1. Introduction
Increasing competition and environmental regulations, alongside the importance of batch and batch-like process operation, have impelled manufacturing industries to seek improved margins via optimization of production processes. Several valuable products, including specialty chemicals and bio-pharmaceuticals, are manufactured in a batch process, and advanced process control techniques that utilize process models are being increasingly sought to improve process operation.
All of the diverse modeling techniques can be classified into one of two distinct modeling approaches: first-principles mechanistic-based modeling, and empirical data-driven modeling. First-principles models are desired for their ability to capture the underlying mechanics of processes directly through the application of physical conservation laws, such as mass or energy balances. However, the development and maintenance of first-principles models remains challenging. As an alternative, the prevalence of historical process data has enabled data-driven modeling to emerge as an attractive alternative.
Myriad modeling methods exist for the purpose of developing models from process data. Recently, neural networks have yielded compelling results in their ability to handle human tasks, such as classification, clustering, pattern recognition, image recognition, and language processing [
1]. Neural networks have particularly been shown to be successful in data classification and segmentation tasks [
2,
3]. The power of neural networks is evidenced by their wide application, from business and social science to engineering and manufacturing. Neural networks are useful because of their versatility, which allows them to handle non-linear and complex behavior [
4]. From the above, it becomes natural to seek to apply neural networks in the context of batch process control. However, the literature remains limited in the application of neural networks toward the development of dynamic models and their use in control in general, and batch process operation in particular.
Instead of neural networks, many statistical modeling approaches are available. One statistical approach is the method of partial least squares (PLS). The PLS method requires data to be partitioned into two matrices: a block for explanatory variables (
X) and a block for response variables (
Y). PLS is inspired by the methods of multi-linear regression (MLR) and principal component regression (PCR). MLR maximizes the correlation between
X and
Y; PCR captures the maximum amount of variance in
X through orthogonal linear combinations of the explanatory variables. PLS seeks to consolidate between the aims of both methods by maximizing the covariance between
X and
Y. PLS achieves this by first projecting the explanatory variables onto a latent variable space to remove collinearity, and then performing linear regression within that latent space [
5]. PLS is desired for its ability to handle collinear data and situations in which there are fewer observations relative to the number of explanatory variables. PLS techniques can also be adapted to incorporate first-principles knowledge via appended variables to the data matrices, as calculated by first-principles equations.
An alternative statistical approach is prediction error methods (PEMs). The premise underlying these methods is to determine the model parameters by minimizing the error between measured and predicted outputs. Constraints can be readily implemented into the optimization so as to impose regularity constraints on model parameters. The advantage of PEM lies in its diverse applicability, as it can be applied to most model structures and can readily handle closed systems. The drawback is the computational cost, as PEM typically requires the solving of non-convex optimization problems.
Yet another popular statistical approach is subspace identification, which identifies state-space models from input/output data. Subspace identification methods comprise two steps. The first is to estimate either the extended observability matrix or the state trajectory sequence from a weighted projection of the row space of the Hankel matrices formed from the input/output data. The second step is to then calculate the system matrices [
6]. Subspace identification methods are desirable since they are computationally tractable and inherently discourage over-fitting through the use of singular value decomposition (SVD) to estimate the model order.
Recently, artificial neural networks (ANNs) have been championed for the purpose of model identification [
7]. The functional form of an ANN is a network of nodes, called neurons, whose values are calculated from a vector of inputs supplied by each neuron in the preceding layer in the network, either the input layer or a hidden layer. Each neuron is connected to all neurons in the previous layer via a weighted connection, essentially leading to a functional form with parameters. The activation in each neuron is calculated as a linear combination of the activations in the previous layer, including a bias, and is modified by an activation function of choice. Common choices for the activation function are the sigmoid, hyperbolic tangent, or rectifier functions.
The networks are trained (i.e., the parameters are determined) by minimizing a cost function with respect to the network parameters, the weights and biases relating each neuron to its preceding layer. To facilitate optimization of the network parameters, the partial derivatives of the cost function with respect to the network’s weights and biases are necessary. The requisite partial derivatives can be calculated by the widely used backpropagation algorithm, which can be conceptualized in two steps. Firstly, the training data are fed to the neural network to calculate the network’s outputs and internal activations. Secondly, the needed partial derivatives are calculated backwards, beginning from the output layer, using the chain rule from differential calculus. Finally, the calculated partial derivatives allow for optimization by such methods as gradient descent [
8]. While neural networks have generally found widespread acceptance, a comparative study of neural networks with other approaches for batch process modeling and control is lacking.
