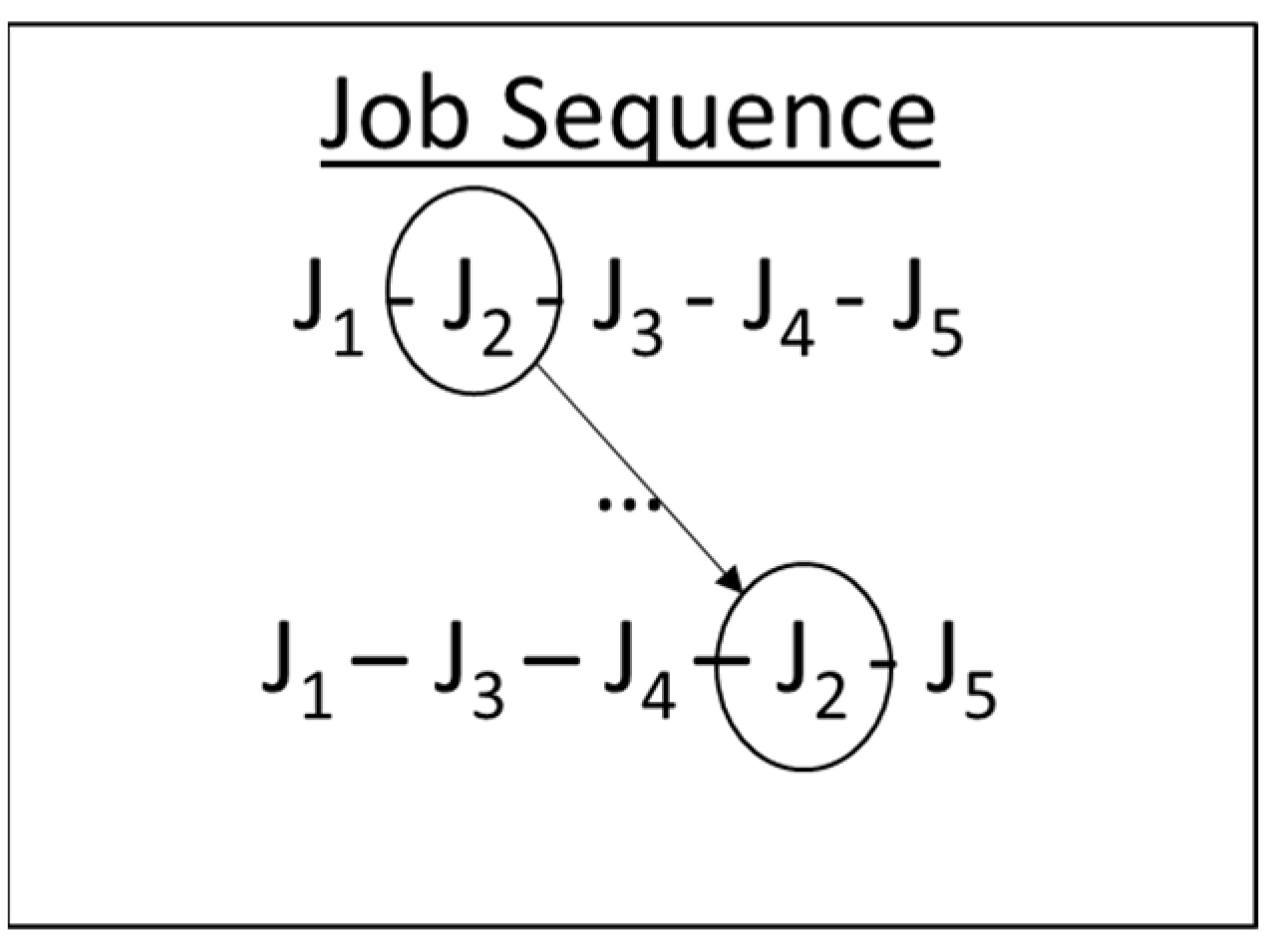
2.1.1. Insert Operation
The insert operation embraces the insertion of a job in the sequence to a specified position. Two positions should be determined for this operation. Usually, these positions are generated randomly or tried successively in an order. Let
and
be integer numbers from the set
. In an insert operation,
is removed from the sequence and inserted into the position prior to
. The positions of the jobs after
slide toward the end of the schedule. An example operation is shown in
Figure 2, where Job 2 is inserted into Position 4.
