1. Introduction
In China, the catalytic cracking process has been vigorously developed in recent years [
1]. The catalytic cracking unit as the core production unit for gasoline and diesel in refineries is an important source of revenue for refineries [
2]. The informatization of catalytic cracking processes has been greatly developed with the assistance of distributed control systems (DCS) [
3]. Using big data processing technology to mine and analyze the accumulated large amount of catalytic cracking operation data and predict the main control variables can improve the stable and safe operation of catalytic cracking units [
4,
5]. In recent years, research on the effective prediction of process parameters based on deep networks has received widespread attention [
6]. LSTM can effectively extract the dependency relationship between time series data [
7].
Li et al. [
8] proposed a multi-parallel cyclic reservoir (MP-CRJ) with jumps by using data at different time scales to train the echo state network (ESN) neural network, which can reduce the spatial complexity brought by parallel ESN and relatively improve the dynamic diversity of the reserve pool. The actual factory data applied to methanol production can improve prediction accuracy while maintaining prediction speed. Based on principal component analysis (PCA) and the backpropagation (BP) neural network, Liu proposed the PCA-BP prediction model for predicting railway passenger volume. The linear correlation between influencing factors was eliminated through principal component analysis. The PCA-BP neural network improved the accuracy of railway passenger volume prediction [
9]. Tao et al. [
10] used the TreNet model to predict the future trend of multi-mode fusion and obtained current time series features through Convolutional Neural Network (CNN) learning and time series trend features through LSTM learning. This method has stronger feature extraction and learning ability, and can be used to learn local and global contextual features for predicting time series trends. Chen and Yu [
11] proposed a prediction method combining a sparse autoencoder and BP neural network. This method extracted nonlinear features through a sparse autoencoder and used the extracted features as the input of a supervised learning model BP neural network to predict the index return. Sun and Wei [
12] adopted the mixed structure of CNN and LSTM to predict the duration of futures prices and positive and negative trends by using the original data series and local trend series. Deng et al. [
13] constructed a deep autoencoder by limiting the Boltzmann machine to encode high-dimensional data into low-dimensional space. Then, the regression model of a low-dimensional coding sequence and stock price based on the BP neural network was established. Compared with the original high-dimensional data, the model can reduce the calculation cost and improve the prediction accuracy by using the encoding data. Guo et al. [
14] extracted the interdependence between sequence information by combining a fully connected network, Bi-LSTM and CNN, to predict the train running time of complex data sets.
There is also a lot of research progress in the deep network prediction of the catalytic cracking process. Yang et al. [
15] developed a special neural network structure to deal with input variables at different time scales. Taking into account the collection characteristics of various variables and the time continuity of large process manufacturing units, the gasoline output prediction model of the catalytic cracking unit was constructed. The new model has better performance than the traditional LSTM network, which contributes to the intelligent upgrade of the FCC process. Tian et al. [
16] proposed a data-driven and knowledge-based fusion method (DL-SDG), which used the LSTM with an attention mechanism and convolution layer to predict the future trend of key variables for the prediction and early warning of abnormal conditions in the catalytic cracking process. Yang et al. [
17] developed a new FCC hybrid prediction framework by integrating the data-driven deep neural network with the lumped dynamics model with physical significance. The new hybrid model showed good prediction performance in all evaluation criteria, realizing rapid prediction and optimization of FCC and other complex reaction processes.