In light of the above, the present study aims to address the dearth of results that compare neural networks to other data-driven control techniques for batch processes. Subspace identification, which remains a prevalent and validated modeling approach for batch process control, is used as the comparative benchmark in this work. Due to its dominance in industrial practice, model predictive control (MPC) was chosen as the framework in which the viability of neural networks for control purposes could be evaluated. The comparison between the two modeling approaches is illustrated by means of a motivating example which is presented in
Section 2.1. Subspace identification and neural networks are explained subsequently in
Section 2.2 and
Section 2.3. Thereafter,
Section 3 presents models identified and validated per both modeling approaches. Finally,
Section 4 presents the closed-loop results of implementing both types of models into an MPC framework, with concluding remarks to be found in
Section 5.
3. Model Identification
The first step in the proposed approach was to identify both (LTI) state-space models and NARX networks for the PMMA polymerization process. To facilitate a comprehensive comparison between the state-space and NARX network models, data sets were built using different input profiles. In particular, three distinct types of input profiles were used to generate the data sets from which the models were identified. The three types of input profiles were formed by implementing three different kinds of input profiles on the PMMA polymerization process. Specifically, the input profiles were as follows:
A PI controller was used to track set-point trajectories.
A pseudo-random binary sequence (PRBS) signal was superimposed onto the input moves generated by a PI controller.
A PRBS signal was superimposed onto a nominal input trajectory.
A major aim of this study was to detect and compare over-fitting issues between subspace and NARX network models. To this end, two different sets of historical data were used to identify all models: data both with and without measurement noise. To generate noisy data, Gaussian noise was superimposed onto all output data. Specifically, measurement noise was generated from standard normal distributions modified by factors of 0.10 for temperature, 0.01 for log(viscosity), and 0.10 for density. Hence, each model was identified and evaluated for performance both in the presence and absence of noise. In this way, state-space and NARX network models were compared in their robustness to over-fitting issues resulting from noisy data.
The identification of ANNs is complicated by inherent randomness in the training algorithms. Randomness is introduced in the training of ANNs via random parameter initialization and sampling division, among other sources [
38]. Such randomness in the training process often leads to a lack of replicability in model identification. To ensure replicability and consistency, the seed was set to a specific and definite value, thereby permitting consistent comparisons between state-space models and NARX networks. However, it is noteworthy that neural networks will often perform differently depending on the seed. A possible explanation for this observation can be the existence of multiple local minima on the surfaces of the cost function. For this reason, it has been suggested to include the seed as a hyperparameter in the identification of neural networks [
39].
The models were fitted against training data, and goodness-of-fit evaluations were calculated as per the normalized root mean squared error (NRMSE) measure, given by
where
y is the predicted output,
is the measured output, and
i indexes the outputs. A large negative value in the NRMSE evaluation indicates a poor fit, zero indicates a perfect fit, and unity indicates that the model is no better than a straight line in explaining the variance of the data.
Three sets of historical data were generated for model identification. Each data set comprised thirty batches, ten batches for each of the three types of input profiles listed above. The first of these data sets was used as training data to identify the initial state-space models and NARX networks; the associated NRMSE calculations yielded the fit of the models. The identified models were then evaluated for predictive power against a second data set, with the NRMSE calculations being taken as an internal validation of the models. The models were then tweaked for improved performance by trial-and-error optimization of the NRMSE evaluations with respect to model parameters, for cases both with and without measurement noise.
However, the goodness of fit of a model does not preclude the possibility of over-fitting. Hence, an approach as described would be naive and insufficient for accurately assessing the predictive power of models. Consequently, it is essential to validate the models against novel data. For this reason, an additional measure of the models was calculated. In this last step, the tweaked models were validated against a third set of data. Finally, these resulting NRMSE evaluations were taken as the validation and true measures of model performance.
The procedure described above was followed in the identification of state-space models. The parameter for the number of states () was tuned by a brute-force search that yielded the best fit, or the best NRMSE evaluation, in comparing model predictions to training data. The lag i was set to twice the number of states. The identified state-space models were tested against the second set of data for the purpose of internal validation. The associated NRMSE calculations were used to tweak model parameters for improved performance; however, this step was found to be unnecessary for state-space models. Finally, the state-space models were validated against the last set of data; the resulting NRMSE calculations were considered the true measures of the models’ predictive power.
In the validation of state-space models, Kalman filters were used for state estimation. The equations for the Kalman filter are given in Equation (
11), where
is the estimated (a priori) covariance,
is the estimated (a posteriori) covariance, and
is the Kalman gain;
Q and
R, calculated as per Equation (
12), are the covariance matrices for both the process and measurement noise, respectively. The two covariance matrices are taken to be time independent.
The initial state estimate was set as the zero vector, and the initial Kalman gain was set as the zero matrix. To ensure convergence, the Kalman filter was allowed to run iteratively until the absolute values of the observation error for each output fell below a threshold, as given in Equation (
13). These threshold values were tuned via trial and error until acceptable convergence was achieved. The first ten data samples were discarded in all NRMSE calculations to allow for the observer to converge.