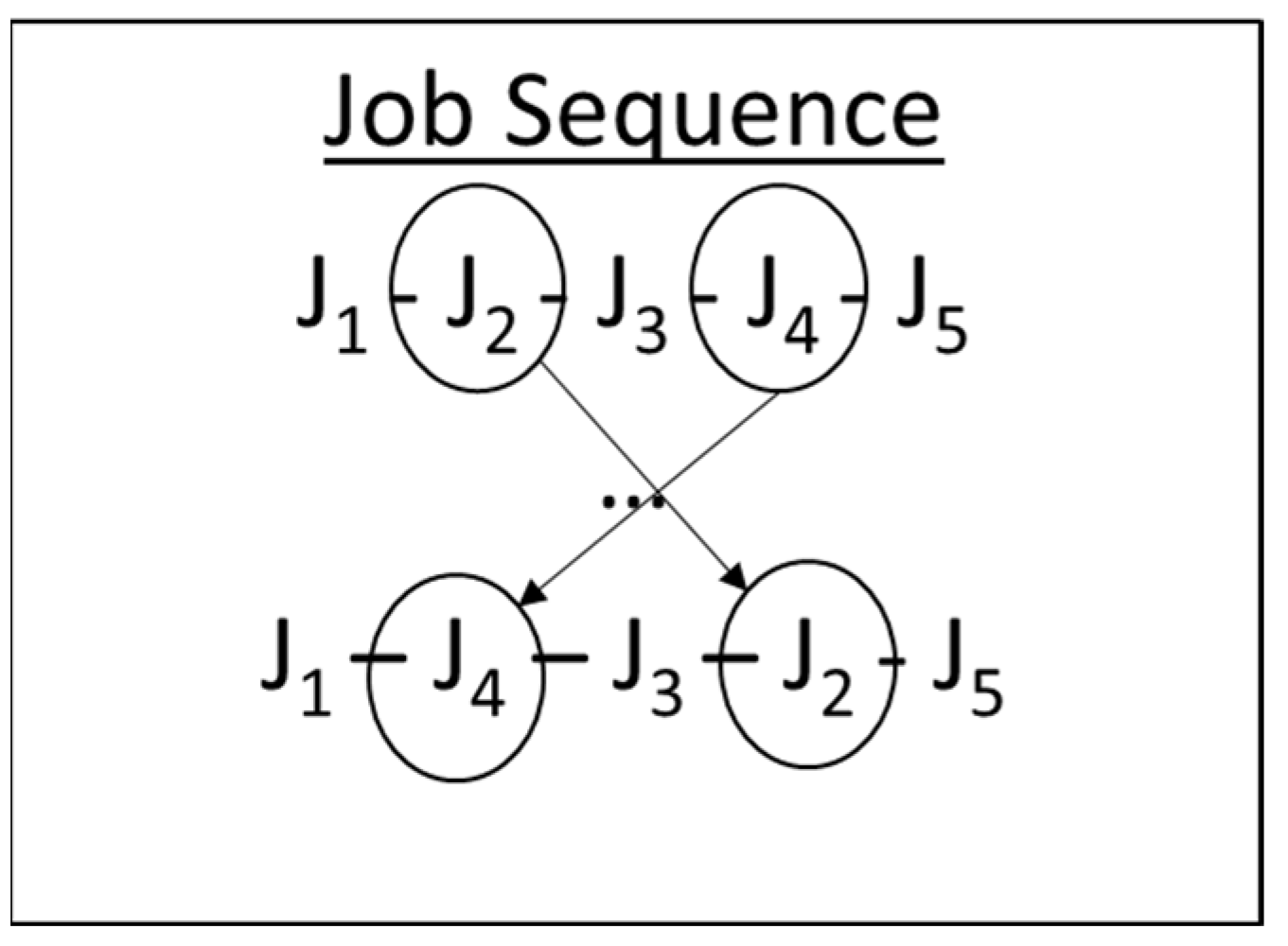
2.1.2. Swap Operation
Congruently to an insert operation, two positions should be determined for swap operations. Let
and
be integers from the set
. In the swap operation, the positions of
and
are changed mutually. The positions of the remaining jobs do not change. The example in
Figure 3 shows the swap operation of Job 2 and Job 4.
2.1.3. Sub-Interchange Operation
Defined by Arabameri and Salmasi [
18], sub-interchange is executed by changing two adjacent jobs
and
. It is believed that running sub-interchange operations after updating the incumbent solution may result in a better solution.