In nature, many organisms have limited survival capabilities, so they use specific group behaviors to solve problems that individual individuals cannot solve. Group behavior has complex behavioral patterns, which enable groups to exhibit strong information exchange capabilities [
18]. In recent years, many scholars hope to achieve better research results by introducing the natural phenomenon of animal group behavior into the field of computer science [
19]. With their continuous development, some swarm intelligence algorithms have been developed, such as the particle swarm optimization algorithm, cuckoo search algorithm, and ant colony algorithm. Liu et al. [
20] proposed a neural network model optimization method for LSTM based on adaptive hybrid mutation particle swarm optimization (AHMPSO) and attention mechanism (AM). The prediction accuracy of chemical oxygen demand of key characteristics in a wastewater treatment plant was improved. The root mean square error (RMSE) decreased by 7.803–19.499%, the mean absolute error (MAE) decreased by 9.669–27.551%, the mean absolute percentage error (MAPE) decreased by 8.993–25.996%, and the determination coefficient (R
2) increased by 3.313–11.229%. Xiao et al. [
21] proposed a fault diagnosis method based on cuckoo search algorithm optimization based on back propagation neural network to improve the accuracy of mechanical rolling bearing fault diagnosis. The fault recognition accuracy of the backpropagation neural network optimized by the CS algorithm is 96.25%. In this paper, the PSO algorithm and CS algorithm are used to optimize the LSTM model. Compared with the results in the previous literature, the optimized PSO-LSTM model and CS-LSTM model showed high predictive performance in the prediction of the main control variables in the catalytic cracking process. R
2 increased significantly, while MAPE, RMSE, and MAE decreased significantly.
In this paper, the missing value processing, outlier processing, noise processing, and Z-Scores standardization processing are carried out for the data of control parameters and related variables to remove the impact of different dimensions on the data. By using Spearman’s rank correlation coefficient analysis and R-type clustering analysis, feature selection is performed on variables to effectively reduce data dimensionality. The prediction model of LSTM contains many network parameters, such as kernel function, learning rate, number of neurons, etc., which will affect the prediction accuracy of the LSTM model. Because these parameters are too dependent on the experience setting, their prediction accuracy is unstable. At the same time, with the different parameter settings, the length of training time of the LSTM model will also change. The problem of selecting parameters manually can be solved by using the particle swarm optimization algorithm to search some network parameters of the LSTM model. Aiming at problems such as low accuracy and weak generalization ability caused by manual parameter settings, this paper uses PSO and CS with a wide search range and fast convergence speed to optimize some super parameters of LSTM to construct the PSO-LSTM model and CS-LSTM model, respectively, and find out the optimal parameter set for LSTM, so as to better improve the prediction accuracy of the model. The organizational structure of the paper is as follows. In