NARX networks were identified following a similar procedure as for state-space models. Firstly, the NARX networks were trained on the first set of data. In the training of all NARX networks, 70% of the input/output data were reserved for training, 15% for validation, and 15% for testing. For all NARX networks, outputs and errors were normalized within the ranges of
and
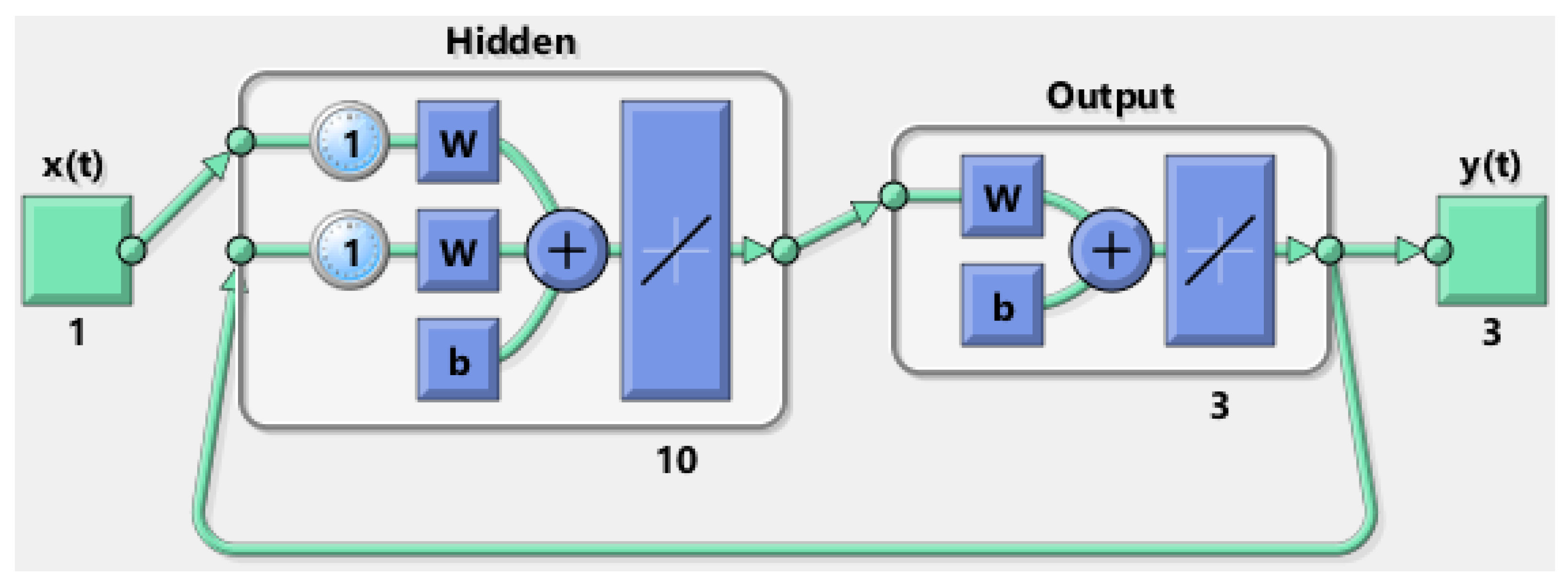
respectively. The initial, rudimentary architecture from which neural networks were developed is shown in
Figure 1. The neural transfer functions, number of hidden layers, and size of the hidden layers were determined by trial and error until the best NRMSE evaluation was found.
Then, the trained networks were internally validated against a second set of input/output data; the model parameters and architectures were tweaked by a trial and error approach. Lastly, the neural networks were validated against the third and final set of data to obtain NRMSE calculations representing the true model performance of the networks.
Figure 2 displays the final architecture of the neural networks identified, both in the absence and presence of measurement noise.
Notably, the first layer of the NARX network incorporates an initial nonlinear element to capture the nonlinear dynamics of the PMMA polymerization process. As discussed earlier, one of the main advantages of ANNs over state-space models is in their ability to handle nonlinearities directly. By including nonlinearity into the model, ANNs allow for the enhanced assimilation of process knowledge and thereby strive to improve predictive and control performance.
Note that while the neural networks do not require an explicitly designed observer as do state-space models, an initial fragment of the input/output data is required to initialize the NARX networks, as is the case for ARX models in general. This initial fragment of input/output data needed by NARX networks can be thought of as representing the role of a state-space observer, with the length of data reflecting the time it would take for the state-space observer to converge to an accurate state estimate.
Table 2 tabulates the NRMSE evaluations associated with the validation of both state-space models and NARX networks. Accordingly,
Figure 3 and
Figure 4 display an example of the validation of state-space models and NARX networks, identified both in the absence and presence of measurement noise, respectively. The state-space models outperformed NARX networks in predictive power, as observed by the lower NRMSE evaluations for state-space models in
Table 2. The data also reveal that both state-space models and NARX networks were resilient to over-fitting measurement noise since the NRMSE evaluations did not increase sharply upon incorporation of measurement noise.