2.2. Proposed Algorithm—Simulated Annealing Multithread (SAMT)
The SAMT algorithm is based on the simulated annealing (SA) metaheuristic. Proposed by Kirkpatrick [
48], the SA simulates the annealing process of solids to solve combinatorial optimization problems. In physics, annealing specifies the process in which solids are heated rapidly to a maximum temperature and cooled down slowly in heat baths to allow them to arrange themselves in the ground state of the solid [
49]. The algorithm is initialized with a high temperature and cooled slowly. These moves during the cooling process avoid algorithm trapping in local optima [
50]. The flow of the classical SA algorithm is stated in Algorithm 1 [
51].
| Algorithm 1 Simulated Annealing |
| 1: Select an initial solution in the solution space |
| 2: Set the initial temperature , |
| 3: Set the temperature iteration counter , |
| 4: Set the maximum number of repetitions |
| 5: While (Stopping criteria are not met) |
| 6: Set , |
| 7: While () |
| 8: Generate a new solution |
| 9: Calculate |
| 10: If () |
| 11: Set |
| 12: Else |
| 13: If () |
| 14: Set |
| 15: Set |
| 16: Do |
| 17: Set |
| 18: Set |
| 19: Do |
A review of the literature suggests that there are still open fields for parallel implementation of the SA algorithm. In this study, a novel approach including the utilization of multiple threads is proposed. The simulated annealing multithread (SAMT) algorithm is proposed to overcome the time disadvantage of the classical SA algorithm and boost the convergence process. The algorithm is named after its pragmatic structure in which classical SA runs on a main thread supported by a sub-thread that iteratively updates the incumbent solution of the main thread with much faster SA runs. Rather than distributing the calculations of the algorithm to available processors, this parallelism aims to run different SAs simultaneously to improve the consumed time and search the solution space intelligently to find the global optimum. The SAMT algorithm falls into the altered generation class of synchronous algorithms considering Greening’s taxonomy [
25] with shared memory. The novel methodology flow is demonstrated in Algorithm 2.
| Algorithm 2 Simulated Annealing Multithread (SAMT) |
| 1: Select initial solutions in the solution space |
| 2: Set the initial temperature |