Section 2, the framework of the SIA-LSTM method is introduced in detail.
Section 3 shows the excellent performance of the LSTM model optimized by the swarm intelligence algorithm in industrial applications.
Section 4 summarizes this paper.
2. Research Method
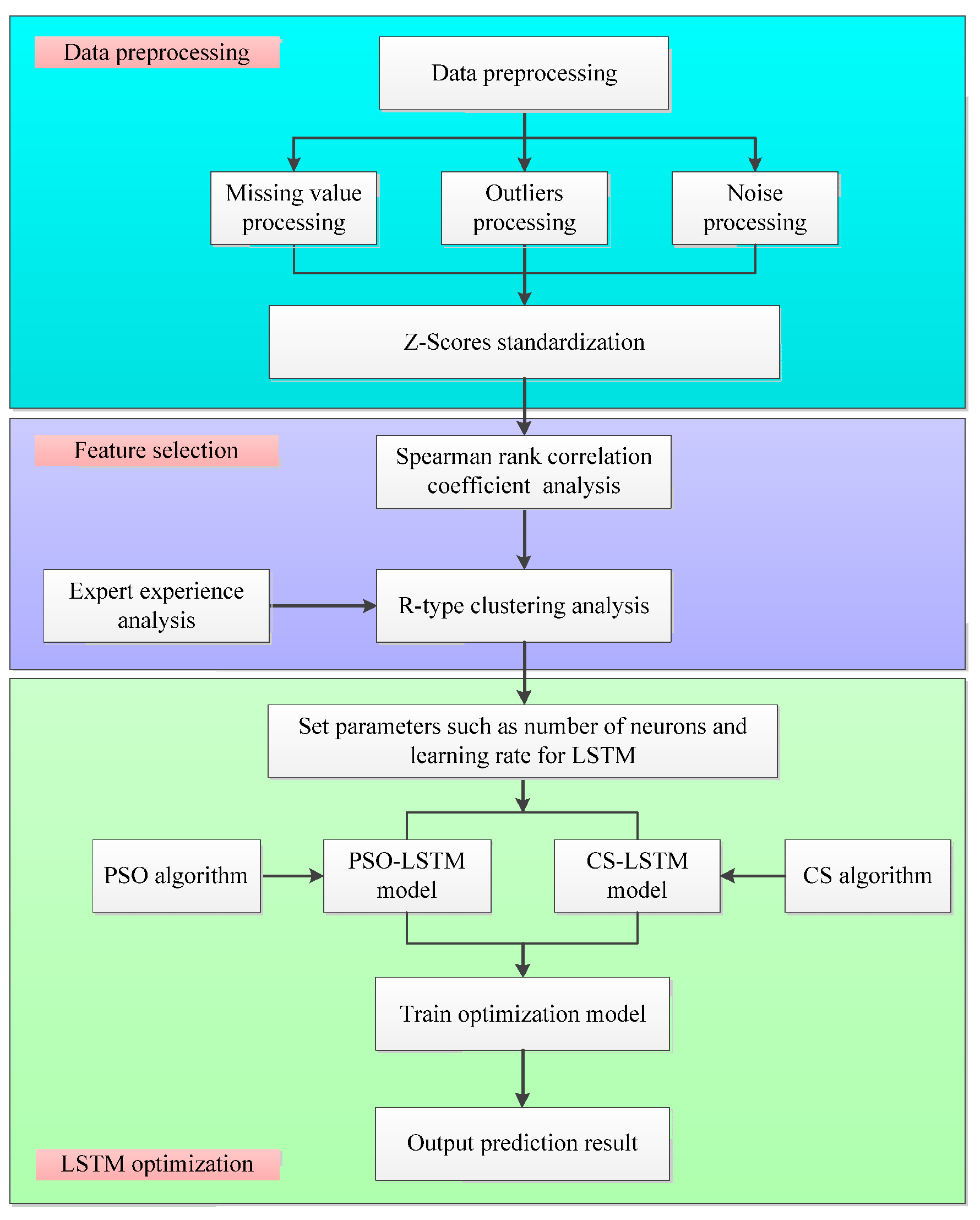
The SIA-LSTM method is composed of three parts: (1) data preprocessing; (2) feature selection; (3) optimization of LSTM using swarm intelligence algorithms. The framework of SIA-LSTM method is shown in
Figure 1.
In the data processing part, the missing value processing, outlier processing, noise processing, and Z-Scores standardization processing are carried out for the data of control parameters and related variables to remove the impact of different dimensions on the data.
In the feature selection part, Spearman’s rank correlation coefficient analysis and R-type clustering analysis are performed on the preprocessed variables. By calculating Spearman’s correlation coefficient and R-type clustering analysis results, feature selection is performed on the variables, successfully achieving the goal of dimensionality reduction.
In the optimization of LSTM using swarm intelligence algorithm part, the PSO algorithm and CS algorithm, which have a wide search range and fast convergence speed, are used to optimize some super parameters of LSTM. PSO-LSTM model and CS-LSTM model are constructed to find the optimal parameter set for LSTM, so as to better improve the prediction accuracy of the model.
Given the missing values, outliers, and noises in the data set, and different dimensions affecting the data analysis results, this paper conducts data preprocessing and Z-Scores standardization on the data set. Excessive variables can lead to a waste of computational resources and hinder the accuracy of prediction models, requiring feature selection. Many network parameters of the LSTM prediction model can affect the prediction accuracy of the LSTM model. However, these parameters are too dependent on empirical settings, resulting in unstable prediction accuracy. This problem is effectively solved by optimizing LSTM using PSO algorithm and CS algorithm.
2.1. Data Preprocessing
2.1.1. Missing Value Processing
Missing values are undesirable and unavoidable for statisticians and data collectors. Some statistical analysis methods are able to delete the observation record with a missing value directly. When there are fewer missing values, there will be no significant problems. However, when the number of missing values is large, a large amount of information will be lost directly and may lead to wrong conclusions, so a more systematic missing value analysis is needed.