To further assess model performance, the identified models were tested against a fourth set of historical plant data. For the purposes of gauging possible over-fitting, this new set of data was generated to be distinct from the three types of data sets used previously in model identification. In particular, the data set was formed via the generation of PRBS input profiles.
Figure 5 contrasts between one of the input profiles used in model identification and one of the input profiles from this fourth data set.
Table 3 tabulates the mean NRMSE evaluations associated with the plant data and model predictions. Concurrently,
Figure 6 and
Figure 7 present examples of prediction performance for the identified models. Here, a large performance gap is observed between the predictive power of state-space models and NARX networks, as observed by the increased difference between NRMSE evaluations between the modeling approaches. NARX networks are shown to be poor in predicting new and distinct data profiles. While the neural networks did not significantly over-fit measurement noise, as was established earlier, they did over-fit the training data. This is clearly evidenced by the worse NRMSE evaluations for NARX networks modeling input/output data that are characteristically distinct from the original training data.
4. Closed-Loop Results
Having identified both state-space models and NARX networks, the models were then implemented into MPC for forward prediction of the evolution of the PMMA polymerization process. The MPC scheme was realized by minimizing the cost function
where
and
are positive definite weighting matrices penalizing input moves and deviation from the reference output trajectory, respectively. MPC was implemented in MATLAB using the
fmincon function; iteratively, at each time step, the
fmincon solver was called to solve the optimization problem for the optimal control moves.
In the case of state-space models, the MPC parameters were tuned such that
was set to the identity matrix,
was set to the zero matrix, and
was set as both the prediction and control horizons. Additionally, a Kalman filter was repeated as similar to
Section 3, except that the initial state vector was now estimated using MATLAB’s
findstates function from training data.
As with ARX models, it is necessary to initialize the internal states of the (closed-loop) NARX networks at each time step to allow for forward prediction. To achieve this, recent plant data were used to iteratively update the internal states of the NARX networks; this can be thought of as being analogous to how state estimation is implemented in the use of state-space models. In particular, the last 10 time steps of input/output data were used to initialize the neural network at each iteration.
In the case of neural networks, the MPC parameters were picked as follows: , , was set as the prediction horizon, and the control horizon. For the first 10 time steps, the plant was allowed to operate under open-loop conditions. Then, closed-loop control was implemented using the NARX networks as predictors for the MPC. At each iteration, the last 10 time steps were used to estimate the current internal state of the neural network.
Table 4 compares the mean errors over all three process outputs in applying MPC using both state-space models and NARX networks. Both types of models were implemented in MPC, and several tests were run for 10 different reference trajectories, which were in turn determined from each of the three types of input profiles as from
Section 3.
Errors between the control and reference trajectories were evaluated via NRMSE calculations; the means of those NRMSE calculations over all 30 implementations are given in
Table 4. State-space models outperformed NARX networks in control of temperature, the output exhibiting the most nonlinear behavior; both models provided almost identical control over the other outputs. The control performance of NARX networks deteriorated more due to noisy conditions than that of state-space models.
Figure 8 and
Figure 9 show examples of the implementation of state-space and NARX network models in MPC.
To further assess model performance, the identified models were used to track novel reference trajectories. For the purposes of gauging over-fitting, this new set of data was generated to be distinct from the data sets used previously in model identification and validation. As discussed in
Section 3, the data set was formed via the generation of PRBS input profiles. Refer back to
Figure 5 to see an example comparison between one of the input profiles used in model identification and one of the input profiles from this final data set.
Table 5 tabulates the mean NRMSE evaluations associated with the plant data and model predictions. State-space models and NARX networks provided similar control performance for the viscosity and density outputs. Additionally, neither model was heavily impacted by measurement noise. However, there was a significant gap between the two modeling approaches in the control of temperature. Therefore, it is concluded that state-space models outperformed NARX networks in the control of novel reference trajectories. The data indicate that NARX networks were less versatile than state-space models in generalizing beyond the range of training data.
Figure 10 and
Figure 11 presents a visual comparison between the prediction performance of both modeling approaches with regards to novel data.
In comparing state-space models and NARX networks, it is worthwhile to not only compare control performance, but also computation times.
Table 6 tabulates the mean computation time it took for the MPC simulations to complete for each type of model. The total simulation time was averaged over the 30 reference trajectories that were tracked. Since the aim was to evaluate computational complexity, and not performance,
was set as both the prediction and control horizons for the NARX networks in order to make fair comparisons between computation times. Judging by computation time, NARX networks exceeded the state space models in computational complexity by an order of magnitude.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}