| 3: Set the temperature iteration counter |
| 4: Set the maximum number of repetitions |
| 5: Set the operator selection probability |
| 6: Set the fast sub-thread’s initial temperature |
| 7: Set the slow sub-thread’s initial temperature |
| 8: Set the fast sub-thread iteration counter |
| 9: Set the fast sub-thread iteration counter |
| 10: Set the thread selection probability coefficient |
| 11: MAIN THREAD: |
| 12: While (Stopping criteria are not met) |
| 13: If (SUB-THREAD is not running) |
| 14: Calculate |
| 15: If () |
| 16: Set |
| 17: Else |
| 18: Set |
| 19: Run (SUB-THREAD) |
| 20: Set , |
| 21: While |
| 22: If ( |
| 23: |
| 24: Else |
| 25: |
| 26: Calculate |
| 27: If () |
| 28: Set |
| 29: Else |
| 30: If () |
| 31: Set |
| 32: Set |
| 33: Do |
| 34: Set |
| 35: Set |
| 36: Do |
| 37: Return and |
| 38: SUB-THREAD: |
| 39: If () |
| 40: While (Stopping criteria are not met) |
| 41: Set , |
| 42: While |
| 43: If |
| 44: |
| 45: Else |
| 46: |
| 47: Calculate |
| 48: If () |
| 49: Set |
| 50: Else |
| 51: If () |
| 52: Set |
| 53: Set |
| 54: Do |
| 55: Set |
| 56: Set |
| 57: Do |
| 58: Else |
| 59: While (Stopping criteria are not met) |
| 60: Set , |
| 61: While |
| 62: If |
| 63: |
| 64: Else |
| 65: |
| 66: Calculate |
| 67: If () |
| 68: Set |
| 69: Else |
| 70: If () |
| 71: Set |
| 72: Set |
| 73: Do |
| 74: Set |
| 75: Set |
| 76: Do |
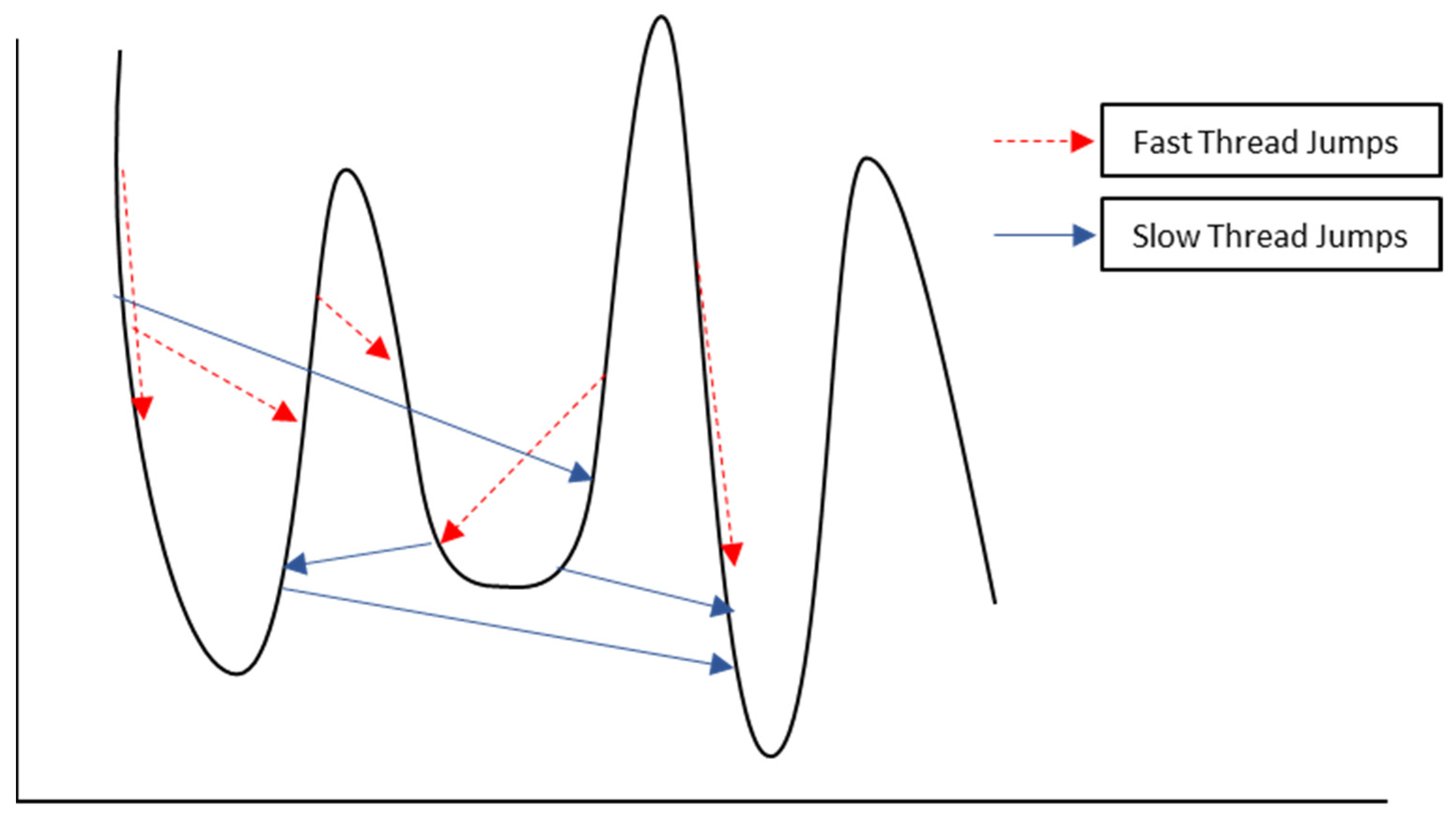
The methodology should be initialized by the setting of parameters. Prior to finalizing this methodology, several alternative policies are considered, compared, and tested in terms of simplicity, runtime, efficiency, and implementation complexity. These policies include a different number of threads with distinct completion times and different schemes of solution updates. The threads in the proposed methodology have different roles. The fast thread decreases the runtime by jumping to better solutions in the vicinity of the current best solution with faster steps. This thread may also manipulate the search by orienting the direction toward different “hills” if the thread provides a better solution. The slow thread has different aims, such as enabling moves to longer distances in the vicinity, jumping to similar solutions of nearby optima, or diverging from local optima. Possible jumps after the completion of a sub-thread are presented in
Figure 4.