A missing value has a certain regularity, and its missing mode can be roughly divided into the following three manners: missing completely at random, missing at random, and missing not at random. A large number of variables are involved in the process of data mining. When only one variable value is missing, the whole variable set should not be deleted. By describing and diagnosing the missing value, the severity of the missing value is evaluated. The correlation matrix, mean value, and covariance matrix with the missing value are estimated. The expected maximization method or regression algorithm is used to replace the missing values [
22].
2.1.2. Outlier Processing
Outliers refer to the observed values that deviate from the whole sample population in the data set. The existence of outliers will reduce the normality of the data and the fitting ability of the model. In the process of data mining, these outliers need to be identified and processed. The detection methods of outliers mainly include cluster analysis, three sigma principle, simple statistics, boxplot method, and t test.
Cluster analysis is to group similar data observations into the same cluster. It mainly includes distance analysis method and density analysis method. Density analysis can discover clusters of any shape. The main idea of this method is that data in a certain region, as long as the density of data points is greater than the preset threshold value, will be divided into clusters similar to it, while data observations less than the threshold value are regarded as outliers. Outliers can be found by using this method [
23].
2.1.3. Noise Processing
Noise data refer to the possible deviation or error of measured value relative to actual value when measuring variables. These data will affect the accuracy and effectiveness of subsequent analysis operations. Noise points can be identified by using data smoothing techniques, regression analysis, cluster analysis, and box-splitting methods.
Data smoothing is used to eliminate noise in signals. Kalman filtering is one of the most widely used filtering methods [
24]. It can estimate the state of the dynamic system from a series of data with measurement noise, and predict the information of the current state of the system according to the previous state of the system, as shown in Equations (1) and (2).
Among them, yL(l|l − 1) is the predicted value of the current state of the system; yL(l − 1|l − 1) is the optimal value in the previous state of the system; HL(l|l − 1) is the covariance corresponding to state yL(l|l − 1); HL(l − 1|l − 1) is the covariance corresponding to yL(l − 1|l − 1); wL(l) is the process noise, and its covariance is PL; vL(l) is the control variable of the current state; AL is the control input matrix; EL is the state transition matrix.
Through the current state composed of the system-predicted values and measured values
CL(
l), the optimal estimate of the current state of the system
TL(
l|l) is calculated, as shown in Equation (3).
Among them,
CL(
l) is the measured value of the system, and
CL(
l) =
DL ×
yL +
uL(
l);
DL is the observation matrix;
uL is the observation noise, and its covariance is
SL;
JL(
l) is the Kalman gain, as shown in Equation (4).
The covariance of the optimal estimated value under the updated state
l is shown in Equation (5).
In the case of a single model and single measurement,
IL = 1. When the system is in the
l + 1 state,
HL(
l|l − 1) is the
HL(
l − 1|
l − 1) in Equation (2) [
25].
2.1.4. Standardized Processing
Differences in order of magnitude can lead to larger orders of magnitude occupying a dominant position and slow iteration convergence speed. Therefore, it is necessary to preprocess the data to eliminate effects with different dimensions. The standardization of data processing involves converting the original data into a small specific interval, such as 0–1 or −1 to 1, through certain mathematical transformations to eliminate differences in the properties, orders of magnitude, and dimensions, making it easy to comprehensively analyze and compare indicators of different units or orders of magnitude. Z-Scores standardization is used to eliminate the influence of dimensions, as shown in Equation (6) [
26].
where
Sj is the standard deviation of the data,
is the mean of the data.
2.2. Feature Selection
According to the experience of experts, a feature selection method based on correlation analysis and R-type clustering analysis is proposed, which can effectively solve the problem of low correlation of some closely related variables in industrial production.
2.2.1. Spearman’s Rank Correlation Coefficient Analysis
Correlation analysis is to explore the degree and direction of correlation between variables with specific similar relationships, and to study whether there is a certain similar relationship between variables. The study of correlation analysis mainly focuses on the degree of closeness between two variables, which is a statistical method to study random variables. Correlation analysis studies the relationships and properties between variables. It is the fundamental work before data mining.