If the sub-thread results in a solution sequence with a better OFV than the global incumbent solution, the global incumbent solution is updated. An adaptive strategy with a single sub-thread provided the best solutions After some experimental runs with different parameters, the results also showed that adjusting the initial temperature and runtime of the sub-thread should be adaptive to achieve elite results. Therefore, the methodology is revised to have a single master (main) thread and a slave (sub) thread, and the assignment of the algorithm speed (slow or fast) is conducted dependent on a predefined parameter. This strategy attempts to seek a larger space and decreases the probability to be stuck in local optima due to premature convergence. Both insert and swap operators work well on the NWFSSP. Both operators are utilized in the proposed methodology to benefit from each and avoid becoming trapped in a cycle. At each iteration, the algorithm runs the insert operator with the probability or the swap operator with the probability . The temperature-dependent type selection function in the first line of the sub-thread determines the type of sub-thread depending on the temperature of the main thread. The value of the constant determines the initial probabilities to select a fast or slow thread. In cases where , the slow thread has a lower probability to be selected at the beginning of the run and the probability increases while decreases. If , then the fast thread has the advantage with a higher probability. The value grants equal probability during all the runs.
2.3. Benchmark Algorithms
The variants of tabu search (TS) and particle swarm optimization (PSO) in the study by Arabameri and Salmasi [
18] were selected as benchmark algorithms since these metaheuristics were applied to the same research problem. The benchmark algorithms are introduced in
Appendix A, where item A1 introduces the TS and its variants: TS with the EDD initial solution and insertion neighborhood (TSEI), the TS algorithm with a random initial solution and insertion neighborhood (TSRI), the TS algorithm with the EDD initial solution and swap neighborhood (TSES), and the TS algorithm with a random initial solution and swap neighborhood (TSRS); while item A2 describes the PSO algorithm supported by integrating two different local search algorithms: insertion (PSOI) and variable neighborhood structure (PSOV).
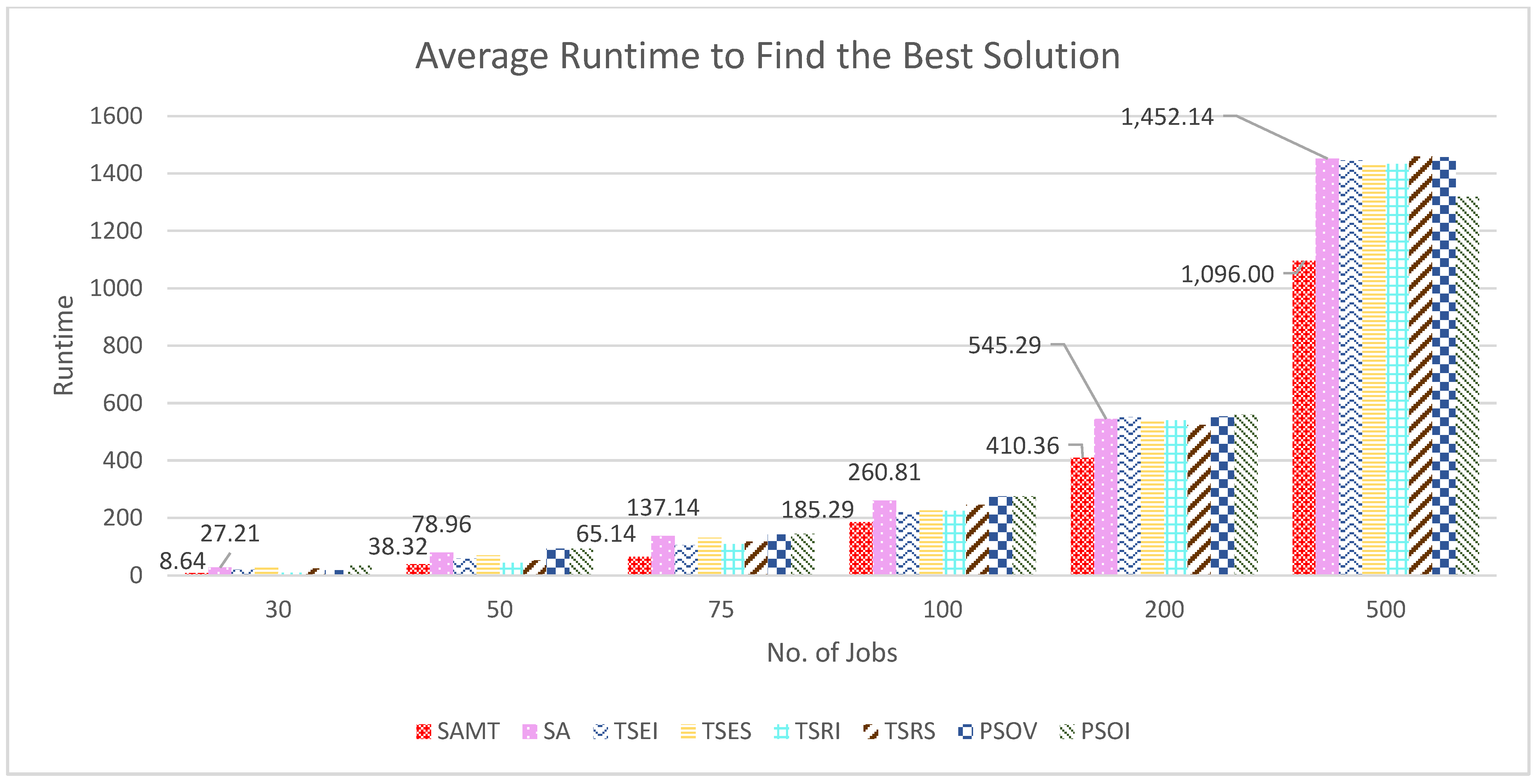
2.4. Test Problems
The test problems are selected from the datasets already introduced by different studies. These problems are widely considered in the literature for benchmark purposes of scheduling problems. The proposed and benchmark algorithms are verified on Carlier’s dataset [
52], which has eight small-sized problems with 7–14 jobs and 4–9 machines. The process times in the dataset are generated with a pattern of sorting the digits adjacently. Another dataset for benchmarking consists of the scheduling problems defined by Reeves [
53]. Reeves generated this dataset to test his proposed genetic algorithm to solve the FSSP problem. The reason for generating this dataset was his failure to find a publicly shared dataset for this purpose since there is some evidence that process times cannot be completely random [
54]. Reeves generated this dataset using the suggestions by Rinnooy [
55] and his parameters. The dataset has a maximum of 75 jobs and 20 machines beginning from 20 jobs and five machines. The famous Taillard dataset [
56] is also included for comparison of the algorithms. The dataset comprises problems with a range of 20–500 jobs and 5–20 machines. Taillard included in his dataset hard problems to be solved. The process times are created randomly from a uniform distribution
. Due to the high number of problems, only the first problems with the same number of jobs and machines in the datasets by Reeves and Taillard are considered.
Due dates for the problems are created according to the rule proposed by Arabameri and Salmasi [
18]. The due date may be randomly produced from the interval in Equation (10).
where
is the lower bound of the makespan,
is the tightness factor, and
is the range parameter. The
and
values are selected from the set
. To avoid the possibility of negative due date creation,
and
combinations are ignored for
and
, respectively. Hence, a total of 27 different problems are solved with seven different due date schemes, resulting in 189 combinations. Among the methods to calculate the
in the literature, the method by Taillard [
56] is preferred due to its concrete and meaningful structure. The
can be calculated according to Equation (11).
where
,
, and
are formulated according to Equations (12)–(14), respectively.
The problems are divided into three groups according to their sizes considering the number of jobs. Small-sized problems in Group 1 have up to 20 jobs to be processed. Medium-sized problems in Group 2 consist of 20–100 jobs. Large-sized problems in Group 3 consist of over 100 jobs.
4. Discussion and Conclusions
In this paper, a novel parallel metaheuristic methodology named SAMT based on SA was proposed. The motivation of the study was to improve the poor runtime performance and search capability of the classical algorithm. In the methodology, a sub-thread runs in parallel to update the search direction of the main thread adaptively. The aim is to increase the capability of classical SA to find better solutions in shorter runtimes. The NWFSSP with earliness and tardiness objectives,
, is considered for benchmarking. The literature review revealed that earliness and tardiness objectives for NWFSSP have not been widely studied. The most common practice to solve the research problem benefits from dispatching rules and heuristics. A major problem with dispatching rules and heuristics is their incapability to update themselves during runtime in contrast to metaheuristics. The study by Arabameri and Salmasi [
18] was selected as the reference for benchmarking since the study included two important metaheuristic algorithms with different parameters.