In feature selection methods, the Pearson or Spearman rank correlation coefficient is often used to quantify the dependence and monotonicity between two sets of data. The Pearson correlation coefficient is shown in Equation (7) [
27].
where
and
are the variable values,
is the sample size.
The value of the Pearson correlation coefficient mainly depends on the size and degree distribution of the network. Especially for large-scale networks, it will converge to zero, which seriously hinders the quantitative comparison of different networks. Spearman’s rank correlation coefficient is a non-parametric measure, which is used when the data show an abnormal distribution between two variables. It is defined as the Pearson correlation coefficient between two rank random variables, recording the difference between the positive rank and the negative rank of each data point. For data samples with a sample size of
n,
xi, and
yi are sorted from small to large and converted into
rgxi and
rgyi, where
rgxi and
rgyi are the ranks of
xi and
yi. If the rank after arrangement is the same, the Pearson correlation coefficient is calculated according to Equation (7). Otherwise,
r is calculated according to Equation (8). The value ranges from −1 to 1.
where
di is the rank difference between
xi and
yi.
2.2.2. R-Type Clustering Analysis
R-type system clustering analysis uses the average inter-group distance method to cluster variables with high similarity, reducing variable dimensions and making data analysis easier [
28]. The flowchart of the R-type clustering method is shown in
Figure 2.
2.3. LSTM Model
The main characteristics of LSTM neural network include the use of gate mechanism to improve the problem of recurrent neural network (RNN) being unable to transmit historical information for a long time, solve the problem of gradient vanishing and exploding during long sequence training, and achieve long-term time series learning [
29]. It consists of input gate, output gate, and forgetting gate, which can selectively learn input information and store valuable information in memory units [
30]. LSTM is widely used in various fields such as unmanned driving, intelligent robots, speech recognition, and other fields. The structure of LSTM is shown in
Figure 3.
In
Figure 3,
ct is the cell status update value at time
t;
ht−1 and
ht respectively represent the output at time
t − 1 and time
t;
Ct−1 and
Ct respectively represent the cell state at time
t − 1 and
t;
Xt is the input at time
t;
ot,
it and
ft represent output gate, input gate, and forgetting gate, respectively;
ot,
it and
ft are all matrices with the element value range of [0, 1];
tanh and
σ are activation functions. Equations (9)–(15) show the information transmission process of LSTM neural network.
Among them,
wo,
wi, and
wf respectively represent the weight matrix of the three gates;
bo,
bi, and
bf respectively represent the bias terms of the three gates;
σ is sigmoid function, which is an S-type function that can map the output results of real numbers within the [0, 1] interval. The value range of the
tanh function is (−1, 1) [
31].
Based on the above LSTM structure diagram and derived equations, the input of the LSTM neural network at time t is determined by the input Xt at the current time and the output ht−1 at time t − 1. The cell status update value ct at time t is determined by the input gate it, which is used to select useful information to update the unit state Ct. The forgetting gate ft is used to control the cell state at t − 1 time and filter storage information. The joint effect of input gate it and forgetting gate ft is to forget worthless information and update useful information to obtain the unit state Ct at time t. The output gate ot is used to control the cell state Ct at time t. Firstly, the tanh function is used to map the value of the cell state Ct to the (−1, 1) interval, and then the input gate ot is used to analyze the output ht at time t.
2.4. Optimization of LSTM Prediction Model by Particle Swarm Optimization
The PSO algorithm can be described as that every bird in the population is a possible solution to the problem to be optimized, and it is called “particle”. All particles will be evaluated using fitness values determined by a function to be optimized [
32]. PSO first initializes the state of the particles, obtaining a set of random parameter information. Then, the particles continuously update their positions through the use of local optimal solutions (
Pbest) and global optimal solutions (
Gbest) during continuous motion, and obtain the optimal parameter set after iteration.
Pbest and
Gbest respectively represent the optimal position of the particle fitness value of the whole population in the iteration process of spatial position. In the process of iteration, its speed and position are updated by Equations (16) and (17).
Among them,
is the current position vector of the particle;
is the optimal position for individual particles;
is the velocity vector of particle motion;
f1 and
f2 are random numbers between (0,1);
e1 and
e2 are the acceleration factors of particles;
gc is the inertia factor [
33].
The LSTM prediction model contains many network parameters, such as kernel function, learning rate, number of neurons, etc., which will affect the prediction accuracy of the LSTM model. Because these parameters are too dependent on the empirical setting, their prediction accuracy is unstable. At the same time, with the different parameter settings, the length of training time of LSTM model will also change [
34]. The problem of selecting parameters manually can be solved by using particle swarm optimization algorithm to search some network parameters of LSTM model [
35]. Aiming at the problems such as low accuracy and weak generalization ability of the model caused by manual parameter settings, this paper uses the PSO algorithm with a wide search range and fast convergence speed to optimize some super parameters of LSTM, build the PSO-LSTM model, and find the optimal parameter set for LSTM, so as to better improve the model prediction accuracy.
Figure 4 shows the flow chart of PSO-LSTM model.
The specific steps of PSO-LSTM prediction model construction are as follows:
Step 1: Data preprocessing. The variable data are collected and the training set and testing set of the model are obtained through data preprocessing.
Step 2: Initialize parameters. Initialize the parameters of PSO, such as learning factor, number of iterations and particles, and so on. At the same time, the optimization range of LSTM parameters such as learning rate, time step, batch processing capacity, and number of hidden layer units is set.
Step 3: Evaluate particles. The mean values of MAE and RMSE between the real and predicted values of the test set in the LSTM model are taken as the particle fitness values. The obtained value is compared with the initial value Pbest and Gbest to obtain the optimal Pbest and Gbest.
Step 4: Update the position and velocity of the particles.
Step 5: Determine the termination condition. If the number of iterations reaches the preset value, stop searching and output the optimal parameter group. If not, return to Step 3 for iterative optimization.
After initializing the velocity and position of particles, PSO algorithm iteratively updates its position to obtain the optimal solution of the model. PSO algorithm has advantages such as good robustness and fast convergence speed for multi-dimensional space function optimization and multi-objective optimization, and is suitable for some hyperparameter optimization in neural networks, providing a theoretical basis for model combination. The PSO-LSTM prediction model optimized by particle swarm optimization algorithm achieves the best prediction effect by continuously iterating and searching for the optimal value of parameters within the given parameter range.
2.5. Optimization of LSTM Prediction Model by Cuckoo Algorithm
Cuckoo search algorithm is a simulation of the parasitic reproduction behavior of cuckoo birds during their breeding period. Cuckoo nests that lay eggs by means of parasitic brood rearing are a solution to the optimization problem, which needs to be updated by cuckoos’ flight. The process of cuckoos’ nest search represents the updated operation of solution. Cuckoo birds use unique Lévy flights and random walks to find new nests [
36].
The CS algorithm is based on the following rules:
Rule 1: Each cuckoo lays only one egg at a time, and a nest is randomly selected for hatch;
Rule 2: From randomly selected bird nests, the nest with the best quality eggs is reserved for the next generation;
Rule 3: The number of nests is fixed, the probability that the original owner found the alien eggs is
Pa, and
Pa ∈ [0, 1]. When the original owner finds the eggs, they will throw them away or abandon the nest, and find another place to rebuild the nest [
37].
Aiming at problems such as low accuracy and weak generalization ability of the LSTM model caused by manual parameter settings, this section adopts CS algorithm with good global and local search ability and fast convergence speed to optimize some super parameters of LSTM, build CS-LSTM model, and find the optimal parameter set for LSTM, so as to better improve the prediction accuracy of the model.
Figure 5 shows the flow chart of CS-LSTM model.
The specific steps of CS-LSTM prediction model construction are as follows:
Step 1: Data preprocessing. Collect variable data and obtain the training and testing sets of the model through data preprocessing.
Step 2: Initialize parameters. Initialize the parameters of CS, such as learning factor, iteration number, and so on. At the same time, the optimization range of LSTM parameters such as learning rate, time step, batch processing capacity, and number of hidden layer units is set.