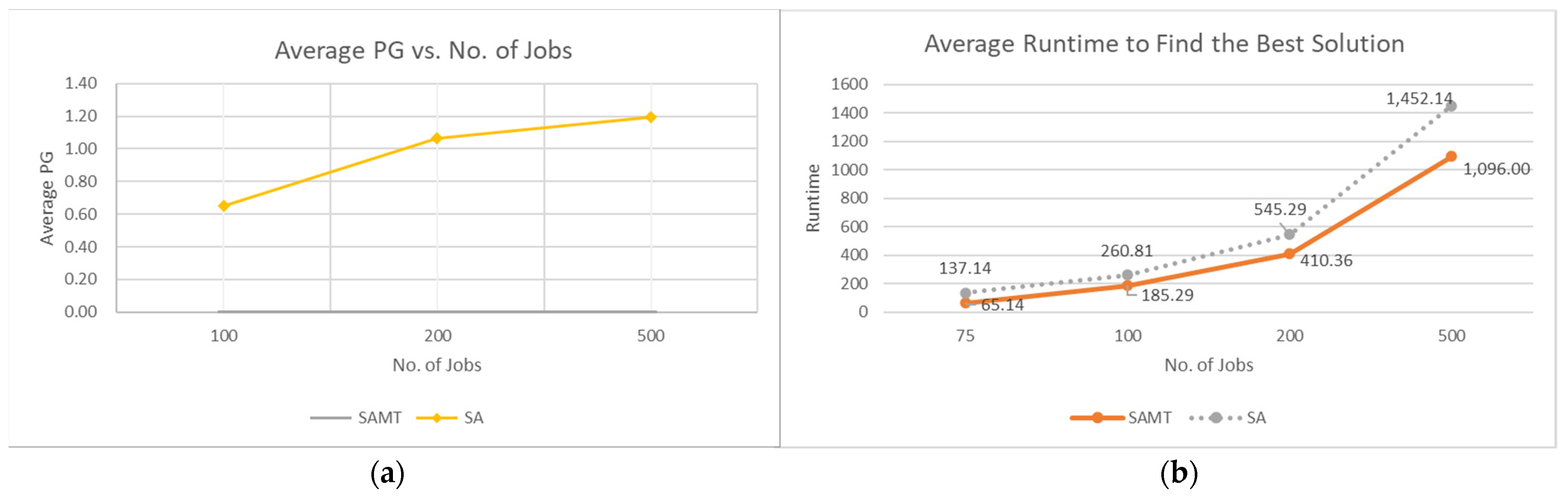
The test runs and results of comparative analyses revealed that the SAMT algorithm could provide more robust solutions compared to the classical SA algorithm, variants of the PSO algorithms, and TS algorithms, whereby the solutions of the SAMT algorithm were slightly better in most cases of medium-sized problems and all cases of large-sized problems, even when the benchmark algorithms ran double asynchronous threads. Another contribution of this study was the enhancement of the runtime to provide a better solution in comparison to the SA algorithm. The SAMT algorithm consumed less time to find the best solution in large problems compared to benchmark problems. Unlike parallel computing, the proposed SAMT algorithm introduces independent parallel threads to enhance the robustness of the solution and overcome the runtime disadvantage of the classical SA algorithm. As intended, multiple threads of the SAMT algorithm grant a divergence–convergence strategy that enables the algorithm to explore the solution space more thoroughly and rapidly. The adaptive search strategy with a single slave thread is the novelty of this study. A temperature-dependent function stochastically determines the speed of the sub-thread at each run. Thus, the algorithm is adapted to jump into the solution space to decrease runtime and increase robustness.
The number of threads and parameters of the SA algorithm for each thread directly affected the performance of the SAMT algorithm. Hence, it is important to fine-tune each parameter systematically. An easy implementation for a single computer is through the FocusILS parameter tuning tool. The contribution of the study is the adaptive parameter tuning strategy of a single slave thread after analysis with the design of experiments (DOE). The purpose of the study was to present that the SA algorithm may be improved in terms of both time and result performance without excessive resource requirements, and the newly proposed algorithm is a robust methodology to solve the NWFSSP with the objective of addressing total earliness and tardiness. In future studies, the method may be enhanced by deploying it on multiple CPUs/GPUs with a distributed programming methodology. This method will be evaluated on different combinatorial optimization problems to confirm its efficiency. Another aspect will be to adapt different types of metaheuristics to a parallel methodology to solve the NWFSSP, before comparing them with the SAMT algorithm.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