Step 3: Set the dimension D of the solution of the actual problem. The maximum number of iterations is L; Cuckoo population size N in the algorithm; C The probability of a cuckoo bird’s egg being discovered is fa. By randomly generating n cuckoo nest locations, , i = 1, 2, …, n, calculate the fitness value, and determine and save the current optimal nest location Gbest.
Step 4: Update the current nest position, calculate and compare the fitness values of the child nest and the parent nest, and save the nest position with better fitness value to the next generation, , i = 1, 2, …, n.
Step 5: Compare the value of the optimal fitness function of the previous generation and update the position
Gbest of the optimal solution of this generation. Judge whether the algorithm meets the convergence condition. If it meets the convergence condition, output the optimal position
Gbest; otherwise, jump back to Step 4 and repeat the optimization iteration until
L iterations are completed [
38].
Step 6: Determine the termination condition. If met, then stop the search, and output the optimal parameter set. If not, then return for iterative optimization.
2.6. Predictive Performance Evaluation Index
This paper mainly selects four indicators as the model evaluation indicators, namely, determination coefficient, mean absolute error, root mean square error, and mean absolute percentage error, so as to evaluate the prediction effect of the model more comprehensively and accurately. The calculation formula is as follows:
- (1)
Determination coefficient
R2 is the coefficient of determination, which measures how well the predicted value fits the real value. R2 ranges from (0 to 1), and the closer it is to 1, the better model fitting is.
- (2)
Mean absolute error
The mean absolute error can be obtained by directly calculating the mean value of the residual error, which represents the mean value of the absolute error between the predicted and observed values. The mean absolute error is a linear fraction in which all observed individual differences are weighted over the mean. The calculation formula is shown in Equation (18).
- (3)
Root mean square error
The root mean square error is the square root of the expected value of the difference between the estimated value and the true value of the data. The root mean square error refers to the sum of the squares of the distances between each data deviation from the true value, which is then averaged and squared. The smaller the index, the higher the accuracy. The calculation formula is shown in Equation (19).
- (4)
Mean absolute percentage error
The mean absolute percentage error is the percentage value, that is, the expected value of the relative error loss, which is the percentage of the absolute error and the true value. In model prediction, the smaller the mean absolute percentage error, the better the accuracy of the model. The calculation formula is shown in Equation (20).
Among them, n is the number of samples; ri is the actual value; pi is the predicted value.
4. Conclusions
In this paper, the missing value processing, outlier processing, noise processing, and Z-Scores standardization processing are carried out for the data of control parameters and related variables to remove the impact of different dimensions on the data. Twelve variables related to TIC1001 and 12 variables related to LIC2001 are obtained. A novel SIA-LSTM method is proposed. The PSO-LSTM model and CS-LSTM model are constructed by using the PSO algorithm and CS algorithm with a wide search range and fast convergence speed to optimize some LSTM super parameters. Compared with the prediction results of the LSTM model, R2, RMSE, MAE, and MAPE indexes of the PSO-LSTM model and CS-LSTM model show excellent prediction performance. In the prediction of reaction temperature, the R2 index of the PSO-LSTM model increased by 3.17%, the MAE decreased by 44.90%, the RMSE decreased by 44.09%, and the MAPE decreased by 42.86%. The R2 index of the CS-LSTM model increased by 2.95%, the MAE decreased by 40.82%, the RMSE decreased by 40.86%, and the MAPE decreased by 39.29%. In the prediction of the liquid level at the bottom of the fractionator, the R2 index of the PSO-LSTM model increased by 3.20%, the MAE decreased by 70.72%, the RMSE decreased by 78.16%, and the MAPE decreased by 70.23%. The R2 index of the CS-LSTM model increased by 2.60%, the MAE decreased by 46.48%, the RMSE decreased by 44.23%, and the MAPE decreased by 45.95%. Both the PSO-LSTM model and CS-LSTM model proposed in this paper have high accuracy and feasibility in predicting the main control variables of the catalytic cracking process.
The potential research directions in the future will include the further optimization and improvement of prediction algorithms to achieve rapid and effective identification and prediction of major control states in industrial production. Further research will be conducted to combine predictive models with early warning models to reduce the occurrence of safety accidents.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}